1 going fast(er) on internet2 campus focused workshop on advanced networks, san diego 4/12/2000 joe...
Post on 19-Dec-2015
214 views
TRANSCRIPT

1
Going Fast(er) On Internet2
Campus Focused Workshop on Advanced Networks, San Diego
4/12/2000
Joe St Sauver ([email protected])
Computing Center
University of Oregon

2
Disclaimer• What we’re going to tell you today is based
on our experiences working primarily with Usenet News at the U of O; it may/may not pertain to other applications elsewhere.
• We tend to look for simple, scalable, workable solutions which we can roll out now, e.g., overprovisioning rather than QoS
• We tend to be cheap, skeptical, and cynical
• We tend to be good at pushing things until they break; it is an acquired/teachable skill.

3
A Sidenote About This Presentation
• It is longer than it should be, but we’ll go until we run out of time and then stop.
• Sorry it is so graphically boring. :-)
• It is outlined in tedious detail because that way we won’t forget what we wanted to say, and thus you won’t need to take notes.
• Hopefully, it will thus be able to be decoded by someone stumbling upon it post hoc.

4
I. Introduction
Or, "Are You Really Sure
You Want to Go Fast(er)?"

5
Now That I'm On I2, Everything Will Get Really
Fast… Right?
• It is a popular misconception that once your campus gets connected to Internet2, everything you do on the network will suddenly, magically, and painlessly go "really, really fast."
• The reality is that going even moderately fast can take patience, detective work, tinkering, and maybe even forklift upgrades.

6
Do You Really NEED or Even WANT To Go Fast(er)?
• Going fast(er) can be a big pain. Huh? …-- It will take a lot of work-- It may cost you some money-- It almost always requires the active assistance of lots of folks-- You may find yourself (in the final analysis) only partially successful, and -- Fast boxes are choice targets for crackers-- Lots of happy people DON’T go fast

7
As-Is/Out-of-the-Box Might Be Good Enough
• Unless you're running into a particular problem (e.g., you HAVE to go fast(er)), one perfectly okay decision might be to just go however fast you happen to go and not worry about anything beyond that.
• E.G., a Concorde may be very fast, but a Concorde might not be the best way to get to the corner store for a loaf of bread.
8
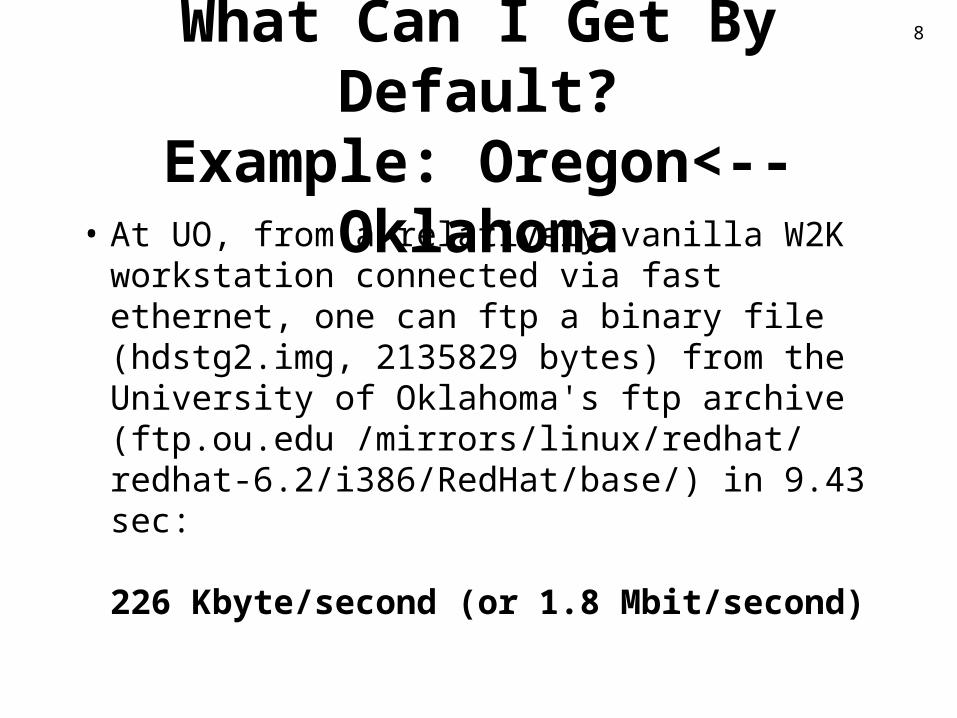
What Can I Get By Default?Example: Oregon<--Oklahoma• At UO, from a relatively vanilla W2K
workstation connected via fast ethernet, one can ftp a binary file (hdstg2.img, 2135829 bytes) from the University of Oklahoma's ftp archive (ftp.ou.edu /mirrors/linux/redhat/redhat-6.2/i386/RedHat/base/) in 9.43 sec: 226 Kbyte/second (or 1.8 Mbit/second)

9
For Comparison, A Second Local-Only Example...
• Retrieving that same file from a local ftp mirror (ftp://limestone.uoregon.edu/.1/ redhat/redhat-6.2/i386/RedHat/base/) that same workstation allowed me to get the filein 0.32 seconds, which translates to:
6,653.67 Kbyte/sec (or 53.2Mbit/sec)

10
Thinking About Those Examples A Little
• As always, closer will usually be faster [mental note… value of replicated content]
• Quoted throughput should be considered approximate (e.g., the times aren't exact).
• There are start up effects (which will tend to pull the overall throughput down); e.g., if the file was larger, we'd look/be "faster"
• Ten seconds or 1/3 of a second, either way you won't have time to go get coffee

11
Make An Effort to Know How Fast You HAVE to Go
• As you try to go fast(er), it will be important for you to know how fast you HAVE to go.
• For example: "I need to be able to deliver 1.0Mbps sustained for MPEG1-quality video" or "I need to be able to transfer 180GB of data per day on a routine basis."
• Get your requirement into Mbps format so you can readily make comparisons

12
Converting Data Transfer Requirements Into Mbps
• Example:
180 gigabytes/day ==
(180,000 megabytes)(8 bits per byte)---------------------------------------------- ==(24 hrs/day)(60 mins/hr)(60 secs/min)
roughly 17 megabits/sec 'round the clock

