8 july 2002 delos summer school, pisa introduction to metadata
TRANSCRIPT

Introduction to Metadata
Thomas Baker, Fraunhofer-GesellschaftDELOS Summer School, Pisa
8 July 2002

Acknowledgements
• Carl Lagoze (Cornell University, USA)• Rachel Heery, Pete Johnston, Andy Powell
(UKOLN, UK)• Eric Miller (W3C, USA)• Howard Besser (UCLA, USA)

Part 1:What is Metadata?

“Metadata”
• “Structured data about other data”• Three traditions:
– Database Management Systems• Schemas of relational databases
– Library Cataloging Tradition (next slide)– Web Metadata (the rest of this talk)

Library Cataloging
• 19th century: bibliographic records (card catalog) and cataloging rules
• 1960s: machine-readable card catalogs (MARC and its variants)
• 1970s-1980s: online library networks and extended cataloging rules (AACR2 , RAK)

Control fields (00X)
Number & code fields (0XX)
Access point (1XX = main entry)
Title, publisher, etc. (2XX)
Physical description (3XX)Series (4XX)
Notes (5XX)
Subject headings (6XX)
Local fields (9XX)

From HoldingsRecord

“One Big Schema”• MARC/AACR2 records combine:
– Description (of different types of objects, such as books and films)
– Subject analysis (what a book or film is about, such as “Trade Unions – Australia”)
– Holdings information: location– Records created by highly trained professionals
• Philosophy: one big schema (“the catalog card”) can meet user needs for all types of works

1994+: the Web asOne Big Information System
• Search engines, but known limitations:– Index coverage is spotty, or simply unknown– Too many hits, too little precision– Advertisers pay for top spots– Spamming (bogus keywords to attract hits)– Resources change addresses, or disappear– Entire Web sites disappear
• Unsolved problems:– Archiving historical snapshots of the Web– Authenticating or trusting Web resources– Access to and payment for Intellectual Property

Evolution towards the “Automated Digital Library”
• “Simple algorithms plus immense computing power often outperform human intelligence” (William Arms)– Librarians and their metadata are expensive!– Automatically analysing citations (linking to objects
cited), matching word patterns, extracting descriptive terms – considerable progress!
– Example: http://google.com• That fully automated systems provide the Model T Ford of
information – cheap but functional

The Library is now “distributed”
• The Web: thousands of new information providers under one global roof– Thousands of local “metadata” systems– Libraries, with their metadata, in a minority– Specialized schemas for describing satellite
photos, video clips, government documents…• How to integrate access to this diversity?

“Warwick Framework” idea (1996)• Metadata “packages” for different uses by
different communities – modularity!Container
PackageDublin Core
PackageMARC record
PackageIndirect Reference
PackageTerms and Conditions
URI
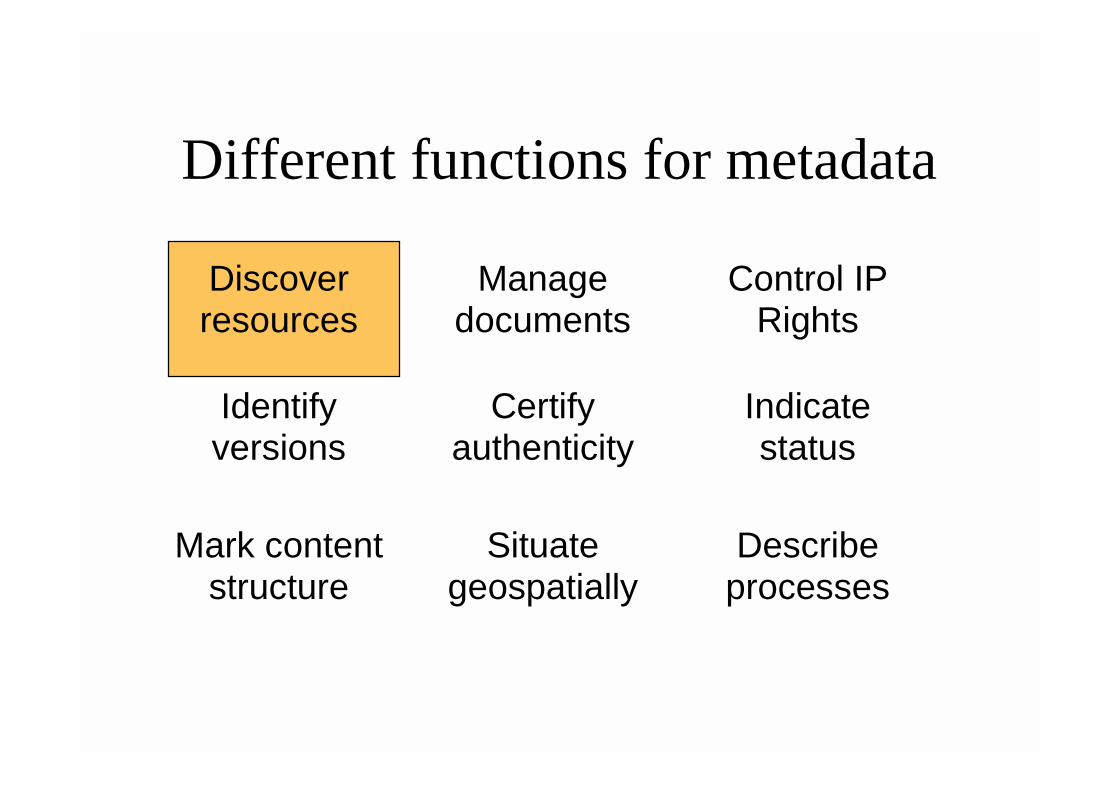
Different functions for metadata
Discover resources
Manage
documents
Control IP
Rights
Identify versions
Certify
authenticity
Indicate status
Mark content
structure
Situate
geospatially
Describe
processes

