1 characterization and evaluation of tcp and udp-based transport on real networks les cottrell, saad...
TRANSCRIPT

1
Characterization and Evaluation of TCP and UDP-based Transport on Real
Networks Les Cottrell, Saad Ansari, Parakram Khandpur, Ruchi Gupta, Richard Hughes-Jones,
Michael Chen, Larry McIntosh, Frank LeersSLAC, Manchester University, Chelsio and Sun
Protocols for Fast Long Distance Networks, Lyon, FranceFebruary, 2005
www.slac.stanford.edu/grp/scs/net/talk05/pfld-feb05.ppt
Partially funded by DOE/MICS Field Work Proposal on Internet End-to-end Performance Monitoring
(IEPM)

2
Project goals• Evaluate various techniques for achieving high bulk-
throughput on fast long-distance real production WAN links
• How useful for production: ease of configuration, throughput, convergence, fairness, stability etc.
• For different RTTs• Recommend “optimum” techniques for data intensive
science (BaBar) transfers using bbftp, bbcp, GridFTP• Provide input for validation of simulator & emulator
findings

3
Techniques rejected• Jumbo frames
– Not an IEEE standard– May break some UDP applications– Not supported on SLAC LAN
• Sender mods only, HENP model is few big senders, lots of smaller receivers– Simplifies deployment, only a few hosts at a few
sending sites– So no Dynamic Right Sizing (DRS)
• Runs on production nets– No router mods (XCP/ECN)

4
Software Transports• Advanced TCP stacks
– To overcome AIMD congestion behavior of Reno based TCPs
– BUT: • SLAC “datamover” are all based on Solaris, while
advanced TCPs currently are Linux only• SLAC production systems people concerned about non-
standard kernels, ensuring TCP patches keep current with security patches for SLAC supported Linux version
• So also very interested in transport that runs in user space (no kernel mods)– Evaluate UDT from UIC folks

5
Hardware Assists• For 1Gbits/s paths, cpu, bus etc. not a problem• For 10Gbits/s they are more important• NIC assistance to the CPU is becoming popular
– Checksum offload– Interrupt coalescence– Large send/receive offload (LSO/LRO)– TCP Offload Engine (TOE)
• Several vendors for 10Gbits/s NICs, at least one for 1Gbits/s NIC
• But currently restricts to using NIC vendor’s TCP implementation
• Most focus is on the LAN– Cheap alternative to Infiniband, MyriNet etc.

6
Protocols Evaluated• TCP (implementations as of April 2004)
– Linux 2.4 New Reno with SACK: single and parallel streams (Reno)
– Scalable TCP (Scalable)– Fast TCP– HighSpeed TCP (HSTCP)– HighSpeed TCP Low Priority (HSTCP-LP)– Binary Increase Control TCP (BICTCP)– Hamilton TCP (HTCP)– Layering TCP (LTCP)
• UDP – UDT v2.

7
• Chose 3 paths from SLAC– Caltech (10ms), Univ Florida (80ms), CERN
(180ms)
• Used iperf/TCP and UDT/UDP to generate traffic
• Each run was 16 minutes, in 7 regions
Methodology (1Gbit/s)
Ping 1/s
Iperf or UDT
ICMP/ping traffic
TCP/UDP
bottleneck
iperf
SLACCaltech/UFL/CERN
2 mins 4 mins

8
Behavior Indicators• Achievable throughput
• Stability S= σ/μ (standard deviation/average)
• Intra-protocol fairness F =
n
ii
n
ii n
1
22
1
n
ii
n
ii n
1
22
1
n
ii
n
ii n
1
22
1

9
Behavior wrt RTT• 10ms (Caltech): Throughput, Stability (small is
good), Fairness minimum (over regions 2 thru 6) (closer to 1 is better)
– Excl. FAST ~ 720±64Mbps, S~0.18±0.04, F~0.95– FAST ~ 400±120Mbps, S=0.33, F~0.88
• 80ms (U. Florida): Throughput, Stability– All ~ 350±103Mbps, S=0.3±0.12, F~0.82
• 180ms (CERN): – All ~ 340±130Mbps, S=0.42±0.17, F~0.81
• The Stability and Fairness effects are more manifest on longer RTT, so focus on CERN

