1 chapter 7 synchronization and multiprocessors. 2 contents u introduction u synchronization in...
TRANSCRIPT

1
Chapter 7
Synchronization and Multiprocessors

2
Contents Introduction Synchronization in traditional UNIX
kernel Multiprocessor system Multiprocessor Synchronization issues Spin locks Condition variables Read-write locks Reference counts

3
Introduction
Compute-intensive Multiprocessors also provides reliability.
MTBF Fault-tolerant Recover from the failure
Performance scales linearly? Other components Synchronization Extra functionality
Three major changes Synchronization Parallelization Scheduling policy

4
7.2 Synchronization in traditional UNIX
The UNIX kernel is reentrant. The UNIX kernel is nonpreemptive.

5
Interrupt Masking
The kernel can be interrupted. The interrupts can be preemptive. The kernel thread keep a current ipl to
mask the interrupts with the ipls lower than it.

6
Sleep and wakeup Flags for shared resources
Locked Wanted
Before accessing, check locked, yes, blocking and set wanted
After accessing, check wanted, yes, awaken all the waiting

7
Limitations Performance problem Mapping resources to sleep queues
Sleep channel(the resource address) and sleep queue(hash map)
>1 may map to the same channel The number of hash queue is much smaller
than the number of different sleep channels. Too much time for awakening
Separate sleep queue for each resource Too many spaces
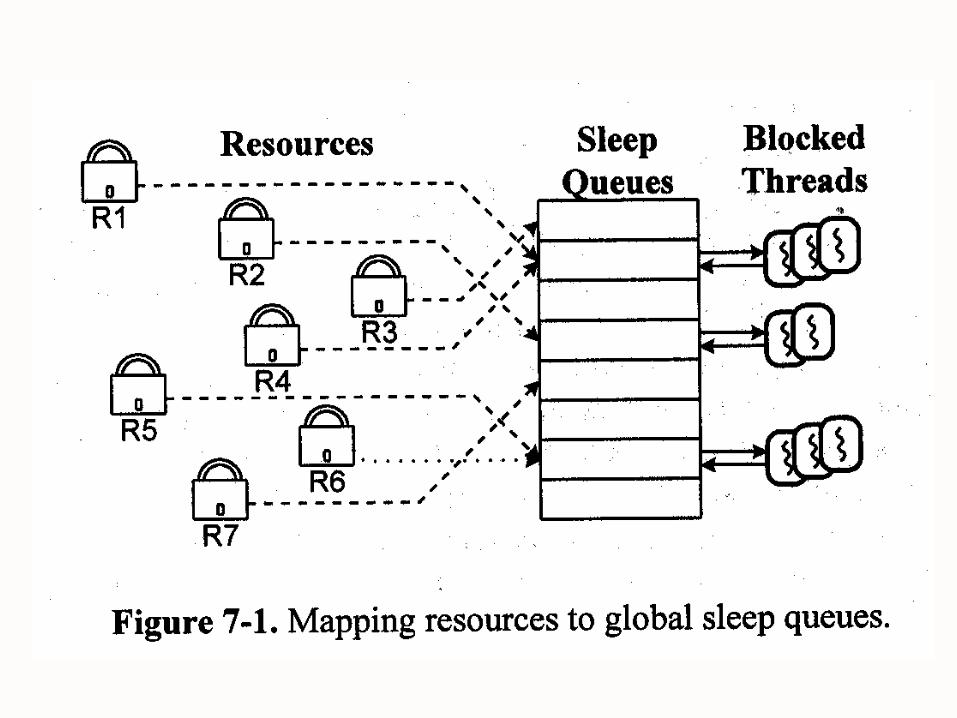
8

9
Per resource sleep queues

10
Alternatives
Separate sleep queue for each resource or event – latency is optimized but requires large memory overhead
Solaris turnstiles –more predictable real-time behaviour with minimal overhead;
It is desirable to have more sophisticated sharing protocol to allow multiple readers but exclusive writing access

