1 open health natural language processing consortium (ohnlp) mayo clinic: guergana savova, ph.d....
TRANSCRIPT

1
Open Health Natural Language Processing Consortium
(OHNLP)
Mayo Clinic:Guergana Savova, Ph.D.
James [email protected]
IBM Watson Research:Anni Coden, Ph.D.Michael Tanenblatt

2
Overview
• OHNLP? Oh, NLP?
• Demo of a clinical OHNLP system (cTAKES)
• Demo of a medical OHNLP system (MedKAT) with extensions to pathology (/P)
• How can I adapt the system to my data?
• Lively discussion: how can I get involved, OHNLP future steps…

3
Open Health Natural Language Processing Consortium
• www.ohnlp.org (part of caBIG Vocabulary Knowledge Center web presence)
• Goal• Foster an open-source collaborative community around
clinical NLP that can deliver best-of-breed annotators, leverage the dynamic features of UIMA flow-control, and establish the infrastructure for clinical NLP.
• Two open source releases as part of OHNLP• Mayo’s pipeline for processing clinical notes (cTAKES)
• IBM’s pipeline for processing medical notes (MedKAT) and pathology reports (MedKAT/P)

4
Other non-OHNLP clinical NLP Systems
• Proprietary• medLEE (Columbia University)• Topaz (University of Pittsburgh)• Vanderbilt University• caTIES (University of Pittsburgh)• MPLUS/Onyx (University of Utah)• VA Hospital system
• Open Source• i2b2 HITEx (Health Information Text Extraction)

5
Clinical example:clinical Text Analysis and
Knowledge Extraction System (cTAKES)
Presenters:Guergana Savova
James Masanz

6
Overview• cTAKES
• Developed at Mayo Clinic
• Goals:
• Phenotype extraction
• Generic – to be used for a variety of retrievals and use cases
• Expandable – at the information model level and methods
• Modular
• Cutting edge technologies – best methods combining existing practices and novel research with rapid technology transfer
• Best software practices (80M+ notes)
• Commitment to both R and D in R&D

7
cTAKES: Components
• Clinical narrative as a sublanguage
• Core components• Sentence boundary detection (OpenNLP technology)
• Tokenization (rule-based)
• Morphologic normalization (NLM’s LVG)
• POS tagging (OpenNLP technology)
• Shallow parsing (OpenNLP technology)
• Named Entity Recognition• Dictionary mapping (lookup algorithm)
• Machine learning (MAWUI)
• Negation and context identification (NegEx)

8
Output Example: Disorder Object
• “No evidence of unstable angina.”
• Disorder• Text: unstable angina
• Associated code: SNOMED 4557003
• Named entity type: disease/disorder
• Status: current
• Negation: true

9
Methods
• Preliminary results:
• Savova, Guergana; Kipper-Schuler, Karin; Buntrock, James and Chute, Christopher. 2008. UIMA-based clinical information extraction system. LREC 2008: Towards enhanced interoperability for large HLT systems: UIMA for NLP.
• Manuscript with detailed system description and evaluation under review (JAMIA)

10
cTAKES demo

11
Medical example:Medical Knowledge Analysis System
MedKAT and MedKAT/P
Presenters:Anni Coden
Michael Tanenblatt

12
Overview
• MedKAT and MedKAT/P• Developed at IBM
• Goal:
• Identification of concepts and their attributes based on a standard or proprietary terminology/ontology
• /P adaptation to pathology reports – relation extraction
• Modular, Generic, Expandable
• Terminology, Conceptual Model
• Easy adaptation to specific corpus and conventions
• Integration into institutional system
• Ongoing commitment to Research and Development

