a09 109/06 · matematici e algoritmi con particolare riferimento ai sistemi artificiali adattivi;...
TRANSCRIPT

A09109/06

Il Piano Triennale è a cura di: Massimo Buscema, Direttore delSemeion
Hanno collaborato i ricercatori del Semeion: Giulia Massini, StefanoTerzi, Marco Intraligi, Guido Maurelli, Massimiliano Capriotti, Ric-cardo Petritoli
Semeion Centro Ricerche di Scienze della ComunicazioneVia Sersale, 11700128 Romaweb: www.semeion.ite–mail: [email protected]

ARACNE
SEMEIONCentro Ricerche di Scienze
della Comunicazione
Piano Triennale
Ricerca di Basee Applicata
Anni 2008–2010
Sintesi delle Ricerche del 2007
6

Copyright © MMVIIIARACNE editrice S.r.l.
via Raffaele Garofalo, 133 A/B00173 Roma
(06) 93781065
ISBN 978–88–548–1768–5
I diritti di traduzione, di memorizzazione elettronica,di riproduzione e di adattamento anche parziale,
con qualsiasi mezzo, sono riservati per tutti i Paesi.
Non sono assolutamente consentite le fotocopiesenza il permesso scritto dell’Editore.
I edizione: maggio 2008

5
Indice 1. Presentazione del Semeion 9
1.1. Componenti del Semeion 13 1.2. I campi d’interesse della ricerca 18
2. Piano Triennale Ricerca di base (2008–2010)
di Massimo Buscema 2. Piano Triennale Ricerca di Base (2008–2010) 23 2.1. Teoria Generale dei sistemi Artificiali Adattivi 24 2.2. La Sintassi delle immagini: le informazioni nas-
coste Active Connection Matrix (ACM) 32 2.3. La Semantica delle immagini: il pixel e il suo con-
testo la Pixel Vector Theory (PVT) 42 2.4. Analisi dei segnali non stazionari Implicit Fun-
ction as Squashing Time (IFAST) 44 2.5. Meta–classificatori e nuove reti supervisionate
(MetaNet) 46 2.6. Reti Auto–Associate non lineari
(Mappe Contrattive) 56 2.7. Teoria dei Grafi e Data Mining (H Function) 70 2.8. Multi Dimensional Scaling (PST e Population) 91 2.9. Virtual Data Generation (PI Function and HID) 98 2.10. Co–Clustering and Bi–Clustering (Visual DB) 106 2.11. Il Clustering Dinamico sulle Traiettorie dei Datasets (DPCA) 115
3. Piano Trennale Ricerca Applicata (2008–2010)
di G. Maurelli 3. Piano Triennale Ricerca Applicata (2008–2010) 125 3.1. Biomedicale settore Imaging 127
3.1.1. Progetto CAD Mr–mammography con Sis-temi Artificiali Adattivi per la classificazione e previsione di masse tumorali 127

6
3.1.2. Progetto CAD Mr–mammography con Sis-temi Artificiali Adattivi per la classificazione di microcalcificazioni tumorali 131
3.1.3. Progetto di svilippo di Meta–Classificatori per l’ottomizzazione delle previsioni sui tumori 133
3.1.4. Sistema di analisi dell’imaging biomedicale per far emergere l’informazione nascosta 134
3.2. Campo Biomedicale settore clinico 136
3.2.1. Corsi di formazione sull’Intelligenza Artifi-ciale per medici specialisti 136
3.2.2. Software applicativi per l’elaborazione complessa di dataset clinici 140
3.2.3. Progetto IMPROVE sul rischio cardiova-scolare 141
3.2.4. Progetto Nazionale Emorragia Digestiva (PNED) 143
3.2.5. Progetto per l’identificazione di nuovi biomarkers nell’Alzheimer Disease 144
3.3. Social Security 147 3.3.1. Progetto Central Drug Trafficking Data-
base (CDTD) 148 3.3.2. Progetto Sicurezza integrata su 4 livelli 149 3.3.3. Progetto telecamera intelligente e firma
micro–gestuale 152 3.3.4. Progetto analisi e previsione del traffico
mercantile nel mediterraneo 155 3.3.5. Progetto Selezione del Personale delle
Forze Armate 156 3.4. Industria, marketing e mondo del lavoro 157
3.4.1. Previsione di classi di fumatori sulla base di analisi cliniche e variabili socio–ana-grafiche 157
3.4.2. Analisi e simulazione dinamica dei com-portamenti di consumo 162

7
3.4.3. Analisi e ottimizzazione dei percorsi lavo-rativi 166
3.4.4. Analisi e previsione della concentrazione di gas sulla base di sistemi nanosensori 169
4. Sintesi delle Ricerche del 2007 a cura di M. Buscema, G. Massini, S. Terzi, M. Intraligi, G. Maurelli
4. Novità della Ricerca di Base nell’anno 2007 175 4.1. Active Connection Martix (ACM): evoluzioni 176 4.2. Clusterig Dinamico 181 4.3. La Funzione Hubness (H): evoluzioni 183 4.4. SOM Maps 185 4.5. Hidden Input Discovery (HID) 188 4.6. Meta–Classificatori modelli e software 189 4.7. Multidimensional Scaling modelli e software 197 4.8. Semantic Connection Map 198
5. Pubblicazioni scientifiche 201
6. Attività di formazione 213
7. Collaborazioni e brevetti 215 7.1. Collaborazioni e cooperazioni istituzionali 215 7.2. Elenco dei brevetti 218
8. Partecipazione a conferenze e convegni 221


9
1. Presentazione del Semeion
Il Centro Ricerche Semeion è un Ente Scientifico senza scopo di lucro, fondato nel 1985, con personalità giuridica riconosciuta nel 1991 dal Ministero dell’Università e della Ricerca (MIUR). Dal 2005 è diventato Istituto Scientifico Speciale del MIUR.
L’attività istituzionale del Semeion è suddivisa in tre ambiti: - ricerca di base e sperimentale nel campo dell’intelligenza
artificiale, volta a scoprire e sperimentare nuovi modelli matematici e algoritmi con particolare riferimento ai Sistemi Artificiali Adattivi;
- ricerca applicata effettuata attraverso la realizzazione di progetti in biomedicina, sicurezza sociale, imaging, economia e finanza;
- formazione di giovani ricercatori, attraverso corsi, seminari e stage, nel campo dell’intelligenza artificiale con particolare attenzione ai nuovi modelli di Reti Neurali Artificiali e Algoritmi Evolutivi e alle procedure di applicazione per risolvere problemi complessi.
L’attività di ricerca sviluppata in ognuno di questi tre ambiti si materializza producendo una serie di oggetti concreti:
- la ricerca di base e sperimentale si concretizza attraverso la realizzazione di scoperte che vengono diffuse nella comunità scientifica tramite la pubblicazione di articoli scientifici e libri, e che spesso pongono le basi per la registrazione di brevetti;
- la ricerca applicata si concretizza tramite la realizzazione di progetti in diversi campi applicativi nei quali i Sistemi Artificiali Adattivi possono portare nuove conoscenze e realizzazione di know-how, i progetti più innovativi e competitivi diventano brevetti sfruttabili dal mondo dell’industria;
- la formazione si realizza attraverso corsi, seminari e stage, che consentono a neolaureati in diverse discipline (informatica, ingegneria, fisica, matematica, medicina, statistica, ecc.) di acquisire nuove competenze nell’ambito del vasto campo dell’Intelligenza Artificiale.

10
Lo schema seguente illustra le diverse ramificazioni dell’attività di ricerca scientifica del Semeion.
Attività di Ricerca
del Semeion
Ricerca di Base e Sperimentale
Ricerca Applicata Formazione
Scoperte e Brevetti
Software di Ricerca
Pubblicazioni Articoli scientifici
Libri
Partecipazione a
convegni
Progetti e Software
applicativo
Seminari Corsi Stage
Nell’organizzazione generale delle attività di ricerca il tempo dedicato alla ricerca di base e sperimentale corrisponde a circa il 60% delle risorse umane in organico al Semeion. Le scoperte e il software di ricerca, che viene parallelamente sviluppato a scopo sperimentale, i brevetti e le pubblicazioni scientifiche, sia libri che articoli scientifici, sono gli oggetti con i quali la ricerca di base comunica i risultati del proprio lavoro alla comunità scientifica. La partecipazione a conferenze e convegni, inoltre, misura il livello di interesse che la comunità scientifica attribuisce al lavoro svolto dai ricercatori del Semeion.
La ricerca applicata, che può essere definita come un insieme di procedure organizzate al fine di verificare il dominio di validità e l’utilità di una teoria, dipende dalla ricerca di base. Ha il compito di verificare la possibilità di sviluppare tecnologie che abbiano la consistenza dei prototipi. Essa misura il grado di sfruttamento di una teoria sul piano della sua utilità economica e sociale. Durante l’attività di ricerca applicata si realizzano i progetti e si costruiscono i

11
prototipi. All’interno del Semeion l’attività di ricerca applicata impegna circa il 30% delle risorse umane.
La formazione, infine, che comprende anche gli stage formativi, nella pianificazione delle attività istituzionali del Semeion, si può definire un’attività di divulgazione scientifica, con intento didattico. Ha lo scopo di formare i nuovi ricercatori nel campo dell’Intelligenza Artificiale e occupa circa il 10% delle risorse umane del Semeion.
L’equipe del Semeion è composta globalmente da 21 persone. Il nucleo centrale è composto di 10 ricercatori di provenienza multidisciplinare: informatici, ingegneri, fisici, economisti e medici. Ognuno è impegnato, con diversi livelli di coinvolgimento, nella ricerca di base, sperimentale e applicata. A questi si aggiungono 6 ricercatori associati e 3 ricercatori esterni che occasionalmente collaborano all’attività del Centro. Le altre due persone gestiscono l’amministrazione e la segreteria.
Nel corso di questi ultimi anni il lavoro dei ricercatori del Semeion ha prodotto numerose scoperte nel campo dell’Intelligenza Artificiale, alcune delle quali sono state brevettate in collaborazione con aziende interessate al loro sfruttamento economico. Nei laboratori del Semeion sono stati ideati, progettati e sperimentati nuovi modelli di Sistemi Artificiali Adattivi (Reti Neurali, Algoritmi Evolutivi, Sistemi di analisi e pre-processamento dei dati), e sono stati sviluppati programmi informatici finalizzati alla sperimentazione di questi modelli. L’attività di ricerca si è concretizzata in oltre 200 pubblicazioni di articoli scientifici su riviste internazionali, 20 libri monografici e 14 brevetti internazionali.
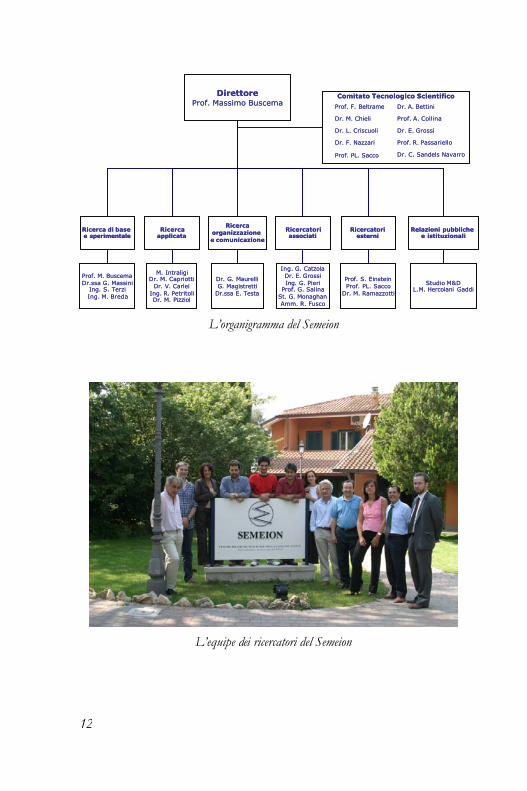
Nel 2007 si è costituito un Comitato Tecnologico Scientifico, composto da diverse personalità del mondo della ricerca sia di ambito pubblico che privato. Il Comitato si riunisce tre volte all’anno e ha una funzione consultiva nell’ottica di contribuire ad orientare l’attività di ricerca di base e applicata che il Semeion svolge. L’organigramma dei componenti del Semeion è così strutturato.
12
DirettoreProf. Massimo Buscema
Comitato Tecnologico Scientifico
Dr. C. Sandels NavarroProf. PL. Sacco
Prof. R. PassarielloDr. F. Nazzari
Dr. E. GrossiDr. L. Criscuoli
Prof. A. CollinaDr. M. Chieli
Dr. A. BettiniProf. F. Beltrame
Relazioni pubbliche e istituzionali
Ricerca di base e sperimentale
Ricercaapplicata
Ricercaorganizzazione e comunicazione
Ricercatoriassociati
Ricercatoriesterni
Prof. M. BuscemaDr.ssa G. Massini
Ing. S. TerziIng. M. Breda
M. IntraligiDr. M. Capriotti
Dr. V. CarleiIng. R. PetritoliDr. M. Pizziol
Dr. G. MaurelliG. Magistretti
Dr.ssa E. Testa
Ing. G. CatzolaDr. E. GrossiIng. G. Pieri
Prof. G. SalinaSt. G. MonaghanAmm. R. Fusco
Prof. S. EinsteinProf. PL. Sacco
Dr. M. Ramazzotti
Studio M&DL.M. Hercolani Gaddi
DirettoreProf. Massimo Buscema
Comitato Tecnologico Scientifico
Dr. C. Sandels NavarroProf. PL. Sacco
Prof. R. PassarielloDr. F. Nazzari
Dr. E. GrossiDr. L. Criscuoli
Prof. A. CollinaDr. M. Chieli
Dr. A. BettiniProf. F. Beltrame
Relazioni pubbliche e istituzionali
Ricerca di base e sperimentale
Ricercaapplicata
Ricercaorganizzazione e comunicazione
Ricercatoriassociati
Ricercatoriesterni
Prof. M. BuscemaDr.ssa G. Massini
Ing. S. TerziIng. M. Breda
M. IntraligiDr. M. Capriotti
Dr. V. CarleiIng. R. PetritoliDr. M. Pizziol
Dr. G. MaurelliG. Magistretti
Dr.ssa E. Testa
Ing. G. CatzolaDr. E. GrossiIng. G. Pieri
Prof. G. SalinaSt. G. MonaghanAmm. R. Fusco
Prof. S. EinsteinProf. PL. Sacco
Dr. M. Ramazzotti
Studio M&DL.M. Hercolani Gaddi
L’organigramma del Semeion
L’equipe dei ricercatori del Semeion

13
1.1 Componenti del Semeion
Prof. Massimo Buscema (1955): Direttore della Ricerca. Computer scientist, fa ricerca da anni sulle Reti Neurali Artificiali e sui Sistemi Artificiali Adattivi. È stato professore presso alla University of Charleston (West Virginia-USA) e direttore del “Department of Science of Communications” della stessa università, è stato, inoltre, professore di “Informatica e Linguistica” presso l’Università di Perugia. Membro dell’Editorial Board di diverse riviste scientifiche internazionali. Ha ideato, costruito e sviluppato nuovi modelli e algoritmi d’intelligenza artificiale. È autore di numerose pubblicazioni scientifiche sugli aspetti teorici della Natural Computation con oltre 150 titoli: articoli scientifici, saggi e libri sullo stesso tema. Inventore di 14 brevetti internazionali. Ricerca di Base e Sperimentale Dr.ssa Giulia Massini (1957): Ricercatore Senior, informatica, svolge attività di ricerca sui Sistemi Artificiali Adattivi. Si occupa dell’applicazione della Neural Computation in prevalenza in ambito sociale e medico. Ha ideato e sviluppato nuovi algoritmi adattivi e software di ricerca, è autrice di numerose pubblicazioni scientifiche. Ing. Stefano Terzi (1970): Ricercatore Senior, ingegnere elettronico, ha sviluppato software di ricerca implementando modelli di Reti Neurali Artificiali e di algoritmi evolutivi, per l’applicazione al campo medico e della sicurezza. Autore di diverse pubblicazioni scientifiche. Ing. Marco Breda (1962): Ricercatore Senior, ingegnere elettronico, ha lavorato in importanti aziende nel settore delle telecomunicazioni (Telecom, Ericsson). Opera come ricercatore presso il Semeion dove si occupa di ricerca di base, contribuendo a diverse pubblicazioni e alla produzione di alcuni pacchetti applicativi. Ricerca Applicata Marco Intraligi (1959): Ricercatore Senior, informatico, esperto in tecniche di preprocessing ed elaborazioni di dati con i Sistemi Artificiali Adattivi. Autore di articoli scientifici sulle applicazioni di

14
modelli artificiali nell’ambito della diagnostica clinica e dei sistemi di trattamento dell’imaging biomedicale. Dr. Massimiliano Capriotti (1964): Ricercatore, informatico, esperto nell’applicazione dei modelli d’intelligenza artificiali al campo della sicurezza e della medicina. Autore di pubblicazioni scientifiche. Ing. Riccardo Petritoli (1970): Ricercatore, ingegnere elettronico, ha sviluppato software applicativi in ambito medico implementando modelli di Reti Neurali Artificiali. È esperto in tecniche di analisi di imaging biomedicale. Autore di pubblicazioni scientifiche. Dr. Marco Pizziol (1980): Ricercatore, laureato in fisica presso l’Università degli Studi di Roma “Tor Vergata”, lavora nell’ambito della ricerca e sviluppo di sistemi adattivi applicati in campo biomedico. Organizzazione e Comunicazione della Ricerca Dr. Guido Maurelli (1957): Ricercatore, laureato in lettere e filosofia, Responsabile della comunicazione. È esperto nell’applicazione dei Sistemi Artificiali Adattivi al campo sociale. Ha pubblicato articoli e saggi su libri e riviste scientifiche internazionali. Si occupa della divulgazione scientifica delle attività di ricerca del Semeion. Dr.ssa Ester Testa (1972): segreteria organizzativa, laureata in Scienze Politiche, si occupa dell’organizzazione interna delle attività del Semeion. Giancarlo Magistretti (1969): ragioniere, responsabile dell’ammini-strazione del Semeion. Ricercatori Associati Ing. Gino Catzola (1953): Ricercatore Associato, ingegnere elettronico, specializzato in Program Management, Computer Science, e Sistemi Dinamici Complessi. Ha lavorato per importanti aziende multinazionali per i mercati Difesa, Spazio, Telecomunicazioni (TIM, Digital Equipment, Alenia Spazio). Attualmente è in Telecom Italia. Collabora all’attività di ricerca del Semeion sui Sistemi Dinamici Complessi, Reti Neurali Artificiali e Intelligenza Artificiale. Dr. Enzo Grossi (1951): Ricercatore Associato, medico, attualmente Direttore Medico della Bracco SpA, Dipartimento Farma Italia. Ha

15
lavorato come manager nell’ambito della Ricerca e Sviluppo di diverse aziende multinazionali del settore medico farmaceutico (Menarini, Ciba Geigy, Beecham-Smith Kline & Beecham). Autore di circa 300 pubblicazioni scientifiche su riviste mediche. Membro di diverse società scientifiche e di board scientifici di riviste internazionali. Collabora all’attività di ricerca del Semeion, contribuendo attraverso numerose pubblicazioni. Ing. Giovanni Pieri (1938): Ricercatore Associato, ingegnere chimico, attualmente è consulente per il trasferimento tecnologico presso imprese e enti pubblici. È stato direttore del Centro Ricerche G. Donegani (Montedison/ENI). Ha pubblicato articoli scientifici sulla fisica delle apparecchiature chimiche. Dr. Vittorio Carlei (1972): Ricercatore Associato, Phd in economia, è Direttore della 2C-srl, una spin-off del Semeion, che opera nell’ambito della business innovation, applicando sistemi intelligenti in campo economico e finanziario per grandi gruppi bancari (Santander, Unicredit). Prof. Gaetano Salina (1960): Ricercatore Associato, Primo Ricercatore dell’Istituto Nazionale di Fisica Nucleare, lavora nella sezione di Roma “Tor Vergata”. I suoi principali campi di interesse sono: computers massivamente paralleli, reti neuronali, elettronica digitale ed analogica (VLSI), meccanica statistica e teoria dei campi. St. Geoff Monaghan (1954): Ricercatore Associato, detective, ha lavorato 25 anni presso nella Metropolitan Police Service di Londra, Scotland Yard, con un’esperienza internazionale nelle strategie di contrasto al traffico di droga. Attualmente è consulente dell’United Nations Office on Drugs and Crime (UNODC) sede di Mosca. Ammiraglio Roberto Fusco (1946): Ricercatore Associato, attualmente è ufficiale ammiraglio della Marina Militare in congedo. Ha percorso l’intera carriera di ufficiale di Stato Maggiore fino al massimo grado di Ammiraglio di Squadra. Laureato in “Scienze marittime e navali”, specializzato in “guerra elettronica” e “telecomunicazioni”. Ha assolto numerosi incarichi di comando navale. Dal 2007 collabora come esperto militare con il Semeion.

