1tops/w software programmable media processor silicon platform main bus 64 50gflops/w (ieee 754 sp)...
TRANSCRIPT

1TOPS/W Software Programmable Media Processor
David Moloney, CTO, Movidius19 August 2011

Movidius Background• Started in 2005 looking at mobile gaming acceleration
– Decided on multicore design to allow software derivatives and meet OPS/W/$ target
– Existing processors poor cost/performance match for target workloads
– Developed SHAVE vector processor with HW support for sparse data-structures (Matrix-Vector)
– Expanded ISA to support C-complier• Talked to mobile phone customers in 2007
– Turned out their real problem was video– Back to the drawing-board!
• Initial 65nm Silicon & all IP on founder & angel funding– Allowed us to close A-round in October 2008!
• 65nm Myriad MM SoC in mass-production– Next generation 28nm SoC H1/2012 with 10x Perf/W

Mobile Video Processing Workload
20/Apr/2011 3

Movidius SHAVE Processor• Streaming Hybrid Architecture Vector Engine
– Hybrid of RISC, DSP, VLIW & GPU architectural features– 128-bit vector arithmetic: 8/16/32-bit INT & fp16/fp32
• Unique proprietary architecture– Tailored to streaming workloads and architected for
outstanding OPS/mW/$ performance• Excellent Graphics and matrix mathematics support
– HW texture unit for good graphics performance– Predicated execution to eliminate branches– Compiler-friendly architecture– HW support for compressed data-structures (ex. matrices)

SHAVE Instruction-Set• RISC-style
– Instruction predication– Extensive integer ISA– Excellent C-compiler
support• DSP-style
– Zero overhead looping– Modulo addressing– Transparent DMA modes– FFT, Viterbi, and other DSP
operation support– Parallel comparisons
• VLIW-style– Parallel functional units
controlled by VLIW instr.– 8/16/32-bit x 1-4 SIMD INT
• GPU-style– Streaming operations– Floating-point operations
(fp16/fp32 IEEE-compliant)– Texture-Management Unit
and L1 Cache

