a perspective ibm system z mainframe capacity deliverypast and future
TRANSCRIPT

Sponsored by:
1
A Perspective IBM System z Mainframe Capacity delivery…past and future by [email protected]
1 © Copyright INNOVATION Data Processing and Robert Rogers, 2013, All rights reserved.

Sponsored by:
Abstract Corporations, governments and other large enterprises always have and always will have a nearly insatiable demand for more mainframe computing capacity. Over the last four decades advances in hardware chip technology met the lion’s share of this demand. However, we are entering an era when hardware advancement is most likely not going to continue at the same pace. So now is a perfect time to review other techniques for growing capacity like multiprocessing and Sysplex clustering; and to prognosticate on how we can continue to grow mainframe capacity, without benefit of the large contributions from chip technology that we are so accustom to. Your future will include expanding the use of MP and Sysplex, but you’ll also have to be ready for some entirely new technologies that are likely to be introduced into your mainframe environment.
Trademarks and statements:
IBM, System z, z900, z990, z9, z10, z196, EC12 and z/OS are trademarks or registered trademarks of International Business Machines Corporation. All other service marks, trademarks or registered trademarks are the property of their respective owners.
2 2 © Copyright INNOVATION Data Processing and Robert Rogers, 2013, All rights reserved.

Sponsored by:
3
Since the introduction of CMOS Mainframes in 1994, the technology has provided phenomenal growth in uniprocessor capacity. The frequency of the G1 in 1994 was less than 60 MHz. The EC12 in 2012 was 5.5 GHz (i.e. 5,500 MHz). That comes out to a 28% CAGR over 18 years. This speed-up was provided by silicon technology and also through incremental design sophistication. Much of the CMOS design sophistication was actually a re-implementation of many of the design tricks developed in Bipolar days. For example: sophisticated branch prediction, superscalar parallelism, high-frequency deep pipelines and out-of-order execution. One new technique has also been employed. This is “cracking”. Complex instructions are “cracked” into a number of simpler instructions that can be executed on a high-frequency pipeline. As the pipeline got faster but memory speeds remained fairly constant, techniques were needed to deal with the relative increase in data (and instruction) access latencies. To help with instruction fetching, additional sophisticated branch prediction techniques were implemented. This enabled instruction fetching to somewhat keep up with the very fast instruction processor. The delay in accessing data was reduced by introducing additional levels of cache – some private to a processor and some shared by a set of processors. The EC12 has four levels of cache in front of main memory. The first two are private caches; the third is an on-chip cache shared by all four processors on the chip; the last is shared by all the processors of a book. It is the last level of cache that maintains coherency across the whole complex so that any processor can access any piece of memory.
3 © Copyright INNOVATION Data Processing and Robert Rogers, 2013, All rights reserved.

