a maturing role of workflows in the presence of heterogenous computing architectures
TRANSCRIPT

A Maturing Role of Workflows in the Presence of
Heterogeneous Compu<ng Architectures
WorDS.sdsc.edu
Dr. Ilkay Al<ntas Founder and Director, Workflows for Data Science (WorDS) Center of Excellence
San Diego Supercomputer Center, UC San Diego

SAN DIEGO SUPERCOMPUTER CENTER at UC San Diego Providing Cyberinfrastructure for Research and Educa<on
• Established as a na<onal supercomputer resource center in 1985 by NSF
• A world leader in HPC, data-‐intensive compu<ng, and scien<fic data management
• Current strategic focus on “Big Data” and “Data-‐intensive HPC”
1985
today

Scien&fic Workflow Automa&on Technologies
Research
Workflows for Cloud Systems
Big Da
ta App
lica&
ons
Re
prod
ucible Scien
ce
Workforce Training and Educa&on
De
velopm
ent a
nd Con
sul&ng
Services
Workflows for Data Science Center
Focus on the ques&on, not the
technology! 10+ years of data science R&D experience as a Center.


Computa<onal Data Science Workflows -‐ Programmable, Reusable and Reproducible Scalability -‐
• Access and query data • Scale computa<onal analysis • Increase reuse • Save <me, energy and money • Formalize and standardize
Real-‐Time Hazards Management wifire.ucsd.edu
Data-‐Parallel Bioinforma<cs bioKepler.org
Scalable Automated Molecular Dynamics and Drug Discovery nbcr.ucsd.edu
kepler-‐project.org WorDS.sdsc.edu

The Big Picture is to Capture the Workflow in an Executable and Reusable Way
Conceptual SWF
Executable SWF
From “Napkin Drawings” to Executable Workflows… SBNL workflow
Local Learner
Data Quality Evaluation
Local Ensemble Learning
Quality Evaluation & Data Partitioning Big Data
Master Learner
MasterEnsemble Learning
Final BN Structure
Insurance and Traffic Data Analy&cs using Big Data Bayesian Network
Learning

Ptolemy II: A laboratory for investigating design
KEPLER: A problem-solving environment for Scientific Workflow KEPLER = “Ptolemy II + X” for Scientific Workflows
Kepler is a Scientific Workflow System
• A cross-project collaboration… initiated August 2003
• 2.5 will be releases soon
www.kepler-project.org
• Builds upon the open-source Ptolemy II framework
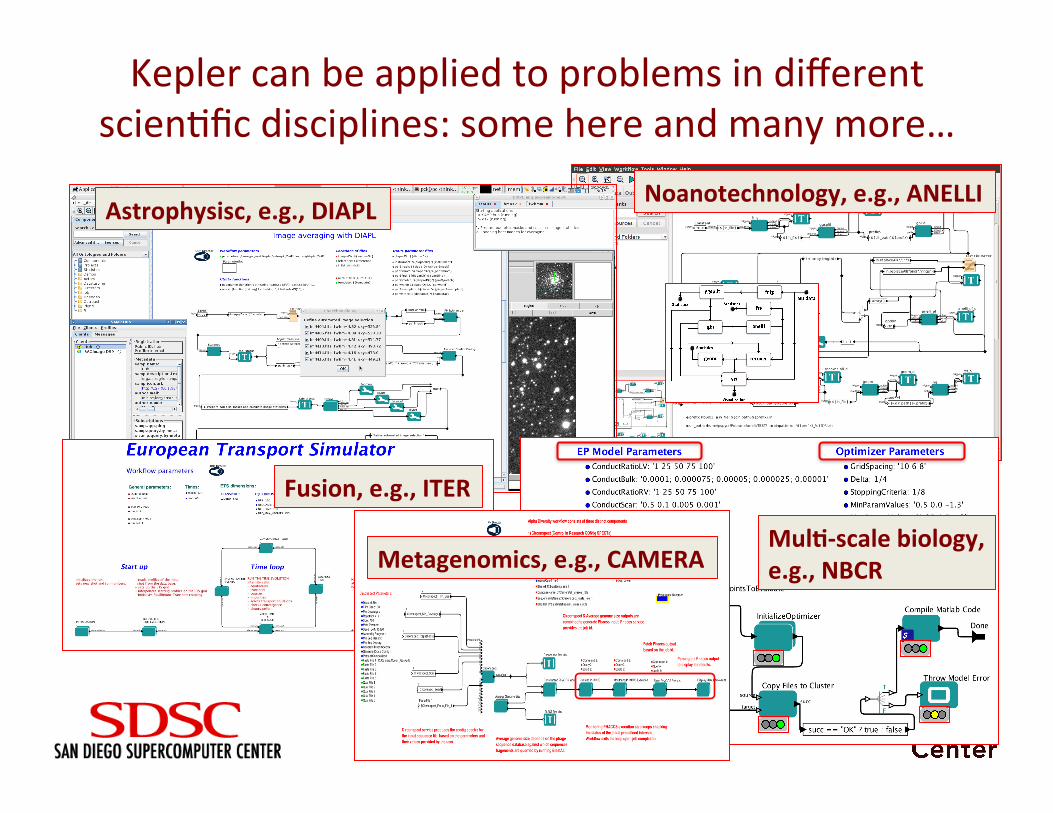
Kepler can be applied to problems in different scien<fic disciplines: some here and many more…
Astrophysisc, e.g., DIAPL Noanotechnology, e.g., ANELLI
Fusion, e.g., ITER
Metagenomics, e.g., CAMERA Mul&-‐scale biology, e.g., NBCR

