a swedish natural language processing pipeline for
TRANSCRIPT

IN DEGREE PROJECT COMPUTER SCIENCE AND ENGINEERING,SECOND CYCLE, 30 CREDITS
, STOCKHOLM SWEDEN 2018
A Swedish Natural Language Processing Pipeline For Building Knowledge Graphs
ALEJANDRO GONZÁLEZ PÉREZ
KTH ROYAL INSTITUTE OF TECHNOLOGYSCHOOL OF ELECTRICAL ENGINEERING AND COMPUTER SCIENCE

School of Electrical Engineering and Computer Science
Kungliga Tekniska Högskolan
A Swedish Natural Language ProcessingPipeline For Building Knowledge Graphs
MASTER THESIS
EIT ICT Innovation and Data Science
Author: Alejandro González Pérez
Supervisor: Thomas Sjöland Examiner: Anne Håkansson
Course 2017-2018

To my parents. For their love, endless support and encouragement.

Acknowledgements
I would like to express my very great appreciation to my colleagues An-ders Baer and Maria Jernstöm for their valuable and constructive sug-gestions during the planning and development of this research work.Their willingness to give their time so generously has been very muchappreciated.
I would like also to express my deep gratitude to Anne Håkanssonand Thomas Sjöland, my research supervisors, for their patient guid-ance, enthusiastic encouragement and useful critiques of this researchwork.


iv
AbstractThe concept of knowledge is proper only to the human being thanks
to the faculty of understanding. The immaterial concepts, independentof the material causes of the experience constitute an evident proof ofthe existence of the rational soul that makes the human being a spiritualbeing"in a way independent of the material.
Nowadays research efforts in the field of Artificial Intelligence aretrying to mimic this human capacity using computers by means of tt-eachingthem how to read and understand human language using Machi-ne Learning techniques related to the processing of human language.However, there are still a significant number of challenges such as howto represent this knowledge so can be used by a machine to infer con-clusions or provide answers.
This thesis presents a Natural Language Processing pipeline thatis capable of building a knowledge representation of the informationcontained in Swedish human-generated text. The result is a system that,given Swedish text in its raw format, builds a representation in the formof a Knowledge Graph of the knowledge or information contained inthat text.

v
AbstractVetskapen om kunskap är den del av det som definierar den nu-
tida människan (som vet, att hon vet). De immateriella begreppenoberoende av materiella attribut är en del av beviset på att människanen själslig varelse som till viss del är oberoende av materialet.
För närvarande försöker forskningsinsatser inom artificiell intelli-gens efterlikna det mänskliga betandet med hjälp av datorer genomatt "lära" dem hur man läser och förstår mänskligt språk genom attanvända maskininlärningstekniker relaterade till behandling av män-skligt språk. Det finns emellertid fortfarande ett betydande antal ut-maningar, till exempel hur man representerar denna kunskap så att denkan användas av en maskin för att dra slutsatser eller ge svar utifråndetta.
Denna avhandling presenterar en studie i användningen av ”Natu-ral Language Processing” i en pipeline som kan generera en kunskap-srepresentation av informationen utifrån det svenska språket som bas.Resultatet är ett system som, med svensk text i råformat, bygger enrepresentation i form av en kunskapsgraf av kunskapen eller informa-tionen i den texten.

Contents
Contents viList of Figures viiiList of Tables ix
1 Introduction 11.1 Background . . . . . . . . . . . . . . . . . . . . . . . . . . 21.2 Problem . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.3 Purpose . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.4 Goal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.4.1 Benefits, Ethics and Sustainability . . . . . . . . . 41.5 Research Methodology . . . . . . . . . . . . . . . . . . . . 5
1.5.1 Philosophical Assumption . . . . . . . . . . . . . . 51.5.2 Research Method . . . . . . . . . . . . . . . . . . . 51.5.3 Research Approach . . . . . . . . . . . . . . . . . . 5
1.6 Delimitations . . . . . . . . . . . . . . . . . . . . . . . . . 61.7 Outline . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2 Framework 72.1 Natural Language . . . . . . . . . . . . . . . . . . . . . . . 72.2 Swedish Language . . . . . . . . . . . . . . . . . . . . . . 8
2.2.1 Alphabet . . . . . . . . . . . . . . . . . . . . . . . . 92.2.2 Nouns . . . . . . . . . . . . . . . . . . . . . . . . . 92.2.3 Adjectives . . . . . . . . . . . . . . . . . . . . . . . 92.2.4 Adverbs . . . . . . . . . . . . . . . . . . . . . . . . 102.2.5 Numbers . . . . . . . . . . . . . . . . . . . . . . . . 102.2.6 Pronouns . . . . . . . . . . . . . . . . . . . . . . . . 102.2.7 Prepositions . . . . . . . . . . . . . . . . . . . . . . 112.2.8 Verbs . . . . . . . . . . . . . . . . . . . . . . . . . . 112.2.9 Conjunctions . . . . . . . . . . . . . . . . . . . . . 112.2.10 Syntax . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.3 Machine Learning . . . . . . . . . . . . . . . . . . . . . . . 122.4 Natural Language Processing . . . . . . . . . . . . . . . . 13
2.4.1 Word and sentence tokenisation . . . . . . . . . . 132.4.2 Part-Of-Speech tagging . . . . . . . . . . . . . . . 142.4.3 Syntactic Dependency Parsing . . . . . . . . . . . 142.4.4 Named Entity Recognition . . . . . . . . . . . . . 152.4.5 Relation and Information Extraction . . . . . . . . 16
2.5 NLP tools and frameworks . . . . . . . . . . . . . . . . . . 162.5.1 Stanford CoreNLP . . . . . . . . . . . . . . . . . . 17
vi

CONTENTS vii
2.5.2 NLTK Python Library . . . . . . . . . . . . . . . . 172.5.3 spaCy . . . . . . . . . . . . . . . . . . . . . . . . . 172.5.4 SyntaxNet . . . . . . . . . . . . . . . . . . . . . . . 18
2.6 Knowledge Representation . . . . . . . . . . . . . . . . . 182.7 Graph databases and Knowledge graphs . . . . . . . . . 19
3 Related Work 213.1 Information and Knowledge extraction . . . . . . . . . . 213.2 Knowledge representation . . . . . . . . . . . . . . . . . . 223.3 Machine Learning & Natural Language Processing . . . . 22
4 Methods 244.1 Data collection . . . . . . . . . . . . . . . . . . . . . . . . . 244.2 Data analysis . . . . . . . . . . . . . . . . . . . . . . . . . . 254.3 Data verification and validation . . . . . . . . . . . . . . . 264.4 Software development . . . . . . . . . . . . . . . . . . . . 27
4.4.1 Software development stages . . . . . . . . . . . . 284.4.2 Software development models . . . . . . . . . . . 28
5 The NLP Pipeline 315.1 Design . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 315.2 Generating information triples . . . . . . . . . . . . . . . 33
5.2.1 Text preprocessing . . . . . . . . . . . . . . . . . . 335.2.2 Part-Of-Speech tagging . . . . . . . . . . . . . . . 365.2.3 Syntactic dependency parsing . . . . . . . . . . . . 375.2.4 Named entity recognition . . . . . . . . . . . . . . 415.2.5 Relation extraction . . . . . . . . . . . . . . . . . . 43
5.3 Integrating information triples . . . . . . . . . . . . . . . 435.4 Constructing the knowledge graph . . . . . . . . . . . . . 44
6 Evaluation 477 Conclusions and Future Work 49
7.1 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . 497.2 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . 507.3 Future work . . . . . . . . . . . . . . . . . . . . . . . . . . 52
Bibliography 53
AppendixA Graphs 65

List of Figures
2.1 Sample Swedish sentence structure analysis [31] . . . . . 122.2 Grammatical Dependency Graph. . . . . . . . . . . . . . . 152.3 Information Extraction example. Source: nlp.stanford.edu 162.4 NLP tools and frameworks accuracy evaluation [73]. . . . 172.5 Graph database example. . . . . . . . . . . . . . . . . . . 192.6 Knowledge graph example. . . . . . . . . . . . . . . . . . 20
4.1 Grammar analysis. . . . . . . . . . . . . . . . . . . . . . . 26
5.1 Main tasks identified. . . . . . . . . . . . . . . . . . . . . . 315.2 Sample triple extracted. . . . . . . . . . . . . . . . . . . . 325.3 Sample triple extracted. . . . . . . . . . . . . . . . . . . . 325.4 Constructed knowledge graph. . . . . . . . . . . . . . . . 335.5 Format of the triples. . . . . . . . . . . . . . . . . . . . . . 335.6 Classification of data quality problems [132]. . . . . . . . 345.7 Text transformations before linguistic analysis [135]. . . . 355.8 Text adjacency graph example. . . . . . . . . . . . . . . . 365.9 Part-of-speech tagging output. . . . . . . . . . . . . . . . 375.10 Dependency annotated graph. . . . . . . . . . . . . . . . . 395.11 Dependency annotated graph. . . . . . . . . . . . . . . . . 405.12 Train data labelling using Prodigy. . . . . . . . . . . . . . 415.13 Named Entity Recognition graph. . . . . . . . . . . . . . . 425.14 Information extraction graph. . . . . . . . . . . . . . . . . 445.15 Relation extracted. . . . . . . . . . . . . . . . . . . . . . . 445.16 SPIED algorithm [140]. . . . . . . . . . . . . . . . . . . . . 455.17 Named Entity Recognition graph. . . . . . . . . . . . . . . 46
6.1 Pipeline generated graph. . . . . . . . . . . . . . . . . . . 486.2 Manually generated graph. . . . . . . . . . . . . . . . . . 48
A.1 Part-of-speech and syntactic dependencies graph. . . . . 66A.2 Dependency annotated graph. . . . . . . . . . . . . . . . . 67A.3 Named Entity Recognition graph. . . . . . . . . . . . . . . 68
List of Tables
viii

LIST OF TABLES ix
4.1 Data row example. . . . . . . . . . . . . . . . . . . . . . . 25
5.1 Syntaxnet Swedish language accuracy. . . . . . . . . . . . 365.2 Main universal syntactic dependency relations [53]. . . . 385.3 Auxiliary universal syntactic dependency relations [53]. . 38

CHAPTER 1
Introduction
Traditionally, knowledge has been presented as something specific to thehuman being that is acquired or related to the "belief" in the existenceof the rational soul that makes it possible to intuit reality as truth [1].
Knowledge was considered to respond to the intellective faculties ofthe soul [2] according to the three degrees of perfection of them: soul asthe principle of life and vegetative self-movement, sensitive or animalsoul and human or rational soul [3].
According to these postulates, all living beings acquire informationfrom their environment through their faculties or functions of the soul[4]:
VegetativeIn vegetables to perform minimal vital functions innately, nutri-tion and growth, reproduction and death.
SensitiveIn the animals that produce adaptation and local self-movementand includes the former faculties. In the degree of superior per-fection, memory, learning and experience appear, but in its de-gree, one can not reach the "true knowledge" of reality.
RationalIn the human being that, in addition to the previous functions,produces the knowledge by concepts that make possible the lan-guage and the conscience of the truth.
The merely material beings, inert, lifeless and soulless, have noknowledge or information about the environment, as entirely passivebeings, only subject to material mechanical causality [3].
Experience, which is common to animals endowed with memory,does not yet offer a guarantee of truth because it is a subjective knowl-edge of those who have sensitive experience; which is valid only forthose who experience it and only at the moment when they experience
1

1.1 Background 2
it. It offers only a momentary, changing truth, and referring to a singlecase [3].
On the contrary, knowledge by concepts is proper only to the hu-man being thanks to the faculty of understanding [5]. The immaterialconcepts, independent of the material causes of the experience consti-tute an evident proof of the existence of the rational soul that makes thehuman being a "spiritual being" in a way independent of the material.Its truth does not depend on the circumstances because its intuitive ac-tivity penetrates and knows reality as such, the essence of things andtherefore science is possible [6].
This is so because the understanding as power or faculty of the soul,agent understanding [7] according to Aristotle, is intuitive and penetratesthe essence of things from experience through a process of abstraction.
1.1 Background
Nowadays most of the research efforts in the field of Computer Sciencepursue the dream of creating an Artificial Intelligence [8] that can beable to mimic or even replace human cognitive capacity. Unfortunately,the time has not yet arrived; challenges are yet to be tackled to achievea fully capable system that resembles human brain processes [9].
One of the main challenges of this path to AI is the representation ofknowledge and reasoning, an area of AI whose fundamental objectiveis to represent knowledge in a way that facilitates inference (draw con-clusions) from that knowledge [10]. It analyses how to think formallyor, in other words, how to use a system of symbols to represent a do-main of discourse, together with functions that allow inferring (makingformal reasoning) about objects.
An approach for solving the challenges of knowledge representa-tion and reasoning are the Knowledge Bases and Knowledge-basedsystems [11], a technology used to store complex structured and un-structured information or data in conjunction with an inference enginethat is able to reason about facts and use rules and other forms of logicto deduce new facts and query for specific information [12]. However,manually creating, maintaining and updating a knowledge base is ahard, time-consuming task [13], especially when the knowledge storedin it changes with high frequency. That is why automatic approachesusing Machine Learning [14], and Natural Language Processing [15]are needed to achieve a solution to the problem of building systems forknowledge representation and reasoning as well as, at the same time,get closer to the dream of a fully functioning AI.

1.2 Problem 3
This work studies and implements a prototype of a system capa-ble of extracting and represent knowledge in the format of knowledgegraphs using ML tools and algorithms for NLP.
1.2 Problem
In this thesis the aim is to construct knowledge graphs, as a way ofrepresenting knowledge, extracting key terms and relationships fromSwedish human-generated text.
Many other projects and research papers approach a solution to thisproblem with more or less success. For example, the work from Fraga,Vegetti et al. [16] Semi-Automated Ontology Generation Process from In-dustrial Product Data Standards and from Embley, Campbell et a. [17]Ontology-based extraction and structuring of information from data-rich un-structured documents where they build systems capable of generatinga knowledge representation of domain-specific data. Also, the projectfrom Al-Zubaide and Issa [18] OntBot: Ontology based ChatBot wherethey present an algorithm capable of extracting knowledge automati-cally from human conversation. However, none of them focus in otherlanguages apart from English and also they are not very flexible regard-ing adding new features or steps to the process of extracting informa-tion.
To solve the problem, literature proved that ML could help withsome of its tools and algorithms focused in enabling a machine to readand understand human language in a way that information can be ex-tracted and structured for further processing or reasoning in this case[19].
The claim is that by building an NLP pipeline with custom stepsand available technologies, a machine might be able to extract valu-able information in the format of graphs that connect concepts, ideasand other information in a way that represents the knowledge beingintegrated in a given piece of human-generated text, not only for theSwedish language, but also others.
The research question that summarises the problem presented inthis thesis report is:
How can ML algorithms for NLP and Graph Databases be integrated andapplied to build a Knowledge Graph using domain-specific human-generatedSwedish text?

1.3 Purpose 4
1.3 Purpose
The purpose of this thesis is to present how different ML techniquesin the field of NLP can be applied for extracting terms or concepts andrelationships between them from Swedish, human-generated text andconstruct simple knowledge graphs that represent this knowledge.
1.4 Goal
The primary goal of this project is to implement a system capable of,using human-generated text in Swedish, extract the essential informa-tion from it and build and maintain a Knowledge Base with all of thedata, not only provided by the input text but by further input that thesystem will eventually receive.
The input of the system may also be recorded voice or other formatsof information which are subject to knowledge extraction.
Once the system is completed, it should be able to reason and pro-vide answers to questions related to the domain of the information be-ing stored in it.
1.4.1. Benefits, Ethics and Sustainability
Being able to automatically generate machine-readable knowledge rep-resentations have an immediate benefit of fostering the developmentof better information systems, as well as contributing to the creation ofmore advanced AI that will not only transform businesses and econ-omy but also will have an impact on the society.
This kind of automatic information gathering systems have a pos-sible impact on ethics since the data needed for training, testing and,in general, developing the system may contain private and sensitive in-formation that needs to be handled with the highest security standards.But not only applying high-security standards will solve the ethics is-sue, but it is also imperative to adequately inform the user of what isgoing to be the use of its data and have the explicit consent to use it.
Finally, concerning sustainability, this project contributes explicitlyto the ninth of the United Nations sustainable development goals [20]which relate to Industry, Innovation and Infrastructure. Specifically,this project is an investment in the field of information and communi-cation technology, crucial for achieving sustainable development andempower communities in many countries. Also, according to the UN,technological progress is the foundation of efforts for achieving envi-ronmental objectives such as increased resource and energy-efficiency.

