a big data lake based on spark for bbva bank-(oscar mendez, stratio)
TRANSCRIPT

A Big Data Lake based on Spark for BBVA
June 2015
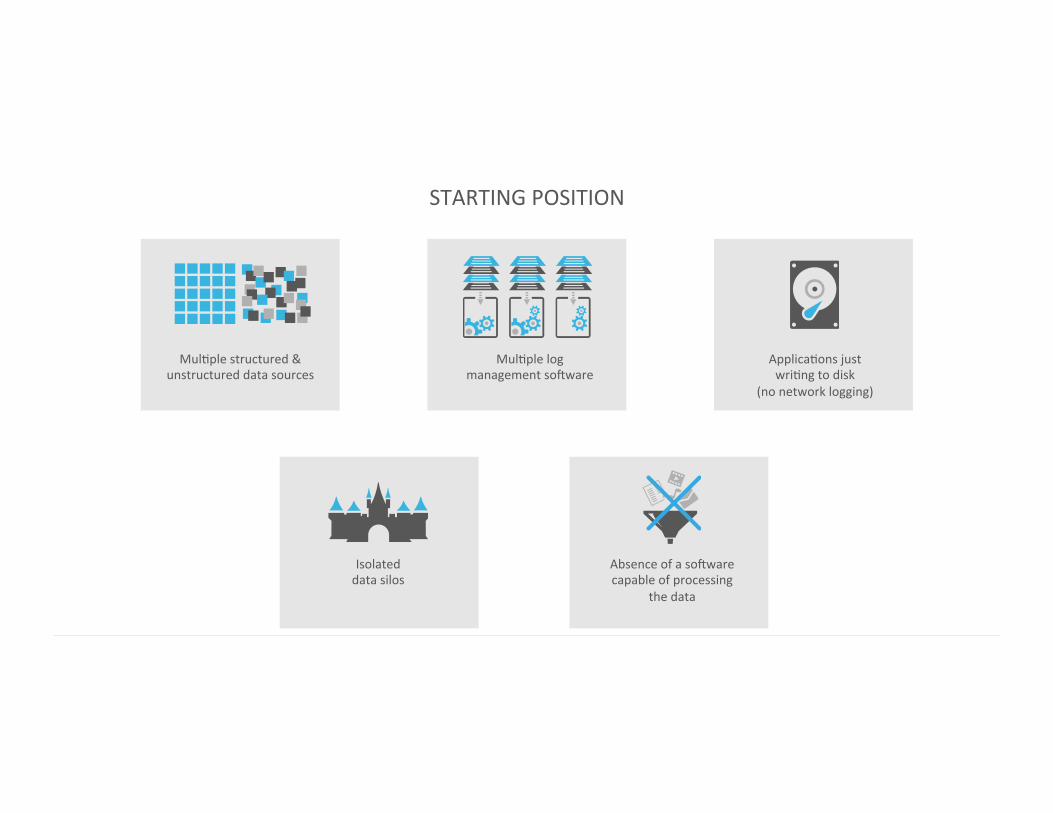
STARTING POSITION
Absence of a soDware capable of processing
the data
Isolated data silos
MulIple structured & unstructured data sources
MulIple log management soDware
ApplicaIons just wriIng to disk
(no network logging)

DRIVERS Countless applicaIons & benefits
FRAUD SECURITY DATA ANALYSIS
MONITORING
SIEM
AUDIT
