1 fit5174 distributed & parallel systems lecture 3 fit5174 parallel & distributed systems...
TRANSCRIPT

1
FIT5174 Distributed & Parallel Systems
Lecture 3
FIT5174 Parallel & Distributed Systems Dr. Ronald Pose Lecture 3 - 2013

2
Overview
• Interprocess Communication (IPC)
• Synchronization in Distributed systems– Clock synchronization– Event Ordering– Distributed Mutual Exclusion– Deadlock

3
Inter-process Communication (IPC)
• IPC basically requires information sharing among two or more processes. Two basic methods-
– Original sharing (Shared data approach)
– Copy Sharing (Message passing approach)
P1 P2Shared
Common Memory Area
P1 P2
Shared data approach Message passing approach

4
Message Passing System• A message-passing system is a sub-system of a distributed system
that provides a set of message-based IPC protocols and does so by shielding the details of complex network protocols and multiple heterogeneous platforms from programmers.
• It enables processes to communicate by exchanging messages
• Allows programs to be written by using simple communication primitives, such as send and receive.
• Serves as a suitable infrastructure for building other higher level IPC systems, such as RPC (Remote Procedure Call) and DSM (Distributed Shared Memory).

5
Desirable features of a good message passing system
• Simplicity• Uniform semantics
– Same primitives for local and remote communication
• Efficiency– Reduce the number of message as far as possible
– Some optimization normally adopted for efficiency include-
• Avoiding the cost of establishing and terminating connections between the same pair of processes for each and every message exchange between them
• Minimizing cost of maintaining connections
• Piggybacking of acknowledgment of previous message with the next message.

6
Desirable features of a good message passing system
• Reliability– Lost and duplicate message handling
• Correctness– Atomicity
– Ordered delivery
– Survivability
• Flexibility– Can drop one or more correctness properties

7
Desirable features of a good message passing system
• Security– Authentication of sender and receiver
– Encryption of messages
• Portability– Message passing system should itself be portable
– The application written by using primitives of the IPC protocol should be portable.

8
Issues in IPC by message passing
• A typical message structure
– Header Addresses
Sender address Receiver address
Sequence number Structural information
Type Number of bytes
– Message

9
Design of an IPC protocol
• Some of the main issues will be:– Identity related– Who is the sender?– Who is the receiver?
– Network Topology related– 1 receiver or many?
– Flow control related– Guaranteed by the receiver?– Sender should wait for reply?
– Error control and channel management– Node crash……what to do?– Receiver not ready….what to do?– Several outstanding messages for the receiver

10
Synchronization in IPC
• Send primitive– Blocking– Non blocking
• Receive primitive– Blocking– Non Blocking
Polling interrupt
IPC Synchronization Semantics
Blocking Non Blocking

11
Synchronous & Asynchronous Communication
• When both the send and receive primitives of a communication between two processes use blocking semantics, the communication is said to be Synchronous; otherwise it is asynchronous.
Sender Receiver
Receive (message)Execution suspended
Execution resumed
Message
AcknowledgmentExecution resumed
Synchronous mode with blocking send and receive primitives

12
Synchronous VS Asynchronous Communication
• Synchronous– Simple and easy to implement
– Contributes to reliability
– No backward error recovery needed
• Asynchronous– High concurrency
– More flexible than synchronous
– Lower deadlock risk than in synchronous communication ( but beware)

13
Buffering
• Synchronous systems– Null buffer
– Single message buffer
• Asynchronous systems– Unbounded capacity buffer
– Finite message (multiple message buffer)