13
Core Components
• Document structure
• Syntactic tools (tokenization ... Shallow parsing)
• Concept identification
• Negation
• Relationship extraction
Extracted data F-scoreAnatomic site 0.95Histology 0.98Size 1.00Date 1.00Grade 0.98Gross Desc 0.80Lymph Nodes 0.81Primary Tumor 0.82Metastatic Tumor 0.65
14
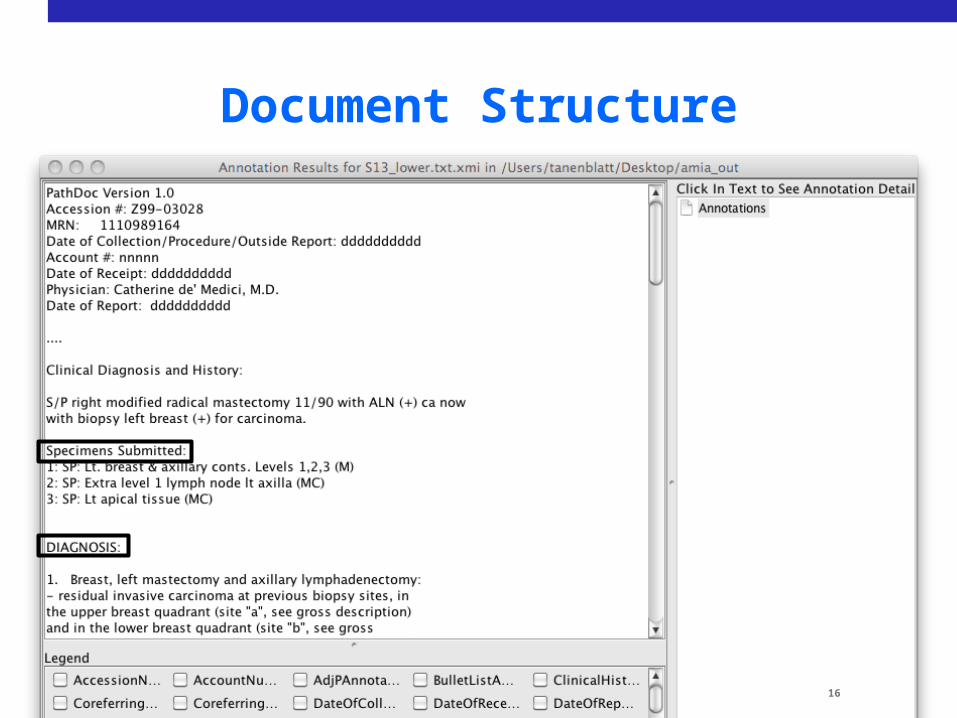
Document Structure
16
15
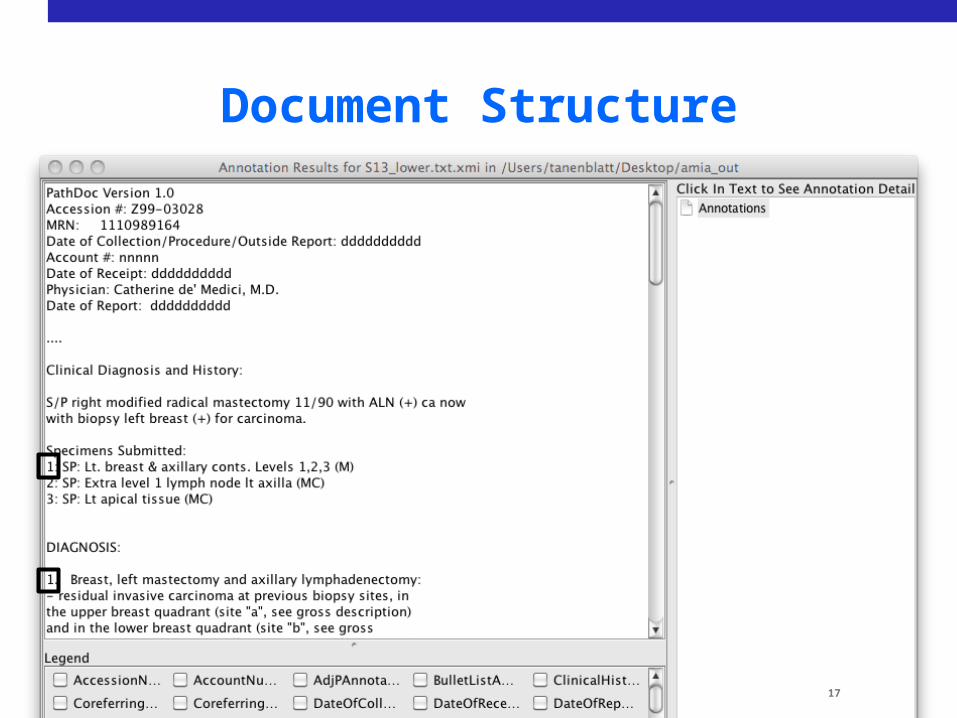
Document Structure
17

