1. 2 indian languages - 2001 adigarokolamimaltorengma afghani / kabuli / pashtogondikommaramsangtam...
TRANSCRIPT

1

2
Indian Languages - 2001Indian Languages - 2001Adi Garo Kolami Malto Rengma
Afghani / Kabuli / Pashto Gondi Kom Maram Sangtam
Anal Halabi Konda Maring Savara
Angami Halam Konyak Miri / Mishing Sema
Ao Hmar Korku Mishmi Sherpa
Arabic / Arbi Ho Korwa Mogh Shina
Balti Jatapu Koya Monpa Simte
Bhili / Bhilodi Juang Kui Munda Tamang
Bhotia Kabui Kuki Mundari Tangkhul
Bhumij Karbi / Mikir Kurukh / Oraon Nicobarese Tangsa
Bishnupuriya Khandeshi Ladakhi Nissi / Dafla Thado
Chakhesang Kharia Lahauli Nocte Tibetan
Chakru / Chokri Khasi Lahnda Paite Tripuri
Chang Khezha Lakher Parji Tulu
Coorgi / Kodagu Khiemnungan Lalung Pawi Vaiphei
Deori Khond / Kondh Lepcha Persian Wancho
Dimasa Kinnauri Liangmei Phom Yimchungre
English Kisan Limbu Pochury Zeliang
Gadaba Koch Lotha Rabha Zemi
Gangte Koda / Kora Lushai / Mizo Rai Zou

3
Annotated, quality language data
(both-text and speech)
and tools in
Indian languages
to
Individuals
Institutions
Industry etc., for
Research and Development.
Created Created
in house,in house,
throughthrough
outsourcinoutsourcing, g,
acquisition.acquisition.
Mission Mission StatementStatement

4
A repository of linguistic resources in all Indian languages in the form of text, speech and lexical corpora. Facilitating creation of such databases by different organizations.Setting standards for data collection and storage of corpora for different research and development activities.Supporting development and sharing of tools for data collection and management. Facilitating training through workshops, seminars etc. in technical as well as process related issues.Creating and maintaining the LDC-IL website that would be the primary gateway for accessing LDC-IL resources.Designing or providing help in creation of appropriate language technology for mass use.Providing the necessary linkages between academic institutions, individual researchers and the masses.
ObjectiveObjectivess

5
Participating Institutions in Participating Institutions in
IndiaIndia
•IISc Bangalore; •All Indian Institutes of Technology; •IIITs at Hyderabad and elsewhere; •ISI Calcutta/Hyderabad/Bangalore; •C-DAC, Pune;•TIFR Mumbai;•Universities like HCU; DU; JNU; NEHU•HP Labs India;•IBM;•Language institutions like KHS, NCPUL & RSKS; and, •Of course, the MCIT-TDIL
All academic institutes, research organizations and Corporate R&D groups from India and abroad working on Indian languages will be encouraged to participate in LDC-IL. The following have already shown interest:

6
Funding & Funding & ManagementManagement
• The core funding from the Government of India. • All activities will be in a project mode.• Will attempt to leverage expertise already available to
cut avoidable cost and delay.• All staff will be on contract.• All receipts and payments through internet gateways,
or through conventional means, will go to the Consolidated Fund.
• However, the Government will release grants required to the Consortium as required. If need be, the support will be extended beyond the initial six year period.
• As the nodal agency, CIIL will further distribute the relevant funding for specific sub-components of the scheme to other academic institutions.
• An annual progress report will be submitted to the government.

7
ArrangemenArrangementsts
1. LDC-IL will be open to all institutions, Research Organizations, and Corporate sector from all over the world.
2. Members will be encouraged to contribute databases and share revenues from sale of the data they contribute
3. The databases will be available for R&D purposes to all members and non-members on payment of the appropriate fee, with a license for use only.
4. The organization will be asked to sign a License Agreement that the databases will not be distributed by it to others either free or for a fee.
5. The IP and the copyright of any product developed as a result of such an R&D activity shall lie with the organization that has created the product.

8
TasksTasks
• Establishing standards
• Creating language resources
• Annotating language data
• Building systems/helping system building
• Creating human resources
• Co-ordinating language resource developing activities

9
Major Areas Major Areas Linguistic Resource DevelopmentLinguistic Resource Development
• Creation of different kinds of Corpora including Pathological speech, Historical/ Inscriptional databases
• Natural Language Processing
• Speech Recognition and Synthesis
• Character Recognition
• By-products like Word finders, lexicons of different kind, thesauri, Usage compilations etc.