13
Be Sure To Remember...
• Very few data transfer requirements are "uniformly distributed 'round the clock" --plan for peaking loads
• Best case/theoretical requirements should be considered a lower (not upper) boundon bandwidth requirements.
• Plan for system/application downtime.
• What's the data transfer rate of growth?
14
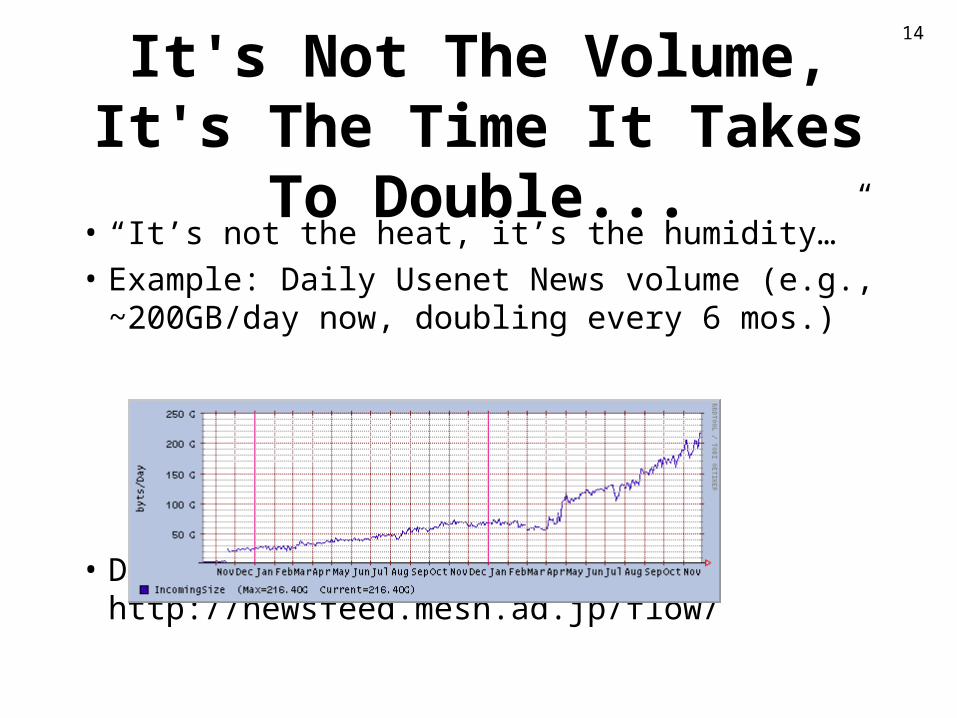
It's Not The Volume, It's The Time It Takes To Double...
• “It’s not the heat, it’s the humidity…”
• Example: Daily Usenet News volume (e.g., ~200GB/day now, doubling every 6 mos.)
• Data from http://newsfeed.mesh.ad.jp/flow/

15
That Implies, For Example...
• Today: 200GB/day (e.g., 18.5 Mbps)
• 6/2001: 400GB/day (37 Mbps)
• 12/2001: 800GB/day (74 Mbps)
• 6/2002: 1.6TB/day (148 Mbps)
• 12/2002: 3.2TB/day (296 Mbps)
• … and of course, that’s assuming we don’t see another upward inflection in the rate of NNTP traffic growth (but trust me, we will).

16
What does ftp.cdrom.com say?
• “Wcarchive is the biggest, fastest, busiest public FTP archive in the world. * * * Each month, more than 10 million people visit wcarchive -- sending out to them more than 30 terabytes of files (as of June, 1999), with the only limit being the Internet backbone(s).” See: ftp://ftp.cdrom.com/ archive-info/configuration
• 30 TB/mo = “only” a steady ~92.6Mbps

17
In Most Cases, The Only Reason You Need to Go Fast
Will Be LOTS Of Data….
• By "LOTS" of data, you should be thinking in terms of hundreds of gigabytes/day on a routine/ongoing basis.
• Assuming even moderate data retention times (e.g., a week), 100’s of GB/day implies use of what would traditionally be considered a large disk farm.

18
Again Looking At cdrom.com...
• In the “old days,” (two or three years ago?) large capacity disk farms were physically large, expensive and quite uncommon...
• For example, Cdrom.com is/was fielding a 1/2 terabyte of disk consisting of 18x18GB plus 20x9.1GB

19
Terabyte of Data on The Desktop, Anyone?
• Now there are 82GB Ultra ATA Maxtors (and for only $300 or so!) and 180GB Ultra160 Barracudas will be shipping soon
• A terabyte of data can now happily run from an undergrad’s desktop PC...

20
The Good News?
• In spite of the cheap availability of large disks, there are really very few applications which NEED to go very fast (either for long periods of time or on a frequently recurring basis between any two particular points).
• That is, most large flows are non-recurring, and not particularly time sensitive. An example might be one scientist ftp'ing one large data set from one colleague one time.

21
Got Non-Reocurring, Non-Time-Sensitive Flows? Relax...
• If you are working with non-recurring, non-time sensitive flows, you have a fair amount of slack: even if you don’t succeed in going fast, the transfer will still get done eventually, one way or the other.
• Put plainly, “Sort of slow may still be fast enough.”

22
The (Sort Of) "Bad" News...
• There are LOTS of folks who WANT to go fast(er) (whether they NEED to or not)
• There are MANY applications that IN AGGREGATE may need to deliver "lots" of data (e.g., not a tremendous amount to any one user, but some to LOTS of users)
• Most apps can't distinguish between Internet2 and the commodity Internet.

23
Why Would A Broad Interest in Going Fast Be (Sort of)
Bad News?• Recall my earlier proposition that going
fast(er) is hard/expensive/requires help from lots of people, and often only sorta works.
• It wouldn’t take a tremendous number of people going really fast to flattop existing Internet2 capacity.
• For now, it is still expensive to buy I2 size pipes to the commodity Internet.

24
Abilene OC3 Cost vs. Commodity Internet Costs
• Abilene (Internet2) OC3: $110,000/yearCWIX OC3: $1,082,400/yearSprint OC3: $1,489,200/yearGenuity OC3: $2,064,000/year==> Commodity OC3's are expensive and it doesn't take many people who're even doing “just” 30 Mbps to fill an OC3.(prices from http://www.boardwatch.com/ isp/bb/Backbone_Profiles.htm)

25
“I asked for a mission, and for my sins they gave me one.”
• When you may be striving to build a campus network enabling high throughput to Internet2, beware: you are ALSO building a network which will deliver high throughput to the commodity Internet.
• If you encourage users to go fast to I2, they will go fast everywhere (assuming they go fast anywhere) because users don’t know when they’re using Internet2.