16
Document Structure
18

17
Output
18
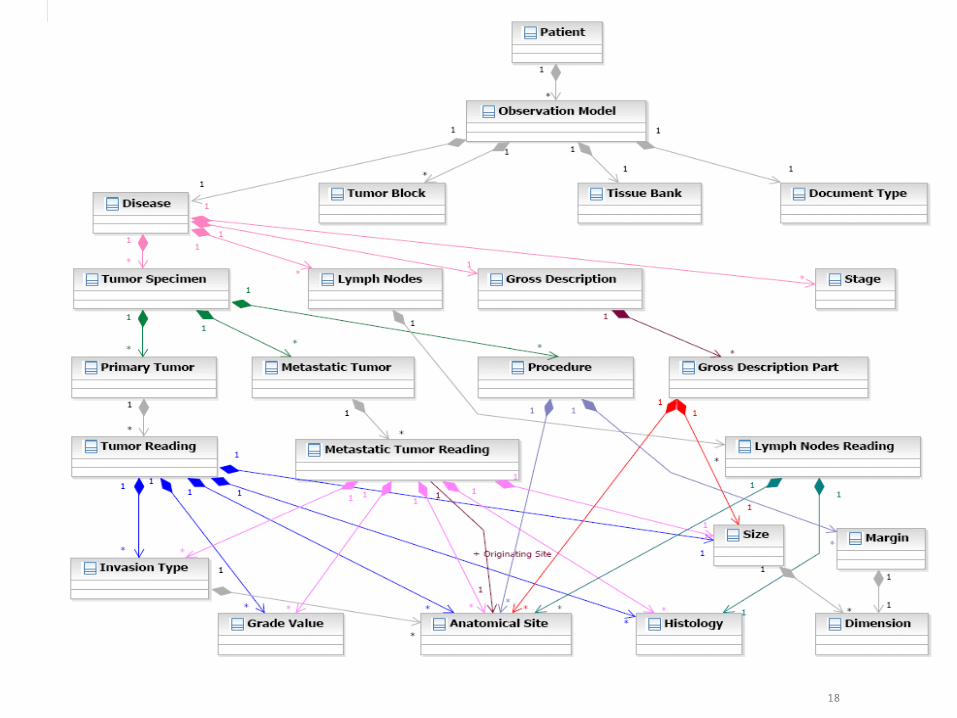
Cancer Disease Knowledge
Representation Model
19
Demos
• Query by Model / Cancer
• Detailed view of annotations in Document Analyzer
• http://domino.research.ibm.com/comm/research_projects.nsf/pages/medicalinformatics.index.html