Sponsored by:
Multiprocessing was introduced as early as S/360 but had little architectural support so was very inefficient. Proper architecture for multiprocessing was introduced in S/370. MVS/370 was designed to support 2-way multiprocessing, but it was not until XA that MVS supported more than the me-and-thee approach of a 2-way design.
XA was designed to support up to 16 processors. But, “supporting” and being able to run reasonably efficiently are two different things. A great deal of hardware and software innovation were required to get reasonable efficiency as the number of processors was increased.
CMOS N-way growth was slow from 1994, with a 6-way G1, until 2000, with the 16-way z900. N-way growth has since exploded up to the 101-way EC12.
Meanwhile hardware and z/OS innovations have helped keep the MP effectiveness ratio somewhat steady even as the N-way number skyrocketed. The MP ratio for maximally configured systems during this time has held fairly steady between 47% and 67%. However, one must bear in mind that since the z990 in 2003, the LSPR numbers for the largest systems are not for a single z/OS image, but for a mixture of z/OS images intended to be more representative of actual customer use of these huge systems. Given that, the MP ratio for the largest systems has held fairly steady between 47% and 67%.
4 © Copyright INNOVATION Data Processing and Robert Rogers, 2013, All rights reserved.
Sponsored by:
5
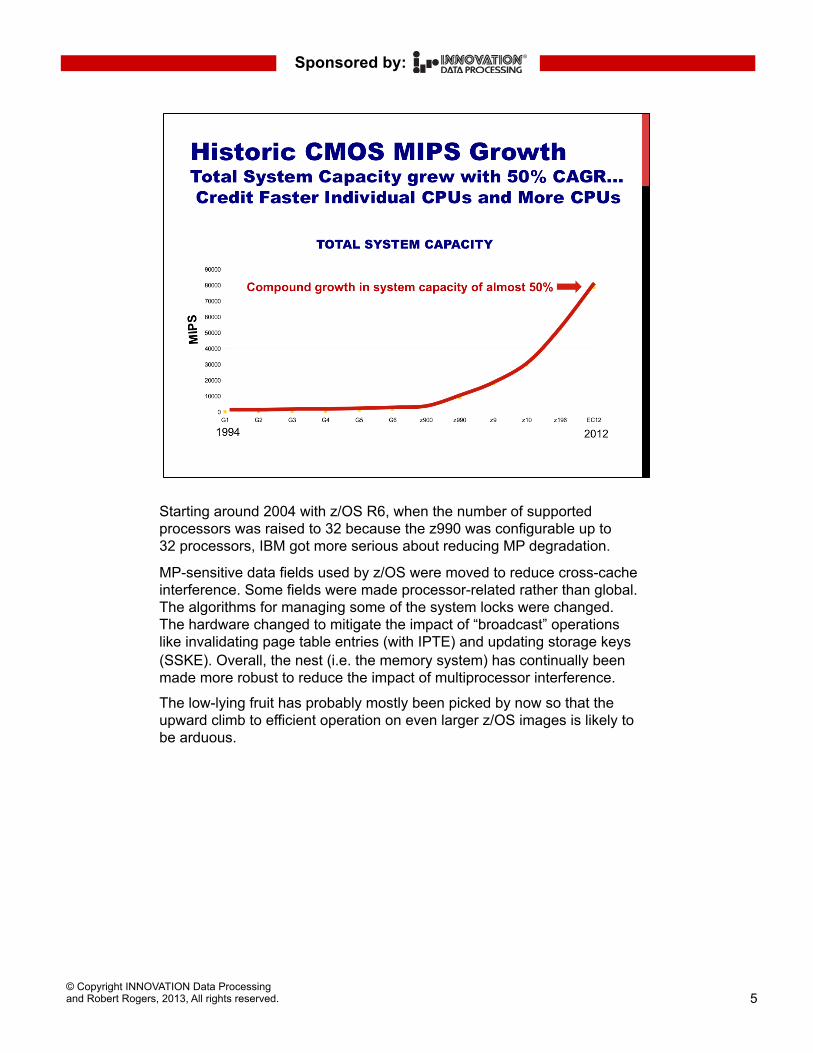
Starting around 2004 with z/OS R6, when the number of supported processors was raised to 32 because the z990 was configurable up to 32 processors, IBM got more serious about reducing MP degradation.
MP-sensitive data fields used by z/OS were moved to reduce cross-cache interference. Some fields were made processor-related rather than global. The algorithms for managing some of the system locks were changed. The hardware changed to mitigate the impact of “broadcast” operations like invalidating page table entries (with IPTE) and updating storage keys (SSKE). Overall, the nest (i.e. the memory system) has continually been made more robust to reduce the impact of multiprocessor interference.
The low-lying fruit has probably mostly been picked by now so that the upward climb to efficient operation on even larger z/OS images is likely to be arduous.
5 © Copyright INNOVATION Data Processing and Robert Rogers, 2013, All rights reserved.

Sponsored by:
6
The System z EC12 processor, at 5.5 GHz, is the highest frequency commercially available general purpose processor. It is unlikely that this frequency will be exceeded in the near future. The main reasons why single engine speed cannot be increased are on the next chart.
The N-way issues are mostly a software concern. The hardware can build very large SMP systems, but memory access times become variable (NUMA) and some accesses can have very large latency. However, if the logical partitions don’t have a large number of processors, PR/SM can place the processors used by each partition in a way that keeps the access latency reasonable (i.e. all the processors that run an image share chip-level or book-level cache). This is what is done by Hiperdispatch with the introduction of the 64-processor z10 in 2008.
Implementing Hiperdispatch helped because it enabled z/OS to run on a smaller number of logical processors and to keep them running nearly constantly. This makes it possible for PR/SM to optimally assign the physical processor for a partition and maintain that assignment. With Hiperdispatch, most of the processors are “nearly dedicated” to the partition using them. This greatly reduces PR/SM dispatching overhead. Hiperdispatch provides a double digit improvement on a 64-way partition.
But, beyond Hiperdispatch, it’s not expected that there can be great gains in MP efficiency for large partitions.
6 © Copyright INNOVATION Data Processing and Robert Rogers, 2013, All rights reserved.

