1 a comparative evaluation of deep and shallow approaches to the automatic detection of common...
TRANSCRIPT

1
A Comparative Evaluation ofDeep and Shallow Approaches to the Automatic Detection ofCommon Grammatical Errors
Joachim Wagner, Jennifer Foster, and Josef van Genabith
2007-07-26
National Centre for Language TechnologySchool of Computing, Dublin City University

2
Talk Outline• Motivation• Background• Artificial Error Corpus• Evaluation Procedure• Error Detection Methods• Results and Analysis• Conclusion and Future Work

3
Why Judge the Grammaticality?
• Grammar checking• Computer-assisted language learning
– Feedback– Writing aid– Automatic essay grading
• Re-rank computer-generated output– Machine translation

4
Why this Evaluation?
• No agreed standard• Differences in
– What is evaluated– Corpora– Error density– Error types

5
Talk Outline• Motivation• Background• Artificial Error Corpus• Evaluation Procedure• Error Detection Methods• Results and Analysis• Conclusion and Future Work

6
Deep Approaches
• Precision grammar • Aim to distinguish grammatical
sentences from ungrammatical sentences
• Grammar engineers– Increase coverage– Avoid overgeneration
• For English:– ParGram / XLE (LFG)– English Resource Grammar / LKB (HPSG)– RASP (GPSG to DCG influenced by ANLT)

7
Shallow Approaches
• Real-word spelling errors– vs grammar errors in general
• Part-of-speech (POS) n-grams– Raw frequency– Machine learning-based classifier– Features of local context– Noisy channel model– N-gram similarity, POS tag set

8
Talk Outline• Motivation• Background• Artificial Error Corpus• Evaluation Procedure• Error Detection Methods• Results and Analysis• Conclusion and Future Work

9
Artificial Error Corpus
Real Error Corpus(Small)
Error Analysis
Common Grammatical Error
Chosen Error Types
Automatic ErrorCreation Modules
Applied to BNC(Big)

10
Common Grammatical Errors
• 20,000 word corpus• Ungrammatical English sentences
– Newspapers, academic papers, emails, …
• Correction operators– Substitute (48 %)– Insert (24 %)– Delete (17 %)– Combination (11 %)

11
Common Grammatical Errors
• 20,000 word corpus• Ungrammatical English sentences
– Newspapers, academic papers, emails, …
• Correction operators– Substitute (48 %)– Insert (24 %)– Delete (17 %)– Combination (11 %)
Agreement errorsReal-word spelling errors

12
Chosen Error Types
Agreement: She steered Melissa around a corners.
Real-word: She could no comprehend.
Extra word: Was that in the summer in?
Missing word: What the subject?

13
Automatic Error Creation
Agreement: replace determiner, noun or verb
Real-word: replace according to pre-compiled list
Extra word: duplicate token or part-of-speech,or insert a random token
Missing word: delete token (likelihood based onpart-of-speech)

14
Talk Outline• Motivation• Background• Artificial Error Corpus• Evaluation Procedure• Error Detection Methods• Results and Analysis• Conclusion and Future Work

15
1
BNC Test Data (1)BNC: 6.4 M sentences
4.2 M sentences (no speech, poems, captions and list
items)
2 3 4 105 …
Randomisation
10 sets with 420 Ksentences each

16
BNC Test Data (2)
1 2 3 4 105…
1 2 3 4 105…
Error creation1 2 3 4 105
…
1 2 3 4 105…
1 2 3 4 105…
Agreement
Real-word
Extra word
Missing word
Error corpus

17
BNC Test Data (3)
1
10
1
10
1
10
…
1
10
…
1
10
…
Mixed error type
¼ each
¼ each

18
BNC Test Data (4)
1 1 1 1 1 1 1 1 1 1
10 10 10 10 10 10 10 10 10 10
… … … … …50 sets
5 error types:agreement, real-word, extra word, missing word, mixed errors
Each 50:50 ungrammatical:grammatical

19
BNC Test Data (5)
1 1 1 1 1 1 1 1 1 1
10 10 10 10 10 10 10 10 10 10
… … … … …
2 2 2 2 2 2 2 2 2 2 Trainingdata
(if requiredby method)
Testdata
Example:1st cross-
validation runfor agreement
errors

