andrei.clubcisco.ro - home - cursuri automatica si...
TRANSCRIPT

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Network of Excellence - Contract no.: IST-508 011www.interop-noe.org
Deliverable D8.1
State of the art and state of the practice including initial possible research orientations
Classification ConfidentialProject Responsible : UHP LORIA (4); CNR-IASI (11)Main Authors : CNR-IASI (11), UNIROMA–DIS (39), UNITILB (44),
KTH (47)Contributors WP8 Partners Task 8.1Status : Version 1.2Date : 2004-11-18

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Table of contents
Executive Summary....................................................................................................................5
I.1 Introduction.......................................................................................................................6
I.2 Methods to produce the deliverable...................................................................................6
I.2.1 Breaking work into Subtasks......................................................................................6
I.3 Main Results......................................................................................................................8
I.4 Conclusions.......................................................................................................................8
PART II.....................................................................................................................................11
II.1 Introduction....................................................................................................................11
II.1.1 Some definitions......................................................................................................12
II.1.2 Key objectives in using an ontology.......................................................................12
II.1.3 Applications Areas and Uses Cases........................................................................13
II.1.4 Anatomy of an ontology..........................................................................................15
II.2 Ontology Representation & Reasoning..........................................................................17
II.2.1 Introduction.............................................................................................................17
II.2.2 Representation.........................................................................................................18
II.2.3 Ontology languages.................................................................................................19
II.2.4 Reasoning................................................................................................................58
II.2.5 References...............................................................................................................61
II.2.6 Annex 1...................................................................................................................68
II.3 Ontology Management and Engineering........................................................................69
II.3.1 Introduction.............................................................................................................69
II.3.2 Building/Authoring.................................................................................................69
Deliverable D8.1 2/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
II.3.3 Automatic techniques for Ontology Learning (e.g., text mining)...........................81
II.3.4 Core Domain Ontologies.........................................................................................83
II.3.5 Merging, Integration................................................................................................97
II.3.6 Validation (wrt usage)...........................................................................................100
II.3.7 Evolution, Versioning...........................................................................................101
II.3.8 Multi-lingual, Multi-cultural, Meta-Data..............................................................102
II.3.9 Social & cultural challenges (e.g., dedicated GW)...............................................103
II.3.10 Conclusions.........................................................................................................103
II.3.11 Bibliography........................................................................................................104
II.3.12 APPENDIX 1: Ontology and knowledge management......................................114
II.3.13 Appendix2: Ontology editor survey results.......................................................129
II.4 Ontology Interoperability.............................................................................................136
II.4.1 Introduction...........................................................................................................136
II.4.2 Preliminary definitions..........................................................................................138
II.4.3 Semantic similarity among ontologies..................................................................143
II.4.4 Ontology mismatches............................................................................................144
II.4.5 Interoperability among ontologies: available solutions........................................147
II.4.6 MultiOntology Architectures & Environments, Federated ontologies.................172
II.4.7 Contexts and sub-ontology factorization...............................................................173
II.4.8 Conclusions...........................................................................................................174
II.4.9 Bibliography..........................................................................................................175
II.5 Ontology-based Services for Enterprise Application Interoperability.........................180
II.5.1 Introduction...........................................................................................................180
II.5.2 Architecture...........................................................................................................182
Deliverable D8.1 3/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
II.5.3 Information interoperability.................................................................................190
II.5.4 Process Interoperability.........................................................................................192
II.5.5 Service Interoperability.........................................................................................194
II.5.6 State of practical use of ontologies for interoperablity.........................................198
II.5.7 Future Research Directions..................................................................................202
II.5.8 References.............................................................................................................203
Deliverable D8.1 4/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Executive Summary
This deliverable is the result of the work conducted in Task 1 of the Work Package 8: “Ontology-based integration of Enterprise Modelling and Architecture & Platforms”
Research on ontologies is one of the three key thematic components that constitutes the core of the INTEROP NoE. Specifically, the aim of Work Package 8 is to investigate the field of ontologies and their potential contribution to the interoperability of enterprise applications.
A good “state of the art and state of the practice” about such field is essential; it represents the starting point for understanding the maturity of the domain and provides the foundation for the productions of original results and solutions.
This deliverable is divided in two main parts:
Part I, is a short section describing the itinerary that led to the realisation of the whole document. In particular such section describes main issues tackled, method of work and results achieved, while, in Part II, the actual content of the investigations done are shown.
Deliverable D8.1 5/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
PART I
I.1 Introduction
In the production of this deliverable important issues had to be faced; first of all, the wideness of the ontology and ontology-related topics, made necessary the exigency of breaking the work to do in more manageable parts to allow partners to better focus their works on specific topics, according to their competencies; the Task1 of the WP8 has been, therefore, subdivided in four thematic subtasks led by four WP partners; the other WP partners decided to allocate their efforts, distributing them onto one or more of such subtasks.
Another important issue was the need of managing the above topics jointly and integrating the contribution of a huge number of partners (WP8 counts 38 partners); the perspective of an significant amount of knowledge resources and competencies could have been vanished by lack of coordination, communication, etc.
The following section will describe in detail the methods of work adopted in the production of this document that tried to overcome the above difficulties.
I.2 Methods to produce the deliverable
I.2.1 Breaking work into Subtasks
The Task 1 of WP8 has been organised in the following subtasks, responsible of investigating the existing literature about a specific facet, expressed by the title of the subtask, of the whole argument of the deliverable:
ST1: “Ontology Representation & Reasoning” led by Maurizio Lenzerini (UNIROMA–DIS partner 39).
ST2: “Ontology Management and Engineering” led by Manfred Jeusfeld (UNITILB partner 44).
ST3: “Ontology Interoperability” led by Fulvio D’Antonio (LEKS, IASI – CNR partner 11).
ST4: “Ontology-based Services for Enterprise Application Interoperability” led by Paul Johannesson (KTH partner 47).
Deliverable D8.1 6/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Internally, each ST was then subdivided in different topics.
It was agreed that the contribution, to the final deliverable, of each ST would have been the production of a document about the corresponding subject and the internal structure of the document should have followed the topics structure. The four documents have then been merged and constitute the main sections and results of this deliverable.
In order to overcome the problem of communication between partners, an intensive use of the INTEROP collaboration platform has been carried on. The INTEROP platform, being a portal based on PLONE, an open source content management system, allows an INTEROP partner to develop new add-ons to extend the existing functionalities and to personalize them according to specific needs.
LEKS - IASI, CNR, the organisation leader of the Work Package, has developed one of such add-on in order to allow WP partners to collect existing documents in literature (papers, references, web-sites, etc.) and to describe them with metadata. The developed add-on was integrated in the INTEROP platform. This new functionality was really easy to use: WP8 partners that wanted to submit a document description had to fill a web-based form.
This is the complete metadata fields description:
Id (Required): An identifier for the document to be used for using as bibliographic reference in the writing of the final document.
Title (Required): The title of the document
Author(s) (Required) : The authors of the document to be described.
Date of publication
Abstract (Required)
Type of document (Required): the type of the document (survey, technical report, scientific paper, etc.)
Paper's URL: if the document is available online, the complete web URL.
WP8 Submitter (Required): useful for keeping track of the partners’ involvement.
Related SoA Topics (Required): The WP8 topics, belonging to one or more subtasks, that are addressed in the document. These keywords are used by the add-on to organize the documents in a
Other Keywords: if additional keywords, wrt the previous field, are required, they can be specified here.
Attached Paper: If the submitter of a description has a copy of the paper it can be uploaded using this field (submitters were warned to be careful of copyright matters).
Deliverable D8.1 7/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
An apposite space in the platform was created to host the templates filled-in by partners. Additional comments could be attached, following a forum-style, to the collected templates and this comments could have been inserted in the drafts of final documents, in order to alleviate the process of writing. The phase of collecting templates has been successful; partners considered easy and advantageous the process of uploading and describing papers in the platform, but rarely added comments (in the forums) to such papers.
The creation of the “WP8 SoA” space in the platform was aimed at collecting material for the production of this deliverable but, being this functionality still active in the platform, also to create of a “living State of the Art”; new material can be added after the release of the final deliverable and can be used as a reference point for getting ontology-related material by all INTEROP partners.
For what concerns the process of writing the chapters that compose the final document (one for each ST), they were written mainly by the ST leaders; such documents went into different stages of refinement passing several cycles of internal review; discussions about the development of such documents were mainly operated remotely (using e-mails, forums) and, obviously, in correspondence of project and workshop meetings, where there has been the most advantageous face-to-face cooperation. In the INTEROP Berlin meeting (21-25 September) the first draft of the deliverable (version 1.0) was presented in the WP8 session; after additional stages of refinement the deliverable reached the actual 1.2 version.
I.3 Main ResultsThe final result is a voluminous State of the Art report (ca. 200 pages), necessarily not omni-comprehensive, given the complexity and extensiveness of the domain, but presenting a very good degree of coverage. The most peculiar characteristic of this report is its internal organization in sections that focus on different aspects of the ontology domain.
There is a number of overlapping between the different chapters produced by the subtasks: for example tools for ontology management (investigated in ST2) include, among the others, tools for ontology mapping/merging/alignment that are mainly addressed in ST3. Indeed the overlapping is on the topic but not on the perspective which is original for each of them. Therefore, generally the role of each ST document is well-defined and autonomous respect to the others.
I.4 Conclusions
As already anticipated, in producing this deliverable, WP8 tried to capitalize the knowledge of the involved partners, dividing the work in well-defined subtasks and proposing new methods of collaboration. The use of the collaborative platform was particularly intense and successful
Deliverable D8.1 8/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
and stimulated a good participation of the partners in the first phase, that is collecting the existing material. The writing phase, instead, was heavily based on ST leaders work, although they have been supported by the other WP partners with a certain number of written contributions .
Deliverable D8.1 9/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
PART II
II.1 Introduction
This State of the Art reports on the recent achievements in the area of Ontology research and advanced development. Such an area has been divided in four sections:
- Ontology modelling and reasoning, with the aim of presenting the relevant ontology languages proposed in the literature and related reasoning techniques
- Ontology engineering and management, with the aim of presenting the main realization in terms of tools and platform for ontology management
- Ontology interoperability, that presents the main problems and the proposed solutions to address the diversity encountered when operating in a multi-ontology environment
- Ontology-based services for Enterprise Application Interoperability, the last section that addresses the actual use of ontologies in problems related enterprise software interoperability.
Before addressing the specific sections, we intend to provide a brief account of some preliminary notions, useful to position ontology research, with a specific focus on the area addressed by INTEROP, including references to the wider area of knowledge representation and management.
It is worth noting that the production of the SoA is a very extensive and time-consuming endeavour. Often it is difficult to sanction that the task has reached an end. Furthermore, there are a high number of similar efforts that every year are performed and, last but not least, a SoA report represents somehow a “perishable” material, since it gets quite quickly obsolete (especially in a very active areas such as the ontology one). For such motivations, we have to accept that this document may have omitted (or explicitly discarded) results that someone may consider fundamental. We will be happy to receive notification of those cases and return later to update the report. Similarly, a SoA report does not pretend to be original, in the scientific sense of the term. On the contrary, we are building on the experience and the results of those who previously produced a similar reports. References to previous SoA reports will be given in the sequel. But one in particular should be cited here, the SoA of the IDEAS project. In fact we wish to recognise to IDEAS the important role of being somehow the precursor, and may be even the “father”, of the INTEROP NoE. The fact that this SoA was inspired BY, and sometimes explicitly reporting, by the results of IDEAS is a confirmation of the validity of the results produced therein.
Deliverable D8.1 10/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
II.1.1 Some definitions
Ontologies represent a new technology with the purpose to improve electronic information organization, management, and understanding. An ontology is a conceptual information model that describes “the things that exist” in a domain (hence the name): concepts, properties, facts, rules and relationships. An ontology acts as a standardized reference model to support information integration and knowledge sharing. Hence, the role of ontologies is twofold:
they support human understanding and communication, they, in machine-processable form, facilitate content-based access, communication and
integration across different information systems. These roles are both achieved by explicating and formalizing the meaning, or semantics, of organization and enterprise application information resources.
Many definitions of ontologies have been proposed, and it seems that the most acceptable one is based on the one proposed by Gruber [5]: An ontology is a formal, explicit specification of a shared conceptualisation. A 'conceptualisation' refers to an abstract model of some phenomenon in the world, which identifies the relevant concepts of that phenomenon. 'Explicit' means that the type of concepts used and the constraints on their use are explicitly defined. 'Formal' refers to the fact that the ontology should be machine understandable. 'Shared' reflects the notion that ontology captures consensual knowledge, that is, it is not restricted to the knowledge view of some individual, but reflects a more general view shared and accepted by a group.
According to W3C Web Ontology Working Group [W3], and ontology defines the terms used to describe and represent an area of knowledge. Ontologies are used by people, databases, and applications that need to share domain information, where a domain is just a specific subject area or a wider area of knowledge, like medicine, tool manufacturing, real estate, automobile repair, financial management, etc. Ontologies include computer-usable definitions of basic concepts in the domain and the relationships among them. They may encode knowledge in a specific domain and also knowledge that spans over multiple domains.
II.1.2 Key objectives in using an ontology
As anticipated, Ontologies facilitate the understanding, communication and cooperation between people and organizations. They allow the key concepts and terms relevant to a given domain to be identified and defined in an unambiguous way. Therefore, the use and exchange of data, information, and knowledge among people and organizations is facilitated. Moreover, ontologies facilitate the integration of different user perspectives, while capturing key distinctions in a given perspective. Furthermore, the use of ontologies allow the cooperation among people at different levels:
Internal Cooperation: within the same organization External Cooperation: among different organizations
Deliverable D8.1 11/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Integrated Cooperation: when different organizations, in order to achieve some complex tasks, intend to share internal knowledge.
When software tools and application systems are involved, Ontologies can be used at the following three levels:
Design and development of software systems. At this level ontologies play an important role in the specification, reliability, and reusability of software systems, as clarified below:
- Specification: Informal Ontologies facilitate the system requirements identification and the relationships among system components. Formal Ontologies allow for a declarative specification of the software system, providing the access to reasoning facilities on what the system has been designed for.
- Reliability: Informal Ontologies provide a basis for manual checking and validation of the specification. Formal Ontologies allow for the automatic consistency checking of the specification by means of ad hoc algorithms or theorem provers.
- Reusability: Ontologies provide a framework for reusing concepts, and adapting data and software components to different classes of problems and environments.
At the Communication level, ontologies facilitate the data exchange: among system designers fostering mutual understanding; among and the among different software tools and application systems fostering reconciliation.
At the Interoperability level, ontology-based services support different software systems to cooperate at different levels:
- Data Interoperability- Function Interoperability- Process Interoperability
II.1.3 Applications Areas and Uses Cases
Ontologies offer a semantic – content and meaning based – approach to electronic information management and exchange. Accordingly, they promise to have a significant impact on areas that must deal with vast amounts of distributed and heterogeneous computer-based information management. The main drivers for commercial applications of ontologies are:
Electronic business, such as content management, supply chain integration, value chain integration, information standardization for electronic marketplaces.
Information and knowledge management, such as corporate information organization, intelligent search/retrieval and semantic access, knowledge sharing, World Wide Web and Intranet information systems.
Furthermore, focused high-value industrial applications, such as engineering, design, maintenance and support services, have shown to be very well suited to ontology solutions.
Ontologies can be used to improve existing Web-based applications and may enable new uses of the Web. W3C Web Ontology Working Group, part of W3C’s Semantic Web Activity
Deliverable D8.1 12/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
[W3], focuses on the development of OWL, a language to extend the semantic reach of current XML and RDF meta-data efforts. In the context of this effort, six representative use cases of web ontologies have been identified:
Web portals. A web portal is a web site that provides information content on a common topic. It allows individuals that are interested in the topic to receive news, find and talk to one another, build a community, and find links to other web resources of common interest. In order to allow more intelligent syndication, web portals can define an ontology for the community. This ontology can provide a terminology for describing content and axioms that define terms using other terms from the ontology, as well as inference capabilities that allow users to obtain search results from the portal that are impossible to obtain from conventional retrieval systems.
Multimedia collections. Ontologies can be used to provide semantic annotations for collections of images, audio, or other non-textual objects. It is even more difficult for machines to extract meaningful semantics from multimedia than it is to extract semantics from natural language text. Thus, these types of resources are typically indexed by captions or metatags. However, since different people can describe these non-textual objects in different ways, it is important that the search facilities go beyond simple keyword matching. Ideally, the ontologies would capture additional knowledge about the domain that can be used to improve retrieval of images.
Corporate web site management. Large corporations typically have numerous web pages concerning things like press releases, product offerings and case studies, corporate procedures, internal product briefings and comparisons, white papers, and process descriptions. Ontologies can be used to index these documents and provide better means of retrieval.
Design and Technical Document Management. This use case is for a large body of engineering documentation, such as that used by the aerospace industry. This documentation can be of several different types, including design documentation, manufacturing documentation, and testing documentation. These document sets each have a hierarchical structure, but the structures differ between the sets. There is also a set of implied axes, which cross-link the documentation sets: for example, in aerospace design documents, an item such as a wing spar might appear in each of them. Ontologies can be used to build an information model which allows the exploration of the information space in terms of the items which are represented, the associations between the items, the properties of the items, and the links to documentation which describes and defines them (i.e., the external justification for the existence of the item in the model). That is to say that the ontology and taxonomy are not independent of the physical items they represent, but may be developed/explored in tandem.
Another common use of this kind of ontology is to support the visualization and editing of charts, which show snapshots of the information space centered on a particular object (class or instance). These are typically activity/rule diagrams or entity-relationship diagrams.
Intelligent agents. The Semantic Web can provide agents with the capability to understand and integrate diverse information resources. This type of agent requires domain ontologies that represent the terms for entities and available services used in providing the required services.
Ubiquitous computing. Ubiquitous computing is an emerging paradigm of personal computing, characterized by the shift from dedicated computing machinery to pervasive
Deliverable D8.1 13/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
computing capabilities embedded in our everyday environments. Characteristic to ubiquitous computing are small, handheld, wireless computing devices. The pervasiveness and the wireless nature of devices require network architectures to support automatic, ad hoc configuration. An additional reason for development of automatic configuration is that this technology is aimed at ordinary consumers. A key technology of true ad hoc networks is service discovery, functionality by which "services" (i.e., functions offered by various devices such as cell phones, printers, sensors, etc.) can be described, advertised, and discovered by others. All of the current service discovery and capability description mechanisms (e.g., Sun's JINI, Microsoft's UPnP) are based on ad hoc representation schemes and rely heavily on standardization (i.e., on a priori identification of all those things one would want to communicate or discuss).
The key issue (and goal) of ubiquitous computing is "serendipitous interoperability," interoperability under "unchoreographed" conditions, i.e., devices which weren't necessarily designed to work together (such as ones built for different purposes, by different manufacturers, at a different time, etc.) should be able to discover each others' functionality and be able to take advantage of it. Being able to "understand" other devices, and reason about their services/functionality is necessary, since full-blown ubiquitous computing scenarios will involve dozens if not hundreds of devices, and a priori standardizing the usage scenarios is an unmanageable task.
Besides the 6 scenarios proposed by the WOW Group of W3C, there is a key problem area that is represented by Enterprise Software Application interoperability. Since the latter is the key focus of the INTEROP NoE, and therefore of our work, this SoA report, whenever deemed necessary, will consider not general issues but elements and aspects specific to our research interest. Similarly, when dealing with ontology technologies, when necessary we will focus on the application domain of enterprise and eBusiness.
Below we address some further issues of ontology technology, introducing the elements used to build an ontology and a sketchy representation of its internal organization.
II.1.4 Anatomy of an ontology
According to Gruber [G93][G95], knowledge in ontologies is mainly formalised using five kinds of components: classes or concepts, relations, functions, axioms and instances.
A class or concept represents a set of entities within a domain. The classes in the ontology are usually organised in taxonomies.
Relations represent the interaction between concepts of the domain. The relations can be organised in taxonomies.
Functions are a special case of relations in which the n-th element of the relationship is unique for the n-1 preceding elements.
Axioms are used to model sentences that are always true. They can be used in an ontology to constrain values of classes, to define the arguments of relations etc.
Instances are used to represent specific individual elements.
Deliverable D8.1 14/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
As illustrated in Figure 1, the elements that compose an ontology can be seen distributed over three layers. Such three layers are structured according to the two main hierarchies found in an ontology: specialization and decomposition hierarchy. The former is mainly used in the upper part while the latter is used in the lower part of the ontology (although in reality there is not such a neat separation).
Upper Business Ontology layer, which incorporates the most general domain concepts, Application Ontology layer, which incorporates the specific concepts of the application
domain, Lower Business Ontology layer, which incorporates attributes and other elementary
concepts that are used to compose Application concepts..
o Figure 1. The Ontology Layers
The rest of this report is structured in four sections, according to the four subtasks in which the WP8 is organised, and the four problem areas that were anticipated above.
Bibliography
[FG97] Mark Fox Michael Gruninger,On Ontologies and Enterprise Modelling, International Conference on Enterprise Integration Modelling Technology 97
[G93] Tom Gruber. A translation approach to portable ontology specifications. Knowledge Acquisition, 5(2):199–220, 1993.
[G95] Tom Gruber. Toward principles for the design of ontologies used for knowledge sharing, 1995.
[W3] http://www.w3.org
Deliverable D8.1 15/206
UpperBusinessOntology
LowerBusinessOntology
ApplicationOntology
- Time, Date, Duration- Address- Distance- Currency, cost, price
- Actor, Process, B-Obj- Event, Goal- Message, commitment- Business Rule
- Manager, Employee- Invoice, RFQ- BOM- Billing
PartOf
Gen
UpperBusinessOntology
LowerBusinessOntology
ApplicationOntology
UpperBusinessOntology
LowerBusinessOntology
ApplicationOntology
- Time, Date, Duration- Address- Distance- Currency, cost, price
- Actor, Process, B-Obj- Event, Goal- Message, commitment- Business Rule
- Manager, Employee- Invoice, RFQ- BOM- Billing
PartOf
Gen

INTEROPInteroperability Research for Networked Enterprises Applications and Software
II.2 Ontology Representation & Reasoning
II.2.1 Introduction
It is widely accepted to consider an ontology as a conceptualization of a domain of interest, that can be used in several ways to model, analyze and reason upon the domain. Obviously, any conceptualization of a certain domain has to be represented in terms of a well-defined language, and, once such a representation is available, there ought to be well-founded methods for reasoning upon it, i.e., for analyzing the representation, and drawing interesting conclusions about it. This paper surveys both the languages proposed for representing ontologies, and the reasoning methods associated to such languages.
When talking about representation languages, it is useful distinguish between different abstraction levels used to structure the representation itself. In this paper, we essentially refer to three levels, called extensional, intensional, and meta, respectively.
1. The extensional level: this is level where the basic objects of the domain of interest are described, together with their relevant properties.
2. The intensional level: this is the level where objects are grouped together to form concepts, and where concepts and their properties are specified.
3. The meta-level: this is the level where concepts singled out in the intensional level are abstracted, and new, higher level concepts are specified and described, in such a way that the concepts of the previous level are seen as instances of these new concepts.
In this survey, we mainly concentrate on the first two levels, since our primary goal is to provide an account for the basic mechanisms for representing ontologies and for reasoning about them. Categories used in the meta-level of ontologies are very much related to specific applications where ontology languages are used. Therefore, relevant issues concerning the meta-level will be addressed in other surveys of workpackage WP8, in particular those concerning the use of ontologies in interoperability.
This paper is organized as follows. In Section 2 we set up a framework for surveying ontology representation languages. The framework will be then used in Section 3 in the description of specific languages and formalisms, so to have a basic unified view for comparison. Section 4 is devoted to a discussion on reasoning over ontologies.
Deliverable D8.1 16/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
II.2.2 Representation
In this section we set up a framework for surveying ontology representation languages. The framework will be then used in Section 3 in the description of specific languages and formalism, so to have a basic unified view for comparison.
The framework is based on three main classification criteria we will use in presenting languages and formalisms. These classification criteria are concerned with the following three aspects:
1. What to express. The first criterion takes into account that ontology is a generic term for denoting domain representation, but specific ontology languages may concentrate on representing certain aspects of the domain. In this paper, we concentrate our attention on classes of languages whose primary goal is to focus on:
Class/relation. We use this class for referring to languages aiming at representing objects/classes/relations.
Action/process. We use this class for referring to languages that provide specialized representation structures for describing dynamic characteristics of the domain, such as actions, processes, and workflows. These languages may also incorporate mechanisms for the representation of the static aspects of the domain (e.g., objects and classes), but they usually provide only elementary mechanisms for this purpose, whereas they are much more sophisticated in the representation of the dynamic aspects.
Everything. We use this class for referring to languages that do not make any specific choice in the aspects of the domain to represent, and, therefore, may be in principle used for any kind of contexts and applications.
2. How to express. This criterion takes into account the basic formal nature of the ontology languages. Under this criterion, we will consider the following classes of languages:
Programming languages
Conceptual and semantic database models
Information system/software formalisms
Logic-based
Frame-based
Graph-based
XML-related
Visual languages
Temporal languages
3. How to interpret the expression. This criterion takes into account the degree in which the various languages deal with the representation of incomplete
Deliverable D8.1 17/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
information iin the description of the domain. Under this criterion, we will consider the following classes of languages:
Single model. Languages of this class represent a domain without any possibility of representing incomplete information. An ontology expressed in this language should be interpreted as an “exact” description of the domain, and not as a description of what we know about the domain. In terms of logic, this means that the ontology should be interpret in such a way that only one model of the corresponding logical theory is a good interpretation of the formal description. This assumption is at the basis of simple ontology languages: for example, if we view the relational model as an ontology languages (where concepts of the domain are represented as relations), then this language is surely a “single model”-ontology language according to our classification.
Multiple models (or, several models). Languages of this class represent a domain taking advantage of the possibility of representing incomplete information. An ontology expressed in this kind of language should be interpreted as specifying what we know about the domain, with the proviso that the amount of knowledge we have about the domain can be limited. This point of view is at the basis of sophisticated ontology languages: for example, languages based on First-order logic represent a domain as a logical theory. It might be the case that this theory allows for different legal interpretations, and such interpretations correspond exactly to several models. Thus, languages based on First-order logic are classified as “several models”-ontology languages.
II.2.3 Ontology languages
In this section we analyze different languages and formalisms proposed in the last years for expressing and specifying ontologies. As we said in the introduction, we refer only to languages for the specification of the intensional and the extensional levels. We present the various languages by grouping them according the first classification criterion mentioned in the previous section, namely the one regarding “how to express”. We refer to several classes of languages, and within a single class, we refer to various languages, each one described in a specific subsection. For each language described in a subsection, we explicitly mention the classes to which the language belongs, according to the three classification criteria of Section 2, namely “what to express”, “how to express”, and “how to interpret”.
II.2.3.1Programming Languages
Programming languages allow representation and manipulation of data in several ways and according to various paradigms. During the years, there has been an evolution towards
Deliverable D8.1 18/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
approaches that favor an abstraction on data types, leading to a cleaner separation between data structures and algorithms that handle them. In the last decade a data-centric approach, the Object Oriented paradigm, has emerged as one of the most influential philosophies, spanning from the programming languages domain to other domains such as that of databases and knowledge representation. The “oo approach” is itself a loosely defined terms, but is generally associated with a number of concepts, such as complex objects, object identity, methods, encapsulation, typing and inheritance. OO programming languages, such as Java, provide a sophisticated framework for modeling taxonomies of classes and manipulating their instances.
Lately, there have been some attempts to use the Java language as an ontology representation language. In particular, there have been some efforts at mapping ontology languages to Java. Research in this field has been performed mostly in the area of Intelligent Agent systems, as a Java APIs generated from ontologies helps fast implementation of applications or agents consistent with the specification defined in the Ontology itself. For instance, in [Eb02] it is presented OntoJava, a cross compiler that translates ontologies written with Protégé and Rules written in RuleML into a unified java object database and rule engine. In [KP04], a tool to map OWL ontology into java is presented. Each OWL class is mapped to a Java interface. Several other tools exist or are in the course of being developed for mapping ontology languages to and from java, like java2owl, FRODO rdf2java, sofa etc.
If, despite their Object-orientedness, the use of imperative languages as ontology representation languages may sound strange, this is not the case for logic-programming and functional languages.
Languages like Prolog and LISP have always been used inside knowledge representation systems. There are some recent examples of the use of both Prolog and LISP as ontology representation languages. In particular, a syntax based on a mix of first order logic and LISP is at the base of various ontology representation languages like Ontolingua and OCML. The Ontolingua Framework has the ability to translate ontologies into Prolog syntax, to allow importing the contents of Ontolingua ontologies into Prolog-based representation systems. XSB inc. [XSB] offers a suite of ontology tools based on extensional CDF, a formalism in which ontologies can be defined using Prolog-style facts.
After the emerging of the OO paradigm, several attempts have been made to bring this philosophy into functional and even logic-programming languages. An example is F-logic, which many consider particularly suited to represent ontologies and is described in greater detail in the next section. F-logic is used for instance as an internal representation model in the OntoEdit tool [OE].
F-logicWHAT to express: EverythingHOW to express: Programming languagesHOW to interpret the expression: Single model
Deliverable D8.1 19/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
F-logic or Frame logic [KL95] is a logical formalism that tries to capture the features of object-oriented approaches to computation and data representation.
It has been developed in order to bridge the gap between object-oriented computing and data representation systems and deductive databases, providing theoretical bases for an object-oriented logic programming language to be used either as a computing tool and as a data representation tool.
Though F-logic is mainly aimed at the representation of object-oriented databases, it is also suitable for representation of knowledge in a frame-based fashion, as frame-based KRS share with object-oriented representation formalisms the central role of complex objects, inheritance and deduction. The name of the language itself is due to this connection with Frame-based languages.
F-logical syntactical framework is not too much dissimilar to that of FOL. As in FOL, the most basic constructs of the language are terms, composed of function symbols, constants and variables. Formulas are constructed from terms with a variety of connectives.
Anyway, elements of the language are intended to represent properties of objects and relations about objects. Terms play the role of logical object ids. They are used to identify objects and access their properties. Function symbols play the role of object constructors. Formulas allow building assertions over objects. In particular, the simplest kind of formulas, called F-molecules, allow asserting either a set of properties for an object, a class-membership relation between two objects or a superclass-subclass relationship between two objects. For example, if O is a term, the syntax O:E represents the fact that O is an instance of E, O::E means that O is a superclass of E and the formula
O[semicolon separated list of “method expressions”]
Allows to associate various properties to the object denoted by O. Method expressions allow specifying properties that correspond, in an object oriented view, to attributes, methods or signatures. Methods consist of a name, a set of arguments and a return value, which may be scalar or set-valued. Attributes are just methods that don’t take any argument. Attributes and method may be specified to be inheritable. Inheritable methods assertions on an object are propagated to objects that are in is-a relationship with the first one, though with a difference between the two kinds of isa: inheritable expressions become not inheritable in member objects. A signature expression specifies a type constraint on the arguments and results of a method. Signatures are used for type checking and are enforced, that is specifying a method without declaring a signature for it raises a type error.
Notice that everything in F-logic is built around the concept of object. There is no distinction between classes and individual objects: they both belong to the same domain. In its most basic version, F-logic doesn’t make any distinction between complex objects and atomic values, either.
F-logic is a logic with model-theoretic semantics. Semantics for the F-language are given in terms of F-structures and satisfaction of F-formulas by F-structures, and a notion of logical entailment is given. In [KL95], a resolution-based proof theory for F-logic is provided. A
Deliverable D8.1 20/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
deductive system consisting of twelve inference rules and one axiom is provided and it’s proved to be sound and complete.
Anyway, F-logic’s intended use is as a logic programming language, to be used both as a computational formalism and as a data specification language. [KL95] describes Horn F-programs, which are made of the equivalent of Horn rules in F-logic, and generalized Horn F-programs. As in classic logic programming, the semantics of Horn F-programs is based on the concept of least models. For a class of generalized programs, a unique canonic model may also be found, in a way similar to that used to define semantics of locally stratified programs in classic logic programming.
Note that the syntactic rules defined for F-logic and its deductive system cannot really enforce that in type-constraint stated with signature rules hold in a canonic model of an F-program. In [KL95], an additional semantic formalization of type rules is given in order to justify the use of static type checking.
Frame logic’s syntax has some higher-order features. Despite this higher order syntax, the underlying semantic formally remains first order, which allows avoiding difficulties normally associated with higher order theories.
II.2.3.2Frame-based languages
Frame based languages are based on the notion of “frame”, first introduced by Minsky to explain certain mental activities [Mi75]. Departing from the initial, largely comprehensive meaning that Minsky gave to this term, the concepts of frame and frame-systems have evolved over time assuming a specific meaning in the context of Knowledge Representation[Fi85][KM95].
A frame is a data structure that provides a representation of an object or a class of objects or a general concept or predicate. Whereas some systems define only a single type of frame, other systems distinguish two or more types, such as class frames and instance frames.
Frames have components called slots. The slots of a frame describe attributes or properties of the thing represented by that frame and can also describe binary relations between that frame and another frame. In the simplest model of a slot, it has a name and a value. In addition to storing values, slots often also contain restrictions on their allowable values, in terms of data types and/or ranges of allowable values. They may also have other components in addition to the slot name, value and value restrictions, for instance the name of a procedure than can be used to compute the value of the slot. These different components of a slot are usually called its facets. Implemented systems often add other properties to slots, or distinguish between different slot types, as in the case of frames.
The description of an object type can contain a prototype description of individual objects of that type; these prototypes can be used to create a default description of an object when its type becomes known in the model.
Deliverable D8.1 21/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
In typical frame-based systems, constructs are available that allow to organize frames that represent classes into taxonomies. In a taxonomic hierarchy, each frame is linked to one or, in some systems, more than one parent frame. Through taxonomic relations, classes may be described as specializations of other more generic classes. Classes in a taxonomy inherit from their super classes features like slot definitions and default values. The precise way in which inheritance is implemented may differ from system to system.
One of the characteristics of frame systems is that information at the top of a class hierarchy is fixed, and as such can provide expectations about specific occurrences of values at individual frames. No slot values are ever left empty within a frame; rather they are filled with "default" values, which are inherited from their ancestors. These default values form the stereotypical object, and are overwritten by values that better fit the more specific case.
When extracting values from slots, a system may first look if a specific value is already specified for a slot. If it is, then this can be returned as it is assumed to be the most reliable and up-to-date value for that slot. Failing this, the system can either look at successive ancestors of the frame in question and attempt to inherit values which have been asserted into one of these frames (which is known as "value inheritance") or the system can look at the frame itself and its ancestors for procedures (known as "daemons") which specify how to calculate the required value (which is known as "if-needed inheritance"). If none of the above succeeds in obtaining a value, then the system resorts to extracting the default values stored for the prototype object in question.
OntolinguaWHAT to express: Class/relationHOW to express: Frame BasedHOW to interpret the expression: Several models
The name Ontolingua is usually employed to denote both a System for the management of portable ontology specifications and the language therein used. The Ontolingua tool, first introduced in a work by Gruber[Gr93] [Gr92][FF96], is not a knowledge representation system. It is a tool to translate ontologies from a common, shared language to the languages or specification formalisms used in various knowledge representation systems.
The idea behind it is that to allow sharing of ontologies among different groups of users, adopting different representations, it is better to have them first represented in a single, expressive language with clearly defined semantics. Ontologies described in such language may be then translated into implemented systems, suitable for the task at hand, possibly with limited expressive and reasoning capabilities. In order to give clear, declarative semantics to ontology specifications, the Ontolingua syntax and semantics are built on top of those of KIF, the knowledge interchange format (cf. Section ). Internally, an Ontolingua ontology is a represented with a theory of KIF axioms.
Deliverable D8.1 22/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Anyway, to express ontologies through the fine-grained constructs available in the predicate calculus is not a straight task. Moreover, this is also far from the spirit of many knowledge representation tools, that often adopt an object-oriented or Frame based approach to representation. Allowing users to specify ontologies in a familiar frame-like style helps both the ontology designer and the developer of a translation module. To meet this purpose, Ontolingua offers a definition language that tries to abstract from specific representation languages offered by various systems and to offer a description facility which is close in spirit to many Frame-based and Object Oriented knowledge representation languages. Ontolingua definitional forms act as wrappers around sets of KIF sentences, allowing better handling and pushing the user to use just certain easily translatable constructs.
Two main mechanisms support the Frame-oriented approach in handling KIF constructs. First, Ontolingua features a simple definition language that allows to associate a symbolic name to a textual string (for documentation), a set of variables and a set of KIF axioms, through LISP-style forms. Forms are provided to define this way relations, classes, functions, objects and theories (the name theory denote sets of Ontolingua definitions in the Ontolingua terminology). Any legal KIF sentence may be used in these definitions. At a logical level, Ontolingua definitions are equivalent to set of KIF sentences (and they may be easily translated into their KIF equivalents, which are used for internal treatment). For example, using the define-class construct is equivalent to specifying a set of assertions on a unary-predicate symbol. Definitional forms serve as a mean to guide the developer in specifying axioms consistently with a conceptualization of modeling construct, which is inherently frame-oriented. Imposing a structure on the definitions used in the ontologies helps the translation task and guides a user in specifying portable ontologies.
Second, an ontology (an Ontolingua theory) called the Frame-ontology specifies a set of terms trying to capture conventions used in many frame systems. The Frame ontology specifies only second-order relations, defining them through KIF axioms. It serves to diverse purposes. It associates precise semantics to concepts used for ontology modeling in Ontoligua itself. For example, a relation in Ontolingua is defined as a set of tuples, based on the set and tuple concepts which are built-in into KIF. A Class in Ontolingua is defined as a unary relation. The axioms contained in the Frame-ontology are implicitly added to each ontology defined through Ontolingua. One can think of KIF plus the Frame ontology as a specialized representation language. Second order terms defined in the Frame Ontology may be used during modeling (for example, in the context of definition forms) as a compact representation for their first order equivalents. The canonical form produced by Ontolingua during translations is based on these second order relations. Ontolingua is capable of recognizing different variants of expanded forms of these relations and converting them to their compact form. This helps overcome stylistic differences among different ontologies. The terms contained in the Frame Ontology are the only second-order constructs for which Ontolingua guarantees translation to the target implemented systems. Defining these constructs in a separate way allows to improve translation, as they are usually linked to special, ad hoc constructs found in the target languages. To help developers, various definition styles and syntactic variants are allowed. Ontologies defined with this language are then normalized translating them into a single, canonical form and passed to different modules that perform the task of translating them to specific system’s representation languages or formalisms.
Deliverable D8.1 23/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
As already noticed, Ontolingua is not a system designed to represent and query knowledge, but a tool to manage portable ontology definitions and to translate them to a set of implemented KR systems. The KIF language, which is used to represent Ontolingua ontologies, has been designed as a mean to communicate knowledge, representing it in a way that is both parsable and human readable, and not to support automated reasoning. It is very expressive, so much that is impossible to implement a tractable theorem-prover, which can answer arbitrary queries in the language. Conversely, most implemented KR systems typically support limited reasoning over a restricted subset of full first order logic. The completeness of the translation of general KIF expressions is limited by the expressiveness of target systems. Only a subset of the legal KIF sentences will be properly handled by a given implemented representation system into which Ontolingua is translating.
As described above, Ontolingua imposes a structure on the definition of terms and is only guaranteed to translate sentences written with a restricted set of easily recognized second-order relations (those contained in the Frame-Ontology). Using the provided definitional forms and second order relations and avoiding certain special constructs found in KIF (such as the non-monotonic consis operator) favors portability. Furthermore, it facilitates the task of translation. However, there is no real limitation on the KIF constructs that may be used in representation. Everything that is legal in KIF 3.0 is also legal in the specification of an Ontolingua theory.
OCMLWHAT to express: Class/relationHOW to express: Frame basedHOW to interpret the expression: Single model
OCML[Mo98] is a knowledge modeling language originally developed in the context of the VITAL project, which was aimed at providing a framework to support development of knowledge-based systems over their whole life cycle. Its main purpose is to support knowledge level modeling. This implies that it focuses on logical more than on implementation level primitives. This approach is consistent with other approaches to knowledge modeling such as that of Ontolingua (cf. Section ). In fact, OCML has been designed with an eye at compatibility with emergent standards such as Ontolingua itself, and its main modeling facilities closely resemble those of Ontolingua.
Differently from Ontolingua, however, OCML is a representation language that is directly aimed at prototyping KB applications. It has operational semantics and provides interactive facilities for theorem proving, constraint checking, function evaluation, evaluation of forward and backward rules. Moreover, in order to allow different approaches to the development of knowledge based applications and to simplify fast-prototyping, OCML provides also non-logical facilities such as procedural attachments. Apart from its operational nature, another difference is that OCML is not only aimed at representing terminological knowledge, but also behavior. This is supported by primitives that allow to specify control structures. While formal semantics may be provided for a subset of OCML constructs, based on that of the
Deliverable D8.1 24/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
corresponding Ontolingua constructs, no formal semantics is provided for the control language and for procedural attachments.
Further differences are due to the fact that OCML has been influenced by the ideas at the base of the Task/method/domain/application (TDMA) framework, that follows a reuse-oriented approach to the development of knowledge-based applications. In order to support this framework, OCML provides primitives to model both domain knowledge and mapping knowledge, which is used to integrate knowledge from generic, reusable knowledge components such as domain independent problem solving methods and multi-functional domain models.
Extensions to the language suitable to specify task and method components are provided as a separated representation ontology. Indeed, OCML comes with a pre-built base-ontology that has a role closely similar to that played by the Frame-Ontology in Ontolingua, except that the definition it contains are operational and it also defines terms needed for task and method modeling.
OCML’s syntax, similarly to that of Ontolingua, is defined by a mixture of LISP style definitional forms and KIF syntax (cf. Section ). It is based on three basic constructs, namely functional terms, control terms and logical expressions. Functional terms and logical expressions may be used to specify relations, functions, classes, slots, instances, rules, and procedures.
Relations, function, classes, slot, procedures and rules definitions allow to specify semantics mixing constructs with formal and operational meaning. Furthermore, some constructs play both-role. For example, in the context of a relation definition, the iff-def keyword specifies that a necessary and sufficient condition hold. It also implies that the condition may be used to enforce a constraint and that the proof mechanisms may be used to decide whether or not the relation holds for some arguments. Procedures define actions or sequences of actions that cannot be characterized as functions between input and output arguments (for instance, updates on slot values). OCML provides an interactive tell/ask interface. The same keywords used to interact with this shell are also used in procedures definitions to specify changes in a KB.
OKBC/GFPWHAT to express: Class/relation HOW to express: Frame Based HOW to interpret the expression: Single model
OKBC (Open Knowledge Base Connectivity)[Ch98][CF98] and its predecessor GFP (Generic Frame Protocol) [KM95] are not languages for the representation of Knowledge Bases. They are APIs and reference implementations that allow to access and interact in a uniform way with knowledge bases stored in different knowledge representation systems. They were
Deliverable D8.1 25/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
developed to allow knowledge application authors to write representation tools (e.g., graphical browsers, frame editors, analysis tools, inference tools) in a system-independent (and thus interoperable) fashion, shielding applications from many of the idiosyncrasies of a specific KRS. GFP was primarily aimed at systems that can be viewed as frame representation systems, while OKBC aims have been extended to general KRSs.
OKBC provides a uniform knowledge model of KRSs, based on a common conceptualization of knowledge bases, classes, individuals, slots, facets, and inheritance. It also specifies a set of operations based on this model (e.g., find a frame matching a name, enumerate the slots of a frame, delete a frame). The OKBC knowledge model is an implicit representation formalism that underlies all the operations provided by OKBC. It serves as an implicit interlingua for knowledge that is being communicated using OKBC, and systems that use OKBC translate knowledge into and out of that interlingua as needed.
The OKBC Knowledge Model supports an object/frame-oriented representation of knowledge and provides a set of representational constructs commonly found in frame-based knowledge representation systems. To provide a precise and succinct description of the OKBC Knowledge Model, the OKBC specification uses KIF, the Knowledge Interchange Format (cf. Section ) as a formal specification language.
A frame is a primitive object that represents an entity in the domain of discourse. A frame has associated with it a set of own slots, and each own slot of a frame has associated with it a set of entities called slot values. Formally, a slot is a binary relation. An own slot of a frame has associated with it a set of own facets, and each own facet of a slot of a frame has associated with it a set of entities called facet values. Formally, a facet is a ternary relation. Slot and facets are in the universe of discourse and may optionally be represented by frames.
A class is a set of entities and is represented with a unary relation. Each of the entities in a class is said to be an instance of the class. An entity can be an instance of multiple classes, which are called its types. A class can be an instance of a class. A class that has instances being themselves classes is called a meta-class. Entities that are not classes are referred to as individuals. A class is represented through a frame. A frame that represents a class is called a class frame, and a frame that represents an individual is called an individual frame.
A class frame has associated with it a collection of template slots that describe own slot values considered to hold for each instance of the class represented by the frame. The values of template slots are said to inherit to the subclasses and to the instances of a class. The OKBC knowledge model includes a simple provision for default values for slots and facets. Template slots and template facets have a set of default values associated with them. Intuitively, these default values inherit to instances unless the inherited values are logically inconsistent with other assertions in the KB, the values have been removed at the instance, or the default values have been explicitly overridden by other default values.
A knowledge base (KB) is a collection of classes, individuals, frames, slots, slot values, facets, facet values, frame-slot associations, and frame-slot-facet associations. KBs are considered to be entities in the universe of discourse and are represented by frames. The frames representing KBs are considered to reside in a distinguished KB called the meta-kb, which is accessible to OKBC applications.
Deliverable D8.1 26/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
The OKBC Knowledge Model includes a collection of classes, facets, and slots with specified names and semantics. It is not required that any of these standard classes, facets, or slots be represented in any given KB, but if they are, they must satisfy the semantics prescribed by the OKBC specification. For example, the OKBC specification defines the meaning of the class :CLASS, which always maps to the class of all classes.
XOLWHAT to express: Class/relationHOW to express: Frame BasedHOW to interpret the expression: Single model
The language called XOL[KC99] was inspired by Ontolingua (cf. Section ) and OML. As Ontolingua, it has been designed as an intermediate language for transferring ontologies among different database systems, ontology-development tools, or application programs. Its syntax is based on XML, and its semantics are defined as a subset of the OKBC knowledge model called OKBC-Lite. OKBC-Lite extracts most of the essential features of OKBC, while not including some of its complex aspects.
The design of XOL uses what its authors call a “generic approach” to defining ontologies, meaning that a single set of XML tags (described by a single XML DTD) defined for XOL can describe any and every ontology. This approach contrasts with the approaches taken by other XML schema languages, in which typically a generic set of tags is used to define the schema portion of the ontology, and the schema itself is used to generate a second set of application-specific tags (and an application-specific DTD) that in turn are used to encode a separate XML file that contains the data portion of the ontology (cf. Section ).
The ontology building blocks defined by the OKBC-Lite Knowledge Model include classes, individuals, slots, facets, and knowledge bases. A main difference from the OKBC knowledge model (cf. Section ) resides in that all references to the notion of ``frame'' have been eliminated. Other differences lie in restrictions to the kind of facets and of basic data types available. OKBC-lite treats classes in much a similar way as OKBC. A class is a set of entities. Each of the entities in a class is said to be an instance of the class. An entity can be an instance of multiple classes, which are called its types. A class can be an instance of another class. A class that has instances that are themselves classes is called a meta-class. Entities that are not classes are referred to as individuals. Thus, the domain of discourse consists of individuals and classes. In the XOL specification, classes and individuals are generically referred to as entities (but note that entities is just a common name to refer to both classes and individuals and not a concept of the model).
The OKBC-Lite knowledge model assumes that every class and every individual has a unique identifier, also known as its name. The name may be a string or an integer, and is not necessarily human readable. As already mentioned, frames are not considered in the OKBC-lite model. Thus, classes and individuals stand for themselves and are not represented through frames. The concept of own slot is transferred to both classes and individuals. Note that,
Deliverable D8.1 27/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
though slots have a unique name like classes and individuals, they may only be used in conjunction with the class that owns them. The same holds for slot values or facets with regards to the owner slot. Instance-of, type–of subclass-of and superclass-of relations may be specified between classes or classes and individuals. Template slots and facets and default values are also modeled in a way similar to how they are modeled in OKBC, and inherited in a pretty similar fashion.
A knowledge base is a collection of classes, individuals, slots, slot values, facets, and facet values. A knowledge base is also known as a module. As the OKBC knowledge model, the OKBC-Lite knowledge model includes a collection of classes, facets, and slots with standard names and semantics.
Differently from the OKBC model, the semantics of the OKBC-lite model are only given in an informal way. The XOL DTD defines the structure of XOL documents, by XML-izing the conceptual components of the OKBC-lite model. The DTD defined in the specification gives necessary but not sufficient rules for the well-formedness of XOL documents. Other rules, for example regarding uniqueness of names and order between elements are specified in the specification in an informal way.
II.2.3.3Conceptual and semantic data models
In the 70s, traditional data models (relational, hierarchical and network), were gaining wide acceptance as bases for efficient data management tools. Data structures used in these traditional models are relatively close to those used for the physical representation of data in computers, ultimately viewing data as collections of records with printable or pointer field values. Semantic (or conceptual) models [HK87] were introduced primarily as schema design tools: a schema could be first designed in a high level semantic model and then translated into one of the traditional, record oriented models such as the relational one, for ultimate implementation. Examples of proposed semantical data models are The ER and Extended ER data model, FDM (Functional data model), SDM (Semantic Data Model). The emphasis of the initial semantic models was then to accurately model data relationships that arise frequently in typical database applications. Consequently, semantic models are more complex than the relational model and encourage a more navigational view of data relationships.
Semantic models provide more powerful abstractions for the specification of databases. The primary components of semantic models are the explicit representation of objects, attributes of and relationships among objects, type constructors for building complex types, ISA relationships and derived schema components. In typical implementations of semantic data models, abstract objects are referenced using internal identifiers that are not visible to users. A primary reason for this is that objects in a semantic data model may not be uniquely identifiable using printable attributes that are directly associated with them.
Not all the basic features listed above are supported by all models. Even if they are supported, most models impose some kind of restriction on the use of these constructs. Some of the models were first proposed with a limited subset of the above-mentioned features, and were subsequently extended to include some other features. For example, the original ER model
Deliverable D8.1 28/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
proposed by Chen did not allow ISA relationships. The Extended Entity Relationship model, which includes ISAs, has been proposed later and is now widely used.
Despite the similarity of many of their features, semantic data models differ from object-oriented models in that the former tend to encapsulate the structural aspects of objects, whereas the latter describe more behavioral aspects. Object oriented models do not typically embody the rich type constructors of semantic models. Semantic models also show many analogies with models traditionally used in the AI field, like those based on frames. Frame-based systems allow representation of abstract types, which are typically organized in ISA hierarchies. Anyway, frame-based systems usually don’t allow explicit type-construction mechanisms such as aggregation and grouping. Furthermore, many frame systems allow slots to hold executable attachments that behave in a way not dissimilar from methods in object-oriented systems.
After the introduction of Semantic data models, there has been increasing interest in using them as the bases for full-fledged database management systems or at least complete front end to existing systems. A major problem in accomplishing this task was to give them give precise semantics and enable reasoning on conceptual schemas. Recent research has focused on the use of Description Logics for this purpose [CC02] .
Conceptual data schemes and ontologies share many similarities, and there are proposals of using conceptual methodologies and tools for ontology modeling. For example, [JD03] proposes a methodology for ontology building with semantic models and a markup language to exchange conceptual diagrams at run-time. The proposed methodology is applied to the ORM (Object-Role Modeling) semantic model, but it may be extended to other semantic models as well.
II.2.3.4Information systems and software formalisms
Several formalisms to aid design of software artifacts and information systems started to appear since the mid seventies. Between the first to be proposed were the Structured Analysis and Design Technique (SADT) and the Requirements Modeling Language (RML)[Gr84] Between the mid 1970s and the late 1980s various object-oriented modelling languages and methodologies started to appear. For instance OOA, the Conceptual Modeling Language (CML) [St86] and Telos[MB90]. The number of OO modelling langues continued to increase during the period between 1989-1994, partly because no one single model seemed completely satisfactory to users. By the mid-1990s, new iterations of these methods began to appear and these methods began to incorporate each other’s techniques, and a few clearly prominent methods emerged. In late 1994 Grady Booch and Jim Rumbaugh of Rational Software Corporation began their work on unifying the Booch and OMT (Object Modeling Technique) methods. In the Fall of 1995, Ivar Jacobson and his Objectory company joined Rational and this unification effort, merging in the OOSE (Object-Oriented Software Engineering) method. This lead to the deveopment of UML (Unified Modeling Language), which is now one of the most widely used formalisms for Information Systems design.
Deliverable D8.1 29/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
UMLWHAT to express: Class/relationHOW to express: IS formalismHOW to interpret the expression: Single model
UML[UML] was originally designed for human-to-human communication of models for building systems in object-oriented programming languages. Over the years, though, its use has been extended to a variety of different aims, including the design of databases schemas, XML document schemas, and knowledge models. Several complementary standards have continued to emerge after the release of UML, such as the OCL (Object Constraint Language) which allows to specify constraints, the OMG MOF[MOF] (Meta Object Facility).
UML primary drawbacks lie in a lack of formally defined semantics, as the OMG standard gives only an informal specification of UML semantics. Another issue is the lack of a standard textual representation. Anyway, the OMG is in the process of adopting XMI(XML Metadata Interchange) [XMI] as a standard for stream-based model interchange.
Various attempts have been made to give formal semantics to the language (e.g. [EF97] [CE97] [Ev98] ). In particular, latest proposals, such as [CC02], are based on Description Logics and try to establish a solid basis for allowing automated reasoning techniques, to be applicable to UML class diagrams.
Concurrently, there have been various proposals that advocate the use of UML for ontology modeling and representation. For example,[CP99] focuses on a subset of the language (In particular the Class Diagram, complemented by the OCL language in order to express constraints and rules). [BM99] examines similarities and differences between UML and ontology languages like DAML+OIL (cf. Section ), and [GW04] analyzes the problem of assigning ontologically well-founded semantics to the UML modeling constructs.
II.2.3.5Graph-based models
The ability to display problems and knowledge in a graphical and thus intuitive way has always had an important role in research fields connected to KR. In particular, several formalisms based on various kinds of graph based or graph-oriented notations have been proposed and studied.
In this section we review some of the most influential graph based formalisms. Two of them, namely semantic networks and conceptual graphs, originated from the AI community, and have been subject of research for a long time. OML/CKML is a framework and markup language for knowledge and ontology representation based (also) on conceptual graphs. Conversely, Topic Maps are a quite recent proposal that originated from the web and XML community.
Semantic Networks
Deliverable D8.1 30/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
WHAT to express: Class/relation HOW to express: Graph based modelsHOW to interpret the expression: Single model
Semantic networks are knowledge representation schemes involving nodes and links (arcs) between nodes. The nodes represent objects or concepts and the links represent relations between nodes. The links are directed and labeled; thus, a semantic network is a directed graph. The term “semantic net” appeared when Richard H. Richens of the Cambridge Language Research used them in 1956 as an "interlingua" for machine translation of natural languages. The term “semantic networks” dates back to Ross Quillian's Ph.D. thesis (1968)[Qu68], in which he first introduced it as a way of talking about the organization of human semantic memory, or memory for word concepts. The idea of Semantic Networks, though, that is of a network of associatively linked concepts, is very much older, as Porphyry’s tree (3rd century AD), Frege’s concept writing (1879), Charles Peirce Existential Graphs (1890’s), Steltz’s concept hierarchies (1920’s) and other similar formalisms used in various fields (philosophy, logic, psychology, linguistics) may all be considered examples of semantic networks.
Quillian's basic assumption was that the “meaning” of a word could be represented by the set of its verbal associations. From this perspective, concepts have no meaning in isolation, and only exhibit meaning when viewed relative to the other concepts to which they are connected by relational arcs. In Quillian's original semantic networks, a relation between two words might be shown to exist if, in an unguided breadth-first search from each word, there could be found a point of intersection of their respective verbal associations. While Quillian's early nets might have appeared to be an attractive psychological model for the architecture of human semantic knowledge, they did not provide an adequate account of our ability to reason with that knowledge. A couple of years later a psychologist, Allan Collins, conducted a series of experiments along with Quillian to test the psychological plausibility of semantic networks as models. The networks they used gave far greater prominence than before to the hierarchical organization of knowledge, being organized as taxonomic trees or isa hierarchies in which each node stated properties that are true of the node and properties of higher nodes are inherited by the lower nodes to which they are connected, unless there is a property attached to a lower node that explicitly overrides it.
As semantic networks seemed to mimic the way the human mind structures knowledge, they were regarded has an attractive way to represent knowledge in AI Knowledge Representation System.
Semantic networks as a representation of knowledge have been in use in artificial intelligence (AI) research in a number of different areas. Another major area in which the use of semantic networks is prevalent, is in models based on linguistics. These stem in part from the work of Chomsky. This latter work is concerned with the explicit representation of grammatical structures of language. It is opposed to other systems that tried to model, in some machine-implementable fashion, the way human memory works. Another approach combining aspects of both the previously mentioned areas of study was taken by Schank in his conceptual dependency approach. He attempted to break down the surface features of language into a
Deliverable D8.1 31/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
network of deeper, more primitive concepts of meaning that were universal and language independent.
Despite their influence, a major problem with semantic networks was a lack of clear semantics of the various network representations. In particular, they lacked a clear meaning for what nodes and arcs represented. Semantic networks do tend to rely upon the procedures that manipulate them. For example, the system is limited by the user's understanding of the meanings of the links in a semantic network. No fundamental distinction is made between different types of links, for example those that describe properties of objects, and those that make assertions, nor between classes of objects and individuals. The interpretation of nodes suffers an analogous ambiguity. One interpretation of generic nodes (ones that refer to a general class or concept) is as sets. Thus the relation holding between a node at one level of a hierarchy and that at a higher level is that of subset to superset. If the generic node is interpreted as a set, then the relation of nodes representing individuals to generic nodes in the network is that of set membership. A second interpretation of generic nodes is as prototypes, and of instance nodes as individuals for whom the generic nodes provide a prototypic description. Individuals will then be more or less like the prototype.
Several studies tried to give more precise semantics to networks (e.g. [Be01][AF82][Be01]). The research trend originating from these first attempts has lead to the development of Description Logics.
In the 1960s to 1980s the idea of a semantic link was developed within hypertext systems as the most basic unit, or edge, in a semantic network. These ideas were extremely influential, and there have been many attempts to add typed link semantics to HTML and XML.
Conceptual GraphsWHAT to express: Class/relationHOW to express: Graph basedHOW to interpret the expression: Single model
A particular use of semantic networks is to represent logical descriptions. Conceptual writing of Frege and the Existential Graphs of Charles S. Peirce represent an early attempt at finding form of diagrammatic reasoning. Conceptual Graphs are a kind of semantic network related to the Existential Graphs of Peirce. They were introduced by John F. Sowa[So84].
Their intended aim is to describe concepts and their relations in a way that is both close to human language and formal, in order to provide a readable, but formal design and specification language. They should also allow a form of reasoning that may be performed directly on their Graphic representation, by means of subsequent transformations applied to the (conceptual) Graph.
Basically, a conceptual graph is a bipartite graph containing two kind of nodes, called respectively concepts and conceptual relations. Arcs link concepts to conceptual relations, and each arc is said to belong to a conceptual relation. There are no arcs that link concepts to concepts or relations to relations. Concepts have an associated type and a referent. A referent
Deliverable D8.1 32/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
is a way to denote the entity of the Universe of Discourse to which the concept refers. It consists of a quantifier, a designator, which either “points” to the referent or describes it, and a descriptor, which is a Conceptual Graph describing some aspects of the referent. Note that a quantifier here may only be of existential kind or specify that a precise number of instances of the referent exist. A descriptor is considered as a Conceptual Graph nested into a concept. The concept is said to be a Context for the nested CG. Conceptual relations are typed, too. A relation type associates to a conceptual relation a valence (equal to the number of arcs that belong to the relation) and a signature that constraint the types of concepts linked to the relation. A complete presentation of CGs is outside of the scope of this document. Some basic notions may be found in [CM92]
The book published by Sowa received conflicting initial reactions[Cl85][Sm87]. Subsequent papers clearly shown some errors in Sowa’s theses, and highlighted the need for a much cleaner formalization of CGs [WebKB]. Various other attempts at formalizing CGs have been proposed during the years. Another problem related to Conceptual Graphs was that, since they have shown to have the same expressive power of first order logic, most of the problems that are interesting when reasoning on conceptual graphs (like validity and subsumption) are undecidable. Several problems remain NP-complete even when reasoning on restricted versions of the Graphs, like Simple Graphs (corresponding to the conjunctive, positive and existential fragment of FOL). To overcome this inconvenient, there have been attempts to identify guarded fragments of CGs [BC03].
Despite all this problems, the ideas behind Conceptual Graphs seem to have been highly influential. For example, there are many similarities between CGs and the Resource Description Framework, RDF (some similarities and differences are explained by Tim Berners Lee in [BH01]). Refer to Section for an introduction of RDF.
Sowa is preparing a proposal for a standardization of Conceptual Graphs, to be submitted to ISO [SCG]. The draft presents conceptual graphs as a graphic representation for logic, with the full expressive power of first-order logic and with extensions to support metalanguage, modules, and namespaces. It describes the abstract syntax on which conceptual graphs are based and also three concrete syntaxes that may be use for actual representation of Conceptual graphs. They are, respectively, a Display Form, which is essentially graphical, a linear form, which is textual, and a machine-readable form, called CGIF (Conceptual Graphs Interchange Format). The draft asserts that CGIF sentences may be converted to logically equivalent sentences in the KIF language, (cf. Section ). This allows to give CGIF sentences the same model theoretic semantics defined for the KIF language. Anyway, the document is still unclear about the translation rules to be used.
The draft also gives a deductive system for Conceptual Graphs based on six “canonical formation rules”. Each rule performs one basic graph operation. Logically, each rule has one of three possible effects: it makes a CG more specialized, it makes a CG more generalized, or it changes the shape of a CG while leaving it logically equivalent to the original. All the rules come in pairs: for each specialization rule, there is a corresponding generalization rule; and for each equivalence rule, there is another equivalence rule that transforms a CG to its original shape. These rules are essentially graphic. Each rule is said to have a correspondent inference rule in predicate calculus. These inference rules, however, are not currently shown in the draft.
Deliverable D8.1 33/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
OML/CKMLWHAT to express: EverythingHOW to express: Graph Based HOW to interpret the expression: Single modelConceptual Knowledge Markup Language (CKML)[Ke99][Ke00][OML] is an application of XML. It follows the Conceptual Knowledge Processing (CKP) approach to knowledge representation and data analysis and also incorporates various principles, insights and techniques from Information Flow (IF), the logical design of distributed systems. CKML incorporates the CKP ideas of concept lattice and formal context, along with the IF ideas of classification (= formal context), infomorphism, theory, interpretation and local logic. Ontology Markup Language (OML), a subset of CKML that is a self-sufficient markup language in its own right, follows the principles and ideas of Conceptual Graphs (CG). OML is used for structuring the specifications and axiomatics of metadata into ontologies. OML incorporates the CG ideas of concept, conceptual relation, conceptual graph, conceptual context, participants and ontology.
OML owes much to pioneering efforts of the SHOE initiative[HH99]. The earlier versions of OML were basically a translation to XML of the SHOE formalism, with suitable changes and improvements. Common elements could be described by paraphrasing the SHOE documentation. Later versions are RDF/Schemas compatible and incorporate a different version of the elements and expressiveness of conceptual graphs.
The Information Flow Framework (IFF)[Ke00], a new markup language related to OML/CKML is currently being designed. It is founded upon the principles and techniques of Information Flow and Formal Concept Analysis, which incorporates aspects (classification, theories, logics, terminologies) from OML/CKML, OIL and RDF/S.
Ideas in OML/CKML and IFF are also at the base of the development of the SUO (Standard Upper Ontology) initiative [SUO].
Topic MapsWHAT to express: Class/relationHOW to express: Graph BasedHOW to interpret the expression: N/A (No formal semantics)
Topic Maps are a way of modelling a set of subjects, the relationships between them and additional information about them, with the same logics of a “back-of-book” index. The topic map paradigm is described in the ISO standard ISO 13250:2002 [TM]. The first edition of the ISO specification (2000), described an an interchange syntax (HyTM) based on SGML. Since then, a separate consortium, TopicMaps.Org[TM], have produced a version of the topic map paradigm for use in a web environment. The XML Topic Maps (XTM) 1.0 specification [PM01] developed by TopicMaps.Org defines an interchange syntax based on XML and
Deliverable D8.1 34/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
XLink. XTM has now been adopted by ISO and the ISO 13250 standard in its second edition now contains both syntaxes.
In essence a topic map can be thought of as consisting of just three things:
o Topics which describe subjects in the real world. A subject may be something that is addressable by a machine (e.g. a web-page with a URL), something which is not addressable (such as a person) or even an abstract concept (such as 'Music').
o Associations which describe the relationships between topics. The association construct may include additional typing information which specifies the nature of the relationship between the topics and also what role each topic plays in the relationship. So an association can be used to represent such common concepts as a hierarchy, or a group but also more complex relationships such as a meeting (with topics representing people and playing roles such as 'chairman', 'scribe' and 'attendee').
o Occurrences which connect a topic to some information resource related to the topic. The occurrence can be used to specify both the information resource (or the information itself) and the nature of the relationship between the information resource and the topic. For example, a topic could represent a person and that topic could have an occurrence which is a URL which points to the 'homepage' of the person. Figure 1:Resource management in the topic maps model.
Furthermore, other important concepts are:
o Topic classes, Occurrences classes, Association classes: allow to group different kinds of topics, occurrences and associations, respectively. Topics, occurrences and associations are instances of such classes. It is important to note that these classes are topics as well. It is possible to define a taxonomic hierachy of these classes.
o Scope: a scope indicates the context within which a characteristic of a topic (a name, an occurrence or a role played in an association) may be considered to be true. One common use of scope is to provide localised names for topics. For example "company" in English could be "société" in French or "Firma" in German. They all describe the same concept and so should be represented by the same topic. Rather than creating separate topics one should instead create a single topic to represent the
Deliverable D8.1 35/206
Conceptual Topic Relation
Conceptual Occurrence
Relation
Conceptual Association Relation
Conceptual Resource Relation