Sponsored by:
7
There are a number of “barriers” that prevent engineers from just continuing to make CMOS processors faster. The Memory Wall is caused by data access latency. While executing a program, the processor executes instructions, but also waits for memory accesses. Since the memory access time is pretty constant across generations (about 2 ns) even as the processor frequency increases, an ever increasing percentage of the time is spent doing something that cannot be accelerated – namely, waiting for data access. The Power Wall is a physics problem. In order to increase the frequency, the chip circuitry must be made denser through miniaturization. But, as a chip runs with higher and higher frequency, it demands greater power. But, this power must be delivered to a smaller area as the processor circuitry is miniaturized. This leads to a “power density” problem such that it’s just not reasonable to pump that much power into that small an area. Both the density and the increase in power lead to more “leakage” to the point where most of the power goes to leakage rather than switching the circuits. The Frequency Wall is a processor design problem. Over the lifetime of CMOS systems, frequency has been increased by implementing a long pipeline. Each stage of the pipeline does less work, requiring less time. The reduced cycle time translates to higher frequency. But this cannot be done indefinitely. We have probably reached the point where the operations performed by the pipeline stages cannot be broken down any further. So, further frequency gains for lengthening the pipeline are not likely. It must be emphasized that these are not just mainframe problems. They are problems for all the industry platforms, including IBM System p and Intel.
7 © Copyright INNOVATION Data Processing and Robert Rogers, 2013, All rights reserved.

Sponsored by:
8
The trend has been a 50% increase in box MIPS for the last few generations, so it seems reasonable to see this as an objective.
However: Engine speed-up is projected to be no more than single digit for some time to come.
That leaves growing the z/OS image size dependent almost solely on raising the N-way. But, N-way is already becoming very inefficient at the currently supported levels.
Growing from where we are is going to be very difficult. Increasing single engine speed and running larger z/OS partitions just can’t do it. Another approach, or “dimension of growth” will be needed. The following chart makes this abundantly clear.
8 © Copyright INNOVATION Data Processing and Robert Rogers, 2013, All rights reserved.

Sponsored by:
Here are some graphs that try to plot past trends and extrapolate them over the next six years. This type of projection can be tricky, but even a prediction twice as optimistic still would be bad.
As a guess, processor single speed is projected to improve an anemic 6% per year. We can also increase the number of CPUs, trying to get the total system capacity to increase by 50% every two years (i.e. 1.5x each 2yrs).
With only small increases in single processor speed, the bulk of the growth must be gotten from increasing the number of processors. But, as the number of processors increases, MP effectiveness drops. The MP effectiveness ratio can be assumed to follow a curve similar to that seen for the EC2 with its up-to 101 processors. This leads to an absurd explosion of the number of processors required which, of course, further lowers the effectiveness. It a vicious cycle that leads to untenable results.
As the graphs show, by the time we are 6 years out, adding more processors adds almost no additional capacity. These projections are probably over optimistic (as bad as they are) because the incremental capacity added by adding another processor almost certainly would go negative before 900 processors.
9 © Copyright INNOVATION Data Processing and Robert Rogers, 2013, All rights reserved.

Sponsored by:
10
Parallel Sysplex was introduced at about the same time as CMOS mainframe processors. At the time, it was stated to entail 10% overhead to run as a 2-sysplex and to have an addition ½% overhead for each addition system added. Almost 2 decades later, these nominal values are still pretty valid although some say that they are actually on the high side.
Customers with very large workloads have adopted parallel Sysplex both for availability and for capacity. Because the single image MP efficiency drops off rather fast, providing capacity through a multi-image Sysplex is more efficient even for modest sized complexes. But, Parallel Sysplex can be deployed only for workloads that are parallelizable. Fortunately, the DB2 for z/OS database server is very effective in a Parallel Sysplex so it’s possible to create very large database servers on z/OS.
10 © Copyright INNOVATION Data Processing and Robert Rogers, 2013, All rights reserved.

Sponsored by:
11
The left 2 graphs are based on the same assumptions for single thread growth (6% annually) and total box MIPS target (1.5x each 2yrs). The baseline for projection is the capacity of 100-way EC12.
By breaking up the capacity into 2 systems in a data sharing Sysplex, the number of processor required to achieve the total capacity target is greatly reduced. The results shown in these graphs are still probably unacceptable, but fortunately sysplexes can be implemented with many more than 2 systems. The current limit is 32 systems in a single data sharing Sysplex.
The maximal configurations shown on the graphs are probably stretching things, but as recently as 6 years ago z/OS only supported up to 16 processors and now there are customers running partitions with more than 32 logical processors. Certainly, there are customers with sysplexes much larger than the capacity of a single box, even if that box has 101 processors.
11 © Copyright INNOVATION Data Processing and Robert Rogers, 2013, All rights reserved.

