「今日から使い切る」ための gnu parallelによる並列処理入門
TRANSCRIPT

「今⽇から使い切る」 ための GNU Parallel による並列処理⼊⾨
Koji Matsuda
1

並列処理: ビッグデータ時代のリテラシー
• 我々が扱うべきデータ量は爆発的に増⼤ – 例)研究室で収集しているツイート:1⽇XXXX万ツイート(圧縮してXGB)、年間XXX億ツイート
• 1CPUの性能向上は年間数⼗%、その代わり、コア数はドンドン増えてる – 乾・岡崎研はXXXコアくらいあります
「今日から使える」「プログラミング言語非依存な」 並列処理(バカパラ)の方法を共有したい
2
既存のコードを変更しなくて良い
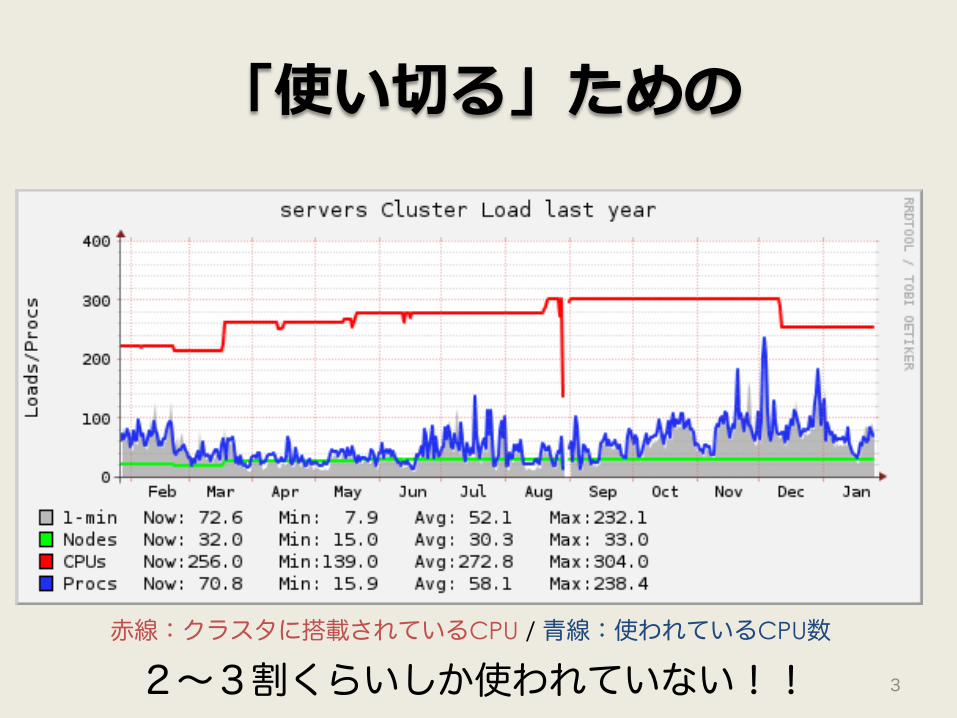
「使い切る」ための
3
赤線:クラスタに搭載されているCPU / 青線:使われているCPU数
2~3割くらいしか使われていない!!

• 並列実⾏関係の機能が詰まったユーティリティ • 便利なソフトウェアではあるのだが、マニュアル
が不親切(※ボリュームがありすぎる)
4
For people who live life in the parallel lane.
http://www.gnu.org/software/parallel/man.html http://www.gnu.org/software/parallel/parallel_tutorial.html
インスピレーションを刺激する例も多くて良いドキュメントだとは思うのですが・・・
研究室生活でよく直面するユースケースに限って説明

