50.530: software engineering sun jun sutd. week 3: delta debugging
TRANSCRIPT

50.530: Software Engineering
Sun JunSUTD

Week 3: Delta Debugging

Debugging
• Question 1: Bug Localization/Identification– How do we know where the bugs are?
• Question 2: Bug Fixing– How do we fix the bugs automatically?
the behaviors we wanted
A B C
the behaviors we have

“YESTERDAY, MY PROGRAM WORKED. TODAY, IT DOES NOT. WHY?”
Andreas Zeller, ESEC/FSE 1999

Motivation
“The GDB people have done it again. The new release 4.17 of the GNU debugger [6] brings several new features, languages, and platforms, but for some reason, it no longer integrates properly with my graphical front-end DDD [10]: the arguments specified within DDD are not passed to the debugged program. Something has changed within GDB such that it no longer works for me. Something? Between the 4.16 and 4.17 releases, no less than 178,000 lines have changed. How can I isolate the change that caused the failure and make GDB work again?”
Andrew Zeller, 1999

Research Question
Assume that we know the bug(s) is due to a finite set of changes, how do we know which change(s) is responsible?

Regression Containmentlet O be the original working program;let N be the new buggy program; let changes be the sequence of changes from O to N;while (true) { apply first half of the changes on O and get ON; if (ON is working) { let O := ON; } else { let N := ON } if (the number of changes from O to N is 1) return;}
What assumptions are needed for this to work?

Complications
• Interference– There may not be one single change responsible for a
failure, but a combination of several changes.• Inconsistency– (in parallel development) combinations of changes
may not result in a testable program• Granularity– A single logical change may affect several hundred or
even thousand lines of code, but only a few lines may be responsible for the failure.

Delta Debugging
• Find a minimal set of changes that cause a program to fail a test case, through automatically generating test cases
Changes could be anything

Delta Debugging
O: applied an empty set of changes N: applied all changes
Let {a, b, c, …, n} be the set of changes.
ON: applied any subset X of the changes

Testing
We assume a function test which produces three outputs– PASS: the test succeeds– FAIL: the test produced the failure it was indented
to capture– ?: the test produced indeterminate results
Let X be a set of changes and test(X) to denote the testing result with the changes in X.

Objective
• Find a set of changes X such that– test(X) != PASS, i.e., failure-inducing– test(Y) != FAIL for all subset Y of X, i.e., minimum
set ON: minimum failure-inducing changes
The complexity is exponential. Why?

Assumptions for Simplification
Monotonicity• If test(X) = FAIL, test(Y) != PASS for all Y which is a
superset of X.Unambiguity • If test(X) = FAIL and test(Y) = FAIL, test(X intersect
Y) != PASS, i.e., a failure is caused by one change set (and not independently by two disjoint sets)
Consistency• test(X) != ? for all X Justified?

DD Algorithm: Example

DD Algorithm: Example

DD Algorithmalgorithm DD(U, R) { if (U has one element only) {
return U; }
partition U into X and Y equally;
if (test(X union R) = FAIL) {return DD(X, R)
} if (test(Y union R) = FAIL) {
return DD(Y, R) }
return DD(X, Y union R) union DD(Y, X union R);}
C: a set of changes; R: changes remain to be applied

Exercise: Complete the Call Graph
DD({1..8}, {})
DD({1..4}, {5..8})
DD({5..8}, {1..4})

Theory
Theorem: Assume monotonicity, unambiguity and consistency, algorithm DD always returns the minimum failure-inducing set of changes.

Informal Proof
algorithm DD(U, R) { if (U has one element only) {
return U; }
partition U into X and Y equally;
if (test(X union R) = FAIL) {return DD(X, R)
} if (test(Y union R) = FAIL) {
return DD(Y, R) }
return DD(X, Y union R) union DD(Y, X union R);}
Justified by monotonicity and unambiguity
Justified by monotonicity and unambiguity
Justified by consistency
Justified by monotonicity and unambiguity

Ambiguity
Unambiguity: If test(X) = FAIL and test(Y) = FAIL, test(X intersect Y) != PASS, i.e., a failure is caused by one change set (and not independently by two disjoint sets)
What if it is ambiguous?
DD will find one failure-inducing changes. Remove this set and apply DD again to find another.