20
Evaluation Measures
• Accuracy on ungrammatical dataacc_ungram =
# correctly flagged as ungrammatical # ungrammatical sentences
• Accuracy on grammatical dataacc_gram =
# correctly classified as grammatical # grammatical sentences
• Independent of error density of test data

21
Accuracy Graph

22
Region of Improvement

23
Region of Degradation
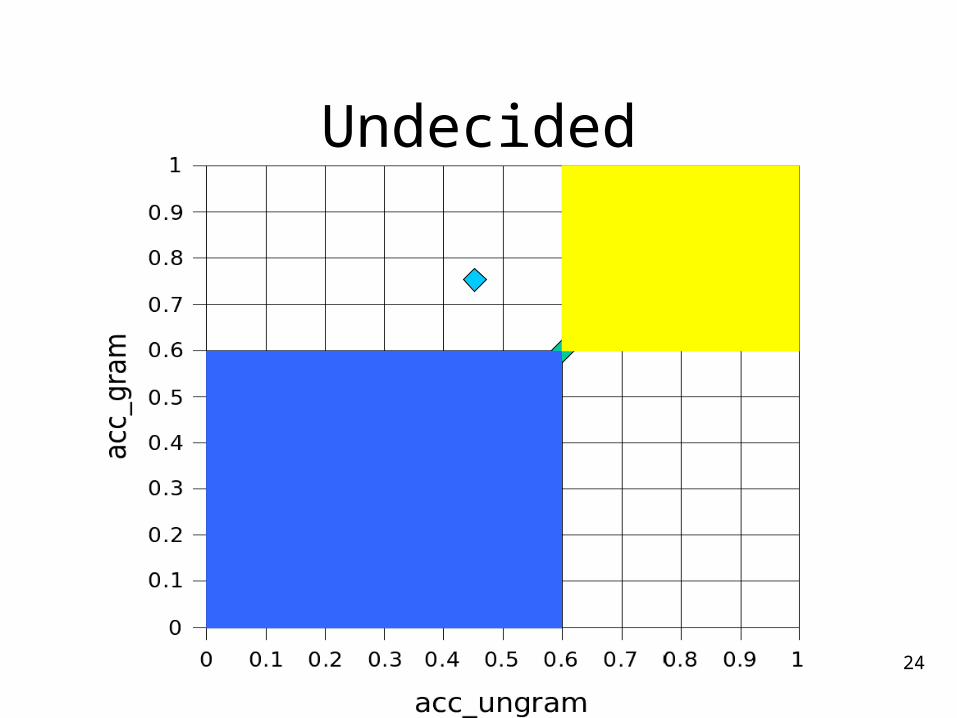
24
Undecided

25
Talk Outline• Motivation• Background• Artificial Error Corpus• Evaluation Procedure• Error Detection Methods• Results and Analysis• Conclusion and Future Work

26
Overview of Methods
M1 M2 M3 M4 M5
XLE Output
POS n-graminformation
Basic methods Decision tree methods

27
Method 1: Precision Grammar
• XLE English LFG• Fragment rule
– Parses ungrammatical input – Marked with *
• Zero number of parses• Parser exceptions (time-out,
memory)
M1

28
XLE Parsing
1 10… 1 10
…
1 10…
1 10…
1 10…
50 x 60 K = 3 M parse results
XLE
First 60 Ksentences
M1

29
Method 2: POS N-grams
• Flag rare POS n-grams as errors• Rare: according to reference
corpus• Parameters: n and frequency
threshold– Tested n = 2, …, 7 on held-out data– Best: n = 5 and frequency threshold 4
M2

30
POS N-gram Information
1 10… 1 10
…
1 10…
1 10…
1 10…
3 M frequency values
Rarest n-gramReference
n-gram table
Repeated forn = 2, 3, …, 7
9 sets
M2

31
Method 3: Decision Trees on XLE Output
• Output statistics– Starredness (0 or 1) and parser
exceptions (-1 = time-out, -2 = exceeded memory, …)
– Number of optimal parses– Number of unoptimal parses– Duration of parsing– Number of subtrees– Number of words
M3