バカパラの三つのパターン1. ⼩さなファイルが超⼤量、それぞれに処理
ex. Wikipediaのすべての記事(100万記事)
2. (1⾏1レコードの)巨⼤なファイル各⾏に処理 ex. ツイートログファイル(1ファイル数GB)
3. パラメータとその組み合わせが⼤量 ex. ディープラーニング • 層数、次元数、初期化、学習率, etc…
GNU Parallel でワンストップに対応
5
参考:実際に動くチュートリアルが、 https://bitbucket.org/cl-tohoku/bakapara_tutorial にあります。 乾研の大半のサーバーには GNU Parallel はインストール済なので、すぐ試せるはず
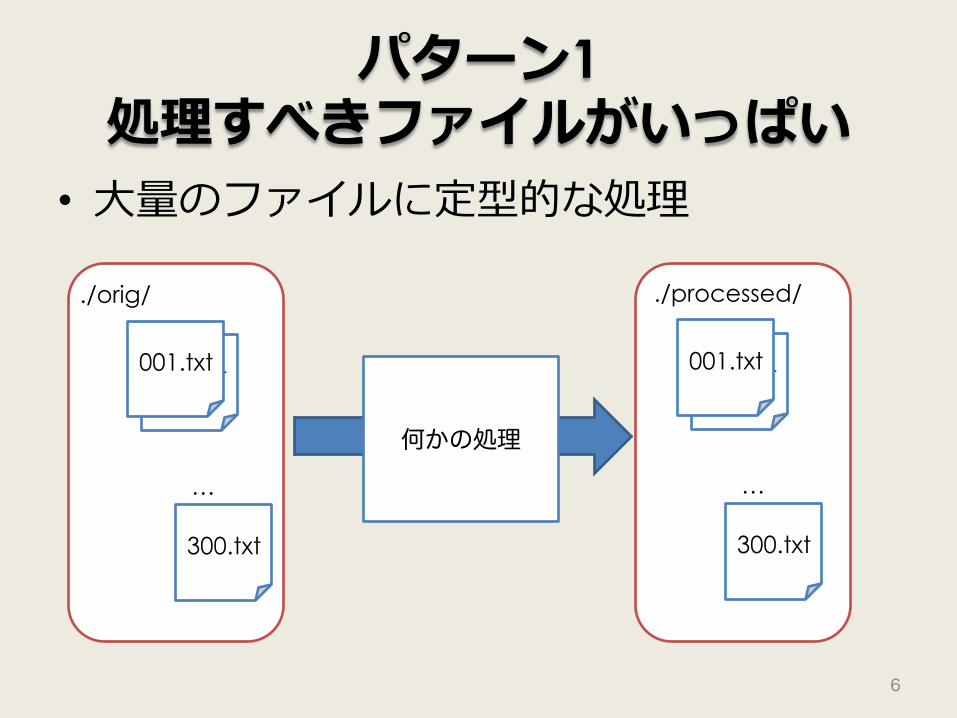
パターン1 処理すべきファイルがいっぱい
• ⼤量のファイルに定型的な処理
6
001.txt 001.txt
./orig/
…
300.txt
./processed/
001.txt 001.txt
…
300.txt
何かの処理

パターン1 処理すべきファイルがいっぱい
• GNU Parallel のファイル名置換を使う
7
ls orig/* | parallel –j 10 “mecab < {} > processed/{/}”
意味: orig/ ディレクトリ以下のすべてのファイルに対して並列で mecab を実行し、processed/ 以下に出力せよ
処理するファイルのリストを生成
{} がファイル名に 置換される
ex. orig/1.txt
{/} はファイル名 からディレクトリを取り除いたもの
ex. orig/1.txt => 1.txt
並列数
並列数(-j) 所要時間(s) 1 13.70 3 4.61
5 3.79
10 3.21
表:並列数に対する所要時間の変化 @tequila

パターン2 ⼤きなファイルのすべての⾏に
8
original.txt (100万行)
processed.txt (100万行) 何かの処理

パターン2 ⼤きなファイルのすべての⾏に
• --pipe オプションを使う
9
cat original.txt | parallel --pipe --L 10000 “hoge.py” > processed.txt
original.txt (100万行)
original.txt を 1万行づつの「塊」に分解して、それぞれを並列に hoge.py にパイプで入力せよ。結果を processed.txtにまとめよ。
1万行 hoge.py
1万行 hoge.py
1万行 hoge.py
1万行 hoge.py
processed.txt (100万行)
並列実行

