a fast recognition framework based on extreme learning machine using hybrid object information
TRANSCRIPT

ARTICLE IN PRESS
Neurocomputing 73 (2010) 1831–1839
Contents lists available at ScienceDirect
Neurocomputing
0925-23
doi:10.1
� Corr
E-m
moham
(Q.M. Jo
journal homepage: www.elsevier.com/locate/neucom
A fast recognition framework based on extreme learning machine usinghybrid object information
Rashid Minhas �, Abdul Adeel Mohammed, Q.M. Jonathan Wu
Computer Vision and Sensing Systems Laboratory, Department of Electrical and Computer Engineering, University of Windsor, Ontario, N9B 3P4, Canada
a r t i c l e i n f o
Available online 19 March 2010
Keywords:
Extreme learning machine
Object recognition
Ferns
Two-dimensional PCA
Object classification
12/$ - see front matter & 2010 Elsevier B.V. A
016/j.neucom.2009.11.049
esponding author. Tel.: +1 519 253 3000x258
ail addresses: [email protected] (R. Minh
[email protected] (A.A. Mohammed), jwu@u
nathan Wu).
a b s t r a c t
This paper presents a new supervised learning scheme, which uses hybrid information i.e. global and
local object information, for accurate identification and classification at considerably high speed both in
training and testing phase. The first contribution of this paper is a unique image representation using
bidirectional two-dimensional PCA and Ferns style approach to represent global and local information,
respectively, of an object. Secondly, the application of extreme learning machine supports reliable
recognition with minimum error and learning speed approximately thousands of times faster than
traditional neural networks. The proposed method is capable of classifying various datasets in a fraction
of second compared to other modern algorithms that require at least 2–3 s per image [14].
& 2010 Elsevier B.V. All rights reserved.
1. Introduction
Object recognition or categorization is a task of classifying anindividual object to belong to a certain category. Automatedvision systems, in general, do not perform better categorizationthan humans due to lack of intelligence, and knowledge. Despitesome early success in automatic recognition; the problem is farfrom being solved due to preserved non-planar geometry andsignificant 3D depth variations in images of natural scenes. Theimage databases are an essential part of recognition research. Forcomparison of emerging algorithms; a number of commonpublicly available databases have been established such as UIUC,Caltech, MIT, GRAZ and PASCAL. These databases have provided acommon ground for evaluation and assessment of fresh algo-rithms. Detecting objects in measurements is a complicated taskowing to their enormously large number of possible poses,appearances in varying image acquisition conditions, and occlu-sions (see Fig. 1 for sample images).
Computer vision community has been following a line ofinvestigation to develop algorithms which can efficiently detectfeatures, global or local, and regions for robust recognition of objectsof interest. Each recognition method proposed in the past has itsown merits and limitations; in general common approaches useimage databases which contain object of interest at perceptible scalewith minor deformations/pose variations. Feature extraction andrepresentation of significant objects in an incoming image using the
ll rights reserved.
0; fax: +1 5199713695.
as),
windsor.ca
generated features is an initial step towards visual recognition. Next,a classifier is trained using the representation established at anearlier stage. The popular classifiers include support vector machines(SVM), Bayes classifier, Fisher linear discriminant and traditionalneural networks, and hidden Markov models (HMM) to name a few.For above classifiers; a degraded classification is observed due tonon-convex feature space caused by images captured underdifferent geometric and lighting environment. Unfortunately, cate-gorization turns out to be a complicated chore due to noticeablechanges in appearance and other deformations caused by variationsin the scene depth.
Classification schemes use a wide variety of features like color,texture, orientation, blob, center of gravity and mutual geometricrelationship amongst feature points to learn a classifier. Visualrecognition frameworks range from constellation of local features[1,2], and complex geometric models [3] to the use of motion cues[4,7]. Object categorization schemes with smaller variations inpose [1,5,6] and manual pre-segmentation of objects to minimizethe computational cost have also been proposed [8]. Part basedschemes [1,5,9,13,22] represent object structure using patchescovering distinctive parts of an object. Such patches are extractedfrom neighborhood of interest points detected using localizedoperators like Harris corner detector. In [14] Ali and Shahproposed a promising approach to use the global structure of anobject by modeling nonlinear subspace of categories using kernelPCA (KPCA) and selecting a discriminative feature set employingAdaBoost algorithm. Opelt et al. [13] used multiple kinds offeatures to encode the extracted patches and later used AdaBoostframework to select the best features for categorization.
The performance deterioration is observed in approacheswhich use only global information, especially in images withconsiderably large background clutter, geometric deformations,

ARTICLE IN PRESS
Fig. 1. Sample images from Caltech database.
1
p
1
i
L
1
m
Decision
Function
Output...
......
...
p inputneurons
L hiddenlayer neurons
m outputneurons
Fig. 2. Simplified structure of ELM.
R. Minhas et al. / Neurocomputing 73 (2010) 1831–18391832
and occlusions. The correlation amongst neighborhood pixels isalso ignored due to vectorization of an image during dimension-ality reduction operations such as PCA and kernel PCA. On otherhand, part based recognition schemes are computationallyexpensive requiring significantly large amount of training sam-ples (extracted/synthesized for different view points) thateventually leads to momentous increase in computational cost.
