a semi-parametric approach for football video...
TRANSCRIPT

A Semi-Parametric Approach for Football Video Annotation
Markos Mentzelopoulos, Alexandra Psarrou, Anastassia Angelopoulou and Jose Garcıa-Rodrıguez
Abstract— Automatic sports video segmentation is a fastgrowth area of research in the visual information retrievalfield. This paper presents a semi-parametric algorithm forparsing football video structures. The approach works on atwo interleaved based process that closely collaborate towardsa common goal. The core part of the proposed method focusperforms a fast automatic football video annotation by lookingat the enhance entropy variance within a series of shot frames.The entropy is extracted on the Hue parameter from theHSV color system, not as a global feature but in spatialdomain to identify regions within a shot that will characterizea certain activity within the shot period. The second part ofthe algorithm works towards the identification of dominantcolor regions that could represent players and playfield forfurther activity recognition. Experimental results shows thatthe proposed football video segmentation algorithm performswith high accuracy.
I. INTRODUCTION
As an important video domain, sports video has beenwidely classified as an increasing attractive area due to itshigh evolution within the commercial, entertaining industryand audience requirements. More keenly than ever, the audi-ence desires professional insights into the games [2][18]. Forthese reasons recent research in sports videos has been focusin algorithms to enable to log the most relevant shots of avideo stream with annotation process towards the detection ofspecial events in football videos providing interactive videoviewing systems for quick browsing, indexing and sum-marization. In addition professional soccer team managersdemand automatic retrieval technologies for tactics analysis,team training and performance evaluation and therefore theyneed frameworks that perform automatic classification inspecial events such as goals, penalties or corner kicks ormutually exclusive states of the game such as ”play” or”break” [3][5][15].
Sports video segmentation could be categorized in twogenre framework based on current research methodologiesboth aim to lead to a semantic classification. The firstcategory, investigates the roles of semantic objects in thescenery and models their trajectories [17], while the second
M. Mentzelopoulos is with the Department of Computer Science andSoftware Engineering, Faculty of Science and Technology, University ofWestminster, UK (e-mail: [email protected]).
A. Psarrou is with the Department of Computer Science and SoftwareEngineering, Faculty of Science and Technology, University of Westminster,UK (phone: +44 (0) 207 911 5000; fax: +44 (0) 207 911 5926; e-mail:[email protected]).
A. Angelopoulou is with the Department of Computer Science andSoftware Engineering, Faculty of Science and Technology, University ofWestminster, UK (phone: +44 (0) 207 911 5000; fax: +44 (0) 207 9115926; e-mail: [email protected]).
J. Garcıa-Rodrıguez is with the Department of Computer Technology,University of Alicante, Spain (phone: +34 678600796; fax: +34 96590; e-mail: [email protected]).
category is using structure analysis of the environment (linesin a basketball, soccer and tennis court) [3][8][12][15][16].
First approaches in sports video retrieval just added thefunctionality for segmentation and key-frame extraction toexisting image retrieval systems. After key-frame extraction,they just apply similarity measurement on them based onlow-level features [10][19][20][22][24]. This is not satis-factory because video is temporal media, so sequencing ofindividual frames creates new semantics, which may not bepresent in any of the individual shots. Therefore what isneeded is techniques for organizing images and videos insemantic meaning [1][4][11]. The process of extracting thesemantic content is very complex, because it requires domainknowledge or user interaction, while extraction of visualfeatures can be often done automatically and it is usuallydomain independent [13].
In this paper we present a semi-parametric method for theautomatic segmentation of a football video and the extractionof its dominant regions, without apriori need of cameracalibration or background extraction. The proposed modelis using an update version of the original Entropy Differencealgorithm[9] and has a double scope: 1) To provide anautomatic video segmentation down to key-frames and 2)To identify the dominant colors in the shot necesary forfurther semantic video interpretation. The rest of the paperis organized as follows: section 2 presents the EnhancedEntropy Difference algorithm and its ability to keep trackof Dominant Color Regions within a shot. Finally, section3 presents experiments on the application to a benchmarkof football videos, followed by our conclusions and futurework.
