1 lsi (lecture 19) using latent semantic analysis to improve access to textual information (dumais...
Post on 22-Dec-2015
213 views
TRANSCRIPT

1
LSI (lecture 19)
Using latent semantic analysis to improveaccess to textual information (Dumais et al, CHI-88)
• What’s thebest sourceof infoaboutComputerScience inDublin?
(look familiar??!?!)COMP-4016 ~ Computer Science Department ~ University College Dublin ~ www.cs.ucd.ie/staff/nick ~ © Nicholas Kushmerick 2001

2
LSI -vs- PageRank, Hub/Auth
• How to solve the familiar problems of term-based IR (synonomy, polysemy)?
• PageRank, Hubs/Authorities: mine valuable evidence about page quality/relevance from relationships across documents (namely, hyperlinks). Documents’ terms play almost a secondary role in retrieval!
• LSI: Don’t throw baby out with bathwater: Terms are incredibly useful/important! The key is to employ statistical analysis to tease apart multiple meanings of a given word (polysemy) and multiple words for a given meaning (synonomy).
• (Of course, LSI predates the Web [and therefore topology-based techniques] by a decade!)
3
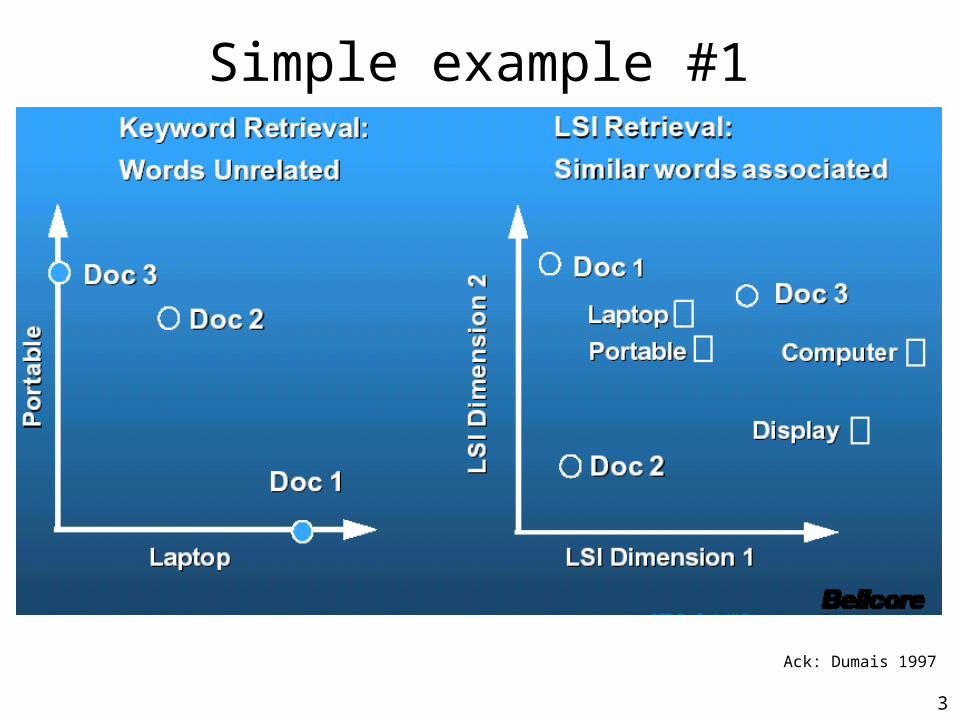
Simple example #1
Ack: Dumais 1997
4
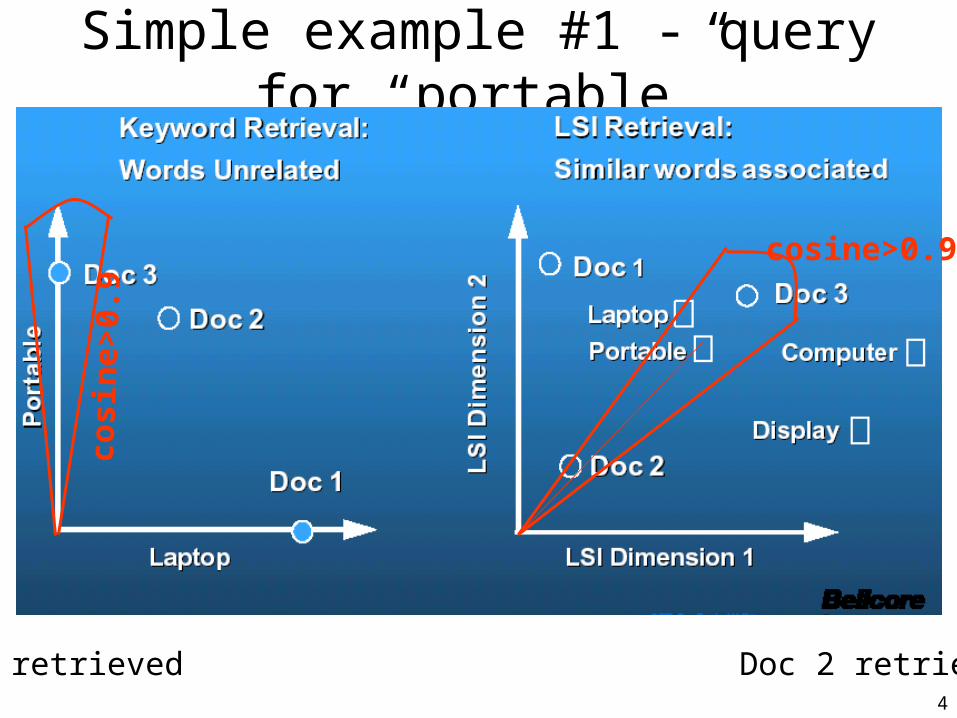
Simple example #1 - query for “portable”
cosine>0.9
cosi
ne>
0.9
Only Doc 3 retrieved Doc 2 retrieved too!
5
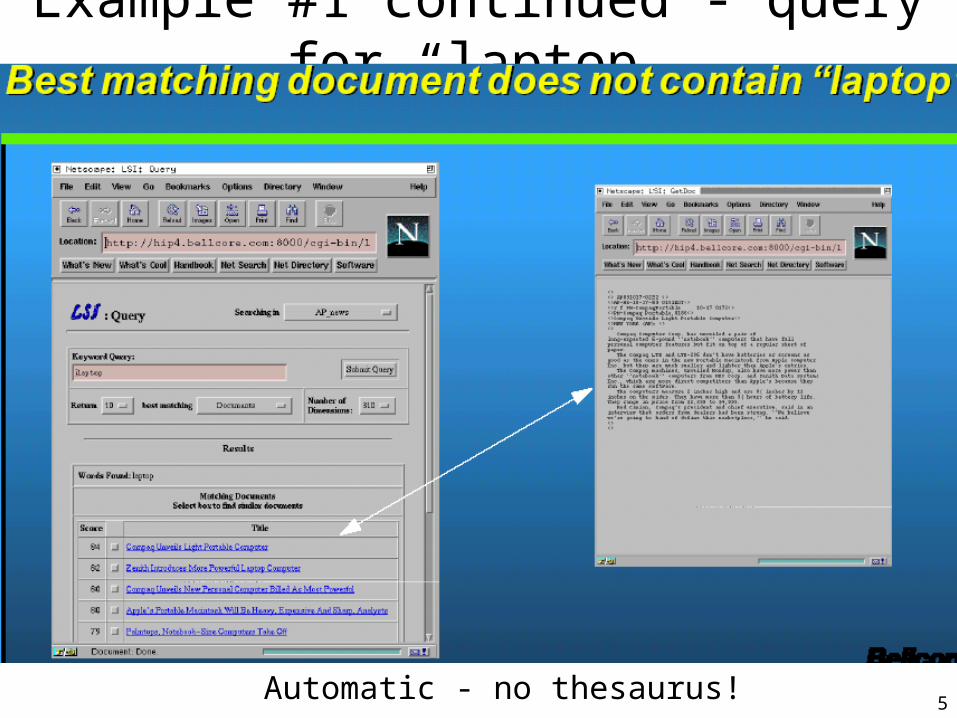
Example #1 continued - query for “laptop”
Automatic - no thesaurus!