11
7.3 Multiprocessor Systems
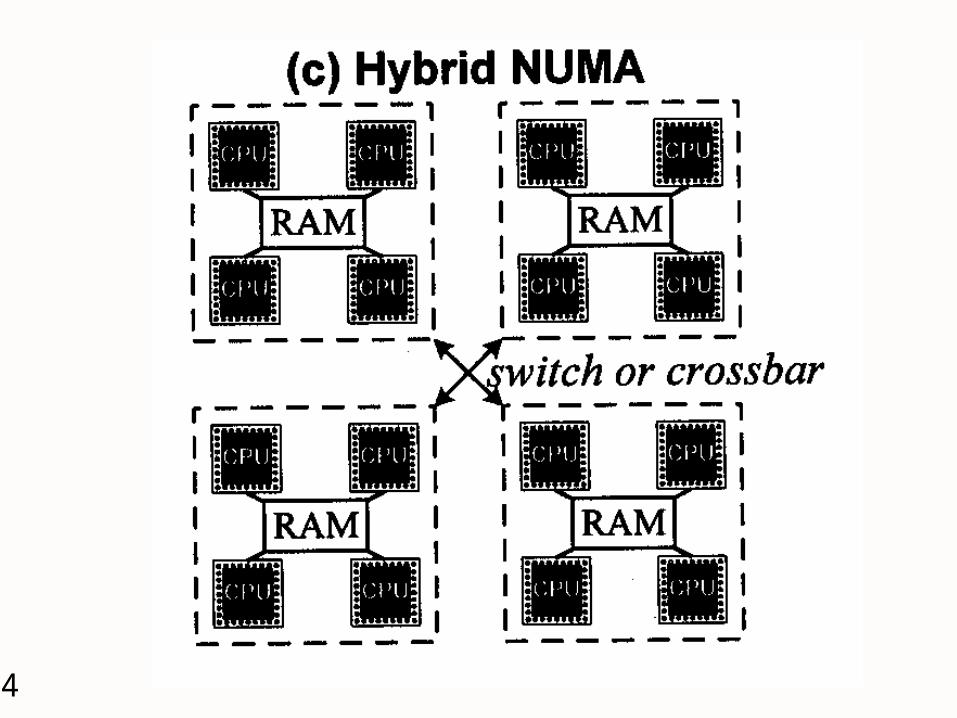
3 important characteristics of MP Memory model, hardware support, &
software architecture Memory Model
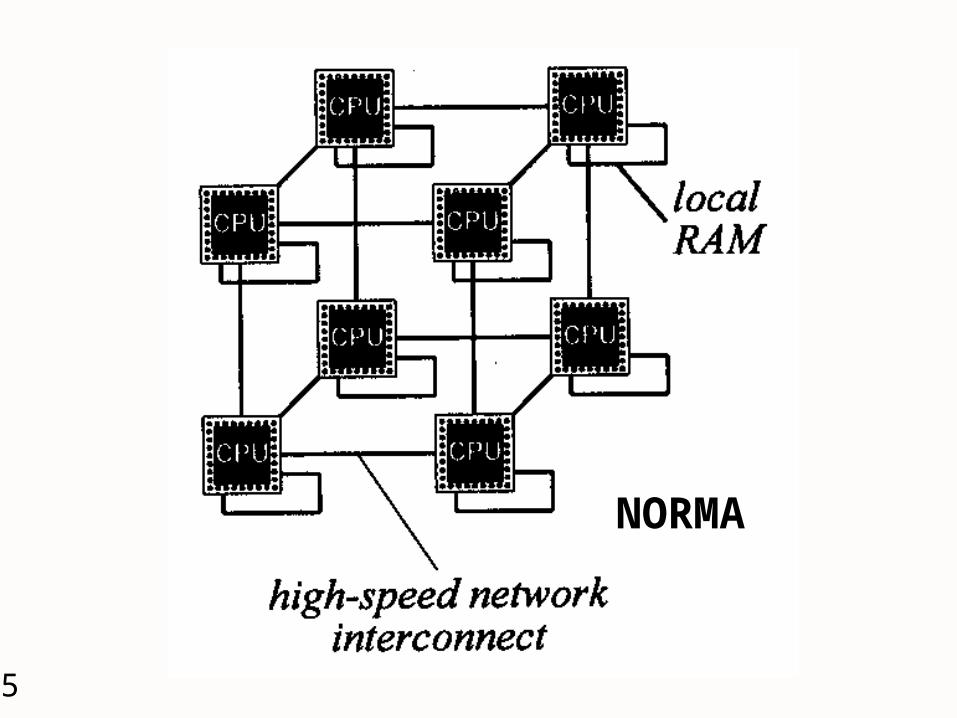
UMA (Uniform Memory Access) NUMA (Non-Uniform Memory Access) NORMA (NO-Remote Memory Access)
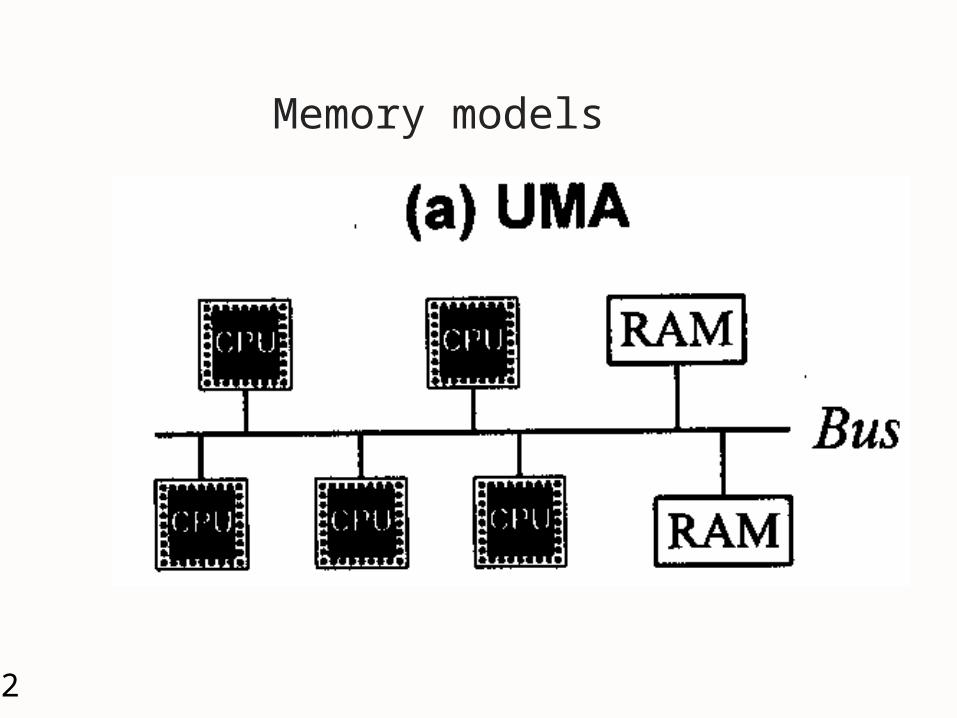
12
Memory models
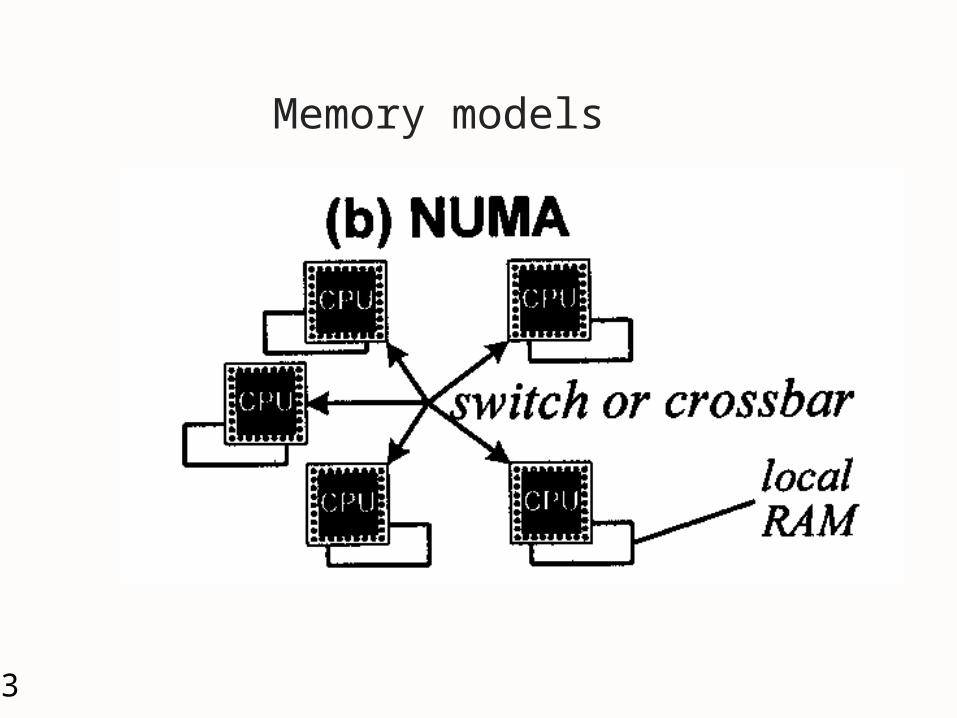
13
Memory models
14
15
NORMA

