1 chapter 2. 2 why study instruction sets? interface of hardware and software efficient mapping:...
Post on 21-Dec-2015
214 views
TRANSCRIPT

1
Chapter 2
2
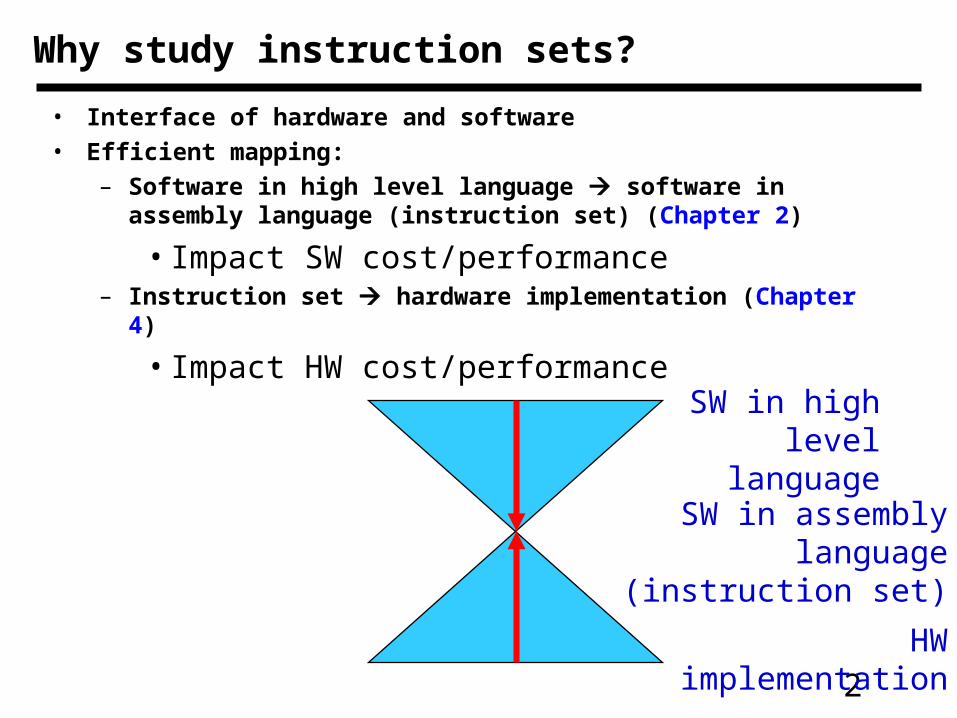
Why study instruction sets?
• Interface of hardware and software
• Efficient mapping:
– Software in high level language software in assembly language (instruction set) (Chapter 2)
• Impact SW cost/performance– Instruction set hardware implementation (Chapter 4)
• Impact HW cost/performance
SW in high level language
SW in assembly language (instruction set)
HW implementation

3
Electronic System Design Laboratory
• GOAL:
– Training of students who are able master the hardware/software co-design, co-simulation, co-verification.
C, C++, SystemC, etc.
Assembly programming
Verilog/VHDL

4
What is “Computer Architecture”?
I/O systemInstr. Set Proc.
Compiler
OperatingSystem
Application
Digital DesignCircuit Design
Instruction Set Architecture
Firmware
• Coordination of many levels of abstraction
• Under a rapidly changing set of forces
• Design, Measurement, and Evaluation
Datapath & Control
Layout

52004 Morgan Kaufmann Publishers
Instructions:
• Language of the Machine
• We’ll be working with the MIPS instruction set architecture
– similar to other architectures developed since the 1980's
– Almost 100 million MIPS processors manufactured in 2002
– used by NEC, Nintendo, Cisco, Silicon Graphics, Sony, …
1400
1300
1200
1100
1000
900
800
700
600
500
400
300
200
100
01998 2000 2001 20021999
Other
SPARC
Hitachi SH
PowerPC
Motorola 68K
MIPS
IA-32
ARM

62004 Morgan Kaufmann Publishers
MIPS arithmetic
• All instructions have 3 operands
• Operand order is fixed (destination first)
Example:
C code: a = b + c
MIPS ‘code’: add a, b, c
(we’ll talk about registers in a bit)
“The natural number of operands for an operation like addition is three…requiring every instruction to have exactly three operands, no more and no less, conforms to the philosophy of keeping the hardware simple”

72004 Morgan Kaufmann Publishers
MIPS arithmetic
• Design Principle: simplicity favors regularity.
• Of course this complicates some things...
C code: a = b + c + d;
MIPS code: add a, b, cadd a, a, d
• Operands must be registers, only 32 registers provided
• Each register contains 32 bits
• Design Principle: smaller is faster. Why?
8
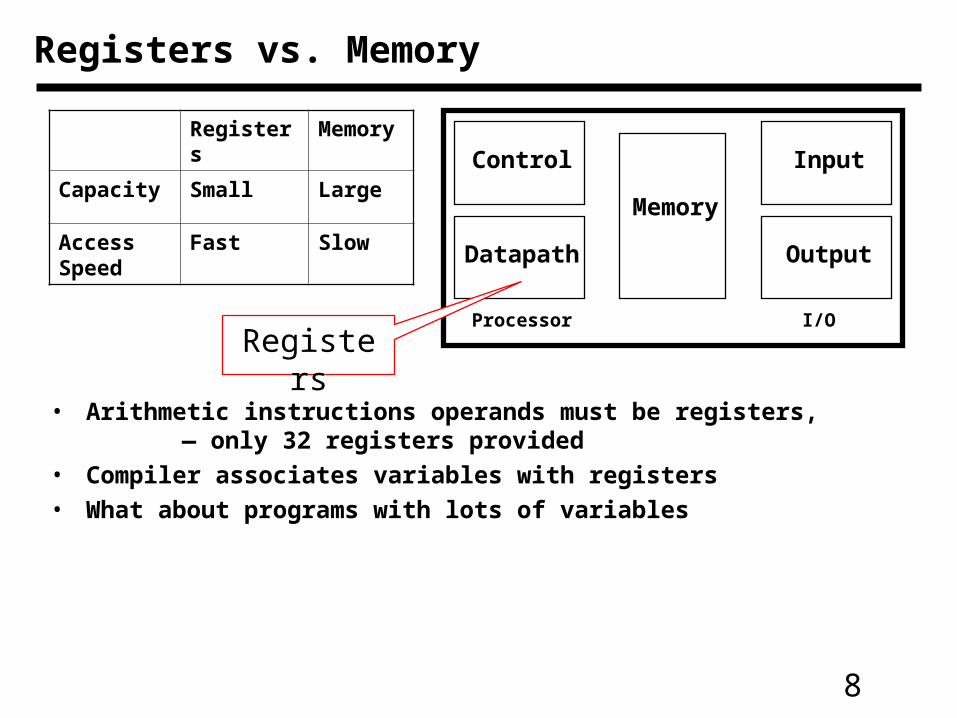
Registers vs. Memory
Processor I/O
Control
Datapath
Memory
Input
Output
• Arithmetic instructions operands must be registers, — only 32 registers provided
• Compiler associates variables with registers
• What about programs with lots of variables
Registers Memory
Capacity Small Large
Access Speed
Fast Slow
Registers

9
Memory Organization
• Viewed as a large, single-dimension array, with an address.
• A memory address is an index into the array
• "Byte addressing" means that the index points to a byte of memory.
0
1
2
3
4
5
6
...
8 bits of data
8 bits of data
8 bits of data
8 bits of data
8 bits of data
8 bits of data
8 bits of data

10
Memory Organization
• Bytes are nice, but most data items use larger "words"
• For MIPS, a word is 32 bits or 4 bytes.
• 232 bytes with byte addresses from 0 to 232-1
• 230 words with byte addresses 0, 4, 8, ... 232-4
• Words are alignedi.e., what are the least 2 significant bits of a word address?
0
4
8
12
...
32 bits of data
32 bits of data
32 bits of data
32 bits of data
Registers hold 32 bits of data

11
MIPS arithmetic (with registers)
• All instructions have 3 operands
• Operand order is fixed (destination first)
Example:
C code: A = B + C
MIPS code: add $s0, $s1, $s2
(associated with variables by compiler)

12
MIPS arithmetic (with registers)
• Design Principle: simplicity favors regularity. Why?• Of course this complicates some things...
C code: A = B + C + D;E = F - A;
MIPS code: add $t0, $s1, $s2add $s0, $t0, $s3sub $s4, $s5, $s0
• Which variables go to which registers?
• Operands must be registers, only 32 registers provided• Design Principle: smaller is faster. Why?• Note
– Additional register usage: $t0 (allocated by the compiler)

13
Operand in Memory
• Base address and offset
C code: g = h + A[8];
MIPS ‘code’: lw $t0, 8($s3); assume $s3 have the start address; of A matrix, 8 is offsetadd $s1, $s2, $t0

14
Instructions
• Load and store instructions• Example:
C code: A[8] = h + A[8];
MIPS code: lw $t0, 32($s3) ; $s3=A, 32=8*4add $t0, $s2, $t0sw $t0, 32($s3)
• Store word has destination last• Remember:
– Operands of arithmetic/logic instructions are registers, not memory!– Load/store instructions have one memory operand.
• Note:– Temporary register: $t0;– Array name: a register $s3;– Displacement: 32, not 8!

