a peek inside the bioinformatics black box - dcamg symposium - mon 20 july 2015
TRANSCRIPT

A peek inside the bioinformatics black box
A/Prof. Torsten Seemann
Victorian Life Sciences Computation Initiative (VLSCI)Doherty Centre for Applied Microbial Genomics (DCAMG)
The University of Melbourne
DCAMG Symposium - Melbourne, AU - Mon 20 July 2015

Bioinformatics

Bioinformatics

What’s inside the black box?

It’s black boxes, all the way down.
Data
Algorithms
Software
Analyses

We use real black boxes too!

The data

The currency of genomics
Reads
Reads are stored in FASTQ files
Genome
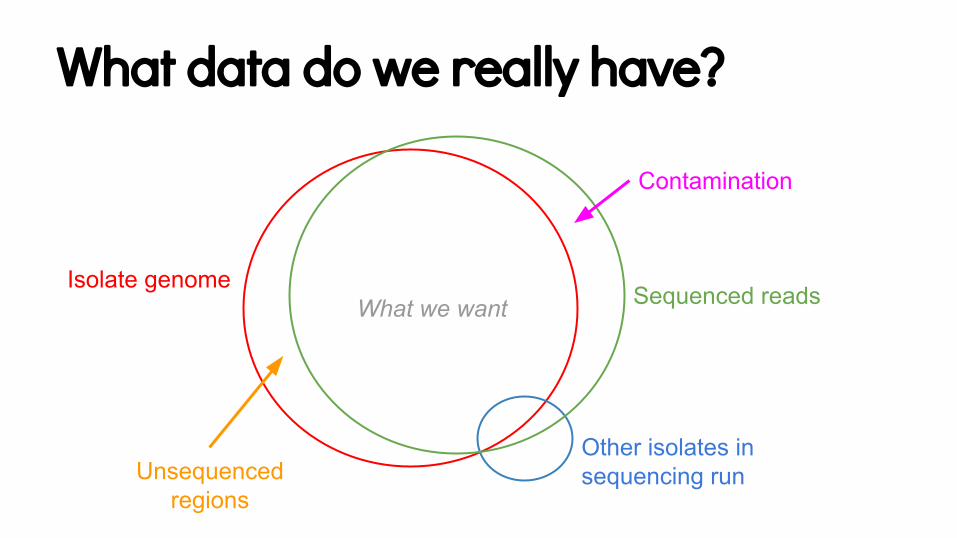
What data do we really have?
Isolate genomeSequenced reads
Other isolates in sequencing run
Contamination
Unsequenced regions
What we want

Metadata
■ Genome data itself is of limited value
■ Needs “extra” information
□ location: Australia 37.8S,145.0E □ date: 2015 2015-07-20□ source: human 60yo male faecal swab□ etc.

Got my reads, now what?

De novo genome assembly

Draft vs. Finished genomes
250 bp - Illumina - $100 8000 bp - Pacbio - $1000

Compare to already assembled genomes
AGTCTGATTAGCTTAGCTTGTAGCGCTATATTATAGTCTGATTAGCTTAGAT
ATTAGCTTAGATTGTAG
CTTAGATTGTAGC-C
TGATTAGCTTAGATTGTAGC-CTATAT
TAGCTTAGATTGTAGC-CTATATT
TAGATTGTAGC-CTATATTA
TAGATTGTAGC-CTATATTAT
SNP Deletion
Reference
Reads

Best practice
■ Use both approaches□ reference-based + de novo
■ Best of both worlds□ and worst of both worlds - interpretation is non-trivial
■ Still need□ good epidemiology, metadata and domain knowledge!

Comparing genomes

Core vs. Pan genome
Core is common to all & has similar sequence.

Pan genome analysis
Rows are genomes, columns are genes.

Phylogenomics
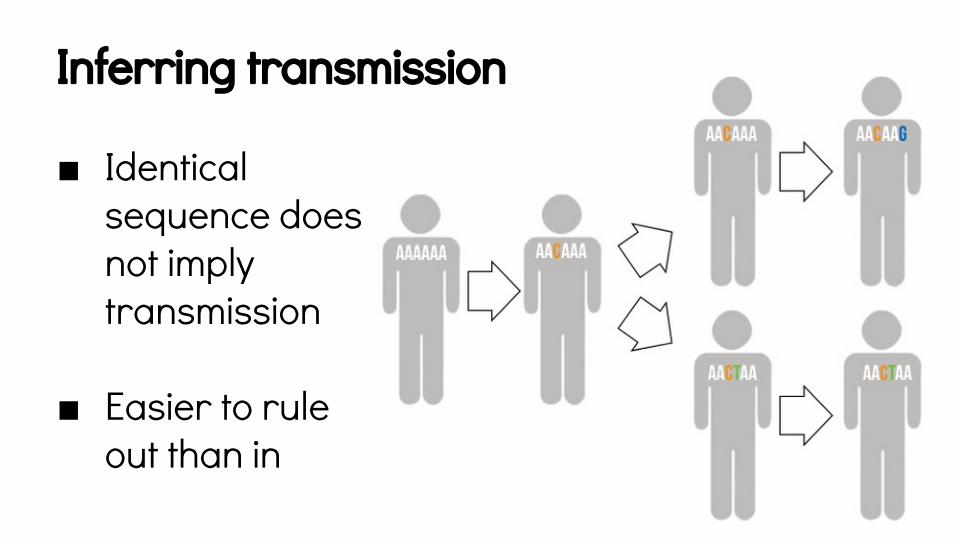
Inferring transmission
■ Identical sequence does not imply transmission
■ Easier to rule out than in

Conclusion

The future
■ Genomics is delivering on the promise□ still not maximally exploited
■ Directions
□ more use of pan-genome□ understanding recombination / horizontal transfer□ dynamics of microevolution□ useful visualization of large data sets□ open science: data sharing, open source software

