1 7-speech recognition (cont’d) hmm calculating approaches neural components three basic hmm...
TRANSCRIPT

11
7-Speech Recognition (Cont’d)7-Speech Recognition (Cont’d)
HMM Calculating ApproachesHMM Calculating Approaches
Neural ComponentsNeural Components
Three Basic HMM ProblemsThree Basic HMM Problems
Viterbi AlgorithmViterbi Algorithm
State Duration ModelingState Duration Modeling
Training In HMMTraining In HMM
22
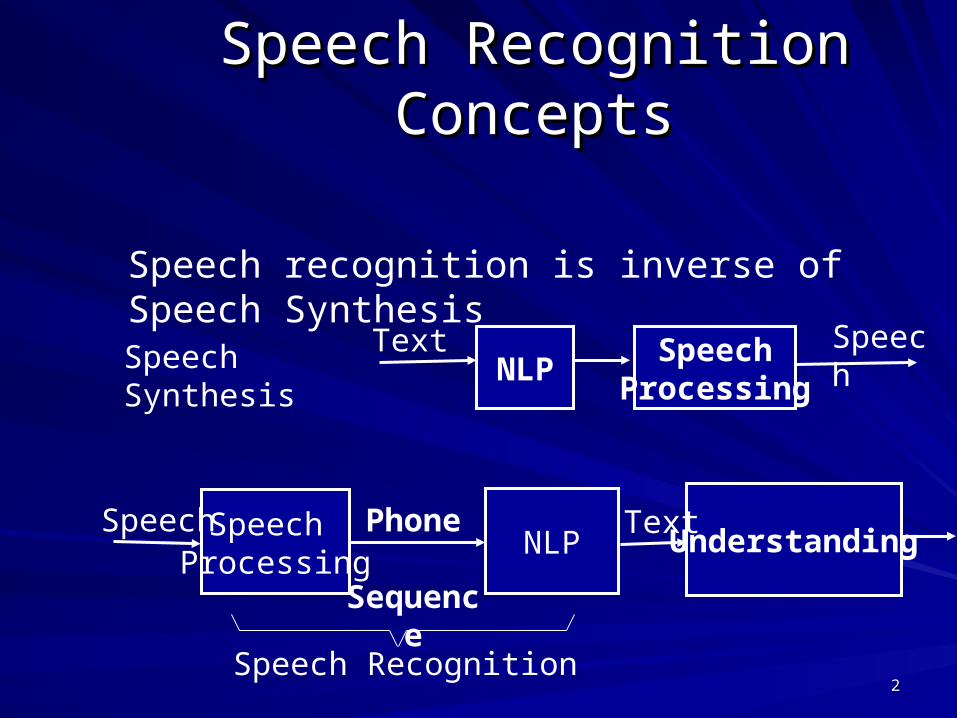
Speech Recognition ConceptsSpeech Recognition Concepts
NLPSpeech
Processing
Text Speech
NLPSpeech
ProcessingSpeech
Understanding
Speech Synthesis
TextPhone Sequence
Speech Recognition
Speech recognition is inverse of Speech Synthesis