32
Decision Tree Example
Star?
<0 >= 0
Star?
<1 >= 1
U
U
Optimal?
<5 >= 5
U G
M3
U = ungrammaticalG = grammatical

33
Method 4: Decision Trees on N-grams
• Frequency of rarest n-gram in sentence
• N = 2, …, 7– feature vector: 6 numbers
M4

34
Decision Tree Example
5-gram?
<4 >= 4
7-gram?
<1 >= 1
G
U
5-gram?
<45 >= 45
U G
M4

35
Method 5: Decision Trees on Combined Feature Sets
Star?
<0 >= 0
Star?
<1 >= 1
U
U
5-gram?
<4 >= 4
U G
M5

36
Talk Outline• Motivation• Background• Artificial Error Corpus• Evaluation Procedure• Error Detection Methods• Results and Analysis• Conclusion and Future Work

37
XLE Parsing of the BNC
• 600,000 grammatical sentences• 2.4 M ungrammatical sentences• Parse-testfile command
– Parse-literally 1– Max xle scratch storage 1,000 MB– Time-out 60 seconds– No skimming

38
Efficiency
10,000 BNCsentences(grammatical)
Time-out

39
XLE Parse Results and Method 1
Gramm. Agree. Real-w. Extra-w. Missing
Covered 67.1% 35.4% 42.7% 40.3% 52.2%
Fragments 29.7% 58.3% 53.8% 56.4% 44.6%
No parse 0.3% 0.4% 0.3% 0.3% 0.3%
Time-out 0.6% 1.1% 0.7% 0.6% 0.6%
Out-of-memory 2.3% 4.8% 2.6% 2.4% 2.2%
Crash (absolute) 2 3 4 3 2
Accuracy M1 67.1% 64.6% 57.3% 59.7% 47.8%

40
XLE Coverage
5 x 600 KTest data

41
Applying Decision Tree to XLE
M3
M1

42
Overall Accuracy for M1 and M3
0.50
0.55
0.60
0.65
0.70
0.75
0% 20% 40% 60% 80% 100%
Error density of test data
Ove
rall a
ccura
cy
M1
M3