A Toolbox with Many Tools
Need expertise to identify which tool to use when and how! Require computation models to schedule and optimize execution!
• Data • Search, database access, IO opera<ons, streaming data in real-‐<me…
• Compute • Data-‐parallel pa_erns, external execu<on, …
• Network opera<ons • Provenance and fault tolerance

So,
how can we use workflows in the
context of applications? … while coupling all scales computing computing within a reusable solution…

Some P’s to focus on…
People
Process
Platforms
Purpose
Programmability

There are more: provenance, publica<on, product, performance, policy, profit, ...

People…
People

Computa<onal Data Scien<st Skill Set h_p://datasciencedojo.com/what-‐are-‐the-‐key-‐skills-‐of-‐a-‐data-‐scien<st/
Need to communicate!
Process
Process

A Typical Workflow-‐Driven Process
Find data Access data Acquire data Move data
Clean data Integrate data Subset data
Pre-‐process data
Analyze data Process data
Interpret results Summarize results Visualize results
Post-‐process results
Some ques<ons to ask: • Where and how do I get the data? • What is the format and frequency of the data, e.g., structured, textual, real-‐<me,
image, …? • How do I integrate or subset datasets, e.g., knowledge representa<on,… ? • How do I analyze the data and what is the analysis func<on? • What are the parameters to customize each step? • What are the compu<ng needs to schedule and run each step? • How do I make sure the results are useful for the next step or as scien<fic products,
e.g., standards compliance, repor<ng, …?
configurable automated analysis

Purpose
People
Process
Purpose

Purpose… “You've got to think about
big things while you're doing small things,
so that all the small things go in the right direc<on.” – Alvin Toffler
use cases => purpose and value

Need toolboxes with many tools for: • data access, • analysis, • scalable execu&on, • fault tolerance, • provenance
tracking, • repor<ng • ...
Integra<on of Many Tools to Serve a Purpose
• Alterna<ve tools • Mul<ple modes of scalability
• Support for each step of the development and produc<on process
• Different repor<ng needs for explora<on and produc<on stages
Build
Explore
Scale
Report

Build Once, Run Many Times…
• Data science process should support experimental work and dynamic scalability on many plalorms
• Scalability based on: – data volume and velocity – dynamic modeling needs – highly-‐op<mized HPC codes – changes in network, storage and compu<ng availability

There are different styles of parallelism!
Task1Task2
Task3Task4
Finished Running Waiting
Running Waiting Waiting
12
Task1 Task2 Task331
2
3
InputDataSet
Running Running Running
Task1 Task2 Task31231
2
3
InputDataSet
...

