a domain specific ontology based semantic web search engine
TRANSCRIPT

8/6/2019 A Domain Specific Ontology Based Semantic Web Search Engine
http://slidepdf.com/reader/full/a-domain-specific-ontology-based-semantic-web-search-engine 1/9
A Domain Specific Ontology BasedSemantic Web Search Engine
Debajyoti Mukhopadhyay 1, 2 Aritra Banik 1 Sreemoyee Mukherjee 1 Jhilik Bhattacharya 1
1 Web Intelligence & Distributed Computing Research Lab, Techno India,West Bengal University of Technology
EM 4/1, Salt Lake Sector V, Calcutta 700091, India [email protected]
Young-Chon Kim 2
2Advanced Communications & Networks Lab, Division of Electronics & Information EngineeringChonbuk National University
561-756 Jeonju, Republic of Korea
ABSTRACT Since its emergence in the 1990s the World WideWeb (WWW) has rapidly evolved into a hugemine of global information and it is growing insize everyday. The presence of huge amount of resources on the Web thus poses a serious
problem of accurate search. This is mainlybecause today’s Web is a human-readable Webwhere information cannot be easily processed bymachine. Highly sophisticated, efficient keyword based search engines that have evolved todayhave not been able to bridge this gap. So comesup the concept of the Semantic Web which isenvisioned by Tim Berners-Lee as the Web of machine interpretable information to make amachine processable form for expressinginformation. Based on the semantic Webtechnologies we present in this paper the designmethodology and development of a semanticWeb search engine which provides exact searchresults for a domain specific search. This searchengine is developed for an agricultural Websitewhich hosts agricultural information about thestate of West Bengal.
Keywords Search engine, Keyword based search, SemanticWeb, Ontology, Resource DescriptionFramework (RDF)
1. INTRODUCTIONA search engine is a document retrieval systemdesigned to help find information stored in acomputer system, such as on the World WideWeb, inside a corporate or proprietary network,or in a personal computer. The search engineallows one to ask for content meeting specificcriteria (typically those containing a given wordor phrase) and retrieves a list of items that matchthose criteria. Regardless of the underlyingarchitecture, users specify keywords that matchwords in huge search engine databases,producing a ranked list of URLs and snippets of Web-pages in which the keywords matched.Although such technologies are mostly used,users are still often faced with the daunting task of sifting through multiple pages of results, manyof which are irrelevant.
Surveys indicate that almost 25% of Web searchers are unable to find useful results inthe first set of URLs that are returned [6].
Tim Berners-Lee, the inventor of theWorld Wide Web, defines the Semantic Web as“The Web of data with meaning in the sense thata computer program can learn enough aboutwhat the data means [in order] to process it” [1].
Rather than a Web filled only withhuman-interpretable information, Berners-Lee’svision includes an extended Web thatincorporates machine interpretable information,enabling machines to process the volumes of

8/6/2019 A Domain Specific Ontology Based Semantic Web Search Engine
http://slidepdf.com/reader/full/a-domain-specific-ontology-based-semantic-web-search-engine 2/9
available information, acting on behalf of theirhuman counterparts [7].
In this paper, we discuss the basic ideaof the semantic Web and describe a design anddevelopment methodology for a domain specificsemantic Web search engine based on ontology
matching w hich not only overcomes theproblem of knowledge overhead but alsosupports complex queries. Further, it is able toproduce exact answers that in one hand satisfyuser queries and on the other hand are self-explanatory and understandable by end users.
2. SEMANTIC WEB SEARCH ENGINE2.1 The working of a regular search engineFor most internet users, a search engine is thestarting point of finding desired information inthe Web. The most common form of text searchused by the majority of popular search engineson the Web is keyword based search that is , they do their text query and retrieval usingkeywords. The working of any regular searchengine may be summarized as follows:
• Search engine searches its enormousdatabase for the keyword - entered bythe user (after pressing the searchbutton.)