16
Ricercatori Esterni Prof. Stanley Einstein (1934): Psicologo clinico e sociale, da molti anni specializzato nel campo delle tossicodipendenze, con particolare riferimento ai problemi di uso ed abuso di droghe. Autore di 14 libri, fondatore ed Editor in Chief della rivista internazionale sulle droghe “Substance Use & Misure” pubblicata da oltre 40 anni, e di altre riviste su problemi sociali come “Violence, Aggression & Terrorism”. Direttore del Middle Eastern Summer Institute on Drug Use, Jerusalem. Prof. Pierluigi Sacco (1964): Professore Ordinario di Politica Economica presso l’Università IUAV di Venezia. Prorettore alla Comunicazione e alle attività editoriali della IUAV. Scrive per il Sole24Ore. Ha pubblicato numerosi articoli e saggi scientifici nel campo della teoria economica, della teoria dei giochi e dell’economia della cultura. Dr. Marco Ramazzotti (1969): Archeologo, Ricercatore presso la Cattedra di “Archeologia e Storia dell’Arte del Vicino Oriente Antico”. È stato fra i primi archeologi che ha applicato modelli matematici (Reti Neurali, Algoritmi Evolutivi) allo studio di database archeologici, pubblicando diversi articoli su importanti riviste del settore. Comitato Tecnologico Scientifico Prof. Francesco Beltrame (1953): Professore Ordinario di Bioingegneria, Dipartimento di Informatica, Sistemistica e Telematica della Facoltà di Ingegneria dell’Università degli Studi di Genova. Direttore del Dipartimento di Tecnologie dell’Informazione e delle Comunicazioni del CNR. Presidente del Comitato Tecnico Scientifico del MUR per la ricerca industriale (legge 297/99). Dr. Andrea Bettini (1953): Manager e consulente di direzione, ha ricoperto ruoli dirigenziali in numerose aziende operanti in diversi settori: informatica, servizi, formazione professionale (Apple Computer Italia, Sodexho Pass, MrTed Italy, Irescogi, Fondazione Consulenti per il Lavoro). Attualmente è partner associato di Boyden International. Dr. Massimo Chieli (1950): Presidente di Alitalia Express e Consulente Aziendale. È autore di articoli e pubblicazioni su temi di

17
organizzazione e di service management e svolge docenze in corsi di formazione e master aziendali e universitari. Prof. Amilcare Collina (1939): Ingegnere chimico, è stato Professore al Politecnico di Milano, per 25 anni ha lavorato nel settore Ricerca & Sviluppo della Montedison con diversi livelli di responsabilità fino ad arrivare a ricoprire il ruolo di Capo dell’Ufficio Tecnologico dell’intero Gruppo. Dal 1994 lavora nel Gruppo Mapei, attualmente è Advisor del CEO per la ricerca e l’innovazione. È membro del Board Ricerca ed Innovazione del Cefic (European Chemical Industry Council). Dr. Luciano Criscuoli (1950): Direttore Generale per il Coordinamento e lo Sviluppo della Ricerca del Ministero dell’Università e della Ricerca dal 1999. È membro permanente di numerose commissioni di studio per l’attuazione delle politiche di intervento nel settore della ricerca. Ricopre incarichi istituzionali di rappresentanza del Ministero nelle sedi nazionali e internazionali. Ha curato la definizione di nuove specifiche normative di settore, e di documenti di programmazione del Ministero per l’attuazione di interventi finalizzati al potenziamento e al sostegno della ricerca (PNR, Linee Guida per la Politica Scientifica e Tecnologica del Governo, PON per il Mezzogiorno, ecc). Dr. Enzo Grossi (1951): già descritto nei ricercatori associati. Dr. Federico Nazzari (1942): Manager nel settore dell’industria Farmaceutica ha svolto le sue mansioni in aziende multinazionali ricoprendo importanti ruoli dirigenziali (Vice Direttore Generale Upjohn SpA, AD della Maggioni Winthrop, Presidente e AD dell’Istituto Luso Farmaco d’Italia SpA. Dal 2000 al 2007 ha operato in Bracco come Group Vice President General Affairs. È stato Presidente di Farmindustria per tre mandati, di cui due consecutivi il terzo nel 2003. Dal febbraio 2007 è entrato nel Consiglio di Recordati SpA con delega per i rapporti istituzionali. Prof. Roberto Passariello (1941): Professore Ordinario di Radiologia e Direttore dell’Istituto di Radiologia dell’Università degli Studi di Roma “La Sapienza”. Autore o co-autore di 10 libri e di oltre 500 pubblicazioni scientifiche, molte delle quali su riviste internazionali. Autore di più di 600 Conferenze, comunicazioni, relazioni su invito e moderazioni a Tavole Rotonde in Italia e all’Estero. Membro

18
Onorario di numerose società scientifiche fra cui: Radiological Society of North America, European Association of Radiology, Cardiovascular and Interventional Society of Europe, Royal College of Radiology. Prof. Pierluigi Sacco (1964): già descritto nei ricercatori associati. Dr. Cristiano Sandels Navarro (1960): Project & Business Manager, si occupa di progetti di sviluppo, organizzazione e gestione aziendale. Ha lavorato nell’ambito della comunicazione, marketing e consulenza aziendale. Collabora con l’Università di Milano con docenze sulla sostenibilità energetica e ambientale. Ha contribuito alla stesura dei contenuti del programma per la candidatura di Milano per l’EXPO 2015. Relazioni pubbliche e istituzionali Luciana Marcellini Hercolani Gaddi (1948): Public & Institutional Relations, fondatrice dello Studio M&D, che svolge tutte le attività necessarie a favorire il contatto e la messa in relazione fra aziende pubbliche, private ed istituzioni. I settori dove lo Studio prevalentemente opera sono quelli della Ricerca, dell’Aeronautica, della Manutenzione. Collabora con il Semeion dal 2005. 1.2 I campi d’interesse della ricerca
L’attività di ricerca del Semeion nelle sue componenti, ricerca di base, ricerca sperimentale e ricerca applicata, ha investito, nel tempo, diversi campi d’interesse. Nel corso degli anni, come è ovvio per un centro ricerche, l’interesse ha subito modifiche determinate essenzialmente da mutate condizioni storico-scientifiche. Queste trasformazioni d’interesse sono state orientate principalmente da due spinte parallele: a) un lavoro di ricerca scientifica sempre più orientato a studiare e
comprendere le logiche di funzionamento dei fenomeni complessi;
b) un’attenzione al contesto storico relativamente allo sviluppo delle dinamiche socio-culturali e alle diverse manifestazioni del mondo naturale.
In questa prospettiva l’esplicitazione dei campi di interesse nei quali la ricerca del Semeion si è sviluppata dalla sua fondazione ad oggi,

19
consentirà di comprendere l’evoluzione scientifica e storica del centro. I campi sono: 1. prevenzione sociale e sanitaria (dal 1985); 2. settore aziendale e industriale (dal 1987); 3. settore scolastico ed educativo (dal 1990); 4. ambiente e territorio (dal 1995); 5. economia e finanza (dal 1996); 6. mondo del lavoro e orientamento professionale (dal 1998); 7. settore medico, biologico e farmaceutico (dal 2000); 8. settore della sicurezza sociale e dei fenomeni criminali (dal
2000).


Piano Triennale Ricerca di Base (2008-2010)
di Massimo Buscema


23
2. Piano Triennale Ricerca di Base (2008-2010) Prima di entrare nella descrizione delle diverse attività svolte dai
ricercatori, è utile fornire una breve definizione di come il Semeion concepisce la ricerca di base e sperimentale
La ricerca di base consiste nella formulazione di teorie adeguatamente formalizzate (linguaggio matematico e/o equivalente implementabile su computer) e nella loro sperimentazione.
Ricerca di base e sperimentale sono due facce della stessa medaglia: la prima senza la seconda è non falsificabile e, quindi, incontrollabile, la seconda senza la prima è un’attività disordinata. La formulazione di teorie e la loro sperimentazione costituiscono i fondamenti della ricerca di base, così come da anni mostra la fisica.
La ricerca di base e quella sperimentale permettono le scoperte fondamentali. Le scoperte fondamentali sono quelle che ridisegnano i criteri con i quali si produce la conoscenza scientifica. Si tratta, quindi, di scoperte che non si limitano ad accrescere la conoscenza scientifica, ma che permettono nel tempo un progresso scientifico forte ed improvviso e un conseguente ritorno esponenziale degli investimenti. Le scoperte incrementali, invece, sono quelle che perfezionano e/o specificano, in un ambito sperimentale o applicativo particolare, le scoperte fondamentali. La ricerca di base si valuta in relazione alla produttività delle scoperte fondamentali e incrementali, e in base al numero di applicazioni tecnologiche che essa permette nel tempo.
La ricerca di base e quella sperimentale, così concepite, sono fra le attività principali del Semeion, all’interno dei settori dell’attività istituzionale. Si tratta delle attività che costituiscono il motore del lavoro di ricerca che si manifesta successivamente sotto diversi aspetti.
La ricerca di base è il luogo di riferimento teorico in relazione al quale la ricerca applicata pianifica la realizzazione dei progetti. È il laboratorio dove si sperimentano nuove teorie e si costruiscono nuovi modelli e algoritmi, realizzando programmi informatici di ricerca che hanno come scopo una pura funzione sperimentale.

24
2.1 Teoria Generale dei Sistemi Artificiali Adattivi
I Sistemi Artificiali Adattivi (AAS) fanno parte del vasto mondo della Natural Computation (NC). La Natural Computation (NC) è un sottoinsieme delle Artificial Sciences (AS).
Con Artificial Science si intendono quelle scienze per le quali la comprensione dei processi naturali e/o culturali si realizza tramite la ricreazione di quei processi stessi per mezzo di modelli automatici.
Nelle AS il computer è ciò che la scrittura rappresenta per la lingua naturale: le AS sono costituite da algebre formali per la generazione di modelli artificiali (strutture e processi), nello stesso modo in cui le lingue naturali sono costituite di una semantica, di una sintassi e di una pragmatica per la generazione di testi.
Nelle lingue naturali la scrittura è la conquista dell’indipendenza della parola dal tempo, tramite lo spazio; nelle AS il computer è la conquista dell’indipendenza del modello dal soggetto, tramite l’automazione.
Così come, tramite la scrittura, una lingua naturale può creare oggetti culturali che prima della scrittura erano impensabili (romanzi, testi giuridici, manuali, ecc.) allo stesso modo le AS, tramite il computer, possono creare modelli automatici di impensabile complessità.
Lingue naturali e Artificial Sciences, senza la scrittura e il computer, restano quindi limitate. Ma una scrittura non basata su una lingua naturale, o un modello automatico non generato da un’algebra formale, è un insieme di scarabocchi (vedi schema nella pagina successiva).
Nelle AS la comprensione di un qualsiasi processo naturale e/o culturale avviene in modo proporzionale alla capacità del modello artificiale automatico di ricreare quel processo. Più la comparazione tra processo originale e modello generato da esito positivo, più è probabile che il modello artificiale abbia esplicitato le regole di funzionamento del processo originale.
Questo confronto, tuttavia, non può essere effettuato in modo ingenuo. Sono necessari sofisticati strumenti di analisi per effettuare una comparazione attendibile tra processo originale e modello artificiale.

25
Artificial Sciences
Algebre Formali
Modelli Artificiali Automatici
Analisi
Generazione Comparazione
Processi Naturali e Culturali
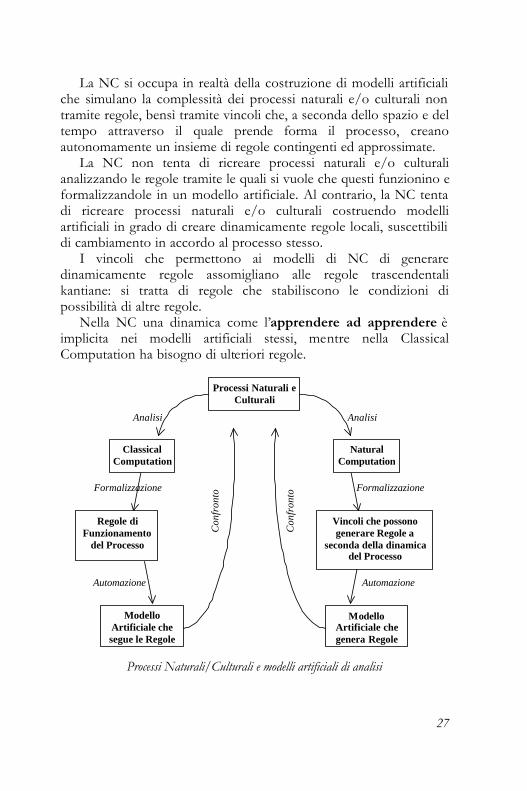
Il grafico mostra come l’analisi dei Processi Naturali e/o Culturali, che si vuole comprendere, parte da una teoria, che adeguatamente formalizzata (Algebre Formali), è in grado di generare Modelli Artificiali Automatici di quei Processi Naturali e/o Culturali. Infine, i Modelli Artificiali Automatici generati devono essere comparati con i Processi Naturali e/o Culturali di cui pretendono esserne il modello e la spiegazione.
La maggioranza degli strumenti di analisi utili per questa comparazione consiste nel confrontare le dinamiche del processo originale e quelle del modello artificiale al variare delle rispettive condizioni al contorno.
In modo sintetico si potrebbe argomentare che: 1. più, al variare delle condizioni al contorno, si ottengono varietà di dinamiche
di risposta sia nel processo originale che nel modello artificiale; e
2. più queste dinamiche tra processo originale e modello artificiale sono omologhe,
allora 3. più è probabile che il modello artificiale sia una buona spiegazione del
processo originale. Nella figura che segue proponiamo un albero tassonomico per la
caratterizzazione delle discipline che, attraverso la Natural Computation e la Classic Computation, compongono il sistema delle Artificial Sciences:

26
Con Natural Computation (NC) si intende quella parte delle Artificial Sciences (AS) che tenta di costruire modelli automatici di processi naturali e/o culturali tramite l’interazione locale di microprocessi non isomorfi al processo originale. Nella NC si assume quindi che: 1. qualsiasi processo sia il risultato, più o meno contingente, di
processi più elementari che tendono ad auto-organizzarsi nel tempo e nello spazio;
2. nessuno dei microprocessi è di per sé informativo circa la funzione che assumerà rispetto agli altri, né del processo globale di cui sarà parte.
Artificial Sciences
Natural Computation Classic Computation
Programming Theory Computer Models Microelectronis Digital Systems
Operative Systems Programming Languages Software Engineering Computer Architectures Compilers Data Base
Real Time Systems Distributed Systems Telematics
Images Acquisition Images Management Images Processing Graphics Systems
Descriptive Systems Generative Systems
Dynamic Systems Theory Dissipative Systems Theory Autopoietic Systems Theory Probabilistic Theory Catastropher Theory Chaos Theory Evidence Theory Fuzzy Logic ………………. ……………….
Physical Systems Adaptive Systems
Evolutionary
Systems
Learning Systems
(Artificial Neural Networks)
…………………. …………………. ………………….
Albero tassonomico delle discipline che compongono il sistema delle Artificial Sciences
Questa filosofia computazionale, poco economica per la creazione di modelli semplici, può essere utilizzata efficacemente per creare qualsiasi tipo di processo o modello che si ispiri a processi complessi, ossia a processi di fronte ai quali le filosofie classiche hanno trovato notevoli inconvenienti.
27
La NC si occupa in realtà della costruzione di modelli artificiali che simulano la complessità dei processi naturali e/o culturali non tramite regole, bensì tramite vincoli che, a seconda dello spazio e del tempo attraverso il quale prende forma il processo, creano autonomamente un insieme di regole contingenti ed approssimate.
La NC non tenta di ricreare processi naturali e/o culturali analizzando le regole tramite le quali si vuole che questi funzionino e formalizzandole in un modello artificiale. Al contrario, la NC tenta di ricreare processi naturali e/o culturali costruendo modelli artificiali in grado di creare dinamicamente regole locali, suscettibili di cambiamento in accordo al processo stesso.
I vincoli che permettono ai modelli di NC di generare dinamicamente regole assomigliano alle regole trascendentali kantiane: si tratta di regole che stabiliscono le condizioni di possibilità di altre regole.
Nella NC una dinamica come l’apprendere ad apprendere è implicita nei modelli artificiali stessi, mentre nella Classical Computation ha bisogno di ulteriori regole.
Processi Naturali e Culturali
Vincoli che possono generare Regole a
seconda della dinamica del Processo
Regole di Funzionamento
del Processo
Natural Computation
Classical Computation
Modello Artificiale che segue le Regole
Modello Artificiale che genera Regole
Analisi Analisi
Formalizzazione Formalizzazione
Automazione Automazione
Con
fron
to
Con
fron
to
Processi Naturali/Culturali e modelli artificiali di analisi

28
Il grafico mostra in modo più dettagliato la formalizzazione, l’automazione e il confronto tra Processi Naturali e/o Culturali e Modelli Artificiali Automatici visti dai due punti di vista (Classical Computation e Natural Computation). Ciascun punto di vista può essere visto come un ciclo che può ripetersi più volte. Da cui si può desumere che il processo scientifico umano che caratterizza entrambi i cicli, assomiglia più a quello della Natural Computation che non a quello della Classical Computation. Della Natural Computation fanno parte:
- Sistemi Descrittivi (SD): si intendono quelle discipline che hanno sviluppato, intenzionalmente o meno, algebre formali che si sono rivelate particolarmente efficaci nell’elaborare opportuni vincoli di funzionamento di modelli artificiali generati all’interno della NC (ad esempio: la Teoria dei Sistemi Dinamici, la Teoria dei Sistemi Autopoietici, la Fuzzy Logic, ecc.).
- Sistemi Generativi (SG): si intendono quelle teorie di NC che hanno previsto esplicitamente delle algebre formali orientate a generare modelli artificiali di processi naturali e/o culturali tramite vincoli che creano regole dinamiche nello spazio e nel tempo.
A loro volta i Sistemi Generativi possono essere distinti in: - Sistemi Fisici (SF): si intende raggruppare quelle teorie di
Natural Computation le cui algebre generative creano modelli artificiali comparabili con processi materiali e/o culturali, solo quando il modello artificiale raggiunge determinati stadi evolutivi (tipo cicli limite). Mentre non necessariamente il percorso tramite il quale i vincoli generano il modello è esso stesso un modello del processo del processo di origine. In breve, in questi sistemi il tempo di generazione del modello non è necessariamente un modello artificiale di evoluzione del tempo del processo (ad esempio: la Geometria dei Frattali, ecc.).
- Sistemi Artificiali Adattivi (AAS): si intendono quelle teorie della Natural Computation le cui algebre generative creano modelli artificiali di processi naturali e/o culturali, il cui processo di nascita del processo è esso stesso un modello artificiale comparabile con la nascita del processo di origine. Si

29
tratta, quindi, di teorie che assumono il tempo di emergenza del modello come un modello formale del tempo del processo stesso.
In breve: per queste teorie, ogni fase di generazione artificiale è un modello comparabile ad un processo naturale e/o culturale.
I Sistemi Artificiali Adattivi a loro volta comprendono: - Learning Systems (Artificial Neural Networks - ANNs): si
intendono algoritmi per l’elaborazione di informazioni che permettono di ricostruire in modo ottimo qualsiasi funzione continua che interpola un certo insieme di dati campionati da un qualsiasi processo, generando autonomamente un propria rappresentazione interna del processo stesso. Siccome l’apprendimento può essere definito come la strategia con cui un soggetto si auto-manipola per annullare il tempo che ha impiegato, tramite prove ed errori, a capire le regole di un processo nuovo, allora si sostenere che questi algoritmi “apprendono dai dati” e quindi, per ricorsione, possono in generale apprendere ad apprendere.
- Evolutionary Systems (ES): si intende la generazione di sistemi adattivi che mutano nel tempo la loro architettura e le loro funzioni per adattarsi all’ambiente nel quale sono inseriti, ovvero per adeguarsi ai vincoli e alle regole che definiscono il loro ambiente e, quindi, il problema da simulare. Fondamentalmente, si tratta di sistemi che si evolvono per trovare dati e/o regole ottime all’interno di vincoli e/o regole determinate staticamente e dinamicamente.
- L’evoluzione di un genotipo da un tempo ti ad un tempo t(i+n) è un buon esempio di evoluzione nel tempo della architettura e delle funzioni di un sistema adattivo.

30
Artificial Adaptive Systems
Artificial Neural Networks Evolutionary Programming
min f ( x ) g i ( x ) ≥ 0 h i ( x ) = 0 Associative Memor ies
x = f ( x , w* ) w ii = 0
AutoPoietic ANN
y ( n+ 1 ) = f ( x ,y ( n ) , w* )
Tools & Algorithms
• Genetic Algorithms • Genetic Programming • Natural Algorithm • Simulated Annealing • Evolutionary Strategies • etc..
Goal linear and non linear optimization
Space / Time Prediction
Values Estimation
Classifications ( Patterns Recognition )
- Multinomial - Binomial
Intelligent Data Mining
CAM
Dynamics Scenarios’ Simulation
Patterns Reconstruction
Natural Clustering
Data Preprocessing
Self Classification
Mapping
From Data to ( optimal ) Rules From Parameters , Rules , or Constraints to ( optimal ) Data
SuperVised ANN
y = f ( x , w* )
Artificial Adaptive Systems
Artificial Neural Networks Evolutionary Programming
min f ( x ) g i ( x ) ≥ 0 h i ( x ) = 0 Associative Memor ies
x = f ( x , w* ) w ii = 0
AutoPoietic ANN
y ( n+ 1 ) = f ( x ,y ( n ) , w* )
Tools & Algorithms
• Genetic Algorithms • Genetic Programming • Natural Algorithm • Simulated Annealing • • etc..
Goal linear and non linear optimization
Space / Time Prediction
Values Estimation
Classifications ( Patterns Recognition )
- Multinomial - Binomial
Intelligent Data Mining
CAM
Dynamics Scenarios’ Simulation
Patterns Reconstruction
Natural Clustering
Data Preprocessing
Self Classification
Mapping
From Data to ( optimal ) Rules From Parameters , Rules , or Constraints to ( optimal ) Data
SuperVised ANN
y = f ( x , w* )
Schema generale degli Artificial Adaptive Systems Lo stato dell’arte al Semeion Il Semeion effettua ricerca di base all’interno dei Sistemi Artificiali Adattivi: 1. Inventa sistemi di equazioni; 2. Analizza e implementa su computer tali sistemi di equazioni
sotto forma di algoritmi; 3. Sperimenta e valuta, secondo complessi protocolli, i nuovi
algoritmi in situazioni reali; 4. Propone l’utilizzazione di tali algoritmi per risolvere problemi di
carattere istituzionale (bene comune) e/o economico (imprese). In poche parole, il compito del Semeion nel campo della scienza
consiste nel “produrre nuove conoscenze e tradurle in valore sociale e/o economico” (F. Beltrame).
Fornire una teorizzazione e una formalizzazione robusta del campo dei Sistemi Artificiali Adattivi fa parte del lavoro di ricerca teorica del Semeion: capire meglio le articolazioni del proprio mondo di ricerca permette di gestire meglio le attività di ricerca attuali e progettare meglio la loro crescita futura.

