a glance at the world of search engines july 2005 matias cuenca-acuna research scientist teoma...
Post on 21-Dec-2015
212 views
TRANSCRIPT

A glance at the world of search engines
July 2005
Matias Cuenca-Acuna
Research Scientist
Teoma Search Development

The numbers behind search engines
• We are the 8th most visited site in the world !– People don’t use bookmarks
• We serve 4B queries per month– Assume you get 0.00001 of them and can sell something to
0.01 of the users that visit your site– You would close 400 operations per month
• Not bad for doing nothing
• We reach 25% of the active US audience– Imagine how effective all the search engines combined are to
deliver a message?• In US search engines reach 126 million people• The largest audience for a TV show ever in US was 177 million
• We push the envelope on several areas of CS– Huge scale distributed systems (thousands of machines)– Terabytes of data– Integrate distributed and scalable systems, fault tolerance,
information retrieval, natural language understanding, etc.

How do search engines work?
+ =
CrawlerIndexing Ranking
Algorithm
SearchResults

Overview of the talk
• Crawling
• Content control & cleaning
• Indexing
• Ranking

Crawling

How much do search engines index?
Search Engine
Self-Report. Size (Billions)
Est. Size (Billions)
Coverage Of Indexed Web
Coverage Of Total Web
Google 8.1 8.0 76.2% 69.6%
Yahoo 4.2(est.) 6.6 69.3% 57.4%
Ask 2.5 5.3 57.6% 46.1%
MSN 5.0 5.1 61.9% 44.3%
Indexed Web 9.4
Total Web 11.5
Source [Gulli & Signorini 2005]

Goals
• Coverage– Download a complete copy of the web
• Freshness– Keep the copy in sync with the source pages
• Politeness– Do it without disrupting the web and obeying the webmasters constrains

The coverage challenge
• The distribution of pages to servers follows a power law– i.e. the majority of the content is on the minority of the servers
• Suppose you want to crawl 100% of wikipedia.org– They have over 11M pages– The average page size is 10KB
• They host 112GB of content
– Suppose you want to be fresh and finish them in 15 days• This content is highly dynamic
– We would have to download 7GB per day !!!• This is not acceptable for a non profit organization
• The deep web– It is estimated that there are 500B pages that are not accessible by
search engines– Scripting languages, dynamic pages, forms, session IDs, non HTML
pages, etc.

The freshness challenge
• On their work [Cho & Garcia-Molina 2003] find that:– After tracking 154 sites for one year, only 24% of the initial links are available. On
average, 25% new links were created every week.– 5% new shingles are downloaded each week vs. 8% new pages are detected
• new pages borrow old content, the creation of pages is the largest source of change (not the modification of existing pages)
– After a year 50% of the content of the web is replaced and 80% of its links
• namestead.com records 250K new .com domains per day
Source [Brewington & Cybenko 2000]

The freshness challenge
• The promise of adaptive crawling [Brewington & Cybenko 2000]– Page updates can be modeled as a Poisson process
• The distribution of update interval is exponential
– Still, If we need 8ms to pull a URL record from disk, to crawl 11B pages we would need 2.7 years!!
• Help from the web masters– Conditional GETs
– Site maps
– RSS
• Although it on their best interest to be indexed not all of them can be trusted

The politeness challenge
• In order to preserve bandwidth webmaster put many constrains on us– Follow Robots.txt standard.
– ‘Crawl Delay’ directive to specify download minimum download interval
– NOARCHIVE – don’t cache this page
– NOINDEX – don’t index this page
– NOFOLLOW – index but don’t follow links
– Use compression to save your bandwidth• up to 75% savings with gzip
• Getting out of crawling traps– Calendars
• We don’t need pages for year 3001
– Session Ids on URLs

Crawling in a nutshell
• Timing, timing, timing• It’s a huge scheduling problem
– It’s like trying to keep 11B customers stoked
• Requires massive bandwidth and storage– 11B pages x 10KB = 112TB!!