Sponsored by:
12
The left 2 graphs, again, are based on the same assumptions for single thread growth (6% annually) and total box MIPS target (1.5x each 2yrs). The baseline for projection is the capacity of 100-way EC12.
Breaking the capacity into 4 systems in a Sysplex makes things even more reasonable. Based on the nominal overhead values, a 4-image Sysplex of 16-way z/OS images is much more efficient than a single 64-way z/OS image. Like so much else, actual results depend very much on the workload.
Current customers with very large SYSPLEXEs typically deploy many more than 4 members in their largest SYSPLEXEs. But, even a 4-way Sysplex of 50-way images on an EC12 uses twice as many engines as are available on a single box.
So, things are not nearly as gloomy for future capacity growth as they might have seemed at first. There are customers who are already running Sysplexes with capacities that would not be possible (or at least not economically reasonable) for a single image system. Sysplex will be very important in the future to raise capacity limits and to improve price-performance.
12 © Copyright INNOVATION Data Processing and Robert Rogers, 2013, All rights reserved.

Sponsored by:
13
Some have spoken loosely, saying, Moore’s Law is that CPU speed doubles ever 18-24 months. More strictly speaking the law is about circuit density. Up until now, increased circuit density has been used to deliver higher frequency which lead to CPU speed-up.
Moore’s law still holds, but the increased circuit density can no longer provide higher frequency. Moore’s law, however, still can enable more cores per die, more and denser cache structures as well as more complex logic such as Simultaneous Multi-threading (SMT).
13 © Copyright INNOVATION Data Processing and Robert Rogers, 2013, All rights reserved.

Sponsored by:
14
More cores on a chip allows more physical processors in a box. If the nest (memory system) is made robust enough this raises the raw capacity of the box.
More capacious caches reduce the average data access times by avoiding the long trip out to the DRAMs.
Combining more cores and more chip area for caches, it’s possible to implement on-chip caches. Then, if the processors of an image can be localized to a single chip or just a few chips, the extra cache shared by multiple processors can greatly reduce average access times.
SMT is discussed in the following charts. The important point here is that it also is something that can be done if the circuit density is sufficient to support the extra logic required.
14 © Copyright INNOVATION Data Processing and Robert Rogers, 2013, All rights reserved.

Sponsored by:
15
The original computers could run only one job at a time. One theme in the history of computing has been to create more and more parallelism to get the most work out of the hardware.
Multitasking was introduced on System/360 very early with the introduction of OS/360 MVT. It could run up to 15 customer jobs “simultaneously” on a single processor. Of course, only one job was actually running at any given moment, but when the running job had to wait for I/O, some other job would be dispatched and the CPU could be kept very busy.
Once the OS could handle multiple concurrent jobs, it could then use multiple processors so that more than one job could be running truly simultaneously. This is called multiprocessing and was introduced in MVT but did not run well until MVS/370.
Simultaneous Multithreading (SMT) is like multiprocessing, but on a single CPU which can execute instructions from a number of software threads simultaneously. This uses the CPU circuitry more efficiently and can get more work done per unit of time. The processor maintains unique status for each of the software threads so that a single processor (or core) looks like multiple CPUs to the software.
15 © Copyright INNOVATION Data Processing and Robert Rogers, 2013, All rights reserved.

Sponsored by:
16
SMT can deliver more throughput per processor core – around 40% more throughput for SMT with two threads. Even more for SMT with four threads. Therefore, SMT can help with the goal of 50% total system capacity growth by delivering more throughput from the same hardware footprint.
IBM System p processors have supported SMT since Power 5. Intel has supported SMT for a decade.
There are IBM presentations that come out and say that “…SMT is planned for a future System z processor…”
16 © Copyright INNOVATION Data Processing and Robert Rogers, 2013, All rights reserved.