14
Buffering
Synchronous System Asynchronous System

15
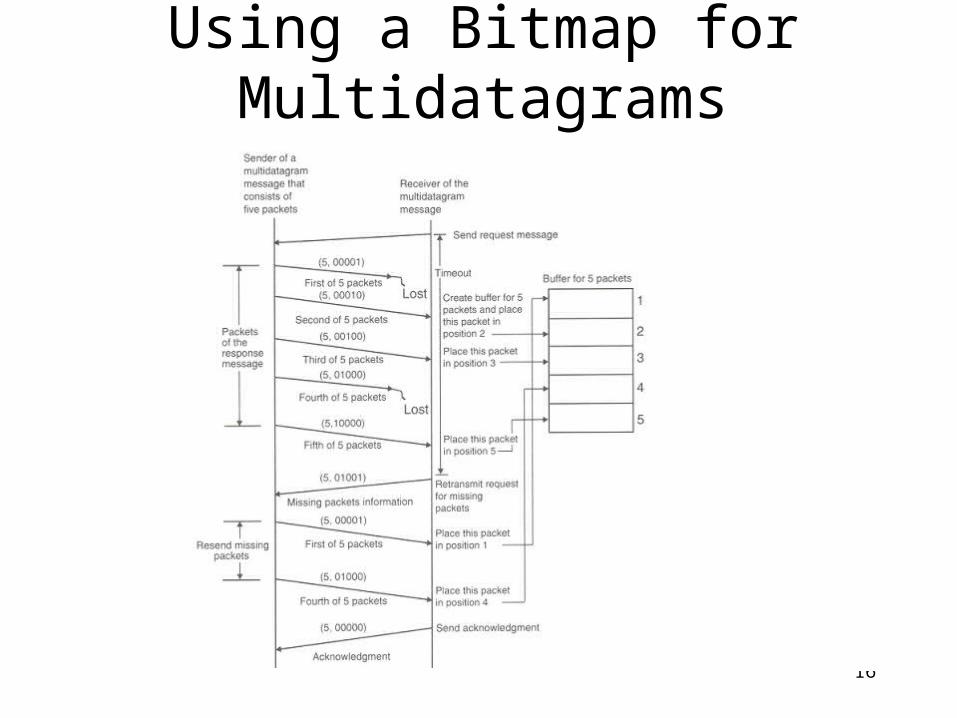
Multi-datagram Messages
• Almost all networks have an upper bound on the size of data that can be transmitted at a time. This is known as MTU (maximum transfer unit).
• Thus a message whose size is greater than MTU has to be fragmented - each fragment is sent in a packet. These packets are known as datagram.
• Thus messages may be single-datagram messages or multi-datagram messages
• Assembling and dissembling is the responsibility of message passing system.
16
Using a Bitmap for Multidatagrams

17
Encoding Decoding
Encoding/Decoding is needed if
• Sender and receiver have different architecture
Even for Homogeneous Encoding/Decoding is needed for
Using an absolute pointerTo know which object is stored in where
and how much storage it requires

18
Process Addressing
• Explicit Addressing
– Send(process_ID, message)– Receive(process_ID, message)
• Implicit Addressing
– Send_any(service_ID, message)– Receive_any(process_ID, message)

19
Failure Handling
• Failure classification1. Loss of request message
2. Loss of response message
3. Unsuccessful execution of the request
crash
sendersender receiverreceiver
Request
sender receiver
Request
Lost
Request
Lost
response

