1 language technologies (1) diana maynard university of sheffield, uk acai 05 advanced course on...
TRANSCRIPT

1
Language Technologies (1)
Diana MaynardUniversity of Sheffield, UK
ACAI 05 ADVANCED COURSE ON KNOWLEDGE
DISCOVERY

2
Text mining and the Semantic Web

3
What is Text Mining?• Text mining is about knowledge discovery
from large collections of unstructured text.• It’s not the same as data mining, which is
more about discovering patterns in structured data stored in databases.
• Similar techniques are sometimes used, however text mining has many additional constraints caused by the unstructured nature of the text and the use of natural language.
• Information extraction (IE) is a major component of text mining.
• IE is about extracting facts and structured information from unstructured text.

4
Challenge of the Semantic Web• The Semantic Web requires machine
processable, repurposable data to complement hypertext
• Once metadata is attached to documents, they become much more useful and more easily processable, e.g. for categorising, finding relevant information, and monitoring
• Such metadata can be divided into two types of information: explicit and implicit.

5
Metadata extraction• Explicit metadata extraction involves
information describing the document, such as that contained in the header information of HTML documents (titles, abstracts, authors, creation date, etc.)
• Implicit metadata extraction involves semantic information deduced from the material itself, i.e. endogenous information such as names of entities and relations contained in the text. This essentially involves Information Extraction techniques, often with the help of an ontology.

6
Motivation
• Implicit or semantic metadata extraction and annotation is the glue that ties ontologies into document spaces
• Metadata is the link between knowledge and its management
• Manual metadata production cost is too high
• State-of-the-art in automatic annotation needs extending to target ontologies and scale to industrial document stores and the web

7
Information Extraction (IE)
8
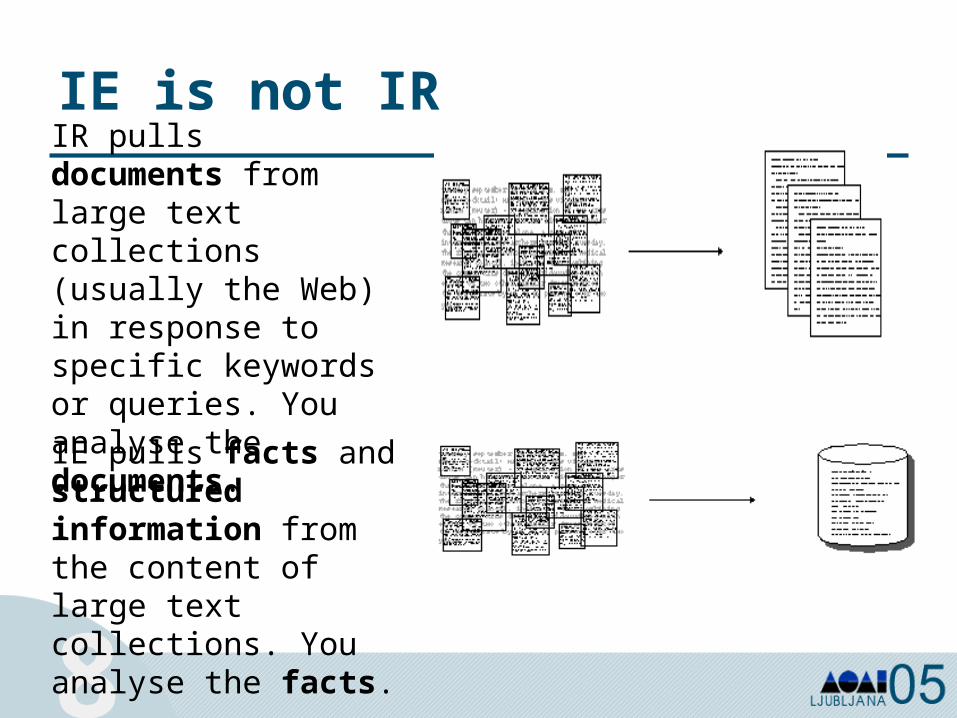
IE is not IR
IE pulls facts and structured information from the content of large text collections. You analyse the facts.
IR pulls documents from large text collections (usually the Web) in response to specific keywords or queries. You analyse the documents.

9
IE for Document Access• With traditional query engines, getting the facts
can be hard and slow•Where has the Queen visited in the last
year?•Which places on the East Coast of the US
have had cases of West Nile Virus? • Which search terms would you use to get this
kind of information?• How can you specify you want someone’s home
page?• IE returns information in a structured way• IR returns documents containing the relevant
information somewhere (if you’re lucky)

10
IE as an alternative to IR
• IE returns knowledge at a much deeper level than traditional IR
• Constructing a database through IE and linking it back to the documents can provide a valuable alternative search tool.
• Even if results are not always accurate, they can be valuable if linked back to the original text

11
Some example applications
• HaSIE• KIM• Threat Trackers

12
HaSIE
• Application developed by University of Sheffield, which aims to find out how companies report about health and safety information
• Answers questions such as:“How many members of staff died or had
accidents in the last year?”“Is there anyone responsible for health and
safety?”“What measures have been put in place to
improve health and safety in the workplace?”