Metadata Challenges• Accommodate multiple varieties
– Wide diversity of metadata creators and maintainers
– Community-specific functionality• Tensions
– “Simple and broad” versus “richly specific” – “Generic” versus “customized”– “Readable by humans” versus “processable by
machines”

Hypotheses of the Web Age
• “Semantic Web” hypothesis– That rough integration of access can be
achieved via architectural standards that allow a servicable, if imperfect, merging of metadata.
• “Pidgin Metadata” hypothesis– That metadata based on a small vocabulary of
terms generically useful across disciplines can efficiently improve searching precision.

Humans vs machines:what balance?
cost
functionality
AACR2/MARC

Humans vs machines:what balance?
cost
functionality
AACR2/MARC
googleDublin Core




“Harvesting” hypothesis
• That globally scalable Digital Libraries can be built by Service Providers harvesting and integrating metadata from a diversity of Content Providers– Presupposes standard element sets– Presupposes record formats– Presupposes conventions for making records
available and protocols for harvesting

“Registry infrastructure” hypothesis
• That the coherent integration of metadata will require an infrastructure for bridging semantic differences machine-processably– Conventions for representing element sets– Describing relations between different metadata
standards– Describing standards-based schemas locally
customised for specific uses

Roadmap
• 1. What is metadata?• 2. Basic resource discovery – Dublin Core• 3. Encoding metadata (Semantic Web)• 4. Harvesting• 5. Metadata Infrastructure• 6. Metadata Landscape

Part 2:Basic Resource Discovery –
The Dublin Core

Motivation (mid-1990s)• Massive amounts of materials posted to a new
World Wide Web• Library standards (eg, MARC/AACR2) too
complex for mass adoption• Can we agree on a simple and intuitive template
for describing Web pages?• Initial metaphor of “catalog card” or “record
format” – “what do we want to see on screen?”• Collective realisation that machine-processability
requires a coherent data model

Fifteen Core Elements (1996)
Creator Title Subject
Contributor Date Description
Publisher Type Format
Coverage Rights Relation
Source Language Identifier

Towards a data model• 1996: “Warwick Framework” proposed at DC-2 workshop:
DC as one specialised module (“resource discovery”) among many
• 1997: “Qualifiers” proposed for specifying meanings– Some early adopters take this to unintended extremes:
“DC.Creator.telephone-number”• 1998: DCMI involvement in emerging Resource
Description Framework and clarification of simple data model for Dublin Core
• 2000: First set of qualifiers officially approved

Towards conventions for encoding• Mid-1990s: HTML tags embedded in Web pages
– Simple, easy to deploy, but inflexible, hard to maintain– Bad tags like DC.Creator.eyecolor imply a non-existent
support for nesting and for entity distinctions• 2000+: Better XML/RDF alternatives (see below)
– RDF metadata supports complex structures without breaking simple DC grammar
– Open Archives Initiative promotes mass adoption of an XML schema for simple, unqualified Dublin Core records – along with a protocol to harvest them!

Inherent tensions• Broad, fuzzy “search buckets” or rigidly prescribed usage?• Generic applicability across domains or intra-domain
precision?• One-size-fits-all or customise-as-you-please?• Simply discovering resources (a few typical search
attributes) or describing them fully (lots of detail)?• Dublin Core primarily as a native record format or
extracted from richer metadata?• Broad-brush minimalism or comprehensive structuralism?

Pidgin Metadata• Recognition that such tensions are in the very nature of
human communication• Like a “pidgin” – speaking simply, so as to be understood:
– Tourist to native speaker: Zwei Bier bitte. Answer: OK.– We are all tourists on a global Web with linguistically
diverse metadata– Like a pidgin, a few “core” words: Creator, Title…– Not subtly expressive, a limited grammar, but easy to
learn and deploy – “good enough” to work

Principle of Least Power
• Tim Berners-Lee (citing Dublin Core among others):– Nowadays we have to appreciate the reasons
for picking not the most powerful solution but the least powerful.
– The less powerful the language, the more you can do with the data stored in that language.(http://www.w3.org/DesignIssues/Principles.html)

Resource has dc:creator „Tom Baker"
Dublin Core statement
<dc:creator>Tom Baker</dc:creator>
XML encoding

Qualifiers add some precision
Resource has dc:date "2002-07-08"Presented
ISO8601
"This resource was presented on 8 July 2002."

...or are "dumbed down" (ignored)
Resource has dc:date "2002-07-08"
"This resource has [some sort of] date [represented by the string] "2002-07-08".

Dumb-Down Principle• The fifteen core elements are usable with or without
qualifiers• Qualifiers make elements more specific:
– Element Refinments narrow meanings, never extend– Encoding Schemes give context to element values
• If your software encounters an unfamiliar qualifier, look it up – or just ignore it!