II. RELATED WORK
Early video segmentation approaches show that there aretwo video segmentation methods, i.e., Shot- Based (typi-cally known as Video Skimming) and Object-Based videosegmentation (Summary Sequence). These two methods areusually used separately and independently in a video anal-ysis framework as they are performing video annotation atdifferent semantic levels [4]. Applying a Video Skimmingframework on unstructured raw data partitions the videosequence into a set of video shots, and extracts key-frames torepresent the major content of each video shot. Thus shot-based video segmentation can provide compact abstractionand delineation for video indexing, browsing and retrieval[8]. Video Skimming can be sub-divided into two frameworktypes: The Summary Sequence (based on audio features) andthe Highlight.
The Highlight contains the most salient frames of theoriginal video sequence, like a movie trailer. The selected
Proceedings of International Joint Conference on Neural Networks, Dallas, Texas, USA, August 4-9, 2013
978-1-4673-6129-3/13/$31.00 ©2013 IEEE 68

scenes usually have important people (Referees, goalkeepers,close-up) and objects (ball, goalpost) that contain frames withhigh-contrast or high-action scenes, with frames containingthe largest frame differences (Reaction of players after scor-ing, or fast gradual change from different camera views). Inorder to give the impression of the game environment, sceneswith basic colour composition similar to the average colourcomposition [stadium high view, game field, backgroundstatistics frame] of the entire video are presented. Finallyall the selected scenes are organized based on time relevance[22]. On the other hand the Summary Sequence video editingis based on audio features relativity [referee whistles, crowdshouting for goals etc]. There limitation on this approachis based on speed speech, beyond which speech becomesincomprehensible.
Differentially, Object-Based video segmentation is to de-compose one video shot into objects and background, whichare usually application-dependent. Unlike shot-based videosegmentation that has a frame as the basic unit; object-basedsegmentation can provide objects that represent a raw videoat a higher semantic level. There are seven distinguishedcategories of constructing key-frames:
• I. Sampling-Based: key-frames are selected randomlyor uniformly at certain time intervals. The selection isautomatic and produced by an algorithm model. Thedrawback is that a shot might be small in time andtherefore if only one key-frame is selected to representit there is the possibility of losing important informationcontent [19].
• II. Segment-Based: Segmentation measure is computedbased on its length and rarity. All segments with theirimportance lower than a certain threshold will be dis-carded. The key-frame of a segment will be the frame,which is closest to the centre of the qualified segment.Finally a frame-packing algorithm will be applied forpictorial summary [14][19].
• III.Motion-Based: Motion-based is better suited forcontrolling number of frames based on temporal dy-namics in the scene. Pixel-based image differences oroptical flow computation are commonly used. Opticalflow for each frame is calculated and then a simplemotion metric is computed [20].
• IV. Mosaic-Based: Can be employed to generate asynthesized panoramic image that can represent theentire content in an intuitive manner [18][20]. It canwork on both background scenes (Static Mosaic) ordynamic foreground (Synopsis Mosaic).The procedureis working in two-steps: 1) fitting a global motion modelto the motion between each pair of successive framesand 2) compose images into a single panoramic imageby changing the images with the estimated cameraparameters
• V. Shot-Based: The first frame of each shot is used as akey-frame. With this way no representation of dynamicvisual content is provided. To interpret the content weneed to employ some low-level visual features, such as
colour and texture or shape [20].• VI. Sharp transition Detection: The most sophisticate
approach, currently used in many variations. Based onsharp transition detection (cuts) a number of algorithmswere implemented to extract key-frames. Zhang andSmoliar [19][22] have proposed three metrics for sharptransition detection which are currently based on pair-wise pixel comparison, likelihood ratio and histogramcomparison. Nagasaka and Tanaka [10] have proposedan algorithm for cut detection based on the normalizedtest , which compares the distance between colourhistograms bins of two consecutive frames. Hampapurand Weymouth [7] have developed cut detection byusing a difference operator applied to two successivecolour frames.
• VII. Clustered based: Video frames are first groupedinto a finite set of clusters in a selected feature space.The selected features are assumed to be able to capturethe salient visual content conveyed by the video and theframes closest to the cluster centres are chosen as thekey-frames [23][6][21]. The great disadvantage of thesealgorithms is that they are heavily threshold-dependent
III. ALGORITHM DESCRIPTION
The propsed method is a hybrid between a Sharp tran-sition Detection and a Motion-Based approach. The al-gorithm presented in this paper is based on the EntropyDifference Algorithm method [9], a distance metric betweenconsecutive frames used for identifying gradually transitionsbetween video shots. Although the algorithm showed highperformance results on various video scenarios, it still hadlimitations when the background was dark, and if there wheresome fast color fluctuations, because of camera calibrationor noise.
