2013.02.04- slide 1is 240 – spring 2013 prof. ray larson university of california, berkeley school...
TRANSCRIPT

2013.02.04- SLIDE 1IS 240 – Spring 2013
Prof. Ray Larson
University of California, Berkeley
School of Information
Principles of Information Retrieval
Lecture 4: Boolean IR System Elements

2013.02.04- SLIDE 2IS 240 – Spring 2013
Review
• Review– Elements of IR Systems
• Collections, Queries• Text processing and Zipf distribution
– Stemmers and Morphological analysis• Inverted file indexes • IR Models - Introduction to the Boolean
Model

2013.02.04- SLIDE 3IS 240 – Spring 2013
Queries
• A query is some expression of a user’s information needs
• Can take many forms– Natural language description of need– Formal query in a query language
• Queries may not be accurate expressions of the information need– Differences between conversation with a
person and formal query expression

2013.02.04- SLIDE 4IS 240 – Spring 2013
Collections of Documents…
• Documents– A document is a representation of some
aggregation of information, treated as a unit.• Collection
– A collection is some physical or logical aggregation of documents
• Let’s take the simplest case, and say we are dealing with a computer file of plain ASCII text, where each line represents the “UNIT” or document.

2013.02.04- SLIDE 5IS 240 – Spring 2013
How to search that collection?
• Manually?– Cat, more
• Scan for strings?– Grep
• Extract individual words to search???– “tokenize” (a unix pipeline)
• tr -sc ’A-Za-z’ ’\012’ < TEXTFILE | sort | uniq –c– See “Unix for Poets” by Ken Church
• Put it in a DBMS and use pattern matching there…– assuming the lines are smaller than the text size limits
for the DBMS

2013.02.04- SLIDE 6IS 240 – Spring 2013
What about VERY big files?
• Scanning becomes a problem• The nature of the problem starts to change
as the scale of the collection increases• A variant of Parkinson’s Law that applies
to databases is:– Data expands to fill the space available to
store it

2013.02.04- SLIDE 7
Document Processing Steps
IS 240 – Spring 2013
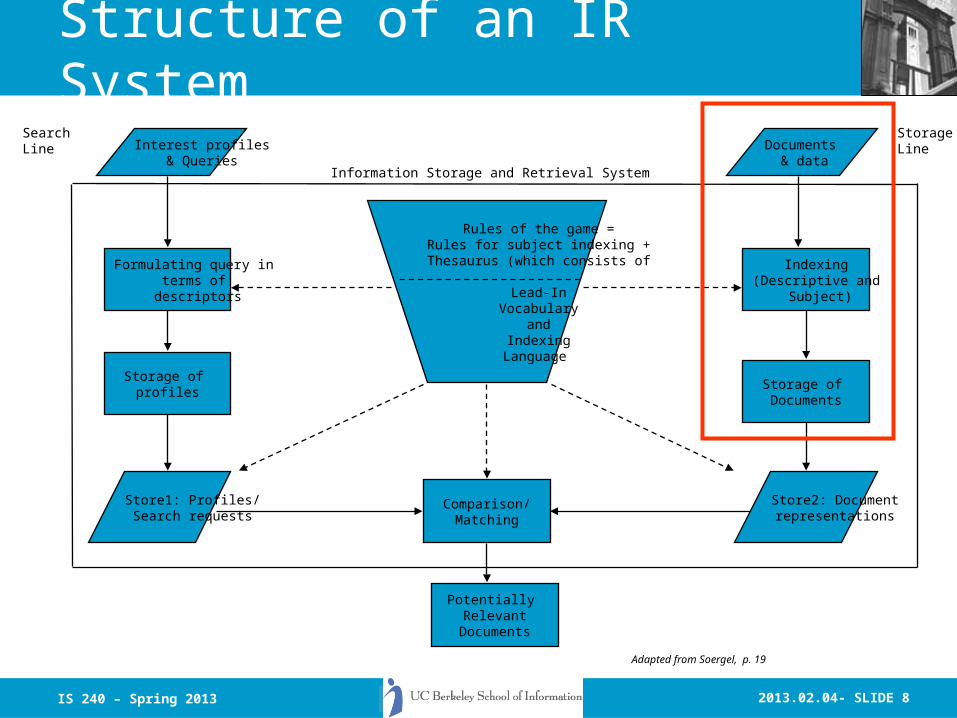
2013.02.04- SLIDE 8IS 240 – Spring 2013
Structure of an IR SystemSearchLine Interest profiles
& QueriesDocuments
& data
Rules of the game =Rules for subject indexing +
Thesaurus (which consists of
Lead-InVocabulary
andIndexing
Language
StorageLine
Potentially Relevant
Documents
Comparison/Matching
Store1: Profiles/Search requests
Store2: Documentrepresentations
Indexing (Descriptive and
Subject)
Formulating query in terms of
descriptors
Storage of profiles
Storage of Documents
Information Storage and Retrieval System
Adapted from Soergel, p. 19