• Every engine has its own collectionsystem to fill its database.
• Indexing system is used to organize thedatabase - permits faster searching
• Returns a list of hit -includes relevant(as well as irrelevant) pages
This keyword based search technique givesrise to several problems listed as follows:
• The Web is growing much faster thanany present-technology search enginecan possibly index. In 2006, some usersfound major search-engines becameslower to index new Web-pages.
• Keyword searches have a tough timedistinguishing between words that are
spelled the same way, but meansomething different. This often resultsin hits that are completely irrelevant tothe query.
• Some search engines also have troublewith stemming, i.e., if the word "big,"
is entered, should it return a hit on theword, "bigger?" What about singularand plural words? What about verbtenses that differ from the wordsomeone entered by only an "s," or an"ed"?
• Search engines also cannot return hitson keywords that mean the same, butare not actually entered in the query. Aquery on heart disease would not returna document that used the word "cardiac"instead of "heart."
• Users are returned thousands to millionsof Web pages in return of their queries,of which majority prove to be irrelevantto the query submitted and is impossiblefor any user to go through.
In view of the above mentioned problems,
come up the concept of semantic Web andsemantic Web search engines.
2.2 Semantic Web and Semantic SearchEngine
“The Semantic Web is the representation of dataon the World Wide Web. It is a collaborativeeffort led by W3C with participation from a largenumber of researchers and industrial partners. Itis based on the Resource Description Framework (RDF), which integrates a variety of applicationsusing XML for syntax and URIs for naming.” –W3C Semantic Web. The Semantic Web is aframework that allows publishing, sharing, andreusing data and knowledge on the Web andacross applications, enterprises, and communityboundaries [4]. Currently, the Semantic Web,consisting of Semantic Web documents typicallyencoded in the languages RDF and OWL, isessentially a Web universe parallel to the Web of HTML documents [5]. Knowledge encoded inSemantic Web languages such as RDF differsfrom both the largely unstructured free textfound on most Web pages and the highlystructured information found in databases. Suchsemi-structured information requires using acombination of techniques for effective indexingand retrieval. RDF and the Web OntologyLanguage (OWL) which are ontology basedprocedures or representing knowledge on theWeb, introduce aspects beyond those used inordinary XML, allowing users to define terms

8/6/2019 A Domain Specific Ontology Based Semantic Web Search Engine
http://slidepdf.com/reader/full/a-domain-specific-ontology-based-semantic-web-search-engine 3/9
(for example, classes and properties), expressrelationships among them, and assert constraintsand axioms that hold for well-formed data. Anapplication of the emerging Semantic Web is aSemantic Web search engine which searches theSemantic Web documents against a user queryfor accurate results. Our work uses RDF encodedSemantic Web documents which are searched inresponse to a user query for exact results.
3. ONTOLOGYAn ontology is an explicit specification of sometopic. For our purposes, it is a formal anddeclarative representation which includes thevocabulary (or names) for referring to the termsin that subject area and the logical statementsthat describe what the terms are, how they arerelated to each other, and how they can or cannotbe related to each other. Therefore, Ontologyprovides a vocabulary for representing andcommunicating knowledge about some topic anda set of relationships that hold among the termsin that vocabulary [2] [3].
Why develop an Ontology?• To enable a machine to use the
knowledge in some application.• To enable multiple machines to share
their knowledge.• To help yourself understand some area
of knowledge better.• To help other people understand some
area of knowledge.• To help people reach a consensus in
their understanding of some area of knowledge.
In our project we used Resource DescriptionFramework or RDF to represent knowledge. Forexample, if we need to describe a subject interms of its classes and their relationships usingRDF, we are creating an Ontology.
As our project deals with the crops domain,the designed ontology is shown in Figure 1. InFigure 2, the general information ontology isdepicted. A relational diagram is shown inFigure 3 to depict some classes, instances, and
relations among them in the crops domain.