20
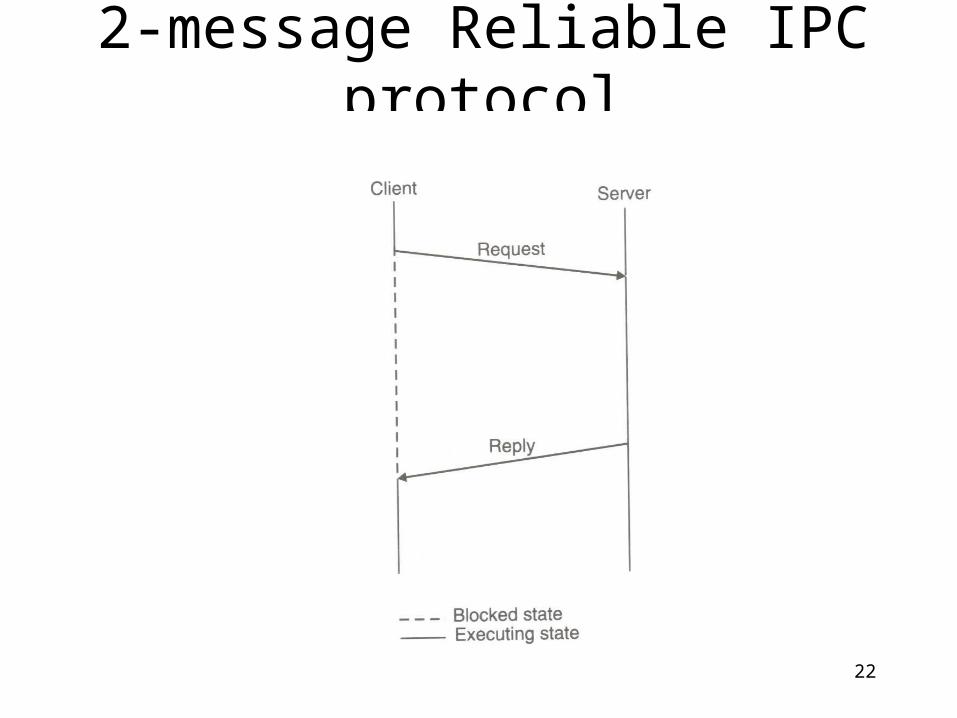
4-message reliable IPC protocol

21
3-message Reliable IPC protocol
22
2-message Reliable IPC protocol

23
Example of Fault Tolerant System

24
IdempotencyWhat is the difference between the following two functions?
• getSqrt(n)
{ return sqrt(n)
}
• Debit (amount)
{ if (balance>amount)
balance= balance-amount
return (“success”, balance)
else return (“failure”, balance)
}

25
A Non-Idempotent Routine
04/18/23Distributed Systems Lecture 2

26
Implementation of Idempotency
• How to implement Idempotency?
– Adding sequence number with the request message– Introduction of ‘Reply cache’

2704/18/23Distributed Systems Lecture 2

28
Group Communication• Group communication may be
– One to many– Many to one– Many to many
• One to many– Group management– Group addressing– Buffered and unbuffered multicast– Send-to-all and Bulletin-Board semantics– Flexible reliability in multicast communication– Atomic multicast

29
Many to Many communication
• The issues related to one-to-many and many-to-one communications also applies here
• In addition, ordered message delivery is an important issue. This is trivial in one-to-many or many-to-one communications.
• For example, two server processes are maintaining a single salary database. Two client processes send updates for a salary record. What happen if they reach in different order? (Will sequencing of messages help in this case?)

30
Semantics for ordered delivery in many-to-many
communications
• No-ordering
No ordering constraint
2

31
Semantics for ordered delivery in many-to-many communications
• Absolute ordering– All messages are delivered to all receiver processes in the exact
order in which they were sent.
– Using global timestamp as message identifiers with sliding window protocol
Absolute ordering semantic

32
Semantics for ordered delivery in many-to-many communications
• Consistent ordering– All messages are delivered to all receivers in the same order. However,
this order may be different from the order in which messages were sent.
Implementation– Make the communication appear as a combination of many-to-one and
one-to-many communication [Chang and Maxemchuk]– Kernels of sending machines send messages to a single receiver
(known as sequencer) that assigns a sequence number to each message and then multicast it.
– Subject to single point of failure and hence has poor reliability.
– A distributed algorithm - ABCAST in ISIS system [Birman and Renesse] (self study)

33
Semantics for ordered delivery in many-to-many
comm.
Consistent ordering semantic

34
Semantics for ordered delivery in many-to-many comm.
• Causal ordering– If the event of sending one message is causally related to the event of
sending another message, the two messages are delivered to all receivers in correct order.
– Two message sending events are said to be causally related if they are corelated by the happened-before relation.
[ The expression a→b is read “a happens before b" and means that all processes agree that first event a occurs, then afterward, event b occurs. The happens-before relation can be observed directly in two situations:
1. If a and b are events in the same process, and a occurs before b, then a→b is true.
2. If a is the event of a message being sent by one process, and b is the event of the message being received by another process, then a→b is also true.
Happens-before is a transitive relation, so if a→b and b→c, then a→c. ]

35
Semantics for ordered delivery in many-to-many comm.
• One example of implementing Causal consistency is CBCAST in ISIS system [Birman et al].
Causal ordering semantic
2nd round m2 is held back
2nd round m2 is held back

36
Remote Procedure Call (RPC)
• The IPC part of a distributed application can be adequately and efficiently handled by using an IPC protocol based on message passing system.
• However, an independently developed IPC protocol is tailored specifically to one application and does not provide a foundation on which to build a variety of distributed applications.
• Therefore, a need was felt for a general IPC protocol that can be used for designing several distributed applications.
• The RPC facility emerged out of this need.