SHAVE ISA Richness

65nm Myriad SoC
16/64MB SDRAM
Die
16/64 MB
SDRAM
SHAVE Variable-Length Instruction
VRF32x128
SRF32x32
IRF32x32
VAUSAUIAULSU0LSU1IDC
CMU
128-bit AXISHAVE Bus
128kB2-way
L2
Myriad
DDR2Cont.
TMU
1kBcache
SHAVEProcessor
BRU DCUPEU
Decodedinstrs
128kB
1kL1
128kBSRAM
Tile
128kBPer
SHAVE
180MHz
16/64 MB
SDRAM
1.5GB/Sec
180MHz
12.2GB/Sec
17.3GB/Sec
128kB
8.6GB/Sec
1kL1
128kBPer
SHAVE
2.9GB/Sec
5.8GB/Sec5.8GB/Sec
PEU LSU0 LSU1BRU VAU SAU CMUIAU TMU DMA
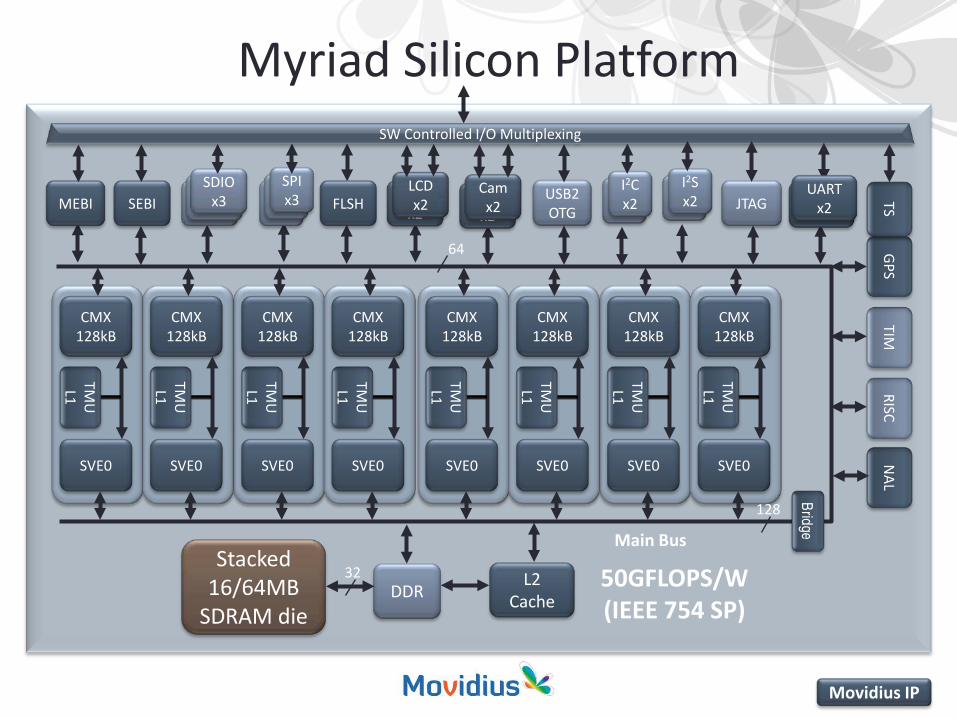
Myriad Silicon Platform
Main Bus
64
50GFLOPS/W(IEEE 754 SP)
Stacked 16/64MB
SDRAM dieDDR
L2 Cache
MEBI
NAL
SEBI SDIOx2
SPIx3
LCD x2
LCD x2 LCD
x2
Camx2
USB2OTG
SDIOx3
SPIx3
SPIx3
SDIOx3
SW Controlled I/O Multiplexing
SPIx3
I2Cx2
SPIx3
I2Sx2
RISC
UARTx2
JTAG
TIMGPS
TSFLSH
Bridge
CMX128kB
SVE0
TMU
L1CMX
128kB
SVE0
TMU
L1
CMX128kB
SVE0
TMU
L1
CMX128kB
SVE0
TMU
L1
CMX128kB
SVE0
TMU
L1
CMX128kB
SVE0
TMU
L1
CMX128kB
SVE0
TMU
L1
CMX128kB
SVE0
TMU
L1
128
32
Movidius IP
UARTx2