15
Our First Example
• Can we figure out the code?
swap(int v[], int k);{ int temp;
temp = v[k]v[k] = v[k+1];v[k+1] = temp;
}swap:
muli $2, $5, 4add $2, $4, $2 ; $s2= addr.of v[k]lw $15, 0($2)lw $16, 4($2)sw $16, 0($2)sw $15, 4($2)jr $31 ; Return addr. is saved in $s31

16
So far we’ve learned:
• MIPS— loading words but addressing bytes— arithmetic on registers only
• Instruction Meaning (Register Transfer Language, RTL)
add $s1, $s2, $s3 $s1 = $s2 + $s3sub $s1, $s2, $s3 $s1 = $s2 – $s3lw $s1, 100($s2) $s1 = Memory[$s2+100] sw $s1, 100($s2) Memory[$s2+100] = $s1

17
• Instructions, like registers and words of data, are also 32 bits long
– Example: add $t0, $s1, $s2– registers have numbers, $t0=8, $s1=17, $s2=18
• Instruction Format:
000000 10001 10010 01000 00000 100000
op rs rt rd shamt funct
• Can you guess what the field names stand for?
Machine Language: add/sub (arithmetic)

18
• Now include the load/store instructions into the same instruction format (regularity principle):
– Example: lw $s1, 32($s2)– registers have numbers, $s1=2, $s2=18
• Using the same Instruction Format as arithmetic operations:
100011 10010 xxxxx 00010 00000 100000
op rs rt rd shamtH shamtL
• Can you see any problem?
Machine Language: load/store

19
• Consider the load-word and store-word instructions,
– What would the regularity principle have us do?
– New principle: Good design demands a compromise
• Introduce a new type of instruction format
– I-type for data transfer instructions
– other format was R-type for register
• Example: lw $t0, 32($s2)
35 18 2 32
op rs rt 16 bit number
• Where's the compromise?
Machine Language: load/store instructions
20
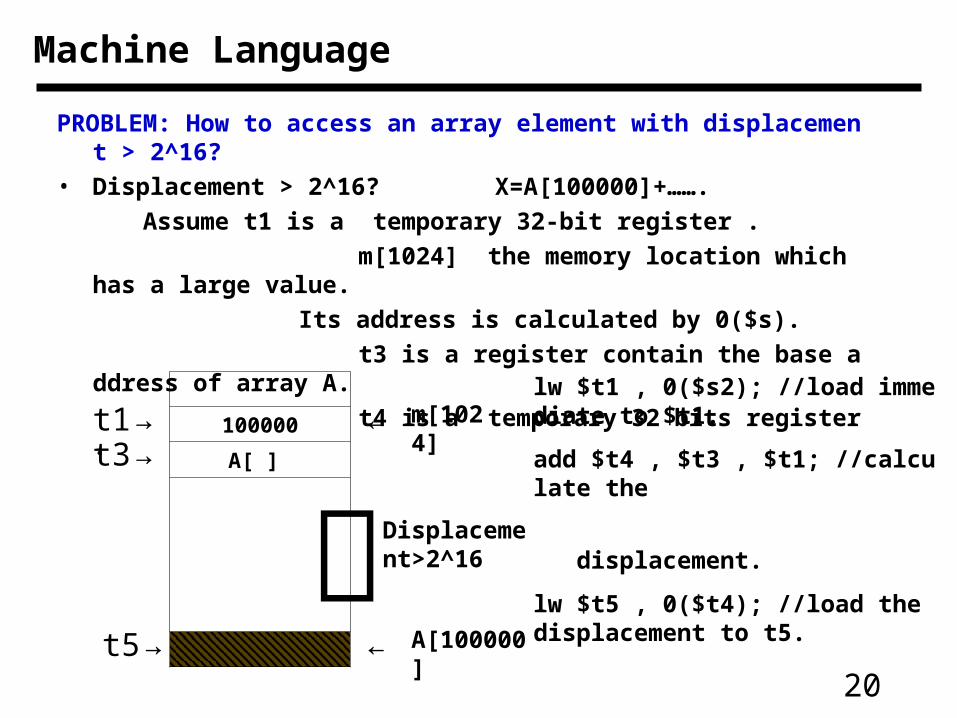
Machine Language
PROBLEM: How to access an array element with displacement > 2^16?
• Displacement > 2^16? X=A[100000]+…….
Assume t1 is a temporary 32-bit register .
m[1024] the memory location which has a large value.
Its address is calculated by 0($s).
t3 is a register contain the base address of array A.
t4 is a temporary 32 bits register .
100000
A[ ]
→t1t3 →
← m[1024]
﹜Displacement>2^16
←→t5 A[100000]
lw $t1 , 0($s2); //load immediate to $t1.
add $t4 , $t3 , $t1; //calculate the
displacement.
lw $t5 , 0($t4); //load the displacement to t5.
21
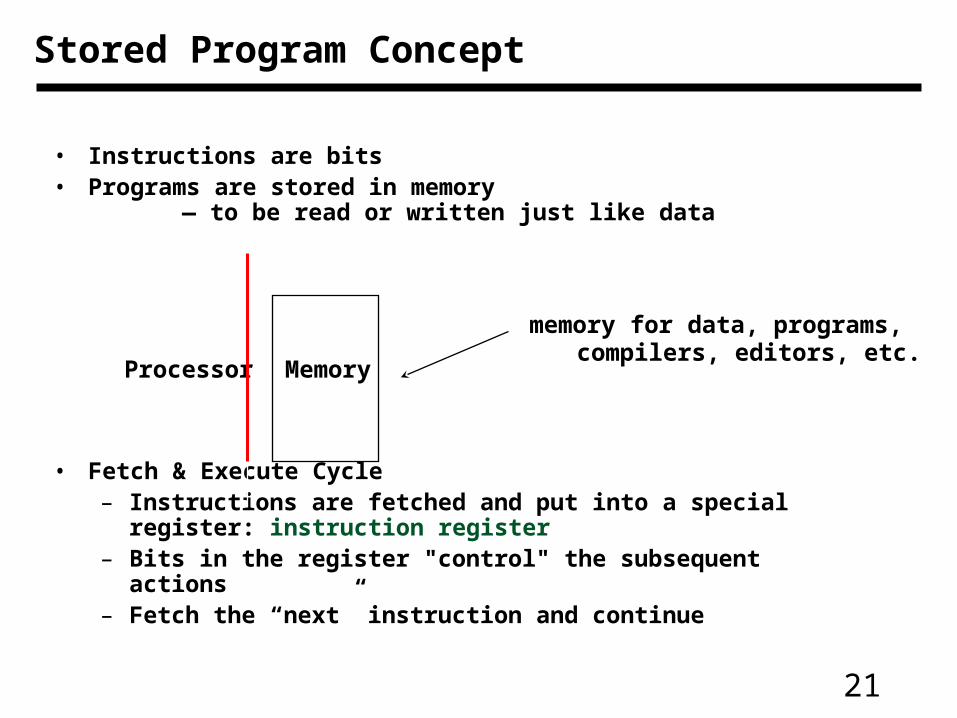
• Instructions are bits• Programs are stored in memory
— to be read or written just like data
• Fetch & Execute Cycle– Instructions are fetched and put into a special register:
instruction register– Bits in the register "control" the subsequent actions– Fetch the “next” instruction and continue
Processor Memory
memory for data, programs, compilers, editors, etc.
Stored Program Concept

22
• Decision making instructions– alter the control flow,– i.e., change the "next" instruction to be executed
• Sequential execution: implicitly implied!
• MIPS conditional branch instructions:
bne $t0, $t1, Label beq $t0, $t1, Label
• Example: if (i==j) h = i + j;
bne $s0, $s1, Labeladd $s3, $s0, $s1
Label: ....
Control

23
• MIPS unconditional branch instructions:j label
• Example:
if (i==j) bne $s4, $s5, Lab1 h=i+j; add $s3, $s4, $s5else j Lab2 h=i-j; Lab1: sub $s3, $s4, $s5... Lab2: ...
• Can you build a simple for loop?
Control

24
• MIPS unconditional branch instructions:j label
• Example:
if (i!=j) beq $s4, $s5, Lab1 h=i-j; sub $s3, $s4, $s5else j Lab2 h=i+j; Lab1: add $s3, $s4, $s5... Lab2: ...
• Can you build a simple for loop?
Control (II)

25
• MIPS conditional branch instructions:
bne $t0, $t1, Label ; branch if not equal
beq $t0, $t1, Label ; branch if equal
• Since bne and beq are complement, can we use and implement only one of them in software and hardware?
Is one enough?
I == J
Y
N
BranchTarget
(Label)
Fall through
(PC++)
I != J
Y
N
BranchTarget
(Label)
Fall through
(PC++)
26
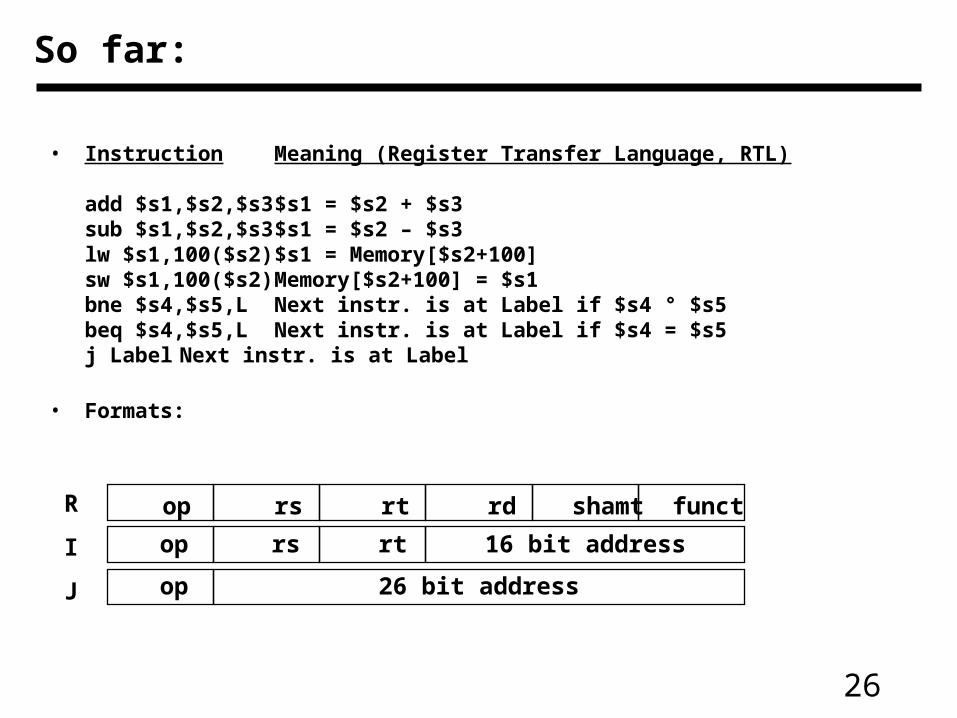
So far:
• Instruction Meaning (Register Transfer Language, RTL)
add $s1,$s2,$s3 $s1 = $s2 + $s3sub $s1,$s2,$s3 $s1 = $s2 – $s3lw $s1,100($s2) $s1 = Memory[$s2+100] sw $s1,100($s2) Memory[$s2+100] = $s1bne $s4,$s5,L Next instr. is at Label if $s4 ° $s5beq $s4,$s5,L Next instr. is at Label if $s4 = $s5j Label Next instr. is at Label
• Formats:
op rs rt rd shamt funct
op rs rt 16 bit address
op 26 bit address
R
I
J