INTEROPInteroperability Research for Networked Enterprises Applications and Software
concept of a company and add to it three separate base names, using scope to indicate that a particular base name should be used for a specific language environment.
In addition to defining these basic structures, the topic map standards also define the way in which two or more topic maps may be combined or merged. Topic map merging is a fundamental and highly useful characteristic of topic maps as it allows a modular approach to the creation of topic maps and it provides a means for different users to share and combine their topic maps in a controlled manner.
Topic Maps are very flexible but difficult to evolve, maintain and keep consistent. Furthermore they have a non-well defined semantics. they represent an informal (or, at least, semi-formal) approach to knowledge representation. Some work is currently being done on a formal data model for topic maps (e.g.[MG01][AO02] ). Despite this lack of formal semantics and the relatively new status of related standards (the ISO specification was published in January 2000, with the XTM specification being completed in February 2001), Topic Maps are used for several Knowledge Management applications. Commercial and non-commercial implementations of so-called 'topic map engines' are already being offered. These 'engines' have certain features in common - all provide the means to persistently store data structured as topic maps and to retrieve that data programmatically via an API. Other commercial and non-commercial applications of those engines are also available, including applications to present topic map data in a user-friendly browser-interface and applications to manually or automatically create topic maps from data sources.
II.2.3.6Logic-based languages
In this section, we introduce the class of languages that are based on logic. Such languages express a domain-ontology, i.e. a conceptualization of the world, in terms of the classes of objects that are of interest in the domain, as well as the relevant relationships holding among such classes.
These kinds of languages have a formal well-defined semantics. Intuitively, this means that, given exact meanings for the symbols of the language, i.e. exact referent in the set of all objects presumed or hypothesized to exist in the world, called universe of discourse (also called domain of interpretation), the semantics of the language tells the exact meaning of arbitrary sentences. Nevertheless, in keeping with traditional logical semantics, it is not possible to know the exact referent in the universe of discourse for every constant in the language, since everybody has his own, incomplete, perception of the objects of the world. Thus, the semantics of the language cannot pick out exact meanings for all expressions in the language, but it does place constraints on the meanings of complex expressions. Therefore, objects in the universe of discourse do not in themselves have any meaning, nor does the choice of any particular set of objects that make up the universe of discourse - what is important is the relationships between objects and sets of objects. Such relationships have to hold in all possible universe of discourse.
More formally, the semantics of a logic-based language is given via interpretations. An interpretation is a couple I=(UI,I), where UI is the domain of interpretation and I is a function that gives to all objects, combinations of objects and relationships of the language, a meaning in the domain UI. Given an ontology expressed in a logic-based language, a model is an interpretation that gives the ontology a meaning that is consistent with respect to the
Deliverable D8.1 36/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
domain UI. An ontology in such languages describes objects and relationships that have to exist and hold respectively in all its possible models.
We will first present languages based on first-order predicate logic. Then we will discuss ontology languages based on Description Logics. Finally, process/action specification-languages will be introduced.
Based on first-order predicate logicIn what follows, we provide a brief presentation of the most common ontology languages that are based on first order predicate logic. An ontology in such languages is described in terms of constants, predicates, functions.
We will present two languages, KIF and CycL, that both provide an important extension of first-order logic, by allowing the reification of formulas as terms used in other formulas. Therefore, KIF and CycL allow meta-level statements. As a matter of fact, such languages are not intended to provide logical reasoning, since this would be necessarily undecidable.
KIF
WHAT to express: Class/relationHOW to express: Logic-basedHOW to interpret the expression: Several models
Knowledge Interchange Format (KIF)[GF92] is a formal language for the interchange of knowledge among disparate computer programs. Different programs can interact with their users in whatever forms are most appropriate to their application. A program itself can use for the computation whatever internal form it prefers for the data it manages. The idea is that when a program needs to communicate with another program, it maps its internal data structures into KIF. Therefore, KIF is not intended neither as a primary language for interaction with human users, nor as an internal representation for knowledge within computer programs. On the contrary, its main purpose is to facilitate the independent development of knowledge-manipulation programs.
Given the following basic features, KIF can be used as a representation language, though.
1. The language has a declarative semantics, which means that it is possible to understand the meaning of the expressions of the language without appeal to an interpreter.
2. The language is logically comprehensive, in that it provides for the expression of arbitrary sentences in the predicate calculus.
3. The language provides means for the representation of knowledge about the representation of knowledge.
4. The language provides for the definition of axioms for constants.
5. The language provides for the specification of non-monotonic reasoning rules.More in details, a knowledge base in KIF consists of a set of forms, where a form is either a sentence, a rule, or a definition. Let us give an insight on these three types of forms. A
Deliverable D8.1 37/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
sentence, which may be quantified universally or existentially, can be either a logical constant, an equation, an inequality, a relation constant associated to an arbitrary number of arguments or, finally, a combination of sentences by means of classic logical operators (negation, conjunction, disjunction, implication and equivalence). Such a sentence may contain (free) variables. A definition, for most purposes, can be viewed as shorthand for the sentences in the content of the definition. It allows to state sentences that are true “by definition”. A rule, that is called forward or reverse depending on the particular operator involved, can be monotonic or non-monotonic. Monotonic rules are similar to inference rules, familiar from elementary logic. Non-monotonic rules provide the user to express his non-monotonic reasoning policy within the language, in order to draw conclusions based, for example on the absence of knowledge.
Note that constants of the language can be either objects constants, function constants, relation constants or logical constants, that express conditions about the world and can be either true or false. There is no way of determining the category of a (non-basic) constant from its syntax. The distinction is entirely semantic, which reifies second-order features in KIF, by letting express statements about statements.
CycL
WHAT to express: Class/relationHOW to express: Logic BasedHOW to interpret the expression: Several models
Begun as a research project in 1984, Cyc [Le95] purpose was to specify the largest common-sense ontology that should provide Artificial Intelligence to computers. Such a knowledge base would contain general facts, heuristics and a wide sample of specific facts and heuristics for analogising as well. It would have to span human consensus reality knowledge: the facts and concepts that people know and those that people assume that others know. Moreover this would include beliefs, knowledge of respective limited awareness of what people know, various ways of representing things, knowledge of which approximations (micro-theories) are reasonable in various context, and so on. Far from having attained this goal, Cyc1 is now a working technology with applications to real-world business problems. Cyc vast knowledge base enables it to perform well at tasks that are beyond the capabilities of other software technologies. At the present time, the Cyc KB contains nearly two hundred thousand terms and several dozen hand-entered assertions about/involving each term.
CycL is the language in which Cyc knowledge base is encoded. It is a formal language whose syntax derives from first-order predicate calculus and from Lisp. In order to express common sense knowledge, however, it extends first order logic, with extensions to handle equality, default reasoning, skolemization, and some second-order features. For example, quantification over predicates is allowed in some circumstances, and complete assertions can appear as intensional components of other assertions. Moreover, CycL extends first-order logic by typing, i.e. functions and predicates are typed.
1? http://www.cyc.com
Deliverable D8.1 38/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
The vocabulary of CycL consists of terms. These are combined into assertions, which constitute the knowledge base. The set of terms can be divided into constants, non-atomic terms, variables, and a few other types of objects (numbers, strings, …). More precisely, constants are the "vocabulary words" CycL. Constants may denote either individuals, collections of other concepts (i.e. sets of the individuals identified by means of unary predicates), arbitrary predicates that allow to express relationships among constants, or functions, which can take constants or other things as arguments, and generate new concepts. A non-atomic term is a way of specifying a term as a function of some other term(s). Every non-atomic term is composed of a function and one or more arguments to that function. Variables stand for constants whose identities are not specified. Finally, an assertion is the fundamental unit of knowledge in the Cyc Knowledge base. Every assertion consists of:
a CycL formula which states the content of the assertion; a CycL formulas has the structure of a Lisp list: it consists of a list of objects, the first of may be a predicate, a logical connective, or a quantifier; the other objects may be atomic constants, non-atomic terms, variables, numbers, strings, or other formulas; to be considered a well-formed formula all the variables it includes need to be bound by a quantifier before being used;
a truth value which indicates its degree of truth; there are five possible truth values, of which the most common are the first two:
o monotonically true: true always and under all conditions;
o default true: assumed true, but subject to exceptions;
o unknown: not known to be true, and not known to be false;
o default false: assumed false, but subject to exceptions;
o monotonically false: false always and under all conditions;
a microtheory of which the assertion is part; a microtheory, also called contexts [RG94], denotes a set of assertions which are grouped together because they share a set of assumptions;
a justification; a justification refers to a reason why the assertion is present in the KB with its truth value; it may be a statement that tells that the formula was explicitly "asserted", or it may be the group of assertions through which the assertion was inferred.
Based on description logicsDescription Logics (DLs) are a family of logic-based knowledge representation formalisms designed to represent and reason about the knowledge of an application domain in a structured and well-understood way. The basic notions in DLs are concepts and roles, which denote sets of objects and binary relations, respectively. Complex concept expressions and role expressions are formed by starting from a set of atomic concepts and atomic roles, i.e., concepts and roles denoted simply by a name, and applying concept and role constructs. Thus, a specific DL is mainly characterized by the constructors it provides to form such complex
Deliverable D8.1 39/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
concepts and roles. DLs differ from their predecessors, such as semantic networks (cf. Section ) and frames (cf. Section II.2.3.2), in that they are equipped with a formal, logic-based semantics. Such well-defined semantics and implemented powerful reasoning tools make DLs ideal candidates for ontology languages [BH04].
In this section, we will present three classes of languages based on description logics. For each of them, we will discuss more deeply some representative languages. Firstly, we will consider languages based on “pure” description logics. Secondly, we will introduce a class of hybrid languages, combining description logics and Horn rules. Thirdly, we will present semantic web ontology languages, whose semantics can be defined via a translation into an expressive DL. An important feature of all the languages that will be discussed is that they come with reasoning procedures that are sound and complete with respect to a specified semantics, i.e. all the sentences that can be inferred from the ontology are true (soundness), and given an ontology, if there is a sentence that is true, then such a sentence can be inferred (completeness).
Observe that, in principle, as long as the trade-off between expressivity of the language and complexity of its reasoning capabilities is investigated and solved with respect to the application domain, any DL language may be used to represent an ontology. However, it is far beyond the scope of this survey to present all the DL languages. For a comprehensive discussion on DLs, [BC03][WS92].
Pure Description Logic languages.An ontology can be expressed in a DL by introducing two components, traditionally called TBox and ABox (originally from “Terminological Box” and “Assertional Box” respectively)2. The TBox stores a set of universally quantified assertions, stating general properties of concepts and roles. Indeed concepts (or roles) are defined intensionally, i.e. in terms of descriptions that specify the properties that objects must satisfy to belong to the concept (or pairs of objects must satisfy to belong to the role). The ABox comprises assertions on individual objects, called instance assertions, that consist basically of memberships assertions between objects and concepts (e.g. a is an instance of C), and between pairs of objects and roles (e.g. a is related to b by the role R). Note that what differentiates one DL from another is the kinds of constructs that allow the construction of composite descriptions, including restrictions on roles connecting objects.
Several reasoning tasks can be carried out on a knowledge base of the above type, in order to deduce implicit knowledge from the explicitly represented knowledge. The simplest forms of reasoning involve computing: i) subsumption relation between two concept expressions, i.e. verifying whether one expression always denotes a subset of the objects denoted by another expression, ii) instance-of relation, i.e. verifying whether an object o is an element denoted by an expression, and iii) consistency algorithm, i.e. verifying whether a knowledge base is non-contradictory.
2 Since TBox and ABox constitute two different components of the same knowledge base, sometimes [FC91] this kind of systems have been also called hybrid. However, we prefer here to distinguish between terminological/assertional hybrid systems in which any of the subsystems may be empty, that we call pure DL systems, and more general hybrid systems that will be presented below.
Deliverable D8.1 40/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
In order to ensure a reasonable and predictable behaviour of a DL system, these inference problems should at least be decidable for the DL employed by the system, and preferably of low complexity. Consequently, the expressive power of the DL in question must be restricted in an appropriate way. If the imposed restrictions are too severe, however, then the important notions of the application domain can no longer be expressed. Investigating this trade-off between expressivity of DLs and the complexity of their deduction capabilities has been one of the most important issues in DL research. As an example of basic DL, we introduce the language ALC in what follows.
The language ALCWHAT to express: Class/relationHOW to express: Logic BasedHOW to interpret the expression: Several modelsALC [SS91] let form concept descriptions starting from atomic concepts, the universal concept (┬) and the bottom concept (), and using basic set operators, namely set complement, intersection and union. It permits a restricted form of quantification realized through so-called quantified role restrictions, that are composed by a quantifier (existential or universal), a role and a concept expression. Quantified role restriction allow one two represent the relationships existing between objects in two concepts. For example one can characterize the set of objects all of whose children are blond as child.Blond as well as the set of objects that have at least one blond child child.Blond. The former construct is called universal role restriction, or also value restriction, while the latter is called qualified existential role restriction.
From the point of view of semantics, concepts are interpreted as subsets of a domain (the universe of discourse) and roles as binary relations over that domain. An interpretation I=(UI,I) over a set A of atomic concepts and a set P of atomic roles consists of a non-empty set UI (also called domain of I) and a function I (called interpretation function of I) that maps every concept a A to a subset AI of UI (the set of instances of A) and every atomic role p P to a subset PI of UI UI (the set of instances of P). The bottom concept is always mapped to the empty set, while the universal concept is mapped to UI. The interpretation function can then be extended to concepts descriptions, inductively, as it follows: (i) the negation of a concept is mapped to the complement of the interpretation of the concept, (ii) the intersection of two concepts is mapped to the intersection of the interpretations of the two concepts, (iii) the union of two concepts is mapped to the union of the interpretations of the two concepts, (iv) the universal role restriction R.C is mapped to the subset of elements a of UI such that if a is related to b by means of the interpretation of R (RI), then b belongs to the interpretation of C, (v) the qualified existential role restriction R.C is mapped to the subset of elements a of UI that are related to an element b of the interpretation of C by means of RI.
Hybrid languages: AL-Log, CARIN.
Hybrid systems are a special class of knowledge representation systems which are constituted by two or more subsystems dealing with distinct portions of a knowledge base and specific reasoning procedures. Their aim is to combine the knowledge and the reasoning of different formalisms in order to improve representational adequacy and
Deliverable D8.1 41/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
deductive power. Indeed, in exchange for a quite expressive description of the domain of interest, DLs pay the price of a weak query language. Indeed, a knowledge base is able to answer only queries that return subsets of existing objects, rather than creating new objects; furthermore, the selection conditions are rather limited. Given such expressive limitations of DL concepts alone as queries, it is reasonable to consider extending the expressive power of standard queries, i.e. Horn Rules, with the structuring power of DLs. In what follows, we will present two languages that have pursued such an issue, each of them is used to specify knowledge in two different hybrid systems.
AL-Log
WHAT to express: Class/relationHOW to express: Logic BasedHOW to interpret the expression: Several modelsAL-Log[DL91] is a system constituted by two subsystems, called structural and relational. The former is based on the DL language ALC and allows one to express knowledge about concepts, roles and individuals. It can be itself regarded as a terminological/assertional system. The latter provides a suitable extensions of Datalog in order to express a form of relational knowledge. The interaction between the two subsystems is realized by allowing the specification of constraints in the Datalog clauses, where constraints are expressed using ALC.. The constraints on the variables require them to range over the set of instances of a specified concept, while the constraints on individual objects require them to belong to the extension of a concept. Therefore DLs is used as a typing language on the variables appearing in the rules, and only unary predicates from the DLs are allowed in the rules.
CARIN
WHAT to express: Class/relationHOW to express: Logic BasedHOW to interpret the expression: Several modelsCARIN [LR96] is a family of representation languages parameterised by the specific DL used, provided it is any subset of the expressive DL ALCNR [BD93], which extends ALC, by unqualified number restrictions, i.e. the possibility to constrain the number of arbitrary objects that are in relationships with a given object, and by intersection of roles. A CARIN-L knowledge base contains three parts: i) a terminology T, i.e. a terminological component expressed in L, ii) a rule base R, i.e. a set of Horn rules, and iii) a set A of ground facts for the concepts, roles and predicates appearing in T and R. CARIN treats concepts and roles as ordinary unary and binary predicates that can also appear in query atoms. This is significant because it allows for the first time conjunctive queries to be expressed over DL ABoxes.
Semantic web ontology languages.Several ontology languages have been designed for use in the Web. Among them, the most important are OIL [FH01], DAML-ONT[HM00] and DAML+OIL[CV01][MF02]. More recently, a new language, OWL [DC03], is being developed by the World Wide Web Consortium (W3C) Web Ontology Working Group, which had to maintain as much compatibility as possible with pre-existing languages and is intended to be proposed as the standard Semantic Web ontology language. The idea of the semantic Web is to annotate web pages with machine-interpretable description of their content. In such a context, ontologies
Deliverable D8.1 42/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
are expected to help automated processes to access information, providing structured vocabularies that explicate the relationships between different terms.
Except for DAML-ONT, that was basically an extension of RDF (cf. Section ) with language constructors from object-oriented and frame-based knowledge representation languages (cf. Section II.2.3.2), and, as such, suffered from an inadequate semantic specification, the above mentioned ontology languages for the Web are all based on DLs. We chose here to focus on the description of OWL, instead of presenting all its predecessors. Refer to [HP03] or a comprehensive survey on the making of OWL from its predecessor.
OWL
WHAT to express: Class/relationHOW to express: Logic BasedHOW to interpret the expression: Several modelsIntuitively, OWL can represent information about categories of objects and how objects are interrelated. It can also represent information about objects themselves. More precisely, on the one side, OWL let describe classes by specifying relevant properties of objects belonging to them. This can be achieved by means of a partial (necessary) or a complete (necessary and sufficient) definition of a class as a logical combination of other classes, or as an enumeration of specified objects. OWL let also describe properties and provide domains and ranges for them. Domains can be OWL classes, whereas ranges can be either OWL classes or externally-defined datatypes (e.g. string or integer). Moreover, OWL let provide restrictions on how properties behave that are local to a class. Thus, it is possible to define classes where a particular property is restricted so that (i) all the values for the property in instances of the class must belong to a certain class or datatype (universal restriction), (ii) at least one value must come from a certain class or datatype (existential restriction), and (iii) there must be at least or at most a certain number of distinct values (cardinality restriction). On the other side, OWL can also be used to restrict the models to meaningful ones by organizing classes in a “subclass” hierarchy, as well as properties in a “subproperty” hierarchy. Other features are the possibility to declare properties as transitive, symmetric, functional or inverse of other properties, and couple of classes or properties as disjoint or equivalent. Finally, OWL represents information about individuals, providing axioms that state which objects belong to which classes, what the property values are of specific objects and whether two objects are the same or are distinguished.
OWL is quite a sophisticated language. Several different influences were mandated on its design. The most important are DLs, the frames paradigm and the Semantic Web vision of a stack of languages including XML and RDF. On the one hand, OWL semantics is formalised by means of a DL style model theory. In particular, OWL is based on the SH family of Description Logics [HS00] , which is equivalent to the ALC DL (cf Section ) extended with transitive roles and role hierarchies. Such family of languages represents a suitable balance between expressivity requirements and computational ones. Moreover, practical decision procedures for reasoning on them are available, as well as implemented systems such as FaCT[Ho98] and RACER[HM01]. On the other hand, OWL formal specification is given by an abstract syntax, that has been heavily influenced by frames and constitutes the surface structure of the language. Class axioms consist of the name of the class being described, a
Deliverable D8.1 43/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
modality indicating whether the definition of the class is partial or complete, and a sequence of property restrictions and names of more general classes, whereas property axioms specify the name of the property and its various features. Such a frame-like syntax makes OWL easier to understand and to use. Moreover, axioms can be directly translated into DL axioms and they can be easily expressed by means of a set of RDF triples (cf. Section ). This property is an essential one, since OWL was also required to have RDF/XML exchange syntax, because of its connections with the Semantic Web.
Given the huge number of requirements for OWL and the difficulty of satisfying all of them in combination, three different versions of OWL have been designed:
OWL DL, that is characterized by an abstract frame-like syntax and a decidable inference; it is based on SHOIN(D) DL, which extends SH family of languages with inverse roles, nominals (which are, in their simplest form, special concept names that are to be interpreted as singleton sets), unqualified number restrictions and support for simple datatypes; SHOIN(D) is very expressive but also difficult to reason with, since inference problems have NEXPTIME complexity;
OWL Lite, that constitutes a subset of OWL DL that is similar to SHIF(D) and, as such, it does not allow to use nominals and allows only for unqualified number restrictions in the form ≤1 R; inference problems have EXPTIME complexity and all OWL DL descriptions can be captured in OWL Lite, except those containing either individuals names or cardinalities greater than 1;
OWL Full, that, unlike the OWL DL and OWL Lite, allows classes to be used as individuals and the language constructors to be applied to the language itself; it contains OWL DL but goes beyond it, making reasoning undecidable; moreover, the abstract syntax becomes inadequate for OWL Full, which needs all the official OWL RDF/XML exchange syntax expressivity.
Process/Action specification languages. A fundamental problem in Knowledge Representation is the design of a logical language to express theories about actions and change. One of the most prominent proposals for such a language is John McCarthy's situation calculus[MH69], a formalism which views situations as branching towards the future. Several specification and programming languages have also been proposed, based on the situation calculus. GOLOG[LR97], maintains an explicit representation of the dynamic world being modeled, on the basis of user supplied axioms about the preconditions and effects of actions and the initial state of the world. This allows programs to reason about the state of the world and consider the effects of various possible courses of action before committing to a particular behavior. The next section describes the Process Specification Language PSL.
PSL
WHAT to express: Process/ActionHOW to express: Logic basedHOW to interpret the expression: Several modelsProcess Specification Language (PSL) [Gr03][GM03] is a first order logic ontology explicitly designed for allowing (correct) interoperability among heterogeneous software applications,
Deliverable D8.1 44/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
that exchange information as first-order sentences. It has undergone years of development in the business process-modeling arena, by defining concepts specifically regarding manufacturing processes and business process. Recently, PSL has become an International Standard (ISO 18629).
PSL can model both “black box” processes, i.e., activities, and “white box” processes, i.e., complex activities, and allows formulae that explicitly quantify over and specify properties about complex activities. The latter aspect, not shared by several other formalisms, makes it possible to express in an explicit manner broad variety of properties and constraints on com-posite activities.
PSL is constituted by (finite) set of first order logic theories defining concepts (i.e., relations and functions) needed to formally describe process and its properties (e.g., temporal constraints, activity occurrences, etc.): they are defined starting from primitive ones, whose meaning is assumed in the ontology. The definitions are specified as set of axioms expressed using the Knowledge Interchange Format, KIF (cf. Section ). PSL is extensible, in the sense that other theories can be created in order to define other concepts: of course, the newly added theories must be consistent with the core theories. Among the latter, Tpslcore defines basic ontological concepts, such as activities, activity occurrences, timepoints, and objects that participate in activities. Additional core theories (see Error: Reference source not found) capture the basic intuitions for the composition of activities, and the relationship between the occurrence of complex activity and occurrences of its subactivities. Among those, it is worthwhile to mention the following ones. Tocctree characterizes an occurrence tree, i.e., a partially ordered set of activity occurrences3. Tdisc_state defines the notion of fluents (state), which are changed only by the occurrence of activities. In addition, activities have preconditions (fluents that must hold before an occurrence) and effects (fluents that always hold after an occurrence). Tcomplex characterizes the relationship between the occurrence of complex activity and occurrences of
3 Occurrence trees are isomorphic to the situation trees that are models of the axioms for Situation Calculus: from this PSL can be considered as a dialect of Situation Calculus.
Deliverable D8.1 45/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
its subactivities: an occurrence of complex activities corresponds to an occurrence tree, i.e., a partially ordered set of occurrences of subactivities. Finally, Tactocc captures the concepts related to occurrences of complex activities, and, in particular, activities trees and their relations which occurrences trees (activities trees are part of occurrence trees).
Error: Reference source not found illustrates (part of) the lexicon of PSL and its intuitive meaning. Most of the terms are primitive fluents, with the following exceptions: successor (a, s) is primitive function, poss(a, s), root_occ(o) and leaf_occ(s, o) are defined in their respective theory (as KIF axiom). For example, the axiom capturing poss(a, s) is:
(forall (?a ?s) (iff (poss ?a ?s)
(legal (successor ?a ?s))))
It states that it is possible to execute an activity a after activity occurrence s if and only if the successor occurrence of the activity a is legal. Note that legal(·) and successor(·) are primitive concepts.
Deliverable D8.1
Figure 2: Primitive Lexicon of PSL
46/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
As far as its semantics, PSL has a model-theoretic semantics, based on trees that represent possible sequences of (atomic) activities that might occur in an execution of an application. The meaning of terms in the ontology is characterized by models for first-order logic. Indeed, the model theory of PSL provides rigorous abstract mathematical characterization of the semantics of the terminology of PSL. This characterization defines the meanings of terms with respect to some set of intended interpretations represented as class of mathematical structures. Furthermore, for each theory in PSL, there are theorems that prove that every intended interpretation is model of the theory, and every model of the theory is isomorphic to some intended interpretation. Therefore, PSL has first-order axiomatization of the class of models, and classes in the ontology arise from classification of the models with respect to invariants (properties of the models preserved by isomorphism). Note that PSL semantics is based on the notion of tree, therefore, it is second order. However, because of the assumption that processes exchange only first order sentences, PSL’s syntax is first order. This implies that PSL cannot express reachability properties (i.e., after activity occurrence a, eventually activity b occurs), since second order formula is needed.
The following example, taken from[Gr03], illustrates some sentences in PSL.
Example:
(x, o) occurrence_of(o, drop(x)) prior(fragile(x),o) holds(broken(x),o)
Intuitively, this formula states that if the object x is fragile, (i.e., fragile(x) is true immediately before activity drop(x) occurs) then x will break when dropped (i.e., broken(x) is true immediately after activity drop(x) occurs). 4
(x, o) occurence_of(o, make(x)) ( o1, o2, o3) occurrence_of (o1 ,cut(x))
occurrence_of (o2, punch(x)) occurence_of (o3, paint(x))
subactivity_occurrence(o1,o) subactivity_occurrence(o2,o)
subactivity_occurrence(o3,o)
min_precedes(leaf_occ(o1), root_occ(o3),make(x))
min_precedes(leaf_occ(o2), root_occ(o3),make(x))
Intuitively, this sentence states that in order to make the frame (activity make(x)), the cutting (activity cut(x)) and the punching (activity punch(x)) should be done in parallel, before doing the painting (activity paint(x)). Specifically, if o is the occurrence of activity make(x), then there exists o1,o2 and o3 which are occurrences of cut(·), punch(·)and paint(·), respectively, and which are subactivities of o. There is partial ordering constraint between o1,o2 and o3: it is imposed that the last atomic subactivities of o1 and o2 take place before the firts atomic
4 The frame problem is implicitly solved by the semantics of holds.
Deliverable D8.1 47/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
subactivity of o3; the parallelism constraint is captured by imposing no ordering constraint on the occurrences of subactivities of o1 and o2. Finally, note that here we are implicitely assuming that the activities are complex, i.e., they are constituted by certain number of subactivities. If this is not the case, i.e., o1 and o2 are primitive5, the fluents min_precedes have o1 and o2 as first component (instead of their roots), and the conjunction primitive(o1) primitive(o2)6 is added to the above sentence.
II.2.3.7XML-related formalisms
XML7 is a tag-based language for describing tree structures with a linear syntax. It has been developed by the W3C XML Working Group and has become the standard de-facto language for exchange of information in the Web. It is self-describing, since by introducing tags and attribute names on documents, it defines their structure while providing semantic information about their content.
Given the popularity of XML in exchange of information, XML–related languages have been considered as suitable for ontology representation (and exchange). In this section we examine how such an issue has been pursued. As for logic-based languages, a domain ontology expressed in XML-related languages describes the domain of interest in terms of classes of objects and relationships between them. We will first present two languages for the validation of XML documents: DTD and XML-Schema languages. Then we will introduce RDF and RDFS, whose aim is to provide a foundation for processing metadata about Web documents.
Languages for the validation of XML documents.Two main languages have been developed to define the structure and constraints of valid XML documents, i.e. to basically define the legal nesting of elements and the collection of attributes for them. Such languages are called Document Type Definition (DTD) and XML-Schema. They can be used to some extent to specify ontologies. From the point of view of semantics, an ontology expressed by means of these languages is interpreted with respect to one logical model, since an ontology described either in a DTD, or in an XML-Schema, represents basically a document instance, i.e. a valid XML document.
DTDWHAT to express: EverythingHOW to express: XML syntaxHOW to interpret the expression: Single model
Since a DTD defines a valid tree structure, it can be used to express an ontological hierarchy. Element attributes can represent objects properties, while by means of element nesting it is possible to express subclass as well more sophisticated relationships between classes of
5 Note that PSL makes a distinction between an atomic and a primitive activity: an activity is called primitive if it has no subactivities; an activity is atomic if either primitive or it is the concurrent aggregation of primitive activities.
6 The term primitive(.) is defined in the Subactivity theory that is not reported here.7 http://www.w3.org/XML/
Deliverable D8.1 48/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
objects. Nevertheless, several problems arises trying to express an ontology with a DTD. Among them, the most notable concern with (i) the need to reify attribute names with class names to distinguish with different appearance of the same attribute name in various concepts, (ii) the need to make subelements ordering irrelevant, (iii) poor means for defining semantics of elementary elements (the only primitive datatype in a DTD is PCDATA, i.e. arbitrary strings), and (iv) the lack of inheritance notion in DTDs. In a nutshell, DTDs are rather weak in regard to what can be expressed with them. Moreover, DTDs do not provide any means More details on ontology description by means of DTDs can be found in [ES99][RD99] .
XML-Schema
WHAT to express: EverythingHOW to express: XML syntaxHOW to interpret the expression: N/A (No formal semantics) ? Single model?
XML-Schema [W3CXMLSchema] provides a means for defining the structure, content and semantics of XML documents. An easily readable description of the XML Schema facilities can be found in [FaSchemaP] . For a formalization of the essence of XML-Schema see [SW03].
As for the DTD (cf. Section ), the purpose of XML Schema is therefore to declare a set of constraints that an XML document has to satisfy in order to be validated. With respect to DTD, however, XML-Schema provides a considerable improvement, as the possibility to define much more elaborated constraints on how different part of an XML document fit together, more sophisticated nesting rules, data-typing. Moreover, XML-Schema expresses shared vocabularies and allow machines to carry out rules made by people. Among a large number of other rather complicated features (XML-Schema specification consists of more than 300 pages in printed form!), we finally mention the possibility, offered by the namespace mechanism, to combine XML documents with heterogeneous vocabulary.
As XML-Schema provides vocabulary and structure for describing information sources that are aimed at exchange, it can be used as an ontology language. However, in XML Schema all inheritance must be defined explicitly, so reasoning about hierarchical relationships is not an issue, and XML-Schema can be only considered as an ontology representation language. For a comprehensive study of the relations existing between ontologies and XML-Schema see [KF00].
Languages for representing information in the Web.As the Web is huge and is growing at a healthy pace, there is the need to describe Web resources, by means of metadata that applications may exchange and process. The Resource Description Framework (RDF) and its ontology-style specialization, the Resource Description
Deliverable D8.1 49/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Framework Schema (RDFS), have both the purpose to provide a foundation for representing and processing metadata about Web documents. This would lead to a characterization of the information in the Web that would let reason on top of the largest body of information accessible to any individual in the history of the humanity.
RDF
WHAT to express: Class/relationHOW to express: XML syntaxHOW to interpret the expression: Several models
The Resource Description Framework (RDF) [KC03] is an XML application (i.e., its syntax is defined in XML) customized for adding semantics to a document without making any assumptions about the structure of the document. It is particularly intended for representing metadata about Web resources, such as the title, author, and modification date of a Web page, copyright and licensing information about a Web document, or the availability schedule for some shared resource. Thus, it enables the encoding, exchange and reuse of structured meta data, by providing a common framework for expressing this information so it can be exchanged between applications without loss of meaning. Search engines, intelligent agents, information broker, browsers and human user can make use of semantic information. However RDF can also be used to represent information about things that can be identified on the Web, even when they cannot be directly retrieved on the Web.
The RDF data model provides three object types: resources, properties, and statements:
o A resource may be either entire Web page, a part of it, a whole collections of pages, or an object that is not directly accessible via the Web;
o A property is a specific aspect, characteristics, attribute, or relation used to describe a resource.
o A statement is a triple consisting of two nodes and a connecting edge. These basic elements are all kinds of RDF resources, and can be variously described as <things> <properties> <values> [Be01b], <object><attribute><value> [MM04], or <subject> <predicate> <object> [BK03]. According to the latter description, a subject is a resource that can be described by some property. For instance a property like name can belong to a dog, cat, book, plant, person, and so on. These can all serve the function of a subject. The predicate defines the type of property that is being attributed. Finally, the object is the value of the property associated with the subject.
The underlying structure of any expression in RDF is a therefore a collection of node-arc-node triples (i.e. statements). A set of such triples is called an RDF graph. . The assertion of an RDF graph amounts to asserting all the triples in it, so the meaning of an RDF graph is the conjunction of the statements corresponding to all the triples it contains. Getting in the heart of RDF statements, a node may be a URIref (standard URI with optional fragment identifier URI reference), a blank node (placeholder for not-yet existing URI), or literal (value from a
Deliverable D8.1 50/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
concrete domain; string, integer, etc.)., a literal, or blank (having no separate form of identification). In the RDF abstract syntax, a blank node is just a unique node that can be used in one or more RDF statements, but has no intrinsic name. Literals are used to identify values such as numbers and dates by means of a lexical representation. Anything represented by a literal could also be represented by a URI, but it is often more convenient or intuitive to use literals. A literal may be the object of an RDF statement, but not the subject or the predicate
The example in Error: Reference source not found from the RDF Primer[MM04] shows how simple RDF graphs can be combined to form full descriptions of resources. The graph also shows that literals are drawn by rectangles. Note also that literal values can only be used as RDF objects and never subjects or predicates.
RDF has a formal model-theoretic semantics[HaRDF] which provides a dependable basis for reasoning about the meaning of an RDF expression. Important aspects of such a formalization are:
o RDF supports rigorously defined notions of entailment which provide a basis for defining reliable rules of inference in RDF data.
o
o The specifications of RDF propose also an alternative way to specify a semantics, that is to give a translation from RDF into a formal logic with a model theory already attached. This 'axiomatic semantics' approach has been suggested and used with various alternative versions of the target logical language [MS98][MF02]. Anyway, this alternative is given with the notice that in the event that any axiomatic semantics fails to conform to the model-theoretic semantics described for RDF, the model theory should be taken as normative.
o RDF semantics is defined associating interpretations to Vocabularies. A Vocabulary is the set of names (URIs and literals) that appear in an RDF Graph. Ground RDF Graphs, that is graphs that do not contain blank nodes, may be given a truth value with regard to an interpretation of their vocabulary. Blank
Deliverable D8.1
Figure 3: Example of RDF graph
51/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
nodes are treated as simply indicating the existence of a thing, without using, or saying anything about, the name of that thing. That is, all blank nodes are treated as having the same meaning as existentially quantified variab
o les in the RDF graph in which they occur, and which have the scope of the entire graph. Unfortunately, some parts of the RDF and RDFS vocabularies are not assigned any formal meaning, as for the notable cases of the reification and container vocabularies.
o RDF is an assertional logic, in which each triple expresses a simple proposition. This imposes a fairly strict monotonic discipline on the language, so that it cannot express closed-world assumptions, local default preferences, and several other commonly used non-monotonic constructs.
In order to use RDF as a means of representing knowledge it is necessary to enrich the language in ways that fixes the interpretation of parts of the language. As described thus far, RDF does not impose any interpretation on the kinds of resources involved in a statement beyond the roles of subject, predicate and object. It has no way of imposing some sort of agreed meaning on the roles, or the relationships between them. The RDF schema is a way of imposing a simple ontology on the RDF framework by introducing a system of simple types.
RDFSWHAT to express: Class/relationHOW to express: XML syntaxHOW to interpret the expression: Single model
RDF Schema (RDFS) [Be01] enriches the basic RDF model, by providing a vocabulary for RDF, which is assumed to have a certain semantics. Predefined properties can be used to model instance of and subclass of relationships as well as domain restrictions and range restrictions of attributes. Indeed, the RDF schema provides modeling primitives that can be used to capture basic semantics in a domain neutral way. That is, RDFS specifies metadata that is applicable to the entities and their properties in all domains. The metadata then serves as a standard model by which RDF tools can operate on specific domain models, since the RDFS metamodel elements will have a fixed semantics in all domain models.
RDFS provides simple but powerful modeling primitives for structuring domain knowledge into classes and sub classes, properties and sub properties, and can impose restrictions on the domain and range of properties, and defines the semantics of containers.
The simple meta modeling elements can limit the expressiveness of RDF/S. Some of the main limiting deficiencies are identified in[KF03]:
o Local scope of properties: in RDFS it is possible to define a range on properties, but not so they apply to some classes only. For instance the property eats can have a range restriction of food that applies to all classes in the domain of the property, but it is not possible to restrict the range to plants for some classes and meat for others.
o Disjointness of classes can not be defined in RDF/S.
Deliverable D8.1 52/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
o Boolean combinations of classes is not possible. For example person cannot be defined as the union of the classes male and female.
o Cardinality restrictions cannot be expressed.
o Special characteristics of properties like transitivity cannot be expressed.
Because of these inherent limitations, RDF/S has been extended by more powerful ontology languages. The currently endorsed language is the Web Ontology Language (OWL) which has been discussed in Section .
II.2.3.8Visual languages and visualization tools
Ontology design is a complex activity. Having languages that offer a graphical, more intuitive view of the ontology could be of great help to the designer. Some of the languages presented in the previous sections have partially visual nature. This is the case of modeling languages like EER or UML. Also some graph based models, like Sowa’s Conceptual Graphs, are inherently graphical. Despite visual features may be attractive, representation languages usually fail in merging successfully formal and graphical nature. In this section, we focus instead on tools that support the design of ontologies trough visual interfaces. Though these are not languages, but software artifacts, they may be backed up by formal, non graphical languages, making their usage more intuitive. Since they’re usage is so closely related to that of representation languages, we have chosen to treat them here.
In the last years several proposals have been presented, concerning methodologies and tools for ontology browsing and querying, focusing on visualization techniques. For instance in [MG04] the authors present ZIMS (Zoological Information Management System), a tool for generating graph based web representations of both data and metadada belonging to an ontology. The authors apply graph layout algorithm that attempts to minimize the distance of related nodes while keeping all the other nodes evenly distributed. The resulting graph drawings provide the user with insights that are hard to see in text.
Built on AT&T's Graphviz graph visualization software, IsAViz [Pi02] is a stand alone application for browsing and authoring RDF documents. In addition to showing instance data, IsAViz shows connections between instances and their originating classes. Though the graphs it generates are suitable for the intended task, because of their layout, they are not very useful while dealing with the overall structure of a set of instances.
The Protégé ontology editor, produced at Stanford University, is one of the more popular open source semantic web tools available today. It is easily extensible, and has two visualization components. OntoViz [Oviz] is an ontology visualizer that shows classes and instances grouped with their properties; Groups are connected by edges denoting relationships between the objects. Jambalaya, another Protégé based visualization tool that shares with SEWASIE the goal of providing a view of the overall structure of ontologies, displays
Deliverable D8.1 53/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
information similarly, with instances and classes being grouped with their respective properties. Jambalaya provides a zooming feature, allowing users to look at the ontology at different levels of detail. Both tools are designed to allow the user for browsing an ontology but, because of they use a visual structure that shows all of the information associated with a specific object as nodes, the overall picture is full of large boxes, overlapped with edges, obscuring much of the associative structure.
The Spectacle system [FS02] is designed to present data instances to users in a way that allows the user for easy data navigation. Exploiting class memberships, instances are arranged in clusters; instances that belong to multiple classes are placed in overlapping clusters. This visualization provides a clear and intuitive representation of the relationships between instances and classes, as well as illustrates the connections between classes as they overlap. In many cases, though, grouping by classes is not the best choice for understanding the underlying data structure. As an example, when looking at data about people, projects, and papers produced by an organization, it is not useful to see people, projects, and papers grouped together. What is more interesting is to see clusters of people based on their interaction: small clusters that group people and papers around their respective projects say much more about how the organization is structured.
While the above proposals focuses on browsing activities, the one hosted on the Ontoweb website [OWeb] are intended for expressing queries as well. In particular in [JP03] the authors describe an interactive "focus + context" visualization technique to support effective search. They have implemented a prototype that integrates WordNet, a general lexical ontology, and a large collection of professionally annotated images. As the user explores the collection, the prototype dynamically changes the visual emphasis, the detail of the images, and the keywords, to reflect the relevant semantic relationships. This interaction allows the user to rapidly learn and use the domain knowledge required for posing effective queries.
An interesting survey is presented in [GS03b], discussing the different user interface tactics that can be implemented with the help of ontologies in the context of information seeking and showing several experiences about ontology-based search interfaces based on thesauri [GS03].
The proposal presented in [KB03] describes a new approach for representing the result of a query against hierarchical data. An interactive matrix display is used for showing the hyperlinks of a site search or other search queries in different hierarchical category systems. The results of a site search are not only shown as a list, but also classified in an ontology-based category system. So the user has the possibility to explore and navigate within the query results. The system offers a flexible way to refine the query by drilling down in the hierarchical structured categories. The user can explore the results in one category with the so-called List Browser or in two categories at the same time with the so-called Matrix Browser. A familiar and well-known interactive tree widget is used for the presentation of the categories and located hyperlinks, so the handling of the system is very intuitive.
Ontobroker [OntBR] uses an hyperbolic browser to view semantic relationships between frames in F-Logic. Ontorama [OR] derives by Ontobroker Java source code, but the code has been substantially re-written since 1999 and its actual version has been developed within the WEBKB-2 project [WebKB].
Deliverable D8.1 54/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
The trend in the field of visualization of ontologies is quite clear: techniques exploiting information visualization issues are increasingly adopted. That affects not only the browsing of the data and metadata but also the activities of building, comparing, and integrating different ontologies.
We can argue that in the next three years such approaches will be validated against real test beds and users, providing a more robust and mature reference scenario.
II.2.3.9Temporal Languages
In this section, we review the common features of temporally extended ontology languages developed to abstract the temporal aspects of information. Without loss of generality, we will specifically refer to a general temporal Entity Relationship (ER) model, and we will consider that it captures the relevant common features of the models introduced by the systems TimeER [GJ98], ERT [TL91], and MADS [SP98]. These models cover the full spectrum of temporal constructs (see [GJ99] for an extensive overview of temporally extended ER models). We refer to ER models because they are the most mature field in temporal conceptual modeling. We use a unifying notation for temporal constructs that will capture the commonalities among the different models [AF82][AF03]. As a main characteristic, an ontology language for time-varying information should support the notion of valid time—which is the time when a property holds, i.e. it is true in the representation of the world. Possibly, the ontology language should also support transaction time—which records the history of database states rather than the world history, i.e. it is the time when a fact is current in the database and can be retrieved. Temporal support is achieved by giving temporal meaning to each standard nontemporal conceptual construct and then adding new temporal constructs. The ability to add temporal constructs on top of a temporally implicit language has the advantage of preserving the nontemporal semantics of conventional (legacy) conceptual schemas when embedded into temporal schemas—called upward compatibility. The possibility of capturing the meaning of both legacy and temporal schemas is crucial in modeling data warehouses or federated databases, where sources may be collections of both temporal and legacy databases. Orthogonality [So84] is another desirable principle: temporal constructs should be specified separately and independently for entities, relationships, and attributes. Depending on application requirements, the temporal support must be decided by the designer. Furthermore, snapshot reducibility [Sn87] of a schema says that snapshots of the database described by a temporal schema are the same as the database described by the same schema, where all temporal constructs are eliminated and the schema is interpreted atemporally. Temporal marks are usually added to capture the temporal behavior of the different components of a conceptual schema. In particular, entities, relationships, and attributes can be either s-marked, in which case they are considered snapshot constructs (i.e. each of their instances has a global lifetime, as in the case they belong to a legacy diagram), vt-marked, and they are considered temporary constructs (i.e. each of their instances has a temporary existence), or unmarked, i.e. without any temporal mark, in which case they have temporally unconstrained instances (i.e. their instances can have either a global or a temporary existence). Participation constraints are distinguished between snapshot participation constraints—true at each point in time and represented by a pair of values in parentheses—and lifespan participation constraints—evaluated during the entire existence of the entity and
Deliverable D8.1 55/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
represented by a pair of values in square brackets[GJ98][So84][Sn87]. Dynamic relationships between entities [So84] can be either transition or generation relationships. In a transition relationship, the instances of an entity may eventually become instances of another entity. The instances of the source entity are said to migrate into the target entity, and the phenomenon is called object migration. In temporal conceptual modeling literature, two types of transitions have been [GH91][GH92][So84]: dynamic evolution when objects cease to be instances of the source entity, and dynamic extension, otherwise. In general, type constraints require that both the source and the target entity belong to the same generalization hierarchy. Generation relationships involve different instances—differently from the transition case: an instance (or set of instances) from a source entity is (are) transformed in an instance (or set of instances) of the target entity. We have considered, so far, a temporally enhanced ontology language able to represent time varying data. Now, we want to introduce a conceptual data model enriched with schema change operators that can represent the explicit evolution of the schema while maintaining a consistent view of (static) instantiated data. The problem of schema evolution becomes relevant in the context of long-lived database applications, where stored data are considered worth surviving changes in the database schema [Ro96]. One of the fundamental issues in the introduction of schema change operators in an ontology language is the semantics of change, which refers to the effects of the change on the schema itself, and, in particular, checking and maintaining schema consistency after changes. In the literature, the problem has been widely studied in relational and object-oriented database papers. In the relational field [DG97][RG94], the problem is solved by specifying a precise semantics of the schema changes, for example, via algebraic operations on catalogue and base tables. However, the related consistency problems have not been considered so far. The correct use of schema changes is completely under the database designer/administrator’s responsibility without automatic system aid and control. In the object-oriented field, two main approaches were followed to ensure consistency in pursuing the “semantics of change” problem. The first approach is based on the adoption of invariants and rules and has been used, for instance, in the ORION [BK87] and O2 [FH01] systems. The second approach, which was proposed in [PO97], is based on the introduction of axioms. In the former approach, the invariants define the consistency of a schema, and definite rules must be followed to maintain the invariants satisfied after each schema change. Invariants and rules are strictly dependent on the underlying object model, as they refer to specific model elements. In the latter approach, a sound and complete set of axioms (provided with an inference mechanism) formalizes dynamic schema evolution, which is the actual management of schema changes in a system in operation. The approach is general enough to capture the behavior of several different systems and, thus, it is useful for comparing them in a unified framework. The compliance of the available primitive schema changes with the axioms automatically ensures schema consistency without the need for explicit checking, as incorrect schema versions cannot actually be generated.
II.2.4 Reasoning
We use the term “reasoning over an ontology” to mean any mechanism/procedure for making explicit a set of facts that are implicit in an ontology. There are many reasons why
Deliverable D8.1 56/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
one would like to have well-founded methods for reasoning about ontologies. Here, we would like to single out two important purposes of reasoning:
Validation. Validating an ontology means ensuring that the ontology is a good representation of the domain of discourse that you aim at modeling. Reasoning is extremely important for validation. For example, checking whether your ontology is internally consistent is crucial: obviously, no inconsistent theory can be a good representation of a domain of discourse. But, in turn, consistency checking is a kind of reasoning, actually the most basic one.
Analysis. While in validation one looks at the ontology and tries to answer the question of whether the ontology correctly models the domain, in analysis one assumes that the ontology is a faithful representation of the domain, and tries to deduce facts about the domain by reasoning over the ontology. In a sense, we are trying to collect new information about the domain by exploiting the ontology. Obviously, analysis can also provide input to the validation phase.
The basic problem to address when talking about reasoning is to establish which is a “correct” way to single out what is implicit in an ontology. But what is implicit in an ontology strongly depends on the semantics of the language used to express the ontology itself. It follows that it makes no sense to talk about reasoning without referring to the formal semantics of the language used to express the ontology.
We remind the reader that in Section 2 we introduced a classification of languages based on three criteria, where the third criterion was the one taking into account the degree in which the various languages deal with the representation of incomplete information in the description of the domain. More precisely, under this criterion, we considered two classes of languages, called “single model” and “multiple models”, respectively. Now, it is immediate to verify that the world reasoning as used in logic usually refers to the task of deriving implicit knowledge in the case of multiple models. On the other hand, when we deal with ontologies interpreted in one model, deriving implicit information is a form of computation over the single model.
Based on the above considerations, in the rest of this section we will deal with the two forms of reasoning in two separate subsections.
In subsection 4.1, we address the issue of “logical reasoning”, i.e., the issue of deriving implicit information in the case where the ontology language has the expressive power to state incomplete information over the domain. As an example, suppose our ontology sanctions that every male is a person, every female is a person, every person has a city of birth, and x is either a male or a female. There are two logical models of this ontology: in one model x is a male, and therefore a person, and therefore has a city of birth, in the other model x is a female, and therefore a person, and therefore has a city of birth. In both cases, one concludes that x has a city of birth. Note that is an instance of pure logical reasoning: what is true in every model of the ontology is a derived conclusion of the ontology.
Deliverable D8.1 57/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
In subsection 4.2, we briefly mention the issue of computing properties that hold in an ontology characterized by a single model. As an example, suppose our ontology is expressed in the form of a relational database. Every query expressed over the database computes a set of tuples, according to the property expressed by the query. Such tuples can be seen as a kind of knowledge that is implicit in the database. However, their elicitation is not obtained by means of a process looking at several models of the ontology. Rather, the tuples are made explicit by means of a computation over the ontology, in particular the one that computes the answers to the query.
II.2.4.1Logical reasoning
Logical reasoning has been the subject of intensive research work in the last decades. Here, we are especially interested in automated reasoning, i.e., in the task of automating reasoning. While this was already the goal of several philosophers in the past centuries, interest in automated reasoning has grown with the birth of Artificial Intelligence and Knowledge Representation.
There are several forms of logical reasoning.
Reasoning in classical logic. The basic one is related to the idea of proving theorems in classical first order logic. This can be characterized as the task of checking whether a certain fact is true in every models of a first-order theory.
Reasoning in non-classical logics. Although reasoning in classical logic is of paramount importance, it is not the only form of reasoning we are interested in when building ontologies. A famous example of reasoning that cannot be captured by classical logic is the so-called defeasible reasoning. Although we can state in an ontology that all birds fly, it is known that penguins are birds that do not fly. This is a form of non-monotonic reasoning: new facts may invalidate old conclusions. Since classical logic is monotone, this goes beyond the expressive power of classical logics.
No matter of whether we are performing reasoning within a classical or a non-classical logic, we can classify reasoning starting from another perspective, namely, the type of desired conclusions we are aiming at. According to this classification, we distinguish among the following:
Deduction. Let W and s be the intensional level and the extensional level of an ontology, respectively. P is a deductive conclusion from W if it holds in every situation (extensional level) coherent with W and s. Examples of classical deductive logical reasoning:
o Check whether a concept is inconsistent, i.e., if it denotes the empty set in all the models of the ontology,
Deliverable D8.1 58/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
o Check whether a concept is a subconcept of another concept, i.e., if the former denotes a subset of the set denoted by the latter in all the models of the ontology
o Check whether two concepts are equivalent, i.e., if they denote the same set in all models of the ontology
o Check whether an individual is an instance of a concept, i.e., if it belongs to its extension in all the models of the ontology
Induction. Let W and s be the intensional level and the extensional level of an ontology, respectively. Let t be a set of observations at the extensional level. We say that P is an inductive conclusion with respect to W,s and t if P is an intensional level property such that
o W,s do not already imply t
o P is consistent with W,s and t
o W,s,P imply tInduction can be used, for example, to single out new important concepts/class in an ontology, or to come up with new axioms regarding such concepts, based on observations on individuals. In this sense, induction is the basic reasoning for learning.
Abduction. Let W and s be the intensional level and the extensional level of an ontology, respectively. Let t be a set of observations at the extensional level. We say that E is an abductive conclusion wrt W,s and t if E is an extensional level property such that
o W,s do not already imply t
o E is consistent with W,s and t
o W,s,E imply tAbduction can be used, for example, to derive explanations of certain facts at the extensional level.
In appendix A, we present a survey of reasoning techniques for a particular scenario, namely the one we believe is the most interesting from the point of view of ontology representation. In particular, we concentrate on the following aspects:
Classical logic
Reasoning for languages of type Object/Class/Relations (see our language classification in Section II.2.2)
Deduction
Deliverable D8.1 59/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
II.2.4.2Computation
As we said before, while logical reasoning aims at characterizing the conclusions that one can draw from an ontology in the case where the language used to express the ontology allows multiple models, computation is the kind of reasoning we perform when the ontology is characterized by a single model.
We distinguish between two types of computation that can be performed over an ontology.
In the first case, computation is performed at the intensional/extensional level of the representation. This kind of reasoning aims at capturing the kind of conclusions we want to draw by looking at a single model, and by eliciting properties that are implicit in this model. A good example of this kind of reasoning is the computation of the result of a query expressed over an ontology. If the ontology is interpreted in a single model, deriving the result of a query is really a computation task: we simply apply the rule governing the evaluation of the query over the single mode, and we derive the results.
In the second case, computation is performed at the meta-level. This is an interesting form of reasoning that aims at capturing the process of coming up with interesting conclusions by looking at the meta-level. Here, we talk about computation because the meta-level of an ontology is usually kept sufficiently simple to be characterized by a single model (although at the meta-level, instead of the object-level). As an example, consider the task of computing the so-called Most Specific Concept (MSC) of an individual in an ontology. Given an ontology O, a concept C is called a most specific concept for an individual a if
a is an instance of C in O