31
A tale scopo si è dato vita a un processo teorico ed analitico il cui scopo è definire in modo formale e rigoroso un modello generativo dei Sistemi Artificiali Adattivi: dal Nodo (Neurone Artificiale) alla Rete e dalla Rete all’Organismo Artificiale. Ricercatori impegnati: Massimo Buscema, Giulia Massini, Stefano Terzi, Marco Breda, Luigi Catzola.

32
2.2 La Sintassi delle immagini: le informazioni nascoste Active Connection Matrix (ACM)
Il problema Ogni Immagine digitale o digitalizzata è composta di Pixels. I
Pixels sono i mattoni di ogni Immagine vista tramite computer. La posizione (x,y) e il valore di ognuno dei Pixels di una Immagine (in molti casi da 0 a 255: 0=Nero, 255=Bianco, per le Immagini a toni di grigio) caratterizza quella Immagine in modo unico. Quindi, ogni Immagine è una matrice di numeri, ognuno posto in modo strategico. Ogni volta che si parla di Immagine bisogna distinguere tra: 1. la Sorgente da cui l’Immagine è tratta (in genere l’oggetto reale); 2. lo Sfondo in cui la Sorgente è inserita e che viene riprodotto
insieme alla Sorgente nell’Immagine stessa; 3. la Macchina tramite la quale l’Immagine è generata a partire
dalla Sorgente e dallo Sfondo; 4. l’Immagine stessa come prodotto della Interazione tra onde
elettromagnetiche, tipo di materia della Sorgente e dello Sfondo, e caratteristiche della Macchina che genera l’Immagine.
Naturalmente, la realizzazione di ogni Immagine dipende da molti fattori, alcuni che dipendono dal tipo di sorgente che si intende ritrarre, altri da condizioni casuali o contigenti: il tipo di illuminazione, l’angolo di ripresa, la taratura della macchina che genera l’immagine, il rumore prodotto dalla macchina stessa, ecc.
In poche parole, generata un Immagine come una matrice di Numeri noti come Pixels, la differenza ogni Pixel ed ogni altro potrà essere: 1. grande ma non significativa, perché frutto di rumore; 2. piccola e non significativa, sempre a causa di rumore; 3. grande e significativa; 4. piccola e significativa.
In ogni Immagine questi quattro casi possono tutti comparire insieme, mescolati nelle differenze di valore tra ogni Pixel ed ogni altro.

33
Il problema della analisi delle Immagini, quindi, è tutto racchiuso in questi quattro punti: quando delle differenze piccole e/o grandi e/o nulle tra Pixels sono significative e quando non lo sono?
Qualsiasi sistema che affronti l’analisi delle Immagini si trova di fronte a questi problemi, sia che sia interessato alla individuazione dei bordi e/o al contorno di una figura, sia che miri alla segmentazione dell’immagine stessa in aree omogenee e significative, oppure sia che intenda analizzare la “texture” dell’immagine stessa. Tutto parte sempre dal valore di ogni Pixel, dalla sua posizione e dalle sue differenze rispetto a tutti gli altri.
Possiamo a questo punto definire contenuto informativo completo di una Immagine l’interazione tra la luminosità di ogni Pixel, la sua posizione nell’immagine e le sue relazioni con tutti gli altri.
Il contenuto informativo di una Immagine esclude il rumore, ma include quella parte di informazioni che una analisi superficiale dell’immagine riconosce come rumore solo perché non in grado di codificarla in modo adeguato.
È necessario a questo punto stabilire una differenza tra contenuto informativo di un’immagine e il suo significato culturale. Il secondo dipende dal primo, ma lo integra con altre conoscenze e abitudini di codifica non presenti nell’immagine né desumibili direttamente da queste, ma dipendenti invece dalla cultura dell’osservatore, dal contesto in cui esso è inserito e dall’uso che intende fare delle informazioni rappresentate dall’immagine. La Sintassi dell’Immagine si occupa solo del contenuto informativo di una Immagine e non del suo significato culturale.
Lo stato dell’arte al Semeion Le Active Connections Matrices (ACM) sono una famiglia di
sistemi artificiali adattivi disegnata dal Semeion a partire dal 2003. Le basi storiche dei sistemi ACM sono negli Cellulars Automata
(CA) e nelle Cellular Neural Networks (CNN). I sistemi ACM rappresentano una evoluzione sostanziale in termini di teoria e di algoritmi di questi ultimi.
I Sistemi ACM sono sistemi di equazioni ricorsive strutturate in specifiche topologie che vengono applicati a basi di dati con

34
topologia pertinente (immagini), allo scopo di rendere visibili tutti i contenuti informativi di tali dati e in particolare quelli che non sono estraibili ne visibili utilizzando l’occhio umano e/o altri sistemi di elaborazione.
I sistemi ACM (Active Connections Matrix) traggono la loro idea di base da alcune considerazioni: 1. In ogni immagine digitale i pixel e le loro relazioni contengono il
massimo dell’informazione disponibile per quella immagine. 2. La posizione che in una immagine ogni pixel occupa rispetto
agli altri, è una informazione strategica per la comprensione del contenuto informativo di quella immagine.
Queste due considerazioni di base sono abbastanza ovvie se considerate a sé stanti, e sono alla base di qualunque elaborazione dell’immagine. Poiché ogni immagine racchiude le informazioni della dinamica di interazione tra un oggetto con la radiazione elettromagnetica che lo investe, ciascuna di esse offre all’apparato della visione umana le informazioni inerenti tale dinamica. L’elaborazione che opera l’apparato della visione umana, tiene conto della intensità luminosa dei pixel e delle reciproche posizioni di ognuno di essi.
In ogni immagine digitale, quindi, ogni pixel ha una posizione P e una luminosità L, ovvero esso è identificabile dalle sue coordinate spaziali e dal valore di luminosità L funzione di esse:
( )( ) M
D LxxxPLPixel 20,.....,, 21 <≤= dove 2M = luminosità massima. La visione umana, però, è in grado di svolgere solo una
elaborazione parziale delle relazioni che ciascun pixel ha con tutti gli altri. Ciò ha come implicazione che alcune informazioni inerenti la dinamica di interazione tra oggetto e luce che lo investe, non risultino visibili all’uomo anche qualora la rilevanza di esse sia significativa.
Alle considerazioni iniziali occorre allora aggiungerne due ulteriori che sono, perciò, peculiari solo dei sistemi ACM: 3. In ogni immagine la luminosità di ogni pixel, la sua posizione

35
nell’immagine e le sue relazioni con gli altri pixel dell’immagine definiscono il contenuto informativo completo di quell’immagine, ovvero della dinamica con cui l’oggetto e il fascio di luce interagiscono.
4. Le relazioni di ogni pixel con gli altri pixel della stessa immagine dipendono dalla dinamica delle connessioni che collegano ogni pixel con i pixel del suo intorno locale. Tale dinamica risente fortemente del modo di interagire dell’oggetto con la luce che lo investe e risulta determinante ai fini dell’evidenziare anche le informazioni che all’apparato visivo umano sfuggono quando osserva l’immagine di partenza assegnata.
Queste considerazioni hanno implicazioni notevoli. La prima consiste nello stabilire una differenza tra contenuto
informativo di un’immagine e il suo significato culturale. Il secondo dipende dal primo, ma lo integra con altre conoscenze e abitudini di codifica non presenti nell’immagine né desumibili direttamente da queste, ma dipendenti invece dalla cultura dell’osservatore, dal contesto in cui esso è inserito e dall’uso che intende fare delle informazioni rappresentate dall’immagine. I sistemi ACM si occupano del contenuto informativo e non del suo significato culturale.
La seconda conseguenza di quanto sostenuto riguarda il processo di generazione del contenuto informativo di una immagine. Si sta sostenendo che il contenuto informativo di un’immagine è il processo tramite il quale i singoli pixel interagiscono localmente e in parallelo nel tempo. Si intende, cioè, dire che il contenuto informativo di un’immagine non è nel processo, né alla fine del processo dell’interazione locale dei suoi costituenti primi (i pixel) ma è il processo stesso. Ciò significa che per visualizzare il contenuto informativo di una singola immagine occorrerebbe scorrere il filmato dell’intero processo di interazione locale tra i pixel. Arrestando il filmato di tale processo si mostrerà una nuova immagine che è una parte ridotta del contenuto informativo dell’immagine di partenza. Si tratterà di definire le condizioni perché un qualsiasi processo di interazione locale dei pixel di un’immagine sia un processo che mostra parte (e quale parte) del contenuto informativo di quell’immagine.

36
In ogni immagine, quindi, l’interazione locale dei suoi pixel nel tempo, è, in certe condizioni, parte del contenuto informativo dell’immagine stessa, contenuto informativo rimasto impresso nei pixel, durante il tempo di esposizione dell’oggetto alla luce che lo ha investito, rappresentativo della loro dinamica di interazione.
La terza conseguenza delle considerazioni precedenti riguarda le connessioni locali di ciascun pixel con i pixel del suo intorno.
Ogni immagine è una rete di pixel connessi localmente. È sufficiente un intorno di raggio 1 per garantire che l’intera immagine sia una rete totalmente connessa di pixel. Questa esigenza di connettività incrementa la dimensionalità di tutti i pixel di una immagine. Se una immagine ha D dimensioni, ogni suo pixel sarà identificato da una posizione specificata da D variabili. Per connettere ogni pixel al suo intorno locale, questi sarà dotato di Q archi (quanti sono i pixel locali ai quali è connesso). Questa nuova architettura situerà ogni pixel in una spazio dimensionale D+1 specificato dalle D variabili di posizione x1, x2, x3, …, xD alle quali si aggiunge la variabile w che identifica gli archi di connessione.
Il nome Matrice Attiva delle Connessioni significa, quindi, che ogni immagine è considerata come una matrice (rete) connessa di elementi (pixel) che si sviluppa nel tempo. Trasformare ogni immagine in una matrice di elementi connessi che attivamente si trasforma nel tempo equivale a rendere visibile il suo contenuto informativo. In altre parole, una immagine anche se appare statica conserva entro di sé tutte le informazioni del proprio contenuto informativo. Quest’ultimo non è statico perché esprime la dinamica delle interazioni locali tra i pixel costituenti l’immagine stessa e per fare ciò ha bisogno di potersi esprimere tramite il tempo: è come se l’immagine di partenza nasconda nel proprio interno un filmato che per poter essere visto deve, ovviamente, scorrere nel tempo.
Nei sistemi ACM alle dimensioni originarie delle immagini vengono, quindi, aggiunte 2 dimensioni nuove: la connessione locale w e il tempo t.
Perciò, la luminosità L, di ogni pixel di un’immagine sarà funzione non solo delle D variabili di posizione x1, x2, x3,…, xD ma anche delle ulteriori due variabili w e t, aumentando le proprie coordinate nel modo seguente:

37
( ) ( )twxxxxPixelxxxxPixel D
ACMD
originale ,,,....,,,,....,,, 321321 → dove: x1, x2, x3,…, xD = coordinate originarie; w = connessioni; t
= tempo. Nei sistemi ACM le coordinate originarie di un’immagine sono
costanti e danno un contributo costante al valore di luminosità L, mentre le connessioni w nel tempo si modificano e direttamente o indirettamente modificano anche la luminosità di ogni pixel nel tempo.
In termini più pratici: data un’immagine bidimensionale di M×N pixel, la sua traduzione nel sistema ACM la trasforma in una matrice di M×N×Q×T pixel, dove Q è il numero delle connessioni tra ogni pixel con quelli del suo intorno e T è il numero di istanti discreti dall’inizio alla fine del processo.
Quindi, in un generico istante di tempo t ad ogni pixel originario Pixel sarà associato un vettore w(t) di Q pixel rappresentativo delle connessioni del pixel originario con quelli del suo intorno:
( ) ( )zyxwyxPixel t ,,, )(→
dove z specifica che ad ogni pixel originario devono essere anche associati tanti pixel diversi quanti sono i pixel con i quali il pixel originario è connesso. Se il valore di questa connettività varia nel tempo, è evidente che in ogni istante di tempo t si potranno generare T matrici diverse di Q pixel, ciascuna delle quali renderà visibili le sole relazioni che esistono tra ogni pixel e ognuno dei suoi vicini.
I sistemi ACM, quindi, rimodellano un’immagine digitale qualsiasi tramite tre operazioni:
- trasformano l’immagine originale in una rete connessa di pixel. Quindi aggiungono una dimensione all’immagine stessa, la dimensione w delle connessioni tra un pixel e i pixel del suo intorno;
- applicano all’immagine trasformata delle operazioni locali, deterministiche e iterative che trasformano direttamente o indirettamente la luminosità originaria di pixel e/o le loro

38
connessioni. Quindi aggiungono all’immagine originaria un’ulteriore dimensione t: il tempo;
- terminano questo processo quando la funzione di costo sulla quale sono fondate le operazioni di trasformazione dell’immagine è soddisfatta. Quindi, considerano finito il tempo delle trasformazioni quando il processo stesso di trasformazione si stabilizza in modo autonomo.
Se le varie immagini che si succedono dipendono dalle connessioni tra i propri pixel, se le operazioni trasformative sono locali, deterministiche e iterative, e se il processo trasformativo tende autonomamente verso un’attrattore stabile, allora il processo di trasformazione dell’immagine è esso stesso parte del contenuto informativo globale di quella immagine.
La prima ipotesi sulla quale, quindi, si fondano i sistemi ACM è la seguente: “ogni immagine a N dimensioni, trasformata in una rete connessa di unità che si sviluppano nel tempo, tramite operazioni locali, deterministiche e iterative, può mostrare, in uno spazio dimensionale più ampio, delle regolarità morfologiche e dinamiche che nelle dimensioni originarie sarebbero non visibili oppure qualificabili come rumore”.
Questa prima ipotesi suppone, a sua volta, un’ulteriore ipotesi. Dal punto di vista dei sistemi ACM si ritiene, infatti, che ogni immagine digitale a N dimensioni è un processo congelato. L’informazione che appare a N dimensioni, quindi, è solo una parte dell’informazione globale a N+1 dimensioni. I sistemi ACM operano una dinamicizzazione dell’immagine originale, tramite l’inserimento delle connessioni tra un pixel e i suoi vicini e la dimensione temporale. Ciò al fine di ricostruire le diverse proiezioni della geometria globale dell’immagine a N+1 dimensioni nello spazio a N dimensioni nel quale l’immagine appare. In altre parole, il modo in cui ogni pixel si trasforma nel tempo, in modo diverso a seconda del pixel vicino con cui sta interagendo, trasforma il pixel originario da unità elementare in unità composita:

39
PixelijConnessioni ai
primi 8 pixel vicini
Pixelij1
Pixelij2
Pixelij...
Pixelij8
PixelijConnessioni ai
primi 8 pixel vicini
Pixelij1
Pixelij2
Pixelij...
Pixelij8 Questa analisi intrapixel focalizza nei sistemi ACM l’importanza
delle connessioni e delle leggi tramite le quali queste nascono, si aggiustano e si stabilizzano.
Si può, a questo punto, affermare che tutte quelle connessioni e tutte quelle equazioni di evoluzione delle connessioni che nel loro sviluppo evidenziano e/o mostrano proprietà poco visibili o quasi invisibili dell’immagine, che invece sono presenti nell’oggetto dal quale l’immagine è stata generata, sono le connessioni e le equazioni che devono essere prese in considerazione perché permettono di accedere ad una parte del contenuto informativo dell’immagine dotato di uno statuto particolare:
- questo è un contenuto informativo reale, in quanto è presente nell’oggetto da cui l’immagine è stata generata;
- questo è un contenuto informativo tanto più pregiato quanto più è invisibile o poco visibile tramite altri strumenti di elaborazione dell’immagine stessa.
È facile dimostrare che non tutte le connessioni e non tutte le equazioni di evoluzione di queste evidenziano caratteristiche dell’immagine presenti nell’oggetto che l’ha generata. Da ciò si può dedurre che esiste un insieme non infinito di connessioni e di equazioni di evoluzione di queste che possono trasformare parte del “rumore” di un’immagine in caratteristiche reali dell’oggetto dal quale questa è stata generata.
Queste osservazioni permettono di esplicitare la seconda ipotesi che è alla base dei sistemi ACM: “ogni immagine contiene al suo interno le matematiche inerenti che l’hanno prodotta”.
L’esplicitazione di queste matematiche interne fornisce informazioni reali sull’oggetto dal quale l’immagine è stata prodotta. In linea teorica questo potrebbe significare che anche per un’immagine che non è generata fisicamente da un oggetto reale

40
sarebbe possibile fare ipotesi corrette sull’oggetto virtuale che avrebbe potuto generarla.
I sistemi ACM, quindi, propongono un rovesciamento epistemologico sul modo di concepire il processamento dell’immagine. Non più partire da una matematica esterna all’immagine per valutare quanto l’immagine stessa si adegua a quella matematica (ad esempio i vari filtri che usano varie forme di convoluzione); bensì usare una meta-matematica che lasci che l’immagine si sviluppi per generare le matematiche interne che la sua rete di pixel implicitamente contiene.
Detto in modo più divulgativo, si tratta di passare da un approccio aristotelico nel quale la regola viene applicata al caso singolo, ad un approccio più socratico nel quale il caso singolo dal basso mostra le proprie regole, in modo quasi maieutico.
Si tratta, quindi, di trasformare l’immagine da oggetto del ricercatore in soggetto che evidenzia la propria oggettività.
Nei sistemi ACM il rapporto tra ricercatore e immagine dovrebbe passare dal “Penso, quindi tu esisti” al “Se mi pensi, allora io esisto”. Pubblicazioni di riferimento: 1. M Buscema, Sistemi ACM e Imaging Diagnostico. Le immagini
mediche come Matrici Attive di Connessioni, Springer-Verlag Italia 2006;
2. M Buscema, L Catzola, E Grossi, Images as Active Connection Matrixes: the J-Net System, in IC-MED (International Journal of Intelligent Computing in Medical Sciences), Vol. 1, No. 3, Issue 1, Page 187 of 213, 2007, TSI® Press USA, in press.
Brevetti: 1. European patent “An algorithm for recognising relationships
between data of a database and a method for image pattern recognition based on the said algorithm” (Active Connection Matrix-ACM). Author: M Buscema. Owner: Bracco, Semeion. Application n. 03425559.6, deposited August 22nd 2003.
2. International patent “An algorithm for recognising relationships between data of a database and a method for image pattern recognition based on the said algorithm” (Active Connection Matrix-ACM). Author: M Buscema. Owner: Bracco, Semeion.

41
Application n. PCT/EP2004/05182, deposited: August 18th 2004.
3. European patent “Active Connection Matrix J-Net. An algorithm for the processing of images able to highlight the information hidden in the pixels”. Author: M Buscema. Owner: Bracco, Semeion. Application n. 07425419.4, deposited: July 6th 2007.
Tesi di Laurea sperimentale: “Identificazione e caratterizzazione con TC delle lesioni polmonari di piccole dimensioni: esperienza preliminare con un nuovo modello di Intelligenza Artificiale basato su un sistema a Matrice Neurale Integrata” di Simone Vetere, Mtr: 937642. Relatore: Prof. Roberto Passariello. Dipartimento di Science Radiologiche, Direttore Prof.Roberto Passariello, Ia Facoltà di Medicina e Chirurgia, “La Sapienza” Università di Roma, Anno Accademico 2006-2007. Gli sviluppi La ricerca di base su questa famiglia di sistemi nel prossimo triennio sarà orientata nelle seguenti direzioni: 1. Creazione di nuove equazioni e algoritmi in grado di recuperare
probabilisticamente nelle immagini le informazioni che durante il processo di riflessione sorgente-immagine vanno perdute (“quella parte di identità che lo specchio assorbe e non riflette”).
2. Creazione di sistemi ACM capaci di gestire le immagini a colori. 3. Creazione di sistemi ACM in grado di elaborare, apprendere e
sintetizzare più tipi di immagini della stessa sorgente (fusion data).
4. Estensione dei sistemi ACM a ricostruzioni 3D. 5. Creazione di sistemi ACM in grado di elaborare dati con
topologia e cronologia pertinente (filmati). 6. Creazione di nuovi indici in grado di misurare in modo più
completo la quantità di informazione presente nelle strutture topologiche (immagini 2d e 3d).
Ricercatori impegnati: Massimo Buscema, Giulia Massini, Riccardo Petritoli, Marco Pizziol.