Crops
Vegetables Fruits Cereals
potato apple ricepumpkin orange wheat instances.... ..... .....
Figure 1. The Crops ontology: Crops is the superclassof its subclasses vegetables, fruits, and cereals
Generalinformatio
n
Season Fertilizer Cost MarketLocation
Figure2. The general information ontology: Generalinformation is the superclass of subclasses: season,
fertlizer, cost, market location
iof
Crops
GeneralInformation
Mango
K123
Fertilizer reqd formango
Subclass of Fruit
Subclass of Fertilizer
iof
iof
Figure 3. Some classes, instances, and relationsamong them in the crops domain; shaded boxes are
used to indicate classes and non-shaded for instances ;iof indicates instance of

8/6/2019 A Domain Specific Ontology Based Semantic Web Search Engine
http://slidepdf.com/reader/full/a-domain-specific-ontology-based-semantic-web-search-engine 4/9
4. OUR APPROACHBased on the ontology as described above, wehave first developed the relevant RDF pages.
4.1. What is RDF (Resource DescriptionFramework)
• Resource Description Framework (RDF) is a framework for describingand interchanging metadata (datadescribing the Web resources) [8] [11].
• RDF provides machine understandablesemantics for metadata.This leads to,
• better precision inresource discoverythan full text search
• assistingapplications asschemas evolve
• interoperability of metadata
Components of RDF data model: [9]• Directed labeled graphs• Model elements:
Resource: Everything described byRDF expressions is called a resource [10]. Everyresource has a URI and it may be an entire Webpage or a part of a Web page.
Property: “A property is a specificaspect, characteristic, attribute, or relation usedtoDescribe a resource” – W3C, ResourceDescription Framework (RDF) Model andSyntax Specification [10]. Note that a property isalso a resource since it can have its ownproperties.
Statements: A statement combines aresource, a property and a value. These threeindividual parts are known as the “subject,”“predicate” and “object”.
For example, “Potato requires the soiltype KR256” is an RDF statement having thefollowing parts:Subject (Resource) PotatoPredicate (Property) soilreqdObject (value) KR256
This can be represented as an RDF graph asshown in Figure 4.
potato KR256soilreqd
Resource Value
property
An RDF statement
Figure 4. An RDF Statement
<?xml version="1.0"?><vegetable rdf:ID="potato"xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"xmlns="http://www.westbengal.org/crops#"><soilreq>KR256</soilreq></vegetable>
This RDF code describes the resource“potato” which in an instance of the “vegetable”class. “KR256” is the value of the property“soilreq.” Similar documents have been createdfor all the classes and instances of each class asspecified in the ontology. A separate RDF codedescribes the class subclass relationships.
RDF Schema: RDF Schema is a simpledata-typing model for RDF [12] so that we candescribe groups of related resources and therelationships among these resources [11]. Forexample, we can say “potato” is a type of “vegetable” and “vegetable” is a subclass of “crops.” The purpose of RDF schema is toexpress classes and their (subclass) relationshipsas well as to define properties and associatethem with classes. The benefit of an RDFSchema is that it facilitates inferencing on thedata, and enhanced searching.
Resources can be divided into “ classes ”which is composed of instances. A class itself isalso a resource which is usually identified byRDF URI References and can be described byRDF properties . We often use the prefix

8/6/2019 A Domain Specific Ontology Based Semantic Web Search Engine
http://slidepdf.com/reader/full/a-domain-specific-ontology-based-semantic-web-search-engine 5/9
“rdfs:” to indicate the term is RDF Schematerm. “rdfs:resource” is the root class of everything in RDF Schema. “ rdf:type ” is aninstance of rdf:Property (class of RDFproperties), and it means that a resource is aninstance of a class. The propertyrdfs:subClassOf is an instance of rdf:Propertythat is used to state that a class is a Subclass of the other. The following RDF code shows that“Crops” is the super-class and “Vegetable” and“Fruits” are subclasses of “Crops.”