33
Speech Recognition Speech Recognition ApproachesApproaches
Bottom-Up ApproachBottom-Up Approach
Top-Down ApproachTop-Down Approach
Blackboard ApproachBlackboard Approach
44
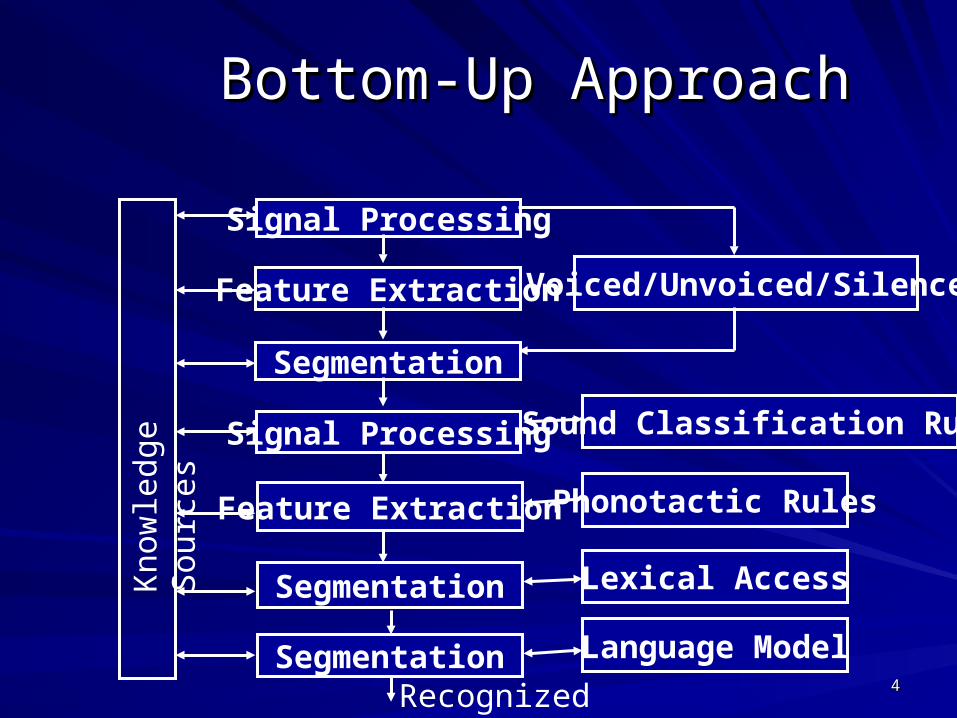
Bottom-Up ApproachBottom-Up Approach
Signal Processing
Feature Extraction
Segmentation
Signal Processing
Feature Extraction
Segmentation
Segmentation
Sound Classification Rules
Phonotactic Rules
Lexical Access
Language Model
Voiced/Unvoiced/Silence
Kno
wle
dge
Sou
rces
Recognized Utterance
55
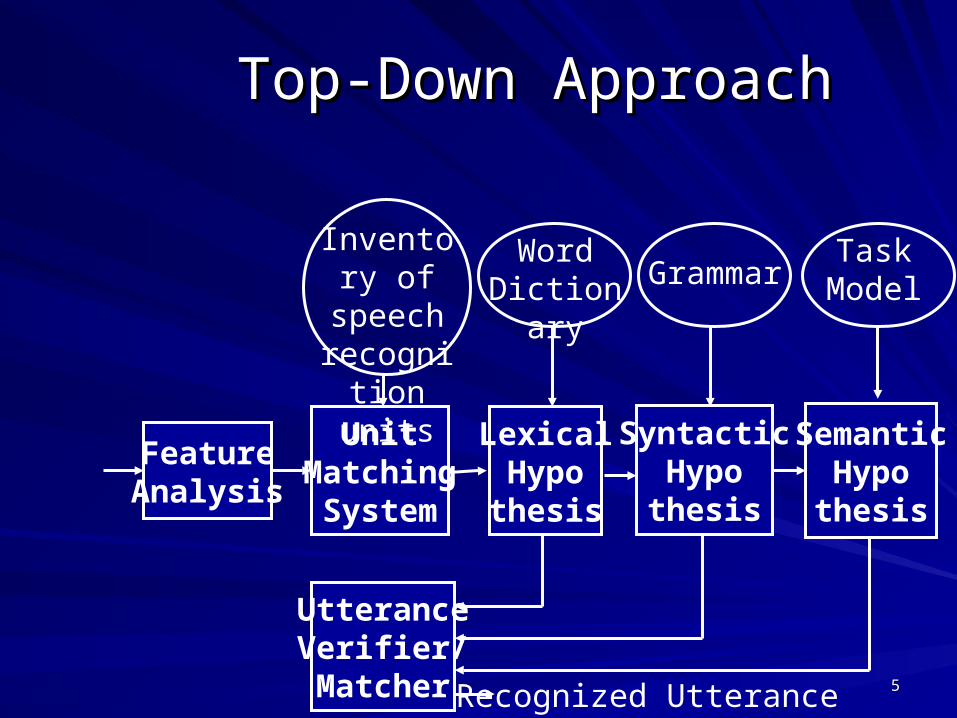
UnitMatching
