1 recap superscalar and vliw processors. 2 a model of an ideal processor provides a base for ilp...
Post on 19-Dec-2015
220 views
TRANSCRIPT

1
Recap
Superscalar and VLIW Processors

2
A Model of an Ideal ProcessorA Model of an Ideal Processor
Provides a base for ILP measurements No structural hazards
Register renaming—infinite virtual registers and all WAW & WAR hazards avoided
Machine with perfect speculation Branch prediction—perfect; no mispredictions Jump prediction—all jumps perfectly predicted
– There are only true data dependences left!– These cannot be avoided

3
Upper Bound on ILPUpper Bound on ILP
gcc espresso li fpppp doducd tomcatv0
20
40
60
80
100
120
140
160
Inst
ruct
ion
iss
ues
per
cyc
le
gcc espresso li fpppp doducd tomcatv
Programs

4
More Realistic HW: Branch ImpactMore Realistic HW: Branch Impact
gcc espresso li fpppp doducd tomcatv0
10
20
30
40
50
60
70
Inst
ruct
ion
issu
es p
er c
ycle
gcc espresso li fpppp doducd tomcatv
Perfect Selective predictor Standard 2-bit Static None
Window: 2000 instructionsMax 64 instr/cycle issueMany registers

5
Renaming Renaming Register impactRegister impact
gcc espresso li fpppp doducd tomcatv0
10
20
30
40
50
60In
stru
ctio
n is
sues
per
cyc
le
gcc espresso li fpppp doducd tomcatv
Infinite 256 128 64 32 None
Window: 2000 instructionsMax 64 instr/cycle issue

6
Window ImpactWindow Impact
gcc espresso li fpppp doducd tomcatv0
10
20
30
40
50
60In
stru
ctio
n is
sues
per
cyc
le
gcc espresso li fpppp doducd tomcatv
Infinite 256 128 64 32 16 8 4
64 instr/cycle issue64 renaming registers

7
How do we take advantage of this large number of ILP
• Superscalar processors
• VLIW (Very Long Instruction Word) processors
• All high-performance modern processors (e.g., Pentium, Sparc, Itanium) use one of the above techniques.

8
Super scalar Pipelines
• A pipeline that can complete more than 1 instruction per cycle is called a super scalar pipeline.
• We know how to build pipelines with multiple functional units (we can execute more than one instruction).
• If we can issue more than 1 instruction into the pipe at a time, then it is possible we can complete more than 1 instruction per cycle.
• This implies that we need to fetch and decode 2 or more instructions per cycle.

9
Multiple Issue Processors
Sperscalar ProcessorsSperscalar ProcessorsVariable number of instructions per clock cycleInstruction Scheduling
StaticallyStatically: Compiler techniqueInstruction execution in order of sequence
dynamicallydynamically: Scoreboarding/Tomasulo’s AlgorithmInstructions are out of order execution
VLIW : Very Long Instruction WordVLIW : Very Long Instruction WordFixed number of instructions formatted as a large
instruction or a fixed instruction packet with parallelism among instructions [EPICEPIC: explicitly parallel Instruction Computing]
Statically scheduled by the compiler

10
Multiple-Issue Processor Types
Common Issue Hazard Scheduling Distinguishing Examples name structure detection characteristics
Super scalar dynamic HW static in-order execution SUN UltraSPARC
(static)
Super scalar dynamic HW dynamic some out of order IBM Power 2 (dynamic)
Super scalar dynamic HW dynamic in-order execution Pentium III/4, Alpha(speculative) with speculation with speculation HP PA8500, IBM RS64III
VLIW/LIW static SW static no hazards between Trimedia,i860 issue packets
EPIC mostly mostly mostly explicit dependency Itaniumstatic SW static marked by compiler

11
Super scalar
0-8 instruction per cycleStatic scheduling
all pipe line hazards are checkedinstructions in order
Pipeline control logic will check hazards between the instructions in execution phase and the new instruction sequences. In case of hazard, only those instructions preceding that one in the instruction sequence will be issued.All instructions are checked at the same time by Issue HW
Issue HWPipeline
Instruction Memory
Issue Packet
Complexity of HWThis stage is pipelined in all dynamic super scalar system

12
Example: Superscalar of degree 3
fetch decode execute write back

13
A Superscalar A Superscalar MIPSMIPS– Issue 2 instructions simultaneously: 1 FP & 1 integer
• Fetch two instr./clock cycle; one integer and one FP • Can only issue 2nd instruction if 1st instruction issues• Need more ports to the register file
•Type Pipe stages•Int. IF ID EX MEM WB•FP IF ID EX MEM WB•Int. IF ID EX MEM WB•FP IF ID EX MEM WB•Int. IF ID EX MEM WB•FP IF ID EX MEM WB

14
Limits to Superscalar ExecutionLimits to Superscalar Execution
– Difficulties in scheduling within the constraints on number of functional units and the ILP in the code chunk
Instruction decode complexity increases with the number of issued instructions
Data and control dependences are in general more costly in a superscalar processor than in a single-issue processor
Techniques to enlarge the instruction window to extract more ILP are important