27
• We have: beq, bne, what about Branch-if-less-than?• New instruction:
if $s1 < $s2 then $t0 = 1
slt $t0, $s1, $s2 else $t0 = 0
• Can use this instruction to build "blt $s1, $s2, Label" — can now build general control structures
• Note that the assembler needs two registers to do this,— there are policy of use conventions for registers
• Pseudo instruction: "blt $s1, $s2, Label" Mapped to
slt $t0, $s1, $s2beq $t0, $t1, Label % $t1=1
Control Flow

28
Compiling Loops in C
• Use shift left logic (sll) to multiply 4
C code: while (save[i] == k)i += 1;
MIPS ‘code’: Loop: sll $t1, $s3, 2add $t1, $t1, $s6lw $t0, 0($t1)bne $t0, $s5, Exitadd $s3, $s3, 1j Loop
Exit:

29
Procedure Call: basic concept
• Caller– The program that instigates a procedure and provides the neces
sary parameter values.• Callee
– A procedure that executes a series of stored instructions based on parameters provided by the caller and then returns control to the caller.
• Return Address– A link to the calling site that allows a procedure to return to the
proper address; in MIPS it is stored in the register $ra• Stack
– A data structure for spilling registers organized as a list-in-first-out queue.
• Stack Point– A value denoting the most revently allocated address in a stack t
hat slow where registers should be spilled or where old register values can be found.
30
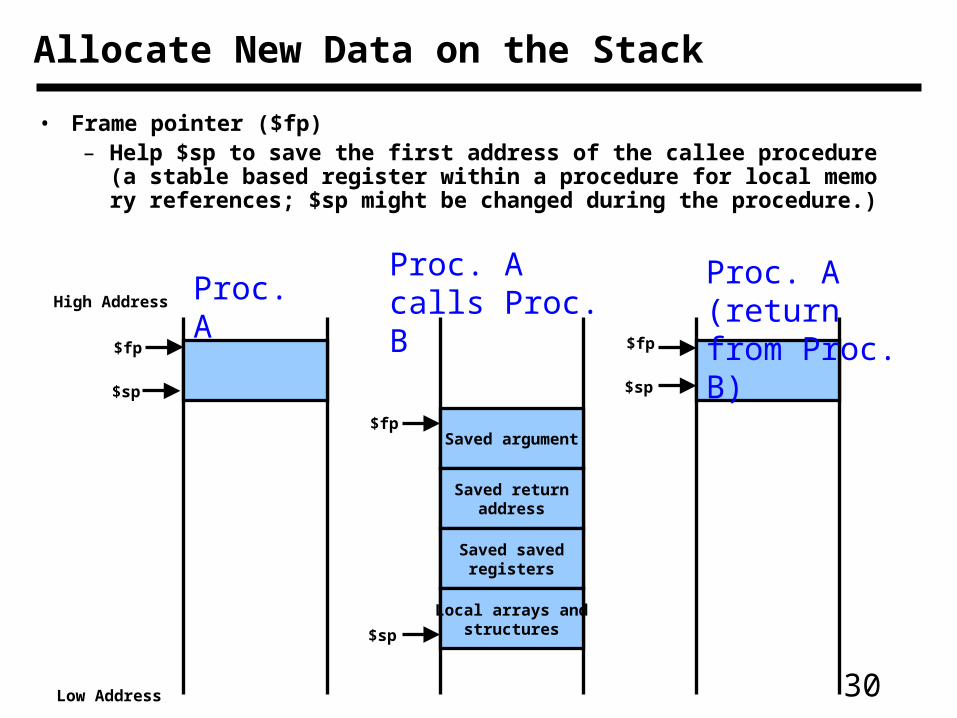
Allocate New Data on the Stack
• Frame pointer ($fp)– Help $sp to save the first address of the callee procedure (a stable
based register within a procedure for local memory references; $sp might be changed during the procedure.)
Saved argument
Saved returnaddress
Saved savedregisters
Local arrays andstructures
High Address
Low Address
$fp
$sp
$fp
$sp
$fp
$sp
Proc. AProc. A calls Proc. B
Proc. A (return from Proc. B)

31
Saving registers
• Both leaf and non-leaf procedures need to save:
– Saved registers
• Non-leaf procedures need to save additionally:
– Argument registers
– Temporary registers
– Return register
32
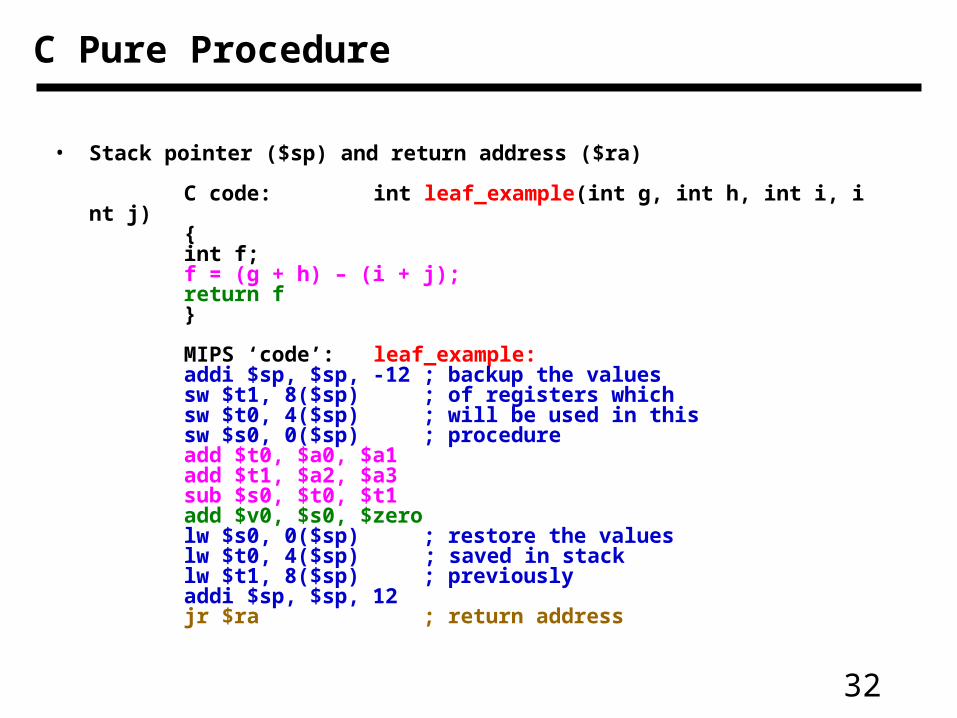
C Pure Procedure
• Stack pointer ($sp) and return address ($ra)
C code: int leaf_example(int g, int h, int i, int j){
int f;f = (g + h) – (i + j);return f
}
MIPS ‘code’: leaf_example:addi $sp, $sp, -12 ; backup the values sw $t1, 8($sp) ; of registers which sw $t0, 4($sp) ; will be used in this sw $s0, 0($sp) ; procedure add $t0, $a0, $a1add $t1, $a2, $a3sub $s0, $t0, $t1add $v0, $s0, $zerolw $s0, 0($sp) ; restore the values lw $t0, 4($sp) ; saved in stack lw $t1, 8($sp) ; previouslyaddi $sp, $sp, 12jr $ra ; return address

33
Recursive Procedure
• Stack pointer ($sp) and return address ($ra)
C code: int fact(int n){
if(n < 1) return (1);else return (n * fact(n-1));
}
MIPS ‘code’: fact:addi $sp, $sp, -8 sw $ra, 4($sp) ; backup the return address
sw $a0, 0($sp) ; & argument n slti $t0, $a0, 1beq $t0, $zero, L1addi $v0, $zero, 1addi $sp, $sp, 8jr $raL1: addi $a0, $a0, -1jal factlw $a0, 0($sp) ; restore the return addres
s lw $ra, 4($sp) ; & argument n addi $sp, $sp, 8mul $v0, $a0, $v0jr $ra ; return to the caller