We propose a hybrid approach for recognition that combinesglobal and local object information for robust and reliablerecognition. The use of two-dimensional PCA (2D-PCA) [19] alongmutually orthogonal directions is proposed to encode globalinformation of an image which can better preserve associationamongst neighboring pixels. Recently, [20] used multidimen-sional PCA for face recognition. The use of general tensordiscriminant analysis (GTDA) for gait recognition, proposed byTao et al. [26], is proven to generate improved accuracy withminimal undersample problem during classification. In [27,28]incremental and supervised approaches for tensor analysis havebeen proposed which generates better-quality recognition withstructure preserving processing in higher dimension data similarto bidirectional 2D-PCA. However, our method differs from [26]for recognition in two ways—using hybrid object information forclassification, secondly, synthesizing images for various affinedeformations to train our classifiers for potential objects’ views.For local object information, feature vectors are generated frompatches around stable feature points detected using Harris cornerdetector. Multiple views of such patches are generated throughaffine deformations which result into considerably increasednumber of training samples. Later, extreme learning machine(ELM) [15] is applied for recognition using both kinds of featurevectors i.e. global and local information.
The use of any other supervised learning framework such asneural network or AdaBoost may require longer training intervalsdue to their specific learning strategy while ELM can finish thesimilar training task at speed approximately thousands times fasterthan traditional neural networks and minimum training error. ELMhas been successfully applied for multicategory classification such asmicroarray gene expression for cancer diagnosis [16] and classifica-tion of music genres [17]. Our proposed method allows to combinestrengths of both types of features and exploits highly discriminativefeature sets for classification using ELM. A wide variety ofexperiments using standard datasets are presented to ascertain thesuperior performance of our proposed scheme over other state-of-the-art methods.
2. Extreme learning machine
Feedforward neural networks (FNN) have been widely used indifferent areas due to their approximation capabilities for nonlinearmappings. It is a well known fact that the slow learning speed ofFNN has been a major bottleneck in different applications. In the
past theoretical research works, the input weights and hidden layerbiases had to be adjusted using some parameter tuning approachsuch as gradient descent based methods. However, gradient descentbased learning techniques are generally time-consuming due toinappropriate learning steps with significantly large latency toconverge to a local maxima. Huang et al. [15,18] showed that single-hidden layer feedforward neural network (SLFNN), also termed asELM in their work, can exactly learn N distinct observations foralmost any nonlinear activation function with at most N hiddennodes (see Fig. 2). Unlike the popular thinking that networkparameters need to be tuned, one may not adjust the inputweights and first hidden layer biases but they are randomlyassigned. Such an approach has been proven to perform learningat an extremely fast speed, and obtains good generalizationperformance for activation functions that are infinitelydifferentiable in hidden layers. ELM transforms the learningproblem into a simple linear system whose output weights can beanalytically determined through a generalized inverse operation ofthe hidden layer weight matrices. Such a learning scheme canoperate at considerable faster speed than learning strategies oftraditional learning frameworks. Improved generalizationperformance of ELM with the smallest training error and the normof weights demonstrate its superior classification capability for real-time applications at an exceptionally fast pace without any learningbottleneck. For N arbitrary distinct samples ðxi,giÞ wherexi ¼ ½xi1,xi2, . . . ,xip�
0ARp and gi ¼ ½gi1,gi2, . . . ,gim�0ARm (The
superscript ‘‘0
’’ represents the transpose), a standard ELM with L
hidden nodes and an activation function g(x) is modeled by
XL
i ¼ 1
bigðxlÞ ¼XL
i ¼ 1
bigðwi � xlþbiÞ ¼ ol, lAf1,2,3, . . . ,Ng, ð1Þ
where wi ¼ ½wi1,wi2, . . . ,wip�0 and bi ¼ ½bi1,bi2, . . . ,bim�
0 represent theweight vectors connecting the input nodes to an i th hidden nodeand from the i th hidden node to the output nodes, respectively. bi
shows a threshold for an i th hidden node, and wi. xl represents theinner product of wi and xl. The above modeled ELM can reliably

ARTICLE IN PRESS
R. Minhas et al. / Neurocomputing 73 (2010) 1831–1839 1833
approximate N samples with zero error as
XN
l ¼ 1
Jol�glJ¼ 0, ð2Þ
XL
i ¼ 1
bigðwi:xlþbiÞ ¼ gl, lAf1,2, . . . ,Ng: ð3Þ
The above N equations can be written as Ub¼G whereb¼ ½b01, . . . ,b0L�
0L�m and G¼ ½g01, . . . ,g0N�
0N�m. In this formulation U is
called the hidden layer output matrix of ELM where i th column of Uis the output of i th hidden node with respect to inputs x1,x2,y,xN. Ifthe activation function g is infinitely differentiable, the number ofhidden nodes are such that L5N. Thus U is represented as
U¼ ðw1, . . . ,wL,b1, . . . ,bL,x1, . . . ,xNÞ: ð4Þ
The training of ELM requires minimization of an error functione in terms of the defined parameters as
e¼XN
l ¼ 1
XL
i ¼ 1
bigðwixlþbiÞ�gl
!2
, ð5Þ
where it is sought to minimize the error, e¼ JUb�GJ. Tradition-ally unknown U is determined using gradient descent basedscheme and the weight vector W, which is a combination of wi, bi,and bias parameters bi, is tuned iteratively by
