2010 ieee world congress on computational · pdf [email protected] ijcnn 2010 program ......
TRANSCRIPT


2010 IEEE WORLD CONGRESS ON COMPUTATIONAL INTELLIGENCE
IJCNN 2010 Program Committee
IJCNN 2010 Conference Chair
Alberto PrietoUniversity of Granada, [email protected]
IJCNN 2010 Program Chair
Vincenzo PiuriUniversity of Milan, [email protected]
IJCNN 2010 Conference CoChairs
Ian CloeteInternational University in Germany, Germanyian.cloete@iu.de
Leonid PerlovskyUnited States Air Force Research Lab., [email protected]
Jose C. PrincipeUniversity of Florida, [email protected]
Danil ProkhorovToyota Research Institute NA, [email protected]
Shiro UsuiRIKEN Brain Science Int, [email protected]
IJCNN 2010 Program Committee

2010 IEEE WORLD CONGRESS ON COMPUTATIONAL INTELLIGENCE
Michel VerleysenUniversité Catholique de Louvain, [email protected]
Lipo WangNanyang Technological University, [email protected]
IJCNN 2010 List of Reviewers
IJCNN 2010 Program Committee

IndexA 5-Chunk Developmental Brain-Mind Network Model for Multiple Events inComplex Backgrounds (N-0741)Juyang Weng . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
A Bayesian Framework for Active Learning (N-0250)Richard Fredlund, Richard Everson and Jonathan Fieldsend . . . . . . . . . . . . . . . . 9
A Bidirectional Associative Memory Based on Cortical Spiking Neurons UsingTemporal Coding (N-0474)Masood Zamani, Alireza Sadeghian and Sylvain Chartier . . . . . . . . . . . . . . . . . . 17
A Biologically Inspired Associative Memory for Artificial Olfaction (N-0620)Miquel Tarzan-Lorente, Agustin Gutierrez-Galvez, Dominique Martinez and San-tiago Marco Colas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
A Classifier with Clustered Sub Classes for the Classification of Suspicious Ar-eas in Digital Mammograms (N-0287)Peter Mc Leod and Brijesh Verma . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
A Clustering Ensemble Method for Clustering Mixed Data (N-0136)Jamil Al Shaqsi and Wang Wenjia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
A Cognitive Developmental Robotics Architecture for Lifelong Learning by Evo-lution in Real Robots (N-0616)Francisco Bellas, Andres Faina, Gervasio Varela and Richard Duro . . . . . . . . 47
A Columnar Primary Visual Cortex (V1) Model Emulation Using a PS3 Cell-BEArray (N-0035)Michael Moore, Morgan Bishop, Robinson Pino and Richard Linderman . . . .55
A Comparative Study of Machine Learning Techniques in Blog Comments SpamFiltering (N-0824)Christian Romero, Mario Garcia and Arnulfo Alanis . . . . . . . . . . . . . . . . . . . . . . . . 63
A Comparative Study of Urban Traffic Signal Control with Reinforcement Learn-ing and Adaptive Dynamic Programming (N-0324)Yujie Dai, Dongbin Zhao and Jianqiang Yi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
A Competitive Network for Multi-object Selection (N-0606)Drazen Domijan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
A Complexity Based Silent Pruning Algorithm (N-0385)Sultan Udiin Ahmed, Fazle Elahi Khan, Md. Shahjahan and Kazuyuki Murase83
A Component Based Approach Improves Classification of Discrete Facial Ex-pressions Over a Holistic Approach (N-0530)
1

Change Detection Tests Using the ICI rule (N-0525)Cesare Alippi, Giacomo Boracchi and Manuel Roveri . . . . . . . . . . . . . . . . . . . . 1190
Chaotic Behavior in Probabilistic Cellular Neural (N-0852)Robert Kozma and Marko Puljic . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1197
Choice of Initial Bias in Max-min Fuzzy Neural Networks (N-0115)Jie Yang, Long Li, Yan Liu, Jing Wang and Wei Wu . . . . . . . . . . . . . . . . . . . . . . 1204
Classification of LIBS Protein Spectra using Support Vector Machines andAdaptive Local Hyperplanes (N-0487)Tia Vance, Natasa Reljin, Aleksandar Lazarevic, Dragoljub Pokrajac and Vo-jislav Kecman . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1207
Classification of Micro-array Gene Expression Data using Neural Networks (N-0584)David Tian and Keith Burley . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1214
Classification of Musical Styles Using Liquid State Machines (N-0327)Han Ju, Jianxin Xu and Antonius M.J. VanDongen . . . . . . . . . . . . . . . . . . . . . . .1222
Classifying Means of Transportation Using Mobile Sensor Data (N-0346)Theresa Nick, Edmund Coersmeier, Jan Geldmacher and Juergen Goetze1229
Classifying Motor Imagery in Presence of Speech (N-0429)Hayrettin Gurkok, Mannes Poel and Job Zwiers . . . . . . . . . . . . . . . . . . . . . . . . . 1235
Clustering using SOFM and Genetic Algorithm (N-0105)Jose Carlos Palomares, Agustin Aguera, Juan Jose Gonzalez and Jose GabrielRamiro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1243
Cohort-based Kernel Visualisation with Scatter Matrices (N-0825)Enrique Romero, Ana Sofia Fernandes, Tingting Mu and Paulo Lisboa . . .1249
Collaborative Pedestrian Tracking with Multiple Cameras: Data Fusion and Vi-sualization (N-0227)Daw-Tung Lin and Kai-Yung Huang . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1257
Combination of Supervised and Unsupervised Algorithms for CommunicationSystems with Linear Precoding (N-0037)Adriana Dapena, Paula M. Castro and Josmary Labrador . . . . . . . . . . . . . . . 1265
Combining Probabilistic Neural Networks and Decision Trees for Maximally Ac-curate and Efficient Accident Prediction (N-0164)Tatiana Tambouratzis, Dora Souliou, Miltiadis Chalikias and Andreas Gregori-ades . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1273
Commutative Quaternion and Multistate Hopfield Neural Networks (N-0737)Teijiro Isokawa, Haruhiko Nishimura and Nobuyuki Matsui . . . . . . . . . . . . . . . 1281
14