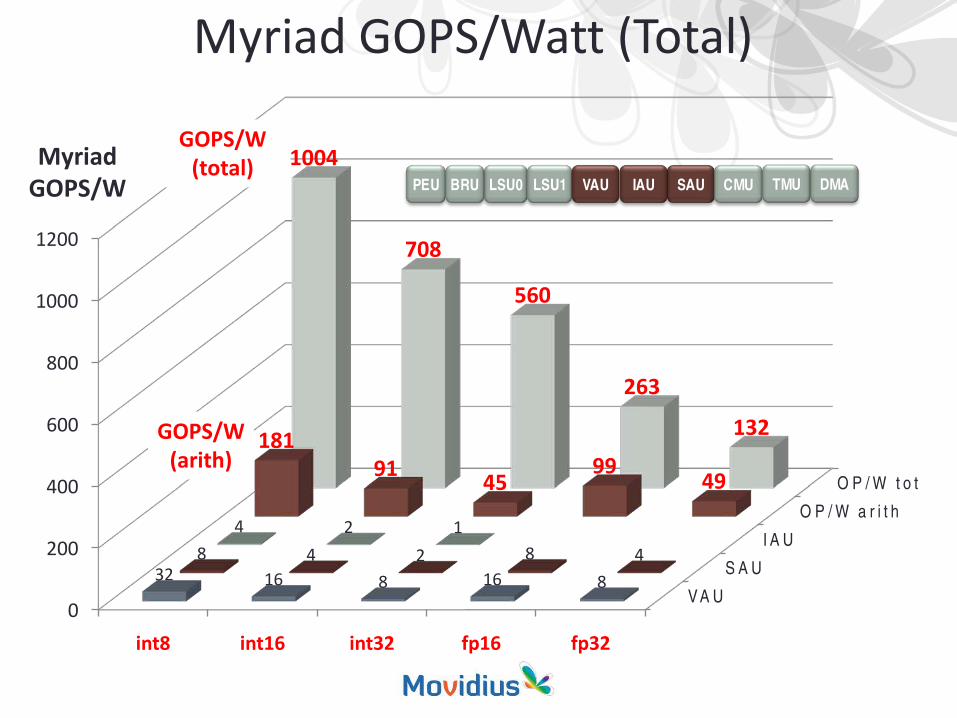
Myriad GOPS/Watt (Total)
VA U
S A U
IA U
O P /W a r i th
O P /W to t
0
200
400
600
800
1000
1200
int8 int16 int32 fp16 fp32
32 16 8 16 88 4 2 8 4
4 2 1
18191 45
99 49
1004
708
560
263
132
MyriadGOPS/W PEU LSU0 LSU1BRU VAU SAU CMUIAU TMU DMA
GOPS/W(total)
GOPS/W(arith)
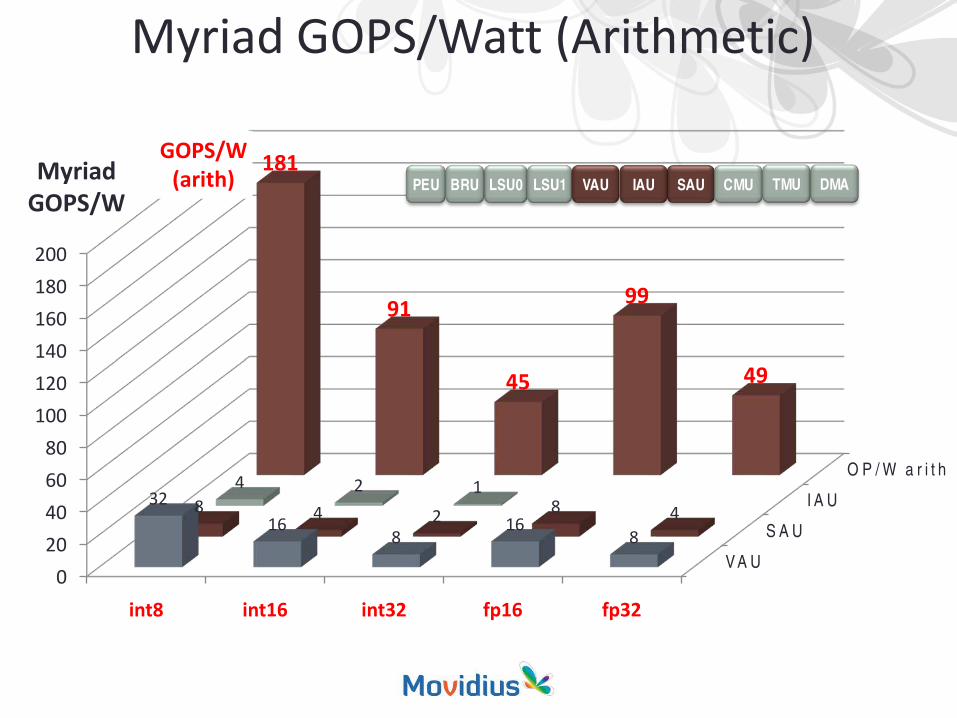
Myriad GOPS/Watt (Arithmetic)
VA U
S A U
IA U
O P /W a r i th
020406080
100120140160180200
int8 int16 int32 fp16 fp32
3216
816
8
8 4 2 8 4
4 2 1
181
91
45
99
49
MyriadGOPS/W
PEU LSU0 LSU1BRU VAU SAU CMUIAU TMU DMA
GOPS/W(arith)
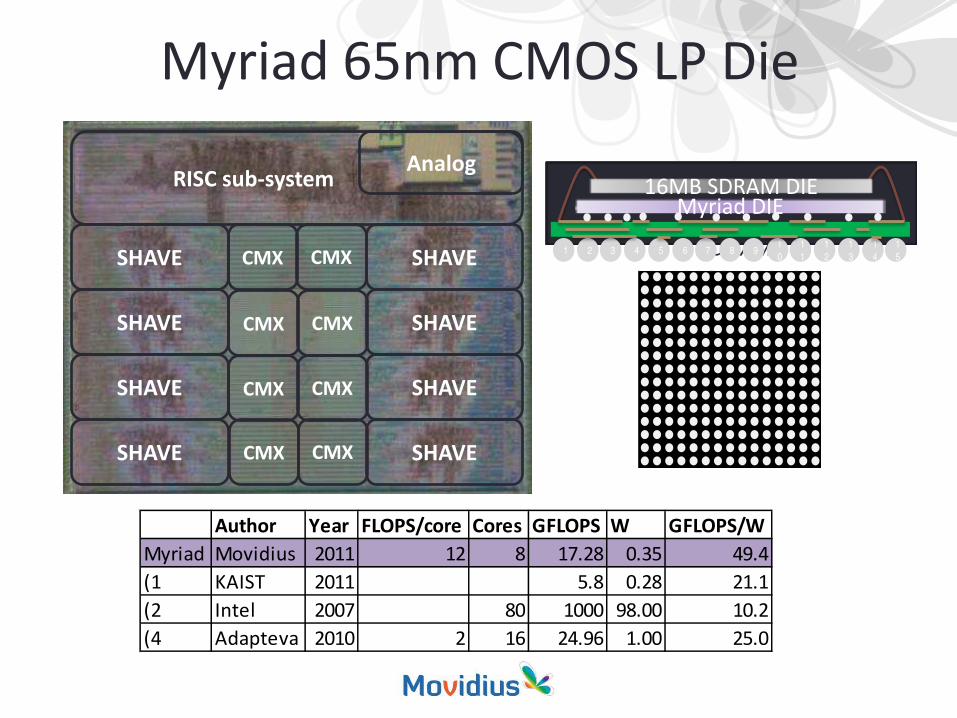
Myriad 65nm CMOS LP Die
SHAVE
SHAVE
SHAVE
SHAVE
SHAVE
SHAVE
SHAVE
SHAVECMX CMX
CMX CMX
CMX CMX
CMX CMX
RISC sub-systemAnalog
Author Year FLOPS/core Cores GFLOPS W GFLOPS/WMyriad Movidius 2011 12 8 17.28 0.35 49.4(1 KAIST 2011 5.8 0.28 21.1(2 Intel 2007 80 1000 98.00 10.2(4 Adapteva 2010 2 16 24.96 1.00 25.0
16MB Stacked SDRAM1 2 3 4 5 6 7 8 9
10
11
12
13
14
15