wk ¼wk�1�r@eðWÞ@W
: ð6Þ
In above relation, the learning rate r significantly affects theaccuracy and learning speed; a small value of r causes the learningalgorithm to converge at a significantly slower rate whereas alarger learning step leads to instability and divergence. Huanget al. proposed minimum norm least-square solution for ELM [15]to avoid aforementioned limitations encountered in conventionallearning paradigm, which states that the input weights and thehidden layer biases can be randomly assigned if the activationfunction is infinitely differentiable. It is an interesting solution;instead of tuning the entire network parameters such randomallocation helps to analytically determine the hidden layer outputmatrix U. For the fixed network parameters, the learning of ELM issimply equal to finding a least-square solution of
JUðw1 , . . . ,wL ,b1 , . . . ,bL Þb�GJ ð7Þ
¼ minwi ,bi ,b
JUðw1, . . . ,wL,b1, . . . ,bLÞb�GJ: ð8Þ
For a number of hidden nodes L5N, U is a non-square matrix,the norm least-square solution of above linear system becomesb ¼ U�G, where U� is the Moore–Penrose generalized inverse of amatrix U. It should be noted that above relationship holds for anon-square matrix U whereas the solution is straightforward forN¼L. The smallest training error is achieved using above modelsince it represents a least-square explanation of a linear systemUb¼G as
JUb�GJ¼ JUU�G�GJ, ð9Þ
¼minb
JUb�GJ: ð10Þ
3. Global feature vector computation
Karlhunen–Loeve expansion, also known as principal compo-nent analysis (PCA), is a data representation technique widely usedin pattern recognition and compression schemes. In [19], Yanget al. proposed two-dimensional PCA for image representation.As opposed to PCA, 2D-PCA is based on 2D image matrices rather
than 1D vectors, therefore the image matrix does not need to bevectorized prior to feature extraction. An image covariance matrixis constructed by directly using the original image matrices. Let X
denotes an M-dimensional unitary column vector. To project aQ�M image matrix A on X; a linear transformation Y¼AX is usedwhich results in a Q-dimensional projected vector Y. The totalscatter of the projected data is introduced to measure thediscriminatory power of a projection vector X. The total scattercan be characterized by the trace of a covariance matrix of theprojected feature vectors, i.e., J(X)¼tr(Sx) where tr(.) representsthe trace of a matrix and Sx denotes the covariance matrix ofprojected feature vectors. The covariance matrix Sx can becomputed as
Sx ¼ E½ðY�EðYÞÞðY�EðYÞÞ0�, ð11Þ
¼ E½½ðA�EðAÞÞX�½ðA�EðAÞÞX�0�, ð12Þ
trðSxÞ ¼ X0½EðA�EðAÞÞ0ðA�EðAÞÞ�X: ð13Þ
The image covariance matrix is defined as Gt ¼ ½ðA�EðAÞÞ0ðA�EðAÞÞ�.It is easy to verify that Gt is a M�M non-negative definite matrix;suppose that there are P training image samples, the j th sample ofsize Q �M is denoted by Aj where 1r jrP. Gt is computed by
Gt ¼1
P
XP
j ¼ 1
½ðAj�AÞ0ðAj�AÞ�, ð14Þ
JðXÞ ¼ X0GtX, ð15Þ
where A represents the average image of all training samples.Above criterion is called the generalized total scatter criterion. Theunitary vector X that maximizes the criterion is called the optimalprojection axis. We usually are required to select a set ofprojection axes, X1, X2,y,Xd (where subscript d is a scalar valuerepresenting the number of dimensions), subject to orthonormalconstraint and to maximize the criterion J(X). Yang et al. [19]showed that extraction of image features using 2D-PCA iscomputationally efficient and better recognition accuracy isachieved than traditional PCA. However, the main limitation of2D-PCA based recognition is the processing of higher number ofcoefficients since it works in row directions only. Zhang and Zhou[21] proposed (2D)2 PCA based on assumption that trainingsample images are zero mean and image covariance matrix can becomputed from the outer product of row/column vectors ofimages. We propose a modified bidirectional 2D-PCA to extractfeatures by computing two image covariance matrices of thesquare training samples in their original and transposed forms,respectively, while training image mean need not be necessarilyzero. The vectorization of mutual product of such covariancematrices results into a considerably smaller sized feature vectorswhich retain better structural and correlation informationamongst neighboring pixels. Fig. 3 shows better ability ofbidirectional 2D-PCA to represent the global structure of variousobject categories. Figs. 3(a and b) are plotted using Caltech(Airplanes and Leaves) and MIT (Cars and Pedestrians) datasets,respectively, whereas Caltech (Airplanes and Motorbikes)datasets have been used for Figs. 3(c and d). The first twocomponents of feature vectors obtained using bidirectional 2D-PCA and Kernel PCA are plotted against each other.
In Fig. 3(a) and (b), we observe close to convexity classes forCaltech and MIT datasets; this validates our claim that 2D PCAachieves superior categorization (see Table 2) for these datasets.For kernel PCA (Fig. 3(d)); it is quite clear that the first twocomponents, representing the largest eigenvalues, are almostidentical and analogous overlap of these feature vectors may leadto poor classification. For the same datasets; use of bidirectional2D-PCA generates classes which are partly converged as shown in

ARTICLE IN PRESS
Fig. 3. Non-linearity captured among various data sets using Bidirectional 2D-PCA for (a-c) (left to right and top to bottom) and KPCA (d) (right -bottom).
Table 1Time spent for training and testing using ELM on global feature vectors.