Color histogram is an important technique for color videoannotation. However, the main problem with color histogramindexing is that it does not take the color spatial distributioninto consideration. Previous researches have proved that theeffectiveness of video retrieval increases when spatial featureof colors is included in video retrieval [22], [10]. In thispaper, two new descriptors, entropy distribution (ED) andAnalysis of Variance in Hue Entropy (ANOVA-Hue-E), willdescribe the spatial information of HUE color feature in timedomain.
A. Entropy Difference
Entropy is a good way of representing the impurity orunpredictability of a set of data since it is dependent on thecontext in which the measurement is taken. In the proposemodel we consider that if we distribute the entropy amongthe image, then the higher entropy distributions will bedescribing the regions containing the salient objects of avideo sequence. Therefore any change in the object appear-ance of one of this salient regions it will affect its relevantsemantic information in the entire story sequence. In orderto eliminate as much as we can the possibility of the changeof brightness during the frame comparison, the original RGB
69

image has been converted to the equivalent HSV system andthe HUE component has been extracted. The color gamutwas further quantized down to 40 colors and then applied amedian filter for region smoothing. The reason for pickingsuch a low color resolution is that in a football field thereare not many different objects we could possible observe.Using the algorithm from [9] we can calculate the EntropyDifference. After applying the video segmentation algorithm,for each extracted key-frame we keep a table of record (DET-Dominant Entropy color Table), that includes the key-frameID number in the shot sequence, the HUE color bin valuesthat include the highest entropy values, the pixel distributionsand the entropy values. Previous research [9] showed thatcolor bins that contain the 70% of the image entropy candescribe sufficient its dominant content.
Fig. 1. Dominant Entropy color Table. Every key-frame includes the HUEcolor bin values with the highest entropy values, the pixel distributions andthe entropy values.
B. Enhanced Entropy Difference
Enhanced Entropy Difference is a post process method onthe algorithm to check for color updates within the framesthat can be used for:
1) Update the DEC Table for its future use on identifyingDominant objects within the Shot
2) Check whether the distance between the current se-lected key-frames that describe a shot is sufficientenough to describe a semantic coherent theme withinthe shot. This means if the variance of a dominantcolor within the shot is high compared to the rest ofthe colors, then an additional key-frame will need tobe necessary within the shot boundaries.
EED is calculated based on the Variance of the Entropy thateach Hue Color Bin contains over the shot time period ofM−frames. Therefore if j is one of the Hue color bins fromthe DEC Table [0 ≤ j ≤ N ] then in the Equation 1tab belowAs is a matrix that contains all the Entropy observations ef,jfor every Dominant Color dj from the DEC table. Wheres = Nrshot, N = numberofcolorbins[i.e : N = 40] andf = Nrframe. Then:
As =
e1,1 e1,2 . . . . . . e1,Ne2,1 e2,2 e2,3 . . . e2,Ne3,1 e3,2 e3,3 . . . e3,N
......
......
. . .
e1,1 e1,2 e1,3 . . .. . .
(1)
The Total Variation is comprised the sum of the squares ofthe differences of each mean with the grand mean. There isthe between group variation and the within group variation.The whole idea behind the analysis of variance is to comparethe ratio of between group variance to within group variance.If the variance caused by the interaction between the samplesis much larger when compared to the variance that appearswithin each group, then it is because the means aren’t thesame. For each row in As we calculate the mean valueof the color over the shot period M and we calculate itsTotal Variation Matrix SST . The Within Group Variationis a 1-Dimensional Vector and calculates the variation dueto differences within our individual color samples, denotedSSW (j) for Sum of Squares Within group color j.
SSW (j) =
M∑i=1
(ei,j − ej) (2)
SST = {SSW [1], SSW [2], . . . , SSW [N ]}T (3)
The for each level j within the SSW [j] if compare its value tothe Mean Group Variation SST we will calculate the OverallVariation SW (s) within the shot s.
OSW (s) =N∑i=1
(SSW [i]− SST ) (4)
Finally we take the likelihood Ratio between each GroupVariation SSW (j) and the Overall Shot Variation OSW (s).