20
Adaptation
Presenters:Anni Coden
Michael Tanenblatt

21
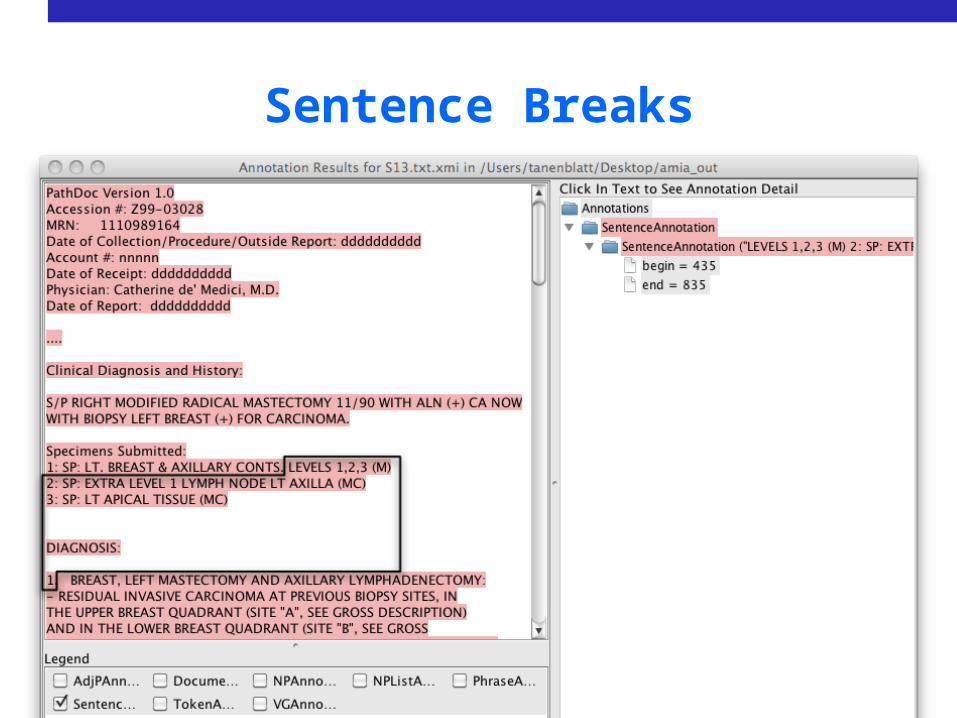
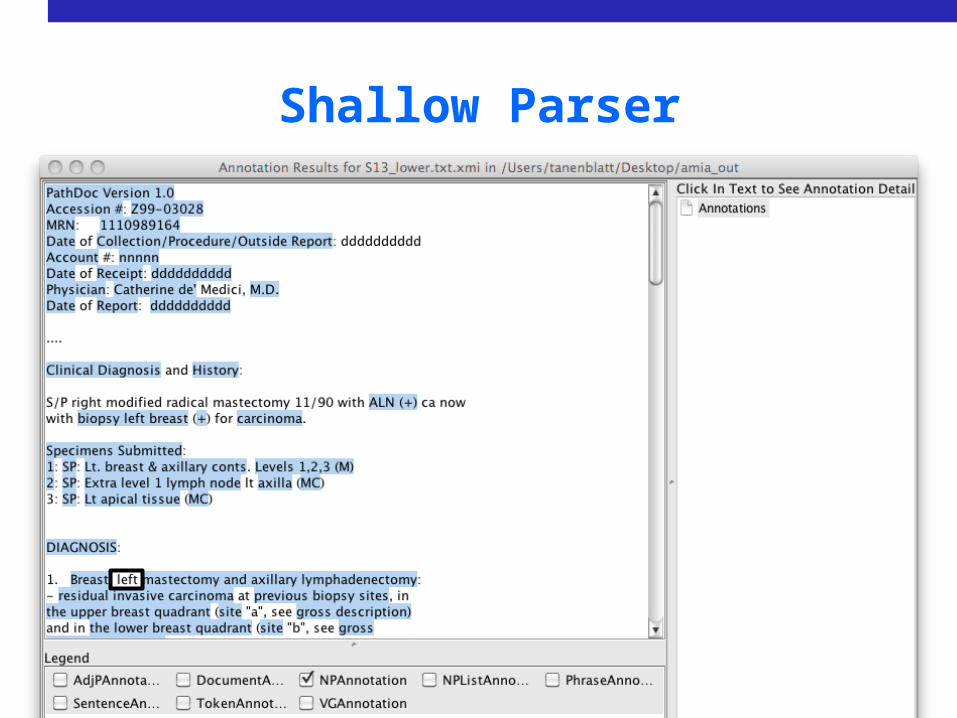
Adaptation
• Sentence breaks
• Text case
• Part of speech tags
• Shallow parser
• Dictionary lookup
• Document structure
22
Sentence Breaks