1.5 Research Methodology 5
1.5 Research Methodology
There are two common methods for research to be categorised: Quanti-tative research method and Qualitative research method[21].
The Quantitative Research method uses mathematical, statistical ocomputational techniques to describe the causes of a phenomenon, re-lations between variables and to verify or falsify theories and hypothe-sis.
On the other hand, the Qualitative Research method refers to themeanings, concepts definitions, characteristics, metaphors, symbols,and description of things and not their numerical measures.
Since this thesis focuses primarily in developing a proof-of-conceptof a pipeline that integrates a collection of ML algorithms, the methodchosen is the Qualitative method, which focuses in the decisions takenfor the implementation itself rather than their numerical values.
1.5.1. Philosophical Assumption
The philosophical assumption followed is the Positivism, which assumesthat the reality is objectively given and independent of the observer andinstruments [21]. This assumption may be the appropriate one sincethis thesis focus primarily on experimenting and testing different ap-proaches that try to solve the problem stated.
1.5.2. Research Method
Concerning the Research method, this thesis is based on the Appliedresearch, since it builds on existing research and uses real-world datafor trying to achieve the goals described [21].
1.5.3. Research Approach
Finally, the research approach chosen is the inductive, which starts withthe observations and theories are proposed towards the end of the re-search process as a result of observations [22]. The reason for choosingthis approach relies on the fact that this research project begins withnone strong hypotheses, the type or nature of the research findings willnot be ready until the end of the study.

1.6 Delimitations 6
1.6 Delimitations
The primary focus of this work is to develop and test a system thatsolves the problem described in previous sections, as opposed to mea-suring the quality or performance of it at least on this first iteration ofthe project. Future work will be required for achieving a more performance-focused solution.
In the development of the proposed solution, risks such as time,data available, quality of that data and computing capacity have beentaken into account. Likewise, measures have been adopted to limit itsimpact. Even so, until the moment of the presentation of the proposedproject, there is no optimal solution for most of the NLP challengeswithin the field of ML. For this reason, it can not be guaranteed that theoutput of the system is entirely reliable or if the approach chosen forsolving the problem is the most adequate.
1.7 Outline
This thesis report is structured as follows:
Chapter 2: FrameworkThe chapter two of this report presents to the reader an introduc-tion to the framework of this thesis. Including a foreword fortopics such as the Swedish language, Machine Learning, NaturalLanguage Processing and so on.
Chapter 3: Related workThe chapter three of this report analyses the related work thatfocuses on common topics for this project.
Chapter 4: MethodsThe chapter four of this report introduces the methods used forconducting the proposed thesis.
Chapter 5: The NLP PipelineThe chapter five of this report presents the proposed solution tothe problem stated, driving into the details of the chosen technol-ogy and the final implemented pipeline.
Chapter 6: EvaluationThe chapter six of this report provides the results of the evalua-tion of the system implemented concerning its accuracy.
Chapter 7: Conclusions and Future WorkThe chapter seven of this report focuses on the conclusion anda self-evaluation of the thesis itself. It also introduces the futurework that will be needed to improve and grow the project itself.

CHAPTER 2
Framework
This chapter presents the framework used to define a solution to theproblem described. The first section will introduce to the reader thebasics of Natural Language and its implications for this work.
After the concept of Natural Language, a comprehensive descrip-tion of the main characteristics of Swedish language will be presentedto provide a better insight into this language and its most relevant com-ponents. Finally, the concepts of Machine Learning, Natural LanguageProcessing, its tools and Knowledge Representations will complete thischapter, citing the most relevant information needed for a better under-standing of the project being gathered on this report.
2.1 Natural Language
The term natural language[23] designates a linguistic variety or formof human language with communicative aims that is endowed withsyntax, and that obeys supposedly to the principles of economy andoptimisation.
According to Hockett et al. [23] there are fifteen Natural Languagefeatures. To highlight some:
Mode of communicationNatural Language has two main channels as a mode of commu-nication: vocal-auditory and manual-visual.
Broadcast transmission and directed receptionIn a speech a message is broadcast that expands in all directionsand can be heard by anyone; however, the human auditory sys-tem allows the identification of where it comes from.
Interchangeable development or interchangeabilityA speaker, under normal conditions, can both broadcast and re-ceive messages.
7

2.2 Swedish Language 8
Total feedbackThe speaker can listen to himself at the precise moment he or sheissues a message.
SemanticityThe signal corresponds to a particular meaning. It is a fundamen-tal element of any method of communication.
ArbitrarinessThere is no correlation between the signal and the sign.
DiscreetityThe basic units are separable, without a gradual transition. Alistener can hear either "t" or "d", and regardless of whether hehears it well, he will distinguish one or the other, without hearinga mixture of both.
DisplacementReference can be made to situations or objects that are not situ-ated by deixis, in the "here and now", that is, separated by time ordistance, or even on things that do not exist or have not existed.
Double articulation or dualityThere is a level or second articulation in which the elements haveno meaning, but they distinguish meaning (phoneme), and an-other level or first articulation in which these elements are groupedto have meaning (morpheme). The elements of the second articu-lation are finite, but they can be grouped in infinite ways.
ProductivityThe rules of grammar allow the creation of new sentences thathave never been created but can be understood.
In a broader perspective, the concept of Natural Language can besummarised as a human communication procedure that does not needto follow a particular set of rules; instead, it evolves and changes withthe time.
2.2 Swedish Language
Swedish is a Scandinavian language [24] currently being spoken bymore than nine million people in the world, mainly in Sweden andparts of Finland, especially on the coast and in the Åland islands [25].Like other Scandinavian languages, Swedish descends from the OldNordic, the common language of the Germans who remained in Scan-dinavia during the Viking era [15].
Standard Swedish is the language that evolved from the dialects ofCentral Swedish in the 19th century and was already well established

2.2 Swedish Language 9
in the early twentieth century [26]. Although there are still differentregional varieties that come from ancient rural dialects, the spoken andwritten language is uniform and standardised. Some dialects are verydifferent from standard Swedish in grammar and vocabulary and arenot always mutually intelligible with standard Swedish [27]. These di-alects are limited to rural areas and are mainly spoken by a small num-ber of people with little social mobility. Although they are not threat-ened with imminent extinction, these dialects have been declining dur-ing the last century, although they are well documented, and their useis encouraged by local authorities [28].
In Standard Swedish, the standard order of the phrases is Subject- Verb - Object, although this can often change to emphasise certainwords or phrases. The morphology of Swedish is similar to English,that is, it has relatively few flexions; two genres, no case, and a dis-tinction between singular and plural. Adjectives are compared as inEnglish, and they are also flexed according to gender, number and ef-fect of definition. The effect of defining the nouns is mainly markedby suffixes (terminations), complemented with definite and indefinitearticles. Prosody presents both accent and tones. The language has arelatively large vowel variety.
2.2.1. Alphabet
The Swedish alphabet is a variant of the Latin alphabet [29]. It consistsof 29 letters, of which three (å, ä and ö) are characteristic of this lan-guage and other Germanic languages. The Swedish vowels are a, e, i,o, u, y, å, ä and ö. It contains the 26 letters of the Latin alphabet.
The Swedish alphabet will then include the following letters:A, B,C, D, E, F, G, H, I, J, K, L, M, N, O, P, Q, R, S, T, U, V, W, X, Y, Z, Å, Ä, Ö
2.2.2. Nouns
A noun in Swedish is, as in other Indo-European languages, a classof words meaning things, objects, places, people, plants, animals, phe-nomena and abstract concepts. It is a different part of speech: it takesa definite or undefined form, it can have a singular and plural number,rudimentary forms of complement cases, and each gender is assigneda type: utrum or neuter. In the sentence, it can act as a subject, object orattachment [24].
2.2.3. Adjectives
Swedish adjectives are declined according to gender, number, and def-initeness of the noun [24].

2.2 Swedish Language 10
2.2.4. Adverbs
The adverb is an invariable part of speech in the Swedish language,functioning in the sentence as an observer. A large part of Swedishadverbs is created by adding the adjective tip t to the basic form.
Some adjectives ending in -lig form adverbs by adding the ending-en or -vis. Adverbs ending in -vis and -en often appear as conditionsfor circumstance or consent.
Other endings of adverbs are: -ledes / -lunda. Many adverbs func-tion completely independently, without being a derivative of any otherexpression [24].
2.2.5. Numbers
In Swedish, we distinguish between primary and order numerals. Theymay in the sentence act as the subject, object and attachment [24]. Nat-ural numbers from 0 to 10: noll, en, ett, två, tre, fyra, fem, sex, sju, åtta,nio, tio.
Creating the second ten numbers (between 11 and 20) is charac-terised by high irregularity. The -ton ending is accompanied by num-bers from 13 to 20, which is the effect of the numeral system in theperiod of using the duodecimal system. Only three numerals: 15, 16and 17 are created entirely regularly.
Unlike other Scandinavian languages, numbers between 21-99 arearrayed by the number of units: tjugo, tjugoen, tjugotvå. The end ofnumbers from 30 to 90 is -tio.
2.2.6. Pronouns
In Swedish, depending on the replaced part of the speech pronouns aredivided into noun, adjectival, adverbial and numeral. Due to the syn-tactic functions, noun pronouns are called independent, and adjectivepronouns [24].
Some pronouns can have both noun and adjective functions so thatthey can be used as a substitute for a noun or as a term. The word towhich the pronoun refers or which it replaces is called the correlate ofthe pronoun. From the degree of specificity of the correlate, we dividethe pronouns in Swedish into three groups [24]:
• Definite pronouns: Which replace a strictly defined correlate andincludes:
– Personal pronouns
– Possessive pronouns
– Demonstrative pronouns

2.2 Swedish Language 11
– Reflexive pronouns
– Pronounced pronouns
– Querying pronouns
• Query pronouns: Which express the question about correlates.
• Indefinite pronouns: Whose correlates are not specified.
2.2.7. Prepositions
The preposition is an invariable part of speech expressing the relationbetween particular elements of a sentence or whole sentences. It ismostly unstressed. The use of a specific preposition does not changethe form of the word. After the preposition, there is usually a pronounin the form of a complement. Many verbs have predetermined prepo-sitions [24]. Prepositions can be:
• Simple
• Complex
• Complete
• Derivatives
2.2.8. Verbs
The verb in Swedish is a different part of speech, although the paradigmof the variety is simplified: its form depends neither on the person northe number. The starting form of the verb to create other forms is theimperative mode, which is also the shortest existing form of the verb.Thus, the verb adopts, basically, the following morphological forms[24]:
• Infinitive
• Present tense
• Past tense, imperfect
• Past tense, perfect
• Future tense
• Supine

2.3 Machine Learning 12
2.2.9. Conjunctions
The conjunction is an unchangeable part of the sentence, and its taskis to combine individual words or entire sentences in compound sen-tences. Conjunctions concerning their function are divided into coordi-nates and subordinates [24].
2.2.10. Syntax
Typically, the Swedish language belongs to the positional language grouplike German or English [30]. The syntax is an important element ofSwedish grammar. Swedish is a Germanic language, Swedish syntaxshows similarities to both English and German. It has a Subject - Verb- Object word order. Like German, Swedish utilises verb-second wordorder in main clauses, for instance after adverbs, adverbial phrases, anddependent clauses. Adjectives generally precede the noun they deter-mine [24].
Figure 2.1: Sample Swedish sentence structure analysis [31]
2.3 Machine Learning
Machine Learning is currently one of the most outstanding subfieldsof Computer Science [32]. It is a branch of the Artificial Intelligenceworld, and its fundamental aspiration is to develop techniques that al-low computers to learn [33].
As a matter of fact, Machine Learning is about creating applicationscapable of generalising behaviours from information provided in theform of examples. It is, therefore, a process of knowledge induction.In many cases, the field of action of Machine Learning overlaps that ofcomputational statistics [34], since the two disciplines are based on dataanalysis [35]. However, machine learning also focuses on the study ofthe computational complexity of problems.

2.4 Natural Language Processing 13
The process of learning can be divided into two main groups, whichalso serve as the two major groups for classifying Machine Learningtechniques:
• Supervised learning
• Unsupervised learning.
Supervised learning is a technique to deduce a function from train-ing data [36]. The training data consist of pairs of objects (usually vec-tors): the first component is the input data and the other, the expectedresult. The output of the function can be a numeric value (as in regres-sion problems) or a class label (as in classification). The target of thistype of learning is to create a function capable of predicting the outputcorresponding to any valid input object after having seen a series ofexamples (or training data). For this, it has to generalise from the datapresented to the situations not previously seen.
In unsupervised learning, on the contrary, there is no a priori knowl-edge [37]. Thus, unsupervised learning typically treats input objects asa set of random variables, with a density model being constructed forthe data set [38].
2.4 Natural Language Processing
Natural Language Processing can be defined as a collection of MachineLearning techniques and algorithms that enables computers to analyse,understand, and derive meaning from human language [39]. NLP, incontrast to standard text processors, considers the hierarchical structure oflanguage: several words make a phrase, several phrases make a sentence and,ultimately, sentences convey ideas [40].
NLP can also organise and structure knowledge, to perform taskssuch as automatic summarising [41], translation [42], named entity recog-nition [43], relationship extraction [44], sentiment analysis [45], speechrecognition [46] and so on.
In general, processes involving Natural Language Processing arecomposed by a sequence of tasks[47]. Each of those tasks has a specificpurpose, such as tokenising text to analyse its words, label each of thosewords with their respective grammar category and so on. The nextsubsections will describe each of those Natural Language Processingtasks that shape a typical pipeline.
2.4.1. Word and sentence tokenisation
Detecting token and sentence boundaries is an important preprocessingstep in Natural Language Processing applications since most of these

2.4 Natural Language Processing 14
operate either on the level of words or sentences. The primary chal-lenges of the tokenisation task stem from the ambiguity of individualcharacters in alphabetic and the absence of explicitly word boundariesin most of the languages [48].
The process of finding boundaries of sentences in a text is oftendone heuristically, using regular expressions. Although best perfor-mance is achieved with supervised Machine Learning models that pre-dict, for example, for each full stop whether it denotes the end of thesentence [49].
2.4.2. Part-Of-Speech tagging
In computational linguistics, grammar labelling (also known as, part-of-speech tagging) is the process of assigning to each of the words intext its grammatical category [50]. This process can be done accordingto the definition of the word or the context in which it appears, forexample, its relation to adjacent words in a sentence or a paragraph.
The grammar labelling is more complicated than it seems at firstglance, it is not as simple as having a list of words and their corre-sponding grammatical categories since some words can have differentgrammatical categories depending on the context in which they appear[51]. This fact often occurs in natural language where a large number ofwords are ambiguous. For example, the word ’given’ can be a singularname or a form of the verb ’give’. That is why Machine Learning algo-rithms for Natural Language Processing are very useful when trying totackle down this problem.
There is also another challenge related to the labelling format used.Since every language in the world is unique, it is hard to agree on oneway of labelling the same type of words [52]. That is why the projectUniversal Dependencies has been making a great effort to try to co-ordinate the work being done around the world related to grammarlabelling. To solve that, Universal Dependencies is a project that is de-veloping cross-linguistically consistent treebank annotation for most ofthe world’s languages, with the goal of facilitating multilingual parserdevelopment, cross-lingual learning, and parsing research from a lan-guage typology perspective [53]. The annotation scheme is based onan evolution of Stanford dependencies [54], Google universal part-of-speech tags [55], and the Interset interlingua for morphosyntactic tagsets[56].
2.4.3. Syntactic Dependency Parsing
Syntactic Dependency Parsing or Dependency Parsing consists on as-signing a syntactic structure to a given well-formed sentence. It is basedon the dependency grammar theory [57], which its fundamental basis

2.4 Natural Language Processing 15
is to consider not only the lexical elements that make up the syntac-tic structure but also the relationships between them [58]. Accordingto this theory, there is a link that relates to the ideas expressed by thewords to form an organised thought [59]. This link is called a connec-tion.
The connections operate hierarchically; thus, when joining two el-ements, one will be considered as regent and the other as governed.When a ruler has several regents a knot is built, which are staggeredin a complex system of dependencies, which culminates in the centralknot.
Figure 2.2: Grammatical Dependency Graph.
The syntactic dependency parsing analysis represented by a dia-gram, or a dependency graph as shown in Figure 2.2.
2.4.4. Named Entity Recognition
The recognition of named entities is one of the most important topicsin Natural Language Processing [60]. It is a subtask of information ex-traction [61] that aims to provide a predefined label or class to entitiesin a given unstructured text.
In the named entity expression, the word named restricts the task tothose entities for which there is a common designator or label. Forexample, in the sentence: Barack Obama was born in 1961 in Honolulu,Hawaii a possible named entity recognition system may produce:
• Barack Obama: PERSON
• 1961: DATE
• Honolulu: PLACE
Recognition of named entities is often divided into two distinct prob-lems [62]: name detection, and name classification according to the typeof entity they refer to.