Time Planes Background Cars Bikes Faces Leaves
TT CT TT CT TT CT TT CT TT CT TT CT
Planes NA NA 0.078 0.062 0.140 0.062 0.078 0.078 0.078 0.062 0.094 0.047
Background 0.094 0.078 NA NA 0.047 0.047 0.094 0.047 0.109 0.031 0.156 0.016
Cars 0.156 0.094 0.031 0.047 NA NA 0.125 0.047 0.140 0.031 0.125 0.031
Bikes 0.125 0.078 0.078 0.047 0.094 0.047 NA NA 0.109 0.047 0.078 0.047
Faces 0.094 0.047 0.140 0.031 0.109 0.031 0.094 0.047 NA NA 0.109 0.016
Leaves 0.094 0.047 0.109 0.016 0.125 0.016 0.140 0.047 0.094 0.016 NA NA
TT: training time (s) and CT: classification time (s).
Table 2Training and detection accuracy using ELM on global feature vectors.
Accuracy Planes Background Cars Bikes Faces Leaves
TA CA TA CA TA CA TA CA TA CA TA CA
Planes NA NA 98 86 100 100 99.5 91.2 100 90.6 100 97.6
Background 96 79.8 NA NA 100 100 97.5 73.7 99.5 82.6 99 92
Cars 100 100 100 100 NA NA 100 100 100 100 100 100
Bikes 99.5 91.6 99 80.1 100 100 NA NA 100 93.8 100 95
Faces 100 97.1 99.5 87 100 100 100 91.3 NA NA 100 92.7
Leaves 100 97.2 97.5 85.8 100 100 100 96.8 100 95.4 NA NA
TA: training accuracy (%age) and CA: classification accuracy (%age).
R. Minhas et al. / Neurocomputing 73 (2010) 1831–18391834

ARTICLE IN PRESS
R. Minhas et al. / Neurocomputing 73 (2010) 1831–1839 1835
Fig. 3(c). Table 1 demonstrates the extremely fast classificationcapability of ELM using global features. However, the accuracyachieved using these global features is not stable and varies withthe selection of datasets in different combinations to representpositive and negative classes during recognition (see Table 2 formutual combinations of Caltech Airplanes, Caltech Backgroundand Caltech Motorbikes) (due to space limitations we do notpresent similar results for MIT and GRAZ datasets). Therefore, wepropose to combine complementary information, i.e. local featurevectors, along with the global contents of an image to attainreliable classification which is independent of view point changesand dataset combinations. It is worth mentioning that all Matlabimplementations of our experiments are executed on a desktopcomputer equipped with Intel Core 2 Duo processor of 2.6 GHzspeed and 2 GB RAM.
4. Local feature vector extraction
Identifying textured patches that are distinctive and detectableunder varying pose and lighting conditions in neighborhood ofstable feature points is a widely researched area with numerousapplications. Different strategies have been proposed to use localpatches or contour based information for object detection withfeatures being shared among different classes [4,22–25]. Thispaper proposes a new object detection scheme where partialobject information is presented using feature vectors computedfrom local patches surrounding a set of stable feature points. Suchfeature vectors are used as complementary information toenhance classification accuracy.
A semi-naive based classifier, recently proposed by Mustafaet al. [12], is used to determine the class of local patchessurrounding stable key points. The solution for patch correspon-dence problem provided in [12] shows promising results,comparable to state-of-the-art, yet simple by exploiting statisticalinformation of pixel intensities. To detect preliminary stable keypoints, randomly selected images of a specific class are deformedand Harris corner detector is applied. We select Harris cornerdetector for its simplified and efficient implementation to detectkey points with minimal computational burden comparedto other schemes such as SIFT, complex filters, PCA-SIFT, and
Fig. 4. Preliminary key points de
cross-correlation [10,11,29]. The parameters for affine deforma-tions are randomly picked from a uniform distribution thereforetwo images of a similar object may have differently been warpedat two different time instances. The corners identified fordeformed set of images change based on chosen parameters andbackground clutter. Authors do realize that the rising number ofaffine warped images can lead to higher computational load,however, it is noticeable that the comprehensive training of ouralgorithm to mimic possible appearances of local patches of anobject generates improved recognition. On other hand, such apronounced computational complexity is defied only in trainingwhereas the recognition of an incoming image during testingphase is undemanding and high-speed procedure.
Fig. 4 shows different feature points detected at varyingdeformations; two sample images from Caltech airplane andmotorbikes datasets are used and it is obvious that number ofdetected feature points are changing in different transformations.A list is maintained to keep track of points, which have beenrepeated the most, to extract local patches. We declare theidentified key points as stable if the their rate of recognition ismore than 75% of the total number of deformations. A highvariation in feature points detection, i.e. corners, is observed;please refer to histogram presented in Fig. 5 where the number ofidentified key points is significantly changing for varying affineparameters. For practicality, white noise is also added so that thepatch is processed in conditions akin to a real life situation. Thepatches surrounding stable key points of size 16�16 areextracted whereas the deformed versions of images help toachieve synthesis to symbolize the possible appearances undervarying poses. Fig. 5(left) shows extracted patches (blue squares),with a height and width of 16 pixels each, using an illustrationimage from Caltech (Airplanes) dataset; please note that therecognized stable key points are represented by the green colorwhereas outliers have been represented by red.
