1 distributed and replicated data seif haridi. 2 distributed and replicated data purpose –increase...
TRANSCRIPT

1
Distributed and Replicated Data
Seif Haridi

2
Distributed and Replicated Data
• Purpose– Increase performance (parallel processing)
– Increase safety (redundancy)
• To some extent contradictory– Safer more complex slower
• Abstraction level of models– Tradeoff between conceptually simple high-level models,
which hide a lot of the detail but are expensive and don’t scale to well, and low-level models which are less expensive and scale better

3
Applications
• Fault tolerance is an issue• The models considered
– Transactions (from database theory)
– Reliable broadcast
– “Update propagation”

4
Transactions
• Transactions: complex state transitions which should seem atomic
x-z SEK y+z SEK
x SEK y SEK
Grandma’s account Grandpa’s account
Transfer: z SEK

5
Transactions
• Usually composed of more primitive read- and write operations:
• “read x; read y; read z; write x-z; write y+z”• If the transaction is interrupted we don’t want to
have as the resulting state the one before the last write (then Grandpa gets angry)
• Also not good if two concurrent transfers A, B to Grandpa’s account are mixed up, so both A and B read the old value of y of his account (then we’ll lose one of the contributions)

6
ACID properties
• A=Atomicity: either all or none of the operations in a transaction are performed
• C=Consistency: the execution of interleaved transactions is equivalent to a serial execution of the transactions in some order
• I=Isolation: partial results of an incomplete transaction are not visible to others before the transaction is successfully committed
• D=Durability: results of a committed transaction will be permanent even if a failure occurs after the commitment
TRpersistentstate
newpersistentstate

7
ACID properties
• The “ACID” properties have some consequences for implementation
• A requires that intermediate results can be done undone if a failure occurs
• C requires that we lock the read/write entities involved in a transaction (e.g. representation of account in a database) while it goes on
• D requires that final results are written to permanent storage, and that beyond a certain commit point “preliminary” results have been recorded as well, so the transaction can be successfully completed even if failures occur

8
Common way to implement transactions
1. Lock all entities read and written by the transaction
2. Compute the results of the transaction (but don’t write them yet)
3. Write a persistent record of the results to a log file (precommit)
4. Write a commit record for the transaction to the log file (commit)
5. Perform the actual writes (updating the database)
6. Unlock the entities involved
• If failure occurs before 4, then the transaction is aborted upon restart, if it occurs after 4 then it is completed
• (This locking discipline, 2PL, is susceptible to deadlock, see later)

9
Centralized Recovery
• We need to recover disk failures during transaction execution so as to ensure the all or nothing property.
• 3 Approaches:– Shadow paging: 2 copies of database.
– Before images: store on disk log of before values and update database immediately. If failure occurs and transaction has not committed restore db based on log.
– After images: Perform updates in a log of after images. If transaction commits, install values in db from log.

10
Transactions in a distributed system
• Data is spread out over different processors• A number of processors may participate in a
transaction (or in different ongoing transactions)• Processors may fail (and recover) during a
transaction• We assume an asynchronous system• How to ensure that the ACID properties are still
fulfilled?

11
A possible solution
• Every processor has its own log file
• Make sure all involved processors agree on every step before proceeding (?)
• That is: if some processor aborts (or fails at a critical moment), then everybody should abort
• If all processors have written commit records to their log files, then the transaction will eventually succeed even if some processors fail
• The processors can vote whether to proceed for each step
• A coordinator collects the votes and decides whether to go ahead or not

12
Distributed Recovery
• Databases reside on sites in a distributed system.• Communication between sites by messages only.• Each transaction has a home site or coordinator,
and a number of participants.• Goal: Either all sites commit or all abort.• When a transaction wants to commit, it must be
sure that all sites agree to commit too.

13
Vote coordination
Time Coordinator Participants
votes
Check ifall yes
Reply COMMITor ABORT

14
Atomic Commitment
• At commit time, the coordinator requests votes from all participants.
• Atomic commitment requires:– All processes reach same decision
– Commit only if all processes vote Yes.
– If there are no failures and all processes vote Yes, decision will be commit.

