12/15/00emtm 5531 emtm 553: e-commerce systems lecture 4: performance and scalability insup lee...
Post on 19-Dec-2015
213 views
TRANSCRIPT

12/15/00 EMTM 553 1
EMTM 553: E-commerce Systems
Lecture 4: Performance and Scalability
Insup Lee
Department of Computer and Information Science
University of [email protected]
www.cis.upenn.edu/~lee
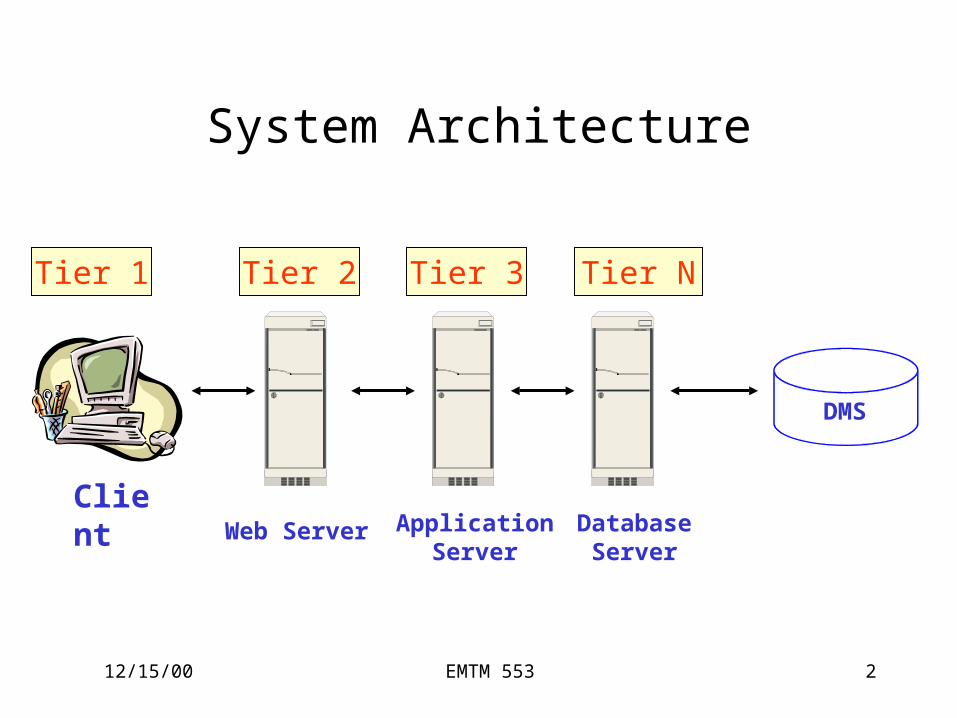
12/15/00 EMTM 553 2
System Architecture
Client
Tier 1
Web Server
Tier 3Tier 2 Tier N
Application Server
Database Server
DMS

12/15/00 EMTM 553 3
Goals and Approaches
• Internet-based E-Commerce has made system growth more rapid and dynamic.
• Improving performance and reliability to provide– Higher throughput– Lower latency (i.e., response time)– Increase availability
• Approaches– Scaling network and system infrastructure
o How performance, redundancy, and reliability are related to scalability
– Load balancing– Web caching