Not Monotonic
Monotonicity: If test(X) = FAIL, test(Y) != PASS for all Y which is a superset of X.
What if it is not monotonic? For instance, what if test({1,2}) = FAIL but test({1..4}) = PASS?
DD will find some failure-inducing changes.

Inconsistency
Consistency: test(X) != ? for all X
Integration failure. A change may require earlier changes that are not included in the configurationConstruction failure. Although all changes can be applied, the resulting program has syntactical or semantic errors, such that construction fails.Execution failure. The program does not execute correctly; the test outcome is unresolved.
Shall we enforce consistency for each commit of changes?

Research Question
How do we modify the DD algorithm so as to handle inconsistency?• Found: If test(X) = FAIL, X contains a failure-
inducing subset. • Interference: If test(X) = PASS = test(Y), X and
Y form an interference.
What if test(X) =? or test(Y) =? or both?

Example
At step 3, can we omit {5..8}?

Example
Preference: If test(X) =? and test(U-X) = PASS, X contains a failure-inducing subset and is preferred.

Example
Scenario: there are 1..8 changes. Change 8 is failure-inducing, and changes 2, 3 and 7 imply each other – that is, they only can be applied as a whole.

Example

Example
Is it necessary to have {5,6}?

DD+ Algorithmalgorithm DD+(U, R, N) { if (U has one element only) {//found
return U; } partition U into N sets X1, X2, …, Xn equally; if (test(Xi union R ) = FAIL for some Xi) {//found in Xi
return DD+(Xi, R, 2); } if (test(Xi union R) = PASS and test((U – Xi) union R) = PASS for some Xi) {//interference
return DD+(Xi, (U-Xi) union R, 2) union DD+(U-Xi-R, Xi union R, 2); } if (test(Xi union R) = ? and test((U – Xi) union R) = PASS for some Xi) {//preference
return DD+(Xi, (U – Xi) union R, 2); } let U’ = U intersect {U – Xi – R| test((U – Xi) union R) = FAIL}; if (N < |U|) {//try again
return DD+(U’, R union {Xi | test(Xi union R) = PASS}, min(|U’|, 2N)); } return U’; //nothing left}

Exercise 1
Convince yourself by applying the algorithm (i.e., DD+({1..8}, {}, 2)) to the following scenario.
There are 1..8 changes. Change 8 is failure-inducing, and changes 2, 3 and 7 imply each other – that is, they only can be applied as a whole.

Reducing Inconsistency
What if we know that 2 and 3 and 7 imply each other?
Partition the set into two sets {1,2,3,7} and {4,5,6,8}.
How do we know what changes imply each other?

Grouping Related Changes
To determine whether changes are related, one can use• process criteria: common change dates or sources,• location criteria: the affected file or directory,• lexical criteria: common referencing of identifiers,• syntactic criteria: common syntactic entities
(functions, modules) affected by the change,• semantic criteria: common program statements
affected by the changed control or data flow.

Example
Assume that each change requires all earlier changes to be consistent.

Case Study: DDD 3.1.2 Dumps Core
DDD 3.1.2, released in December, 1998, exhibited a nasty behavioral change: When invoked with a the name of a non-existing file, DDD 3.1.2 dumped core, while its predecessor DDD 3.1.1 simply gave an error message.
The DDD configuration management archive lists 116 logical changes between the 3.1.1 and 3.1.2 releases. These changes were split into 344 textual changes to the DDD source.

Random Clustering
start with 344 changes
reduced to 172 changes
8 subsets of changes
reduced to 16 changes
reduced to 1 change
31 tests in total

Grouping Changes
1. Changes were grouped according to the date they were applied.
2. Each change implied all earlier changes.
12 test runs and 58 minutes

Case Study: GDB
178,000 changed GDB lines, grouped into 8721 textual changes in the GDB source, with any two textual changes separated by at least two unchanged lines. No configuration management archive to obtain change dates, etc.

Random Clustering
Most of the first 457 tests result in ?At test 458, one set containing 36 changes resulted in FAIL470 tests in total; 48 hours.