15
Two Phase Commit (2PC)
• Coordinator– send vote-request
– Collect votes. If all Yes, then Commit, else Abort.
– Send decision
• Participant
– receive vote-request
– send Yes or No
– Wait for decision

16
Failures and Blocking
• What does a process do if it does not receive a message it is expecting? I.e., on timeout?
• 3 cases:– participant waiting for vote-request abort
– coordinator waiting for vote abort
– participant waiting for decision uncertain• Note: coordinator never uncertain

17
The Two-phase Commit Algorithm (2PC)
• Code for coordinator (details regarding locking etc. are suppressed):
2PC_Coordinator() precommit the transaction For every participant p, send(p, VOTE_REQ) wait up to T seconds for VOTE messages Vote(sender;vote_response): if vote_response = YES then increment the number of YES votes if every participant responded with YES vote then commit the transaction /* write YES vote and a commit record to log */ for every participant p, send(p, COMMIT) else abort the transaction /* write ABORT record to log */ for every participant p, send(p, COMMIT)

18
2PC Participants
2PC_Participant() while(True) wait for a message from the coordinator VOTE_REQ(coordinator): if I can commit the transaction then precommit the transaction write a YES vote to the log send(coordinator, YES) else abort the transaction send(coordinator, NO) COMMIT(coordinator): commit the transaction ABORT(coordinator): abort the transaction

19
If a processor goes down during the transaction
Execute a recovery protocol when it comes up again:
• Any processor before precommit: abort (and vote NO if participant)
• Coordinator after precommit: can choose (typically continue). Any votes lost due to the failure will yield abort
• Participant after precommit: wait to see how the others voted. (though COMMIT or ABORT message from the coordinator) (?)
• Any processor after commit or abort: complete the respective operation

20
Implication of Asynchronous communication
• Asynchronous error model implies that in certain phases the transaction cannot be aborted on timeouts
• It’s OK for the coordinator to count votes not received within T as NO votes (still safe, only means we’ll abort in few cases when late YES message would have admitted the transaction to proceed)
• But, if the coordinator goes down during the vote then the participants must wait for it to come up

21
Termination Protocol
• Can participant find help from other participants?• Send to all participants: “Help, what is decision?’’
– if any participant has committed or aborted
send commit or abort decision.
– If a participant has not yet voted abort and send abort decision.
– If all participants voted Yes all live participants uncertain
• Transaction BLOCKED!
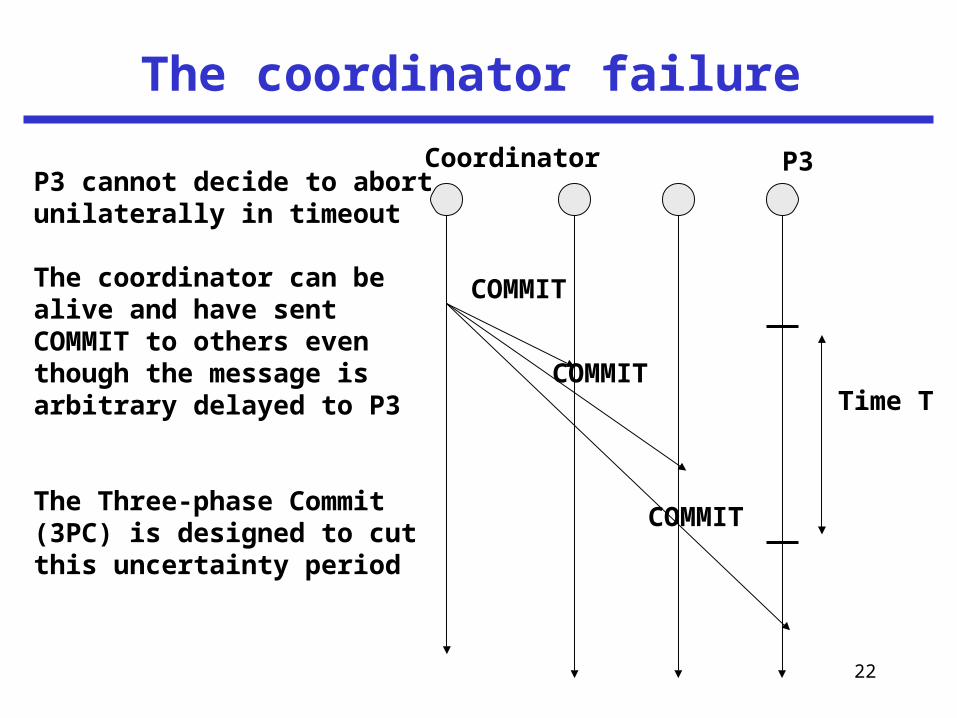
22
The coordinator failure
Coordinator
COMMIT
COMMIT
COMMIT
Time T
P3P3 cannot decide to abortunilaterally in timeout
The coordinator can be alive and have sentCOMMIT to others eventhough the message is arbitrary delayed to P3
The Three-phase Commit (3PC) is designed to cutthis uncertainty period