E-‐COMMERCE
USER-‐TR
ACKING
DEVELOPMENT DEBUGGING REGULATORY COMPLIANCE
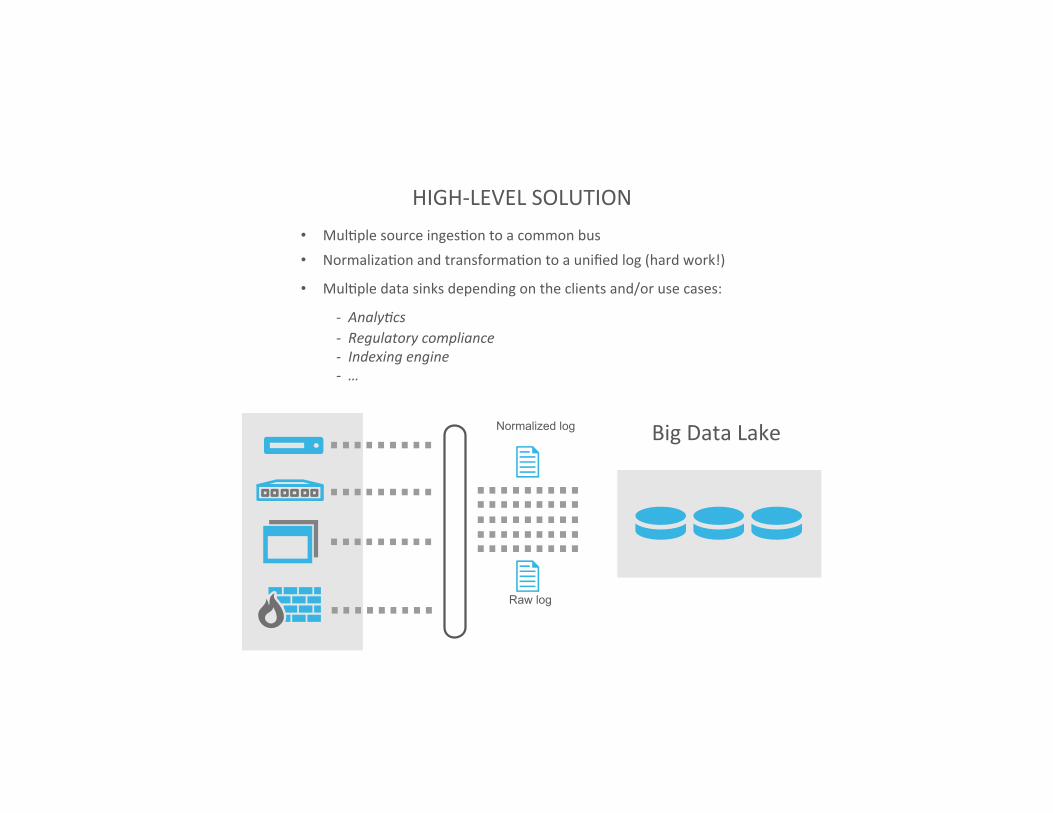
HIGH-‐LEVEL SOLUTION • MulIple source ingesIon to a common bus • NormalizaIon and transformaIon to a unified log (hard work!)
• MulIple data sinks depending on the clients and/or use cases:
-‐ Analy(cs -‐ Regulatory compliance -‐ Indexing engine -‐ …
Big Data Lake Normalized log
Raw log
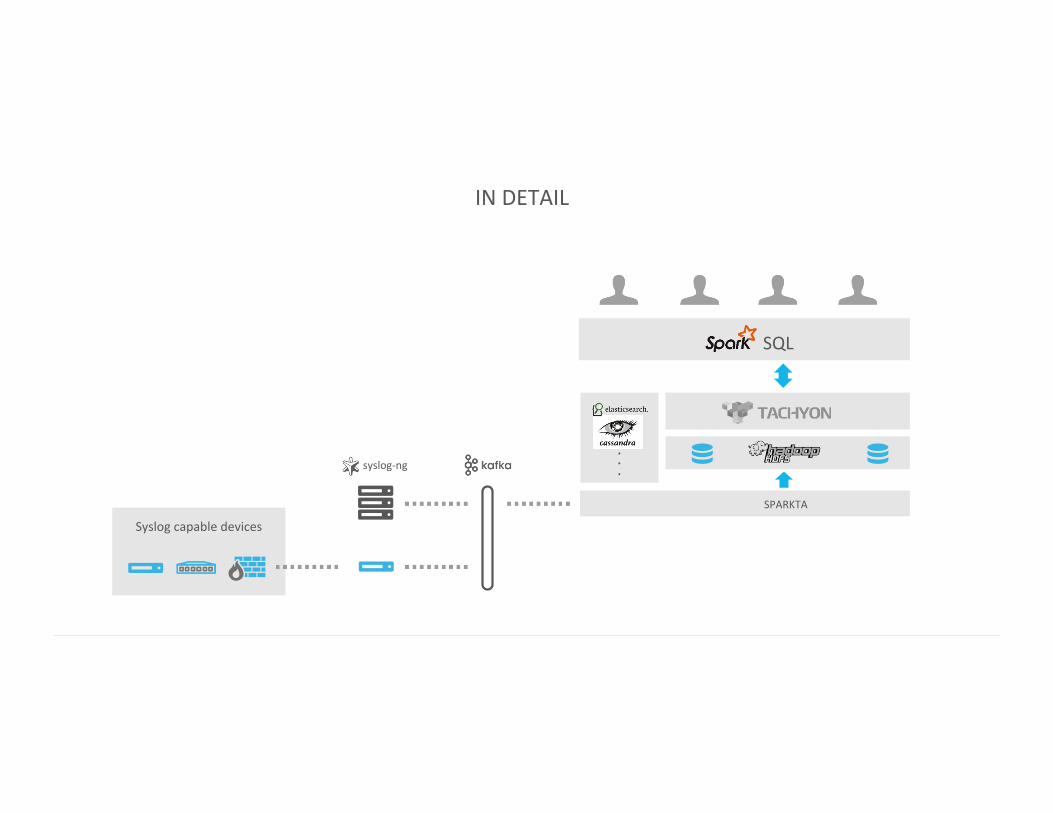
IN DETAIL
Syslog capable devices
syslog-‐ng
SQL
. . .