15
Some Some VLIWVLIW Characteristics Characteristics
Can be hard to exploit parallelism• n functional units and k pipeline stages
implies n x k independent instructions
Memory and register bandwidth Complexity increases with the number of functional
units Code size
Relies heavily on compiler technology

16
Unrolled Loop that Minimizes Stalls for 1-issue pipelines
1 Loop: LD F0,0(R1)2 LD F6,-8(R1)3 LD F10,-16(R1)4 LD F14,-24(R1)5 ADDD F4,F0,F26 ADDD F8,F6,F27 ADDD F12,F10,F28 ADDD F16,F14,F29 SD 0(R1),F410 SD -8(R1),F811 SD -16(R1),F1212 SUBI R1,R1,#3213 BNEZ R1,LOOP14 SD 8(R1),F16 ; 8-32 = -24
14 clock cycles, or 3.5 per iteration
LD to ADDD: 1 CycleADDD to SD: 2 Cycles
17
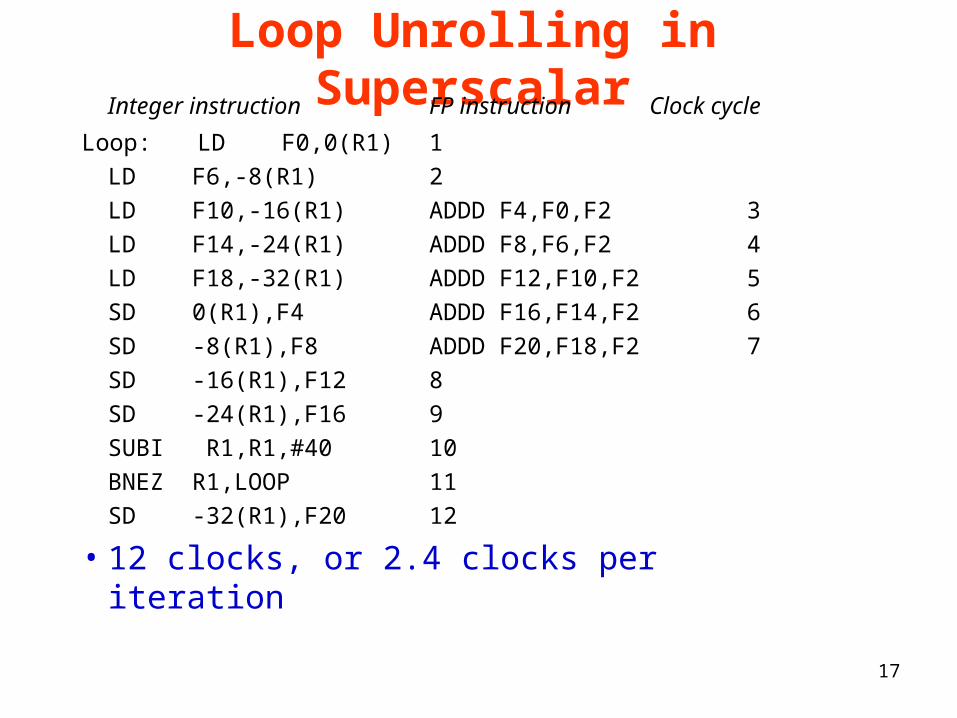
Loop Unrolling in SuperscalarInteger instruction FP instruction Clock cycle
Loop: LD F0,0(R1) 1
LD F6,-8(R1) 2
LD F10,-16(R1) ADDD F4,F0,F2 3
LD F14,-24(R1) ADDD F8,F6,F2 4
LD F18,-32(R1) ADDD F12,F10,F2 5
SD 0(R1),F4 ADDD F16,F14,F2 6
SD -8(R1),F8 ADDD F20,F18,F2 7
SD -16(R1),F12 8
SD -24(R1),F16 9
SUBI R1,R1,#40 10
BNEZ R1,LOOP 11
SD -32(R1),F20 12
• 12 clocks, or 2.4 clocks per iteration

18
Multiple Issue Challenges
• While Integer/FP split is simple for the HW, get CPI of 0.5 only for programs with:
– Exactly 50% FP operations AND No hazards
• If more instructions issue at same time, greater difficulty of decode and issue:
– Even 2-scalar => examine 2 opcodes, 6 register specifiers, & decide if 1 or 2 instructions can issue;
• Reducing the stalls becomes extremely difficult.
• Use all the techniques we covered and more advanced ones.