After extraction of local patches; assigning each patch to amost probable object class is a subsequent task. Let ci, i¼1,2,y,Hbe a set of classes and fj, j¼1,2,y,Z be a set of binary features tobe computed from extracted patches. We want to classify a patchbased upon binary features as follows:
ci ¼ arg maxci
PðC ¼ cijf1,f2, . . . ,fzÞ, ð16Þ
tected under varying poses.

ARTICLE IN PRESS
Ferns Features
Feature Detection Analysis
0
100
200
300
400
500
600
700
800
900
1
Affine Transformations
No.
of
Key
Poi
nts
MotorbikesAirplanes
2 3 4 5 6 7 8
Fig. 5. Left: extracted local patches for Ferns computation and right: histogram of identified key points for varying affine deformation parameters.
Labels
TrainingImage Set
Test ImageSet
GlobalInformation
LocalInformation I
LocalInformation n-1
ELM (1)
ELM (2)
ELM (n)
ELM (1)
ELM (2)
ELM (n)
FinalHypothesis
Majority Voting
Majority Voting
Fusion for FinalClassification Labeled Image
Training:
Testing:
DataRepository
FeatureExtraction Training / Classification
Fig. 6. Different steps involved in our algorithm.
R. Minhas et al. / Neurocomputing 73 (2010) 1831–18391836
PðC ¼ cijf1,f2, . . . ,fzÞ ¼Pðf1,f2, . . . ,fzjC ¼ ciÞPðC ¼ ciÞ
Pðf1,f2, . . . ,fzÞ: ð17Þ
Assuming uniform prior probability P(C) and denominatorP(f1,f2,y, fz) as scaling factor; our problem is reduced to
ci ¼ arg maxci
Pðf1,f2, . . . ,fzjC ¼ ciÞ: ð18Þ
The computation of each binary feature fj depends upon mutualrelationship of two pixel intensities located at dj,1 and dj,2 in thepatch.
fj ¼1 if Iðdj,1Þo Iðdj,2Þ,
0 otherwise,
(ð19Þ
where I(.) represents an image patch. Assuming a completeindependence between features leads us to
Pðf1,f2, . . . ,fzjC ¼ ciÞ ¼Yz
j ¼ 1
PðfjjC ¼ ciÞ: ð20Þ
However, the correlation amongst neighboring pixels of apatch is ignored hence an acceptable compromise can bemodeled as
Pðf1,f2, . . . ,fzjC ¼ ciÞ ¼YM
k ¼ 1
PðFkjC ¼ ciÞ, ð21Þ
where M represents number of feature clusters of size S¼Z/Meach, a fern Fk is represented by
Fk ¼ fsðk,1Þ,fsðk,2Þ, . . . ,fsðk,SÞ, ð22Þ
where sðk,SÞ shows a random permutation function with range1,y,Z. A reliable and fast patch correspondence usingabove relationship is reported in [12]. A performance andcomputational load trade-off is observed for varying values of M
and S. In training phase, class condition probabilities forindividual ferns are estimated which are combined to labelcorresponding extracted patches. We generate M+1 dimensionallocal feature vectors for individual patches which comprise ofconditional probabilities of mutually independent ferns and theircombined information to compute the conditional probability of alocal patch. Finally, such feature vectors are used for training andtesting purposes using ELM as classifier working on local type offeatures.
5. Learning classifiers with parallel ELMs
The classification algorithm is provided with a set of trainingimages where positive label indicates that an object of interest ispresent in an image while negative label represents its absence.All images are converted to gray level and resized to squaredimension matrices. There is no further pre-processing applied todatasets and we assume no prior information about location, viewpoint and/or image acquisition constraints. To avoid the curse ofdimensionality, bidirectional 2D-PCA is employed which requiresmultiplication between two covariance matrices (one for each ofrow and column directions). The output of this dimensionalityreduction step is a square matrix which is vectorized and termedas global feature vector.

ARTICLE IN PRESS
R. Minhas et al. / Neurocomputing 73 (2010) 1831–1839 1837
The proposed recognition scheme declares an incoming imageas positive class if the relevant object is present. For fast pre-processing direct intensity values are used to extract both kinds offeatures i.e. global and local. Generating a variety of featuresrepresenting various contents of an image allows to knob varyinggeometric attributes of an object and achieve better categoriza-tion. Fig. 6 represents a generalized framework that supportsintegration of a wide variety of learnable local descriptors forenhanced classification. We used only single type of local featurevector generated using Ferns [12] style patches surroundingstable feature points identified using Harris corner detector.
Due to significantly shorter training time, and minimizedcomputational burden; we use more than one ELMs in a parallelfashion to process all categories of image feature simultaneouslyfor real-time classification. The training process for an ELMoperating on global feature vectors is not the same as one usingset of local features. Computed global training feature vectors aredirectly input to an ELM, whereas training for a ELM that dealswith local features, starts with application of corner detector bydeforming the training images and keeping a track of the numberof times same feature point is identified. Such image deformationsare suggested to train our classifier for possible pose variations,and is proved to be feasible due to fundamentally soaring trainingspeed (see Tables 1 and 3). The number of feature vectorsrepresenting the local patches of an image may vary dependingupon stable key points detected from a synthesized set of imagesfor different affine deformations. A majority voting scheme isadopted for reliable estimation of an image class since we observefalse alarms for individual local patches due to low informationcontent and an accidental matching among different regions of
Table 3Computational time (s) for GRAZ dataset.