6
Stochastic model of language generation
“financial institution”
“part of river”
My favorite bank is AIB, located near the south bank of
the Liffey on Dame Street. On the other
hand, the north quay is home to
numerous bureaux de change.
‘concept’ probability distribution over words used to express the concept Synonymy: A given word can have >0 probability for several concepts Polysemy: Several words can have >0 probability for a given concept Goal: offline: use statistics over many documents to estimate distributions online: use distributions to estimate most-likely concept ‘explaining’
the words observed in some particular document

7
Example 2
Presence of “information” and “computer” in Doc#2 are “typos”the author “should have” said “bits” and “device” (resp.) instead
(Polysemy)
Absence of “information” and “computer” in Doc#1 are “mistakes”the author “meant to” include them but “forgot” and used“document” and “access” instead
(Synonomy)
the “right answer”

8
The Singular Value Decomposition• A fact from linear algebra: Any matrix X can be
decomposed as
X = T0 · S0 · D0
X T0
S0
D0
t x d t x r r x r r x d
· ·
=
term
s
documents
r = the rank of X = number of linearly independent columns/rows ie, number of non-duplicate (up to constant multiple) rows/columns
0
0

9
SVD, continued
• S0 has a very special structure: diagonal elements are sorted, and non-diagonal elements are zero
• Also…– T0 and D0
T must satisfy some additional properties (“orthogonal unit-length columns”)
– Refer to D0 rather than D0 to simplify some of the theoretical
descriptions of the SVD• Algorithm: computing the SVD just means solving a big set
of simultaneous equations; it’s slow, but but there’s no magic or wizardry needed
S0
0
0interesting evidence of latent structure
noise, coincidences, anomolies, …

10
The Idea• Perform SVD on term-document matrix X, with one extra
pseudo-document representing the query• The diagonal values in S0 encode the “weight” of the
various “higher-order” semantic concepts that give rise to observed terms X
• Retain only the top K50 high-weight values; these are the “dominant” concepts that were used to stochastically generate the observed terms
• Plot documents & query in this lower-dimensional space, and used good-old-fashioned cosine similarity to retrieve relevant documents
• Discard the low-weight “noise” values; these represent an attempt to “make sense” of the noise/typos/mistakes in the observed terms
11
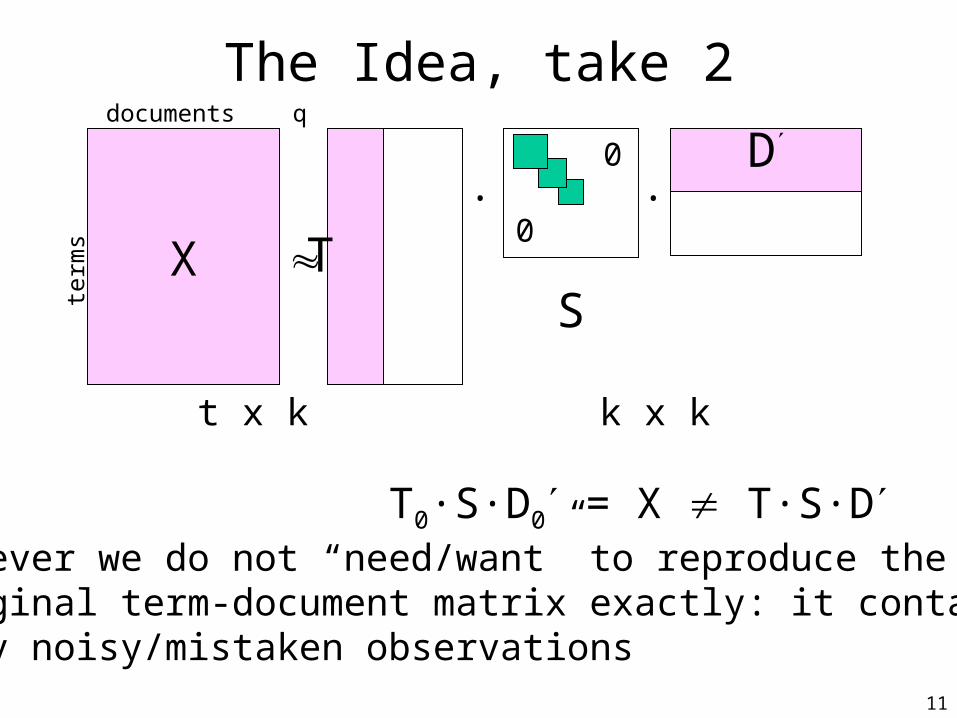
The Idea, take 2
X T
S
D
t x d t x k k x k k x d
· ·
term
s
documents q
0
0
T0·S·D0 = X T·S·Dhowever we do not “need/want” to reproduce theoriginal term-document matrix exactly: it containsmany noisy/mistaken observations

12
Example #3 -- 1

13
Example #3 - 2

14
Example #3 - 3
LSI Factor 1
LS
I F
acto
r 2
using K=2…
“differentialequations”
“applications& algorithms”
T
Each term’s coordinates specified in first K valuesof its row.
Each doc’s coordinates specified in first K valuesof its column.
D

15
Some real results

16
“Exotic” uses of LSI - example: Cross-language retrieval
In English, ship is a synonym for boatIn Franglish, ship is a synonym bateau The idea:

17
Cross-language retrieval - Evaluation

18
Cross-language retrieval - Application

19
Summary• We all know that term-based information retrieval has
serious deficits (namely: synonymy & polysemy)• Latent semantic indexing/analysis: Simple statistically
rigorous technique for transforming original document/term matrix into a (more compact and reliable!) “concept space”
• Probabilistic model of document/query generation: synonymy and polysemy terms are a kind of noise, so the IR system’s job is to estimate the original “signal” (latent semantic “meaning”)
• Highly effective, and lots of other more “exotic” applications, too.