2013.02.04- SLIDE 9IS 240 – Spring 2013
Query Processing
• In order to correctly match queries and documents they must go through the same text processing steps as the documents did when they were stored
• In effect, the query is treated like it was a document
• Exceptions (of course) include things like structured query languages that must be parsed to extract the search terms and requested operations from the query– The search terms must still go through the same text
process steps as the document…

2013.02.04- SLIDE 10IS 240 – Spring 2013
Steps in Query processing
• Parsing and analysis of the query text (same as done for the document text)– Morphological Analysis– Statistical Analysis of text

2013.02.04- SLIDE 11IS 240 – Spring 2013
Plotting Word Frequency by Rank
• Say for a text with 100 tokens• Count
– How many tokens occur 1 time (50)– How many tokens occur 2 times (20) …– How many tokens occur 7 times (10) … – How many tokens occur 12 times (1)– How many tokens occur 14 times (1)
• So things that occur the most often share the highest rank (rank 1).
• Things that occur the fewest times have the lowest rank (rank n).

2013.02.04- SLIDE 12IS 240 – Spring 2013
Many similar distributions…
• Words in a text collection• Library book checkout patterns• Bradford’s and Lotka’s laws.• Incoming Web Page Requests (Nielsen)• Outgoing Web Page Requests (Cunha &
Crovella)• Document Size on Web (Cunha &
Crovella)
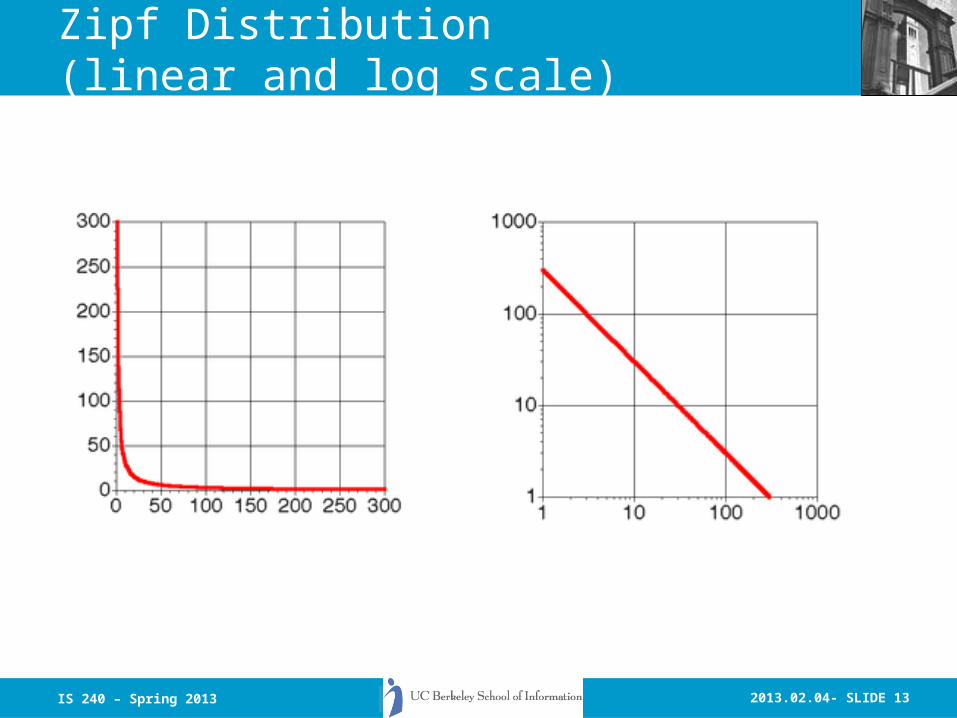
2013.02.04- SLIDE 13
Zipf Distribution(linear and log scale)
IS 240 – Spring 2013

2013.02.04- SLIDE 14IS 240 – Spring 2013
Resolving Power (van Rijsbergen 79)
The most frequent words are not the most descriptive.