23
Blocking of 2PC
• 2PC is a blocking protocol.• Basic intuition: When a participant is in wait
(uncertain) state, some other participants may be in commit and others in abort states.
• Solution: Introduce a buffer state so that if any operational site is uncertain, no process can have decided to Commit [Skeen 82].
• 3 Phase commit protocol only assumes site failures.

24
Three Phase Commit (3PC)
• Coordinator– send vote-request
– Collect votes. If all Yes, then send Pre-Commit, else send Abort.
– Collect all Acks, and send Commit
• Participant– receive vote-request
– send Yes or No
– if receive abort, then Abort, else, send Ack
– If receive commit, then Commit.

25
Failure handling in 3PC
5 cases:– participant waiting for vote-request abort
– coordinator waiting for vote abort
– coordinator waiting for Ack commit
– participant waiting for decision elect new leader
– participant waiting for commit elect new leader
Note: In (5) a participant may still be waiting for decision.

26
Termination for 3PC
• Leader sends to all participants requesting state.– if any participant has committed or aborted
send commit or abort decision.
– If a participant has not yet voted
abort and send abort decision.
– If all participants voted Yes
all live participants uncertain.
– If some participant has pre-committed
leader sends Pre-commit to all and wait for acks
send commit

27
Commit Protocols Summary• 2 PC blocks with failures• 3PC is non-blocking with site failures only.• 3PC blocks with partitioning failures.
Partition 1 Partition 2• Theorem [Skeen82]: There is no non-blocking atomic
commitment protocol in the presence of partitioning failures.
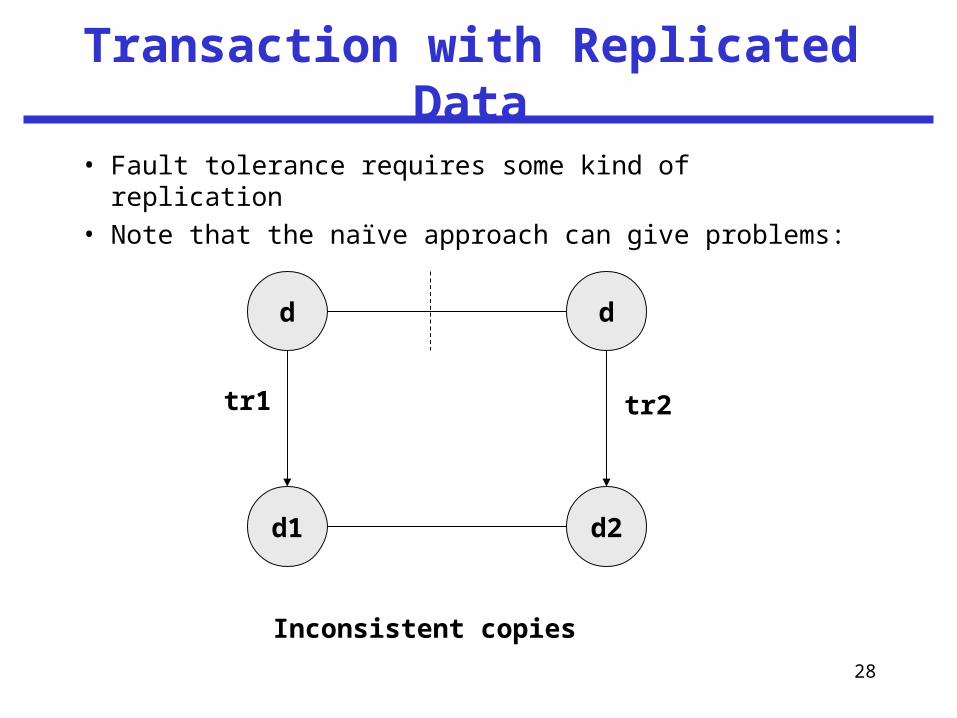
28
Transaction with Replicated Data
• Fault tolerance requires some kind of replication
• Note that the naïve approach can give problems:
d d
d1 d2
tr1 tr2
Inconsistent copies