Authors Index
A
Abdul, Satti 3347Abdullah, Siti Norbaiti 2621Abe, Shigeo 1426, 1967Abou-Nasr, Mahmoud 3890Abouzar, Taherkhani 3551Abraham, Jacob 0800Adams, Rod 3332Adankon, Mathias 3678Adeodato, Paulo 3325Afshar, Ahmad 3307Agelidis, Vassilios 1772Aghaei, Amirhossein S. 3788Agostini, Alejandro 3485Aguera, Agustin 0971, 1243Aguilar, Luis T. 0506Ahmad Hijazi, Mohd Hanafi 3501Ahmed, Sultan Udiin 0083, 2629Aihara, K. 3412Aizenberg, Igor 2577Akbarzadeh, Mohammad Reza 2452Aksenova, Tetiana 0628Al Shaqsi, Jamil 0039Al-Qunaieer, Fares 3183Alahakoon, Damminda 2381Alanis, Arnulfo 0063Albo-Canals, Jordi 3514Aleo, Ignazio 2397, 3605Alexander, Shane 2577Ali, A B M Shawkat 1999Ali, Shawkat 3598Alimi, Adel M. 1953, 3190Alippi, Cesare 1190, 4206Allen, Gabrielle 4112Allen, William 3355
1

Cardenas-Maciel, Selene L. 0506Carmona, Cristobal Jose 0349Carrillo Sanchez, Richard Rafael 1182Carroll-Mayer, Moira 1822Carvalho, Andre C.P.L.F. 0098Carvalho, Andre Carlos P. L. F. 3064Carvalho das Neves, Joao 1986Carvalho Jr, Manoel 3439Casey, Matthew 3722Castaneda, Carlos 1615Castillo, Oscar 0288, 0506, 1623, 2238, 2969, 3212Castro, Felix 2077Castro, Juan R. 0506Castro, Paula M. 1265Castro-Bleda, M.J. 4136Caudill, Matthew 2577Cavalcanti, George D. C. 0316, 0744, 0864, 2345Cawley, Gavin 1531Cecchi, Guillermo 2472Celaya, Enric 3485Cerda, Joaquin 4219Cernadas, E. 0341, 1940Cerri, Ricardo 3064Chairez, Isaac 1638, 2706Chakraborty, Basabi 2225Chakraborty, Goutam 0800, 2225Chakravarthy, Srinivasa 0484, 3847Chalasani, Rakesh 3622Chalavadi, Krishna Mohan 1743Chalikias, Miltiadis 1273Chalup, Stephan 0090Chandana, Sandeep 1338Chang, Chuan-Yu 1068, 3277Chang, Fang-Jung 1392Chang, Oscar 0420Chang, Rui 3107Chang, Wan-Lin 1725Chang, Wen-Lung 0259Chang, Won-Du 0124Changuel, Sahar 1039Chartier, Sylvain 0017, 3478
6

D
D’ Amico, Arnaldo 0991, 3900d’Avila Garcez, Artur 3754Dai, Bo 3005Dai, Jing 1696Dai, Yujie 0070Dambre, Joni 2669Damialis, Athanasios 2023Damien, Coyle 3347Dancey, Darren 3590Daniel, Burns 0636Danilo, Mandic 4083Dapena, Adriana 1265Darneva, Tamara 3058Dashti, Hesam 2700Davey, Neil 3332, 3763David, Looney 4083Davies, Sergio 0649, 2302de A. Araujo, Ricardo 0392, 0807De Baets, Bernard 1413De Coensel, Bert 1413De La Cruz, Irving 1623De Moor, Bart 3291De Silva, Daswin 2381De Vito, Saverio 0991Decherchi, Sergio 0252Defoin-Platel, Michael 0933Del Giudice, Paolo 3657del Jesus, Maria Jose 0349Del-Moral-Hernandez, Emilio 3860Delcea, Camelia 0203Demmler, Joanne 3867Deng, Wanyu 3375Deng, Xin 1119Depeursinge, Adrien 1010Desai, Sachi 2857Dhahri, Habib 3190di Bernardo, Diego 2100Di Francia, Girolamo 0991
9

Ksouri, Mekki 3557Kuh, Anthony 2692Kuhn, Andreas 0160Kumar, Mrinal 2805Kunita, Daichi 0114Kuo, Bor-Chen 0714, 1671Kuo, Che-Cheng 3341Kuo, T. C. 2072Kuo, Yau-Hwang 1780, 2901Kuroe, Yasuaki 2561Kursun, Olcay 3803Kussul, Ernst 2929, 2955Kwok, James 2639
L
Labiod, Lazhar 3493Labrador, Josmary 1265Labroche, Nicolas 1039Lacassie, Juan 0955Lai, Hsiang-Wei 3563Lai, Pei-Chen 0714, 1671Lampton, Amanda 2805Lang, Elmar 1142, 1792, 3577, 3730Lange, Sascha 1509Lazarevic, Aleksandar 1207Lazzerini, Beatrice 3582Le, Trung 0909Lebbah, Mustapha 4043Lechon, Miguel 3982Lee, Hong 3233Lee, Jie Qi 0977Lee, John A. 4163Lee, John Aldo 1599Lee, Kerry 0977Lee, Minho 2084, 4035Lee, Tong Heng 1719Leeson, Mark 1709
20