Hj = logSSW (j)
OSW (s)< α; (5)
Using the Hypothesis that an object change within the shotis happening if the variation is more than a Threshold valueα [0 ≤ α ≤ 1], then Hj will be a binary array containingthe Hypothesis for each j component. If the sum of the Hj
Hypothesis is more than 40% , that means that more than40% of the overall objects have changed within the shot,then a new Key-frame K is essential to be taken within theprevious key-frame boundaries.
IV. EXPERIMENTAL RESULTS
Using the proposed model, we evaluated a footage of 6football video clips from various genres. The videos weretaken from live match coverage (videos 5 & 6), gamesimulation (video 1- PES2012 1) and from football highlightstaken from BBC(2-4). The video resolution varies on everyvideo, that’s why we applied a re-scaled process on everyframe to reduce its dimensionality to a more computationallyefficient size of 420 x 340 pixels /frame. The frame rate wasthe same for all videos at 30fps. The results are summarizedover Tables I- III. For each video pattern we calculatedRecall (R) [Figure 3 shows a Recall (R) comparison ofthe proposed algorithm with other models introduced insection 2] and Precision (P) to quantitatively evaluate theperformance, which are defined as:
R = nc/(Gt) (6)
1Pro Evolution Soccer 2012
70
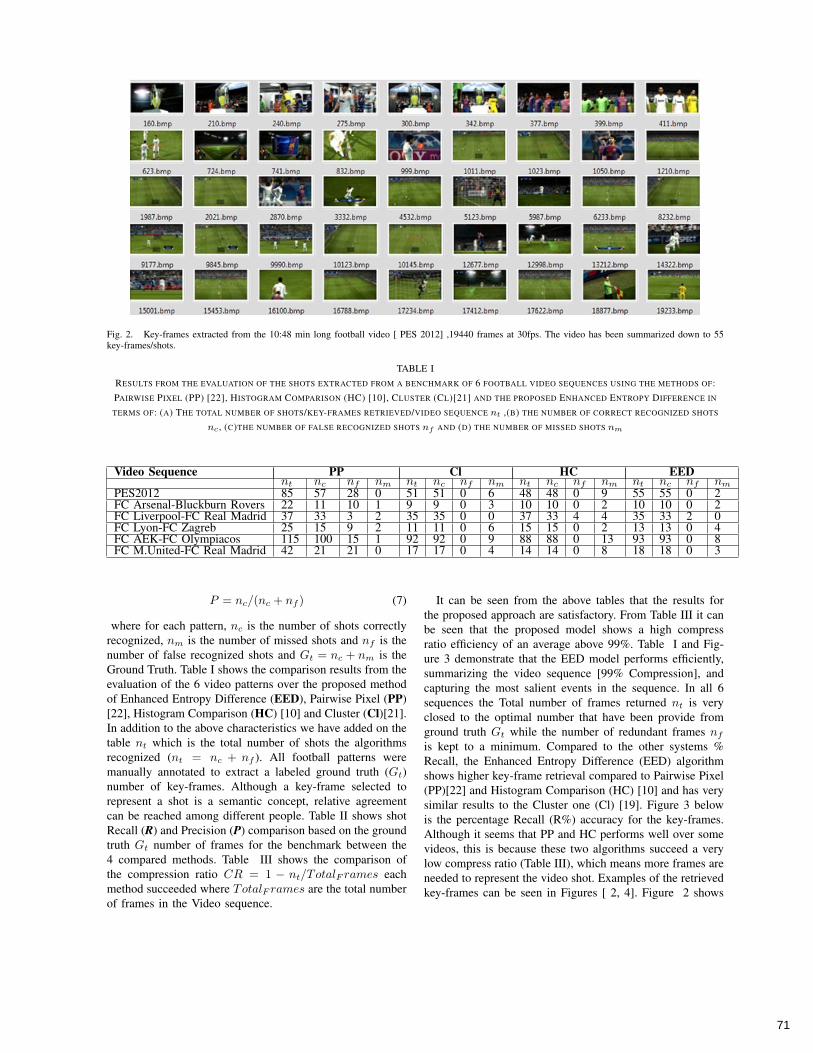
Fig. 2. Key-frames extracted from the 10:48 min long football video [ PES 2012] ,19440 frames at 30fps. The video has been summarized down to 55key-frames/shots.