System
Top-Down ApproachTop-Down Approach
FeatureAnalysis
LexicalHypothesis
SyntacticHypothesis
SemanticHypothesis
UtteranceVerifier/Matcher
Inventory of speech
recognition units
Word Dictionary Grammar
TaskModel
Recognized Utterance
66
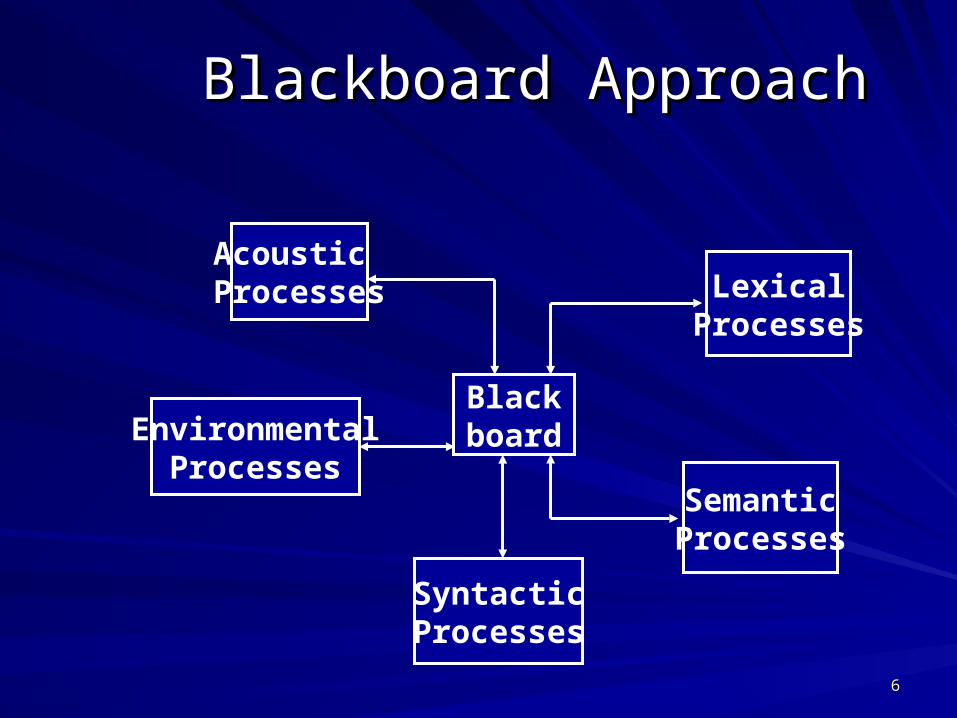
Blackboard ApproachBlackboard Approach
EnvironmentalProcesses
Acoustic Processes Lexical
Processes
SyntacticProcesses
SemanticProcesses
Blackboard
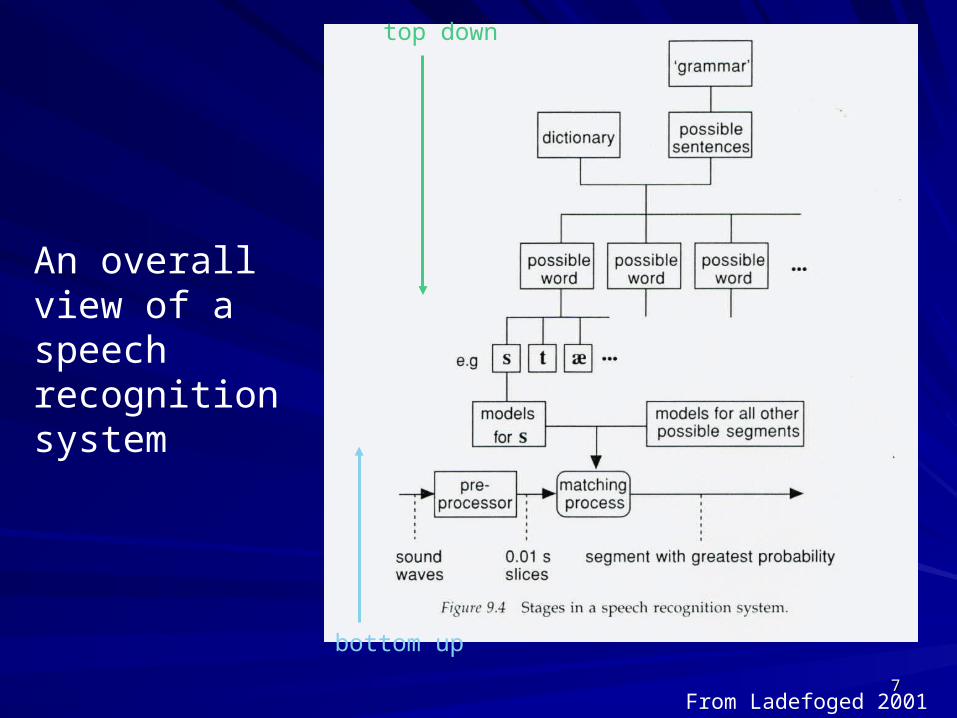
77
An overall view of a speech recognition system
bottom up
top down
From Ladefoged 2001

