1/1/ / faculty of electrical engineering eindhoven university of technology speeding it up part 3:...
TRANSCRIPT

1/
/ faculty of Electrical Engineering
eindhoven university of technology
Speeding it upPart 3: Out-Of-Order and SuperScalar execution
dr.ir. A.C. VerschuerenEindhoven University of
TechnologySection of Digital Information
Systems

1/
/ faculty of Electrical Engineering
eindhoven university of technology
Moving instructions around• It is possible to change the execution order
of instructions which do not have dependencies
without renaming: with renaming:1) R1 := R2 + 3 R1b := R2a + 32) R3 := R1 x 2 R3b := R1b x 23) R1 := R6 + R2 R1c := R6a + R2a4) R2 := R1 - 15 R2b := R1c - 15
True dependencies: 2) comes after 1), 4) comes after 3)
With renaming, these are the only sequence restrictions !
3) R1c := R6a + R2a4) R2b := R1c - 151) R1b := R2a + 32) R3b := R1b x 2
3) R1c := R6a + R2a1) R1b := R2a + 32) R3b := R1b x 24) R2b := R1c - 15

1/
/ faculty of Electrical Engineering
eindhoven university of technology
Out-of-order (OOO) execution• Changing the order of instruction execution
can remove pipeline stalls and/or fill delay slots:
increase the performance– Instructions can be re-ordered in the program,
but this is not OOO execution !
• OOO execution: instructions are sent to the operational units (ALU, load/store...) in a different order than the program specifies
OOO memory accessing is not discussed here

1/
/ faculty of Electrical Engineering
eindhoven university of technology
Instruction buffers for OOO execution• To be able to change the execution order,
fetched instructions must be buffered
fetch &decode
ALU
load/store
scheduler
scheduler
reservationstation
reservationstation
(renamed)registers
schedulercentralinstructionwindow
programmemory
fetch &decode
ALU
load/store
(renamed)registers
1) Separate instruction buffers for each functional unit
2) Central instruction buffer
programmemory

1/
/ faculty of Electrical Engineering
eindhoven university of technology
Differences between buffer strategies• Reservation stations have advantages
+Smaller buffers, schedulers are simpler
+Buffer entries can be tailored to instruction format
+Routing of instructions across chip simpler
• The central instruction window also has advantages+Total number of buffered instructions can be smaller
+The single scheduler can take better decisions
+No ‘false locking’ with identical functional units

1/
/ faculty of Electrical Engineering
eindhoven university of technology
False locking between functional units
Instruction sequence: A1, B1, A2, B2, A3, B3, A4, B4
1
2
scheduler
scheduler
reservation stations
(renamed)registers
ALU’s
fetch &decode
programmemory
A4 A3 A2 A1
B4 B3 B2 B1
A1
B1
A4 A3 A2
B4 B3 B2
A1
B2
A4 A3 A2
B4 B3
A1
B3
A4 A3 A2
B4
A1
B4
A4 A3 A2 A1
A4 A3 A2 A1
B1
A4 A3 A2
B4 B3 B2
lockedlockedA4 A3 B2
A1
B4 B3 A2 B1
A1
B1
A4 A3 B2
B4 B3 A2
A1
B1
A4 A3 B2
B4 B3 A2
lockedlockedA4 A3 B2
B4 B3 A2
A1
A4 A3 B2
B4 B3 A2
A1
false
lockingfalse
locking
This will not happen with a central instruction window !
Hybrid solution: one reservation station + one scheduler
for multiple identical functional units

1/
/ faculty of Electrical Engineering
eindhoven university of technology
Scheduler operation• The schedulers actually have only a simple task
Pick ready-to-execute instructions from their buffers and send them to the appropriate operational units
'ready-to-execute' with all source values known
• Try to calculate conditional jump results ASAP
• Otherwise: oldest instructions first

1/
/ faculty of Electrical Engineering
eindhoven university of technology
‘Ready to execute’ determination• The scheduler(s) depend on other system
parts to determine which instructions can be executed
The fetch unit knows the original order of the instructions and must determine the dependencies
The operational units signal the end of a dependency when writing a result operand
The instruction buffer(s) determine from this information which instructions are ready to execute and store this knowledge in status flags

1/
/ faculty of Electrical Engineering
eindhoven university of technology
The ‘scoreboard’, again• A simple scoreboarding technique can be
used for ‘ready to execute’ determination
– Renamed registers get a flag bit which indicates the register does not contain a result yet
– Each renamed destination register write sets the attached flag bit to indicate the result is available
• An instruction is ready to execute when all the flag bits of it's renamed source registers are set

1/
/ faculty of Electrical Engineering
eindhoven university of technology
The problem with interrupts and traps• OOO completion means instructions results
may be written in an order which differs from the instruction sequence in the program
– If an instruction generates a trap,instructions following it may already have changed registers (and/or memory locations !)
– If an interrupt must break off processing,some instructions may not completewhile later ones in the program have already completed