Bikes Cars Persons
Training timeBikes NA 4.29 4.31
Cars 4.30 NA 4.34
Persons 4.30 4.37 NA
Classification timeBikes NA 3.21 2.93
Cars 3.25 NA 3.01
Persons 2.91 2.96 NA
Fig. 7. Classification accuracy for MIT datas
two different objects. The ELM operating on global feature vectorsdoes not require any such voting scheme since one-to-one
correspondence holds between feature vectors and individualimages. Finally, a fusion process is initiated to combine n
estimates originating from all ELMs based on normalizedweighted sum strategy that allows us to assign importance toeach approximation based on confidence (as follows):
fj ¼þ1 for
Xn
i ¼ 1
wi:eiZTh;Xn
i ¼ 1
wi ¼ 1,
�1 otherwise,
8><>: ð23Þ
where wi, ei and Th represent weight, estimate for individual ELMand threshold, respectively. In our proposed framework, user hasbetter control over preference to be given to an individual featuretype. Since the penchant strategy for different feature types issolely dependent upon application, photometric and geometricelements of individual objects. The value for threshold, i.e. Th,may vary between zero and one depending upon requiredconfidence. It is obvious that a high value of Th may result intoincreased reliability of classification with lower false positives andincreased chance of false negative alarms. During experiments,we assigned a 0.5 weight values to each of the estimatesoriginating from two ELMs operating on both kinds of featurevectors whereas a threshold of 0.75 is setup for final classification.Different steps involved in our proposed algorithm are presentedin Fig. 6.
6. Results and discussion
We used standard datasets to test the viability of our proposedmethod. The datasets from Caltech include Airplanes, Cars Brad,Faces, Leaves, Background, and Motorbikes whereas GRAZ andMIT image sets comprised of Bikes, Cars, Persons, and Pedestrians,respectively.
et using varying principal components.
Table 4Details of datasets used in analysis of changing threshold against accuracy.
Positive class Negative class Training images Testing images
Caltech Leaves Faces 200 436
MIT Pedestrians Cars 300 1140
GRAZ Bikes Persons 200 476
ARTICLE IN PRESS
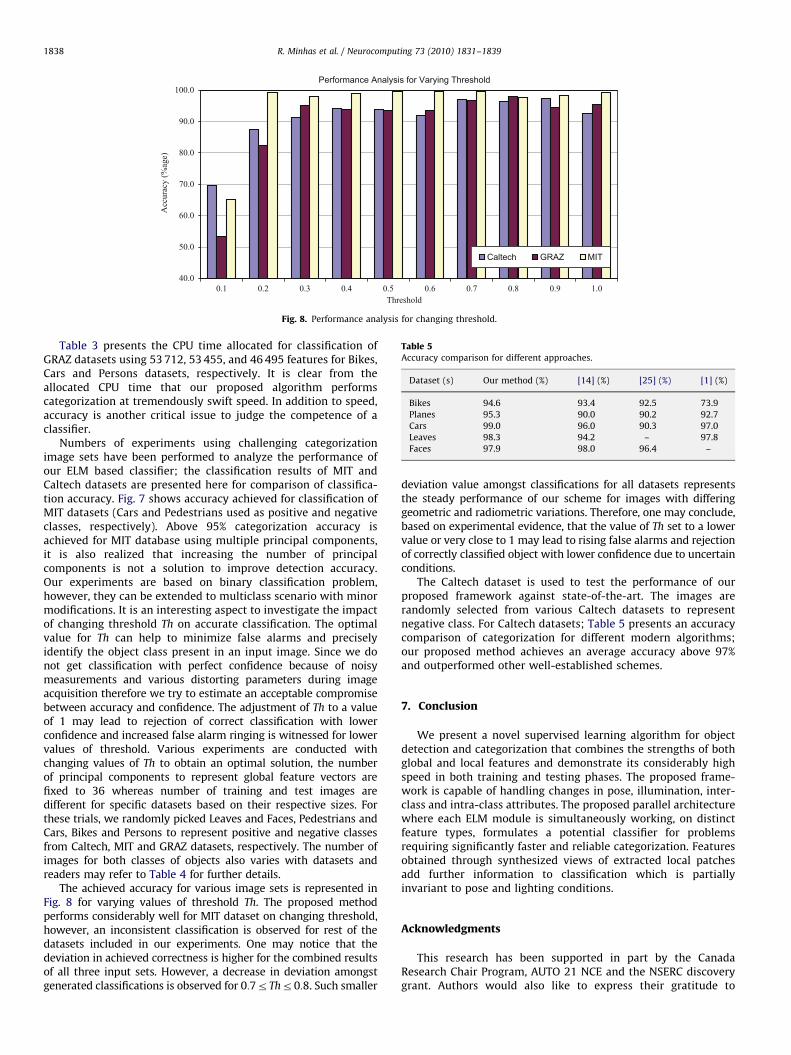
Fig. 8. Performance analysis for changing threshold.
Table 5Accuracy comparison for different approaches.
