a visual recognition model based on hierarchical feature
TRANSCRIPT

A Visual Recognition Model Basedon Hierarchical Feature Extraction
and Multi-layer SNN
Xiaoliang Xu, Wensi Lu, Qiming Fang(B), and Yixing Xia
School of Computer, Hangzhou Dianzi University, Hangzhou, China{xxl,fangqiming,yixingx}@hdu.edu.cn, [email protected]
Abstract. In this paper, a visual pattern recognition model is proposed,which effectively combines hierarchical feature extraction model and cod-ing method on multi-layer SNN. This paper takes HMAX model as fea-ture extraction model and adopts independent component analysis (ICA)to improve it, so that the model can satisfy the sparsity of informationextraction and the output result is more suitable for SNN processing.Multi-layer SNN is used as classifier and the firing of spikes is not limitedin the learning process. We use valid phase coding to connect these twoparts. Through the experiments on the MNIST and Caltech101 datasets,it can be found that the model has good classification performance.
Keywords: Visual pattern recognition · Multi-layer SNNHMAX · Phase coding
1 Introduction
In recent years, the bio-inspired object recognition frameworks have become anincreasingly active field of research [1]. HMAX model [2] as a biologically basedfeedforward hierarchical architecture for object recognition, has many extendedmodels [3]. Original HMAX model applies template matching and MAX poolingmethods to achieve selectivity and invariance. In order to learn higher features,some researchers have made several adjustments for the model [4,5]. There aretwo main extensions: one is to reduce calculation cost, the other is to changearchitecture of the HMAX model. Some researches use sparse-based techniqueto reduce calculation cost. Mutch et al. [6] adopt sparsity constrain in a sim-ilar model like HMAX model. Hu et al. [7] combine independent componentanalysis and the standard sparse coding with HMAX model. For changing thearchitecture of the HMAX model, one method is adjusting the layer number ofthe model. Hu et al. introduced a high-layer architecture including six layers.In [8], using only the earlier stages (one S layer and one C layer) of HMAXmodel, yet achieves good or better performance. Another method is carryingout the feedback operation into the HMAX model [9] to replace the feedforwardarchitecture.c© Springer Nature Switzerland AG 2018L. Cheng et al. (Eds.): ICONIP 2018, LNCS 11301, pp. 525–534, 2018.https://doi.org/10.1007/978-3-030-04167-0_47

526 X. Xu et al.
When combining the HMAX model with the multiclass linear SVM for goodclassification performance [10], some researchers have focused on more biologi-cally realistic classifier. Spiking neural networks (SNNs) [11] have the same capa-bility of processing spikes as biological neural system, especially adopting tem-poral encoding mechanism [12]. Various learning algorithms for SNNs have beenproposed, mainly can be divided into two types: single-layer learning algorithmsand multi-layer learning algorithms. For single-layer algorithms, the researchcan be classified into three types: based on convolution of spike train, gradientdescent and synaptic plasticity mechanism, respectively. Typical algorithms ofthese three types are PSD [13], SpikeProp [14] and STDP [15]. Compared withsingle-layer learning algorithms, there are few researches on multi-layer learn-ing algorithms. Effective multi-layer learning algorithms include the SpikeProp[14], Multi-ReSuMe [16] and the recurrent network learning rules [17]. The mainreason for the lack of the typical multi-layer learning algorithm is that the neu-ronal spike-timing in the SNN is discontinuous, which leads to the difficulty ofinformation feedback.
A lot of work has been done on HMAX model and SNNs in their respectivefields. However, there is litter work to combine HMAX model with biologicalclassifiers. In the HMAX+SVM model, the classifier is a mathematical methodand does not have biological interpretability. Inspired by [5,7,18], in this paper,we propose a hierarchical computation architecture for visual pattern recognitionwhich integrates HMAX and SNN into an integrated model that is biologicallyinterpretable. In this model, we use multi-layer SNN to learn, FastICA to improveHMAX to better integrate with SNN, and Adam [22] to optimize the learningrate.
