1 branch prediction techniques 15-740 computer architecture vahe poladian & stefan niculescu...
Post on 22-Dec-2015
217 views
TRANSCRIPT

1
Branch Prediction Techniques
15-740
Computer Architecture
Vahe Poladian & Stefan Niculescu
October 14, 2002

2
Papers surveyed
A Comparative Analysis of Schemes for Correlated Branch Prediction by Cliff Young, Nicolas Gloy, and Michael D. Smith.
Improving Branch Predictors by Correlating on Data Values by Timothy Heil, Zak Smith, and James E Smith.
A Language for Describing Predictors and its Application to Automatic Synthesis by Joel Emer and Nikolas Gloy.

A Comparative Analysis of Schemes for Correlated
Branch Prediction

4
Framework
b5,1 b3,1 b4,0 b5,1
Execution Stream
Divider Substreams Predictors
Branch execution = (b,d), b is PC, d is 0 or 1
All prediction schemes described by this model

5
Differences among prediction schemes
Path History vs Pattern History
Path: (b1,d1), … , (bn,dn), pattern: (d1, … , dn)
Aliasing extent
Multiple streams using the same predictor
Extent of cross-procedure correlation
Adaptivity
Static vs dynamic

6
Path History vs. Pattern History
Path potentially more accurate
Compared to baseline 2 bit per branch predictor, path only slightly improves over pattern
Path requires significant storage
Result holds both in static and dynamic predictors

7
Can be constructive, destructive, harmless
Completely removing aliasing slightly improves accuracy over GAs and Gshare with 4096 2-bit counters Should we spend effort on techniques reducing aliasing?
Unliased path history slightly better vs. unaliased pattern history With aliasing constraint, this distinction might be
insignificant, so designers should be careful
Further, under equal table space constraint, path history might even be worse
Aliasing vs Non-Aliasing

8
Often mispredictions of the branches just after procedure entry or just after procedure return
Static predictor with cross-procedure correlation support performs significantly better than one without
Strong bias per stream increased
This result somewhat meaningless, as hardware predictors do not suffer from this problem
Cross-procedure Correlation

9
Static vs Dynamic
Number of distinct streams for which static predictor better is higher, but
Number of branches executed in dynamic streams for which dynamic is better, is significantly higher
Is it possible to combine static and dynamic predictors?How?
Assign low bias streams to dynamic

10
Summary - lessons learnt
Path history performs slightly better than pattern history
Removing the effects of aliasing decreases misprediction, but increases predictor size
Exploiting cross-procedure correlation improves the prediction accuracy
Percentage of adaptive streams small, but dynamic branches executed are significant
Use hybrid schemes to improve accuracy

Learning Predictors Using
Genetic Programming

12
Genetic Algorithms
Optimization technique based on simulating natural selection process
High probability that the global optimum is among the results
Principles:
The stronger individuals survive
The offsprings of stronger parents tend to combine the strengths of the parents
Mutations may appear as result of the evolution process

13
An Abstract Example
Distribution of Individuals in Generation 0
Distribution of Individuals in Generation N

14
Prediction using GAs
Find Branch Predictors that yield low misprediction rates
Find Indirect Jump predictors with low misprediction rates
Find other good predictors (not addressed in the paper, but potential for a research project)

15
Prediction using GAs
Algorithm Find efficient encoding of predictors
Start with a set of random predictors (“generation 0”) - 400
Given generation I (20-30 overall):Rank predictors according to fitness function
Choose best to make generation i+1: Copy
Crossover
Mutation

16
Primitive predictor
d
wIndex
Update
Result
Primitive Predictor – P[w,d](Index;Update)
• Basic memory unit
• Depth - number of entries
• Width - number of bits per entry

17
Algebraic notation – BP expressions
Onebit[d](PC;T) = P[1;d](PC;T);
Counter[n,d](I;T)=
= P[n,d](I; if T then P+1 else P-1);
Twobit[d](PC;T)=
= MSB(Counter[2,d](PC;T));

18
Predictor Tree – an example
MSB
PC
P
SELF 1
SSUB
2
Update
Index
SELF 1
SADD
2
IF
T
Two Bit predictor
Question: how to do crossover and mutation?

19
Constraints
Validity of expressions
E.g. of NOT valid BP: in crossover, terminal T may become the index of another predictor
If not valid, try to modify the individual to a valid BP expression (e.g. T=1)
Encapsulation
Size of storage limited to 512Kbits
When bigger, reduce size by randomly decreasing the side of a predictor node by one

20
Fitness function
Intuitively, the higher the accuracy, the better a predictor is:
fitness(P) = accuracy(P) To compute fitness:To compute fitness:
Parse expression Parse expression
Create subroutines to simulate predictorCreate subroutines to simulate predictor
Run a simulator over benchmarks (SPECint92, Run a simulator over benchmarks (SPECint92, SPECInt95, IBS compiled for DEC Alpha) to SPECInt95, IBS compiled for DEC Alpha) to compute accuracy of the predictorcompute accuracy of the predictor
Not efficient ... Why? Suggestions?Not efficient ... Why? Suggestions?