SPARKTA

SOFTWARE PIECES
1. LOGS SENT FROM SYSLOG-‐NG DEVICES THAT DON'T SUPPORT INSTALLATION OF SYSLOG-‐NG,
SEND LOGS VIA SYSLOG TO A SYSLOG-‐NG RELAY
2. LOGS SENT FROM SYSLOG-‐NG
USED AS A DISTRIBUTION HUB
A TOPIC PER CONSUMER/CLIENT
3. NEW APPLICATIONS TO WRITE DIRECTLY TO KAFKA
4. MULTIPLE DESTINATIONS
SPARKTA
ELK
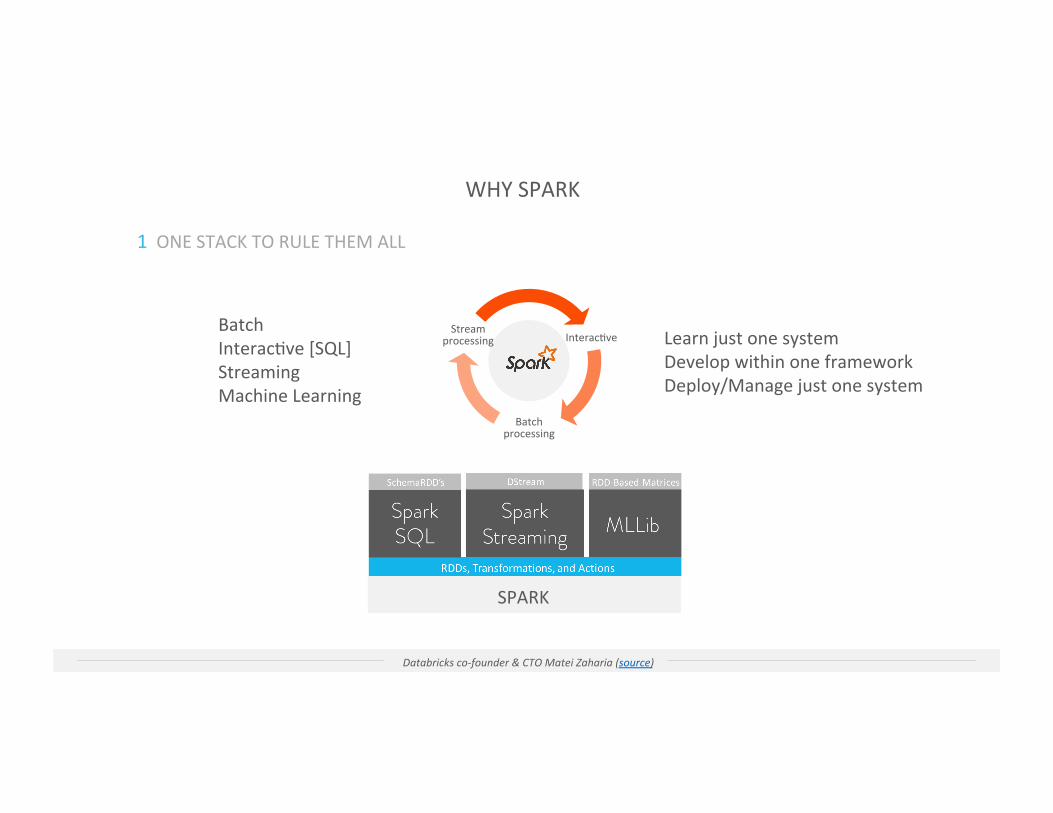
RDD-‐Based Matrices
Batch InteracIve [SQL] Streaming Machine Learning
WHY SPARK
1 ONE STACK TO RULE THEM ALL
Learn just one system Develop within one framework Deploy/Manage just one system
InteracIve
Batch processing
Stream processing
SPARK
Databricks co-‐founder & CTO Matei Zaharia (source)