Dataset (s) Our method (%) [14] (%) [25] (%) [1] (%)
Bikes 94.6 93.4 92.5 73.9
Planes 95.3 90.0 90.2 92.7
Cars 99.0 96.0 90.3 97.0
Leaves 98.3 94.2 – 97.8
Faces 97.9 98.0 96.4 –
R. Minhas et al. / Neurocomputing 73 (2010) 1831–18391838
Table 3 presents the CPU time allocated for classification ofGRAZ datasets using 53 712, 53 455, and 46 495 features for Bikes,Cars and Persons datasets, respectively. It is clear from theallocated CPU time that our proposed algorithm performscategorization at tremendously swift speed. In addition to speed,accuracy is another critical issue to judge the competence of aclassifier.
Numbers of experiments using challenging categorizationimage sets have been performed to analyze the performance ofour ELM based classifier; the classification results of MIT andCaltech datasets are presented here for comparison of classifica-tion accuracy. Fig. 7 shows accuracy achieved for classification ofMIT datasets (Cars and Pedestrians used as positive and negativeclasses, respectively). Above 95% categorization accuracy isachieved for MIT database using multiple principal components,it is also realized that increasing the number of principalcomponents is not a solution to improve detection accuracy.Our experiments are based on binary classification problem,however, they can be extended to multiclass scenario with minormodifications. It is an interesting aspect to investigate the impactof changing threshold Th on accurate classification. The optimalvalue for Th can help to minimize false alarms and preciselyidentify the object class present in an input image. Since we donot get classification with perfect confidence because of noisymeasurements and various distorting parameters during imageacquisition therefore we try to estimate an acceptable compromisebetween accuracy and confidence. The adjustment of Th to a valueof 1 may lead to rejection of correct classification with lowerconfidence and increased false alarm ringing is witnessed for lowervalues of threshold. Various experiments are conducted withchanging values of Th to obtain an optimal solution, the numberof principal components to represent global feature vectors arefixed to 36 whereas number of training and test images aredifferent for specific datasets based on their respective sizes. Forthese trials, we randomly picked Leaves and Faces, Pedestrians andCars, Bikes and Persons to represent positive and negative classesfrom Caltech, MIT and GRAZ datasets, respectively. The number ofimages for both classes of objects also varies with datasets andreaders may refer to Table 4 for further details.
The achieved accuracy for various image sets is represented inFig. 8 for varying values of threshold Th. The proposed methodperforms considerably well for MIT dataset on changing threshold,however, an inconsistent classification is observed for rest of thedatasets included in our experiments. One may notice that thedeviation in achieved correctness is higher for the combined resultsof all three input sets. However, a decrease in deviation amongstgenerated classifications is observed for 0:7rThr0:8. Such smaller
deviation value amongst classifications for all datasets representsthe steady performance of our scheme for images with differinggeometric and radiometric variations. Therefore, one may conclude,based on experimental evidence, that the value of Th set to a lowervalue or very close to 1 may lead to rising false alarms and rejectionof correctly classified object with lower confidence due to uncertainconditions.
The Caltech dataset is used to test the performance of ourproposed framework against state-of-the-art. The images arerandomly selected from various Caltech datasets to representnegative class. For Caltech datasets; Table 5 presents an accuracycomparison of categorization for different modern algorithms;our proposed method achieves an average accuracy above 97%and outperformed other well-established schemes.
7. Conclusion
We present a novel supervised learning algorithm for objectdetection and categorization that combines the strengths of bothglobal and local features and demonstrate its considerably highspeed in both training and testing phases. The proposed frame-work is capable of handling changes in pose, illumination, inter-class and intra-class attributes. The proposed parallel architecturewhere each ELM module is simultaneously working, on distinctfeature types, formulates a potential classifier for problemsrequiring significantly faster and reliable categorization. Featuresobtained through synthesized views of extracted local patchesadd further information to classification which is partiallyinvariant to pose and lighting conditions.
Acknowledgments
This research has been supported in part by the CanadaResearch Chair Program, AUTO 21 NCE and the NSERC discoverygrant. Authors would also like to express their gratitude to

ARTICLE IN PRESS
R. Minhas et al. / Neurocomputing 73 (2010) 1831–1839 1839
anonymous reviewers and editor for valuable suggestions toimprove this manuscript.
References
[1] R. Fergus, P. Perona, A. Zisserman, Object class recognition by unsupervisedscale-invariant learning, in: Proceedings of International Conference on CVPR,2003, pp. 264–272.
[2] M. Weber, M. Welling, P. Perona, Unsupervised learning of models forrecognition, in: Proceedings of Sixth ECCV, 2000, pp. 18–32.
[3] P. Felzenszwalb, D. Huttenlocher, Pictorial structures for object recognition,IJCV 61 (1) (2004) 55–79.
[4] P. Viola, M. Jones, Rapid object detection using a boosted cascade of simplefeatures, in: Proceedings of the International Conference on CVPR, 2001,pp. 511–518.
[5] S. Agarwal, D. Roth, Learning sparse representation for object detection, in:Proceedings of ECCV, 2002, pp. 113–130.
[6] B. Leibe, A. Leonardis, B. Schiele, Combined object categorization andsegmentation with an implicit shape model, in: Proceedings ECCV WorkshopSL in C. Vision, 2004, pp. 17–32.
[7] P. Viola, M. Jones, D. Snow, Detecting pedestrians using patterns and motionappearance, IJCV (2003) 734–741.
[8] G.Y. Dorko, C. Schmid, Selection of scale-invariant parts for object classrecognition, in: Proceedings of ICCV, 2003, pp. 634–640.
[9] H. Schneiderman, T. Kanade, Object detection using the statistics of parts,IJCV 56 (3) (2004) 151–177.