29
Replicated data
• In general, correct handling of replicated data requires some kind of consistency: that accesses to data seems to come in the same order for everyone.
d d
d1 d2
d2 d1
Either or
write1
write2
write2
write1

30
Transaction data
• In particular in transaction systems, the transactions themselves must seem executed in the same order for everyone:
Either … tr1; tr2 … or … tr2; tr1 …

31
Serializability• A database consists of a set of objects: x,y,z.
• Each object has a value.
• The values of the all the objects form the state of the database, and these states must satisfy the database integrity constraints.
• Database objects support 2 atomic operations: read[x], write[x].

32
Preliminaries
• A transaction is a set of operations executed in some order. We will assume total order.
• A transaction is assumed to be correct, i.e., if executed alone on a consistent database, it transforms it into another consistent state.
• Example: r1[x] r1[y] w1[x] w1[y] is an example of a transaction t1 that transfers some amount of money from account x to account y.

33
Serializability
• 2 operations conflict if the order of execution is important, i.e. if one of them is a write.
X x xa a a
t1
R
t1
W(y)
t1
R
t2
R
t2
W(z)
t2
W(y)
no conflict conflict conflict

34
A Quorum-based Protocol
• Idea: access to datum d requires a “vote” among P(d), the set replicating d
• All voters read and update (if write access) its copy
• Require enough votes to ensure that accesses which must be serialized (conflicting RW, WR, WW) have some processors in common
P'pp )()(v
ifonly allowed is P(d)P'set processor thefrom d of readA
)( thresholdWrite
)( thresholdRead
)()( weight Vote
dRd
dW
dR
dPdvp

35
Quorum based Protocol
)()()(
)()(2
commonin processors have always WW andRW that ensure To
)()(
ifonly For write,
)()(
ifonly allowed is P(d)P'set processor thefrom d of readA
)( thresholdWrite
)( thresholdRead
)()( weight Vote
)(
P'p
P'p
dVdWdR
vdVdW
dWdv
dRdv
dW
dR
dPdv
dPpp
p
p
p

36
Read & Write
)( maximal with P'p some from d of value theread
READ
P'in d of copies all Unlock .5
1)(max to)(set and d tod' write,P'p allFor 4.
d of d' valuenew Compute 3.
P'in d of copies allLock .2
such that Decide 1.
WRITE
dfor )(number version a has Each
'
dn
dndn
W(d)(d)vP'
dnP(d)p
p
pPpp
P'pp
p
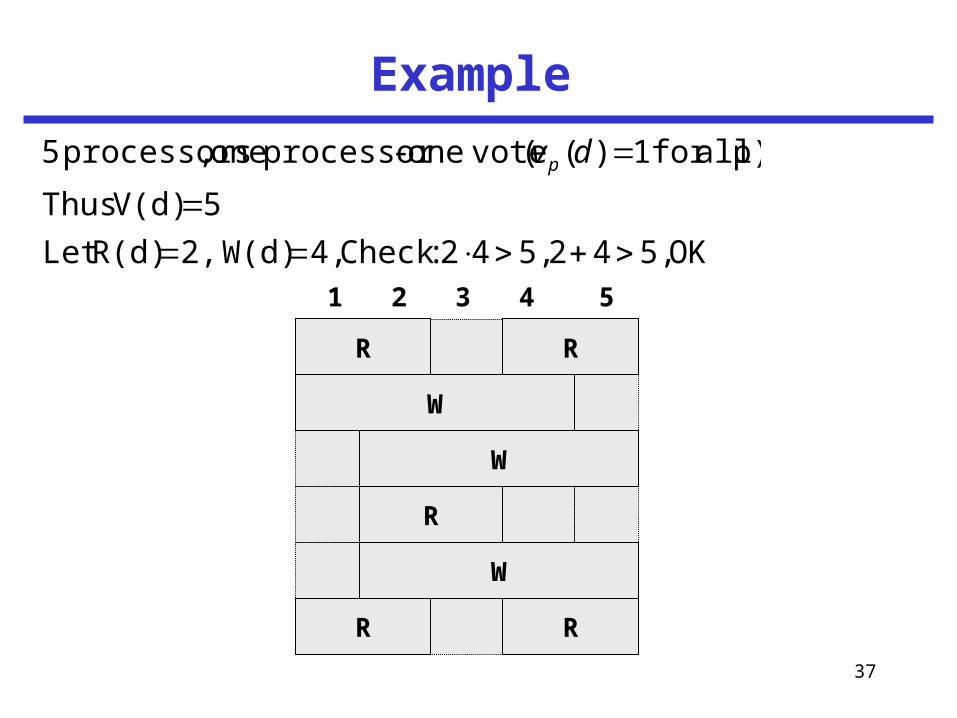
37
Example
OK 5,42 5,42 :Check 4, W(d)2, R(d)Let
5 V(d) Thus
p) allfor 1)(( voteone -processor one ,processors 5
dvp
R R
W
W
R
W
R R
1 2 3 4 5