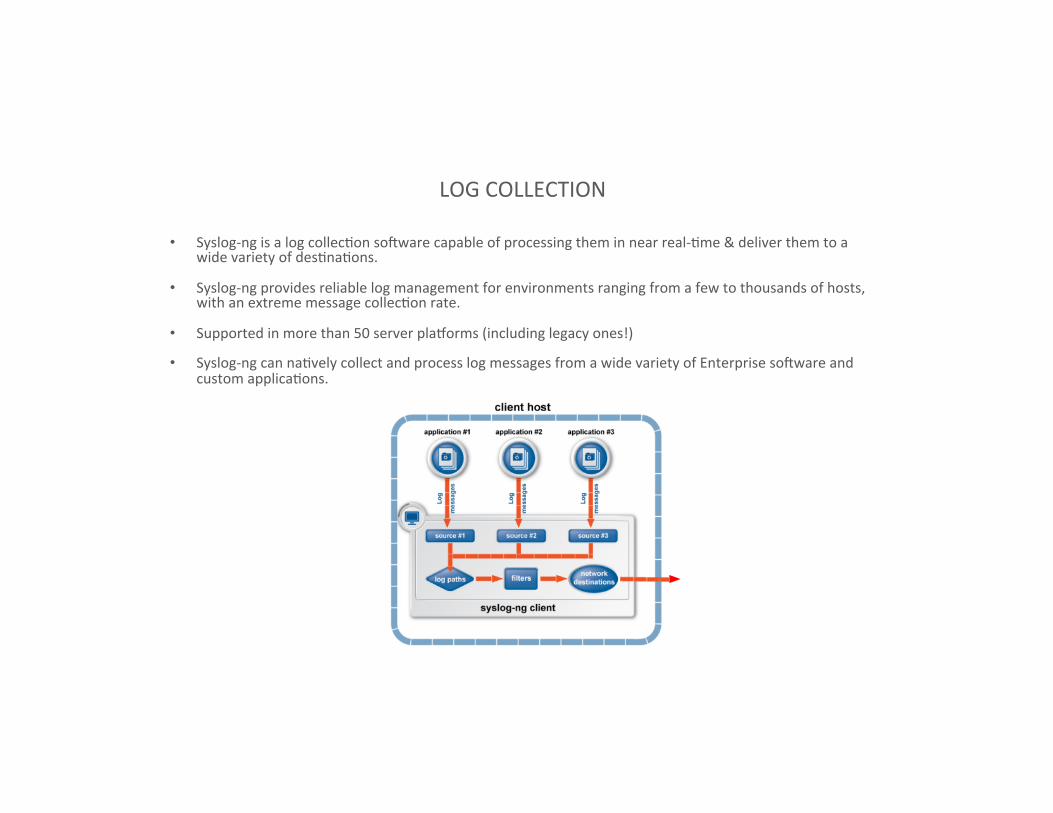
LOG COLLECTION
• Syslog-‐ng is a log collecIon soDware capable of processing them in near real-‐Ime & deliver them to a wide variety of desInaIons.
• Syslog-‐ng provides reliable log management for environments ranging from a few to thousands of hosts, with an extreme message collecIon rate.
• Supported in more than 50 server plahorms (including legacy ones!)
• Syslog-‐ng can naIvely collect and process log messages from a wide variety of Enterprise soDware and custom applicaIons.
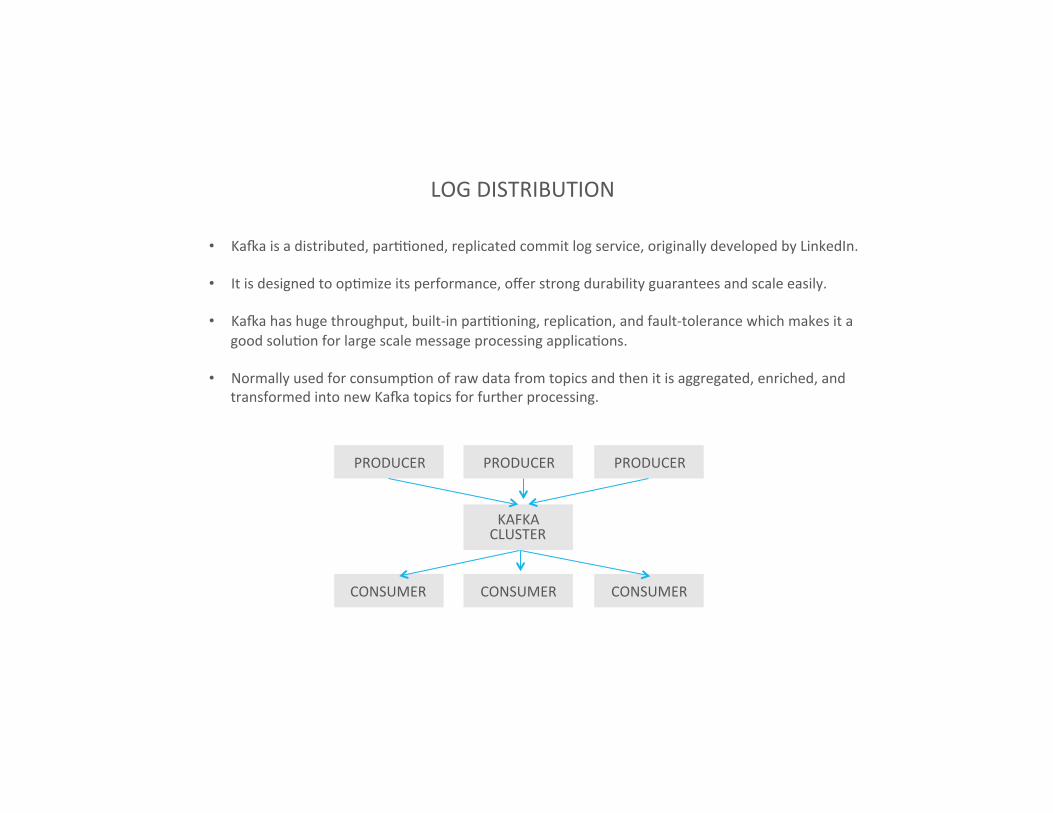
LOG DISTRIBUTION
• Kaia is a distributed, parIIoned, replicated commit log service, originally developed by LinkedIn.