2.4 Natural Language Processing 16
The first phase is usually reduced to a segmentation problem [63]:the names are a contiguous sequence of tokens, without overlappingor nesting, so that Barack Obama is a unique name, although that withinthis name appears, the substring Obama which is itself a name.
Temporal expressions and some numerical expressions (money, per-centages and so on) can also be considered entities in the context of theNamed Entity Recognition. While some cases of these types are goodexamples of rigid designators, there are also many invalids [64], for ex-ample, Barack Obama was born in August. In the first case, the year 1961refers to the 1961 year of the Gregorian calendar. In the second case, themonth of August can refer to the month of any year. The definition ofa named entity is not strict and often has to be explained in the contextin which it is being used.
2.4.5. Relation and Information Extraction
Relationships, in the context of information retrieval [65], are the gram-matical and semantic connections between two entities in a sentence.
The task of extracting information from unstructured text aims toautomatically extract structured, or semi-structured information fromdocuments readable by a computer [66] is also one of the most signifi-cant challenges in the context of Natural Language Processing [67].
Figure 2.3: Information Extraction example.Source: nlp.stanford.edu
In the past few decades, different approaches to solve this problemhave been studied and implemented with more or less success [68],most of the time involving the use of domain ontologies [69] whichproved to not be cost-efficient and difficult to maintain [70]. Other ap-proaches involved some new techniques such as Machine Learning [71]which proved to leverage most of the previously implemented solu-tions [72].

2.5 NLP tools and frameworks 17
2.5 NLP tools and frameworks
The current state of the art of the field of Natural Language Processinginvolves new tools and frameworks that serve as building blocks for allthe projects that require, in all levels of complexity, to process NaturalLanguage.
This section presents the four major projects that currently are themost widely used, accepted and validated for such NLP tasks [36] [73].
Figure 2.4: NLP tools and frameworks accuracy evaluation [73].
2.5.1. Stanford CoreNLP
Stanford CoreNLP provides a set of human language technology tools[74]. It is an integrated framework which aims to facilitate the applica-tion of linguistic analysis to human-generated raw text.
It is currently the most commonly used library in software engi-neering research related to the processing of Natural Language in allits levels since it has a wide range of grammatical analysis tools andsupport for all the major languages.
Amongst its features, the most interesting ones are: giving the baseforms of words, their parts of speech, Named Entity Recognition, syn-tactic dependencies, indicate which noun phrases refer to the same en-tities, indicate sentiment, extract particular or open-class relations be-tween entity mentions, and so on.
2.5.2. NLTK Python Library
NLTK is a platform for building Python programs to work with human-generated text data. It incorporates a suite of text processing librariesfor classification, tokenisation, stemming, tagging, parsing, and seman-tic reasoning and also wrappers for the leading industrial-strength NLPlibraries [75]. Similar to the Stanford CoreNLP library, NLTK providesmany integrations for different programming languages and comes withmany resources.

2.6 Knowledge Representation 18
2.5.3. spaCy
SpaCy[76] is a library also written in Python [77] and Cython [78]. Itis primarily aimed at commercial applications since it is substantiallyfaster than many other libraries. It includes all the features of the pre-viously introduced libraries.
2.5.4. SyntaxNet
SyntaxNet[79] is a framework for syntactic parsing built as a NeuralNetwork [80] implemented in Google’s Deep Learning framework Ten-sorFlow [81]. Given a sentence as input, it tags each word with a part-of-speech tag that describes the word’s function in a given sentence,and it determines the relationships between those words, representedin the dependency parse tree. It is currently one of the most accurateparsers, achieving, on average and depending on the language, morethan 90% of accuracy.
2.6 Knowledge Representation
Knowledge representation and reasoning is a field of Artificial Intelli-gence whose fundamental purpose is to represent knowledge in a waythat facilitates inference, that is, drawing conclusions from that knowl-edge [82].
There is a set of representation techniques [83] such as frames, rules,labelling and semantic networks, which have their origin in theories ofhuman information processing. As knowledge is used to achieve intel-ligent behaviour, the fundamental objective of knowledge representa-tion is to represent knowledge in a way that facilitates reasoning [84].A good representation of knowledge must be declarative, in additionto fundamental knowledge.
In general, knowledge representation can be understood concern-ing five fundamental roles [85]:
• A representation of knowledge is fundamentally a substitute, asubstitute for an object from real life.
• It is a group of ontological commitments, an answer to the ques-tion about the terms in which one should think about the world.
• It is a part of the theory of intelligent reasoning, expressed regard-ing three components: The fundamental concept of the represen-tation of intelligent reasoning; The set of inferences that the rep-resentation sanctions; The set of inferences that it recommends.

2.7 Graph databases and Knowledge graphs 19
• It is the computational environment in which thought takes place,given by the guidance that a representation provides a method toorganise information in a way that facilitates making inferences.
• It is a mode of human expression, a language in which thingsabout the world are expressed.
In the field of artificial intelligence, problem-solving can be simpli-fied with an appropriate choice of knowledge representation [86]. Someproblems are easier to solve by representing knowledge in a certainway.
2.7 Graph databases and Knowledge graphs
A graph-oriented database [87] represents the information as nodes ofa graph and its relationships with the edges of it, so graph theory[88]can be used to traverse the database since it can describe attributes ofthe graphs nodes (entities) and the edges (relationships)[88].
Figure 2.5: Graph database example.
A graph database must be standardised; this means that each ta-ble would have only one column and each relation only two, with thisbeing achieved that any change in the structure of the information hasonly a local effect [89].
The graph databases also offers new or improved characteristicssuch as broader queries and not demarcated by tables [90]. Also, thereis no need to define a certain number of attributes. Moreover, therecords are also of variable length, avoiding having to define a size andalso possible faults in the database. Besides, graph databases can di-rectly be navigated hierarchically, getting the root node from the leafnode and vice versa.
In the field of Knowledge Representation, Graph databases presenta crucial role [86], since its main advantage is the versatility, as theycan store both relational and complex semantic data [91]. The exam-ple this conjunction between graph databases and knowledge are theKnowledge Graphs [92], a representation of knowledge in the format ofgraphs, which offer a more powerful way of representing knowledge.
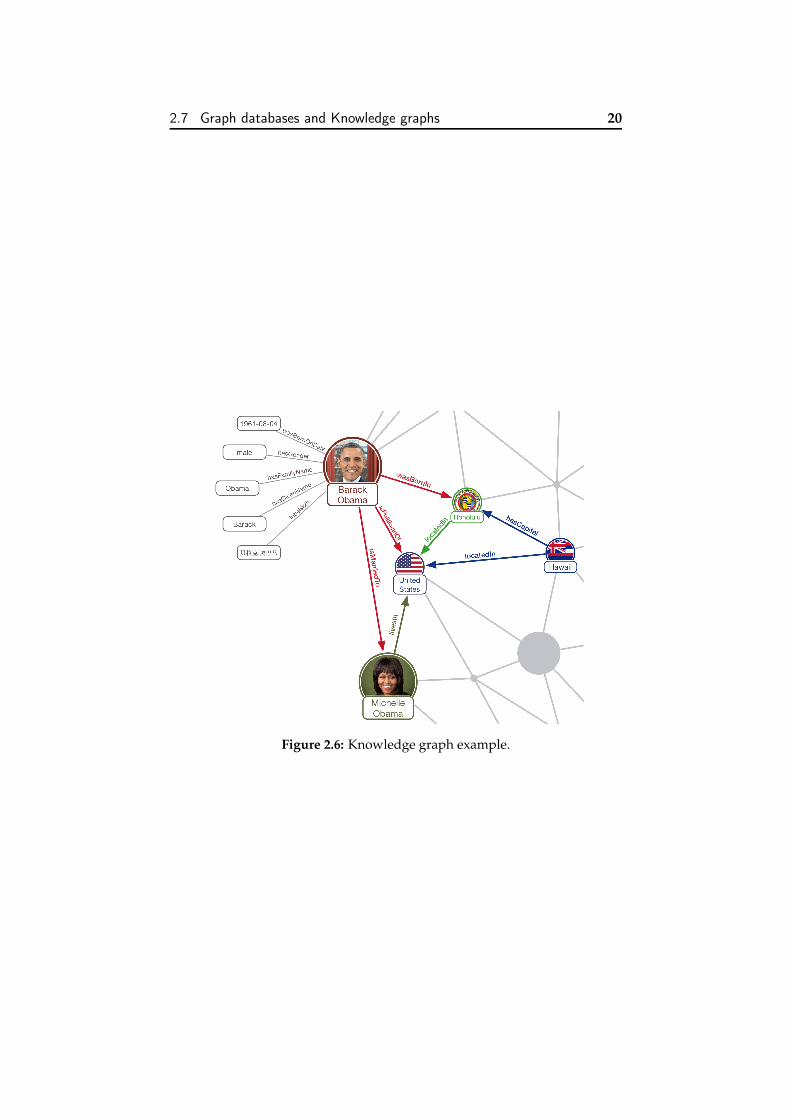
2.7 Graph databases and Knowledge graphs 20
Figure 2.6: Knowledge graph example.

CHAPTER 3
Related Work
This chapter introduces the most relevant related work for the topic be-ing considered in this project. First and foremost, it will focus on theareas of Natural Language Processing systems, techniques and frame-works for information and knowledge extraction for building knowl-edge graphs. Besides, modern knowledge representation techniquesand research will be introduced. Finally, it will conclude with an in-troduction to relevant research and projects for Machine Learning, andNatural Language Processing approaches.
3.1 Information and Knowledge extraction
In the area of information and knowledge extraction it is important tohighlight the work of Jingbo, Jialu et al. Automated Phrase Mining fromMassive Text Corpora [93] which presents an interesting approach to thetask of automated phrase mining, which leverages a large amount ofhigh-quality phrases in an effective way, achieving better performancecompared to limited human labeled phrases. Parts of this strategy willbe used for sentence tokenisation and phrase from text extraction dur-ing the implementation of the proposed solution in further chapters.
On the other hand, it is also interesting the survey done by Krzy-wicki, Wobcke et al. Data mining for building knowledge bases: Techniques,architectures and applications [61] which analyses the state-of-the-art lit-erature on both current text mining methods (emphasising stream min-ing) and techniques for the construction and maintenance of knowl-edge bases. Specifically, its focus on mining entities and relations froman unstructured human-generated text that presents a challenge con-cerning entity disambiguation and entity linking. This survey is themain inspiration for the steps taking in the solution to extract entitiesand its relations.
Also interesting is the review on relation extraction done by Bachand Badaskar A review of relation extraction [68] which focus on methods
21

3.2 Knowledge representation 22
for recognising relations between entities in unstructured text. Alsopart of the inspiration on the information retrieval parts of this project.
Finally, it is also interesting to cite the following research projects:Leveraging Linguistic Structure For Open-Domain Information Extraction[94], A text processing pipeline to extract recommendations from radiology re-ports [95], Fast rule mining in ontological knowledge bases with AMIE+ [96]and Semi-Automated Ontology Generation Process from Industrial ProductData Standards [16] which also influenced to a greater or lesser extentthe decisions taking for solving the problem proposed.
3.2 Knowledge representation
Another important topic related to the project being discussed in thisreport is the approaches for effectively representing knowledge.
In this area, it is essential to mention the paper from Pilato, Augelloet al. A Modular System Oriented to the Design of Versatile Knowledge Basesfor Chatbots [97] which illustrates a system that implements a frame-work oriented to the development of modular knowledge bases andalso part of the justification in terms of the decisions taken in order torepresent knowledge in this project.
To add on the field of knowledge representation the work fromSchuhmacher and Ponzetto Knowledge-based graph document modelling[98] which propose a graph-based semantic model for representing doc-ument content also motivated the decisions on how to build the knowl-edge graphs.
Finally, more on this topic can be found in the following papers:WHIRL: a world-based information representation language [99], ScaLeKB:scalable learning and inference over large knowledge bases [100], Experience-based knowledge representation: Soeks [101], Ontology-based extraction andstructuring of information from data-rich unstructured documents [102] andOpen-domain Factoid Question Answering via Knowledge Graph Search [103].
3.3 Machine Learning & Natural Language Pro-cessing
One of the most crucial components of the presented work is the Ma-chine Learning techniques for Natural Language Processing.
One of the most interesting readings is the paper presented by Lavelli,Califf et al. Evaluation of machine learning-based information extraction al-gorithms: Criticisms and recommendations [72] which surveys the eval-uation methodology adopted in information extraction, as defined ina few different efforts applying machine learning to Information Ex-

3.3 Machine Learning & Natural Language Processing 23
traction and served as a methodology for evaluating the system imple-mented.
Moreover, the research from Ireson, Califf et al. Evaluating machinelearning for information extraction [71] which also presented an interest-ing approach for evaluating Machine Learning techniques for Informa-tion Extraction.
Finally, also important to mention the next two papers: A review ofrelational machine learning for knowledge graphs [104] and R-Net: MachineReading Comprehension With Self-Matching Networks [105].

CHAPTER 4
Methods
This chapter introduces the methods used for both obtaining the datarequired for the system and the software development techniques usedfor implementing the system.
4.1 Data collection
Data collection is the process of collecting and measuring informationon variables of interest, in a systematic methodology established toallow someone to answer questions from presented research, test hy-potheses and evaluate results [106]. The research component of thedata collection is common to all fields of study, including the physical,social, human and business. While methods vary by discipline, the em-phasis on certifying an accurate and honest collection remains the same[107].
Regardless of the field of study or preference of data definition (quan-titative or qualitative), accurate data collection is essential to maintainthe integrity of research [108]. Both instrument selections appropriatefor the collection (existing, modified, or newly developed) and deliber-ately clear instructions for its correct use in order to reduce the likeli-hood of errors occurring [109].
A formal data collection process is necessary to ensure that the dataobtained are as well defined as accurate and that subsequent decisionson arguments based on the information found are valid. The processcreates a baseline in which to measure and in some instances a target tobe improved [110].
Concerning this research project, data collected is Qualitative [111],since it consists of extraction from the support forum of Telia Com-pany website1. This data contains threads of conversation betweencustomers and support agents. The format of the data extracted isComma Separated Values which contains information such as conver-
1https://forum.telia.se
24

4.2 Data analysis 25
sation thread id, text, publishing date and collection of thread replies.Figure 4.1 shows an excerpt of the data collected.
The main methods for collecting qualitative data are:
• Individual interviews
• Focus groups
• Observations
• Action Research
id date text reply_id2508 20180111 Beställer du e-faktura, så skickas inga papper/brev till dig och du slipper avgiften på. 2511
Table 4.1: Data row example.
The chosen methods for data collection for this project are Observa-tion [112] and Action Research[113], since they fit to the natural sourceand type of the data presented.
4.2 Data analysis
Qualitative and Quantitative data also require different types of analy-sis to be applied. In the case of qualitative-oriented researches, wherethe data falls into the types of interviews, text or other non-numericaldata analysis involves identifying common patterns within the responsesand critically analysing them in order to achieve research aims and ob-jectives [114]. Data analysis for quantitative data [115], on the contrary,involves analysis and interpretation of numerical data and attempts tofind the rationale behind findings [116].
As previously discussed, the data gathered for this project is, in gen-eral, qualitative, which refers to non-numeric information such as textdocuments. That means a qualitative data analysis will be applied.
Qualitative data analysis can be divided into the following cate-gories [117]:
• Content analysis Which is the process of categorising verbal orbehavioural data.
• Narrative analysis Which involves the reformulation of storiespresented by respondents of a survey taking into account the con-text.
• Discourse analysis Which systematically studies written and spo-ken discourse as a form of the use of language.