1/
/ faculty of Electrical Engineering
eindhoven university of technology
Solution: a ‘safe state’ register set• With these imprecise interrupts and traps, it
is almost impossible to get the processor in a state from which it can be safely restarted
• We must find a way to maintain the 'visible' set of processor registers in a 'safe state':
updated in the normal program order
– We don't care if this updating of the safe statelags behind the normal updating of the renamed set

1/
/ faculty of Electrical Engineering
eindhoven university of technology
'reorder buffer'
renamedregisters
saferegister
set
Implementation of the safe state• One common way to provide this 'safe' register
set is by using a so-called 'reorder buffer'
result bus(es)
renamedregisternumber
read pointerwrite
pointer
'head'
'tail'
simulated FIFO
ren
am
ed
realregisternumber
in-order updates
sourceoperand0
1
valid
flag
s
operandvalid
1/
/ faculty of Electrical Engineering
eindhoven university of technology
Safe register set
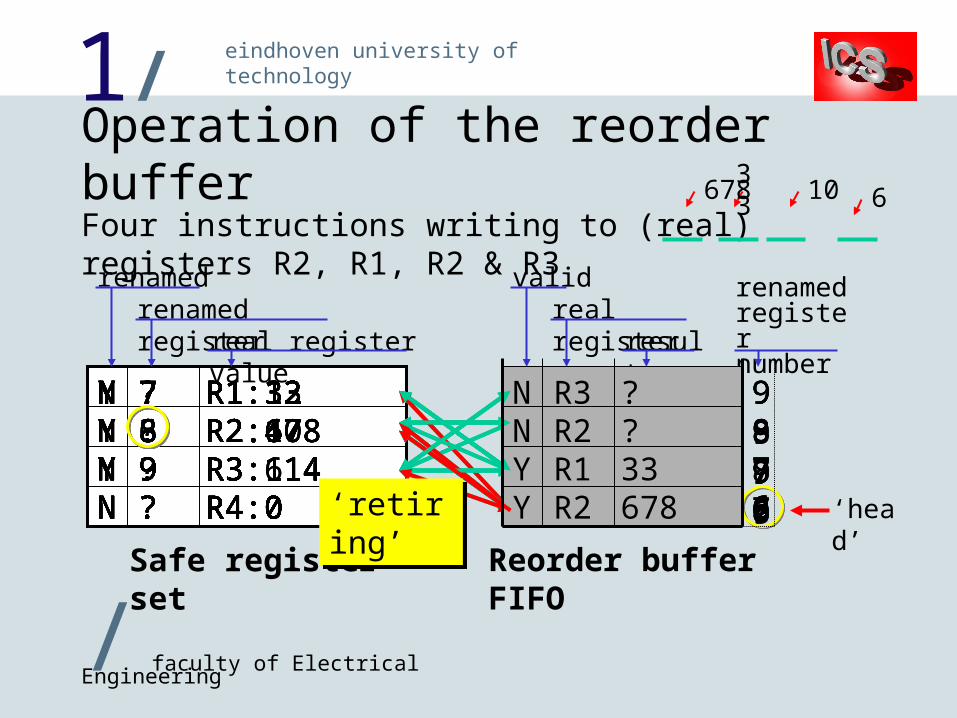
Operation of the reorder bufferFour instructions writing to (real) registers R2, R1, R2 & R3renamed
renamed registerreal register
value
validreal registerresult
renamedregisternumber
‘head’
N R2 ? 6
N ? R1: 12Y 6 R2: 47N ? R3: 114N ? R4: 0
N R1 ? 7N R2 ? 6
Y 7 R1: 12Y 6 R2: 47N ? R3: 114N ? R4: 0
Y 7 R1: 12Y 8 R2: 47N ? R3: 114N ? R4: 0
N R2 ? 8N R1 ? 7N R2 ? 6
Y 7 R1: 12Y 8 R2: 47Y 9 R3: 114N ? R4: 0
N R3 ? 9N R2 ? 8N R1 ? 7N R2 ? 6
N ? R1: 12N ? R2: 47N ? R3: 114N ? R4: 0
Y 7 R1: 12Y 8 R2: 47Y 9 R3: 114N ? R4: 0
N R3 ? 9N R2 ? 8Y R1 33 7N R2 ? 6
33
Y 7 R1: 12Y 8 R2: 47Y 9 R3: 114N ? R4: 0
N R3 ? 9N R2 ? 8Y R1 33 7Y R2 678 6
678
Y 7 R1: 12Y 8 R2: 678Y 9 R3: 114N ? R4: 0
N R3 ? 9N R2 ? 8Y R1 33 7
N ? R1: 33Y 8 R2: 678Y 9 R3: 114N ? R4: 0
N R3 ? 9N R2 ? 8Y R1 33 7
N ? R1: 33Y 8 R2: 678Y 9 R3: 114N ? R4: 0
N R3 ? 9N R2 ? 8
6
N ? R1: 33Y 8 R2: 678Y 9 R3: 114N ? R4: 0
Y R3 6 9N R2 ? 8
10
N ? R1: 33Y 8 R2: 678Y 9 R3: 114N ? R4: 0
Y R3 6 9Y R2 10 8
N ? R1: 33N ? R2: 10Y 9 R3: 114N ? R4: 0
Y R3 6 9Y R2 10 8
N ? R1: 33N ? R2: 10Y 9 R3: 114N ? R4: 0 Y R3 6 9
N ? R1: 33N ? R2: 10N ? R3: 6N ? R4: 0 Y R3 6 9
N ? R1: 33N ? R2: 10N ? R3: 6N ? R4: 0
Y 7 R1: 12Y 8 R2: 678Y 9 R3: 114N ? R4: 0
N R3 ? 9N R2 ? 8Y R1 33 7Y R2 678 6‘retirin
g’‘retiring’ Reorder buffer
FIFO