13
HASIE
• Identification of such information is too time-consuming and arduous to be done manually
• IR systems can’t cope with this because they return whole documents, which could be hundreds of pages
• System identifies relevant sections of each document, pulls out sentences about health and safety issues, and populates a database with relevant information

14
HASIE

15
KIM
• KIM is a software platform developed by Ontotext for semantic annotation of text.
• KIM performs automatic ontology population and semantic annotation for Semantic Web and KM applications
• Indexing and retrieval (an IE-enhanced search technology)
• Query and exploration of formal knowledge

16
KIMOntotext’s KIM query and results

17
Threat tracker
• Application developed by Alias-I which finds and relates information in documents
• Intended for use by Information Analysts who use unstructured news feeds and standing collections as sources
• Used by DARPA for tracking possible information about terrorists etc.
• Identification of entities, aliases, relations etc. enables you to build up chains of related people and things

18
Threat tracker

19
Named Entity Recognition: the cornerstone of IE• Identification of proper names in texts,
and their classification into a set of predefined categories of interest
• Persons• Organisations (companies, government
organisations, committees, etc)• Locations (cities, countries, rivers, etc)• Date and time expressions• Various other types as appropriate

20
Why is NE important?
• NE provides a foundation from which to build more complex IE systems
• Relations between NEs can provide tracking, ontological information and scenario building
• Tracking (co-reference) “Dr Head, John, he”• Ontologies “Manchester, CT”• Scenario “Dr Head became the new
director of Shiny Rockets Corp”

21
Two kinds of approachesKnowledge Engineering• rule based • developed by
experienced language engineers
• make use of human intuition
• require only small amount of training data
• development can be very time consuming
• some changes may be hard to accommodate
Learning Systems• use statistics or other
machine learning • developers do not
need LE expertise • require large amounts
of annotated training data
• some changes may require re-annotation of the entire training corpus

22
Typical NE pipeline
• Pre-processing (tokenisation, sentence splitting, morphological analysis, POS tagging)
• Entity finding (gazeteer lookup, NE grammars)
• Coreference (alias finding, orthographic coreference etc.)
• Export to database / XML

23
An example: GATE• GATE (Generalised Architecture for Text
Engineering) is a framework for language processing
GATE also includes:• plugins for language processing, e.g.
parsers, machine learning tools, stemmers, IR tools, IE components for various languages...
• tools for visualising and manipulating ontologies
• ontology-based information extraction tools• evaluation and benchmarking tools

24
GATE Users
•American National Corpus project •Perseus Digital Library project, Tufts University, US•Longman Pearson publishing, UK•Merck KgAa, Germany•Canon Europe, UK•Knight Ridder, US•BBN (leading HLT research lab), US•SMEs: Melandra, SG-MediaStyle, ...•a large number of other UK, US and EU Universities•UK and EU projects inc. SEKT, PrestoSpace, KnowledgeWeb, MyGrid, CLEF, Dot.Kom, AMITIES, CubReporter, …

25
Past Projects using GATE
• MUMIS: conceptual indexing: automatic semantic indices for sports video
• MUSE: multi-genre multilingual IE• HSL: IE in domain of health and safety• Old Bailey: IE on 17th century court reports• Multiflora: plant taxonomy text analysis for
biodiversity research in e-science• EMILLE: creation of S. Asian language corpus• ACE / TIDES: IE competitions and collaborations
in English, Chinese, Arabic, Hindi• h-TechSight: ontology-based IE and text mining

26
Current projects using GATE• ETCSL: language tools for Sumerian
digital library• SEKT: Semantic Knowledge Technologies• PrestoSpace: Preservation of audiovisual
data• KnowledgeWeb: Semantic Web network
of excellence• SWAN: Large-scale semantic annotation• LIRICS: Linguistic infrastructure for
Interoperable Resources and Systems

27
Architectural principles ofGATE
• Non-prescriptive, theory neutral (strength and weakness)
• Re-use, interoperation, not reimplementation (e.g. diverse XML support, integration of Protégé, Jena, Weka...)
• (Almost) everything is a component, and component sets are user-extendable
• (Almost) all operations are available both from API and GUI