4.3 Data verification and validation 26
• Framework analysis Which consists of several stages such as fa-miliarisation, identifying a thematic framework, coding, charting,mapping and interpretation.
• Grounded theory It begins with an analysis of a single case toformulate a theory. Later on, additional cases are examined to seeif they contribute to the theory established at the beginning.
For the project being discussed in this report, the principal dataanalysis conducted with the data collected from Telia’s forum is a Dis-course analysis [118], focusing primary on the text grammar, discerningabout well-formed sentences (according to the grammar) and non-wellformed ones, as it is shown in Figure 4.1. The rationale behind thisdecision focuses primarily on the fact that for the required data thatwill be fed to the implemented solution, it is essential to have availablequality text where the sentences are well formulated, and its grammaris correct.
Figure 4.1: Grammar analysis.
4.3 Data verification and validation
The processes of verification and validation of the quality or reliabilityof the information obtained through qualitative methods are differentfrom those obtained through quantitative methods [119]. The verifica-tion of the reliability of qualitative information is an essential elementof the design and development of the study that increases the quality ofthe information collected [120]. It is not a group of tests applied to thecollected data (unlike the statistical tests), but instead of verificationsmade before starting the data collection and monitored during the re-search [121].
Regarding the verification of qualitative data strategies, it can bedistinguished between [122]:

4.4 Software development 27
• Methodological coherence Which ensures consistency betweenthe research question and the components of the method. The de-velopment of the research is not a linear process since the qualita-tive paradigm allows flexibility to adapt the methods to the datathroughout the process of collecting them.
• Proper sampling Which consists in recovering the participantsthat best represent or have knowledge about the subject in ques-tion, thus achieving an efficient and efficient saturation of the cat-egories, as well as replication of patterns.
• Collection and analysis of concurrent information Which forma mutual interaction between what is known and what one hasto know. This dynamic and flexible interaction is requested bythe data itself, thus changing, if necessary, the preliminary designchosen by the researcher.
• Theoretical thinking The ideas coming from the data are recon-figured in new data, which give rise to new ideas that must, inturn, be contrasted with the data that is being collected.
• Development of theory Which means to move with deliberationbetween the micro perspective of the data and a macro conceptu-al/theoretical understanding.
During the development of this project, data collected has beenmonitored through the process of extracting it until the usage to guar-antee compliance with the strategies mentioned before.
4.4 Software development
The software development process [123] (or software development lifecycle) is a part of the software development which is defined as a se-quence of activities that must be followed by a team of developers togenerate or maintain a coherent set of developed software or prod-ucts. In this context, a process can be defined as a framework of workthat helps the control regarding management and engineering activi-ties. This helps establish the "who does what, when and how" and acontrol mechanism to see the evolution of the project.
The Rational Unified Process (RUP)[124] is a software developmentprocess proposed by the Rational Software company which incorpo-rates knowledge called best practices and is supported by a set of tools,such as Unified UML Modelling Language [125]. These methods of-fer modelling techniques for the different stages of the developmentprocess, including individual annotations, graphs and criteria for de-veloping quality software.

4.4 Software development 28
4.4.1. Software development stages
The most common stages of a typical software development process are[126]:
Requirements analysisThe main objective of this stage is to obtain the document speci-fying the requirements [127]. This document is known as a func-tional specification. The specification is understood as the task ofwriting in detail the software to be developed in a mathematicallyrigorous way. These specifications are agreed with stakeholders,which usually have a very abstract view of the final result, but notabout the functions that the software should fulfil. The analysisof requirements is regulated by the IEEE SA 830-1998 [128] docu-ment which contains recommended practices for the specificationof the requirements of the software.
Design and architectureThis stage determines the general functioning of the software with-out entering specific details about its technical implementation.The necessary technological implementations, such as the hard-ware and the network, are also taken into account.
ProgrammingThe complexity and duration of this stage depend on the pro-gramming languages used, as well as the previous design gen-erated.
TestsAt this stage, software developers verify that it worked as ex-pected and specified in previous stages. This is a crucial stagebecause it allows detecting errors in the operation of the softwarebefore being delivered to the end user. It is considered a goodpractice that tests are carried out by people different from soft-ware developers.
Deployment and maintenanceThe deployment consists of the delivery or implementation of thesoftware to the end user. It occurs once it has been duly testedand evaluated.
4.4.2. Software development models
Software development models are an abstract representation of the stagesdefined in the previous subsection [126]. They can be adapted andmodified according to the needs of the software during the develop-ment process.
The number of available software development methods is vast [129].Amongst others, the most common ones are:

4.4 Software development 29
Cascade modelAlso known as a traditional model, it is called "cascaded" by theposition of the development phases in it, which make the impres-sion that they fall as if they were a waterfall (down) [126]. In thiscase, the stages have a course strictly, that is, until a phase has notfinished, it does not "go down" to the next. Reviews can be donebefore beginning the next phase, which opens up the possibilityof changes, as well as ensuring that the phase has been executedcorrectly.
Prototype modelThe software prototype model consists in the construction of ap-plications (incomplete prototypes) that show the functionality ofthe product while it is in development, given that the final resultmay not follow the logic of the original software [126]. It enablesthe stakeholders to know the software requirements in the earlystages of the development process. It also helps developers un-derstand that the product is expected to be in the developmentphase.
Incremental development modelThe incremental development model consists of increasing thecontent of the phase-by-stage model (design, implementation andtesting phase) constantly until the software is finished. It includesboth the development of the product and its subsequent mainte-nance. The main advantages are that after each iteration a reviewcan be made to verify that everything has been corrected and theerrors that may have been found can be changed [126]. In thiscase, the stakeholders can respond to the changes and constantlyanalyse the product for possible changes.
Iterative and incremental development modelThe model obtained by combining the iterative model with theincremental development model [126]. The relationship betweenthem is determined by the methodology of development and theprocess of building the software. It facilitates the process of de-tecting important errors and problems before they are manifestand can cause a disaster.
Spiral modelThe activities of this model are formed in a spiral, in which eachloop or iteration represents a set of activities. These activities areselected according to the risk factor they represent, starting withthe previous loop [126]. It combines key aspects of the cascademodel and the fast application model to try to take advantage ofboth models.
Rapid application developmentThe Rapid Application Development (RAD) model combines the

4.4 Software development 30
iterative development with the rapid construction of prototypesinstead of long-term planning [126]. The lack of this planningusually allows the software to be written much faster and makesthe change of requirements easier. The rapid development pro-cess begins with the development of preliminary data modelsand the use of structured techniques for processing models. Inthe next phase, the requirements are verified through prototypes.These phases are repeated iteratively.
Agile development modelIt is a group of software development methodologies based on theiterative development, where requirements and solutions evolvethrough collaborations between organised teams [126]. Iterativedevelopment is used as a basis to advocate a lighter point of viewand centred on people than in the case of traditional solutions.Agile processes use feedback instead of planning as the main con-trol mechanism. This feedback is channelled through periodictests and various versions of the software.
In the case of this thesis, the software development methodologyused is based on the Agile development model [130], based on the iter-ative development, where requirements and solutions evolve throughcollaborations between organised teams. Iterative development is usedas a basis to advocate a lighter point of view and centred on peoplethan in the case of traditional solutions. Agile processes use feedbackinstead of planning as the central control mechanism. This feedback ischannelled through periodic tests and numerous versions of the soft-ware.

CHAPTER 5
The NLP Pipeline
This chapter presents a description of the solution proposed and thesystem implemented. It also provides a comprehensive explanation ofthe decisions taken concerning the design, technologies, strategies andapproaches used to develop the system.
Chapter’s design section proposes a layout strategy to take up theproblem stated at the introduction of this document. Further sectionswithin this chapter will exhibit the actual implementation, referencingframeworks, tools and technologies used in each part of the system.
To clarify, provide context and exemplify each part of the imple-mented pipeline, through this chapter a sentence will be utilised as anexample input data and to explain how it will traverse each of the steps,ending up building the actual knowledge graph. This mentioned sen-tence is När den inkluderade surfmängden i ditt abonnemang är slut kan dufylla på med mer för att fortsätta att surfa på MittTelia and its translation toEnglish: "When the included amount of surfing in your subscription isover, you can fill in more to continue browsing at MittTelia".
5.1 Design
The underlying idea behind the goal of this project is to produce simpleknowledge graphs that represent the information enclosed in any givenwell-formed (conforms to the grammar of the language of which it is apart) phrase or batch of text in the Swedish language. Since this goalis broad, during this design phase, it will be narrowed to smaller andsimpler tasks or processes.
Figure 5.1: Main tasks identified.
31

5.1 Design 32
After studying the problem statement, three main tasks have beenidentified. As the Figure 5.1 shows, those tasks are:
• Generate information triples: Extract the basic information unitsfrom a given text in the format of (e1, r, e2) triples, where e1,e2are entities or concepts and r is the relation that links those twoconcepts.
• Integrate information triples: Once the triples are generated, in-tegrate them so all the important information within the inputtext data is gathered.
• Construct knowledge graph: Finally, construct the knowledgegraph representing the information contained in any given text.
In order to represent this idea, given an example sentence Telia, etttelekomföretag, är verksamt i Sverige the next two Figures show how theextraction of triples is made.
Figure 5.2: Sample triple extracted.
Figure 5.3: Sample triple extracted.
As shown in Figures 5.2 and 5.3 the phrase: Telia, ett telekomföretag,är verksamt i Sverige. has been transformed into a triple that representspart of the information being disclosed in the utterance.
Following the task flow described above, the Figure 5.4 will repre-sent the final knowledge graph extracted from the given sentence.
As described along this section, the proposed solution needs to solvethe three main tasks proposed. To do so, specific tools, technologies andframeworks are to be used and integrated to produce the required out-put. The next sections will explain, in more detail, how the main tasksdefined are implemented.

5.2 Generating information triples 33
Figure 5.4: Constructed knowledge graph.
(e1, r, e2)
Figure 5.5: Format of the triples.
5.2 Generating information triples
The first task is to generate information triples with presented in Figure5.5 . Those triples represent fundamental information in the given inputtext data. Those triples are composed of two entities (concept, idea oraction) and one relation (that establishes the primary relationship).
The task of generating those triples is not trivial and requires differ-ent sub-tasks to accomplish its purpose. The following subsections de-scribe the process followed to transform a chunk of text into a straightinformation triple.
5.2.1. Text preprocessing
The primary source of input data for this project is human-generatedtext from different sources such as manuals, social networks, internaldatabases and forums. Therefore it is expected that the data wouldrequire to go into a cleaning process to make it suitable for further pro-cessing.
According to the Cross-Industry Standard Process for Data Mining[131], preprocessing and data cleansing are essential tasks that gener-ally must be carried out so that the data can be used effectively for taskssuch as Machine Learning. Raw data (such as the one extracted fromthe sources stated above) is often noisy and unreliable, so the use of thisdata for modelling can produce misleading results. These tasks typi-cally follow an initial exploration of the data that is going to be used todetect and plan the necessary preprocessing.

5.2 Generating information triples 34
Figure 5.6: Classification of data quality problems [132].
Preprocessing and cleaning tasks can be performed in a wide vari-ety of environments and with various tools and languages, such as R[133] or Python [77], depending on where the data is stored and how itis formatted. This section presents several concepts of data processingand tasks that will be carried out before entering data in the system.
Text cleaning
The first step is cleaning the text of unwanted and unnecessary char-acters or words. This includes: escaping HTML characters, removingpunctuation signs, URLs, unrecognised characters for the given lan-guage and emojis or other types of unwanted encoded text.
To perform the mentioned text cleaning tasks, the Python [134] li-brary NLTK (Natural Language Toolkit) [75] will be used. This tool isespecially interesting since include functions such as:
• Text tokenisation
• Punctuation removal
• Case normaliser
• Stop words filtering
• Word stemming
• Text cleaning using regular expressions
The decision regarding which of this functions are going to be usedwill depend on a previous observation and analysis of the data gath-ered. Hence, not all the functions are always required.

5.2 Generating information triples 35
Word and sentence tokenisation
Once the data, in this context: text, has been cleaned, the next step is totokenise it. Grefensette et al. quoted: "Any linguistic treatment of freelyoccurring text must provide an answer to what is considered a token." [135]Which proves the importance of having a tool or method capable ofsplitting text into sentences and tokens in a meaningful way.
Figure 5.7: Text transformations before linguistic analysis [135].
For this project scope, a token can be understood in two differentways or levels:
• Each of the words that compose a sentence.
• Each of the sentences that compose a chunk of text.
This step will specially focus on the second level of tokenisation,which is meant to recognise sentence boundaries since it is the unit ofthe system being implemented consider as the unit of treatment. Butnot to be forgotten that word level tokenisation is also needed for fur-ther processing steps that will be described later.
The tool chosen to perform this task is the Syntaxnet [136] projectinside TensorFlow [81] framework for large-scale machine learning cre-ated by Google. Syntaxnet provides a specific Machine Learning modelfor word and sentence tokenisation that has been trained specially forthe Swedish language1.
The output of this step is a collection of adjacency graphs that rep-resent each of the detected sentences. Those graphs are composed oflinked work tokens that follow a relationship described by the wordnext. This simple relationship indicates which word follows each otherin a given sentence, as the Figure 5.8 shows. The reason behind keepingthe word order is to conduct metrics and statistics around word order,but lacks interest within the goal of this project, since that is part of thefuture work.
1Syntaxnet Swedish model: https://github.com/tensorflow/models

5.2 Generating information triples 36
Figure 5.8: Text adjacency graph example.
5.2.2. Part-Of-Speech tagging
As introduced before, part-of-speech tagging is the process of classi-fying words into their parts of speech and labelling them accordingly.The Syntaxnet framework also offers a Swedish part-of-speech taggerthat uses the Universal Dependencies, introduced previously on thisdocument, to perform a grammar labelling for Swedish text. As we cansee in the Figure 5.1 the accuracy of this tagger (in average) is above90% which means that for most of the times the POS label representinga given word is the correct one.
Language # of tokens POS fPOSSwedish 20377 96.27% 94.13%
Table 5.1: Syntaxnet Swedish language accuracy.
The part-of-speech tagging step is crucial in the Natural LanguageProcessing pipeline since the output of this task will provide grammat-ical meaning to a given sentence. The input of this step will be theoutput of the previous one.
The Figure 5.9 shows an example of the output produced by thetagger environment for the example sentence.
This output represents a table containing (ordered from left to right)[53]:

5.2 Generating information triples 37
Figure 5.9: Part-of-speech tagging output.
1. ID: Word index, integer starting at 1 for each new sentence; maybe a range for tokens with multiple words.
2. FORM: Word form or punctuation symbol.
3. LEMMA: Lemma or stem of word form.
4. UPOSTAG: Universal part-of-speech tag drawn from our revisedversion of the Google universal POS tags [55].
5. XPOSTAG: Language-specific part-of-speech tag; underscore ifnot available.
6. FEATS: List of morphological features from the universal featureinventory or from a defined language-specific extension; under-score if not available.
7. HEAD: Head of the current token, which is either a value of IDor zero (0).
8. DEPREL: Universal Stanford dependency relation to the HEAD(root iff HEAD = 0) or a defined language-specific subtype of one.
9. DEPS: List of secondary dependencies (head-deprel pairs).
10. MISC: Any other annotation.
5.2.3. Syntactic dependency parsing
Syntactic dependency parse is the task that provides the syntactic struc-ture of a sentence concerning relations between words. As an example,a verb will be linked to its dependents: arguments and modifiers. These
5.2 Generating information triples 38
relations form a tree-like directed acyclic graph representing the wholesyntactic analysis of a sentence. Dependency parsing is also a crucialtask in the process of building the knowledge graph. Understandinghow actions (e.g. verbs) relate to their arguments and modifiers gives aclue on where the information, within a sentence, may be located.
Universal Dependencies [53] lists 37 universal syntactic relation rep-resented in Table 5.2. This is a revised version of the relations describedin the Universal Stanford Dependencies: A cross-linguistic typology(de Marneffe et al. 2014).
Nominals Clauses Modifier words Function Words
Core argumentsnsubjobjiobj
csubjccompxcomp
Non-core dependents
oblvocativeexpldislocated
advcladvmoddiscourse
auxcopmark
Nominal dependentsnmodapposnummod
acl amoddetclfcase
Table 5.2: Main universal syntactic dependency relations [53].
The table is divided into two parts: the upper part follows the pri-mary organising principles of the taxonomy: rows represent relationsto the head (the root of the tree), and columns represent basic categoriesof the dependent.
Coordination MWE Loose Special Other
conjcc
fixedflatcompound
listparataxis
orphangoeswithreparandum
punctrootdep
Table 5.3: Auxiliary universal syntactic dependency relations [53].
For this task, the previously introduced tool: Syntaxnet, will pro-duce the tree representing the dependencies as can be seen in Figure5.10 (A excerpt of the graph that can be fully seen in Appendix A. Also,Figure 5.11 represents more clearly the relations established. Graph’srow direction has been inverted for clarity.
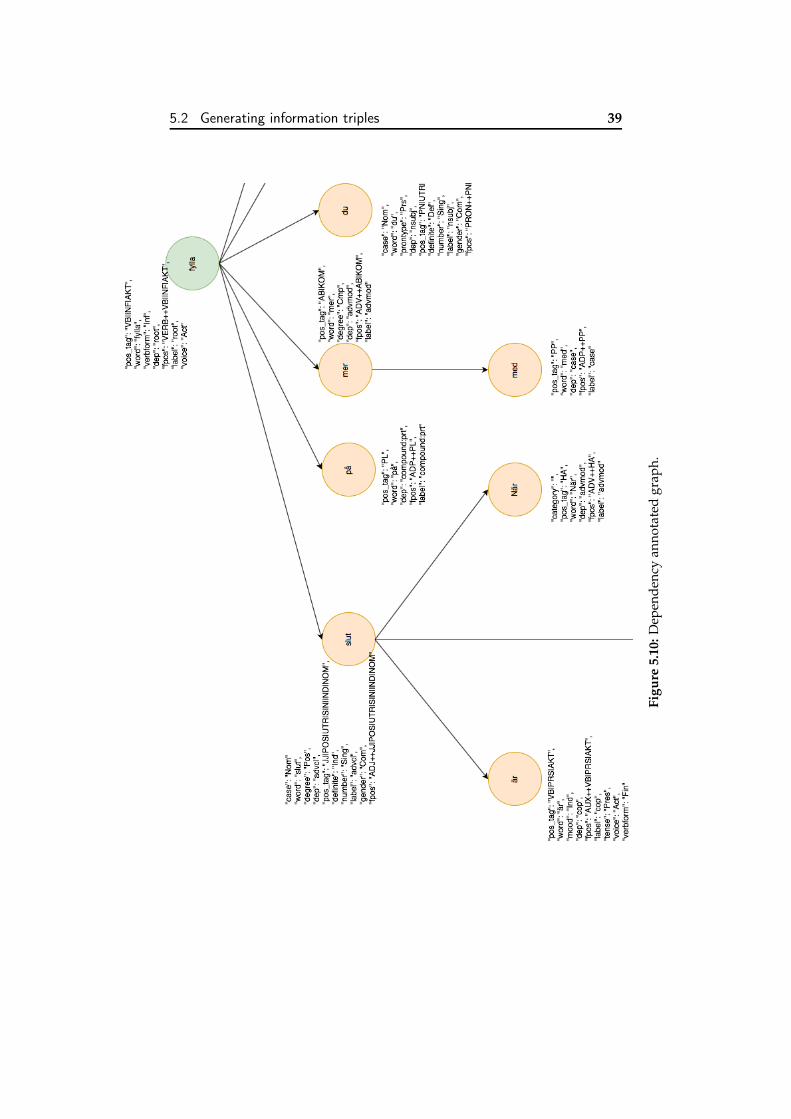
5.2 Generating information triples 39
Figu
re5.
10:D
epen
denc
yan
nota
ted
grap
h.
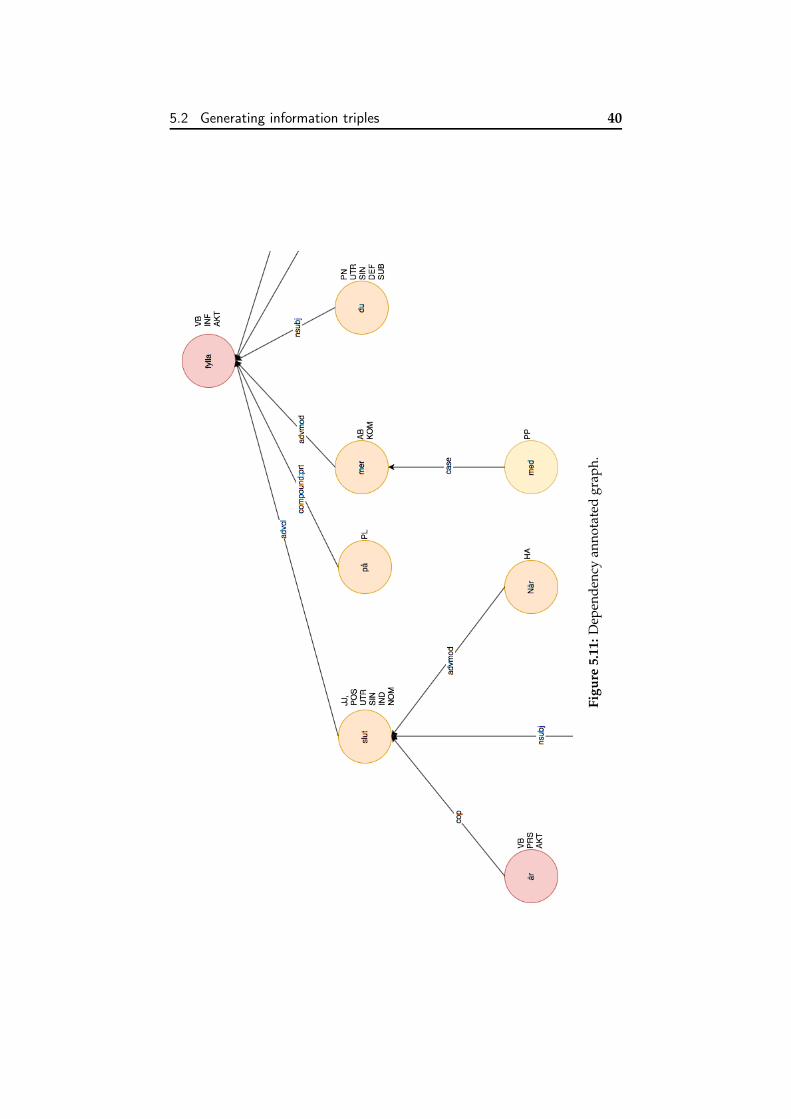
5.2 Generating information triples 40
Figu
re5.
11:D
epen
denc
yan
nota
ted
grap
h.

5.2 Generating information triples 41
5.2.4. Named entity recognition
The task of extracting keywords in a given sentence is called NamedEntity Recognition. It is a sub-task for identifying names, places, prod-ucts, locations, organisations and so on. This task is also crucial since,after it, the pipeline produces a more specific graph that represents onlythose parts of the text that are of interest for extracting information and,later on, generating the knowledge graph.
Implementing a Named Entity Recognition system can be seen asa Machine Learning classification problem. To help with that, the firsttool used to implement this classifier is the Stanford CoreNLP NamedEntity Recogniser [74], which implements a Conditional Random FieldClassifier [137][138], which is a stochastic model commonly used to la-bel and segment data sequences or extracting information from textdata.
One of the challenges of this type of Machine Learning classifiers isthe amount of data they need for training. In order to generate enoughlabeled data, Prodigy2 [76] (an interactive tool for labelling text data forMachine Learning) is used. The Figure 5.12 shows part of the interfacefor training data for the Named Entity Recognition model.
Figure 5.12: Train data labelling using Prodigy.
Figures A.3 (a excerpt of the full graph available in Appendix A)and 5.14 shows the output of this step, where the previous graph hasbeen completed with all the identified named entities.
2Prodigy: https://prodi.gy
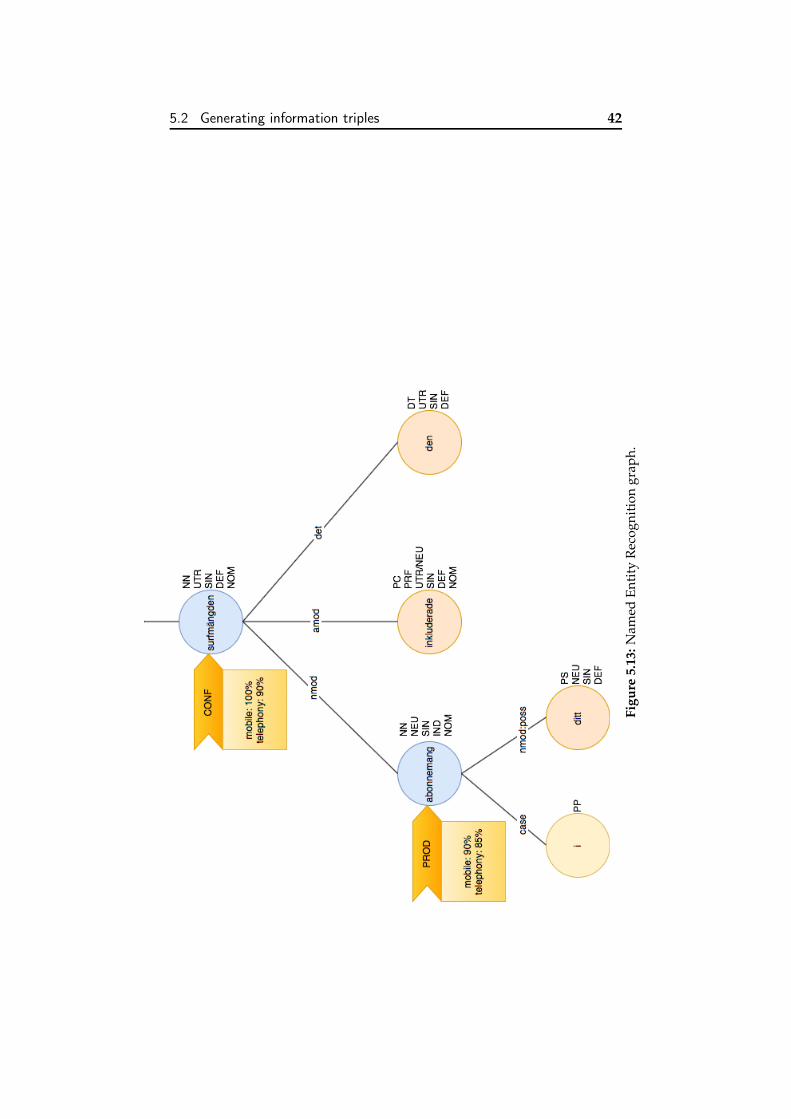
5.2 Generating information triples 42
Figu
re5.
13:N
amed
Enti
tyR
ecog
niti
ongr
aph.

5.3 Integrating information triples 43
To evaluate the accuracy of the proposed Named Entity Recognitionmodel, several measures have been defined. Token-level accuracy isone of the available measures, but it has two problems: most tokens inhuman-generated texts are not part of named entities, which means theprobability of a system to classify "not an entity" is very high, usuallygreater than 90%; and an error in the delimitation of a named entity isnot adequately penalised. For example, detecting only the first nameof the person when his last name is after that it is scored with half theaccuracy.
In academic conferences such as CoNLL[43], a variant of the F-valuehas been defined as follows:
• Accuracy is the number of named entities that exactly match theevaluation set.
• Recall is the number of entities in the evaluation set that appearexactly in the same position in the predictions.
• F-Value is the harmonic mean of the Accuracy and the Recall. Itfollows from the above definition that any prediction that misiden-tifies a token as part of a named entity or stops detecting a tokenthat is a named entity or misclassifies it will not contribute to ac-curacy nor recovery.
5.2.5. Relation extraction
The final task related to generating information triples is the relationextraction. It consists of finding relations between words in the givensentence. To do so, Stanford CoreNLP provides a Machine Learningalgorithm for extracting relations, based on global inference via lin-ear programming formulation [139]. The relations extractor has beentrained with custom data representing the most common relationshipsof the domain being studied in this project.
Figure 5.15 shows one of the triples extracted. It represents a basicunit of knowledge present in the given sentence.
5.3 Integrating information triples
Once the triples have been generated, they need to be integrated to,later on, build the final knowledge graph. This process involves theStanford Pattern-based Information Extraction and Diagnostics [140]which provides a method for learning entities from an unlabelled textand provides a metric for scoring patterns. This algorithm uses man-ually defined patterns to extract information that later can be used tointegrate the information triples.
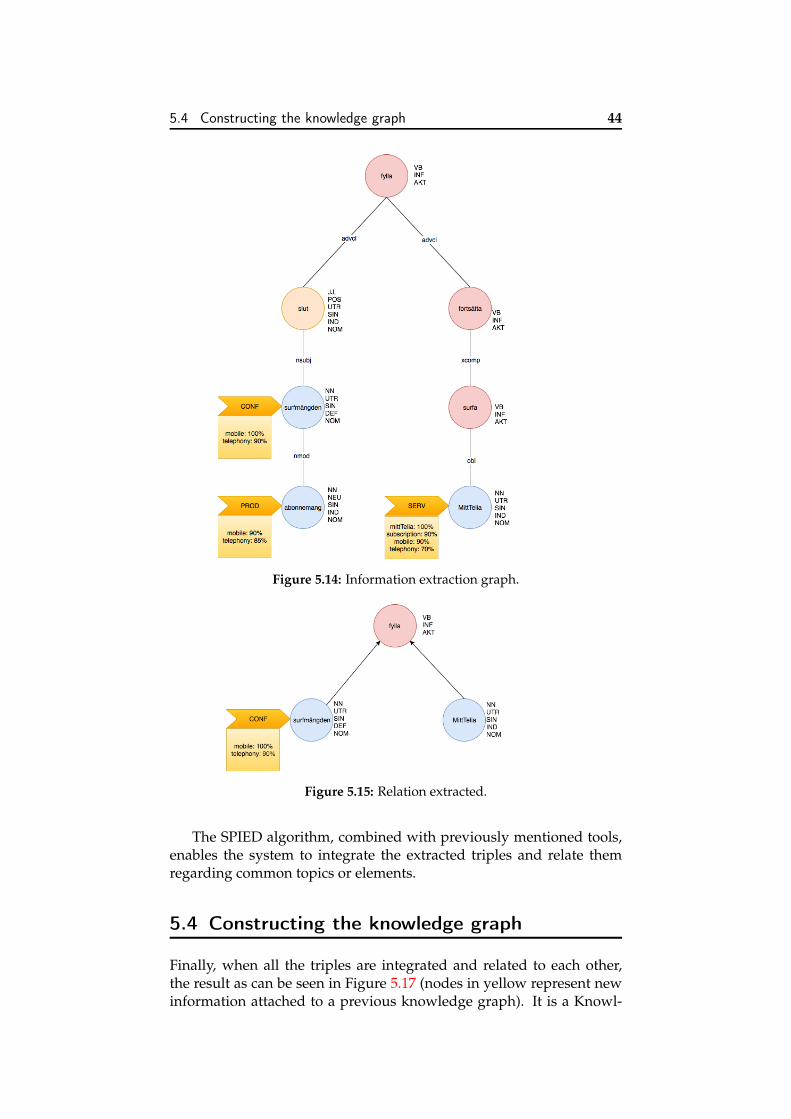
5.4 Constructing the knowledge graph 44
Figure 5.14: Information extraction graph.
Figure 5.15: Relation extracted.
The SPIED algorithm, combined with previously mentioned tools,enables the system to integrate the extracted triples and relate themregarding common topics or elements.
5.4 Constructing the knowledge graph
Finally, when all the triples are integrated and related to each other,the result as can be seen in Figure 5.17 (nodes in yellow represent newinformation attached to a previous knowledge graph). It is a Knowl-