Myriad DIE16MB SDRAM DIE
A1 A2 A3 A4 A5 A6 A7 A8 A9 A10 A11 A12 A13 A14 A15
A1 A2 A3 A4 A5 A6 A7 A8 A9 A10 A11 A12 A13 A14 A15
A1 A2 A3 A4 A5 A6 A7 A8 A9 A10 A11 A12 A13 A14 A15
A1 A2 A3 A4 A5 A6 A7 A8 A9 A10 A11 A12 A13 A14 A15
A1 A2 A3 A4 A5 A6 A7 A8 A9 A10 A11 A12 A13 A14 A15
A1 A2 A3 A4 A5 A6 A7 A8 A9 A10 A11 A12 A13 A14 A15
A1 A2 A3 A4 A5 A6 A7 A8 A9 A10 A11 A12 A13 A14 A15
A1 A2 A3 A4 A5 A6 A7 A8 A9 A10 A11 A12 A13 A14 A15
A1 A2 A3 A4 A5 A6 A7 A8 A9 A10 A11 A12 A13 A14 A15
A1 A2 A3 A4 A5 A6 A7 A8 A9 A10 A11 A12 A13 A14 A15
A1 A2 A3 A4 A5 A6 A7 A8 A9 A10 A11 A12 A13 A14 A15
A1 A2 A3 A4 A5 A6 A7 A8 A9 A10 A11 A12 A13 A14 A15
A1 A2 A3 A4 A5 A6 A7 A8 A9 A10 A11 A12 A13 A14 A15
A1 A2 A3 A4 A5 A6 A7 A8 A9 A10 A11 A12 A13 A14 A15
A1 A2 A3 A4 A5 A6 A7 A8 A9 A10 A11 A12 A13 A14 A15
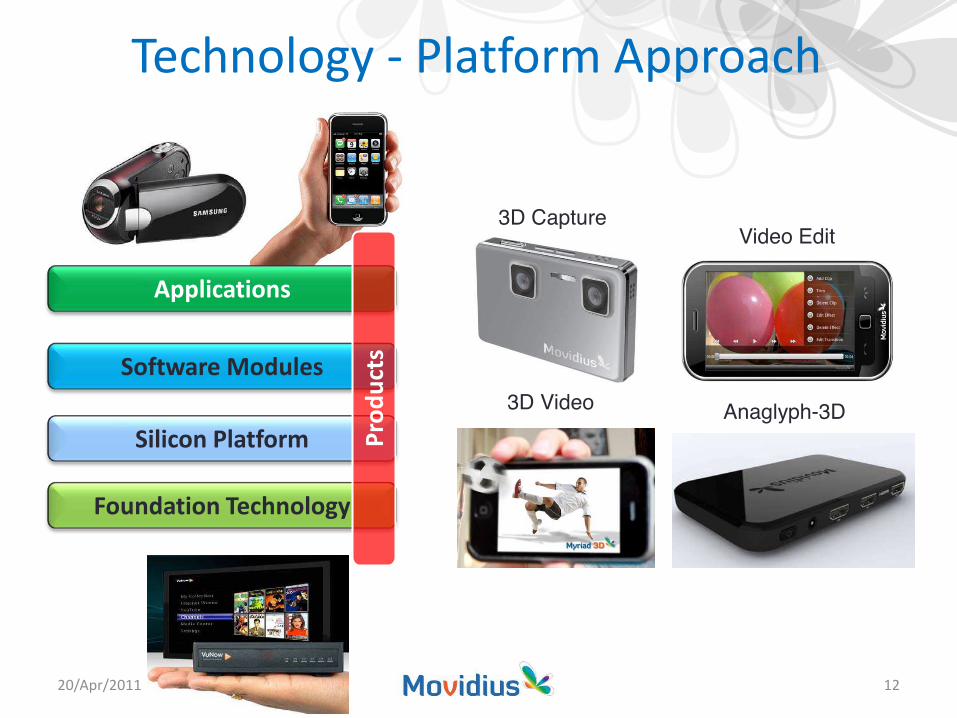
Silicon Platform
Applications
Foundation Technology
Software ModulesPr
oduc
ts
Technology - Platform Approach
20/Apr/2011 12
Video Edit
3D Video
3D Capture
Anaglyph-3D