Value Encoding Schemes• Says that the value is
– a term from a controlled vocabulary (e.g., Library of Congress Subject Headings)
– a string formatted in a standard way (e.g., that "05/02" means May 2nd, not February 5th)
• Even if a scheme is not known by software, the value should be "appropriate" and usable for resource discovery.

Element Refinements• Make element meanings narrower, more specific:
– a Date Created versus Date Modified– an IsReplacedBy versus Replaces Relation
• Note: In XML/RDF, a clear trend to use refinements as stand-alone tags instead of with elements:
– <dc:created>2002-08-04</dc:created>, instead of:– <dc:date><dct:created>2002-08-04 </dct:created><dc:date>
– Implicitly relies on schemas for „dumbing-down“ to broader concepts (e.g., Date Created to just Date)
– For now, Dublin Core is simple enough to support both usages; one or the other will prevail with time, and naming conventions will adjust

DCMI Namespace Policy• All DCMI metadata terms are given unique
identity within three namespaces:– http://purl.org/dc/elements/1.1/ - the legacy DC-15– http://purl.org/dc/terms/ - all other elements/qualifiers– http://purl.org/dc/dcmitype/ - a Type vocabulary– Example: http://purl.org/dc/elements/1.1/title
• Policy on long-term stability of namespace URIs– Changes not substantially “semantic” (i.e., corrections)
will not result in change of namespace URIs– “Semantic” changes must trigger a change of name– Version turnover of a “document management” nature
will have no effect on namespace URIs

DCMI Registry• Prototype database based for serving up term
definitions, translations, and application profiles related to Dublin Core
• Plain-vanilla, good-practice application of open Web standards (e.g., RDF schemas)
• Liaison with related initiatives on defining shared conventions for declaring vocabularies on the Web (e.g., EU CORES Project)
• Planning for machine interface to future registry-using applications

DCMI Usage Board• DCMI term set must evolve as implementors coin new
terms and usage patterns emerge• Usage Board reviews proposals for new metadata terms
(elements, refinements, encoding schemes, Type terms)– Evaluates proposals in light of grammatical principle,
usefulness, clarity of definition, overlap with existing terms• Reviews application profiles that are based substantially
(though not exclusively) on Dublin Core• Tiered model of approval status: conforming,
recommended, obsolete

Formal Standardisation• CEN Workshop Agreement (EU)
– Dublin Core elements endorsed as CWA13874– Usage guidelines for European industry
• NISO Z39.85 (USA)– National Information Standards Organization,
an ANSI affiliate

Open Participation
• Join the DC-General mailing list
• Join a working group
• Information on lists and working groups at http://dublincore.org

DC-2002 in Florence
• 13-17 October 2002• Technical working group meetings• Implementation reports and research papers• Introduction and tutorials for non-experts• http://www.bncf.net/dc2002/

Part 3:Encoding Metadata

Syntax Alternatives: HTML• Advantages:
– Simple to deploy: META tags embedded in content
– Widely available tools and knowledge• Disadvantages
– Limited structural richness: no support for tree-structured data or multiple “entities”

Dublin Core in HTML
<link rel="schema.DC" href="http://purl.org/dc/elements/1.1"> <meta name="DC.Title" content="Business Unusual”><meta name=“DC.Title” lang=“es” content=“negocio inusual”> <meta name="DC.Creator" content="Carl Lagoze"> <meta name="DC.Subject" content="bibliographic control web cataloging "> <meta name="DC.Date.Created" scheme="W3CDTF"
content="2000-10-23"> <meta name="DC.Format" content="text/html"> <meta name="DC.Identifier"
content="http://lcweb.loc.gov/lagoze_paper.html">

Dublin Core in HTML• <link> to establish pseudo-namespace• <meta> for metadata statements
– name attribute for DC element (DC.element.ER)
– content attribute for element value– scheme attribute for encoding scheme or
controlled vocabulary – lang attribute for language of element value

Syntax Alternatives:XML
• W3C standard for networked text and data• XML (vs. HTML)
– Familiar angle bracket markup– No pre-defined markup tags
• Separation of structure and appearance• Community extensibility

DTDs and XML schemas• Purpose: to describe structures of XML tags
– E.g. define a tag address with nested tags street, city, state, zip
• For structuring of instance data (metadata records)– Allows notion of data conformance– Facilitates construction and efficiency of data
storage and querying

Dublin Core in XML<metadata
xmlns:dc="http://www.openarchives.org/OAI/dc.xsd"><dc:creator>
Carl Lagoze</dc:creator><dc:title>
Accommodating Simplicity and Complexity inMetadata
</dc:title><dc:date>
2000-07-01</dc:date><dc:publisher>
Cornell University, Computer Science</dc:publisher>
</metadata>

XML Namespaces:Unique contexts for tag names
<metadataxmlns:dc="http://dublincore.org"xmlns:abc="http://ilrt.bris.uk/harmony"><dc:creator>
Carl Lagoze</dc:creator><abc:organization>
Cornell University</abc:organization>
</metadata>

"Bad example" of nested XML: Who is the creator?
<creator>
<name>
<family>Smith</family>
<given>Joe</given>
<nick>”the lion”</nick>
<title>Dr.</title>
</name>
<affiliation>New York University</affiliation>
<email>[email protected]</email>
<shoeSize>12W</shoeSize>
<bday>1978-05-01</bday>
</creator>