34

35
Policy of Use Conventions
Register number Usage Preserved on call?0 the constant value 0 n.a.
2-3 values for results and expression evaluation no4-7 arguments (parameter passing) yes
8-15 temporaries no 16-23 saved yes24-25 more temporaries no
28 global pointer (for static data) yes29 stack pointer (for procedure call/return) yes30 frame pointer (for local data within a procedure) yes31 return address yes
Register 1 ($at) reserved for assembler, 26-27 for operating system
36
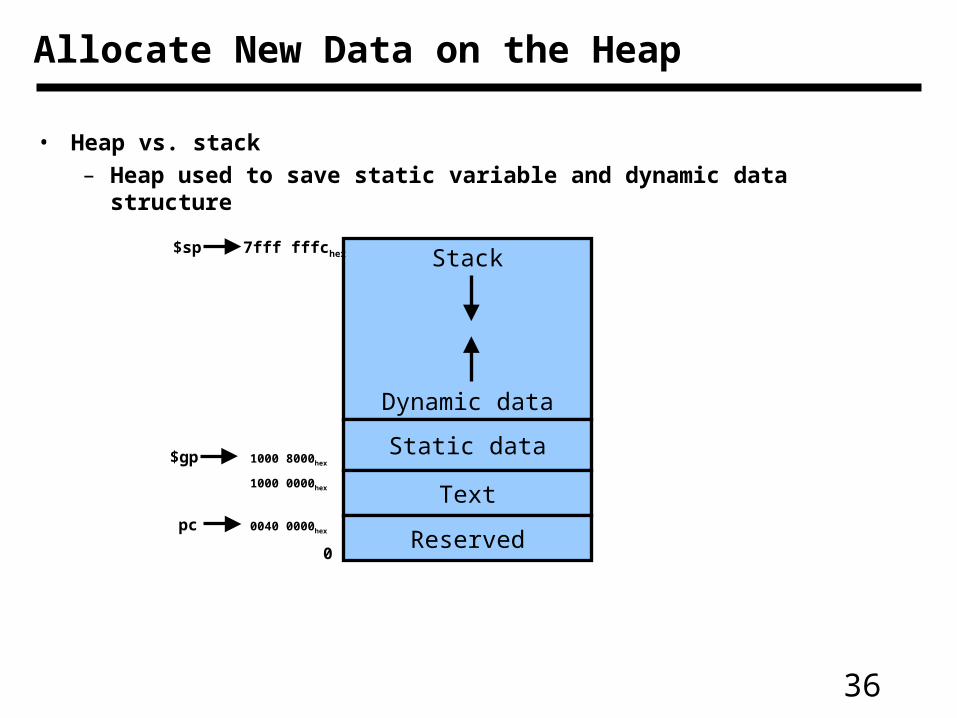
Allocate New Data on the Heap
• Heap vs. stack
– Heap used to save static variable and dynamic data structure
Stack
Dynamic data
Static data
Text
Reserved
$sp
$gp
7fff fffchex
1000 8000hex
1000 0000hex
0040 0000hexpc
0

37
String Copy Procedure
• Stack pointer ($sp) and return address ($ra)
C code: void strcpy(char x[], char y[]){
int i;i = 0;while((x[i] = y[i]) != ‘\0’)
i += 1;}
MIPS ‘code’: strcpy:addi $sp, $sp, -4 sw $s0, 0($sp) ; backup $s0 add $s0, $zero, $zero ; initial i to 0L1: add $t1, $s0, a1lb $t2, 0($t1)add $t3, $s0, $a0sb $t2, 0($t3)beq $t2, $zero, L2addi $s0, $s0, 1j L1 L2: lw $s0, 0($sp) ; end of stringaddi $sp, $sp, 4jr $ra ; return to the caller
38
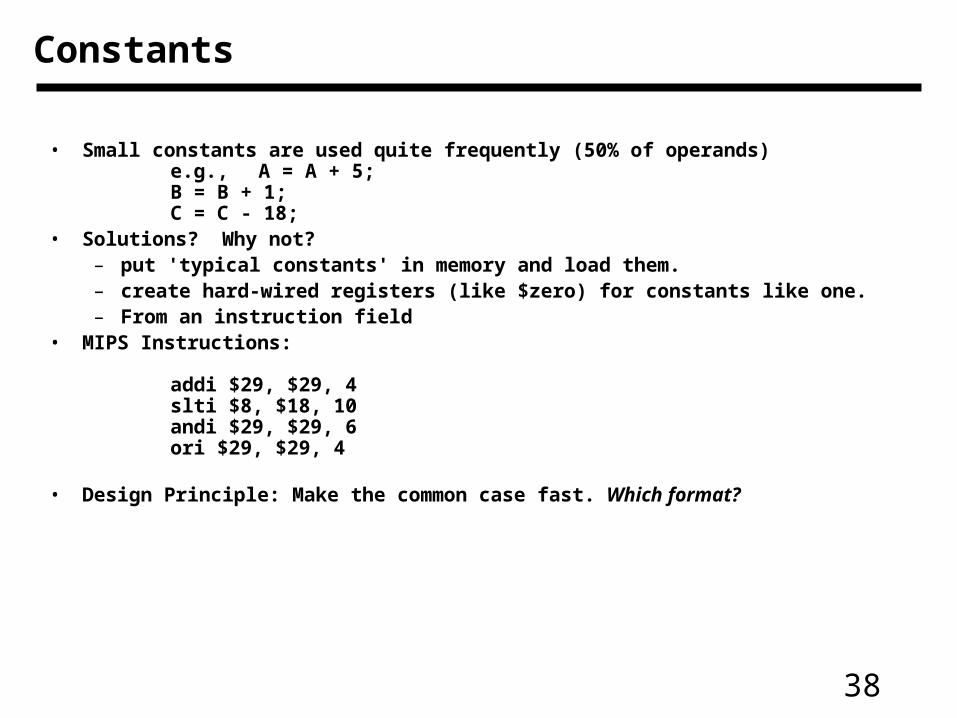
• Small constants are used quite frequently (50% of operands) e.g., A = A + 5;
B = B + 1;C = C - 18;
• Solutions? Why not?– put 'typical constants' in memory and load them. – create hard-wired registers (like $zero) for constants like one.– From an instruction field
• MIPS Instructions:
addi $29, $29, 4slti $8, $18, 10andi $29, $29, 6ori $29, $29, 4
• Design Principle: Make the common case fast. Which format?
Constants

39
• We'd like to be able to load a 32 bit constant into a register
• Must use two instructions, new "load upper immediate" instruction
lui $t0, 1010101010101010
• Then must get the lower order bits right, i.e.,
ori $t0, $t0, 1010101010101010
1010101010101010 0000000000000000
0000000000000000 1010101010101010
1010101010101010 1010101010101010
ori
1010101010101010 0000000000000000
filled with zeros
How about larger constants?

40
• Assembly provides convenient symbolic representation
– much easier than writing down numbers
– e.g., destination first
• Machine language is the underlying reality
– e.g., destination is no longer first
• Assembly can provide 'pseudoinstructions'
– e.g., “move $t0, $t1” exists only in Assembly
– would be implemented using “add $t0,$t1,$zero”
• When considering performance you should count real instructions
Assembly Language vs. Machine Language

41
• Things we are not going to cover in lecturesupport for procedureslinkers, loaders, memory layoutstacks, frames, recursionmanipulating strings and pointersinterrupts and exceptionssystem calls and conventions
• Some of these we'll talk about later
• We've focused on architectural issues
– basics of MIPS assembly language and machine code
– we’ll build a processor to execute these instructions.
Other Issues
42
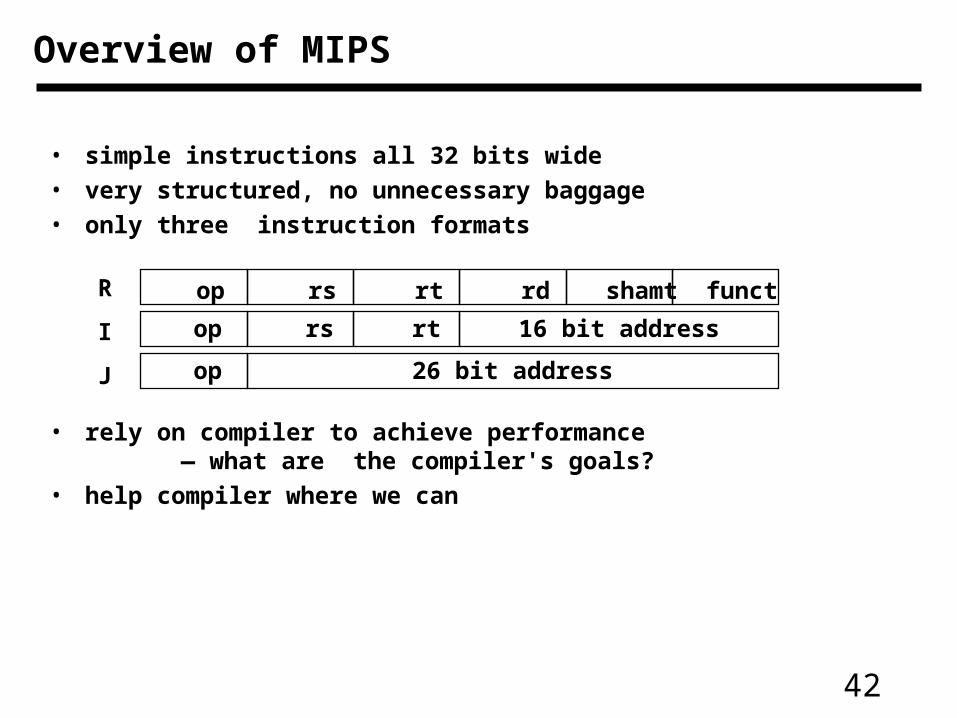
• simple instructions all 32 bits wide
• very structured, no unnecessary baggage
• only three instruction formats
• rely on compiler to achieve performance— what are the compiler's goals?
• help compiler where we can
op rs rt rd shamt funct
op rs rt 16 bit address
op 26 bit address
R
I
J
Overview of MIPS

43
• Instructions:
bne $t4,$t5,Label Next instruction is at Label if $t4°$t5beq $t4,$t5,Label Next instruction is at Label if $t4=$t5
• Formats:
• Could specify a register (like lw and sw) and add it to address– use Instruction Address Register (PC = program counter)– most branches are local (principle of locality)
• Jump instructions just use high order bits of PC – address boundaries of 256 MB
op rs rt 16 bit addressI
Addresses in Branches