TABLE IRESULTS FROM THE EVALUATION OF THE SHOTS EXTRACTED FROM A BENCHMARK OF 6 FOOTBALL VIDEO SEQUENCES USING THE METHODS OF:PAIRWISE PIXEL (PP) [22], HISTOGRAM COMPARISON (HC) [10], CLUSTER (CL)[21] AND THE PROPOSED ENHANCED ENTROPY DIFFERENCE IN
TERMS OF: (A) THE TOTAL NUMBER OF SHOTS/KEY-FRAMES RETRIEVED/VIDEO SEQUENCE nt ,(B) THE NUMBER OF CORRECT RECOGNIZED SHOTS
nc , (C)THE NUMBER OF FALSE RECOGNIZED SHOTS nf AND (D) THE NUMBER OF MISSED SHOTS nm
Video Sequence PP Cl HC EEDnt nc nf nm nt nc nf nm nt nc nf nm nt nc nf nm
PES2012 85 57 28 0 51 51 0 6 48 48 0 9 55 55 0 2FC Arsenal-Bluckburn Rovers 22 11 10 1 9 9 0 3 10 10 0 2 10 10 0 2FC Liverpool-FC Real Madrid 37 33 3 2 35 35 0 0 37 33 4 4 35 33 2 0FC Lyon-FC Zagreb 25 15 9 2 11 11 0 6 15 15 0 2 13 13 0 4FC AEK-FC Olympiacos 115 100 15 1 92 92 0 9 88 88 0 13 93 93 0 8FC M.United-FC Real Madrid 42 21 21 0 17 17 0 4 14 14 0 8 18 18 0 3
P = nc/(nc + nf ) (7)
where for each pattern, nc is the number of shots correctlyrecognized, nm is the number of missed shots and nf is thenumber of false recognized shots and Gt = nc + nm is theGround Truth. Table I shows the comparison results from theevaluation of the 6 video patterns over the proposed methodof Enhanced Entropy Difference (EED), Pairwise Pixel (PP)[22], Histogram Comparison (HC) [10] and Cluster (Cl)[21].In addition to the above characteristics we have added on thetable nt which is the total number of shots the algorithmsrecognized (nt = nc + nf ). All football patterns weremanually annotated to extract a labeled ground truth (Gt)number of key-frames. Although a key-frame selected torepresent a shot is a semantic concept, relative agreementcan be reached among different people. Table II shows shotRecall (R) and Precision (P) comparison based on the groundtruth Gt number of frames for the benchmark between the4 compared methods. Table III shows the comparison ofthe compression ratio CR = 1 − nt/TotalF rames eachmethod succeeded where TotalF rames are the total numberof frames in the Video sequence.
It can be seen from the above tables that the results forthe proposed approach are satisfactory. From Table III it canbe seen that the proposed model shows a high compressratio efficiency of an average above 99%. Table I and Fig-ure 3 demonstrate that the EED model performs efficiently,summarizing the video sequence [99% Compression], andcapturing the most salient events in the sequence. In all 6sequences the Total number of frames returned nt is veryclosed to the optimal number that have been provide fromground truth Gt while the number of redundant frames nf
is kept to a minimum. Compared to the other systems %Recall, the Enhanced Entropy Difference (EED) algorithmshows higher key-frame retrieval compared to Pairwise Pixel(PP)[22] and Histogram Comparison (HC) [10] and has verysimilar results to the Cluster one (Cl) [19]. Figure 3 belowis the percentage Recall (R%) accuracy for the key-frames.Although it seems that PP and HC performs well over somevideos, this is because these two algorithms succeed a verylow compress ratio (Table III), which means more frames areneeded to represent the video shot. Examples of the retrievedkey-frames can be seen in Figures [ 2, 4]. Figure 2 shows
71

Fig. 3. Graphical representation of the results from the key-frame extraction algorithms comparison over the 6 different sport video clips. On the X-axisare the video benchmarks 1-6) while in the Y-axis is the % Recall of the key-frames extracted compared to the Ground Truth key-frames Gt. The comparedalgorithms are: Pairwise Pixel (PP), Cluster, Histogram Comparison (H C) and Enhanced Entropy Difference (E D).