38
Example
Common case: “read one/write all”W(d)= V(d)R(d) = 1Local reads, but writes go to all processors

39
Replicated Servers
• A server is really an interface to a service -- can be implemented by several processors
• A server can be replicated over a set of processors P
• A client contracts some p in P, which acts as a coordinator for the transaction
• The methods treaded so far can be used to handle the transaction
• Alternative: primary copy -- single processor coordinating all transactions
• + Simplifies things, e.g. no distributed locks necessary
• - No performance gain from parallelism
• If primary copy fails a new can be elected

40
Preliminaries
• Given a set of transactions T, a history H over T is a partial order over all transaction operations and the order reflects the operation execution order (transaction order and conflicting operations order).
• A schedule is any linear order consistent with H’s partial order

41
Example of a history
T1: r1[x] w1[x] c1
T2: r2[x] w2[y] w2[x] c2
T3: r3[y] w3[x] w3[y] w3[z] c3
r1[x] w1[x] c1
r3[y] w3[x] w3[y] w3[z] c3
r2[x] w2[y] w2[x] c2

42
Correctness
• A history is serial if for every 2 transactions, either all operations of one appear before the other or vice-versa.
• Since every transaction is correct, a serial history must be correct, and if executed on a consistent database, will result in a consistent database.
• But we want to allow concurrent transactions…

43
Example of concurrent execution: transfer 100 from account x to y
Serial execution Concurrent execution
r1[x] returns 200 r1[x] returns 200
w1[x] writes 100 w1[x] writes 100
r1[y] returns 200 r2[x] returns 100
w1[y] writes 300 r1[y] returns 200
commit t1 w1[y] writes 300
r2[x] returns 100 commit t1
r2[y] returns 300 r2[y] returns 300
commit t2 commit t2
BOTH TRANSACTIONS OBSERVE AND WRITE SAME VALUES!

44
Serializability
• A history is serializable if it is equivalent to a serial history over the same set of transactions.
• 2 histories are view equivalent of they have the same effects, i.e. same values are written by all transactions. Since we do not know what transactions write, we require that transactions read from the same transactions and final written values are the same.

45
Conflict Serializability
• Recall: 2 operations conflict if one of them is a write operation.
• Two histories, H1 and H2, are conflict equivalent if the order of conflicting operations is the same in both histories, i.e., if o1 in t1 and o2 in t2 conflict, then
– o1 < o2 in H1 iff o1 < o2 in H2.
• H is conflict serializable if it is conflict equivalent to a serial history.

46
Serialization Graphs• How do we prove a history H is (conflict) serializable?
• Serialization Graph SG(H):– nodes are transactions,
– t1 -> t2 if o1 in t1 and o2 in t2 conflict and o1 < o2 in H
H: w1[x]w1[y]c1r2[x]r3[y]w2[x]c2w3[y]c3
t1 t2 t3
• Serializability Theorem: A history H is serializable iff SG(H) is acyclic.
• A concurrency control protocol ensures serializability.

47
Example
• t0: w0[a := 100] w0[b:=20] c0
• t1: r1[a] r1[b] w1[c := a+b] w1[d := a-b] c1
• t2: r2[a] r2[b] w2[c := a-b] w2[d := a+b] c2
• Assume t0 completed first, t1 and t2 are executed
simultaneously
• If t1<t2 we get (120,80) < (80,120)
• If t2<t1 we get (80,120) < (120,80)
• Any other result is illegal