12/15/00 EMTM 553 4
Network Hardware Review• Firewall
– Restricts traffic based on rules and can “protect” the internal network from intruders
• Router– Directs traffic to a destination based on the “best” path;
can communicate between subnets
• Switch– Provides a fast connection between multiple servers on
the same subnet
• Load Balancer– Takes incoming requests for one “virtual” server and
redirects them to multiple “real” servers
SOURCE: SCIENT
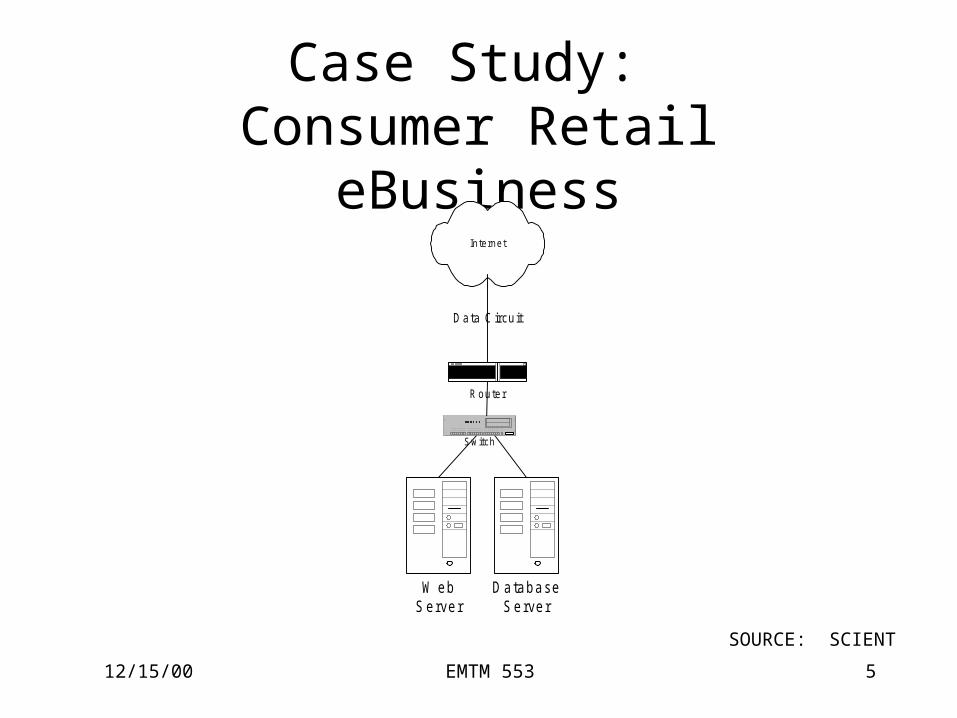
12/15/00 EMTM 553 5
Case Study: Consumer Retail eBusiness
Internet
R ou te r
W ebS erver
D atabaseS erver
Switch
D ata C ircu it
SOURCE: SCIENT
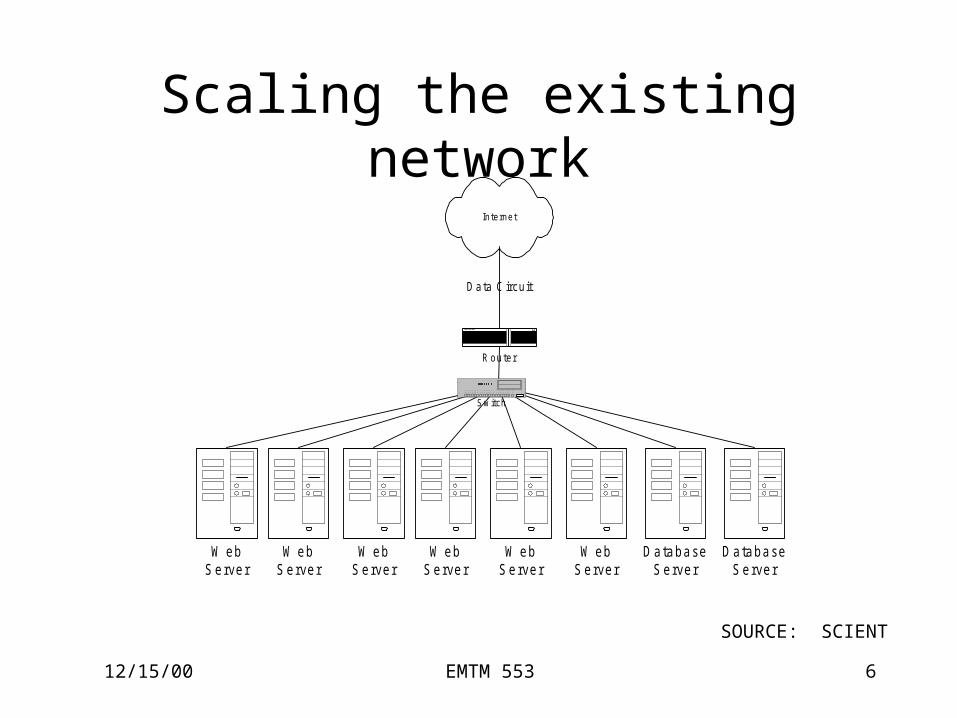
12/15/00 EMTM 553 6
Scaling the existing network
Internet
R ou te r
W ebS erver
D atabaseS erver
W ebS erver
W ebS erver
W ebS erver
W ebS erver
D atabaseS erver
W ebS erver
Switch
D ata C ircu it
SOURCE: SCIENT
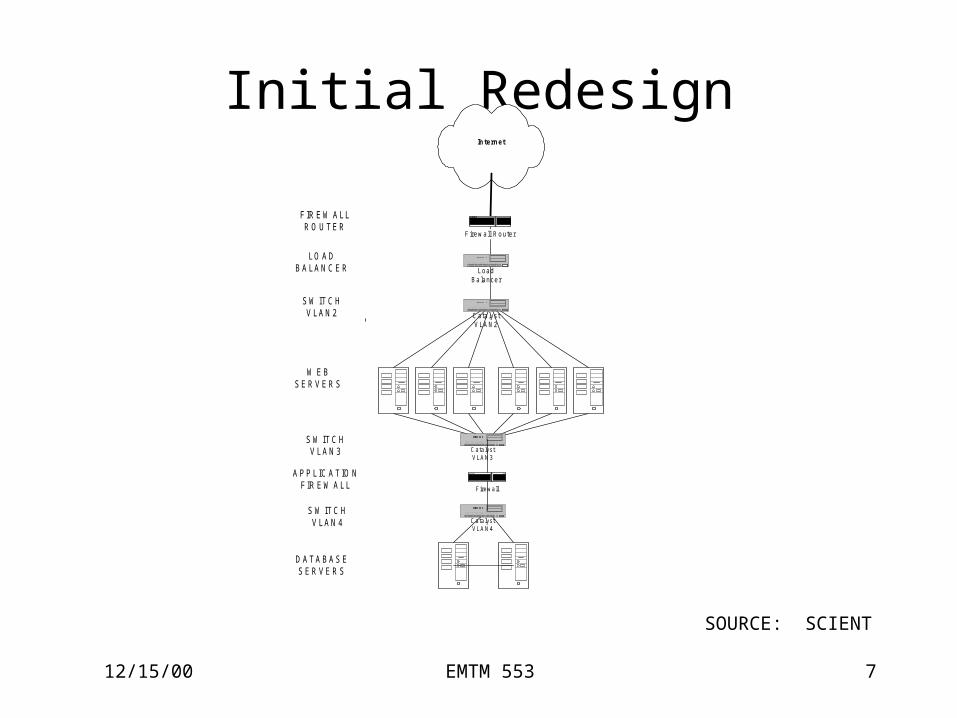
12/15/00 EMTM 553 7
Initial Redesign
C ata lys tV LA N 2
Internet
CatalystVLAN4
F irew a ll R ou te r
W E BS E R V E R S
FIR E W A LLR O U TE R
LO A DB A LA N C E R
S W ITC HV LA N 2
S W ITC HV LA N 3
S W ITC HV LA N 4
A P P LIC A T IO NFIR E W A LL
D A TA B A S ES E R V E R S
CatalystVLAN3
LoadB a lance r
Firewall
SOURCE: SCIENT
12/15/00 EMTM 553 8
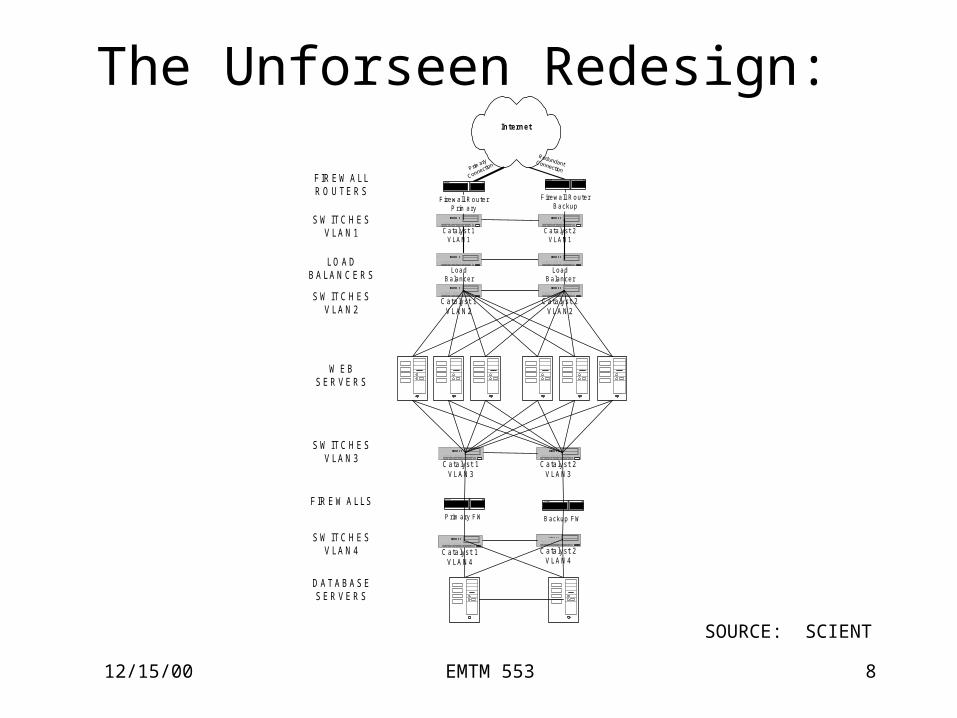
The Unforseen Redesign: Internet
Primary
Connection
RedundantConnection
C ata lys t 2V LA N 4
Catalyst 2VLAN1
C ata lys t 2V LA N 2
C ata lys t 1V LA N 2
Catalyst 1VLAN1
C ata lys t 1V LA N 4
Firewall RouterBackup
Firewall RouterPrim ary
C ata lys t 2V LA N 3
C ata lys t 1V LA N 3
Prim ary FW Backup FW
LoadBalancer
LoadBalancer
W E BS ER V E R S
FIR EW ALLR O U TE R S
S W ITC H ESV LAN 1
LO A DB ALA N C E R S
S W ITC H ESV LAN 2
S W ITC H ESV LAN 3
S W ITC H ESV LAN 4
FIR EW ALLS
D A TA BA S ES ER V E R S
SOURCE: SCIENT