パターン2’ ボトルネックの部分を並列化
• --pipe の真髄:パイプラインの⼀部を並列
10
cat a.txt | hoge.py | fuga.py | piyo.py > b.txt
遅い 速い 速い
cat a.txt | hoge.py | parallel –pipe –L 100 fuga.py | piyo.py > b.txt
ここだけ並列化してボトルネック解消!
(余談) ボトルネックの定量化には pv (pipe-viewer) コマンドが便利
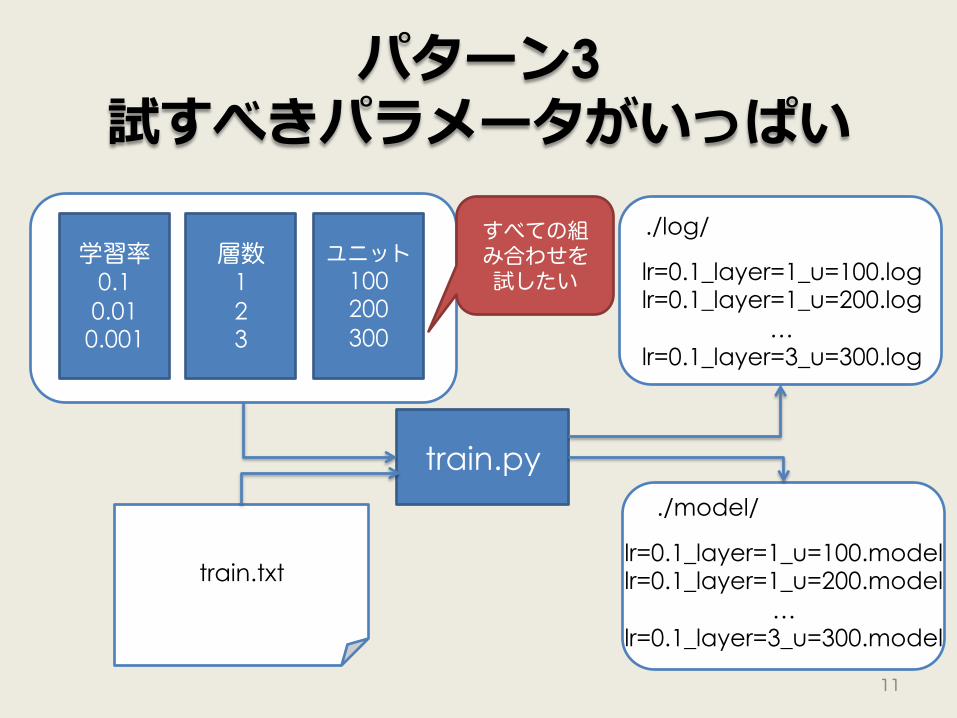
パターン3 試すべきパラメータがいっぱい
11
train.txt
学習率 0.1
0.01 0.001
層数 1 2 3
ユニット 100 200 300
train.py
./log/ lr=0.1_layer=1_u=100.log lr=0.1_layer=1_u=200.log
… lr=0.1_layer=3_u=300.log
./model/ lr=0.1_layer=1_u=100.model lr=0.1_layer=1_u=200.model
… lr=0.1_layer=3_u=300.model
すべての組み合わせを試したい
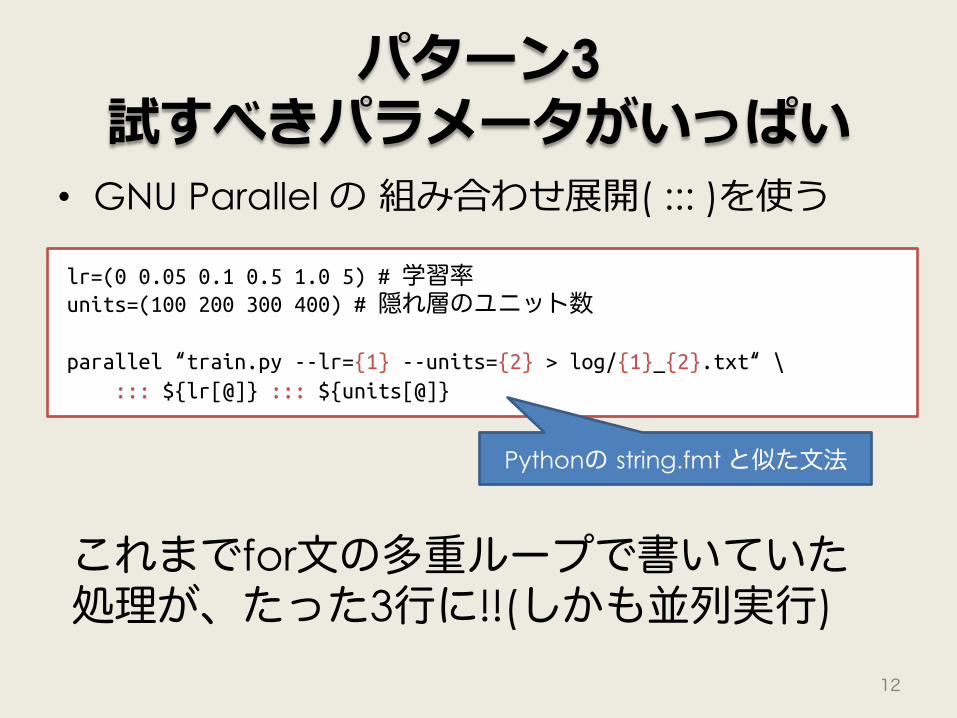
パターン3 試すべきパラメータがいっぱい
• GNU Parallel の 組み合わせ展開( ::: )を使う
12
lr=(0 0.05 0.1 0.5 1.0 5) # 学習率!units=(100 200 300 400) # 隠れ層のユニット数!!parallel “train.py --lr={1} --units={2} > log/{1}_{2}.txt“ \!
"::: ${lr[@]} ::: ${units[@]}
これまでfor文の多重ループで書いていた 処理が、たった3行に!!(しかも並列実行)
Pythonの string.fmt と似た文法

注意点 / Tips• 気をつけておきたいこと: – time コマンドでこまめに計測
• とくにパイプ並列の場合、早くならないこともある – IO / メモリが重い処理は控えめな並列数で – ⻑時間占有する場合は –nice オプションを – まずは --dry-run オプションをつけて実⾏
• どういうコマンドが実⾏されるか、教えてくれる
• Tips – --bar : 進捗状況を表⽰、残り時間の推定 – -S オプション: マシンを跨いだ並列処理 – 並列数は –j オプションで指定、デフォルトではCPU数
13
--bar の例:63%のタスクが終了し、残りは8秒

まとめ• GNU Parallel を使うことのメリット: – J簡潔に書けて – J柔軟に実⾏できる – J既存のコードとの組み合わせが容易
• GNU Parallel を使うことのデメリット: – Lあまりにも簡単なので、計算機資源の奪い合い
が・・?
• 是⾮「今⽇から」使ってみてください • 他にもいい使い⽅があったらシェアしてくだ
さいJ
14