XML: many ways to do it!• "XML allows users to add arbitrary structure to
their documents but says nothing about what the structures mean" -- Tim Berners-Lee, 2001
• Different XML schemas have different structures, all "good" (and valid)
• Humans may be able to interpret, but machines need prior knowledge of parent-child elementrelations
• Not scalable in an open Web, where machines are always encountering unknown schemas

Semantic Web vision

What is it?• Standards-making activity of World Wide Web
Consortium (W3C)• Making Web-accessible data easier to process• Making machine-readable statements about all
kinds of things (Web pages, organisations, people, concepts, products, etc) and the links between them
• Explicit form for stating relationships between things

Core architectural principles• Simple linked data model
– a Web link means "has something to do with"• URIs: everything has a unique address
– Both resources and the metadata terms used to describe them
• XML: universal file format• XML namespaces: unique identifiers for
metadata vocabulary terms

Why?• Not only display Web data for people, but process
automatically (by software)• To share data between programs and resources
designed independently– Essential trait of a massively distributed Web– Incorporate, reuse, re-purpose data for unanticipated
objectives– Allow diverse communities to communicate on the
basis of partial (imperfect) understanding

How?
• Create webs of information about related things using explicit statements
• Statements follow a common model and use machine-processable vocabularies
• URIs ensure that vocabulary terms are tied to uniquely identified within the global context of the Web

"RDF"• Set of conventions for applications exchanging
metadata• Basic model for making statements about:
– Resources: anything named with a URI– Description: stating the properties of the resource using
terms named by URIs– Framework: a common model (grammar) for
statements using diverse vocabularies
• Statements most commonly written in XML

RDF Model Primitives
ResourceProperty
ValueResource
Statement

Simple statement in RDF
<?xml version="1.0"?>
<rdf:RDFxmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"xmlns:dc="http://purl.org/dc/elements/1.1/” ><rdf:Description about="http://doc” ><dc:creator> Joe Smith </dc:creator>
</rdf:Description></rdf:RDF>
"http://doc was created by 'Joe Smith'."
http://doc "Joe Smith"dc:creator

"http://doc was created by 'Joe Smith',who was born on May 1 and wears Size 12W shoes"
...with added information...
http://docdc:creator http://smith.
com/joe
"Joe Smith"
"1978-05-01"
"12W"
x:shoeSize
rdfs:la
bel
x:bday

"http://doc was created by [a person represented byURI http://smith.com/joe and named] 'Joe Smith'..."
...which the processor can ignore
http://docdc:creator http://smith.
com/joe
"Joe Smith"
rdfs:la
bel

"http://doc was created by 'Joe Smith'..."
...to read as a simple statement
http://docdc:creator
"Joe Smith"

URIs: Everything defineduniquely on the Web
Tim Berners-Lee:
“The most fundamental specification of Web architecture, while one of the simpler, is that of the Universal Resource Identifier, or URI. The principle that anything, absolutely anything, ‘on the Web’ should be identified distinctly is core.”

URIs as anchors for merging data• URIs are fixed points on global Web for:
– Metadata vocabulary terms, defined with "dictionary entries" in namespace schemas
– The resources described by those terms• These points can be used to superimpose
graphs, merging statements• Creates market for aggregation, data
merging, annotation, and filtering services