In the next section we will introduce the methods we use, including hierar-chical feature extraction, phase encoding, and the learning algorithm used formulti-layer SNNs. Section 3 mainly discusses the experimental simulation results.The conclusion is given in Sect. 4.
2 Methods
2.1 Hierarchical Model for Feature Extraction
We use a four-layer model for feature extraction similar to HMAX, and makeimprovements in S2, C2 layers. The overall structure is shown in Fig. 1 and thespecific method is described as follows.
(a) S1 layer : The results of the S1 layer are obtained by convolving the inputimage with Gabor filter on four directions (0o, 45o, 90o, 135o).
(b) C1 layer : We use max pooling over local neighborhood which increases thetolerance to 2D transformations from layer S1 to C1. The specific operationis to use the n × n sliding window to select the strongest response value asthe feature map of C1 in the window, and the window slides with 1/2 windowoverlaps.

A Visual Recognition Model 527
(c) S2 layer : In order to extract more information and not limited by handcraftfeatures [7], we adopt FastICA to learn filters, which is different from theoperation of the S1 layer. Computational neuroscience indicates that filtersused by the S1 layer can be considered as the result of sparse coding, whileICA is also closely related to sparse coding [20]. The process description isshown below:
X = AS (1)
minimize ‖X − AS‖2F + λk∑
i=1
‖si‖1 (2)
subject to ‖ai‖2
� 1,∀i = 1, . . . , m
Where each column of X is a patch xi, each column of A is a basis ai andeach column of S is a vector si ∈ �m consisting of coefficients of the m bases forreconstructing xi. ‖·‖F is the Frobenius norm and λ is a positive constant. Forthe sake of simplicity, we set A as an invertible matrix, then Eq. 2 can be solvedby ICA algorithm.
maximizek∑
i=1
m∑
j=1
log fj(wT
j xi
)+ k log |det W | (3)
where W = A−1, wTj is the j − th row of W , xi is the i − th column of X, and
fj (·) denotes a sparse probability distribution function.(d) C2 layer: ICA is a linear model that can extract linear statistical featuresfrom input. But in fact, many images contain nonlinear statistical information.Therefore, we apply max pooling on the result of the S2 layer so that nonlinearstatistical information can be extracted.
2.2 Phase Encoding
When using SNN for image recognition, coding becomes an important bridgeto establish the relationship between images and SNN. We make some minorchanges to phase encoding algorithm [19] to make it more suitable for our sim-ulation experiments. The precise time of each pixel in the receptive field (RF)depends not only on the intensity value but also on the position, which can becalculated as
step1 : ti = (i − 1) ∗ t step + j−1n tmax, xi ∈ jth encoding neuron
step2 : if ti > tmax
ti = ti − tmax
(4)
where xi is the intensity value of pixel i, t step is calculation interval, n is numberof encoding neuron, and tmax is the maximum value of the time window. From

528 X. Xu et al.
Input
S1 C1 S2 C2
Convolution( )fastICA
Convolution(W)Max
pooling Max
pooling
Fig. 1. Hierarchical model for feature extraction: The S layers show the results of theinput image under different filtering effects. The S1 represents the result of Gabor filter-ing with different orientation (0o, 45o, 90o, 135o), and S2 shows the result of processingwith FastICA. The C layers represent the results of the S layers after max pooling.The difference is that the sliding windows of the C1 layer overlap, while the C2 layerdo not.
Eq. 4 we can find that each encoding neuron approximates the periodic oscillationof a cosine function.
The encoding process is shown in Fig. 2. For the sake of simplicity, we justconsider excitatory and inhibitory encoding neurons in the RF. And in the align-ment step, time is adjusted to its nearest time in the time list of correspondingneurons. Finally, the firing time collected by the sampling window is mapped tothe input neurons.