19
VLIW Processors• Very Long Instruction Word (VLIW) processors
– Tradeoff instruction space for simple decoding
– The long instruction word has room for many operations– By definition, all the operations the compiler puts in the
long instruction word can execute in parallel
– E.g., 2 integer operations, 2 FP ops, 2 Memory refs, 1 branch
• 16 to 24 bits per field => 7*16 or 112 bits to 7*24 or 168 bits wide
– Need compiling technique that identify the instruction to be put

20
Loop Unrolling in VLIWMemory Memory FP FP Int. op/ Clockreference 1 reference 2 operation 1 op. 2 branchLD F0,0(R1) LD F6,-8(R1) 1
LD F10,-16(R1) LD F14,-24(R1) 2
LD F18,-32(R1) LD F22,-40(R1) ADDD F4,F0,F2 ADDD F8,F6,F2 3
LD F26,-48(R1) ADDD F12,F10,F2 ADDD F16,F14,F2 4
ADDD F20,F18,F2 ADDD F24,F22,F2 5
SD 0(R1),F4 SD -8(R1),F8 ADDD F28,F26,F2 6
SD -16(R1),F12 SD -24(R1),F16 7
SD -32(R1),F20 SD -40(R1),F24 SUBI R1,R1,#48 8
SD -0(R1),F28 BNEZ R1,LOOP 9
• Unrolled 7 times to avoid delays
• 7 results in 9 clocks, or 1.3 clocks per iteration

21
CommercialCommercial Superscalar Superscalar and VLIW and VLIW
ProcessorsProcessors

22
1Fetch
2Fetch
3Decode
4Decode
5Decode
6Rename
7ROB Rd
8Rdy/Sch
9Dispatch
10Exec
3 4TC Fetch
5Drive
6Alloc
9Que
10Sch
12Sch
13Disp
14Disp
15RF
16RF
17Ex
18Flgs
19BrCk
20Drive
1 2TC Nxt IP
7 8Rename
11Sch
Typical P6 Pipeline
Typical Pentium 4 Pipeline
Pentium 4 Pipeline Stages vs. Pentium 3 Pipeline Stages

23
Pentium 3 Pipeline Architecture
• It is a It is a 3-way3-way issue supersclar issue supersclar
• It has 5 execution units (Integer ALU, integer multiply, FP It has 5 execution units (Integer ALU, integer multiply, FP multiply, FP add, FP divide)multiply, FP add, FP divide)

24
Pentium 3 Pipeline stages
1 Fetch
2 Fetch
3 Decode
4 Decode
5 Decode
6 Rename registers
7 ROB (reordering instructions)
8 Rdy/Sch (Scheduling Instructions to be executed)
9 Dispatch
10 Exec

25
Pentium 4 pipeline stages
Stage Work
1 Trace Cache next instruction pointer
2 Trace Cache next instruction pointer
3 Trace Cache fetch
4 Trace Cache fetch
5 Drive
6 Allocation
7 Rename
8 Rename
9 Queue
10 Schedule
11 Schedule
12 Schedule
13 Dispatch
14 Dispatch
15 Register Files
16 Register Files
17 Execute
18 Flags
19 Branch Check
20 Drive
Increasing the number of pipeline stages increases the clock frequency
• It took the industry 28 years to hit 1 GHz and only 18 months to reach 2 GHz.
• The price paid for deeper pipelines is that it is very difficult to ovoid stalls (That is why when Pentium 4 was introduced its performance was worse than Pentium 3.)
It is a 5-issue supersclar It is a 5-issue supersclar processorprocessor

26
3 4TC Fetch
5Drive
6Alloc
9Que
10Sch
12Sch
13Disp
14Disp
15RF
16RF
17Ex
18Flgs
19BrCk
20Drive
1 2TC Nxt IP
7 8Rename
11Sch
3.2 GB
/s System
Interface
L2 Cache and Control
BTB
BT
B &
I-TL
B
Decoder
Trace C
ache
Renam
e/Alloc
op Q
ueues
Schedulers
Integer RF
FP
RFCode
ROM
StoreAGULoad AGUALUALUALUALU
FP moveFP store
FmulFaddMMXSSE
L1 D
-Cache and D
-TL
BTC Nxt IP: Trace cache next instruction pointerPointer indicating location of next instruction.
27
3.2 GB
/s System
Interface
L2 Cache and Control
BTB
BT
B &
I-TL
B
Decoder
Trace C
ache
Renam
e/Alloc
op Q
ueues
Schedulers
Integer RF
FP
RFCode
ROM
StoreAGULoad AGUALUALUALUALU
FP moveFP store
FmulFaddMMXSSE
L1 D
-Cache and D
-TL
B
3 4TC Fetch
5Drive
6Alloc
9Que
10Sch
12Sch
13Disp
14Disp
15RF
16RF
17Ex
18Flgs
19BrCk
20Drive
1 2TC Nxt IP
7 8Rename
11Sch
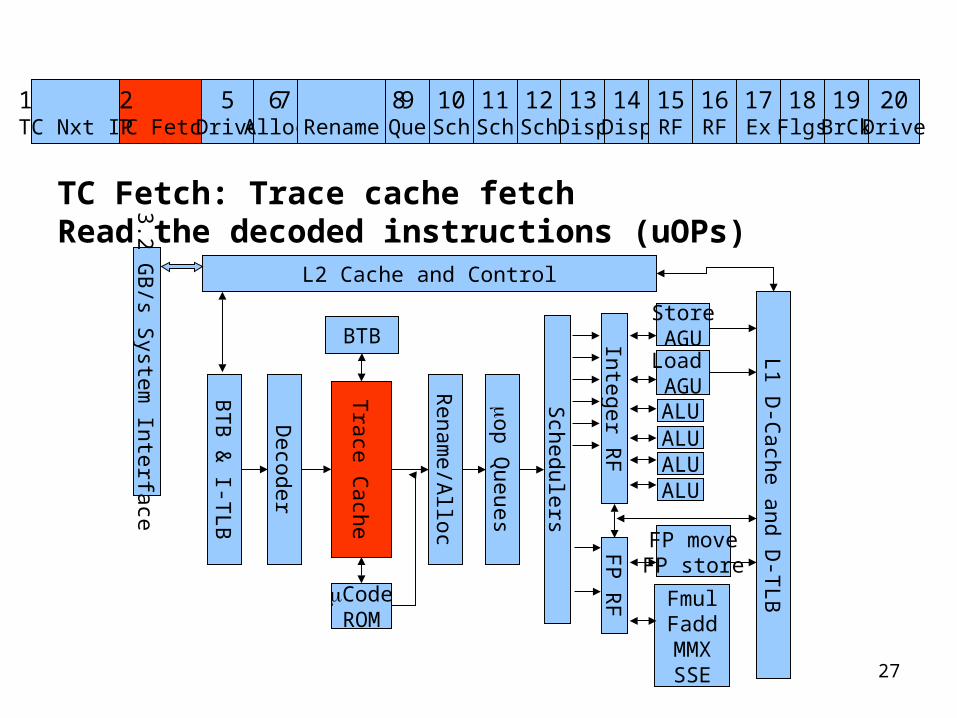
TC Fetch: Trace cache fetchRead the decoded instructions (uOPs)