16
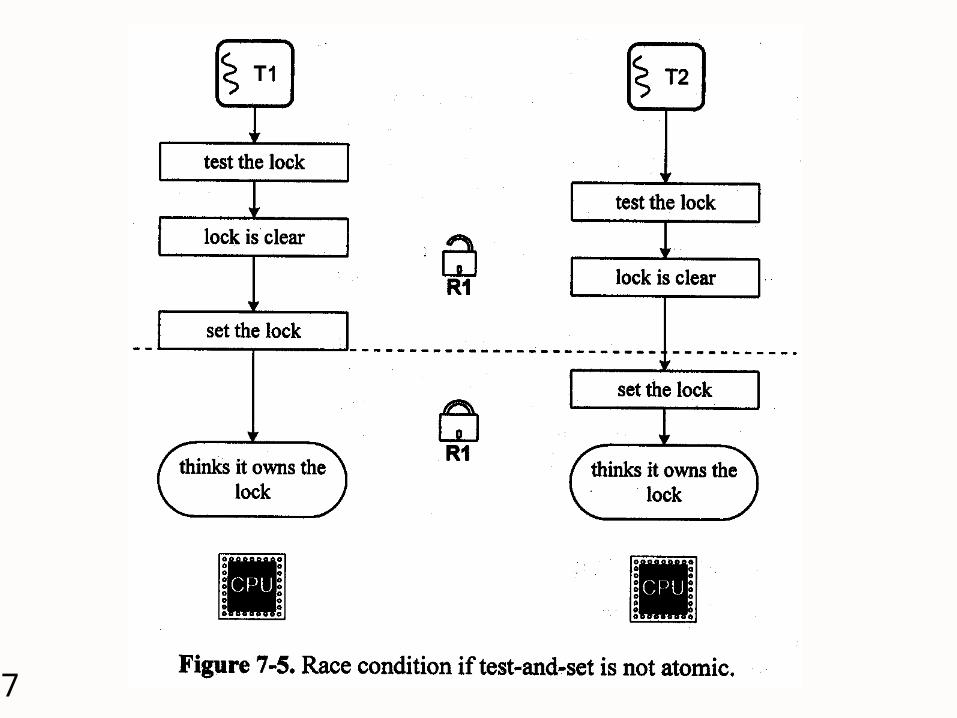
Synchronization Support Locking a resource for exclusive use
Read the flag If the flag is 0, then set it to 1 Return true if the lock was obtained, else
false. Atomic test-and-set
test&set->access ->reset Load-linked & store-conditioned
loadl(M,R)-> access(R)->storec(M,R)
17