• It is designed to opImize its performance, offer strong durability guarantees and scale easily.
• Kaia has huge throughput, built-‐in parIIoning, replicaIon, and fault-‐tolerance which makes it a good soluIon for large scale message processing applicaIons.
• Normally used for consumpIon of raw data from topics and then it is aggregated, enriched, and transformed into new Kaia topics for further processing.
PRODUCER PRODUCER PRODUCER
KAFKA CLUSTER
CONSUMER CONSUMER CONSUMER

LOG STORAGE
• HDFS is a distributed file system that provides high performance access to data stored in a cluster. • It is the ‘de facto’ clustered-‐storage soluIon in the Hadoop ecosystem, supported by the vast majority of
Big Data soDware. HDFS is a key technology when you are required to process, specially when it is staIc data.
• It is designed to achieve high availability, high performance and easy scalability. • Parquet is an efficient columnar storage format. Parquet is built to support very efficient compression
and encoding schemes. • Apache Avro is a data serializaIon system with rich data structures and a compact, fast, binary data
format.
Developer(s): Apache SoDware FoundaIon Stable release: 2.7.0/April 2015 OperaIng system: Cross-‐plahorm Type: Distributed filesystem License: Apache License 2.0 Website: hadoop.apache.org

…IN APROX. 200 SERVERS
STREAMED 11 TB/DAY
>2000 APPLICATIONS/DEVICES
FIGURES
NOT YET FULLY DEPLOYED
