a portal for access to complex distributed information about energy jose luis ambite, yigal arens,...
Post on 21-Dec-2015
214 views
TRANSCRIPT

A Portal for Access to Complex Distributed Information about Energy
Jose Luis Ambite, Yigal Arens,
Eduard H. Hovy, Andrew Philpot
DGRCInformation Sciences Institute
University of Southern California
Walter Bourne, Peter T. Davis, Steven Feiner, Judith L. Klavans,
Samuel Popper, Ken Ross, Ju-Ling Shih, Peter Sommer, Surabhan
Temiyabutr, Laura ZadoffDGRC
Columbia University
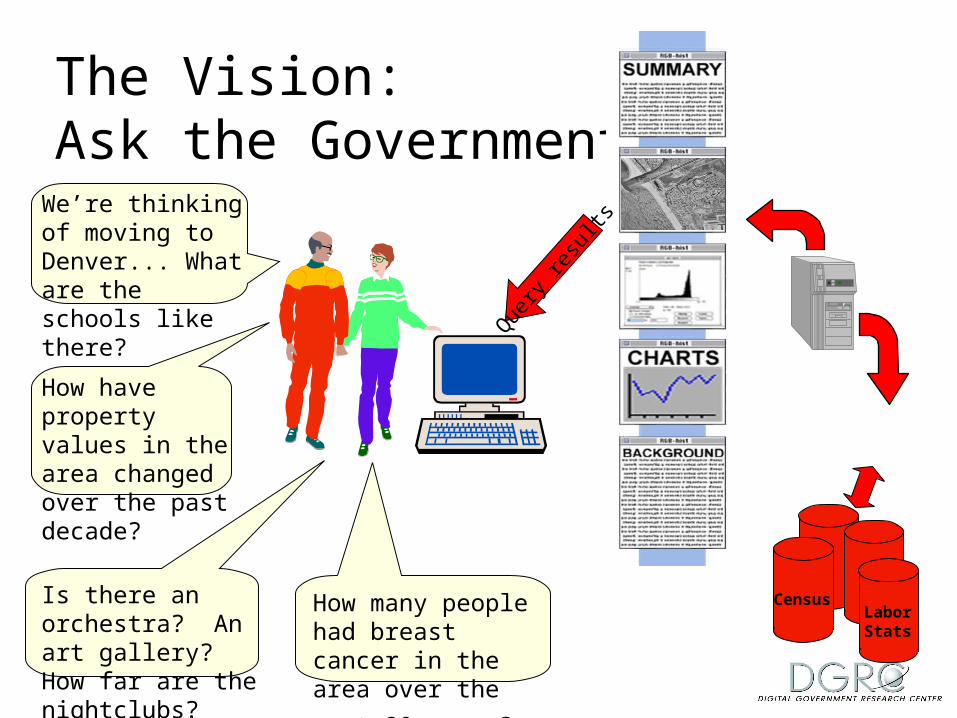
The Vision: Ask the Government...
How have property values in the area changed over the past decade?
How many people had breast cancer in the area
over the past 30 years?
Is there an orchestra? An art gallery? How far are the nightclubs?
We’re thinking of moving to Denver... What are the schools like there?
CensusLaborStats
Query
resu
lts
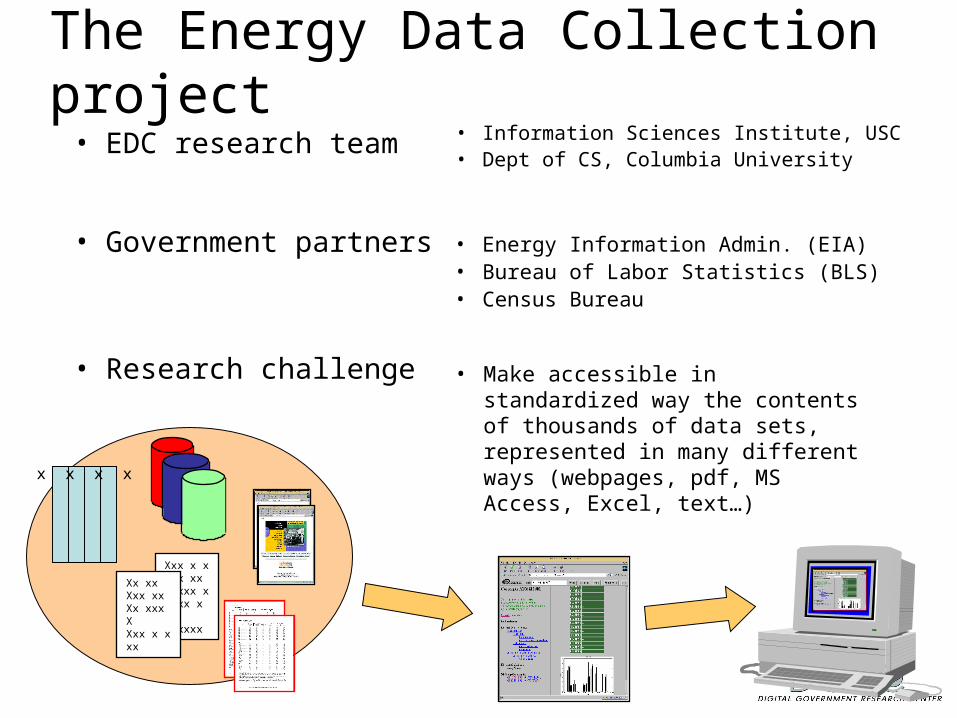
The Energy Data Collection project• EDC research team
• Government partners
• Research challenge
• Information Sciences Institute, USC • Dept of CS, Columbia University
• Energy Information Admin. (EIA)• Bureau of Labor Statistics (BLS)• Census Bureau
• Make accessible in standardized way the contents of thousands of data sets, represented in many different ways (webpages, pdf, MS Access, Excel, text…)
Xxx x xXxx xxX xxx xXxxx xXxxxxxxx
Xx xxXxx xxXx xxxX Xxx x xxx
x x x x