21
Results – branch prediction
The 6 best predictors kept – 30 generations
Predictor SPEC IBS Predictor SPEC IBS
Onebit[1,512K] 17.7 10.0 GP1 9.7 5.7
Twobit[2,256K] 13.1 6.7 GP2 9.5 5.0
GShare[18] 6.7 2.7 GP3 9.7 5.7
GAg[18] 7.9 4.0 GP4 7.2 3.0
PAg[18,8K] 7.9 4.5 GP5 7.0 2.9
PAp[9,18,8K] 11.2 5.5 GP6 7.1 2.9

22
Results – Indirect jumps
Best handcrafted predictors: 47% miss
Best learnt predictor: 15% miss
Very complicated structure
Simple learnt predictor with 33.4% miss

23
Summary
A powerful algebraic notation for encoding multiple types of predictors
Genetic Algorithms can be successfully applied to obtain very good predictors
Best learnt branch predictors comparable with GShare
Best learnt indirect jump predictors outperform the already existing ones
In general the best learnt predictors are too complex to implement
However, subexpressions of these predictors might be useful for creating simpler, more accurate predictors.

24
References:
Genetic Algorithms: A Tutorial* by Wendy Williams
Automatic Generation of Branch Predictors via Genetic Programming by Ziv Bar-Yossef and Kris Hildrum
* Note: we reused some slides with author’s consent

25
Where are we right now?

Improving Branch Predictors by Correlating on Data Values

27
The Problem
Despite improvements in prediction techniques, such as
Adding global path info
Refining prediction techniques
Reducing branch table interference
… Branch misprediction still a big problem
Goals of work
Understand why
Remedy the problem

28
Mispredicted Branches
Loops that iterate too many times
Last branch almost always mispredicted, since history (global or local) not long enough
Large switch statement close to a branch
Gets the predictors confused
Common in applications such as a compiler
Insight: PC: CondJmpEq Ra, Rb, Target
Use the data value

29
Using Data Values Directly
Global History
BranchPredictorBranch PC
Data Value History

30
Using Data Values Directly
Challenges:
Large number of data values (typically two values involved)
Out-of-order execution delays the update of values needed
Global History
BranchPredictorBranch PC
Data Value History

31
Intricacies – Too Many Values
Store differences of source registers
Store value patterns, not values
Handle only exceptional casesA special predictor, called REP, which is the
primary predictor, if value pattern already in it
If pattern not yet in REP, i.e. a non-exceptional case, let Backup (gselect) handle
If Backup mispredicts, then insert value to REP
REP provides data correlation and reduces interference for Backup
Replacement policy of REP critical

32
Intricacies – Guessing values
Value not available when predicting
Using committed data not accurate
Employing data prediction expensive
Idea: use last-known good value + a dynamic counter indicating outstanding instances (fetched but not committed) of that same branch

33
Branch Difference Predictor

34
Optimal Configuration Design
Design space of BCD very large – how to come up with a good (optimal) one?
Use the results of extensive experiments to determine various configuration parameters
No claim of optimality, but pretty good
Optimal configuration:
REP: indexed by GBH + PC, 6 KB table, 2048 x 3 byte entries. 10 bits for “pattern” tag, 8 for branch prediction, 6 for replacement policy
VHT: 2 separate tables: the data cache, and the branch count table, indexed by PC

35
Comparative Results

36
The Role of the REP

37
Conclusions / Discussion
Adding data value information useful to branch prediction
Rare event predictor useful way to handle large number of data values and reduce interference in the traditional predictor
Can be used with other kinds of predictors