18
Implement test-&-set by load-link & store-conditional
void test&set(int s)//primitive { while (s!=0); s=1; } void test&set(int s) //primitive { register r; while (loadl(r,s)& r!=0); r=1; storec(r,s); }

19
Software Architecture Three types of multiprocessor systems
Master-slave One for kernel, the others for user One for I/O, the others for computing
Functionally asymmetric multiprocessors Different CPU is for different types of
applications Symmetric multiprocessing
All CPUs are peer-to-peer, share a kernel code, run the user program.

20
7.4 Multiprocessor Synchronization issues
Need to protect all the data shared Two kernel threads may access the data
simultaneously Locked flag is not enough
Test&set Impossible to block an interrupt
Other CPU running the handler may corrupt a data being accessed.
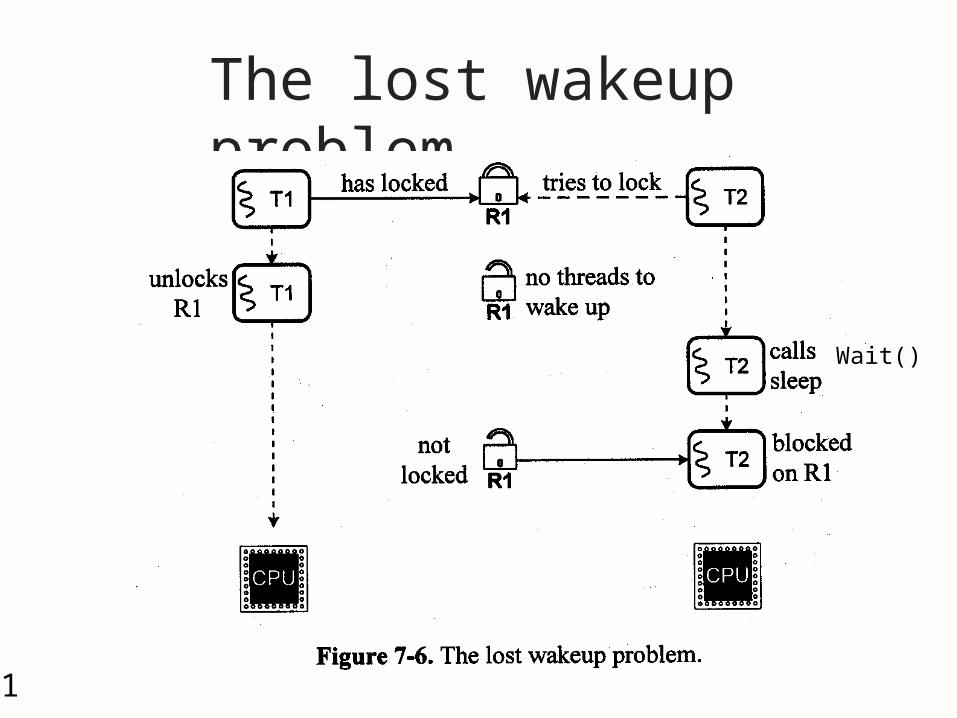
21
The lost wakeup problem
Wait()

22
The Thundering Herd Problem
Uni-processor When releasing the resource, wake up all
the threads waiting for it. Multiprocessor
All waked up, all the threads will run on different CPUs.What a mess!
It is the Thundering Herd Problem.