for every D such that a is an instance of D in O, C is a subconcept of D in O
Note that this notion can help in abstracting a given portion of the extensional level of the ontology, or in defining concepts by examples.
II.2.5 References
[AF82] J.F. Allen, A.M. Frisch. What's in a semantic network? Proceedings of the 20th conference on Association for Computational Linguistics, Toronto, Ontario, Canada, 1982[AF02] A. Artale, E. Franconi, F. Wolter, and M. Zakharyaschev. A temporal description logic for reasoning over conceptual schemas and queries. Proc. of the 8th European Conference on Logics in Artificial Intelligence (JELIA-2002), 2002.[AF03] A. Artale, E. Franconi, and F. Mandreoli. Description logics for modelling dynamic information. Logics for Emerging Applications of Databases (J. Chomicki, R. van der Meyden, and G. Saake, eds.), Springer-Verlag, 2003.[AO02] P. Auillans, P. Ossona de Mendez, P. Rosenstiehl, B. Vatant. A Formal Model for Topic Maps. International Semantic Web Conference 2002: 69-83.
Deliverable D8.1 60/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
[BC03] F. Baader, D. Calvanese, D. L. McGuinness, D. Nardi and P. F. Patel-Schneider. The Description Logic Handbook: Theory, Implementation, and Applications. Cambridge University Press, 2003.[BH04] F. Baader, I. Horrocks and U. Sattler. Description Logics: Handbook on Ontologies. International Handbooks on Information Systems Springer 2004: pages 3-28, 2004.[BM99] F. Baader, R. Molitor and S. Tobies. Tractable and Decidable Fragments of Conceptual Graphs. In Proceedings of the Seventh International Conference on Conceptual Structures (ICCS'99), LNCS 1640.[Ba01] K.Backlawski et al. Extending UML to support Ontology Engineering for the semantics Web. International Conference on UML, 2001.[BK87] J. Banerjee, W. Kim, H.J. Kim, and H. F. Korth. Semantics and Implementation of Schema Evolution in Object-Oriented Databases. In Proc. of the ACM-SIGMOD Annual Conference (San Francisco, CA): pages 311–322, May 1987.[Be01b] T. Berners-Lee, J. Hendler, and O. Lassila. The Semantic Web, Scientific American, May 2001.[Be01] T. Berners Lee. Conceptual Graphs and the Semantic Web. Available on the web at http://www.w3.org/DesignIssues/CG.html, 2001.[Br79] R.J. Brachman. On the epistemological status of semantic networks. In N.V. Findler, editor, Associative Networks: The Representation and Use in Computers, pages 3-50. New York. Academic Press Inc, 1979.[Br83] R.J. Brachman. What IS-A Is and Isn't: An Analysis of Taxonomic Links in Semantics Networks. IEEE Computer, 16(10):pages 30-36, 1983.[BG03] D. Brickley and R. V. Guha. RDF Vocabulary Description Language 1.0: RDF Schema. W3C Working Draft, 2003. Available at http://www.w3.org/TR/2003/WD-rdf-schema-20030123.[BK03] J. Broekstra, A. Kampman, F. van Harmelen. Sesame. In Spinning the Semantic Web, Fensel, D., Hendler, J., Lieberman, H., Eds. , MIT Press, Cambridge, MA, 2003.[BD93] M. Buchheit, F. M. Donini, and A. Shaerf. Decidable reasoning in terminological knowledge representation systems. Journal of Artificial Intelligence Research, Volume 1: 109-138, 1993. [Bu02] H. M. Butler. Barriers to real world adoption of semantic web technologies. Technical Report, Hewlett Packard, Filton Road Bristol BS34 8QZ UK, 2002.[CC02] A. Calì, D. Calvanese, G. De Giacomo, M. Lenzerini. A Formal Framework for Reasoning on UML Class Diagrams. ISMIS 2002.[CL98] D. Calvanese, M. Lenzerini, D. Nardi. Description Logics for conceptual data modeling. In Logics for Databases and Information Systems, Kluwer, 1998.[Ch98] V. K. Chaudhri et al. Open Knowledge Base Connectivity 2.0.3 specification, April 1998.[CF98] V. K. Chaudhri, A. Farquhar, R. Fikes, P.D. Karp, and J. P. Rice. OKBC: A Foundation for Knowledge Base Interoperability. In Proceedings of the National Conference on Artificial Intelligence, 1998.[CM92] M. Chein, M. Mugnier. Conceptual Graphs: fundamental notions, Revue d’Intelligence Artificielle, 6(4), pages 365-406, 1992.[Cl85] W. J. Clancey. Sowa's book review. Artificial Intelligence, 27, (1985), 113-128.[CE97] T. Clark and A. S. Evans. Foundations of the Unified Modeling Language. In D. Duke and A. Evans editors, Proc. of the 2nd Northern Formal Methods Workshop. Springer-Verlag,1997.
Deliverable D8.1 61/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
[SCG] Conceptual Graphs ISO Standard draft. http://users.bestweb.net/~sowa/cg/cgstand.htm[CV01] D. Connolly, F. van Harmelen, I. Horrocks, D. L. McGuinness, P. F. Patel-Schneider, and L. A. Stein. DAML+OIL (March 2001) reference description. W3C Note, 18 December 2001. Available at http://www.w3.org/TR/2001/NOTE-daml+oil-reference-20011218.
[CP99] S. CraneField, M. Purvis. UML as an ontology modeling language. In Workshop on intellingent information integration, International Joint Conference on Artificial Intelligence, IJCAI-99, 1999.[DG97] C. De Castro, F. Grandi, and M. R. Scalas. Schema Versioning for Multitemporal Relational Databases, Information Systems 22 (1997), no. 5: 249–290.[DC03] M. Dean, D. Connolly, F. van Harmelen, J. Hendler, I. Horrocks, D. L. McGuiness, P. F. Patel-Schneider, and L. A. Stein. OWL web ontology language reference. W3C Working Draft, 31 March 2003. Available at http://www.w3.org/TR/2003/WD-owl-ref-20030331.
[DL91] F. M. Donini, M. Lenzerini, D. Nardi, and A. Shaerf. A hybrid system with datalog and concept languages. Trends in Artificial Intelligence, Volume LNAI 549, Springer Verlag, 1991.
[Eb02] A. Eberhart. Automatic Generation of Java/SQL based Inference Engines from RDF Schema and RuleML. In I.Horrocks and J.Hendler eds., Proceedings of International Semantic Web Conference 2002, Chia, Sardinia, Italy, 2002. [ES99] M. Erdmann and R. Studer. Ontologies as Conceptual Models for XML Documents. Research report, Institute AIFB, University of Karlsruhe, 1999.[Ev98] S. Evans. Reasoning with UML class diagrams. In Second IEEE Workshop on Industrial Strength Formal Specification Techniques (WIFT’98). IEEE Computer Society Press, 1998.[EF97] A. Evans, R. France, K. Lano, and B. Rumpe. The UML as a formal modeling notation. In Proc. of the OOPSLA’97 Workshop on Object oriented Behavioral Semantics: pages 75–81. Technische Universitat Munchen, TUM-I9737, 1997.[FaSchemaP] D. C. Fallside. XML Schema Part 0: Primer W3C Recommendation. 2 May 2001. Available at: http://www.w3.org/TR/xmlschema-0/[FF96] A. Farquhar, J. Fikes and J. Rice. The Ontolingua Server: A Tool for Collaborative Ontology Construction. Knowledge Systems Laboratory Technical Report, Stanford, California, USA, 1996. [FH01] ]D. Fensel, F. von Harmelen, I. Horrocks, D. L. McGuinness, and P. F. Patel-Schneider. OIL: An ontology infrastructure for the semantic web. IEEE Intelligent Systems, 16(2): 38-45, 2001.[FM95] F. Ferrandina, T. Meyer, R. Zicari, G. Ferran, and J. Madec. Schema and Database Evolution in the O2 Object Database System. Proc. of the 21st Int’l Conf. on Very Large Databases (VLDB) (Zurich, Switzerland), September 1995, pp. 170–181.[Fi85] R. Fikes. The role of frame based representation in reasoning, Communications of the ACM, 1985.[FS02] C. Fluit, M. Sabou, F. van Harmelen. Ontology-based Information Visualization. Proceedings of Information Visualization, 2002.[FC91] A. M. Frisch and A. G. Cohn. Thought and afterthoughts on the 1998 workshop on priciples of hybrid reasoning. Rivista di informatica: 77-83, 1991.
Deliverable D8.1 62/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
[GS03b] E. Garcia and M. A. Sicilia. User Interface Tactics in Ontology-Based Information Seeking". Psychology Journal, Volume 1, Number 3, 242-255, 2003.[GS03] E. García and M. A. Sicilia. Designing Ontology-Based Interactive Information Retrieval Interfaces. Proceedings of the Workshop on Human Computer Interface for Semantic Web and Web Applications, Springer Lecture Notes in Computer Science 2889, 152-165, 2003.[GF92] M. R. Genesereth and R.E. Fikes. Knowledge Interchange Format, Version 3.0, Reference Manual. Technical Report, Logic-92-1, Computer Science Dept., Stanford University, 1992. Available at http://www.cs.umbc.edu/kse/.
[Gr84] S. Greenspan. Requirements Modeling. A Knowledge Representation Approach to Requirements Definition. Ph.D. thesis, Department of Computer Science, University of Toronto, 1984.[GJ99] H. Gregersen and J. S. Jensen. Temporal Entity-Relationship models - a survey. IEEE Transactions on Knowledge and Data Engineering 11 (1999), no. 3, 464–497.[GJ98] H. Gregersen and J.S. Jensen. Conceptual modeling of time-varying information. Tech. Report TimeCenter TR-35, Aalborg University, Denmark, 1998.[Gr93] T. R. Gruber. A Translation Approach to Portable Ontology Specification. Knowledge Acquisition, 5(2), 199-220, 1993.[Gr92] T. R. Gruber. Ontolingua: A Mechanism to Support Portable Ontologies. Knowledge Systems Laboratory Technical Report, Stanford, California, USA, 1992[Gr03] M. Gruninger. Guide to the Ontology of the Process Specification Language. In S. Staab and R. Studer (eds.), Handbook of Ontologies, pages 575–592. Springer-Verlag, 2003. [GM03] M. Gruninger and C. Menzel. Process Specification Language: Theory and Applications. AI Magazine, 24:63–74, 2003. [GW04] G. Guizzardi, G. Wagner, N. Guarino, P. McBrien, N. Rizopoulos. An Ontologically Well-Founded Profile for UML Conceptual Models. CAiSE 2004.[GH92] R. Gupta and G. Hall, An abstraction mechanism for modeling generation. Proc. of ICDE’92, 1992, pp. 650–658.[GH91] R. Gupta and G. Hall. Modeling transition. Proc. of ICDE’91, 1991, pp. 540–549. [HM01] V. Haarslev and R. Möller. RACER system description. In Proc. Of the Int. Joint Conf. on Automated Reasoning (IJCAR 2001), volume 2083 of Lecture Notes in Artificial Intelligence: 701-705. Springer-Verlag, 2001.[HaRDF] P. Hayes. RDF Semantics. Available at http://www.w3.org/TR/rdf-mt/[HH99] J. Heflin, J. Hendler and S. Luke. SHOE: A Knowledge Representation Language for Internet Applications. Technical Report, CS-TR-4078 (UMIACS TR-99-71), Dept. of Computer Science, University of Maryland.[HM00] J. Hendler and D. L. McGuinness. The DARPA Agent Markup Language. IEEE Intelligent Systems, 15(6): 67-73, 2000.[Ho98] I. Horrocks. Using an expressive description logic: FaCT or fiction? In Proc. Of the 6th Int. Conf. on Principles of Knowledge Representation and Reasoning (KR ’98): pages 636-647, 1998.[HP03] I. Horrocks. P. F. Patel-Schneider, and F. von Harmelen. From SHIQ and RDF to OWL: The Making of a Web Ontology Language. J. of Web Semantics, 1(1):pages 7-26, 2003.
Deliverable D8.1 63/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
[HS00] I. Horrocks. U. Sattler, and S. Tobies: Practical reasoning for very expressive description logics. Journal of the Interest Group in Pure and Applied Logic, 8(3): pages 239-264, 2000.[HK87] R. Hull and R.King. Semantic Database Modeling: Survey, Applications and Research Issues. ACM Computing Surveys, vol. 19 n.3, 1987. [SUO] IEEE Standard Upper Ontology Working Group home page. http://suo.ieee.org/[JP03] P. Janecek and P. Pu. Searching with Semantics: An Interactive Visualization Technique for Exploring an Annotated Image Collection. Proceedings of the Workshop on Human Computer Interface for Semantic Web and Web Applications, Springer Lecture Notes in Computer Science 2889, 187-196, 2003. [JD03] M. Jarrar, J.Demey, R. Meersman. On using Conceptual data Modeling for Ontology Engineering. In S. Spaccapietra, S. March, K. Aberer (eds.), Journal on Data Semantics. LCNS, vol. 2800, Springer, October 2003.[JC98] S. Jensen, J. Clifford, S. K. Gadia, P. Hayes, S. Jajodia et al. The Consensus Glossary of Temporal Database Concepts.In O. Etzion, S. Jajodia, and S. Sripada (eds.), Temporal Databases - Research and Practice, Springer-Verlag, 1998, pp. 367–405.[KP04] A. Kalyanpur, D. Pastor, S. Battle, J. Padget. Automatic Mapping of OWL Ontologies into Java. Proceedings of Sixteenth International Conference on Software Engineering and Knowledge Engineering (SEKE), June 20-24, 2004, Banff, Canada.[KM95] P. D. Karp, K. Myers, and T. Gruber. The Generic Frame Protocol. in Proceedings of the 1995 International Joint Conference on Artificial Intelligence, pp. 768--774, 1995. [Ka93] P. D. Karp. The Design Space of Frame Knowledge Representation Systems. Technical Note 520, Artificial Intelligence Center, SRI International,1993.[KC99] P.D. Karp, V.K. Chaudhri and J. Thomere. XOL: An XML-Based Ontology Exchange Language. Version 0.4, 1999, available on line at http://www.ai.sri.com/pkarp/xol/ xol.html. [Ke00b] R.E. Kent. Conceptual Knowledge Markup Language: An Introduction. In Netnomics: Economic research and electronic networking. Special Issue on Information and Communication Middleware, vol.2, 2000.[Ke99] R.E. Kent. Conceptual Knowledge Markup Language: The Central Core. In the Electronic Proc. of the Twelfth Workshop on Knowledge Acquisition, Modeling and Management (KAW'99), Banff, Alberta, Canada, 16–21 October 1999.[Ke00] R.E. Kent. The Information Flow Foundation for Conceptual Knowledge Organization. In Proc. of the Sixth International ISKO Conference. Advances in Knowledge Organization 7: 111–117, Ergon Verlag, 2000.[KL95] Kifer, G. Lausen and J.Wu, Logical Foundations of Object-Oriented and Frame-Based Languages, Journal of ACM 1995, vol. 42, p. 741-843 [KF03] M. Klein, D. Broekstra, F. Fensel, F. van Harmelen, and I. Horrocks. Ontologies and Schema Languages on the Web. In D. Fensel, J. Hendler, H. Lieberman (eds.), Spinning the Semantic Web, MIT Press, Cambridge, MA, 2003.[KF00] M. Klein, D. Fensel, F. van Harmelen, and I. Horrocks. The relation between ontologies and schema-languages: Translating OIL-specifications in xml-schema. In Proceedings of the ECAI'00 workshop on applications of ontologies and problem-solving methods, Berlin, August 2000.[KC03] G. Klyne and J. J. Carroll. Resource Description Framework (RDF): Concepts and abstract syntax. W3C Working Draft, 2003. Available at http://www.w3.org/TR/2003/WD-rdf-concepts-20030123.
Deliverable D8.1 64/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
[KB03] C. Kunz and V. Botsch. Visual Representation and Contextualization of Search Results. List and Matrix Browser, 2003.[Le95] D.B. Lenat. CYC: A Large-Scale Investment in Knowledge Infrastructure. Communications of the ACM, 38 (11): 32-38, 1995.
[LR97] H. Levesque, R. Reiter, Y. Lesperance, F. Lin and R. Scherl. Golog: A logic programming language for dynamic domains. Journal of Logic Programming, 31:59—84, 1997. [LR96] A. Y. Levy and M. C. Rousset. CARIN: A Representation Language Combining Horn Rules and Description Logics. In Proc. Of the 12th European Conference on Artificial Intelligence, 1996. [MM04] F. Manola and E. Miller. RDF Primer, W3C Recommendation 10 February 2004, 2004. Available at http://www.w3.org/TR/rdf-primer/[MS98] M. Marchiori and J. Saarela. Query + Metadata + Logic = Metalog. Available at http://www.w3.org/TandS/QL/QL98/pp/metalog.html.[MH69] J. McCarthy and P. C. Hayes. Some Philosophical Problems from the Standpoint of Artificial Intelligence. Machine Intelligence n.4, 1969.[MF02] D. L. McGuinness, R. Fikes, J. Hendler and L. A. Stein. DAML+OIL: An Ontology Language for the Semantic Web. IEEE Intelligent Systems, Vol. 17, No. 5, September/October 2002.[MOF] Meta-Object Facility (MOF) specification, version 1.4, available at http://www.omg.org. [Mi75] M. Minsky. A Framework for Representing Knowledge. The Psychology of Computer Vision, P. Winston (Ed.), McGraw-Hill, 1975.[MG01] G. Moore and L.M. Garshol (eds). Topic map foundational model requirements. Available at: http://www.y12.doe.gov/sgml/sc34/document/0266.htm , 2001.[Mo98] E. Motta. An Overview of the OCML Modelling Language. 8th Workshop on Knowledge Engineering Methods and Languages (KEML '98), 1998. [MG04] P. Mutton and J. Golbeck. Visualization of Semantic Metadata and Ontologies. 2004. [MB90] J. Mylopoulos, A. Borgida, M. Jarke and M. Koubarakis. Telos: Representing Knowledge About Information Systems. ACM Transactions on Information Systems, October 1990. [OML] OML/CKML/IFF website. http://www.ontologos.org[OR] Ontorama. Available at http://www.ontorama.org/ [OE] OntoEdit. http://www.ontoprise.de/co_produ_tool3.htm [Oviz] The Ontoviz Tab: Visualizing Protégé Ontologies. Available at http://protege.stanford.edu/plugins/ontoviz/ontoviz.html - 2004.[OWeb] OntoWeb browser. Available at http://134.184.65.65:8180/OntoWeb/Browse/index.html.[PO97] R. J. Peters and M. T. Ozsu. An Axiomatic Model of Dynamic Schema Evolution in Objectbase Systems. ACM Transactions On Database Systems 22 (1997), no. 1, 75–114.[Pi02] E. Pietriga. IsaViz, a Visual Environment for Browsing and Authoring RDF Models. Eleventh International World Wide Web Conference Developers Day, 2002.[Qu68] M. R. Quillian. Semantic memory. In M. Minsky (ed.), Semantic Information Processing. MIT Press, 1968.
Deliverable D8.1 65/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
[RD99] A. Rabarijoana, R. Dieng, and O. Corby. Exploitation of XML for Corporative Knowledge Management. In D. Fensel and R. Studer (eds.), Knowledge Acquisition, Modeling, and Management, Proceedings of the European Knowledge Acquisition Workshop (EKAW-99), volume 1621 of Lecture Notes in Artificial Intelligence. Springer-Verlag, 1999.
[RG94] R. Ramanathan, V. Guha, Douglas B. Lenat. Enabling Agents to Work Together. Communications of the ACM, 37 (7): 126-142, 1994.
[RS95] J. F. Roddick and R. T. Snodgrass, Schema Versioning, The TSQL2 Temporal Query Language, Kluwer, 1995, pp. 427–449.
[Ro96] J. F. Roddick. A Survey of Schema Versioning Issues for Database Systems. Information and Software Technology 37 (1996), no. 7, 383–393.
[SS91] M. Schmidt-Schau and G. Smolka. Attributive concept descriptions with complements. Artificial Intelligence, 48(1): 1-26, 1991.[OntBR] Semantic Web & Ontology Related Initiatives. http://ontobroker.semanticweb.org/
[SW03] J. Siméon and P. Wadler. The essence of XML. In Conference Record of POPL 2003: The 30th SIGPLAN-SIGACT Symposium on Principles of Programming Languages, New Orleans, Louisisana: pages 1-13, January 15-17, 2003.
[Sm87] S. W. Smoliar. Sowa's book review. Artificial Intelligence, 33, (1987), 259-266.[So84] J. Sowa. Conceptual Structures, Addison-Wesley Reading, 1984. [SP98] S. Spaccapietra, C. Parent, and E. Zimanyi. Modeling time from a conceptual perspective. Int. Conf. on Information and Knowledge Management (CIKM98), 1998.[St86] M. Stanley. CML: A Knowledge Representation Language with Applications to Requirements Modeling. M.Sc. thesis, Department of Computer Science, University of Toronto, 1986.[Sn87] R. T. Snodgrass. The temporal query language tquel. ACM Transaction on Database Systems 12 (1987), no. 2, 247–298. [Ta91] B. Tauzovich. Towards temporal extensions to the entity-relationship model. Proc. of the 10th International Conference on the Entity-Relationship Approach (ER’91), 1991, pp. 163–79. [TL91] C. Theodoulidis, P. Loucopoulos, and B. Wangler. A conceptual modeling formalism for temporal database applications. Information Systems 16 (1991), no. 3, 401–416.[TM] TopicMaps.org website. http://www.topicmaps.org [UML] Unified Modeling Language (UML) specification, version 1.5, Available at http://www.omg.org.[WebKB] WebKB. Available at http://meganesia.int.gu.edu.au/~phmartin/WebKB/ [We95] M. Wermelinger. Conceptual Graphs and First Order Logic. LNCS 954. 1995. [W75] W. A. Woods. What's in a link: foundations for semantic networks. In D.G. Bobrow and A.M. Collins, editors, Representation and Understanding: Studies in Cognitive Science, pages 35-82. New York: Academic Press, 1975.
Deliverable D8.1 66/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
[WS92] W. A. Woods and J. G. Schmolze. The KL-ONE family. In F. W. Lehmann, editor, Semantic Networks in Artificial Intelligence: 133–178, 1992. Pergamon Press. Published as a special issue of Computers & Mathematics with Applications, Volume 23, Number 2–9.[TM02] ISO/IEC 13250, Topic Maps, Second Edition, 19 May 2002, available at http://www.y12.doe.gov/sgml/sc34/document/0322_files/iso13250-2nd-ed-v2.pdf
[XMI] XML Metadata Interchange (XMI) specification, version 1.2. Available at: http://www.omg.org . [W3CXMLSchema] XML-Schema (W3C web site). Available at: http://www.w3.org/XML/Schema . [PM01] S.Pepper and G. Moore (eds), XML Topic Maps (XTM) 1.0. Available at http://www.topicmaps.org/xtm, 2001. [XSB] XSB inc. website. http://www.xsb.com/
II.2.6 Annex 1
See the annexed compressed file.
Deliverable D8.1 67/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
II.3 Ontology Management and Engineering
II.3.1 Introduction
Ontologies are an application-independent way to represent knowledge about the entities of an enterprise. In this report, we present an overview of the aspect of managing ontologies and engineering their content by a group of experts. Hence, rather than reporting on languages and (reasoning) methods (topics addressed in Chapter 1 of this report), this report concentrates on
how to build an ontology
what tools are available to support the building process
how to reach consensus about disputed elements in an ontology
which workflows are available to create ontologies
how to maintain ontology versions and control their evolution
how to learn ontologies automatically from sources
what are the specificity of ontologies for enterprise application integration
The last item is expected to be the more difficult one since the use of ontologies for enterprise application integration is a relatively new idea. Furthermore, this topic will be extensively addressed in Chapter 4 of this State of the Art. Section 2 is devoted to the state of the art in ontology building and authoring. Section 3 is addressing ontology learning tools. Section 4 gives an overview on core domain ontologies. Section 5 investigates the issues of merging and integration. Section 6 presents the state of the art in validating ontologies. Section 7 addresses evolution and versioning and section 8 multi-lingual and multi-cultural aspects in ontology engineering. Finally, section 9 presents social and cultural challenges that might be an obstacle to the creation of ontologies.
II.3.2 Building/Authoring
II.3.2.1State of the art on creation and maintenance of ontologies
Deliverable D8.1 68/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Ontologies are seen as "explicit specifications of a conceptualisation" (e.g., Wache et al. 2001); in this sense, ontologies are used in the integration task to describe the information source semantics, expliciting their content, so that they can be used for the identification of semantic interrelationships between concepts in the different contexts. In this section the focus is on tools to support users to design ontologies and integrate them. Therefore, we concentrate on the role of ontologies in supporting high-level user-oriented tasks; on the one hand the creation and maintenance of the knowledge by knowledge engineers (our ontology engineers), and on the other the knowledge exploration by both knowledge engineers and final (non expert) users as well (our end-users). We focus here on the creation and maintenance task. In the next section we propose a brief survey on methodologies and methods for creating and maintaining ontologies; after that we show the main systems supporting such an activity.
Methodologies and methods for creating and maintaining ontologies
Different methodologies for building ontologies exist and we can classify (Gomez and Lopez et al 2002) them as follows:
Methods and methodologies for building ontologies starting from scratch;
Methods for reengineering ontologies;
Methods for cooperative ontology construction.
Ontology merge methods.For each methodology we will present a brief description and the main research issues.
Methods and Methodologies for building ontologies from scratch. A bunch of approaches have been reported to build ontologies. (Lenat and Guha 1990) published the general steps and some interesting points related to the CYC development process.The CYC methodology consists of the following steps: first, one have to extract, by hand, common sense knowledge that is implicit in different sources. Next, once enough knowledge in the ontology is vailable, new common sense knowledge can be acquired either using nural language or machine learning tools. Some years later (Uschold and King 1995) published the main steps followed in the development of the Enterprise Ontology. The ethod proposes some general steps to develop ontologies, which are:
1. to identify the purpose;
2. to capture the concepts and the relationships among these concepts and the terms used to denote both of them;
3. to codify the ontology.
The ontology has to be documented and evaluated. Other ontologies can be used to build the new one. Michael Gruninger and Mark Fox reported the methodology used for
Deliverable D8.1 69/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
building the TOVE (TOronto Virtual Enterprise) ontology in the domain of enterprise modelling (TOVE 1999). One year later, (Uschold and Gruninger 1996) proposed some methodological approach for building ontologies. First, they propose to identify intuitively the main scenarios (possible applications in which the ontology will be used). Later, a set of natural language questions, called competency questions, are used to determine the scope of the ontology, that is, the questions that could be answered using the ontology. These questions are used to extract the main concepts, their properties, relationships and axioms, which are formally defined in Prolog. Therefore, this is a very formal methodology that takes advantage of the robustness of classic logic, and can be used as a guide to transform informal scenarios in computable models.
(Bernaras at al 1996) presented a method used to build an ontology in the domain of electrical networks as part of the Esprit KACTUS project. The ontology is built on the basis of an application knowledge base (KB), by means of an abstraction process. The more the applications, the more general the ontology. In other words, they propose to start the process building a KB for a specific application and, when a new knowledge base in a similar domain is needed, to generalise the first KB into an ontology and adapt it for both applications. Applying this method recursively allows for capturing within the ontology the consensual knowledge needed in all the applications.
Methontology (Fernandez et al 1997) appeared at the same time and was extended a few years later. It is a methodology for building ontologies either from scratch, or by a re-engineering process. The Methontology framework enables the construction of ontologies at the knowledge level. It includes: identification of the main ontology development process activities (i.e., evaluation, configuration management, conceptualisation, integration, implementation, etc.); a life cycle based on evolving prototypes; and the methodology itself, which specifies the steps to be taken to perform each activity, the techniques used, the output products and the way to evaluate them.
In 1997, a methodology has been proposed for building ontologies based on the Sensus ontology (Swartout et al 1997). The proposed method is a top-down approach for deriving domain specific ontologies from huge ones. The authors propose to identify a set of terms that are relevant to a particular domain. Such terms are linked manually to a broad-coverage ontology (in that case, the Sensus ontology, which contains more than 50,000 concepts). They select automatically the relevant terms for describing the domain and pruning the Sensus ontology. Consequently, the algorithm delivers the hierarchically structured set of terms for describing a domain that can be used as a skeletal foundation for a KB.
Methods for ontologies re-engineering. Ontological reengineering is the process of retrieving and mapping a conceptual model of an implemented ontology to another, more suitable, conceptual model, which is re-implemented. The Ontology Group of Artificial Intelligence Laboratory at UPM presented a method for reengineering ontologies that adapts Chikofsky's software reengineering schema to the ontology domain (Gomez-Perez and Rojas
Deliverable D8.1 70/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
1999). Three main activities were identified: reverse engineering, restructuring, and forward engineering.
Methods for cooperative ontology construction. An ontology is a shared and common understanding of a domain. Right now, emphasis has been put on the ontology content consensus, i.e., on the collegial agreement on the formal specification of the concepts, relationships, attributes, and axioms the ontology provides. However, the problem of to jointly construct an ontology in a distributed environment is still unsolved. (Euzenat 1995,1996) identified the following problems:
1. concerning collaborative construction of ontologies: management of the interaction and communication among people;
2. data access control;
3. recognition of a moral right about the knowledge (attribution);
4. error detection and management;
5. concurrent management.
Two are the main detailed proposals about how to collaboratively build ontologies, CO4 (Euzenat 1996) proposed for collaborative construction of KBs at INRIA and KA (Euzenat 1995) used in ontologies building at the Knowledge Annotation Initiative of the Knowledge Acquisition Community. CO4 is a protocol to reach consensus among several KBs and it is based on the main idea that people can discuss and commit about the knowledge introduced in the KBs. These KBs are built to be shared, and they have consensual knowledge, hence they can be considered ontologies. The experimentation has been done, above all, in the molecular genetic domain. According to Euzenat's proposal, the KBs are organised in a tree. The leaves are called user KBs, and the intermediate nodes, group KBs. On the one hand, it is not mandatory that the user KBs share consensual knowledge. On the other, each group KB represents the consensual knowledge among its sons (called subscriber KBs). The goal of the Knowledge Annotation Initiative of the Knowledge Acquisition community, also acknowledged as the KA initiative (Decker et al 1999), is to model the knowledge-acquisition community using ontologies developed in a joint effort by a group of people at different locations using the same templates and language.
To make the process of building the Research-Topic ontology easier, the ontology coordinating agent distributes a template among the Ontopic agents, which used e-mail in their intra-communication and also to send their results to the coordinating agents (experts in different topics). The ontology is generated from the knowledge introduced by the template. Once the ontology coordinating agents got all the portions of the ontologies
Deliverable D8.1 71/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
from the Ontopic agents, they integrated them, activity that benefits from the presence of a common pattern
II.3.2.2Ontology Management Systems
In this section, we will provide a broad overview of some of the available tools and environments - not already mentioned above - that can be used for building ontologies, either from scratch or reusing other existing ones. These tools usually provide a graphical user interface allowing for creating ontologies without using a formal specification language. We will provide a brief description of most important proposals.
Apollo (Apollo 2003) is a user-friendly knowledge modelling application. Modelling is based on the basic primitives, such as classes, instances, functions, relationships, etc.. The internal model is build as a frame system according to the internal model of the OKBC protocol. Apollo performs a full consistency check while editing. The application is not bound to any representation language and can be adapted to support different storage formats through I/O plug-in. The user interface has an open architecture (view based) and allows for implementing additional views of the knowledge base. The software is written in Java and is available for the download.
JOE (Java Ontology Editor) is a tool for building and viewing ontologies developed in the Centre for Information Technology, University of South Carolina (JOE 2003). The JOE basic idea is to provide a knowledge management tool that supports multiple cooperative users and distributed, heterogeneous operating environments. Ontologies are represented using a frame-based approach and can be viewed in three different formats: as ER diagrams, as a hierarchies akin to Microsoft Windows file manager, or as a graphical tree structures. JOE allows for writing queries by using a visual representation of the ontology and a point-and-click approach for adding query conditions.
OntoEdit (OntoEdit 2003) is an ontology engineering environment developed at the Knowledge Management Group (AIFB) of Karlsruhe University. It is a stand-alone application that provides a graphical ontology editing environment (that enables inspecting, browsing, codifying, and modifying ontologies, supporting in this way the ontology development and maintenance task) and an extensible architecture for adding new plug-in. The conceptual model of an ontology is internally stored using a powerful ontology model, which can be mapped onto different, concrete representation languages. Ontologies are stored in relational databases (in its commercial version) and can be implemented in XML, FLogic, RDF(S) and DAML+OIL.
Deliverable D8.1 72/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Protégé-2000 (Protege 2003) is a graphical and interactive ontology-design and knowledge-acquisition environment that is being developed by the Stanford Medical Informatics group (SMI) at Stanford University. It is an open source, stand alone application that provides a graphical ontology editing environment and an extensible architecture for the creation of customized knowledge-based tools. Its knowledge model is OKBC-compatible. Its component-based architecture enables system builders to add new functionalities by creating appropriate plug-in. The Protégé plug-in library contains plug-in for graphical visualisation of knowledge bases, inference-engines for verification of first-order logic constraints, acquisition of information from remote sources such as UMLS and WordNet, semi-automatic ontology merging, etc. It also provides translators to FLogic, OIL, Ontolingua and RDF(S), and can store ontologies in any JDBC-compatible relational database. Plug-in, applications, and ontologies, which have been developed both by the Protégé group and other Protégé users, are available in the Protégé Contributions Library.
Chimaera (Chimera 2003) is a tool mainly intended for merging knowledge base (KB) fragments, which also supports users in creating and maintaining distributed ontologies on the Web. Its two major functions are merging multiple ontologies and diagnosing individual or multiple ontologies. It supports users in reorganizing taxonomies, resolving name conflicts, browsing ontologies, editing terms, etc. The process of KB merging typically involves activities as resolving name conflicts and aligning the taxonomy. This tool has special support for finding name conflicts and for pointing out interesting places in the merged taxonomy.
OILEd is a graphical ontology editor developed by the University of Manchester
(Bechhofer et al 2001) that allows the user to build ontologies using DAML+OIL. The knowledge model of OILEd is based on that of DAML+OIL, although this is extended by the use of a frame-like presentation for modelling. Thus OILEd offers a familiar frame-like paradigm for modelling while still supporting the rich expressiveness of DAML+OIL where required. The main task that OILEd is targeted at is that of editing ontologies or schemas, as opposed to knowledge acquisition or the construction of large knowledge bases of instances. A key aspect of OILEd behaviour is the use of the FaCT reasoner (Horrocks 1998) to classify ontologies and check consistency via a translation from DAML+OIL to the SHIQ description logic (Horrocks et al 1999). This allows the user to describe their ontology classes and have the reasoner determine the appropriate place in the hierarchy for the definition. The DAML+OIL RDF Schema (March 2001) is used for loading and storing ontologies.
ICOM is a tool supporting the conceptual design phase of an information system, and in particular of an integration information system -- such as a data warehouse. The tool is an evolution of part of the conceptual modelling demonstrators suite (Jarke et al 2000) developed within the European ESPRIT Long Term Research Data Warehouse Quality (DWQ) project (Jarke et al 1999). ICOM adopts an extended Entity-Relationship (EER) conceptual data model, enriched with multidimensional aggregations and interschema constraints. ICOM is fully integrated with a very
Deliverable D8.1 73/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
powerful description logics reasoning server which acts as a background inference engine. The tool supports multiple schemas with interschema constraints but it turned out to be extremely useful also in supporting the conceptual modelling of "classical'' databases involving a single rich schema with integrity constraints, and in designing ontologies for various purposes. ICOM reasons with (multiple) diagrams by encoding them in a single description logic knowledge base, and shows the result of any deductions such as inferred links, new or stricter constraints, and inconsistent entities or relationships. Theoretical results from the DWQ project guarantee the correctness and the completeness of the reasoning process: the system uses the SHIQ description logic, as a mean to provide the core expressivity of the DLR logic developed by (Calvanese et al 1998). ICOM has been installed in more than 1,200 locations.
The MOMIS methodology (Bergamaschi et al 2001) follows a semantic approach to information integration based on the object-oriented logical schema of the information sources. In order to create a global virtual schema of involved sources, MOMIS generates a common thesaurus of terminological intensional and extensional relationships describing intra and inter-schema knowledge about classes and attributes of the source schemata. On the basis of the common thesaurus content, MOMIS evaluates affinity between intra and inter-sources classes and groups similar classes together in clusters using hierarchical clustering techniques. A global class, that becomes representative of all the classes belonging to the cluster, is defined for each cluster. The global view for the involved source data consists of all the global classes. A graphical tool, the Source Integration Designer, SI-Designer, supports the MOMIS methodology (Bergamaschi et al 1999).
SymOntoX (Missikofff and Taglino 2003) is an ontology management system that makes use of a web-based interface and targets specifically the management of ontologies for the eletronic business domain. SymOntoX allows the management for multipole ontologies, supports access rights for different user profiles, and supports multiple languages. It provides for a set of feature types to decribe concepts: similar concepts, narrower concepts, part-of concepts, and attributes of concepts. By means of access rights, certain roles can be defined for the creation of ontologies. For example, only a super user can propose new terms while ordinary users are restricted to browsing.
The book Ontological Engineering (Gómez-Pérez et al, 2004) provides a comprehensive list of ontology tools. These include
Ontolingua: a web-based server that allows to enter ontology definitions using a large number of possible slots; no reasoning capabilities; reasoning rather done by external tools; LISP-like syntax with the ability to define logical axioms
OntoSaurus: browser for LOOM-based ontologies; LOOM is a variant of description logics supporting concept classification and instance matching
WebOnto: a front-end to the OCML ontology definition language; largely compatible with Ontolingua; graphical user inferface integrated into web browsers via Java applets; OCML supports rules and definitions for relations
Deliverable D8.1 74/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
and functions; checks consistency constraints and correct typing of attribute values
WebOde: extensible ontology engineering suite with ports to different external formals (DAML-OIL, RDF(S), F-Logic, etc.); includes an editor and tools for merging and integration of ontologies; includes editor for first-order axioms; querying via its internal concept definition formaty OKBC or via Prolog; several plug-ins have been developed, e.g. ODEClean for checking consistency of concept taxonmies
KAON: ontology engineering suite based on extension of RDF(S); graphical user interface; links to pre-defined core ontologies accessible via HTTP; support for multi-lingual labels
PROMPT (Noy and Musen 2000), is an algorithm that provides a semi-automatic approach to ontology merging and alignment. PROMPT performs some tasks automatically and guides the user in performing other tasks for which his intervention is required. PROMPT also determines possible ontology inconsistencies and suggests ways to fix them. PROMPT is based on an extremely general knowledge model and therefore can be applied across various platforms.
The method of FCA-Merge (Kietz et al 2000) is guided by application-specific instances of the given source ontologies that are to be merged. Natural language processing and formal concept analysis techniques are applied, in order to derive a lattice of concepts. The generated result is then explored and transformedinto the merged ontology with human interaction.
GLUE: machine learning algorithm for finding similar concepts
OBSERVER: a merging tool scanning for synonyms and hyponyms; can deal with heterogeneous ontology sources
ONIONS (ONtological Integration Of Naive Sources) is a methodology for conceptual analysis and ontological ntegration or merging of terminologies (Gangemi et at 1999). ONIONS aims to provide extensive axiomatisation, clear semantics, and ontological depth in he domain terminologies that are to be integrated or merged. Extensive axiomatisation is obtained through a careful conceptual analysis of the terminological sources and their representation in a logical language with a rigorous semantics. Analysis ontological depth is obtained by reusing a library of foundational ontologies, on which the axiomatisation depends. Such a library may include multiple choices among partially incompatible ontologies. Consequently, the tools that implement ONIONS (Calvanese et al 2001) should support enough expressivity and classification services.
When comparing the import/export compatibility of the above-mentioned tools, WebODE supports the most ontology dialects and has ports to most plug-in tools. Next follower is Protégé. The main difference is that WebOde favors DAML-OIL (now called OWL-DL by (W3C, 2004)) whereas Protégé is following a first-order axioms representation (now called OWL-Full).
Deliverable D8.1 75/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Starting 2003, the ontology community has started to structurally compare ontology tools (Sure and Corcho, 2003) and to develop metrics aboput the expressiveness and performance of ontology tools. The metrics are based on a DAML library of concept definitions. Experiments on ontology parsers and validators (A. Gómez-Perez et al, 2003) showed that RDF(S)-based validation tools could read DAML-OIL ontologies but not detect all types ot errors, whereas DAML-OIL-based tools could read and validate RDF(S)-based ontologies. In general, the report showes that import/export are not yet fully understood.
The survey (Ribiere and Charlton, 2001) lists besides the well-known ontology languages KIF, OKBC, RDF(S), XOL, OIL, DAML+OIL the ontology management tools Protege2000 and OntoEdit.
The papers (Cui et al 2001, Cui and O'Brian 2000) discuss a so-called Domain Ontology Management Environment for creating and mapping between ontologies, browsing and constructing queries. The DOME prototype was developed mainly for integrating e-commerce applications and to bridge the semantic gap in this domain. Their method combines both top-down and buttom-up developement of ontologies. However, not many details are given how that is actually achieved.
The survey (Denny 2002) lists editing tools available and links to building ontology and comparison of languages. It lists more than 50 ontology editing tools. The survey shows that the ontology tools are quite diverse on the ontology language they support. The main languages supported are: XML, RDF, UML, DAML, LOOM, F-Logic, Prolog, CycL. Exchange formats include XML, RDF, ERD, DAML OIL, and KIF. OntoBuilder and OntoLingua have the broadest support for import/export. Very fiew porvide graphical views of the ontologies. If they do, they rely on UML or ER-like representations. The tools based on a formal representation language also tend to provide support for consistency checks. The majority of tools does not support multiple users. Details are listed in appendix 2.
This paper by (Klein et al 2002a) addresses how the ontologies need to be stored, sometimes aligned and also how it is possible to manage their evolution. It provides an introduction on these themes and addresses also ontology mapping, proposing the RDFT (RDF Transformation) mapping meta-ontology, that specifies a small ontology for mapping XML DTDs to/and RDF Schemas and is built on top of RDF Schema. According to (Stojanovic 2002) ontology editors are main tools for ontology development. Ontologies must be able to evolve for a number of reasons including changing user needs and changes in the application domain. An ontology editor thus has to support ontology evolution. A more recent survey on ontology editors is contained in (Sure, Corcho 2003). In one paper (Troncy et al. 2003), the DOE tool and its methodology is presented. The tool relies on XSLT style cheets for exchaniging ontology models. Two transformation techniques for ontology mappings are investigated. One uses RDFS, the other OWL. The OpenGalen system (Rector et al, 2001) has
Deliverable D8.1 76/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
been used extensively in the medical domain, in particular for dealing with SNOMED. It follows an elaborated workflow.
The report by (Noy et al 2002) considers the very complex domain of human anatomy and discusses what sorts of logical formalisms are required. There is a discussion of the connection between "frame based" systems and FOL, and a discussion of the implementation in Protege.
The paper of (Kim 2001) extensively discusses and presents a methodology for ontology development (combining both data driven and process driven approaches) called BPD/D Ontology Engineering Methodology.
II.3.2.3Consensus Systems and Groupware for Ontology Communities
The OntoWeb project (OntoWeb 2002) has created a survey of the most relevant methodologies and methods used for building, maintaining, evaluating and reengineering ontologies. It addresses also some of the main ontology merging methods and tools (ONIONS method, PROMPT, FCA-Merge, IFOM, and MOMIS).
The work by (von Buol 1999) presents a detailed process model for coordinating the work of ontology builders. First, she proposes to define so-called reference models that define which types of ontological concepts are allowed in which relations are pre-defined. These reference models also can contain specific constraints. Second, she defines quality models both for the products (the ontologies) as for the production process (building the ontologies). Other than for the constraints in the reference models, the quality models measure properties by metrics. In case of low quality, a change process is started.Thirdly, an execution model based on events is proposed that defines which experts are to be involved in which situations during the ontology building. The approach has been investigated in the area of medical ontologies. She indentifies the following steps for building ontologies:
1. Goal definition: specifies the goal of ontology building project. It also defines the type of the ontology to be built. This step can not be revised.
2. Team forming: the members of the ontology building project are invited
3. Project milestones: the team defines improtant milestones in their calendar; criteria for milestone fulfillment are defined
4. Role assignement: depending on the expertise of team members, responsibilities for certain sub-sections of the ontology are assigned
5. Document acquisition: literature about the domain is collected
6. Concept extraction: experts extract the important concepts out of the documents
7. Concept grouping: the extracted concepts are grouped into hierarchies
Deliverable D8.1 77/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
8. Concept relations: experts create links between the concepts dependent on the type of the ontology (the type defines the allowed links)
9. Quality check on hierarchy: experts evaluate whether the concepts are classified into the rights position in the hierarchy; they also check whether tere are missing concepts
10. Quality check on redundancy: in particular synonyms and polysems
11. Variant check: if there are multiple definitions for a concept (e.g. proposed by different experts), these variants are resolved, e.g. by voting
12. Detailed concept definition: the detailed definition of a given concept is created
13. Decision on naming: the preferred name and possibly alternative names (synonyms) are decided
14. Quality check on naming and detailed concept definition
The DOE editor by (Bachimont et al 2002) realizes a tool-supported methododology for ontology building. In particular it helps users to organize concepts in subsumption hierarchies.
II.3.2.4Limitations of the Current Approaches
Today, the key role of ontologies in information management in general and the Semantic Web in particular, has led to the rapid development of a large number of ontologies. These ontologies have, however, usually been developed in an ad-hoc manner by domain experts, often with only a limited understanding of the semantics of ontology languages. The result is that many ontologies are of low quality - they make poor use of the languages in which they are written and do not accurately capture the author's rich knowledge of the domain. To the best of our knowledge, an ontology building methodology which uses the support provided by state-of-the-art logic based ontology languages and also helps the user to take advantage of the full expressive power of such a language providing a positive and constructive end user interaction experience is still missing.
Such a methodology is indeed needed within an ontology design tool, in order to build high-quality ontologies since (1) domain experts are, in general, not experts in the ontology language they are using, (2) formalising one's knowledge in any kind of formalism is, in general, a highly complicated task which requires a lot of discipline, perseverance, and/or support. These problems are often aggravated by the fact that one ontology is built by several domain experts, and that ontologies need to be maintained, extended, and most importantly integrated/interoperated over the time.
Deliverable D8.1 78/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Other limitations of the current methodologies arise from the current status of the reasoning techniques employed by the state-of-the-art ontology systems. First of all, the expressive power required for representing high-quality ontologies is still not fully provided. Secondly, the sheer size of realistic ontologies pose problems that may require new optimisation techniques for reasoning. Thirdly, the fact that ontologies need to be integrated and interoperated requires the investigation of novel paradigms (such as a mixed global-as-view and local-as-view approach) and of reasoning problems tailored to supporting these tasks.
Poor quality ontologies usually require localised "tuning'' in order to achieve the desired results within applications. This leads to further degradation in their overall quality (e.g., their interpretability), increases the brittleness of the applications that use them, and makes interoperability and re-use difficult or impossible. These considerations will be of crucial importance in the Semantic Web projects, where it is expected that (very large numbers of) web pages will be marked up using multiple ontologies, without the authors of the ontologies having a precise idea of what would be the effects of inserting the authored ontology in the larger integrated context generated by the brokering agents.
In particular, ontologists need clear and measurable quality criteria, and tools that take them into account when building, maintaining, and inter-operating ontologies. To "take into account'' means both to measure the quality of an ontology w.r.t. specific quality criteria as well as to support the user when operating an ontology. The latter point requires that the user, when operating an ontology, can state her quality requirements, which are then taken into account by the system supporting this operation.
The OntoClean method (Guarino and Welty 2002) is about annotating concepts (or its properties) of an ontology by concepts of a backbone ontology. The backbone ontology is about concepts like essence (how rigid is a concept) and identity (how to tackle the problem of changes to an object over time). The goal of OntoClean is the correct use of relationship types (like 'isA') between concepts.
Deliverable D8.1 79/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
II.3.3 Automatic techniques for Ontology Learning (e.g., text mining)
Comprehensive ontology construction and learning has been an active research field in the past few years. Several workshops (ECAI, 2000) (ECAI, 2002) (ECAI, 2004) and (IJCAI, 2001) have been dedicated to ontology learning and related issues.
The majority of papers in this area propose methods to extend an existing ontology with new words, using natural language processing, statistical and machine learning techniques. Very often, the existing ontology is WordNet, a linguistic general purpose ontology, or MeSH, a taxonomically organized thesaurus in medicine. The motivation is that these resources, though partly or scarcely compliant with the computer science formal view of an ontology, have a large coverage and are widely available.
In (Agirre at al, 2000) a method is proposed to enrich WordNet with topic signatures extracted from on-line documents. In (Alfonseca and Manandhar 2002) an algorithm is presented to enrich Wordnet with unknown concepts on the basis of hyponymy patterns. For example, the pattern: hypernim(N2,N1):-appositive(N2,N1) captures an hyponymy relations between Shakespeare and poet in the appositive NP: “Shakespeare, the poet...”.
(Berland and Charniak, 1999) propose a method to extract whole-part relations from corpora and enrich an ontology with this information. A method to extract taxonomic relations from heterogeneous evidences (extracted from corpora and web sites) is proposed in (Cimiano et al., 2004). Both these paper do not rely on a specific existing ontology.
A few papers propose methods to extensively enrich an ontology with domain terminology. For example (Vossen, 2001) use statistical methods and string inclusion to create syntactic trees, as we do (see Figure 4). However, no semantic disambiguation of terms is performed. Very often, in fact, ontology learning papers regard domain terms as concepts. (Navigli and Velardi, 2004) propose a method for assigning a sense to complex multiword expressions based on compositional interpretation and a novel algorithm for semantic disambiguation. The method is applied to several domains (e.g. tourism, ecomomy, computer networks). An integrated ontology management and learning architecture, based on the system extensively presented in (Navigli and Velardi, 2004) is proposed in (Missikoff et al., 2002).
A statistical classifier for automatic identification of semantic roles between terms is presented in (Gildea and Jurafsky, 2001). In order to tag texts with the appropriate semantic role they use a training set of 50,000 sentences manually annotated within the FrameNet semantic labeling project.
Deliverable D8.1 80/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
(Missikoff et al 2002) have developed a software environment, centered around the OntoLearn tool, that can build and assess a domain ontology for intelligent information integration within a virtual community.
Finally, in (Maedche and Staab, 2000 and 2001) an architecture is presented to help ontology engineers in the difficult task of creating an ontology. The main contribution of this work is in the area of ontology engineering, although machine learning methods are also proposed to automatically enrich the ontology with semantic relations.
Deliverable D8.1 81/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
II.3.4 Core Domain Ontologies
II.3.4.1WordNet
WordNet is an extremely large and freely available online English lexical database (WordNet 2003). The database is divided by part of speech into nouns, verbs, adjectives, and adverbs, The nouns are organized as a hierarchy of nodes. In version 2.0 of WordNet, there are 141690 noun synsets, 24632 verb synsets, 31015 adjectives and 5808 adverbs. WordNet is continually updated, and several versions of the database currently used in Information Retrieval and Natural Language Processing applications.
Figure 4.1: Links between words in WordNet
English nouns, verbs, adjectives and adverbs are organized into synonym sets, each representing one underlying lexical concept. Different relations link the synonym sets (Fig. 4.2).
Deliverable D8.1 82/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Figure 4.1 illustrates links between word signification and forms and synonym words. This allows to make a clear difference between WordNet and a classic dictionaries. In fact, the relationships (is-a, part-of, synonymie, etc.) offer the possibility to find the signification of concepts and their relationships with other concepts. For example, if we want to know the components of a taxi, we can’t find them in a dictionary but we can find them in Wordnet.
Figure 4.2. Example of word structuring in WordNet
EuroWordNet is a multilingual database with WordNets for several European languages (Dutch, Italian, Spanish, German, French, Czech and Estonian) (Vossen Piek 1999). The wordnets are structured in the same way as the WordNet in terms of synsets (sets of synonymous words) with basic semantic relations between them. Each wordnet represents a unique language-internal system of lexicalizations.
II.3.4.2Upper Cyc
The Upper Cyc ontology captures the most general concepts of human consensus reality. It includes more than 3000 terms and assertions which relate those terms. This ontology is divided into many (currently thousands of) "microtheories", each of which is essentially a bundle of assertions that share a common set of assumptions. CycL, the Cyc representation language, is a large and extraordinarily flexible knowledge representation language. It is essentially an augmentation of first-order predicate calculus (FOPC) (CycL 2004). This ontology is used for natural language processing.
Deliverable D8.1 83/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Figure 4.3. The Upper Cyc ontology
Deliverable D8.1 84/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
II.3.4.3Sowa's Ontology
Sowa’s ontology is for representing knowledge. It is based on his book “Knowledge Representation”. The upper level of this ontology is presented by Fig. 4.4. In this ontology, T is the universal type and is the type absurd (interpreted by the empty set). The structure of this ontology is the trellis. The trellis (or lattice) is a structure that has a relationship of order and has two operators ( and ) with the following proprieties:
a b a et a b b.
If c is an element of L for which c a and c b, then c a b.
a a b and b a b.
If c is an element of L for which a c and b c, then a b c.
The nodes of the trellis can be concepts or attributes. This ontology uses as structure of representation the trellis and the FCA – « Formal Concept Analysis » to do improvements [Sowa01].
Figure 4.4. The upper level of Sowa’s ontology
Deliverable D8.1 85/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
II.3.4.4Sensus
Sensus is a taxonomy of approximately 50,000 symbols that represent the semantic meanings conveyed in translations, for natural language processing. It is being constructed at USC/ISI by extracting knowledge from a variety of sources (the most important one is Wordnet).
Figure 4.5: The sources of the ontology Sensus
The architecture of Sensus and its sources are presented by Figure 4.5. It is represented in Loom, FrameKit, and Prolog (Swartout 1997).
II.3.4.5 The Enterprise Ontology
The Enterprise Ontology (Enterprise Ontology 2003) is a collection of terms and definitions concerning the business domain. This ontology was developed by “Artificial Intelligence Applications Institute” of the University of Edinburgh in order to improve the enterprise activity. A best definition of concepts of enterprise and relationships between them allows a best modeling and analyze of enterprise. This ontology is devised on several parties: Activities and processes, Organization, Strategy and Marketing.Developed on Ontolingua, it includes 92 classes, 68 relationships, 483 axioms, 10 individuals and 7 functions. In the top of hierarchy, Classes are Eo-Entity, Role-Class, Segmentation-
Deliverable D8.1 86/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Variable, Set-Class, State-Of-Affairs. Classes, slots and axioms are constructed automatically on KIF. Fig 4.6 represents the graphic interface of Ontolingua. This figure presents the class Eo-Entity as seen on Ontolingua browser. We can observe classes to which it belongs (for example Thing, Relation, etc.) (1) and information about this class (2). Also, in this page, we can find sub*classes (for example Activity-or-Spec, For-Sale, Good-Service-or-Money, Legal-Entity, Market, Misc-Special-Detail, Need, Special-Actor, Potential-Sale, Sale), super-classes (for example Individual-Thing, Individual, Thing) and axioms.
The Enterprise Ontology has been developed to provide a method and a set of computer tools for enterprise modelling. It is intended:
1. to ensure non ambiguous communication between enterprise parties (from business managers to software engineers),
2. to help in information exchange between users, tasks and systems,
3. to improve interoperability thanks to the development of translators that convert terms used by a tool or an IT system to be integrated.
The proposed EO is not a final one nor an exhaustive one. It needs to be extended to include more details related to to specific business applications. Indeed, the idea is that the EO contains most of the general terms related to an enterprise (e.g. sales, strategy, etc.) and that the applications extend the EO with their own terms (e.g. bid analysis, project portfolio analysis, etc.). In this work, EO has various forms as shown on figure 4.7.
Deliverable D8.1
2
1
Figure 4.6:Class Eo-Entity of Enterprise Ontology - on Ontolingua
87/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Figure 4.7. Forms of the Enterprise Ontology
Deliverable D8.1 88/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Further, the EO definition process was performed thanks to the following steps:1. Identify the scope and the boundaries for the ontology,
2. Choose the terms,
3. Provide a definition to the choosed terms. These definitions may rely on a a restricted number of building blocks (like Entity, Relationship, State of Affairs, Time and Roles) referred to as a “meta-onotology”: Entities pays roles ine relationships and States of Affairs designate situations characterized by a combination of entities being in relationships with one another.
Figure 4.8 sumarizes the content of the proposed EO (see (Uschold and al 1997) for the actual definition of the terms) where the columns: ACTIVITY contains terms related to processes and planing (like activity, planning,
authority, Resource allocation), ORGANISATION contains terms that concern an organization structure (like person,
organizational unit, legal entity), STRATEGY includes terms relevant to high level planning (like purpose, mission,
decision, success factors), MARKETING contains terms related to marketing and selling of goods and services
(like sale, customer, produc and price) TIME includes terms that concern time (like time interval) together with terms that
constitue the meta-ontology.
Together with the unformal definition of the terms, a translation of the unformal EO into a formal EO is proposed where axioms may be introduced to formally specify termes properties and constraints.Futhermore, to enable effective use of the EO and tool integration, an agent-based architecture for an Enterprise Tool Set has been designed. This includes:
1. An Agent Toolkit that transforms a tool into an agent and registers that agent in the Tool Set,
2. a Procedure Builder that generates process models and makes them available to the Tool Set,
3. a Task Manager that enacts process models and runs end users applications. The Tool Set also includes facilities to edit and browse a hierarchy of ontology terms.
Finally, the defined EO has been experimented in various applications, including bid analysis, market analysis and continuos process improvement.
Deliverable D8.1 89/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
ACTIVITY, etc. ORGANISATION STRATEGY II.3.4.6 MARKETING II.3.4.7 TIMEActivity Person Purpose Sale Time LineActivity Specification
Machine Hold Purpose Potential Sale Time Interval
Execute Corporation Intended Purpose
For Sale Time Point
Executed Activity Specification
Partnership Purpose-Holder Sale Offer
T-Begin Partner Strategic Purpose
Vendor
T-End Legal Entity Objective Actual CustomerPre-Condition Organizational
UnitVision Potential Customer
Effect Manage Mission CustomerDoer Delegate Goal ResellerSub-Activity Management
LinkHelp Achieve Product
Authority Legal Ownership Strategy Asking PriceActivity Owner Non-Legal
OwnershipStrategic Planning
Sale Price
Event Ownership Strategic Action MarketPlan Owner Decision Segmentation
VariableSub-Plan Asset Assumption Market SegmentPlanning Stakeholder Critical
AssumptionMarket Research
Process Specification
Employment Contract
Non-Critical Assumption
Brand
Capability Share Influence Factor ImageSkill Shareholder Critical
Influence FactorFeature
Resource Non-Critical Influence Factor
Need
Resource Allocation
Critical Success Factor
Market Need
Resource Substitute
Risk Promotion
CompetitorFigure 4.8. Overview of Enterprise Ontology
Deliverable D8.1 90/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
II.3.4.8TOVE
The TOVE Ontology (Toronto Virtual Enterprise) is set of integrated ontologies to create a model of data having the following characteristics:
It provides a shared terminology for enterprise, that can be understand and used by each agent
It defines the sense of each term.
It constructs a set of axioms to describe the semantic with which it is possible to answer to many questions.
It defines modality of representing terms and concepts graphically
Entities of TOVE are objects with proprieties and relationships. Objects are structured on taxonomies and the definitions of objets, attributes and relationships are specified on the logic of the first order. This ontology is built as follows: Objects are identified and represented by constants and variables. Then, proprieties of objets are identified and represented by predicates. A set of axioms isconstituted on a "microtheory" that provides a specification for activities to model. These "microtheories" should contain a set of axioms to resolve problems.
The first ontology is the ontology of the time and actions. It is based on the relationship "<" that represents ordering between time/action instances. The second is the ontology of states (Fig. 4.9).
Figure 4.9. TOVE ontology of states The third one is to represent resources. Resources are considered as roles and entities implied on activities. The others are the ontologies of product, organization, and the management of the cost. All these ontologies are put together to define the model of the enterprise (TOVE 1999).
Another important business ontology is contained in the Process Handbook of MIT (MIT Process Handbook 2003). It defines about 3000 business activities subsumed under 'buying', 'making' and 'selling'. The business concepts are defined textually with some ability to define related concepts and properties of concepts. The concepts (activities) defined oin the process handbook are linked to a generic business activity model which relates the key activities. Activities are decomposed into sub-activities.
Deliverable D8.1 91/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
DOLCE (Descriptive Ontology for Linguistic and Cognitive Engineering) (Masolo et al 2003) is reference point to clarify the assumptions underlying an ontology. It follows the philosphical roots of ontologies by distinguishing natures of entities, e.g. whether they are enduring (objects that do not change) are perduring (objects who acquire new properties over time). The DOLCVE ontology has been used as founding ontology for domain ontologies.
II.3.4.9 Other Related Work
Product ontologies are used to unify the reference to product groups. They appear in form of classification (or coding systems). The E-class classification system (E-class 2004) is a comprehensive effort to provide a four-level classification system for products regardless of the industrial sector. E-class is a commercial effort from German industry and is directed to e-procurement. It supports multi-lingual access. At the lowest level, describing attrributes can be attached to the concepts. A similar proposal (Jeusfeld 2004) has been developed by the Esprit MEMO project (Mediating and monitoring electronic commerce). It designed multi-lingual product ontologies (multiple versions for different roles on a veretival market) where concepts and concept attributes (size, color, fire resistance etc.) are treated uniformly. The goal of the MEMO product ontologies is to provide access to source product databases regardless of the structure of the source databases.
The REA (Resource-Event-Agent) framework builds on Sowas ontology to provide an enterprise ontology, i.e. an ontology of the core concepts in an enterprise (McCarthy 1979,1982; Geerts and McCarthy 2000). It extends Sowas ontology by concepts for value chains and commitments. Its goal is to describe the interaction of agents in an enterprise and to formulate axioms for these interactions. REA distinguishes operational infrastructure (tasks, processes, scripts) from the knowledge infrastructure (process types, exchange types). The latter can be seen as the type lavel for the former. It is also used for expressing enterprose policies.
SUMO (Suggested Upper Merged Ontology) was promoted by the IEEE Standard Upper Ontology effort (SUMO 2003). The SUMO was created by merging publicly available ontological content into a single, comprehensive, and cohesive structure. As of February 2003, the ontology contains 1000 terms and 4000 assertions. It is implemented in DAML+OIL.
Many ontologies are built for different domains. In this section, several ontologies classified according the domain considered are presented. Some of them have been discussed before.
Linguistic domain
Wordnet is a lexical database for the English language
Upper Cyc is an ontology concerning a database of generic knowledge.
Sensus is a composition of many sources of knowledge
Deliverable D8.1 92/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
SUMO – “Suggested Upper Merged Ontology” is an ontology for the upper level proposed by IEEE.
GUM – “Generalized Upper Model” is an ontology for organizing information to express them on the natural language. It is developed on LOOM.
EuroWordNet, Germanet – it is an ontology similar to Wordnet.
Medical domain
UMLS (Unified Medical Language System) is an ontology that contains more than 1000000 concepts and 2500000 words that define concepts. A concept can have denominations in many languages. Eleven types of different relationships can be existed between concepts (UMLS 2001).
TAMBIS – is an ontology to describe biologic information. It is developed on DAML+OIL (Tambis 2001).
Geographic domain
CIA World Factbook is an ontology built by CIA to describe the state of the world. This ontology is modified each year. It provides social and geographic information (CIA 2001). An example of a country description can be found in: http://www.cia.gov/cia/publications/factbook/geos/fr.html
Enterprise domain
BMPO (Business Process Management Ontology) – is an ontology that provides a platform to define business processes. This ontology uses the language BMPN (Business Process Modeling Notation). It has as elements: entities, tasks and context.
TOVE – “Toronto Virtual Enterprise” is a set of integrated ontologies for enterprise.
Enterprise Ontology is a collection of terms concerning the business domain.
PH: Process Handbook developed by Massachussets Institute of Technology (MIT Process Handbook 2003)
The paper by (Söderström 2002) addresses ontologies in the e-business domain and finds that even the concept of 'standard' is hard to agree upon.
Deliverable D8.1 93/206
1