26
Are We Racing To The Precipice? Probably Not...
• Good news is (may be?) coming… • Some vendors (e.g., Cogent Communications)
will soon be selling 100Mbps of commodity transit for $3K/month, flat rate… if you're in one of the “NFL cities” where they have a POP.
• Perversely, one of the things that determines where carriers build out their POPs is the existing/demonstrated bandwidth demand!

27
“I can’t get cheap commodity transit where I’m located…”
• If you can’t get cheap commodity transit, the only bandwidth provisioning solution that financially scales to the high bandwidth scenarios we’re all moving toward is to go after settlement free peering with large network service providers. Doing this implies you need fiber to one or more exchange points, and you need to be able to convince providers of interest to peer…

28
Some University-Affiliated Commodity Exchange Points
• Oregon IX (http://www.oregon-ix.net/)
• Hawaii IX (http://www.lava.net/hix/)
• SD-NAP (http://www.caida.org/projects/sdnap/content/)
• BC IX (http://www.bcix.net/)
• Hong Kong IX (http://www.cuhk.hk/hkix/)
• and many more… see http://www.ep.net/

29
“What if those sort of strategies aren’t right for us?”
• You have (or soon will have) problems
• You will spend your time making users go slower, not helping them to go fast(er)
• Transparent web caching may help (some), but watch out for witch hunt opportunities.
• Maybe try going after edge content delivery networks (Akamai, iBeam , etc.)? Maybe try bandwidth management appliances?

30
But...
• Users will go faster, even if you work hard at trying to slow them down
• Transparent web caching may reduce your traffic by a factor of two (but if your traffic is doubling every 6 months, that implies doing caching is only going to buy you 6 months worth of breathing room, and then you’re back where you started from...)

31
But… But…
• Edge content delivery networks may help with some specific content, but there’s still a lot of other content that will NOT be getting distributed via those ECDN’s.
• Bandwidth management appliances invite user efforts to “beat the system” by exploiting any weaknesses in your traffic management model (just like in the bad old mainframe chargeback days, ugh!)

32
On The Other Hand...
• Everybody may be talking about OC12’s, OC48’s and OC192’s, but even a major NSP like Abovenet still has a lot of OC3’s, fast ethernet and DS3 class links...
• See Above.Net’s publicly available traffic reports (http://west-boot.mfnx.net/traffic/)
• The lesson of Above.Net’s stats? OC3 class traffic is still relatively rare/a big deal... and not something to treat casually.

33
Free Advice (And You Know What That’s Worth)
• Be sure you really need/want to go fast(er)
• Strive to understand your current traffic requirements
• Never lose sight of the fact that going fast on Internet2 will mean that you probably need to go fast on the commodity Internet, too
• Work to deploy scalable solutions

34
II. So Who’s Going Fast On Internet2
Right Now?
“The All News Network, All The Time.” [CNN moto]

35
Large TCP/IP Flows
• Our focus/interest is on large TCP/IP flows which result in lots of bytes getting transferred.
• We’re not worried about/interested in UDP traffic; it will implode on its own. :-)
• We ignore brief one-off spikes associated with demonstations/stunts/denial of service attacks/etc. -- long term real base load is of the greatest interest to us.

36
We Don’t Have a Per Application Breakdown
for Abilene, But….
• … Canarie DOES report the most common applications (including reporting the most popular applications for the three Canarie-Abilene peering points).
• See http://www.canet3.net/stats/reports.html(the Abilene/CANet3 peering points are labeled Abilene, AbileneNYC & SNAAP)

37
Making Traffic Statistics Intuitively Meaningful
• While we could compare application traffic in terms of Mbps or percentages or other abstract units, it may help to characterize I2 traffic relative to a common traffic base we all intuitively understand: WWW activity.(excellent idea, CANet, bravo!)
• On the commodity Internet, we all know that WWW traffic is the dominant protocol. But what about on Internet2?

38Most Popular TCP/IP Apps at CANet/Abilene Peering Points, Relative to HTTP as 1.0X for
the week ending 11/5/2000
• Abilene (Chicago): NNTP 2.31XFTP 1.59X
• Abilene (NYC): NNTP 4.11XFTP 1.35X
• SNNAP (Seattle): NNTP 13.9XFTP 1.23X

39
Most Popular TCP/IP Apps at Selected CANet3 Sites,
11/05/2000, Relative to HTTP,and As A % of Total Octets
• BCNet: NNTP 49.4X 77.1%FTP 2.14X 3.3%
• MRNet: NNTP 90.7X 74.6%FTP 8.81X 7.2%
• RISQ: NNTP 31.1X 72.0%FTP 1.31X 3.0%

40
==> Usenet News & FTP Are The Dominant Applications
on I2 (Thank God…!)• Usenet News (NNTP) is the dominant
TCP/IP application (which is good, since most campuses centrally administer Usenet news, and thus can manage it carefully)
• FTP is the second largest TCP/IP application (which is also good since it is typically non-time sensitive/non-recurring, or is it non-recurring?)

41
Why Is Usenet News The Most Successful Application on I2?
• News admins have been working hard at making systems go fast for a long time now
• NNTP is architected to scale well
• News admins have a long history of collaborating well with their peers. :-)
• Non-I2 News traffic quickly gateways onto and off of I2 news servers at multiple points
• Performance matters (e.g., ‘Freenix effects’)

42
An Hypothesis About Internet2 FTP Traffic Levels
• FTP, as the number two application on Internet2, is also of interest to us. As we began to think about it, we came up with a hypothesis about what that FTP traffic represented. All that FTP traffic *could* be wild-haired misbuttoned boffins happily transferring gigabytes and gigabytes worth of spatial data on the mating habits of Peruvian tree frogs... but we doubted it.

43
OR That FTP Traffic Could Be Site-to-Site Mirroring Traffic
• Just beginning to think about this...
• Will we be able to differentiate mirroring traffic from user traffic? Maybe, maybe not.
• Some observable flow characteristics:-- both endpoints would be ftp servers (duh)-- chronological patterns (e.g., assume cron’d invocation of mirroring software)
• FTP log analysis from major FTP sites? (particularly looking for ls -lR transfers…)

44
Interactive vs. Automated FTP Traffic SubHypotheses
• SubHypothesis 1: web distribution of files should have virtually replaced anonymous ftp retrieval of files
• SubHypothesis 2: scp should be replacing non-anonymous interactive ftp’ing
• SubHypothesis 3: cvsup should be replacing traditional development tree mirroring

45
More SubHypotheses...• SubHypothesis 4: to account for the volume
we’re talking about, there should be multi-threaded mirroring tools in use (see, e.g., “Mirror Master” available from ftp://sunsite.org.uk/packages/mirror/ )
• SubHypothesis 5: user-level semi-automated ftp tools may cloud the analysis (e.g., http://www.ncftp.com/ncftp/); trueWindows-based mirroring software also exists (e.g., http://www.netload.com.au/)

46
Do We Even Know What Mirror’ers Are Doing?
• Smart mirroring tools should minimize unnecessary transfers by only transfering that which has “changed” -- but what’s a change? Later mtime and different file size? MD5 hash delta? ==> Varies by package.
• Field work opportunity for computer anthropologists: go talk to the guys who run the big ftp servers out there…

47
III. Thinking About Your Application and I2
Or, "What do you mean I can't make a lemon chiffon cake out of a
package of venison T-bones?"