42
2.3 La Semantica delle immagini: il pixel e il suo contesto la Pixel Vector Theory (PVT)
Il problema Una volta che tutto il contenuto informativo di un’immagine è
stato reso palese è necessario insegnare a dei sistemi artificiali adattivi ad associare parti diverse dell’immagine a precisi contenuti culturali: quali forme rappresentano lo sfondo, quali oggetti rilevanti per l’analisi, quali vanno ignorate in quanto artefatti prodotti dalla macchina che ha generato l’immagine, ecc.
Questa parte dell’imaging processing consiste nel tentare di istruire un sistema artificiale ad apprendere le conoscenze e l’expertise di un soggetto umano specialista in un settore specifico della lettura delle immagini: un radiologo, un ingegnere dei materiali, ecc.
L’obiettivo consiste nell’addestrare un esperto artificiale a coadiuvare gli esperti umani nel valutare in contenuto semantico delle immagini stesse nelle diverse professioni.
Lo stato dell’arte al Semeion La Pixel Vector Theory (PVT) è una nuova tecnica ideata dal
Semeion nel 2001 per organizzare l’analisi delle immagini basata sulla conversione di ogni pixel in un vettore di valori.
La PVT consiste in un nuovo modo di insegnare a delle Reti Neurali e/o a dei Sistemi Artificiali Adattivi ad apprendere la “semantica delle immagini”; cioè la connessione che esiste tra i pixels di una o piu immagini e i contenuti generali e/o specialistici che questi rappresentano per diverse categorie di soggetti umani culturalmente orientati.
La PVT si distingue dagli altri modelli di elaborazione del contenuto semantico delle immagini perché non fa uso di indici statistici per raggruppare l’informazione dei pixels, bensì considera ogni pixel dell’immagine come base per la costruzione di vettori e matrici di dimensioni diverse.
Brevetti: 1. European patent “A method for encoding image pixels, a
method for processing images and a method for processing

43
images aimed at qualitative recognition of the object reproduced by one or more image pixels” (Pixel Vector Theory). Author: M Buscema. Owner: Bracco, Semeion. Application n. 02425141.5, deposited: March 11th 2002.
2. International patent “A method for encoding image pixels, a method for processing images and a method for processing images aimed at qualitative recognition of the object reproduced by one or more image pixels” (Pixel Vector Theory). Author: M Buscema. Owner: Bracco, Semeion. Application n. PCT/EP03/02400, deposited: March 10th 2003.
La PVT è stata applicata con successo in molte sperimentazioni di medical imaging, anche se finora si è preferito non pubblicare nulla per ragioni industriali.
Gli sviluppi La ricerca di base sulla PVT nel prossimo triennio sarà orientata
nelle seguenti direzioni: 1. Nuovi sistemi per la codifica dei Pixel tramite intorni a
geometria variabile (esagonali, ecc); 2. Nuove algoritmi per l’estrazione di informazione rilevante dalle
matrici di pixels; 3. Uso di Reti Neurali per far apprendere le regolarità e le
irregolarità dei tessuti naturali a partire dalle matrici di pixels; 4. Sperimentare la PVT basata su immagini pre-processate dai
sistemi ACM; 5. Estensione della PVT alle immagini 3d e ai filmati.
Ricercatori impegnati: Massimo Buscema, Giulia Massini, Stefano Terzi, Riccardo
Petritoli, Massimiliano Capriotti.

44
2.4 Analisi dei segnali non stazionari Implicit Function as Squashing Time (IFAST)
Il problema L’analisi dei segnali non stazionari provenienti da sorgenti
multicanale pone problemi diversi: 1. individuazione delle Invarianti spaziali e temporali di più segnali
originati dalla stessa sorgente; 2. separazione di uno stesso segnale in più segnali (BSS); 3. sistemi di associazione non lineare di Matrici di sistemi dinamici
(es: EEG su 19 canali di più soggetti). Lo stato dell’arte al Semeion Una prima risposta a questi problemi è stata l’ideazione del
sistema IFAST (Implicit Function as Squashing Time). Il sistema è stato già ritenuto degno di brevetto e applicato con successo.
Riassumiamo il senso di questa tecnica citando da un paper già pubblicato:
“I.F.A.S.T. is an acronym for “Implicit Function as Squashing Time”. It is a method, therefore, that tries to understand the implicit function in a multivariate data series by compressing the temporal sequence of data into spatial invariants.
This method is based on [..] general observations: Any multivariate sequence of signals coming from the same source represents
a non-synchronous temporal phenomenon: the behaviour of every channel is the synthesis of the influence of the other channels at previous but not identical times and in different quantities, and of its own activity at that moment. At the same times, the activity of every channel at a certain moment in time is going to influence the behaviour of the others at different times and in different quantities. Therefore, every multivariate sequence of signals coming from the same natural source is a complex asynchronous dynamic system, highly nonlinear, in which each channel’s behaviour is understandable only in relation to all the others.
Given a multivariate sequence of signals generating from the same source, the implicit function defining said asynchronous process is the conversion of that same process into a complex hyper-surface, representing the interaction in time of all the channels’ behaviour. The parameters of the said nonlinear function define a meta-pattern of interaction of all channels in time.” (da M. Buscema et Al, IFAST Model […], AIIM, 2007, 40, 127-141).”

45
Pubblicazioni di riferimento M. Buscema, P.M. Rossini, C. Babiloni and Enzo Grossi, The
IFAST model, a novel parallel nonlinear EEG analysis technique, distinguishes mild cognitive impairment and Alzheimer’s disease patients with high degree of accuracy, Artificial Intelligence in Medicine 40, pp. 127-141, Elsevier 2007.
Brevetti 1. European patent “Method of processing multichannel and
multivariate signals and method of classifying sources of multichannel and multivariate signals operating according to such processing method” (Implicit Function As Squashing Time – IFAST). Application n. 06115223.7, deposited: June 9ht 2006.
2. International Patent, “Method of processing multichannel and multivariate signals and method of classifying sources of multichannel and multivariate signals operating according to such processing method” (Implicit Function As Squashing Time – IFAST). Author: M Buscema. Owner: Semeion. Application n. PCT/EP2007/055646, deposited June 8th 2007).
Gli sviluppi La ricerca di base sui segnali non stazionari multicanale nel
prossimo triennio sarà orientata nelle seguenti direzioni: 1. Sperimentazione del Sistema IFAST su altri tipi di sorgenti
(Filmati, Immagini 3D, segnali satellitari, ecc); 2. Creazione di nuovi algoritmi per la separazione intelligente di un
segnale in più segnali indipendenti. Ricercatori Senior impegnati: Massimo Buscema, Marco Intraligi, Massimiliano Capriotti.

46
2.5 Meta-Classificatori e nuove Reti Supervisionate (MetaNet)
Il problema L’obiettivo della progettazione di un sistema di classificazione è
quello di ottenere il miglior risultato possibile in termini di accuratezza. La maggior parte degli sforzi fino ad oggi si è concentrata sullo sviluppo di algoritmi con schemi di classificazione diversi, questo ha condotto ad una vasta libreria di strumenti disponibili per affrontare il problema. Il risultato più evidente che emerge dalle ricerche svolte in questi anni, è che non esiste il ‘classificatore’ perfetto. Pur potendo in realtà costruire un ordinamento rispetto all’efficacia di ciascuna tipologia di classificatore, l’evidenza maggiore è che i risultati sono sensibili all’insieme di dati utilizzati per addestrare e valutare il modello in esame. Nell’affrontare un problema reale il processo standard è addestrare, con un opportuno protocollo di validazione, differenti tipologie di classificatori e selezionare quello con le caratteristiche migliori. Se si guarda al processo di classificazione come ad una estrazione di informazione, si verifica che ogni classificatore può classificare gli stessi input in classi diverse. Questo significa che la quantità e la qualità dell’informazione estratta varia da classificatore a classificatore; in particolare certe tipologie di classificatori come le reti neurali e gli alberi decisionali presentano una grande variabilità interna, producendo quindi modelli anche sensibilmente diversi, quando applicati sullo stesso problema. Nel processo standard che abbiamo prima brevemente descritto, questa diversità di modelli che viene prodotta non viene sfruttata, ma si mira a scegliere un singolo classificatore, scartando tutti gli altri. Un altro tipo di strategia, invece, consiste nel fondere più classificatori con l’obiettivo di sfruttare la possibile complementarietà delle informazioni estratte da ogni singolo classificatore.
Dietterich suggerisce tre motivazioni per cui la fusione dei singoli classificatori dovrebbe generarne uno più efficace: una statistica, una computazionale e una relativa alla rappresentazione.
Da un punto di vista statistico la “fusione” di più classificatori diminuisce la probabilità di scegliere un singolo classificatore

47
inadeguato quindi, anche se non è garantito che l’insieme di classificatori sia migliore rispetto a tutti i singoli classificatori, la fusione comporta una diminuzione del rischio di fare una scelta scorretta. Dal punto di vista computazionale, molti dei classificatori usano algoritmi di ottimizzazione euristici per la definizione dei parametri ottimi che possono arrestarsi in ottimi locali, l’aggregazione di questi può condurre a soluzioni più prossime all’ottimo globale pur partendo da ottimi locali. L’ultima motivazione è riguarda lo spazio delle soluzioni dei singoli classificatori che può non contenere la soluzione ottima del problema di classificazione, in questo caso l’insieme dei classificatori può espandere questo spazio delle soluzioni ottenendo risultati migliori ( ad es: un set di classificatori lineari non può raggiungere singolarmente la soluzione di un problema non separabile linearmente, ma una loro combinazione si).
Il problema della costruzione di un metaclassificatore è abbastanza complesso, risulta quindi utile una schematizzazione delle possibili alternative e la definizione di una terminologia e di una tassonomia che vista la natura del problema saranno necessariamente soggette ad eccezioni di varia natura.
In generale le dimensioni di progetto nello sviluppo di un metaclassificatore sono fondamentalmente quattro:
- la base di dati per l’addestramento e la validazione; - la selezione delle variabili significative; - la scelta e l’addestramento dei singoli classificatori; - la definizione della strategia di combinazione.

48
Z
D1 D2 DL
Dataset
Metaclassificatore
....
Livello della combinazione:Diversi algoritmi di combinazione delle uscite
Livello dei classificatori:Utilizzo di diverse tipologie di classificatori
Livello delle variabili:Scelta di differenti sottoinsiemi di variabili
Livello dei dati:Scelta di differenti sottoinsiemi di dati
Z
D1 D2 DL
Dataset
Metaclassificatore
....
Livello della combinazione:Diversi algoritmi di combinazione delle uscite
Livello dei classificatori:Utilizzo di diverse tipologie di classificatori
Livello delle variabili:Scelta di differenti sottoinsiemi di variabili
Livello dei dati:Scelta di differenti sottoinsiemi di dati
L’attenzione maggiore è probabilmente da rivolgere al quarto livello, cioè allo sviluppo di particolari strategie di combinazione dei singoli classificatori. Va comunque sottolineato che il terzo e il quarto livello sono spesso strettamente legati. Le scelte fatte riguardo all’uno hanno infatti conseguenze sulle possibili scelte nell’altro e viceversa.
Le possibili scelte riguardo le strategie di combinazione ricadono in due ampie classi: la fusione e la selezione; nel primo caso ogni singolo classificatore contribuisce alla definizione dell’etichetta della classe di appartenenza di ogni record; nel secondo ad ognuno dei classificatori viene attribuita la responsabilità di produrre la classificazione per una particolare regione dello spazio di ingresso. Esistono ovviamente dei Metaclassificatori che appartengono in modo sfumato ad entrambe queste categorie. Fino ad oggi la maggior parte dello sviluppo è stato dedicato alla fusione, anche se una fusione selettiva potrebbe essere la più efficiente delle due strategie.
Un’altra dimensione di analisi della progettazione di un Metaclassificatore riguarda l’obiettivo del processo di ottimizzazione, sono possibili due condizioni, anche questa volta sfumate, da una parte l’ottimizzazione riguarda il tipo e i parametri della strategia di combinazione (Decision Optimization) per un insieme fisso di classificatori; dall’altra l’ottimizzazione riguarda i parametri dei classificatori data una strategia di combinazione fissa.

49
I classificatori utilizzabili nei Metaclassificatori possono produrre uscite di tipo crisp, l’etichetta della classe stimata, o sfumata, un vettore di dimensione pari a quello delle classi del problema che rappresenta la ‘plausibilitá’ dell’appartenenza del record a ciascuna delle classi in esame; potremo quindi distinguere ulteriormente i Metaclassificatori in funzione del tipo di uscita dei classificatori di base che utilizzano.
Il Semeion ha operato alcune distinzioni chiave che possono articolare il mondo dei Metaclassficatori in diverse categorie logiche: 1. Categoria Algoritmica: ogni Metaclassificatore può definire le
sue caratteristiche in due modi: a. Dinamico: con un apprendimento che si effettua sulle
caratteristiche e sui risultati dei classificatori che lo compongono;
b. Statico: con un calcolo delle caratteristiche e dei risultati dei classificatori che lo compongono.
2. Categoria Dimensionale: ogni Metaclassificatore può definire le sue caratteristiche su base: a. Locale: ogni classificatore componente fornisce in modo
autonomo al Metaclassificatore delle caratteristiche; b. Globale: le caratteristiche e i risultati di tutti i classificatori
componenti interagiscono tra loro definendo globalmente le caratteristiche del Metaclassificatore.
3. Categoria Teleologica: ogni Metaclassificatore può definire le sue caratteristiche su base: a. Supervisionata: l’importanza di ogni classificatore
componente viene pesata sulla base dei risultati giusti e errati che ha prodotto;
b. Autopoietica: l’importanza di ogni classificatore componente viene pesata sulla base dei risultati che ha prodotto, senza considerare i suoi errori e i suoi successi. I Metaclassificatori Autopoietici, ovviamente, offrono prestazioni interessanti quando tutti i classificatori componenti hanno una matrice di confusione che rispetta la seguente condizione:

50
, ,1,
Target 0;N
i i i i jj j i
Err Err= ≠
= − <∑
Cioè, quando, per ogni Uscita, il numero degli errori è minore del numero della somma delle false attribuzioni.
4. Categoria Funzionale: ogni Metaclassificatore può valutare ogni nuovo Input di ingresso in modo: a. Feedforward: il Metaclassificatore fornisce una singola
risposta di classificazione per ogni nuovo Input di ingresso; b. Ricorsivo: il Metaclassificatore genera più risposte, ognuna
che considera le precedenti, finchè il processo non si satura (fornendo sempre la stessa risposta di classificazione).
Lo stato dell’arte al Semeion Nuovi Meta-Classificatori e Classificatori ideati dal Semeion fino al 2007: 1) Sine Net:
a) ideato da: M Buscema nel 1999, b) implementato da: M Buscema nel 2000. Attualmente in:
i) SuperVised vers.12.5”, shell to program feed forward and highly recurrent ANNs. Semeion Software n. 12, Rome 1999-2007. Programming Language: C.
c) pubblicato in: i) M Buscema, M Breda, S Terzi, Using Sinusoidal Modulated
Weights Improve Feed-Forward Neural Network Performances in Classification and Functional Approximation Problems, in WSEAS Transactions on Information Science & Applications, Issue 5, vol. 3, May 2006 pp. 885-893.
ii) M Buscema, M Breda, S Terzi, A feed Forward sine based neural network for functional approximation of a waste incinerator emissions, Proceedings of the 8th WSEAS Int. Conference on Automatic Control, Modeling and Simulation , Praga, March 12-14, 2006.
d) Brevettato: International Patent, “An Artificial Neural Network” (Sine Net). Application n. PCT/EP2004/05189, author: M Buscema, owner: Semeion, deposited August 28th 2004.

51
2) Bi-Modal: a) Ideato da: M Buscema nel 1999. b) Implementato da: M Buscema nel 2000. Attualmente in:
i) SuperVised vers.12.5”, shell to program feed forward and highly recurrent ANNs. Semeion Software n. 12, Rome 1999-2007. Programming Language: C.
3) Supervised Contractive Map: a) Ideato da: M Buscema nel 1999. b) Implementato da M Buscema nel 2000. Attualmente in:
i) SuperVised vers.12.5”, shell to program feed forward and highly recurrent ANNs. Semeion Software n. 12, Rome 1999-2007. Programming Language: C.
4) Training and Testing System: a) Ideato da: M Buscema nel 2001. b) Implementato da M Buscema nel 2001.Attualmente in:
i) T&T (Training and Testing) vers.1.0, Semeion Software n. 16, Rome 2001.
ii) TWIST (Input Search & T&T reverse), ver. 2.0, Semeion Software n. 39, 2007.
c) Pubblicato: M Buscema et Al, An Optimized Experimental Protocol Based on Neuro-Evolutionary Algorithms. Application to the Classification of Dyspeptic Patients and to the Prediction of the Effectiveness of Their Treatment, in Artificial Intelligence in Medicine (AIIM), 34, 279-305, 2005.
d) Brevettato: i) US Patent “System and method for optimization of a
database for the training and testing of prediction algorithms” (T&T – Training and Testing) Application n. US60/440,210, deposited: January 15th 2003.
ii) International Patent “System and method for optimization of a database for the training and testing of prediction algorithms” (T&T – Training and Testing). Application n. PCT/EP04/00157, deposited January 13th 2004).
5) Input Search: a) Ideato da M Buscema nel 2001. b) Implementato da M Buscema nel 2001. Attualmente in:

52
i) I.S. (Input Search) vers. 2.0, Semeion Software n. 17, Rome 2002.
ii) TWIST (Input Search & T&T reverse), ver. 2.0, Semeion Software n. 39, 2007.
c) Pubblicato: M Buscema et Al, An Optimized Experimental Protocol Based on Neuro-Evolutionary Algorithms. Application to the Classification of Dyspeptic Patients and to the Prediction of the Effectiveness of Their Treatment, in Artificial Intelligence in Medicine (AIIM), 34, 279-305, 2005.
6) Meta-MultiSom: a) Ideato da G Massini nel 2003. b) Implementato da G Massini nel 2003. Attualmente in:
i) MultiSom, Semeion Software n 28, 2005, Rome. 7) Tasm ANN (Time As Subjective Memory):
a) Ideato da M Buscema nel 2000. b) Implementato da M Buscema nel 2000. Attualmente in:
i) SuperVised vers.12.5, shell to program feed forward and highly recurrent ANNs. Semeion Software n. 12, Rome 1999-2007. Programming Language: C.
c) Pubblicato: i) M Buscema, M Breda, S Terzi, Complex Recurrent
Networks, in Semeion Technical Papers n 27, Rome 2002.
ii) M Buscema, M Breda, S Terzi, New Recurrent Neural Architectures, in Proceedings of the 2006 WSEAS International Conference on Mathematical Biology and Ecology, Miami, Florida, USA, January 18-20, 2006 (pp174-201).
8) Self-Recurrent ANN: a) Ideato da M Buscema nel 1997. b) Implementato da M Buscema nel 2000. Attualmente in:
i) SuperVised vers.12.5, shell to program feed forward and highly recurrent ANNs. Semeion Software n. 12, Rome 1999-2007. Programming Language: C.
c) Pubblicato:

53
i) M Buscema, M Breda, S Terzi, Complex Recurrent Networks, in Semeion Technical Papers n 27, Rome 2002.
ii) M Buscema, M Breda, S Terzi, New Recurrent Neural Architectures, in Proceedings of the 2006 WSEAS International Conference on Mathematical Biology and Ecology, Miami, Florida, USA, January 18-20, 2006 (pp174-201).
9) AQ (Adaptive Quantization): a) Ideato da M Buscema nel 2007. b) Implementato da M Buscema nel 2007. Attualmente in:
i) SuperVised vers.12.5, shell to program feed forward and highly recurrent ANNs. Semeion Software n. 12, Rome 1999-2007. Programming Language: C.
10) Local Meta-Bayes: a) Ideato da M Buscema nel 1994. b) Implementato da M Buscema nel 1994. Attualmente in:
i) SuperVised vers.12.5, shell to program feed forward and highly recurrent ANNs. Semeion Software n. 12, Rome 1999-2007. Programming Language: C.
ii) MetaNet ver 1.0, shell to program Meta-Classifiers, Semeion Software n. 44, Rome 2007. Programming Language C.
c) Pubblicato: MetaNet: The Theory of Independent Judges, in Substance Use & Misuse, Vol. 33, n. 2 (Models), Marcel Dekker, Inc., New York, 1998, pp. 439-461.
11) Local Meta-AutoAssociative ANN. a) Ideato da M Buscema nel 1994. b) Implementato da M Buscema nel 1994. Attualmente in:
i) SuperVised vers.12.5, shell to program feed forward and highly recurrent ANNs. Semeion Software n. 12, Rome 1999-2007. Programming Language: C.
ii) MetaNet ver 1.0, shell to program Meta-Classifiers, Semeion Software n. 44, Rome 2007. Programming Language C.

54
c) Pubblicato: MetaNet: The Theory of Independent Judges, in Substance Use & Misuse, Vol. 33, n. 2 (Models), Marcel Dekker, Inc., New York, 1998, pp. 439-461.
12) Local Meta-Sum. a) Ideato da M Buscema nel 2007. b) Implementato da M Buscema nel 2007. Attualmente in:
i) MetaNet ver 1.0, shell to program Meta-Classifiers, Semeion Software n. 44, Rome 2007. Programming Language C.
13) Global Prior Probability Algorithm (PPA): a) Ideato da M Buscema nel 2007. b) Implementato da M Buscema nel 2007. Attualmente in:
i) MetaNet ver 1.0, shell to program Meta-Classifiers, Semeion Software n. 44, Rome 2007. Programming Language C.
14) Global Meta-Auto Contractive Maps: a) Ideato da M Buscema nel 2007. b) Implementato da M Buscema nel 2007. Attualmente in:
i) SuperVised vers.12.5, shell to program feed forward and highly recurrent ANNs. Semeion Software n. 12, Rome 1999-2007. Programming Language: C.
ii) MetaNet ver 1.0, shell to program Meta-Classifiers, Semeion Software n. 44, Rome 2007. Programming Language C.
15) Meta-Gen: a) Ideato da M Buscema nel 2007. b) Implementato da M Buscema nel 2007. Attualmente in:
i) SuperVised vers.12.5, shell to program feed forward and highly recurrent ANNs. Semeion Software n. 12, Rome 1999-2007. Programming Language: C.
Gli sviluppi La ricerca di base sui Meta-Classificatori e sui Classificatori nel prossimo triennio sarà orientata nelle seguenti direzioni: 1. Sperimentazione delle capacità dei nuovi Meta-classficatori del
Semeion rispetto a tutti quelli esistenti in letteratura;

55
2. Ideazione di nuovi Meta-classificatori non supervisionati; 3. Ideazione di nuovi algoritmi di preprocessing per i Meta-
classificatori; 4. Ideazione di nuovi protocolli scientifici per la misura multi-
dimensionale dei Classificatori e dei Meta-classificatori; 5. Ideazione di una nuova teoria e tipologia generativa di Meta-
classificatori; Ricercatori impegnati: Massimo Buscema, Stefano Terzi, Giulia Massini, Marco Breda, Marco Intraligi.