<?xml version="1.0"?><rdf:RDFxmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xml:base="http://
www.westbengal.org/crops#"><rdfs:Class rdf:ID="Vegetable">
< rdfs:subClassOfrdf:resource =" #Crops "/></rdfs:Class><rd
< rdfs:subClassOfrdf:resource =" #Crops "/>
fs:Class rdf:ID="Fruits">
</rdfs:Class>......
</rdf:RDF>
Another important RDF technique thatwe have utilized in our design methodology isthe specification of the RDF domain and range.
RDF Domain and Range: Domain is usedto indicate the classes that a property will beused with. One may specify zero, one, ormultiple rdfs:domain properties [10][11].
Range is used to indicate the type of valuesthat a property will contain.One may specifyzero, one, or multiple rdfs:range properties.
The following RDF code snippet shows theusage of domain and range. It describes an RDFproperty “seasonreqd” whose domain is thevegetable class i.e. it can be used with this classand its range is the “season” class i.e. it can takevalues of the type “season” only.
<rdf:Propertyrdf:ID="seasonreqd">
<rdfs:domainrdf:resource="#Vegetable"/>
<rdfs:rangerdf:resource="#season"/></rdf:Property>
Thus, using RDF schema a class isdefined separately and its relations to otherclasses are indicated, again properties are definedseparately, associated with the respective classes,having their domains and ranges specified.
4.2. The Design of the Semantic Web SearchEngineThe basic components of the ontology basedsemantic Web search engine is shown inFigure5.
ClassDatabase
InstanceDatabase
Class,Instance
Extractor
UserInterface
RelationIdentifier
Ontology Tree
wordClassname Instance
name
query
result
Subclassor
instancesuperclass
Class,instancename
Figure 5. Basic Components of the semantic Websearch engine

8/6/2019 A Domain Specific Ontology Based Semantic Web Search Engine
http://slidepdf.com/reader/full/a-domain-specific-ontology-based-semantic-web-search-engine 6/9
As shown in the Figure 5, the main parts of our design of the search engine are:
• A Class, instance extractor• A class database• An instance database• An Ontology tree•
A Relation identifier
An user interface is designed where the userenters his query and the results are returned back to him. As the search engine works for aspecified domain, it directly retrieves the resultsrather than the URLs (as returned by aconventional search engine) and displays them.The different modules of the search engine arediscussed below.
The Class Instance Extractor: Thismodule is responsible for the extraction of classor instance names present , if any , in the queryentered by the user i.e. it takes as input the userquery and returns as output the class or instancename or both, if present in the query, whichmatch with those defined in the RDF codes. Fore.g., from a query “season required for mango,”it will extract the words “season” and “mango”as they correspond to the class “season” and theinstance “mango” defined in the RDF codes. Itdoes so with the help of the class database andthe instance database by checking each word of the user query with the class and instance namesstored in these databases.
The Class Database: This module is asimple database which contains all the names of the classes used in the RDF codes and theircorresponding synonyms. It is implemented as atwo column table where one column stands forthe class names and the other its correspondingsynonym. A class name may have one or moresynonyms. It checks each word supplied to it bythe class instance extractor if it matches with thewords stored. If yes, it returns that word back tothe class instance extractor.
The Instance Database: The function andimplementation of this module is similar to theclass database except that it stores the instancenames as defined in the RDF codes.
The Ontology Tree: This module is nothingbut the entire ontology, stored in the form of RDF codes as described previously. It is thestorage of the class subclass instancerelationships as RDF codes to facilitate theworking of the relation identifier, which uses this
module to find out the class of an instance or thesuperclass of a subclass etc.