INTEROPInteroperability Research for Networked Enterprises Applications and Software
The paper (Hoy 2001) lists a few reference ontologies such as CYC (general domain), SENSUS (general domain), MIKROKOSMOS (natural langue translation).
Deliverable D8.1 94/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
II.3.5 Merging, Integration
II.3.5.1Mapping, Merging, Integration: a tentative definition
Ontology mapping is an activity that attempts to relate the vocabulary of two ontologies that share the same domain of discourse. There is lot of work originating from different communities that express some relevance to ontology mapping. For example, terms and work encountered in the literature include alignment, merging, articulating, fusion, integration, morphism and so on.
(Kalfoglou and Schorlemmer 2003) gives a state of the art report on ontology mapping including theoretic frameworks, methods, and tools. They also provide experiments comparing some tools.
They adopt an algebraic approach where an ontology is a pair O=(S, A) where S denotes the ontological signature (it describes the vocabulary) and A denotes a set of ontological axioms (roughly speaking, A expresses the intended interpretation of S). The mapping is then defined as a function that preserves the mathematical structure of ontological signatures and their intended interpretations, as specified by the ontological axioms i.e. mapping considered as ontology morphisms (like for instance, a morphism of posets i.e. a function f that preserves a partial order: a b implies f(a) f(b) ). Ontology mappings are then characterized as morphisms of ontological signatures and the mapping may be total or partial.
(Pinto and al 99) have a less formal approach in separating ontology integration into three cases: integration, merge and use. In the following, we rely on their definitions.
Integration when building a new ontology reusing other available ontologies. In integration we have one or more ontologies (O1, O2,… , On) that exist, and a new one (O) is created as a result from the integration process. Each ontology integrated in the resulting ontology usually is about a different domain either from the resulting ontology (D) or the various integrated ontologies domains (D1,D2,… ,Dk). The resulting ontology usually encompasses whole or parts of the ontologies that are used in the integration process. It may also include additional knowledge.
Merge when building an ontology by merging several ontologies (at least two) into a single one that unifies all of them. O1,O2,… ,On are merged into O. The goal is to make a more general ontology about a subject (S) by gathering knowledge from several other ontologies in that same subject. The subject of both the merged and the resulting ontologies are usually the same (S).
Deliverable D8.1 95/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Use when building an application using one or more ontologies. In use, there are one or more ontologies involved (O1,O2,… ,On) and there is no resulting ontology. One cannot draw any conclusions as to the architecture of the resulting application because that depends on the application itself.
II.3.5.2Some approaches to Ontology integration and merge
(Klein et al 2002) argue that ontologies need to be stored, sometimes aligned and also require facilities to manage their evolution. They provides an introduction on these themes and addresses also ontology mapping, proposing the RDFT (RDF Transformation) mapping meta-ontology, that specifies a small ontology for mapping XML DTDs to/and RDF Schemas and is built on top of RDF Schema.
(Stumme and Maedche 2003) specifically address ontology merging, namely the FCA-Merge method. This method is exploiting representations of examples of ontology concepts, natural-language processing, and formnal concept analysis. It is not automatic but iassists the human expert in her merging activity.
The paper by (Hovy 2001) proposes a concept-by-concept approach to compare two ontologies. By that one can also find justifications for the presence in one ontology by its presence in the other ontology. The work is motivated by the search for a standard reference ontology. The relative match between two ontology concepts (stemming from different ontologies) is expressed by a score.
Another approach to mapping focused of the study on lexical and figurative meaning (Ahrens and al 2003). Some online electronic dictionaries were developed for assisting the processing of natural languages. They support some relationships between the terms (name of concept), as name equality, synonyms, homonyms, hyponyms, abbreviations and so on. Some of these studies are briefly reviewed hereafter.
Additional information on ontology merging is contained in the survey by (OntoWeb 2002). Let us now turn our attention to ontology integration as compared to database schema integration.
II.3.5.3Database Schema Integration vs Ontology Integration
Some work performed in the database schema integration domain might also be applicable to ontology merging and integration. See for example (Parent and Spaccapietra 2000) and the very wide literature about view and schema integration in database domain8. Most of recent approaches map local schemas to a global (or canonical) data model. The purpose of such an
8 In the database domain, work on this topics has been initiated a long time ago: see, for example, (Batini and al. 1986) and (Sheth and Kashyap 1993.
Deliverable D8.1 96/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
integration may be, for instance, a uniform access to distributed databases or database evolution.
Even though from the ontology domain some authors argue that ontology evolution is not the same as schema evolution (Noy and Klein 2002), in the following we elaborate on some approaches for schema matching that use artificial intelligence techniques.
Schema matching is a basic problem in many database application domains, such as heterogeneous database integration, E-commerce, data warehousing, and semantic query processing. Most work on schema match has been motivated by schema integration. Given a set of independently developed schemas, construct a global view has been investigated (Spaccapietra and Parent 1998). In an artificial intelligence setting, this is the problem of integrating independently developed ontologies into a single one.
(Rahm and Bernstein 2001) presents an analysis of seven published prototype implementations that uses AI techniques for schema and data sources matching.
The SemInt (Clifton and Li 2000) match prototype creates a mapping between individual attributes of two schemas (i.e. its match cardinality is 1:1). SemInt uses neural networks to determine match candidates. This approach requires similar attributes of the first input schema to be clustered together. SemInt represents a powerful and flexible approach to hybrid matching, since multiple match criteria can be selected and evaluated together.
The LSD (Learning Source Descriptions) system uses machine-learning techniques to match a new data source against a previously determined global schema, producing a 1:1 atomic-level mapping (Doan and al 2001). It represents a composite match scheme with an automatic combination of match results. A global matcher that uses the same machine-learning technology is used to merge the lists into a combined list of match candidates for each schema element. It can take self-describing input, such as XML, and make its matching decisions by focusing on the schema tags while ignoring the data instance values.
The SKART (Semantic Knowledge Articulation Tool) prototype follows a rule-base approach to semi-automatically determine matches between two ontologies (Mitra and al 1999). Rules are formulated in first-order logic to express match and mismatch relationships and methods are defined to derive new matches. SKAT is used within the NION (Mitra and al 2000) architecture for ontology integration. In ONION, ontologies are transformed into a graph-based object-oriented database model.
The TransScm prototype (Milo and Zohar 1998) uses schema matching to derive an automatic data translation between schema instances. The matching is performed node by node (element-level, 1:1) starting at the top and presumes a high degree of similarity between the schemas. In (Palopoli and Sacc 1999,Sacc and Ursino 1998), Palopoli et al. propose algorithms to automatically determine synonym and inclusion (is-a, hypernym) relationships between objects of different entity-relationship schemas. The algorithms are based on a set of user-specified synonym, homonym, and inclusion properties that include a numerical "plausibility factor" (between 0 and 1) about the certainty that the relationship is expected to hold. This algorithms are embodied in the DIKE system.
Deliverable D8.1 97/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
ARTEMIS is a schema integration tool (Castano 2001). It first computes "affinities" in the range 0 to 1 between attributes, which is a match-like step. It then completes the schema integration by clustering attributes based on those affinities and then construction views based on the clusters. ARTEMIS is used as component of a heterogeneous database mediator, called MOMIS (Mediator envirOment for Multiple Information Sources).
Cupid is a hybrid matcher based on both element and structure level matching (Madhavan and al 2001). It is intended to be generic across data models and has been applied to XML and relational examples. It uses auxiliary information sources for synonyms, abbreviations, and acronyms.
II.3.6 Validation (wrt usage)
A white paper by (Angele and Sure 2002) offers some thoughts on how to validate ontologies. Among others, they investigate the tool OntoGenerator to generate artificial ontologies that can then be used to validate tools. Some metrics like depths of nesting are shortly discussed but not further elaborated. The approach is further followed in the EON workshop series (Sure and Corcho 2003) which however focuses more on comparing ontology tools rather than on ontologies.
Many interesting papers have recently been published on the related topic of ontology evaluation. They propose different methods for quantitative and qualitative evaluation, the former being based on formal characteristics of ontology representation, the latter involving the user or the expert in rating the defined ontology.
An example of the first approach is the paper of (Gòmes-Pérez and. Suárez-Figueroa, 2004), where an in depth evaluation of parser and platforms using the most popular RDF(S), DAML+OIL and OWL formalisms for ontology representation has been conducted. The evaluation metric is based on circularity problems, partition errors and grammatical redundancy problems detection capabilities of the investigated tools, and has been applied to ten widely used ontology parsers and validators.
On the qualitative side, in order to classify the possible approaches, (Brewster et al., 2004) suggested to focus the evaluation on the principles used in ontology construction, on the effectiveness of ontology in the context of an application, or on the congruence (fit) between an ontology and a domain of knowledge.
In the same paper they propose a data driven method able to estimate the ontological fit, as a measure of vocabulary overlap between the concepts contained in a given ontology and the terms extracted from a corpus of texts related to the domain. Their ontology evaluation in view of a corpus is based on three steps: identification of keywords/terms (based on latent semantic analysis and a clustering algorithm), query expansion (by using a two-step hypernyms WordNet look up) and ontology mapping.
Deliverable D8.1 98/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
An example of evaluation made in the context of an application is given by (Porzel and Malaka, 2004). They define a schema able to test an ontology on a given task on three basic levels: the scope (or fit) of the vocabulary, the wellness (fit) of the taxonomy, i.e. the generalization or isa hierarchy and the adequacy of the non-taxonomic relations, i.e. the fit of the semantic relations. The method has been applied to the task of tagging the ontological relations that hold between ontologically marked-up entities, showing good results regarding the evaluation of the qualities of each individual level of the ontological model with respect to a gold standard.
Finally, in (Navigli et al., 2004), an original method for qualitative evaluation of linguistic ontologies is presented. The authors moved from the consideration that ontology construction, apart from the technical aspects of a knowledge representation task (i.e. choice of representation languages, consistency and correctness with respect to axioms, etc.), is a consensus building process, one that implies long and often harsh discussions among the specialists of a given domain. To facilitate this process, they define an algorithm for automatic generation of textual explanations (glosses) for the multi-word expression defined in an ontology. Such description, expressed in natural language, can be used by domain experts to compare their intuition of a domain with its description, as provided by the ontology concepts, thus facilitating a qualitative per-concept evaluation of the congruence between the ontology and the modelled domain.
II.3.7 Evolution, Versioning
(Klein et al. 2002a) investigated the requirements for ontology management systems (OMS_ and found that versioning would be very important but that almost no system (except SHOE) supports it! More work exists on evolution (change) since this is a core task of any OMS. The distiguish types of changes like change of a natural language text, structural (logical) change, addition of definitions, deletion of definition etc.
(Noy and Klein 2003) argue that much can be learned from schema evolution but that ontology evolution also has some peculiarities: namely, different semantics, different usage paradigms. They see no difference between evolution and versioning since an ontology should contains its complete history, i.e. all its versions.
The paper (Klein et al 2002b) distinguishes conceptual changes (the way a domain is interpreted) from explication changes (the way how concepts are specified). For example, adding a new slot to an existing concept is an explication change when the interpretation of the concept is not affected. The difference can however not ne detected by analyzing the ontology or the ontology change since it is a categorization of the change before it is submitted to the ontology. The paper also presents the versioning system of OntoView, which is inspired by the CVS versioning system. Currently, OntoView supports versioning when importing external ontology sources into its repository, much like adding a new module to CVS. At import time, the user specifies some meta data about the imported ontology source.
Deliverable D8.1 99/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
In the future, explicit changes to the ontology shall be supported as well. Thes changes can be:
non-logical changes: for example, changes to the natural language description of a concept
logical changes: changes in the definition of a concept that affects its formal semantics
name change: changing the identifying label of a concept
addition of a concept
removal of a conceptLogical changes can be specified by a production rules that control which (property) changes are admissable. The rules are formulated on RDF triples and remind very much of integrity rules in (deductive) databases.
In (Klein and Noy 2003), changes to an ontology are seen as sequences of individual update operations like a log file of a database system. They discuss minimal transformations between two given ontology states, i.e. how to go from one state to the other with the smallest set of individual updates and how to construct complex update operators from sequences of individual updates (represented as minimal transformations). These update operations can themselves be organized as an ontology and offered to the user in a menu.
II.3.8 Multi-lingual, Multi-cultural, Meta-Data
There is little research done on multi-ligual and multi-cultural aspects of ontology development. One of the fe exceptions is the MACS project (MACS 2004). MACS aims to provide multilingual subject access to library catalogues. MACS enables users to simultaneously search the catalogues of the project's partner libraries in the language of their choice (English, French, German). The partners are: the Swiss National Library (SNL), project leader, the Bibliothèque nationale de France (BnF), The British Library (BL) and Die Deutsche Bibliothek (DDB).
The IST project MKBEEM (Multilingual Knowledge Based European Electronic Marketplace) develops a mediation system which adapts the language and the trading conditions of an Internet sales point according to its international customership. MKBEEM has developed a multi-lingual ontology for an e-marketplace broker (Leger et al 2002).
Another example of a multi-lingual ontology is EUROWORDNET (Vossen Piek 1999). It is the multi-lingual version of WordNet covering about half a dozen European languages.
Deliverable D8.1 100/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
In the medical domain, a huge effort is being made every decade to translate the American SNOMED taxonomy (www.snomed.org). SNOMED covers more than 350.000 clinical terms along the dimensions clinical findings (diseases), procedure/therapy, observable entity, body structure, organisms, substances etc. Besides these terms, there are roughly 1 million synonyms and 1,5 million relationships between concepts. Translation projects exist for English to Spanish and English to German. Each translation effort takes several years and is carefully planned.
Multi-lingual product catalogs were investigated in (Jeusfeld 2004). The idea is to separate catalog data structures from product ontologies and classify elements in product catalogs to concepts in product ontologies. These concepts then have multi-lingual labels allowing multi-lingual accesses to the heterogeneous product catalogs. Besides supporting multiple languages, the approach also allows managing several parallel product ontologies - each specialized for a certain market. The approach is implemented by the ConceptBase system (www.conceptbase.cc). It has also been used for the ontology system developed by (vBuol 2000).
The paper by (Brase and Nejdl 2003) discusses ontologies and meta-data. The application domain is E-learning. It builds on the standard Dublin Core for document meta-data (providing fields for author, creation, subject, etc.). The link to ontologies is made via the 'subject' field, in their case linking to the ACM Computer Classification System and the SWEBOK ontology. The querying is done via Datalog engines ranging over regular meta-data but also the ontologies linked to the documents.
II.3.9 Social & cultural challenges (e.g., dedicated GW)
The appears to be little work on this in the ontology domain. Some work from software engineering (Wangler and Persson 2002, Wangler et al 2003) draws on intentions of stakeholders in the software development process. They demand certain skills of people involved in a software development project like listening skills. Another interesting aspect is to make goals explicit. That is state of the art in software engineering literature but appears to be under-developed in the field of ontology engineering. For a counter example see (vBuol 2000). She lists goal definition as one of the first steps on ontology engineering projects.
II.3.10 Conclusions
The overall conclusion of this report is that there is a rather good selection of ontology management tools but there is little known on how to create 'good' ontologies in a multi-lingual and multi-cultural setting.
Deliverable D8.1 101/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Concerning ontology managament tools, there is basically the choice between tools originating from the US and tools originating from Europe. A prominent example the first category is OntoLingua. It provides a the schema for representing concepts but leaves reasoning services basically to external tools such as Prolog. The second category is characterized by relying on a strong ontology language foundation, namely description logic, and provides integrated services for reasoning within ontologies, e.g. to find out whether one concept is more special than another concept.
Given this state of the art, we recommend investigating the following questions:
1. What are the ingredients of an ontology language for enterprise application integration? Specifically, shall we represent processes, organizational units, business goals, business entities?
2. How to separate ontology engineering from enterprise application modeling (WP 5)? We must avoid to duplicate work and define the precise border and link between an enterprise model and an enterprise ontology.
3. How to cope with multi-linguality and multiple cultures? One goal of an ontology is to increase the level of understanding between different people, potentially with different cultural background.
4. Which role can ontologies play in an evolving collection of inter-related enterprise applications? Can ontologies an integral part of enterprise applications in the sense of self-aware software systems?
II.3.11 Bibliography
Ahrens, Kathleen , Fong Chung, Siaw and Huang, Chu-Ren (2003): Conceptual metaphors: Ontology-based representation and corpora driven mapping principles. In Mark Lee John Barnden, Sheila Glasbey and Alan Wallington, editors, Proceedings of the ACL 2003 Workshop on the Lexicon and Figurative Language, pages 35-41, 2003.
Deliverable D8.1 102/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Batini, C., Lenzerini, M. and Navathe, S.B. : A Comparative Analysis of Methodologies for Databases Schema Integration. ACM Cmputing Surveys, Vol.18(4), December 1986, pp.323-364.
S. Bechhofer, I. Horrocks, C. Goble, R. Stevens (2002): "OilEd: A Reason-able Ontology Editor for the Semantic Web. Proceedings Description Logics 2001, http://ceur-ws.org/Vol-49.
S. Bergamaschi, S. Castano, M. Vincini (1999): Semantic Integration of Semistructured and Structured Data Sources SIGMOD Record 28(1).
S. Bergamaschi, S. Castano, D. Beneventano, M. Vincini (2001): Semantic Integration of Heterogeneous Information Sources. Data & Knowledge Engineering 36(1), pp. 215-249.
A. Bernaras, I. Laresgoiti and J. Corera (1996): Building and Reusing Ontologies for Electrical Network Applications. Proceedings European Conference on Artificial Intelligence (ECAI’96).
Jan Brase, Wolfgang Nejdl (2003): Ontologies and Metadata for eLearning. In "Handbook on Ontologies", Springer-Verlag 2003, ISBN 1-58603-345-X.
D. Calvanese, G. De Giacomo, M. Lenzerini, D. Nardi, R. Rosati (1998): Description Logic Framework for Information Integration. In Proceedings KR-1998, Morgan Kaufman, pp. 2-13.
D. Calvanese, G. De Giacomo, M. Lenzerini (2001): A Framework for Ontology Integration, Proceedings of 2001 Int. Semantic Web Working Symposium.
Clifton, Christopher W. and Li, Wen-Syan (2000): Semint: A tool for identifying attribute correspondences in heterogeneous databases using neural networks. Data and Knowledge Engineering, 33(1), April 2000.
V. De Antonellis and S. Castano (2001): Global viewing of heterogeneous data sources. IEEE Transcation on Knowledge and Data Engineering, 13(2):277-297, April 2001.
S. Decker, M. Erdmann, D. Fensel and Rudi Studer (1999): Ontobroker: Ontology Based Access to Distributed and Semi-Structured Information. In "Semantic Issues in Multimedia Systems", Proceedings of DS-8, Kluwer Academic Publisher, 1999, pp. 351-369.
A. Doan, P. Domingos and A.Y. Halevy (2001): Reconciling schemas of disparate data sources: A machine-learning approach. In SIGMOD Conference, 2001.
J. Euzenat (1995): Building consensual knowledge bases: context and architecture. In "Building and sharing large knowledge bases", IOP Press, pp. 143-155.
J. Euzenat (1996): Corporative memory through cooperative creation of knowledge bases and hyper-documents. Proceedings 10th KAW, Banff (Canada).
Deliverable D8.1 103/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
M. Fernandez, A. Gomez-Perez and N. Juristo (1997): METHONTOLOGY: From Ontological Art Towards Ontological Engineering. Symposium on Ontological Engineering of AAAI, Stanford, California, 1997, pp. 33-40.
A. Gangemi, D.M. Pisanelli, G. Steve (1999): An Overview of the ONIONS Project: Applying Ontologies to the Integration of Medical Terminologies. Data & Knowledge Engineering 31, pp. 183-220.
G.L. Geerts, W.E. McCarthy (2000): The Ontological Foundation of REA Enterprise Information Systems. Working paper, Michigan State University (August 2000).
A. Gomez-Perez and M.D. Rojas (1999): Ontological Reengineering and Reuse. European Knowledge Acquisition Workshop (EKAW) 1999.
I. Horrocks (1998): Using an Expressive Description Logic: FaCT or Fiction? Proceedings KR-98, pp. 636-647.
I. Horrocks, U. Sattler, S. Tobies (1999): Practical Reasoning for Expressive Description Logics. In Proceedings LPAR 1999, LNAI 1705, Springer-Verlag, 1999, pp. 161-180.
M. Jarke et al (1999): Fundamentals of Data Warehousing. Springer-Verlag, 1999.
M. Jarke et al. (2000): Concept Based Design of Data Warehouses: The DWQ Demonstrators. In Proceedings SIGMOD 2000.
M.A. Jeusfeld: Integrating Product Catalogs via Multi-language Ontologies. Proceedings EAI 2004, http:/ceur-ws.org/Vol-93.
J. Kietz, A. Maedche, R. Volz (2000): A Method for Semi-Automatic Ontology Acquisition from a Corporate Intranet. Workshop on Ontologies and Texts, http://ceur-ws.org/Vol-51/
C. Masolo et al (2003). The WonderWeb Library of Foundational Ontologies. WonderWeb Deliberable D17. http://www.loa-cnr.it/Papers/DOLCE2.1-FOL.doc
W.E. McCarthy (1979): An Entity-Relationship View Of Accounting Models. The Accounting Review (October): 667-86.
W.E. McCarthy (1982): The REA Accounting Model: A Generalized Framework for Accounting Systems in A Shared Data Environment. The Accounting Review (July), pp. 554-578.
Mitra P.; Wiederhold G.; Jannink J (1999): Semi-automatic integration of knowledge sources. Proceedings of Fusion '99, July 1999, (9), July 1999.
Mitra Prasenjit, Wiederhold Gio, and Kersten, Martin (2000): A graph-oriented model for articulation of ontology interdependencies. Lecture Notes in Computer Science, 1777:86+, 2000.
Deliverable D8.1 104/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Madhavan, Jayant, Bernstein, Philip A. and Rahm, Erhard (2001): Generic schema matching with cupid. In The VLDB Journal, pages 49-58, 2001.
Miller, George A. and al (2003): Wordnet 2.0, 2003. http://www.cogsci.princeton.edu/ wn/.
Milo, Tova and Zohar, Sagit (1998): Using schema matching to simplify heterogeneous data translation. In Proceedings of the 24rd International Conference on Very Large Data Bases, pages 122-133. Morgan Kaufmann Publishers Inc., 1998.
Spaccapietra, S. and Parent, C. (1998): Issues and approaches of database integration. CACM, 41(5):166-178, 1998.
Piek. Vossen, Eurowordnet (1999): A multilingual database with lexical semantic networks. EuroWordNet General Document, 3, July 19 1999.
Rahm, Erhard and Bernstein, Philip A. (2001): A survey of approaches to automatic schema matching. VLDB Journal: Very Large Data Bases, 10(4):334-350, September 2001.
Sheth, A.P. and Kashyap, V (1993): So far (schematically) Yet so near (semantically). In Interoperable Database Systems, Elsevier Science, North Holland, D.K. Hsiao, E-J. Neuhold and R. Sack-Davis Eds, 1993.
Palopol, L., Sacc, D. and D. Ursino (1998): Semi-automatic, semantic discovery of properties from database schemes. In Proceedings of the 1998 International Symposium on Database Engineering & Applications, page 244. IEEE Computer Society, 1998.
Von Buol, B. (2000): Qualitätsgestützte, kooperative Terminologiearbeit. Shaker-Verlag, Aachen, Germany, 2000, ISBN 3-8265-7096-0
Dehli,, Einar, Smith-Meyer Henrik and Lillehagen Frank, July 2003, Metis LEARN, Enterprise Architecture paper presented at CE 2003, Madeira, Portugal; see http://www.ce2003.org/.
Camarinho-Matos, Luis and all, June 2004; Virtual Organization systems and Practices, Book to be published, see chapter 1.4 Ontology and Knowledge Management.
Fox, Mark and Grueninger M., September 1997, The TOVE Ontologies, presentations at the Globeman 21 project workshop, Japan, see also http://www.eil.utoronto.ca/enterprise-modelling/tove/.
Gavrilova, Tatiana and Gorovoi, Vladimir, October 2003; “Ontological Engineering for Knowledge Portal Design”, Slides presented at the PROVE 2003 conference in Lugano, Italy.
A. Gómes-Pérez, M.C. Suárez-Figueroa (2003): Results of Taxonomic Evaluation of RDF(S) and DAML+OIL ontologies using RDF(S) and DAML+OIL Validation Tools and Ontology Platforms import services. In Proceedings EON2003, http://ceur-ws.org/Vol-87/EON2003_Figueroa.pdf
Deliverable D8.1 105/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
A. Gómes-Pérez, M. Fernández-López, O. Corcho: Ontollogical Engineering. Springer-Verlag, 2004.
A. Gómes-Pérez, M. Fernández-López, O. Corcho (2002): Technical Roadmap D.1.1.2. OntoWeb Consortium.
D.B. Lenat and R.V. Guha (1990): Building Large Knowledge-Based Systems: Representation and Inference in the CYC Project. Addison Wesley.
Lillehagen, Frank, Computas, 1997 and 2002, The Foundations of the AKM technology, last presented at the CE 2004 conference, Madeira July, 2003, see also www.akmii.net.
Lillehagen, Frank and others, July 2003, IDEAS report D 2.4: Visions of 2010, for IDEAS project, see also www.ideas-roadmap.net.
Lillehagen, Frank:, February 2004; Enterprise Modeling Tutorial, presented at the Athena project kick-off meeting; Valencia, Spain. Go to: www.athena-ip.com.
Lillehagen, Frank, Solheim Helge and Tinella, Stefano, Enterprise Knowledge Spaces, providing scenes for new approaches to SE and KM, Paper to be presented.
McElroy, Mark and Firestone Joe, The New Knowledge Management, Book published by Butterworth Heineman, ISBN: 0-7506-7608-6.
Noy, Natalia F. and McGuinness, Deborah L., Summer 2003, Ontology Development 101: A Guide to Creating Your First Ontology http://protege.stanford.edu/publications/ontology_development/ontology101.pdf.
Petit, Michael et al., April 2003, State-of-the-art in Enterprise Modeling. UEML project report and presentation; see www.UEML.org.
Rohlenko, Oleg, Spring 2002, Ontology Seminar, Given at the Interop NoE project Kick-off; Bordeaux, France.
Ross, Hugh, “ SADT – Structural Analyses and Development Tool”, presentation at IFIP seminar Røros, Norway, 1969.
York Sure, Oscar Corcho (2003): Evaluation of ontology-based tools. Proceedinds EON2003, http://ceur-ws.org/Vol-87
W3C (204): OWL Web Ontology Language Overview. http://www.w3.org/TR/owl-features/Zhan Cui, Paul O'Brien (2002): Domain Ontology Management Environment, Proceedings of
Business to Business E-Commerce, HICSS33, January 2000, http://more.btexact.com/projects/ibsr/papers/b2bCommerce.doc
Deliverable D8.1 106/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Zhan Cui, Dean Jones, Paul O'Brien (2001): Issues in Ontology-based Information Integration, Proc. IJCAI01 Workshop on E-Business and the Intelligent Web, Seattle, USA, August 5, 2001.
M. Denny (2002): Ontology Building: A Survey of Editing Tools, http://www.xml.com/pub/a/2002/11/06/ontologies.html, 2002.
Michel Klein, Ying Ding, Dieter Fensel, Borys Omelayenko (2002): Ontology management - Storing, aligning and maintaining ontologies, http://homepage.uibk.ac.at/~c703205/download/Chap5-final.pdf, 2002.
L. Stojanovic, B. Motik (2002): Ontology Evolution with Ontology Editors, http://km.aifb.uni-karlsruhe.de/eon2002/EON2002_Stojanovic.pdf, 2002.
York Sure, Oscar Corcho (2003): Evaluation of Ontology-based Tools, Proceedings of the 3rd Workshop ADIS-2002, El Escorial, Madrid, Spain, November 18, 2002, http://CEUR-WS.org/Vol-87/
Raphael Troncy, Antoine Isaac, and Veronique Malaise (2003): Using XSLT for Interoperability: DOE and The Travelling Domain Experiment, Proceedings EON 2003, http://CEUR-WS.org/Vol-87/EON2003_Troncy.pdf
Alan L Rector, Chris Wroe et al. (2001): Untangling Taxonomies and Relationships:Personal and Practical Problems in Loosely coupled development of large ontologies, http://www.cs.man.ac.uk/~rector/papers/rector-k-cap-untangling-taxonomies-web.pdf.
N. F. Noy; M. A. Musen; J. L.V. Mejino; Jr., C. Rosse (2002): Pushing the Envelope: Challenges in a Frame-Based Representation of Human Anatomy, http://smi-web.stanford.edu/pubs/SMI_Abstracts/SMI-2002-0925.html.
Ontoweb Project Partners (2002): A survey on methodologies for developing, maintaining, evaluating and reengineering ontologies, Ontoweb Project (del 1.4), http://ontoweb.aifb.uni-karlsruhe.de/About/Deliverables/D1.4-v1.0.pdf.
M. Missikoff, R. Navigli, P. Velardi (2002): Integrated approach to web ontology learning and engineering, IEEE Computer, 2002, http://www.dsi.uniroma1.it/~velardi/IEEE_C.pdf
M. Missikoff, F. Taglino (2003): SymOntoX: A Web-Ontology Tool for eBusiness Domains. Proceedings Fourth International Conference on Web Information Systems Engineering (WISE'03) December 10 - 12, 2003, Roma, Italy, pp. 343 ff.
B. Bachimont, A. Isaac A. and R. Troncy R. (2002): Semantic Commitment for Designing Ontologies: A Tool Proposal, 13th International Conference on Knowledge Engineering and Knowledge Management (EKAW'2002).
Eva Söderström (2002): Standardising the Business Vocabulary of Standards, The ACM Symposium on Applied Computing (SAC 2002).
Deliverable D8.1 107/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Michel Klein, Ying Ding, Dieter Fensel, Borys Omelayenko (2002a): Ontology management - Storing, aligning and maintaining ontologies, OntoKnowledge Project Report, http://homepage.uibk.ac.at/~c703205/download/Chap5-final.pdf
Michel Klein, Atanas Kiryakov, Damyan Ognyanov, and Dieter Fensel (2002b): Ontology Versioning and Change Detection on the Web. In 13th International Conference on Knowledge Engineering and Knowledge Management (EKAW02), Sigüenza, Spain, October 1-4, 2002.
Michel Klein and Natasha F. Noy (2003): A component-based framework for ontology evolution. In Proceedings of the Workshop on Ontologies and Distributed Systems, IJCAI '03, Acapulco, Mexico, 2003.
C. Parent and S. Spaccapietra (2000): Database integration: The key to data interoperability, in Advances in Object–Oriented Data Modeling, M. Papazoglou, S. Spaccapietra, Z. Tari (Eds.), MIT Press.
G. Stumme and A.Maedche (2003): Ontology Merging for Federated Ontologies on the Semantic Web, Proceedings IJCAI 2003, www.tzi.de/buster/IJCAIwp/Finals/stumme.pdf.
Y. Kalfoglou and M. Schorlemmer (2003): Ontology mapping: the state of the art, The Knowledge Engineering Review, Vol. 18:1, 1–31.
Hoy (2001): Comparing sets of semantic relations in ontologies, Kluwer, 2001.
J. Angele and Y. Sure (2002): Evaluation of Ontology-based Tools, Whitepaper, www.ontoweb.org.
N.F. Noy and M. Klein (2002): Ontology Evolution: Not the Same as Schema Evolution, submitted to Knowledge and Information Systems; also available as Smi-2002-0926, University of Stanford, Stanford medical Informatics.
N.F. Noy M.A. Musen (2000): PROMPT: Algorithm and Tool for Automated Ontology Merging and Alignment. Proceedings of the Seventeenth National Conference on Artificial Intelligence (AAAI-2000).
B. Wangler and A. Persson (2002): Capturing Collective Intentionality in Software Development, n Fujita, H. and Johannesson, P. (eds.), New Trends in Software Methodologies, Tools and Techniques, IOS Press, Amsterdam, Netherlands, pp 262-270.
B. Wangler, A. Persson, P. Johannesson, L. Ekenberg (2003): Bridging High-Level Enterprise Models to Implementation-Oriented Models, The Lyee Workshop, Stockholm, 2003.
Macs (2004): Multilingual access to subjects. Online http://infolab.uvt.nl/prj/macs/, Sep. 2004.
Alfonseca E. and Manandhar S. (2002): Improving an Ontology Refinement Method with Hyponymy Patterns. Language Resources and Evaluation (LREC-2002), Las Palmas, Spain, May 2002.
Agirre E., Ansa O., Hovy E. and Martinez D. (2000): Enriching very large ontologies using the WWW, in ECAI 2000 Ontology Learning Workshop http://ol2000.aifb.uni-karlsruhe.de.
Deliverable D8.1 108/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
M. Berland and E. Charniak. (1999): Finding Parts in Very Large Corpora. In Proceedings of the the 37th Annual Meeting of the Association for Computational Linguistics (ACL-99), pp 57-64
Cimiano P., Pivk A., Schmidt-Thieme L. and Staab S. : Learning taxonomic relations from heterogeneous evidence, in ECAI-2004 Workshop on Ontology Learning and Population (http://olp.dfki.de/ecai04/cfp.htm)
Gildea D. and D. Jurafsky, (2001): Automatic Labeling of Semantic Roles, Computational Linguistics, vol. 99 n.9.
N. Guarino, C. Welty (2002). Evaluating ontological decisions with OntoClean. CACM 45(2):61-65.
Jeusfeld, M.A. (2004): Integrating Product Catalogs via Multi-language Ontologies. Proceedings Workshop Enterprise Application Integration, Oldenburg, Germany, 2004.
Léger, A., Michel, G., Barret P. et al (2000): Ontology Domain Modeling Support for Multi-lingual services in E-Commerce, Proceedings Workshop on Applications of Ontologies and Problem solving Methods at ECAI'00, Berlin, Germany, August 20-25, 2000.
Maedche A. and Staab S. (2000) : Semi-automatic Engineering of Ontologies from Text Proceedings of the Twelfth International Conference on Software Engineering and Knowledge Engineering (SEKE'2000).
Maedche A. and Staab S. (2001): Ontology learning for the Semantic Web, IEEE Intelligent Systems, 16(2), 2001
R. Navigli ,Velardi P.,. (2004).: Learning Domain Ontologies from Document Warehouses and Dedicated Web Sites”. Computational Linguistics. vol. 50 (2), 2004.
M. Missikoff, R. Navigli, Velardi P. (2002): An integrated approach for Web ontology learning and engineering. IEEE-Computer., Nov. 2002.
Vossen P. (2001) : Extending, Trimming and Fusing WordNet for technical Documents, NAACL 2001 workshop on WordNet and Other Lexical Resources, Pittsbourgh, July 2001.
C. Brewster, H. Alani, S. Dasmahaptra, Y. Wilks (2004): Data Driven Ontology Evaluation, Proceedings of the 4th Language Resources and Evaluation Conference (LREC2004), Lisbon, Portugal, May 2004.
A. Gòmes-Pérez, M.C. Suárez-Figueroa (2004): Ontology evaluation Functionalities of RDF(S)m DAML+OIL, and OWL Parsers and Ontology Platforms, Proceedings of the 4th Language Resources and Evaluation Conference (LREC2004), Lisbon, Portugal, May 2004.
R. Navigli, P. Velardi, A. Cucchiarelli, F. Neri (2004): Quantitative and Qualitative Evaluation of the OntoLearn Ontology Learning System, Proceedings of the 20th
Deliverable D8.1 109/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
International Conference on Computational Linguistics (COLING2004), Geneva, CH, 2004.
R. Porzel, R.Malaka (2004): A Task-Based Approach for Ontology Evaluation, Proceedings of the ECAI 2004 Workshop on Ontology Learning and Population, 1-6, Valencia, Spain, 2004.
B. Swartout, R. Patil, K. Knight, T. Russ (1997): Toward Distributed Use of Large-Scale Ontologies, Symposium on Ontological Engineering of AAAI, Stanford, California, 1997. http://ksi.cpsc.ucalgary.ca/KAW/KAW96/swartout/Banff_96_final_2.html
M. Denny (2002): Ontology Building: A Survey of Editing Tools, http://www.xml.com/pub/a/2002/11/06/ontologies.html
M. Uschold and M. Gruninger (1996): Ontologies: Principles Methods and Applications. Knowledge Engineering Review 2, pp. 93-155.
M. Uschold and M. King (1995): Towards a methodology for building ontologies. Proceedings IJCAI-95 Workshop on Basic Ontological Issues in Knowledge Sharing, Montreal, Canada.
H. Wache, T. Vogele, U. Visser et al. (2001): Ontology-Based Integration of Information A Survey of Existing approaches. IJCAI-01 Workshop: Ontologies and Information Sharing, Seattle, WA, pp. 108-117.
Harmoconsys Team. Harmonise Deliverable 3D.1 - Solution Transfer and Adaptation of a Co-operative System for Consensus Process HarmoConSys: A Consensus System for Collaborative Ontology Building, Laboratory for Enterprise Knowledge and Systems (LEKS) IASI-CNR, Italy.
II.3.11.1 Ontology Links
Apollo (2003): http://apollo.open.ac.ukChimera (2003): http://www.ksl.stanford.edu/software/chimaeraCIA (2001): CIA World Factbook http://www.cia.gov/cia/publications/factbook/geos/fr.htmlCycL (2004]) Ontological Engineer’s Handbook, http://www.cyc.com/doc/handbook/oe/06-el-hl-and-the-canonicalizer.htmlE-Class (2004): http://www.eclass.de/
Deliverable D8.1 110/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Enterprise Ontology (2003): Enterprise Ontology Project, http://www.aiai.ed.ac.uk/project/enterprise/enterprise/ontology.htmlJOE (2003): http://www.engr.sc.edu/research/CIT/demos/java/joeMIT Process Handbook (2003): http://ccs.mit.edu/ph/OntoEdit (2003): http://ontoserver.aifb.uni-karlsruhe.de/ontoeditProtege (2003): http://protege.stanford.eduSnomed (2004). http://www.snomed.orgSowa J.F. (2001): Sowa Ontology, http://www.jfsowa.com/ontology/SUMO (2004): Suggested Upper Merged Ontology – http://suo.ieee.org/SUO(2003): The ieee standard upper ontology web site, 2003. http://suo.ieee.org.Tambis (2001): TAMBIS, http://imgproj.cs.man.ac.uk/tambis/TOVE (1999): TOVE Manual, http://www.eil.utoronto.ca/tove/ontoTOC.htmlUMLS (2001): Unified Medical Language System, http://www.nlm.nih.gov/research/umls/
II.3.11.2 Ontology learning workshops
(ECAI, 2000) 1st ECAI-2000 Workshop on Ontology Learning (http://ol2000.aifb.uni-
karlsruhe.de)
(IJCAI, 2001) 2nd IJCAI-2001 Workshop on Ontology Learning (http://ol2001.aifb.uni-
karlsruhe.de)
(ECAI, 2002) ECAI-2002 Workshop on Machine Learning and Natural Language
Processing for Ontology Engineering (http://www-
sop.inria.fr/acacia/WORKSHOPS/ECAI2002-OLT/)
(ECAI, 2004) ECAI-2004 Workshop on Ontology Learning and Population (http://olp.dfki.de/ecai04/cfp.htm)
Deliverable D8.1 111/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
II.3.12 APPENDIX 1: Ontology and knowledge management
This chapter gives an overview of ontology and knowledge management approaches as applied to Virtual Organizations. It focuses on research efforts from the mid-nineties, and briefly describes approaches, implementations, and innovative achievements.
The dominant approach is for VO projects to develop application systems and tools and to integrate them through common databases and ICT architectures. Ontology tools and ontology structures, knowledge management systems and knowledge elements are developed and managed disjoint from other systems.
However, recent model-based approaches, creating ontology and knowledge services as reusable tasks, are indicating a paradigm-shift in the approach.
II.3.12.1 Background Work
Research on ontology and knowledge engineering and management as technologies contributing towards developing quality virtual organizations and extended enterprises goes back to the provision of the first web-servers in the early nineties.
Both areas and technologies have been researched as potential contributors to new industrial approaches to systems development and engineering, process and product design, organizational development and solutions delivery. The recent development of many new innovative technologies is adding to the visions of an entirely new approach to industrial computing, solutions design and collaboration.
The technologies that give rise to the coming paradigm-shift involving Model Designed Solutions and Model Generated Workplaces are:
Web technologies with services, repositories and standards
Agent technologies with plug-and-play ICT architectures
Portal-based Ontology and Knowledge Engineering Environments
The Active Knowledge Modeling technology and visual knowledge spaces
The first generation of Knowledge Engineering (KE) tools targeted the reconstruction of semantic space of human expertise, and repertory grid-centered tools like the Expertise Transfer System (ETS) [Boose, 1986], AQUINAS [Boose, Shema, Bradshaw, 1989] and others. The second generation KE tools - visual knowledge engineering - provides ideas of
Deliverable D8.1 112/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
CASE technology to AI [Aussenac-Gilles, Natta, 1993;]. These early tools did not fit into any sustainable approach or architecture so they were bound to fail, but they contributed to our understanding.
In the mid-nineties industry was flooded with Knowledge Management Systems (KMS). They were, as many other systems, sold with the promise to support creative work, and were dramatically oversold. The knowledge entities or nuggets as some chose to call the knowledge elements were stored as entities in traditional databases. Storage and retrieval of content depended on carefully defined identity schemes and categorization structures, and the context for reuse was not adequately captured. These KMS systems were nothing other than advanced information and file management systems, but they provided novel methods for navigation of contents.
The new generation of KE tools enables knowledge capture, structuring and reuse, and helps cut down the revise and review cycle-times. They promise to refine, structure and test human knowledge and expertise in the form of ontology [PROTEGE, WebOnto, OntoEdit, 2001-2003], but they are standalone tools.
Enterprise Modeling has also provided approaches capturing, expressing and sharing enterprise knowledge. Some projects have created prototypes that demonstrate the possibility of achieving model designed solutions, and models for execution. Knowledge-model driven approaches are becoming available from leading tool vendors [Computas AS, Ptech Inc., and MEGA, 2000-2003], and some of them also provide methodology and infrastructure to support reuse.
The role of Ontology and Knowledge Engineering
The role of ontology and knowledge management in VO development and operations is to express and share knowledge that can be extended and adapted to support model-designed solutions and operations. Capturing situated knowledge, achieving interoperable solutions, and providing interactive views are important for increased stakeholder participation. The ICT and KE architecture, transforming IT component and semantics, must be dynamically extended. Capabilities needed are:
Semantics mediation and transformation
Capturing, expressing and storing knowledge
Separating the architectural layer and their respective constructs Ontology and knowledge modeling must provide integrated services to enable model extension and adaptation. Models are reused from enterprise knowledge repositories. Abstract enterprise models are pure ontology structures, but there are many types and kinds of ontology structures that must be aligned, re-designed and combined.
Deliverable D8.1 113/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
II.3.12.2 Approaches and Implementations
The dominant approach for VO projects so far has been to develop application systems and tools and to integrate them towards common databases and ICT architectures. Ontology tools and ontology structures, knowledge management systems and knowledge elements are developed and managed disjoint from other application systems and tools. Most approaches are based on fairly traditional client-server architectures, but some novel web-based software architectures have been prototyped. Moving to the web and exploiting web-standards some projects have developed more comprehensive architectures. These projects have been able to demonstrate plug-and play capabilities of software components [e-Colleeg, 2001- 2003]. One project [EXTERNAL, 2000-2002] has experimented with a layered architecture, and a model-driven approach to systems development and engineering. The layered architecture is no doubt a break-through, separating business behavior and execution from enterprise knowledge processing and from ICT –architectures. The layered architecture is further described in section 1.4.
State-of-the-art
There is a wide spectrum of approaches, methodologies and achieved prototypes that have been researched. However, the practical solutions are based on standardized IT architectures and interfaces, rigidly integrating existing applications, databases and tools. The most frequently met tools cover process modeling and simulation, enterprise knowledge modeling and management (including information management), and more recently ontology tools manifested as topic-maps and concept maps.
Knowledge processing and management is dependent on the encoder’s proximity to actions and events, on the medium, method and language of encoding, and on concurrently capturing knowledge, designing and performing work. Designing and developing working environments, workplaces, rules and habits, and generating operational solutions are interactive tasks performed by users while executing work. Knowledge engineering should focus on company core competencies and activities, that is strategy, business, human capital, architectures, platforms, operational solution, and infrastructure and services.
Use of ontology to design VOsOntology defines the basic terminology and relations comprising the structured vocabulary of a topic area. Ontology has to do with naming conventions for industrial nomenclature of all types of core knowledge structures of any enterprise. This is illustrated in figure 1.
Deliverable D8.1 114/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
“Ontology is an explicit specification of a conceptualization or a hierarchically structured set of terms for describing a domain that can be used as a skeletal foundation for a knowledge base”(Gruber, 1993).
Figure 2 An ontology is a structure relating concepts and artefacts by their identity, enhancing the total meaning.
Ontology tools are becoming available as web services, but the structures to be transformed are not easily imported and exported out of the systems and databases out there.
Model-driven solutions OMG and many other institutions are pushing model-driven approaches to systems architecture and development. The models referred to are UML diagramming models. When executing these models there is no feedback or services to update the models based on execution and performance experiences. This cyclic behavior of model-generated task solutions, and task execution-driven model development is enabled by the AKM technology [Fox, 1997]. By this approach a closed loop is created between visual modeling, execution, value-creation and experience gathering, thus implementing learning by doing.
Knowledge Spaces and AKM technologyActive Knowledge Modeling (AKM) technology [Lillehagen, 2003] is an innovative way of expressing, representing and continuously developing an interactive layered enterprise architecture, separating business operations and models from enterprise knowledge architecture and constructs, and from ICT architecture and components.
The AKM technology is built on the paradigm-shifting concept that enterprises and working organizations are cascaded knowledge spaces implemented as pro-active visual scenes.
II.3.12.3 Ontology tools
Deliverable D8.1 115/206
TypeHierarchies Classes Categories
Ontology as
Enterprise structures
Meta-modelstructures
TypeHierarchies Classes Categories
Ontology as
Enterprise structures
Meta-modelstructures