Grouping Changes• At top-level, changes were grouped according to directories. This was
motivated by the observation that several GDB directories contain a separate library whose interface remains more or less consistent across changes.
• Within one directory, changes were grouped according to common files. The idea was to identify compilation units whose interface was consistent with both “yesterday’s” and “today’s” version.
• Within a file, changes were grouped according to common usage of identifiers. This way, we could keep changes together that operated on common variables or functions.
• Finally, failure resolution loop: After a failing construction, scans the error messages for identifiers, adds all changes that reference these identifiers and tries again. This is repeated until construction is possible, or until there are no more changes to add.

Grouping Changes
After 9 tests, 2547 changes leftAfter 280 tests, 18 changes left (of two files only)289 tests in total, 20 hours

Question
Is Delta Debugging an over-kill?

“SIMPLIFYING AND ISOLATING FAILURE-INDUCING INPUT”
Andreas Zeller, IEEE Transactions on Software Engineering, 2002

Motivation
In July 1999, Bugzilla, the Mozilla bug database, listed more than 370 open bug reports—bug reports that were not even simplified. With this queue growing further, the Mozilla engineers “faced imminent doom”. Overwhelmed with work, the Netscape product manager sent out the Mozilla BugAThon call for volunteers: people who would help simplify bug reports. “Simplifying” meant: turning these bug reports into minimal test cases, where every part of the input would be significant in reproducing the failure.

Motivation: Example<td align=left valign=top><SELECT NAME="op sys" MULTIPLE SIZE=7><OPTION VALUE="All">All<OPTION VALUE="Windows 3.1">Windows 3.1<OPTION VALUE="Windows 95">Windows 95<OPTION VALUE="Windows 98">Windows 98<OPTION VALUE="Windows ME">Windows ME<OPTION VALUE="Windows 2000">Windows 2000<OPTION VALUE="Windows NT">Windows NT<OPTION VALUE="Mac System 7">Mac System 7<OPTION VALUE="Mac System 7.5">Mac System 7.5<OPTION VALUE="Mac System 7.6.1">Mac System 7.6.1<OPTION VALUE="Mac System 8.0">Mac System 8.0<OPTION VALUE="Mac System 8.5">Mac System 8.5<OPTION VALUE="Mac System 8.6">Mac System 8.6<OPTION VALUE="Mac System 9.x">Mac System 9.x<OPTION VALUE="MacOS X">MacOS X<OPTION VALUE="Linux">Linux<OPTION VALUE="BSDI">BSDI<OPTION VALUE="FreeBSD">FreeBSD<OPTION VALUE="NetBSD">NetBSD<OPTION VALUE="OpenBSD">OpenBSD<OPTION VALUE="AIX">AIX<OPTION VALUE="BeOS">BeOS<OPTION VALUE="HP-UX">HP-UX<OPTIONVALUE="IRIX">IRIX<OPTION VALUE="Neutrino">Neutrino<OPTION VALUE="OpenVMS">OpenVMS<OPTION VALUE="OS/2">OS/2<OPTION VALUE="OSF/1">OSF/1<OPTION VALUE="Solaris">Solaris<OPTION VALUE="SunOS">SunOS<OPTION VALUE="other">other</SELECT> </td><td align=left valign=top> <SELECT NAME="priority" MULTIPLE SIZE=7><OPTION VALUE="--">--<OPTION VALUE="P1">P1<OPTION VALUE="P2">P2<OPTION VALUE="P3">P3<OPTION VALUE="P4">P4<OPTION VALUE="P5">P5</SELECT></td><td align=left valign=top><SELECT NAME="bug severity" MULTIPLE SIZE=7><OPTION VALUE="blocker">blocker<OPTION VALUE="critical">critical<OPTION VALUE="major">major<OPTIONVALUE="normal">normal<OPTION VALUE="minor">minor<OPTION VALUE="trivial">trivial<OPTION VALUE="enhancement">enhancement</SELECT></tr></table>
Loading this HTML page into Mozilla and printing it causes a segmentation fault.

Research Question
How do we automatically minimize a test case?

Research Question
How do we automatically minimize a test case?
Solution: using Delta Debugging• Yesterday: test(“”) = PASS• Today: test(that html page) = FAIL• The set of changes = {insert one character}
Is this the best definition?