Second source
http://pj.org/doc/1subject
XML

Third source
http://pj.org/person/pete
organisation
UKOLN
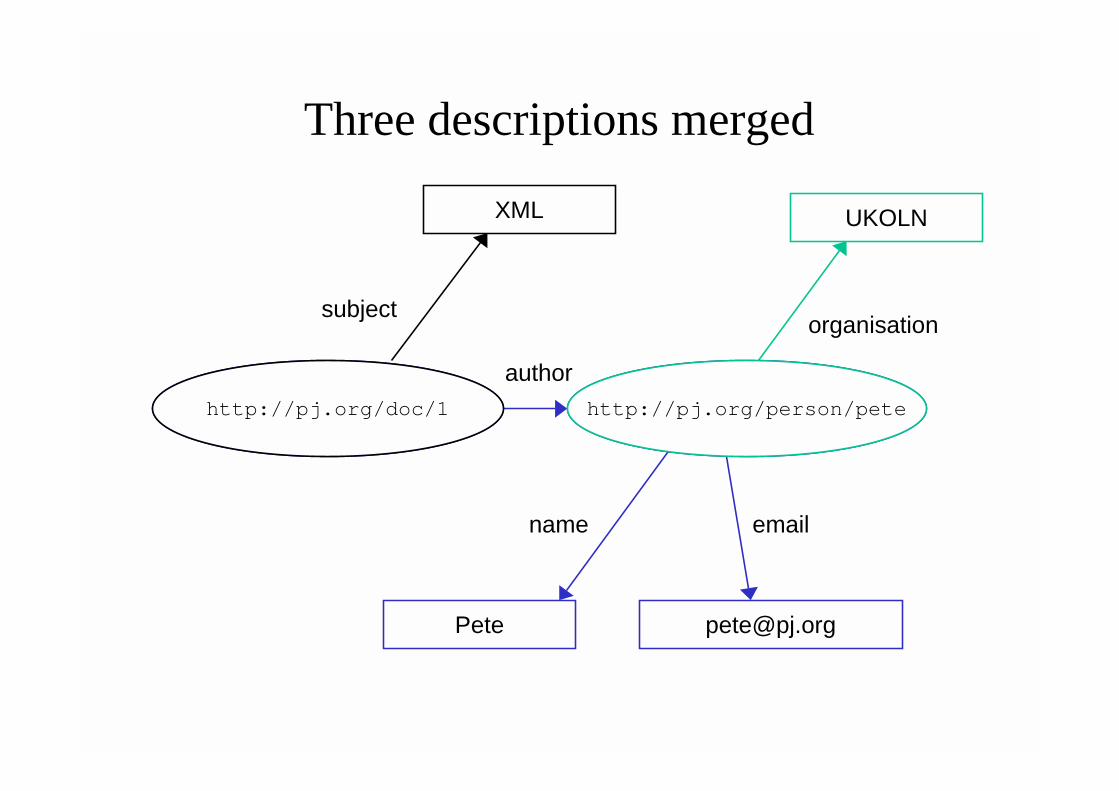
Three descriptions merged
http://pj.org/doc/1
author
Pete
http://pj.org/person/pete
name email
http://pj.org/doc/1
subject
XML
http://pj.org/person/pete
organisation
UKOLN
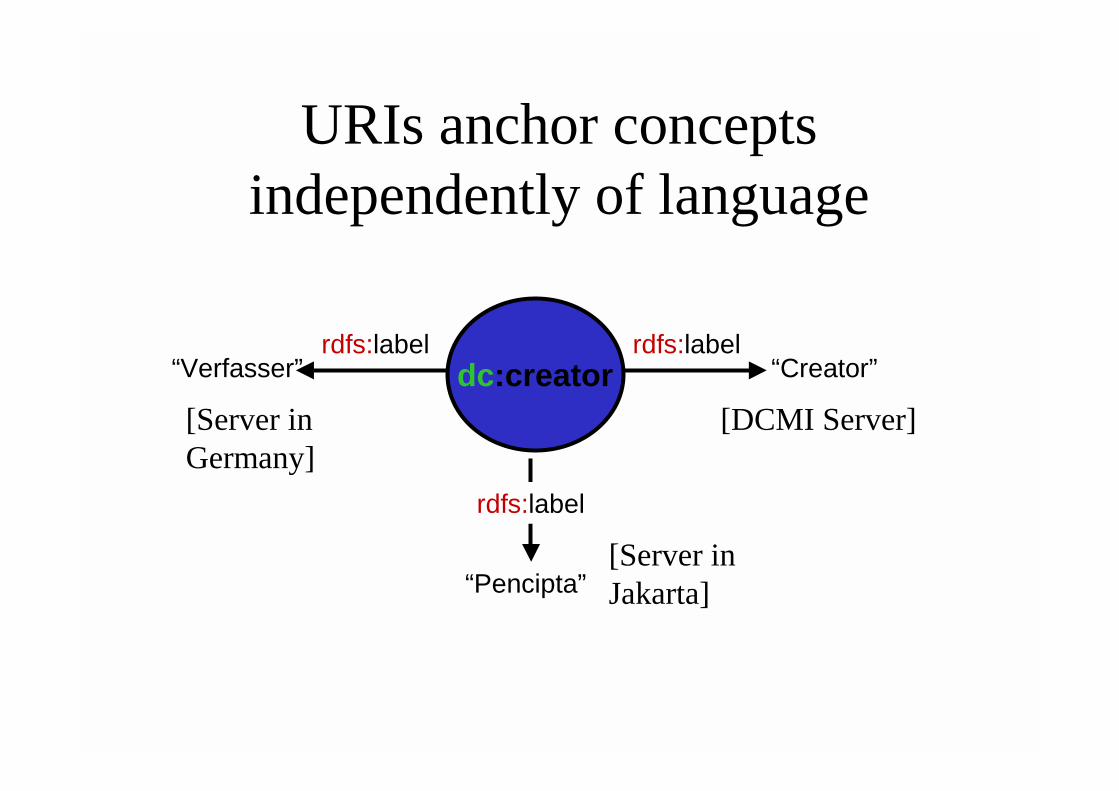
URIs anchor conceptsindependently of language
dc:creator“Verfasser”rdfs:label
“Creator”rdfs:label
“Pencipta”
rdfs:label
[Server inGermany]
[Server inJakarta]
[DCMI Server]

Elementary sentences• In RDF, meaning is expressed by Subject,
Predicate, and Object– This simple structure can be used to describe
most of the data processed by machines– More complex will not interoperate in the
diverse Web environment• Instead of asking machines to understand
people's language, ask people to make the extra effort [Tim Berners-Lee]

Partial understanding• As in real world, anyone on Web can assert
(in RDF sense) anything about anything • Assumption: you will understand some of
these statements but not all.– Ignore the ones you don't understand– Tolerance of inconsistency and errors
• Web itself: "Error 404: File not found", but unchecked exponential growth

Part 4:Metadata Harvesting –
The Open Archives Initiative

Motivation (1999)• Universal Preprint Service meeting (1999)
– Representatives of ePrint, library, publishing, communities
– Goal: to define an interoperability framework among ePrint providers
– Increase impact of eprint initiatives through federation
– Santa Fe Convention: metadata harvesting among member archives

“Metadata harvesting” hypotheses
• That exposing metadata in various forms will facilitate the creation of value-added services
• That the key to deployable digital library infrastructure is low-entry cost
• That individual communities can and will customize the common infrastructure

OAI Philosophy• Spectrum of Interoperability
– Embrace collections with rich metadata and technology– Accommodate those with limited metadata, technology
• “Open”-ness– Follows library tradition of metadata sharing– Rooted in eprint movement towards reforming
scholarly publishing– But technology neutral with respect to economic model
• Technology– Automated methods to generate, normalize, and
translate metadata– Distribute metadata to service providers

OAI Protocol for Metadata Harvesting (OAI-PMH)
The goal of the Open Archives Initiative Protocol for Metadata Harvesting … is to supply and promote an application-independent interoperability framework that can be used by a variety of communities who are engaged in publishing content on the Web. The OAI protocol … permits metadata harvesting.