Myriad Example Applications
20/Apr/2011 13
SHAVE 1 SHAVE 2 SHAVE 3 SHAVE 4 SHAVE 5 SHAVE 6 SHAVE 7 SHAVE 8
SHAVE 1 SHAVE 2 SHAVE 3 SHAVE 4 SHAVE 5 SHAVE 6 SHAVE 7 SHAVE 8
SHAVE 1 SHAVE 2 SHAVE 3 SHAVE 4 SHAVE 5 SHAVE 6 SHAVE 7 SHAVE 8
SHAVE 1 SHAVE 2 SHAVE 3 SHAVE 4 SHAVE 5 SHAVE 6 SHAVE 7 SHAVE 8
SHAVE 1 SHAVE 2 SHAVE 3 SHAVE 4 SHAVE 5 SHAVE 6 SHAVE 7 SHAVE 8
SHAVE 1 SHAVE 2 SHAVE 3 SHAVE 4 SHAVE 5 SHAVE 6 SHAVE 7 SHAVE 8
SHAVE 1 SHAVE 2 SHAVE 3 SHAVE 4 SHAVE 5 SHAVE 6 SHAVE 7 SHAVE 8

MoviSim ISS ArchitectureRuntime
OpenCL
Task
Allo
cato
r
Mem
ory
Allo
cato
r
SABRE Debugger
MoviSimM
essa
ging
Inst
rum
enta
tion
Thre
ad 0
SHAV
E IS
S
Thre
ad 1
SHAV
E IS
S
SHAV
E IS
S
Thre
ad n
-1LE
ON
/ARM
ISS
Mod
el A
PIHe
tero
gene
ous
Core
ISS
Thre
ad m
-1DR
AM
Thre
ad m
Sim
ulat
ion
Engi
ne
XML
Pars
erXM
L Ar
chite
ctur
e De
scrip
tion

Fragrak 28nm Platform
Main Bus
64
450GFLOPS/W(IEEE 754 SP)
Stacked 256/512MBSDRAM die
DDR3 LP
L2 512kB
MEBI
NAL
SEBI SDIOx2
SPIx3
LCD x2
MIPIDSI 2x
LCD x2
MIPI CSI 2x
USB2OTG
SDIOx3
SPIx3
SPIx3
SDIOx3
SW Controlled I/O Multiplexing
SPIx3
I2Cx2
SPIx3
I2Sx2
RISC
UARTx2
JTAG
TIMGPS
TSFLSH
Bridge
12864
Movidius IP
UARTx2
15
ICB
CMX128kBSHAVE
0
CMX128kBSHAVE
1
CMX128kBSHAVE
0
CMX256kBSHAVE
04
ICB
CMX128kBSHAVE
0
CMX128kBSHAVE
1
CMX128kBSHAVE
0
CMX256kBSHAVE
08
ICB
CMX128kBSHAVE
0
CMX128kBSHAVE
1
CMX128kBSHAVE
0
CMX256kBSHAVE
12
ICB
CMX128kBSHAVE
0
CMX128kBSHAVE
1
CMX128kBSHAVE
0
CMX256kBSHAVE
16
XCB

Any questions?
The research leading to these results has received funding from the European Union Seventh Framework Programme (FP7/2007-2013) under grant agreement n°248481 (PEPPHER Project, www.peppher.eu)

Abstract• The rationale and architecture behind a new software programmable
multimedia coprocessor for mobile devices is outlined.• The focus of the architecture is on power-efficient operation, allowing
functions which are traditionally implemented in fixed-function hardware to be implemented competitively in software.
• For instance the sustained single-precision IEEE 754 rate is 50GFLOPS/W allowing existing applications to be ported with great ease. The device supports 8, 16, 32 and some 64-bit integer operations as well as fp16 (OpenEXR) and fp32 arithmetic and is capable of an aggregate 1 TOPS/W maximum 8-bit equivalent operations in a low-cost plastic BGA package with integrated 16 or 64MB SDRAM.
• New architectural features such as support for random-accessible sparse data-structures are implemented for the first time improving memory utilization and bandwidth efficiency. Power efficiency is paramount and the device contains a total of 11 power-islands with 8 dedicated to each of the integrated SHAVE processors, allowing very fine-grained power control.
• Comparisons to previous work based on 65nm silicon and applications are shown to illustrate the power of the device.