88
Recognition TheoriesRecognition Theories
Articulatory Based RecognitionArticulatory Based Recognition– Use from Articulatory system for recognitionUse from Articulatory system for recognition– This theory is the most successful until nowThis theory is the most successful until now
Auditory Based RecognitionAuditory Based Recognition– Use from Auditory system for recognitionUse from Auditory system for recognition
Hybrid Based RecognitionHybrid Based Recognition– Is a hybrid from the above theoriesIs a hybrid from the above theories
Motor TheoryMotor Theory– Model the intended gesture of speakerModel the intended gesture of speaker

99
Recognition ProblemRecognition Problem
We have the sequence of acoustic We have the sequence of acoustic symbols and we want to find the words symbols and we want to find the words that expressed by speakerthat expressed by speaker
Solution : Finding the most probable Solution : Finding the most probable word sequence having Acoustic symbolsword sequence having Acoustic symbols

1010
Recognition ProblemRecognition Problem
A : Acoustic SymbolsA : Acoustic Symbols
W : Word SequenceW : Word Sequence
we should find so that we should find so that w)|(max)|ˆ( AwPAwP
w

1111
Bayse RuleBayse Rule
),()()|( yxPyPyxP
)(
)()|()|(
yP
xPxyPyxP
)(
)()|()|(
AP
wPwAPAwP

1212
Bayse Rule (Cont’d)Bayse Rule (Cont’d)
)(
)()|(max
AP
wPwAPw
)|(max)|ˆ( AwPAwPw
)()|(max
)|(maxˆ
wPwAPArg
AwPArgw
w
w

1313
Simple Language ModelSimple Language Model
nwwwww 321
)|()( 1211
wwwwPwP iii
n
i
Computing this probability is very difficult and we need a very big database. So we use from Trigram and Bigram models.

1414
Simple Language Model Simple Language Model (Cont’d)(Cont’d)
)|()( 211
iii
n
iwwwPwP
)|()( 11
ii
n
iwwPwP
Trigram :
Bigram :
)()(1
i
n
iwPwP
Monogram :

1515
Simple Language Model Simple Language Model (Cont’d)(Cont’d)
)|( 123 wwwP
Computing Method :Number of happening W3 after W1W2
Total number of happening W1W2
AdHoc Method :
)()|()|()|( 332321231123 wfwwfwwwfwwwP

1616
7-Speech Recognition7-Speech Recognition
Speech Recognition Concepts Speech Recognition Concepts
Speech Recognition ApproachesSpeech Recognition Approaches
Recognition TheoriesRecognition Theories
Bayse RuleBayse Rule
Simple Language ModelSimple Language Model
P(A|W) Network TypesP(A|W) Network Types

1717From Ladefoged 2001

1818
P(A|W) Computing P(A|W) Computing ApproachesApproaches
Dynamic Time Warping (DTW)Dynamic Time Warping (DTW)
Hidden Markov Model (HMM)Hidden Markov Model (HMM)
Artificial Neural Network (ANN)Artificial Neural Network (ANN)
Hybrid SystemsHybrid Systems