Combination of Supervised and Unsupervised Algorithms forCommunication Systems with Linear Precoding
Adriana Dapena,Senior Member, IEEE, Paula M. Castro,Member, IEEEand Josmary Labrador,Student Member, IEEE
Abstract—It is well–known that precoding is an attractiveway to remove interferences because it reduces cost and powerconsumption in the receive equipment. When implementingprecoding, however, the base station should know theChannelState Information (CSI) which is normally acquired at the receiverside by using pilot symbols. InFrequency Division Duplex (FDD)systems, this information is sent by means of a feedback channel.In order to reduce the overhead inherent to the periodicaltransmission of training data, we propose to obtain the CSI bymeans of combining supervised and unsupervised algorithms.The simulation results show that the performance achieved withthe proposed scheme is clearly better than that with standardalgorithms.
I. I NTRODUCTION
Current transmission standards forMultiple-Input/Multiple-Output (MIMO) systems include precoders in order to guaran-tee that the link throughput is maximized [1], [2]. Precodingalgorithms for MIMO can be sub-divided into linear andnonlinear precoding types. In this work, we will considerLinear Precoding (LP) approaches because they achieve rea-sonable throughput performance with lower complexity thannonlinear precoding approaches. Different LP schemes canbe obtained by means of a joint optimization of the receiveand transmit filters [3]–[5]. Therefore, the design of thesesystems is already known for the ideal case where CSI at thetransmitter is perfectly known. We resort to aMean SquareError (MSE) criterion together with this precoding schemedue to its superiority over other criteria [2], [6]–[9].
Most work on precoding with imperfect CSI has mainlyfocused onTime Division Duplex (TDD) systems. Contrarily,in this work we focus on the more extended case of FDDsystems where the transmitter cannot obtain the CSI fromthe received signals, even under the assumption of perfectcalibration, because the channels are not reciprocal [10].Instead, the receiver estimates the channel and sends the CSIback to the transmitter by means of a feedback channel. Incurrent standards, the channel estimation is performed byusing supervised algorithms which periodically send pilotsymbols from the transmitter to the receiver. However, theinclusion of pilot symbols reduces the system throughput(or equivalently, it reduces the system spectral efficiency)and wastes transmission energy because pilot sequences donot convey information. For this reason, we will investigatethe performance of unsupervised algorithms which allow to
The authors are with the Department of Electronics and Systems, Universityof A Coruna, Campus de Elvina s/n, 15071 A Coruna, Spain (phone: +34 981167000; email:{adriana,pcastro,jlabrador}@udc.es).
recover the uncoded signals (sources) from the received signals(observations) assuming that the sources and the channelare completely unknown. This lack of prior knowledge maylimit the achievable performance, but makes unsupervised ap-proaches more robust against calibration errors (i.e. deviationsof the model assumptions from real ones) than conventionalarray processing techniques [11].
The combination of different types of unsupervised andsupervised algorithms have been recently used for severalapplications like image classification [12] or beamforming[13]. We also recommend the overview of semi-blind ap-proaches presented recently in [14]. However, the developmentof combined methods is an open issue for many commu-nication applications, as in the case of precoded systems.Along this work, we develop a new combined approach forFDD-LP systems based on well–known methods forBlindSource Separation (BSS) [15] which only require mutuallyindependent and non–gaussian sources. As shown in the finalcomputer simulations, the proposed scheme leads to goodperformances in terms ofBit Error Rate (BER). These resultslet us to state that this new scheme could be used in recentcommunications standards which implement linear precoding,although such standards are highly sensitive to errors in theCSI available at the transmitter, with the enormous advantageof avoiding periodical training data and thus reducing theoverhead of the real system.
This work is organized as follows. Sections II describes thesignal and channel models, and in Section III the linear pre-coding design is developed. Section IV presents our proposedalgorithms for combined supervised and unsupervised channelestimation and detection. Illustrative computer simulations arepresented in Section VI, and some concluding remarks aremade in Section VII.
All derivations are based on the assumption of zero–meanand stationary random variables. Vectors and matrices are de-noted by lower case bold and capital bold letters, respectively.We useE[•], tr(•), (•)∗, (•)T, (•)H, det(•), adj(•), and‖•‖2, for expectation, trace of a matrix, complex conjugation,transposition, conjugate transposition, determinant of a matrix,adjunct matrix, and Euclidean norm, respectively. Thei-thelement of a vectorx is xi.
II. SYSTEM MODEL
We consider a MIMO system withNt transmit antennasand Nr receive antennas, as plotted in Figure 1. The pre-coder generates the transmit signalx from all data symbols
WCCI 2010 IEEE World Congress on Computational Intelligence July, 18-23, 2010 - CCIB, Barcelona, Spain IJCNN
978-1-4244-8126-2/10/$26.00 c©2010 IEEE 1265

......Precoder Receiver
n1
u2
h1,1
u1 x1 y1
uNr xNt hNrNt
nNr
u1
uNryNr
Fig. 1. System with Precoding over Flat MIMO Channel.
u = [u1, . . . , uNr ] belonging to the different receive antennas1, . . . , Nr. We denote the equivalent lowpass channel impulseresponse at timet to an impulse at timet− τ between thej–th transmit antenna and thei–th receive antenna ashi,j(τ, t),whereτ is the variable of delay [16], [17]. Thus, the randomlytime-varying channel is characterized by theNr × Nt matrixH(τ, t) defined as
H(τ, t) =
h1,1(τ, t) h1,2(τ, t) · · · h1,Nt(τ, t)h2,1(τ, t) h2,2(τ, t) · · · h2,Nt(τ, t)
......
. . ....
hNr,1(τ, t) hNr,2(τ, t) · · · hNr,Nt(τ, t)
.
Suppose that the transmitted signal from thei–th transmitantenna isxi(t). Then, the receive signal at thej–th receiveantenna is given by
yj(t) =Nt∑
i=1
hj,i(τ, t) ∗ xi(t) + ηj(t)
where ηj(t) is the additive noise. In matrix notation, thisequation can be rewritten as
y(t) = H(τ, t) ∗ x(t) + η(t)
where x(t) = [x1(t), . . . , xNt(t)]T ∈ CNt , y(t) =[y1(t), . . . , yNr(t)]T ∈ CNr , andη(t) = [η1(t), . . . , ηNr(t)]T ∈CNr . For flat fading channels, the channel matrixH(τ, t) istransformed into the matrixH(t) given by
H(t) =
h1,1(t) h1,2(t) · · · h1,Nt(t)h2,1(t) h2,2(t) · · · h2,Nt(t)
......
. . ....
hNr,1(t) hNr,2(t) · · · hNr,Nt(t)
(1)
and the received signal is now
yj(t) =Nt∑
i=1
hji(t)xi(t) + ηj(t)
which can be expressed in matrix form as
y(t) = H(t)x(t) + η(t). (2)
In general, if we letf [n] = f(nTs + ∆) denote samples off(t) everyTs seconds with∆ being the sampling delay andTs
the symbol time, then samplingy(t) everyTs seconds yieldsthe discrete time signaly[n] = y(nTs + ∆) given by
y[n] = H [q]x[n] + η[n] (3)
wheren = 0, 1, 2, . . . corresponds to samples spaced withTs
and q denotes the slot time. The channel remains unchangedduring a block ofNB symbols, i.e, over the data frame. Notethat this discrete time model is equivalent to the continuoustime model in Equation (2) only ifInterSymbol Interference(ISI) between samples is avoided, i.e. if the Nyquist criterionis satisfied. In that case, we will be able to reconstruct theoriginal continuous signal from the samples by means ofinterpolation. This channel model is known as time-varyingflat block fading channel and this assumption is made alongthis work.
For brevity, we omit the slot indexq in the sequel.
III. L INEAR PRECODING DESIGN
The equalization task can be performed at the transmitter,so the channel is pre-equalized or precoded before trans-mission with the goal of simplifying the user requirements.Such operation prior to transmission is only possible for acentralized transmitter, as in the downlink of a cellular system,for example. In this section, we assume that the receivefilter is an identity matrix (multiplied by a scalarg, withg ∈ C) allowing for decentralized receivers. The goal is tofind the optimum transmit filterF . Therefore, the transmitand receive filters are given by the matricesF ∈ CNt×Nr andG = gI ∈ CNr×Nr , respectively. In other words, the numberof scalar data streams isNr. The resulting communicationssystem is shown in Figure 2. It can be seen from the figurehow the data symbolsu[n] are passed through the transmitfilter F to form the transmit signalx[n] = Fu[n] ∈ CNt . Notethat the constraint for the transmit energy must be fulfilled, i.e.
E[‖x[n]‖2
2
]= tr
(FCuF H
) ≤ Etx
whereCu = E[u[n]uH[n]] denotes the covariance of the datasymbols andEtx is the transmit energy. The received signal isgiven by
y[n] = HFu[n] + η[n] ∈ CNr
1266