Firing time
Enconding
Alignment
Map
Input neurons
120.4,1
120,1Firing time distribution
Fig. 2. Phase encoding: (upper left corner) input image is the result of C2 layer; (right)encoding process of the phase encoding algorithm, different color curves represent dif-ferent encoding neurons; (lower left corner) the distribution of encoded spike trainsonto the 2D axis. (Color figure online)

A Visual Recognition Model 529
2.3 Learning Algorithm
In order to explore the learning performance of SNNs, we choose the multi-layerSNN. The learning algorithm [18] uses the maximum probability of generatingthe target spike trains as an objective function, and makes it suitable for multi-layer SNN by combining error back propagation algorithm and STDP. The objectfunction is
P(zref |y)
= exp
(∫ T
0
log (ρ0 (t|y, zo)) zrefo (t) − ρ (t|y, zo) dt
)(5)
where y is the spike train generated by the hidden layer, zo is the actual outputspike train and zrefo represents the target spike train. T is the time window andρ (t) denotes the stochastic intensity of generating spikes at t. P (z|y) representsthe probability of producing z under y conditions.
3 Simulation Results
In the real world, object recognition is a complex issue because external stim-uli are diverse. Here we mainly experiment with the MNIST and Caltech101datasets, and all images are processed into grayscale images.
3.1 Experimental Setup of Image Coding
Each image has an appropriate conversion process before it enters the spikingneural network. We collectively refer to feature extraction and phase encodingas the encoding process. In S1 layer we choose Gabor filters in four differentorientations (0o, 45o, 90o, 135o). And the other parameters are set to γ = 0.3, σ =2.8, λ = 3.5 and the filter size is 7 × 7 pixels. After getting the result of S1layer, we perform max pooling operation on it. The sliding window size is 6 × 6pixels and the overlap window is set to be 3 pixels in one axis (x or y). InS2 layer, fastICA is used to autonomously learn 4 bases from the C1 results,and the max pooling used in C2 is to make the linear result become nonlinear.The window size is 4 × 4 pixels without overlap. After the hierarchical featureextraction operation, we use phase encoding which plays an important role inour model. In the process of phase encoding, the parameters are set to: the typeof encoding neurons encoding neuron = 2, time window tmax = 500 ms, timestep t step = 1 ms.
3.2 Performance of Multi-layer Learning Rule
In order to improve network performance, we use the multi-layer SNN learningalgorithm mentioned in [18]. In this learning algorithm, “escape noise” [11] isused to solve the problem of the discontinuous nature of neuronal spike-timing.We specify some parameters: the threshold Vthr = 15mV and the reset kernel
530 X. Xu et al.
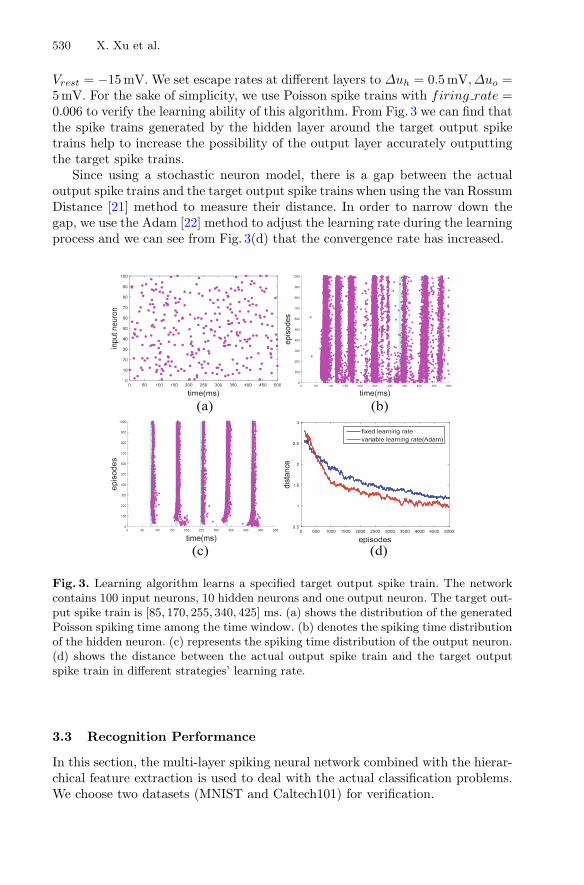
Vrest = −15mV. We set escape rates at different layers to Δuh = 0.5mV,Δuo =5mV. For the sake of simplicity, we use Poisson spike trains with firing rate =0.006 to verify the learning ability of this algorithm. From Fig. 3 we can find thatthe spike trains generated by the hidden layer around the target output spiketrains help to increase the possibility of the output layer accurately outputtingthe target spike trains.