1919
Dynamic Time Warping Dynamic Time Warping Method (DTW)Method (DTW)
To obtain a global distance between two speech patterns a time alignment must be performed
Ex :A time alignment path between a template pattern “SPEECH” and a noisy input “SsPEEhH”
2020
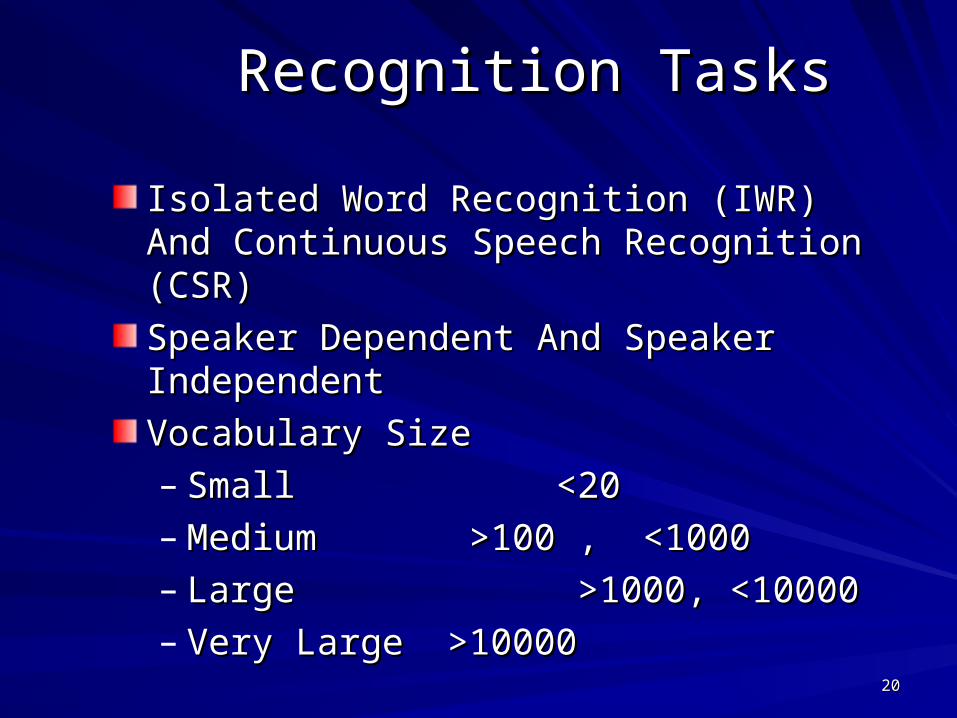
Recognition TasksRecognition Tasks
Isolated Word Recognition (IWR) And Isolated Word Recognition (IWR) And Continuous Speech Recognition (CSR)Continuous Speech Recognition (CSR)
Speaker Dependent And Speaker Speaker Dependent And Speaker Independent Independent
Vocabulary SizeVocabulary Size– Small <20Small <20– Medium >100 , <1000Medium >100 , <1000– Large >1000, <10000Large >1000, <10000– Very Large >10000Very Large >10000

2121
Error Production FactorError Production Factor
Prosody (Recognition should be Prosody (Recognition should be Prosody Independent)Prosody Independent)
Noise (Noise should be prevented)Noise (Noise should be prevented)
Spontaneous SpeechSpontaneous Speech
2222
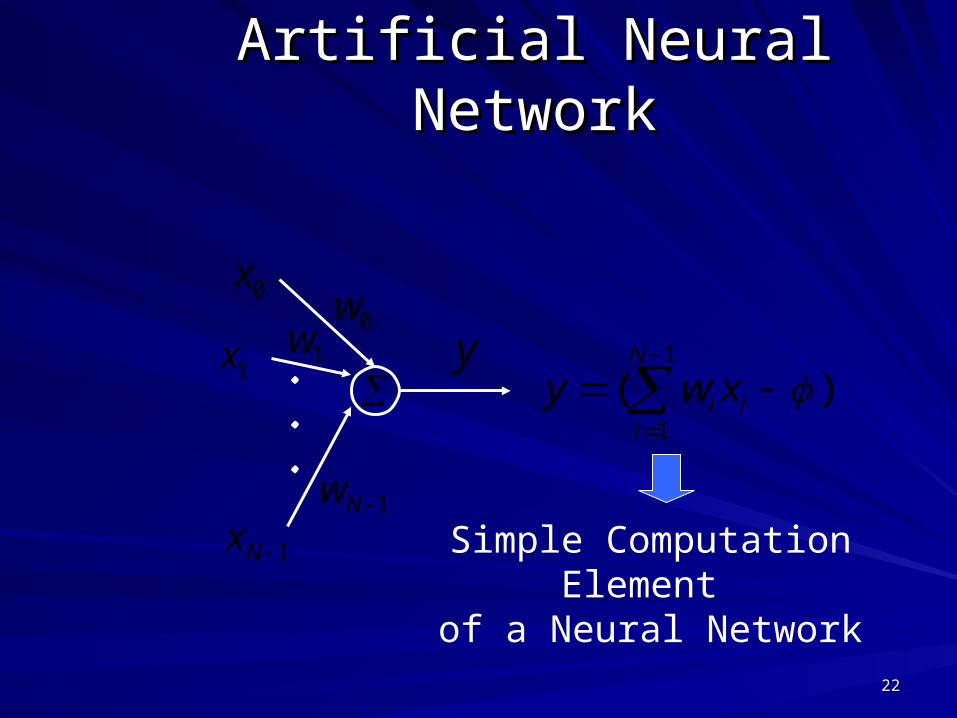
Artificial Neural NetworkArtificial Neural Network
...
1x
0x
1w0w
1Nw
1Nx
y)(
1
1
i
N
iixwy
Simple Computation Element of a Neural Network