28
GATE

29
Information Extraction for the Semantic Web• Traditional IE is based on a flat structure, e.g.
recognising Person, Location, Organisation, Date, Time etc.
• For the Semantic Web, we need information in a hierarchical structure
• Idea is that we attach semantic metadata to the documents, pointing to concepts in an ontology
• Information can be exported as an ontology annotated with instances, or as text annotated with links to the ontology

30
Richer NE Tagging
• Attachment of instances in the text to concepts in the domain ontology
• Disambiguation of instances, e.g. Cambridge, MA vs Cambridge, UK

31
Another example: Magpie
• Developed by the Open University• Plugin for standard web browser• Automatically associates an ontology-based
semantic layer to web resources, allowing relevant services to be linked
• Provides means for a structured and informed exploration of the web resources
• e.g. looking at a list of publications, we can find information about an author such as projects they work on, other people they work with, etc.

32
MAGPIE in action

33
MAGPIE in action

34
Evaluation

35
Evaluation metrics and tools
• Evaluation metrics mathematically define how to measure the system’s performance against human-annotated gold standard
• Scoring program implements the metric and provides performance measures – for each document and over the entire corpus– for each type of NE– may also evaluate changes over time
• A gold standard reference set also needs to be provided – this may be time-consuming to produce
• Visualisation tools show the results graphically and enable easy comparison

36
Methods of evaluation
• Traditional IE is evaluated in terms of Precision and Recall
• Precision - how accurate were the answers the system produced?
correct answers/answers produced• Recall - how good was the system at finding
everything it should have found? correct answers/total possible correct answers • Usually a tradeoff between precision and
recall, so a weighted average of the two (F-measure) is generally also used.

37
GATE AnnotationDiff Tool

38
Metrics for Richer IE• Precision and Recall are not sufficient for
ontology-based IE, because the distinction between right and wrong is less obvious
• Recognising a Person as a Location is clearly wrong, but recognising a Research Assistant as a Lecturer is not so wrong
• Similarity metrics need to be integrated so that items closer together in the hierarchy are given a higher score, if wrong
• Also possible is a cost-based approach, where different weights can be given to each concept in the hierarchy, and to different types of error, and combined to form a single score

39
Learning Accuracy
• LA [Hahn98] originally defined to measure how well a concept had been added in the right level of the ontology
• LA measures “the degree to which the system correctly predicts the concept class which subsumes the target concept to be learned”.
• Used by Cimiano et al [2003] to measure how well the instance has been added in the right place in the ontology.

40
Learning Accuracy Metric
SP = the shortest length from root to the key conceptFP = shortest length from root to the predicted
concept. If the predicted concept is correct, then FP = 0, i.e. FP is only considered in the case that the answer given by the system is wrong.
CP = shortest length from root to the MSCA (the lowest concept common to SP and FP paths)
DP = shortest length from MSCA to predicted concept
If predicted concept is correct, i.e. if FP =0, then LA = CP / SP = 1
If predicted concept is incorrect, LA = CP / FP + DP

41
Problems with LA
• LA doesn’t consider the height of the Key concept, which means that however far away the Key is from the MSCA, the score is the same
• It also means that similarity is not bidirectional, which is intuitively wrong
• We propose an alternative to LA, known as BDM (Balanced Distance Metric) which takes this into account

42
BDM
• MSCA – most specific concept common to Key and Response
• CP – distance from root to MSCA• DPR – distance from MSCA to Response
concept• DPK – distance from MSCA to Key conceptEach one is normalised wrt average length
of chain in which Key and Response occurThis makes the penalty in terms of node
traversal relative to the semantic density of the concepts in question

43
BDM - normalisations
n1: average length of the set of chains containing the key or the response concept, computed from the root concept.
n2: average length of all the chains containing the key concept, computed from the root concept.
n3: average length of all the chains containing the response concept, computed from the root concept.

44
BDM – the metric
• BDM is calculated for all correct and partially correct responses
)3()2()1(
1
nDPRnDPKnCP
nCPBDM
CP = distance from root to MSCA
DPK = distance from MSCA to Key
DPR = distance from MSCA to Response

45
BDM: observations
• BDM considers the relative specificity of the taxonomic positions of the key and response
• It does not distinguish between the directionality of this relative specificity, however.
• For instance, the key can be a specific concept (e.g. 'car') and the response can be a general concept (e.g. 'relation'), or vice versa.
• Either way, the score will be the same.