u[n] x[n]
η[n]
F H gIu[n] Q(•) u[n]
Fig. 2. MIMO System with Linear Transmit Filter (Linear Precoding).
whereH ∈ CNr×Nt (see Equation (1)), andη[n] ∈ CNr is theAdditive White Gaussian Noise (AWGN), whose covariancematrix is given byCη = E[η[n]ηH[n]].
After multiplying by the receive gaing, we get the estimatedsymbols
u[n] = gHFu[n] + gη[n] ∈ CNr . (4)
Clearly, the restriction that all the receivers apply the samescalar weightg is not necessary for decentralized receivers.ReplacingG by a diagonal matrix suffices (e.g. [18]). How-ever, usually no closed form can be obtained for the precoderif G is diagonal with different diagonal elements. Fortunately,F can be found in closed form forG = gI. Thus, we useG = gI in the sequel.
Although Wiener filtering for precoding has been dealt withby only a few authors [8] compared to other criteria forprecoding, it is a very powerful transmit optimization thatminimizes the MSE with a transmit energy constraint [2], [6],[7], [9], [19], i.e.
{FWF, gWF} = argmin{F ,g}
E[‖u[n]− u[n]‖2
2
]s.t.: tr(FCuF H) ≤ Etx. (5)
Thus, we form the following Lagrangian function
L (F , g, λ) = tr (Cu)− tr(g∗CuF HHH
)− tr (gHFCu)
+ |g|2 tr(HFCuF HHH
)+ |g|2 tr (Cη)
+ λ(tr(FCuF H
)− Etx).
Setting the derivatives with respect toF and g to zero, andtaking into account that the MSE in Equation (5) is notconvex, we obtain the necessaryKarush-Kuhn-Tucker (KKT)conditions [20]–[23]:
∂L (•)∂F ∗ = −g∗HHCu + |g|2 HHHFCu + λFCu = 0
∂L (•)∂g
= − tr (HFCu) + g∗ tr(HFCuF HHH
)+ g∗ tr (Cη) = 0
tr(FCuF H
) ≤ Etx
λ(tr(FCuF H
)− Etx)
= 0 with λ ≥ 0. (6)
The gaing∗ obtained from the second equation is given by
g∗ =tr (HFCu)
tr (HFCuF HHH + Cη). (7)
Multiplying the first KKT condition byF H from the right andapplying the trace operator, we get
g∗ tr(HHCuF H
)− |g|2 tr(HFCuF HHH
)= λ tr
(FCuF H
).
And now, combining this result with the expression forg∗ inEquation (7) yields
λ tr(FCuF H
)= |g|2 tr (Cη) (8)
where tr∗(HFCu) = tr(HHCuF H) has been applied.From the above result,λ = |g|2 tr(Cη)
tr(F CuF H) > 0 if the trivialsolution F = 0 is not allowed. Therefore, the transmitenergy constraint is an equality, i.e.tr(FCuF H) = Etx,and consequentlyλ = |g|2 ξ, where, for brevity, we haveintroduced the notation to be used in the sequel
ξ =tr (Cη)
Etx. (9)
If we plug this result forλ into the first KKT condition, weget
F =1g
(HHH + ξI
)−1HH. (10)
By considering the transmit energy constrainttr(FCuF H) =Etx and the above expression forF , it is obtained that
|g|2 =tr((
HHH + ξI)−2
HHCuH)
Etx
which leads to a unique solution if we restrictg to beingpositive real. Then, if we considerg ∈ R+, the solution forthe Wiener filter is given by
FWF = g−1WF
(HHH + ξI
)−1HH
gWF =
√√√√ tr((HHH + ξI)−2
HHCuH)
Etx.
(11)
IV. A DAPTIVE ALGORITHMS
The model explained in Section II states that the obser-vations are linear and instantaneous mixtures of the transmitsignalsx[n] of Equation (3), i.e.
y[n] = Hx[n] + η[n]. (12)
For the case of the linear precoder described in Section III,this equation can be rewritten as follows
y[n] = HFu[n] + η[n]. (13)
This means that the observationsy[n] are instantaneous mix-tures of the uncoded symbolsu[n], where the mixing matrix isgiven byHF . For brevity, we will denote this mixing matrixasA in the sequel, so the observationsy[n] can be obtainedin this general way
y[n] = Ad[n] + η[n]. (14)
In accordance with our target, the matrixA may represent thechannel matrix,H , with d[n] being the coded sources,x[n]
1267