10
Reno single stream• Low performance on fast long distance paths
– AIMD (add a=1 pkt to cwnd / RTT, decrease cwnd by factor b=0.5 in congestion)
– Net effect: recovers slowly, does not effectively use available bandwidth, so poor throughput
• Remaining flows do not take up slack when flow removed
Congestion has a dramatic effect
Recovery is slow
Multiple streams increase recovery rate
SLAC to CERN
RTT increases when achieves best throughput
11
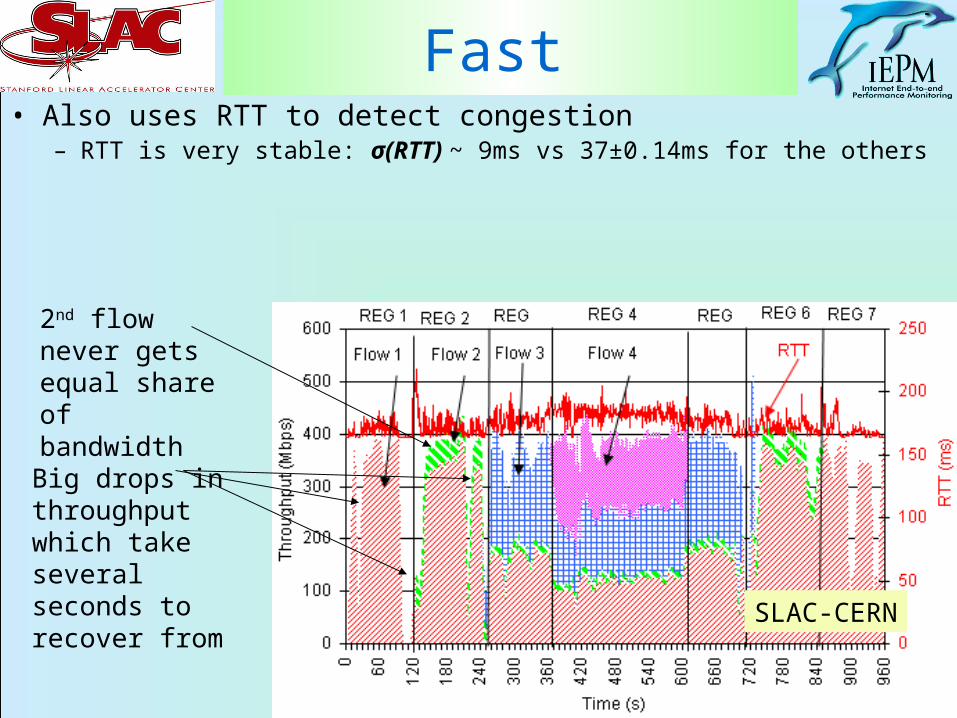
Fast • Also uses RTT to detect congestion
– RTT is very stable: σ(RTT) ~ 9ms vs 37±0.14ms for the others
SLAC-CERN
Big drops in throughput which take several seconds to recover from
2nd flow never gets equal share of bandwidth

12
HTCP• One of the best performers
– Throughput is high– Big effects on RTT when achieves best throughput– Flows share equally
Appears to need >1 flow toachieve best throughput
Two flows share equally
SLAC-CERN
> 2 flows appears less stable