5.4 Constructing the knowledge graph 45
Figure 5.16: SPIED algorithm [140].
edge Graph that integrates all the extracted concepts not only from thesentence given as an example but also from other text sources. Thisgraph is structured in a way that provides a global overview of con-cepts, terms and relations that represents information about a specificdomain.
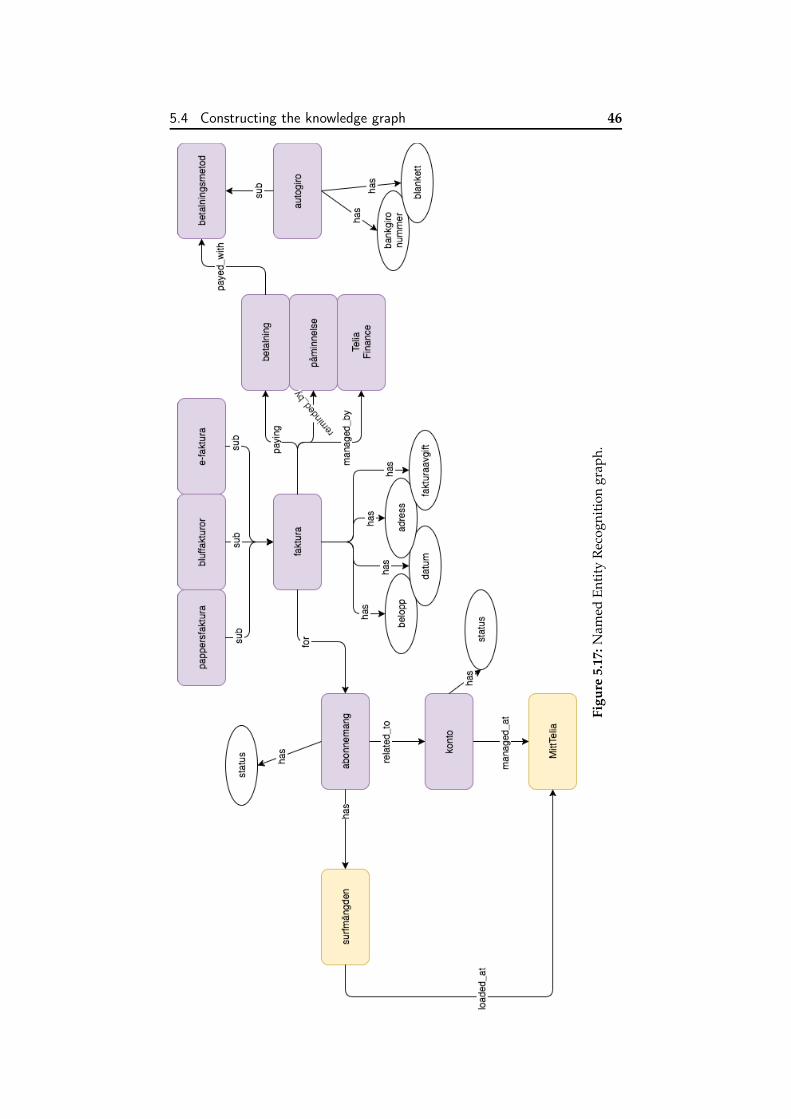
5.4 Constructing the knowledge graph 46
Figu
re5.
17:N
amed
Enti
tyR
ecog
niti
ongr
aph.

CHAPTER 6
Evaluation
This chapter presents the evaluation of the implemented solution, in-cluding a description of the techniques used for such evaluation andthe results obtained.
The technique used for evaluating the system consists of an assess-ment of the correctness of the knowledge graph generated. To do so,fifty text documents extracted from the Telia’s support forum1 wereprepared to be processed by the pipeline. This preparation consisted inmanually extract all the knowledge and information considered repre-sentative of those texts and manually build example knowledge graphs.
After the preparation, the same texts were processed using the de-veloped pipeline. The output knowledge graphs were stored togetherwith the manual generated ones to be evaluated regarding entities ex-tracted and relationships generated.
The primary metrics chosen for evaluating the effectiveness of thepipeline are the Precision and Recall. They measure the extent to whichthe system produces the appropriate output (recall) and only the appro-priate output (precision), in other words, completeness and correctness.
Precision =correct
correct + incorrect(6.1)
In this case, correct are the number of correctly identified and ex-tracted relations and incorrect the number of errors produced.
Recall =correcttotal
(6.2)
In case of the Recall, total expresses the number of expected relationsand entities to be represented in the knowledge graph generated.
To obtain a more fine-grained measure of the performance of thesystem, the f-measure is used as a weighted harmonic mean of preci-sion and recall.
1https://forum.telia.se
47

48
Fmeasure =(β2 + 1 ∗ precision ∗ recall)
(β2 + 1) + recall(6.3)
In this case, beta is a non-negative value that adjusts the relativeweighting for recall and precision.
The results obtained in the evaluation of the system obtained a pre-cision and recall values of 0.88 and 0.90 respectively, with an f-measureof 0.88.
These metrics represent the correctness of the Knowledge Graphgenerated by the automatic pipeline presented in this document. Tocalculate them, the process followed use two different versions of thesame Knowledge Graph: one which is the actual graph generated bythe pipeline and another which is generated manually by humans per-forming the tasks of knowledge extraction and representation.
Figure 6.1: Pipeline generated graph.
Figure 6.2: Manually generated graph.
Once the two graphs are in place, they are compared between eachother regarding the two elements they represent: nodes and links. Theso-called Golden Standard in this calculation is the manually generatedgraph, which is considered, to all extent, correct. For each of the el-ements (nodes and links) being compared, if there is an inconsistencybetween both graphs, it is considered an error (incorrect) and will affectthe precision and recall as described in the formulas previously on thischapter.
To exemplify this, Figure 6.1 represent a sample graph that let’s sup-pose was generated by the pipeline. On the other hand, Figure 6.2 rep-resent the manually generated one. As we can see, there is an error onthe graph comparison, since the manually generated graph includes alink between two nodes that is not present in the pipeline graph.

CHAPTER 7
Conclusions and FutureWork
7.1 Conclusion
The primary goal of this thesis is to implement a system capable of, us-ing human-generated text in Swedish, extract the essential informationfrom it and build and maintain a Knowledge Base with all of the data,not only provided by the input text but by further input that the systemwill eventually receive.
Current developments in the field of Knowledge Representationhad proved to be very valuable not only to the field of Artificial Intel-ligence, but also other related fields that demand a massive amount ofinformation in a format that can produce valuable information throughreasoning using the information stored. Unfortunately, creating andmaintaining Knowledge Bases using classical approaches is a time con-suming task that prevents its further development and penetration intoreal use cases.
Automating the task of creating and maintaining those KnowledgeBases is one of the current challenges not only in the field of Knowl-edge Representation but also automatic reasoning. Being able to havea system capable of generating a Knowledge Base that is self-sufficientconcerning adding new information to it, is one of the most compellingwork areas that the mentioned field has.
Machine Learning has proven its capability of solving complex prob-lems that humans never believed a computer could solve before. Imagerecognition or language understanding are just examples of what thistechnology is capable of. Because of that, Machine Learning is a frame-work worth testing for trying to narrow the current gap of automati-sation that Knowledge Representation is having. Because of that, thisthesis focuses on testing Machine Learning algorithms as a tool for solv-ing the problem stated, as the research question identified states: Howcan ML algorithms for NLP and Graph Databases be integrated and applied
49

7.2 Discussion 50
to build a Knowledge Graph using domain-specific human-generated Swedishtext?
As a result of this problem description, a Machine Learning (ormore specifically, a Natural Language Processing) pipeline is imple-mented to test the capabilities of this sort of techniques that MachineLearning provides. This pipeline consumes raw text data and, usingdifferent transformation steps, extracts valuable information from thattext in the format of triples that represents knowledge. Once thoseknowledge triples are generated, they are combined in a KnowledgeBase that represents information about a domain.
After all, the results of the implemented pipeline show that indeedMachine Learning can be used as a way of automating the task of cre-ating and maintaining Knowledge Bases.
7.2 Discussion
The present project concludes reaching the goal of implementing a sys-tem capable of building knowledge bases in the format of knowledgegraphs using an NLP pipeline that integrates state-of-the-art algorithmsand methods for extracting information enclosed in Swedish human-generated text. The research conducted, the literature review and theapproach used proves the feasibility of this kind of systems for automa-tise the task of constructing and maintaining structures for knowledgerepresentation.
Now, to close the learning cycle started with the development ofthis work, and with the aim of highlighting the lessons learned, it is nec-essary to finish this report with a critical reflection on the work done.
Natural language is the mean we use on a daily basis to establishour communication with other people. The richness of its semanticcomponents gives natural languages their great expressive power andtheir value as a tool for subtle reasoning. However, this valuable char-acteristics of natural language are challenges for the field of NaturalLanguage Processing, that is, natural language has properties that re-duce the effectiveness of textual information retrieval systems:
• They are developed by progressive enrichment before any attemptto form a theory.
• The linguistic variation creates the possibility of using differentwords or expressions to communicate the same idea.
• The linguistic ambiguity makes possible to have more than oneinterpretation for the same piece of text.

7.2 Discussion 51
The last two properties affect the information retrieval process differ-ently. Linguistic variation causes information silence, that is, the omis-sion of relevant information to cover the need for knowledge since thesame terms that appear in the document have not been used. On theother hand, ambiguity implies documentary noise, that is, the inclu-sion of information that is not significant, since information that usesthe term but with a different meaning are also recovered. These twocharacteristics make the automated processing of the language a majorchallenge yet to be solved.
In general, the field of NLP, and more specifically Knowledge Ex-traction, is still evolving and it is essential to take into account that itdid not reach the plateau yet. This means that improvements are to beexpected shortly; thus better approaches for solving this problem willundoubtedly appear and may invalidate partially the work done so far.As an example, most of the current projects related to KE are limited tothe extraction of binary relations, in the boundary of a sentence. Thisdoes not allow to derivate more complex structures [66] [141] whichcan represent information with higher fidelity, which would ease theprocess being described in this thesis.
Moreover, it is important to mention that the only way to get a realreasoning system based on information and knowledge, is to enable itto store ideas in its "memory" so that it can manipulate them and usethem when needed. However, what is sought is the ability of machinesto represent ideas.
Currently, the main Machine Learning techniques are teaching com-puters to represent languages and simulate reasoning (not to reason).A "model of ideas" that is independent of language is needed. The in-terface with that model would be a kind of translator between its lan-guage and the machine ideas model language. However, very little isbeing accomplished in this area. One option is to build a new model ofthinking for computers manually. This would require a massive collab-oration among computer scientists, linguists, neuroscientists, philoso-phers, mathematicians and others.
Still, it seems that it is a problem that needs to be tackled eventu-ally. Once a model of ideas is available, instead of a language, a realreasoning system may be created. Not only will it learn associationsbetween words like a chatbot, but it will be able to draw conclusionsafter combining ideas. It will take much work to achieve this level ofgeneralised reasoning, but what it is the truth is that continuous workon Knowledge Bases and Knowledge Representation is needed to getclose to that idea.

7.3 Future work 52
7.3 Future work
The perspective of the developed solution, already implemented, isquite encouraging, and can be extended to other fields or use cases,as well as other entities that would like to use this technology. How-ever, in order to improve and expand the work done, several lines ofwork are proposed for the future:
Enriching the Knowledge Graph using external sourcesUsing external data sources such as DBpedia[142], the knowledgegraph can be filled with even more facts and interesting informa-tion.
Accuracy improvementDue to time limitations, accuracy was not one of the main focuspoints to implement this solution. That is why one of the most im-portant future work tasks is to try different algorithms and con-figurations to improve accuracy.
ScalingAnother interesting area for future work is to measure how wellthe knowledge graph can scale when it contains a vast amount offacts and relationships.

Bibliography
[1] Robert Glenn Friedman. Aristotle: The Desire to Understand (re-view). Journal of the History of Philosophy, 29(2):301–302, 1991.
[2] Victor Caston. Aristotle’s Psychology. In A Companion to AncientPhilosophy, pages 316–346. 2012.
[3] Robert Schwartz. Aristotle, "On the Soul.", 2004.
[4] F.D. Miller Jr. and R. Porreco. Aristotle on practical knowledgeand moral weakness. pages 131–144, 1984.
[5] Humberto R. Maturana and J. Varela, Francisco. The Tree of Kn-woledge: The Biological Roots of Human Understanding. New ScienceLibrary/Shambhala Publications, 1987.
[6] G W Leibniz and P Remnant. New essays on human understanding.Cambridge University Press, 1996.
[7] Paulina Sliwa. IV - Understanding and knowing. In Proceedingsof the Aristotelean Society, volume 115, pages 57–74, 2015.
[8] Stuart J Russell and Peter Norvig. Artificial Intelligence: A ModernApproach. Pearson Education, 2 edition, 2003.
[9] Peter Stone, Rodney Brooks, Erik Brynjolfsson, Ryan Calo, OrenEtzioni, Greg Hager, Julia Hirschberg, Shivaram Kalyanakrish-nan, Ece Kamar, Sarit Kraus, Kevin Leyton-Brown, David Parkes,William Press, AnnaLee Saxenian, Julie Shah, Milind Tambe andAstro Teller. Artificial Intelligence and Life in 2030. One HundredYear Study on Artificial Intelligence: Report of the 2015-2016 StudyPanel, page 52, 2016.
[10] Ronald Brachman and Hector Levesque. Knowledge Representa-tion and Reasoning. 2004.
[11] Nicola Guarino and Pierdaniele Giaretta. Ontologies and Knowl-edge Bases: Towards a Terminological Clarification. Towards VeryLarge Knowledge Bases. Knowledge Building and Knowledge Sharing,1995.
53

BIBLIOGRAPHY 54
[12] Rajendra Akerkar and Priti Sajja. Knowledge-Based Systems.Knowledge-Based Systems, 2010.
[13] Mohd Syazwan Abdullah, Chris Kimble, Ian Benest, and RichardPaige. Knowledge-based systems: A re-evaluation, 2006.
[14] Ryszard S Michalski, Jaime G Carbonell, and Tom M Mitchell.Machine learning: An artificial intelligence approach. Springer Sci-ence & Business Media, 2013.
[15] Xuedong Huang, Alejandro Acero, Alex Acero, and Hsiao-WuenHon. Spoken language processing: a guide to theory, algorithm, andsystem development, volume 1. Prentice hall PTR Upper SaddleRiver, 2001.
[16] Alvaro L Fraga, Marcela Vegetti, and Horacio Leone. Semi-Automated Ontology Generation Process from Industrial Prod-uct Data Standards. In 46o Jornadas Argentinas de Informática, 2017.
[17] David W. Embley, Douglas M. Campbell, Randy D. Smith, andStephen W. Liddle. Ontology-based extraction and structuring ofinformation from data-rich unstructured documents. In Proceed-ings of the seventh international conference on Information and knowl-edge management - CIKM ’98, pages 52–59, 1998.
[18] Hadeel Al-Zubaide and Ayman A. Issa. OntBot: Ontology basedChatBot. In 2011 4th International Symposium on Innovation in In-formation and Communication Technology, ISIICT’2011, 2011.
[19] J Cowie and W Lehnert. Information extraction. Communicationsof the ACM, 39(1):80–91, 1996.
[20] Open Working Group, Sustainable Development Goals,Open Working Group, Sustainable Development Goals, Devel-opment Goals, and Sustainable Development Goals. SustainableDevelopment Goals and targets. United Nations, 2015.
[21] Anne Håkansson. Portal of Research Methods and Methodolo-gies for Research Projects and Degree Projects. Proceedings of theInternational Conference on Frontiers in Education: Computer Scienceand Computer Engineering FECS’13, pages 67–73, 2013.
[22] C.R. Kothari. Research Methodology: An introduction, volume IX.Juta and Company Ltd, 2012.
[23] C. F. Hockett. A Course in Modern Linguistics. Language Learn-ing, 8(3-4):73–75, 1958.
[24] G. Leitner. Swedish as a pluricentric language. Pluricentric lan-guages: Differing norms in differing nations, pages 179–237, 1992.
[25] Anatoly Liberman. The Nordic Languages, 2005.

