a probabilistic classifier for table visual analysis william silversmith tango research project nsf...
Post on 21-Dec-2015
213 views
TRANSCRIPT
A Probabilistic Classifier for Table Visual Analysis William Silversmith
TANGO Research Project
NSF Grant # 0414644 and 04414854
Greetings Prof. Embley!

Outline
Motivation High level view Algorithm Results of a small experiment Discussion Appendix

Motivation (1) Tables use visual cues to present information. Known approaches (to us) exclusively use
structure or pay little attention to visual information.
Potential use: Segment category regions from delta cells, allowing further automation of TANGO.
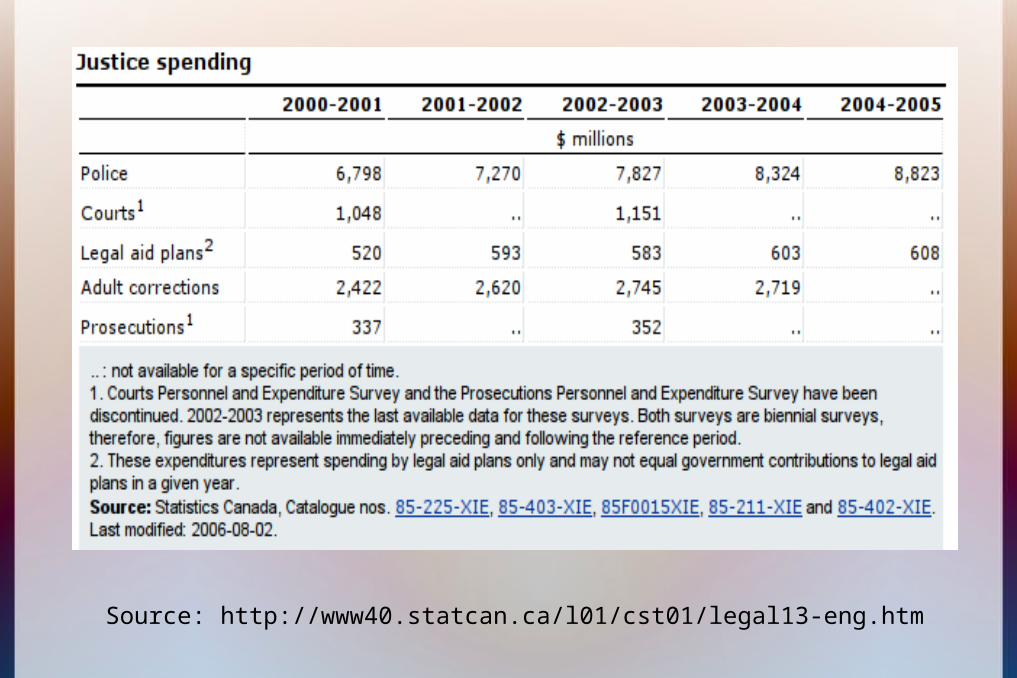
Source: http://www40.statcan.ca/l01/cst01/legal13-eng.htm

Motivation (2) However,visual features are not used consistently Ideally, automatically analyze them anyway:
Globally Within an internet domain (ie Canada Statistics) Within a subject domain
Train a program to understand a given domain!

High Level View Find a group of tables that are accompanied by a
listing of their categories and delta cells Train the program on them to recognize how
visual features predict the splits Use trained program on new tables to allow
TANGO to mine data

Algorithm (1) Find a training set (tables with verifying data) Select visual features to analyze
Examples: Font, Indentation, Empty Cells, Background
Color, Font Color, Many More!

Algorithm (2)
• Training the classifier:
for each attribute:Form the “difference table” // See appendix
Sum along the rows and columns
The highest row and column indicates the horizontal and vertical split indicated by the attribute
Compare this coordinate with the one indicated by the verification data
Track the number of hits and misses persistently

Algorithm (3)
• The probability that each attribute predicts a correct answer is its weight.
• Weights can be tabulated for horizontal features, vertical features, and combined.
– Certain features may be more sensitive along a given direction

Algorithm (4)
• Use classifier:for each table in the data set:
Form the difference table by summing all weighted attributes together for each difference
Sum the resulting distinctions along rows and columns
The highest sum for the top or leftmost split for horizontal and vertical splits respectively is the predicted category/delta segmentation

Experiment (1)
• A small experiment was conducted by hand to test the efficacy of the algorithm.
• Procedure:
– Select six tables from Canada Statistics
– Use four to train the classifier
– Assess it on the last two
• By chance, one of the training set tables was a concatenated table.

Experiment (2)
• Analyzed characteristics:
– Font style (normal/italic/bold)
– Indentation (left/center/right/offset)
– Data type (string or reasonably recognizable number)
– Adjacent empty cell (whitespace)
• Empty/Nonempty transitions do not count except for the whitespace measure

Experiment: Training Results (3)
Attribute Horizontal Cut
VerticalCut
BothCuts Weight
Font Style
X 0.00
X 0.00
X 0.00
Indentation
X 0.00
X 1.00
X 0.00

Experiment: Training Results (4)
Attribute Horizontal Cut
VerticalCut
BothCuts Weight
Data Type X 0.25
X 1.00
X 0.25
Whitespace X 1.00
X 0.75
X 0.75

Experiment: Classifier Results (5)
• Both data set targets were properly segmented using both combined and distinct weights approaches for horizontal and vertical cuts
• Neither of the targets were concatenated tables

Experiment: Classifier Results (6)
Uniformly random classifier:
P( T1 and T2 ) = (1/49)(1/120) = 1 in 5880 trials
P( T1 or T2 ) = (1/49)(119/120)+(1/5880)+(1/120)(48/49)
= 1 in 35 trials
Sample space = # points in the table

Discussion: Results (1)
• Font style: less important that previously thought
• Font style still seemed to indicate the presence of aggregates
• Some decisions made by slim margins
• Vertical cuts predicted by indentation

Discussion: Results (2)
• Whitespace is useful, but sometimes misleading
• A row of whitespace below the column categories confuses the classifier.
• Some choices of validating splits are debatable

Discussion: Future Issues (3)
• Current formulation ignorant of number of cuts?
• Potentially useful in describing large numbers of similar tables
• Where is the training data?

Discussion: Future Issues (4)
• Sources of training data are hard (or possibly expensive) to come by:
– Canada Statistics provides access to internal databases for ~$5000
• Luckily, Raghav produced about 200 samples by accident!
• Format is DoclabXML!
Hooray for Raghav and TAT!

Discussion: Enhancements (5)
• Use a rule based learning system?
• Detect visual patterns?
• Combine other approaches?

Appendix 1: Difference Table
Form a difference table by taking all the cells adjacent on the top, bottom, left, and right and checking to see if there is a difference in the attribute(s) you are looking at.
A difference returns 1, no difference returns 0.
Do this for all cells in the table.
Edges of the table do not count as cells.

Experimental Data Sources• Canada Statistics:
Training Set:
– http://www40.statcan.ca/l01/cst01/legal13-eng.htm
– http://www40.statcan.ca/l01/cst01/serv11a-eng.htm
– http://www40.statcan.ca/l01/cst01/famil36a-eng.htm
– http://www40.statcan.ca/l01/cst01/labor50a-eng.htm
Data Set:
– http://www40.statcan.ca/l01/cst01/serv22-eng.htm
– http://www40.statcan.ca/l01/cst01/agrc18a-eng.htm