37
Remote Procedure Call
• While the RPC is not the universal panacea for all types of distributed applications but for a fairly large number of distributed applications.
• The RPC has become a widely accepted IPC mechanism in DS. Its features –
– Simple call syntax.– Familiar semantics.– Specification of a well defined interface.– Ease of use.– Generality. “In single-machine computations procedure calls are
often the most important mechanism for communication between the parts of the algorithm” [Birrell and Nelson].
– Its efficiency

38
RPC model• RPC model is similar to “Procedure call” model.
• Procedure call is same as function call or subroutine call
• Local Procedure Call - The caller and the callee are within a single process on a given host.
• Remote Procedure Call (RPC) - A process on the local system invokes a procedure on a remote system. The reason we call this a “procedure call” is because the intent is to make it appear to the programmer that a local procedure call is taking place.

39
Local and Remote Procedure Call
Local Procedure Call Remote Procedure Call

40
A Typical Model of RPC

41
Implementing RPC
• To achieve the goal of semantic transparency, the implementation of an RPC mechanism is based on the concept of stubs
• Stubs provide a perfectly normal (local) procedure call abstraction
• To hide the distance and functional details of underlying network, an RPC communication package (known as RPCRuntime) is used.
• Thus RPC implementation involves five elements-– The client– The client stub– The RPCRuntime– The server stub– The server

42
RPC in Detail

43
Stubs
• Client and server stubs are generated from interface definition of server routines by development tools.
• Interface definition is similar to class definition in C++ and Java.

44
Parameter Passing Mechanisms
• When a procedure is called, parameters are passed to the procedure as the arguments. There are three methods to pass the parameters.
◦call-by-value
◦call-by-reference
◦call-by-copy/restore

45
Call by value• The values of the arguments are copied
to the stack and passed to the procedure.
• The called procedure may modify these, but the modifications do not affect the original value at the calling side.

46
Call-by-Reference• The memory addresses of the variables
corresponding to the arguments are put into the stack and passed to the procedure.
• Since these are memory addresses, the original values at the calling side are changed if modified by the called procedure.

47
Call-by-Copy/Restore• The values of the arguments are copied to the
stack and passed to the procedure.• When the processing of the procedure
completes, the values are copied back to the original values at the calling side.
• If parameter values are changed in the subprogram, the values in the calling program are also affected.

48
Parameter Passing in RPC
• Which parameter passing mechanisms are possible?
◦It is possible to implement all of the three mechanisms if you wish. Usually call-by-value and call-by-copy/restore are used.
◦Call-by-reference is difficult to implement. All data which may be referenced must be copied to the remote host and the reference to the copied data is used.
• Do we need to convert the values of the arguments into a standard format to transmit over the network?

49
Parameter Passing in RPC
• Reasons to convert the values of the arguments into a standard format to transmit over the network
◦Different machines use different character codes. E.g., IBM main frames use EBCDIC, while PCs use ASCII.
◦Representation of numbers may differ from machine to machine.
◦Big endian and little endian

50
Parameter Passing in RPC
• If a standard format is not used, two message conversions are necessary.
◦If format information is attached to the message, only one conversion at the receiver will suffice.
◦However, the receiver must be able to handle many different formats.

51
RPC Messages
• Generally two types of messages– Call messages
– Reply messages
A typical RPC Call message formatA typical RPC Reply message format
(successful and unsuccessful)

52
Variations of RPC
Asynchronous RPC– RPC (When a client requests a remote procedure, the client wait
until a reply comes back in RPC.
– If no result is to be returned, unnecessary wait time overhead.
– In asynchronous RPC, the server immediately sends accept message when it receives a request.

53
Call-Back RPC
One-way RPC
• In one-way RPC, the client immediately continues after sending the request to the server.

54
Some special types of RPC
• Callback RPC
• Broadcast RPC
• Batch-mode RPC
• Lightweight RPC

55
Optimizations for better Performance
• In Six Different Ways– Concurrent access to multiple servers
– Serving multiple requests simultaneously
– Reducing per-call workload of servers
– Reply caching of idempotent remote procedures
– Proper selection of timeout values
– Proper design of RPC protocol specification

56
Concurrent Access to Multiple Servers
• One of the following three may be adopted:– Threads
• Use of Threads in the implementation of a client process where each thread can independently make remote procedure calls to different servers.
• Addressing in underlying protocol should be rich enough to provide correct routing of responses.
– Early reply approach [Wilbur and Bacarisse]• A call is split into two separate RPC calls- one passing parameters and
other requesting the result• Server must hold the result causing congestion or unnecessary
overhead.
– Call buffering approach [Gimson]• Clients and servers do not interact directly but via a call buffer server• A variant of this approach was implemented in MIT (Mercury
Communication System)

57
Early Reply Approach

58
Call Buffering Approach

59
Serving Multiple Requests Simultaneously
• Following types of delays are common-– A server, during the course of a call execution, may wait for a shared
resource– A server calls a remote function that involves computation or transmission
delays
• So the server may accept and process other requests while waiting to complete a request.
• Multiple-threaded server may be a solution.