46
Augmented Precision and Recall
SpuriousnAP
BDMMissingn
AR
BDM
AR)AP(5.0
ARAP
F
BDM is integrated with traditional Precision and Recall in the following way:

47
Creating a gold standard corpus• OntoNews corpus: 292 news articles
from 3 news agencies (Guardian, Financial Times, Independent)
• 3 topics: international politics, UK politics and business.
• covers August – October 2001• Corpus annotated manually wrt KIMO
ontology

48
KIMO: a reference ontology• KIMO is earlier version of the Proton
ontology, created by Ontotext in scope of KIM platform
• http://proton.semanticweb.org• Contains around 250 classes and 100
relations• Domain-independent and modular
(comprises top ontology and more specific lower ontology)

49
Annotating OntoNews
• Annotation set covers range of levels and types of semantic annotation
• Decomposable into subsets that constitute 3 types of ontologies:– Named entities– Top ontology (20 high level concepts)– Common nouns
• Coverage is significantly greater than previous initiatives, e.g. MUC, ACE

50

51
Tools for semantic annotation• Semi-automatic:
– MnM– S-CREAM/OntoMat
• Automatic: – SemTag– KIM– h-Techsight

52
MnM
• Semi-automatic in that it requires initial training by user
• Uses pre-defined set of concepts in ontology• User browses web and manually annotates
his chosen pages• System learns annotation rules, tests them,
and takes over annotation, populating ontologies with the instances found
• Precision and recall are not perfect, however retraining is possible at any stage

53
S-CREAM
• Semi-automatic CREAtion of Metadata• Uses Onto-O-Mat + Amilcare• Trainable for different domains• Aligns conceptual markup (which
defines relational metadata) provided by e.g. Ont-O-Mat with semantic markup provided by Amilcare

54
Annotated data in S-CREAM

55
Amilcare
• Amilcare learns IE rules from pre-annotated data (e.g. using Ont-O-Mat)
• Uses GATE (ANNIE) for pre-processing + applies rules learnt in training phase to new documents
• Concepts need to be pre-defined, but system can be trained for new domain
• Can be tuned towards precision or recall

56
Automatic methods
• SemTag• KIM• h-Techsight

57
SemTag and KIM
• SemTag and KIM both annotate webpages using instances from an ontology
• Main problem is to disambiguate such instances which occur in multiple parts of the ontology
• SemTag aims for accuracy of classification, whereas KIM aims more for recall (finding all instances)
• KIM also uses IE to find new instances not present in ontology

58
SemTag
• Automated semantic tagging of large corpora, using TAP ontology (contains 65K instances)
• Largest scale semantic tagging effort to date• Uses concept of Semantic Label Bureau• Annotations are stored separately from web
pages (standoff markup)• Uses corpus-wide statistics to improve
quality of tagging, e.g. automated alias discovery
• Tags can be extracted using a variety of mechanisms, e.g. search for all tags matching a particular object

59
SemTag Architecture

60
KIM
• Uses an ontology (KIMO) with 86K/200K instances
• Lookup phase marks instances from the ontology
• Disambiguation uses an Entity Ranking algorithm, i.e., priority ordering of entities with the same label based on corpus statistics
• Lookup is combined with rule-based IE system (from GATE) to recognise new instances of concepts and relations
• Special KB enrichment stage where some of these new instances are added to the KB

61
KIM (2)

62
h-TechSight KMP
• Knowledge management platform for fully automatic metadata creation and ontology population, and semi-automatic ontology evolution, powered by GATE and ToolBox.
• Data-driven analysis of ontologies enables trends of instances to be monitored
• Uses GATE to support the instance-based evolution of ontologies in the Chemical Engineering domain.
• Analysis of unrestricted text to extract instances of concepts from such ontologies

63
Visualisation of
New Instances
1234
DB
Evolution of Ontologies
Analysis of Results
Ontology in
EmploymentWeb site
URL

64
Ontology-based IE in h-TechSight• Ontology-Based IE for semantic tagging of
job adverts, news and reports in chemical engineering domain
• Semantic tagging used as input for ontological analysis
• Terminological gazetteer lists are linked to classes in the ontology
• Rules classify the mentions in the text wrt the domain ontology
• Annotations output into a database or as an ontology

65
Limitations of h-TechSight• h-Techsight uses rule-based IE
system• Requires human expert to write rules• Accurate on restricted domains with
small ontologies• Adaptation to a new domain /
ontology may require some effort

66
Summary of Semantic Annotation Tools• Tradeoff between semi-automatic
and fully automatic systems, dependent on application, corpus size etc
• Tradeoff between rule-based and ML techniques for IE
• Tradeoff between dynamic vs static systems

67
Summary
• Introduction to Human Language Technologies and how they can be used to enhance the development of the Semantic Web
• Focused on text mining and information extraction techniques
• Examples of different SOA applications• Examined development of traditional
methods to encompass ontologies• New techniques for evaluation

68
Human Language Technologies: Part 2• Part 2 of this tutorial will focus in
detail on some new developments in adapting traditional HLT methods for the Semantic Web
• Mixed Initiative Information Extraction extends capabilities of traditional OBIE
• RichNews aims at automating annotation of multimedia news programs