• A parallel and scalable programming model for
Big Data– Input data is automatically partitioned onto multiple
nodes– Programs are distributed and executed in parallel on
the partitioned data blocks
Distributed-‐Data Parallel Compu<ng
Images from: h_p://www.stratosphere.eu/projects/
Stratosphere/wiki/PactPM
MapReduceMove program
to data!

Distributed Data-‐Parallel (DDP) Pa_erns
• A higher-‐level programming model – Moving computa<on to data – Good scalability and performance accelera<on – Run-‐<me features such as fault-‐tolerance – Easier parallel programming than MPI and OpenMP
Pa_erns for data distribu&on and parallel data processing
Images from: h_p://www.stratosphere.eu/projects/Stratosphere/wiki/PactPM

Hadoop • Open source implementa<on of MapReduce
• A distributed file system across compute nodes (HDFS) – Automa=c data par==on – Automa=c data replica=on
• Master and workers/slaves architecture
• Automa<c task re-‐execu<on for failed tasks
Spark • Fast Big Data Engine
– Keeps data in memory as much as possible
• Resilient Distributed Datasets (RDDs) – Evaluated lazily – Keeps track of lineage for fault tolerance
• More operators than just Map and Reduce
• Can run on YARN (Hadoop v2)

Scalability across plalorms…
People
Process
Platforms
Purpose

Running on Heterogeneous Computing Resources
- Execution of programs on where they run most efficiently -
Gordon Trestles
Local Cluster Resources
NSF/DOE: TeraScale Resources (XSEDE)
(Gordon) (Comet)
(Stampede) (Lonestar)
Private Cluster: User Owned Resources
Different executables have different compu&ng architecture needs!
e.g., memory-‐intensive, compute-‐intensive, I/O-‐intensive

Challenges for Heterogeneous Compu<ng
• Dynamic scheduling op<miza<on – Based on network availability – Data transfer and locality – Energy efficiency – Availability of exascale memory hierarchies – Workload changes – Dynamic memory or file-‐based coupling
• Be_er programmable communica<on between workflow systems and infrastructure for compu<ng, storage and network
• Harder form of reproducibility • Harder to program using scripts

Programmability for scalability, reusability and reproducibility
People
Process
Platforms
Purpose
Programmability

Using Big Data Computing in Bioinformatics- Improving Programmability, Scalability and Reproducibility-
biokepler.org

Kepler
bioKepler
ComputeAmazon
EC2
FutureGridSun Grid Engine
Adhoc Network
Data
CAMERA
Ensembl
Genbank
Deploy & Execute
Bioinformatics Tools
Clustering
MappingAssembly
Transfer
Customize & Integrate
Data-Parallel Execution PatternsMap-Reduce Master-Slave All-Pairs
Triton Resource
Provenance
Execution HistoryData Lineage
Reporting
PDF GenerationReport Designer
Fault-Tolerance
Error HandlingAlternatives
Run Manager
TagSearch
Director
Executable Workflow Plan
Scheduler
Execution EngineBioinformatician
Workflow
bioActorsBLASTHMMERCD-HIT
bioKepler’s Conceptual Framework
Private Repositories
…XSEDE

Gateways and other user environments
bioKepler Kepler and Provenance Framework
BioLinux Galaxy Clovr Hadoop
…
CLOUD and OTHER COMPUTING RESOURCES e.g., SGE, Amazon, FutureGrid, XSEDE
www.bioKepler.org
A coordinated ecosystem of biological and technological packages for bioinformatics!