2013.02.04- SLIDE 15IS 240 – Spring 2013
Other Models
• Poisson distribution• 2-Poisson Model• Negative Binomial• Katz K-mixture
– See Church (SIGIR 1995)

2013.02.04- SLIDE 16IS 240 – Spring 2013
Stemming and Morphological Analysis
• Goal: “normalize” similar words• Morphology (“form” of words)
– Inflectional Morphology• E.g,. inflect verb endings and noun number• Never change grammatical class
– dog, dogs– tengo, tienes, tiene, tenemos, tienen
– Derivational Morphology • Derive one word from another, • Often change grammatical class
– build, building; health, healthy

2013.02.04- SLIDE 17IS 240 – Spring 2013
Stemming and Morphological Analysis
• Goal: “normalize” similar words• Morphology (“form” of words)
– Inflectional Morphology• E.g,. inflect verb endings and noun number• Never change grammatical class
– dog, dogs– tengo, tienes, tiene, tenemos, tienen
– Derivational Morphology • Derive one word from another, • Often change grammatical class
– build, building; health, healthy

2013.02.04- SLIDE 18IS 240 – Spring 2013
Simple “S” stemming
• IF a word ends in “ies”, but not “eies” or “aies”– THEN “ies” “y”
• IF a word ends in “es”, but not “aes”, “ees”, or “oes”– THEN “es” “e”
• IF a word ends in “s”, but not “us” or “ss”– THEN “s” NULL
Harman, JASIS Jan. 1991

2013.02.04- SLIDE 19IS 240 – Spring 2013
Stemmer Examples
The SMARTstemmer
The Porterstemmer
The IAGO!stemmer
% tstem ateate% tstem applesappl% tstem formulaeformul% tstem appendicesappendix% tstem implementationimple% tstem glassesglass
% pstem ateat% pstem applesappl% pstem formulaeformula% pstem appendicesappendic% pstem implementationimplement% pstem glassesglass
% stemate|2eat|2apples|1apple|1formulae|1formula|1appendices|1appendix|1implementation|1implementation|1glasses|1 glasses|1

2013.02.04- SLIDE 20IS 240 – Spring 2013
Too Aggressive Too Timid
organization/organpolicy/police
execute/executivearm/army
european/europecylinder/cylindrical
create/creationsearch/searcher
Errors Generated by Porter Stemmer (Krovetz 93)

2013.02.04- SLIDE 21IS 240 – Spring 2013
Automated Methods
• Stemmers:– Very dumb rules work well (for English)– Porter Stemmer: Iteratively remove suffixes– Improvement: pass results through a lexicon
• Newer stemmers are configurable (Snowball)– Demo…
• Powerful multilingual tools exist for morphological analysis– PCKimmo, Xerox Lexical technology– Require a grammar and dictionary– Use “two-level” automata– Wordnet “morpher”

2013.02.04- SLIDE 22IS 240 – Spring 2013
Wordnet
• Type “wn word” on a machine where wordnet is installed…
• Large exception dictionary:• Demo
aardwolves aardwolf abaci abacus abacuses abacus abbacies abbacy abhenries abhenry abilities ability abkhaz abkhaz abnormalities abnormality aboideaus aboideau aboideaux aboideau aboiteaus aboiteau aboiteaux aboiteau abos abo abscissae abscissa abscissas abscissa absurdities absurdity…
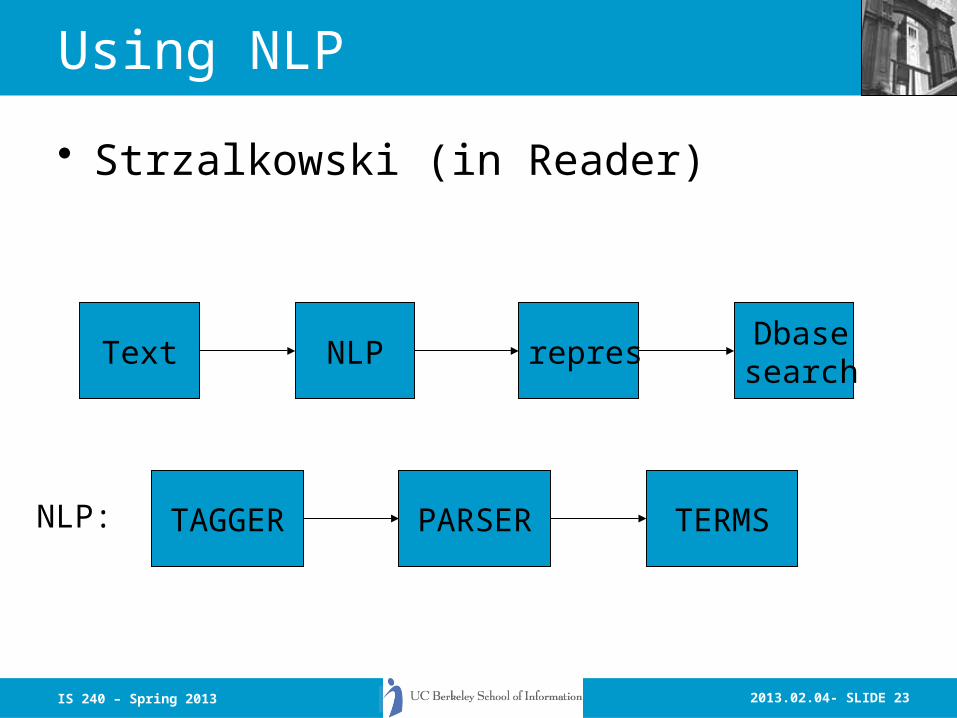
2013.02.04- SLIDE 23IS 240 – Spring 2013
Using NLP
• Strzalkowski (in Reader)
Text NLP represDbasesearch
TAGGERNLP: PARSER TERMS