OAI-PMH Technical Features
• “Deploy now” technology – 80/20 rule• Two-party model – providers (data providers) and
consumers (service providers)• Simple HTTP encoding• XML schema for some degree of protocol
conformance• Extensibility
– Multiple item-level metadata– Collection level metadata

Discovery CurrentAwareness Preservation
Service Providers
Data Providers
Metad ata
harvesting
World According to OAI-PMH

Supporting protocol requests:• Identify• ListMetadataFormats• ListSets
Harvesting protocol requests:• ListRecords• ListIdentifiers• GetRecord
repos i tory
harves ter
service provider data providerOAI-PMH Requests

Support for metadata formats
• Support for harvesting multiple metadata formats– metadata schema: each format must have a validating
XML schema at a publicly accessible URL (communities may define shared formats and schema)
– metadata prefix: each repository maps a prefix to the schema it supports, which is used in protocol requests
• Support for unqualified Dublin Core is mandatory– DC OAI record syntax builds on base DCMI schema– reserved prefix oai_dc

OAI Metadata Record<record>
<header><identifier>oai:eg:001</identifier><datestamp>1999-01-01</datestamp><setSpec>cs</setSpec>
</header><metadata>
<dc xmlns=“http://purl.org/dc”><title>My Example</title>
</dc></metadata><about>
<ea xmlns=“http://www.arXiv.org/ea”<usage>No restrictions</usage>
</ea></about>
</record>
protocol support
format-specificmetadata
community-specificrecord data

Item Identifier• Uniquely identifies an item within a repository• Used in OAI-PMH requests for extracting
metadata from the item• Record is uniquely identified by combination of:
– Item identifier– Metadata format– Date of change or modification

OAI Identifiersoai-identifier = oai:archive-identifier:record-identifier
Registered URI
Scheme
Archive Identifier:Registered within
OAI
Unique ID within archive: (syntax is archive-specific)
example = oai:ncstrl:ncstrl.cornellcs/TR94-1418

Support for “sets” of resources• Optional construct for grouping items for the
purpose of selective harvesting • Repositories define their own set organization
– meaning of sets or of set hierarchy is not defined in protocol
– individual communities may formulate common set configurations
• Each item in a repository may be organized in one set, several sets, or no sets at all

OAI-based Initiatives• European Community
– Open Archives Forum– Cyclades Project
• Andrew W. Mellon Foundation– Funding for seven service providers
• Digital Library Federation– Gateways for access to DLF-member collections
• National Science Foundation– National Science Digital Library core infrastructure

NSDL Size and Diversity
• Large-scale digital library technology– 1,000,000 users– 10,000,000 items– 100,000 collections
• Diverse participants– Libraries– Academic/research institutions– Individuals

NSDL Metadata strategy
• Principle: “Metadata is too expensive to create much. Use existing metadata when possible.”
• Strategy:– Support eight standard formats (next slide)– Collect all existing metadata in these formats– Provide crosswalks to Dublin Core– Assemble all metadata in a central repository– Expose all such records to harvesters– Focus limited human effort on collection-level MD– Use automatic generation to augment item-level MD

NSDL Supported formats• Dublin Core• For educational materials:
– Dublin Core with DC-Ed extensions– IMS (educational resources)– Sharable Content Object Reference Model (SCORM)
• MARC21 (library catalogs)• Content Standard for Digital Geospatial Metadata
(FGDC)• Global Information Locator Service (GILS)• Encoded Archival Description (EAD)

OAI Measures of Success• 72 “registered” data providers
– Actual number is probably double• Basis for research and implementation
– JCDL Conference, May 2002:• “OAI” as a category for paper submission!• Numerous papers building on OAI
– Research projects and funding

A Collective Experiment
• Organizational model lean and mean while encouraging community-specific exploitation
• Encouraging testing, especially through deployment and especially service development
• Types of metadata beyond Dublin Core– Preservation, document access, authentication

Open Participation
• Listservs– oai-general – discussion of OAI related issues– oai-implementers – sharing technical questions
and agendas• OAI website
– Post news and links to OAI related activities– http://www.openarchives.org

Part 5:Metadata Infrastructure

Metadata is language• Metadata makes statements about
resources:– Book has Title "Gone with the Wind"– Web page has Publisher "Springer Verlag"
• Its words (terms, or elements) are defined in standards like Dublin Core
• Grammars and data models constrain what metadata can say, and how

But languages evolve with use• Inevitably, languages resist stability• People stretch official definitions• Implementers misunderstand the intended
meaning or use of elements • Implementors coin local terms and extensions• If the application does not fit the standard, the
standard is often "customized" to fit the application

What metadata languages lack
• Comprehensive dictionaries – Where can one get an overview of vocabulary
terms used in metadata languages?• A publication context for implementers
– Where can you see how information providers are using metadata?
• Standard grammars– Do metadata models share common principles?