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Ontology tools and ontology structures created are not currently part of the operational enterprise systems, except for ontology structures embedded in entity relationship diagrams and modeling languages. There is no support for interactive development and adaptation of ontology structures. Enterprise structures, flows and working rules must be modeled and embedded in active models driving operational architectures and solutions, integrating all enterprise knowledge dimension.
Figure 2 the Porto BAE portal ontology:
Some of the most well-known tools are: OntoEdit (www.ontoprise.de),
Apollo (www.apollo.open.ac.uk), WebOnto (kmi.open.ac.uk),
CAKE/VITA (www.csa.ru/ailab/) and PROTEGE (www.protege.stanford.edu).
II.3.12.4 KM systems and KE tools
Knowledge engineering and management cannot be achieved by introducing KM systems and ontology tools alone. Knowledge engineers, workers and systems analysts, designers of information systems in the different subject domains, must be directly engaged in expressing, embedding and executing their knowledge.
Deliverable D8.1 116/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
II.3.12.5 Scientific Foundations
Ontology and knowledge structures and processes are created, used and supported by most cognitive sciences. It is therefore an integral part of all our sciences and solutions. So expressing knowledge and building the enterprise and VO knowledge architectures are major challenges faced by IT providers and users when attempting to converge and integrate dispersed enterprise knowledge, and when exploiting the new digital multi-media. The ontology of the physical world or what exists in other media encoded by use of other languages does not necessarily readily apply.
Pedagogic and Epistemological Views
Ontology is not only a philosophical (epistemological, about knowing and knowledge evolution) discipline studying the being. It is about knowledge artifact naming, identity, identification, coding schemes, categorization, classification, and thesauruses, taxonomies and glossary. It is about the entire enterprise logical description, the meta- and operational views of the enterprise. The challenge is manifold when we integrate across enterprises to form VOs, and when we start expressing and representing the meta-knowledge of the enterprise practisioners.
Figure 3 defines four zones of knowledge perception and representation, each delimited by a perceptive horizon or border, defining knowledge existence, form and value as dependent on proximity to action and method of knowledge representation and diffusion. The innermost zone exists only in collaborative scenes.
Figure 3 Existence of knowledge as defined by pedagogy and epistemology.
Knowledge Spaces
Deliverable D8.1 117/206
4 Layers of Knowledge:
Expert knowledge -internal and tacit - a
Participative knowledgesocial and external – bSensed knowledge -our real world percept.- cGeneral acquiredknowledge - d
Proximity, media and encoding is vital for knowledge representation.
Horizon of Particip.
Horizon of reason
a
Horizon of comfort
Horizon of Externb
c
d
4 Layers of Knowledge:
Expert knowledge -internal and tacit - a
Participative knowledgesocial and external – bSensed knowledge -our real world percept.- cGeneral acquiredknowledge - d
Proximity, media and encoding is vital for knowledge representation.
Horizon of Particip.
Horizon of reason
a
Horizon of comfort
Horizon of Externb
c
d