Sponsored by:
17
As more and more circuits could be put on a chip, processor engineers implement a form of instruction level parallelism call superscalar. Multiple instructions can be executed simultaneously because the processor (or core) has multiple instruction execution pipelines. Over time, the number of pipelines has increased. Now, it is a challenge to be able to keep the many pipelines busy.
Here, SMT helps because it allows the processor to look at the multiple instruction streams for the multiple threads that are active on the core. The pipeline can be used more efficiently so that a core running in SMT mode can deliver more throughput than a core in single-thread mode.
Because an SMT core does not require appreciably more space, power or cooling than a single-thread core, it does not further limit the number of cores that can be put together in a single system.
The fact that System p and Intel could use SMT to increase throughput, put the System z mainframe at a disadvantage when the metric is throughput per core. When System z implements SMT, this will level the playing field.
17 © Copyright INNOVATION Data Processing and Robert Rogers, 2013, All rights reserved.

Sponsored by:
18
SMT provides more threads, but they are slower. For example, an SMT-2 core provides twice the number of threads. It nominally delivers 40% extra throughput, so each of two threads will run on average at only 70% of single-thread speed (140/2 = 70).
Since more SMT threads are needed to provide the same raw capacity, the “MP overhead” is increased.
SMT creates a new dimension of variability. There is always a CPU capacity variable between one processor design and the next. And, due to the sharing of higher level caches, there is variability over time based on how the various part of the workload use cache.
The intimate sharing of lower level resources among SMT threads makes the “SMT boost” even more variable. For SMT-2, threads can run as slow as 50% speed and up to as fast as 100% speed, depending on the nature of the two instruction streams.
18 © Copyright INNOVATION Data Processing and Robert Rogers, 2013, All rights reserved.

Sponsored by:
19
IBM has been talking about special purpose accelerators of several kinds to help with specific types of workloads. I assume that IBM has in mind some of the new trends in IT like Analytics and Big Data. These workloads require a lot of computing power, considerably raising capacity needs. Often these high-demand workloads can be assisted by special purpose processors.
IBM has not said enough to be specific so we’ll just reiterate what was on the chart.
• Processor accelerators (inboard) - Computation engines for analytics - Assists for dynamic software optimization
• PCIe-attached accelerators (outboard) - Use industry-standard interface and form factor - Leverage flexibility of application-specific integrated circuits (ASIC) and field-programmable gate arrays (FPGA) for special functions - Inline processing of data entering or leaving System z - Include specialized processors under the System z covers
19 © Copyright INNOVATION Data Processing and Robert Rogers, 2013, All rights reserved.

Sponsored by:
20
This presentation has pointed out that CPU speed in not going to be increasing very quickly and that the introduction of SMT is likely to further reduce single thread speed. If you suspect that you have applications or workloads that require more CPU speed in order to get the work done on time, you need to determine whether this is really the case. If it is, something will need to be done to enable the workload to grow with the business needs. If the problem involves a vendor product (including IBM) then get the vendor to help you with the analysis and remedy.
It was also shown that for fairly large systems, using Parallel Sysplex can be more efficient that running just a single z/OS image for a workload. It’s probably the case that a Sysplex of two 8-way systems can provide more productive capacity than a single 16-way system. So, if you have a system that is at least 16-way, it’s probably worth figuring out whether using Sysplex would be more efficient and save money.
In order to exploit SMT when it becomes available, you’ll have to deal with the additional variability in execution speed. The capacity represented by one CPU second can be very different from that of another CPU second. You can ease the transition to exploitation of SMT if you adopt a charge-back method that is not so tightly tied to CPU seconds.
20 © Copyright INNOVATION Data Processing and Robert Rogers, 2013, All rights reserved.

Sponsored by:
QUESTIONS
21 21 © Copyright INNOVATION Data Processing and Robert Rogers, 2013, All rights reserved.

Sponsored by:
22
Acknowledgements and References Benchmark data taken from the TechNews website is based on IBM testing: http://www.tech-news.com/publib/
Slides in this presentation addressing potential future System z developments are adapted from material given at System z Technical University while I was employed by IBM. None of the slides contain IBM proprietary information.
For a bit more on the history on the System z capacity delivery, see my January 09, 2013 Destination z article on Reduced Preemption http://destinationz.org/Mainframe-Solution/Systems-Administration/How-MVS-Designers-Turned-one-Multiprocessing-Chall.aspx
For more on the processor pipeline, see my article Built for Speed in the January 2012 issue of IBM Systems Magazine, Mainframe Editionhttp://www.ibmsystemsmag.com/mainframe/administrator/performance/cpu_pipeline/
For more information on SMT, do what I did – Google it.
22 © Copyright INNOVATION Data Processing and Robert Rogers, 2013, All rights reserved.