OBJETIVES / ESTIMATION
CONSIDERATIONS
REPLICATION
COMPRESSION
BOTTLENECKS
FAILURES
APROX. 2PB OF STORE DATA

SPARKTA REAL-TIME Challenges at Stratio 2

Towards a generic real-time aggregation platform
At Stratio, we have implemented several real-time analytic projects based on Apache Spark, Kafka, Flume, Cassandra, or MongoDB. These technologies were always a perfect fit, but we soon found ourselves writing the same pieces of integration code over and over again.
Towards a generic real-time aggregation platform
Some initiatives have tried to solve this problem, but until now most of them were complex or obsolete while others were not open source. For this reason, Stratio created SPARKTA: an open source and full-featured platform for real-time analytics, based on Apache Spark.

Distributed, high-volume & pluggable analytics framework
Our goals:
Since Aryabhatta invented zero, Mathematicians such as John von Neuman have been in pursuit of efficient counting and architects have constantly built systems that computes counts quicker. In this age of social media, where 100s of 1000s events take place every second, we designed a aggregation engine to deliver real-time
service
• No need of coding, only declarative aggregation workflows
• Data continuously streamed in & processed in near real-time
• Ready to use out of the box • Plug & play: flexible workflows (inputs, outputs, parsers,
etc…) • High performance • Scalable and fault tolerant
nice intro from countandra
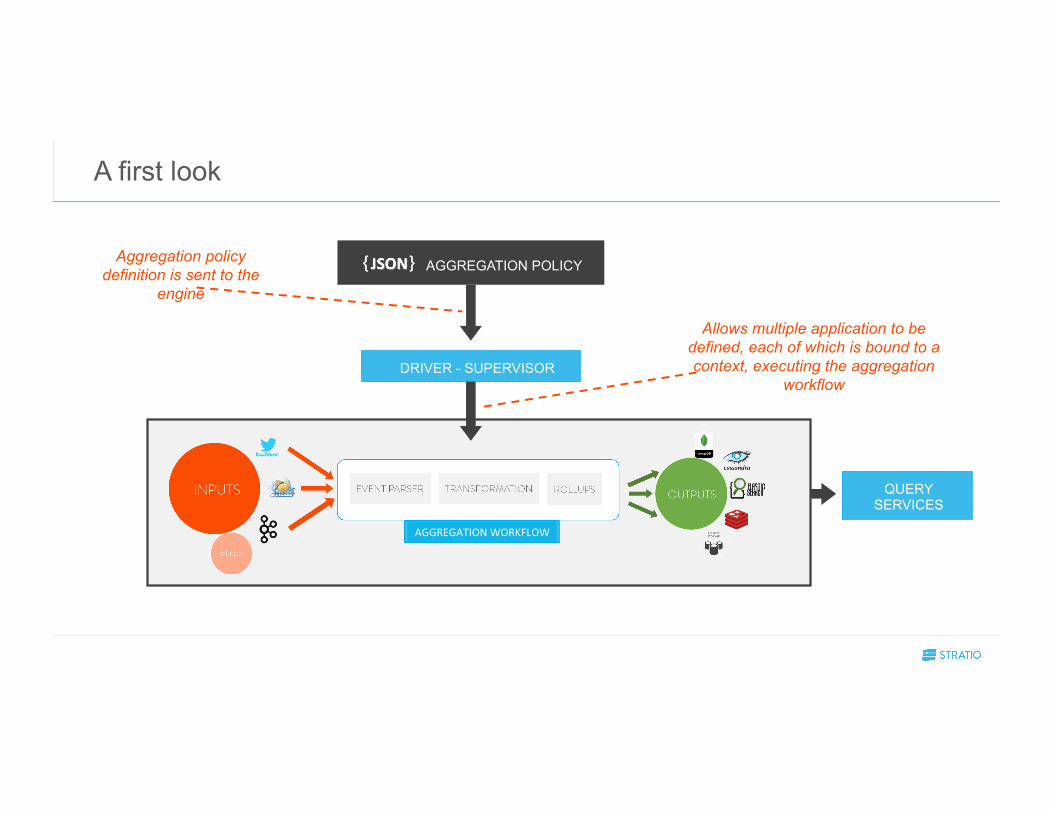
A first look
DRIVER - SUPERVISOR
AGGREGATION POLICY
QUERY SERVICES
Aggregation policy definition is sent to the
engine
Allows multiple application to be defined, each of which is bound to a context, executing the aggregation
workflow
others AGGREGATION WORKFLOW
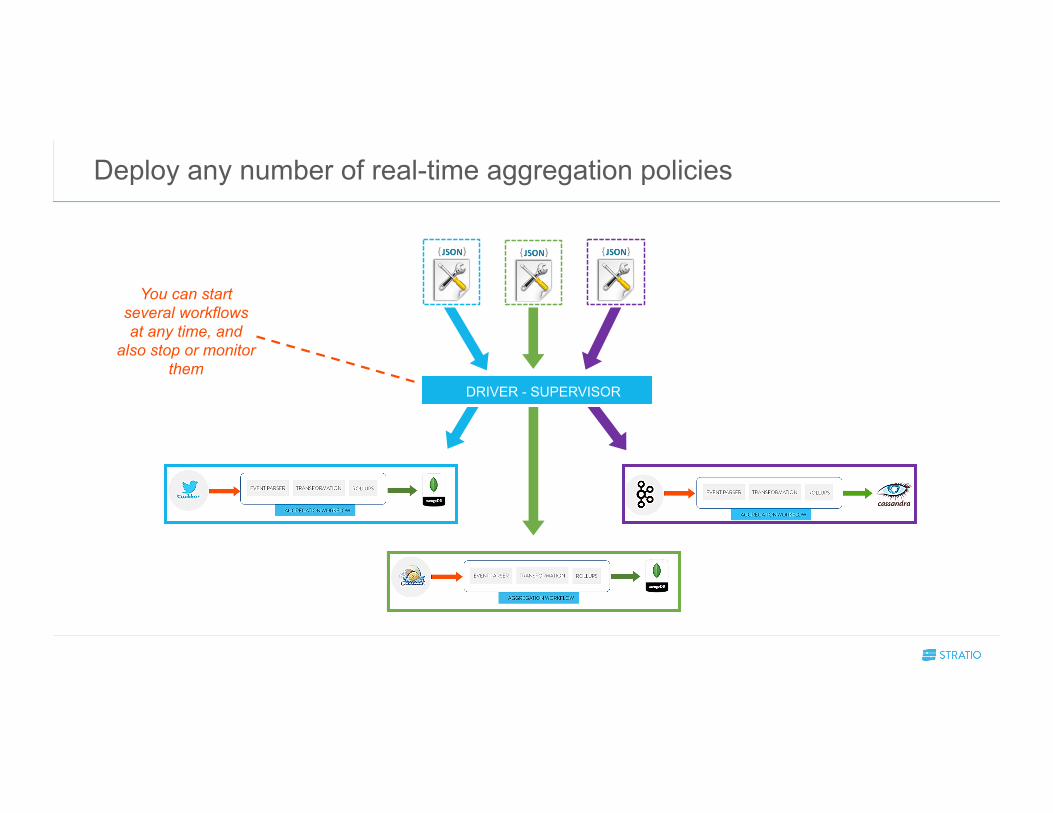
Deploy any number of real-time aggregation policies
DRIVER - SUPERVISOR
You can start several workflows at any time, and
also stop or monitor them
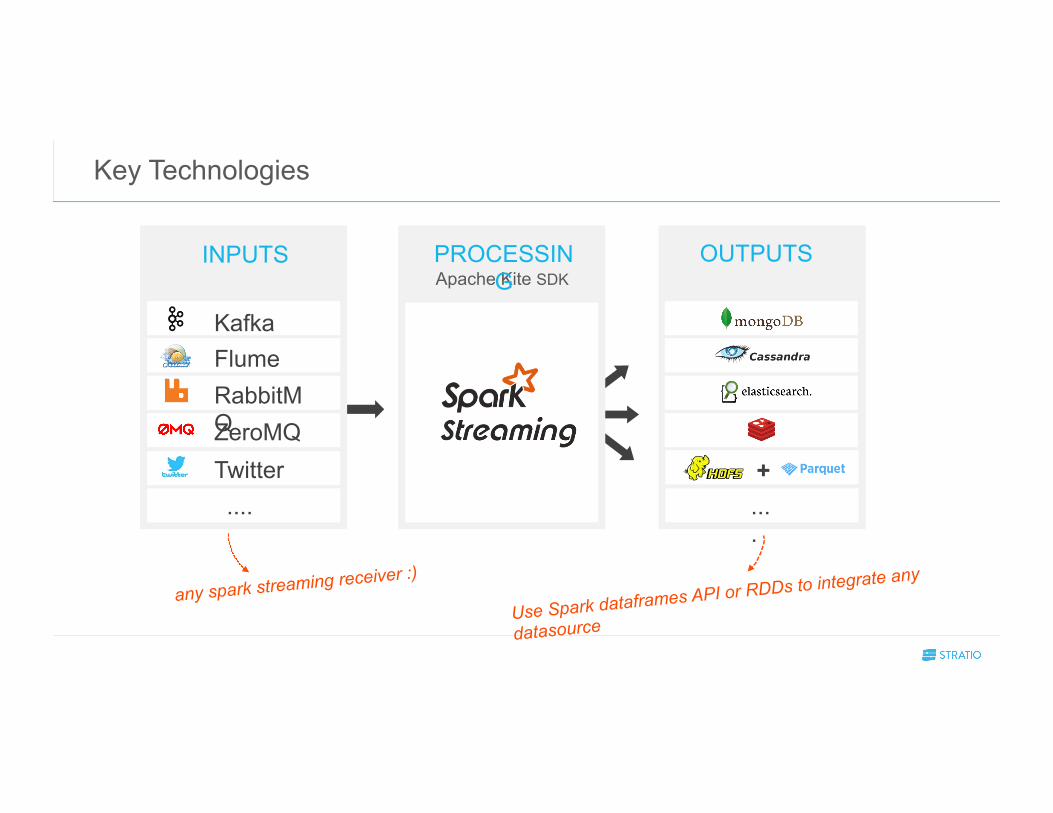
Key Technologies
any spark streaming receiver :)
Use Spark dataframes API or RDDs to integrate any
datasource
+
Apache Kite SDK INPUTS PROCESSIN
G
RabbitMQ ZeroMQ Twitter
Flume Kafka
....
OUTPUTS
...
.

Define your real-time needs
AGGREGATION POLICY
Remember: no need to code anything. Define your workflow in a JSON document, including:
INPUT Where is the data coming from?
OUTPUT(s) Where should aggregate data be stored?
DIMENSION(s) Which fields will you need for your real-time needs? ROLLUP(s) How do you want to aggregate the dimensions?
TRANSFORMATION(s) Which functions should be applied before aggregation?
SAVE RAW DATA Do you want to save raw events?
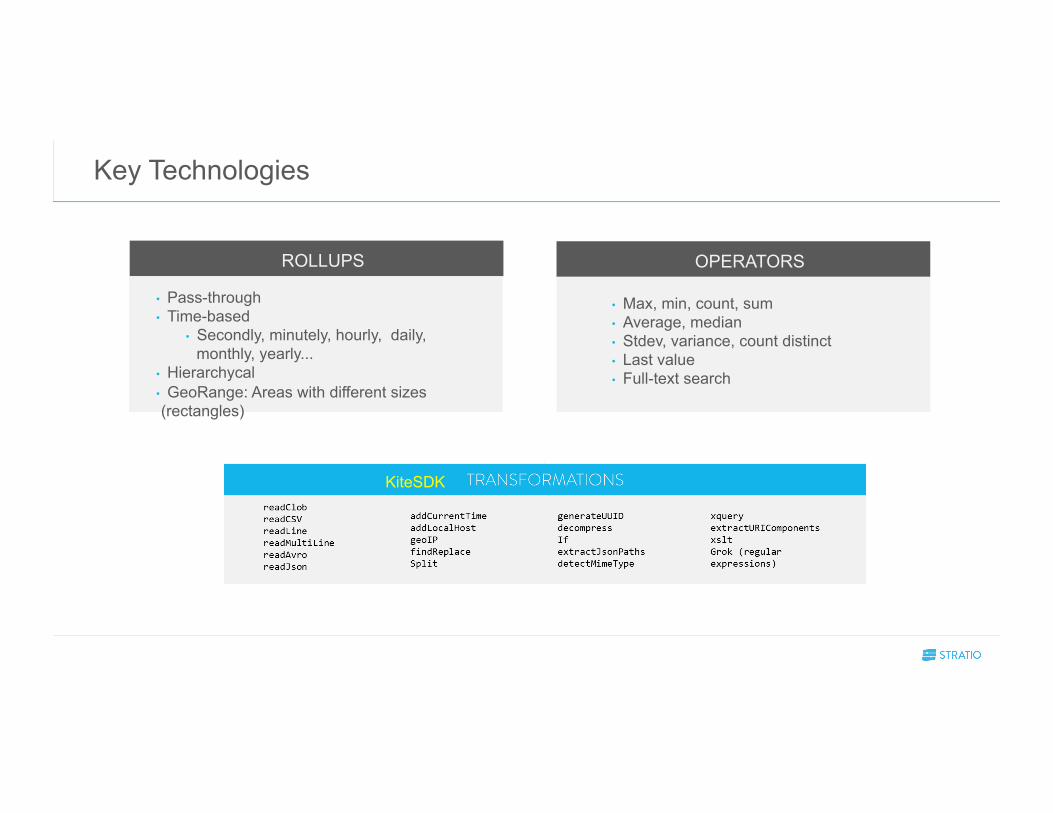
Key Technologies
ROLLUPS
• Pass-through • Time-based
• Secondly, minutely, hourly, daily, monthly, yearly...