43
Varying Training Error Density
M3 50%
M1
M3 40%
M3 33%20% 25%
M3 60%
M3 67%
M3 75%

44
Varying Training Error Density
M3 50%
M1
M3 40%
M3 33%20% 25%
M3 60%
M3 67%
M3 75%
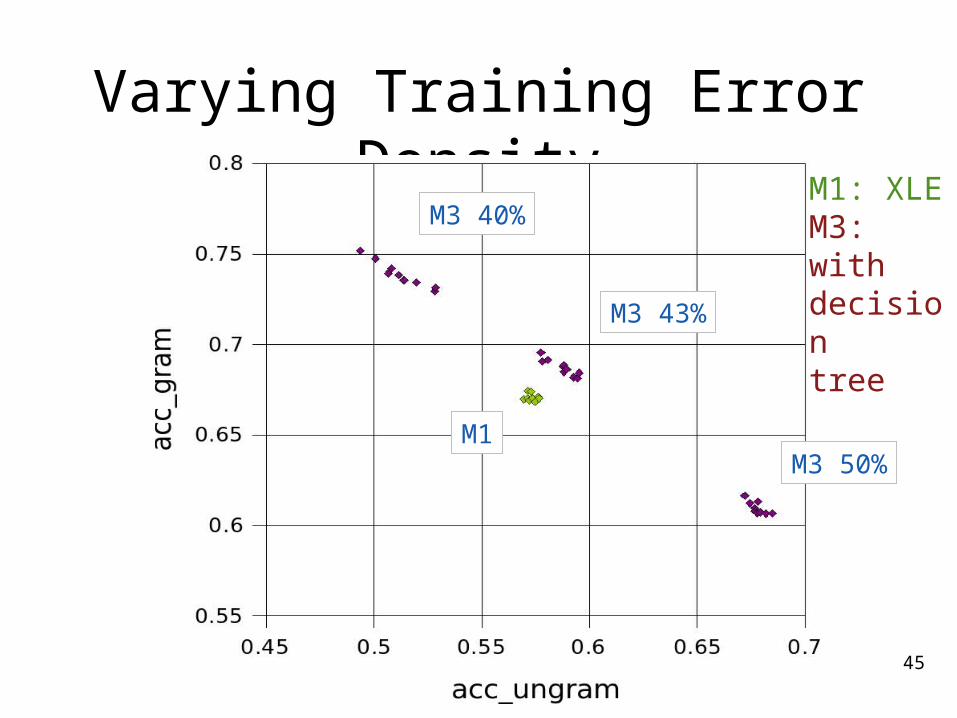
45
Varying Training Error Density M1: XLE
M3: withdecisiontree
M3 50%M1
M3 40%
M3 43%
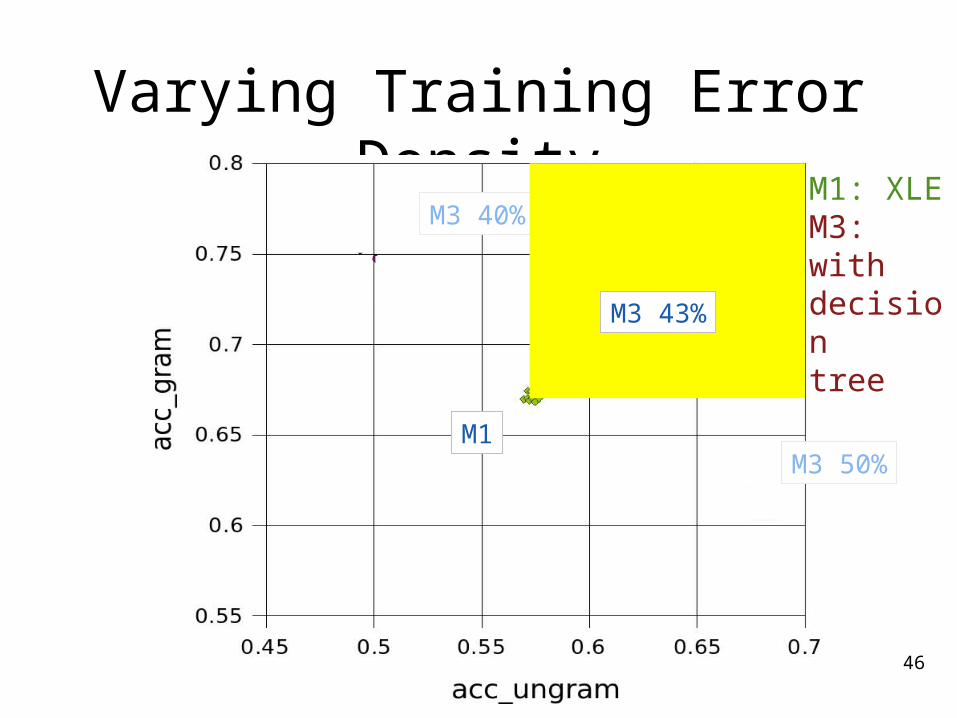
46
Varying Training Error Density M1: XLE
M3: withdecisiontree
M3 50%M1
M3 40%
M3 43%

47
N-Grams and DT (M2 vs M4)
M4 50%
M4 67%
M4 25%
M4 75%
M2
M2: NgramM4: DT

48
Methods 1 to 4
M3 43%
M3 50%
M4 50%
M2
M1: XLEM2: NgramM3/4: DT
M1

49
Combined Method (M5)
50%
67%
25%
75%
80%
90%
10%, 20%

50
All MethodsM1: XLEM2: NgramM3/4: DTM5: comb
M3 43%
M3 50%
M2
M1 M5 50%
M5 45%
M4

51
Breakdown by Error Type
m.w. r.w. e.w. ag.
m.w. r.w. e.w. ag.
m.w. r.w. e.w. ag.M5 45%
M1
M5 50%

52
Breakdown by Error Type
m.w. r.w. e.w. ag.
m.w. r.w.e.w. ag.
m.w. r.w. e.w. ag.
r.w.e.w. M5 45%
M1
M5 50%
M3 43%
M3 50%