Content control & cleaning

Goals
• “Bad pages” can hurt relevancy– Porn
– Spam• Pages whose sole purpose is to manipulate ranking
– Duplicates
• Must recognize and remove– Each is time-consuming, formidable tasks
– Not exact science, constantly evolving
• Must do a good job– Otherwise we get angry phone calls from parents, or get sued
– Not a laughing matter as you might have thought
• Requires a mixture of algorithmic and editorial solutions

A case of automatic spam content

A sample duplicate

Indexing

Purpose
• Create and efficient data structure for answering queries• Forwarding Indexing
– Creating page-to-word index– Recognize as many page properties as possible
• Last modified, language, etc.
• Inverted Indexing– A transposition of the forward indexing
• Containing equivalent information
– Creating word-to-page index
• Also keep information about individual pages– Last modified time– Language– others

Ranking
(i.e. the secret sauce)

Goals
• Return relevant results– How do we pick the best 10 pages out of billions?
• Understand the intent of the user– A query is more than just words
– What is the meaning behind it?
• Structured data - Smart Answers– Sometimes the best answer is not on the web

General Link Analysis Methods
A link from page A to page B (or C ) is a vote or recom-mendation by the author or page A for page B (or C )
A link from page A to page B (or C ) is a vote or recom-mendation by the author or page A for page B (or C )
<title>Dogs</title>
<meta>Dogs</meta>
<body><H1>Dogs</H1><H2>Dogs</H2>Dogs lorem ipsumdolor Dogs sit.
</body>
<title>Laps</title>
<meta>Laps</meta>
<body><H1>Laps</H1><H2>Laps</H2>Laps lorem ipsumdolor Laps sit.
</body>
<title>Ears</title>
<meta>Ears</meta>
<body><H1>Ears</H1><H2>Ears</H2>Ears lorem ipsumdolor Ears sit.
</body>
AA
BB
CC
The greater the number… First proposed by Kleinberg (known as the HITS algorithm)

Highlights of the technologies behind Jeeves
• Teoma search technology– Finding authoritative pages in a community of pages in real time
– Only engine that solves this computational issue
• DirectHit feedback technology
• Natural language question answering– Answering queries that are posed as questions

Understanding Teoma’s view of the Web
Local Subject Communitiesof Sites

Teoma’s Approach at a Glance Search the index to collect & calculate global information 2 Break the index into
communities
4 Apply all Pertinent global and local information
1
Collect & calculate local subject-specific information3
Local Subject
Community
Hub
Authority