RAMMCAP - Rapid Clustering and Functional Annotation for Metagenomic Sequences
Data size
CPU <me
Memory
Parallel
KB MB GB TB
Second Hour Day Month Year
GB 10GB 100GB
No need No Mul< threading MPI Map Reduce
QC
tRNA
cd-‐hit
hmmer
metagene
blast
QC tRNA cd-‐hit hmmer metagene blast
QC tRNA cd-‐hit hmmer metagene blast
QC tRNA cd-‐hit hmmer metagene blast hmmer blast
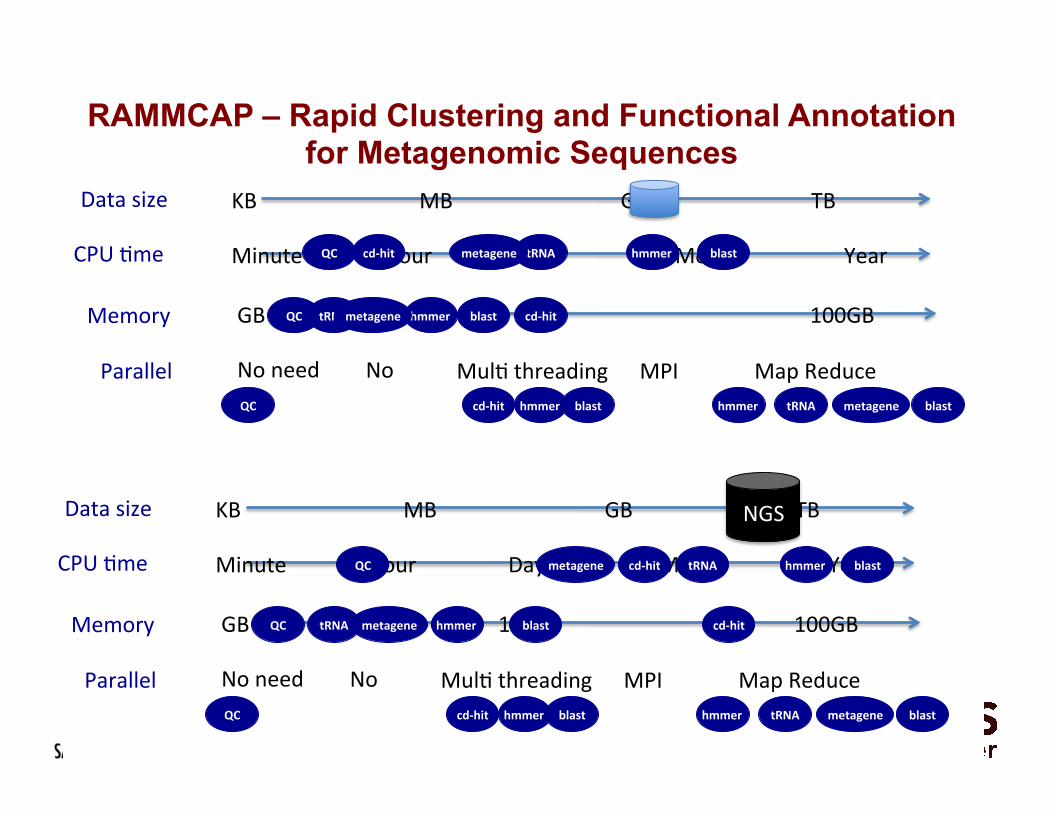
RAMMCAP – Rapid Clustering and Functional Annotation for Metagenomic Sequences
Data size
CPU <me
Memory
Parallel
KB MB GB TB
Minute Hour Day Month Year
GB 10GB 100GB
No need No Mul< threading MPI Map Reduce
QC tRNA cd-‐hit hmmer metagene blast
QC tRNA cd-‐hit hmmer metagene blast
QC tRNA cd-‐hit hmmer metagene blast hmmer blast
Data size
CPU <me
Memory
Parallel
KB MB GB TB
Minute Hour Day Month Year
GB 10GB 100GB
No need No Mul< threading MPI Map Reduce
NGS
QC tRNA cd-‐hit hmmer metagene blast
QC tRNA cd-‐hit hmmer metagene blast
QC tRNA cd-‐hit hmmer metagene blast hmmer blast

Source: Larry Smarr, Calit2 PI: (Weizhong Li, CRBS, UCSD):
NIH R01HG005978 (2010-2013, $1.1M)
Computa<onal NextGen Sequencing Pipeline: From Sequence to Taxonomy and Func<on

Same approach can be applied to machine learning and other
applica<on areas!
-‐ REUSABILITY and REPURPOSABILITY-‐

Flexible programming of K-‐means • R: Programming
language and sorware environment for sta<s<cal compu<ng and graphics.
• KNIME: Plalorm for data analy<cs.
• MlLib: Scalable machine learning library running on Spark cluster compu<ng framework
• Mahout: Scalable machine learning library based on MapReduce.