28
3.2 GB
/s System
Interface
L2 Cache and Control
BTB
BT
B &
I-TL
B
Decoder
Trace C
ache
Renam
e/Alloc
op Q
ueues
Schedulers
Integer RF
FP
RFCode
ROM
StoreAGULoad AGUALUALUALUALU
FP moveFP store
FmulFaddMMXSSE
L1 D
-Cache and D
-TL
B
3 4TC Fetch
5Drive
6Alloc
9Que
10Sch
12Sch
13Disp
14Disp
15RF
16RF
17Ex
18Flgs
19BrCk
20Drive
1 2TC Nxt IP
7 8Rename
11Sch
Drive: Wire delayDrive the uOPs to the allocator

29
3.2 GB
/s System
Interface
L2 Cache and Control
BTB
BT
B &
I-TL
B
Decoder
Trace C
ache
Renam
e/Alloc
op Q
ueues
Schedulers
Integer RF
FP
RFCode
ROM
StoreAGULoad AGUALUALUALUALU
FP moveFP store
FmulFaddMMXSSE
L1 D
-Cache and D
-TL
B
3 4TC Fetch
5Drive
6Alloc
9Que
10Sch
12Sch
13Disp
14Disp
15RF
16RF
17Ex
18Flgs
19BrCk
20Drive
1 2TC Nxt IP
7 8Rename
11Sch
Alloc: Allocate resources required for execution. Theresources include Load buffers, Store buffers, etc..