Key challenges
• Solving the problem in real-time– 200 ms or less to do this computation for each query, millions of times
per day
• Identifying the communities– Link structure on the web is noisy
– Hubs link to multiple topic areas
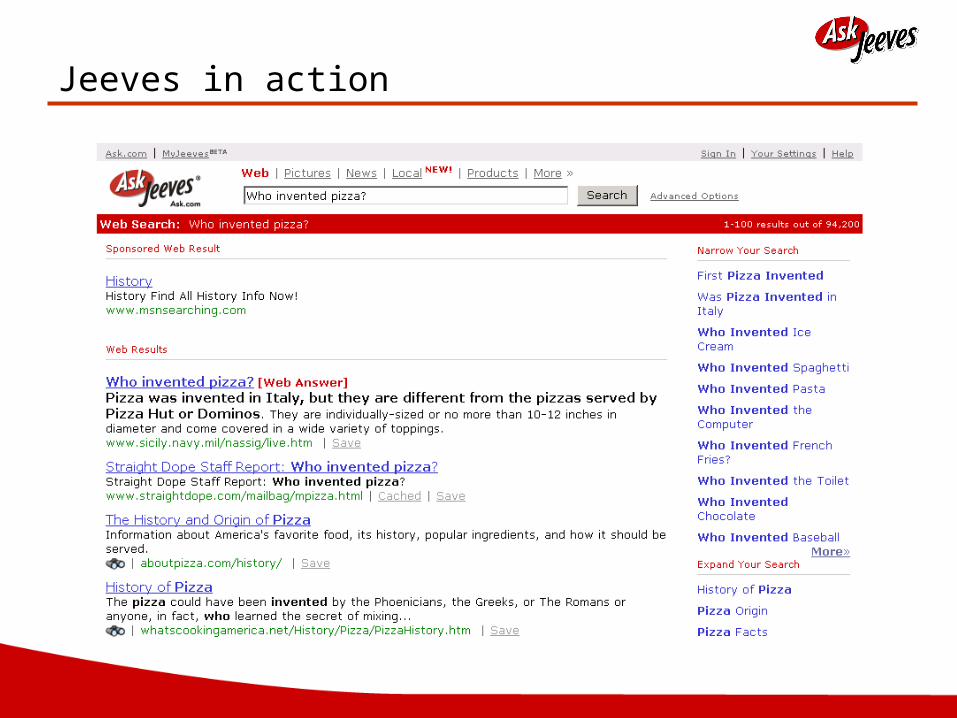
Jeeves in action
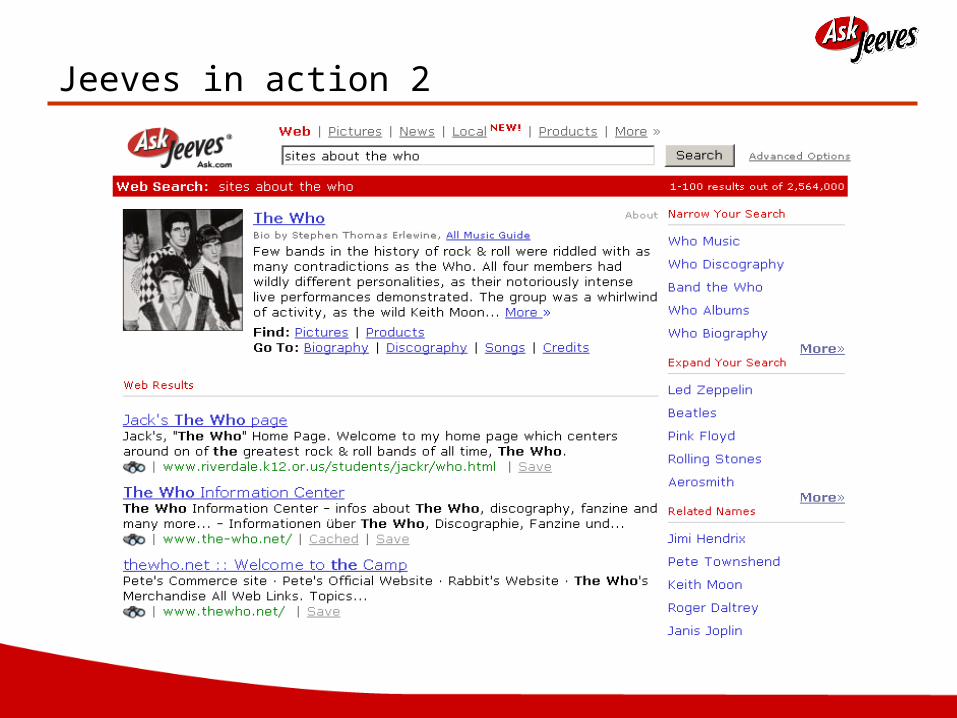
Jeeves in action 2

What happens when you don’t understand the query

Conclusion
• The key factors for a search engine are– Coverage
• How much of the web do we index?
– Freshness• What id the average staleness of the database
– Ranking• Given a 1M pages how do we select the 10 most relevant?
– Query understanding• What is the intent of the user?
• Simple problems become very challenging– 1000’s of machines
– TB’s of data
– Millions of daily queries requiring sub-second response time

A sample problem
• Assume we have a 2TB file with urls– 6B urls coming from 100M hosts
– Stored on a 10MB/sec disk (2.3 days needed to read it)
– Assume 300 bytes max. url size and 100 bytes max host name size
• How would you find the top 10 largest hosts?• What if we had more than one machine to do it?
– Still the file is on one disk
• What if we know that the page to host distribution follows a power law?

Questions?