60
Summay of IPC (1)
• What is the purpose of IPC?– information sharing among two or more processes
• Differences between Synchronous and Asynchronous Communications?
– When both the send and receive primitives of a communication between two processes use blocking semantics, the communication is said to be Synchronous; otherwise it is asynchronous
• List the Types of Failure in IPCLoss of request message, Loss of response message,
Unsuccessful execution of the request

61
Summary of IPC (2)
• How to implement Idempotency?– Adding sequence number with the request
message and Introduction of ‘Reply cache’
• Three main types of Group Communications?– One to many, Many to one, Many to many
• One of the greatest challenges in Many to Many?
• Ordered Delivery
• Name an all propose IPC protocol?– Remote Procedure Call (RPC)

62
Summaary of IPC (3)
• Name a few ways to optimise RPC?– Concurrent Access to Multiple Servers,
Serving Muliple Requests Concurrently, Reducing Call Workload per Server
• Three different techniques for implementing Concurrent Access to Multiple Servers?– Threads, Early Reply, Call Buffering

63
References for IPC1. Birman, K. P. and Renesse, R. V. Reliable Distributed
Computing with the ISIS Toolkit. IEEE Computer Society Press, 1994.
2. Birrell, A. D. and Nelson, B. J. Implementing remote procedure calls. ACM Trans. Comput. Syst. 2(1), 39-59, 1984.
3. Wilbur, S. and Bacarisse, B. Building distributed systems with remote call, Software Engineering Journal, 2(5), 148-159, 1987.
4. R. Gimson. Call buffering service. Technical Report 19, Programming Research Group, Oxford University, Oxford University, Oxford, England, 1985.

64
Why Study Synchronisation, MUTEX, Deadlock?
• Synchronisation, mutual exclusion and deadlocks are very common problems which arise when multiple entities are competing for access to shared resources;
• All three are usually covered in units or textbooks dealing with operating systems, where the shared resources are CPU/core time and shared main memory, and sometimes I/O devices;
• In a distributed / parallel system the problem is complicated by the need to allow for transmission delays in passing messages through the IPC between tasks (processes), which makes some solutions used in operating systems problematic;
• Failure to properly address these problems will result in often catastrophic applications failures or bugs.

65
What is Synchronisation?• World English Dictionary: synchronize or synchronise (ˈsɪŋkrə
ˌnaɪz): to occur or recur or cause to occur or recur at the same time or in
unison to indicate or cause to indicate the same time: synchronize your
watches ( tr ) films to establish (the picture and soundtrack records) in
their correct relative position ( tr ) to designate (events) as simultaneous• Synchronisation is about making two or more entities achieve a
known state or condition at a known or identical time – for instance a receiver (e.g. task) must be ready before it can accept a message from a transmitter (e.g. task).

66
Synchronisation in Distributed Systems
• A Distributed System consists of a collection of distinct processes that are spatially separated and run concurrently;
• In systems with multiple concurrent processes, it is economical to share the system resources;
• Sharing may be cooperative or competitive;• Both competitive and cooperative sharing require
adherence to certain rules of behavior that guarantee that correct interaction occurs – otherwise chaotic behaviour may arise;
• The rules of enforcing correct interaction are implemented in the form of synchronization mechanisms;
• Synchronisation mechanisms may be part of an operating system, or communications mechanism like a library;

67
Issues in implementing synchronization
• In single CPU systems, synchronization problems such as mutual exclusion can be solved using semaphores and monitors. These methods rely on the existence of shared memory, which can be accessed very quickly by all tasks;
• We cannot use semaphores and monitors in distributed systems since two processes running on different machines cannot expect to have access to any shared memory;
• In a distributed system there are always finite time delays from messages to travel from one process to another, so any mechanism we use must account for these delays;
• Even simple matters such as determining if one event happened before another event require careful thought.