10
Text Corpora - Monolingual / Parallel Text Corpora - Monolingual / Parallel Corpora (SL)Corpora (SL)
Sl. No. Languages 1st Year 2nd Year 3rd Year 4th Year 5th Year Total
1 Assamese 2 2 2 2 2 10
2 Bengali 2 2 2 2 2 10
3 Bodo 0.6 0.6 0.6 0.6 0.6 3
4 Dogri 0.6 0.6 0.6 0.6 0.6 3
5 Gujarati 2 2 2 2 2 10
6 Hindi 2 2 2 2 2 10
7 Kannada 2 2 2 2 2 10
8 Kashmiri 1 1 1 1 1 5
9 Konkani 1 1 1 1 1 5
10 Maithili 1 1 1 1 1 5
11 Malayalam 2 2 2 2 2 10
12 Manipuri 1 1 1 1 1 5
13 Marathi 2 2 2 2 2 10
14 Nepali 2 2 2 2 2 10
15 Oriya 2 2 2 2 2 10
16 Punjabi 2 2 2 2 2 10
17 Sanskrit 0.4 0.4 0.4 0.4 0.4 2
18 Santali 0.6 0.6 0.6 0.6 0.6 3
19 Sindhi 0.6 0.6 0.6 0.6 0.6 3
20 Tamil 2 2 2 2 2 10
21 Telugu 2 2 2 2 2 10
22 Urdu 2 2 2 2 2 10

11
Tools for Corpora Management & Tools for Corpora Management &
AnalysisAnalysis Frequency analyzers for character, word, sentence.KWIC and KWOC retrievers.Tool for Automatic transliterations from Indian language scripts to Roman and vice versa: Kannada, Tamil, Telugu, Assamese, Bengali, Manipuri, Manipuri, Malayalam, Punjabi, Oriya, Gujarati.Parallel corpora tools for text alignment, including sentence alignment tool and chunk alignment tool as well as an interface for aligning corpora.Tools for• Morphological analysis• POS tagging• Semantic tagging• Syntactic tree bank

12
Computational Grammars for Indian Computational Grammars for Indian LanguagesLanguages
Task 1: Hierarchical POS Tag set Task 2: Dictionary - (a) closed class words and
(b) open class wordsTask 3: Morphological analyzer and generatorTask 4: Manual POS annotation and
development of an automatic taggerTask 5: Semantic taggingTask 6: ChunkerTask 7: Tree bankingTask 8: Shallow parser, which will eventually
turn into a deep parser

13
Linguistic ResearchLinguistic Research
• Lexical studies• Semantics• Pragmatics & Discourse analysis• Sociolinguistics• Dialectology & Variation studies• Stylistics• Language teaching• Historical linguistics• Psycholinguistics• Social psychology• Cultural studies

14
Speech Speech CorporaCorpora
Develop tools that facilitate collection of high quality speech data
Collect data that can be used for building speech recognition. speech synthesis and provide speech-to-speech translation from one language to another language spoken in India (including Indian English).
Apart from these like applications in the area of text corpora, speech corpora also, main efforts are on the engineering side. So, efforts shall also be made to collect
Child language corpora Pathological speech/language data and Speech error Data

15
Applications Applications
• Speech Recognition and Speech Synthesis
• Speech to Speech translation for a pair of Indian languages
• Command and control applications • Multimodal interfaces to the computer
in Indian languages • E-mail readers over the telephone• Readers for the visually disadvantaged• Speech enabled Office Suite etc

16
Speech DatasetSpeech Dataset
1. Phonetically Balanced Vocabulary2. Phonetically Balanced Sentences3. Connected Text created using
phonetically balanced vocabulary4. Date Format5. Command and Control Words6. Proper Nouns 500 place and 500 person
names7. Most Frequent Words: 10008. Form and Function Words9. News domain: news, editorial, essay -
each text not less than 500 words

17
Number of SpeakersNumber of Speakers
• Data will be collected from minimum of 300 (150 Male and 150 Female) speakers of each language. In addition to this, natural discourse data from various domains too shall be collected for Indian languages for research into spoken language.
• Data for speech synthesis shall be collected from limited number of speakers - 3 male and 3 female in the studio environment. They shall invariably have very good voice quality and are professional voice givers/media announcers.