48
Not All Applications Are Well Suited to Going Fast on I2
• We did an article for the UO Computing Center newsletter describing what sort of applications are well suited to Internet2; the NLANR Application Support Team liked it well enough that they now have a version of it up at http://dast.nlanr.net/Guides/ writingapps.html

49
Mentally Categorizing Applications
• Applications where you can control WHO you work with, WHERE they are working from, WHAT they are doing and WHEN they are doing it, tend to work best on I2
• Simplest example: getting one file to one colleague one time via a passworded server
• Degenerate case: large video on demand files on a generically accessible web server

50
CONTROLLEDSERVER WITHCONTENT/APP
SINGLECOLLABORATOR
USING CONTENT/APP
Internet2
"idealized" model of I2 application (rarely an accurate model)
versus amore
realisticmodel of I2
content/apps
PUBLICSERVER WITH
CONTENT
USER #1 ATCAMPUS A
VIA GIGAPOPALPHA
USER #2 VIATHE
COMMODITYINTERNET
USER #3 FROMA FOREIGN
RESEARCH ANDEDUCATIONNETWORK
USER #5 FROMAN I2 CAMPUS(BUT OVER A
DIALIN MODEM)
USER #4FROM THE
LOCALCAMPUS
USER #6 ALSOFROM CAMPUSA VIA GIGAPOP
ALPHA
USER #7 FROMCAMPUS B WITH
ASYMMETRICROUTES
USER #NFROM ?

51
Why Is The Worst Case Scenario So Bad?
• The worst case scenario is problematic because “tricks” you can try using to optimize flows in the idealized case simply don't work in less controlled scenarios -- specialized solutions that work for one user don't scale to many users, and tricks that work on the lossless I2 fall apart in the face of the packet loss that's common on the commodity Internet.

52
Other Problems With The Real (vs. Idealized) Scenario
• You can’t (really) tell anything about the potential throughput of a user by their address (e.g., someone at an I2 campus connected by an OC12 could still be coming in over dialup -- no way for you to tell)
• You may get MULTIPLE users from the same site at the same time, which means that each will get at most 1/N of the potential thruput that one might have gotten

53
Looking For Long Term and Generalized Return on Effort
• The other factor is that when you are going to tweak an application to improve its throughput, you prefer an application that will generalize and be of long term value -- fixing an application that will only be used one time, or which is of interest to a very limited audience (“stunt applications”), reduces the payoff associated with the effort you're putting in, and may defer other work.

54
Examples of Apps That Tend to Work Well Over Internet2
• Usenet News
• Mirroring of FTP sites
• Web cache hierarchies
• MPEG1 IP multicast video
• Peer to peer networking (e.g., Napster) with path preference (http://bestpath.iu.edu/)

55
But That's Not To Say That Most Applications Can't Be
Made to Run Faster...
• … because they usually can.

56
IV. Gathering Baseline Measurements
Or, "If only we'd known where we were, we'd probably have had a lot easier time going somewhere else."

57
Measuring Your Current Throughput As A Baseline
• In some cases, the application you're using may already report the throughput it is getting (e.g., when you ftp a file, it provides a report of bytes per second transfer speed automatically).
• If your application is running on a dedicated box, you can watch the throughput of that interface directly or you may be able to use SNMP to measure your throughput.

58
Example of Watching Throughput under W2K...
• On W2K (or Windows NT) you can go to Settings-->ControlPanel -->Administrative Tools -->Performance and then click on the "+" (Add Counters) to let you add "Network Interface" "Bytes Sent/Sec" and "Bytes Received/Sec" values derived from your ethernet adapter.
• You can also look at those counters via SNMP (Simple Network Mgmt Protocol).

59
Using SNMP...
• A variety of SNMP agents (such as SNMX) are available which can allow you to monitor network traffic by successively polling SNMP counters
SNMX is available online at:http://www.ddri.com/Products/ace-snmx.html

60
Example SNMX Script
• #!/usr/local/bin/snmxconnect 128.223.abc.defrepeatecho $ifInOctets.3 $ifOutOctets.3 | myprogsleep 15endrepeatquit
• … where "myprog" computes and prints the rate over time for those two SNMP counters

61
That Sort of Tool Generates at Least Basic Throughput Info...
• Time…. Input Bps Output Bps
12:00:17 36606820 12132023612:00:32 36870705 11515037012:00:47 39005785 112971435[etc.]

62
Why Not Just Use Something Like HP OpenView?
• Match the tool to the task: simple tasks should be handled with simple tools
• Users often won’t have a workstation to dedicate to network monitoring tasks
• Simple tools are easier to explain to users and easier for them to master
• It works well enough (even if it isn’t perfect)
63
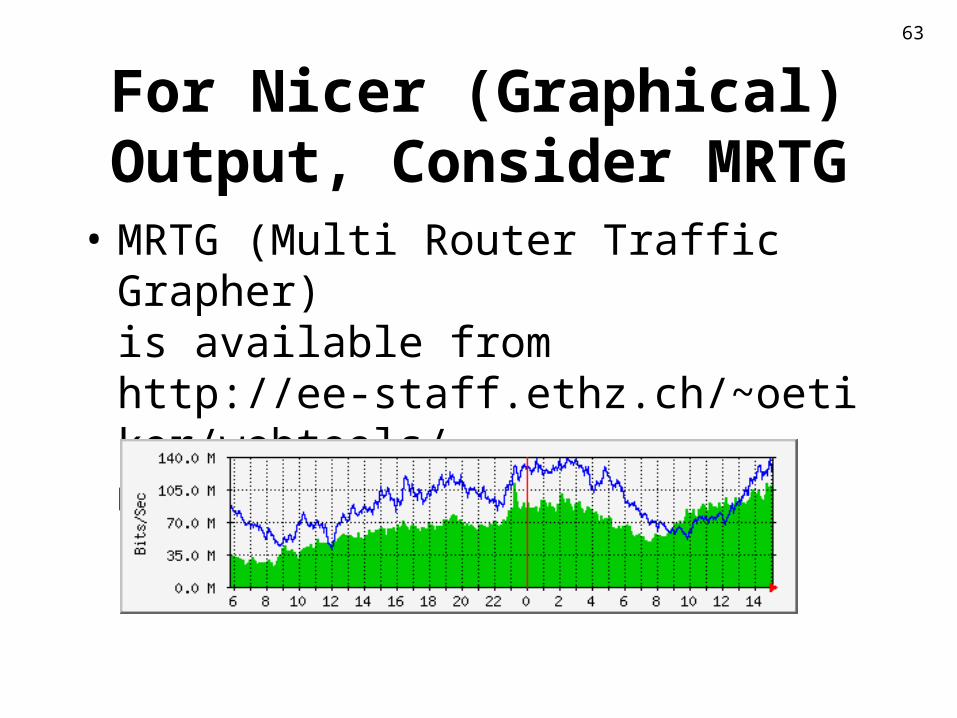
For Nicer (Graphical) Output, Consider MRTG
• MRTG (Multi Router Traffic Grapher)is available from http://ee-staff.ethz.ch/~oetiker/webtools/mrtg/mrtg.html) and makes nice graphs:

64
But MRTG Isn’t Perfect, Either
• It is easy for MRTG configuration files to end up out-of-date as interfaces get added or deleted on routers, cables get moved around on switches, etc.
• There’s also the problem that MRTG can run into when centrally monitoring lots of ports: it builds all of its graphs all of the time, even if no one is looking at them

65
Yes, I Know About RRDtool
• RRDtool does indeed fix the problem of trying to continually remake millions of graphs that no one may ever look at, however… RRDtool actually makes it hard for those of us who like to build composite web pages which monitor only one graph from page X and another graph from page Y, and a third graph from page Z (since those graphs won’t pre-exist)
66
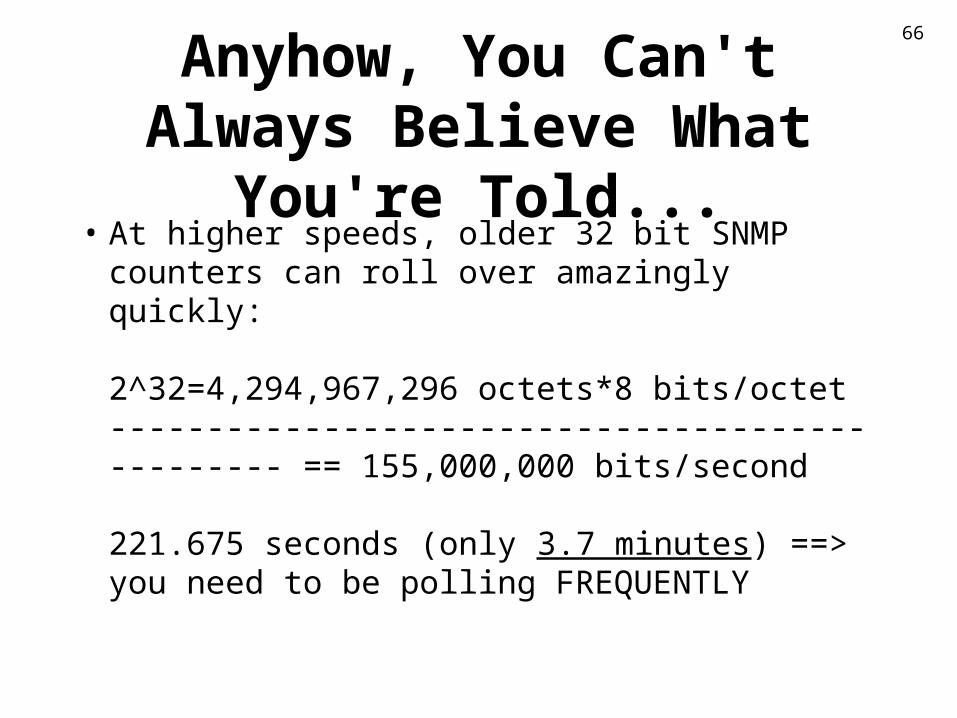
Anyhow, You Can't Always Believe What You're Told...
• At higher speeds, older 32 bit SNMP counters can roll over amazingly quickly:
2^32=4,294,967,296 octets*8 bits/octet------------------------------------------------ == 155,000,000 bits/second
221.675 seconds (only 3.7 minutes) ==>you need to be polling FREQUENTLY

67
Example of An Incorrect Plot Due to Counter Rollover
• Note the “picket fence” appearance and the high average utilization rate (this plot was done with five minute sampling intervals)
• None of this is new; see RFC 2233 3.1.6 for a discussion of 32 bit counter problems.

68
And Then There Are Vendor-Specific Problems, Such As...
• Microsoft Knowledge Base article Q146004 (http://support.microsoft.com/support/kb/articles/Q146/0/04.asp) confirms that SNMP counters for a variety of variables are broken when NT/W2K is running on SMP (multiprocessor) machines. The Knowledge Base article states that “This will not be fixed.” Ugh.

69
Once You Know How Fast You're Currently Going...
• Once you know how fast you're currently going, you can then determine how much of a change you'll need to make (if any).
• Let's assume you do still need to make some changes...

70
Throughput Is Limited by the "Tightest Pipe" in the Network• Network traffic between any two points
may pass through many links, some large and some small, some congested and some almost completely unused.
• Possible network throughput is physically bounded by the link in that chain which has the lowest available capacity. Even big pipes can still end up getting filled up!

71
Examples of Constraining Links...
• If you are dialing in, the obvious and clearly pertinent constraining link is the speed of your modem; nothing else you can try can overcome the throughput limit of that link.
• If you are connecting from a shared (half duplex) 10Mbps ethernet port, your throughput will never be as potentially great as that of someone who is on a switched (full duplex) 100Mbps fast ethernet port.

72
But There Can Be More Subtle Constraints...
• A prime suspect for the most common campus-level choke point will be upstream campus fast ethernet router interfaces which may end up seeing aggregated traffic from multiple downstream fast ethernet server connections. While the clear solution is to migrate those interfaces to gigabit, the interfaces can be expensive (outright, and in terms of using up scarce chassis slots)

73
And Router Horsepower...
• Another potential choke point can be the CPU horsepower of your router and the throughput of its backplane (and the software feature you burden it with, e.g., long ACLs, encryption, etc.).