2013.02.04- SLIDE 24IS 240 – Spring 2013
Using NLP
INPUT SENTENCEThe former Soviet President has been a local hero ever sincea Russian tank invaded Wisconsin.
TAGGED SENTENCEThe/dt former/jj Soviet/jj President/nn has/vbz been/vbn a/dt local/jj hero/nn ever/rb since/in a/dt Russian/jj tank/nn invaded/vbd Wisconsin/np ./per

2013.02.04- SLIDE 25IS 240 – Spring 2013
Using NLP
TAGGED & STEMMED SENTENCEthe/dt former/jj soviet/jj president/nn have/vbz be/vbn a/dt local/jj hero/nn ever/rb since/in a/dt russian/jj tank/nn invade/vbd wisconsin/np ./per

2013.02.04- SLIDE 26IS 240 – Spring 2013
Using NLP
PARSED SENTENCE
[assert
[[perf [have]][[verb[BE]]
[subject [np[n PRESIDENT][t_pos THE]
[adj[FORMER]][adj[SOVIET]]]]
[adv EVER]
[sub_ord[SINCE [[verb[INVADE]]
[subject [np [n TANK][t_pos A]
[adj [RUSSIAN]]]]
[object [np [name [WISCONSIN]]]]]]]]]

2013.02.04- SLIDE 27IS 240 – Spring 2013
Using NLP
EXTRACTED TERMS & WEIGHTS
President 2.623519 soviet 5.416102
President+soviet 11.556747 president+former 14.594883
Hero 7.896426 hero+local 14.314775
Invade 8.435012 tank 6.848128
Tank+invade 17.402237 tank+russian 16.030809
Russian 7.383342 wisconsin 7.785689

2013.02.04- SLIDE 28IS 240 – Spring 2013
Same Sentence, different sys
Enju ParserROOT ROOT ROOT ROOT -1 ROOT been be VBN VB 5been be VBN VB 5 ARG1 President president NNP NNP 3been be VBN VB 5 ARG2 hero hero NN NN 8a a DT DT 6 ARG1 hero hero NN NN 8a a DT DT 11 ARG1 tank tank NN NN 13local local JJ JJ 7 ARG1 hero hero NN NN 8The the DT DT 0 ARG1 President president NNP NNP 3former former JJ JJ 1 ARG1 President president NNP NNP 3Russian russian JJ JJ 12 ARG1 tank tank NN NN 13Soviet soviet NNP NNP 2 MOD President president NNP NNP 3invaded invade VBD VB 14 ARG1 tank tank NN NN 13invaded invade VBD VB 14 ARG2 Wisconsin wisconsin NNP NNP 15has have VBZ VB 4 ARG1 President president NNP NNP 3has have VBZ VB 4 ARG2 been be VBN VB 5since since IN IN 10 MOD been be VBN VB 5since since IN IN 10 ARG1 invaded invade VBD VB 14ever ever RB RB 9 ARG1 since since IN IN 10

2013.02.04- SLIDE 29IS 240 – Spring 2013
Other Considerations
• Church (SIGIR 1995) looked at correlations between forms of words in texts

2013.02.04- SLIDE 30IS 240 – Spring 2013
Assumptions in IR
• Statistical independence of terms• Dependence approximations

2013.02.04- SLIDE 31IS 240 – Spring 2013
Statistical Independence
Two events x and y are statistically independent if the product of their probability of their happening individually equals their probability of happening together.