Scalable Bayesian Network Learning
Conceptual SWF
Executable SWF
From “Napkin Drawings” to Executable Workflows… SBNL workflow
Local Learner
Data Quality Evaluation
Local Ensemble Learning
Quality Evaluation & Data Partitioning Big Data
Master Learner
MasterEnsemble Learning
Final BN Structure
Insurance and Traffic Data Analy&cs using Big Data Bayesian Network
Learning

Focus on the use case, not the
technology!

Using Workflows and Cyberinfrastructure for Wildfire Resilience
- A Scalable Data-Driven Monitoring and Dynamic Prediction Approach -
wifire.ucsd.edu

A Scalable Data-‐Driven Monitoring, Dynamic Predic<on and Resilience Cyberinfrastructure for Wildfires (WIFIRE)
Development of: “cyberinfrastructure” for “analysis of large dimensional heterogeneous real-‐<me sensed data” for fire resilience before, during and a@er a wildfire

What is lacking in disaster management today is…
a system integra<on of real-‐<me sensor networks, satellite imagery, near-‐real <me data management
tools, wildfire simula<on tools, and connec<vity to emergency command centers
. …. before, during and arer a firestorm.

h_p://nbcr.ucsd.edu/
Integrated Mul<-‐Scale Biomedical Modeling Workflows in NBCR

Identify gaps in multiscale modeling capabilities and develop new methods and tools that allow us to bridge
across these gaps
Å nm – µm 0.1mm - mm cm
fs - µs µs - ms ms - s s - lifespan
Molecular & Macromolecular Sub-Cellular Cell Tissue Organ
Spa&
al and
Tempo
ral Scales
Driving Biomedical Projects propel technology development across multi-scale modeling capability gaps, from simulation to
data assembly & integration
• Models at different scales are generally not designed to inform each other
• Specialized interfaces to communicate large number of parameters and data are needed
• Provenance of experiments needs to be portable
• Models require different levels of scalability
• Deployable sorware maintenance requires exper<se
Rommie Amaro, UCSD