1/
/ faculty of Electrical Engineering
eindhoven university of technology
Other solutions and variations• Both 'history buffer' and 'future file' are (minor)
variations/extensions on the reorder buffer
• A central instruction window can combine the reorder buffer and instruction buffer functions
• 'Checkpoint repair' makes backups of the complete register set when problems may occur
– Only instructions which were already in execution at the time of the backup modify the backup's state (these must complete execution)

1/
/ faculty of Electrical Engineering
eindhoven university of technology
OOO execution & conditional jumps• Machines uncapable to move instructions
across (conditional) jumps will not perform well
– Basic block sizes of 4..6 instructions are normal for CISC's (6..8 instructions for RISC's)
– Around half of the jumps is conditional !
• The problem with conditional jumps
– If the prediction is wrong, the processor state must be restored to the point of the jump instruction
In fact, the same as if a trap occurred

1/
/ faculty of Electrical Engineering
eindhoven university of technology
‘Speculative’ OOO conditional jumps (1)• 'Speculative fetching’
fetches and decodes instructions after the conditional jump,
but does not take them in execution
• 'Speculative execution’also executes instructions in the predicted path,using renaming as buffer for the in-order (safe) state
– The speculative renamed registers are discardedwhen the prediction was incorrect
– Rename indexes must be restored ! (checkpoint repair ?)

1/
/ faculty of Electrical Engineering
eindhoven university of technology
‘Speculative’ OOO conditional jumps (2)• 'Multi-path speculative execution’
extends speculative execution to handle both paths following a conditional branch
– may also allow multiple condition tests to be unresolved (needs more checkpointing buffers)
• Retiring of renamed registers is frozen for speculative renamed registers until the branch outcome is known

1/
/ faculty of Electrical Engineering
eindhoven university of technology
Handling more instructions per clock• Fetching more than one instruction per
clock is generally not such a problem
– Make the bus to the instruction memory wider !
• Need more than one functional unit to actually execute the instructions in parallel
• Must also decode more than one instruction per clock to get a 'superscalar' processor

1/
/ faculty of Electrical Engineering
eindhoven university of technology
Superscalar parts we have already seen• Instruction decoders can easily send multiple
instructions to separate reservation stations
– With a minor increase in complexity even multiple instructions to the same reservation station
• The central instruction window can be modified to receive multiple instructions in a single cycle
– The scheduler can be changed to handle multiple instructions in parallel

1/
/ faculty of Electrical Engineering
eindhoven university of technology
Superscalar dependency detection• Instruction dependency determination
must now be partially implemented in a parallel form
– Renamed register indexes must be forwarded between concurrently decoded instructions
– It must be possible to create multiple renamed registers in a single cycle
• It must also be possible to update multiplein-order (safe) registers in parallel !

1/
/ faculty of Electrical Engineering
eindhoven university of technology
Another method to go superscalar• Very Large Instruction Word (VLIW)
machines pack several ‘normal’ instructions in a single ‘superinstruction’
– They execute this superinstruction using separate functional units
With all scheduling done by the compiler !
– Programming VLIW machines in assembly language is virtually impossible
faster

1/
/ faculty of Electrical Engineering
eindhoven university of technology
VLIW, but not exactly• The Intel 80860 processor uses another trick
which resembles VLIW operation
– It always fetches two instructions at a time
– If the first one is a floating point operation, it checks a flag in this instruction
– If this flag is set, it assumes the second one is not a floating point operation and executes both in parallel
• Intel Pentium ‘pairs’ instructions without flags