The Relation Identifier: This moduleperforms the most important task of identifyingrelationships between the class and instanceextracted from a query by the class instanceextractor. It tries to relate the extracted class andinstance by a predefined property i.e., a propertydefined in the RDF codes. Consider the query“season required for mango.” The relationidentifier will first look up all the propertydefinitions to find a property whose domain ismango and range is season. As mango is aninstance and not a class, it will not be able findany such property. It will then move up one levelupwards in the ontology tree to find the class of the instance “mango” and will try to find aproperty whose domain is fruits and range isseason. It will find the property season_req,predefined in the RDF code for mango, whichrelates mango and season. A simplifieddiagrammatic representation of this mapping isshown in the Figure 6.
crops
vegetable fruits
eneralinf o
season
<classes>
<classes>
mango Season reqd formango<instance><instance>
Seasonreqd <property>
Figure 6: Mapping from instance to Class
On being able to successfully relate the classand the instance the relation identifier will alsofind the value of this property from the RDF
codes and will return that value as the finalresult.
In any Natural Language Processing model,a parser is an obvious part. It helps to identifythe semantic correctness of the sentence orquery. But in case of an ontology based design,

8/6/2019 A Domain Specific Ontology Based Semantic Web Search Engine
http://slidepdf.com/reader/full/a-domain-specific-ontology-based-semantic-web-search-engine 7/9
the parsing rules are already present in the formof RDF codes. The property itself identifies themapping as it includes its domain and range asattributes in the RDF codes where they aredefined. If a direct relation in the form of rangeand domain is not present, we have to look further in the ontology tree in order to identifythe relation or mapping. Thus our ontology basedsemantic Web search engine also works forindirect queries , or queries which do not containa class or instance name directly.
Suppose the query is: “K123 required forwhich crops?” K123 stands for a fertilizer. In thiscase the relation identifier gets from the classinstance extractor the words “K123” and“crops.” Therefore it first checks whether there isany property whose domain is K123 and range iscrops. If not present, it goes one level upward inthe ontology tree and checks if there exists anyproperty whose domain is fertilizer and range iscrops. Here the property is defined as
fertilizerreqd . As the property name is known, itsearches every subclass of crops and theirinstances in order to identify the instances forwhich the value of the property fertilizerreqd isK123 .
On the other hand, if a query “cropsrequired for which K123” is given, it repliesback an error message as there is no propertypresent whose domain is fertilizers and range iscrops.
Thus our semantic Web search enginegives accurate, meaningful, exact results of a
user query.
5. EXPERIMENTAL RESULTSIn our prototype the domain specific ontologybased search engine is developed as anextendable J2EE application where each of themodules as specified above have been developedusing java. An user interface is also developed asa part of the crops Website where the user entershis query for search. Some screenshots of theuser interface containing the search query and itsresults are shown in Figure 7 and Figure 8.
Figure 7. Given query is “Fertilizer required formango”
Figure 8. Results for the query “Fertilizers requiredfor mango”

8/6/2019 A Domain Specific Ontology Based Semantic Web Search Engine
http://slidepdf.com/reader/full/a-domain-specific-ontology-based-semantic-web-search-engine 8/9
5.1. Performance Analysis:It can be shown that even in the worst case theperformance of the semantic Web search engineis much better than a regular search engine withincreasing number of pages. It works faster thana regular search engine when the world wideWeb is considered to be divided into severaldomains of similar ontologies (Figure 9). For ageneral semantic Web search engine, the task remains only to search domain-wise and hencefind the resultant page from the Web.
Figure 9. The World Wide Web divided intodomains
Let us consider the world wide Web to
be divided into say ‘r’ domains (D 1 to D r) eachcontaining Web sites or pages of similarontologies. Let each domain be further dividedinto ‘r’ domains. Node D 1 divided into domainsD11 to D 1r . Let the height of this tree be ‘h’ andthe total number of elements in this tree be ‘n’which is equal to the total number of Web-pagespresent in the Web.Now, from the above tree,n = 1+ r + r*r + r*r*r +..........+ r h
rh -1n =
r-1
log(n(r-1)+1)or, h =
log r
or, h = log r (n(r-1)+1)
To derive this equation , we have considerednumber of subdomains for each and everydomain is ‘r’.But in reality, the number of subdomains for each domain may not beconstant . The number of subdomains explicitlydepends on the design schema. Here we haveconcentrated for the average case analysisassuming r as the average number of sub-domains for each domain
Best Case: In this case, the queryfollows a straight path as a domain path, i.e. thequery starts from D 1 then goes to D 11 , D 111 ...soon. Therefore, the complexity of search is in theorder of h , which is equal to the order of WWW
D1 D r
D1r D rr
......