12/15/00 EMTM 553 9
How to get rid of the last SPOF:Internet
California
C ata lys t 2V LA N 4
Catalyst 2VLAN1
C ata lys t 2V LA N 2
C ata lys t 1V LA N 2
Catalyst 1VLAN1
C ata lys t 1V LA N 4
Firewall RouterBackup
Firewall RouterPrim ary
C ata lys t 2V LA N 3
C ata lys t 1V LA N 3
Primary Connection Redundant Connection
Prim ary FW Backup FW
LoadBalancer
LoadBalancer
New York
C ata lys t 2V LA N 4
Catalyst 2VLAN1
C ata lys t 2V LA N 2
C ata lys t 1V LA N 2
Catalyst 1VLAN1
C ata lys t 1V LA N 4
Firewall RouterBackup
Firewall RouterPrim ary
C ata lys t 2V LA N 3
C ata lys t 1V LA N 3
Primary Connection
Redundant Connection
Prim ary FW Backup FW
LoadBalancer
LoadBalancer
SOURCE: SCIENT

12/15/00 EMTM 553 10
Scaling Servers: Two Approaches
• Multiple smaller servers – Add more servers to scale – Most commonly done with web servers
• Fewer larger servers to add more internal resources– Add more processors, memory, and disk space– Most commonly done with database servers
SOURCE: SCIENT

12/15/00 EMTM 553 11
Where to Apply Scalability
• To the network • To individual servers• Make sure the network has capacity
before scaling by adding servers
SOURCE: SCIENT

12/15/00 EMTM 553 12
Performance, Redundancy, andScalability
• People scale because they want better performance
• But a fast site that goes down because of one component is a Bad Thing
• Incorporate all three into your design in the beginning - more difficult to do after the eBusiness is live
SOURCE: SCIENT

12/15/00 EMTM 553 13
Lessons Learned
• Don’t take the network for granted.• Most people don’t want to think about the
network - they just want it to work.• You will never know everything up front so
plan for changes.• Warning: as you add redundancy and
scalability the design becomes complicated.
SOURCE: SCIENT

12/15/00 EMTM 553 14
Approaches to Scalability
• Application Service Providers (sites) grow by – scale up: replacing servers with larger servers – scale out: adding extra servers
• Approaches– Farming– Cloning– RACS– Partitioning– RAPS
• Load balancing• Web caching

12/15/00 EMTM 553 15
Farming
• Farm - the collection of all the servers, applications, and data at a particular site.– Farms have many specialized services (i.e.,
directory, security, http, mail, database, etc.)

12/15/00 EMTM 553 16
Cloning
• A service can be cloned on many replica nodes, each having the same software and data.
• Cloning offers both scalability and availability.– If one is overloaded, a load-balancing system can be
used to allocate the work among the duplicates.– If one fails, the other can continue to offer service.