53
Talk Outline• Motivation• Background• Artificial Error Corpus• Evaluation Procedure• Error Detection Methods• Results and Analysis• Conclusion and Future Work

54
Conclusions
• Basic methods surprisingly close to each other
• Decision tree– Effective with deep approach– Small and noisy improvement with
shallow approach• Combined approach best on all but
one error type

55
Future Work
• Error types:– Word order– Multiple errors per sentence
• Add more features• Other languages• Test on MT output• Establish upper bound

56
References• E. Atwell: How to detect grammatical errors in a text without
parsing it. In Proceedings of the 3rd EACL, pp 38-45, 1987• M. Butt, H. Dyvik, T. H. King, H. Masuichi, and C. Rohrer: The
parallel grammar project. In Proceedings of COLING-2002• J. Foster: Good Reasons for Noting Bad Grammar: Empirical
Investigations into the Parsing of Ungrammatical Written English. Ph.D. thesis, University of Dublin, Trinity College, 2005
• J. Wagner, J. Foster and J. van Genabith: A Comparative Evaluation of Deep and Shallow Approaches to the Automatic Detection of Common Grammatical Errors. In Proceedings of EMNLP-CoNLL 2007
• I. H. Witten and E. Frank: Data Mining: Practical Machine Learning Tools and Techniques with Java Implementations. Morgan Kaufmann Publishers, 2000

57
Thank You!
Djamé Seddah(La Sorbonne University)
National Centre for Language TechnologySchool of Computing, Dublin City University

58
Why not use F-Score?
• Precision and F-Score– Depend on error density of test data– What are true positives?– Weighting parameter of F-score
• Recall and 1-Fallout– Accuracy on ungrammatical data– Accuracy on grammatical data

59
Results: F-Score
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
Agreement Real-word Extra word Missing word Mixed errors
XLE
ngram
XLE+DT
ngram+DT
combined

60
F-Score (tp=correctly flagged)
0.0
0.2
0.4
0.6
0.8
1.0
0% 20% 40% 60% 80% 100%
Error density of test data
F-S
core Baseline
M1
M3

61
POS n-grams and Agreement Errors
n = 2, 3, 4, 5
Best F-Score 66 %
Best Accuracy 55 %
XLE parserF-Score 65 %

62
POS n-grams and Context-Sensitive Spelling Errors
Best F-Score 69 %
n = 2, 3, 4, 5
XLE 60 %
Best Accuracy 66 %

63
POS n-grams and Extra Word Errors
n = 2, 3, 4, 5
Best F-Score 70 %XLE 62 %
Best Accuracy 68 %

64
POS n-grams and Missing Word Errors
n = 2, 3, 4, 5
Best F-Score 67 %
XLE 53 % Best Accuracy 59 %

65
Inverting Decisions

66
Why Judge Grammaticality? (2)
• Automatic essay grading• Trigger deep error analysis
– Increase speed– Reduce overflagging
• Most approaches easily extend to– Locating errors– Classifying errors

67
Grammar Checker Research
• Focus of grammar checker research– Locate errors– Categorise errors– Propose corrections– Other feedback (CALL)
• Approaches:– Extend existing grammars– Write new grammars

68
N-gram Methods
• Flag unlikely or rare sequences– POS (different tagsets)– Tokens– Raw frequency vs. mutual information
• Most publications are in the area of context-sensitive spelling correction– Real word errors– Resulting sentence can be grammatical

69
Test Corpus - Example
• Missing Word Error
She didn’t to face him
She didn’t want to face him

70
Test Corpus – Example 2
• Context-sensitive spelling error
I love then both
I love them both

71
Cross-validation
• Standard deviation below 0.006• Except Method 4: 0.026• High number of test items• Report average percentage

72
Example
Run F-Score
1 0.654
2 0.655
3 0.655
4 0.655
5 0.653
6 0.652
7 0.653
8 0.657
9 0.654
10 0.653
Stdev 0.001
Method 1 – Agreement errors:
65.4 % average F-Score