BIBLIOGRAPHY 55
[26] Einar Ingvald Haugen. Scandinavian language structures: a com-parative historical survey, volume 5. M. Niemeyer, 1982.
[27] Gösta Bruce and Eva Gårding. A prosodic typology for Swedishdialects. Working Papers in Linguistics, 17(1), 1978.
[28] Tommaso M Milani. Voices of endangerment: A language ideo-logical debate on the Swedish language. Discourses of endanger-ment: Ideology and interest in the defence of languages, pages 169–196, 2007.
[29] Katrin. Hiietam. Swedish: A comprehensive grammar (review), vol-ume 83. Routledge, 2007.
[30] Immanuel Björkhagen. Modern Swedish Grammar. Svenska Bok-förlaget, Norstedts, 1962.
[31] Joakim Nivre, Jens Nilsson, and Johan Hall. Talbanken05: ASwedish treebank with phrase structure and dependency anno-tation. In Proc. of the 5th International Conference on Language Re-sources and Evaluation (LREC-2006), volume 6, pages 1392–1395,2006.
[32] Shai Shalev-Shwartz and Shai Ben-David. Understanding Ma-chine Learning. In ACM Computing Surveys. Cambridge Univer-sity Press, 2014.
[33] Tom Dietterich. Machine learning. In ACM Computing Surveys,volume 28, pages 3–es, 1996.
[34] Kevin P. Murphy. Machine Learning. In SpringerReference, 1991.
[35] Yuhong Yang. Information Theory, Inference, and Learning Al-gorithms. In Journal of the American Statistical Association, volume100, pages 1461–1462, 2005.
[36] Rich Caruana and Alexandru Niculescu-Mizil. An empiricalcomparison of supervised learning algorithms. In Proceedingsof the 23rd international conference on Machine learning - ICML ’06,pages 161–168, 2006.
[37] H B Barlow. Unsupervised Learning. Neural computation, 1989.
[38] Erkki Oja. Unsupervised learning in neural computation. Theo-retical Computer Science, 287(1):187–207, 2002.
[39] R. Collobert, J. Weston, L. Bottou, M. Karlen, K. Kavukcuoglu,and P. Kuksa. Natural Language Processing (Almost) fromScratch. Journal of Machine Learning Research, 2011.
[40] A A Sattikar and R V Kulkarni. Natural language processingfor content analysis in social networking. International Journal ofEngineering Inventions, 1(4):6–9, 2012.

BIBLIOGRAPHY 56
[41] Vitaly Klyuev and Vladimir Oleshchuk. Semantic retrieval: anapproach to representing, searching and summarising text docu-ments. International Journal of Information Technology, Communica-tions and Convergence, 1(2):221, 2011.
[42] Mariana Neves. Example-Based Machine Translation. Machinetranslation, 14(2):113–157, 2017.
[43] Erik F. Tjong Kim Sang and Fien De Meulder. Introduction to theCoNLL-2003 Shared Task: Language-Independent Named EntityRecognition. In Proceedings of the seventh conference on Natural lan-guage learning at HLT-NAACL 2003-Volume 4, pages 142–147. As-sociation for Computational Linguistics, 2003.
[44] Cory B. Giles and Jonathan D. Wren. Large-scale directional re-lationship extraction and resolution. In BMC Bioinformatics, vol-ume 9, page S11. BioMed Central, 2008.
[45] Lei Zhang and Bing Liu. Sentiment Analysis and Opinion Min-ing. Encyclopedia of Machine Learning and Data Mining, 5(1):1–10,2016.
[46] Jinyu Li, Li Deng, Reinhold Haeb-Umbach, and Yifan Gong. Fun-damentals of speech recognition, volume 14. PTR Prentice Hall En-glewood Cliffs, 2016.
[47] Rodrigo Agerri, Xabier Artola, Zuhaitz Beloki, German Rigau,and Aitor Soroa. Big data for Natural Language Processing: Astreaming approach. Knowledge-Based Systems, 79:36–42, 2015.
[48] Bryan Jurish. Word and Sentence Tokenization with HiddenMarkov Models. Journal for Language Technology and Computa-tional Linguistics, 2013.
[49] J. R. Méndez, E. L. Iglesias, F. Fdez-Riverola, F. Díaz, and J. M.Corchado. Tokenising, Stemming and Stopword Removal onAnti-spam Filtering Domain. In Conference of the Spanish Asso-ciation for Artificial Intelligence, pages 449–458. Springer, 2006.
[50] Atro Voutilainen. Part-of-speech tagging. The Oxford handbook ofcomputational linguistics, pages 219–232, 2003.
[51] R. D. Levine and W. D. Meurers. Head-Driven Phrase StructureGrammar. Number 17. University of Chicago Press, 2006.
[52] Daniel Zeman, Martin Popel, Milan Straka, Jan Hajic, JoakimNivre, Filip Ginter, Juhani Luotolahti, Sampo Pyysalo, SlavPetrov, Martin Potthast, and Others. CoNLL 2017 shared task:multilingual parsing from raw text to universal dependencies.Proceedings of the CoNLL 2017 Shared Task: Multilingual Parsingfrom Raw Text to Universal Dependencies, pages 1–19, 2017.

BIBLIOGRAPHY 57
[53] Joakim Nivre, Marie-catherine De Marneffe, Filip Ginter, YoavGoldberg, Christopher D Manning, Ryan Mcdonald, Slav Petrov,Sampo Pyysalo, Natalia Silveira, Reut Tsarfaty, and Daniel Ze-man. Universal Dependencies v1: A Multilingual Treebank Col-lection. Proceedings of the 10th International Conference on LanguageResources and Evaluation (LREC 2016), pages 1659–1666, 2016.
[54] Marie-catherine De Marneffe and Christopher D Manning. Stan-ford typed dependencies manual. 20090110 Httpnlp Stanford,2010.
[55] Slav Petrov, Dipanjan Das, and Ryan McDonald. A UniversalPart-of-Speech Tagset. arXiv preprint arXiv:1104.2086, 2011.
[56] Daniel Zeman. Reusable Tagset Conversion Using TagsetDrivers. In LREC, volume 2008, pages 28–30, 2008.
[57] G. J.M. Kruijff. Dependency Grammar. In Encyclopedia of Lan-guage & Linguistics, pages 444–450. 2006.
[58] Sandra Kübler, Ryan McDonald, and Joakim Nivre. DependencyParsing. Synthesis Lectures on Human Language Technologies, 2009.
[59] Joakim Nivre. Dependency Grammar and Dependency Parsing.MSI report, 2005.
[60] D. Nadeau. A survey of named entity recognition and classifica-tion. Lingvisticae Investigationes, 30(1):3–26, 2007.
[61] Alfred Krzywicki, Wayne Wobcke, Michael Bain, John CalvoMartinez, and Paul Compton. Data mining for building knowl-edge bases: Techniques, architectures and applications. Knowl-edge Engineering Review, 31(2):97–123, mar 2016.
[62] Radu Florian, Abe Ittycheriah, Hongyan Jing, and Tong Zhang.Named entity recognition through classifier combination. In Pro-ceedings of the seventh conference on Natural language learning atHLT-NAACL 2003 -, volume 4, pages 168–171, 2003.
[63] Silviu Cucerzan. Large-Scale Named Entity DisambiguationBased on Wikipedia Data. In EMNLP-CoNLL 2007, pages 708–716, 2007.
[64] Lev Ratinov and Dan Roth. Design challenges and misconcep-tions in named entity recognition. In Proceedings of the ThirteenthConference on Computational Natural Language Learning - CoNLL’09, page 147, 2009.
[65] Amit Singhal. Modern Information Retrieval: A Brief Overview.Readings, pages 1–9, 2001.

BIBLIOGRAPHY 58
[66] Jakub Piskorski and Roman Yangarber. Information Extraction:Past, Present and Future. In Multi-source, Multilingual InformationExtraction and Summarization. 2013.
[67] Meiji Cui, Li Li, Zhihong Wang, and Mingyu You. A Survey onRelation Extraction. In Communications in Computer and Informa-tion Science, 2017.
[68] Nguyen Bach and Sameer Badaskar. A review of relation extrac-tion. Literature review for Language and Statistics II, 2007.
[69] Alexander Maedche and Steffen Staab. Knowledge Engineer-ing and Knowledge Management Methods, Models, and Tools.Knowledge Engineering and Knowledge Management Methods, Mod-els, and Tools, 1937, 2000.
[70] Flavio S. Correa Da Silva, Wamberto W. Vasconcelos, David S.Robertson, Virginia Brilhante, Ana C.V. De Melo, Marcelo Finger,and Jaume Agustí. On the insufficiency of ontologies: Problemsin knowledge sharing and alternative solutions. Knowledge-BasedSystems, 15(3):147–167, 2002.
[71] Neil Ireson, Fabio Ciravegna, Mary Elaine Califf, Dayne Freitag,Nicholas Kushmerick, and Alberto Lavelli. Evaluating machinelearning for information extraction. In Proceedings of the 22nd in-ternational conference on Machine learning - ICML ’05, pages 345–352. ACM, 2005.
[72] Alberto Lavelli, Mary Elaine Califf, Fabio Ciravegna, Dayne Fre-itag, Claudio Giuliano, Nicholas Kushmerick, Lorenza Romano,and Neil Ireson. Evaluation of machine learning-based infor-mation extraction algorithms: Criticisms and recommendations.Language Resources and Evaluation, 42(4):361–393, 2008.
[73] Fouad Nasser A. Al Omran and Christoph Treude. Choosing anNLP Library for Analyzing Software Documentation: A System-atic Literature Review and a Series of Experiments. In IEEE Inter-national Working Conference on Mining Software Repositories, pages187–197, 2017.
[74] Christopher Manning, Mihai Surdeanu, John Bauer, Jenny Finkel,Steven Bethard, and David McClosky. The Stanford CoreNLPNatural Language Processing Toolkit. In Proceedings of 52nd An-nual Meeting of the Association for Computational Linguistics: SystemDemonstrations, pages 55–60, 2014.
[75] Steven Bird and Edward Loper. NLTK: the natural languagetoolkit. In Proceedings of the ACL 2004 on Interactive poster anddemonstration sessions, page 31. Association for ComputationalLinguistics, 2004.

BIBLIOGRAPHY 59
[76] Eunjeong L Park, Masato Hagiwara, Dmitrijs Milajevs, and Lil-ing Tan. Proceedings of Workshop for NLP Open Source Soft-ware (NLP-OSS). In Proceedings of Workshop for NLP Open SourceSoftware (NLP-OSS), 2018.
[77] Jr. Guido van Rossum and Fred L. Drake. The Python LanguageReference Manual. Network Theory Ltd., 2003.
[78] Stefan Behnel, Robert Bradshaw, Craig Citro, Lisandro Dalcin,Dag Sverre Seljebotn, and Kurt Smith. Cython: The best of bothworlds. Computing in Science and Engineering, 13(2):31–39, 2011.
[79] Lingpeng Kong, Chris Alberti, Daniel Andor, Ivan Bogatyy, andDavid Weiss. DRAGNN: A Transition-based Framework for Dy-namically Connected Neural Networks. CoRR, abs/1703.0, 2017.
[80] Yann Lecun, Yoshua Bengio, and Geoffrey Hinton. Deep learn-ing. Nature, 521(7553):436–444, 2015.
[81] Mart\’\in Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen,Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat,Geoffrey Irving, Michael Isard, and Others. TensorFlow: A Sys-tem for Large-Scale Machine Learning. In Osdi, volume 16, pages265–283, 2016.
[82] Stuart C. Shapiro. Knowledge Representation: Logical, Philosophical,and Computational Foundations, volume 27. 2001.
[83] P. Doherty, W. Łukaszewicz, A. Skowron, and A. Szałas. Knowl-edge representation techniques: A rough set approach, volume 202.Springer, 2006.
[84] Léon Bottou. From machine learning to machine reasoning. Ma-chine Learning, 94(2):133–149, 2013.
[85] Nicola Guarino. Formal ontology, conceptual analysis andknowledge representation. International Journal of Human-Computer Studies, 1995.
[86] Usama Fayyad, G Piatetsky-Shapiro, and Padhraic Smyth. Fromdata mining to knowledge discovery in databases. AI magazine,1996.
[87] A.G Fallis. Graph Databases, volume 53. " O’Reilly Media, Inc.",2013.
[88] Martin Loebl. Introduction to Graph Theory, volume 2. Prenticehall Upper Saddle River, 2010.
[89] Xifeng Yan, Philip S Yu, and Jiawei Han. Substructure similaritysearch in graph databases. In Proceedings of the 2005 ACM SIG-MOD international conference on Management of data, pages 766–777. ACM, 2005.

BIBLIOGRAPHY 60
[90] Peter T Wood. Query languages for graph databases. ACM SIG-MOD Record, 41(1):50–60, 2012.
[91] Alon Y Levy. Combining artificial intelligence and databases fordata integration. In Artificial Intelligence Today, pages 249–268.Springer, 1999.
[92] Alexandra Hofmann, Samresh Perchani, Jan Portisch, SvenHertling, and Heiko Paulheim. DBkWik: Towards knowledgegraph creation from thousands of wikis. In Proceedings of the Inter-national Semantic Web Conference (Posters and Demos), Vienna, Aus-tria, pages 21–25, 2017.
[93] Jingbo Shang, Jialu Liu, Meng Jiang, Xiang Ren, Clare R Voss,and Jiawei Han. Automated Phrase Mining from Massive TextCorpora, feb 2018.
[94] Gabor Angeli, Melvin Jose Johnson Premkumar, and Christo-pher D Manning. Leveraging Linguistic Structure For Open Do-main Information Extraction. In Proceedings of the 53rd AnnualMeeting of the Association for Computational Linguistics and the 7thInternational Joint Conference on Natural Language Processing (Vol-ume 1: Long Papers), pages 344–354, 2015.
[95] Meliha Yetisgen-Yildiz, Martin L Gunn, Fei Xia, and Thomas HPayne. A text processing pipeline to extract recommenda-tions from radiology reports. Journal of Biomedical Informatics,46(2):354–362, 2013.
[96] Luis Galárraga, Christina Teflioudi, Katja Hose, and Fabian M.Suchanek. Fast rule mining in ontological knowledge bases withAMIE+. VLDB Journal, 24(6):707–730, dec 2015.
[97] Giovanni Pilato, Agnese Augello, and Salvatore Gaglio. A Mod-ular System Oriented to the Design of Versatile Knowledge Basesfor Chatbots. ISRN Artificial Intelligence, 2012:1–10, mar 2012.
[98] Michael Schuhmacher and Simone Paolo Ponzetto. Knowledge-based graph document modeling. In Proceedings of the 7th ACMinternational conference on Web search and data mining - WSDM ’14,pages 543–552, 2014.
[99] William W. Cohen. WHIRL: a world-based information represen-tation language. Artificial Intelligence, 118(1-2):163–196, apr 2000.
[100] Yang Chen, Daisy Zhe Wang, and Sean Goldberg. ScaLeKB: scal-able learning and inference over large knowledge bases. VLDBJournal, 25(6):893–918, dec 2016.
[101] Cesar Sann and Edward Szczerbicki. Experience-based knowl-edge representation: Soeks. Cybernetics and Systems, 40(2):99–122,feb 2009.