12/15/00 EMTM 553 17
Two Clone Design Styles
•Shared Nothing is simpler to implement and scales IO bandwidth as the site grows.
•Shared Disc design is more economical for large or update-intensive databases.

12/15/00 EMTM 553 18
RACS
• RACS (Reliable Array of Cloned Services) – a collection of clones for a particular service– shared-nothing RACS
o each clone duplicates the storage locallyo updates should be applied to all clone’ s storage
– shared-disk RACS (cluster)o all the clones share a common storage managero storage server should be fault-toleranto subtle algorithms need to manage updates (cache
invalidation, lock managers, etc.)

12/15/00 EMTM 553 19
Clones and RACS
• can be used for read-mostly applications with low consistency requirements.– i.e., Web servers, file servers, security servers…
• the requirements of cloned services:– automatic replication of software and data to new
clones– automatic request routing to load balance the work– route around failures– recognize repaired and new nodes
12/15/00 EMTM 553 20
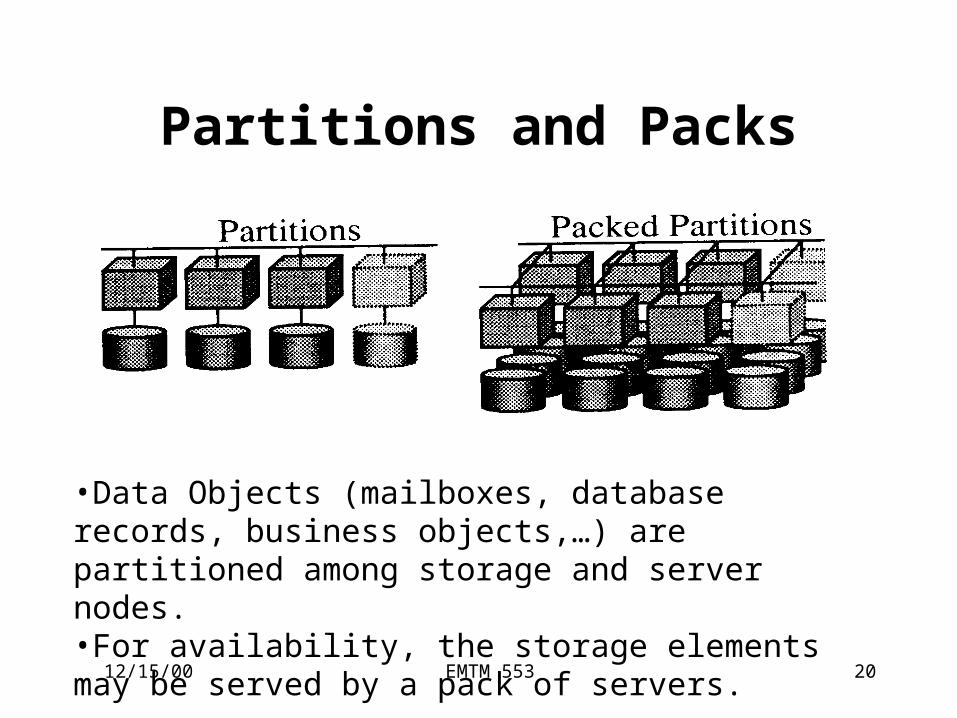
Partitions and Packs
•Data Objects (mailboxes, database records, business objects,…) are partitioned among storage and server nodes.•For availability, the storage elements may be served by a pack of servers.

12/15/00 EMTM 553 21
Partition
• grows a service by – duplicating the hardware and software– dividing the data among the nodes (by object), e.g.,
mail servers by mailboxes
• should be transparent to the application– requests to a partitioned service are routed to the
partition with the relevant data
• does not improve availability– the data is stored in only one place- partitions are implemented as a pack of two or more
nodes that provide access to the storage
12/15/00 EMTM 553 22
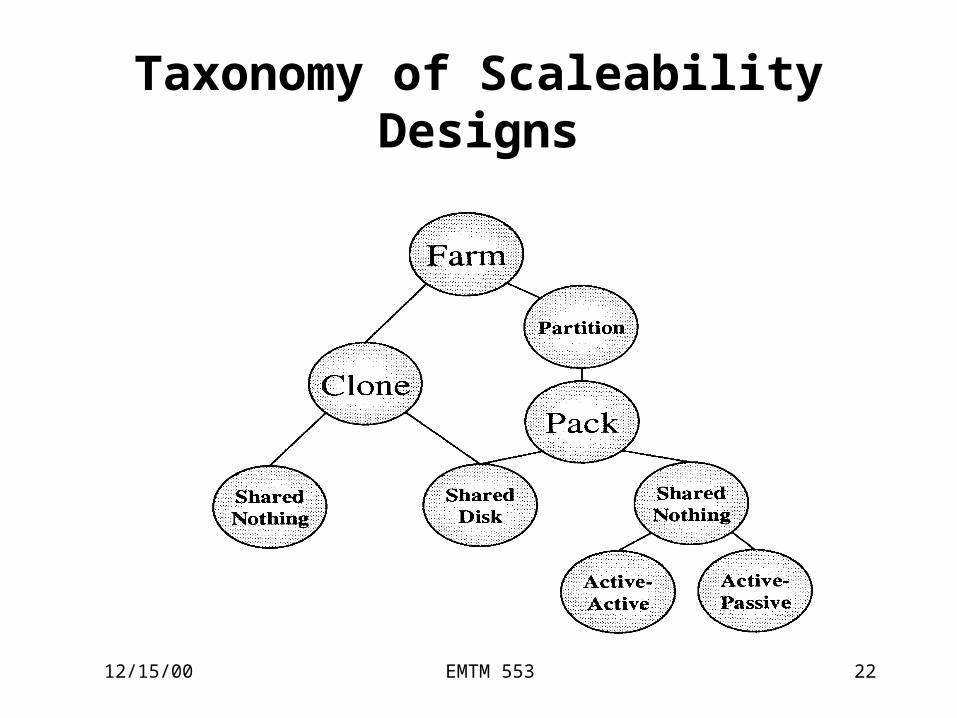
Taxonomy of Scaleability Designs

12/15/00 EMTM 553 23
RAPS
• RAPS (Reliable Array of Partitioned Services)– nodes that support a packed-partitioned service– shared-nothing RAPS, shared-disk RAPS
• Update-intensive and large database applications are better served by routing requests to servers dedicated to serving a partition of the data (RAPS).