[cf. Equation (12)], or the whole coding–channel matrix,HF ,whered[n] are the uncoded sources,u[n] [cf. Equation (13)].We assume that the mixing matrix is unknown but full ranknevertheless. Without any loss of generality we can supposethat the source data have a normalized power equal to onesince possible differences in power may be included into themixing matrix A.
The source data can be recovered by means of a linearsystem (given byW [n]) whose output is a combination ofthe observations, expressed as
z[n] = W H[n]y[n]. (15)
Given a cost (or contrast) functionJ to be minimized toachieve the separation, gradient-based approaches calculate theoptimum separating matrix using the recursion in the form
W [n + 1] = W [n]− µ ∇W J (16)
where∇W J denotes the gradient of the functionJ with res-pect toW [n]. An alternative form to compute the minimumof this cost function consists in using a relative gradient.Asshown in [24], [25], it can be obtained by means of multiplyingthe gradient byW [n]W H[n], i.e. the recursion takes the form
W [n + 1] = W [n]− µ W [n]W H[n]∇W J. (17)
A. Supervised Approach
An important family of adaptive filtering algorithms arisesfrom considering the minimization of the MSE between theoutputsz[n] and the desired signalsd[n] [26], [27]. Mathe-matically, the cost function is written as
JMSE =Nt∑i=1
E[|zi[n]− di[n]|2]
= E[tr((W H[n]y[n]− d[n])(W H[n]y[n]− d[n])H
)].
(18)
The gradient of this cost function is obtained as
∇W JMSE = E[y[n](W H[n]y[n]− d[n])H
]. (19)
In general, the expectation included in∇W JMSE is unknownso it must be estimated from the available data. In particular,by considering only one sample, we obtain theLeast MeanSquares (LMS) algorithm, also called delta rule of Widrow-Hopf [27] in the context of Artificial Neural Networks, whichadapts the coefficients by means of using the recursion
W [n + 1] = W [n]− µz[n](W H[n]y[n]− d[n])H. (20)
The classical stability analysis for gradient-based algorithmsin the form described by Equation (20) consists in the studyof the point where the gradient vanishes and in the definitionof the Hessian matrix containing the second derivatives ofJ[28]. It can be demonstrated that the stationary points of thisrule are obtained as
∇W JMSE = 0 ⇒ Wopt = C−1y Cyd (21)
where Cy = E[y[n]yH [n]] is the autocorrelation of theobservations andCyd = E[y[n]dH[n]] is the crosscorrelation
between the observations and the desired signals. In practice,the desired signal is considered as known only during a finitenumber of instants (pilot symbols) and the expectations areestimated by sample averaging.
B. Unsupervised Approach
The inclusion of pilot symbols reduces the system through-put (or equivalently, it reduces the system spectral efficiency)and wastes transmission energy because pilot sequences do notconvey information. In order to avoid this limitation, we couldrestrict the sources to be uncorrelated with unit power, i.e.Cu = I. Note that our ultimate goal is to estimate the wholematrix A = HF , and therefore we will used[n] = u[n] inthe sequel. As a consequence, we can express Equation (19)as follows
∇W JMSE = E[y[n](W H[n]y[n]− u[n])H
]= E
[y[n](z[n] − u[n])H
]= E
[y[n]zH[n]
]− E[y[n]uH [n]
]= E
[y[n]zH[n]
]−HF E[u[n]uH[n]
]= E
[y[n]zH[n]
]−HF . (22)
In practice, the expectation is estimated using only one sample,so we obtain the following adaptive algorithm
W [n + 1] = W [n]− µ(y[n]zH[n]−HF
)(23)
which can be interpreted as a generalization of the P-vectoralgorithm described by Griffiths in [29]. In this case, theseparating system needs to have the information about themixing matrix HF .
Both pilot symbols and mixing matrix knowledge canbe avoided by using BSS algorithms which simultaneouslyestimate the mixing matrixA and the realizations of thesource vectoru[n] from the corresponding realizations ofthe observed vectory[n] [14]. One of the best known BSSalgorithms has been approached by Bell and Sejnowski in[30]. Given an activation functionh(•), the idea proposedby these authors is to obtain the weighted coefficients ofa Neural Network,W [n], in order to maximize the mutualinformation between the outputs before the activation function,h(z[n]) = h(W H[n]y[n]), and its inputs,y[n], which is givenby
JMI (W [n]) = ln(det(W H[n])) +Nt∑i=1
E[ln(h′i(zi[n]))] (24)
where hi(•) is the i–th element of the vectorh(•) and ′
denotes the first derivative. The maximum of this cost functioncan be obtained using a gradient algorithm [30] or a relativegradient algorithm [24], [31]. Both approaches use the gradient
1268