A general need tomanage vocabularies
• Library world– Controlled vocabularies, thesauri, classification– Subject headings: „Jamaica – History, modern“
• Corporate world– Taxonomies („key to searching“ in enterprise portals)– Product types: „Laptops, PDAs, Printers, Modems...“
• Research world– Ontologies of concepts, topic maps

Declaring metadata terms• Declare the names and definitions
(semantics) of metadata terms (elements)– Range from official standards to project-
specific schemas– Printed documentation or Web pages– Or machine-processable schemas in XML or
XML/RDF

Types of term declarations• Namespace schemas: declare a unique set of
elements and definitions– Ideally, addressed on the Web with a URI– May be an XML or XML/RDF schema
• Profiles: declare how an application uses which terms in its metadata– May mix-and-match from multiple namespaces

Declaring metadata termswith RDF schemas
• RDF schemas as a uniform data model and XML format for declaring metadata terms
• Example: "Title" (Dublin Core)– Human-readable label and definition:
• Title: A name given to the resource.– Unique, machine-readable identifiers
• dc:title
• Support for cross-references– between terms in related standards– between local adaptations and related standards



A global Semantic Webof metadata terms?
A distributed corpus of term declarations in RDF could be harvested and indexed as one huge database
• Click on cross-references to follow term-to-term links between vocabularies
• Point-to-point, like the Web itself?– In 1992, Gopher located the right file within
directory trees (but not points within the file)– HTML enabled point-to-point links between
documents

Cross-communityconsensus needed
• Need for shared conventions:– To declare element sets and other metadata terms
(namespaces)– To declare how local communities use or adapt
standards (profiles)• Cross-community consensus-building is needed
– W3C metadata standards and URIs as a shared basis?– EU CORES Project: explore possible agreement among
major standards initiatives such as DCMI, DOI, OASIS, TEI, CERIF, GILS, MPEG, and FGDC

Emerging registry efforts• Scope: Anything related to the semantics of metadata
terms and definitions– Metadata element sets (DCMI, DOI...)– Controlled vocabularies (NKOS...)– Crosswalks between standards (SUB Goettingen...)– Application profiles (SCHEMAS Project...)– Elements in multiple languages (ULIS...)– XML schemas and DTDs (OASIS...)– Ontologies (OntoWeb...)
• Granularity of indexing in registries may differ:– Schemas (sets of elements) as wholes– Individual terms

Tools for harmonization• Implementers want to know how their peers
design metadata – avoid "reinventing the wheel"• Information providers need to harmonize metadata
usage for improved access within domains, e.g.:– Between countries (Nordic Metadata Project)– Preprint repositories (Open Archives Initiative)– Subject gateways (Renardus)– Theses and dissertations (NDLTD)– Mathematics and physics (MathNet, PhysNet)

Potential roles of registries• To resolve or translate queries using different
metadata systems• Like dictionaries, both to pre-scribe
(recommended usage) and de-scribe (how terms are actually used)
• To help metadata vocabularies evolve more like other human languages– Historically, dictionaries have helped to harmonise
and standardize (national) languages– Traditional standards are defined top-down– Could also be bottom-up, in response to usage

Part 6:Metadata Landscape
Acknowledgements:Howard Besser, UCLA, Los AngelesThe SCHEMAS Project

Metadata Landscape – a sample• Metadata functions besides resource discovery
– structural, longevity, management, identification• Metadata for particular applications
– Scholarly resources– Government Information– Rights Management – Specific domains (education, museums)– Industrial sectors– Geospatial description– News feeds– Multimedia (audio and video)
• National and regional programs (EU, UK, USA…)• Models, frameworks, and tools• Conferences and sources of information

Structural metadata
• Not merely display a work, but navigate• Example: digital book
– View Table of Contents, turn pages, jump to a particular chapter
– Link to footnotes and citations – and back!– http://www.firstmonday.dk/issues/issue7_6/besser/index.html

Administrative metadata
• Information necessary to keep a work accessible over time– Location and format of files constituting an object– Specification of software needed to access
• Commercial vs open formats: – Proprietary formats convenient (eg, Adobe’s PDF), but
dangerously dependent on long-term availability of software
– Emerging open-standard alternative: METS

Metadata for identification
• Proliferation of versions and editions– New versions issued frequently on the Web– Single work, many formats (HTML, Postscript,
PDF, MS-Word…)– Different resolution of images (eg, thumbnails)
• “Families” of objects sharing (inheriting) common metadata

Metadata for longevity• Keeping digital material accessible over long
periods of time– The Viewing Problem: opening a Wordstar file from 1986– The Scrambling Problem: so many compression formats…– The Inter-relation Problem: where are the boundaries of works
consisting of multiple files?– The Custodial Problem: who is responsible for saving digital
content?– The Translation Problem: converting formats, sometimes lossily
• First efforts towards consensus on metadata for preservation
• http://www.gseis.ucla.edu/~howard/Papers/sfs-longevity.html

Scholarly resources• Open Archives Initiative (repositories)• Subject Gateways (portals)
– EU Renardus Project integrating portals at national libraries (DC-based)
• Theses and Dissertations– Networked Digital Library of Theses and
Dissertations (NDLTD)
• MARC 21: Machine Readable Cataloging– Record format and related vocabularies for libraries