TABLE IIPERFORMANCE ANALYSIS FOR THE 6 FOOTBALL VIDEOS.THE TABLE INCLUDES THE GROUND TRUTH Gt NUMBERED OF KEY-FRAMES FOR EACH
VIDEO SEQUENCE AND THE RECALL (R), PRECISION (P) CALCULATED USING THE EQUATIONS 6-7 FOR ALL DIFFERENT METHODS: PAIRWISE PIXEL
(PP) [22], HISTOGRAM COMPARISON (HC) [10], CLUSTER (Cl)[21], ENHANCED ENTROPY DIFFERENCE (EED)
Video Sequence PP Cl HC EEDGt R(%) P(%) R(%) P(%) R(%) P(%) R(%) P(%)
PES2012 57 100.00 67.06 89.47 100.00 84.21 100.00 96.49 100.00Arsenal-Bluckburn Rovers 12 92.30 54.55 75.00 100.00 83.33 100.00 83.33 100.00Liverpool-Real Madrid 35 94.44 91.89 100.00 100.00 94.29 89.19 94.29 94.29Lyon-Zagreb 17 88.88 64.00 64.71 100.00 88.24 100.00 76.47 100.00AEK-Olympiacos 101 99.01 87.83 91.09 100.00 87.13 100.00 92.08 100.00M.United-Real Madrid 21 100.00 51.22 80.95 100.00 66.66 100.00 85.71 100.00
TABLE IIICOMPRESSION RATIO FOR THE 6 FOOTBALL VIDEOS.THE TABLE INCLUDES THE NUMBER OF FRAMES FOR EACH VIDEO SEQUENCE AND THE TIME
DURATION: PAIRWISE PIXEL (CRPP ) [22], HISTOGRAM COMPARISON (CRHC ) [10], CLUSTER (CRCl)[21], ENHANCED ENTROPY DIFFERENCE
(CREED )
Video Sequence Nr Frames Duration CRPP CRCl CRHC CREED(min:sec) (%) (%) (%) (%)
PES2012 19892 10:48 99.57 99.74 99.76 99.72Arsenal-Bluckburn Rovers 2070 01:09 98.94 99.56 99.52 99.52Liverpool-Real Madrid 7350 04:05 99.50 99.52 99.49 99.50Lyon-Zagreb 3480 01:56 99.28 99.68 99.57 99.63AEK-Olympiacos 21150 11:45 99.45 99.56 99.58 99.56M.United-Real Madrid 3930 02:11 98.93 99.56 99.64 99.54
the key-frame extracted from the PES 2012 video sequencewhile Figure 4 are the key-frames from FC Arsenal vs.Blackburn video.
V. CONCLUSIONS
Sports video segmentation is the first step for seman-tic game abstraction based on tactic patterns analysis andimportant player behaviors within the pitch. In this paperwe have presented an architecture to automatic performVideo Annotation down to Key-Frame representation/shot byadapting the original Entropy Difference algorithm [9]. Thealgorithm is robust to common sources of disturbance suchas camera illumination changes, noise and background setup.Instead of using the Intensity color information as a metric,we extract the HUE feature from the original HSV colorsystem and we are performing an Analysis of Variance overthe scene period. The processing of the ANOVA over the
HUE level allows us to identify important changes within theframe transitions in a video sequence, and check with highaccuracy whether new objects have been included in the shot,or wether an entire new shot has appeared. Experimentalresults prove that the approach performs in high standardscompare to other state-of-the-art methods. As future work wewill try to model the color transitions within each extractedvideo shot to identify behavior of the color regions forsemantic sport video annotation.
REFERENCES
[1] S. Abburu. Semantic segmentation and event detection in sports videousing rule based approach. International Journal of Computer Scienceand Network Security (IJCSNS), 10:pp 35–40, 2010.
[2] J. Assfalg, M. Bertini, C. Colombo, A. D. Bimbo, and W. Nunziati.Semantic annotation of soccer videos: automaitc highlights identifica-tion. Computer Vision and Image Understanding, 2004.
[3] J. Assfalg, M. Bertini, C. Colombo, A. D. Bimbo, and W. Nunziati.Semantic annotation of soccer videos: automaitc highlights identifica-tion. Computer Vision and Image Understanding, 2004.
72

Fig. 4. Key-frames extracted from football Highlight video from FC Arsenal vs. Blackburn (2070 frames at 30fps). The video has been summarized downto 10 key-frames/shots.