44
• Instructions:
bne $t4,$t5,Label Next instruction is at Label if $t4 ° $t5
beq $t4,$t5,Label Next instruction is at Label if $t4 = $t5
j Label Next instruction is at Label
• Formats:
• Addresses are not 32 bits — How do we handle this with load and store instructions?
op rs rt 16 bit address
op 26 bit address
I
J
Addresses in Branches and Jumps
45
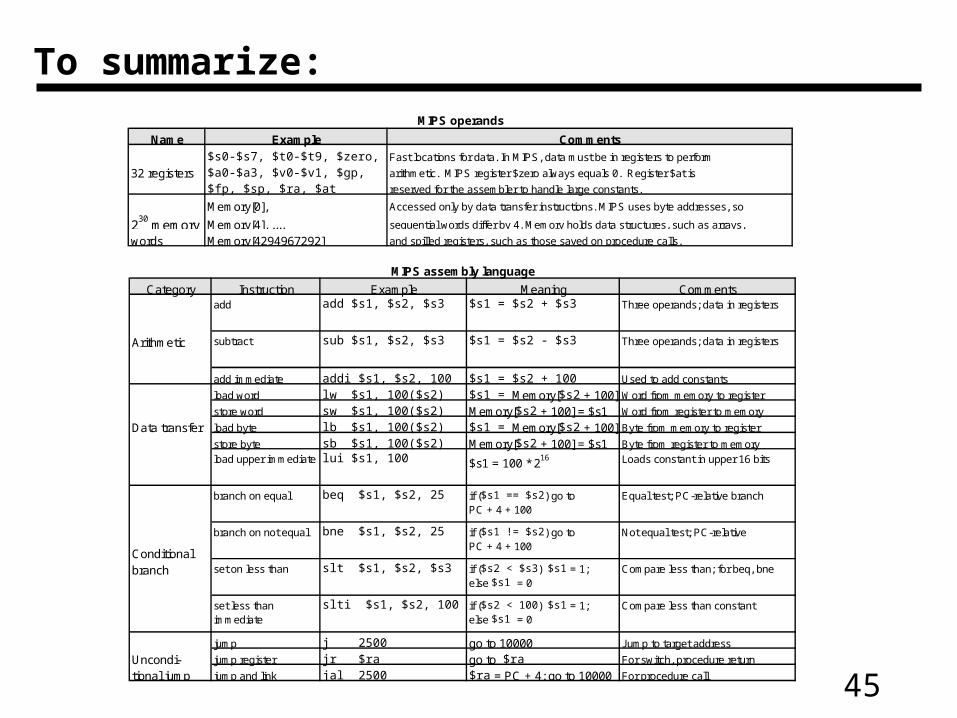
To summarize:MIPS operands
Name Example Comments$s0-$s7, $t0-$t9, $zero, Fast locations for data. In MIPS, data must be in registers to perform
32 registers $a0-$a3, $v0-$v1, $gp, arithmetic. MIPS register $zero always equals 0. Register $at is $fp, $sp, $ra, $at reserved for the assembler to handle large constants.
Memory[0], Accessed only by data transfer instructions. MIPS uses byte addresses, so
230 memory Memory[4], ..., sequential words differ by 4. Memory holds data structures, such as arrays,
words Memory[4294967292] and spilled registers, such as those saved on procedure calls.
MIPS assembly language
Category Instruction Example Meaning Commentsadd add $s1, $s2, $s3 $s1 = $s2 + $s3 Three operands; data in registers
Arithmetic subtract sub $s1, $s2, $s3 $s1 = $s2 - $s3 Three operands; data in registers
add immediate addi $s1, $s2, 100 $s1 = $s2 + 100 Used to add constants
load word lw $s1, 100($s2) $s1 = Memory[$s2 + 100] Word from memory to register
store word sw $s1, 100($s2) Memory[$s2 + 100] = $s1 Word from register to memory
Data transfer load byte lb $s1, 100($s2) $s1 = Memory[$s2 + 100] Byte from memory to register
store byte sb $s1, 100($s2) Memory[$s2 + 100] = $s1 Byte from register to memory
load upper immediate lui $s1, 100 $s1 = 100 * 216 Loads constant in upper 16 bits
branch on equal beq $s1, $s2, 25 if ($s1 == $s2) go to PC + 4 + 100
Equal test; PC-relative branch
Conditional
branch on not equal bne $s1, $s2, 25 if ($s1 != $s2) go to PC + 4 + 100
Not equal test; PC-relative
branch set on less than slt $s1, $s2, $s3 if ($s2 < $s3) $s1 = 1; else $s1 = 0
Compare less than; for beq, bne
set less than immediate
slti $s1, $s2, 100 if ($s2 < 100) $s1 = 1; else $s1 = 0
Compare less than constant
jump j 2500 go to 10000 Jump to target address
Uncondi- jump register jr $ra go to $ra For switch, procedure return
tional jump jump and link jal 2500 $ra = PC + 4; go to 10000 For procedure call

Byte Halfword Word
Registers
Memory
Memory
Word
Memory
Word
Register
Register
1. Immediate addressing
2. Register addressing
3. Base addressing
4. PC-relative addressing
5. Pseudodirect addressing
op rs rt
op rs rt
op rs rt
op
op
rs rt
Address
Address
Address
rd . . . funct
Immediate
PC
PC
+
+
displacement
47
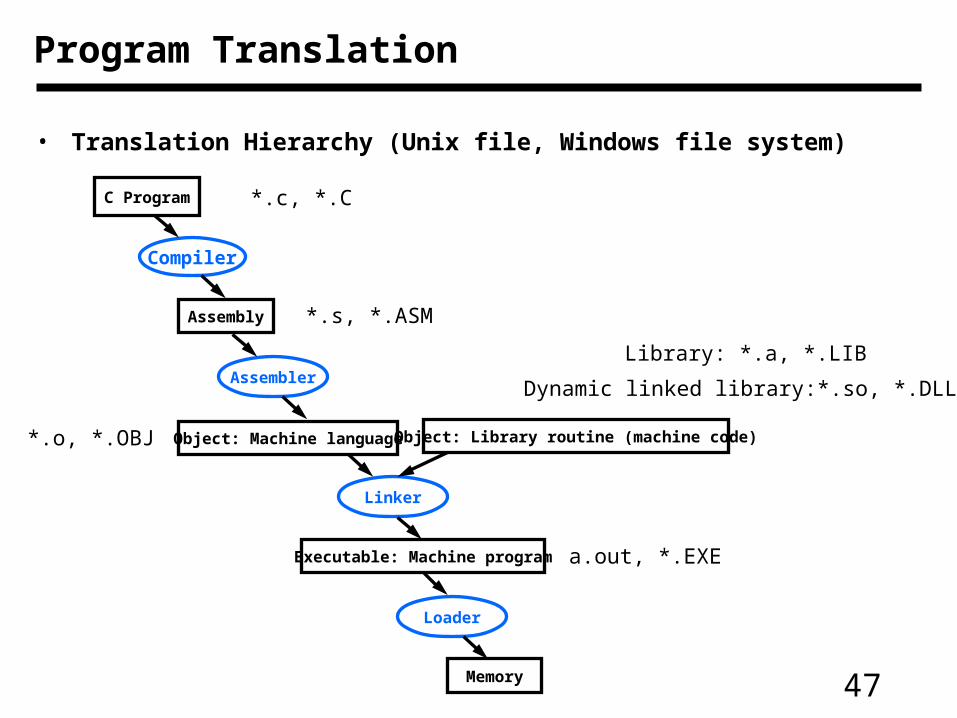
Program Translation
• Translation Hierarchy (Unix file, Windows file system)
C Program
Compiler
Assembly
Assembler
Object: Machine language
Linker
Object: Library routine (machine code)
Executable: Machine program
Loader
Memory
*.c, *.C
*.s, *.ASM
*.o, *.OBJ
Dynamic linked library:*.so, *.DLL
Library: *.a, *.LIB
a.out, *.EXE

48
Linking Object Files
• Reallocate the address in text segment and data segment
– Link procedure A & BObject file header
Name Procedure A
Text size 100hex
Data size 20hex
Text segment Address Instruction
0 lw $a0, 0($gp)
4 jal 0
… …
Data segment 0 (X)
… …
Relocation information Address Instruction type
Dependency
0 lw X
4 jal B
Symbol table Label Address
X -
B -
Object file header
Name Procedure B
Text size 200hex
Data size 30hex
Text segment Address Instruction
0 sw $a1, 0($gp)
4 jal 0
… …
Data segment 0 (Y)
… …
Relocation information Address Instruction type
Dependency
0 sw Y
4 jal A
Symbol table Label Address
Y -
A -
49
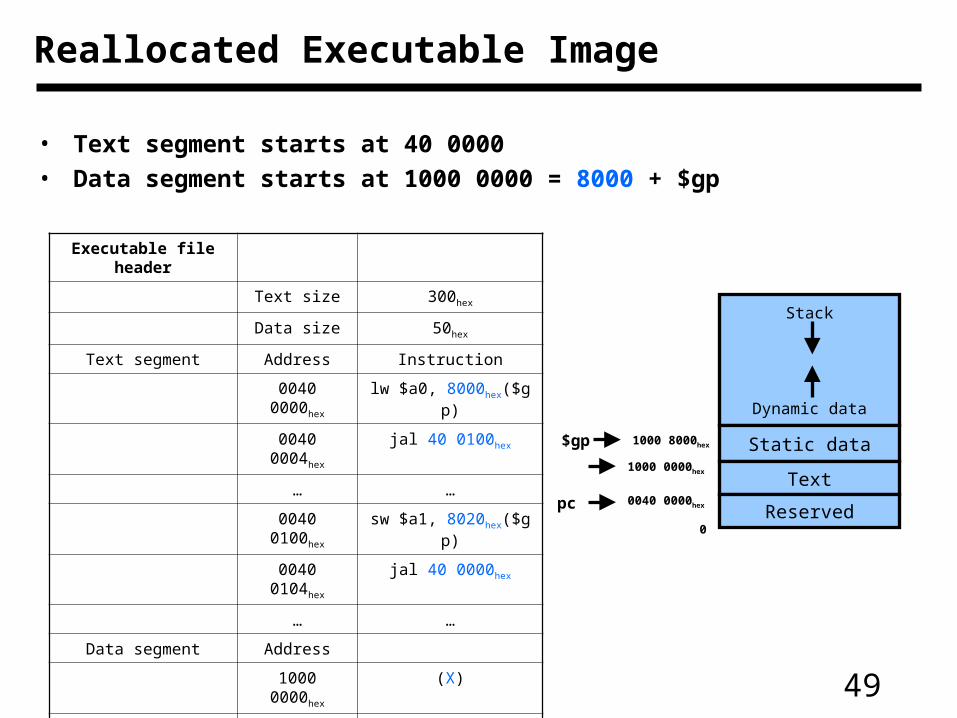
Reallocated Executable Image
• Text segment starts at 40 0000
• Data segment starts at 1000 0000 = 8000 + $gp
Executable file header
Text size 300hex
Data size 50hex
Text segment Address Instruction
0040 0000hex lw $a0, 8000hex($gp)
0040 0004hex jal 40 0100hex
… …
0040 0100hex sw $a1, 8020hex($gp)
0040 0104hex jal 40 0000hex
… …
Data segment Address
1000 0000hex (X)
… …
1000 0020hex (Y)
… …
Stack
Dynamic data
Static data
Text
Reserved
1000 0000hex
0040 0000hexpc
0
$gp 1000 8000hex