68
Issues implementing synchronization in DS/PS
• In distributed systems, it is usually not possible and often not desirable to collect all the information about the system in one place and synchronization among processes is difficult due to the following features of distributed systems:
The relevant information is scattered among multiple machines. Processes make decisions based only on local information. Any single point of failure in the system should be avoided. No common clock or other precise global time source exists.
• Synchronisation in distributed/parallel systems requires unique algorithms which account for the unique behaviours in such systems, especially time delays.

69
Time in Distributed Systems: Why?
• External reasons: We often want to measure time accurately For billings: How long was computer X used? For legal reasons: When was credit card W charged? For traceability: When did this attack occurred? Who did it?
– System must be in sync with an external time reference• Usually the world time reference: UTC (Universal Coordinated Time)
or derived GPS master clock;
• Internal reasons: many distributed algorithms use time Kerberos (authentication server) uses time-stamps This can be used to serialise transactions in databases This can be used to minimise updates when replicating data
– System must be in sync internally - No need to be synchronised on an external time reference

70
Clock Synchronization• Time is unambiguous in a centralized system – every process
“sees” the same master clock in the machine.• A process can simply make a system call to learn the time – the
operating system then looks at the clock hardware.• If process A asks for the current time, and a little later process B
asks for the time, the value of B_time > A_time.• In a distributed system, if process A and B are on different
machines, B_time may not be greater than A_time.• This is because the hardware clocks on these machines may not
be precisely synchronised.• Even if the clocks are synchronised, there may be a
synchronisation error which is large enough to matter.
• Example: Recent CERN quantum physics experiment failure.

71
Imperfect Clocks
• Human-made clocks are imperfect– They run slower or faster than “real”
physical time– How much faster or slower is termed
“clock drift”– A drift of 1% (i.e. 1/100=10-2) means the
clock adds or loses a second every 100 seconds
• Suppose, when the real time is t, the time value
of a clock p is Cp(t). If the maximum drift rate allowable is ρ, a clock is said to be non-faulty if
the following condition holds - ρρ +≤≤− 11
dt
dC

72
Clock Synchronisation
Let’s synchronise. I’ve got 12:07.
And You?
12:05
12:11
12:2312:09
12:15
12:07
12:1912:09
12:21
OK. Done.
Done.
I’ve got 12:11Let’s agree on 12:09.
OK?
Alic
e
Bob

73
Cristian’s Algorithm
• This algorithm synchronizes clocks of all other machines to the clock of one machine, time server.
• If the clock of the time server is adjusted to the real time, all the other machines are synchronized to the real time.
• Every machine requests the current time to the time server.• The time server responds to the request as soon as possible.
• The requesting machine sets its clock to Cs +(T1 −T0 − I)/2.
• In order to avoid clocks moving backward, clock adjustment must be introduced gradually.

74
The Berkeley Algorithm• Developed by Gusella and Zatti. • Unlike Cristian’s Algorithm the server process in Berkeley algorithm, called the
master periodically polls other slave process. • Generally speaking the algorithm is as follows:
– A master is chosen with a ring based election algorithm (Chang and Roberts algorithm).
– The master polls the slaves who reply with their time in a similar way to Cristian's algorithm
– The master observes the round-trip time (RTT) of the messages and estimates the time of each slave and its own.
– The master then averages the clock times, ignoring any values it receives far outside the values of the others.
– Instead of sending the updated current time back to the other process, the master then sends out the amount (positive or negative) that each slave must adjust its clock. This avoids further uncertainty due to RTT at the slave processes.
– Everybody adjusts their time.

75
Averaging Algorithm• Both Cristian ’s algorithm and the Berkeley algorithm are
centralized algorithms with the disadvantages such as the existence of the single point of failure and high traffic volume concentrated in the master clock server.
• The “Averaging algorithm” is a decentralized algorithm.
• This algorithm divides time into resynchronization intervals with a fixed length R.
• Every machine broadcasts the current time at the beginning of each interval according to its clock.
• A machine collects all other broadcasts for a certain interval and sets the local clock by using the average of the arrival times.