...
.....
D r1
....
D11
log r (n(r-1)+1).Worst Case: In this case, the search
topic requires at most ‘r’ searches per level todetermine the domain of the query. Therefore thenumber of searching required is r(h-1) which isequal to r *(log r (n(r-1)+1)-1).
5.2 Graph Plotting:Here, by the term performance we have referredto the number of searches needed for asuccessful query processing. Other factors likestorage capacity or query parsing time can beignored for a domain containing huge number of pages such as the World Wide Web.
Figure 10. Performance graph of the semantic Websearch engine for r=50.
For a regular search engine, to identifya single query it requires ‘n’ number of searcheswhere n is the total number of pages present. InFigure 10, we have shown the total number of
8/6/2019 A Domain Specific Ontology Based Semantic Web Search Engine
http://slidepdf.com/reader/full/a-domain-specific-ontology-based-semantic-web-search-engine 9/9
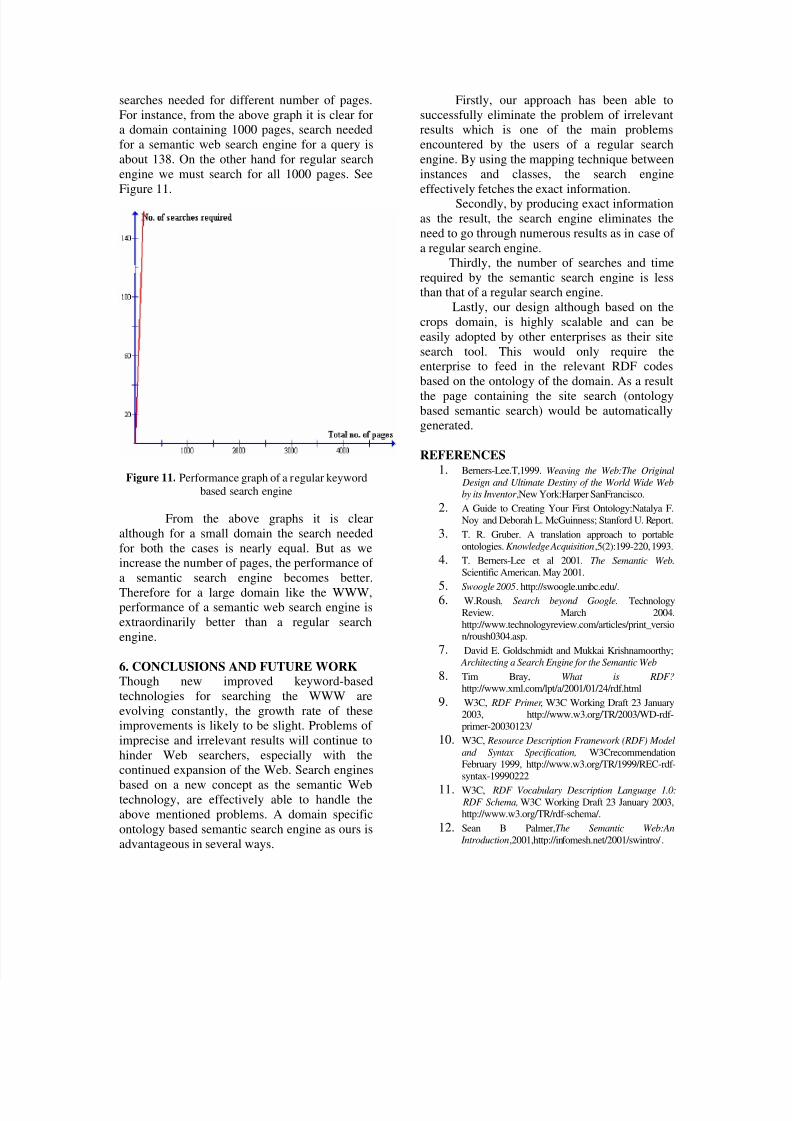
searches needed for different number of pages.For instance, from the above graph it is clear fora domain containing 1000 pages, search neededfor a semantic web search engine for a query isabout 138. On the other hand for regular searchengine we must search for all 1000 pages. SeeFigure 11.