12/15/00 EMTM 553 24
Performance and Summary
• What is the right building block for a site?– IBM mainframe (OS390): highly available, .99999 up
(less than 5 mins outage per year)– Sun UE1000– PC servers– Homogenous site is easier to manage (all NT, all
FreeBSD, Solaris, OS390)
• Summary,– For scalability, replicate.– Shared-nothing clones (RACS)– For databases or update-intensive services, packed-
partition (RAPS)

12/15/00 EMTM 553 25
Load Sharing

12/15/00 EMTM 553 26
Load Sharing
• What is the problem?– Too much load– Need to replicate servers
• Why do we need to balance load?

12/15/00 EMTM 553 27
Load Sharing Strategies
• Flat architecture– DNS rotation, switch based, MagicRouter
• Hierarchical architecture • Locality-Aware Request Distribution
12/15/00 EMTM 553 28
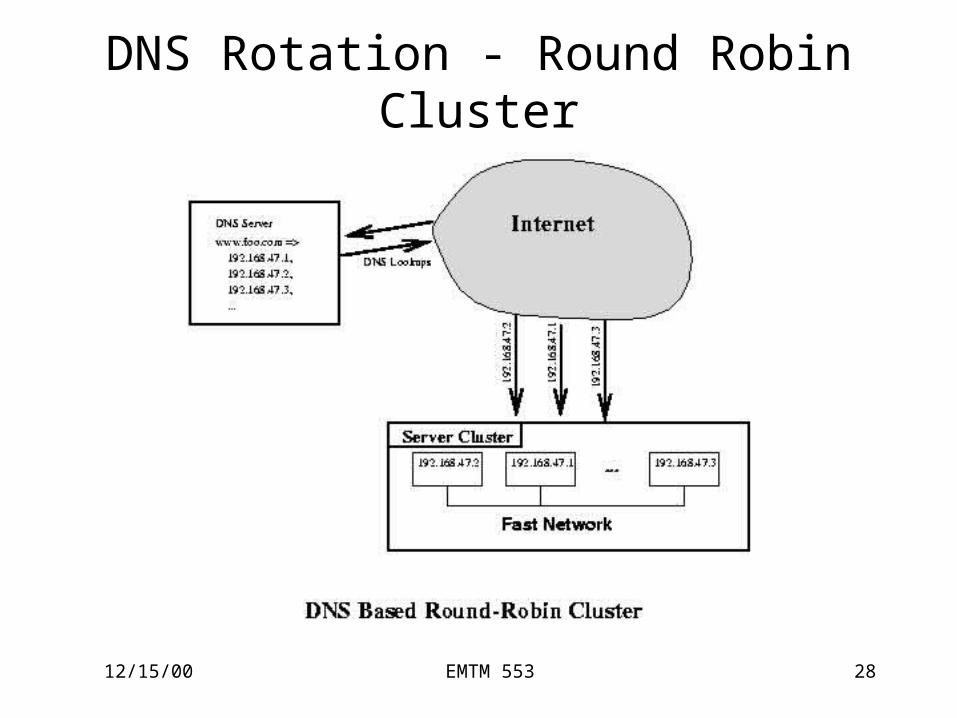
DNS Rotation - Round Robin Cluster

12/15/00 EMTM 553 29
Flat Architecture - DNS Rotation• DNS rotates IP addresses of a Web site
– treat all nodes equally • Pros:
– A simple clustering strategy• Cons:
– Client-side IP caching: load imbalance, connection to down node
• Hot-standby machine (failover)– expensive, inefficient
• Switching products– Cisco, Foundry Networks, and F5Labs– Cluster servers by one IP– Distribute workload (load balancing)– Failure detection
• Problem– Not sufficient for dynamic content

12/15/00 EMTM 553 30
Switch-based Cluster

12/15/00 EMTM 553 31
Flat Architecture - Switch Based
• Switching products– Cluster servers by one IP– Distribute workload (load balancing)
o typically round-robin– Failure detection– Cisco, Foundry Networks, and F5Labs
• Problem– Not sufficient for dynamic content
12/15/00 EMTM 553 32
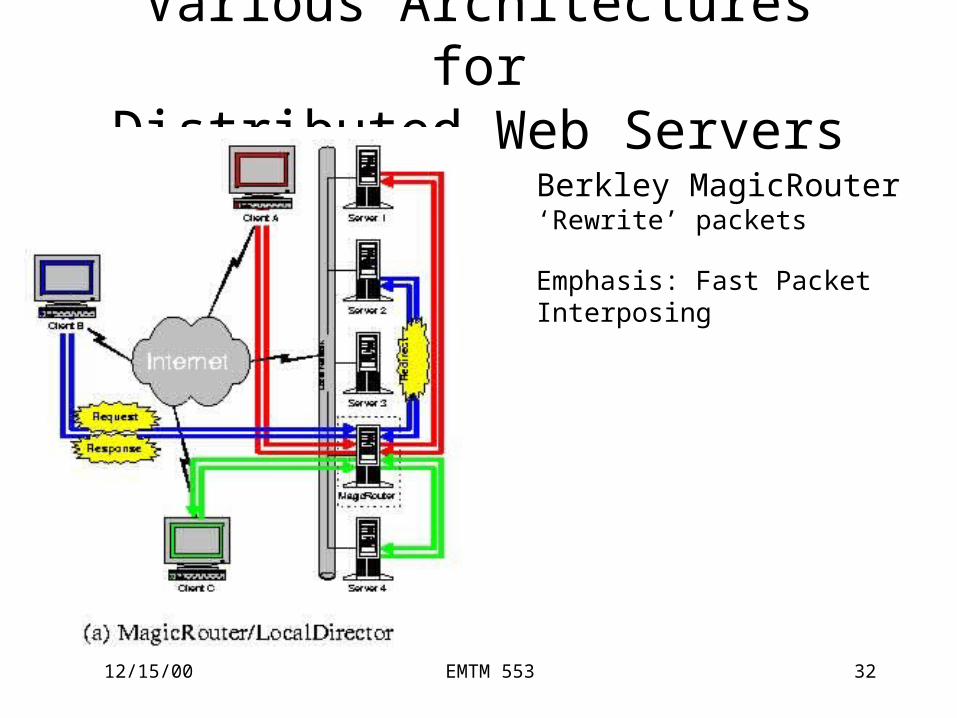
Various Architectures forDistributed Web Servers
Berkley MagicRouter‘Rewrite’ packets
Emphasis: Fast Packet Interposing