Example

Generalize DD
A change can be anything which changes the circumstances of a program run, e.g., • program code changes (as we have seen)• program input changes (as we’re about to see)• system configurations?

Generalize DD
DD Requires• a set of primitive changes (which can be
composed)
• a test function (with different outputs like: PASS, FAIL, ?)
What should be the primitive changes?

Minimal Test Case
Let U be the set of changes containing the primitive change of inserting one character at a position in the input.
The problem is to find the minimum set X (which corresponds to the minimum input) such that test(X) = FAIL.

Minimality
Local Minimum: a test case (represented as a set of changes X) is local minimum if test(X) = FAIL and test(Y) != FAIL for all subset Y of X.
1-Minimal test case: a test case X is 1-minimal if test(X) = FAIL and test(Y) != FAIL for all set Y which is one-element less of X.
Why? Because global minimum is hard to achieve.

DDmin Algorithm
algorithm DDmin(U, N) { if (|U| = 1) {//minimum
return U; } partition U into X1, X2, …, Xn equally; if (test(Xi) = FAIL for some Xi) {//reduce to subset
return DDmin(Xi, 2); } if (test(U - Xi) = FAIL for some Xi) {//reduce to complement
return DDmin(U - Xi, max(N-1, 2)); } if (N < |U|) {//increase granularity
return DDmin(U, min(|U|, 2N)); } return U;}

Example
DDmin({1..8}, 2)
DDmin({5..8}, 2)
DDmin({7..8}, 2)
DDmin({7}, 2)


Exercise
Show how DDmin works for this example.

Theory
DDmin(U, 2) is guaranteed to return a 1-minimal test case.
algorithm DDmin(U, N) { if (|U| = 1) {//minimum
return U; } partition U into X1, X2, …, Xn equally; if (test(Xi) = FAIL) {//reduce to subset
return DDmin(Xi, 2); } if (test(U - Xi) = FAIL) {//reduce to complement
return DDmin(U - Xi, max(N-1, 2)); } if (N < |U|) {//increase granularity
return DDmin(U, min(|U|, 2N)); } return U;}
Reduce U in these cases
If U can’t be reduced further, eventually we would test every sunset of U with one less element.

Research Question
Why not simply apply the DD+ algorithm?

Case Study: GCC
This program causes GNU C compiler (GCC version 2.95.2 on Intel-Linux with optimization enabled) to crash.
Each change inserts the i-th character into the program.

Case Study: GCC
After 731 tests generated by DDmin (and 34 seconds)
Does it make sense to reduce the method name?

Case Study: GCC
GCC has 31 options
Can we find out which option is relevant?
Yes, simply run DDmin again.

Isolation
• The DDmin algorithm is designed to find a failing test case with “minimal” difference from the known passing test case test({}).
• The problem of isolation: find a failing test case with “minimal” difference from any passing test case.

Example
Test 4 and 7 show one character difference which changes the testing result from PASS to FAIL. Useful?