2323
Artificial Neural Network Artificial Neural Network (Cont’d)(Cont’d)
Neural Network TypesNeural Network Types– PerceptronPerceptron– Time DelayTime Delay– Time Delay Neural Network Computational Time Delay Neural Network Computational
Element (TDNN)Element (TDNN)
2424
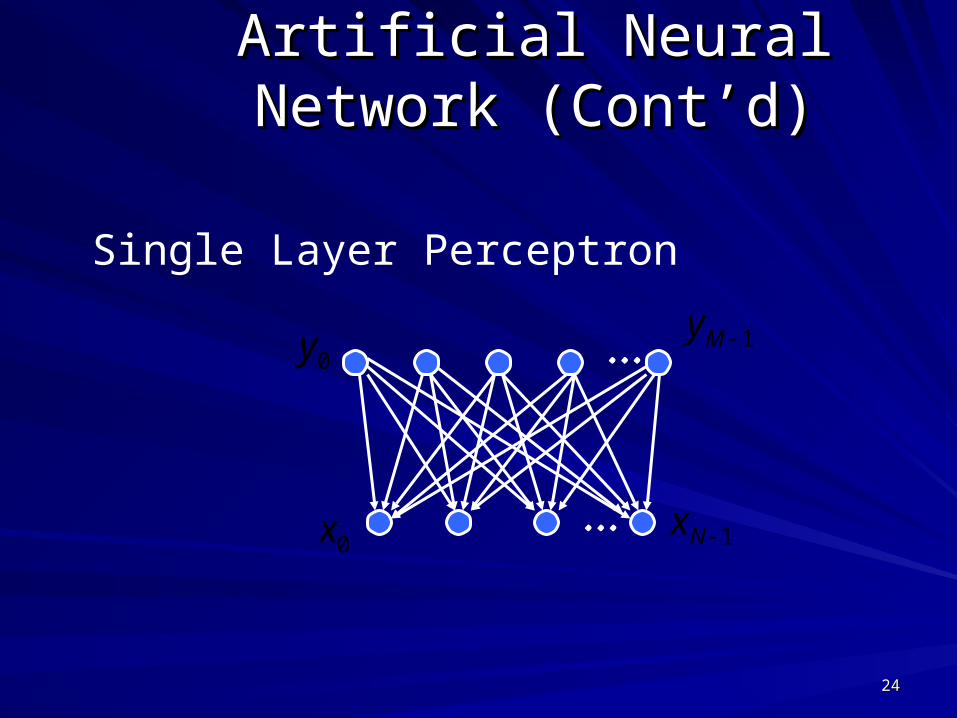
Artificial Neural Network Artificial Neural Network (Cont’d)(Cont’d)
. . .
. . .0x
0y1My
1Nx
Single Layer Perceptron
2525
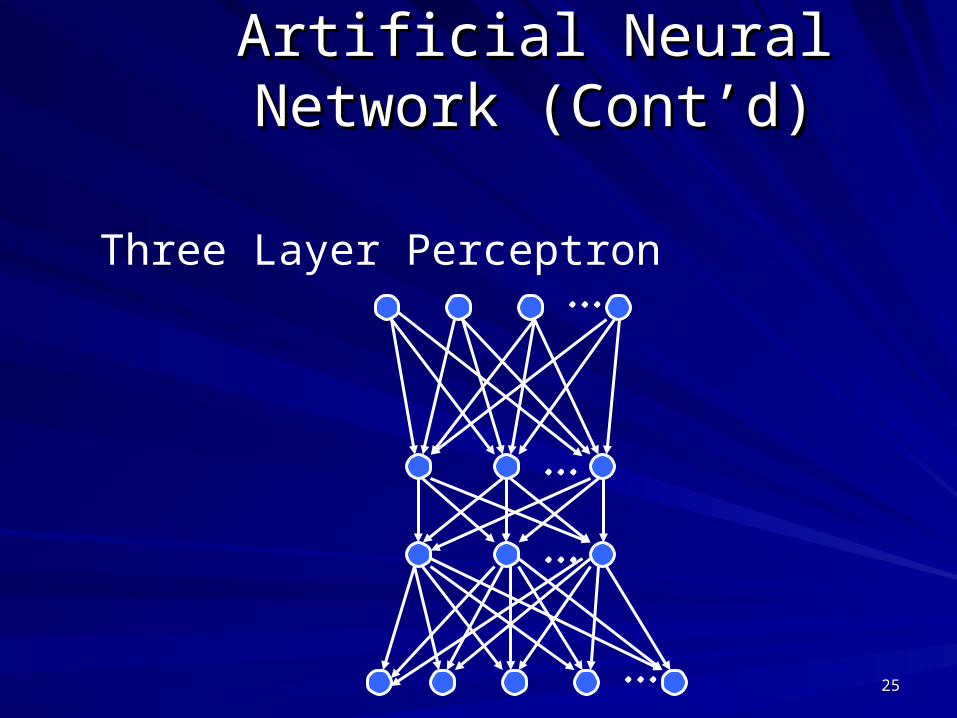
Artificial Neural Network Artificial Neural Network (Cont’d)(Cont’d)
. . .
. . .
Three Layer Perceptron
. . .
. . .
2626
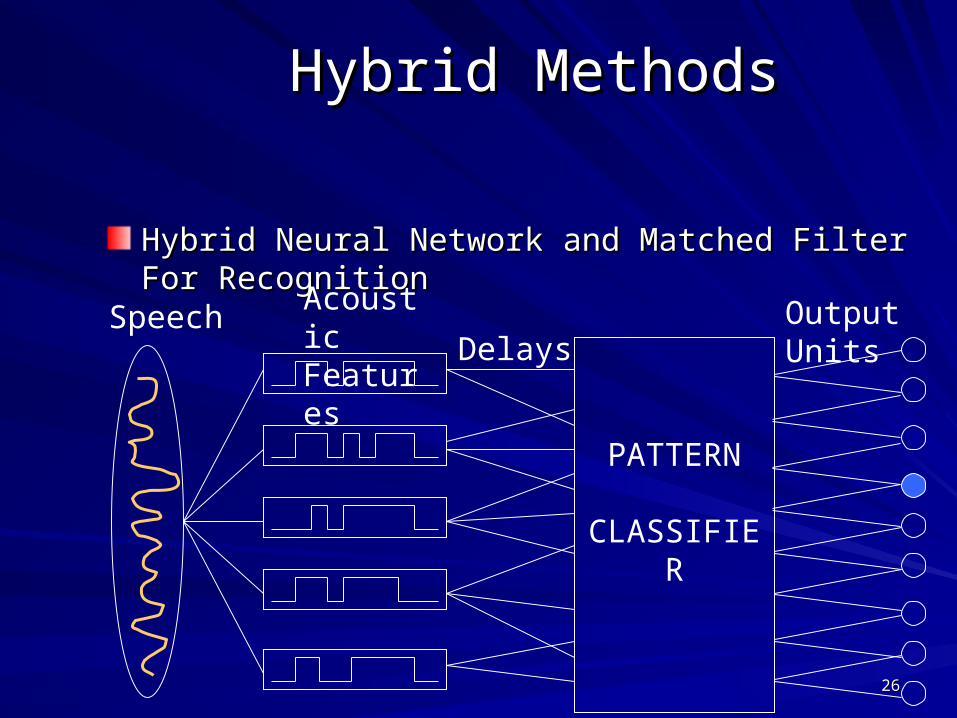
Hybrid MethodsHybrid Methods
Hybrid Neural Network and Matched Filter For Hybrid Neural Network and Matched Filter For RecognitionRecognition
PATTERN
CLASSIFIER
SpeechAcoustic Features Delays
Output Units

2727
Neural Network PropertiesNeural Network Properties
The system is simple, But too much The system is simple, But too much iterativeiterative
Doesn’t determine a specific structureDoesn’t determine a specific structure
Regardless of simplicity, the results are Regardless of simplicity, the results are goodgood
Training size is large, so training should be Training size is large, so training should be offlineoffline
Accuracy is relatively goodAccuracy is relatively good

2828
Hidden Markov ModelHidden Markov Model
Observation : O1,O2, . . . Observation : O1,O2, . . .
States in time : q1, q2, . . .States in time : q1, q2, . . .
All states : s1, s2, . . .All states : s1, s2, . . .
tOOOO ,,,, 321
tqqqq ,,,, 321
Si Sjjiaija