Myriad GOPS/Watt (Total/Arithmetic)
P E U
L S U 0
VA U
I AU
D M A
R I S C
O P/ W t o t
0
200
400
600
800
1000
1200
int8 int16 int32 fp16 fp32
16 16 167 7 7
11 7 5
32 16 8 16 88 4 2 8 4
4 2 1
80 40 20 40 20
48 48 4824 22 21
18191 45 99 49
1004
708560
263132
MyriadGOPS/W
GOPS/W (total)
GOPS/W (arith)
PEU LSU0 LSU1BRU VAU SAU CMUIAU TMU DMA
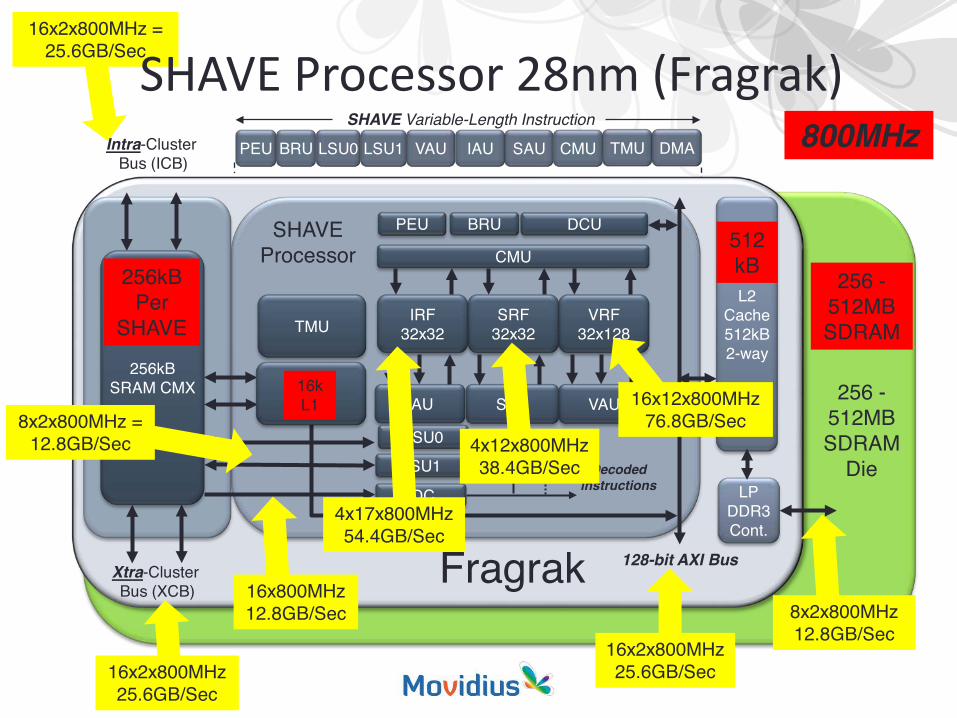
16x2x800MHz = 25.6GB/Sec
SHAVE Variable-Length Instruction
VRF32x128
SRF32x32
IRF32x32
VAUSAUIAU
LSU0
LSU1
IDC
CMU
128-bit AXI BusXtra-Cluster Bus (XCB)
L2Cache512kB2-way
Fragrak
LPDDR3Cont.
TMU
1kBcache
SHAVEProcessor
BRU DCUPEU
Decodedinstructions
256 -512MB SDRAM
Die
SHAVE Processor 28nm (Fragrak)
16x12x800MHz 76.8GB/Sec
16x2x800MHz 25.6GB/Sec
8x2x800MHz 12.8GB/Sec
16x2x800MHz 25.6GB/Sec
800MHzIntra-Cluster Bus (ICB)
512kB
256 -512MB SDRAM
4x12x800MHz 38.4GB/Sec
16k L1
16x800MHz 12.8GB/Sec
256kBSRAM CMX
256kBPer
SHAVE
8x2x800MHz = 12.8GB/Sec
4x17x800MHz 54.4GB/Sec