74
In the case of Cisco boxes...
• The VIP’s installed on routers in your path may hit you quicker than you might think. VIP 2/40’s, for example, at 65K pps, may be an issue at bandwidths under 300Mbps (in plus out) depending on packet sizes. See the discussion http://puck.nether.net/lists/cisco-nsp/ entitled “RSP/VIP performance question”

75
And Even If Your Own House Is In Order (As It Surely Is)...
• Everything that can choke your throughput locally can (and will) also be potentially an issue for the OTHER end of the pipe (which will be even harder to try to identify and get fixed).

76
Identifying and Eliminating Network Choke Points
• Users need to do some network detective work so they can understand the network topology that lies between them and their collaborators.
• An excellent starting point for users is to teach them to use the traceroute command.

77
What About Traceroutes In The Other Direction?
• Reverse paths may be completely different (e.g., routing may be/will often be asymmetric); http://www.internet-2.org.il/i2-asymmetry/index.html
• You need/want a traceroute gateway at each site you work with so you can traceroute in both the forward and the reverse direction

78
Some Internet2 Sites Already Have Traceroute Gateways Up• http://darkwing.uoregon.edu/~llynch/cgi-bin/trace.cgi
(UO via Abilene Denver or Abilene Sacramento)• http://www.net.cmu.edu/cgi-bin/netops.cgi
(CMU via Abilene; can get a ping report, too)• http://netview.cc.iastate.edu/cgi-bin/trace
(Iowa State via vBNS, includes a ping report, too)• http://noc.net.umd.edu/cgi-bin/traceroute/trace
(Maryland via Abilene)
• Plus many more, but by no means allInternet2 sites (unfortunately); see http://www.traceroute.org/ for add’l sites.

79
What Can Traceroute Tell Your Users?
• Are they even using Internet2?
Odd note: users may need help learning to make inferences from traceroute output (such as references to Abilene or the vBNS or to their local Gigapop)…
“But it never said Internet2 on any of the traceroute output…”

80
Traceroute also hints about geography/capacity/technology• Many link labels will mention locations
(e.g., kscy-dnvr for Kansas City-Denver)
• Links may have labels that allude to their speed, e.g., "OC3" (155Mbps), "OC12" (622Mbps), "FE" (fast ethernet, 100Mbps), "GE" (gigabit ethernet, 1000Mbps), etc.
• Links may refer to "ATM" (asynchonous transfer mode) or "POS" (packet over sonet)

81
Traceroute Will Also Help Make Latencies Meaningful
• Part of moving toward going fast is developing a sense of “normal” latency values
• Users should learn that local links should have very small times (just a few msec), and remote links should run on the order of 25msec to LA, 75msec to NYC, or 220msec or more to remote locations such as Tokyo

82
Be sure they know what to do when the news isn’t good...
• Occaisionally, if they traceroute to remote destinations, they will see large round trip times. This should not immediately make them “freak out.”
• Large round trip times, particularly when they only appear sporadically/during certain times of the day, may be an indication that there is a congested link in the path...

83
BUT Large RTT's May Also Mean...
• … that they are simply going to a very remote destination
• … that they are going via satellite rather than via fiber
• … that ping traffic has been deprioritized by a network device along the way (regular TCP/IP traffic may be rolling along just fine)

84
Link Capacity vs. Available Link Capacity
• Once they have an idea of how they're going to a particular site, their next goal should be to see if there's available capacity on the links between them and their remote partner.
• In order to be able to do this, you will need to know the speed of each link in the path plus its usage (or try to infer link capacity by watching for flat-topped usage graphs).

85
Looking Step by Step to See if There's Capacity...
• In many cases, the only way to get true link speeds is to talk to network engineers responsible for those links (but in some cases it may be viewed as impolite to ask how big one's pipes are -- sort of like asking how much money someone makes or how much a person weighs)… or there may be multiple or alternate paths that may make it hard to get an applicable answer.

86
An Aside About Automated Per Hop Throughput
Estimators...
• There are some automated throughput estimators such as pathchar (see:http://www.caida.org/tools/utilities/others/pathchar/) however we've had mixed results from them…

87
Measuring End to End Available Bandwidth
• Easiest solution may be to use ttcp (ftp://ftp.arl.mil/pub/ttcp/), assuming you can run a daemon on the remote end to which you'd like to estimate throughput.
• See also netperf (http://www.netperf.org/)
• Problem: act of measuring changes that which is being measured… e.g., ttcp or netperf can/will fill up your pipes.

88
Network Usage Data
• So… when it comes to usage data, you're basically hunting for MRTG (or comparable) SNMP graphs for each link between you and your remote site of interest….

89
Campus Level Traffic
• For data about traffic on local (campus) links, users should talk to campus network administrators. Network administrators may or may not have that data, and it may or may not be publically available to your users for a variety of reasons.

90
For Gigapop-level Usage Data...
• See: http://monon.uits.iupui.edu/abilene/and then click on a core node, and then click on "Connector Stats" for the node you selected.
• For the Oregon Gigapop, for example, see the Denver and Sacramento (soon to be Sunnyvale) core nodes.

91
For I2 Backbone Usage Data...
• See the Abilene Weather Map that's athttp://hydra.uits.iu.edu/~abilene/traffic/
• For foreign peering networks, see:http://monon.uits.iupui.edu/ abilene/peers.html

92
What About Remote Peer Campus' MRTG pages?
• They may or may not be available; your remote colleagues should check with the network engineers at their site for information. Again, this data may not be available.

93
What If I'm Working With MANY remote sites?
• Repeat the above process for all of them, one at a time, and recognize that stuff is constantly changing, and go crazy…
• OR assume that so long as traffic is going via I2, it is probably flowing via an uncongested link; the problem thus becomes one of monitoring what exit traffic takes -- does it go via I2, or some other network?

94
One Approach to Monitoring Traffic Exits…
• See my talk "Monitoring Traffic Exits In a Multihomed I2 Environment"http://www.ncne.nlanr.net/news/workshop/2000/000515/Talks/sauver-jt05152000/

95
The Abilene Backbone Isn’t Congested, True…
• The one chunk of the end-to-end network path that probably won't be congested at all is the Abilene backbone….

96
But ... Be Prepared for Some Possible Indirect Routes...
• At least in the past, Abilene’s sparse number of routing nodes and limited number of peering points with other networks (e.g., the old approach of hauling all foreign connections to StarTap in Chicago, the absence of a west coast Abilene-vBNS interconnect, etc.) has meant that some traffic was routed sub-optimally in terms of its geographic route/latency.