• Hierarchycal • GeoRange: Areas with different sizes (rectangles)
OPERATORS
• Max, min, count, sum • Average, median • Stdev, variance, count distinct • Last value • Full-text search
KiteSDK
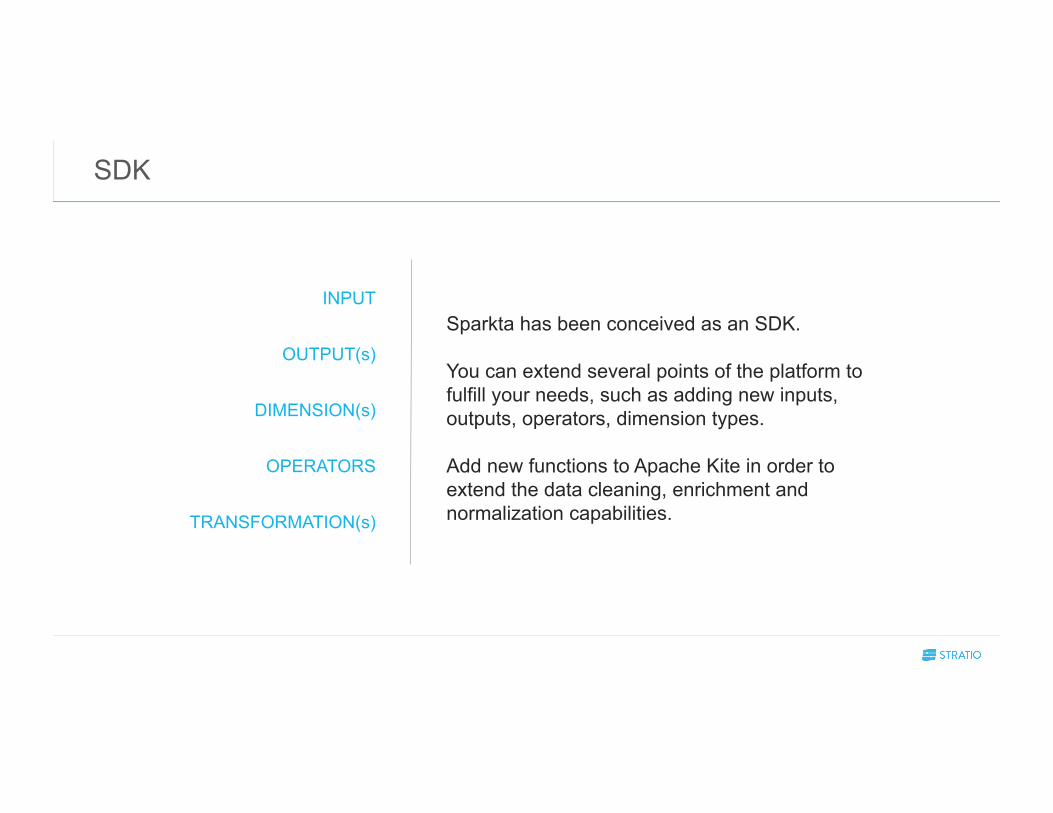
SDK
INPUT
OUTPUT(s)
DIMENSION(s)
OPERATORS
TRANSFORMATION(s)
Sparkta has been conceived as an SDK. You can extend several points of the platform to fulfill your needs, such as adding new inputs, outputs, operators, dimension types. Add new functions to Apache Kite in order to extend the data cleaning, enrichment and normalization capabilities.


BIG DATA CHILD’S PLAY