18
Annotation of data: Annotation of data: 1. Data to be used for speech recognition
shall be annotated at phoneme, syllable, word and sentence levels
2. Data to be used for speech synthesis shall be annotated at phone, phoneme, syllable, word, and phrase level.
Annotation tools:Annotation tools: Tools will be developed for semiautomatic annotation of speech data. These tools will also be useful for annotating speech synthesis databases.

19
Coverage of languagesCoverage of languages
I Year II Year III Year III Year
1. Bengali 7. Manipuri 13. Maithili 19. Sindhi
2. Hindi 8. Malayalam 14. Dogri 20. Oriya
3. Tamil 9. Punjabi 15. Bodo 21. Marathi
4. Telugu 10. Urdu 16. Konkani 22. Khasi
5. Assamese 11. Kannada 17. Santali 23. Tulu
6. Nepali 12. Gujarati 18.Kashmiri 24. Kodava

20
Indian Sign Language Indian Sign Language corporacorpora
Northern India : Delhi 1st yearSouthern India: Mysore 2nd year North-eastern India: Shillong 3rd year Western India: Lchalkaranji 4th year Eastern Indian: Kolkata 5th year
Lexical items 15000Sentences 2500Production data 50

21
Character RecognitionCharacter Recognition
• Development of standards, tools and linguistic resources (datasets) for the fields of Online HWR, Offline HWR and OCR.
• Promotion of development of these technologies.
• Promotion of development of important and challenging applications of these technologies in the context of Indic languages and scripts.

22
By-products like lexicon, By-products like lexicon, thesauri, WordNet etcthesauri, WordNet etc
• Creation of frequency dictionaries - five per year• First year: Bengali, Hindi, Kannada, Manipuri, Urdu.• Second year: Bodo, Dogri, Maithili, Nepali, Konkani.• Third year: Assamese, Gujarati, Oriya, Punjabi, Tamil,• Fourth year: Kashmiri, Malayalam, Marathi, Sanskrit,
Santali.• Fifth year : other languages
• Multilingual multi directional dictionary - an ongoing process
• Aiding wordnet creation and collaborating with others for the same - an ongoing process

23
Licensing PolicyLicensing Policy
Licensing is an important issue for LDC-IL. The draft policy for licensing shall be evolved through discussions within one year. The same shall be finalized within another one year by the time the annotated data is available for delivery purposes.

24
EvaluationEvaluation
The data that the LDCIL creates and obtains has to be evaluated. For each kind of data, tool etc., matrices have to be evolved. Bench marking, good standards etc., have to be developed. In one year time frame, the same shall be accomplished for first set of tools. In the next year/s the same for other data and tools shall be developed