23
7.5 Semaphores void initsem(semaphore *sem, int val)
{ *sem = val;}
void P(semaphore *sem){*sem-=1; while(*sem<0) sleep;}
void V(semaphore *sem){*sem+=1; if(*sem>=0) wakeup a thread blocked on sem;}
boolean_t CP(semaphore *sem){
if(*sem>0) {
*sem-=1;
return TRUE; }
else return FALSE;
}
Semaphore operations

24
Mutual Exclusion;/*initialization*/
semaphore sem
initsem(&sem,1);
/*on each use*/
P(&sem);
Use resource;
V(&sem);

25
Event-Wait
semaphore event;
initsem(&event,0);
P(&event);
Doing something;
V(&event);
If (event occurs)
V(&event);

26
Countable resources
semaphore counter;
Initsem(& counter,resourceCount);
P(&counter);
Use resource;
V(&counter);

27
Drawbacks of semaphores It needs the hardware to support its
atomicity. Context switching is time-costing, so
blocking is expensive for a short-term using resource.
May hide the details for blocking, e.g., buffer cache .
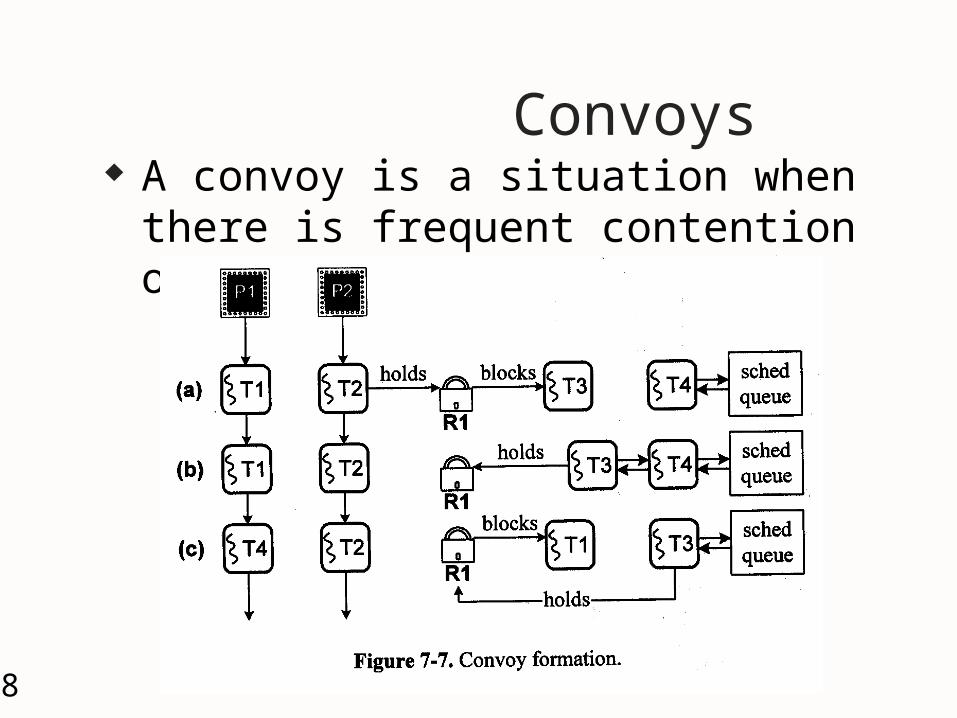
28
Convoys A convoy is a situation when there is
frequent contention on a semaphore.

29
Spin Locks Also called simple lock or a simple mutex
void spin_lock(spinlock_t *s) {
while (test_and_set (s) !=0);
}
void spin_unlock(spinlock_t *s) {
*s=0;
}

30
Another version For saving time of locking the bus void spin_lock(spinlock_t *s) { while (test_and_set (s) !=0)
while (*s!=0); } void spin_unlock(spinlock_t *s) { *s=0;}

31
Using spin-locks The difference between UNIP and MP. Spin-lock is not expensive. Ideal for locking data structures that need to
be accessed briefly (removing item from a list)spin_lock_t list; spin_lock( &list); item->forw->back = item->back; item->back ->forw = item ->forw; spin_unlock(&list);

32
Condition Variables
v – condition variable, m – mutex lock predicate x==y;Thread Aa: lock_mutex(&m);b: while (x!=y)c: cond_wait(&v, &m);/*atomically releases*/
/* the mutex and blocks*//*when unblocked by the cond_signal, it reacquires the
mutex*/d: /*do something with x and y*/e: unlock_mutex(&m);