30
3.2 GB
/s System
Interface
L2 Cache and Control
BTB
BT
B &
I-TL
B
Decoder
Trace C
ache
Renam
e/Alloc
op Q
ueues
Schedulers
Integer RF
FP
RFCode
ROM
StoreAGULoad AGUALUALUALUALU
FP moveFP store
FmulFaddMMXSSE
L1 D
-Cache and D
-TL
B
3 4TC Fetch
5Drive
6Alloc
9Que
10Sch
12Sch
13Disp
14Disp
15RF
16RF
17Ex
18Flgs
19BrCk
20Drive
1 2TC Nxt IP
7 8Rename
11Sch
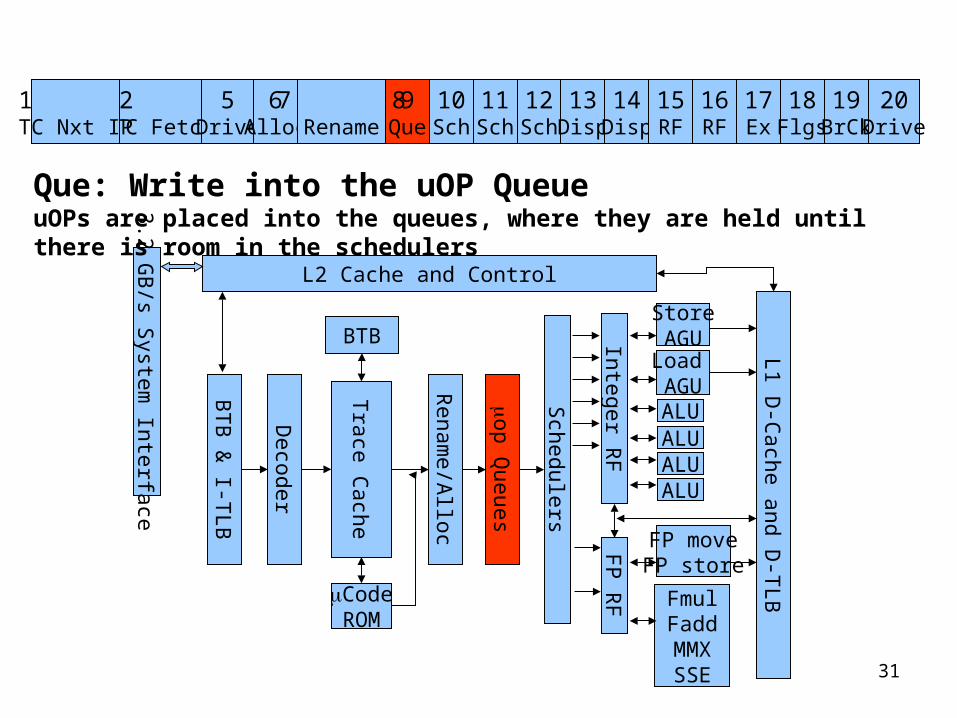
Rename: Register renaming
31
3.2 GB
/s System
Interface
L2 Cache and Control
BTB
BT
B &
I-TL
B
Decoder
Trace C
ache
Renam
e/Alloc
op Q
ueues
Schedulers
Integer RF
FP
RFCode
ROM
StoreAGULoad AGUALUALUALUALU
FP moveFP store
FmulFaddMMXSSE
L1 D
-Cache and D
-TL
B
3 4TC Fetch
5Drive
6Alloc
9Que
10Sch
12Sch
13Disp
14Disp
15RF
16RF
17Ex
18Flgs
19BrCk
20Drive
1 2TC Nxt IP
7 8Rename
11Sch
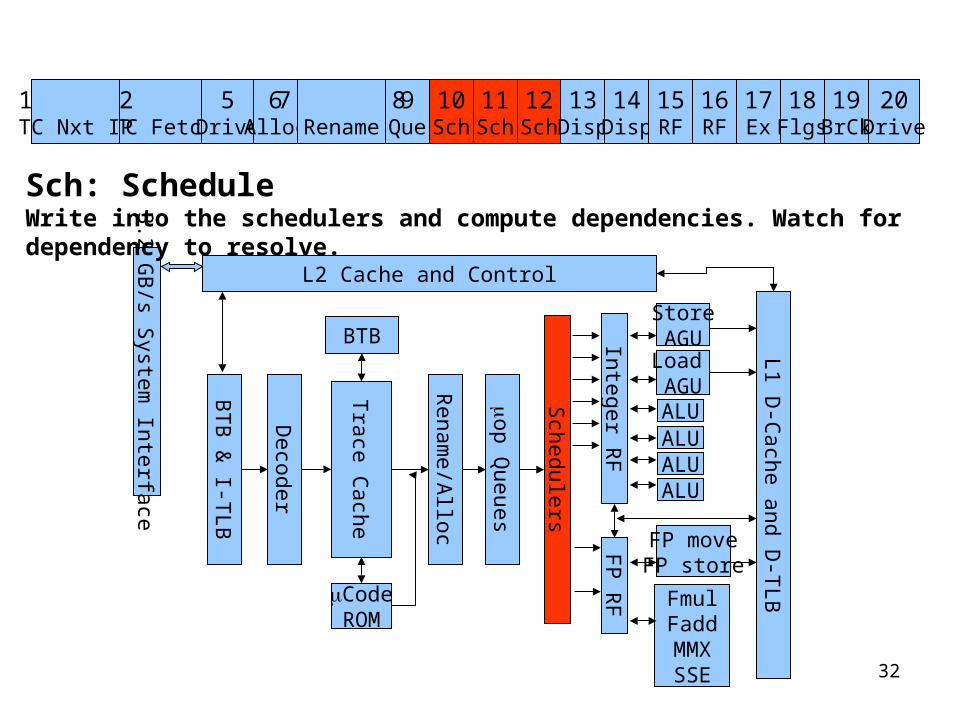
Que: Write into the uOP QueueuOPs are placed into the queues, where they are held until there is room in the schedulers
32
3.2 GB
/s System
Interface
L2 Cache and Control
BTB
BT
B &
I-TL
B
Decoder
Trace C
ache
Renam
e/Alloc
op Q
ueues
Schedulers
Integer RF
FP
RFCode
ROM
StoreAGULoad AGUALUALUALUALU
FP moveFP store
FmulFaddMMXSSE
L1 D
-Cache and D
-TL
B