56
2.6 Reti Auto-Associate non lineari (Mappe Contrattive) Il problema Le relazioni tra Rete e Ambiente ( o altre Reti) definiscono i tipi
di funzione di costo che ogni Rete tenta di soddisfare. Quindi, l’obiettivo del suo funzionamento.
Le relazioni tra Rete e Ambiente (o altre Reti) possono essere di 3 tipi: 1. L’ambiente trasmette alla Rete i segnali di Input che deve
processare e i segnali di Output che la Rete deve apprendere a generare. In questo caso la Rete si definisce Supervisionata.
2. L’ambiente trasmette alla Rete i segnali di Input e si aspetta come Output i parametri dell’iper-superfice continua della funzione implicita che connette ogni Nodo di Input ad ogni altro. In questo caso la Rete si definisce Auto-Associata.
3. L’ambiente attiva N Nodi di Input della Rete, la quale proietta lo spazio N-dimensionale di Input in un suo spazio a L dimensioni, dove in genere L è molto più piccolo di N, in modo tale che le informazioni della metrica e della topologia originaria siano alterate in modo minimo. Lo spazio di proiezione L può anche essere costituito di una classe di sottospazi, iL , ciascuno di dimensioni analoghe o più piccole dello spazio N di origine. In questo modo la Rete restituisce all’ambiente solo le informazioni più rilevanti di tutti gli input che ha ricevuto, proiettandole in solo spazio L o distribuendole in più sottospazi,
iL . In questi casi la Rete si definisce Proiettiva. Le Reti Auto-Associate e Proiettive sono anche dette in modo
generico Non Supervisionate. Le Reti AutoAssociate, inoltre, possono avere anche proprietà proiettive, quando sono dotate di uno strato di Nodi Nascosti.
Le Reti Supervisionate sono definite da una funzione di costo, [ ]SE , del seguente tipo:

57
(12)
[ ]
1
vettore delle uscite richieste dall'ambiente detto Target;
vettore delle entrate generate dall'ambiente;
funzione in genere composta e non lineare;
Numero dell
( );
dove :
( )
PattS
p pp
E g
gPatt
=
= −
==⋅ =
=
∑ t u
tu
e coppie Entrata-Uscita generate dall'ambiente.
Nelle Reti Auto-Associate l’equazione (12) prende la seguente
forma:
(13) [ ]
1
( );Patt
Ap p
p
E g=
= −∑u u
Nelle Reti Auto-Associate è sono i Nodi di Input a funzionare da
vincolo. Nelle Reti Proiettive la funzione di costo può essere
genericamente scritta nel modo seguente:
(14) [ ]
1
( );
dove e' un vettore che regola la proiezione.
PattP
p pp
E g=
= −∑ v u
v
In tutte e tre le equazione il termine [ ]E ⋅ rappresenta l’errore
della Rete durante la fase di apprendimento. In realtà, [ ]E ⋅ funziona come una forma di energia vincolata, che ogni Rete tenta di minimizzare:
(15) [ ]lim 0
dove rappresenta un ciclo di funzionamento della Rete.nE
n
⋅
→∞=

58
È ovvio che la minimizzazione della Energia [ ]E ⋅ non è necessario che sia esplicita nell’algoritmo di ogni Rete. In modi diversi, ogni Rete tenta sempre di minimizzare qualcosa (errore, distanza, ecc.). Riteniamo che la funzione di costo di ogni Rete sia riconducibile sempre alla minimizzazione di un qualche tipo di energia vincolata.
Inoltre, è opportuno evidenziare che mentre le Reti Supervisionate e Auto-Associate tendono a soddisfare vincoli provenienti dall’ambiente (i vettori t e u), le Reti Proiettive generano dal loro interno in modo dinamico il vincolo che tendono a soddisfare ( il vettore V).
Per questa ragione queste ultime possono essere anche definite Reti Proiettive o Auto-Poietiche (che generano da sole il loro obiettivo).
Tutte le Reti Proiettive sono anche Auto-Poietiche, mentre le Reti Auto-Associate possono essere Proiettive, ma non Auto-Poietiche.
Lo stato dell’arte al Semeion Negli ultimi anni (2000-2007) la ricerca di base al Semeion sugli
Auto-Associatori non Lineari si è concentrata sulla ideazione di particolari algoritmi contrattivi. Algoritmi in grado, cioè, di comprimere il segnale di ingresso in modo tale che una parte opportuna di tale contrazione andasse ad addestrare le connessioni tra le stesse variabili. Questi studi hanno portato alla definizione di un nuovo tipo di Rete Neurale a cui è stato dato il nome di Auto Contractive Map (M. Buscema, Squashing Theory and Contractive Map Networks, Semeion Technical Paper n. 23, 2000, Rome, e M. Buscema, Auto Contractive Maps, H Function and Maximally Regular Graph, Semeion Technical Paper n. 32, 2007, Rome).
L’Auto Contractive Map (CM) ha un’architettura a tre strati: uno strato di Input, dove il segnale viene catturato dall’ambiente, uno strato Hidden, dove il segnale viene modulato all’interno della CM, e uno strato di Output tramite il quale la AutoCM agisce sull’ambiente in relazione agli stimoli ricevuti in precedenza (Figura 1).
Ogni strato è composto da N unità. Quindi l’intera CM è composta da 3N unità. Le connessioni tra lo strato di Input e lo strato Hidden sono mono-dedicate, mentre le connessioni tra lo

59
strato Hidden e quello di Output sono a gradiente massimo. Quindi, rispetto alle unità, il numero delle connessioni Nc è dato da: Nc = N (N + 1).
La figura mostra un esempio di Auto CM con N = 4.
Tutte le connessioni della CM possono essere inizializzate sia con
valori uguali che con valori random. La prassi migliore è inizializzare tutte le connessioni con lo stesso valore positivo, prossimo allo zero.
L’algoritmo di apprendimento della CM può essere sintetizzato in quattro passi ordinati: 1. Trasferimento del segnale dallo strato di Input allo strato
Hidden; 2. Aggiustamento del valore delle connessioni tra strato di Input e
strato Hidden; 3. Trasferimento del segnale dallo strato Hidden allo strato di
Output; 1 4. Aggiustamento del valore delle connessioni tra strato Hidden e
strato di Output. Indichiamo con m[s] le unità dello strato di Input (sensori), scalati
tra 0 e 1, con m[h] le unità dello strato Hidden e con m[t ] quelle dello strato di Output (target del sistema). Definiamo v il vettore delle connessioni monodedicate, w la matrice delle connessioni tra strato Hidden e strato di Output, e n il tempo discreto dell’evoluzione dei pesi.
1 i passi 2 e 3 possono avvenire in parallelo.
] Input layer
] Hidden layer
] Output layer

60
Le equazioni del trasferimento forward del segnale e quelle di apprendimento sono quattro:
a. Trasferimento del segnale dall’Input all’Hidden:
(1) ( )
( ) ( )
[ ] [ ] 1 n
n n
ih si i
vm m
C
= −
dove C è un numero reale
positivo, chiamato Fattore di Contrazione. b. Modifica delle connessioni
)( niv attraverso le
( )niv∆ che intrappolano le differenze di energia generate
dall’equazione (1);
(2) ( ) ( )
( ) ( ) ( )
[ ] [ ] 1 n
n n n
is hi i i
vv m m
C
∆ = − ⋅ −
;
(3) ( 1) ( ) ( )n n ni i iv v v
+= + ∆ ;
c. Trasferimento del segnale dallo strato Hidden all’Output:
(4) ( )
( ) ( )
,[ ] 1 ;n
n n
Ni jh
i jj
wNet m
C
= ⋅ − ∑
(5) ( )
( ) ( )
[ ] [ ] 1 n
n n
it hi i
Netm m
C
= −
.
d. Modifica delle connessioni
( ), ni jw tramite le
( ), ni jw∆ che intrappolano le differenze di energia, generate dall’equazione (5):

61
(6) ( ) ( )
( ) ( ) ( ) ( )
,[ ] [ ] [ ], 1 n
n n n n
i jh t hi j i i j
ww m m m
C
∆ = − ⋅ − ⋅
;
(7)
( 1) ( ) ( ), , ,n n ni j i j i jw w w+
= + ∆ Il valore
( )
[ ]n
hjm dell’equazione (6) è usato per proporzionare la
variazione delle connessioni ( ), ni jw alla quantità di energia liberata
dal nodo ( )
[ ]n
hjm in favore del nodo
( )
[ ]n
tim .
Le Auto Contractive Maps non si comportano come una normale rete neurale artificiale, infatti apprendono anche a partire da tutte le connessioni settate allo stesso valore. In questo modo non risentono del problema delle connessioni simmetriche.
Durante l’apprendimento, sviluppano per ogni connessione solo valori positivi. Quindi, le reti Auto-CM non presentano relazioni inibitorie tra i nodi, ma solo diverse energie di connessioni eccitatorie.
Auto-CM può apprendere anche in condizioni complicate, vale a dire quando le connessioni della diagonale principale della seconda matrice delle connessioni sono rimosse e non risentono del numero degli input in termini di convergenza. Quando il processo di apprendimento è organizzato in questo modo, l’Auto-CM sembra trovare una specifica relazione tra ogni variabile e le altre.
Dopo il processo di apprendimento, ogni vettore di input, appartenente al set di addestramento, genererà un vettore di output nullo. Quindi, la minimizzazione dell’energia dei vettori di apprendimento è rappresentata da una funzione attraverso la quale le connessioni addestrate assorbono completamente i vettori di apprendimento di Input. Sembra che Auto CM impari a trasformare sé stessa in un corpo nero.
Alla fine della fase di apprendimento ( 0, =∆ jiw ), tutte le componenti del vettore dei pesi v raggiungono lo stesso valore:

62
(8) ( )
limnin
v C→∞
= .
La matrice w quindi rappresenta la conoscenza della CM su tutto
il dataset. È possibile trasformare la matrice w anche in una matrice delle
transizioni probabilistiche tra le variabili m:
,',
',
,'
,1
(9a) ;
(9b) ;
i jw
i j C
i ji j N
i jj
ewew
pw
=
=
=
∑
(10) 1)( ,][ == ∑
N
iji
sj pmP
La nuova matrice p può essere letta come la probabilità di transizione da una variabile-stato ad ogni altra:
(11) jis
jt
i pmmP ,][][ )( = .
Allo stesso tempo la matrice w può essere trasformata in una metrica della distanza non Euclidea (a-metric), quando addestriamo la CM con la diagonale principale della matrice w fissata al valore C.
Ora se consideriamo C come valore limite per tutti i pesi della matrice w, possiamo scrivere:
(12) ,
, 1i jw
i j C
ed
e= −
La nuova matrice d è anch’essa una matrice quadrata simmetrica dove la diagonale principale rappresenta la distanza nulla tra ogni variabile e sé stessa.
L’applicazione di filtri quali il Minimum Spanning Tree alla matrice delle distanze, generata da una rete Auto-CM, ha dimostrato di essere un clusterizzatore ottimo dei rapporti tra le variabili di un qualsiasi database. Molte sperimentazioni comparative sono state effettuate su DB medici, su DB connessi alla criminalità e su DB

63
artificialmente creati. Le AutoCM sono state comparate con diversi algoritmi di AutoAssociazione Lineare e Non Lineare tra variabili: 1. Distanza Euclidea 2. Mutual Information 3. Linear Correlation 4. Principal Component Analysis 5. Auto_Associative Back Propagation 6. Prior Probality Algorithm 7. Ecc.
Allo stato attuale le AutoCM hanno sempre mostrato una schiacciante superiorità rispetto agli altri algoritmi.
Esempio sul Db giocattolo Gang:

64
a. Trasformazione numerica:
Gang 14x27 Jet Sharks 20' 30' 40' JS COL HS Single Married Divorced Pusher Bookie Burglar ART 1 0 0 0 1 1 0 0 1 0 0 1 0 0AL 1 0 0 1 0 1 0 0 0 1 0 0 0 1SAM 1 0 1 0 0 0 1 0 1 0 0 0 1 0CLYDE 1 0 0 0 1 1 0 0 1 0 0 0 1 0MIKE 1 0 0 1 0 1 0 0 1 0 0 0 1 0JIM 1 0 1 0 0 1 0 0 0 0 1 0 0 1GREG 1 0 1 0 0 0 0 1 0 1 0 1 0 0JOHN 1 0 1 0 0 1 0 0 0 1 0 0 0 1DOUG 1 0 0 1 0 0 0 1 1 0 0 0 1 0LANCE 1 0 1 0 0 1 0 0 0 1 0 0 0 1GEORGE 1 0 1 0 0 1 0 0 0 0 1 0 0 1PETE 1 0 1 0 0 0 0 1 1 0 0 0 1 0FRED 1 0 1 0 0 0 0 1 1 0 0 1 0 0GENE 1 0 1 0 0 0 1 0 1 0 0 1 0 0RALPH 1 0 0 1 0 1 0 0 1 0 0 1 0 0PHIL 0 1 0 1 0 0 1 0 0 1 0 1 0 0IKE 0 1 0 1 0 1 0 0 1 0 0 0 1 0NICK 0 1 0 1 0 0 0 1 1 0 0 1 0 0DON 0 1 0 1 0 0 1 0 0 1 0 0 0 1NED 0 1 0 1 0 0 1 0 0 1 0 0 1 0KARL 0 1 0 0 1 0 0 1 0 1 0 0 1 0KEN 0 1 1 0 0 0 0 1 1 0 0 0 0 1EARL 0 1 0 0 1 0 0 1 0 1 0 0 0 1RICK 0 1 0 1 0 0 0 1 0 0 1 0 0 1OL 0 1 0 1 0 0 1 0 0 1 0 1 0 0NEAL 0 1 0 1 0 0 0 1 1 0 0 0 1 0DAVE 0 1 0 1 0 0 0 1 0 0 1 1 0 0 b. Trasposizione matriciale:
Gang 27x14 ART AL SAM CLYDE MIKE JIM GREG JOHN DOUG LANCE GEORGE PETE FRED GENE RALPH PHIL IKE NICK DON NED KARL KEN EARL RICK OL NEAL DAVE
Jet 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0Sharks 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1
20' 0 0 1 0 0 1 1 1 0 1 1 1 1 1 0 0 0 0 0 0 0 1 0 0 0 0 030' 0 1 0 0 1 0 0 0 1 0 0 0 0 0 1 1 1 1 1 1 0 0 0 1 1 1 140' 1 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0JS 1 1 0 1 1 1 0 1 0 1 1 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0
COL 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 1 1 0 0 0 0 1 0 0HS 0 0 0 0 0 0 1 0 1 0 0 1 1 0 0 0 0 1 0 0 1 1 1 1 0 1 1
Single 1 0 1 1 1 0 0 0 1 0 0 1 1 1 1 0 1 1 0 0 0 1 0 0 0 1 0Married 0 1 0 0 0 0 1 1 0 1 0 0 0 0 0 1 0 0 1 1 1 0 1 0 1 0 0
Divorced 0 0 0 0 0 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1Pusher 1 0 0 0 0 0 1 0 0 0 0 0 1 1 1 1 0 1 0 0 0 0 0 0 1 0 1Bookie 0 0 1 1 1 0 0 0 1 0 0 1 0 0 0 0 1 0 0 1 1 0 0 0 0 1 0Burglar 0 1 0 0 0 1 0 1 0 1 1 0 0 0 0 0 0 0 1 0 0 1 1 1 0 0 0
c. AutoCM weights:

65
d. AutoCM Distances:
e. MST comparison:

66

67

68
Sulle AutoCM esiste un articolo già pubblicato su SMC-IEEE 2007 di Massimo Buscema ed Enzo Grossi
A novel adapting mapping method for emergent properties discovery in data bases: experience in medical field
Abstract: We describe here a new mapping method able to find out connectivity traces among variables thanks to an original mathematical approach. This method is based on an artificial adaptive system able to define the strength of the associations of each variable with all the others in any dataset, the Auto Contractive Map (AutoCM). After the training phase, the weights matrix of the AutoCM represents the warped landscape of the dataset. We apply a simple filter to the weights matrix of AutoCM system to show the map of the main connections between the variables. The example of gastro-oesophageal reflux disease data base is extremely useful to figure out how this new approach can help to re design the overall structure of factors related to a specific disease description. This new form of data mining can be expected to contribute to a better understanding of complexity of some wicked diseases.
Manuscript received March 16, 2007. E un articolo in press su IJDMB 2007: The Semantic Connectivity Map: an adapting self-organizing knowledge
discovery method in data bases. Experience in Gastro-oesophageal reflux disease Massimo Buscema, Enzo Grossi

69
Abstract: We describe here a new mapping method able to find out connectivity traces among variables thanks to an original mathematical approach. This method is based on an artificial adaptive system able to define the strength of the associations of each variable with all the others in any dataset, the Auto Contractive Map (AutoCM). After the training phase, the weights matrix of the AutoCM represents the warped landscape of the dataset. We apply a simple filter to the weights matrix of AutoCM system to show the map of the main connections between the variables. The example of gastro-oesophageal reflux disease data base is extremely useful to figure out how this new approach can help to re design the overall structure of factors related to a specific disease description. This new form of data mining can be expected to contribute to a better understanding of complexity of some wicked diseases.
Gli Sviluppi La ricerca di base Mappe Contrattive nel prossimo triennio sarà
orientata nelle seguenti direzioni: 1. Approfondimento matematico delle Mappe Contrattive in
confronto con l’algebra tensoriale da un lato,e la teoria delle probabilità da un altro.
2. Nuovi algoritmi di contrazione capaci di contrarre lo spazio tra le variabili in rapporto solo a certi tipi di similarità e a certi tipi di ortogonalità (risonanze).
3. Nuovi indici per studiare la complessità dei grafi e degli alberi, orientati e no, che possono essere generati dalla matrice delle connessioni delle AutoCM (la funzione H e la funzione Delta H).
4. Approndire la natura matematico-topologica del Maximally Regular Graph (M.R.G.)recentemente scoperto come filtro per la lettura delle connessioni delle AutoCM.
Ricercatori impegnati: Massimo Buscema, Stefano Terzi, Giulia Massini, Marco Breda,
Marco Pizziol, Riccardo Petritoli, Luigi Catzola.

70
2.7 Teoria dei Grafi e Data Mining (H Function) Il problema Il Minimum Spanning Tree (MST) Un grafo è un’astrazione matematica utile per risolvere molti tipi
di problemi. Fondamentalmente un grafo consiste in un insieme di vertici e in un insieme di archi, dove un arco è qualcosa che connette due vertici nel grafo. Più precisamente, un grafo è una coppia (V, E), dove V è un insieme finito ed E è una relazione binaria su V, a cui è possibile attribuire un valore scalare (in questo caso i pesi sono le distanze ,i jd ).
V è detto insieme vertice e i suoi elementi sono chiamati vertici. E è un gruppo di archi, dove un arco è una coppia (u, v) con u, v appartenenti a V. In un grafo diretto, gli archi sono coppie ordinate che connettono un vertice sorgente ad un vertice target. In un grafo indiretto gli archi sono coppie disordinate e connettono i due vertici in entrambe le direzioni, quindi in un grafo indiretto (u, v) e (v, u) sono due modi di scrivere lo stesso arco.
Non si è detto cosa rappresenta un vertice o un arco. Potrebbero essere città con strade di collegamento, o pagine web con hyperlinks. Questi dettagli sono lasciati fuori dalla definizione di grafo per un’importante ragione; non fanno parte necessariamente dell’astrazione di grafo.
Una rappresentazione tramite la matrice di adiacenza di un grafo è una struttura a due dimensioni V x V, dove le righe rappresentano la lista dei vertici e le colonne rappresentano gli archi tra i vertici. Ogni elemento nella tabella è immagazzinato con un valore booleano che indica se l’arco (u, v) è nel grafo.
Una matrice delle distanze tra i V vertici rappresenta un grafo indiretto pesato, dove ogni vertice è collegato con tutti gli altri, tranne sé stesso. Per definizione la matrice è simmetrica e con diagonale principale nulla.
A questo punto è utile introdurre il concetto di Minimum Spanning Tree (MST).
Il problema del Minimum Spanning Tree si può definire come segue: trovare un sottoinsieme aciclico T di E che connetta tutti i

71
vertici nel grafo e il cui peso totale sia minimizzato, dove il peso totale è dato da:
(13) 1
, ,0 1
( ) ,N N
i j i ji j i
d T d d−
= = +
= ∀∑ ∑ .
T è chiamato spanning tree e MST è il T con la minore somma dei suoi archi pesati.
(14) { ( )}kMst Min d T= . Dato un grafo indiretto G, che rappresenta una matrice delle
distanze d con V vertici completamente collegati gli uni gli altri, il numero totale dei loro archi (E) è:
(15) ( 1)2
V VE
⋅ −= ;
e il numero dei suoi possibili alberi: (16) 2VT V −= . Kruskal nel 1956 scoprì un algoritmo in grado di determinare il
MST di ogni grafo ad albero indiretto in un numero quadratico di passi, nel caso peggiore. Ovviamente, l’algoritmo di Kruskal genera uno dei possibili MST. Infatti in un grafo pesato sono possibili più di un unico MST.
Dal punto di vista concettuale il MST rappresenta lo stato di minimizzazione di energia di una struttura. Infatti, se consideriamo gli elementi atomici di una struttura come i vertici di un grafo e la forza tra loro come il peso di ogni arco che collega una coppia di vertici, il MST rappresenta l’energia minima necessaria perché tutti gli elementi della struttura continuino a rimanere insieme.
In un sistema chiuso, tutti i componenti tendono a minimizzare l’energia totale. In questo modo il MST, in situazioni specifiche, può rappresentare lo stato più probabile a cui tende il sistema.
L’algoritmo di Pruning di un grafo Il criterio più facile per studiare la matrice di adiacenza è ordinare
il numero di collegamenti di ogni nodo; questo algoritmo definisce la connettività di ogni nodo:

72
∑=N
jjii lC ;,
(28) dove: se Mstl ji ∈, allora jil , = 1;
se Mstl ji ∉, allora jil , = 0;
jil , = possibile connessione diretta tra il Nodoi e Nodoj. I nodi con solo una connessione sono chiamati Foglie. Le foglie
definiscono i limiti del grafo MST. I nodi con due connessioni sono chiamati Connettori. I nodi con più di due connessioni sono chiamati Hub. Ogni Hub ha un grado specifico di connettività:
(29) 2i iHubDegree C= − . Un secondo indice della qualità di un grafo MST è la forza di
clusterizzazione di ognuno dei suoi nodi. La forza di clusterizzazione di ogni nodo è proporzionale al
numero delle sue connessioni e dal numero di connessioni dei nodi direttamente connessi con lui;
(30) 2
1
i
ii C
jj
CS
C=
=
∑.
Un terzo indice è il grado di protezione di ogni nodo in un
grafo MST. Questo indice definisce il grado di centralità di ogni nodo all’interno dell’albero, quando è applicato al grafo un algoritmo iterativo di pruning (potatura).
Algoritmo di Pruning Rank=0; Do { Rank++;

73
Considera_Tutti_Nodi_con_il_Numero_Minimo_di_Link(); Cancella_Questi_Link ();
Assegna_un_Grado_a_Tutti_Nodi_Senza_Link(Rank); Aggiorna_Il_Nuovo_Mst(); Controlla_Numero_di_Links(); } while Almeno_un _link_è _presente; Più alto è il grado di un nodo, maggiore è la centralità della sua
posizione all’interno del grafo. Gli ultimi nodi ad essere “potati” sono anche i nodi centrali del grafo.
Sia dato un grafo formato da N nodi e A connessioni. Si applichi il seguente algoritmo (Algoritmo di Pruning):
- individuare sul grafo tutti i nodi a gradiente minimo, ovvero tutti quei nodi con il minor numero di connessioni;
- ‘liberare’ tutti i nodi individuati nel passo precedente eliminando le relative connessioni;
- applicare i due passi precedenti in modo iterativo fino alla ‘liberazione’ di tutti i nodi del grafo (disconnessione completa del grafo).
Definiamo come numero di cicli di pruning il numero di iterazioni necessarie per disconnettere completamente il grafo e lo indichiamo con M.
Esempio 1: si consideri il seguente grafo (N = 8 e A = 11):
Applichiamo l’algoritmo di pruning:

74
1° ciclo di pruning: Gradiente minimo = 1 Connessioni eliminate = 1 Nodi liberati = 1
2° ciclo di pruning: Gradiente minimo = 2 Connessioni eliminate = 4 Nodi liberati = 2
3° ciclo di pruning: Gradiente minimo = 2 Connessioni eliminate = 5 Nodi liberati = 3
4° ciclo di pruning: Gradiente minimo = 1 Connessioni eliminate = 1 Nodi liberati = 2

75
Risulta che il numero di cicli di pruning è pari a 4. Questo algoritmo è stato ideato e applicato per la prima volta per
misurare la complessità di un albero da Giulia Massini (Massini 2006) e poi generalizzato per ogni tipo di grafo da Massimo Buscema.
La Funzione H: La misura della complessità di un grafo L’algoritmo di pruning può essere usato per definire la
complessità globale di ogni grafo. Infatti, se assumiamo µ come il numero medio di nodi senza
alcuna connessione dopo ogni iterazione di potatura, allora possiamo definire l’indice di Hubbità globale di un grafo qualsiasi con N nodi. Definiamo 0H tale indice di Hubbità globale di un grafo pesato:
(32) 0 0
1; 0 2;H H
Aµ ϕ⋅ −
= < <
dove: ;1
MN
NdM
M
ii == ∑µ ∑=
P
jjTGS
P;1ϕ
A = numero di collegamenti del grafo (N-1 per gli alberi);
M = numero di iterazioni dell’algoritmo di potatura; P = numero di tipi di potatura; Ndi = numero di nodi deconnessi al passo i; STG j = successione di tipi di gradienti di potatura.
L’indice H (equazione 32) rappresenta la Hubbità globale di un
grafo. Quando H=0, l’albero è una linea uni-dimensionale e la sua complessità è minima. Quando H=1, l’albero presenta un solo Hub, e la sua complessità è massima. La complessità di un grafo, infatti è collegata alla sua quantità di informazione.
La quantità di informazione è collegata al diametro del grafo e alla connettività dei vertici: con lo stesso numero di vertici, più corto è il diametro, maggiore è l’informazione.
Cominciando dal concetto di Entropia possiamo scrivere:

76
(36) ln( );N
i ii
E K p p= − ⋅ ⋅∑
Se chiamiamo ( )E G l’entropia topologica di un grafo generico, possiamo scrivere:
(37) ( ) ln ;N
i i
i
C CAE G
M A A = − ⋅ ⋅
∑ .)(0 ∞<< GE
dove: A = numero di collegamenti del grafo (N-1
per gli alberi); N = Numero dei vertici del grafo; M = numero di cicli di pruning necessari per
disconnettere completamente il grafo; Ci = grado di connettività di ogni vertice.
L’equazione iCA
misura la probabilità che un generico nodo Cj ,
dove ij ≠ , sia direttamente connesso al nodo Ci. Questo vuol dire che l’Entropia (Negativa) di un albero, ( )E G , aumenterà, quando il numero dei vertici con un gran numero di connessioni aumenta. Allo stesso modo, la probabilità di ordinare le connessioni di N vertici, usando un processo random, in una catena lineare è la più bassa. Di conseguenza, più alto è il numero di cicli di pruning, M, necessari per un albero, più piccola è l’entropia dell’albero.
Ma è necessario offrire qualche esempio di come la Funzione H sia applicabile ad ogni tipo di grafo a-diretto. Infatti secondo la equazione (32), la funzione H ha il seguente intervallo:
00 2H< < .
Per tutti i tipi di Albero la Funzione H è 0
10
2H< < , tranne nel
caso degli “Alberi a Stella”, nei quali 0 1H = . Per un grafo regolare, invece, l’intervallo della Funzione H è il seguente:
01.6 2H≤ < .

77
Per ogni altro Grafo che non sia un albero la Funzione H può
prendere qualsiasi valore dell’intervallo previsto dalla equazione (32): più aumentano le simmetrie del grafo più, aumenta il valore della Funzione H.
In conclusione, la funzione H permette di misurare la complessità topologica di ogni tipo di grafo.
La Funzione Delta H La funzione Delta H permette di misurare il contributo di ogni
nodo alla complessità di un grafo. Quando in un grafo pesato uno o più vertici vengono cancellati, gli altri vertici riordinano le loro connessioni in accordo con la loro metrica e ai loro vincoli, per connettersi di nuovo gli uni agli altri.
A questo punto, possiamo definire un indice H per un numero N di un grafo, ciascuno generato dall’originale matrice delle adiecenze, cancellando un vertice ad ogni calcolo:
(38) 1
; 0 2 ;1
i ii iH H
Aµ ϕ⋅ −
= ≤ <−
dove: ;
1MN
NdM
M
jji == ∑µ
∑=P
kkTGS
P;
1ϕ
A = numero di collegamenti del grafo (N-1 per gli alberi);
M = numero di iterazioni dell’al goritmo di potatura;
P = numero di tipi di potatura; Ndj = numero di nodi deconnessi al passo j; STG k = successione di tipi di gradienti di potatura.
Ogni Hi rappresenta la complessità dell’albero della stessa matrice delle adiecenze quando il vertice i-mo è cancellato.
Di conseguenza, la differenza tra la complessità dell’intero Grafo (cioè H0) e la complessità di ogni Grafo generato senza uno dei

78
vertici del grafo (Hi), è la misura del contributo di ogni vertice del grafo alla complessità globale:
(39) 0 .i iH H Hδ = − Questo nuovo indice stabilisce quanto ogni vertice contribuisce
ad aumentare ( 0iHδ < ) o a diminuire ( 0iHδ > ) l’informazione del grafo assegnato.
Abbiamo denominato questa funzione Funzione Delta H. Si tratta di una funzione applicabile non solo ai grafi ad albero, ma ad ogni tipo di grafo.
Esempio della Funzione Delta H sul Db giocattolo Gang:

79
a. Trasformazione Numerica: b.
Gang 14x27 Jet Sharks 20' 30' 40' JS COL HS Single Married Divorced Pusher Bookie Burglar ART 1 0 0 0 1 1 0 0 1 0 0 1 0 0AL 1 0 0 1 0 1 0 0 0 1 0 0 0 1SAM 1 0 1 0 0 0 1 0 1 0 0 0 1 0CLYDE 1 0 0 0 1 1 0 0 1 0 0 0 1 0MIKE 1 0 0 1 0 1 0 0 1 0 0 0 1 0JIM 1 0 1 0 0 1 0 0 0 0 1 0 0 1GREG 1 0 1 0 0 0 0 1 0 1 0 1 0 0JOHN 1 0 1 0 0 1 0 0 0 1 0 0 0 1DOUG 1 0 0 1 0 0 0 1 1 0 0 0 1 0LANCE 1 0 1 0 0 1 0 0 0 1 0 0 0 1GEORGE 1 0 1 0 0 1 0 0 0 0 1 0 0 1PETE 1 0 1 0 0 0 0 1 1 0 0 0 1 0FRED 1 0 1 0 0 0 0 1 1 0 0 1 0 0GENE 1 0 1 0 0 0 1 0 1 0 0 1 0 0RALPH 1 0 0 1 0 1 0 0 1 0 0 1 0 0PHIL 0 1 0 1 0 0 1 0 0 1 0 1 0 0IKE 0 1 0 1 0 1 0 0 1 0 0 0 1 0NICK 0 1 0 1 0 0 0 1 1 0 0 1 0 0DON 0 1 0 1 0 0 1 0 0 1 0 0 0 1NED 0 1 0 1 0 0 1 0 0 1 0 0 1 0KARL 0 1 0 0 1 0 0 1 0 1 0 0 1 0KEN 0 1 1 0 0 0 0 1 1 0 0 0 0 1EARL 0 1 0 0 1 0 0 1 0 1 0 0 0 1RICK 0 1 0 1 0 0 0 1 0 0 1 0 0 1OL 0 1 0 1 0 0 1 0 0 1 0 1 0 0NEAL 0 1 0 1 0 0 0 1 1 0 0 0 1 0DAVE 0 1 0 1 0 0 0 1 0 0 1 1 0 0
c. Trasposizione matriciale:
Gang 27x14 ART AL SAM CLYDE MIKE JIM GREG JOHN DOUG LANCE GEORGE PETE FRED GENE RALPH PHIL IKE NICK DON NED KARL KEN EARL RICK OL NEAL DAVE
Jet 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0Sharks 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1
20' 0 0 1 0 0 1 1 1 0 1 1 1 1 1 0 0 0 0 0 0 0 1 0 0 0 0 030' 0 1 0 0 1 0 0 0 1 0 0 0 0 0 1 1 1 1 1 1 0 0 0 1 1 1 140' 1 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0JS 1 1 0 1 1 1 0 1 0 1 1 0 0 0 1 0 1 0 0 0 0 0 0 0 0 0 0
COL 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 1 1 0 0 0 0 1 0 0HS 0 0 0 0 0 0 1 0 1 0 0 1 1 0 0 0 0 1 0 0 1 1 1 1 0 1 1
Single 1 0 1 1 1 0 0 0 1 0 0 1 1 1 1 0 1 1 0 0 0 1 0 0 0 1 0Married 0 1 0 0 0 0 1 1 0 1 0 0 0 0 0 1 0 0 1 1 1 0 1 0 1 0 0
Divorced 0 0 0 0 0 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1Pusher 1 0 0 0 0 0 1 0 0 0 0 0 1 1 1 1 0 1 0 0 0 0 0 0 1 0 1Bookie 0 0 1 1 1 0 0 0 1 0 0 1 0 0 0 0 1 0 0 1 1 0 0 0 0 1 0Burglar 0 1 0 0 0 1 0 1 0 1 1 0 0 0 0 0 0 0 1 0 0 1 1 1 0 0 0
d. AutoCM weights:
80
e. AutoCM Distances:
Il MST della rete globale ottenuta con il sistema AutoCM
Gli indici locali per questo albero sono i seguenti:

81
Grado del vertice Forza di clusterizzazione Grado di pruning Equazione (28) Equazione (30) Equazione (31)
Gli indici globali per la Hubbità globale ( 0 , iH H ) e per
l’Entropia del Grafo ( 0, iE E ) sono: Global Hubness Entropia del Grafo Equazioni (32) – (38) Equazioni (37)

82
Dal punto di vista dell’Hubness e dell’Entropia, se rimuoviamo dal grafico Rick, o Mike, o Neal, o Don, la complessità del grafo, e di conseguenza la sua entropia, aumenta; mentre se rimuoviamo dal grafo Al, la complessità del grafo, e di conseguenza la sua entropia, decresce.
Questo non è evidente se analizziamo lo stesso grafo comparando gli indici locali. Da un punto di vista ingenuo, si potrebbe pensare esattamente l’opposto: visto che Mike è un grande Hub (5 connessioni), se viene rimosso, allora la rete globale deve diventare più semplice. Ma da un punto di vista globale, la riorganizzazione della rete senza alcuni dei suoi vertici funzione in maniera completamente differente:
Il MST della rete globale segnato (H0=0.10989)
Se rimuoviamo dalla figura precedente i vertici all’interno dei
cerchi rossi, il nuovo MST mostrerà una struttura più complessa, mentre se rimuoviamo i vertici all’interno dei cerchi blu, il nuovo MST sarà più semplice.

83
Nuovo MST senza Mike (H0=0.133333)
Nuovo MST senza Al (H0=0.09)
Il Maximally Regular Graph (M.R.G.) Il MST evidenzia quali tra tutte le caratteristiche di un sistema
vanno direttamente connesse per permettere al sistema stesso di spendere il minimo di energia e restare compatto. La quantità d’energia è misurata in questo caso come la somma dei pesi delle distanze tra i nodi che il MST ha connesso direttamente.

84
Il MST, quindi, mostra i legami importanti tra le caratteristiche di un sistema. Ma non è detto che tutti i legami più importanti di quel sistema siano selezionati dal MST.
Tale limite è dovuto alla stessa natura del MST: ogni legame, per quanto importante, se genera un ciclo nel grafo viene escluso.
Più in dettaglio, se il numero totale delle connessioni di una
matrice quadrata di N nodi è 2
2N N
C−
= e il numero delle
connessioni sfruttate dal MST è 1P N= − , allora il numero M delle connessioni ancora disponibili sarà dato dalla seguente equazione:
(41) 2 ( 1) ( 2)
( 1) .2 2
N N N NM N
− − ⋅ −= − − =
Il MST, quindi, rappresenta nel “data mining” il sistema nervoso
minimo di una qualsiasi struttura di dati. Ma per spiegare in modo più completo la complessità di un sistema è necessario aggiungere alle connessioni del MST quelle ulteriori connessioni tra variabili che abbiano almeno due caratteristiche:
- che siano importanti dal punto di vista quantitativo; - e che siano capaci di creare, dal punto di vista qualitativo,
microstrutture cicliche regolari, interne alla struttura globale del sistema stesso.
In questo modo il grafo ad albero del MST si trasforma in un grafo indiretto dotato sempre di cicli interni.
La presenza di cicli interni introduce nel grafo la dimensione del tempo e il grafo stesso si trasforma in un sistema dinamico.
Mentre il MST fornisce informazioni chiave sulla struttura di una base di dati, questo nuovo grafo fornirà indicazioni sulla struttura e il funzionamento delle variabili della stessa base di dati.
Per costruire questo nuovo grafo del sistema abbiamo bisogno di 3 presupposti:
- la struttura del MST, che doterà il nuovo grafo della sua piattaforma iniziale;

85
- la lista, in ordine d’importanza, delle connessioni tra variabili che il MST ha escluso per ragioni strutturali;
- l’indice H, visto in precedenza, che misura la complessità di un qualsiasi grafo.
Abbiamo denominato questo nuovo tipo di grafo Maximally Regular Graph (M.R.G) e lo definiamo nel modo seguente: il M.R.G. è quel grafo con l’indice H massimo, generato aggiungendo in ordine di importanza al MST le prime R connessioni scartate prima di completare il MST.
Quindi, riprendendo alcune equazioni già analizzate (32) possiamo scrivere:
La variabile “R” è una variabile chiave in questo processo. Essa,
infatti, può assumere anche valore nullo, nel caso la costruzione del MST avvenga selezionando dalla lista ordinata per importanza (distanza minore, maggiore importanza) le prime N-1 connessioni, senza saltarne alcuna. In una base dati del genere, non esisterebbe un MRG.
Questa variabile, inoltre assicura che, l’ultima connessione aggiunta al grafo è la meno importante tra quelle aggiunte, ma al tempo stesso è sempre più importante della meno importante connessione generata per creare il MST.
Il MRG, quindi, aggiungendo al MST i legami più importanti tra le variabili, tende a individuare il grafo che presenta il massimo numero di microstrutture regolari all’interno del sistema.
Quanto più la funzione H individuata in questo processo avrà valori alti rispetto alle altre, tanto più significative saranno le microstrutture cicliche catturate dal MRG.
0
/* Funzione generica su un Grafo con archi e Nodi */
/* Funzione specifica di calcolo della H, dove rappresenta la complessita' del MST */
( ( , ));
1;
{ }.
pi p
p pi
p
i
A N
H
H f G A N
HA
MRG Max H
µ ϕ
=
⋅ −=
= /* Funzione di scelta del Grafo con il valore H massimo */
/* Indice della funzione H */
/* indice che conta il numero di archi del Grafo*/
[0,1,2,..., ]; [ 1, , 1,..., 1 ].
( 1)0,1,..,
i Rp N N N N R
NR
∈∈ − + − +
− ⋅∈ Numero delle connessioni saltate durante la costruzione del MST */( 2) ; /*
2N −

86
Riprendiamo a titolo di esempio il dataste Gang, calcoliamo il MRG sulla base della matrice delle distanze generate dal sistema AutoCM e compariamo il grafo MRG con quello del MST precedente.
H(0)= 0.1099H(1)= 0.1130 AL JOHNH(2)= 0.1250 SAM PETEH(3)= 0.0897 LANCE GEORGEH(4)= 0.0758 JIM JOHNH(5)= 0.1261 JOHN GEORGEH(6)= 0.0953 DOUG NEALH(7)= 0.1538 PHIL DONH(8)= 0.1493 PHIL NEDH(9)= 0.1450 DON NED
H(10)= 0.1410 ART CLYDEH(11)= 0.1293 DOUG RALPHH(12)= 0.1090 ART GENEH(13)= 0.1128 AL RALPHH(14)= 0.0907 DOUG FREDH(15)= 0.0941 IKE NICKH(16)= 0.1190 ART FREDH(17)= 0.1163 GREG JOHNH(18)= 0.1000 GREG LANCEH(19)= 0.0978 SAM CLYDEH(20)= 0.0957 NICK KENH(21)= 0.1367 GREG PETEH(22)= 0.1167 RALPH IKEH(23)= 0.1008 PHIL DAVEH(24)= 0.1343 OL DAVEH(25)= 0.1317 KEN EARLH(26)= 0.1440 NED KARLH(27)= 0.1212 DOUG NICK
MST

87
Hubbness del MRG sul dataset “Gang” La funzione H raggiunge un suo picco dopo aver aggiunto il
settimo dei legami scartati dal MST. Quindi, MRG prevede un grafo con sette connessioni in più rispetto a quelle selezionate dal MST. Questo grafo, inoltre, prevede una crescita di complessità di oltre il 50% rispetto alla complessità che la funzione H definiva per il MST di partenza (H(0)=10.99, H(7)=15.38).
Ed è logico che anche la qualità dei due grafi, quello del MST e quello del MRG, sia significativamente diversa:

88
MST sul dataset “Gang”
MRG sul Dataset “Gang”
L’informazione presente nel MRG completa quella presente nel
MST: il confine tra Jets e Sharks è gestito da un quadrangolo formato da due soggetti per banda (Neal e Ken appartengono agli

89
Sharks, mentre Doug e Mike appartengono ai Jets). Si potrebbe sostenere che il bordo tra le due bande è un bordo sfumato e negoziabile. I quattro soggetti che definiscono tale bordo sono, infatti, soggetti atipici all’interno delle loro rispettive bande. Essi potrebbero essere definiti soggetti prototipici della ibridazione tra le due bande.
Inoltre, all’interno della banda dei Jets il soggetto Al risulta al vertice di un circuito quasi automono che potrebbe costituire una terza banda.
Dal MRG si comprende bene come la banda dei Jets sia più complessa della banda degli Sharks (maggiore numero di cicli di similarità tra soggetti).
Infine, il ciclo triangolare tra Don, Ol e Phil rappresenta una specie di prototipo del soggetto Sharks, con caratteristiche distanti dagli altri soggetti Jets. Al contrario, i prototipi di soggetto Jets sono due: il primo rappresentato dal quadrangolo Gene, Sam, Fred e Pete; il secondo dall’altro quadrangolo che include John, Gorge, Lance e Jim. Secondo il MRG, le caratteristiche di ogni prototipo sarebbero le seguenti:
- Prototipo della ibridazione tra bande:
30'Jets JuniorSchool
Single BookieSharks HighSchool
+ + + +
- Prototipo del soggetto appartenente alla banda degli Sharks:
30' .Pusher
College MarriedBurglar
+ + +
- Primo Prototipo del soggetto appartenente alla banda dei Jets:
20' .College Bookie
SingleHighSchool Pusher
+ + +
- Secondo Prototipo del soggetto appartenente alla banda dei Jets:
20' .Married
JuniorSchool BurglarDivorced
+ + +

90
Sviluppi La ricerca di base sulle misure per l’analisi della complessità e la
tipologia dei grafi pesati per il prossimo triennio sarà nelle seguenti direzioni: 1. La ideazione di un sistema evolutivo tale da identificare su un
grafo generato da una matrice delle adiacenze la classe minima di nodi da eliminare per creare dalla stessa matrice un grafo di H massima o minima.
2. Creazione di un Software in grado di testare i grafi pesati dal punto di vista della Funzione H e di altre misure esistenti in letteratura.
3. Ideare una nuova tipologia di grafi a partire dalla Funzione H. 4. Sperimentare le proprietà del MRG su matrici delle distanze
naturali (problema di Ising in fisica). 5. Tentare l’applicazione della Funzione H per l’analisi delle
Immagini. Ricercatori impegnati Massimo Buscema, Pieluigi Sacco, Giulia Massini, Marco Breda,
Marco Pizziol, Riccardo Petritoli, Gaetano Salina.