[10] D.G. Lowe, Distinctive image features from scale-invariant keypoints, IJCV 60(2) (2004) 91–110.
[11] K. Mikolajczyk, C. Shmid, An affine invariant interest point detector, in:Proceedings of ECCV, 2002, pp. 128–142.
[12] M. Ozuysal, V. Lepetit, P. Fua, Fast key point recognition using random ferns,IEEE Trans. PAMI, in press.
[13] A. Opelt, M. Fussenegger, A. Pinz, P. Auer, Weak hypothesis and boosting forgeneric object detection and recognition, in: Proceedings of ECCV, 2004, pp.71–84.
[14] S. Ali, M. Shah, A supervised learning framework for generic object detectionin images, in: Proceedings of ICCV, 2005, pp. 1347–1354.
[15] G.-B. Huang, Q.-Y. Zhu, C.-K. Siew, Extreme learning machine: theory andapplications, Neurocomputing (2005) 489–501.
[16] R. Zhang, G.-B. Huang, N. Sundarajan, P. Saratchandran, Multicategoryclassification using an ELM for gene expression for cancer diagnosis, Comput.Biol. 1 (2007) 485–495.
[17] Q.-J. Benedict, S. Emmanuel, ELM for classification of music genres, in:Proceedings of the ICARCV, 2006, pp. 1–6.
[18] G.-B. Huang, H.A. Babri, Upper bound on number of hidden neurons in F.N.with arbitrary bounded nonlinear activation functions, Neural Networks(1998) 224–229.
[19] J. Yang, D. Zhang, F. Frangi, J.-Y. Yang, Two-dimensional PCA: a new approachto appearance based face representation and recognition, IEEE Trans. PAMI 26(1) (2004) 131–137.
[20] P. Sanguansat, W. Asdornwised, S. Marukatat, S. Jitapunkul, Two-dimensionalrandom subspace analysis for face recognition, in: Proceedings of ISCIT, 2007,pp. 628–631.
[21] D. Zhang, Z.-H. Zhou, (2D)2PCA for efficient face representation andrecognition, anonymous.
[22] R. Minhas, A.A. Mohammed, J. Wu, A generic moments invariant basedsupervised learning framework for classification using partial objectinformation, in: Proceedings of Conference on CRV, Canada, 2009, pp. 45–52.
[23] A. Opelt, A. Pinz, A. Zisserman, Incremental learning of object detectors usinga visual shape alphabet, in: Proceedings of International Conference on CVPR,2006, pp. 3–10.
[24] J. Shotton, A. Blake, R. Cippola, Contour-based learning for object detection,in: Proceedings of ICCV, 2005, pp. 503–510.
[25] A. Torralba, K.P. Murphy, W.T. Freeman, Sharing features: efficient boostingprocedures for multiclass object detection, in: Proceedings of InternationalConference on CVPR, 2004, pp. 762–769.
[26] D. Tao, X. Li, X. Wu, S.J. Maybank, General tensor discriminant analysis andgabor features for gair recognition, IEEE Trans. PAMI 29 (10) (2007)1700–1715.
[27] J. Sun, D. Tao, S. Papadimitriou, P.S. Yu, C. Faloutsos, Incremental tensoranalysis: theory and applications, ACM Trans. Knowl. Discovery Data 2 (3)(2008) 11:1–11:37.
[28] D. Tao, X. Li, X. wu, W. Hu, S.J. Maybank, Supervised tensor learning, Knowl.Inf. Systems (2007) 13:1–42.
[29] K. Mikolajczyk, C. Schmid, A performance evaluation of local descriptors, IEEETrans. PAMI 27 (10) (2005) 1615–1630.
Rashid Minhas is a Ph.D. Candidate at Computer Vision andSensing Systems Laboratory, Department of Electrical En-gineering, University of Windsor Canada. He completed B.Sc.Computer Science from BZU Multan Pakistan and MSMechatronics from GIST Korea. His research interestsinclude object and action recognition, image registrationand fusion using machine learning and statistical techni-ques.
Abdul Adeel Mohammed is a Ph.D. student at Departmentof Electrical Engineering, University of Windsor, ont.,Canada. He completed his Bachelor of Engineering (2001)from Osmania university (India) and Masters of AppliedScience from Ryerson University (Canada) in 2005. His mainarea of research is 3D pose estimation, robotics, computervision, image compression and pattern recognition.
Jonathan Wu (M’92, SM’09) received his Ph.D. degree inElectrical Engineering from the University of Wales, Swan-sea, UK, in 1990.
From 1995, he worked at the National Research Council ofCanada (NRC) for 10 years where he became a SeniorResearch Officer and Group Leader. He is currently aProfessor in the Department of Electrical and ComputerEngineering at the University of Windsor, Canada. Dr. Wuholds the Tier 1 Canada Research Chair (CRC) in Automotive
Sensors and Sensing Systems. He has published more than150 peer-reviewed papers in areas of computer vision, image processing,intelligent systems, robotics, micro-sensors and actuators, and integrated micro-systems. His current research interests include 3D computer vision, active videoobject tracking and extraction, interactive multimedia, sensor analysis and fusion,and visual sensor networks.
Dr. Wu is an Associate Editor for IEEE Transaction on Systems, Man, andCybernetics (Part A). Dr. Wu has served on the Technical Program Committees andInternational Advisory Committees for many prestigious conferences.