of the function in Equation (24) which is obtained as follows
∇W JMI = ∇W
(ln(det(W H[n]))
)+∇W
(Nt∑i=1
E[ln(h′i(zi[n]))]
)
=adj(W H[n])det(W H[n])
− E[y[n]gH(z[n])]
= W−H[n]− E[y[n]gH(z[n])] (25)
whereg(•) depends on the activation function and is expressedas
g(z[n]) =[−h′′1(z1[n])
h′1(z1[n]), · · · ,−h′′Nr
(zNr [n])h′Nr
(zNr [n])
]T.
Finally, when the expectation is estimated by using only onesample as before, we obtain the learning rules named gradientalgorithm and relative gradient algorithm given by
• Gradient Algorithm:
W [n + 1] = W [n] + µ(W−H[n]− y[n] gH(z[n])
)= W [n]− µ
(y[n] gH(z[n]) −W−H[n]
)(26)
• Relative Gradient Algorithm (Infomax algorithm):
W [n + 1] = W [n]− µW [n]W H[n]
· (y[n] gH(z[n]) −W−H[n])
= W [n]− µW [n](z[n]gH(z[n])− I
).(27)
The expression in Equation (24) admits an interesting in-terpretation by means of the use of the non–linear functiong(z) = z∗(1 − |z|2). In this case, Castedo et al. [32] haveshown that the Bell and Sejnowski rules are equivalent tothe Constant Modulus Algorithm (CMA) proposed by Godardin [33]. More information for readers about adaptive BSSalgorithms can be found in the tutorial [15].
V. COMBINED APPROACH
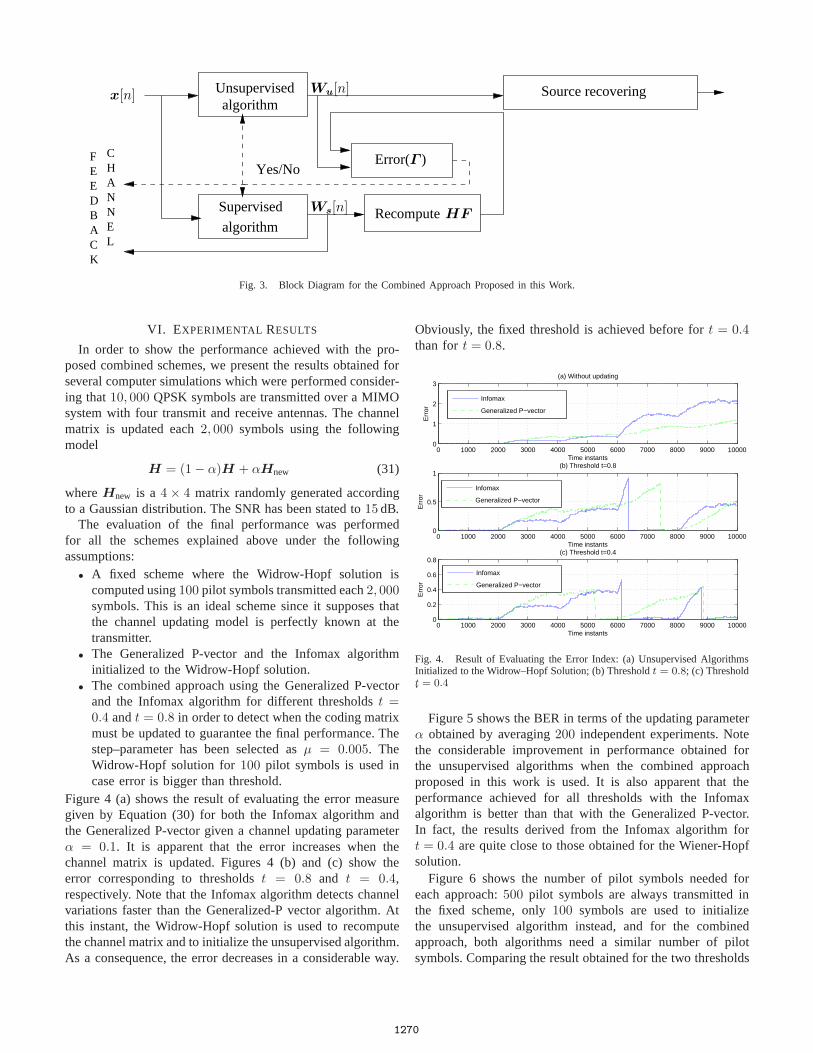
All the above supervised and unsupervised approaches havethe common goal of recovering the transmit sources. Unsuper-vised algorithms are attractive to track low channel variations,while the LMS algorithm (or the Wiener-Hopf solution) pro-vides a fast channel estimation for low or high variations atthe cost of using pilot symbols. In this section, our objectiveis to combine the advantages of both approaches withoutpenalization in performance. Figure 3 shows a simplified blockdiagram for this combined approach.
We will denote by Wu[n] and Ws[n] the matrices ofcoefficients for the unsupervised and the supervised modules,respectively. We start with an initial estimation of the channelmatrix obtained using the Widrow-Hopf solution given byEquation (21). This estimation is used at the transmitterin order to obtain the optimum coding matrixF and atthe receiver with the goal of initializing the unsupervisedalgorithm to Wu[n] = (HF )−H. At each time instant, thematrix Wu[n] is adapted and the original uncoded symbols
u[n] are recovered by means of usingz[n] = W Hu [n]y[n]. In
particular, as shown in Section VI, we will consider the rulescorresponding to the Generalized P-vector (see Equation (23))and to the Infomax algorithm (see Equation (27)).
A decision module determines if the channel has suffereda significant change. When this occurs, the receiver sends an“alarm” to the transmitter by means of the feedback channel.At this instant, a pilot frame is sent by the transmitter. Thereceiver estimates the channel matrix using the Widrow-Hopfsolution of Equation (21) by means of considering thatd[n]are the coded signals at the precoder output. This solutionprovides us the channel matrix estimate. This estimation isused at the transmitter to precode the following frames andat the receiver to compute the matrixF and to initialize theunsupervised algorithm toWu[n] = (HF )−H.
A. Decision criterion
The question now is how to detect significant variations inthe channel. By combining both Equations (13) and (15), theoutput z[n] can be rewritten as a linear combination of thesources
z[n] = Γ [n]u[n] (28)
where Γ [n] = W H[n]HF represents the overall mi-xing/separating system. Sources are optimally recovered whenthe matrixW [n] is selected such as every output extracts adifferent single source. This occurs when the matrixΓ [n] hasthe form
Γ [n] = D[n]P [n] (29)
where D[n] is a diagonal invertible matrix andP [n] is apermutation matrix. According to Equation (29), we know thatthe optimum separation matrix produces a diagonal matrix,and therefore the mismatch ofΓ [n] with respect to a diagonalmatrix allows us to measure the variations in the channel.In addition, an interesting consequence of using a linearprecoder is that the permutation indeterminacy associatedtounsupervised algorithms (see Equation (29)) is avoided dueto the initializationWu[n] = (HF )−H. This means that thesources are recovered in the same order as transmitted.
As a consequence, we propose the following simple proce-dure to detect channel variations. From the initial estimation ofthe channel matrixH provided by the supervised algorithm,the receiver computes an initial estimation of the whole matrixHF , denoted asHF . At each iteration of the unsupervisedalgorithm, we compute the gain matrixΓ [n] = W H
u [n]HFand the following “error” index
Error(Γ [n]) =Nt∑i=1
Nt∑j=1,j 6=i
( |γij [n]|2|γii[n]|2 +
|γji[n]|2|γii[n]|2
)(30)
whereγii[n] denotes thei–th diagonal element ofΓ [n]. The“alarm” is sent to the transmitter when the error is greater thana thresholdt, i.e. Error(Γ [n]) > t.
1269
FEEDBACK
CHANNEL
Yes/No
algorithmUnsupervised
algorithm
Supervised
Source recoveringx[n]
RecomputeHF
Wu[n]
Ws[n]
Error(Γ )
Fig. 3. Block Diagram for the Combined Approach Proposed in this Work.
VI. EXPERIMENTAL RESULTS
In order to show the performance achieved with the pro-posed combined schemes, we present the results obtained forseveral computer simulations which were performed consider-ing that10, 000 QPSK symbols are transmitted over a MIMOsystem with four transmit and receive antennas. The channelmatrix is updated each2, 000 symbols using the followingmodel
H = (1− α)H + αHnew (31)
whereHnew is a 4 × 4 matrix randomly generated accordingto a Gaussian distribution. The SNR has been stated to15 dB.
The evaluation of the final performance was performedfor all the schemes explained above under the followingassumptions:
• A fixed scheme where the Widrow-Hopf solution iscomputed using100 pilot symbols transmitted each2, 000symbols. This is an ideal scheme since it supposes thatthe channel updating model is perfectly known at thetransmitter.
• The Generalized P-vector and the Infomax algorithminitialized to the Widrow-Hopf solution.
• The combined approach using the Generalized P-vectorand the Infomax algorithm for different thresholdst =0.4 andt = 0.8 in order to detect when the coding matrixmust be updated to guarantee the final performance. Thestep–parameter has been selected asµ = 0.005. TheWidrow-Hopf solution for100 pilot symbols is used incase error is bigger than threshold.
Figure 4 (a) shows the result of evaluating the error measuregiven by Equation (30) for both the Infomax algorithm andthe Generalized P-vector given a channel updating parameterα = 0.1. It is apparent that the error increases when thechannel matrix is updated. Figures 4 (b) and (c) show theerror corresponding to thresholdst = 0.8 and t = 0.4,respectively. Note that the Infomax algorithm detects channelvariations faster than the Generalized-P vector algorithm. Atthis instant, the Widrow-Hopf solution is used to recomputethe channel matrix and to initialize the unsupervised algorithm.As a consequence, the error decreases in a considerable way.
Obviously, the fixed threshold is achieved before fort = 0.4than for t = 0.8.
0 1000 2000 3000 4000 5000 6000 7000 8000 9000 100000
1
2
3
Time instants
Err
or
(a) Without updating
0 1000 2000 3000 4000 5000 6000 7000 8000 9000 100000
0.5
1
Time instants
Err
or
(b) Threshold t=0.8
0 1000 2000 3000 4000 5000 6000 7000 8000 9000 100000
0.2
0.4
0.6
0.8
Time instants
Err
or
(c) Threshold t=0.4
Infomax
Generalized P−vector
Infomax
Generalized P−vector
Infomax
Generalized P−vector
Fig. 4. Result of Evaluating the Error Index: (a) Unsupervised AlgorithmsInitialized to the Widrow–Hopf Solution; (b) Thresholdt = 0.8; (c) Thresholdt = 0.4.
Figure 5 shows the BER in terms of the updating parameterα obtained by averaging200 independent experiments. Notethe considerable improvement in performance obtained forthe unsupervised algorithms when the combined approachproposed in this work is used. It is also apparent that theperformance achieved for all thresholds with the Infomaxalgorithm is better than that with the Generalized P-vector.In fact, the results derived from the Infomax algorithm fort = 0.4 are quite close to those obtained for the Wiener-Hopfsolution.
Figure 6 shows the number of pilot symbols needed foreach approach:500 pilot symbols are always transmitted inthe fixed scheme, only100 symbols are used to initializethe unsupervised algorithm instead, and for the combinedapproach, both algorithms need a similar number of pilotsymbols. Comparing the result obtained for the two thresholds
1270