Since using a stochastic neuron model, there is a gap between the actualoutput spike trains and the target output spike trains when using the van RossumDistance [21] method to measure their distance. In order to narrow down thegap, we use the Adam [22] method to adjust the learning rate during the learningprocess and we can see from Fig. 3(d) that the convergence rate has increased.
(a) (b)
(c) (d)
Fig. 3. Learning algorithm learns a specified target output spike train. The networkcontains 100 input neurons, 10 hidden neurons and one output neuron. The target out-put spike train is [85, 170, 255, 340, 425] ms. (a) shows the distribution of the generatedPoisson spiking time among the time window. (b) denotes the spiking time distributionof the hidden neuron. (c) represents the spiking time distribution of the output neuron.(d) shows the distance between the actual output spike train and the target outputspike train in different strategies’ learning rate.
3.3 Recognition Performance
In this section, the multi-layer spiking neural network combined with the hierar-chical feature extraction is used to deal with the actual classification problems.We choose two datasets (MNIST and Caltech101) for verification.

A Visual Recognition Model 531
(1) The effectiveness of coding strategies: Phase encoding plays an importantrole in our approach. We compare three coding methods, one is the linearmapping that converts pixels directly into corresponding spikes, the second isto convert the pixels into Gaussian distributed spikes and the third is phaseencoding used in this paper. We select three categories (0, 1, 2) of images toverify the performance of each encoding method. Each method is run 10 timesduring the training, and each run contains 100 episodes. During the testingprocess, each test set consists of 300 images randomly selected from threecategories (0, 1, 2) of MNIST. As can be seen from Fig. 4, the training/testingaccuracy of phase encoding is higher than the other two methods in the samesituation. The main reason for this phenomenon is that the spikes obtainedby image2spike and GRF methods are very narrowly distributed in the timewindow, making less time information available for the learning process. Thephase encoding makes spikes more widely distributed in the time window sothat the time information of each pixel can be fully utilized.
(2) The effect of different output forms of the feature extraction layer: In differentHMAX methods, there are two different output forms, one is an image andthe other is a vector, as shown in Fig. 5. The hierarchical feature extractionmethod used in this paper and the HMAX method in [5] correspond to thesetwo different output forms. Ten types (0–9) of handwritten digits are selected,the training set size is 1000 images/type and the test set is 100 images/type.These two forms are used as input to the multi-layer SNN to obtain two setsof test results. The test accuracy obtained by our method is 89.6%, and theaccuracy of using vector as input is 10.2%. The main reason for this gap inaccuracy is that when the vector is used as an input to the SNN, the effectiveinformation it provides is limited and cannot be fully used by the SNN.
(3) The classification accuracy of different methods: Table 1 shows the classifi-cation accuracy of different methods on the MNIST dataset. Method I andmethod II represent different HMAX enhancement methods and have thesame form of output as our method. Method I mainly considers the architec-ture and uses only the S1 and C1 layers of the hierarchical feature extraction[8]. Method II considers from internal operation which uses sparse HMAX [7]to extract features. From Table 1, it can be seen that although our methodand method II both use the four-layer feature extraction model, the accuracyof our method is higher, and the accuracy of method II isn’t higher thanonly SNN. According to the experimental results, it can be concluded that anaive combination of SNN and feature extraction methods may not necessar-ily improve the classification performance. And the key to make the modelmore effective is that feature extraction results should highlight the uniquefeatures of each category.