PEU LSU0 LSU1BRU VAU SAU CMUIAU TMU DMA
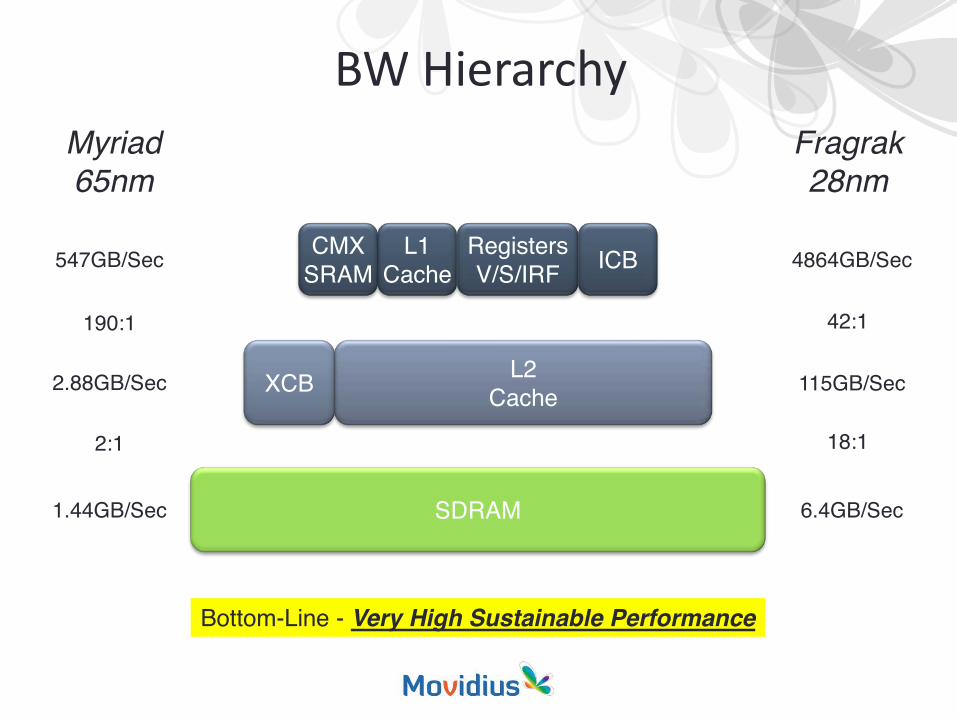
BW Hierarchy
SDRAM 6.4GB/Sec1.44GB/Sec
2.88GB/Sec 115GB/Sec
4864GB/Sec547GB/Sec
Bottom-Line - Very High Sustainable Performance
Myriad65nm
Fragrak28nm
L1Cache
RegistersV/S/IRF
CMXSRAM ICB
L2CacheXCB
190:1
2:1
42:1
18:1
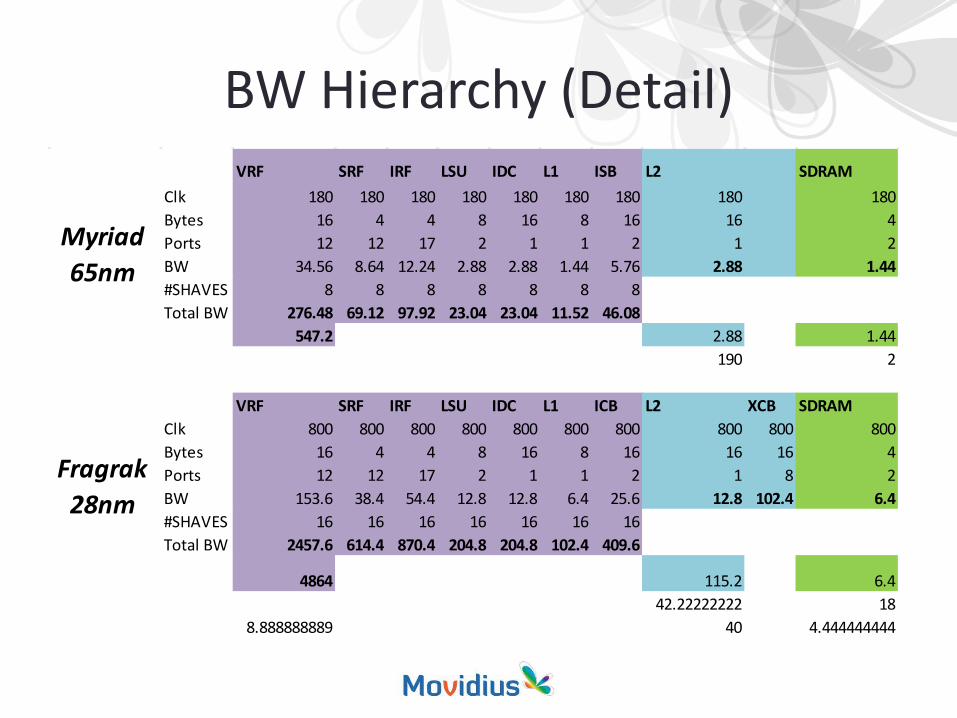
BW Hierarchy (Detail)VRF SRF IRF LSU IDC L1 ISB L2 SDRAM
Clk 180 180 180 180 180 180 180 180 180Bytes 16 4 4 8 16 8 16 16 4Ports 12 12 17 2 1 1 2 1 2BW 34.56 8.64 12.24 2.88 2.88 1.44 5.76 2.88 1.44#SHAVES 8 8 8 8 8 8 8Total BW 276.48 69.12 97.92 23.04 23.04 11.52 46.08
547.2 2.88 1.44190 2
VRF SRF IRF LSU IDC L1 ICB L2 XCB SDRAMClk 800 800 800 800 800 800 800 800 800 800Bytes 16 4 4 8 16 8 16 16 16 4Ports 12 12 17 2 1 1 2 1 8 2BW 153.6 38.4 54.4 12.8 12.8 6.4 25.6 12.8 102.4 6.4#SHAVES 16 16 16 16 16 16 16Total BW 2457.6 614.4 870.4 204.8 204.8 102.4 409.6
4864 115.2 6.442.22222222 18
8.888888889 40 4.444444444
Myriad 65nm
Fragrak 28nm