BIBLIOGRAPHY 61
[102] David W. Embley, Douglas M. Campbell, Randy D. Smith, andStephen W. Liddle. Ontology-based extraction and structuring ofinformation from data-rich unstructured documents. In Proceed-ings of the seventh international conference on Information and knowl-edge management - CIKM ’98, pages 52–59, 1998.
[103] Ahmad Aghaebrahimian and Filip Jurcícek. Open-domain Fac-toid Question Answering via Knowledge Graph Search. In Pro-ceedings of the Workshop on Human-Computer Question Answering,pages 22–28. Association for Computational Linguistics, 2016.
[104] Maximilian Nickel, Kevin Murphy, Volker Tresp, and EvgeniyGabrilovich. A review of relational machine learning for knowl-edge graphs, mar 2016.
[105] S E L F Atching N Etworks. R-Net: Machine Reading Compre-hension With Self-Matching Networks *. arXiv, pages 1–11, 2017.
[106] Catherine Marshall and Gretchen B. Rossman. Data CollectionMethods. Designing qualitative research, 1995.
[107] University of Texas. Data Collection and Sampling. University ofTexas at Dallas, 2002.
[108] P. Gill, K. Stewart, E. Treasure, and B. Chadwick. Methods of datacollection in qualitative research: Interviews and focus groups.British Dental Journal, 2008.
[109] a J Onwuegbuzie, N L Leech, and K M T Collins. Innovativedata collection strategies in qualitative research. Qualitative Re-port, 2010.
[110] Michelle Cleary, Jan Horsfall, and Mark Hayter. Data collectionand sampling in qualitative research: Does size matter? Journalof Advanced Nursing, 2014.
[111] M.Q. Patton. Qualitative evaluation and research methods. SAGEPublications, inc, 2015.
[112] Shazia Jamshed. Qualitative research method-interviewing andobservation. Journal of Basic and Clinical Pharmacy, 2014.
[113] Bruce L. Berg. Action Research, 2004.
[114] Cynthia S Jacelon and Katharine K O’Dell. Analyzing qualitativedata. 2005.
[115] P. Burnard, P. Gill, K. Stewart, E. Treasure, and B. Chadwick.Analysing and presenting qualitative data. British Dental Journal,2008.

BIBLIOGRAPHY 62
[116] D L Driscoll, A Appiah-Yeboah, P Salib, and D J Rupert. Merg-ing qualitative and quantitative data in mixed methods research:How to and why not. Ecological and Environmental Anthropology(University of Georgia), page 18, 2007.
[117] John Dudovskiy. Qualitative Data Analysis, 2018.
[118] Marianne Jorgensen and Louise J Phillips. Discourse Analysis asTheory and Method. Theory, 2002.
[119] W. L. Oberkampf and J. Roy, C. Verification and Validation in Sci-entific Computing. Cambridge University Press, 2010.
[120] Matthew B., Miles A., and Michael Huberman. Qualitative DataAnalysis: An expanded Sourcebook, volume 20. sage, 1999.
[121] Matthew B Miles and A Michael Huberman. Drawing validmeaning from qualitative data: Toward a shared craft. Educa-tional researcher, 13(5):20–30, 1984.
[122] Janice M. Morse, Michael Barrett, Maria Mayan, Karin Olson,and Jude Spiers. Verification Strategies for Establishing Relia-bility and Validity in Qualitative Research. International Journal ofQualitative Methods, 1(2):13–22, 2002.
[123] Yu Beng Leau, Wooi Khong Loo, Wai Yip Tham, and Soo FunTan. Software development life cycle AGILE vs traditional ap-proaches. In International Conference on Information and NetworkTechnology, volume 37, pages 162–167, 2012.
[124] Paper Rational Software White. Rational Unified Process BestPractices for Software. Development, 2004.
[125] F. Vernadat. UEML: Towards a unified enterprise modelling lan-guage. International Journal of Production Research, 2002.
[126] Nayan B. Ruparelia. Software development lifecycle models.ACM SIGSOFT Software Engineering Notes, 2010.
[127] William M. Wilson, Linda H. Rosenberg, and Lawrence E. Hyatt.Automated analysis of requirement specifications. In Proceedings- International Conference on Software Engineering, 1997.
[128] IEEE. IEEE Recommended Practice for Software RequirementsSpecification, 1998.
[129] Alan M Davis, Edward H Bersoff, and Edward R Comer. A strat-egy for comparing alternative software development life cyclemodels. IEEE Transactions on software Engineering, 14(10):1453–1461, 1988.
[130] Jim Highsmith and Alistair Cockbrun. Agile software develop-ment: The business of innovation. Computer, 34(9):120–122, 2009.

BIBLIOGRAPHY 63
[131] Colin Shearer, Hugh J Watson, Daryl G Grecich, Larissa Moss,Sid Adelman, Katherine Hammer, and Stacey a Herdlein. TheCRISP-DM model: The New Blueprint for Data Mining. Journalof Data Warehousing, 5(4):13–22, 2000.
[132] E Rahm and Hh Do. Data cleaning: Problems and current ap-proaches. IEEE Data Eng. Bull., 2000.
[133] R Development Core Team. R Language Definition. Web, 0:62,2011.
[134] Fabian Pedregosa, Vincent Michel, Olivier Grisel, Mathieu Blon-del, Peter Prettenhofer, Ron Weiss, Jake Vanderplas, David Cour-napeau, Fabian Pedregosa, Gaël Varoquaux, Alexandre Gram-fort, Bertrand Thirion, Olivier Grisel, Vincent Dubourg, Alexan-dre Passos, Matthieu Brucher, Matthieu Perrot andÉdouardand,AndÉdouard Duchesnay, and FRÉdouard Duchesnay. Scikit-learn: Machine Learning in Python. Journal of Machine LearningResearch, 12(Oct):2825–2830, 2011.
[135] Gregory Grefenstette and Pasi Tapanainen. What is a word, whatis a sentence? Problems of tokenization. COMPLEX 1994: 3rdconference on computational lexicography and text research, Budapest,Hungary, 7-10 July, pages 79–87, 1994.
[136] Chris Alberti, Daniel Andor, Ivan Bogatyy, Michael Collins, DanGillick, Lingpeng Kong, Terry Koo, Ji Ma, Mark Omernick, SlavPetrov, Chayut Thanapirom, Zora Tung, and David Weiss. Syn-taxNet Models for the CoNLL 2017 Shared Task. arXiv preprintarXiv:1703.04929, 2017.
[137] John Lafferty, Andrew McCallum, and Fernando C N Pereira.Conditional random fields: Probabilistic models for segmentingand labeling sequence data. ICML ’01 Proceedings of the EighteenthInternational Conference on Machine Learning, 2001.
[138] Charles Sutton and Andrew McCallum. An Introduction to Con-ditional Random Fields. Machine Learning, 2011.
[139] Dan Roth and W Yih. Global inference for entity and relationidentification via a linear programming formulation. Introductionto Statistical Relational . . . , pages 553–580, 2007.
[140] Sonal Gupta and Christopher Manning. Improved Pattern Learn-ing for Bootstrapped Entity Extraction. In Proceedings of theEighteenth Conference on Computational Natural Language Learning,pages 98–108, 2014.
[141] Anthony Fader, Stephen Soderland, and Oren Etzioni. ExtractingSequences from the Web. Proceedings of the ACL 2010 ConferenceShort Papers, (July):286–290, 2010.

BIBLIOGRAPHY 64
[142] Sören Auer, Christian Bizer, Georgi Kobilarov, Jens Lehmann,Richard Cyganiak, and Zachary Ives. DBpedia: A nucleus fora Web of open data. In Lecture Notes in Computer Science (includ-ing subseries Lecture Notes in Artificial Intelligence and Lecture Notesin Bioinformatics), volume 4825 LNCS, pages 722–735. Springer,2007.

APPENDIX A
Graphs
65
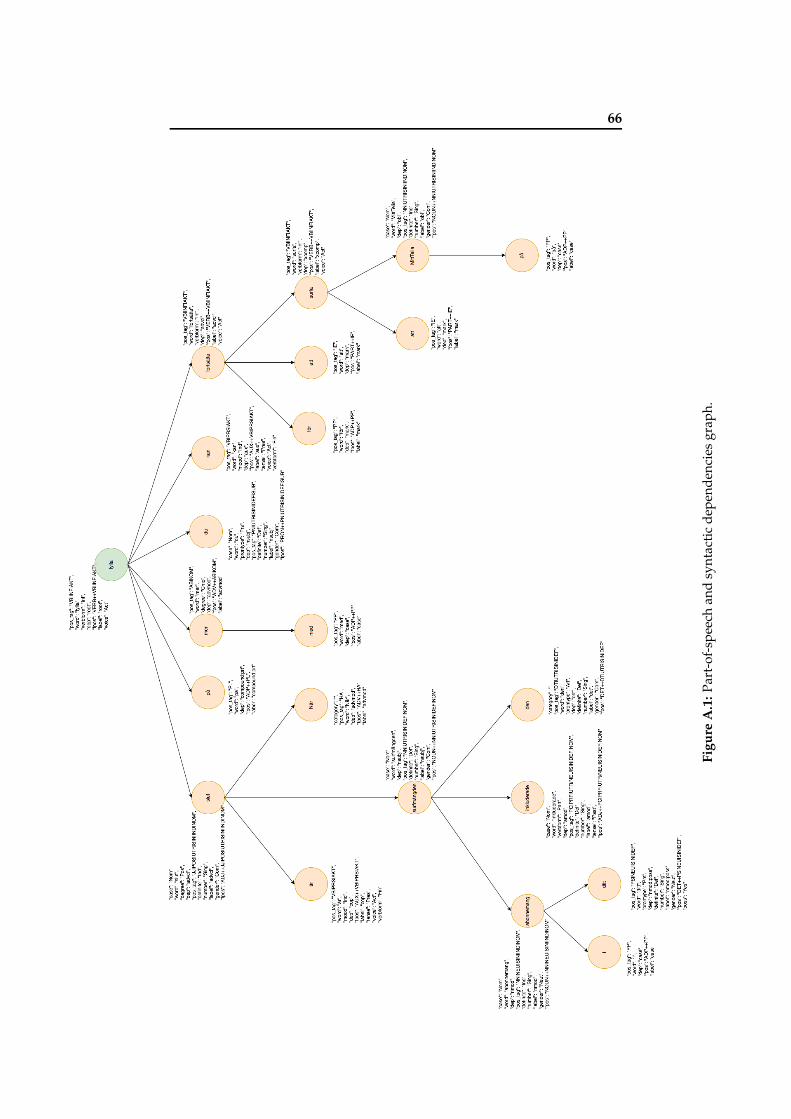
66
Figu
reA
.1:P
art-
of-s
peec
han
dsy
ntac
tic
depe
nden
cies
grap
h.
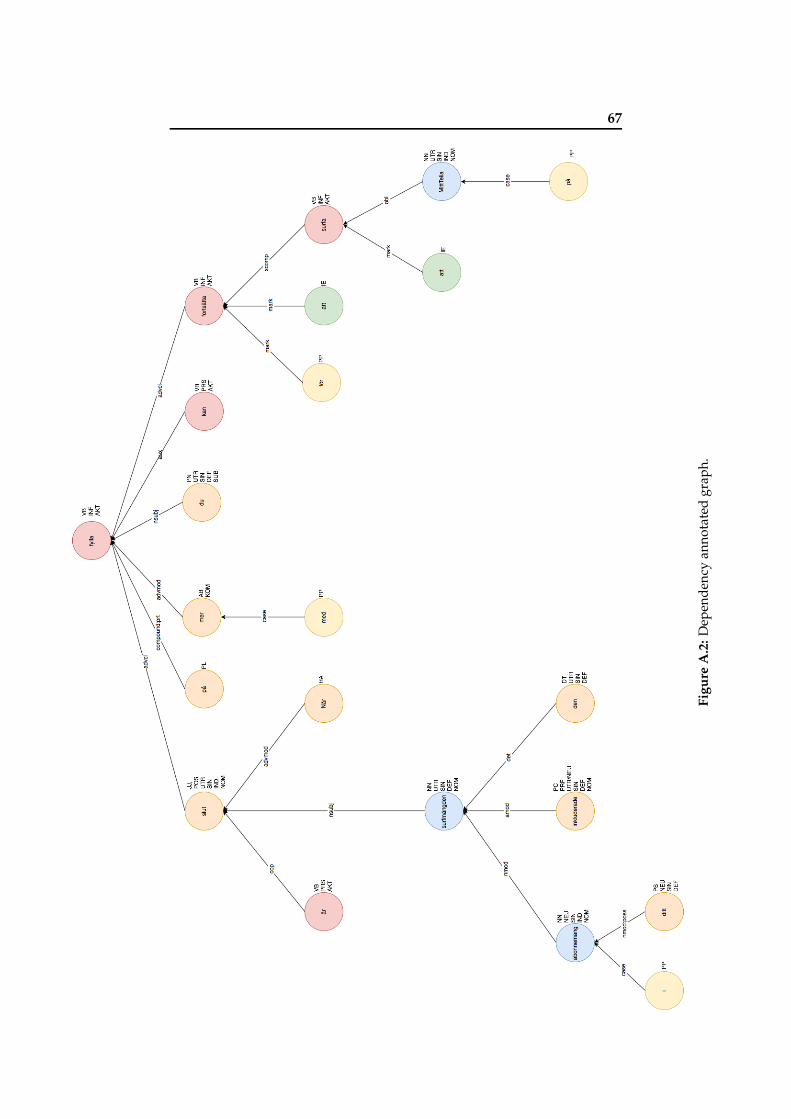
67
Figu
reA
.2:D
epen
denc
yan
nota
ted
grap
h.
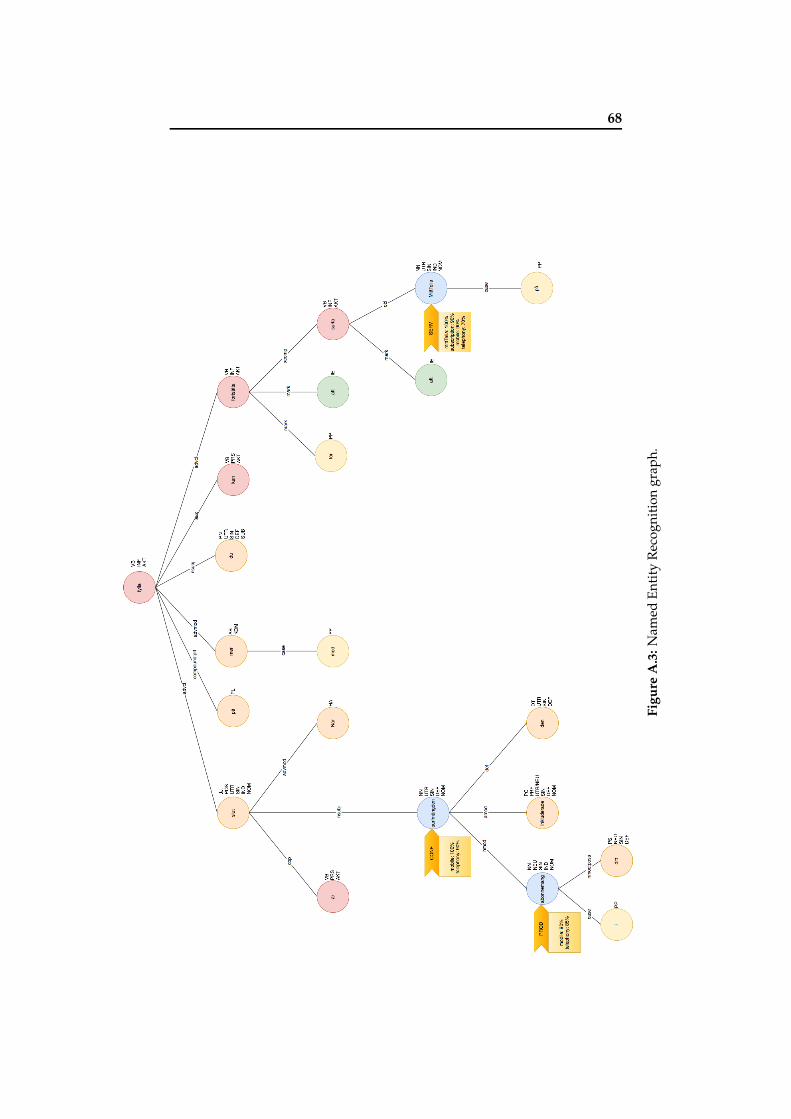
68
Figu
reA
.3:N
amed
Enti
tyR
ecog
niti
ongr
aph.

TRITA TRITA-EECS-EX-2018:600
www.kth.se