12/15/00 EMTM 553 33
Flat Architectures in General
• Problems– Not sufficient for dynamic content– Adding/Removing nodes is difficult
o Manual configuration required– limited load balancing in switch

12/15/00 EMTM 553 34
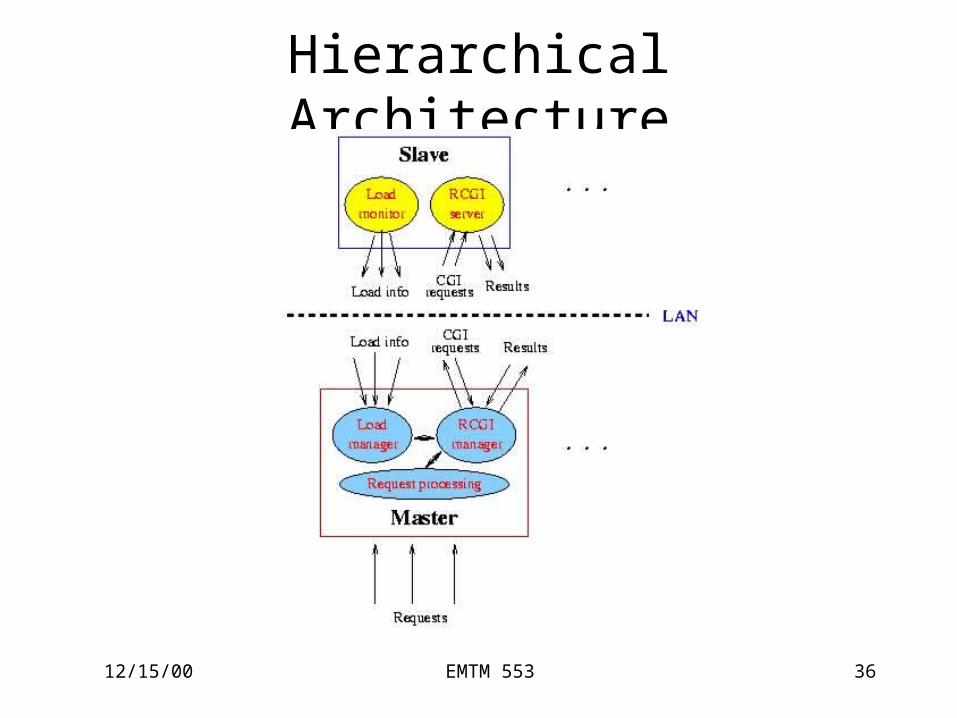
Hierarchical Architecture
• Master/slave architecture • Two levels
– Level Io Master: static and dynamic content
– Level IIo Slave: only dynamic

12/15/00 EMTM 553 35
Hierarchical Architecture
M/S Architecture
12/15/00 EMTM 553 36
Hierarchical Architecture

12/15/00 EMTM 553 37
Hierarchical Architecture• Benefits
– Better failover supporto Master restarts job if a slave fails
– Separate dynamic and static contento resource intensive jobs (CGI scripts) runs by slave

12/15/00 EMTM 553 38
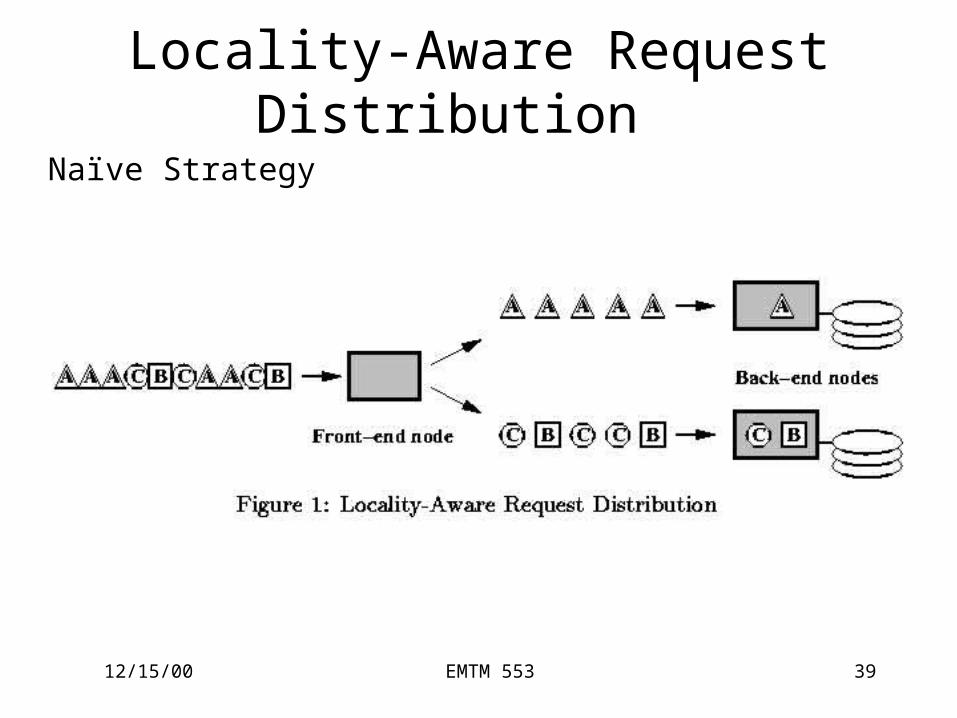
Locality-Aware Request Distribution
• Content-based distribution– Improved hit rates– Increased secondary storage– Specialized back end servers
• Architecture– Front-end
o distributes request– Back-end
o process request
12/15/00 EMTM 553 39
Locality-Aware Request Distribution
Naïve Strategy