0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.110
−3
10−2
10−1
Channel updating parameter
Bit
erro
r ra
te
Infomax
Infomax t=0.4
Infomax t=0.8
Generalized P−vector
Generalized P−vector t=0.4
Generalized P−vector t=0.8
Widrow−Hopf
Fig. 5. BER in Terms of the Channel Updating Parameter with the Averageof 200 Independent Experiments.
mentioned before, we can see that it is higher fort = 0.4 thanfor t = 0.8, but the number of pilot symbols is smaller thanfor the fixed scheme in both cases, especially ift = 0.4 isselected.
0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.150
100
150
200
250
300
350
400
450
500
550
Channel updating parameter
Pilo
t sym
bols
Infomax
Infomax t=0.4
Infomax t=0.8
Generalized P−vector
Generalized P−vector t=0.4
Generalized P−vector t=0.8
Widrow−Hopf
Fig. 6. Pilot Symbols in Terms of the Channel Updating Parameter with theAverage of200 Independent Experiments.
VII. C ONCLUSIONS
In order to reduce the overhead due to the transmission ofpilot symbols in FDD-LP systems, we have proposed to com-bine supervised and unsupervised algorithms. The algorithmselection is done by using a simple decision rule which allowsto detect the instant where the channel has suffered a consider-able variation. This information is sent to the transmitterusingthe feedback channel. The experimental results show that thecombined approach is an attractive solution because it provides
an adequate BER with a reduced number of training data. Inspecial, the best performance has been obtained combiningthe Widrow–Hopf solution and the unsupervised Informaxalgorithm.
ACKNOWLEDGMENT
This work was supported by Xunta de Galicia, Ministeriode Educacion y Ciencia, Ministerio de Ciencia e Innovacionof Spain and FEDER funds of the European Union un-der grants number 09TIC008105PR, TEC2007-68020-C04-01,and CSD2008-00010.
REFERENCES
[1] R. F. H. Fischer,Precoding and Signal Shaping for Digital Transmission.John Wiley & Sons, 2002.
[2] M. Joham, Optimization of Linear and Nonlinear Transmit SignalProcessing. PhD dissertation. Munich University of Technology, 2004.
[3] J. P. Costas, “Coding with Linear Systems,”Proceedings of the I.R.E.,vol. 40, pp. 1101–1103, September 1952.
[4] A. Scaglioni, G. B. Giannakis, and S. Barbarossa, “Redundant FilterbankPrecoders and Equalizers Part I: Unification and Optimal Designs,” IEEETransactions on Signal Processing, vol. 47, pp. 1988–2006, July 1999.
[5] A. Scaglioni, P. Stoica, S. Barbarossa, and G. B. Giannakis, “OptimalDesigns for Space–Time Linear Precoders and Decoders,”IEEE Trans-actions on Signal Processing, vol. 50, pp. 1051–1064, May 2002.
[6] R. L. Choi and R. D. Murch, “New Transmit Schemes and SimplifiedReceiver for MIMO Wireless Communication Systems,”IEEE Trans-actions on Wireless Communications, vol. 2, no. 6, pp. 1217–1230,November 2003.
[7] H. R. Karimi, M. Sandell, and J. Salz, “Comparison between Transmitterand Receiver Array Processing to Achieve Interference Nulling andDiversity,” in Proc. PIMRC, vol. 3, September 1999, pp. 997–1001.
[8] M. Joham, K. Kusume, M. H. Gzara, W. Utschick, and J. A. Nossek,“Transmit Wiener Filter for the Downlink of TDD DS-CDMA Systems,”in Proc. ISSSTA, vol. 1, September 2002, pp. 9–13.
[9] J. A. Nossek, M. Joham, and W. Utschick, “Transmit Processing inMIMO Wireless Systems,” inProc. of the 6th IEEE Circuits and SystemsSymposium on Emerging Technologies: Frontiers of Mobile and WirelessCommunication, May/June 2004, pp. I–18 – I–23, Shanghai, China.
[10] D. Love, R. Heath, W. Santipach, and M. L. Honig, “What isthe Valueof Limited Feedback for MIMO Channels?”IEEE CommunicationsMagazine, vol. 42, no. 10, pp. 54–59, October 2004.
[11] J. F. Cardoso and A. Souloumiac, “Blind Beamforming forNon–Gaussian Signals,”IEEE Proceedings-F, vol. 140, no. 6, pp. 362–370,1993.
[12] U. Markowska-Kaczmar and T. Switek, “Combined Unsupervised–Supervised Classification Method,”Lecture Notes in Computer Science:Knowledge-Based and Intelligent Information and Engineering Systems,vol. 5712/2009, pp. 861–868, 2009.
[13] J. Bourgeois and W. Minker, “Comparison of LCMV Beamformingand Second–Order Statistics BSS,”Lecture Notes in Computer Science:Time-Domain Beamforming and Blind Source Separation, vol. 3, pp.125–146, 2009.
[14] P. Coomon and C. Jutten,Hardbook of Blind Source Separation,Independent Component Analysis and Applications. Academic Press,2010.
[15] J. V. Stone,Independent Component Analysis: A Tutorial Introduction.MIT Press, 2004.
[16] A. Goldsmith,Wireless Communications. Cambridge University Press,2005.
[17] A. Paulraj, R. Nabar, and D. Gore,Introduction to Space-Time WirelessCommunications. Cambridge University Press, 2003.
[18] R. Hunger, M. Joham, and W. Utschick, “Extension of Linear andNonlinear Transmit Filters for Decentralized Receivers,”in EuropeanWireless 2005, April 2005, pp. 40–46, vol. 1.
[19] M. Joham, W. Utschick, and J. A. Nossek, “Linear Transmit Processingin MIMO Communications Systems,”IEEE Transactions on SignalProcessing, vol. 53, no. 8, pp. 2700–2712, August 2005.
[20] W. Karush,Minima of Functions of Several Variables with Inequalitiesas Side Conditions. M.S. Thesis. The University of Chicago, 1939.
1271