Fig. 5. Key-frames extracted from the 04:05 min long football video from FC Liverpool vs Arsenal ,7350 frames at 30fps. The video has been summarizeddown to 37 key-frames/shots. Second row below are the additional Key-frames that were extracted using the Cluster Algorithm
[4] L. Duan, M. Xu, T. Chua, Q. Tian, and C. Xu. A mid-levelrepresentation framework for semantic sports video analysis. In Proc.of ACM MM 2003, pages 33–44, 2002.
[5] A. Ekin, A. M. Tekalp, and R. Mehrota. Automatic soccer videoanalysis and summarization. IEEE Transaction on Image Processing,12:796–807, 2003.
[6] A. Girgensohn and J. Boreczky. Time-constrained keyframe selectiontechnique. Multimedia Tools and Applications, 11:pp 347–358, 2000.
[7] A. Hampapur, R. Jain, and T. Weymouth. Digital video segmentation.ACM Multimedia, pages pp 357–364, 1994.
[8] S. Jiang, Q. Ye, W. Gao, and T. Huang. A new method to segmentplayfield and its applications in match analysis in sports videos. ACMMultimedia (ACM MM 2004), pages pp 292–295, Oct 10-16 2004.
[9] M. Mentzelopoulos and A. Psarrou. Key-frame Extraction AlgorithmUsing Entropy Difference. In Proc. of the 6th ACM SIGMMAInternational Workshop on Multimedia Information Retrieval (MIR04), pages 39–45, 2004.
[10] A. Nagasaka and Y. Tanaka. Automaitc video indexing and full-motionvideo search for object appearences. Visual Database Systems II, pages113–127, 1992.
[11] K. Okuma, J. Little, and D. Lowe. Automatic acquisition of motiontrajectories: Tracking hockey players. SPIE Proceeedings 5304, pages
pp 202–213, 2003.[12] J. Pers and S. Kovacic. Tracking people in sport : Making use of
partially controlled environment. In: SKARBEK, Wladyslaw (Ed.).Computer analysis of images and patterns : 9th international con-ference, CAIP, pages 374–382, 2001.
[13] M. Petkovic. Content-based video retrieval. Centre For Telematicsand Information Technology, University Of Twente, 2001.
[14] X. Sun and M.Kankanhalli. Video summarization using r-sequences.Real-time Imaging, pages pp 449–459, 2000.
[15] X. Tong, Q. Liu, L. Duan, H. Lu, C. Xu, and Q. Tian. A unifiedframework for semantic shot representation of sports video. ACMMultimedia Information Retrieval MIR 2005, pages 127–134, Nov 10-11 2005.
[16] D. Xavier, H. Jean-Bernard, D. Jean-Franois, P. Justus, and M. Benot.Trictrac video dataset: Public hdtv synthetic soccer video sequenceswith ground truth. Workshop on Computer Vision Based Analysis inSport Environments (CVBASE), pages 92–100, 2006.
[17] L. Xie, P. Xu, S.-F. Chang, A. Divakaran, and H. Sun. Structureanalysis of soccer video with domain knowledge and hidden markovmodels. Pattern Recognition Letters, 25:767–775, 2004.
[18] F. Yan, W. Christmas, and J. Kittler. A tennis ball tracking algorithmfor automatic annotation of tennis match. BMVC 2005, 2:619–628,
73

2005.[19] Y.Li, T.Zhang, and D.Tretter. An overview of video abstraction
techniques. HP, 2001.[20] Y.Rui, S.Thomas, H.Mehrota, and S.Mehrota. Exploring video struc-
ture beyond the shots. IEEE International Conference on MultimediaComputing and Systems, pages pp 237–240, 1998.
[21] X. Yu, L. Wang, Q. Tian, and P. Xue. Multilevel video representationwith application to keyframe extraction. 10th International MultimediaModelling Conference, pages 117–123, 2004.
[22] H. Zhang, A. Kankanhalli, and S. Smoliar. Automatic partitioning offull-motion video. Multimedia Systems, 3(1):10–28, 1993.
[23] Y. Zhuang, Y. Rui, T. Huang, and S. Mehrotra. Adaptive key frameextraction using unsupervised clustering. in Proc. ICIP, 1:pp 866–870,1998.
[24] Z.Li, Q.Wei, Z.Stan, L. S.Yang, Q.Yang, and H.J.Zhang. Key-frameextraction and shot retrieval using nearest feature line (nfl). Interna-tional Workshop on Multimedia Information Retrieval, in conjunctionwith ACM Multimedia Conference, 2000.
74