12/15/00 EMTM 553 40
Various Architectures forDistributed Web Servers

12/15/00 EMTM 553 41
Web Caching

12/15/00 EMTM 553 42
World Wide Web
• A large distributed information system• Inexpensive and faster accesses to information• Rapid growth of WWW (15% per month)• Web performance and scalability issues
– network congestion – server overloading

12/15/00 EMTM 553 43
Web Architecture
• Client (browser), Web server
Web server
Client (browser)
12/15/00 EMTM 553 44
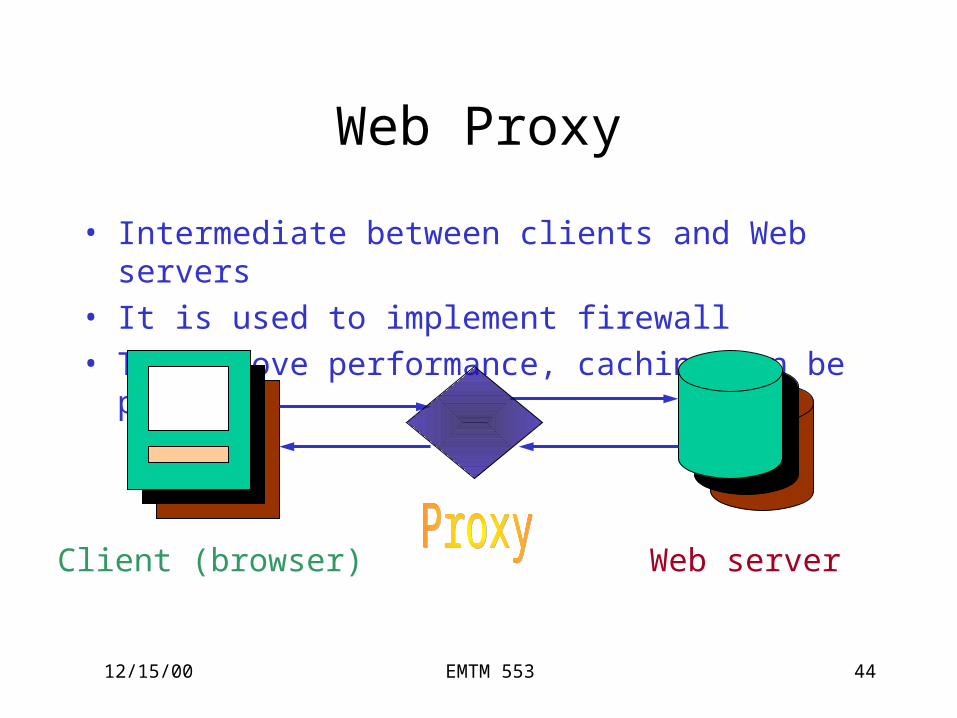
Web Proxy
• Intermediate between clients and Web servers• It is used to implement firewall• To improve performance, caching can be
placed
Client (browser) Web server

12/15/00 EMTM 553 45
Web Architecture• Client (browser), Proxy, Web server
Web server
Proxy
Client (browser)
Firewall
12/15/00 EMTM 553 46
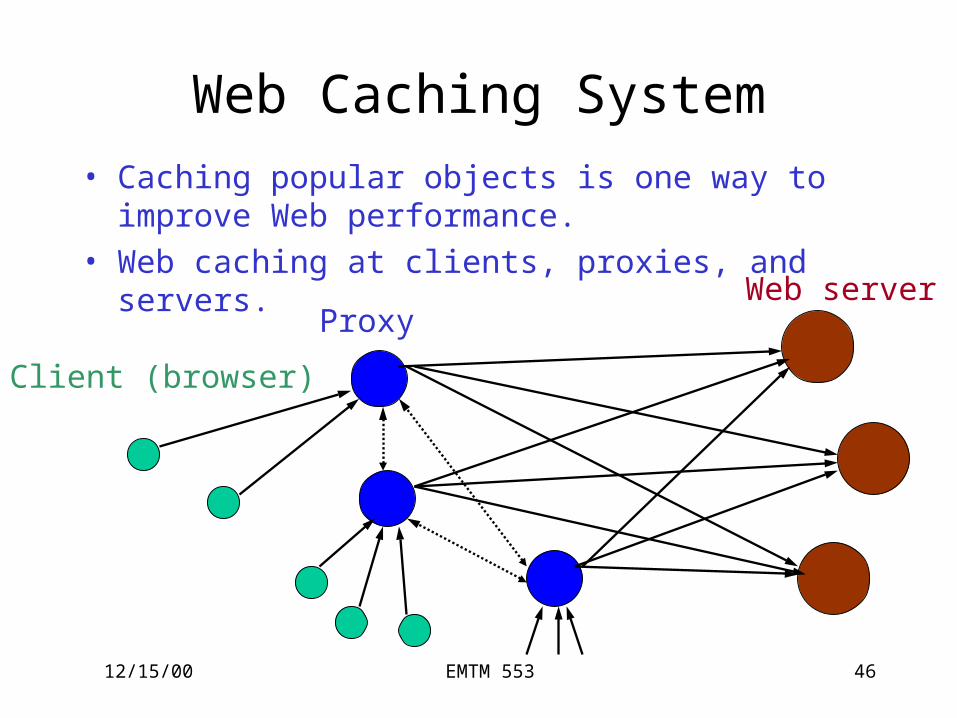
Web Caching System• Caching popular objects is one way to improve
Web performance.• Web caching at clients, proxies, and servers.
Proxy
Client (browser)
Web server