50
Loader
• Operating system read executable file to memory and start it
Read header determine size of text and data segment
Create space for text and data segment
Copy instructions and data into memory
Copy parameter to main program
Initialize register and stack pointer
Jump to start-up routine
Exit system call

51
Dynamic Linked Library
• Disadvantage of static library routine:– In update: the library become old in code when new one is released– In size: library routine become part of the code
• Lazy procedure linkage– Overhead on first time called– Pay nothing when return from the library
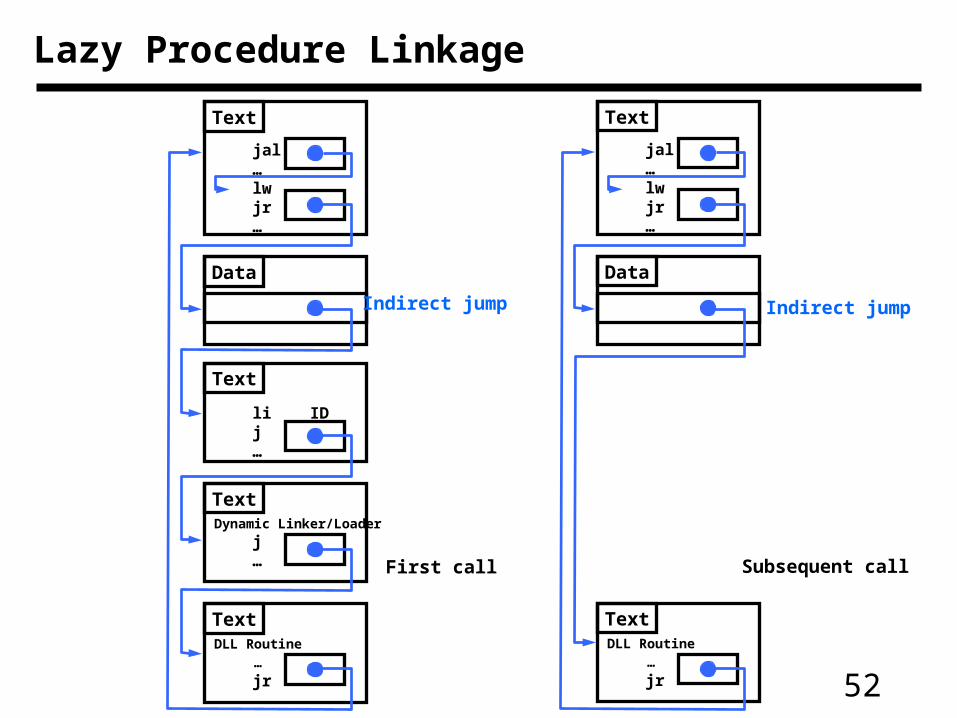
52
Lazy Procedure Linkage
jal … lw jr …
Text
Data
li ID j …
Text
Dynamic Linker/Loader
j …
Text
DLL Routine
… jr
Text
jal … lw jr …
Text
Data
DLL Routine
… jr
Text
First call Subsequent call
Indirect jump Indirect jump
53
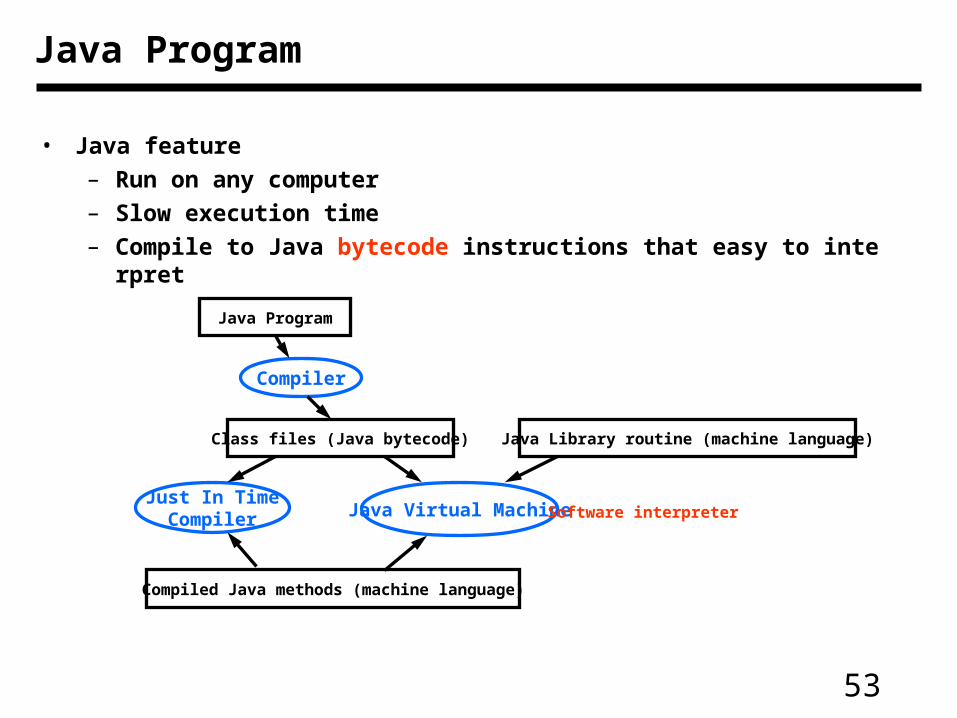
Java Program
• Java feature
– Run on any computer
– Slow execution time
– Compile to Java bytecode instructions that easy to interpret
Java Program
Compiler
Class files (Java bytecode)
Java Virtual MachineJust In Time
Compiler
Java Library routine (machine language)
Compiled Java methods (machine language)
Software interpreter
54
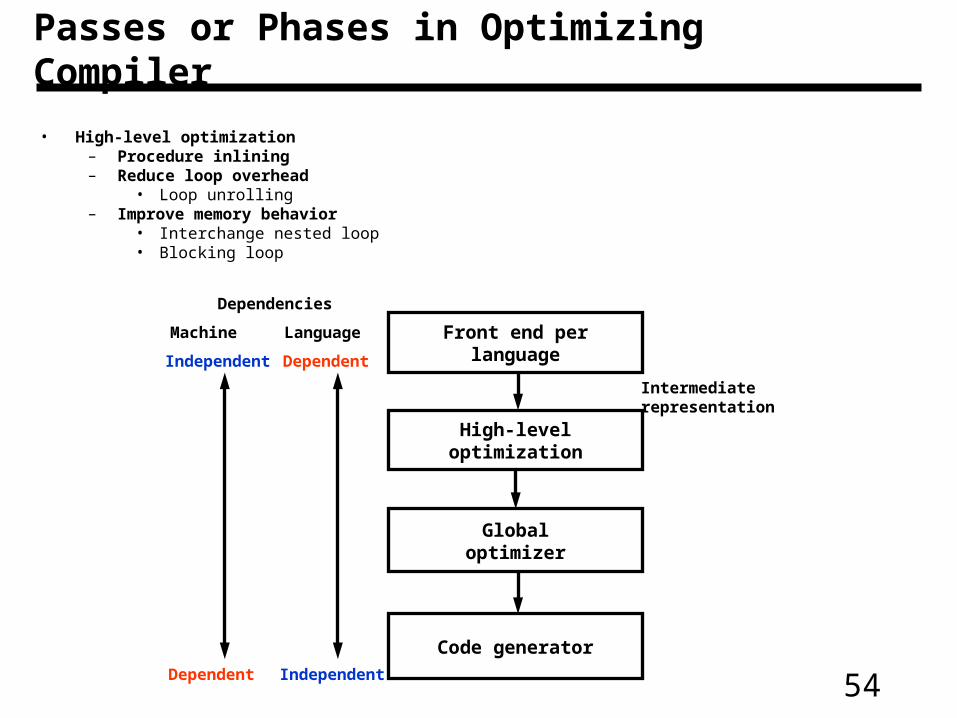
Passes or Phases in Optimizing Compiler
• High-level optimization– Procedure inlining– Reduce loop overhead
• Loop unrolling– Improve memory behavior
• Interchange nested loop• Blocking loop
Front end perlanguage
High-leveloptimization
Globaloptimizer
Code generator
Intermediaterepresentation
Dependencies
Machine Language
Dependent
IndependentDependent
Independent

55
Local Optimizations
• Common subexpression elimination# to compute x[i] = x[i] +4
# x[i] + 4li R100, x li R100, xlw R101,i lw R101,imult R102, R101, 4 mult R102, R101, 4add R103, R100, R102 add R103, R100, R102lw R104, 0(R103) lw R104, 0(R103)# x[i] in R104add R105, R104, 4 add R105, R104, 4# x[i] = li R106, x sw R105, 0(R103)lw R107, imult R108, R107, 4add R109, R016, R107sw R105, 0(R109)
• Strength reduction: replace mult by shift left• Constant propagation: collapse constant whenever possible• Copy propagation: eliminate the need to reload value• Dead store elimination: eliminate “store” value not used again• Dead code elimination: eliminate the code which not affect final result

56
Global Optimization
• The same as local optimization and more
• Code motion
– eliminate invariant loop
• Induction variable elimination:
– reduce overhead on indexing array into pointer accesses