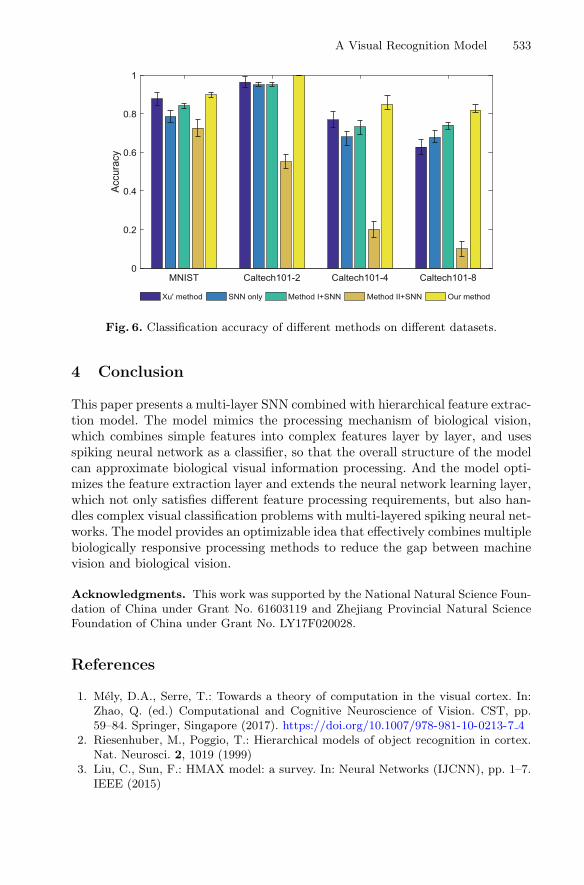
To verify our method’s ability to handle different datasets, we did exper-iments on Caltech101. The four methods chosen are the combined model ofHMAX+PSD proposed by Xu et al. [23] which uses single-layer SNN, and thethree methods that are gradually extended from the structure mentioned in thispaper. From Fig. 6, it can be seen that our method has advantages over the

532 X. Xu et al.
Fig. 4. The training/testing accuracy obtained by different coding schemes, GRF rep-resents gaussian receptive field.
S2 C2Max pooling C1 fastICA
Convolution(W)
Filter (L2 RBF)Max pooling
Fig. 5. Feature extraction model with different output forms.
Table 1. The classification accuracy of different methods.
Accuracy (%) MNIST
Training accuracy (%) Testing accuracy (%)
SNN only 84.45 ± 2.1 78.5 ± 3.1
Method I + SNN 91.8 ± 0.9 84.1 ± 1.2
Method II + SNN 90.05 ± 0.75 72.5 ± 4.5
Our method 93.25 ± 0.85 89.7 ± 1.1
other three methods in dealing with complex datasets, that accuracy obtainedon all four datasets is higher, especially Caltech101-8. Caltech101-8 indicatesthat eight categories were selected from the Caltech101 dataset. Comparing Xu’smethod with the method using multi-layer SNN only, it can be clearly seen thatin complex datasets, the processing capacity of multi-layer SNN is better thansingle-layer SNN.
A Visual Recognition Model 533
MNIST Caltech101-2 Caltech101-4 Caltech101-80
0.2
0.4
0.6
0.8
1
Accu
racy
Xu' method SNN only Method I+SNN Method II+SNN Our method
Fig. 6. Classification accuracy of different methods on different datasets.
4 Conclusion
This paper presents a multi-layer SNN combined with hierarchical feature extrac-tion model. The model mimics the processing mechanism of biological vision,which combines simple features into complex features layer by layer, and usesspiking neural network as a classifier, so that the overall structure of the modelcan approximate biological visual information processing. And the model opti-mizes the feature extraction layer and extends the neural network learning layer,which not only satisfies different feature processing requirements, but also han-dles complex visual classification problems with multi-layered spiking neural net-works. The model provides an optimizable idea that effectively combines multiplebiologically responsive processing methods to reduce the gap between machinevision and biological vision.
Acknowledgments. This work was supported by the National Natural Science Foun-dation of China under Grant No. 61603119 and Zhejiang Provincial Natural ScienceFoundation of China under Grant No. LY17F020028.