Government Information
• GILS: Government Information Locator Service (USA)
• eGMS: e-Government Metadata Standard, UK Cabinet Office (DC-based)
• AGLS: Australian Government Locator Service (DC-based)

Rights Management
• INDECS: a model for transaction events involving people making deals about intellectual property
• DOI: using Indecs with Digital Object Identifiers to describe and link scientific, technical, and medical journals
• XRML: eXtensible rights Markup Language to describe rights, fees, and conditions for use– Works with patented technologies requiring licensing

Domains: education
• Teachers seeking appropriate classroom materials on Web may want to know:– for which age group?– has it already been used successfully in classrooms?– will it work on my equipment?
• GEM: Gateway to Educational Materials portal uses lightly extended Dublin Core metadata
• IMS: Templates for rich descriptions of learning resources

Museums• International Council of Museums: object-oriented
model (CIDOC) designed for describing multiple entities that may be– physical (e.g., museum objects)– conceptual (e.g., works)– temporal (e.g., historical periods)– spatial (e.g., places)
• Implies an integrated information space of "encyclopedic" scope

Industrial sectors
• ONIX: Online Information eXchange– XML templates for publishers to distribute
electronic information to booksellers– “The more information customers have about a
book, the more likely they are to buy it.”– Synopsis, reviews, author biography… - 200
data elements in ONIX DTD– Amazon, Borders…

Geospatial description• (US) FGDC Content Standard for Digital
Geospatial Metadata– Access to resources about a particular area
• Government, education, and business needs– Emergency management– Integrated databases and comprehensive maps– City planning– Environmental control

News feeds
• Rich Site Summary (RSS)– Metadata for content syndication (news feeds)– Used in developing media content portals– Built on established vocabularies (DC), uses
RDF syntax– Layers of application-specific semantics:
syndication vocabularies, annotation vocabularies, etc.

Multimedia
• Moving Picture Experts Group– MPEG 4: encoding and interacting with audio-
visual objects– MPEG 7: multimedia content description
interface for such objects– MPEG 21: ambitious "umbrella" framework
describing the infrastructure for delivering and consuming multimedia content

Programs: European Union• Fifth Framework Programme, 1998-2002
– several dozen projects of several countries each– Digital Heritage, Cultural Content, Electronic
Publishing, Multimedia
• Sixth Framework Programme (to start 2003)• DELOS Network of Excellence
– Communication within European digital library research community and international networking
– Sponsors of this Summer School

Programs: UK• Distributed National Electronic Resource (DNER)
– A managed environment for Internet access to scholarly journals and other materials relevant to higher education in the UK
– Uses international standards (eg, Dublin Core)– National purchase and licensing agreements for best
value to UK education community– eLib research funding since mid-1990s emphasized
incremental improvement of standards and services

Programs: USA
• National Science Foundation (NSF) Digital Library Initiative– Phase I (1994-1998): six large-scale testbeds involving
research universities, industrial partners, and next-generation technologies
– Phase II (1999+): expanded scope, smaller projects as well as large testbeds, emphasis on service to users and new types of content
• National Science Digital Library (NSDL):– building innovative, production-quality library services

Object models
• Metadata Encoding and Transmission Standard, http://www.loc.gov/standards/mets/– Document object model specified for US Digital
Library Federation– XML encoding for packages of descriptive and
administrative metadata for related files constituting a digital object
– Consistent with Open Archive Information System (OAIS) Reference model

Event-based models• ABC Model
– “Historical events” as anchor points for describing objects as they are created, evolve, and transform over time
– Designed for answering who, what, when, where queries that are difficult in simpler models
– A rich model designed for easily generating other formats (Dublin Core, MPEG…)

Metadata tools
• Where to even begin listing them…?• Eprints.org software: document repositories• Sesame: managing and querying RDF
repositories (ICS-FORTH, Greece)• Redland RDF Application Framework
(ILRT, UK)• XML parsers: Expat, XMLSpy…

Conferences
• Joint Conference on Digital Libraries, May 2002, Portland, Oregeon
• European Conference on Digital Libraries, September 2002, Rome
• DC-2002, October 2002, Florence• International World Wide Web Conference, May
2002, Honolulu• International Conference on Asian Digital
Libraries, December 2002, Singapore

Why the Web won• Tim Berners-Lee's original model was very
simple, and it was easy to implement• Real-world experience with simple HTML led
iteratively to better understanding of priorities– As with bicycles and airplanes, there was no
"theory" for design -- design was perfected iteratively, starting simple
• Complex standards impose significant costs, especially if legacy data must be converted

Evolving with experience
• People are only human – the most perfect language is always subject to interpretation
• By design, metadata languages must allow for innovation and evolution
• Physics and art history, Chinese and Finnish --different languages are inevitable in real life
• Diversity of metadata languages likewise inevitable• Interoperability over "everything" is inevitably lossy

Big Questions
• How much metadata is “enough”?• What role for human experts versus clever
algorithms?• How can we merge metadata coherently?• Through what means will we know who
stands behind what we see on the screen?

Further information• "Metadata Watch Reports“, SCHEMAS Project
– http://www.schemas-forum.org• D-Lib Magazine, http://www.dlib.org/dlib/• Ariadne, http://www.ariadne.ac.uk• IFLANET Metadata Resources
– http://www.ifla.org/metadata.htm• National Library of Australia Meta Matters
– http://www.nla.gov.au/meta/• UKOLN Metadata
– http://www.ukoln.ac.uk/metadata/