Figure 11. Performance graph of a regular keywordbased search engine
From the above graphs it is clearalthough for a small domain the search neededfor both the cases is nearly equal. But as weincrease the number of pages, the performance of a semantic search engine becomes better.Therefore for a large domain like the WWW,performance of a semantic web search engine isextraordinarily better than a regular searchengine.
6. CONCLUSIONS AND FUTURE WORKThough new improved keyword-basedtechnologies for searching the WWW areevolving constantly, the growth rate of theseimprovements is likely to be slight. Problems of imprecise and irrelevant results will continue tohinder Web searchers, especially with thecontinued expansion of the Web. Search engines
based on a new concept as the semantic Webtechnology, are effectively able to handle theabove mentioned problems. A domain specificontology based semantic search engine as ours isadvantageous in several ways.
Firstly, our approach has been able tosuccessfully eliminate the problem of irrelevantresults which is one of the main problemsencountered by the users of a regular searchengine. By using the mapping technique betweeninstances and classes, the search engineeffectively fetches the exact information.
Secondly, by producing exact informationas the result, the search engine eliminates theneed to go through numerous results as in case of a regular search engine.
Thirdly, the number of searches and timerequired by the semantic search engine is lessthan that of a regular search engine.
Lastly, our design although based on thecrops domain, is highly scalable and can beeasily adopted by other enterprises as their sitesearch tool. This would only require theenterprise to feed in the relevant RDF codesbased on the ontology of the domain. As a resultthe page containing the site search (ontologybased semantic search) would be automaticallygenerated.
REFERENCES1. Berners-Lee.T,1999. Weaving the Web:The Original
Design and Ultimate Destiny of the World Wide Webby its Inventor ,New York:Harper SanFrancisco.
2. A Guide to Creating Your First Ontology:Natalya F.Noy and Deborah L. McGuinness; Stanford U. Report.
3. T. R. Gruber. A translation approach to portableontologies. Knowledge Acquisition ,5(2):199-220, 1993.
4. T. Berners-Lee et al 2001. The Semantic Web. Scientific American. May 2001.
5. Swoogle 2005 . http://swoogle.umbc.edu/.6. W.Roush, Search beyond Google. Technology
Review. March 2004.http://www.technologyreview.com/articles/print_version/roush0304.asp.
7. David E. Goldschmidt and Mukkai Krishnamoorthy; Architecting a Search Engine for the Semantic Web
8. Tim Bray, What is RDF? http://www.xml.com/lpt/a/2001/01/24/rdf.html
9. W3C, RDF Primer , W3C Working Draft 23 January2003, http://www.w3.org/TR/2003/WD-rdf-primer-20030123/
10. W3C, Resource Description Framework (RDF) Modeland Syntax Specification, W3CrecommendationFebruary 1999, http://www.w3.org/TR/1999/REC-rdf-syntax-19990222
11. W3C, RDF Vocabulary Description Language 1.0: RDF Schema, W3C Working Draft 23 January 2003,http://www.w3.org/TR/rdf-schema/.
12. Sean B Palmer, The Semantic Web:An Introduction ,2001,http://infomesh.net/2001/swintro/ .