References
1. Mely, D.A., Serre, T.: Towards a theory of computation in the visual cortex. In:Zhao, Q. (ed.) Computational and Cognitive Neuroscience of Vision. CST, pp.59–84. Springer, Singapore (2017). https://doi.org/10.1007/978-981-10-0213-7 4
2. Riesenhuber, M., Poggio, T.: Hierarchical models of object recognition in cortex.Nat. Neurosci. 2, 1019 (1999)
3. Liu, C., Sun, F.: HMAX model: a survey. In: Neural Networks (IJCNN), pp. 1–7.IEEE (2015)

534 X. Xu et al.
4. Serre, T., Wolf, L., Poggio, T.: Object recognition with features inspired by visualcortex. In: 2005 IEEE Computer Society Conference Computer Vision and PatternRecognition. CVPR 2005, vol. 2, pp. 994–1000 (2005)
5. Serre, T., Wolf, L., Bileschi, S., et al.: Robust object recognition with cortex-likemechanisms. IEEE Trans. Pattern Anal. Mach. Intell. 29, 411–426 (2007)
6. Mutch, J., Lowe, D.G.: Object class recognition and localization using sparse fea-tures with limited receptive fields. Int. J. Comput. Vis. 80, 45–57 (2008)
7. Hu, X., Zhang, J., Li, J., et al.: Sparsity-regularized HMAX for visual recognition.Plos One 9, e81813 (2014)
8. Ma, B., Su, Y., Jurie, F.: Covariance descriptor based on bio-inspired featuresfor person re-identification and face verification. Image Vis. Comput. 32, 379–390(2014)
9. Dura-Bernal, S., Wennekers, T., Denham, S.L.: Modelling object perception incortex: hierarchical Bayesian networks and belief propagation. In: 2011 45th AnnualConference on Information Sciences and Systems (CISS), pp. 1–6. IEEE (2011)
10. Sufikarimi, H., Mohammadi, K.: Speed up biological inspired object recognition,HMAX. In: Intelligent Systems and Signal Processing (ICSPIS) (2017)
11. Gerstner, W., Kistler, W.M.: Spiking Neuron Models: Single Neurons, Populations,Plasticity. Cambridge University Press, Cambridge (2002)
12. Zheng, Y., et al.: Sparse temporal encoding of visual features for robust objectrecognition by spiking neurons. IEEE Trans. Neural Netw. Learn. Syst. 1–11(2018). https://doi.org/10.1109/TNNLS.2018.2812811
13. Yu, Q., Tang, H., Tan, K.C., et al.: Precise-spike-driven synaptic plasticity: learninghetero-association of spatiotemporal spike patterns. Plos One 8, e78318 (2013)
14. Bohte, S.M., Kok, J.N., La Poutre, H.: Error-backpropagation in temporallyencoded networks of spiking neurons. Neurocomputing 48, 17–37 (2002)
15. Caporale, N., Dan, Y.: Spike timing-dependent plasticity: a Hebbian learning rule.Annu. Rev. Neurosci. 31, 25–46 (2008)
16. Sporea, I., Gruning, A.: Supervised learning in multilayer spiking neural networks.Neural Comput. 25, 473–509 (2013)
17. Pyle, R., Rosenbaum, R.: Spatiotemporal dynamics and reliable computations inrecurrent spiking neural networks. Phys. Rev. Lett. 118(1), 018103 (2017)
18. Gardner, B., Sporea, I., Gruning, A.: Learning spatiotemporally encoded patterntransformations in structured spiking neural networks. Neural Comput. 27, 2548–2586 (2015)
19. Nadasdy, Z.: Information encoding and reconstruction from the phase of actionpotentials. Front. Syst. Neurosci. 3, 6 (2009)
20. Olshausen, B.A., Field, D.J.: Sparse coding with an overcomplete basis set: a strat-egy employed by V1? Vis. Res. 37, 3311–3325 (1997)
21. Rossum, M.V.: A novel spike distance. Neural Comput. 13, 751–763 (2001)22. Kingma, D.P., Ba, J.: Adam: a method for stochastic optimization. Computer
Science (2014)23. Xu, X., Jin, X., Yan, R., et al.: Visual pattern recognition using enhanced visual
features and PSD-based learning rule. IEEE Trans. Cogn. Dev. Syst. 10, 205–212(2017)