bitmap31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0 field 0 0 0 0
0 1 0 0 41 0 0 4
1 1 0 0 41 0 0 0 8
2 1 0 0 41 1 0 0 12
3 1 0 0 41 0 0 0 0 16
4 1 0 0 41 0 1 0 0 20
5 1 0 0 41 1 0 0 0 24
6 1 0 0 41 1 1 0 0 28
7 1 0 0 41 0 0 0 0 0 32
IRF[base_addr]
IRF bm0bm7 bm6 bm5 bm4 bm3 bm2 bm1
6
�
f[0]
�
6
�
f[1]
�
6
�
f[2]
�
6
�
f[3]
�
6
�
f[4]
�
6
�
f[5]
�
6
�
f[6]
�
6
�
f[7]
�
000001010
�addr[1:0]
011100101110111
0
0
word_cnt
44444444
33333333
66666666
32
6 6 6 6 6 6 6
addr_gen
bru_hold
1
RAM_wr
1
RAM_rd
1
pw_config
instr_f[7:0]
fen[2:0]
�
RAM_addr[31:0]
32
6
f[7:0]
LSU HW Sparse-Data Support

Sparse Data-Structure Examplebitmap description data address
0 1 sx sx sy base+0
1 0 0.0 sz 1.0 base+2
2 0 0.0 x0 x1 base+4
3 0 0.0 x2 x3 base+6
4 0 0.0 y0 y1 base+8
5 1 sy y2 y3 base+10
6 0 0.0 z0 z1 base+12
7 0 0.0 z2 z3 base+14
8 0 0.0 addr bmp base+16
9 0 0.0
10 1 sz
11 0 0.0
12 0 0.0
13 0 0.0
14 0 0.0
15 1 1.0
16 1 x0
17 1 x1
18 1 x2
19 1 x3
20 1 y0
21 1 y1
22 1 y2
23 1 y3
24 1 z0
25 1 z1
26 1 z2
27 1 z3
28 1 pointer to next str. addr
29 1 next str. Bitmap bmp
30 0 0
31 0 0
4-element vector
64-bit RAM word
4x4 scaling matrix
4-element vector
4-element vector

References1) H-E. Kim, J-S. Yoon, K-D. Hwang, Y-J. Kim, J-S. Park, L-S.
Kim, "A 275mw heterogeneous Multimedia processor for ic-Stacking on Si-interposer" Proc. ISSCC 2011
2) S.Vangal, J.Howard, G.Ruhl, S.Dighe, H.Wilson, J.Tschanz, D.Finan, P.Iyer,A. Singh, T.Jacob, S.Jain, S.Venkataraman, Y.Hoskote and N.Borkar, "An 80-Tile 1.28TFLOPS Network-on-Chip in 65nm CMOS", Proc. ISSCC 2007, pp.5-7
3) A. Olofsson, R. Trogan, O. Raikhman, ”A 25 GFLOPS/Watt Software Programmable Floating Point Accelerator”, HPEC 2010, 15-16 Sep 2010
4) C.Y. Park, N.I. Cho, "A fast algorithm for the conversion of DCT coefficients to H.264 transform coefficients", ICIP 2005 Proceedings, pp.664-7
20/Apr/2011 24