3 4TC Fetch
5Drive
6Alloc
9Que
10Sch
12Sch
13Disp
14Disp
15RF
16RF
17Ex
18Flgs
19BrCk
20Drive
1 2TC Nxt IP
7 8Rename
11Sch
Sch: ScheduleWrite into the schedulers and compute dependencies. Watch for dependency to resolve.
33
3.2 GB
/s System
Interface
L2 Cache and Control
BTB
BT
B &
I-TL
B
Decoder
Trace C
ache
Renam
e/Alloc
op Q
ueues
Schedulers
Integer RF
FP
RFCode
ROM
StoreAGULoad AGUALUALUALUALU
FP moveFP store
FmulFaddMMXSSE
L1 D
-Cache and D
-TL
B
3 4TC Fetch
5Drive
6Alloc
9Que
10Sch
12Sch
13Disp
14Disp
15RF
16RF
17Ex
18Flgs
19BrCk
20Drive
1 2TC Nxt IP
7 8Rename
11Sch
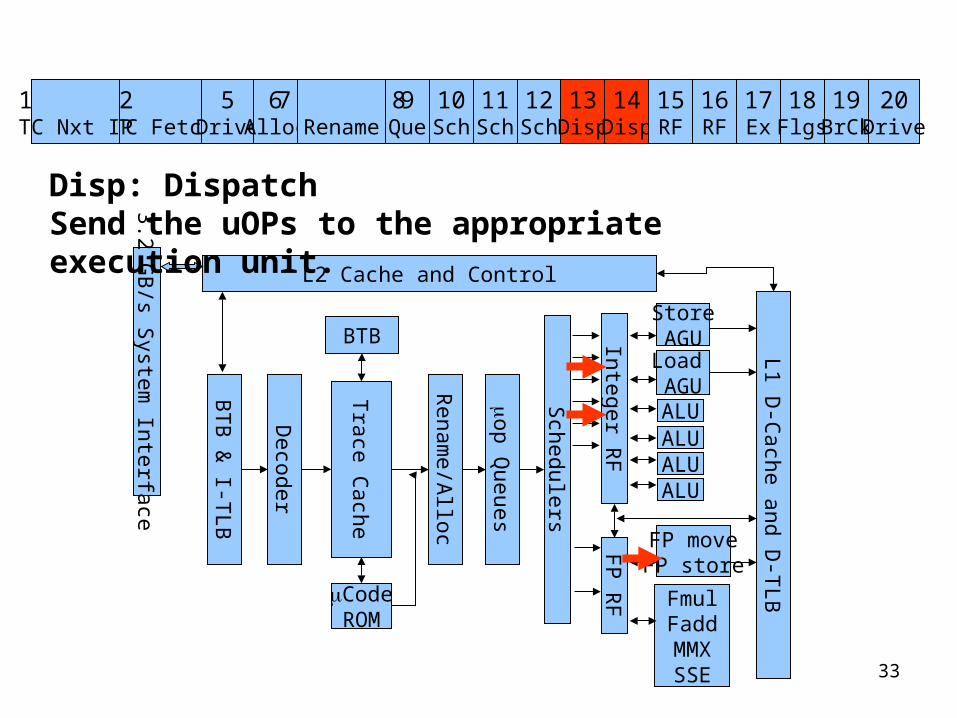
Disp: DispatchSend the uOPs to the appropriate execution unit.
34
3.2 GB
/s System
Interface
L2 Cache and Control
BTB
BT
B &
I-TL
B
Decoder
Trace C
ache
Renam
e/Alloc
op Q
ueues
Schedulers
Integer RF
FP
RFCode
ROM
StoreAGULoad AGUALUALUALUALU
FP moveFP store
FmulFaddMMXSSE
L1 D
-Cache and D
-TL
B
3 4TC Fetch
5Drive
6Alloc
9Que
10Sch
12Sch
13Disp
14Disp
15RF
16RF
17Ex
18Flgs
19BrCk
20Drive
1 2TC Nxt IP
7 8Rename
11Sch
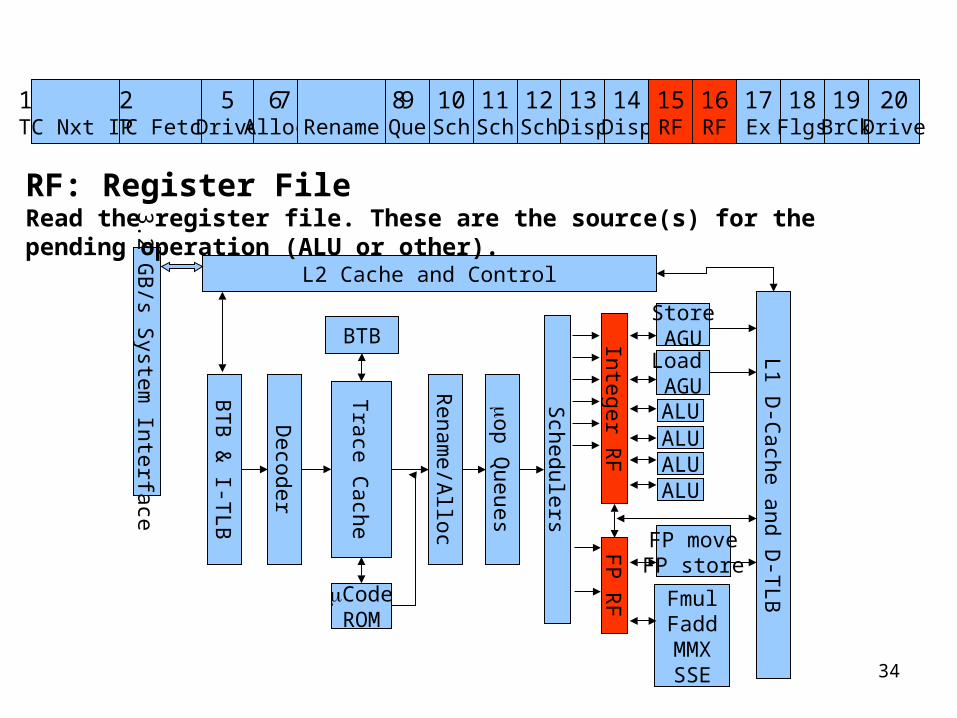
RF: Register FileRead the register file. These are the source(s) for the pending operation (ALU or other).