91
2.8 Multi Dimensional Scaling (PST e Population) Il problema Diverse tecniche sono state ideate per comprimere e proiettare un
dataset da uno spazio a molte dimensioni ad uno con meno dimensioni, con l’obiettivo di conservare nel modo migliore la metrica presente nello spazio di origine.
Multidimensional Scaling, Topographic Mapping, ecc. sono spesso i nomi per le tecniche di proiezione e clustering.
Uno dei limiti maggiori nell’analisi dei dati multidimensionali è l’impossibilità di fornire visualizzazioni efficaci delle relazioni esistenti tra record e tra variabili in un dataset.
Più in generale, è di notevole utilità uno strumento in grado di comprimere le informazioni, contenute in un insieme di dati, da uno spazio K dimensionale ad uno spazio P dimensionale ( con P<<K e P=2 o P=3 nel caso in cui l’obiettivo sia quello della rappresentazione grafica).
Il problema, quindi, si presenta come segue: data una misura delle relazioni esistenti tra elementi di uno spazio, proiettare questi elementi in un spazio differente con minori dimensioni, minimizzando la distorsione delle relazioni originarie.
È un problema analogo a quello risolto dalla Self Organizing Map [11]; la differenza sostanziale è nell’approccio: possiamo parlare, nel caso della SOM, di proiezione vettoriale, cioè del fatto che nel processo di proiezione non vengono considerate ad ogni passo tutte le informazioni, cioè le posizioni degli altri punti, ma una sintesi di queste, cioè i codebook delle celle della SOM. Al contrario, i modelli del Semeion implementano quella che potremo definire proiezione coordinata, cioè la collocazione dei punti originali in un sottospazio, tenendo conto della contemporanea presenza di tutti gli altri.
Un problema di questo tipo è definito in letteratura di “Topographic Mapping” (TM), ed esistono molti algoritmi per affrontarlo. L’obiettivo è preservare le caratteristiche della “struttura geometrica” dei dati in una rappresentazione di questi a dimensionalità ridotta.
Il concetto di “struttura geometrica” è connesso a quello di distanza. Quindi, preservare la struttura geometrica dei dati originari

92
significa che, dopo l’applicazione dell’algoritmo di mappatura, gli elementi che nello spazio originario erano “vicini” si trovino vicini anche nello spazio ridotto, ed anche che elementi distanti nello spazio originario risultino ancora separati nello spazio destinazione.
Nel caso in cui si considera importante la preservazione della specifica metrica dello spazio originario, l’obiettivo consiste nel mirare all’isometria tra lo spazio originario e la mappa risultante.
Si può anche considerare rilevante, invece, la sola conservazione dell’ordine topologico tra i due spazi; in questo caso si tende al solo mantenimento dell’ordinamento delle distanze tra i punti tra lo spazio originario e quello di destinazione.
Nel caso in cui l’obiettivo dell’analisi sia la conservazione della metrica delle distanze originarie, il problema può essere formalizzato come segue: data una matrice quadrata A di dimensione N, simmetrica e con diagonale nulla, posizionare in uno spazio P dimensionale, generalmente con P<K, N punti in modo da minimizzare una funzione di errore E che tenga conto della dissimilarità tra la matrice A e la matrice delle distanze tra gli N punti proiettati nel sottospazio P dimensionale.
Il problema quindi si presenterà in questa forma: dati N punti { }NxxX ,....,1= o le loro distanze in uno spazio K dimensionale,
trovare la distribuzione di questi punti { }NyyY ,....,1= in uno spazio P dimensionale, con P<K, in modo da minimizzare la “differenza” tra le distanze originali e quelle nello spazio proiettato.
Se definiamo: la matrice delle distanze di mappa ),(:)( ji
Pij yyDMdYMd = ,
la matrice delle distanze originali ),(:)( jiK
ij xxDRdXRd = , e una misura della dissimilarità tra le due matrici
),( RdMdEE = , allora la funzione obiettivo è trovare una configurazione di punti
{ }NyyY ′′=′ ,....,1 , tale che: [ ]))(),((min* XRdYMdEE ′=

93
Questo problema generale genera un’ampia gamma di sottoproblemi, in funzione delle scelte fatte per la distanza D e per la funzione obiettivo E.
Per la distanza D, in particolare, possiamo distinguere distanze metriche e non metriche (quelle che non soddisfano la disuguaglianza triangolare).
Ad esempio:
Distanza Euclidea: ( ) ; :),( 2
1
2∑=
−=L
kjkikijji
K xxDxxD
Distanza Pesata:
( ) ; :),( 2
1
2∑=
−=L
kjkikkijji
K xxwDWxxD
Correlazione lineare:
( )( )
; 2
1
:),(
1
Lss
xxxx
DWxxD ji xx
L
kjjkiik
ijjiK
∑=
−−−
=
Grado di associazione:
].,[ ; ]1,0[ )1()1(
)1()1(
ln:),( ji,
1,,
1,,
1,,
1,,
+∞−∞∈∈−⋅−
⋅⋅
⋅−⋅
⋅−
−=
∑∑
∑∑
==
==
Ax
L
xx
L
xx
L
xx
L
xx
AxxD L
kkikj
L
kkikj
L
kkikj
L
kkjki
ijjiK
Anche per la funzione obiettivo sono possibili più scelte, ad esempio:
∑∑= =
−−
=N
i
N
ijijij RdMd
NNE
1)1(2
(2a)

94
∑∑= =
−
−=
N
i
N
ij ij
ijij
Rd
RdMd
NNE
1)1(2
(2b)
Nel caso della funzione obiettivo (2a), la stima dell’errore della proiezione dei dati sulla mappa considera in modo uguale tutte le distanze, nel secondo caso (2b),invece, le distanze tra punti più vicini “pesano” maggiormente nella valutazione della qualità di una soluzione. La (2b) è la nota equazione di ‘stress’ utilizzata da molti algoritmi che si occupano di topographic mapping [7].
Questo problema può essere ulteriormente classificato in mappatura lineare e nonlineare secondo la relazione esistente tra le coordinate dei punti originari e di quelli proiettati: la mappatura lineare é una mappatura da uno spazio originale ad uno destinazione, il cui scopo è di mantenere una relazione di tipo lineare tra gli assi dello spazio originale e quello di destinazione.
Gli algoritmi di proiezione lineare più noti sono la PCA (Principal Component Analysis) [6] e la ICA (Independent Component Analysis) [2]; la prima presuppone una distribuzione gaussiana dei dati, mentre l’altra non pone vincoli sulla distribuzione.
Se le relazioni tra le variabili sono di tipo non lineare, i metodi su elencati non sono in grado di preservare con adeguata accuratezza la struttura geometrica dello spazio d’origine. Nella compressione, infatti, molte informazioni importanti sono perdute. Nasce, quindi, la necessità di eliminare il vincolo di linearità tra gli assi e trovare una mappatura non lineare tra lo spazio originale e quello destinazione in grado di conservare il più possibile le relazioni tra le variabili.
Lo Stato dell’arte al Semeion Il Semeion ha messo a punto due algoritmi originali a tale scopo.
Il primo denominato P.S.T.: - Nome del sistema: Pick and Squash Tracking. - Ideato da M Buscema tra il 1999 e il 2003. - Implementato da M Buscema nel 1999, attualmente in: a. M Buscema, Pst, ver 7.0, Semeion Software n. 11, 1999-2007;

95
b. M Buscema, S Terzi, Pst Recall, ver 1.0, Semeion Sofware n.18, 2005;
c. G Massini, Pst on Map, ver 1.0, Semeion Software n.25, 2003; d. M Buscema, Pst Cluster, ver 2.0, Semeion Software n.34,
2006. Pubblicato: a. M Buscema, Genetic Doping and P.S.T.: A New Mapping
System, Technical Paper n. 20, Edizioni Semeion, Roma, 2001.
b. M Buscema, S Terzi, A new Evolutionary Approach to topographic mapping, Proceedings of the 7th WSEAS International Conference on Evolutionary Computing, Cavtat, Croatia, June 12-14, 2006, pp. 12-19.
c. M Buscema, S Terzi, PST: An Evolutionary Approach to the Problem of Multi Dimensional Scaling, in WSEAS Transactions on Information Science & Applications, Issue 9, vol. 3, September 2006 pp. 1704-1710.
Brevettato: a. Brevetto Europeo, denominato “Algoritmo per la proiezione
di dati di informazioni appartenenti ad uno spazio multidimensionale in uno spazio avente meno dimensioni. Un metodo per l’analisi cognitiva dei dati di informazioni multidimensionali “basati su detto algoritmo e un programma comprendente il detto algoritmo memorizzato su un supporto registrabile” (Pick and Squash Tracking - PST). (Domanda n. 03425436.7, depositato il 01-07-2003).
b. Brevetto Internazionale, denominato: “An Algorithm for projecting information data belonging to a multidimensional space into a space having less dimensions a method for the cognitive analysis of multidimensional information data based on the said algorithm and a program comprising the said algorithm stored on a recordable support” (Pick and Squash Tracking - PST). (Domanda n. PCT/EP2004/051190, depositato il 22-06-2004).
Il secondo Algoritmo è stato denominato “Population”. Si basa sulla stessa funzione di costo, è meno potente del PST, ma è

96
estremamente rapido e consente di trattare un numero di “punti” molto alto, che per il PST sarebbero proibitivi.
- Nome del sistema: Population - Ideato da G Massini nel 2007. - Implementato da G Massini nel 2007, attualmente in: a. G Massini, Population, ver 2.0, Semeion Software n. 42, 2007; Questi due algoritmi si sono dimostrati per ragioni diverse molto
superiori agli altri in termini di qualità di proiezione e di informazioni supplementari che forniscono al ricercatore durante la proiezione stessa (clustering intelligente dei tratti più rilevanti). In particolare il PST è risultato nettamente superiore a diversi metodi in uso per il Multi Dimensional Scaling:
- PCA; - Sammon Map; - Direct Search; - PCG (Preconditioned Conjugate Gradients) – fminunc (Math
Optimization Toolbox). Il PST, inoltre, si è rivelato un ottimo post-processing per le Self
Organizing Map (SOM). Uno degli ultimi sviluppi del PST (Buscema 2001-2007, non
pubblicato) è consistito nel dotare l’algoritmo della capacità di “inventarsi” un punto nascosto da aggiungere a quelli proiettati in modo da diminuire l’errore di proiezione. Questa Hidden Unit che il PST crea dinamicamente si è dimostrata matematicamente e sperimentalmente diversa dal centroide dei punti, e di recente è stata utilizzata con successo per individuare il centro operativo di un soggetto che innescava ordigni esplosivi sul territorio italiano (caso diventato famoso sui mass media).
Gli sviluppi La ricerca di base sul tema dello squashing per il prossimo
triennio sarà nelle seguenti direzioni: 1. Approfondimento matematico e neurologico del modo di
operare del PST quando individua una o più unita nascoste da aggiungere nella proiezione;
2. Creazione di nuovi algoritmi in grado di individuare le variabili (coordinate) dell’unità nascosta nello spazio di origine;

97
3. Sperimentazioni su Population nel trattare grandi quantità di dati provenienti dalla gnomica, proteinomica e metabolomica.
4. Creazione di nuovi algoritmi in grado di migliorare le prestazioni del Multi Dimensional Scaling.
5. Uso del Pst e di Population, anche come post processing per le reti SOM, per definire una tessellizzazione di Voronoi sui dati e/o sui codebooks.
Ricercatori impegnati: Massimo Buscema, Giulia Massini, Stefano Terzi.

98
2.9 Virtual Data Generation (PI Function and HID)
Il Problema Un dataset è un insieme di iper-punti in uno spazio N-
dimensionale, dove N è il numero delle variabili di ogni iper-punto. Un caso tipico è quello di un dataset nel quale alcune delle
coordinate (variabili) di alcuni iper-punti siano mancanti (i cosiddetti “missing data”).
Le soluzioni più usuali sono: a. Si elimina il record mancante (l’iper-punto incompleto); b. Si elimina la coordinata mancante in tutto il dataset; c. Si assegna alla coordinata mancante un nuovo valore, secondo
uno specifico algoritmo che sarà basato più o meno direttamente sul valor medio che quella coordinata assume negli altri records (iper-punti).
Tutte queste soluzioni sono insoddisfacenti. Infatti, la soluzione più teoricamente corretta dovrebbe consistere nel definire in modo ottimo la funzione continua che interpola tutti i dati completi, per poi ripopolare il dataset di dati nuovi, rispettando la densità di probabilità della funzione interpolata, e completare, sempre per interpolazione, le coordinate (variabili) di quelli mancanti.
Lo stato dell’arte al Semeion Il primo sistema ideato dal Semeion per la ricostruzione dei dati
mancanti ha preso il nome di PI-Function, ed è stato ideato da M Buscema tra il 1998 e il 2007.
Pubblicazioni: a. M Buscema et al, Application of Artificial Neural Networks to
Eating Disorders, Substance Use & Misuse, 33(3), 765-792, Dekker, 1998.
b. C Meraviglia, G Massini, D Croce, M Buscema, GenD: An Evolutionary System for Resampling in Survey Research, Quality & Quantity, 2006, 40, 825-859, Springer.
La procedura per implementare questa tecnica è piuttosto
semplice.

99
U
A2
a1 A1
A
A
1. Dato il campione A di popolosità n dell’universo U , tale
campione viene prima sottoarticolato in modo casuale in 2 sottocampioni A1 e A2 di uguale numerosità n/2 con intersezione nulla.
2. Dal sottocampione A1 viene estratto in modo casuale un sottocampione (a1) di numerosità n/2/10.
3. Una Rete Neurale Artificiale (ANN) di tipo supervisionato è addestrata in fase di training a interpolare la funzione f(x), il cui dominio è U, sulla base degli elementi del sottocampione A1 (ANNC). Altre c ANN supervisionate ma con strutture topologiche e leggi di apprendimento diverse vengono costruite e addestrate separatamente e in modo indipendente sul sottocampione a1 di A1 (ANNR1, ANNR2… ANNRc). In questa fase, dunque, le ANN devono modificare le proprie connessioni al fine di trovare una soluzione stabile ottimale che associ ad ognuno dei vettori di input (composto delle variabili indipendenti) presenti nel sottocampione l’esatto valore della variabile di output (variabile indipendente). Le c ANNR saranno costruite con strutture e regole di apprendimento il più possibile diverse allo scopo di offrire soluzioni distanti e articolate.
4. Per ognuna delle ANN (impostata al punto 3) viene valuta la capacità di ricostruzione della funzione f(x) sulla base del testing che viene effettuato per tutte sull’intero sottocampione A2 di

100
numerosità n/2. In questa fase vengono valutati per ogni ANN la percentuale di errori che compie nell’attribuire ad ogni record il giusto target. In altre parole, ogni ANN sulla base delle connessioni trovate nella fase di training, e senza modificarle, deve associare ad ogni vettore di input (composto delle variabili indipendenti il cui valore le è noto) il valore della variabile indipendente (il cui valore in questa fase, le è ignoto). In questa fase, dunque si valuta capacità di generalizzazione delle ANN addestrate sui casi presenti in A1 sul nuovo insieme di casi presenti nel sottocampione A2. Sulla base della % di errore si può valutare quanto le funzioni stimate attraverso le ANN siano simili alla funzione f(x) reale.
5. Al termine della fase 4 si confrontano le percentuali di errori che le varie ANN hanno compiuto. La aspettativa è che la performance della ANNC , che ha fittato la funzione f(x) sull’intero sottocampione A1, sia migliore delle performance ottenute dalle ANNR1, ANNR2… ANNRc addestrate sui sottocampioni di A1.
6. Viene impostato un Algoritmo Evolutivo, Genetic Doping Algorithm (GenD), su le cui impostazione , regole e struttura rimandiamo a M Buscema, Genetic Doping Algorithm (GenD). Theory and Applications, in Expert Systems, May 2004, Vol. 21, no. 2, pp. 63-79.
7. L’algoritmo Evolutivo GenD viene avviato per c volte per t target in modo indipendente per ogni avvio. GenD ha lo scopo
di ricostruire il sottoinsieme complementare di A, A , e dunque di ricostruire un sottocampione di U i cui elementi comunque soddisfino le funzioni individuate dalle c ANNR. I genoma che compongono la popolazione di GenD hanno un numero i di geni pari al numero di variabili indipendenti presenti nei vettori di input delle NNA. Il valore di ogni gene viene impostato all’inizio in modo casuale. Il numero di genoma generati è impostato in proporzione % al numero della varietà con cui si presenta la variabile indipendente all’interno del sottocampione a di A1. Se il valore della variabile indipendente è continuo allora verrà prima discretizzata sulla base di un range. GenD ha dunque il compito di invertire le funzioni individuate dalle ANNR. Per

101
ogni avvio di GenD viene fissato il valore del target e vengono generati nuovi genoma inizializzati in modo casuale. Ogni popolazione ha il proprio ‘valutatore’ di fitness: una delle reti ANNR. Ad ogni generazione (ciclo in cui GenD ricombina i propri geni all’interno di tutti i genoma presenti) la rete ANNR assegnata giudica se i genoma presenti sono soddisfano la funzione di assegnazione del target. La singola popolazione evolve fino a quando il fitness è raggiunto e cioè la rete giudica congruenti quei vettori (genoma) al target stabilito. Al termine, i genoma vengono salvati e archiviati come possibili elementi di
A . Viene quindi generata una nuova popolazione e avviato un nuovo processo evolutivo.
8. Il numero di genoma creati saranno: stcP ××= dove c è il numero di ANNR, t e la varietà del target e s è un numero intero che determina la ampiezza della popolazione di A .
9. Viene impostata una nuova ANN (ANNV) con struttura e regola di apprendimento analoga a ANNC , ma che viene addestrata in
training sul campione composto dalla popolazione P creata da GenD.
10. Al termine della fase 9 viene effettuato il testing con ANNV sullo stesso sottocampione A2 sul quale sono state valute tutte le precedenti ANN. La aspettativa è che la performance della ANNV sia migliore o uguale alla performance ottenuta da ANNC.
Una seconda tecnica elaborata da Buscema al Semeion nel 2007, e
ancora in fase di sperimentazione, è stata denominata Hidden Input Discovery (HID).
HID consiste nell’immaginare che ogni dataset che preveda variabili indipendenti e dipendenti possa essere incompleto. Cioè che esista dell’informazione di input non presente nel dataset, informativa sulle variabili dipendenti e non correlata alle altre variabili indipendenti.
La metodica implementata da HID consiste nel costruire un algoritmo evolutivo (tipo GenD), nel quale ogni individuo della popolazione sia una ipotesi di Input mancante da sottoporre in test cieco a più Reti Neurali Supervisionate.

102
Se il dataset originale può essere risolto da una Rete Neurale Supervisionata che computi una funzione di questo tipo:
1 2 ...
( ,* );
( ).
dove:
vettore di Output della rete;
vettore di Input, tale che { , , , };
* i parametri della funzione oggetto di ricerca della rete;
Errore a fine apprendimento.
n
Y f X W
E g T Y
Y
X X x x x x
W
E
=
= −
=
= =
=
=
Allora ciò che l’algoritmo evolutivo cerca è una situazione di questo tipo:
* *
* *
*
*
*1 2 ... 1
( ,* );
( );
tale che :
.
dove:
vettore di Output della nuova rete;
vettore di Input esteso, tale che { , , , ,* };
* i parametri della funzione oggetto di ricerca delln n
Y f X V
E g T Y
E E
Y
X X x x x x x
V+
=
= −
<<
=
= =
=*
a nuova rete;
Nuovo errore a fine apprendimento.E =
Questa dinamica può essere sintetizzata nel modo seguente: 1. Si crea una popolazione di N individui, ciascuno di lunghezza M
(numero dei records in training); 2. Si inizializza la popolazione con valori reali random tra 0 e 1; 3. Si prende ogni individuo come target dei valori di input del
dataset e si addestra una rete supervisionata a computarne la funzione (Rete Server);
4. Si prende lo stesso individuo e lo si aggiunge come input a tutti i records del dataset di training, e sul target dello stesso dataset viene addestrata una seconda rete neurale supervisionata (Rete Client);

103
5. Si utilizza la Rete Server, già addestrata, per attribuire ad ogni record di testing del dataset un Input Aggiuntivo conseguente;
6. Si utilizza la Rete Client, già addestrata, per stabilire l’output di ogni record di testing del dataset provvisto di Input Aggiuntivo;
7. Si valuta l’errore della Rete Client e si attribuisce una Fitness opportuna all’individuo da cui è partito il processo;
8. Si ripete tale processo per ogni individuo della popolazione (dal punto iii);
9. Si procede alla applicazione sulla popolazione degli operatori di ricombinazione, ottimizzazione e mutazione previsti dall’algoritmo evolutivo;
10. Si riparte dal punto iii con una nuova popolazione; 11. Si ferma l’algoritmo quando gli operatori non producono più
miglioramenti evolutivi. Un semplice schema può riassumere la dinamica del sistema HID:
I risultati sperimentali finora raggiunti dal sistema HID sono
molto incoraggianti. Prendiamo come esempio giocattolo il dataset Iris di Fisher, già diviso in training e testing: si tratta di 150 records

104
in totale, 75 in training e 75 in testing, che individuano ciascuno un tipo di Iris con 4 variabili indipendenti (Larghezza e Lunghezza dei Petali, e Larghezza e Lunghezza dei Sepali) e 3 classi di appartenenza possibile (Setose, Versicolor, Virginiche).
Abbiamo addestrato in modo indipendente 4 diversi tipi di Reti Neurali in training e poi le abbiamo validate in testing cieco; questi i risultati:
DB Originale Setose Virginiche Versicolor Mean ErrorsANN1 100.00% 92.00% 100.00% 97.33% 2ANN2 100.00% 92.00% 100.00% 97.33% 2ANN3 100.00% 92.00% 100.00% 97.33% 2ANN4 100.00% 96.00% 92.00% 96.00% 3ANN5 100.00% 96.00% 92.00% 96.00% 3
In seguito abbiamo applicato il sistema HID, la cui evoluzione è mostrata nella figura seguente:

105
La dinamica evolutiva di HID mostra in modo chiaro che dopo circa 150 generazioni l’algoritmo ha trovato una nuova soluzione che ha poi perfezionato nel tempo.
I due nuovi vettori di Input sono stati aggiunti sia al training set che al testing set. Il nuovo dataset è stato, quindi, addestrato con le stesse 5 reti neurali supervisionate usate nella prima sperimentazione, le quali sono state, infine, validate sul testing, dotato anch’esso del nuovo Input Aggiuntivo. I risulati sono riassunti nella seguente tabella:
DB+Input Nuovo Setose Virginiche Versicolor Mean ErrorsANN1 100.00% 100.00% 100.00% 100.00% 0ANN1 100.00% 100.00% 100.00% 100.00% 0ANN3 100.00% 100.00% 100.00% 100.00% 0ANN4 100.00% 100.00% 100.00% 100.00% 0ANN4 100.00% 100.00% 100.00% 100.00% 0
È interessante notare come il nuovo input che HID ha ideato sia per il training set, che per il testing set non sia correlato con gli Input già presenti nel dataset. Quindi il sistema HID sembra essere capace di “ideare” nuova informazione, non presente del dataset di partenza, ma compatibile con la funzione che da quel dataset si intende trovare.
Gli sviluppi In questo settore di ricerca per i prossimi 3 anni si intende
procedere nel modo seguente: 1. Generalizzare la PI-Function, per il completamento dei dati e
per la generazione di dati virtuali anche per le funzioni continue;
2. Ideare altri algoritmi per creare dati virtuali, più veloci e più stabili;
3. Effettuare più sperimentazioni sul sistema HID su dataset di grosse dimensioni;
4. Ideare altri algoritmi più veloci per indurre l’input nascosto in una base di dati.
Ricercatori impegnati: Massimo Buscema, Giulia Massini, Marco Intraligi.