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Visual organization of subjective space [Fox, 1997], the perception and evaluation of its coordinates, colors and shapes are different in the right and left halves of the human brain. The right provides isomorphic reflection of objects and scenes, while the left introduces an object into generalized classes of phenomena and episodes, and provides for logical context and operations. Therefore visual techniques and graphical approaches, activating right-half functions, work as versatile cognitive tools for more transparent and effective data/knowledge base design procedures.
The AKM technology and way of thinking [Lillehagen, 2003] opens up for model designed approaches, methodologies, intelligent infrastructures and dynamically generated solutions. This implies that in all enterprise activity there are four major knowledge dimensions involved: Approach, Methodology, Infrastructure and Solution. (AMIS).
Figure 4 The value of knowledge according to existence and form.
These four-dimensional spaces are the source of the four logical flows of process as discovered by Hugh Ross as far back as 1969 [Dehli et al, 2003].
Enterprises have many knowledge spaces; the innovative, the operational, the strategic and the social. This defines the foundation of the AKM technology. [Lillehagen, 1991 – 2004]. The core knowledge of these knowledge spaces is the knowledge within the two inner zones of figure 4. Action knowledge typically has a set of intrinsic properties; reflective views, recursive processes, repetitive tasks and replicable meta-views, that do not exist in the outer zones. Expressing this knowledge is still a challenge for Enterprise Modeling languages and tools.
II.3.12.6 Enterprise Architectures
Enterprise model-designed architectures supporting execution will play an increasingly important role in future VOs. They will be a source of precise knowledge for managers and users as well as systems engineers and providers as regards all aspects of user model-designed solutions, support and maintenance.
Deliverable D8.1 118/206
a
Informal knowl.: ”J ustified true belief”
Derived, and sensedknowl.: ”structured info”
Participativeknowledge
Action knowledge
Nat. Language and paper
Diagrams and charts
Functional views
Meta-viewscore logic
aaa
Informal knowl.: ”J ustified true belief”
Derived, and sensedknowl.: ”structured info”
Participativeknowledge
Action knowledge
Nat. Language and paper
Diagrams and charts
Functional views
Meta-viewscore logic

INTEROPInteroperability Research for Networked Enterprises Applications and Software
In figure 5 there are three layers that are glued together by an intelligent infrastructure visualized as barrels and the customizable EKA box.. The architecture of the infrastructure is, contrary to the remaining architectures, independent of industrial sectors, applications and user solutions, so it is generic. The two barrels are services that are stored in the process repository as repeatable tasks. These services can be re-activated and adapted to any given platform and solution.
Figure 5 Layers of Enterprise Architecture – integrated by an Intelligent Infrastructure.
The Business Model Architecture (BMA)
The concepts at the core of the Business Model Architecture concern the integrated representation of law, business rules, project norms, project and working rules and habits, and new rules of collaborative practices. Support to define and assess the adherence to these rules and regulations must be available in an e-Business network. Law, contracted values, rules and obligations are controls on business processes. Business rules are typically agreements on value and risk sharing, division of tasks and responsibilities, and agreements on liabilities and life-cycle support. These mutual expectations and controls must be expressed in a separate business model and correlated with program and project performance indicators. Being able to predict and track performance, and assessing the degree of adherence to contract and key performance indicators, are important properties for successful collaboration. These capabilities all warrant a separate set of models where rules and regulations of working together apart must be continuously refined and managed, and where the rules of collaboration are continuously changed to fit local practices and habits.
The Enterprise Knowledge Architecture (EKA)
The Enterprise Knowledge Architecture is a set of inter-dependent knowledge dimensions that allow us to de-couple, engineer and manage enterprise knowledge constructs, methodologies and operational solutions. The six major enterprise knowledge dimensions are composed of these structures and constructs:
Deliverable D8.1 119/206
Business layer:Meth. model, operations, strategy, governance,..
Enterprise Knowledge Arch., EKA layer:POPS meth. , EIS templates, UEML +++
ICT Architecture, UEPS, services as reusable tasks, servers and AKM repositories
Law, rules, principles, agreed practices and norms, day to day routines
Userviews (types and kinds), Enterprise-models and sub-models, Meta-models: Languages, Structures and Type-hierarchies
Access services, capabilities to integrate legacy systems, extract data, handle parameterised sub-models
Custom.EKA
Layers, aspects: Logic and content:Business layer:Meth. model, operations, strategy, governance,..
Enterprise Knowledge Arch., EKA layer:POPS meth. , EIS templates, UEML +++
ICT Architecture, UEPS, services as reusable tasks, servers and AKM repositories
Law, rules, principles, agreed practices and norms, day to day routines
Userviews (types and kinds), Enterprise-models and sub-models, Meta-models: Languages, Structures and Type-hierarchies
Access services, capabilities to integrate legacy systems, extract data, handle parameterised sub-models
Custom.EKACustom.EKA
Layers, aspects: Logic and content:

INTEROPInteroperability Research for Networked Enterprises Applications and Software
1. User enterprise views (types and kinds), the kinds of views are comparable to many Extended Enterprises frameworks (Zachman, Cimosa, and GERAM), but the types are not described and explained by these frameworks,
2. Enterprise models and sub-models, and structures of integrated solution models, supporting distributed working,
3. Partial meta-model of many types and supporting many kinds of services,
4. Language, core visual constructs form the basis for modeling languages,
5. Structures of meta-model objects and constructs, and finally,
II.3.12.7 Type-hierarchies representing standardized industrial knowledge.
These enterprise knowledge structures are vital for the formation, integration and operation of intelligent enterprises and smart virtual organizations, and must be visually editable and manageable in order to harvest the full benefits of models of knowledge spaces as visual scenes. The EKA is the most important and common knowledge asset of any enterprise, integrating mental models and augmenting the minds of all employees, for which the EKA is an active visual support system. The EKA represents the nervous centre and the communication central of the enterprise. It is the main source of manageable Enterprise Intellectual Capital.
The ICT Architecture
Figure 6 The ICT Architecture layer has four tiers
Deliverable D8.1 120/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Figure 6 illustrates the ICT architecture as implemented in the EXTERNAL project. It shows that the user meets the infrastructure through a portal-based project engineering and management environment. This provides a set of web services to support modelling, model designed solutions engineering, work execution, value-metrics and experience gathering. The project environment acts as an integrator and as a platform to plug in and perform all kinds of services: software, tasks and applications. Among the services provided are services to build knowledge models (Metis), services to cooperate and collaborate (XCHIPS), services to do project simulation (SimVision), services to do work management (Workware) and services to perform work, enactment and execution (FrameSolutions). The portal-based technology used was prototyped in the project. As a front end, it has the main objective of generating a dynamic and personalized user interfaces, bridging the gaps among the available systems, tools and functions and the users.
Combining the Intelligent Infrastructure with techniques enabling dynamic generation of user interfaces, we are able to describe, implement, and deploy software platforms capable of generating operational solutions, driven and managed by knowledge models.
II.3.12.8 Supporting Design and Engineering
The AMIS knowledge space of four main extensively dependent dimensions was discovered by industrial practitioners and not by researchers. The figure below, termed the “Railway-crossing Diagram” is from the Globeman 21 project. Japanese industry partners directed our attention to the fact that the project, the plant, the production and the building site (infrastructure) were actually designed, engineered and evolving in parallel, but that current methods and systems are not able to adequately support concurrent engineering of these flows. With enterprise knowledge spaces and the AKM technology, implementing the spaces
as visual scenes, performing concurrent knowledge engineering work will be possible.
Figure 7 The four knowledge dimensions of construction industry.
Deliverable D8.1 121/206
9
Confidential
Industrial exampleIndustrial exampleVRIDGE LIFE-CYCLE DIAGRAMVRIDGE LIFE-CYCLE DIAGRAM
ää Click to add textClick to add textLaboratory
ManufacturizationBench Scale Test
Product QualityData Implementation
Operation StrategyOperator Training
Manufacturing(Operation)
Maintenance
Production
Logistic
Consumer
Waste
Construction
ProcurementBasic & Detail
Design
Pilot Test
Scale-up Technology
Production System(Engineering Firm))
Product(Production Firm)
Recycle
Renewal
Scrap
Recycle
Cost Estimation
Production ProcessTechnology
PreliminaryDesign
Pilot Test
BRIDGEBRIDGE
Life-cycle of Xylene Life-cycle of Xylene as a Product as a Product
Life-cycle of Life-cycle of the Xylene Plantthe Xylene Plant
Life-cycle ofLife-cycle ofthe Vridge Inc.the Vridge Inc.