38
Stop
39
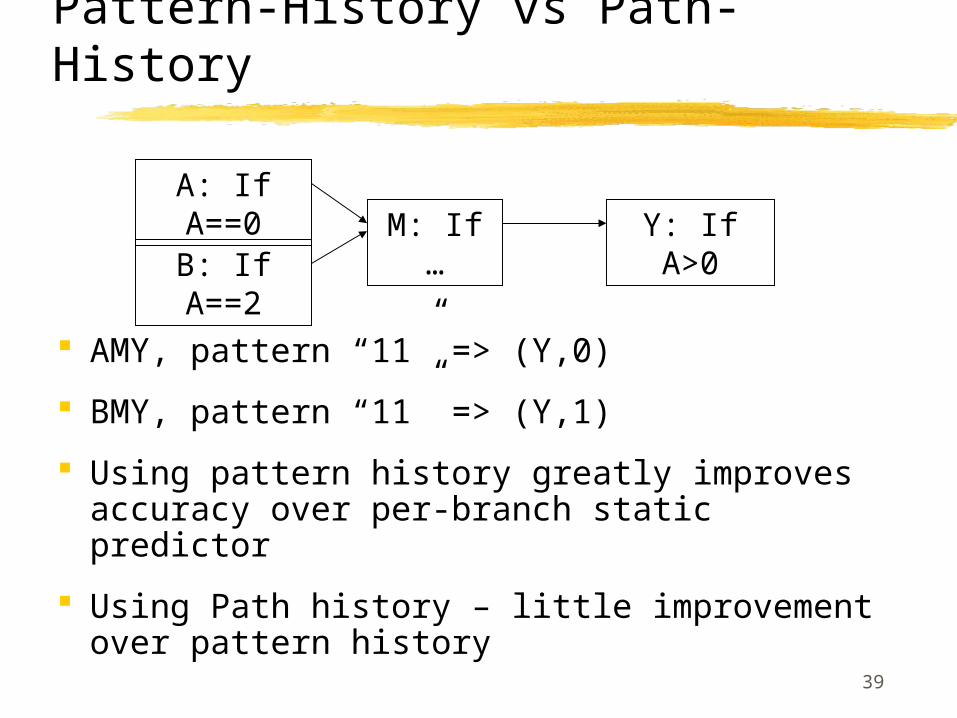
AMY, pattern “11” => (Y,0)
BMY, pattern “11” => (Y,1)
Using pattern history greatly improves accuracy over per-branch static predictor
Using Path history – little improvement over pattern history
Pattern-History vs Path-History
B: If A==2
A: If A==0M: If … Y: If A>0

40
Algebraic notation – BP expressions
Onebit[d](PC;T) = P[1;d](PC;T);
Counter[n,d](I;T)=
= P[n,d](I; if T then P+1 else P-1);
Twobit[d](PC;T) =MSB(Counter[2,d](PC;T));
Hist[w,d](I;V) = P[w,d](I;P||V);
Gshare[m](PC;T) =
= Twobit[2m](PC ⊕ Hist[m,1](0;T); T);

41
Tree Representation
Three types of nodes:Predictors
Primitive predictor + width + height
Has two descendants:• Left: index expression• Right: update expression
Functions … not an exhaustive list XOR, CAT, MASKHI/MASKLO, IF, SATUR,MSB
Terminals … not an exhaustive list PC, Result of the branch (T), SELF(value P)

42
Results – Indirect jumps
Existing jump predictors’ performance:
Description BP Expression Misprediction rate
4 traces, 35M jumps
Use target of previous jump
P[12,1](1;target) 63%
Table of previous jumps, indexed by PC
P[12,4096](PC;target) 47%
Target of previous jumps, indexed by PC
and SP
P[12,4096](PC[9..0]||SP[4..0];target)
54%

43
Crossover
Randomly choose a node in each of the Randomly choose a node in each of the parents and interchange the corresponding parents and interchange the corresponding subtreessubtrees
What bad things could happen?What bad things could happen?

44
Mutation
Applied to children generated by crossoverApplied to children generated by crossover
Node Mutation:Node Mutation:
Replace functions with functionsReplace functions with functions
Replace terminal with another terminalReplace terminal with another terminal
Modify width/height of predictorModify width/height of predictor
Tree Mutation:Tree Mutation:
Randomly pick a node NRandomly pick a node N
Replace Subtree(N) with random subtree of Replace Subtree(N) with random subtree of same height same height

45
Using Data Values
Global HistoryBranch
Predictor
Data Value Predictor
Branch PC
Data Value History
Chooser
Branch Execution
What are some of the problems with this approach?

46
Using Data Values: Problems
Uses either branch history or data values, but not both
Latency of prediction too high
The data value predictor requires one or two serial table accesses
Plus execution of the branch instruction

47
Experimentation - initial
Use interference-free tables, fully populated REC, for each PC, global history, value, and count combination
Values artificially “aged “ by throwing away n most recent values, thus making branch counts (n+1)
Compare with gselect
Run with 5 of the less predictable apps of SPECint95: compress, gcc, go, jpeg, li.
Vary the amount of difference values stored, from 1 to 3

48
Results - initial
BDP outperforms gselect
Best gain when using a single branch difference – adding second and third give little improvement
The older the branch difference, the worse the prediction, but degradation slow
Effect on individual branches – varies, but on average, BDP does better, with very few exceptions