07 the problem of over fitting-introduction to machine learning
TRANSCRIPT

Regularization
1

The problem of overfitting• So far we've seen a few algorithms • Work well for many applications, but can suffer from
the problem of overfitting
2

Overfitting with linear regressionExample: Linear regression (housing prices)
Overfitting: If we have too many features, the learned hypothesis may fit the training set very well ( ), but fail to generalize to new examples (predict prices on new examples).The hypothesis is just too large, too variable and we don't have enough data to constrain it to give us a good hypothesis
Pric
e
Size
Pric
e
Size
Pric
e
Size
3

Example: Logistic regression
( = sigmoid function)
x1
x2
x1
x2
x1
x2

Addressing overfitting:
Pric
e
Size
size of houseno. of bedroomsno. of floorsage of houseaverage income in neighborhoodkitchen size
• Plotting hypothesis is one way to decide whether overfitting occurs or not
• But with lots of features and little data we cannot visualize, and therefore:
• Hard to select the degree of polynomial• What features to keep and which to drop

Addressing overfitting:
Options:1. Reduce number of features. (but this means loosing
information)― Manually select which features to keep.― Model selection algorithm (later in course).
2. Regularization.― Keep all the features, but reduce magnitude/values of
parameters .― Works well when we have a lot of features, each of
which contributes a bit to predicting .

Cost function
7

Intuition
Suppose we penalize and make , really small.
Pric
e
Size of house
Pric
e
Size of house

Small values for parameters ― “Simpler” hypothesis― Less prone to overfitting
Regularization.
Housing:― Features: ― Parameters:
Unlike the polynomial example, we don't know what are the high order terms
How do we pick the ones that need to be shrunk?
With regularization, take cost function and modify it to shrink all the parameters
By convention you don't penalize θ0 - minimization is from θ1 onwards
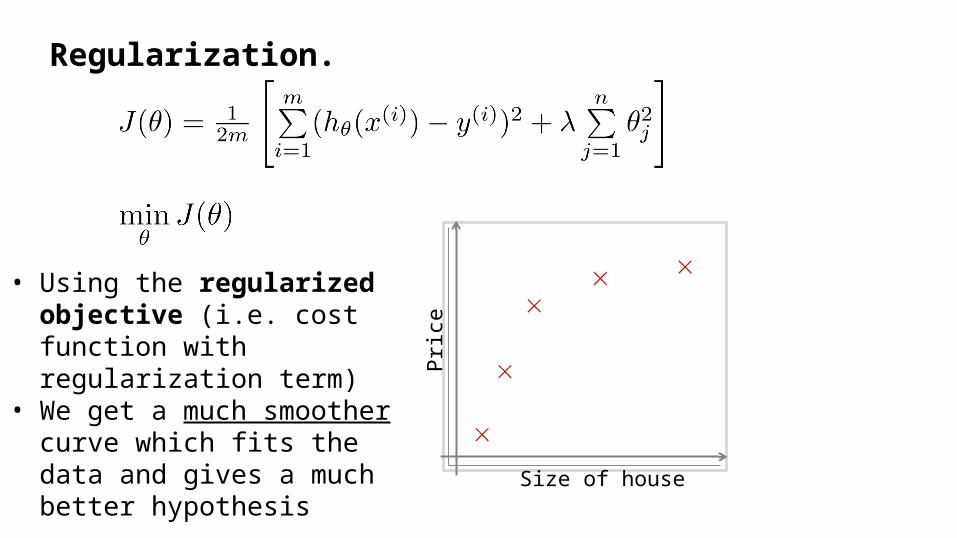
Regularization.
Pric
e
Size of house
• Using the regularized objective (i.e. cost function with regularization term)
• We get a much smoother curve which fits the data and gives a much better hypothesis

λ is the regularization parameter
Controls a trade off between our two goals
1) Want to fit the training set well
2) Want to keep parameters small

In regularized linear regression, we choose to minimize
What if is set to an extremely large value (perhaps too large for our problem, say )?- Algorithm works fine; setting to be very large can’t hurt it- Algorithm fails to eliminate overfitting.- Algorithm results in underfitting. (Fails to fit even training data
well).- Gradient descent will fail to converge.

In regularized linear regression, we choose to minimize
What if is set to an extremely large value (perhaps for too large for our problem, say )?
Pric
e
Size of house

Regularized linear regression
14

Regularized linear regression

Gradient descentRepeat
[+𝝀𝒎 𝜽 𝒋 ] (regularized)
𝜕𝜕𝜃0
𝐽 (𝜃)
Interesting term: Usually learning rate is small and m is large Ex.
Same as before

Normal equation
𝜃= (𝑋𝑇 𝑋 )−1 𝑋𝑇 𝑦

Suppose ,Non-invertibility (optional/advanced).
(#examples) (#features)
If ,

Regularized logistic regression
19

Regularized logistic regression.
Cost function:x1
x2

Gradient descentRepeat
[+𝝀𝒎 𝜽 𝒋 ] (regularized)

gradient(1) = [ ];
function [jVal, gradient] = costFunction(theta)
jVal = [ ];
gradient(2) = [ ];
gradient(n+1) = [ ];
code to compute
code to compute
code to compute
code to compute
Advanced optimization
gradient(3) = [ ];code to compute

End
23