Data Integration
Trade
EPA
Census
EIA
Labor
Heterogeneous Data
Sources
User InterfaceInformation Access
DataAccess
andQuery
Processing
Metadata and TerminologyManagement
User Evaluation
Interface Design and
Task-basedEvaluation
ConceptOntology
TerminologySources

Data access using SIMS• ‘Hide’ from user details of data sources:
1. ‘Wrap’ each source in software that handles access to its data
2. Record the types of info in each source in a ‘Source Model’
3. Arrange all source models together in the same space—the Domain Model
• SIMS data access planner transforms user’s request into individual access queries
• SIMS extracts the right data from the appropriate sources
• Current databases and models:– Databases: 58,000+ series (EIA OGIRS and others) – Webpages: 60+ (BLS, CEC tables) SENSUS ontology: 90,000
nodes (from ISI’s NLP technology)– Domain model: 500 nodes (manual; for database access planner) – LKB: 6000 nodes (NL term/info extraction from glossaries)
Xxx x xXxx xxX xxx xXxxx xXxxxxxxx
Xx xxXxx xxXx xxxX Xxx x xxx
Sources:
Models:
x x x x
(Ambite et al., ISI)

Data access using in-memory query processing• How can you provide fast access to millions of data values?
• Cache data that doesn’t change much in data warehouse • Create rich multidimensional index structures; keep in memory • Adapt index depending on user’s patterns of use
• Technical details:• Same engine for many data sets• Client/server parallel• Branch Misprediction• SIMD• Asynchronous work
• Use:• Real-time interactive
data exploration: ‘fly’ over the data
(Ross et al., Columbia)
MediatorMediator
Data RequestData Request
UnifiedUnifiedResultsResults
UserUserWeb
......Graphical User Graphical User InterfaceInterface
Dynamic QueryDynamic Query
Data Filese.g., PUMS
Dynamic Query Dynamic Query EngineEngine

Large ontology(SENSUS)
Datasources
Domain-specificontologies
(SIMS models)Logicalmapping
LinguisticMapping (semi-automated)
Concepts fromglossaries (by GlossIT)
The Heart of EDC(Hovy et al., ISI)

http://edc.isi.edu:8011/dino
• Taxonomy, multiple superclass links
• Approx. 90,000 concepts
• Top level: Penman Upper Model (ISI)
• Body: WordNet 1.6 (Princeton), rearranged
• New information added by text mining
• Used at ISI for machine translation, text summarization, database access
SENSUS and DINO browser
(Knight et al., ISI)

Extracting term info from online sources
• GetGloss: given a URL, find all the glossary files • ParseGloss: given a set of NL glossary definitions,
extract and format the important information
(Klavans et al., Columbia)
• GetGloss:– Glossary identification rules
consider format tags, etc. – F-score: 0.68 (2nd after
SVM at 0.92)
• ParseGloss:– Identify term, def, head
noun, etc. – Evaluation underway

Term-to-ontology alignmentHow to link new concepts into the Ontology (or
Domain Model) in the right places?
• Manual approach expensive: NxM steps
• Approach: try to automatically propose links, then hand-check only the best proposals– Created and tested various match heuristics
(NAME, DEF, TAXONOMY, DISPERSAL)– Tried various clustering methods: CLINK, SLINK,
Ward’s Method…, new version of k-Means (Euclidean and spherical distance measures)
– Tested numerous parameter combinations (stemming, etc.) in EDC and NHANES domains; see http://edc.isi.edu/alignment/
Results not great
(Hovy et al., ISI)
?

User interface testbed
• Ontology entry shown in beam for selected item– Located as near as
possible– Color coding
shows parental
and semantic relationships
• Fisheye magnification of region of interest– Magnified group laid out to avoid internal overlap
• Menu presented as grid of alternating rows and columns
(Feiner et al., Columbia)

AskCal: User requests in English
• ATN:– 341 nodes– 14 question
types
• Automated paraphrase to confirm
• Dialogue continues via menus for detailed selection
(Philpot et al., ISI)

Interface/usage evaluationEvaluation study, started late
2001
What to evaluate?• Variables
– Category display– Magnifying columns– Fisheye proximity &
magnification– Searchlight– Synonyms
• Methods– Observe cognitive styles– Examples in other domains
• Research on content – Energy vs. Census domains
(Sommer et al., Columbia)
Task evaluation• Process
– Task scenario– Interview– Observation
• Goal– User behaviors– User intuitiveness for different
groups of users– Strengths and weaknesses of
the design
• Participants– Content experts– Government agency workers– Faculty and students

Thank you!
Please come see our demos this afternoon!