2013.02.04- SLIDE 32IS 240 – Spring 2013
Statistical Independence and Dependence
• What are examples of things that are statistically independent?
• What are examples of things that are statistically dependent?

2013.02.04- SLIDE 33IS 240 – Spring 2013
• How likely is a red car to drive by given we’ve seen a black one?
• How likely is the word “ambulence” to appear, given that we’ve seen “car accident”?
• Color of cars driving by are independent (although more frequent colors are more likely)
• Words in text are not independent (although again more frequent words are more likely)
Statistical Independence vs. Statistical Dependence

2013.02.04- SLIDE 34IS 240 – Spring 2013
Lexical Associations
• Subjects write first word that comes to mind– doctor/nurse; black/white (Palermo & Jenkins 64)
• Text Corpora yield similar associations• One measure: Mutual Information (Church and Hanks
89)
• If word occurrences were independent, the numerator and denominator would be equal (if measured across a large collection)
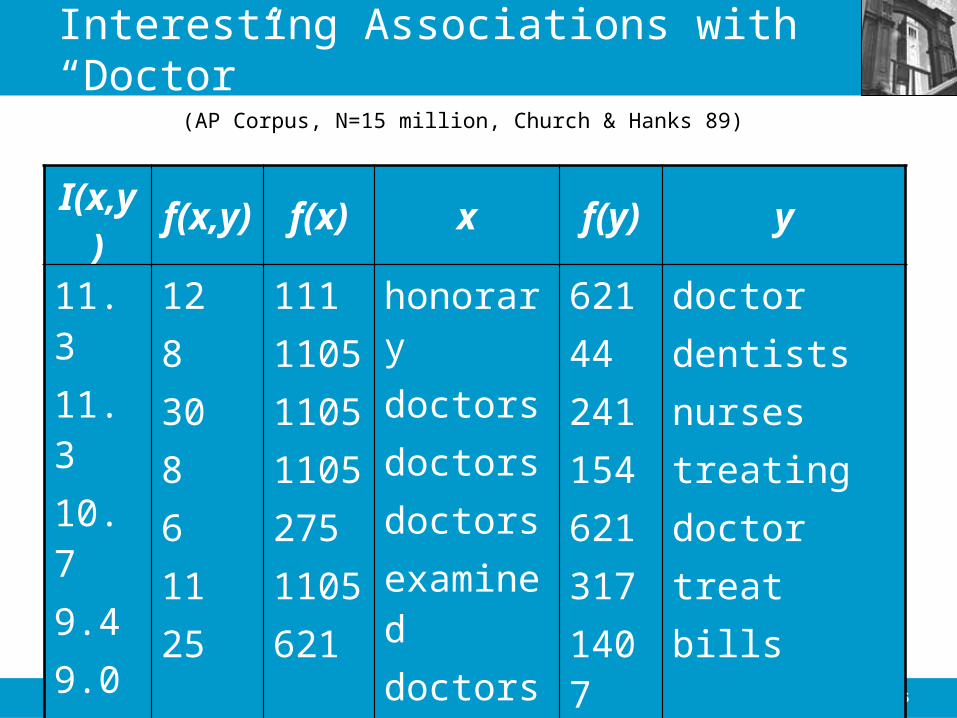
2013.02.04- SLIDE 35IS 240 – Spring 2013
Interesting Associations with “Doctor”
(AP Corpus, N=15 million, Church & Hanks 89)
I(x,y) f(x,y) f(x) x f(y) y
11.311.310.79.49.08.98.7
12830861125
1111105110511052751105621
honorarydoctorsdoctorsdoctorsexamineddoctorsdoctor
621442411546213171407
doctordentistsnursestreatingdoctortreatbills

2013.02.04- SLIDE 36IS 240 – Spring 2013
These associations were likely to happen because the non-doctor words shown here are very commonand therefore likely to co-occur with any noun.
Un-Interesting Associations with “Doctor”
I(x,y) f(x,y) f(x) x f(y) y
0.960.950.93
64112
62128469084716
doctorais
7378511051105
withdoctorsdoctors