Sensi&vity Analysis (SA) for Uncertainty Quan&fica&on (UQ)
Computa(onal SA techniques to effec=vely and efficiently iden<fy computa=onal error and model sensi=vity for differen=al equa=ons (DE)
Biomedical Theory and Experimental Data
Nonlinear DE System as Mathema=cal Model
Numerical Solu=on of Nonlinear DE Model
Extrac=on of Quan=ty of Interest from Simula=on
The Standard Scien(fic Simula(on Workflow for DE Modeling in NBCR
Numerical solu=on of Nonlinear DE Model
Standard Nonlinear Solve of Primal Problem
Solu<on of linearized Dual Problem for Performing SA
Use of SA informa<on for UQ (error es<ma<on) to build an improved numerical discre<za<on
Output of Numerical Solu<on with UQ/SA Info
FETK & FEniCS
Support for end-‐to-‐end computa&onal scien&fic process Battling complexity while facilitating collaboration and increasing reproducibility.
Aim 1
Goal: Extract Quan<ty of Interest (QoI) from accurate numerical simula<on.
Mike Holst, UCSD
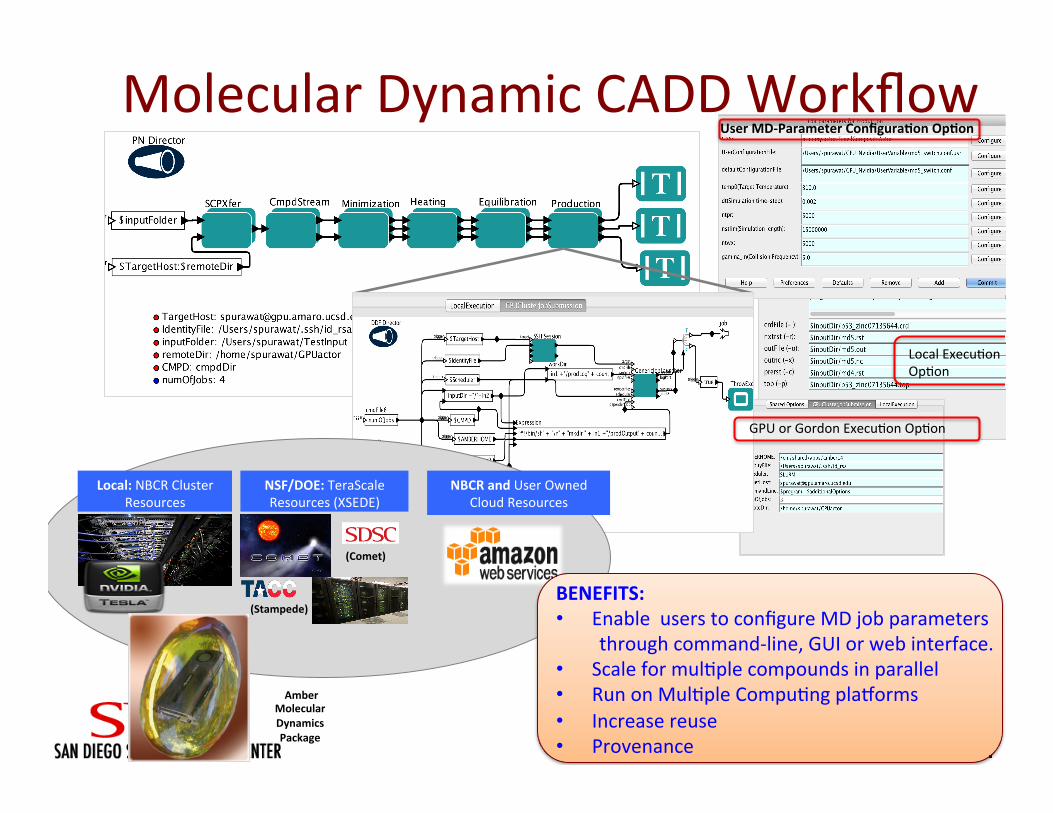
Local Execu<on Op<on
User MD-‐Parameter Configura&on Op&on
Molecular Dynamic CADD Workflow
Amber Molecular Dynamics Package
Local: NBCR Cluster Resources
NSF/DOE: TeraScale Resources (XSEDE)
(Stampede)
NBCR and User Owned Cloud Resources
(Comet)
BENEFITS: • Enable users to configure MD job parameters through command-‐line, GUI or web interface. • Scale for mul<ple compounds in parallel • Run on Mul<ple Compu<ng plalorms • Increase reuse • Provenance
GPU or Gordon Execu<on Op<on

h_p://hpc.pnl.gov/IPPD/
Predic<ng Workflow Performance from Provenance
IPPD IDEA: Use past workflows e xecu<on t r a ce s along with system, a p p l i c a < o n a n d execu<on profiles for dynamic predic<ve scheduling.

h_ps://smartmanufacturingcoali<on.org/
Workflows-‐as-‐a-‐Service

To Sum Up• Workflows and provenance are well-adopted in scientific
infrastructures today, with success• WorDS Center applies these concepts to advanced
dynamic data-driven analytics applications
• One size does not fit all! • Many diverse environments and requirements• Need to orchestrate at a higher level• Higher level programming components for each domain
• Lots of future challenges on• Optimized execution on heterogeneous platforms
• Programmable interface to workload, storage and network needed• Increasing reuse within and across application domains• Querying and integration of workflow provenance data into
performance prediction

Que
s<on
s?
Ilkay Al<ntas, Ph.D.
Email: al<n
tas@
sdsc.edu
Thanks to our many collaborators and funders!
Twi_er: @WorDS_SDSC