Isolation: Definition
Let P and F be two sets of changes such that test(P) = PASS and test(F) = FAIL and P is a subset of F. F-P is minimal if test(P union X) != PASS and test(F-X) != FAIL for all proper subset X of F-P.
F-P is 1-minimal if test(P union {x}) != PASS and test(F-{x}) != FAIL for all element x of F-P.
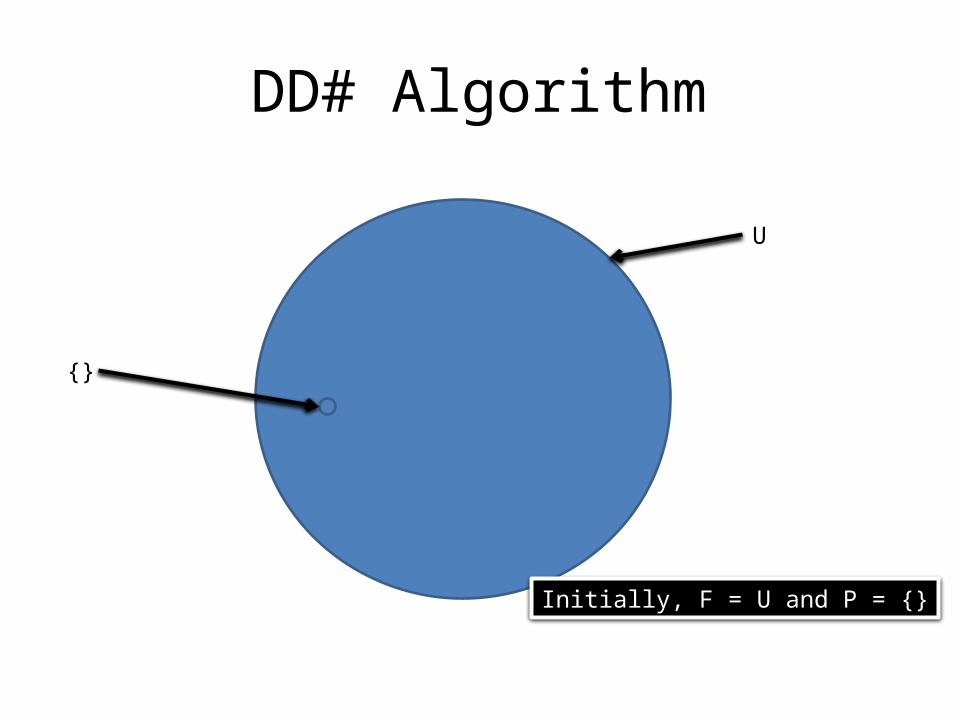
DD# Algorithm
U
{}
Initially, F = U and P = {}

DD# Algorithm
U
{}
Gradually grow P and reduce FP
F

DD# Algorithmalgorithm DD#(P, F, N) { partition F-P into X1, X2, …, Xn equally; if (test(P union Xi) = FAIL for some Xi) {//reduce F
return DD#(P, P union Xi, 2); } if (test(F - Xi) = PASS for some Xi) {//grow P
return DD#(F-Xi, F, 2); } if (test(P union Xi = PASS)) {//grow P
return DD#(P union Xi, F, max(N-1, 2))); } if (test(F - Xi = FAIL)) {//reduce F
return DD#(P, F-Xi, max(N-1, 2))); } if (N < |F-P|) {//increase granularity
return DD#(P, F, min(2N, |F-P|)); } return (P, F);}

Example
DD#(T1, T2, 2) DD#(T3, T2, 2) DD#(T3, T4, 2)
DD#(T5, T4, 2) DD#(T6, T4, 2) DD#(T7, T4, 2)

Theory
DD#({},U,2) is guaranteed to return a 1-minimal difference test case.
algorithm DD#(P, F, N) { partition F-P into X1, X2, …, Xn equally; if (test(P union Xi) = FAIL for some Xi) {//reduce F
return DD#(P, P union Xi, 2); } if (test(F - Xi) = PASS for some Xi) {//grow P
return DD#(F-Xi, F, 2); } if (test(P union Xi = PASS)) {//grow P
return DD#(P union Xi, F, max(N-1, 2))); } if (test(F - Xi = FAIL)) {//reduce F
return DD#(P, F-Xi, max(N-1, 2))); } if (N < |F-P|) {//increase granularity
return DD#(P, F, min(2N, |F-P|)); } return (P, F);}
Why?

Case Study: GCC
DDmin: after 731 test cases, the result is
DD#: (PASS means compilation succeeded; FAIL means compiler crashed; ? means all other cases) after 59 tests, the result is (see next page)

Case Study: GCC
This suggests a problem with inlining the expression i+j+1 in the array Accesses z[i] on the following line

Exercise 2
Take this program and this input as example. Apply delta debugging to locate the bug.

Research Question
How would you improve Delta Debugging?

Research Question
How would you improve Delta Debugging?
Are all generated test cases meaningful?How do we partition the input?

Research Question
How would you improve Delta Debugging?
Which test case to run first?

Research Question
How would you improve Delta Debugging?
What if there are multiple failure-inducing inputs?

Discussion
• Assume we given the following program and Delta Debugging run.
How do we make of the result?

Research Question
How would you improve Delta Debugging?
How can Delta Debugging be used to identify which statement in a program is buggy? (for simplicity, assume there
is only one statement which is buggy).