97
For example, Oregon to China ...via the Midwest
• Traffic from Abilene to CERNet sites (such as Peking University or Tsinghua University) goes via StarTAP in Chicago, which adds approximately 60 msec worth of latency to packets from West Coast sites.
• Arguably, given that the total latency to some overseas sites will be > 1000msec, maybe we could ignore that extra 60msec...

98
An Example Where The I2 Topology IS Material...
• Oregon Abilene-connected schools going to NM vBNS-connected schools via Chicago:UNM ==> 99 msecNMSU ==> 106 msec vs.LANL ==> 48 msec (ESNet via Calren)
But DOE’s Albuquerque NM Operations Office (www.doeal.gov) is 110 msec (via ESNet Chicago!)

99
A 2nd Example Where I2’s Topology Works Against Itself
• UO to Portland State via the OWEN/NERO statewide network: ~13.5 msec
• UO to OGI (also in the Portland Area, but connecting via the gigapop in Seattle) --travels down to Sacramento, then up to Seattle, then back to Portland: ~33 msec
• Rhetorical-ish question: what is the “best” path selection criteria for I2 schools with multiple connectivity options?

100
Abilene Is Getting Better, But...
• Examples: now three peering points with CANet3, International Transit Network, etc.
• BUT if Abilene won’t/can’t/prefers not to fix its sparse number of routing nodes and limited interconnections with some other networks, the only viable solution (where it is an issue) may be to obtain direct links to networks where there are routing/latency problems (where possible).

101
And About Those Mission Networks...
• For some mission networks this simply won’t be possible at all; see: www.es.net/hypertext/ESNetUniversityPolicy.html[Clearly the federal mission networks want to be supportive of Internet2, and they want to simplify their own lives, and the want to avoid having people collect mission network connectivity just for bragging rights rather than for functional purposes.]

102
Let’s Come Back to the “Easy” Part: The Campus...
• If your user’s local system isn't connected via a fast ethernet (or a gig ethernet) connection, get that connection upgraded. Here at UO, there is a one time $150/port charge to get fast ethernet service (where it is available). Pay the money and make that "last 100 meters” entirely a non-issue.

103
Possibly Choke Point #1: Campus Backbone
• If you’ve got fast ethernet to the desktop, you should have gigabit ethernet at the campus core. UO currently has a gigabit core, but there are other campuses that may still be running with a fast ethernet or FDDI core..
• If the core of your campus backbone isn't running gigabit ethernet at this point, it's (past) time to begin planning to upgrade it.

104
And Dig Into What’s On Those Routers
• Just because it has fast interfaces or gig interfaces doesn’t mean that it will keep up with the traffic being shoved at it.
• Are you monitoring router CPU loads?
• Do you know what sort of VIPs are between you and the world?

105
Possible/Likely Choke Point #2: Intrastate backhaul links
• If your Internet2 traffic is currently backhauled to a regional gigapop over intrastate DS3 speed links, that obviously is going to limit your potential Internet2 throughput.
• Those sort of potential choke points could be upgraded to leased OC3’s (but fiber based solutions would be more flexible)

106
Lighting Dark Fiber Becoming Increasingly Affordable
• Traditional SONET-based solutions were (and are) outrageous, but some optical vendors are offering financially attractive alternatives (e.g., see: http://www.luxn.net/)
• I have a fiber optic primer and tutorial available that you’re welcome to check out;see: http://cc.uoregon.edu/cnews/summer2000/fiber.html

107
Possible/Likely Choke Point #3: International Links
• International links are particularly expensive, and hence tend NOT to be overprovisioned.
• If I had to make a bet about where the choke point would be for flows going to an overseas destination, my money would always be on the international link itself
• We (in the US) have little room to gripe, however, since we aren't willing to help pay

108
Going Fast Isn’t Just A Matter of Eliminating Network
Choke Points, However...
• You need to tackle the operating system, the system hardware, and the application, too...

109
V. Operating System Issues
Or, "There are two major products that come out of Berkeley: LSD and UNIX. We don't believe this to be a coincidence." Jeremy S. Anderson

110
Ugly Reality Number One: Your User May Not Run
the OS You Prefer
• Prime example: the application I work with most (NNTPRelay) is only available in a production quality package for NT/W2K, which means that I am unable to run a flavor of Unix or OpenVMS for most of my work. On the other hand, you may prefer NT or W2K but have to run Unix (example: NT and W2K still lack production IPv6...)

111
Basic HPC Mantra for OS Tuning… Handle Bandwidth
Delay Product Issues
• Nutshell description of problem: you need to be able to buffer the data being sent via TCP/IP until it has been acknowledged as having been sucessfully received at the remote site. This requires large buffers for high bandwidth flows to remote sites.

112
PSC OS Tuning Guide
• "Enabling High Performance Data Transfers on Hosts" (http://www.psc.edu/networking/perf_tune.html)
• Beginning to age, but still an excellent resource
• BEWARE: Assumes small number of flows; using large buffers can impact paged and non-paged memory pool requirements

113
Paged and Non-Paged Pools
• Another strange-but-true Microsoft NT/W2K factoid: according to Microsoft Knowledge Base article Q126402, Windows NT and W2K have hard caps on the maximum size of the paged and non-paged pools. E.G., even by tweaking the registry, you cannot exceed 300-340MB worth of paged pool, or 256MB worth of non-paged pool.

114
Linux is Not 100% Free of Actual or Potential TCP/IP
Issues, However, Either...
• See, for example, “Linux 2.2.12 TCP Performance Fix for Short Messages” at the ICASE Coral site:www.icase.edu/coral/LinuxTCP2.html
• Much worth learning about TCP/IP idiosyncrasies from the Beowulf community

115
Another Favorite Recommendation: SACK
• Another popular recommendation is to enable SACK (selective acknowledgements); a SACK enabled receiver is able to inform the sender about all packets received so that the sender needs to resend only the packets that have actuallybeen dropped.

116
SACK May Be Inconsistent With SYN Flood Protection...
• SACK and protection against SYN flooding may not be simultaneously possible under some OS's (see: http://www.microsoft.com/TechNet/network/tcpip2k.asp for example)
• And note that many major sites (surprise, surprise) don’t implement SACK (see:http://www.aciri.org/tbit/nanog-tbit.pdf), and only 6% of sites implement it correctly.