57
Optimization in gcc Level
Optimization name Explanation gcc level
High level
Procedure integration
At or near the source level; processor independent
Replace procedure call by procedure body O3
Local
Common subexpression elimination
Constant propagation
Stack height reduction
Within straight-line code
Replace two instances of the same computation by single copy
Replace all instances of a variable that is assigned a constant with the constant
Rearrange expression tree to minimize resources needed for expression evaluation
O1
O1
O1
Global
Global common subexpression elimination
Copy propagation
Code motion
Induction variable elimination
Across a branch
Same as local, but this version crosses branches
Replace all instances of a variable A that has been assigned X (i.e., A=X) with X
Remove code from a loop that computes same value each iteration of the loop
Simplify/eliminate array addressing calculations within loops
O2
O2
O2
O2
Processor dependent
Strength reduction
Pipeline scheduling
Branch offset optimization
Depends on processor knowledge
Many examples; replace multiply by a constant with shifts
Reorder instructions to improve pipeline performance
Choose the shortest branch displacement that reaches target
O1
O1
O1
58
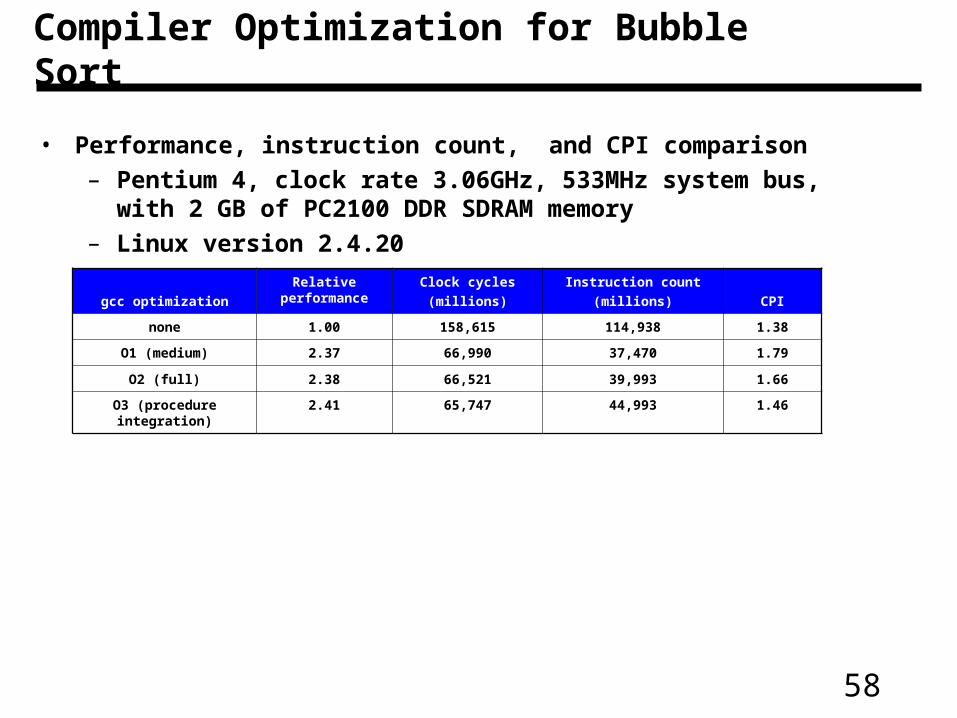
Compiler Optimization for Bubble Sort
• Performance, instruction count, and CPI comparison
– Pentium 4, clock rate 3.06GHz, 533MHz system bus, with 2 GB of PC2100 DDR SDRAM memory
– Linux version 2.4.20
gcc optimization
Relative performance
Clock cycles
(millions)
Instruction count
(millions) CPI
none 1.00 158,615 114,938 1.38
O1 (medium) 2.37 66,990 37,470 1.79
O2 (full) 2.38 66,521 39,993 1.66
O3 (procedure integration)
2.41 65,747 44,993 1.46
59
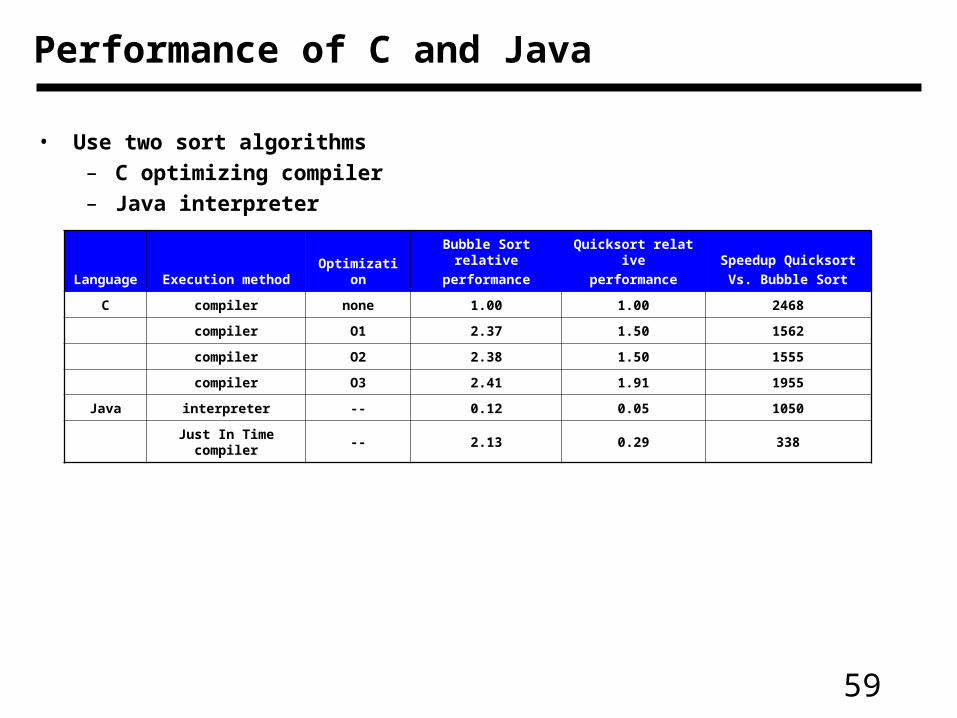
Performance of C and Java
• Use two sort algorithms– C optimizing compiler– Java interpreter
Language Execution method Optimization
Bubble Sort relative
performance
Quicksort relative
performance
Speedup Quicksort
Vs. Bubble Sort
C compiler none 1.00 1.00 2468
compiler O1 2.37 1.50 1562
compiler O2 2.38 1.50 1555
compiler O3 2.41 1.91 1955
Java interpreter -- 0.12 0.05 1050
Just In Time compiler -- 2.13 0.29 338

60
C Swap Example
• Swap two location in memory
C code: void swap(int v[], int k){
int temp;temp = v[k];v[k] = v[k+1];v[k+1] = temp;
}
MIPS ‘code’: swap: sll $t1, $a1, 2 ; $t1 = k * 4add $t1, $a0, $t1 ; $t1 = v + (k * 4)lw $t0, 0($t1) ; temp = v[k]
lw $t2, 4($t1) ; $t2 = v[k+1] sw $t2, 0($t1) ; v[k] =$t2 sw $t0, 4($t1) ; v[k+1] = tempjr $ra

61
C Sort Example
• Sort function call swap
C code: void sort(int v[], int k){ int i,j; for( i = 0; i < n; i += 1){
for( j = i - 1; j >= 0 && v[j] > v[j+1]; j -= 1){swap(v, j);}
} }

62
MIPS Code Translation (I)
• Saving registersort: addi $sp, $sp, -20
sw $ra, 16($sp)sw $s3, 12($sp)sw $s2, 8($sp)sw $s1, 4($sp)sw $s0, 0($sp)
• Move parametersmove $s2, $a0move $s3, $a1
• Outer loopmove $s0, $zero ; i = 0
for1tst: slt $t0, $s0, $s3 ; if( i >= n)beq $t0, $zero, exit1 ; then go to exi
t1… (inner loop)… (pass parameters and call)
exit2: addi $s0, $s0, 1j for1tst

63
MIPS Code Translation (II)
• Inner loopaddi $s1, $s0, -1 ; j = i - 1
for2tst: slti $t0, $s1, 0 ; if(j < 0)bne $t0, $zero, exit2 ; then go to exit2sll $t1, $s1, 2add $t2, $s2, $t1lw $t3, 0($t2)lw $t4, 4($t2)slt $t0, $t4, $t3beq $t0, $zero, exit2… (pass parameters and call)addi $s1, $s1, -1j for2tst
• Pass parameters and callmove $a0, $s2move $a1, $s1jal swap
• Restoring registerlw $s0, 0($sp)lw $s1, 4($sp)lw $s2, 8($sp)lw $s3, 12($sp)
lw $ra, 16($sp)addi $sp, $sp, 20
• Procedure returnjr $ra

642004 Morgan Kaufmann Publishers
• Design alternative:
– provide more powerful operations
– goal is to reduce number of instructions executed
– danger is a slower cycle time and/or a higher CPI
• Let’s look (briefly) at IA-32
Alternative Architectures
–“The path toward operation complexity is thus fraught with peril.
To avoid these problems, designers have moved toward simpler
instructions”

652004 Morgan Kaufmann Publishers
IA - 32
• 1978: The Intel 8086 is announced (16 bit architecture)• 1980: The 8087 floating point coprocessor is added• 1982: The 80286 increases address space to 24 bits, +instructions• 1985: The 80386 extends to 32 bits, new addressing modes• 1989-1995: The 80486, Pentium, Pentium Pro add a few instructions
(mostly designed for higher performance)• 1997: 57 new “MMX” instructions are added, Pentium II• 1999: The Pentium III added another 70 instructions (SSE)• 2001: Another 144 instructions (SSE2)• 2003: AMD extends the architecture to increase address space to 64 bits,
widens all registers to 64 bits and other changes (AMD64)• 2004: Intel capitulates and embraces AMD64 (calls it EM64T) and adds
more media extensions
• “This history illustrates the impact of the “golden handcuffs” of compatibility
“adding new features as someone might add clothing to a packed bag”
“an architecture that is difficult to explain and impossible to love”