33
Condition Variables
Thread B
f: lock_mutex(&m);
g: x++;
h: cond_signal(&v);
i: unlock_mutex(&m);
34
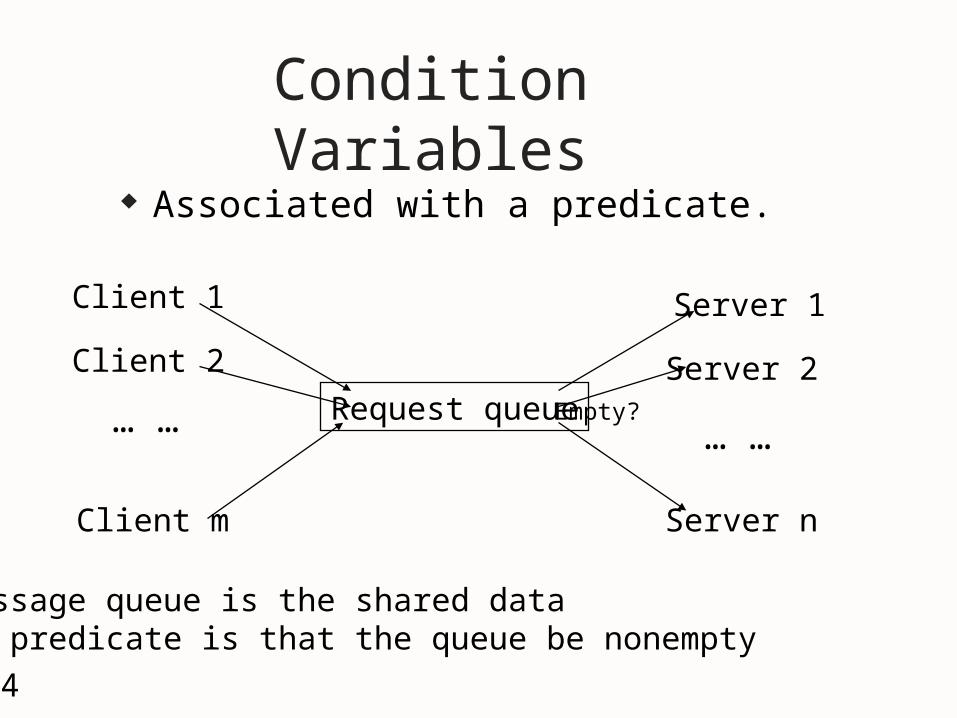
Condition Variables Associated with a predicate.
Request queue
Client 1
Client 2
Client m
… …
Server 1
Server 2
Server n
… …Empty?
A message queue is the shared data The predicate is that the queue be nonempty.

35
implementation Atomic operation to test the predicate.
struct condition{
proc *next;
proc *prev;
spinlock_t listlock;
}

36
wait() void wait(condition *c, spinlock_t *s) {
spin_lock(&c->listlock);
add self to the linked list;
spin_unlock(&c->listlock);
spin_unlock(s);
swtch();
spin_lock(s);
return;
}

37
void do_signal()
void do_signal(condition*c){
spin_lock(&c->listlock);
remove one thread from linked list, if it is nonempty;
spin_unlock(&c->listlock);
if a thread was removed from the list, make it runnable;
return;
}

38
void do_broadcast()
void do_broadcast(condition*c){ spin_lock(&c->listlock); while (linked list is nonempty){ remove one thread from linked list,
make it runnable; } spin_unlock(&c->listlock);}

39
Accessing conditional variables
condition c;spinlock_t s;mesageQueue msq;server() {spin_lock(&s); if (msq.empty()) wait(&c,&s); get message; spin_unlock(&s); do_signal( &c );}
client()
{spin_lock(&s); if (msq.full()) wait(&c,&s); put message; spin_unlock(&s); do_signal( &c );
}

40
Events Combines a done flag, the spinlock
protecting it and a condition variable
Operations – awaitDone, setDone or testDone
Blocking locks combines locked flag on the resource and the sleep queue; operations – lock() and unlock()

41
7.8 Read-Write locks Support one-writer & many readers lockShared() // Reader unlockShared() // Reader lockExclusive() // Writer unlockExclusive() // Writer upgrade() // from shared to exclusive downgrade() //from exclusive to shared

42
Design consideration Avoid needless wake up Reader release
only the last to wake up a single writer Writer release:
prefer writer Reader starvation
wake up all the readers Writer starvation lockShared() block if there is any writer waiting
//new readers

43
Implementation struct rwlock{ int nActive;// number of readers, -1 means a writer is active
int nPendingReads;
int nPendingWrites;
spinlock_t sl;
condition canRead;
condition canWrite;
};

44
un/lockShared
void unlockShared(struct rwlock *r) {
spin_lock(&r->sl);
r->nActive --;
if (r-> nActive ==0) {
spin_unlock (&r->sl);
do_signal(&r->canWrite);
} else
spin_unlock(&r->sl);
}
void lockShared(struct rwlock *r) {
spin_lock(&r->sl);
r->nPendingReads++;
if (r->nPendingWrites>0)
wait(&r->canRead, &r->sl);
while(r->nActive <0)
wait(&r->canRead, &r->sl);
r->nActive++;
r->nPendingReads--;
spin_unlock(&r->sl);
}

45
un/lockExclusive
void unlockExclusive(struct rwlock *r) {
boolean_t wakeReaders;
spin_lock(&r->sl);
r->nActive =0;
wakeReaders = (r->PendingReads!=0);
spin_unlock(&r->sl);
if (wakeReaders) {
do_broadcast(&r->canRead);
else
do_signal(&r->canWrite);
}
void lockExclusive(struct rwlock *r) {
spin_lock(&r->sl);
r->nPendingWrites++;
while(r->nActive)
wait(&r->canWrite, &r->sl);
r->nPendingWrites--;
r->nActive =-1;
spin_unlock(&r->sl);
}