[21] R. Fletcher,Practical Methods of Optimization. John Wiley & Sons,1967.
[22] D. G. Luenberger,Linear and Nonlinear Programming. Addison-Wesley, 1989.
[23] H. W. Kuhn and A. W. Tucker, “Nonlinear Programming,” inProc.Second Berkeley Symposium on Mathematical Statistics and Probability.J. Neyman, University of California Press, 1951, pp. 481–492.
[24] S.-I. Amari, “Gradient learning in structured parameter spaces: Adaptiveblind separation of signal sources,” inProc. WCNN’96. San Diego,1996, pp. 951–956.
[25] J.-F. Cardoso and B. Laheld, “Equivariant adaptive source separation,”IEEE Transactions on Signal Processing, vol. vol. 44, no. no. 12, pp.pp. 3017–3030, December 1996.
[26] S. Haykin,Adaptive Filter Theory. 3rd. ed., Prentice Hall, 1996.[27] ——, Neural Networks A Comprehensive Foundation. Macmillan
College Publishing Company, New York, 1994.[28] A. Benveniste, M. Metivier, and P. Priourent,Adaptive Algorithms and
Stochastic Approximations. Springer-Verlag, New York, 1990.[29] L. J. Griffiths, “A simple adaptive algorithm for real-time processing
in antenna arrays,”Proceedings IEEE, vol. vol. 57, pp. pp. 1696–1704,1969.
[30] A. Bell and T. Sejnowski, “An information-maximization approach toblind separation and blind deconvolution,”Neural Computation, vol. vol.7, no. no. 6, pp. pp. 1129–1159, November 1995.
[31] C. Mejuto and L. Castedo, “A neural network approach to blindsource separation,” inProc. Neural Networks for Signal Processing VII.Florida, USA, September 1997, pp. 486–595.
[32] L. Castedo and O. Macchi, “Maximizing the information transfer foradaptive unsupervised source separation,” inProc. SPAWC’97. Paris,France, April 1997, pp. 65–68.
[33] D. N. Godard, “Self–recovering equalization and carrier tracking intwo–dimensional data communications systems,”IEEE Transactions onCommunications, vol. COM-28, pp. 1867–1875, 1980.
1272