76
Logical Clocks versus Physical Clocks
• Lamport showed that:– Clock synchronization need not be absolute– If two processes do not interact their clocks need not be
synchronized.– What matters is they agree on the order in which events occur.
• For many purposes, it is sufficient that all interacting machines agree on the same time – they share a “frame of reference”. It is not essential that this agreed time is the same as “real time”.
• Clocks which agree across a group of computers but not necessarily with “real time” are termed “logical clocks”.
• Clocks that agree in time values, within a certain time limit (i.e. error), are “physical clocks”.

77
Lamport’s Synchronization Algorithm• This algorithm only determines event order, but does not
synchronize clocks.• “Happens-before” relation:
– “A →B” is read “A happens before B”: This means that all processes agree that event A occurs before event B.
• The happens-before relation can be observed directly in two situations:
– If A and B are events in the same process, and A occurs before B, then A→B.
– If A is the event of a message being sent by one process, and B is the event of the message being received by another process, then A→B
.• “Happens-before” is a “transitive” relation – if element a is related to
an element b, and b is in turn related to an element c, then a is also related to c

78
Lamport’s Synchronization Algorithm• If two events, X and Y happen in different processes that do
not exchange messages (not even indirectly via third parties), then neither X →Y nor Y →X is true. These events are then termed “concurrent”
• What we need is a way to assign a time value C(A) on which all processes agree for every event A. The time value must have the following properties:
◦If A →B, then C(A) < C(B).
◦Clock time must always go forward, never backward.• Suppose there are three processes which run on different
machines as in the following figure. • Each processor has its own local clock. The rates of the local
clocks are different.

79
MUTEX / Mutual Exclusion in Distributed Systems
• When multiple processes access shared resources, using the concept of critical sections is a relatively easy way to manage access to shared resources:
A critical section is a section in a program that accesses shared resources.
A process enters a critical section before accessing the shared resource to ensure that no other process will use the shared resource at the same time.
• Critical sections are protected using semaphores and monitors in single-processor systems. We cannot use either of these mechanisms in distributed systems due to the time delays in propagating messages between machines.

80
A Centralized Algorithm – Coordinator Process
• This algorithm simulates mutual exclusion in single processor systems.
• One process is elected as the “coordinator”.• When a process wants to enter a critical section of the code, it
sends a request to the coordinator stating which critical section it wants to enter.
• If no other process is currently in that critical section, the coordinator returns a reply granting permission.
• If a different process is already in the critical section, the coordinator queues the request.
• When the process exits the critical section, the process sends a message to the coordinator releasing its exclusive access.
• The coordinator takes the first item off the queue of deferred request and sends that process a grant message.

81
A Centralized Algorithm

82
A Centralized Algorithm
Advantages Since the service policy is first-come first-serve, it is fair and no
process waits forever. It is simple and thus easy to implement. It requires only three messages, request, grant, and release, per
use of a critical section.
Disadvantages If the coordinator crashes, the entire system may go down. Processes cannot always distinguish a dead coordinator process
from a “permission denied” message; A single coordinator may become a performance bottleneck if
requests arrive at a high frequency, or the propagation delay of the messages is large.

83
A Distributed Algorithm• The distributed algorithm proposed by Ricart and Agrawala requires ordering of
all events in the system. We can use the Lamport’s algorithm for the ordering.• When a process wants to enter a critical section, the process sends a request
message to all other processes. The request message includes – Name of the critical section– Process number– Current time
• The other processes receive the request message.– If the process is not in the requested critical section and also has not sent a
request message for the same critical section, it returns an OK message to the requesting process.
– If the process is in the critical section, it does not return any response and puts the request to the end of a queue.
– If the process has sent out a request message for the same critical section, it compares the time stamps of the sent request message and the received message.

84
A Distributed Algorithm• If the time stamp of the received message is smaller than the
one of the sent message, the process returns an OK message.• If the time stamp of the received message is larger than the
one of the sent message, the request message is put into the queue.
• The requesting process waits until all processes return OK messages.
• When the requesting process receives all OK messages, the process enters the critical section.
• When a process exits from a critical section, it returns OK messages to all requests in the queue corresponding to the critical section and removes the requests from the queue.
• Processes enter a critical section in time stamp order using this algorithm.
• This is a “consensus” mechanism as all processes must agree it is “OK to enter critical section”.