46
Up/downgrade() void downgrade(struct rwlock *r) {
boolean_t wakeReaders;
spin_lock(&r->sl);
r->nActive =1;
wakeReaders =
(r->PendingReads!=0)
spin_unlock(&r->sl);
if (wakeReaders) {
do_broadcast(&r->canRead);
}
void upgrade(struct rwlock *r) {
spin_lock(&r->sl);
if (r->nActive ==1) r->nActive =-1;
else{
r->nPendingWrites++;
r->nActive--;
while (r->nActive)
wait(&r->canWrite, &r->sl);
r->nPendingWrites--;
r->nActive =-1;
}
spin_unlock(&r->sl);
}

47
Using R/W locks rwlock l; T1() { lockShared(&l); reading; upgrade(&l) writing; downgrade(&l) unlockShared(&l); }
T2() {
lockExclusive(&l);
writing;
downgrade(&l);
reading;
upgrade(&l);
unlockExclusive(&l);
}

48
Reference Counts A number kept with an object to show how
many threads have pointers to it. To keep the threads pointing to it can access
it. When creating, set to one. When one thread gets a pointer to it, the
number increments. When the thread release it, the kernel will
decrement it. When the count is decreased to 0, the kernel
will de-allocate it.

49
Deadlock avoidance
Hierarchical locking – imposes an order on related locks and requires that all threads take locks in the same order, e.g. thread must lock condition variable before locking the linked list;
Stochastic locking – when order violation may occur try_lock() is used instead of lock(). If the lock cannot be acquired because it is allocated already it returns a failure instead of blocking.

50
Recursive locks
Lock, which is owned by a thread is acquired by a lower level routine which is called by the thread to perform some operation on resource locked by the thread. Without recursion there would be deadlock.

51
To block or spin
If the thread already holds a simple mutex it is not allowed to block;
If the thread tries to acquire another simple mutex, it will busy wait;
If the thread tries to acquire a complex lock, it will release the mutex it already holds
One solution – a hint (advisory or mandatory, set by the owner of the lock) in a lock suggesting whether the contending thread should spin or lock,
Alternative – adaptive lock of Solaris – threads T1 and T2 - T1 tries to get a lock held by T2, - if T2 is active then T1 busy wait, - if T2 is blocked, T1 blocks as well,

52
Others issues
What to lock – data, predicates, invariants or operations;
Granularity - from a single lock for the whole kernel – to separate lock for each data variable
Duration – it is best to hold the lock for as short a time as possible, to minimize contention on it – sometimes it makes sense to keep it longer without an intermediate release