2013.02.04- SLIDE 37IS 240 – Spring 2013
Query Processing
• Once the text is in a form to match to the indexes then the fun begins– What approach to use?
• Boolean?• Extended Boolean?• Ranked
– Fuzzy sets?– Vector?– Probabilistic?– Language Models? – Neural nets?
• Most of the next few weeks will be looking at these different approaches

2013.02.04- SLIDE 38IS 240 – Spring 2013
Display and formatting
• Have to present the the results to the user• Lots of different options here, mostly
governed by – How the actual document is stored – And whether the full document or just the
metadata about it is presented
2013.02.04- SLIDE 39IS 240 – Spring 2013
Review
• Review– Elements of IR Systems
• Collections, Queries• Text processing and Zipf distribution
– Stemmers and Morphological analysis• Inverted file indexes • IR Models - Introduction to the Boolean
Model

2013.02.04- SLIDE 40IS 240 – Spring 2013
What to do with terms…
• Once terms have been extracted from the documents, they need to be stored in some way that lets you get back to documents that those terms came from
• The most common index structure to do this in IR systems is the “Inverted File”

2013.02.04- SLIDE 41IS 240 – Spring 2013
Boolean Implementation: Inverted Files
• We will look at “Vector files” in detail later. But conceptually, an Inverted File is a vector file “inverted” so that rows become columns and columns become rows

2013.02.04- SLIDE 42IS 240 – Spring 2013
How Are Inverted Files Created
• Documents are parsed to extract words (or stems) and these are saved with the Document ID.
Now is the timefor all good men
to come to the aidof their country
Doc 1
It was a dark andstormy night in
the country manor. The time was past midnight
Doc 2
TextProcSteps

2013.02.04- SLIDE 43IS 240 – Spring 2013
How Inverted Files are Created
• After all document have been parsed the inverted file is sorted

2013.02.04- SLIDE 44IS 240 – Spring 2013
How Inverted Files are Created
• Multiple term entries for a single document are merged and frequency information added

2013.02.04- SLIDE 45IS 240 – Spring 2013
Inverted Files• The file is commonly split into a Dictionary
and a Postings file

2013.02.04- SLIDE 46IS 240 – Spring 2013
Inverted Files
• Lots of alternative implementations – E.g.: Cheshire builds within-document
frequency using a hash table during document parsing. Then Document IDs and frequency info are stored in a BerkeleyDB B-tree index keyed by the term.

2013.02.04- SLIDE 47IS 240 – Spring 2013
Btree (conceptual)
B | | D | | F |
AcesBoilers
Cars
F | | P | | Z |
R | | S | | Z |H | | L | | P |
DevilsMinors
PanthersSeminoles
Flyers
HawkeyesHoosiers
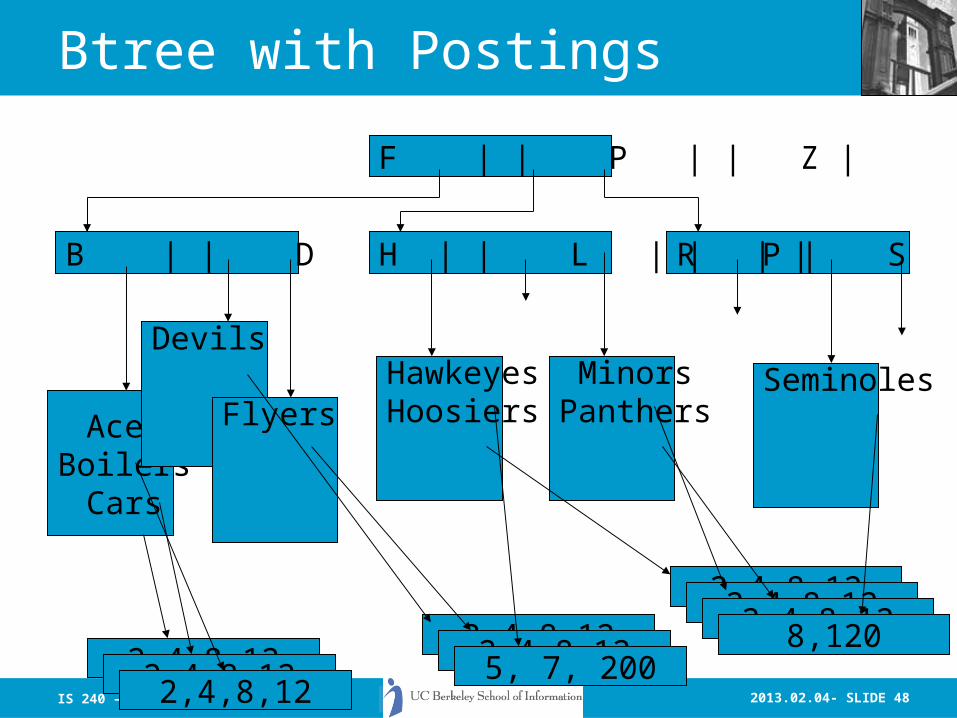
2013.02.04- SLIDE 48IS 240 – Spring 2013
Btree with Postings
B | | D | | F |
AcesBoilers
Cars
F | | P | | Z |
R | | S | | Z |H | | L | | P |
DevilsMinors
PanthersSeminoles
FlyersHawkeyesHoosiers
2,4,8,122,4,8,122,4,8,12
2,4,8,12
2,4,8,12
2,4,8,125, 7, 200
2,4,8,122,4,8,128,120