85
A Distributed Algorithm

86
Mutual Exclusion Algorithms: A Comparison
• The number of messages exchanged (i.e. messages per entry/exit of a single critical section):
A. Centralized: 3B. Distributed: 2*(n − 1)C.Ring: 2
• Reliability problems which can disable the mutual exclusion mechanism:
A. Centralized: coordinator crashesB. Distributed: any process crashesC. Ring: lost token, process crashes

87
Deadlocks in Distributed Systems• A deadlock is a condition where a process cannot proceed
because it needs to obtain a resource held by another process and it itself is holding a resource that the other process needs.
• We can consider two types of deadlock:– communication deadlock occurs when process A is trying to send
a message to process B, which is trying to send a message to process C which is trying to send a message to A.
– A resource deadlock occurs when processes are trying to get exclusive access to devices, files, locks, servers, or other resources.
• We will not differentiate between these types since we can consider communication channels to be resources without loss of generality.

88
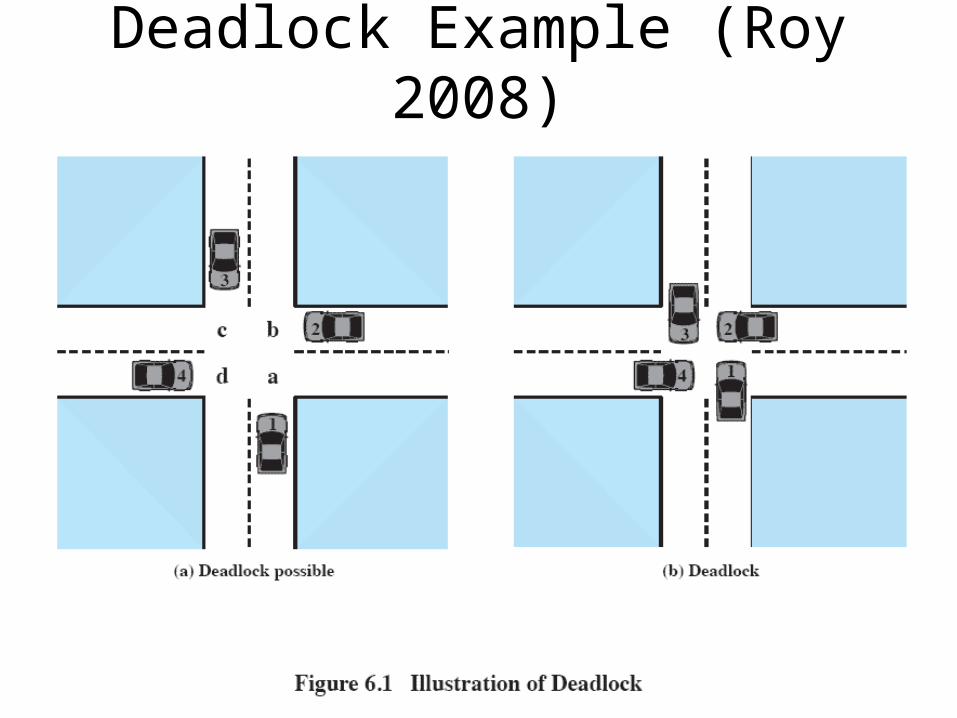
What is a Deadlock? (Roy 2008)
• Permanent blocking of a set of processes that either compete for system resources or communicate with each other
• No efficient solution
• Involve conflicting needs for resources by two or more processes
89
Deadlock Example (Roy 2008)

90
Necessary Conditions for a Deadlock• Four conditions have to be met for deadlock to be present:
– Mutual exclusion. A resource can be held by at most one process
– Hold and wait. Processes that already hold resources can wait for another resource.
– Non-preemption. A resource, once granted, cannot be taken away from a process.
– Circular wait. Two or more processes are waiting for resources held by one of the other processes.

91
Handling Deadlocks in DS/PS
• Strategies:
A. The “Ostrich algorithm”;
B. Deadlock detection and recovery;
C. Deadlock prevention by careful resource allocations;
D. Deadlock avoidance by designing the system in such a way that deadlocks simply cannot occur;

92
Summary of Synchronisation, mutual exclusion and deadlock
• Three Real Time Clock Synchronisation Methods– Cristian’s Method– Berkeley Algorithm– Averaging Algorithm
• Logical (Clock) Synchronisation Techniques– Lamport
• Mutual Exclusion Approaches– Centralised– Distributed
• Main Deadlock Modeling Areas– Necessary condition for occurrence– Deadlock Detection– Deadlock Handling