INTEROPInteroperability Research for Networked Enterprises Applications and Software
The AKM technology and the adapting AMIS approach have the potential to support concurrent knowledge engineering and execution of project-oriented work.
Active Knowledge Spaces
AKM technology will enable model-designed solutions, and work-driven active model development and knowledge engineering. This means that ontology and Enterprise Modeling tools must be integrated in the ICT architecture and described as tasks to work on the structures of the EKA, in order that semantic ambiguities and flaws may be detected and corrected. Ontology engineering is an integral service of active knowledge modeling. This means that most Enterprise Modeling approaches also have to open up, and recognize the true nature of enterprise knowledge. Enterprise Modeling has to capture and engineer structures and support work execution in knowledge spaces. “Enterprise Modeling is externalizing situated knowledge (4th horizon KM) and building the Enterprise Knowledge Architecture.”
Interoperability, integration and reuse are facilitated by the layered architecture, and the services supported and provided by the EKA. Situated knowledge always involve four major inter-dependent knowledge dimensions. This has long been accepted in problem-solving and design theories.
By this approach all systems are federated and integrated systems, embedded in the VO knowledge space and all its cascaded knowledge spaces for innovation, business operation, strategy governance and balanced values assessment.
II.3.12.9 The Future of Ontology and Knowledge Management
Work to develop the three layers of the described Enterprise Architecture integrated by the Intelligent Infrastructure and its services is underway [x].
Model Designed Solutions
Knowledge models should have web components and user environments defined in their meta-models. Then the knowledge that is externalized and managed in models can be reused to generate truly dynamic user interfaces.
Deliverable D8.1 122/206MetaData
Data
Model-generated UIUI EditorUser Interface (UI ) Model
MetaData
Data
Model-generated UIUI EditorUser Interface (UI ) Model

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Figure 7 Model-generated workplaces and task execution views.
Once a user environment has been built and its behavior defined, we still need to guide the users’ performance of their task assignments.
The powers of knowledge spaces and visual scenes
These capabilities are not obtainable in other settings than visual scenes:
Continuous knowledge development and capture, modeling processes and views, executing tasks, and aggregating values and experiences,
Knowledge creation and processing, meta-modeling, executing and monitoring task execution as adaptive services,
Knowledge use and value creation, performing model interrogations and task and method executions, and providing value metrics,
Knowledge management, developing meta-models, reflective meta-model views, handling architectures, and generating governance views,
Cognitive and Generative Learning, preparing knowledge for practical use as competence and skill profiles.
There are properties, such as pro-active learning, that are only possessed by scenes.
II.3.12.10 Recommendations
Enterprise Interoperability concerns how to express, share and represent enterprise knowledge. Software is nothing but knowledge encoded for the digital multi-media to execute and manage, so our challenges are to de-couple the knowledge that must be computed, from that needing interactive enhancement by users, from that which has to be simple but yet powerful in supporting on-demand business opportunities.
Understanding the importance of continuously being able to express and represent knowledge and for stakeholders to be able to continuously interact with their knowledge through lifecycles has been and still is a major challenge.
Enterprise Architecture (EA) development is still only able to capture descriptive legacy views and limited dependencies, but there are initiatives towards also supporting operational solution architectures,
Conceptual knowledge drives work and actions, work yields values, values yield experiences and behavior, and experiences drive enhanced knowledge, so this human learning cycle will be closed. The degree of interaction with the contents of the enterprise knowledge architecture will vary across sectors, type of knowledge work, and platforms, and the ambition of the foreseen solutions.
Deliverable D8.1 123/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
II.3.12.11 Future research directions
Business Models, Business Architectures and Enterprise Knowledge Architectures still require a lot of research and experimentation to become viable industrial solutions. To get business people involved in modelling, the user interface must be truly simple to use and the value contributed by the models and the platform supporting them must be substantial. Business case analyses must be easily performed. Enterprise Modelling must be progressed to support the capturing of knowledge in enterprise knowledge spaces, and to exploit the services of intelligent infrastructures turning models into executable workplaces and tasks.
Semi-automatic Knowledge management
Extending the services of the Enterprise Knowledge Architecture it is possible to start researching the objective of automating knowledge management in the area of design and knowledge engineering. Intelligent Infrastructures act as a ”reflective enterprise visual memory”, supporting the intrinsic properties of knowledge, and will allow us to also collapse the temporal dimension. This means cycles are represented by task patterns and we may be relieved of revisions and nested versioning.
Integrating Enterprise Modeling and Ontology
Integrating ontology tools and services to: - edit ontology structures of the enterprise knowledge architecture, - transform ontology structures between cultures and many global enterprise architectures, - compare ontology structures to validate changes and incompliance, and propose corrective actions, and finally to manage ontology structures as part of the enterprise Knowledge Architecture and its life-cycles.
Work Execution and Management
Project engineering and management environments (PEME), supporting model generated workplaces and tasks execution, are needed to move knowledge work to the web. Web services will be of at least four types: software services, dynamic agents, adaptive work process tasks and application capabilities,
Enterprise Visual Scenes (EVS) hold the key to a new style of computing that will enhance creativity, reduce complexity, and augment human capacity.
Deliverable D8.1 124/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Enterprise Knowledge Architectures
Structures of coherent meta-models, the EKA and its services, seamlessly integrate enterprises; creating situated semantics, syntax and work action context,
Systems Development
Systems Engineering is transforming to Solutions Engineering, separating business, enterprise and IT specific logic and views. The solutions will be model designed, and all solutions will be embedded in knowledge spaces.
Support for Governing Networked Organizations
In any research project use-cases must be modeled as knowledge spaces as early as possible. VO research needs true industrial user involvement and good user environments for concurrent modeling, meta-modeling, work execution and monitoring. Some key R&D results:
Each use-case meta-knowledge integrates and validates the results,
Specific enterprise knowledge architectures yield interoperable solutions,
Knowledge models and architectures are major results of the project,
Services of many types and kinds will have to be developed.
Enterprise Modeling as services adapts and extends the generic architectures.Knowledge Management means building knowledge architecture solutions. Semantics alone is not the key to interoperability. Patterns of work in reproducing contexts will be needed. Interoperability is all about knowledge architectures and services to extending and adapting models to capture the situation as we execute work.
Deliverable D8.1 125/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
II.3.13 Appendix2: Ontology editor survey results
Excerpted from (Denny 2002). Please zoom to see the content.
Tool Version
Release Date
Source Modeling Features/Limita
tions
Base Langua
ge
Web Support & {Use}
Import/Export Formats
Graph View
Consistency Checks
Multi-user Support
Merging Lexical Support
Information Extraction
Comments Contact
Apollo 1.0 beta 5
9/20/02 Knowledge Media Institute of Open University (UK )
Classes with slots plus relations; functions; hierarchical views.
OKBC model
No, but {server is planned}.
CLOS; OCML
No, but planned.
Yes No No No No None mailto:[email protected]
CIRCA Taxonomy Administrator
1.1 3/1/02 Applied Semantics, Inc.
Maps designed taxonomies to built-in general lexical ontology using weighted concept clusters ("gist"). No definable relations.
Proprietary
No (RDFS planned)
Browsing of ontology (not for editing).
Yes, limited.
No Yes, via common mapping.
Yes Via other CIRCA tools.
Part of CIRCA Auto-Categorizer. A future (4Q'02) product may support relations and RDF import/export.
CoGITaNT
5.1.0 9/14/02 LIRMM CNRS (France)
Conceptual graph (CG) modeling with rules; nested typed graphs; projections.
CG model
{Web based client access}
BCGCT; CGXML; XML
Browsing of ontology.
Yes No No No No Open Source server, client and underlying C++ library; also Java API.
mailto:[email protected]
Coherence 2.0.1; 2.1
1/1/02 ; 4Q'02
Unicorn Solutions
Roundtrip transformation of ontologies from XML Schema and RDB schemas. Class and property hierarchies; business rules.
XML {Internet client for sharing ontologies}
XML Schema; RDB schema; XML; RDF(S); DAML+OIL (in 2.1 release)
No, but planned.
Schema synchronization and dependency (referential integrity) to show impact of changes.
(Yes, in 2.1 release)
(Planned) Explicit mapping between lexicons is possible.
No, except as explicit mappings from RDB.
Ontology functions are part of an enterprise data integration product. Additional input/output: entity-relation diagrams, COBOL Copybooks, HTML.
Contextia 2.1 8/1/02 Modulant
Basic concepts and relations with datatypes are represented in schemas.
Express Referenced ontologies (URLs); URIs
Entity relation diagrams; XML Schema
For editing single ontology (using FirstStep XG).
Express model (ISO 10303) validation; cross-ontology consistencies
No Schema mapping including aggregation/generalization; "context" mapping.
Synonym mappings; term matching
No, except as explicit mappings from structured and semi-structured sources.
Ontology functions are part of an enterprise data integration product. Ontology editing supported by FirstStep XG included with Contextia.
COPORUM OntoBuilder
1.5 8/1/02 CognIT AS
Basic concepts and relations are represented with single inheritance. Representation of concepts and relations extracted from content may be extended with WordNet information.
RDFS {Web based repository; Web services in development}
DAML+OIL; RDF(S)
Browsing of ontology.
RDF consistency via repository.
(Under development)
Flat merging via Sesame.
Yes, based on WordNet and RDF Query Language; also in Sesame
Yes, based on meaning and distribution.
Tool embedded in On-To-Knowledge project tool set and requires Sesame RDF repository. Focus on generating editable ontologies automatically from natural language documents.
mailto:[email protected]
DAG-Edit 1.3.1.2 3/20/02 Berkeley Drosophila Genome Project (BDGP)
Mixed part-of and isa concept hierarchies are represented along with synonym and search facilities. No properties.
Directed (cyclic or acyclic) graph notation
{Read input via URLs}
Gene Ontology: RDF; Gene Ontology Postgres Database Schema (experimental); (DAML+OIL in GOET)
No, but tree view of flattened graph.
No No Yes, especially at the term level; also change history tracking.
Yes, for synonyms.
No, but allows regular expression search.
While intended for gene expression ontologies, it can be used for any taxonomy. Generic version - GOET - is under development (alpha).
DAMLImp (API)
0.7.0 7/15/02 AT&T Government
DAML+OIL constructs. Basic Java
DAML+OIL
URIs DAML+OIL; RDF
No No Possible No, but Ontology Manager aids
No No DARPA DAML project
Deliverable D8.1 126/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Solutions
library for analysis and manipulation of DAML+OIL ontologies.
mapping.
Differential Ontology Editor (DOE)
1.1 9/1/02 National Audiovisual Institute - INA (France )
Creates lattice of concepts and lattice of relationships between concepts, plus a set of instances. Concepts cannot be defined intentionally with constraints. Only types of the domains of relationships can be specified. No axiom editor is provided.
XML & CGXML
Load ontology by URL
DAML+OIL; RDFS
No, but tree view.
Arity and type inheritance on relation domains; detects cycles in hierarchies.
No No Term definitions, synonyms and preference; methodology for differential definitions.
No Supports methodology of Bruno Bachimont; to be used with other editors.
mailto:[email protected]
Disciple Learning Agent Shell
2.6 4/1/02 George Mason University , Learning Agents Laboratory
Semantic network representation with functions, extended to allow partially learned entities. A hierarchy of objects and a hierarchy of features, with their descriptions, are represented as frames. Also, general problem solving rules can be expressed with terms from the ontology.
OKBC-like
{Ontology summaries output in HTML}
Import: CYC ontologies
Browse classes, properties and individuals.
Syntactic consistency is always maintained; can commit multiple changes to persistent ontology in single operation.
No Yes, two ontologies.
Search for terms
No The shell is used by subject matter experts to rapidly form knowledge and reason about a specific domain. Users, via a set of task reduction rules, create Disciple-RKF agents that can be combined into a single knowledge base.
mailto:[email protected]
Domain Ontology Management Environment (DOME)
2.0 8/1/02 Btexact Technologies
Concepts, relations and constraints are mapped to ER-like specifications.
CLASSIC & FaCT
{Web access}
OKBC; XML ER diagrams
Yes Yes (Under development)
(Under development)
Semi-automatic and rule-based extraction from RDBs and web pages.
Available externally by individual agreements with limited support.
mailto:[email protected]
DUET 0.3.0 7/17/02 AT&T Government Solutions
Represents only UML static constructs available on class diagrams.
UML URLs and namespaces are preserved in UML package naming
DAML Editing using UML class diagrams (via Rose or Argo products)
Valid UML diagrams will produce valid DAML+OIL and conversely.
Supports multi-user capabilities of Rational Rose.
Multiple ontologies may be imported for comparison and merging.
No No DARPA DAML project. Additional output: HTML views of UML models. Also under development for GentileWare Poseidon UML.
mailto:[email protected]
Enterprise Semantic Platform (ESP) including Knowledge Toolkit
3.0 11/30/02 (expected)
Semagix, Inc
Description models composed of hierarchical categories and attributes with named relationships. Type system for heterogeneous media content. Instances supported by simple constraints on entities (cardinality, range) and entity properties, as well as inferencing. Automatic assertion and maintenance of instances is possible.
Graph & XML
URIs; {partial HTML client; HTTP API}
XML; (RDF(S) is planned)
Connected tree browsing via TouchGraph
Yes, includes automatic and user interactive checks; dynamic content management.
Limited, user privileges prevent concurrent update of the same ontology parts.
No Synonym based term normalization.
Automatic ontology directed classification and semantic annotation of heterogeneous content.
ESP is an application platform for semantic integration of heterogeneous content including media and enterprise databases. It includes the Knowledge Toolkit for building ontologies.
http://www.semagix.com/
EOR 1.01 7/10/01 Dublin Core Metadata Initiative
RDF models as sets of triples. Can be used to build, insert (infuse) and query instance knowledge bases for DAML+OIL, RDFS, etc. ontologies.
RDF URIs RDF No Validate RDF
No Yes, by adding sets of RDF statements.
No No Developed by OCLC.
mailto:[email protected]
ExClaim & CommonKADS Workbench
release 12/1/01 National Institute for Research and Development in Informatics (Romania )
Description logic modeling plus primitive problem solving actions.
DL model
No CML Browsing of ontology.
Knowledge verification and model validation (for DL representation).
User roles No No No Uses the CommonKADS Workbench based on SWI-Prolog and the XPCE GUI.
mailto:[email protected]
GALEN Case
5 8/1/02 Kermanog
Description logic terminological
GRAIL No GRAIL No, but filtered
Explicit grammatic
No Compiles differences in
GALEN concept
No Although, developed
Deliverable D8.1 127/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Environment (GCE)
modeling without support for individuals. Composite concepts are automatically classified according to their criteria (relationships with other concepts). New concepts can be created interactively and according to user-defined rules.
tree views allow editing.
al and sensible sanctions are enforced when combining terms.
concepts, hierarchies and criteria (properties) between two ontologies.
identifiers can be associated with synonyms and word forms.
primarily as a medical terminology model builder, the tool can serve as a general purpose ontology editor. GCE is part of the Classification Workbench with support to manage domain classification schemes.
ICOM 1.1 4/25/01 Free University of Bozen-Bolzano, Italy
EER (extended entity relations) modeling plus inheritance hierarchies, multidimensional aggregations and multiple schema relations.
Description logic
No XML; UML (future)
Native editing of ER diagrams (UML diagrams planned).
Verify the specification via DL classifier (FaCT).
No Supports inter-ontology mappings with graphical interface.
No No Graphically editing of native UML class diagrams planned for next release.
mailto:[email protected]
Integrated Ontology Development Environment
1.6.1 7/1/02 Ontology Works, Inc.
Distinguishes between properties and relations; allows contexts; default reasoning; temporal model relations; higher-arity relations; meta-properties and meta-relations.
OWL (based on KIF; not related to W3C WebOnt language of same name.)
{Web client - control panel}
KIF; UML; RDB; XML DTD
UML diagrams
Top-level ontology consistency per Guarino & Welty.
Yes (slated for version 1.8 in Q2 2003)
Synonyms; English-language names
No Supports OntoClean methodology (Guarino & Welty); supports relational and other databases
IsaViz 1.1 5/23/02 W3 Consortium
Supports RDFS level specifications. Can specify any model based on RDF such as DAML+OIL.
RDF model
URI namespaces
RDF; N-Triple; SVG
Native creation and editing of resources, literals and properties.
RDF model correctness.
No Yes No No None mailto:[email protected]
JOE Demo 7/21/99 University of South Carolina Center for IT
Basic concept and relations modeling ala ER.
KIF No ER (LDL++) No No No No No No No current development. Available as an applet.
mailto:[email protected]
KAON (including OIModeller)
1.2 9/25/02 FZI Research Center & AIFB Institute, University of Karlsruhe
Extends RDFS with symmetric, transitive and inverse relations, relation cardinality, meta-modeling, etc. Similar to F-Logic using axiom patterns. Editor currently only supports concept hierarchy.
KAON (proprietary extension of RDFS)
{Browsing ontologies via KAON Portal; Web services API under development}
RDFS No Yes, for evolution of ontology.
Concurrent access control with transaction oriented locking and rollback.
(Under development)
Explicit lexical representation in model. Synonyms; stemming; multilingual.
(Under development)
OIModeller is part of KAON tool suite for business applications that uses RDB persistence layer for scalability. The ontology editor is under development.
KBE -- Knowledge Base Editor (for Zeus AgentBuilding Toolkit)
1.3 3/22/00 Institute for Software Integrated Systems, Vanderbilt University
Zeus ontology model of concepts, attributes and values; multiple inheritance; modularization within a closed world model. (Also defines agent interaction protocols.)
GME No Zeus ontology file (.edf)
UML-like diagrams for browsing only.
Yes No No No No KBE is layered on top of the Zeus environment for building agents and extends the ontology editor functions. The underlying GBE model specification system could be used as the basis of other ontology builders.
mailto:[email protected]
LegendBurster Ontology Editor
1.1.2 10/5/02 GeoReference Online Ltd
Semantic network hierarchy of concepts, attributes, attribute values and explicitly represented truth-status flags. Inheritance within hierarchies with lateral links. Full reified relations; inverse relations (partial). Metadata for all entities (at node level). Separate tree list editor.
Proprietary (uses Prolog)
No No, except across projects (proprietary).
No, except SVG export of instance and query graphs.
Partial, with strict attribute context checks but arities currently unchecked.
No Yes, if from LegendBurster. (User must check semantic consistency.)
Term search and alphabetical sort.
Semi-automatically capture and import vocabulary present in attribute tables of maps of interest.
While LedgendBurster is principally a GIS application, the Ontology Editor is suitable for general purpose ontology development. Standalone editor with instance description and fuzzy query expected in early 2003.
LinKFacto release 7/1/02 Languag Description logic Extende {LinKFa XML; No Checks Yes, with Compares and Strict Yes, via text LinKFactory [email protected]
Deliverable D8.1 128/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
ry Workbench
e & Computing nv
T-box (terminological) and A-box (assertional) model. Multiple inheritance over concepts and relationships; identification of necessary and sufficient criteria for concept definition. Manage multiple conflicting ontologies in one T-box. Versioning metadata.
d description logic
ctory Server supports Internet clients; WebInfo spider component.}
RDF(S); DAML+OIL/OWL
cover role restrictions, formal disjoints, sanctioning over subsumers, etc.
author privileges and auditing specific to concept hierarchies.
links ontologies via a core ontology; related concepts matched on formal relationships and lexical information.
concept/term distinction; lexeme-description; part-of-speech. Search with wildcards.
analyses and automatic linkage to ontology. WebInfo spider gleans domain-specific concepts/terms on Web.
Workbench includes a database server, application server and clients. Originally designed for very large medical ontologies. It has a Java beans API and optional Application Generators for semantic indexing, automatic coding, and information extraction.
Medius Visual Ontology Modeler
0.18 beta
7/1/02 Sandpiper Software, Inc
UML modeling of ontologies with frame systems support.
UML with extensions for OKBC model
URI support in DAML generator; {read-only browser support from Rose}
XML Schema; RDF; DAML+OIL
Yes, as UML diagrams via Rose.
Limited Yes Native Rose model merging support
Search for terms and relations.
No Operates as a Rational Rose plug-in.
mailto:[email protected]
NeoClassic release 12/15/00
Bell Labs (Lucent Technologies)
Framework representation of descriptions, concepts, roles, individuals and rules. Concepts can be derived from necessary and sufficient conditions for individual membership. Subsumption and classification are inherent inference. (Command line editor only.)
DL model
No No No Yes No No No No This C++ implementation of the original CLASSIC system is the only currently supported version.
mailto:[email protected]
OilEd 3.4 4/12/02 University of Manchester Information Management Group
DAML constraint axioms; same-class-as; limited XML Schema datatypes; creation metadata; allows arbitrary expressions as fillers and in constraint axioms; explicit use of quantifiers; one-of lists of individuals; no hierarchical property view.
DAML+OIL
RDF URIs; limited namespaces; very limited XML Schema
RDFS; SHIQ Browsing Graphviz files of class subsumption only.
Subsumption and satisfiability (FaCT)
No No Limited synonyms
No None mailto:[email protected]
OLR3 Schema Editor
1 4/1/02 Institute for Information Systems, University of Hannover
Instantiation and editing of external or custom schemas conforming to RDFS. Concept-specific filtering to present choice of legal properties.
RDFS RDF URIs; {browser based}
RDF No Yes, for property constraints, etc.
No No No No Part of the Open Learning Repository Version 3 (OLR3) system for course specification.
mailto:[email protected]
OntoBuilder
1.0 6/13/02 Institute for Medical Information, Statistics and Epidemiology University of Leipzig
Manages compilation of domain terms, their description, and contexts using natural language.
Natural language; (logical representation language planned)
{Web access}
No No Not automatically
Yes, with editor, moderator and administrator user group types.
No Representation of synonyms; search on terms and descriptions; lexical rules for term input
No Semantic analysis using a formal model based on a top level ontology and a logic-based representation language are planned. Domain focus is on medicine.
Onto-Builder
3.0 5/1/02 University of Savoy ; Ontologos
Distinguishes "what contributes to the essence of things and what describes them", defining concepts by their "specific difference". Thus, logical and set-oriented semantics are derived a posteriori.
LOK (Language for Ontological Knowledge) written in Smalltalk
{Web access}
Input: DAML-OIL; XML, LOK Output: DAML+OIL; XML; KIF; Conceptual Graph
Yes, for browsing.
Yes, based on logic and on the specific-difference theory.
User groups.
Yes, for ontologies based on the OK Model.
Lexicon management including synonyms
Extraction of lexicons from texts with OK lexical tools (based on Brill's tagger).
Part of Ontological Knowledge Station. Building OK ontologies is based on a dedicated methodology.
mailto:[email protected]
OntoEdit 2.5.2 8/6/02 Ontoprise GmbH
F-Logic axioms on classes and relations;
F-Logic Resource URIs
RDFS; F-Logic; DAML+OIL
Yes, via plug-in
Yes, via OntoBroker
Transaction locking at the
Yes Multiple lexicons via plug-in
No Free and commercial (Professional
mailto:[email protected]
Deliverable D8.1 129/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
algebraic properties of relations; creation of metadata; limited DAML property constraints and datatypes; no class combinations, equivalent instances.
(limited); RDB
object and whole subtree levels.
) versions are available, with continuing development of the commercial version.
Ontolingua with Chimaera
1.0.649; 0.1.42
11/214/01; 7/24/02
Stanford Knowledge Systems Lab
OKBC model with full KIF axioms.
Ontolingua
{Web access to service.}
Import & Export: DAML+OIL; KIF; OKBC; Loom; Prolog; Ontolingua; CLIPS. Import only: Classic; Ocelot; Protégé.
No Elaborate with Chimaera; Theorem proving (via JTP)
Write-only locking; user access levels.
Semi-automated via Chimaera
Search for terms in all loaded ontologies.
No Online service only (at http://www-ksl-svc.stanford.edu); Chimaera is being enhanced under DARPA funding in 2002.
Ontology Builder & Server
1.1 9/1/01 Verticalnet, Inc.
Classes with slots, datatypes and cardinality constraints; node documentation; inclusion. No axioms.
Partial OKBC model
Fully qualified names; {HTTP browser and server}
RDFS & DAML+OIL (future)
No Limited to term validity and graph cycles.
User roles and security; global locking.
Simple difference and merge process.
Yes No Currently available only as part of their enterprise solution product.
Ontology Directed Extraction (ODE) Tools
alpha 4/8/02 XSB, Inc.
Multiple inheritance subsumption class hierarchies. Support for typed attributes of classes and relations between classes. Supports schema and object information.
Tabled Prolog
No No No Yes No Yes, with limitations.
Yes Yes Tool supports construction of domain ontologies used to guide lexical classification and information extraction.
mailto:[email protected]
Ontopia Knowledge Suite
1.3.4 8/28/02 Ontopia AS
Constraint modeling specifically and solely for Topic Map representations.
Ontopia Schema Language (OSL)
{Web access and Web API}
OSL; XTM; LTM (import only); HyTM
No, but tree view.
Validation against the OSL schema.
Full concurrency and transaction support when running with RDBMS.
For ontologies and instance data, but not (currently) for constraints.
Full-text search
No, but application framework allows this.
Although primarily an IDE for Topic Map applications, the framework supports ontologies.
Ontosaurus
1.9 3/28/02 USC Information Sciences Institute
Rich KB browser with simple editing; contexts; same-class-as; metaclasses.
Loom {HTTP browser}
KIF; Loom; OKBC
Browsing class hierarchy
Yes Global locking
No No No Online access to KBs hosted on CL HTTP server.
mailto:[email protected]
OntoTerm 0.9.98 6/1/99 University of Malaga
Concept and property hierarchies with concept instances; properties distinguished as attributes or relations. Metadata (natural language definitions).
n/a {HTML output}
n/a No, but cross-linked tree views indicate legal element associations or types, and allow editing.
No No No Word lists No Although intended to be a terminology management system, OntoTerm can be used for general ontology development. Ongoing development and support of the software is unknown.
OpenCyc Knowledge Server
0.6.0b 4/3/02 Cyc Corp.
FOPC extended with contexts, equality, default reasoning, skolemization, quantification over predicates. (Basic ontology editing via KB Browser Create Term tool.)
CycL (& SubL)
{HTTP server}
DAML+OIL (native KB only)
No Directed inferencing and queries; truth maintenance
Yes No Yes, via Cyc-NL with KB-linked lexicon for syntactic and semantic disambiguation.
English parsing possible with Cyc-NL.
Knowledge base subset and browser only. Future release of ontology building tools: Template-based knowledge entry, Index Overlap, Similarity Tool and Salient Descriptor.
mailto:[email protected]
OpenKnoMe
5.4c 9/27/02 University of Manchester Medical Informatics
Description logic terminological modeling without support for individuals or type system. Arbitrarily complex structures may be composed from primitive concepts and relations. Role hierarchy with inverses, and reasoning over relationships such as part-of. No formal
GRAIL Not as configured.
CLIPS; XML No Logical coherence ala DL and a meta-model system for declaring inherited semantic constraints and permissions. Also, declarative query language (GQL) can be used to
User roles and read/write privileges; version control. Users see each other's changes only when they check modules back in.
Via explicit mappings (reifications) to GALEN Common Reference Model. Focus is on linking rather than mapping to reference model.
Can use GALEN language module that links its concept identifiers with synonyms and word forms, and provides segment grammar for semantic links.
No Although, developed primarily as a medical terminology model builder, the tool can serve as a general purpose ontology editor. Currently requires OpenGALEN terminology server and CINCOM VisualWorks
mailto:[email protected]
Deliverable D8.1 130/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
negation, disjunction or conjunction. Limited support for cardinality. No reasoning over numbers or ranges. Toolset for managing intermediate representations.
author checks of modeling consistency.
runtime environment.
PC Pack 4 1.0 beta (unreleased)
4/27/2001 (predecessor)
Epistemics Ltd
Knowledge acquisition and modeling. Multiple inheritance; n-ary relations; rules and methods. User definable templates for modeling formalisms like CommonKADS and Moka.
XML {HTML output via XSLT}
XML ER diagrams; class hierarchies; OO views
Only logically consistent models can be created.
Yes No No No Suite of many integrated KADS inspired tools.
mailto:[email protected]
Protégé-2000
1.7; 1.8 beta
4/10/02 ; 10/22/02
Stanford Medical Informatics
Multiple inheritance concept and relation hierarchies (but single class for instance); meta-classes; instances specification support; constraint axioms ala Prolog, F-Logic, OIL and general axiom language (PAL) via plug-ins.
OKBC model
Limited namespaces; {can run as applet; access through servlets}
RDF(S); XML Schema; RDB schema via Data Genie plug-in; (DAML+OIL backend due 4Q'02 from SRI)
Browsing classes & global properties via GraphViz plug-in; nested graph views with editing via Jambalaya plug-in.
Plug-ins for adding & checking constraint axioms: PAL; FaCT.
No, but features under development.
Semi-automated via Anchor-PROMPT.
WordNet plug-in; wildcard string matching (API only).
No Support for CommonKADS methodology.
RDFAuthor
alpha 5/9/02 Damian Steer
Create RDF instance data against RDFS schemas.
RDF URIs; {Web links; remote RDF query}
XML; RDF Creating and editing instances as graphs.
RDF errors
No No No No Currently available for Mac OS X; also as a Java Swing application. Additional output: SVG, PNG, TIFF, PDF.
mailto:[email protected]
RDFedt 1.02 2/25/01 Jan Winkler
Textual language editor only.
RDF model
RSS RDFS; DAML; OIL; Shoe
No, but tree view.
Writing mistakes only.
No No No No None mailto:[email protected]
SemTalk 1.1.3 8/18/02 Semtation GmbH
Subset of RDFS and DAML extended with inverse relations and process modeling.
Visual Basic
URI namespaces; {distributed development}
XML; F-Logic; ARIS models; Bonapart models
Yes, for design and browsing.
Subsumption and name usage across multiple models; meta-model specific checks.
No Yes, with simple filtering.
Synonyms; homonyms; stop words; some POS; glossaries via Babylon .
No, but interfaces to appropriate Ontoprise and TextTech products.
Microsoft Visio extension and SmartTags. Additional output include: Rational Rose UML class diagrams, RDF annotated HTML, MS Excel, MS Project, SAP IPC, HTML/VML.
mailto:[email protected]
Specware 3.1 6/1/01 Kestrel Technology
Logical and functional axioms. (Text based language editor only.)
Metaslang
No None No Proofs via Gandalf and SNARK.
No Yes, via composition operations (e.g., co-limits).
No No While primarily a tool for the formal, compositional specification of software, Specware can be used to define domain theories.
SymOntos 2.2 4/1/02 Institute for the Analysis of Information Systems - CNR (Italy )
XML Schema modeling constructs with subsumption of classes and relations; specified relation types of isa, part-of, similarity and predicate. Business-oriented predefined classes such as: actor, process, event, and message.
XML {Web access}
XML; RDF(S)
(Planned release 4Q'02)
Concept hierarchy validity, range restrictions and graph cycles.
Simple user groups
Possible via XML encoding.
Word lists of synonyms; term query support.
No Online service; academic level support; can support collaborative ontology building. SymOntoX version in progress with language for process, actor, event and goal.
mailto:[email protected]
Taxonomy Builder
2.0 8/1/02 Semansys Technologies
General taxonomy of elements assigned data types and substitution groups. Predefined
XML Schema
XML namespaces; {taxonomy browser; Internet client}
XML; XML Schema
No Yes, relative to XBRL core schema.
No Yes No No Available separately or as part of the Semansys XBRL Composer Professional. Additional
Deliverable D8.1 131/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
XBRL relation types via links.
outputs include CSV, TXT and SQL.
TOPKAT prototype
6/17/95 AIAI, University of Edinburgh
Supports representation of the various models of CommonKADS (circa 1995). Underlying these models are dictionaries of concepts, properties, property values, inferences, and tasks. Production rules can be represented using a combination of these primitives.
HARDY and CLIPS
No CML Native graph view for editing.
Limited No No, except for models within a single ontology.
Term equivalence through the data dictionary.
Simple natural language parser can identify possible concepts and property values in a protocol transcript.
The Open Practical Knowledge Acquisition Toolkit (TOPKAT) supports CommonKADS knowledge acquisition techniques including: laddered grid, card sort, repertory grid, protocol analysis. Final diagrams also output in HTML. No support.
mailto:[email protected]
Visio for Enterprise Architects
2002 SR-1
4/2/02 Microsoft Corp.
Most object-role modeling (ORM) constructs, but imposes relational logical constraints on specification.
ORM No XML (via add-on); DDL
ORM class diagrams
Yes Yes Yes No No ORM modeler may be effective for specifying domain ontologies; part of Visual Studio.NET Enterprise Architect
http://customerservice.support.microsoft.com/default.aspx?scid=fh;en-us;CSSCONTACTFIND&style=flat
WebKB 2.0 9/10/02 Distributed Systems Technology Centre (DSTC), Australia
Basic conceptual graph modeling and manipulation that includes contexts, constraint checking and querying. Can derive new statements (e.g., relations) from necessary and sufficient conditions.
FS (extended CGs)
URIs for element references; Web access of KBs; {CGI and HTML interfaces; Web script language}
Export (partial only): DAML/RDF; CGIF; KIF
Hyperbolic-like browsing (of taxonomies only) via KVO's OntoRama.
Syntactic and logical including transitive cycles, disjoint relations, relation signatures. Also lexical checking.
KB sharing restricts editing so each element has an associated author.
No, but separate ontologies can share the same KB "framework" including a WordNet based upper ontology.
WordNet nouns and adjectives; aliases; element searching by author or name.
No On-line service (www.webkb.org); also source and binary code available.
mailto:[email protected]
WebODE 2.0.6 7/10/02 Technical University of Madrid UPM
Concepts (class and instance), attributes and relations of taxonomies; disjoint and exhaustive class partitions; part-of and ad-hoc binary relations; properties of relations; constants; axioms; and multiple inheritance. Inference engine for subset of OKBC primitives and axioms.
Prolog translation of FOL and frames per OKBC model.
URIs as imported terms; {browser client}
DAML+OIL; RDFS; X-CARIN; FLogic; Prolog; XML
Native graph view with editing of classes, relations, partitions, meta-properties, etc.
Type and cardinality constraints; disjoint classes and loops, taxonomy style (OntoClean), etc.
Yes, with synchronization; authentication and access restrictions per user groups.
Unsupervised (ODEMerge methodology) using synonym and hyperonym tables; custom dictionaries and merging rules.
Synonyms and abbreviations; (EuroWordNet support under development)
Using WebPicker (UNSPSC, RosettaNet)
Supports Methontology methodology (Fern‡ndez-L—pez et al, 1999); offered as online service; successor to ODE; ontology storage in RDB.
WebOnto 2.3 5/1/02 Knowledge Media Institute of Open University (UK )
Multiple inheritance and exact coverings; meta-classes; class level support for prolog-like inference.
OCML {Web service deployment site}
Import: RDF; Export: RDFS, GXL, Ontolingua, OIL
Native graph view of class relationships.
For OCML code
Global write-only locking with change notification.
No No (Available from OCML based tool MnM.)
Online service only.
mailto:[email protected]
Deliverable D8.1 132/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
II.4 Ontology Interoperability
II.4.1 Introduction
In the last period, there has been much research related to the new frontiers of the World Wide Web, aimed at introducing more semantic capability: the so called Semantic Web. The hope is that the Semantic Web can reduce, and in some cases solve, some of the problems encountered with the current web, where the resources (such as documents, web pages, etc.) contain data expressed in a machine-readable, but not machine-understandable form. The goal is to enable computers to process the interchanged data in a more "intelligent" way. To this end ontologies are seen as the enabling technology, that allows the formalization of the semantics of information and the unambiguous interpretation.
Ontologies play a prominent role on the Semantic Web; they could be key elements in many applications such as information retrieval, web-services search and composition, and web site management (for organization and navigation). Researchers do also believe that ontologies will contribute to solve the problem of interoperability between software applications across different organisations, providing a shared understanding of common domains. Ontologies allow applications to agree on the terms that they use when communicating. Thus, ontologies, if shared among the interoperating applications, allow the exchange of data to take place not only at a syntactic level, but also at a semantic level.
However, the Semantic Web community agrees on the fact that a single, universal ontology can not be built. Because of the large variety of information sources on the Web, documents on it will inevitably result from many different ontologies. We foresee that in the future most information systems will use ontologies. We must expect an explosion in the number of ontologies, even when considering similar domains.
For these reasons, a key challenge in building the Semantic Web is enabling the interoperability among different ontologies. Ontologies can interoperate only if correspondences between their elements have been identified and established. Today, if two ontologies need to interoperate, the mapping is mainly achieved by hand. But this task is tedious, error-prone, and time consuming. According to the above scenario, the manual solution of the ontology interoperability problem could be a bottleneck in building a network of cooperating information management systems. Hence, the introduction of new methodologies and user-friendly tools that support the knowledge engineer in discovering semantic correspondences is crucial to the success of the Semantic Web.
In this chapter we aim at surveying the existing approaches to establishing correspondences between different ontologies.
Another issue, strictly related to ontology interoperability, is the development of creation and maintenance environments that support evolution and versioning of ontologies as they
Deliverable D8.1 133/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
become larger, more distributed, and longer-lived; mappings between two versions of a same ontology can put in light the changes occurred.
In this chapter we will first describe which kind of mismatches can occur among different ontologies and then will see which are the solutions available in literature, to deal with such mismatches.
Deliverable D8.1 134/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
II.4.2 Preliminary definitions
When talking about ontology interoperability the following, in literature, are considered relevant operations:
Ontology mapping/matching
Ontology alignment
Ontology translation
Ontology transformation
Ontology merging/integrating
Ontology checking
Ontology evolution/versioning
Mappings management
In the next sections we will describe in more detail each of them.
II.4.2.1 Ontology mapping/matching
Establishing mappings between two ontologies means that for each entity (concept, relation, attribute, etc.) in one ontology we try to find a corresponding entity in the second ontology, with the same or the closest intended meaning; usually this correspondence is expressed by 1 to 1 functions. We will see in the next section that mappings can be established after an analysis of the similarity, according to a certain metric, of the entities in he compared ontologies. It is important to note that the mapping process do not modify the involved ontologies and produce, as output, only a set of correspondences. See also [KS03] [OW03] for surveys on ontology mapping methods.
Deliverable D8.1 135/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
II.4.2.2Ontology alignment
In literature, ontology alignment is considered a synonym of ontology mapping. In this chapter we will refer to ontology alignment as the process of bringing two or more ontologies into mutual agreement, making them consistent and coherent with one and another; this process may require a transformation of the involved ontologies eliminating the “non-needed” information (wrt a negotiation of the interoperability needs) while the missing information must be integrated. In contrast with mapping, this operation might result in changes of one or more of the involved ontologies [KS03][KY02].
Deliverable D8.1 136/206
BB
BA
AFigure 1: Ontology mapping

INTEROPInteroperability Research for Networked Enterprises Applications and Software
II.4.2.3Ontology translation
Sometimes there’s the need to change the formalism in which a particular ontology is expressed, for example if we decide to reuse an ontology (or part of an ontology) using a tool or language that is different from those ones in which the ontology is available; a good translation will leave the semantics of the translated ontology unaltered, or as closest as possible, to the original [refs].
II.4.2.4Ontology transformation
This process consist in changing the structure of an ontology leaving unaltered its semantics (lossless transformations) or modifying it slightly (if we have a loss of information we talk
Deliverable D8.1 137/206
A B
BAFigure 2: Ontology alignment

INTEROPInteroperability Research for Networked Enterprises Applications and Software
about “lossy” transformations) to make it suitable for different purposes other than the original one.
II.4.2.5Ontology merging/integrating
When we build a new ontology starting from two or more existing ontologies (in general with overlapping parts) we talk about ontology merging while when reusing existing ontologies, assembling extending and specializing them, this is usually referred as ontology integration [KS03].
Deliverable D8.1 138/206
A
A’Figure 3: Ontology translation/tansformation

INTEROPInteroperability Research for Networked Enterprises Applications and Software
II.4.2.6Ontology checking
Once an ontology has been created (as the result of an integration/merging) or transformed (as the result of a translation/transformation/alignment), the result must be checked in order to identify possibly inconsistencies or information losses. Validation of an ontologies is commonly performed by reasoners or theorem provers. See [TH03] for more information.
II.4.2.7Ontology evolution/ versioning
Ontologies describe a reusable portion of knowledge about a specific domain. However, they may change over time. Domain changes, adaptations to different tasks, or changes in the conceptualization require modifications of the ontology. A versioning mechanism may be useful to reduce the problems related to ontology changes [EK04]. For example if we have a web page annotated with an expression over the elements of an ontology and, successively such ontology changes, the annotations could contain unknown terms or have a different interpretation [NK03].
II.4.2.8Mappings management
Deliverable D8.1 139/206
B
C
A
Figure 4: Ontology merging