35
3.2 GB
/s System
Interface
L2 Cache and Control
BTB
BT
B &
I-TL
B
Decoder
Trace C
ache
Renam
e/Alloc
op Q
ueues
Schedulers
Integer RF
FP
RFCode
ROM
StoreAGULoad AGUALUALUALUALU
FP moveFP store
FmulFaddMMXSSE
L1 D
-Cache and D
-TL
B
3 4TC Fetch
5Drive
6Alloc
9Que
10Sch
12Sch
13Disp
14Disp
15RF
16RF
17Ex
18Flgs
19BrCk
20Drive
1 2TC Nxt IP
7 8Rename
11Sch
Ex: ExecuteExecute the uOPs on the appropriate execution port.

36
3.2 GB
/s System
Interface
L2 Cache and Control
BTB
BT
B &
I-TL
B
Decoder
Trace C
ache
Renam
e/Alloc
op Q
ueues
Schedulers
Integer RF
FP
RFCode
ROM
StoreAGULoad AGUALUALUALUALU
FP moveFP store
FmulFaddMMXSSE
L1 D
-Cache and D
-TL
B
3 4TC Fetch
5Drive
6Alloc
9Que
10Sch
12Sch
13Disp
14Disp
15RF
16RF
17Ex
18Flgs
19BrCk
20Drive
1 2TC Nxt IP
7 8Rename
11Sch
Flgs: FlagsCompute flags (zero, negative, etc..). These are typically input to a branch instruction.

37
3.2 GB
/s System
Interface
L2 Cache and Control
BTB
BT
B &
I-TL
B
Decoder
Trace C
ache
Renam
e/Alloc
op Q
ueues
Schedulers
Integer RF
FP
RFCode
ROM
StoreAGULoad AGUALUALUALUALU
FP moveFP store
FmulFaddMMXSSE
L1 D
-Cache and D
-TL
B
3 4TC Fetch
5Drive
6Alloc
9Que
10Sch
12Sch
13Disp
14Disp
15RF
16RF
17Ex
18Flgs
19BrCk
20Drive
1 2TC Nxt IP
7 8Rename
11Sch
Br Ck: Branch CheckThe branch operation compares result of actual branch direction with the prediction.
38
3.2 GB
/s System
Interface
L2 Cache and Control
BTB
BT
B &
I-TL
B
Decoder
Trace C
ache
Renam
e/Alloc
op Q
ueues
Schedulers
Integer RF
FP
RFCode
ROM
StoreAGULoad AGUALUALUALUALU
FP moveFP store
FmulFaddMMXSSE
L1 D
-Cache and D
-TL
B
3 4TC Fetch
5Drive
6Alloc
9Que
10Sch
12Sch
13Disp
14Disp
15RF
16RF
17Ex
18Flgs
19BrCk
20Drive
1 2TC Nxt IP
7 8Rename
11Sch
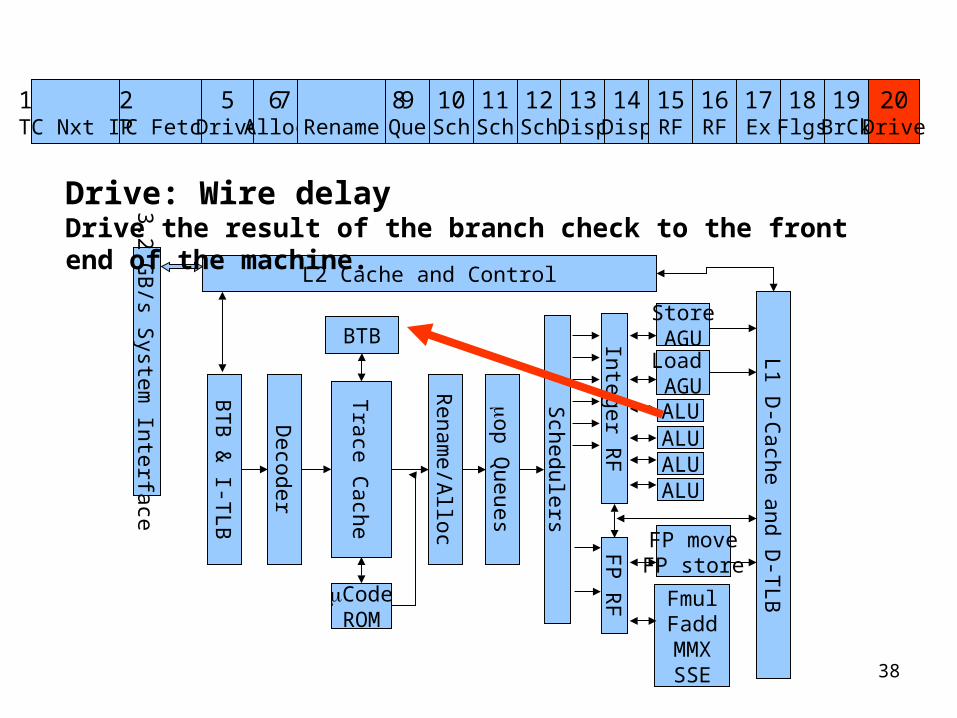
Drive: Wire delayDrive the result of the branch check to the front end of the machine.