13
BICTCP• Needs > 1 flow for best throughput

14
UDTv2• Similar behavior to better TCP stacks
– RTT very variable at best throughputs– Intra-protocol sharing is good– Behaves well as flows add & subtract
15
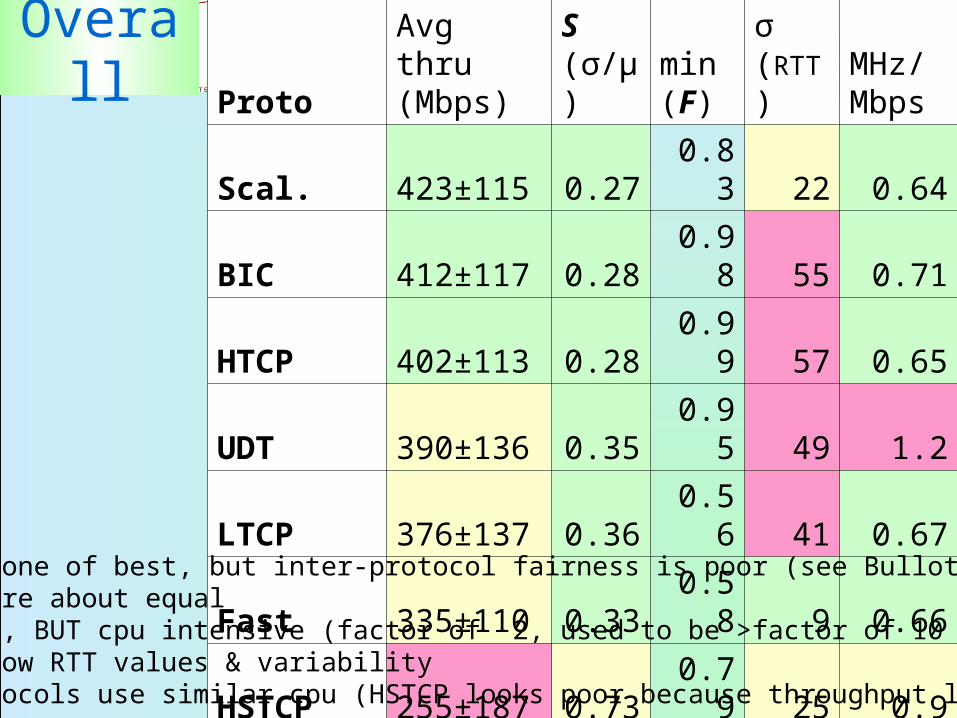
Overall ProtoAvg thru (Mbps)
S (σ/μ)
min (F)
σ (RTT)
MHz/ Mbps
Scal. 423±115 0.27 0.83 22 0.64
BIC 412±117 0.28 0.98 55 0.71
HTCP 402±113 0.28 0.99 57 0.65
UDT 390±136 0.35 0.95 49 1.2
LTCP 376±137 0.36 0.56 41 0.67
Fast 335±110 0.33 0.58 9 0.66
HSTCP 255±187 0.73 0.79 25 0.9
Reno 248±163 0.66 0.6 22 0.63
HSTCP-LP 228±114 0.5 0.64 33 0.65
Scalable is one of best, but inter-protocol fairness is poor (see Bullot et al.)BIC & HTCP are about equalUDT is close, BUT cpu intensive (factor of 2, used to be >factor of 10 worse)Fast gives low RTT values & variabilityAll TCP protocols use similar cpu (HSTCP looks poor because throughput low)

16
10Gbps tests• At SC2004 using two 10Gbps dedicated paths
between Pittsburgh and Sunnyvale– Using Solaris 10 (build 69) and Linux 2.6– On Sunfire Vx0z (dual & quad 2.4GHz 64 bit AMD
Opterons) with PCI-X 133MHz 64 bit– Only 1500 Byte MTUs
• Achievable performance limits (using iperf)– Reno TCP (multi-flows) vs UDTv2, – TOE (Chelsio) vs no TOE (S2io)

17
Results• UDT limit was ~ 4.45Gbits/s
– Cpu limited
• TCP Limit was about 7.5±0.07 Gbps, regardless of:– Whether LAN (back to back) or WAN
• WAN used 2MB window & 16 streams
– Whether Solaris 10 or Linux 2.6– Whether S2io or Chelsio NIC
• Gating factor=PCI-X – Raw bandwidth 8.53Gbps– But transfer broken into segments to allow interleaving– E.g. with max memory read byte count of 4096Bytes with Intel
Pro/10GbE LR NIC limit is 6.83Gbits/s
• One host with 4 cpus & 2 NICs sent 11.5±0.2Gbps to two dual cpu hosts with 1 NIC each
• Two hosts to two hosts (1 NIC/host) 9.07Gbps goodput forward & 5.6Gbps reverse

18
TCP CPU Utilization• CPU power important• Each cpu=2.4GHz• Throughput increases with
flows• Util. not linear(throughput) • Depends on flows too
Chelsio(TOE)
• Normalize GHz/Gbps• Chelsio + TOE + Linux 2.6.6• S2io + CKS offload + Sol10
– S2io supports LSO but Sol10 did not, so not used
– Microsoft reports 0.017GHz/Gbps with Windows+S2io/LSO, 1 flow

19
Conclusions• Need testing on real networks
– Controlled simulation & emulation critical for understanding
– BUT need to verify, and results look different than expected (e.g. Fast)
• Most important for transoceanic paths• UDT looks promising, still needs work for >
6Gbits/s• Need to evaluate various offloads (TOE, LSO ...)
• Need to repeat inter-protocol fairness vs Reno• New buses important, need NICs to support
then evaluate

20
Further Information• Web site with lots of plots & analysis
– www.slac.stanford.edu/grp/scs/net/papers/pfld05/ruchig/Fairness/
• Inter-protocols comparison (Journal of Grid Comp, PFLD04)– www.slac.stanford.edu/cgi-wrap/getdoc/slac-pub-10402.pdf
• SC2004 details– www-iepm.slac.stanford.edu/monitoring/bulk/sc2004/