23
Sentence Breaks
• Some solutions:• Use annotator to re-break sentences• Retrain tagger

24
Case/Part of Speech Tags

25
Case/Part of Speech Tags
• Some solutions:• Retrain tagger• Use UIMA annotator to create a “true
case” view

26
Part of Speech Tags

27
Part of Speech Tags
• Some solutions:• Retrain tagger• Use dictionary lookup to modify
incorrect tags• Create rule-based annotator to
modify incorrect tags
28
Shallow Parser

29
Shallow Parser
31
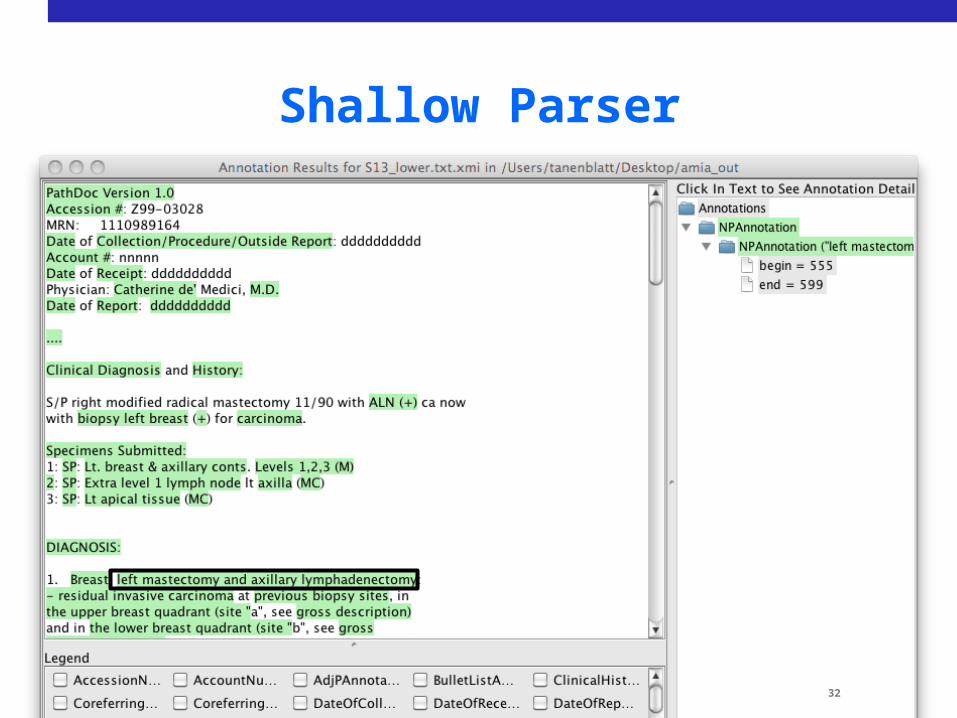
30
Shallow Parser
32

31
Dictionary Lookup
• Dictionary entries can be added, changed, deleted
• Dictionary entry attributes can be added, changed, deleted
• Search parameters can be modified
• Post processing filters
• Tokenization of text and dictionary should be the same

32
Document Structure
• Plain text or XML (e.g., CDA)
• Processes specific document section types (e.g., diagnosis)
• Detection of formatting (e.g. bullets)
• Detection of relations between sections
• Making implicit conventions explicit (e.g. meaning of title)

Discussion: Future of OHNLP.ORG
• Provided seed annotators and tools
• Goal: growing community• Annotators, tools• Methodologies• Gold standards
• Common type system for plug-and-play
• What are the hurdles?

34
Hands-on Customization

35
MedKAT
• Dictionary adaptation
• Concept identification parameters
• Document structure detection

36
cTAKES
• Negation window
• Lookup window
• Dictionary modifications

37
Questions?