39
CommercialCommercial EPIC EPIC ProcessorsProcessors
ItaniumItanium

40
Itanium® Processor Family Architecture
•EPIC: explicitly parallel instruction computing
•Instruction encoding•Bundles and templates
•Large register resources •128 integer
•128 floating point
•Support for•Software pipelining
•Predication
•Speculation (Control, Data, Load)

41
EPIC – Explicitly Parallel Instruction Computing
• Focused on parallel execution
• Instructions are issued in bundles
• Instructions distributed among processor’s execution units according to type
• Currently up to two complete bundles can be dispatched per clock cycle
» Pipeline stages: 10 (Itanium®1), 8 (Itanium® 2)

42

43
Instruction Format: Bundles & Templates
•Bundle•Set of three instructions (41 bits each)
•Template •Identifies types of instructions in bundle

44
Instruction Format: Bundles & Templates
•Instruction types
– M: Memory
– I: Shifts and multimedia
– A: Integer Arithmetic and Logical Unit
– B: Branch
– F: Floating point
– L+X: Long (move, branch, …)

45
Bundle Templates
• Not all combinations of A, I, M, F, B, L and X are permitted
• Group “stops” are explicitly encoded as part of the template– can’t stop just anywhere
Some bundles identicalexcept for group stop

46
instrinstrinstr ;;instrinstr ;;instrintsrinstrinstrinstr ;;instrinstr ;;instr…
instr instr instr tmplinstr instr instr tmplinstr instr nop tmplinstr nop nop tmplinstr instr nop tmplinstr instr nop tmplintsr instr instr tmpl…
instr instr instr tmplinstr instr instr tmpl
Handwritten code
Code generator
Instruction bundles
FetchExecution
Code generator creates bundles,possibly including nops.
Can the bundle pairExecute in parallel ?
Itanium® fetches 2 bundles at a time for execution.They may or may not execute in parallel.
There are two difficulties:1) Finding instruction triplets matching the defined templates.2) Matching pairs of bundles that can execute in parallel.

47
MEM MEM INT INT FP FP B B B
128-bit instruction bundles from I-cacheS2 S1 S0 T
Fetch one or more bundles for execution(Implementation, Itanium® takes two.)
Try to execute all instructions inparallel, depending on available units.
Retired instruction bundles
Processor
Explicitly Parallel Instruction ComputingEPIC
functional units
MEM MEM INT INT FP FP B B B

48
Itanium 8-stage Pipelines
• In-order issue, out-of-order completion– All functional units are fully pipelined
• Small branch misprediction penalties
FP1 FP2
IPG ROT
Inst
ruct
ion
Bu
ffe
r
EXP REN REG
MM1 MM2
EXE DET WRB
L1D1 L1D2 L1D3
FP3 FP4
MemoryMemory
IntInt
MultiMediaMultiMedia
Floating PointFloating Point

49
Itanium 2 Eight-stage Pipeline
EXPEXP RENRENROTROTIPGIPG REGREG EXEEXE DETDET WBWB
FP1FP1 FP2FP2 FP3FP3 FP4FP4 WBWB
L2NL2N L2IL2I L2AL2A L2ML2M L2DL2D L2CL2C L2WL2W
CoreCore
FPFP
L2L2
IPGIPG IP Generate, L1I cache (6 inst) and TLB access
EXEEXE ALU Execute, L1D Cache and TLB Access + L2 Cache Tag Access
ROTROT Instruction Rotate and Buffer (6 inst) DETDET Exception Detect, Branch Correction
EXPEXP Expand, Port assignment and routing WBWB Writeback, INT register update
RENREN INT and FP register rename FP1-WBFP1-WB FP FMAC pipeline (2) + register write
REGREG INT and FP register file read L2N-L2IL2N-L2I L2 Queue Nominate/Issue (4)(speculatively issued with L1 requestspeculatively issued with L1 request)
L2A-L2WL2A-L2W L2 Access, Rotate, Correct, Write (4)