662004 Morgan Kaufmann Publishers
IA-32 Overview
• Complexity:
– Instructions from 1 to 17 bytes long
– one operand must act as both a source and destination
– one operand can come from memory
– complex addressing modese.g., “base or scaled index with 8 or 32 bit
displacement”
• Saving grace:
– the most frequently used instructions are not too difficult to build
– compilers avoid the portions of the architecture that are slow
“what the 80x86 lacks in style is made up in quantity, making it beautiful from the right perspective”
672004 Morgan Kaufmann Publishers
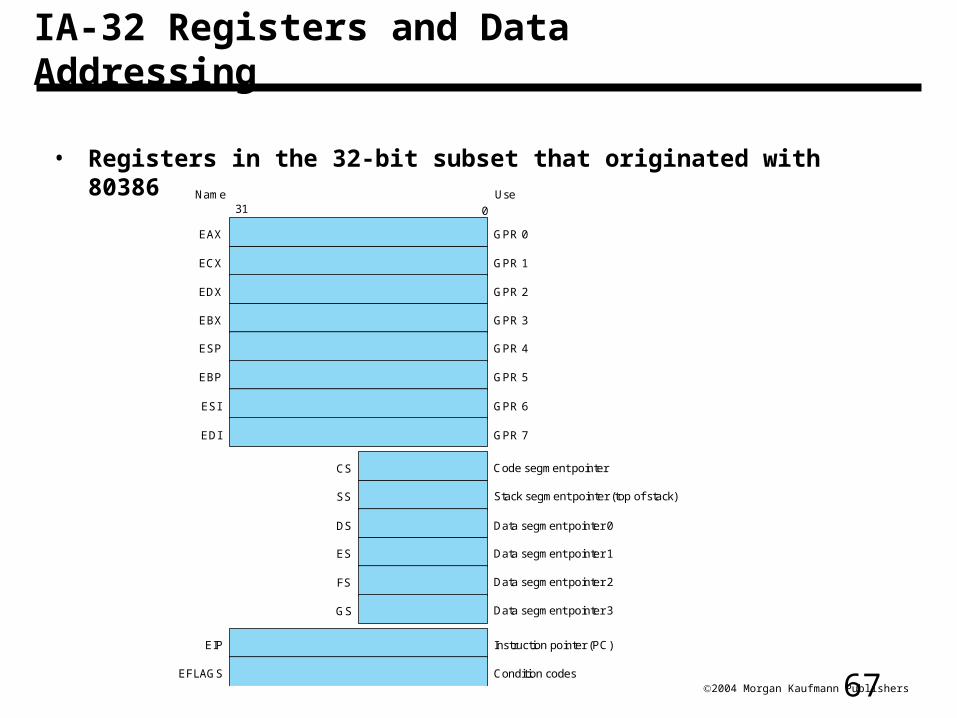
IA-32 Registers and Data Addressing
• Registers in the 32-bit subset that originated with 80386
GPR 0
GPR 1
GPR 2
GPR 3
GPR 4
GPR 5
GPR 6
GPR 7
Code segment pointer
Stack segment pointer (top of stack)
Data segment pointer 0
Data segment pointer 1
Data segment pointer 2
Data segment pointer 3
Instruction pointer (PC)
Condition codes
Use
031Name
EAX
ECX
EDX
EBX
ESP
EBP
ESI
EDI
CS
SS
DS
ES
FS
GS
EIP
EFLAGS

682004 Morgan Kaufmann Publishers
IA-32 Register Restrictions
• Registers are not “general purpose” – note the restrictions below

692004 Morgan Kaufmann Publishers
IA-32 Typical Instructions
• Four major types of integer instructions:
– Data movement including move, push, pop
– Arithmetic and logical (destination register or memory)
– Control flow (use of condition codes / flags )
– String instructions, including string move and string compare

702004 Morgan Kaufmann Publishers
IA-32 instruction Formats
• Typical formats: (notice the different lengths)a. JE EIP + displacement
b. CALL
c. MOV EBX, [EDI + 45]
d. PUSH ESI
e. ADD EAX, #6765
f. TEST EDX, #42
ImmediatePostbyteTEST
ADD
PUSH
MOV
CALL
JE
w
w ImmediateReg
Reg
wd Displacementr/m
Postbyte
Offset
DisplacementCondi-tion
4 4 8
8 32
6 81 1 8
5 3
4 323 1
7 321 8

712004 Morgan Kaufmann Publishers
Optimization in gcc Level
Optimization name Explanation gcc level
High level
Procedure integration
At or near the source level; processor independent
Replace procedure call by procedure body O3
Local
Common subexpression elimination
Constant propagation
Stack height reduction
Within straight-line code
Replace two instances of the same computation by single copy
Replace all instances of a variable that is assigned a constant with the constant
Rearrange expression tree to minimize resources needed for expression evaluation
O1
O1
O1
Global
Global common subexpression elimination
Copy propagation
Code motion
Induction variable elimination
Across a branch
Same as local, but this version crosses branches
Replace all instances of a variable A that has been assigned X (i.e., A=X) with X
Remove code from a loop that computes same value each iteration of the loop
Simplify/eliminate array addressing calculations within loops
O2
O2
O2
O2
Processor dependent
Strength reduction
Pipeline scheduling
Branch offset optimization
Depends on processor knowledge
Many examples; replace multiply by a constant with shifts
Reorder instructions to improve pipeline performance
Choose the shortest branch displacement that reaches target
O1
O1
O1
722004 Morgan Kaufmann Publishers
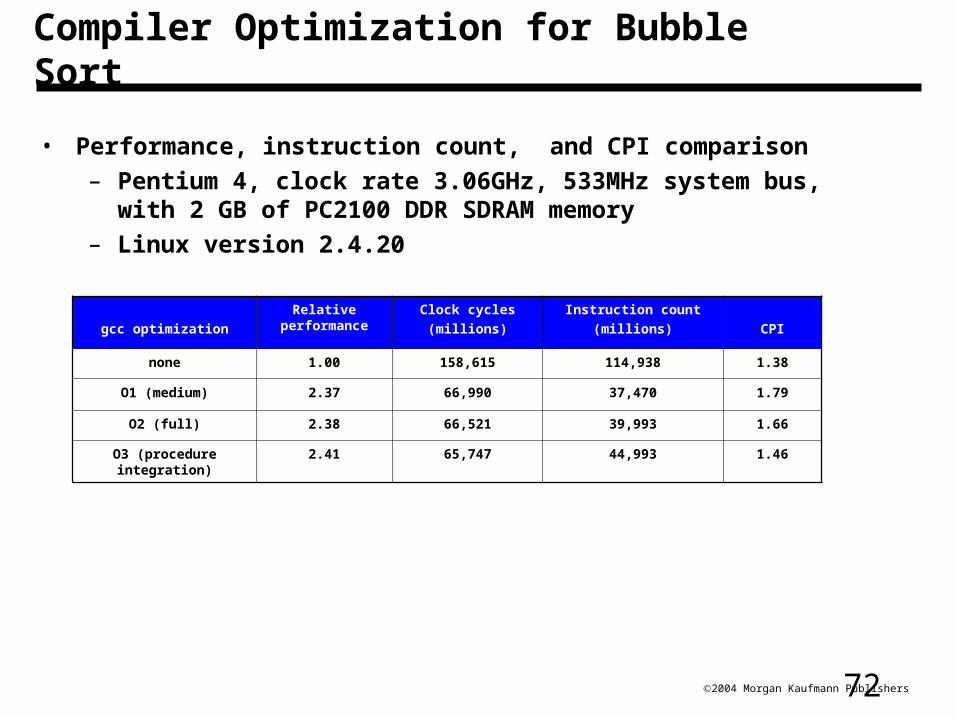
Compiler Optimization for Bubble Sort
• Performance, instruction count, and CPI comparison
– Pentium 4, clock rate 3.06GHz, 533MHz system bus, with 2 GB of PC2100 DDR SDRAM memory
– Linux version 2.4.20
gcc optimization
Relative performance
Clock cycles
(millions)
Instruction count
(millions) CPI
none 1.00 158,615 114,938 1.38
O1 (medium) 2.37 66,990 37,470 1.79
O2 (full) 2.38 66,521 39,993 1.66
O3 (procedure integration)
2.41 65,747 44,993 1.46

732004 Morgan Kaufmann Publishers
Performance of C and Java
• Use two sort algorithms– C optimizing compiler– Java interpreter
Language Execution method Optimization
Bubble Sort relative
performance
Quicksort relative
performance
Speedup Quicksort
Vs. Bubble Sort
C compiler none 1.00 1.00 2468
compiler O1 2.37 1.50 1562
compiler O2 2.38 1.50 1555
compiler O3 2.41 1.91 1955
Java interpreter -- 0.12 0.05 1050
Just In Time compiler -- 2.13 0.29 338

742004 Morgan Kaufmann Publishers
• Instruction complexity is only one variable
– lower instruction count vs. higher CPI / lower clock rate
• Design Principles:
– simplicity favors regularity
– smaller is faster
– good design demands compromise
– make the common case fast
• Instruction set architecture
– a very important abstraction indeed!
Summary

75
A dominant architecture: 80x86
• See your textbook for a more detailed description• Complexity:
– Instructions from 1 to 17 bytes long– one operand must act as both a source and destination– one operand can come from memory– complex addressing modes
e.g., “base or scaled index with 8 or 32 bit displacement”• Saving grace:
– the most frequently used instructions are not too difficult to build– compilers avoid the portions of the architecture that are slow
“what the 80x86 lacks in style is made up in quantity, making it beautiful from the right perspective”

76
PowerPC
• Indexed addressing– example: lw $t1,$a0+$s3 #$t1=Memory[$a0+$s3]– What do we have to do in MIPS?
• Update addressing– update a register as part of load (for marching through arrays)– example: lwu $t0,4($s3) #$t0=Memory[$s3+4];$s3=$s3+4– What do we have to do in MIPS?
• Others:– load multiple/store multiple– a special counter register “bc Loop”
decrement counter, if not 0 goto loop

77
• Design alternative:
– provide more powerful operations
– goal is to reduce number of instructions executed
– danger is a slower cycle time and/or a higher CPI
• Sometimes referred to as “RISC vs. CISC”
– virtually all new instruction sets since 1982 have been RISC
– VAX: minimize code size, make assembly language easy
instructions from 1 to 54 bytes long!
• We’ll look at PowerPC and 80x86
Alternative Architectures