25
Beyond RoadmapBeyond Roadmap
Above all and in addition to what LDCIL has projected in the roadmap the LDC-IL will positively respond to the specific language data needs of the individuals, institutions and industry by taking up their requests on priority basis for licensing purposes. In the beginning the derivatives of the databases shall be licensed and after all the licensing issues are resolved the databases shall also be licensed.
26
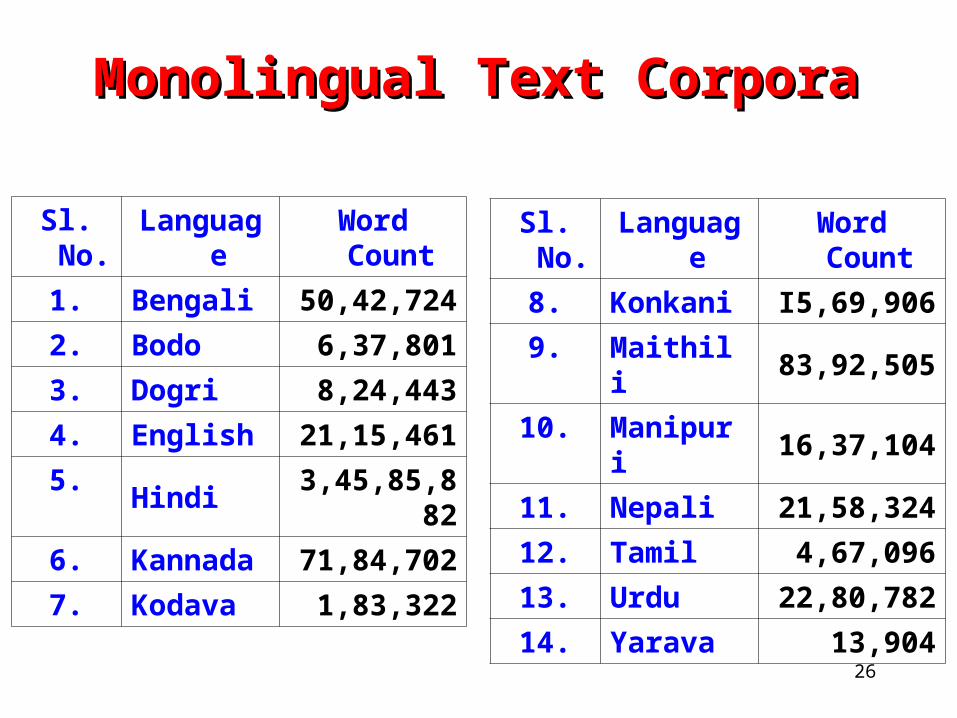
Monolingual Text CorporaMonolingual Text Corpora
Sl. No. Language Word Count
1. Bengali 50,42,724
2. Bodo 6,37,801
3. Dogri 8,24,443
4. English 21,15,461
5. Hindi 3,45,85,882
6. Kannada 71,84,702
7. Kodava 1,83,322
Sl. No. Language Word Count
8. Konkani I5,69,906
9. Maithili 83,92,505
10. Manipuri 16,37,104
11. Nepali 21,58,324
12. Tamil 4,67,096
13. Urdu 22,80,782
14. Yarava 13,904

27
Parallel Text CorporaParallel Text Corpora
Sl. No. Language Texts Word Count
1English Bengali
051,26,828
93,952
2EnglishDogri
0488,02593,293
3English Hindi
7317,57,73617,53,235
4English Kannada
327,79,2584,76,855
5English Maithili
071,59,4191,36,421
6EnglishNepali
112,63,2562,02,157

28
Speech Data Set DetailsSpeech Data Set Details
Assamese Bengali
Gujarati Hindi Kannada
Phon. Bal. Vocabulary
439 561 689 800 390
Phon. Bal. Sentences
200 200 200 500 150
Connected Texts
6 6 6 6 6
Command & Control Words
250 238 296 250 82
Proper Nouns 841 823 902 824 1018
Most Frequent Words
- 1000 - 1000 1000
Form & Function Words
265 178 232 200 432
News Domain texts
150 150 150 150 150

29
Speech Data Set DetailsSpeech Data Set Details
Maithili Manipuri
Nepali Tamil Urdu
Phon. Bal. Vocabulary
509 374 421 565 775
Phon. Bal. Sentences 208 200 200 228 195
Connected Texts 6 6 6 6 6
Command & Control Words
187 243 74 369 141
Proper Nouns 824 825 834 908 500
Most Frequent Words 1000 1000 1000 1000 1000
Form & Function Words
243 189 190 598 380
News Domain texts 150 150 150 150 150
Other languages to be completed before March 31, 2009Malayalam, Punjabi

30
Speech CorporaSpeech Corpora
Other languages to be completed before March 31, 2009Malayalam, Punjabi, Urdu
LanguageInformants Duration
Male Female Minutes Hours
Assamese 81 81 1985 33.05
Bengali 238 234 14850 247.50
Gujarati 77 83 3769 62.49
Hindi 314 316 11483 191.23
Kannada 82 82 2940 49.00
Maithili 82 82 3340 55.40
Manipuri 82 82 2602 43.22
Nepali 48 60 3307 55.07
Tamil 78 71 5127 85.45

31
Frequency Dictionaries: Frequency Dictionaries: Most frequent 5000 Most frequent 5000 wordswords
Published
Sl. No. Language
1. Bengali
2. Hindi
3. Kannada
4. Manipuri
To be published by March 31, 2009
Sl. No. Language
1. Nepali
2. Urdu

32
Development of ToolsDevelopment of Tools
The following packages will be developed:
1. KWIC and KWOC Retriver
2. Tool for Semi Automatic Annotation of Speech Data.
Corpora management packages developed:
1. Word Frequency Analyser
2. N-Gram (Bi-Gram, Tri-Gram) for word and character
3. Speech Annotation Manual prepared and published

»Interns LDC-
33

34