12/15/00 EMTM 553 47
Advantages of Web Caching
• Reduces bandwidth consumption (decrease network traffic)
• Reduces access latency in the case of cache hit
• Reduces the workload of the Web server• Enhances the robustness of the Web service • Usage history collected by Proxy cache can be
used to determine the usage patterns and allow the use of different cache replacement and prefetching policies.

12/15/00 EMTM 553 48
Disadvantages of Web Caching
• Stale data can be serviced due to the lack of proper updating
• Latency may increase in the case of a cache miss
• A single proxy cache is always a bottleneck.• A single proxy is a single point of failure• Client-side and proxy cache reduces the hits
on the original server.

12/15/00 EMTM 553 49
Web Caching Issues
• Cache replacement• Prefetching• Cache coherency• Dynamic data caching

12/15/00 EMTM 553 50
Cache Replacement
• Characteristics of Web objects– different size, accessing cost, access pattern.
• Traditional replacement policies do not work well– LRU (Least Recently Used), LFU (Least Frequently
Used), FIFO (First In First Out), etc
• There are replacement policies for Web objects:– key-based– cost-based

12/15/00 EMTM 553 51
Two Replacement Schemes
• Key-based replacement policies:– Size: evicts the largest objects– LRU-MIN: evicts the least recently used object among ones
with largest log(size)– Lowest Latency First: evicts the object with the lowest
download latency
• Cost-based replacement policies – Cost function of factors such as last access time, cache
entry time, transfer time cost, and so on– Least Normalized Cost Replacement: based on the access
frequency, the transfer time cost and the size.– Server-assisted scheme: based on fetching cost, size, next
request time, and cache prices during request intervals.

12/15/00 EMTM 553 52
Prefetching
• The benefit from caching is limited.– Maximum cache hit rate - no more than 40-50%– to increase hit rate, anticipate future document
requests and prefetch the documents in caches
• documents to prefetch– considered as popular at servers– predicted to be accessed by user soon, based on the
access pattern
• It can reduce client latency at the expense of increasing the network traffic.

12/15/00 EMTM 553 53
Cache Coherence
• Cache may provide users with stale documents.• HTTP commands for cache coherence
– GET : retrieves a document given its URL– Conditional GET: GET combined with the header IF-
Modified-Since. – Progma: no-cache : this header indicate that the
object be reloaded from the server.– Last-Modified : returned with every GET message and
indicate the last modification time of the document.
• Two possible semantics– Strong cache consistency– Weak cache consistency

12/15/00 EMTM 553 54
Strong cache consistency
• Client validation (polling-every-time)– sends an IF-Modified-Since header with each access
of the resources– server responses with a Not Modified message if the
resource does not change
• Server invalidation– whenever a resource changes, the server sends
invalidation to all clients that potentially cached the resource.
– Server should keep track of clients to use.– Server may send invalidation to clients who are no
longer caching the resource.

12/15/00 EMTM 553 55
Weak Cache Consistency
– Adaptive TTL (time-to-live)o adjust a TTL based on a lifetime (age) - if a file has not been
modified for a long time, it tends to stay unchanged.o This approach can be shown to keep the probability of stale
documents within reasonable bounds ( < 5%).o Most proxy servers use this mechanism.o No strong guarantee as to document staleness
– Piggyback Invalidationo Piggyback Cache Validation (PCV) - whenever a client
communicates with a server, it piggybacks a list of cached, but potentially stale, resources from that server for validation.
o Piggyback Server Invalidation (PSI) - a server piggybacks on a reply to a client, the list of resources that have changed since the last access by the client.
o If access intervals are small, then the PSI is good. But, if the gaps are long, then the PCV is good.

12/15/00 EMTM 553 56
Dynamic Data Caching
• Non-cacheable data – authenticated data, server dynamically generated data, etc.– how to make more data cacheable– how to reduce the latency to access non-cacheable data
• Active Cache– allows servers to supply cache applets to be attached with
documents.– the cache applets are invoked upon cache hits to finish
necessary processing without contacting the server.– bandwidth savings at the expense of CPU costs– due to significant CPU overhead, user access latencies are
much larger than without caching dynamic objects.

12/15/00 EMTM 553 57
Dynamic Data Caching
• Web server accelerator– resides in front of one or more Web servers– provides an API which allows applications to explicitly
add, delete, and update cached data.– The API allows static/dynamic data to be cached. – An example - the official Web site for the 1998
Olympic Winter Gameso whenever new content became available,
updated Web reflecting these changes were made available within seconds.
o Data Update Propagation (DUP, IBM Watson) is used for improving performance.

12/15/00 EMTM 553 58
Dynamic Data Caching
• Data Update Propagation (DUP)– maintains data dependence information between
cached objects and the underlying data which affect their values
– upon any change to underlying data, determines which cached objects are affected by the change.
– Such affected cached objects are then either invalidated or updated.
– With DUP, about 100% cache hit rate at the 1998 Olympic Winter Games official Web site.
– Without DUP, 80% cache hit rate at the 1996 Olympic Games official Web site.

12/15/00 EMTM 553 59
Q&A