117
What If There's Packet Loss?
• For a nice general treatment that users may like, explaining what happens when they try to go fast but hit packet loss, see:
"TCP Response Under Loss Conditions"(http://www.academ.com/nanog/feb1997/ tcp-loss/index.html)

118
If You Want to Measure/ Monitor Packet Loss...
• AMP Active Measurement Program(round trip)http://amp.nlanr.net/active/ amp-uoregon/HPC/body.html
• Surveyor (one way)http://www.advanced.org/surveyor/

119
Maybe We Don’t Need to Worry About All This OS Tuning Stuff??? Web100
• Goal is to AUTOMATICALLY tune Linux hosts to achieve 100 Mbps class throughput over Abilene and comparable networks.
• $2.9 million in funding from the NSF
• See: http://www.web100.org/

120
VI. System Hardware Issues
Or, "It is really hard to beat the price performance of commodity PC
hardware these days."

121
If You Want to Go Fast, Bottomline, You Need
At Least Okay Hardware
• Relevant hardware components include:-- motherboard-- CPU-- memory-- Disk I/O-- NIC-- network switch

122
”I Need Okay Hardware" Does Not Necessarily Translate to “I’ve Got to Buy Traditional
Unix Workstations”• You will have a very hard time beating the
price/performance ratio of commodity PC workstations.
• The big question is “should I build from scratch or should I buy a prebuilt system?”

123
Build or Buy?
• We assume you’re fussy about what you run (or you’re cheap like us) and will roll your own
• But beware: if you’re planning on building and running NT/W2K, Microsoft certifies ONLY complete systems, not components.
• Until recently, too, you couldn’t really buy a good cheap server class motherboard

124
Motherboards
• Key? You want a motherboard with 66MHz 64 bit PCI slots
• See, for example: SuperMicro 370DE6(dual FCPGA PIII, ServerWorks ServerSet III HE-SL chipset, 133Mhz front side bus, up to 4GB registered ECC SDRAM, 2 64 bit 66MHz PCI slots, 4 64 bit 33MHz PCI slots, Adaptec dual Ultra160 SCSI) ~ $650

125
Or Maybe...
• Tyan Thunder HEsl (S2567), with 64 bit 66MHz and 64 bit 33 MHz PCI slots, 2 PIII processors, 2GB worth of DIMMs, dual Ultra160 controllers, etc. (the Tyan web site says “coming soon.”)

126
Network Interface Cards
• Don't expect to generally get 100 Mbps from fast ethernet cards, nor 1000Mbps from gigabit cards for a variety of reasons (most notably because of small 1500 byte MTUs, checksum-related overhead, and non-zero-copy TCP/IP stacks)

127
“Measured By Weight, Not Volume”
• For typical “gigabit” cards, you may only get 350Mbps to a little over 600Mbps…
• See: http://www.cs.duke.edu/ari/trapeze/tcp-clarity.html: “typical TCP socket implementations running over typical gigabit LANS (e.g., a Gigabit Ethernet using the standard 1500-byte MTU) deliver about half a gigabit per second.”

128
See also...
• http://www.lanquest.com/labs/reports/gigabitethernet/pci/IntelNP1288a.html
• http://www.nwfusion.com/news/1999/0705gigabit.html
• http://www.networkcomputing.com/916/916r1side4.html

129
Beware of NIC Interrupt Load
• Many network cards generate a large number of interrupts, which can really hammer your system's CPU -- Intel appears to be doing a good job at minimizing this problem... However we still tend to use Netgear GA620 gigabit NICs because they are inexpensive (~$330) and work well enough for our requirements.

130
CPU
• To go fast on the network, you really want multiple fast CPUs or you are liable to see CPU saturation from the NIC
• Some dual motherboards may/may seem to have stability issues under heavy load
• We do PIII’s; we’ve not been convinced that Xeons (even with lots of cache) merit their price premium (but we’d love to see empirical benchmarks on this topic).

131
Network Switches
• We currently use 3Com gig ether switches because some were generously donated
• We’re considering moving to HP4000M's with 1000baseT gig-over-copper interfaces because of their pricing; we know they have limited backplane throughput (but that may not be an issue for moderate port densities and practically realized throughput levels)

132
Disk I/O
• News guys used to think: “for good throughput, use lots of disks striped across multiple controllers”…
• SCSI (in the fastest flavor then available), was the customary prescription, but now check out Promise & 3Ware for some inexpensive IDE RAID possibilities (www.promise.com and www.3ware.com)

133
Beware Filesystem Dynamics
• Filesystem dynamics can also impact disk I/O throughput (e.g., inode insertion in UFS becomes problematic when there are “lots” of files in a single directory). Fast machines should consider using alternative file systems, such as either a cyclical file system or perhaps XFS.

134
See...
• http://www.usenix.org/publications/library/proceedings/lisa97/full_papers/14.fritchie/14_html/main.html
• http://oss.sgi.com/projects/xfs/

135
Doing A Stripe of Lots of Spindles: Sorta Old School...
• We’ve now come to realize that for really high throughput, you simply can't touch disk at all -- all the data has to be kept in memory.

136
RAM Disks
• Dropping price of commodity PC RAM makes RAM disks economically feasible for the first time
• Popular PC motherboards can now accommodate 2-4GB worth of RAM
• 512MB PC133 ECC Registered DRAM's are down to $499/each now…
• Compare that to a Quantum 1.6GB solid state drive at $14,499 or so...

137
W2K Ram Disk
• There is a limit to how big a "conventional" ram disk can be in W2K because it is normally carved out of paged/non-paged pool space (which has a hard cap, etc., etc.).
• See http://www.jlajoie.com/ramdskNT/ for information about a product that can use excluded memory to create up to 2GB ram disks in NT/W2K

138
Speaking of Memory...
• Traditional logic: more memory is always a good thing -- "If you're swapping, add memory"
• My app was swapping under NT/W2K, so I tried adding memory only to find that NT/W2K "wouldn't use it" -- no way to explicitly set working set quotas under NT/W2K as one can under OpenVMS.

139
Windows 2000 Memory Hell
• If you are planning to use W2K for applications that have lots of large files open, note that 1MB worth of paged pool gets used up for each GB worth of files which are open.
• C.F. earlier discussion regarding hard limits to paged and non-paged pool under W2K

140
Couple of Nice Additional Resources
• “TCP/IP and Network Performance Tuning”http://sd.wareonearth.com/woe/Briefings/tcptune/sld001.htm
• “Tuning Your TCP/IP Stack”http://www.rvs.uni-hanover.de/people/ voeckler/tune/EN/tune.html
• “SQUID Frequently Asked Questions”http://www.squid-cache.org/Doc/FAQ/ Many good practical OS-specific tips/quirks