2013.02.04- SLIDE 49IS 240 – Spring 2013
Inverted files
• Permit fast search for individual terms• Search results for each term is a list of
document IDs (and optionally, frequency, part of speech and/or positional information)
• These lists can be used to solve Boolean queries:– country: d1, d2– manor: d2– country and manor: d2

2013.02.04- SLIDE 50IS 240 – Spring 2013
Review
• Review– Elements of IR Systems
• Collections, Queries• Text processing and Zipf distribution
– Stemmers and Morphological analysis• Inverted file indexes • IR Models - Introduction to the Boolean
Model

2013.02.04- SLIDE 51IS 240 – Spring 2013
Now we have a system…
• Except for the matching and ranking between the query representation and the document representation– Stored in the inverted files
• We will start to take a look at one model for matching today
• The Boolean Model

2013.02.04- SLIDE 52IS 240 – Spring 2013
IR Models
• Set Theoretic Models– Boolean– Fuzzy– Extended Boolean
• Vector Models (Algebraic)• Probabilistic Models (probabilistic)• Others (e.g., neural networks, etc.)

2013.02.04- SLIDE 53IS 240 – Spring 2013
Boolean Model for IR
• Based on Boolean Logic (Algebra of Sets).• Fundamental principles established by
George Boole in the 1850’s• Deals with set membership and operations
on sets• Set membership in IR systems is usually
based on whether (or not) a document contains a keyword (term)

2013.02.04- SLIDE 54IS 240 – Spring 2013
• Intersection – Boolean ‘AND’ -- -- • Union – Boolean ‘OR’ -- --• Negation – Boolean ‘NOT’ -- --
– Usually means “AND NOT” in IR • Exclusive OR – ‘XOR’ – seldom used,
– Instead
Boolean Operations on Sets

2013.02.04- SLIDE 55IS 240 – Spring 2013
Boolean Logic
A B

2013.02.04- SLIDE 56IS 240 – Spring 2013
Boolean Logic
A B

2013.02.04- SLIDE 57IS 240 – Spring 2013
Boolean Logic
A B

2013.02.04- SLIDE 58IS 240 – Spring 2013
Boolean Logic
A B

2013.02.04- SLIDE 59IS 240 – Spring 2013
Boolean Logic
A B

2013.02.04- SLIDE 60IS 240 – Spring 2013
Boolean Logic
A B

2013.02.04- SLIDE 61IS 240 – Spring 2013
Boolean Logic
A B

2013.02.04- SLIDE 62IS 240 – Spring 2013
Boolean Logic
A B

2013.02.04- SLIDE 63IS 240 – Spring 2013
Query Languages
• A way to express the query (formal expression of the information need)
• Types: – Boolean– Natural Language– Stylized Natural Language– Form-Based (GUI)

2013.02.04- SLIDE 64IS 240 – Spring 2013
Simple query language: Boolean
• Terms + Boolean operators– terms
• words• normalized (stemmed) words• phrases• thesaurus terms
– Operators• AND• OR• NOT
– parentheses (for grouping operations)

2013.02.04- SLIDE 65IS 240 – Spring 2013
Boolean Queries
• Cat
• Cat OR Dog
• Cat AND Dog
• (Cat AND Dog)
• (Cat AND Dog) OR Collar
• (Cat AND Dog) OR (Collar AND Leash)
• (Cat OR Dog) AND (Collar OR Leash)

2013.02.04- SLIDE 66IS 240 – Spring 2013
Boolean Queries
• (Cat OR Dog) AND (Collar OR Leash)– Each of the following combinations works:

2013.02.04- SLIDE 67IS 240 – Spring 2013
Boolean Queries
• (Cat OR Dog) AND (Collar OR Leash)– None of the following combinations works:

2013.02.04- SLIDE 68IS 240 – Spring 2013
Boolean Queries
• Usually expressed as INFIX operators in IR– ((a AND b) OR (c AND b))
• NOT is UNARY PREFIX operator– ((a AND b) OR (c AND (NOT b)))
• AND and OR can be n-ary operators– (a AND b AND c AND d)
• Some rules - (De Morgan revisited)– NOT(a) AND NOT(b) = NOT(a OR b)– NOT(a) OR NOT(b)= NOT(a AND b)– NOT(NOT(a)) = a
2013.02.04- SLIDE 69IS 240 – Spring 2013
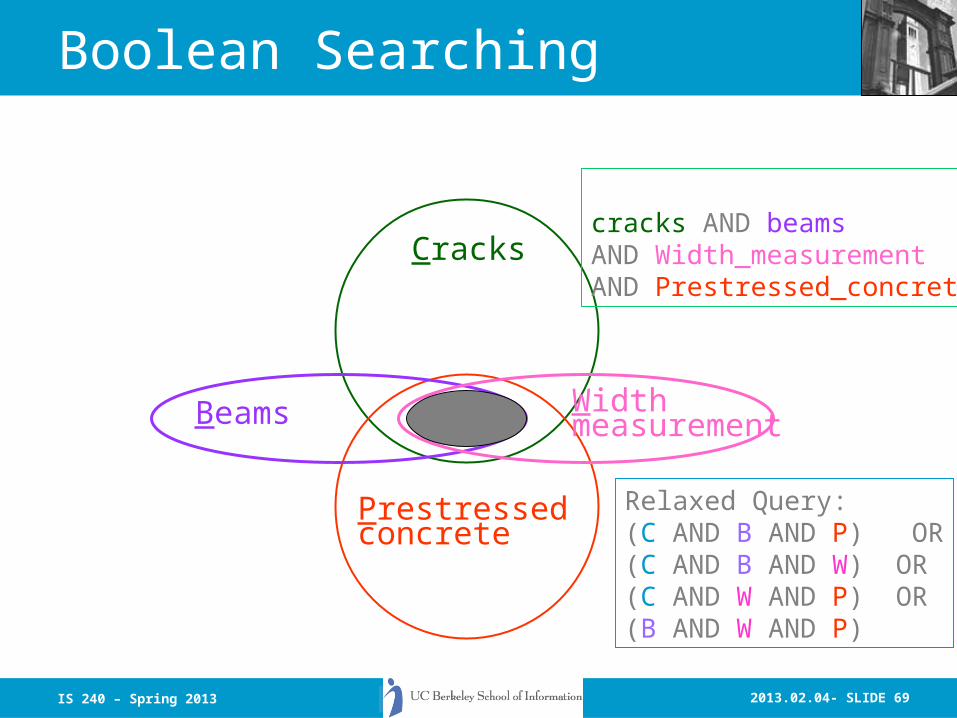
Boolean Searching
Formal Query:cracks AND beamsAND Width_measurementAND Prestressed_concrete
Cracks
Beams Widthmeasurement
Prestressedconcrete
Relaxed Query:(C AND B AND P) OR(C AND B AND W) OR(C AND W AND P) OR(B AND W AND P)
Relaxed Query:(C AND B AND P) OR(C AND B AND W) OR(C AND W AND P) OR(B AND W AND P)

2013.02.04- SLIDE 70IS 240 – Spring 2013
Boolean Logic
t3
t1 t2
D1D2
D3
D4D5
D6
D8D7
D9
D10
D11
m1
m2
m3m5
m4
m7m8
m6
m2 = t1 t2 t3
m1 = t1 t2 t3
m4 = t1 t2 t3
m3 = t1 t2 t3
m6 = t1 t2 t3
m5 = t1 t2 t3
m8 = t1 t2 t3
m7 = t1 t2 t3

2013.02.04- SLIDE 71IS 240 – Spring 2013
Precedence Ordering
• In what order do we evaluate the components of the Boolean expression?– Parenthesis get done first
• (a or b) and (c or d)• (a or (b and c) or d)
– Usually start from the left and work right (in case of ties)
– Usually (if there are no parentheses)• NOT before AND• AND before OR

2013.02.04- SLIDE 72IS 240 – Spring 2013
Next Time
• More on the Boolean Model including facetted searching, query parse trees and extended Boolean approaches