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Mappings correlate entities in different ontologies; they can be expressed in the same formalism as the ontologies, as well as into another “ad hoc” formalism. Once mappings are created, important needs arise in the context of their management:
Are mappings resilient to ontology changes over time?If the source ontologies are modified or transformed, existing mappings relating such ontologies, could become not valid, so there’s a need for a mechanism to update them.
Is there any mechanism for composition of mappings? Consider you have the ontologies O1, O2,O3, and that M1 is the set of mappings established between O1 and O2 and M2 is the set of mappings established between O2 and O3. An algebra for the composition of mappings should allow the creation of the set of the set M3, that contains the mappings that correlate elements between O1 and O3.
Is there any kind of second order mapping? Mappings themselves could be examined to discover interrelation between them; a possible scenario in which this “second order” mappings could be used is the following: given the ontologies O1, O2, P1, P2 and the set of mappings M1 correlating O1 and O2 and M2 correlating P1 and P2, and the set M correlating M1 and M2, we could be able to automatically create mappings between O1 and P1, O2 and P2, etc.
II.4.3 Semantic similarity among ontologies
In order to detect correspondences between different ontologies, describing overlapping domains, the semantic similarity between every concept in them, according to a specified metric must be computed; this computation associate to each pair of entities a coefficient (usually in the normalized interval [0,1]) proportional to the relative closeness between them; this coefficient is usually referred as the similarity degree of the entities. Obviously several definitions of similarity are possible, each being appropriate for given situations. Similarity analysis can be carried out at the intensional level, inspecting entities descriptions to find structural similarity, or analyzing the terminological part of the descriptions (e.g. the label used to name a concept or a relation) and so on. A difference in the way one entity is represented in two different conceptualisation is usually referred as an ontology mismatch, that will be described in detail in the next section. At the extensional level a typical similarity measure (see section about GLUE, FCA-Merge) is the notion of the joint probability distribution between any two concepts A and B (i.e. the fraction of instances that belong both to A and B).
Deliverable D8.1 140/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
II.4.4 Ontology mismatches
In general we can say that mismatches between concept descriptions in two ontologies can occur at three different levels: language, content, organisation. In presenting this classification we referred to the classification made by Klein [KL01], modifying it slightly.
II.4.4.1 Language level mismatches
These mismatches are related to the language or the representation formalism used to represent the ontologies to be compared.
Syntax
Different ontology modelling languages, usually differ in syntax; for example, to define the class of cars in OWL, the used syntax is <owl:Class rdf:ID = "Car"> whereas in LOOM, you have to use the expression (defconcept Car) to define the same class. This mismatch usually is one of the less difficult to solve using some mechanism of language translation. Several tools in literature, as a first step, transform the input sources to a common ontology language (see section about Onion, Prompt ).
Expressive power
The possibility of translating one ontology in a given language to another is strictly related to the expressive power of the source and target languages; a difference in the expressive power means that one of the language is able to express things not expressible in the other and, consequently that not every ontology of one must be translated in the other, and/or vice versa, without loss of information. For example KIF’s [ref] expressive power is that of full first order logic while with OWL [ref] DL it is possible to express only a subset of it.
Semantics of primitives
A more subtle problem can be detected when two languages contain constructs with the same name but the semantics of such constructs differ. For example in OIL RDF Schema [FH01] the interpretation of the <rdfs:domain> construct is the intersection of the arguments whereas in RDF-S is the union of the arguments.
Deliverable D8.1 141/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
II.4.4.2 Organisation level mismatches
Organisation level mismatches can be found when two or more ontologies that describe (totally or partially) overlapping domains are compared and there is a difference in the way the conceptualization is specified. Obviously these mismatches may occur when the ontologies are written in the same language, as well as when the languages are different.
At this level, a very important mismatch occurs when two corresponding concepts are presented at different levels of abstraction. This mismatch may occur at intensional level or extensional level. The first case is represented by the following example. You have a Car Maker that produces different models, for instance FIAT produces tha Punto. So Punto is an instance of the car models produced by FIAT. But then my_car_Punto is an instance of the Punto model. The latter, in this second perspective, is seen as a class and no more as an instance.
Synonym terms/ Multi-Language
Concepts with the same intended meaning in different ontologies are labelled with different names. For example is the use of term ”car” in one ontology and the term ”automobile” in another ontology. A special kind is the use of different languages to name the concepts (the name of the concepts in one ontology are in Italian whereas in the another are in French)
Homonym terms
The compared ontologies contains overlapping terminology but with different meanings. For example, the term ”conductor” in the music domain and in the electric engineering domain have completely different meaning.
Concept structuring
This type of differences may depend on the design decisions of the knowledge engineer i.e. several choices can be made for the modelling of concepts in the ontologies. An example is the way of representing the concept Person: in one ontology we have the definition of a class “Person” with two disjoint subclasses “Man”, ”Woman” while in another we have a class “Person” with a qualifying attribute “Sex”.
Deliverable D8.1 142/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
In other cases the same thing can be expressed using different language constructs. For example, in some languages, it is possible to state explicitly that two classes are disjoint (e.g. disjoint A B), whereas it is necessary to use negation in subclass statements in other languages (e.g.. A subclass-of (NOT B), B subclass-of (Not A)). Some languages have specific constructs to state classes equivalence whereas others may express the same using subclass constructs.
Encoding
An encoding mismatch is a difference in value formats, like expressing temperature in Celsius or Fahrenheit degrees. Usually this mismatch can be solved using conversion functions.
Paradigm
Different paradigms can be used to represent concepts such as time, action, plans, causality, propositional attitudes, etc. For example, one model might use temporal representations based on interval logic while another might use a representation based on point.
II.4.4.3Content level mismatches
Scope
Scope mismatches happen when two concepts seem to have the same intended meaning, but do not have the same instances, although they may intersect. A typical example is the class ”employee”, where several administrations use slightly different concepts of employee, (see Wiederhold [MW00]).
Model coverage and granularity
This is a mismatch in the part of the domain that is covered by the ontology, or the level of detail to which that domain is modelled. In Chalupsky [C00] we find the example of an ontology about cars: one ontology might model cars but not trucks. Another one might represent trucks but only classify them into a few categories, while a third ontology might
Deliverable D8.1 143/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
make very fine-grained distinctions between types of trucks based on their physical structure, weight, purpose, etc. and a fourth ontology doesn’t model cars and trucks at all.
II.4.5 Interoperability among ontologies: available solutions
Several solutions have been proposed in literature to address the ontology interoperability problem. Different methods tackle different aspects of the problem.
Some of the existing approaches are aimed at enabling interoperability at the language level. It means that they try to map the formalisms used to represent the ontologies, in order to homogenize the descriptions and then to compare the elements belonging to the different ontologies (OntoMorph provides transformation rules between languages constructs, using OKBC ontologies can be mapped to a common knowledge model).
Several approaches are interactive and suggest to the user possible alignments and mappings. Among them, we can find linguistic based approaches and approaches based on the analysis and evaluation of the structural and model similarity.
There are also tools that provides additional services, such as results diagnosis and checking. For instance Chimaera allows to perform domain independent validation checks, based on heuristics; in OntoMorph and in PROMPT reasoning based verification is implemented.
Finally, some tools (e.g., SHOE) have some features aimed at supporting ontology evolution; interesting services are the possibility of revising and integrating definitions without invalidating existing ontologies, the possibility of creating a new ontology that extends existing ones or that is the result of the intersection of existing ones, the possibility of performing mutual revisions of ontologies.
In the following, a detailed description of the most relevant solutions for interoperability among ontologies available in literature is presented. The relevant features of each selected solution are reported in the following tables.
II.4.5.1 FCA- Merge
Developed by AIFB - Karlsruhe UniversityType of solution Tool Method
Tool name:Version:
Date of 2001
Deliverable D8.1 144/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
issue/developm.Last updateLevel Concepts Instances Problem addressed Merging Mapping Alignement Level of automation Manual Semi-automated Fully Automated
Language(s) supportedDescription Fca-Merge [SM01] is a method proposed by Stumme and Maedche
for ontology merging. For the source ontologies, it extracts instances from a given set of domain-specific text documents by applying natural language processing techniques. Based on the extracted instances, mathematically founded techniques are applied taken from Formal Concept Analysis [GW99] to derive a lattice of concepts as a structural result. The produced result is explored and transformed to the merged ontology by the ontology engineer. They use lexical analysis to perform, among other things, retrieval of domain-specific information.
Special Features (e.g., learning method; use of a reference ontology, similarity reasoning, rule-base editable)
Techniques from natural language processing and formal concept analysis are applied
II.4.5.2IF – map
Developed by Kalfoglou and SchorlemmerType of solution Tool Method
Tool name:Version:
Date of issue/developm.
2002
Last updateLevel Concepts Instances Problem addressed Merging Mapping Alignement Level of automation Manual Semi-automated Fully Automated
Language(s) supported
RDF, KIF, Ontolingua, to native Protege KBs and Prolog KB
Description IF - map is an automatic method for ontology mapping developed
Deliverable D8.1 145/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
by Kalfoglou and Schorlemmer [KS02] based on the Barwise-Seligman theory of information flow [BS99]. Their method draws on the proven theoretical ground of Barwise and Seligman’s channel theory, and provides a systematic and mechanised way for deploying it on a distributed environment to perform ontology mapping among a variety of different ontologies. These mappings are formalised in terms of logic infomorphismsAn infomorphism is a morphism between local logics; every ontology have associated a local logic, a triple (set of instances, set of types, classification relation) .
IF-Map is declaratively specified in Horn logic and executed with a standard Prolog engine. Therefore, we partially translate a variety of input formats to Horn clauses with the aim of a customised translator. We deal with a variety of formats ranging from RDF, KIF, Ontolingua, to native Protege KBs and Prolog KB. Infomorphisms are expressed in RDF.
Special Features (e.g., learning method; use of a reference ontology, similarity reasoning, rule-base editable)
II.4.5.3PROMPT
Developed by Stanford UniversityType of solution Tool Method
Tool name: PROMPT SuiteVersion:2.1.3
Date of issue/developm.
2000
Last update 2004Level Concepts Instances Problem addressed Merging Mapping Alignement Level of automation Manual Semi-automated Fully Automated
Language(s) supported
OKBC
Description PROMPT [NM00] is a tool for the Protegè ontology development environment developed from Noy and Musen. The knowledge model underlying PROMPT is frame-based and it is compatible with OKBC [CF98]. At the top level, there are classes, slots, facets, and instances:
· Classes are collections of objects that have similar properties.
Deliverable D8.1 146/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Classes are arranged into a subclass–superclass hierarchy with multiple inheritance. Each class has slots attached to it. Slots are inherited by the subclasses.
· Slots are named binary relations between a class and either another class or a primitive object (such as a string or a number). Slots attached to a class may be further constrained by facets.
· Facets are named ternary relations between a class, a slot, and either another class or a primitive object. Facets may impose additional constraints on a slot attached to a class, such as the cardinality or value type of a slot.
· Instances are individual members of classes.
These definitions are the only restrictions that they impose on the input ontologies for PROMPT. Since this knowledge model is extremely general, and many existing knowledge representation systems have knowledge models compatible with it, the solutions to merging and alignment produced by PROMPT can be applied over a variety of knowledge representation systems.
PROMPT takes two ontologies as input and guides the user in the creation of one merged ontology as output. First PROMPT creates an initial list of matches based on class names. Then the following cycle happens: (1) the user triggers an operation by either selecting one of PROMPT’s suggestions from the list or by using an ontology-editing environment to specify the desired operation directly; and (2) PROMPT performs the operation, automatically executes additional changes based on the type of the operation, generates a list of suggestions for the user based on the structure of the ontology around the arguments to the last operation, and determines conflicts that the last operation introduced in the ontology and finds possible solutions for those conflicts.
Special Features (e.g., learning method; use of a reference ontology, similarity reasoning, rule-base editable)
iterative suggestions for concept merges based on linguistic and structural knowledge
II.4.5.4Prompt-Diff
Developed by Stanford UniversityType of solution Tool Method
Tool name: Prompt SuiteVersion: 2.1.3
Deliverable D8.1 147/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Date of issue/developm.
2002
Last update 2004Level Concepts Instances Problem addressed Merging Mapping Alignement Level of automation Manual Semi-automated Fully Automated
Language(s) supported
OKBC
Description The PromptDiff algorithm combines an arbitrary number of heuristic matchers, each of which looks for a particular property in the unmatched frames. All the matchers must conform to the monotonicity principle: Matchers do not retract any matches already in the table. They may delete the rows where one of the frames is null by creating new matches. But it must keep all the existing matches.
Special Features (e.g., learning method; use of a reference ontology, similarity reasoning, rule-base editable)
Designed for Ontology versioning
II.4.5.5CHIMAERA
Developed by KSL, Stanford UniversityType of solution Tool Method
Tool name:Version:
Date of issue/developm.
2000
Last updateLevel Concepts Instances Problem addressed Merging Mapping Alignement Level of automation Manual Semi-automated Fully Automated
Language(s) supportedDescription Chimaera [MF00] is an interactive tool by McGuinness et al., and
the engineer is in charge of making decisions that will affect the merging process. Chimaera analyses the ontologies to be merged,
Deliverable D8.1 148/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
and if linguistic matches are found, the merge is done automatically, otherwise the user is prompted for further action. It appears to be similar to PROMPT; they are both embedded in ontology editing environments and give interactive suggestions to the user.
Special Features (e.g., learning method; use of a reference ontology, similarity reasoning, rule-base editable)
It solves mismatches at the terminological level in a very light way, provides interactive suggestions to the users, provides diagnostic function.
II.4.5.6GLUE
Developed by Univ. Of WashingtonType of solution Tool Method
Tool name: GLUEVersion:
Date of issue/developm.
2002
Last update 2004Level Concepts Instances Problem addressed Merging Mapping Alignement Level of automation Manual Semi-automated Fully Automated
Language(s) supportedDescription Doan et al. [DM02] developed a system, GLUE, which employs
machine learning techniques to find mappings. Given two ontologies, for each concept in one ontology, GLUE finds the most similar concept in the other ontology using probabilistic definitions of several practical similarity measures.
The authors claim that this is their difference when comparing their work with other machine-learning approaches, where only a single similarity measure is used. In addition to this, GLUE also uses multiple learning strategies, each of which exploits a different type of information either in the data instances or in the taxonomic structure of the ontologies .
The similarity measure they employ is the joint probability distribution of the concepts involved, so instead of committing to a particular definition of similarity, GLUE calculates the joint
Deliverable D8.1 149/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
distribution of the concepts, and lets the application use the joint distribution to compute any suitable similarity measure.
The authors says that GLUE uses a multi-learning strategy; a learner can inspect instances in many different ways. It can exploit the frequencies of words in the text value of instances, the instance names, the value formats, or the characteristics of value distributions. The authors developed two learners, a content learner and a name learner. The content learner uses a text classification method, called Naive Bayes larning. The name learner is similar to the content learner but uses the full name of the instance instead of its content. Then there’s another learner called the meta-learner that combines the predictions of the two learners assigning to each one of them a learner weight that indicates how much its predictions is trustable. The authors also used a technique, relaxation labelling, that assigns labels to nodes of a graph, given a set of constraints. The authors applied this technique to map two ontologies taxonomies, O1 to O2, by regarding concepts (nodes) in O2 as labels, and recasting the problem as finding the best label assignment to concepts (nodes) in O1, given all knowledge they have about the domain and the two taxonomies. That knowledge can include domain-independent constraints like “two nodes match if nodes in their neighbourhood also match” – where neighbourhood is defined to be the children, the parents or both – as well as domain-dependent constraints like “if node Y is a descendant of node X, and Y matches professor, then it is unlikely that matches assistant professor”. The system has been empirically evaluated with mapping two university course catalogues.
Special Features (e.g., learning method; use of a reference ontology, similarity reasoning, rule-base editable)
It uses machine learning strategies and probabilistic measures of similarity.
II.4.5.7CAIMAN
Developed byType of solution Tool Method
Tool name:Version:
Date of issue/developm.
2001
Last updateLevel Concepts Instances Problem addressed Merging Mapping Alignement
Deliverable D8.1 150/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Level of automation Manual Semi-automated Fully Automated
Language(s) supportedDescription The ontology mapping in CAIMAN [LG01] is based on a approach
which considers the concepts in an ontology implicitly represented by the documents assigned to each concept. Using machine learning techniques for text classification, a concept in a personal ontology is mapped to a concept in community ontology.
Special Features (e.g., learning method; use of a reference ontology, similarity reasoning, rule-base editable)
Use machine learning methods
II.4.5.8ONION
Developed by Stanford UniversityType of solution Tool Method
Tool name: OnTo-Agents toolkit Version: under development
Date of issue/developm.
2000
Last updateLevel Concepts Instances Problem addressed Merging Mapping Alignement Level of automation Manual Semi-automated Fully Automated
Language(s) supportedDescription The ONION (ONtology compositiON) [MW00] system was
developed by Mitra, Wiederhold et al. in the Stanford University Database Group. They propose a scalable and mantainable approach based on the use rules that creates an articulation or linkage between the systems. The rules are generated using a semi-automatic articulation tool with the help of a domain expert. To make the sources ontologies compliant for automatic composition, based on the accumulated knowledge rules, they represent them using a graph-oriented model extended with a small algebraic operator set. For example, one information source may use UML as modelling language and another using DAML+OIL, ONION will convert the ontologies associated with both information sources to the ONION
Deliverable D8.1 151/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
conceptual model.
They intend to support a small number of classes of such ontology models that are in use providing wrappers which will convert from these models to the ONION format. Conversion of ontologies from their native models to the ONION format can be also be performed declaratively generating rules that correlate parts of one ontology to parts of another based on semantic similarity.
Special Features (e.g., learning method; use of a reference ontology, similarity reasoning, rule-base editable)
II.4.5.9Breis and Bejar Framework
Developed by Fernández-Breis and Martínez-BéjarType of solution Tool Method
Tool name:Version:
Date of issue/developm.
2002
Last updateLevel Concepts Instances Problem addressed Merging Mapping Alignement Level of automation Manual Semi-automated Fully Automated
Language(s) supportedDescription Fernández-Breis and Martínez-Béjar [FM02] describe a cooperative
framework for integrating ontologies. Their system is aimed towards ontology integration and is intended for use by normal and expert users. The former are seeking information and provide specific information with regard to their concepts, whereas the latter are integration-derived ontology constructors, in the authors’ jargon. As the normal users enter information regarding the concepts’ attributes, taxonomic relations and associated terms in the system, the expert users process this information and the system helps them to derive the integrated ontology. The algorithm that supports this integration is based on taxonomic features and on detection of synonymous concepts in the two ontologies. It also takes into account the attributes of concepts and the authors have defined a typology of equality criteria for concepts. For example, when the name-based equality criterion is called upon, both concepts must have the same attributes.
Deliverable D8.1 152/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Special Features (e.g., learning method; use of a reference ontology, similarity reasoning, rule-base editable)
II.4.5.10 MAFRA
Developed by Karlsruhe UniversityType of solution Tool Method
Tool name: MApping FRAmeworkVersion: 0.2
Date of issue/developm.Last update 2003Level Concepts Instances Problem addressed Merging Mapping Alignement Level of automation Manual Semi-automated Fully Automated
Language(s) supportedDescription MAFRA [MM02] is part of a multi-ontology system, and it aims to
automatically detect similarities of entities contained in two different department ontologies. Both ontologies must be normalized to a uniform representation, eliminating syntax differences and making semantic differences between the source and the target ontology more apparent.
This normalisation process is done by a tool, LIFT, which brings DTDs, XML-Schema and relational databases to the structural level of the ontology. Another interesting contribution of the MAFRA framework is the definition of a semantic bridge. This is a module that establishes correspondences between entities from the source and target ontology based on similarities found between them. All the information regarding the mapping process is accumulated, and populate an ontology of mapping constructs, the so called Semantic Bridge Ontology (SBO). The SBO is in DAML+OIL format, and the authors argue, one of the goals in specifying the semantic bridge ontology was to maintain and exploit the existent constructs and minimize extra constructs, which could maximize as much as possible the acceptance and understanding by general semantic web tools.
Special Features The tool tries to identify similarity between entities belonging to
Deliverable D8.1 153/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
(e.g., learning method; use of a reference ontology, similarity reasoning, rule-base editable)
the source and the target ontology and allows to establish a correspondence between these entities.Transformation rules for translating the instances can be derived from the established mappings and executed.Cooperative mapping facilities are provided.
II.4.5.11 OIS
Developed by Calvanese, De Giacomo, LenzeriniType of solution Tool Method
Tool name: Version:
Date of issue/developm.
2001
Last updateLevel Concepts Instances Problem addressed Merging Mapping Alignement Level of automation Manual Semi-automated Fully Automated
Language(s) supported
DL
Description Calvanese et al. [CD01] proposed a formal framework for Ontology Integration Systems – OISs. The framework provides the basis for ontology integration, which is the main focus of their work. Their view of a formal framework is deals with a situation where we have various local ontologies, developed independently from each other, assisting the task to build an integrated, global ontology as a means for extracting information from the local ones.
Ontologies in their framework are expressed as Description Logic (DL) knowledge bases, and mappings between ontologies are expressed through suitable mechanisms based on queries. Although the framework does not make explicit any of the mechanisms proposed, they are employing the notion of queries, which allow for mapping a concept in one ontology into a view, i.e., a query, over the other ontologies, which acquires the relevant information by navigating and aggregating several concepts.
They propose two approaches to realise this query/view-based mapping: global-centric and local-centric. The global-centric approach is an adaptation of most data integration systems. In such systems, the authors continue, sources are databases, the global ontology is actually a database schema, and the mapping is
Deliverable D8.1 154/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
specified by associating to each relation in the global schema one relational query over the source relations. In contrast, the local-centric approach requires reformulation of the query in terms of the queries to the local sources.
Special Features (e.g., learning method; use of a reference ontology, similarity reasoning, rule-base editable)
II.4.5.12 Madhavan et al. Framework
Developed by Madhavan, Bernstein and RahmType of solution Tool Method
Tool name: CUPIDVersion:
Date of issue/developm.
2001
Last updateLevel Concepts Instances Problem addressed Merging Mapping Alignement Level of automation Manual Semi-automated Fully Automated
Language(s) supportedDescription Madhavan et al. [MB01] developed a framework and propose a
language for ontology mapping. Their framework enables mapping between models in different representation languages without first translating the models into a common language, the authors claim. The framework uses a helper model when it is not possible to map directly between a pair of models, and it also enables representing mappings that are either incomplete or involve loose information. The models represented in their framework are representations of a domain in a formal language, and the mapping between models consists of a set of relationships between expressions over the given models. The expression language used in a mapping varies depending on the languages of the models being mapped. The authors claim that mapping formulae in their language can be fairly expressive, which makes it possible to represent complex relationships between models. They applied their framework in an example case with relational database models. They also define a typology of mapping properties: query answerability, mapping inference and mapping composition.
Deliverable D8.1 155/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
The authors argue that a mapping between two models rarely maps all the concepts in one model to all concepts in the other. Instead, mappings typically lose some information and can be partial or incomplete.
Question answerability is a proposed formalisation of this property. Mapping inference provides a tool for determining types of mapping, namely equivalent mappings and minimal mappings; and mapping composition enables one to map between models that are related by intermediate models.
Special Features (e.g., learning method; use of a reference ontology, similarity reasoning, rule-base editable)
II.4.5.13 Kiryakov et al. Framework
Developed byType of solution Tool Method
Tool name: Version:
Date of issue/developm.
2001
Last updateLevel Concepts Instances Problem addressed Merging Mapping Alignement Level of automation Manual Semi-automated Fully Automated
Language(s) supportedDescription Kiryakov et al. [KD01] developed a framework for accessing and
integrating upper-level ontologies. They provide a service that allows a user to import linguistic ontologies onto a Web server, which will then be mapped onto other ontologies. The authors argue for a uniform representation of the ontologies and the mappings between them, a relatively simple meta-ontology (OntoMapO) of property types and relation-types should be defined.
Apart from the OntoMapO primitives and design style, the authors elaborate on a set of primitives that OntoMapO offers for mapping. There are two sets of primitives defined, InterOntologyRel and
Deliverable D8.1 156/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
IntraOntologyRel, each of which has a number of relations that aim to capture the correspondence of concepts originating from different ontologies (i.e. equivalent, more specific, meta-concept). A typology of these relations is given in the form of a hierarchy and the authors claim that an initial prototype has been used to map parts of the CyC ontology to EuroWordNet.
Special Features (e.g., learning method; use of a reference ontology, similarity reasoning, rule-base editable)
II.4.5.14 IFF
Developed by Robert E. KentType of solution Tool Method
Tool name:IFFVersion:
Date of issue/developm.Last updateLevel Concepts Instances Problem addressed Merging Mapping Alignement Level of automation Manual Semi-automated Fully Automated
Language(s) supportedDescription Kent (2000) proposed a framework for ontological structures to
support ontology sharing. It is based on the Barwise-Seligman theory of information flow [GW99]. Kent argues that IFF represents the dynamism and stability of knowledge. The former refers to instance collections, their classification relations and links between ontologies specified by ontological extension and synonymy (type equivalence); it is formalised with Barwise and Seligman’s local logics and their structure-preserving transformations – logic infomorphisms. Stability refers to concept/relation symbols and to constraints specified within ontologies; it is formalised with Barwise and Seligman’s regular theories and their structure-preserving transformations. IFF represents ontologies as logics, and ontology sharing as a specifiable ontology extension hierarchy. An ontology, Kent continues, has a classification relation between instances and concept/relation symbols, and also has a set of constraints modelling the ontology’s semantics. In Kent’s proposed framework, a community ontology is the basic unit of ontology sharing;
Deliverable D8.1 157/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
community ontologies share terminology and constraints through a common generic ontology that each extends, and these constraints are consensual agreements within those communities. Constraints in generic ontologies are also consensual agreements but across communities.
Special Features (e.g., learning method; use of a reference ontology, similarity reasoning, rule-base editable)
Reasoning on type equivalence.Specific for ontology sharing
II.4.5.15 ODEMerge
Developed by Universidad Politécnica de MadridType of solution Tool Method
Tool name: WEBOdeVersion: 2.0.2
Date of issue/developm.Last update 2003Level Concepts Instances Problem addressed Merging Mapping Alignement Level of automation Manual Semi-automated Fully Automated
Language(s) supported
Importing ontologies written in XML, RDF(S) or CARIN, and exporting into XML, RDF(S), OIL, DAML+OIL, CARIN, FLogic, Prolog, Jess, Java and HTML
Description ODEMerge [CP01] is a tool to merge ontologies that is integrated in WebODE, the software platform to build ontologies that has been developed by the Ontology Group at Technical University of Madrid. It is a client-server tool that works in the Web.
This tool is a partial software support for the methodology for merging ontologies elaborated by de Diego [D01]. This methodology proposes the following steps:
1) transformation of formats of the ontologies to be merged;
2) evaluation of the ontologies;
3) merging of the ontologies;
Deliverable D8.1 158/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
4) evaluation of the result;
5) transformation of the format of the resulting ontology to be adapted to the application where it will be used.
The methodology exposes in a very detailed way the sequence of steps that must be executed to perform the task of merging two ontologies, who have to perform each step, how he has to perform it, and which should be the products of such steps. For the evaluation and merging of ontologies, very detailed rules are proposed. The methodology is based on the experience merging e-commerce ontologies.
WebODE helps in steps (1), (2), (4) and (5) of the merging methodology, and ODEMerge carries out the merge of taxonomies of concepts in step (3). Besides, ODEMerge helps in the merging of attributes and relations, and it incorporates many of the rules identified in the methodology.
ODEMerge uses the following inputs:
the source ontology 1 to be merged;
the source ontology 2 to be merged;
the table of synonyms, which contains the synonymy relationships of the terms of ontology 1 with the terms of the ontology 2.
the table of hyperonyms, which contains the hyperonymy relationships of the terms of ontology 1 with the terms of the ontology 2.
ODEMerge processes the ontologies together with the information of the tables of synonymy and hyperonymy, and it generates a new ontology, which is the merge of the ontology 1 and the ontology 2. New versions of the tool will include electronic dictionaries and other linguistic resources that can substitute the tables of synonyms and hyperonyms.
This tool can be easily extensible to consider new rules of merging that can be identified. Another important characteristic of ODEMerge is that it can be used to merge ontologies in a large number of ontology implementation languages. The WebODE import module allows importing ontologies written in XML, RDF(S) or CARIN, and allows exporting into XML, RDF(S), OIL, DAML+OIL, CARIN, FLogic, Prolog, Jess, Java and HTML.
Special Features (e.g., learning method; use of a reference ontology, similarity reasoning, rule-base editable)
Use of a common model of representation of the ontologies.
Deliverable D8.1 159/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
II.4.5.16 HELIOS
Developed by Università degli Studi di MilanoType of solution Tool Method
Tool name: HELIOSVersion:
Date of issue/developm.Last updateLevel Concepts Instances Problem addressed Merging Mapping Alignement Level of automation Manual Semi-automated Fully Automated
Language(s) supported
RDF(S), DAML+OIL, OWL, ODLi3
Description HELIOS (Helios Evolving Interaction-based Ontology knowledge Sharing) [CF03b] is a framework for supporting dynamic ontology-based knowledge sharing and evolution in P2P networks and more generally in open distributed systems.
The knowledge sharing and evolution processes in HELIOS are based on peer ontologies, describing the knowledge of each peer (that is, the knowledge a peer brings to the network and the knowledge the peer has of network), and on interactions among peers, allowing information search and knowledge acquisition/extension, according to pre-defined query models and dynamic ontology matching techniques.
The matching techniques implemented in HELIOS are based on the H-MATCH [CF03] algorithm which considers both the linguistic features and contextual features of concepts in the ontology of a given node. Linguistic features are constituted by the semantic content of terms used as names of concepts and properties. Contextual features are constituted by the concept properties and adjacent concepts (i.e., concepts having a semantic relation with the considered concept).
The ontology matching process is based on a thesaurus, where the meaning of each term in the ontology of a given node is represented by the set of terminological relationships that it has with other terms. The thesaurus is built by exploiting WordNet as a reference source of lexical information.
H-MATCH provides four different matching models that are used for
Deliverable D8.1 160/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
dynamically suiting the matching process to different levels of richness in ontology descriptions.
H-MATCH is used in HELIOS in order to enable knowledge sharing and resource discovery in open distributed systems. When a peer receives a query from another peer, the query is processed against its own ontology in order to extract the target concept(s) and the matching model to use. Once concepts matching a target concept have been identified using H-MATCH, they are returned to the requesting peer through a query answer.
A detailed description of HELIOS and H-MATCH is provided in [CF03, CF03b]
Special Features (e.g., learning method; use of a reference ontology, similarity reasoning, rule-base editable)
Dynamic ontology matching algorithm based on linguistic and contextual features of concepts for evaluating concept similarity; absence of an a priori agreement among peers for ontology specification; use of WordNet for linguistic matching.
II.4.5.17 ARTEMIS
Developed by Università degli Studi di Milano – Università degli Studi di BresciaType of solution Tool Method
Tool name: ARTEMISVersion:
Date of issue/developm.Last updateLevel Concepts Instances Problem addressed Merging Mapping Alignement Level of automation Manual Semi-automated Fully Automated
Language(s) supported
ODLi3
Description The Artemis tool environment performs the semantic integration of strongly heterogeneous data sources both structured and semi-structured The integration process is based on the construction of a semantically rich representation of the data sources to be integrated by means of a common data model based on the ODLi3 language and allows the construction of a global integrated view of data at different sources.
Deliverable D8.1 161/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
ARTEMIS exploits interschema knowledge expressed through intensional properties and extensional properties.All interschema properties are stored in a thesaurus. Three different alternatives are supported in ARTEMIS for building the thesaurus: i) to use a domain-dependent thesaurus manually constructed by the designer; ii) to use a domain-independent thesaurus extracted from the WordNet lexical system; iii) to use a hybrid thesaurus, which is a combination of the previous two.
The integration process is performed by the ARTEMIS mediator environment, which is composed by schema matching and unification environments.
Schema matching has the goal of identifying schema elements candidate to integration, that is, schema elements that describe the same or semantically related information in different source schemas. Schema matching in ARTEMIS is performed through affinity-based and clustering techniques based on the interschema knowledge stored in the thesaurus.
The output of clustering is an affinity tree, where classes are the leaves and intermediate nodes have an associated affinity value, holding for all cluster members. Clusters to be unified (i.e.,candidate clusters) are interactively selected from the affinity tree using a threshold-based mechanism.
Schema unification has the goal of defining the mediation scheme as a collection of global views, out of candidate clusters in the affinity tree. The unification process is performed through rule-based techniques, by which names and properties of schema elements in a cluster are properly reconciled into a global, unified representation. To support global query rewriting, a set of mapping rules are also specified for each global view, stating how to map each global property onto local properties of schema elements of the provenance cluster.
The ARTEMIS integration process and associated tool environment are pioneer in proposing affinity-based metrics and clustering procedures for schema matching and integration. Such innovative and featuring techniques have been subsequently imported and further refined in developing the MOMIS system, whose schema matching process is entirely based on the ARTEMIS techniques. Moreover, ARTEMIS has been recently extended to support domain ontology construction by extracting ontological concepts and semantic relationships among them from global views. Ontological concepts are defined according to different structures of global views. Three types of semantic relationships are considered: generalization (is-a), disjunction (two disjoint concepts have disjoint sets of their
Deliverable D8.1 162/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
instances), equivalence (equivalent concepts have the same sets of instances). Concepts and semantic relationships are exploited to implement semantic search modalities in a given domain.
In particular, in [BD04] is presented a related ontology-based approach to support effective use and sharing of knowledge coming from several organizations to enhance communication intra and inter organizations.
For a theoretical overview of the foundation of ARTEMIS refer to [AC01].
Special Features (e.g., learning method; use of a reference ontology, similarity reasoning, rule-base editable)
Affinity based clustering techniques for performing schema matching; rule-based unification techniques for global views construction; use of interschema properties and terminological relationships.
II.4.5.18 SWAP
Developed by University of KarlsruheType of solution Tool Method
Tool name: SWAPVersion:
Date of issue/developm.Last updateLevel Concepts Instances Problem addressed Merging Mapping Alignement Level of automation Manual Semi-automated Fully Automated
Language(s) supported
RDF, RDF(S), SeRQL
Description In the project SWAP (Semantic Web and Peer-to-Peer) [ET03] semantic descriptions of datasources stored by peers and semantic descriptions of peers themselves are exploited for formulating queries such that they can be understood by other peers, for merging the answers received from other peers, and for routing queries across the network. In particular, ontologies and Semantic Web techniques have been used for the semantic descriptions of contents and queries in the P2P system. To this purpose an RDF(S) metadata model for encoding semantic information is introduced allowing peers to handle heterogeneous and even contradictory views on the domain of interest. Each peer
Deliverable D8.1 163/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
implements an ontology extraction method to extract from its different information sources an RDF(S) description (ontology) compatible with the SWAP metadata model.
Such ontologies are used by the SeRQL Query Language to perform query processing; peers storing knowledge semantically related to a target concept are localized through SeRQL views defined on specific similarity measures. Views from external peers are integrated through an ontology merging method to extend the knowledge of the receiving peer according to a specific rating model.
Special Features (e.g., learning method; use of a reference ontology, similarity reasoning, rule-base editable)
Use of a RDF(S) model for ontology specification; use of the SeRQL query language for query resolution over ontologies.
II.4.5.19 MOMIS
Developed by University of Modena, University of Milano, University of BresciaType of solution Tool Method
Tool name: ODB tools+ ARTEMISVersion:
Date of issue/developm.
1999
Last updateLevel Concepts Instances Problem addressed Merging Mapping Alignement Level of automation Manual Semi-automated Fully Automated
Language(s) supported
Deliverable D8.1 164/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Description The MOMIS (Mediator envirOnment for Multiple Information Sources) [BC99] is a framework to perform information extraction and integration from both structured and semistructured data sources. An object-oriented language, with an underlying Description Logic, called ODL-I3, derived from the standard ODMG is introduced for information extraction. Information integration is then performed in a semi-automatic way, by exploiting the knowledge in a Common Thesaurus (defined by the framework) and ODL-I3 descriptions of source schemas with a combination of clustering techniques and Description Logics. This integration process gives rise to a virtual integrated view of the underlying sources (the Global Schema) for which mapping rules and integrity constraints are specified to handle heterogeneity. The MOMIS system, based on a conventional wrapper/mediator architecture, provides methods and open tools for data management in Internet-based information systems by using a CORBA-2 interface.
Special Features (e.g., learning method; use of a reference ontology, similarity reasoning, rule-base editable)
II.4.5.20 SHOE
Developed by University of MarylandType of solution Tool Method
Tool name: Knowledge Annotator, Expose’ (http://www.cs.umd.edu/projects/plus/SHOE/)Version:
Date of issue/developm.
1997
Last update no longer being actively maintainedLevel Concepts Instances Problem addressed Merging Mapping Alignement Level of automation Manual Semi-automated Fully Automated
Language(s) supported
SHOE
Description SHOE [LS97] is a superset of HTML which adds the tags necessary to embed arbitrary semantic data into web pages. SHOE tags are divided into two categories. First, there are tags for constructing ontologies. SHOE ontologies are sets of rules which define what kinds of assertions SHOE documents can make and what these
Deliverable D8.1 165/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
assertions mean. For example, a SHOE ontology might say that a SHOE document can declare that some data entity is a 'dog', and that if it does so, that this 'dog' is permitted to have a 'name'. Secondly, there are tags for annotating web documents to subscribe to one or more ontologies, declare data entities, and make assertions about those entities under the rules proscribed by the ontologies.The mergin fo different ontologies is obtained by using inference rules, defined to map the common items between the ontologies to be merged. Terminological differences are solved by defining if-and-only-if rules; Scope differences are solved by specifying mapping to most specific category (based on subsumption); encoding differences are handled by mapping individual values.
Special Features (e.g., learning method; use of a reference ontology, similarity reasoning, rule-base editable)
SHOE allows to prove some results of ontology difference, but ontologies must be written in the same language (SHOE)
II.4.5.21 INFOSLEUTH
Developed by Telcordia technologiesType of solution Tool Method
Tool name:Version:
Date of issue/developm.Last updateLevel Concepts Instances Problem addressed Merging Mapping Alignement Level of automation Manual Semi-automated Fully Automated
Language(s) supported
OKBC
Description InfoSleuth [NF99] is an agent-based system that can be configured to perform many different information management activities in a distributed environment. InfoSleuth agents provide a number of complex query services that require resolving ontology-based queries over dynamically changing, distributed, heterogeneous resources. These include distributed query processing, location-independent single-resource updates, event and information monitoring, statistical
Deliverable D8.1 166/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
or inferential data analysis, and trend discovery in complex event streams. It has been used in numerous applications, including the Environmental Data Exchange Network and the Competitive Intelligence System.
Ontologies are specified in OKBC [CF98] and are stored in an OKBC server and accessed via ontology agents. These agents provide ontology specifications to users for request formulation, to resource agents for mapping and to other agents that need to understand and process requests and information in the application domain.
Special Features (e.g., learning method; use of a reference ontology, similarity reasoning, rule-base editable)
Agent based
II.4.5.22 KRAFT
Developed by Alun Preece, Trevor Bench-Capon, Dean Jones et al.http://www.csd.abdn.ac.uk/research/kraft.html
Type of solution Tool Method Tool name: KRAFTVersion:
Date of issue/developm.
1997
Last updateLevel Concepts Instances Problem addressed Merging Mapping Alignement Level of automation Manual Semi-automated Fully Automated
Language(s) supportedDescription In KRAFT [PH99] translations between different ontologies are
done by special mediator agents which can be customized to translate between different ontologies and different languages. Different kinds of mappings are distinguished in this approach starting from simple one-to-one mappings between classes and values up to mappings between compound expressions. This approach aims at reaching a great flexibility, but it fails to ensure a preservation of semantics: the user is free to define arbitrary
Deliverable D8.1 167/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
mappings even if they do not make sense or produce conflicts.Special Features (e.g., learning method; use of a reference ontology, similarity reasoning, rule-base editable)
Use of customizable mediator agents
II.4.5.23
II.4.5.24 ONIONS
Developed by CNR, Conceptual Modeling Group, RomeType of solution Tool Method
Tool name:Version:
Date of issue/developm.
1996
Last updateLevel Concepts Instances Problem addressed Merging Mapping Alignement Level of automation Manual Semi-automated Fully Automated
Language(s) supportedDescription ONIONS [GS96] methodology can be summarized in the following 6
phases:
• 1: Creating a corpus of validated textual sources of a domain. Sources must be individuated
together with an assessment of their diffusion and validation inside the domain community.
• 2: Taxonomic analysis. If lacking, taxonomies are constructed.
• 3: Local source analysis. The conceptual analysis of terms in order to locate their free-text descriptions and other constraints (local definitions).
• 4: Multi-local source analysis. The conceptual analysis of the descriptions allows to link the local definitions with multi-local
Deliverable D8.1 168/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
concepts and general knowledge (paradigms).
• 5: Building an integrated ontology library. An ontology library covers all the local definitionsand the paradigms that have been used in building multi-local, integrated definitions.
• 6: Implementing and classifying the library. These steps pertain to the diffusion, use, classification, and validation of the model.
Special Features (e.g., learning method; use of a reference ontology, similarity reasoning, rule-base editable)
II.4.5.25 OBSERVER
Developed by E. Mena V. Kashyap A. Sheth A. Illarramendi
Type of solution Tool Method Tool name: OBSERVER
Version:Date of issue/developm.
1996
Last update 2003Level Concepts Instances Problem addressed Merging Mapping Alignement Level of automation Manual Semi-automated Fully Automated
Language(s) supportedDescription OBSERVER [MK96] is a system developed by E. Mena, V. Kashyap,
A. Sheth and A. Illarramendi. In order to access heterogeneous data repositories, the objects in such repositories are represented as intensional descriptions by pre-existing ontologies expressed in Description Logics characterizing information in different domains. User queries are rewritten by using interontology relationships to
Deliverable D8.1 169/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
obtain semantic preserving translations across the ontologies. There are two types of mappings: one type links each term in an ontology with structures in data repositories are used in order to access and retrieve data from the repositories; the other type (Interontology Relationships Manager ) relates the terms in various ontologies.
Special Features (e.g., learning method; use of a reference ontology, similarity reasoning, rule-base editable)
Query rewriting
II.4.5.26 ONTOMORPH
Developed by Hans Chalupsky
Type of solution Tool Method Tool name: LOOM, PowerLoom
Version: 4.0Date of issue/developm.
2000
Last update 2004Level Concepts Instances Problem addressed Merging Mapping Alignement Level of automation Manual Semi-automated Fully Automated
Language(s) supportedDescription OntoMorph [C00] provides a powerful rule language to represent
complex syntactic transformations and a rule interpreter to apply them to arbitrary KR language expressions. OntoMorph is fully integrated with the PowerLoom KR system to allow transformations based on any mixture of syntactic and semantic criteria. OntoMorph's successful application as an input translator for a critiquing system and as the core of a translation service for agent communication. We further show how knowledge base merging can be cast as a translation problem and motivate how OntoMorph
Deliverable D8.1 170/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
can be applied to knowledge base merging tasks. Special Features (e.g., learning method; use of a reference ontology, similarity reasoning, rule-base editable)
Syntactic/Semantic rewriting
II.4.6 MultiOntology Architectures & Environments, Federated ontologies
One of the most interesting aspects of the Semantic Web is its idea of decentralization. A proposal for software interoperability is that of having a federated system. Such a system expects that every software applications maintain its data structures modelled by a local ontology, and, in order to support communication and knowledge exchange with others, a mechanism is provided to normalize the local ontologies onto a common ontology model. We report an architecture for federated ontologies as proposed in [SM03].
1. local ontologies (the conceptual models of the autonomous applications), each of them with its specific underlying ontology/metadata repository or database,
2. normalized ontologies (transformation of the local ontologies into a common data model),
3. export ontologies (view on the normalized ontology that describes the relevant parts of the ontology for the federation),
4. one merged ontology (global ontology derived from the combination of the two export schemas), and
5. different applications in the upper layer (external schema layer), which use the merged ontology with their specific views on it.
Deliverable D8.1 171/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Figure 1: An architecture for federated ontologies
II.4.7 Contexts and sub-ontology factorization
The notion of context plays a crucial role in different disciplines, such as pragmatics, natural language semantics , linguistics, cognitive psychology, and artificial intelligence (for instance, in NLP techniques, to assign an interpretation to or disambiguate assertions; in distributed AI, contexts are used to design systems of autonomous agents) [BG96]. In logic, the first representation of context as a formal object was by the philosopher C. S. Peirce; but for nearly eighty years, his treatment was unknown outside its research group. In the 1980s, three different approaches led to related notions of context: Kamp's discourse representation theory; Barwise and Perry's situation semantics; and Sowa's conceptual graphs, which explicitly introduced Peirce's theories to the AI community. During the 1990s, John McCarthy and his students developed a closely related notion of context as a basis for organizing and partitioning knowledge bases. See [SO01] for further details.
For what concerns the application of contexts in the ontology interoperability solutions some solutions consider an ontology as a graph, with a node for each concept and an arc for each relation/attribute; in this perspective they define the "context of a concept" as the neighbourhood of a concept in the ontology graph and use similarity measures based on this kind of contexts.
Deliverable D8.1 172/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Other interesting solutions at the state of the art [KS96] propose to evaluate if objects belonging to different ontologies have some semantic similarity with respect to a specific context. This context, called context of comparison, is a reference point that allows to establish the "semantic proximity" of two concepts. This method has been presented for the integration and mapping of database objects, but results very interesting also for ontology mapping purposes.
II.4.8 Conclusions
We have seen in this chapter, how the field of ontology interoperability is very active; an increasing number of tools and methodologies were developed to address this issue. Unfortunately, at now, no solution seems to be the “winning” one, due to several problems:
there’s a great heterogeneity in the kind of techniques adopted (linguistic similarity, structural similarity, graph matching, heuristics, instance-based similarity,) and it seems that is difficult to find a “balanced mix” of such techniques to have a “general purpose” mapping/merging/alignment tool
The ontology languages support given by the tools is oftent very limited; to try a tool or a methodology on our own ontology it usually has to be transformed to a common representation format (and we have seen that changing the representation formalism is often not a trivial task )
Most of the solutions are out-to-date, it is not so easy to understand if a project is still alive, which is the last date of issue/development, not all the tools are still available.
Deliverable D8.1 173/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
II.4.9 Bibliography
[AC01] Global Viewing of Heterogeneous Data Sources, 2001; S. Castano (WP8 member), V. De Antonellis (WP8 member), S. De Capitani Di Vimercati
[BC99] Semantic Integration of Semistructured and Structured Data Sources, S. Bergamaschi, S. Castano e M. Vincini, SIGMOD Record Special Issue on Semantic Interoperability in Global Information, Vol. 28, No. 1, March 1999. http://citeseer.ist.psu.edu/bergamaschi99semantic.html
[BD03] The Uni-Level Description: A uniform framework for representing information in multiple data models, 2003; Shawn Bowers; Lois Delcambre
[BD04] Ontology-based interoperability for interorganizational applications, 2004; D. Bianchini; V. De Antonellis; M. Melchiori (authors from UNIBS, INTEROP partner)
[BE03] A Metadata Model for Semantics-Based Peer-to-Peer Systems, 2003; J Broekstra, M Ehrig, P Haase, F. van Harmelen, A. Kampman, M. Sabou, R. Siebes, S. Staab, H. Stuckenschmidt, C. Tempich
[BG96] Contexts, Locality and Generality, P. Bouquet, E. Giunchiglia & F. Giunchiglia:, Mathware & Soft Computing, III (1-2), 1996 (pp. 47-57).
[BH01] T. Berners-Lee, J. Hendler, and O. Lassila. The Semantic Web. Scienti_c American, 279, 2001
[BM03] A SAT-based Algorithm for Context Matching, 2003; P. Bouquet, B. Magnini, L. Serafini, S. Zanobini
[BS99] Information Flow: the logic of distributed systems, J.Barwise, J.Seligman. Tracts in Theoretical Computer Science 44, Cambridge University Press, ISBN: 0-521-58336-1, 1999
[C00] OntoMorph: A Translation System for Symbolic Knowledge. H. Chalupsky, Principles of Knowledge Representation and Reasoning: Proceedings of the Seventh International Conference on Knowledge Representation and Reasoning (KR-2000), Breckenridge, Colorado, USA, April 2000. http://citeseer.ist.psu.edu/chalupsky00ontomorph.html
[CD01] Description logics for information integration. Diego Calvanese, Giuseppe De Giacomo, and Maurizio Lenzerini. In Computational Logic: From Logic Programming into the Future (In honour of Bob Kowalski), Lecture Notes in Computer Science. SpringerVerlag, 2001. http://citeseer.ist.psu.edu/calvanese01description.html
Deliverable D8.1 174/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
[CF03] H-MATCH: an Algorithm for Dynamically Matching Ontologies in Peer-based Systems, 2003; S. Castano (WP8 member), A. Ferrara (WP8 member), S. Montanelli (WP8 member)
[CF03b] Helios: A General Framework for Ontology-Based Knowledge Sharing and Evolution in P2P Systems, 2003; S. Castano (WP8 member), A. Ferrara (WP8 member), S. Montanelli (WP8 member), D. Zucchelli
[CF98] OKBC: A Programmatic Foundation for Knowledge Base Interoperability, Vinay K. Chaudhri, Adam Farquhar, Richard Fikes, Peter D. Karp, James P. Rice, Proc. AAAI'98 Conference, Madison, WI, July 1998. http://citeseer.ist.psu.edu/chaudhri98okbc.html
[CO01] Issues in Ontology-based Information Integration, 2001; Zhan Cui Dean Jones Paul O'Brein
[CP01] Solving Integration Problems of E-commerce Standards and Initiatives through Ontological Mappings, Corcho, O. and Gomez-Perez, A. In: Proceedings of the Workshop on E-Business and Intelligent Web at the Seventeenth International Joint Conference on Artificial Intelligence (IJCAI2001) , Seattle, USA, August 5, 2001. http://citeseer.ist.psu.edu/corcho01solving.html
[D01] de Diego, R. Método de mezcla de catálogos electrónicos. Final Year Project. Facultad de Informática de la Universidad Politécnica de Madrid. Spain. 2001.
[DM02] Learning to Map between Ontologies on the Semantic Web, A. Doan, J. Madhavan, P. Domingos, and A. Halevy. Proc. of the World-Wide Web Conf. (WWW-2002).
[EK04] Johann Eder (WP8 member), Christian Koncilia (WP8 member). Modelling Changes in Ontologies. Proceedings of On The Move - Federated Conferences, OTM 2004, Springer, LNCS 3292
[ET03] Ehrig, M., Tempich, C., Broekstra, J., van Harmelen, F., Sabou, M., Siebes, R., Staab, S., Stuckenschmidt, H.: SWAP - ontology-based knowledge management with peer-to-peer technology. In Sure, Y., Schnurr, H.P., eds.: Proceedings of the 1st National "Workshop Ontologie-basiertes Wissensmanagement (WOW2003)". (2003) To appear 2003. http://citeseer.ist.psu.edu/article/ehrig03swap.html
[FG97] On Ontologies and Enterprise Modelling, 1997; Mark Fox, Michael Gruninger
[FM02] A cooperative framework for integrating ontologies, Jesualdo Tomás Fernández-Breis, Rodrigo Martínez-Béjar,, International Journal of Human-Computer Studies, v.56 n.6, p.665-720, June 2002
[GS96] ONIONS: An Ontological Methodology for Taxonomic Knowledge Integration, GANGEMI, A., STEVE, G. and GIACOMELLI, F. (1996) ECAI-96 Workshop on Ontological Engineering, Budapest, August 13th. http://citeseer.ist.psu.edu/gangemi96onions.html
Deliverable D8.1 175/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
[GW99] B. Ganter and R. Wille. Formal Concept Analysis: Mathematical Foundations. Springer, Berlin -- Heidelberg, 1999.
[KD01] OntoMap: Ontologies for Lexical Semantics, Atanas Kiryakov, Marin Dimitrov, Kiril Iv. Simov. In: Proceedings of RANLP - 2001"Recent Advances in NLP", 5-7 September 2001, Tzigov Chark, Bulgaria.
[KL01] Michel Klein. Combining and relating ontologies: an analysis of problems and solutions. IJCAI2001 Workshop on Ontologies and Information Sharing, 2001.
[KS02] Information Flow based ontology mapping, Y.Kalfoglou, M.Schorlemmer. In Proceedings of the 1st International Conference on Ontologies, Databases and Application of Semantics (ODBASE'02), Irvine, CA, USA, October 2002
[KS03] Ontology mapping: the state of the art, 2003; Y. Kalfoglou, M. Schorlemmer
[KS96] Semantic and schematic similarities between database objects:a context-based approach, 1996; Vipul Kashyap, Amit Sheth
[KY02] Ontology management - Storing, aligning and maintaining ontologies, 2002; Michel Klein, Ying Ding, Dieter Fensel, Borys Omelayenko
[L01] Ontology and interoperability, 2001; R.Laurini
[LG01] Facilitating the exchange of explicit knowledge through ontology mappings. M. Lacher and G. Groh. In Proceedings of the 1,ith International FLAIRS conference, Key West, FL, USA, May 2001. http://citeseer.ist.psu.edu/lacher01facilitating.html
[LS97] Ontology-based Web agents. S. Luke, L. Spector, D. Rager, and J. Hendler. In W. L. Johnson, editor, Proceedings of the 1st International Conference on Autonomous Agents, pages 59--66. ACM, 1997. http://citeseer.ist.psu.edu/luke97ontologybased.html
[MB01] Generic schema matching with CUPID. Jayant Madhavan, Philip A. Bernstein, and Erhard Rahm. In Proceedings of the 27th International Conferences on Very Large Databases, pages 49--58, 2001. http://citeseer.ist.psu.edu/madhavan01generic.html
[MF00] The Chimaera Ontology Environment , 2000; D. McGuinness, R. Fikes, J. Rice, and S. Wilder.
[MK96] OBSERVER: An approach for Query Processing in Global Information Systems based on Interoperation across Pre-existing Ontologies, E. Mena, V. Kashyap, A. Sheth and A. Illarramendi, Proceedings of the 1 st IFCIS International Conference on Cooperative Information Systems (CoopIS '96), Brussels, Belgium, June 1996. http://citeseer.ist.psu.edu/article/mena00observer.html
[ML00] The Chimaera Ontology Environment. McGuinness, Deborah L., Richard Fikes, James Rice, and Steve Wilder. " Proceedings of the Seventeenth National Conference on Artificial Intelligence (AAAI 2000). Austin, Texas. July 30 - August 3, 2000.
Deliverable D8.1 176/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
[MM02] Alexander Maedche, Boris Motik, Nuno Silva, and Raphael Volz. Mafra - a mapping framework for distributed ontologies. In Proceedings of the EKAW 2002, 2002.
[MW00] A Graph-Oriented Model for Articulation of Ontology Interdependencies. P. Mitra, G. Wiederhold , and M. Kersten. In: Proceedings Conference on Extending Database Technology 2000 (EDBT'2000), Konstanz, Germany, 2000. http://citeseer.ist.psu.edu/mitra00graphoriented.html
[NF99] An Overview of Active Information Gathering in InfoSleuth ;Marian Nodine, Jerry Fowler and Brad Perry. In Proceedings of the International Symposium on Cooperative Database Systems for Advanced Applications, 1999.
[NK03] Ontology Evolution: Not the Same as Schema Evolution, 2003; Natalya F. Noy, Michel Klein
[NM00] N. F. Noy & M. A. Musen. PROMPT: Algorithm and Tool for Automated Ontology Merging and Alignment In the Proceedings of the Seventeenth National Conference on Artificial Intelligence (AAAI-2000), Austin, TX. Available as SMI technical report SMI-2000-0831 (2000)
[NM02] N. F. Noy & M. A. Musen PromptDiff: A Fixed-Point Algorithm for Comparing Ontology Versions. In the Proceedings of the Eighteenth National Conference on Artificial Intelligence (AAAI-2002), Edmonton, Alberta, August 2002. Available as SMI technical report SMI-2002-0927 (2002)
[NM03] The PROMPT Suite: Interactive Tools For Ontology Merging And Mapping, 2003; Noy N. F., M.A. Musen
[O03] Ontologies for Semantically Interoperable Systems, 2003; Leo Obrst
[OW03] Ontoweb deliverable 1.4: A survey on methodologies for developing, maintaining, evaluating and reengineering ontologies, 2003
[PH99] The KRAFT Architecture for Knowledge Fusion and Transformation. A. D. Preece, K.-Y. Hui, W. A. Gray, P. Marti, T. J. M. Bench-Capon, D. M. Jones, and Z. Cui. In 19th SGES Int. Conf. on Knowledge-based Systems and Applied Articial Intelligence (ES'99). SpringerVerlag, 1999. http://citeseer.ist.psu.edu/article/preece99kraft.html
[PS00] Database integration: The key to data interoperability, 2000; C. Parent, S. Spaccapietra
[RB01] A Survey of Approaches to Automatic Schema Matching, 2001; E. Rahm, P.A. Bernstein
[RB01] A survey of approaches to automatic schema matching, 2001; E. Rahm; P.A. Bernstein
Deliverable D8.1 177/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
[SA03] Relationships at the Heart of Semantic Web: Modeling, Discovering, and Exploiting Complex Semantic Relationships , June 2003; Amit Sheth; I. Budak Arpinar; Vipul Kashyap
[SK03] Integrity and change in modular ontologies, 2003; Stuckenschmidt, H. and Klein, M
[SM01] FCA-Merge: Bottom-up merging of ontologies. G. Stumme and A. Madche. In 7th Intl. Conf. on Artificial Intelligence (IJCAI '01), pages 225--230, Seattle, WA, 2001. http://citeseer.ist.psu.edu/stumme01fcamerge.html
[SM03] Ontology Merging for Federated Ontologies on the Semantic Web, 2003; G.Stumme, A.Maedche
[TH03] DL reasoner vs. first-order prover. Dmitry Tsarkov and Ian Horrocks. In Proc. of the 2003 Description Logic Workshop (DL 2003), volume 81 of CEUR (http://ceur-ws.org/), pages 152-159, 2003.
[TP03] Using Semantic Web Technology to Enhance Current Business-to-Business Integration Approaches, 2003; David Trastour, Chris Preist, Derek Coleman
[WV01] Ontology-Based Integration of Information - A Survey of Existing Approaches, 2001; H. Wache T. Vogele U.Visser et alii
[YP03] Using transformations to improve semantic matching, 2003; P.Z. Yeh, B. Porter, K. Barker
Deliverable D8.1 178/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
II.5 Ontology-based Services for Enterprise Application Interoperability
II.5.1 Introduction
Interoperability has been defined in many different ways, e.g. as “the ability of a system or a product to work with other systems or products without special effort on the part of the customer”, [IDEAS], as “the ability to share and exchange information using common syntax and semantics to meet an application-specific functional relationship through the use of a common interface”, [ISO16100] or as “the unrestricted sharing of data and business processes among any connected applications and data sources in the enterprise”, [Linthicum03]. One of the major problems in achieving interoperability between systems is to understand and compare the meanings of the components of the systems. One instrument for addressing this problem is the use of ontologies, which provide a shared terminology and understanding for the domain in which the systems are situated.
In order to clarify the notion of interoperability, it can be helpful to structure system aspects by means of a framework like Graal, [WBFE03]. This framework for information processing systems proposes a distinction between process and product; see Fig. 1 (based on Fig. 1 in Graal and extended with aspects for Process). Product aspects are first divided into internal aspects and external aspects, and external aspects are classified into functional and quality aspects. Functional aspects tell what a system does and what it offers to the environment, while quality aspects tell how well the system functions for its stakeholders. Typical quality aspects are usability, efficiency, and security for system users, and maintainability and portability for developers.
For functionality, the basic aspect is the services the system provides to its environment. By providing services, the system delivers value to its environment, which is the raison d’etre of the system. The behaviour aspect has to do with the ordering and control flow of services and activities. The communication aspect concerns interactions with other entities, like people, hardware, and software. Finally, the meaning aspect addresses the interpretation of symbols used in services. It can be noted that the meaning aspect is only relevant for information processing systems, as these provide services through the exchange of symbols. In contrast, other systems can provide their services through physical processes such as the delivery of chemicals or power.
Deliverable D8.1 179/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
For process aspects, it is possible to identify four aspects for the exploitation of a system in the context of interoperability: description, discovery, composition, and execution, as suggested in [CS03]. Description is the activity of describing the product aspects of the system. Ontology can play a major role in this activity and provide a basis for well-founded and consistent descriptions of different systems. Discovery is the activity of discovering which information and services that can be provided by a system. Ontologies can become useful also in this activity and provide common terminology that supports a user searching for information or services. Composition is the activity of comparing and combining information, services, and processes from different sources. Finally, execution is the activity of actually using the services of a system that may be composed of several subsystems.
The organisation of this report will reflect the structure of system aspects introduced above. Section 2 gives an overview of alternative architectures of relating ontologies to systems together with the introduction of various levels (or types) of ontology. Section 3 discusses the use of ontologies for interoperability of the functional aspect meaning and is structured according to the four exploitation aspects (description, discovery, composition and execution), as are also structured sections 4 and 5. The use of ontologies for the interoperability of the behaviour (process) aspect is discussed in Section 4 and of the service aspect in Section 5. Practical applications of ontologies for interoperability are discussed in Section 6. Finally, Section 7 suggest a number of future research directions in the area.
Deliverable D8.1 180/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
II.5.2 Architecture
II.5.2.1Types of HeterogeneityOn the issue of heterogeneity, Ouskel and Sheth, [OS99], have identified the following types of heterogeneity:
Information Heterogeneity: o Semantic Heterogeneity o Structural or Representational or Schematic Heterogeneity o Syntactic Heterogeneity
System Heterogeneityo Information System Heterogeneity (Ex: heterogeneity in digital media
repository management systems, Database Management systems)o Platform Heterogeneity (Ex: Differences in Operating systems,
hardware/system, etc.)Based on the above classification of the various types of heterogeneity, Ouskel and Sheth [OS99], discuss the need for the following levels of interoperability:
Semantic Interoperability Structural Interoperability Syntactic Interoperability System Interoperability
Research and ongoing standardisation process has achieved notable progress in regard to system (IIOP for interactions between distributed objects, KQML for interaction between agents), structural (RDF, MPEG-4, KIF etc) and syntactic interoperability (XML). However, semantic interoperability is still an immature area. By semantic interoperability, we mean that the intended meaning of the modelled terminology and their relationships should be made clear and machine-readable. Cui and O’Brien [CJO01] have discussed semantic heterogeneity and defined the term to refer to both mismatch of conceptualisations as well as mismatch of the modelled realities. Cui and O’Brien classify semantic heterogeneity as seen in the excerpt from [CJO01]:
1. “Semantically equivalent concepts Different terms are used to refer the same concept by two models. These terms are
often called synonyms. However, synonyms in their common usage do not necessarily denote semantically equivalent concepts.
Different properties are modelled by two systems. For example, for the same product, one catalogue has included its colour but the other has not.
Property type mismatches. For example, the concept length may be in kilometres or miles.
2. Semantically unrelated concepts Conflicting term - the same term may be chosen by two systems to denote
completely different concepts. For example, apple is used to denote fruit or computer.
3. Semantically related concepts
Deliverable D8.1 181/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Generalisation and specialisation One system has only the concept of fruit, but the other has the concepts of apple, orange, etc. Another example is that student in one system refers to all students, but the other only to PhD students.
Definable terms or abstraction - A term may be missing from one ontology, but it can be defined in other terms in the ontology.
Overlapping concepts. For example, kids in one ontology means persons aged between 5 to 12 years old, but in the other means persons aged between 3 and 10 years old, and in yet another ontology, young persons means persons aged between 10 and 30 years old.
Different conceptualisation. For example, one ontology classifies person as male, female. The other person as employed, unemployed.”
A more detailed discussion of semantic heterogeneity can be found in ST3, Section 3.1. Semantic heterogeneity can be resolved by mutual agreements or standardisation processes. However, given the distributed and global nature of most domains, this is a non-trivial task that cannot be achieved without automated support. In this context, ontologies are viewed as essential instruments in managing semantic heterogeneity.
II.5.2.2Architectures of Ontologies for InteroperabilityCiocoiu et. al. [CGN00], Ontologies for Integrating Engineering Applications discuss two approaches for the use of ontology in interoperability. First, the standardisation approach, wherein all are encouraged to use a common, shared, standardised ontology for their enterprise applications. Such an approach has, however, been deemed impractical. Secondly, the interlingua approach, wherein ontology is used as an interlingua and interpreters/translators are written from the ontology to/from the software applications.
The single ontology approach works well if an ontology is to be designed and modelled from scratch. However, the ontology is usually limited to the purpose of its application. That is, it has limited reusability outside the scope of its application. Multiple local ontologies are generally applicable and reusable but difficult to implement practically. Thus, as Ciocoiu et al, propose, the Interlingua approach is a middle road approach. It tries to overcome the applicability problems of a single ontology while keeping translation problems at a manageable level. They propose to have a shared ontology and use it as an Interlingua for translating between communicating systems (much like P2P interoperability). It allows the communicating systems to have their own local ontologies. This approach also has the advantage that the networked system can be easily extended to include other systems as well, without having to create a large number of mapping relations (See figure 2a).
In practice, the implementation of point to point translators between every pair of applications (shown in figure 2a ) , requires N(N-1) translators for N applications. Further, if any new application is to be added, N new point-to-point translators are required. With the use of a common shared ontology (which provides all the applications with a common set of terminology and semantics), the number of point to point translators required is reduced to N translators, from each application to the common translator (as depicted in figure 2b). The drawback with this approach is that all the interoperating applications need to understand the formalism /ontology representation language of the shared ontology. Or else they need to be able to interoperate or translate within the different ontology representation formalisms like
Deliverable D8.1 182/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
KIF, DAML, RDFS to name a few. Also, a minimum consensus view for the common ontology needs to be arrived at trough mutual agreements or standardisation process.
Figure 2 a : Point to Point Interoperability Between N applications (not complete)
Figure 2b : Use of common ontology to reduce the number of translators between N applications
Wache et al [WVNSSVH01] have presented a survey of about 25 contemporary approaches for ontology based information integration including SIMS, TSIMMIS, OBSERVER [MKSI96], CARNOT [WC93], InfoSlueth, KRAFT, PICSEL, DWQ, Ontobroker, SHOE. In addition to their evaluatory survey, they have also discussed succinctly the major types of
Deliverable D8.1 183/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
ontology design architectures. They identify three main architectures: single ontology, multiple ontology, and hybrid.
Single Ontology Approaches: Single Ontology approaches use one global ontology providing a shared vocabulary for the specification of the semantics (Figure 3 below). Example: the SIMS model [AHK96] of the application domain includes a hierarchical terminological knowledge base. The global ontology can also be a combination of several specialized ontologies, supporting a modular approach in lieu of a large monolithic ontology. The combination has been supported by ontology representation formalisms like ONTOLINGUA [G93]
Figure 3: Single Ontology ApproachThe single ontology approach works best if all the systems to be integrated share the same view of the domain. But when a single application has a different view, then it becomes difficult to find the minimal ontological commitment to define the global ontology. Also, it is difficult to maintain the changes to the single ontology with every change in any of the information sources. This led to the development of the multiple ontologies approaches.
Multiple Ontologies Approaches:
Deliverable D8.1 184/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Figure 4: Multiple Ontology Approach
In Multiple Ontologies approaches (figure 4), each information source is described by its own ontology definition like that of OBSERVER. The advantage is that no minimal ontology commitment [G95] is required. Each of the source ontologies can be developed with respect to other sources or their ontologies. However, the lack of a common vocabulary makes the task of comparing different source ontologies difficult. An additional inter-ontology mapping is required to identify the semantically corresponding terms of different source ontologies.
Figure 5 : Hybrid Approach
Deliverable D8.1 185/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Hybrid Approaches: To overcome the drawbacks of the multiple and single ontology approaches, a hybrid approach (figure 5) was developed. Each information source was defined by its own ontology, but each ontology is built from a global shared vocabulary. An example is COIN [SM91] in which the local description of information is an attribute value vector. In MECOTA [W99] each source concept is annotated by a label which combines the primitive terms from the shared vocabulary in BUSTER (H Stuckenschmidt et al 2000 [SW00]), which has a shared vocabulary covering attribute value ranges for its defined concepts. Advantages of hybrid approaches are that new information sources can be easily added without the need for modification. The use of a shared common ontology also makes the source ontologies comparable. However, this approach has the disadvantage of having limited reusability outside the scope of the intended use for a source application. Furthermore, the source ontologies and the common ontology all need to be defined using the same ontology representation language, which would not be a problem if all the information source ontologies were to be developed from scratch. But in cases when the information sources have pre-existing ontologies, then rework or mapping issues appear. Further discussions on multiple ontology architectures can be found in ST3, Section 1.5.
A typical architecture of a system supporting interoperability by means of ontologies is the one proposed by OKMS, which is based on the Ontologging project (www.ontologging.com) and illustrated in figure 6. The OKMS is a EU funded project focusing on distributed ontology based knowledge management systems and investigates how ontologies may improve traditional knowledge management systems.
Maedche et al describe the OKMS architecture in [MBS03]: a short excerpt is given below.
Deliverable D8.1 186/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Figure 6: The architecture of the Ontologging ontology based knowledge management system OEKM (reprinted from http://www.computer.org/intelligent/ex2003/x2026.pdf)
“A GUI front-end is provided as an interface to various target user groups, providing facilities to set up, evolve the ontology, or to create mappings between autonomous ontologies. The enterprise knowledge portal provides an integrated platform for different knowledge management tools available. The user profile editor allows the users to express their interests in some part of the domain, so that the system can select relevant information for the users. With the query, browsing and knowledge-editing tool the user can search and navigate through the knowledge base, upload documents and create new instances. Integration to other applications like MS Office through plugins is also available.
All GUI front-ends are realized on top of a core integration layer that coordinates the interaction of various system components. The OKMS uses Web Service technology to realize this layer. This layer also has a set of intelligent services and agents that improve user interaction with the system by tracking user behaviour.
The Core Integration Layer is realized on top of the Ontology server and the Document Server. The document server stores documents that are annotated using the ontologging domain ontology, and the ontology server stores this information.
The system defines wrappers that lift content from different existing applications to the ontology level. For example, the system has a wrapper for integrating Lotus Notes with the ontologies using a set of rules. The Ontology server component of the OKMS is based on another project: the Karlsruhe Ontology and Semantic Web Framework (www.kaon.semanticweb.org). KAON focuses on integrating traditional technologies for ontology management with those used for business applications like relational databases. The KAON architecture addresses issues like evolution, change reversibility, concurrency conflict detection, optimized loading and query answering.“
Another architecture for management of distributed information systems including business processes is HELIOS [CFMZ], which is again an ontology-based framework for knowledge sharing. However, HELIOS focuses on peer-to-peer networking and supports knowledge sharing and evolution between P2P systems. The HELIOS framework consists of a peer, peer knowledge, peer data, and peer interaction. The Peer knowledge is organized as ontology. The HELIOS toolkit consists of a query processing manager, a matching manager and an ontology manager. Various types or levels of ontologies may be made available with no regard to the architecture of a system that supports interoperability based on ontologies. This is discussed in the next section.
II.5.2.3Ontology Architectures Distributed heterogeneous ontologies, whether they are single global ontology or multiple local ontologies or a hybrid specialized ontology, still need to be able to interoperate with each other. There are generally three approaches for combining distributed heterogeneous ontologies [MBS03]:
Deliverable D8.1 187/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Ontology Inclusion in which the source ontology is simply included within the target ontology. All definitions from the source ontology are included within the target ontology and it is not possible to include only parts of the source ontology.
Ontology Mapping in which a part of the source ontology is related to the target ontology’s entities. The drawback is the need for flexible mechanisms for transformations.
Ontology Merging using Mediators The most complex approach combines several data sources into a single integrated ontology. A mediator is used to answer queries . The TSIMMIS system (global-as-is-view) and the Manifold system (local-as-is-view) take two different approaches for obtaining the integrated single ontology. Details may be found in [GM97] and [LR096].
Corcho and Gomez-Perez [CGP01] propose multi-layered ontology architecture for promoting interoperability between heterogeneous e-commerce applications. They use a tool WebPicker for integrating various e-commerce related standards like UNSPSC, e-cl@ss, RosettaNet, NAICS, SCTG, etc. They build on previously identified and classified ontology types like that of Mizoguchi [M03] who distinguishes between domain ontologies, common-sense ontologies, meta-ontologies and task ontologies. Also Van Heijst [VHSW96] classifies ontologies with respect to amount and type of structure of ontology and subject of conceptualisation. Corcho and Gomez-Perez [CGP01] propose a common framework for understanding both the above two classifications as shown in figure. As the figure illustrates, ontologies are built in top of other ones (application domain ontologies on top of domain ontologies, domain ontologies on top of generic ontologies, etc.). Corcho and Gomez-Perez propose this structure having the following advantages:
1. Maximum monotonic extensibility [G93]: since new terms either general or specialised terms ca be included without requiring a revision of existing ontologies;
2. Clarity: [G93] the structure of terms implies the separation between non similar terms .
Representation Ontology: Frame Ontology
General /Common Ontologies: time, space
Generic Domain O: components Generic Task O: plan
Domain O: body Domain Task O:Plan-surgery
Application Domain O: heart disease
Application Domain Task O: surgery heart
Figure 7 : Multi Layered Ontology architecture proposed by Corcho- Gomez-Perez
Deliverable D8.1 188/206
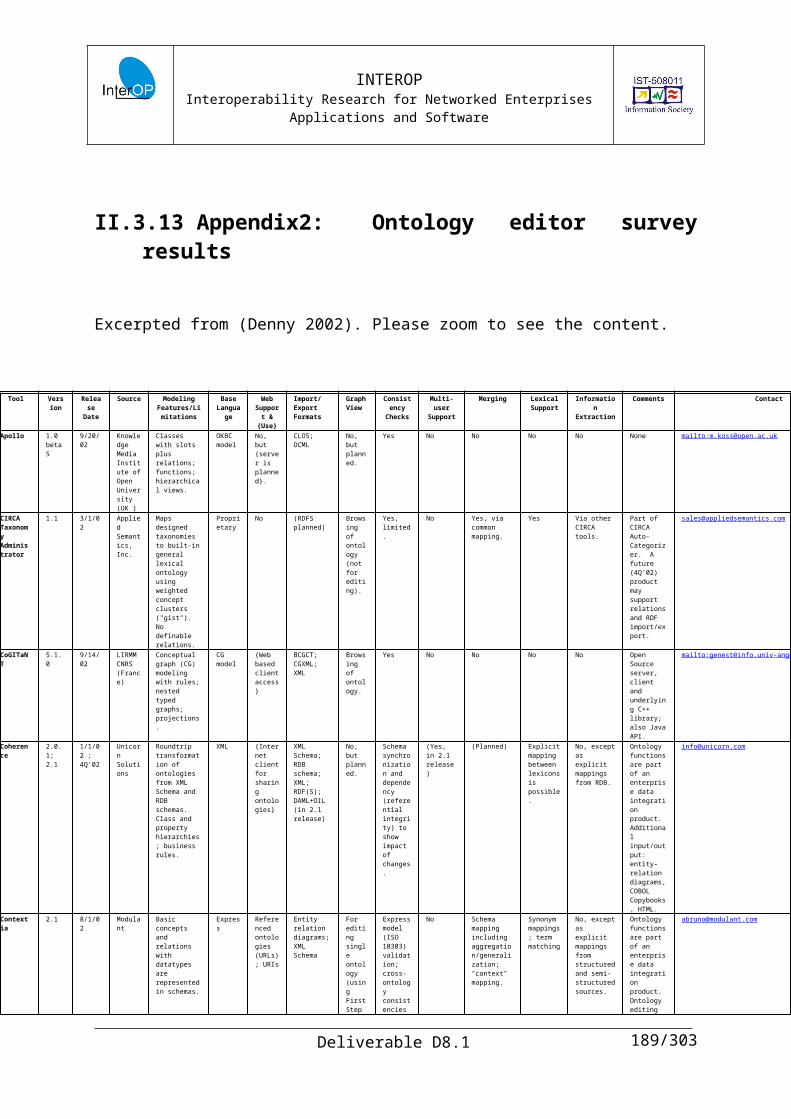
INTEROPInteroperability Research for Networked Enterprises Applications and Software
Guarino [G92] has defined ontologies as logical theory accounting for the intended meaning of a formal vocabulary, i.e. its ontological commitment to a particular conceptualization of the world. He has further classified ontologies, depending upon their generality as (figure 8):
Top-level ontologies: Top-level ontologies to describe general concepts like time, space, matter, and event that are independent of domain or a particular problem.
Domain Ontologies and Task Ontologies: are described to be ontologies pertaining to a specific domain or task.
Application Ontologies: Describe concepts that depend upon both a domain and a particular task, usually being specializations of both ontologies.
Figure 8: Classification of Ontology by Guarino
Top-level ontology
Domain ontology Task ontology
Application ontology
We see that Guarino’s approach is similar to multiple ontology approach as discussed by Wache et al. The perspective and usage view of ontology differs. Guarino’s approach for ontology design needs to be integrated with other methodologies for integration with pre-existing knowledge sources. In this section, we have introduced different architectures for relating ontologies to systems. In the following we will move into the different aspects of information processing systems and study how ontologies can help to achieve interoperability of information, processes, and services.
II.5.3 Information interoperability
In this section, we discuss how ontologies can be used to achieve interoperability of different information sources.
II.5.3.1DescriptionThe first step in the use of ontologies for information interoperability is to relate each information source to ontologies. Some of the general approaches of relating information sources to ontologies may be summarised as: [WVNSSVH01]
Deliverable D8.1 189/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
Structural resemblance: This scheme for connecting an ontology to a database schema creates a one-to-one mapping between the elements in the information source and the concepts in the ontology. As an example, a term “auto” in the information source could be mapped to a term “car” in the ontology. This approach has been implemented in the SIMS mediator [AHK96] and also by TSIMMIS system [GM97].
Definition of terms: The above approach does not make the semantics of the database schema clear as it only provides a one-to-one mapping. Systems like BUSTER, H stuckencschmidt [S03], use the ontology to further define terms in the database scheme. This is done by relating elements in the information source to definitions in the ontology. As an example, a term “salary” in the information source could be mapped to a definition “base salary + bonus” expressed in the ontology.
Structural enrichment: This is the most common approach for relating ontologies to information sources. It is a combination of the previous two approaches. A logical model of the structure is built, while at the same time semantically enriching the definitions of the concepts. Detailed discussion on semantic enrichment may be found in Kashyap and Sheth [KS96a]. Systems that use structure enrichment are OBSERVER [MKSI96], KRAFT [K04], PICSEL [GLR00] and DWQ [DWQ].
Meta-annotation: Meta-Annotation adds semantic information to the information sources and this approach is useful for integrating information source on the internet. OntoBroker [OB] uses annotations that resemble part of the real information. SHOE [SHOE] uses annotations avoiding redundancy.
II.5.3.2DiscoveryWhen discovering relations between elements from distinct information sources, it is typically not sufficient to compare only the syntax and the structure of the elements – the semantics also has to be taken into account. This is typically done by starting from the information elements to be compared, then relating them to structures in an ontology(see Section 3.1) and finally compare these ontological structures in order to measure the similarity between the information elements. There exists a large number of algorithms and approaches for comparing and measuring similarity. One example is HMATCH, an Algorithm for Dynamically Matching Ontologies in Peer-based Systems. Castano et al, [CFMZ03] discusses an algorithm called HMatch for matching heterogeneous information systems (Peer-to Peer) as a part of the HELIOS project. Another example is [BAM03], which presents an ontology design approach based on semi-automated analysis and classification techniques to derive ontological concepts and semantic relationships from document descriptions and service specifications. Further discussion on finding semantic similarities can be found in ST3, Section 1.2.
II.5.3.3CompositionWhen similarities between elements in different information sources have been found, these can be composed into new complex elements. This is typically done using common data abstractions like specialisation, aggregation, and grouping. Furthermore, the elements in the information sources can also be composed with structures in ontologies. Kashyap and Sheth [KS96b] have carried out work on migrating from database to ontologies and have proposed methods to reconcile the database schematic conflicts with ontology modelling. Stuckenschmidt [S03] also discusses the use of ontology for structuring weakly structured data sources.
Deliverable D8.1 190/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
II.5.3.4ExecutionAs discussed in Section 2, ontologies may work as hubs for a number of information sources that are to be interoperable. Ontologies as an interlingua may then channel all execution and querying between the various information sources, which means that users may pose queries using the terminology of the ontology instead of the different terminologies of the individual information sources. This also reduces the compatibility issue of querying in the different languages of each information source, as compared to one ontology representation and querying formalism. The development of the semantic web, and the adoption of OWL as the web ontology language, makes such executions simpler and easier.
II.5.4 Process Interoperability
In this section, we discuss how ontologies can be used to achieve interoperability of different processes. Process interoperability, which means comparing, matching, and integrating business processes, is much less researched than information interoperability. Most of the work on process interoperability is presented in the context of service interoperability. To enable service composition, one needs to define interoperable process models. The role of ontologies per se in either case is still limited. In the case of services, it is rather the technology, like Web Services, which comes to front as the vehicle for interoperability
II.5.4.1DescriptionThe first step in the use of ontologies for process interoperability is to describe processes according to an ontology. There are several languages for describing and modelling process, BPML, BPEL4WS, YAWL, UMM BPSS, etc. These languages contain specific constructs for process concepts, like activity, event, condition, message, etc. In this way, each language can be seen as defining a high level ontology for process concepts. Specific processes will then be defined using one of these ontologies.
Mark Klein in [KB02] advocates the use of process ontology (modelled on the MIT handbook) as a step to improve the semantic search and retrieval facility for services on the web. A Process Query Language (PQL) has also been defined to retrieve process models from a process ontology. Examples of process models as well as queries can be found in [KB02].
Another project called Process Integration for Electronic Commerce (PIEC) aimed to develop a framework for the analysis of inter-organizational processes and identification and modelling of transaction services for networked enterprises. The PIEC defined a Service Description Language to describe and represent different types of e-services. A Component Definition Language (CDL) has been used to describe the interfaces of the business and legacy systems. Also a Service Request language (SRL) has been used for customers to construct their requests for the service. The comprehensive and integrated framework also includes a service ontology for defining the service. Examples and case study may be referred from the [YHP01].
The Process Interchange Format (PIF) Project was developed to support the automatic process descriptions among business process modelling and support systems such as workflow tools, process simulation tools, process repositories, etc. PIF is a formal ontology (core ontology) with a set of extensions known as partially shared views (PSVs). The PIF core ontology
Deliverable D8.1 191/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
defines basic elements like activity, object, agent, timepoint and their relations like performs, uses, creates, modifies, etc.
The objective for the NIST Process Specification Language (PSL) project is to create a process specification language to facilitate complete and correct exchange of process information among manufacturing applications (like scheduling, process planning, simulation, project management, workflow, etc.). The PSL ontology has three major components-the axioms of PSL-Core, core theory extensions, and definitional extensions. All concepts in PSL are defined using KIF. A more detailed discussion of PSL can be found in ST1, Section 3.8.3.
In [FG97] a case study for the use of a common ontology as an Interlingua has been discussed. The approach used PSL as an Interlingua medium to translate between two manufacturing process applications, ProCAP (using IDEF3) and ILOG (C++ constraint-based scheduling).
II.5.4.2DiscoveryProcess definitions may differ from each other in many different ways: syntactically, structurally, and semantically. Some examples of differences are:
- one process may require a set of activities to be carried out in sequence, while another similar process allows them to be carried out in parallel;
- one process may require an acknowledgement message, while a similar process does not;- one process may send and receive complex messages in one single activity, while a
similar process divides the messages between several activities.How to identify processes that are similar in spite of such differences is still a problem that has not been much investigated. In particular, how to use ontologies to address these problems is not clear. There exist a few initial attempts in the area, like the ECIMF project, [ECIMF], that studies the use of high-level business models for supporting process integration in the area of e-commerce. Shared repositories like the ebXML Core Components [ebXML], CORBA [CORBA], the MIT Process Handbook [MITPH] or even WordNet [Miller90], provide another means for integrating processes. Via the shared repositories business agents may discover each others business offerings as well as establish agreements to invoke cooperation between their respective business processes. Some of these repositories provide hierarchical relationships (such as isa-relationships, aggregation, etc.) between process concepts, which make it possible to infer the degree of similarity between differently described or named concepts [NVG03].
II.5.4.3Composition and ExecutionComposition of processes and services is an active research area, but there is not much work on how to use ontologies for supporting process composition.
One major framework intended to support Description, Discovery as well as Composition and Execution of business processes and services across the Internet is ebXML (Electronic Business using eXtensible Markup Language [ebXML]). Composition of services is provided through the ebXML Business Process Specification Schema (ebXML BPSS [ebXML]) and supporting ebXML E-commerce and Negotiation Patterns [ebXML]. The meta-model of BPSS allows to define concepts such as processes, activities etc., and these concepts may in turn be combined into larger chunks via a set of collaboration
Deliverable D8.1 192/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
patterns. The collaboration patterns suggest structures and/or interactions that occur frequently in a certain context or domain. An issue addressed by the Negotiation patterns is how to combine patterns of processes and services (as opposed to combine processes and services themselves) , and how to avoid combining them in an incorrect way [BJJW04].The aforementioned shared repositories like the MIT Process Handbook [MITPH] or the ebXML Core Components [ebXML] define hierarchical relationships between processes (and subprocesses). These relationships are typically used as instruments in both composition and decomposition of processes.
II.5.5 Service Interoperability
In this section, we discuss how ontologies can be used to achieve interoperability of services. There are many different kinds of services. One of the most basic is the information service, where the service provides static information upon request. More generally, there are services that not only provide information but also produce some effect or change of the environment, e.g. establishing a contract or manipulating a mechanical device.
II.5.5.1 DescriptionThe description of a service can be divided into the following three parts [CS03]:
- Capability representation: what the service does;- Quality of Service representation: how well the service works;- Process representation: how the service is carried out.There are two main forms of capability representation: explicit capability representation and implicit capability representation, [SKW99]. For explicit capability representation, it is assumed that an ontology provides an explicit representation of the capability of a service. More precisely, the ontology describes each task by one concept, and the capability of a service is equal to a set of tasks, i.e. the tasks that the service is able to perform. An advantage of the explicit representation is that the ontology directly represents the tasks that the service can perform, which gives a clear and simple description of the service and reduces the effort of modelling the service. However, explicit capability representation may require huge ontologies, as every task that some service can perform requires its own concept in the ontology. Such large ontologies may be difficult to manage and they may be hard to use for search, as the user needs to understand a large number of concepts. An alternative and complement to external capability representation is implicit capability representation, which focuses on the state transformation and information transfer produced by a service. In this type of representation, the tasks performed by a service are not directly represented; instead they can be inferred from state transformation and information transfer. Implicit capability representation has the advantage that it does not necessarily require large ontologies, as tasks are not modelled but only the domain of the services. On the other hand, search may become more difficult as tasks are not made explicit but only inferred.
An example of an ontology used for explicit capability representation is the MIT Process Handbook, [KB02]. Figure 9 shows a small part of the ontology, which shows a specialisation hierarchy, where the root is the process “Sell financial services”. In addition to the specialisation concept, the ontology also provides a structuring mechanism through the
Deliverable D8.1 193/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
decomposition of processes. Using this ontology, a service that sells management services would be associated with the concept “Sell management services” in the ontology.
Fig. 9 Explicit Capability Representation From [SKW99]
In implicit capability representation, a service is described by its state transformation and information transfer, i.e. the input, output, preconditions, and effects of the service have to be described:
- Input: the information the service needs to execute, similar to arguments of functions in programming languages;
- Output: the information produced by executing the service; - Preconditions: conditions that must be satisfied for the process to execute;- Effects: the changes in the environment produced by executing the service;All these four components are described using an ontology that models the domain in which the service is situated. An example of a language that uses implicit capability representation is OWL-S. An example, taken from [SKW99], of a service description is given in Fig.10. The service provides stock reports; its input is a ticker symbol, the output is a quote for that ticker, the precondition is a valid credit card, and the effect is that the account is charged.
<profile: precondition>
<profile: ParameterDescription rdf: ID = ”valid_membership”>
<profile: restrictedTo rdf:resource = ”Financial_valid(account)”\>
<\profile: ParameterDescription>
<\profile:precondition>
Deliverable D8.1 194/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
<profile: effect>
<profile: ParameterDescription rdf: ID = ”charged_account”>
<profile: restrictedTo rdf:resource = ”Financial_charged(account)”\>
<\profile: ParameterDescription>
<\profile:effect>
Fig. 10 OWL-S example
In the paragraphs above, we have discussed different approaches to the capability representation of a service and the role of ontology. Additionally, a service can be described by its QoS attributes, and for this purpose a QoS ontology can be used. A service can also be described by a process representation, which could utilise ontologies as discussed in Section 4.
II.5.5.2Discovery
The process of discovering services can be viewed as consisting of the following steps:
1. Define a Service Target, i.e., describe what service you are looking for; this can be done using explicit or implicit capability representations as discussed in the previous section.
2. Relate the components of the Service Target to ontology, i.e. relate task descriptions, input, output, preconditions and effects to one or several ontologies.
3. Identify (a large number of) potential Service Objects, i.e. offered services that may satisfy the Target Service; this can be done by simple name matching techniques resulting in high recall but low precision.
4. Relate the components of the Service Objects to ontology, i.e. relate task descriptions, inputs, outputs, preconditions, and effects to one or several ontologies.
5. For each Service Object, compare its distance to the Service Target.Amit Sheth and Jorge Cardoso [CS02] have discussed issues in semantic interoperability of services. They propose the need for enhancing workflow systems and process models in order to enable service discovery and composition. The paper provides detailed analysis of semantic matching functions to improve QoS.
Some approaches presented in literature try to improve discovery by means of better semantic characterization of services by adding semantic annotations to the service descriptions. One of these approaches is described in [KDHPS03], where an extension of WSDL service description language, called WSSP (Web Service Semantic Profile), is proposed to encode semantic information by annotating I/O entities with concepts defined in RDF, DAML+OIL
Deliverable D8.1 195/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
or OWL domain ontologies and by expressing constraints on service inputs and outputs. Semantic annotations can be used both when a new service is registered into the UDDI Registry and when a service request is formulated. A semantic matchmaker then performs matchmaking among a service request and the registered service descriptions. The matchmaker applies different filtering techniques to allow service retrieval at different levels of precision both according to user request and available information on services. Firstly, the matchmaker uses the well-known information retrieval technique of TD/IDF (Term Frequency/Inverse Document Frequency) as a first filter to select candidate services in the UDDI Registry even if no semantic information has been provided. Then two other filtering techniques are possibly applied, based on semantic description of services: (i) a type-based filter, that is able to establish if subtype relationships hold among inputs and outputs (defined as classes in the domain ontologies) in the request and in the service descriptions; (ii) a constraint-based filter, that is able to establish if a logical implication holds among constraints in the request and in the service descriptions by means of automated logical reasoning. Other works such as Sriharee and Senivongse [SS03] and Shet et al. [SVSM03] stress the extension of industrial standards for e-services to allow rich representation of service semantics for discovery purposes. In particular, in the [SS03] approach, an upper ontology is used to model capability of services according to a behavior-oriented representation that is based on description of operations, inputs, outputs, preconditions and effects. On the basis of this upper ontology, a DAML+OIL shared ontology for a particular service domain can be defined and, if it does not cover all needed concepts for describing a particular service, it can be supplemented by a specific local ontology for that service. Concepts within shared and local ontologies are used to annotate WSDL descriptions of services, while other semantics extensions (like preconditions and effects) are added as extra elements. Specifications of operations, inputs, outputs, preconditions and effects are used in queries as constraints to enhance service discovery. Authors propose a framework that allows for storing elements used for service description with ontological annotations expressed as triples <subject, predicate, object> and they use a reasoning engine for these triples to find exact matching between the query and available services.
The following approaches are instead based on service ontologies to organize services according to semantic relationships in order to enhance the discovery and to allow its scalability when a large number of services is considered. In [KB02], already cited in Section 5.1, the proposed process ontology is the basis of an approach for indexing and retrieval of services. In this approach, indexing a service means to exploit its structure to classify both the service and its constituents (sub-activities, inputs, outputs and so on) in the ontology. A service target is expressed as (possibly partially specified) service model by means of the Process Query Language (PQL) and the matchmaking process exploits the semantic relationships in the process ontology to retrieve those services that satisfy the service target. Puyal et al. [PMI03] studied selection and execution of remote services on mobile devices and proposed a system, REMOTE, where a service ontology stores information about the available services in a frame-based way by simply using service categories and keywords to classify services in a taxonomy (where only generalization relationships are taken into account). When a service request is posed, a corresponding concept (that is the target service) is created from it and automatically classified into the taxonomy with the support of a Description Logic reasoner. The child nodes in the ontology of the classified concept as resulting from the classification process are the answer given to the user. This happens since the child nodes specialize the target service and therefore they represent services having the
Deliverable D8.1 196/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
same or more specific features than the required ones. [BAM03] discusses ontology-based techniques and tools for the classification of services by considering offered functionalities and reference quality parameters. In particular, firstly the services to be classified are compared among them to evaluate their similarity by analyzing the affinity of both service operations names and input and output parameter names on the basis of a thesaurus, where terms are related by weighted semantic relationships to allow quantification of their similarity. Then, services are clustered on the basis of their similarity and are organized by means of semantic relationships (equivalence, specialization/ generalization, disjunction.), that are exploited during the discovery phase to enhance service retrieval. Moreover, construction of cluster representatives and service categories are provided to organize the service ontology on different levels of abstraction and support more retrieval methods.
II.5.5.3Composition and Execution
Composition of processes and services is an active research area, but there is as yet not much work on how to use ontologies for supporting service composition. One contribution to the area is Blake et al [BWP03], that provides a technique to define a global consensus ontology for the automated composition of Web services adopting B2B agents, and Papazoglou and Yang, 2002 [YP02] that addresses the issue of packaging together elementary or complex services in a consistent and uniform manner. For futher discussion see section 4.3 on composition of processes and services through collaboration patterns and common repositories.
II.5.6 State of practical use of ontologies for interoperablity
This section introduces a number of practical applications of ontologies for interoperability. As can be seen from these, applications of ontologies in this area are still very few and preliminary.
II.5.6.1 Interoperability in TC industry (technologies and experiences)
Extremely high needs. The T/C (Textile/Clothing) industry is characterised by an extreme urgence of interoperability but, in the same time, is in difficulty to adopt interoperability technologies.
Deliverable D8.1 197/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
The sector is characterised by a supply chain of many rings (the processes are complex, and there are many different and independent actors that are specialised in specific ones), but also by the presence of large and very small firms that have to co-operate to obtain products that have a very long lead time (from design to the availability on the shelves might be 50 weeks) and a very short commercial life (few weeks). All these enterprises are forced to co-operate strictly but the request for higher integration between existing systems is hampered by the traditional difficulties in the duiffusion of ICT in the sector.
The diffusion of EDI based approaches (typical of other sectors) is very poor and limited to the final phase of relationships between retail organisations and garment producers, and poorly diffused yet.
There is a difficulty in this area and large organisations involved in standardisation for retailing organisation and B2B, such as EAN, are facing a great difficulty to have a diffusion in this portion of the Supply Chain differently from, for example, the food and beverage sector.
In the upstream side of the supply chain (production of yrans, fabrics and garments) the situation is, if possible, more disappointing.
Activity towards inter-company co-operation. There is a large number of actors, mainly SMEs; only very recently (2003) the CEN/ISSS workshop TexSpin has lead to the definition of a common prenormative platform of XML based messages for B2B in the T/C sector (accordingly with the CEN/ISSS policy to build sectorial standardisation initiatives in specific sectors: Health, Building, Footwear, Textile/Clothing 9). More information of TexSpin in note10.
Presently this approach, based on an XML and Internet based evolution of the EDI peer-to-peer architecture is poorly diffused, and is trying to gain a critical mass of users to become a de facto standard.
TexSpin was a standardisation activity; in parallel or previously the main initiatives of system integration were based on three main architectures:
9 see “CEN/ISSS report and recommendations on key eBusiness standards issues 2003-2005”, which is available at http://www.cenorm.be/sh/eBiz 10 CEN/ISSS TEXSPIN Workshop (http://www.uninfo.polito.it/WS_TEXSPIN/default.htm or http://www.cenorm.be/isss), co-ordinated by Euratex (european association of the industrial associations of the sector) and comprehending the contribution of MODA-ML and eTeXML experiences. The goal of TEXSPIN Workshop is to supply a pre-normative platform of data exchange models, XML messages and dictionaries of terms that cover different aspects of the supply chain, from sales organization to production in its different aspects.
This means that TEXSPIN supplies some suggested models and an exchange language that technological solutions providers and enterprises will be able to conveniently use for implementing their own solutions.
Deliverable D8.1 198/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
- peer-to-peer exchanges of XML documents (more or less XML evolution of EDI) like Moda-ML (an IST Take Up Action, see www.moda-ml.org) and eTeXML (a french national initiative centered on Web EDI)
- asp integration services through a center of services (e-Chain, TextileBusiness, Italfabrics and others)
- private company portals dedicated to sales agent, supplier or subcontractors based on many different WEB technologies.
The main point is that around TexSpin is arising a sector-specific dictionary of terms and experiences have been proposed to approach its organisation and maintenance with an ontology based approach.
The most relevant is the Leapfrog IP Proposal (submitted in June 2004) that aims, in one of its tasks, to the creation of a sectorial collaborative framewok using ontologies to facilitate the creation and maintenance of a common dictionary.
Between other more specific research projects can be mentioned the Sewasie project (www.sewasie.org)11 that is experiencing the creation of a sectorial ontology in the T/C sector 11 SEWASIE (SEmantic Webs and AgentS in Integrated Economies) will design and implement an advanced search engine that provides access via a machine-processable semantics of data, which can form the basis of structured web-based communication. Tools and methods will be developed to create and maintain multilingual ontologies, with an inference layer grounded in W3C standards (XML, XML Schema, RDF(S)), that are the basis for the advanced search mechanisms; these will provide the terminology for the structured communication exchanges.
SEWASIE has the following specific objectives:
To develop an agent-based, secure, scalable and distributed system architecture for semantic search (ontology based) and for structured web-based communication (for electronic negotiation).
To develop a general framework responsible for the implementation of the semantic enrichment processes leading to semantically-enriched virtual data stores that constitute the information nodes accessible by the users.
To develop a general framework for query management and information reconciliation taking into account the semantically enriched data stores.
To develop an information-brokering component that includes methods for collecting, contextualising and visualising semantically-rich data.
To develop structured communication processes that enable the use of ontologies. The communication tool enables structured negotiation support for human negotiators engaging in business-to-business electronic commerce and employing intelligent software agents for some routine communication task.
Deliverable D8.1 199/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
to build an agent based system and other less recent experiences of ontology creation for the Supply chain management.
II.5.6.2 Aspects related with standardisation procedures and potential role of ontologies
The world of standards for B2B interoperability is strongly focused on the EDI approach (not the EDIFACT technology) based on electronic document interchange (different document templates are corresponding different actions that are asked or answered.
The basic reason to work with a new EDI approach, let say an XML/EDI approach, is that companies has huge systems that are a legacy that is quite difficult to ignore and that cannot be simultaneously redesigned in order to activate collaborative networks of enterprises with significant numbers.
ebXML is presently considered as the most complete meta-standard, a standard to create standards or, more precisely, collaborative frameworks addressed to specific domains. It is promising but still in Europe the implementation are not very spreaded (despite the CEN/ISSS committment) while in Asia and USA it appears more adopted.
Some statements are emerging from the world of standardisation (for example eBiz group and eBif Forum) at CEN/ISSS: there is acknowldegement about the fact that the duration of the standard building/updating processes is too long and their implementation is often too difficult for software house developers.
Key action lines are emerging:
a. sectorial action lines facilitates diffusion in sectors dominated by SMEsb. facilitation of the integration front-end/back-end
But a further aspect has to be taken in account and deals with the essence of a standard for interoperability:
We have a problem of convergence of standardisation initiatives (and of management of potential overlapping or conflicts) and of improvement of the flexibility of their paradigms.
Presently is running the OIDDI initiative for the construction of a methodology to make comparable and ‘orthogonal’ dictionaries, created by different bodies and related to different domains.
The starting point of this approach is that many different domains require different vocabularies and that the two main actions to pursue are the creation of a common way to
To develop end-user interfaces for both the semantic design and the query management.
Deliverable D8.1 200/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
address the dictionaries (unique global coding) and to assure their orthogonality or identify the area of overlapping.
The project is starting in summer 2004 and foresees to adopt ontologies, built on top of the dictionaries, in order to make them comparable.
Presently the activities of creation of standards, being devoted to the only inter company collaboration aspects, could be a starting point for the creation of reference ontologies that could simplify the work of construction of tools for management and integration based on ontologies for interoperability.
II.5.6.3Applications in the Tourism Sector
In Missikoff 2003 [MI03], the main issues of an Ontology-based platform for semantic interoperability, with particular attention to the underlying methodology, are illustrated. The solutions presented have been developed in the context of Harmonise, an IST project aimed at developing an interoperability platform for SMEs in the tourism sector. The illustrated platform is an advanced software solution, based on the use of computational ontologies, aiming at the reconciliation of conceptual, structural, and formatting differences that hamper information exchange. The proposed approach relies on the availability of a domain ontology, used as a semantic reference for cooperating systems. The approach addresses semantic clashes, arising when a conceptual local schema is contrasted with the ontology. Semantic clashes are taken into account when the elements of a conceptual local schema are semantically annotated. Semantic annotation is requested to reconcile existing differences of cooperating information systems.
II.5.7 Future Research Directions
Based on this state-of-the-art report, the following future research directions can be identified:
1. The use of ontologies for process interoperability. There has been much work done on the use of ontologies for information interoperability and service interoperability, but much less on process interoperability. This could be a fruitful area, where there is still much work to be done. Furthermore, ontology support for process interoperability would also be relevant for service interoperability, which adds to the significance of the topic.
2. Empirical studies. Most work on ontologies for interoperability has a very theoretical flavour. There is clearly a need for empirical studies that apply and evaluate the usefulness of ontologies as a support for interoperability. Such studies should preferably have a large scale and can, therefore, constitute good projects for cooperation among INTEROP partners.
3. There has been much work on how to use ontologies for describing and discovering information, processes and services. In contrast, there are not many results on how to use ontologies for composition and execution of processes and services. Investigating
Deliverable D8.1 201/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
this topic would be worthwhile, as it could provide a basis for methods and tool support for concrete tasks in interoperability.
II.5.8 References
[AHK96] Yigal Arens, Chun-Nan Hsu, and Craig A. Knoblock. Query processing in the sims information mediator. In Advanced Planning Technology. AAAI Press , California , USA , 1996.
[AAMH00] Agirre, Eneko, Olatz Ansa, David Martinez, and Eduard Hovy. ``Enriching very large ontologies using the WWW'' In: Proceedings of the Ontology Learning Workshop, organized by ECAI, Berlin, Germany, 2000.
[BAM03] Bianchini, D.; De Antonellis, V.; Melchiori, M.;E-service classification techniques to support discovery in a mobile multichannel environment, Web Information Systems Engineering Workshops, 2003. Proceedings Fourth International Conference on ??, 13 Dec. 2003.
[BBB97] Bayardo, Bohrer, Brice et al, InfoSlueth:Agent-Based Semantic Integration of Information in Open and Dynamic Environments, ACM SIGMOD Vol 26, 1997, pages???.
[BJJW04] Bergholtz Maria, Jayaweera Prasad, Johannesson Paul and Wohed Petia, A pattern and dependency based approach to the design of process models, to be published in the proceedings of the 23th International Conference on Conceptual Modelling, ER’04, Shanghai, China
[BWP03] B Blake, A Williams A Padmanabhan, Local Consensus Ontologies for B2B-Oriented Service Composition, AAMAS 2003
[CFMZ03] S Castano, A Ferrara,S Montanelli,D Zucchelli, HELIOS:a general framework for Ontology-based Knowledge Sharing and evolution in P2P systems, Proc. of DEXA'03 2nd Web Semantics Workshop, Prague, Czech Republic, September 2003
[CGN00] Mihai Ciocoiu, Michael Gruninger,Dana s Nau, “Ontologies for Integrating Engineering Applications”, Journal of Computing and Information Science in Engineering, 2000.
[CGP01] [Gomez-Perez] Oscar Corcho,Asuncion Gomez-Perez, “Solving integration problems of e-commerce standards and initiatives through ontological mappings”.IJCAI 2001
[CJO01] Zhan Cui , Dean Jones and Paul O’Brien , Issues in Ontology-based Information Integration, Proc. IJCAI01 workshop on Ebusiness and Intelligent Web., 2001
[CO00] Zhan Cui and Paul O’Brien , Domain Ontology Management Environment, Proceedings of Business to Business E-Commerce, HICSS33, January 2000
Deliverable D8.1 202/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
[CS02] Jorge Codoso and Amit Sheth, “Semantic e-Workflow Composition”, Journal of Intelligent Information Systems,Kluwer Academic Publishers, 2002
[CS03] Jorge Cordosa and Amit Sheth, Semantic e-Workflow Composition, published in Journal of Intelligent Information Systems,Kluwer Academic Publishers, 2002 , 2003 ????
[CORBA] http://www.corba.org/
[DWQ] http://www.dbnet.ece.ntua.gr/~dwq/
[ebXML] http://www.ebxml.org/specs/index.htm
[FG97] Mark Fox Michael Gruninger,On Ontologies and Enterprise Modelling, International Conference on Enterprise Integration Modelling Technology 97
[G92] Guarino, N. 1992. Concepts, Attributes and Arbitrary Relations: Some Linguistic and Ontological Criteria for Structuring Knowledge Bases. Data & KnowledgeEngineering, 8: 249-261
[G93] Tom Gruber. A translation approach to portable ontology specifications. Knowledge Acquisition, 5(2):199–220, 1993.
[G95] Tom Gruber. Toward principles for the design of ontologies used for knowledge sharing, 1995.
[GLR00] François Goasdoué, Véronique Lattès, and Marie-Christine Rousset, “The Use of Carin Language and Algorithms for Information Integration: The PICSEL System.”,. International Journal of Cooperative Information Systems, 9(4):383--401, décembre 2000
[GM97] H Garcia-Molina et al., “The TSIMMIS Approach to Medaition:Data Models and Languages,” J Intelligent Information Systems, Vol 8, no 2 , Mar/Apr , 1997 , pp-117-132
[GPFV96] Ascuncion G´omez-P´erez, M. Fern´andez, and A. de Vicente. Towards a method to conceptualize domain ontologies. In Workshop on Ontol ogical Engineering, ECAI ’96, pages 41–52, Budapest, Hungary, 1996.
[WBFE03] R.J. Wieringa, H.M. Blanken, M.M. Fokkinga, and P.W.P.J. GrefenAligning application architecture to the business contextIn Conference on Advanced Information System Engineering (CAiSE 03), 2003.
[IDEAS] IDEAS Web site, http://www.ideas-roadmap.net/
[ISO16100] http://www.iso.org/iso/
[K04] KRAFT - Knowledge Re-use And Functional Transformation http://www.cs.cf.ac.uk/kraft/
Deliverable D8.1 203/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
[KB02] Mark Klein and Abraham Bernstein ,“Searching for Services on the Semantic Web using Process Ontologies”, In Proc. of The First Semantic Web Working Symposium (SWWS-1). Stanford (CA US), July 29th-August 1st, 2001.
[KDHPS03] T. Kawamura, J.-A. De Blasio, T. Hasegawa, M. Paolucci, and K. Sycara. “Preliminary Report of Public Experiment of Semantic Service Matchmaker with UDDI Business Registry”. In Proc. of First Int. Conf. on Service Oriented Computing (ICSOC 2003), Trento, Italy, December 15-18th 2003.
[KS96a] V Kashyap and A Sheth , “Semantic and schematic similarities between database objects:a context-based approach”, VLDB Journal 1996 , vol 5, pp-276-304
[KS96b] Vipul Kashyap and Amit Sheth. Semantic heterogeneity in global information systems: The role of metadata, context and ontologies. In M. Papazoglou and G. Schlageter, editors, Cooperative Information Systems: Current Trends and Applications. 1996.
[Linthicum03] Next Generation Application Integration: From Simple Information to Web Services by David S. Linthicum Addison-Wesley, 2003
[LRO96] AY Levy, A Rajaraman, JJ Ordille, “Querying Heterogeneous Information sources Using Source Descriptions,” Proc. 23rd International Conference Very Large Databases, Morgan Kaufman, 1996, pp- 251- 262
[Miller90] Miller, George A., Richard Beckwith, Christiane Fellbaum, Derek Gross and Katherine J. Miller: “Introduction to WordNet: an on-line lexical database.'' International Journal of Lexicography 3 (4), 1990, pp. 235 - 244
[M03] R. Mizogouchi, Ontology Engineering Environments, Handbook on Ontologies, S. Staab and R. Studer (editors), (2003) pp. 275-295.
[MBS03] A Maedche, B Motik, L Stojanovic et al., “Ontologies for Enterprise Knowledge Management, Journal IEEE Intelligent Systems, IEEE, 2003
[MI03] M. Missikoff "The Architecture of Harmonise: an Ontology-based Platform for Semantic Interoperability" SEBD 2003, Eleventh Italian Symposium on Advanced Database Systems Cetraro (CS), Italy, June 24-27, 2003
[MITPH] http://ccs.mit.edu/ph/
[MKSI96] E Mena, V Kashyap,A Sheth,Illaramendi, OBSERVER: An Approach for query processing in Global Information Systems based on Interoperation between pre-existing Ontologies, CoOpIS 1996
[NVG03] Navigli, Roberto and Paola Velardi and Aldo Gangemi "Ontology learning and its application to automated terminology translation" In: IEEE Intelligent Systems, vol. 18, n. 1,January/February 2003, pp. 22-31 http://www.dsi.uniroma1.it/~velardi/IEEE-IS.pdf
[OB] http://ontobroker.aifb.uni-karlsruhe.de/index_ob.html
Deliverable D8.1 204/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
[OS99] Aris M Ouskel and Amit Sheth , “Semantic Interoperability in Global Information Systems”, a brief introduction to the research area and the special section, SIGMOD Record Vol 28, No 1 March 1999.
[PMI03] J. M. Puyal, E. Mena, and A. Illarramendi. “REMOTE: a Multiagent System to Select and ExecuteRemote Software Services in a Wireless Environment”. In Proc. of WWW 2003 Workshop on E-Services and the Semantic Web (ESSW2003), Budapest, Hungary, May 2003.
[S03] H Stuckenschmidt, Ontology Based Information Sharing in Weakly Structured Environments, PHD thesis, Vrije University 2003
[SHOE] http://xml.coverpages.org/shoe.html
[SKW99] Katia Sycara,Matthias Klusch and Seth Widoff, Dynamic Service Matchmaking among Agents in Open Information Systems, SIGMOD record Vol 28, No. 1, 1999.
[SM91] M. Siegel and S.Madnick, "A Metadata Approach to Resolving Semantic Conflicts," In Proceedings of the 17th Conference on Very Large Data Bases, 1991.
[SS03] N. Sriharee, T. Senivongse, “Discovering Web Services Using Behavioural Constraints and Ontology”, in Proc. of the 4th IFIP International Conference on Distributed Applications and Interoperable Systems (DAIS 2003), Paris, France, November 2003.
[SVSM03] Kaarthik Sivashanmugam, Kunal Verma, Amit P. Sheth, John A. Miller “Adding Semantics to Web Services Standards”. In Proc. of 2nd International Semantic Web Conference (ICWS 2003): 395-401.[SW00] H. Stuckenschmidt and H. Wache: Context Modeling and Transformation for Semantic Interoperability In: Knowledge Representation meets Databases - Proceedings of the Workshop at ECAI 2000, 2000.
[VHSW96] G. van Heijst, A. Th. Schreiber, and B. J. Weilinga. Using explicit ontologies in kbs development. International Journal of Human and Computer Studies, 46(2-3):183--292, 1996.
[W99] Holger Wache. Towards rule-based context transformation in mediators. In S. Conrad, W. Hasselbring, and G. Saake, editors, International Workshop on Engineering Federated Information Systems (EFIS 99), K uhlungsborn, Germany, 1999. Infix-Verlag.
[WBFG03] RJ Wieringa, Hm Blanken, MM Fokkinga, P W PJ Grefen Aligning Application Architecture to Business Context, Caise 2003.LNCS 2681, pp 209- 225
[WC93] D Woelk P Cannata et al., Using Carnot for Enterprise Information Integration, International conference on distributed and parallel information systems, 1993
[WVNSSVH01] H Wache, T Vogele, H Nuemann, H Stuckenschmidt, G Schuster, U Visser, S Hubner, ”Ontology-Based Integration of Information - A Survey of Existing Approaches” Proc. Of IJCAI-01 workshop, Ontologies and Information Sharing, 2001
Deliverable D8.1 205/206

INTEROPInteroperability Research for Networked Enterprises Applications and Software
[YHP01] J Yang, W J van den Heuvel, MP Papazoglou ,” Service Deployment for Virtual Enterprises”, Workshop On Information Technology for VE, 2001
[YP02] Yang, J. & Papazoglou, M.P.: Web Component: A Substrate for Web Service Reuse and Composition. In Proceedings of Advanced Information Systems Engineering 14th International Conference, CAiSE 2002 Toronto, Canada, May 27-31, 2002. Editors: Banks Pidduck, A., Mylopoulos, J., Woo, C.C., Tamer Ozsu, M. Pages 21-36
Deliverable D8.1 206/206