53
Case study - SVR4.2/MP Basic locks, Read-write locks, Sleep locks, Synchronization variables.

54
Linux Kernel Concurrency Mechanisms
Includes all the mechanisms found in UNIX
Atomic operations execute without interruption and without interference
55
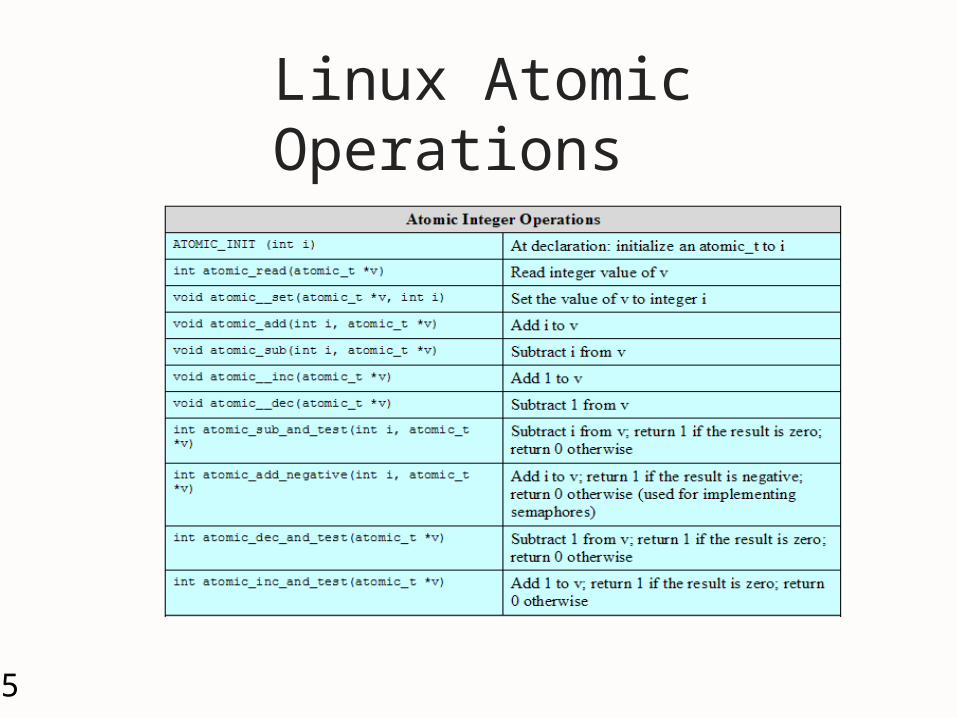
Linux Atomic Operations
56
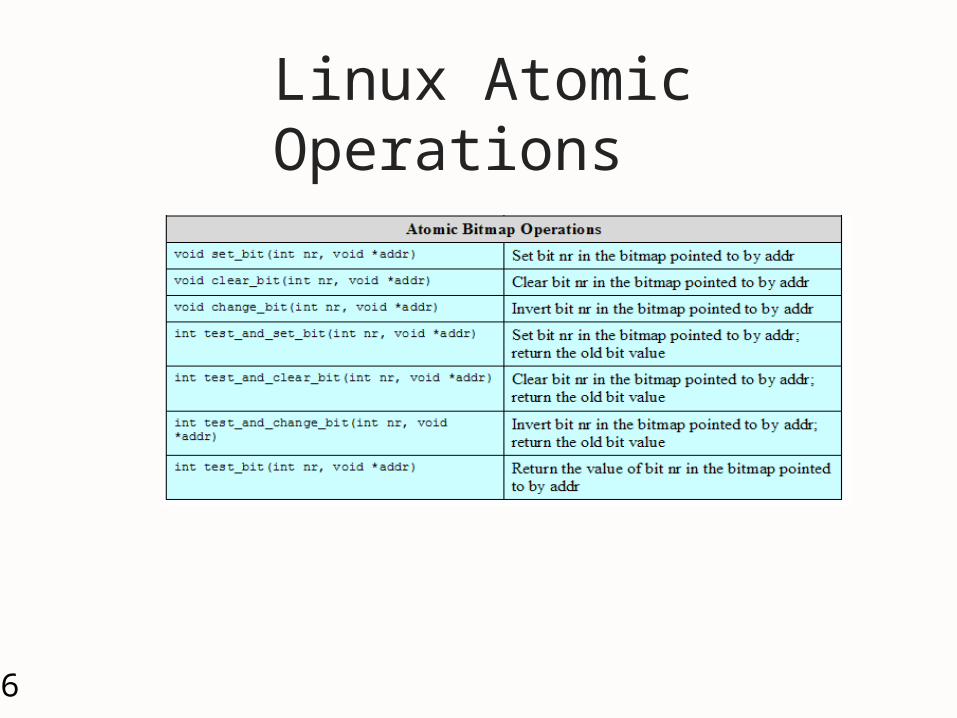
Linux Atomic Operations

57
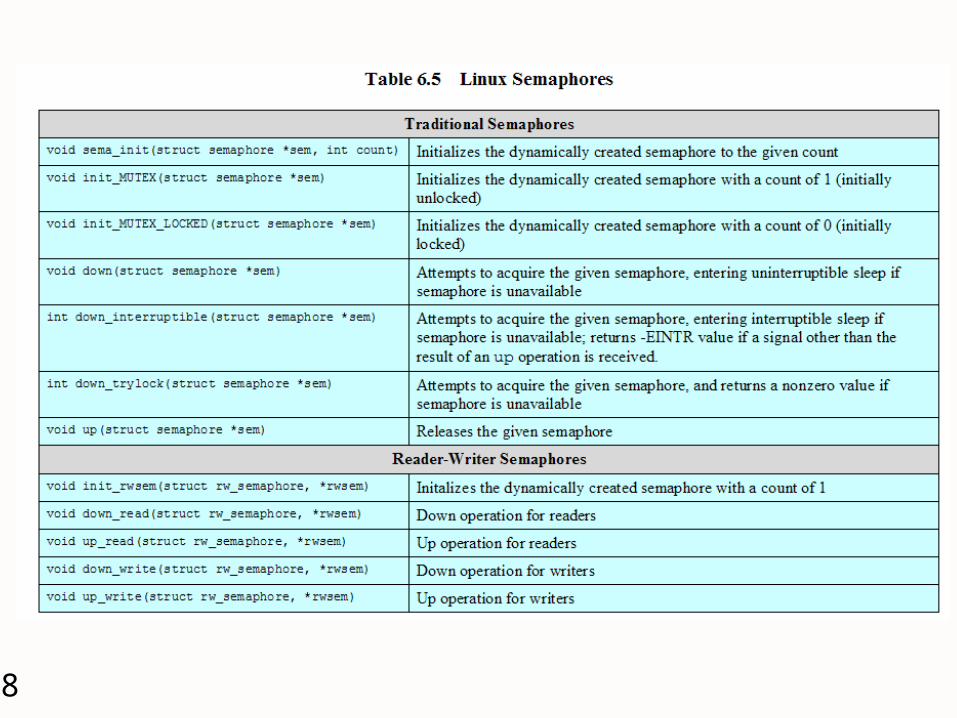
Linux Kernel Concurrency Mechanisms
Spinlocks Used for protecting a critical section
58

59
Linux Kernel Concurrency Mechanisms