106
2.10 Co-Clustering and Bi-Clustering (Visual DB)
Il Problema Uno dei problemi di classificazione più difficili è il Clustering
Non Supervisionato (CNS) di una serie di dati. Il CNS dipende da: a. la popolosità del campione; b. il numero delle variabili di ogni punto (record); c. la metrica utilizzata per misurare la distanza tra ogni punto ed
ogni altro; d. il numero dei clusters in cui si decide di raggruppare il
campione dei dati; e. l’algoritmo di clustering scelto e dalla conseguente funzione di
costo adottata; Si distinguono normalmente tecniche gerarchiche e tecniche non
gerarchiche di clustering. Tra le prime si utilizzano vari tipi di alberi, tra le seconde
algoritmi quali K-Means, Fuzzy K-Means, Simulated Annealing, SelfOrganing Map, ecc. Il problema di tutte queste tecniche è 1. nella metrica: se si sceglie una metrica euclidea e/o monotona
alla metrica euclidea, alcuni effetti nella distribuzione dei dati, magari ovvi a due dimensioni per l’occhio umano, verranno sempre ignorati (esempio: distribuzione dei punti a spirale 3D);
2. nel numero di clusters da individuare e/o nei criteri di separazione dei punti: tali numeri e/o criteri non si conoscono a priori e se imposti, non è detto che siano ottimi per mostrare i legami “naturali” tra i dati.
3. nel tipo di algoritmo scelto: se l’algoritmo applica una o più regole predefinite rischia di ignorare la specificità della distribuzione dei dati, ma se cerca di captare localmente le regole annidiate nei dati si scontra con un problema di efficienza, la possibilità di soluzioni sub-ottime rispetto a quella teoricamente ottima.
4. alcune di queste tecniche sono sensibili anche al rapporto tra righe e colonne del dataset. Ma una situazione nella quale il

107
dataset presenti pochi punti e molte variabili è normale per esempio nella analisi genomiche e proteinomiche (microarray).
Lo stato dell’arte al Semeion Dopo aver sperimentato le diverse tecniche presenti in letteratura
le ideazioni che più delle altre meritano un approfondimento nella ricerca di base hanno preso il nome di Visual DB.
Il Visual DB
Questo metodo si base su una premessa e su una ipotesi: a) Premessa: ogni dataset è riconducibile ad una matrice numerica
a 2 dimensoni, righe x colonne; quindi, ogni dataset in quanto matrice a due dimensioni mantiene la propria identità per qualsiasi permutazione delle sue righe e/o delle sue colonne. L’insieme, quindi, di tutte le permutazioni possibili, P, è definito dalla seguente equazione:
! !
Numero delle Righe; Numero delle Colonne.
P R CRC
= ⋅==
Da cui si comprende che il numero delle permutazioni possibili cresce in modo esponenziale al crescere del numero delle righe e/o del numero delle colonne. b) Ipotesi: L’ipotesi che abbiamo formulato è che in questo
insieme di permutazioni possibili ne esista una che sia ottima. Se, infatti, definiamo ,
ki jS la somma dei quadrati delle differenze
tra i valori della cella della i-esima riga e della j-esima colonna nella permutazione k-esima, e i suoi primi vicini (intorno di Moore):
( )2
, , , ;
Intorno di Moore.
N Nki j i j i l j z
l z
S a a
N
+ += −
=
∑∑
Allora la rugosità totale della k-esima permutazione, kD , sarà data da:
,
R Ck k
i ji j
D S= ∑∑ .

108
La nostra ipotesi è che la permutazione ottima del dataset sia quella con minore rugosità:
* { };
{1,2,..., }
kD Min Dk P
=∈
Visual DB è il nome di questa premessa, di questa ipotesi e del
metodo che abbiamo ideato per arrivare alla soluzione di un problema che si presenta come hard completo non risolvibile in tempo polinomiale.
In pratica si tratta di una ricerca della permutazione di righe e di colonne in un dataset, tale che la superficie del dataset risulti il più morbida possibile. Questa soluzione permette di effettuare un clustering geografico del dataset: zone simili si troveranno vicino a zone simili e le discontinuità che resteranno sono quelle che definiscono i bordi naturali e ineliminabili tra righe e colonne. Inoltre, questo metodo permette anche un clustering locale e coniugato tra righe (records) e colonne (variabili).
Il Visual DB trasforma in pratica un dataset in una immagine, dove la posizione delle righe e delle colonne rappresenta la permutazione naturale di quel dataset, la sua matrice madre, quella dalla quale, in teoria, è stato originato tramite un randomizzazione dell’ordine delle sue righe e quello delle sue colonne.
Una volta che Visual DB ha trovato la permutazione ottima di un DB, la sua analisi dettagliata in cluster può essere continuata anche con gli strumenti tipici usati per l’analisi delle immagini: edges detection, segmenation, equalization, ecc.
Esempio 1: la scacchiera: Una scacchiera può essere letta come un dataset con variabili e
record distribuite in due classi ortogonali. Una K-Means individua sempre due classi, quella dei records pari
e quella dei records dispari, anche quando viene impostata per trovarne quattro.
In realtà, le classi naturali presenti in una scacchiera sono quattro: a) Records dispari e Variabili dispari; b) Records dispari e Variabili pari;
109
c) Records pari e Variabili pari; d) Records pari e Variabili dispari.
Scacchiera 40x40
Stato iniziale Soluzione di Visual DB
Esempio 2: I Cibi e l’Europa
Questo dataset giocattolo riporta il consumo in tonnellate di nove tipi di cibo in 16 paesi europei in un giorno (media):
Abbiamo effettuato una analisi di questo dataset con algoritmi lineari (PCA) e non lineari (PST, Sammon Map e Direct Search). Qui riportiamo i risultati medi di distorsione della matrice delle

110
distanze originali effettuata dai diversi algoritmi su 10 prove ( da M Buscema, S Terzi, PST: An Evolutionary Approach to the Problem of Multi Dimensional Scaling, in WSEAS Transactions on Information Science & Applications, Issue 9, vol. 3, September 2006 pp. 1704-1710).
Mostriamo, infine, la proiezione a 2d effettuata dal Pst (il
migliore) e dalla PCA (la peggiore in quanto a distorsione):
Principal Componet Analysis

111
P.S.T. con tessellizazione di Voronoi
Il Visual DB genera, dopo pochi cicli, la seguente matrice di
questo dataset a permutazione ottima (ricordiamo che la matrice in questione è toroidale sulle righe e sulle colonne e che tutte le variabili del dataset sono state scalate tra 0 e 1):

112
Una segmentazione di questa matrice generata dal sistema ACM-
CM-Quot-Mean (vedi M Buscema, Sistemi ACM e Imaging Diagnostico. Le immagini mediche come Matrici Attive di Connessioni, Sprinter-Verlag Italia 2006) raggruppa tutte le celle in 5 clusters naturali (Nero, Grigio Scuro, Grigio, Grigio Chiaro, Bianco):

113
Una colorazione conforme della Matrice generata da Visual DB
permette di ottenere informazioni molto dettagliate sui diversi raggruppamenti records-variabili (nazioni-cibi):

114
Visual DB è stato ideato da M Buscema tra il 2004 e il 2007. È implementato in:
- M Buscema, Visual DB, ver 5.0, Semeion Software n.31, Roma, 2005-2007.
Visual DB non è attualmente brevettato e non ci sono pubblicazioni che lo trattano.
Gli sviluppi Per i prossimi 3 anni si prevede di approfondire i seguenti punti: 1. Miglioramenti dell’algoritmo di ottimizzazione (attualmente
una guided local search è implementata); 2. Ideazione di un’algoritmo di clustering sensibile alla
organizzazione geografica di Visual DB; 3. Confronto con altri algoritmi di letteratura su dataset di
microarrays. Ricercatori impiegati: Massimo Buscema, Stefano Terzi.

115
2.11 Il Clustering Dinamico sulle Traiettorie dei Datasets (DPCA)
Il problema I metodi attuali di clustering usano molti e diversi algoritmi. Tutti
però hanno in comune un tratto: clusterizzano i dati del dataset (per riga, per colonna o insieme).
Un dataset, però, non è un oggetto statico, ma un insieme di “forze congelate” in uno specifico istante o intervallo di tempo. Alcune di queste forze potrebbero essere costanti, altre variabili, altre ancora congelate in istanti diversi, ma in tutti casi si tratta di forze e non di stati. Quindi, un dataset è un oggetto complesso teso tra un suo passato ignoto e la serie di suoi futuri possibili.
Quando, tramite una Rete AutoAssociata Non Lineare si definisce la funzione implicita di un dataset è come se i pesi che la rete ha definito fossero il sistema osseo, nervoso e muscolare di un “cadavere”: l’insieme di vincoli che specifica le possibilità e gli stili di movimento di quel “corpo inerte”.
Una volta stabiliti i vincoli di un dataset (le matrici di pesi della sua funzione implicita) è necessario “rianimare” il dataset per far interagire le variabili di ogni record tra di loro e, di conseguenza, i records tra di loro.
Le variabili di ogni record, infatti, sono oggetti elementari che interagiscono tra di loro continuamente, perché in quanto “forze” negoziano i loro valori all’interno di ogni record, che di tali variabili rappresenta la membrana e/o il tessuto connettivo. I records, a loro volta, interagiscono tra di loro ad un livello più complesso. Se, infatti, un dataset rappresenta un campione di oggetti che nell’universo reale sono collocati in qualche forma di contiguità spazio-temporale, è ovvio che ogni record negozi in parallelo i valori di tutte le sue variabili con gli altri records, in una sorta di gioco evolutivo, sia competitivo che cooperativo.
Queste considerazioni hanno una conseguenza: le informazioni complete di ogni dataset non possono emergere solo tramite l’interpolazione, seppure non lineare, di tutti i suoi records (punti). Solo una analisi che preveda le variabili e i records come soggetti attivi del processo stesso di analisi sarà in grado di far emergere in

116
contenuto informativo di quel dataset. Contenuto informativo che è costituito soprattutto non da come il dataset “è fatto”, ma da cosa quel dataset “può fare” essendo “fatto in quel modo”.
Queste riflessioni implicano che la funzione implicita di ogni dataset è una parte del suo Funzionale, il quale è costituito da tutte quelle funzioni che disegnano le “traiettorie” che quel dataset può frequentare, se opportunamente attivato, e che sono compatibili con la sua funzione implicita.
Intendiamo per clustering dinamico il clustering di un dataset effettuato su tutte le sue traiettorie, ottenute dalla interazione tra sue variabili e tra suoi records, a partire dalla funzione implicita che ne definisce l’insieme di vincoli iniziale.
Un esempio: il Dataset Gang:

117
Gang 14x27 Jet Sharks 20' 30' 40' JS COL HS Single Married Divorced Pusher Bookie Burglar ART 1 0 0 0 1 1 0 0 1 0 0 1 0 0AL 1 0 0 1 0 1 0 0 0 1 0 0 0 1SAM 1 0 1 0 0 0 1 0 1 0 0 0 1 0CLYDE 1 0 0 0 1 1 0 0 1 0 0 0 1 0MIKE 1 0 0 1 0 1 0 0 1 0 0 0 1 0JIM 1 0 1 0 0 1 0 0 0 0 1 0 0 1GREG 1 0 1 0 0 0 0 1 0 1 0 1 0 0JOHN 1 0 1 0 0 1 0 0 0 1 0 0 0 1DOUG 1 0 0 1 0 0 0 1 1 0 0 0 1 0LANCE 1 0 1 0 0 1 0 0 0 1 0 0 0 1GEORGE 1 0 1 0 0 1 0 0 0 0 1 0 0 1PETE 1 0 1 0 0 0 0 1 1 0 0 0 1 0FRED 1 0 1 0 0 0 0 1 1 0 0 1 0 0GENE 1 0 1 0 0 0 1 0 1 0 0 1 0 0RALPH 1 0 0 1 0 1 0 0 1 0 0 1 0 0PHIL 0 1 0 1 0 0 1 0 0 1 0 1 0 0IKE 0 1 0 1 0 1 0 0 1 0 0 0 1 0NICK 0 1 0 1 0 0 0 1 1 0 0 1 0 0DON 0 1 0 1 0 0 1 0 0 1 0 0 0 1NED 0 1 0 1 0 0 1 0 0 1 0 0 1 0KARL 0 1 0 0 1 0 0 1 0 1 0 0 1 0KEN 0 1 1 0 0 0 0 1 1 0 0 0 0 1EARL 0 1 0 0 1 0 0 1 0 1 0 0 0 1RICK 0 1 0 1 0 0 0 1 0 0 1 0 0 1OL 0 1 0 1 0 0 1 0 0 1 0 1 0 0NEAL 0 1 0 1 0 0 0 1 1 0 0 0 1 0DAVE 0 1 0 1 0 0 0 1 0 0 1 1 0 0
La sua traduzione numerica permette di approssimare le relazioni tra le sue variabili tramite semplici equazioni di co-occorenza:
, , , ,21 1
,
, , , ,21 1
,
1(1 ) (1 )
ln ; 1
(1 ) (1 )
- ; [0,1]; , [1,2,..., ]
N N
i k j k i k j kk k
i j N N
i k j k i k j kk k
i j
x x x xN
wx x x x
N
w x i j M
= =
= =
⋅ ⋅ − ⋅ − ⋅= −
⋅ ⋅ ⋅ − ⋅ −
∞ ≤ ≤+∞ ∈ ∈
∑ ∑
∑ ∑
La matrice delle connessioni tra tutte le variabili sarà quindi di
questo tipo:

118
A questo punto utilizziamo una rete Constraints Satisfaction (vedi M Buscema, Constraint Satisfaction Neural Networks, in Substance Use & Misuse, Vol. 33, n. 2 (Models), Marcel Dekker, Inc., New York, 1998, pp. 389-408) per generare un campione rappresentativo di tutte traiettorie che si possono ottenere stimolando la matrice dei pesi.
Abbiamo, quindi, generato 5000 traiettorie, che sono più del 30% di tutte quelle ottenibili ( 16384).
Il nuovo dataset, quindi, consisteva di 785178 records, in quanto ogni traiettoria poteva avere lunghezza diversa, dovuta a cicli di convergenza diversi per ogni stimolazione.
Su questo nuovo dataset abbiamo calcolato la matrice dei pesi con lo stesso algoritmo di co-occorrenza utilizzato in precedenza.
La nuova matrice dei pesi è stata la seguente:
Per confrontare queste due matrici abbiamo utilizzato il MST, per vedere se nei due casi le relazioni fondamentali tra queste due elaborazioni fossero in che misura simili o diverse.

119
MST della Matrice dei pesi del dataset originale
MST della Matrice dei pesi del dataset delle Traiettorie

120
I due Grafi sono simili e diversi: 1. mantengono relazioni simili nel definire i primi vicini
prototipici della variabile Gang: a) Jets ha come primi vicini nei due grafi le stesse variabili; b) Sharks nel secondo grafo come primi vicini 4 variabili, 3
sono le stesse di quelle scelte per il primo grafo, la quarta è diversa ma la sua posizione è statisticamente pertinente.
2. Presentano relazioni diverse su molti relazioni, meno statisticamente definibili con sicurezza: a) Nel primo grafo HS sembra specifico della gang Sharks e
isolato dall’altra gang, mentre nel secondo grafo, pur essendo ancora specifico della gang Sharks, è connesso con 4 gradi di separazione con la gang Jets. Ciò è più sensato, in quanto 4 Jets presentano il titolo HS e 3 su 4 sono “Single”.
b) Il centro del primo grafo è la variabile “Burglar”, che è presente 5 volte nei Jets e 4 volte negli Sharks, anche se sembra più tipica di questi ultimi, mentre il centro del secondo grafo è la variabile “40’s”, di cui sono presenti due esemplari per gang.
In ogni caso, il grafo ottenuto tramite clustering dinamico sembra sensato quanto il primo generato dai dati originari; anzi, in alcuni casi sembra più informativo e preciso. Quindi, l’argomento del Clustering Dinamico entra a far parte della ricerca di base del Semeion, anche se, a parte alcuni sw creati da M Buscema per una prima verifica di queste prime idee, non esistono pubblicazioni precedenti su questo argomento. Denominiamo questa nuova filosofia di ricerca Dynamic Paths Clustering Activaction (D.P.C.A.).
Gli sviluppi Per il prossimo triennio si intendono approfondire i seguenti
punti: 1. Ideazione di una batteria di sperimentazioni numeriche atte a
stabilire quanto il clustering dinamico sia più o meno informativo di quello tradizionale;

121
2. Ideazione di algoritmi idonei a sviluppare traiettorie anche su dataset con variabili continue;
3. Sviluppo dell’algoritmi più efficaci nel definire la funzione implicita di un dataset;
4. Ideazione di algoritmi in grado di far attivare e interagire tra di loro anche i records.
Ricercatori impegnati: Massimo Buscema, Marco Pizziol, Riccardo Petritoli.


Piano Triennale Ricerca Applicata (2008-2010)
di Guido Maurelli


125
3. Piano Triennale Ricerca Applicata (2008-2010) La ricerca applicata rappresenta il ponte tra la ricerca di base e
quella industriale. Ha lo scopo di verificare la trasferibilità e la produttività delle scoperte che provengono dalla ricerca di base nei diversi settori sociali e industriali.
La comunicazione efficiente tra ricerca di base e ricerca applicata è il punto critico per la efficace implementazione di quest’ultima. In un progetto di ricerca applicata, i riferimenti a teorie sperimentate e validate devono essere chiari e dettagliati.
Un modo per rendere efficiente la comunicazione tra ricerca di base e ricerca applicata è quello di formare esperti di ricerca applicata che siano in grado di comprendere a fondo le teorie sperimentate in quel campo, avendo la capacità di estrarre da esse idee applicative vantaggiose sotto il profilo sociale ed economico.
In questa prospettiva il Semeion ha formato, e continua a formare, ricercatori con un profilo che identifica gli esperti di ricerca applicata come persone competenti tecnicamente nei diversi ambiti di interesse, principalmente orientati alla applicazione industriale e/o sociale della ricerca di base.
Questa organizzazione dell’attività di ricerca favorisce la realizzazione di tecnologie innovative e competitive orientate al mercato, interpretando i diversi bisogni sia delle imprese sia del settore pubblico.
L’attività di ricerca istituzionale del Semeion si ferma quindi alla soglia della ricerca industriale, che deve essere intesa come la traduzione delle tecnologie possibili in prodotti e/o processi innovativi, utilizzabili in un mercato di consumatori e/o utenti. L’ideazione di brevetti è il risultato della logica produttiva della ricerca applicata, che ha anche il compito di proteggere le architetture dei processi di produzione e dello stesso prodotto finale.
All’interno del Semeion la ricerca applicata si concretizza nell’effettuazione di elaborazioni e sperimentazioni su ogni tipo di problema che sia articolato in uno specifico Database. Tali sperimentazioni vengono fatte utilizzando i modelli e gli algoritmi ideati e scoperti nell’attività di ricerca di base; i risultati sono il prodotto dei singoli progetti di ricerca.

126
Per effettuare questa attività i ricercatori del Semeion hanno messo a punto metodi di elaborazione dotati di specifici protocolli di validazione, utilizzando procedure che fanno riferimento agli standard internazionali.
Il piano triennale 2008-2010 prevede che l’attività di ricerca applicata sia focalizzata su 3 campi applicativi:
- biomedicale: imaging diagnostico e clinico-farmaceutico; - sicurezza sociale e fenomeni criminali; - industriale, marketing e mondo del lavoro. Per coerenza con la struttura del piano triennale sulla Ricerca di
Base abbiamo deciso di riportare i singoli progetti di Ricerca Applicata strutturati in schede articolate nel seguente modo:
- obiettivo del progetto; - risultati conseguiti; - equipe di ricerca e partner esterno; - sviluppi.

127
3.1 Biomedicale settore Imaging Il campo biomedicale è attivo dalla fine del 2000 ed è stato
oggetto di innumerevoli progetti di ricerca applicata nel corso degli ultimi sette anni, nonché di numerose pubblicazioni su riviste scientifiche internazionali. Il partner principale interessato ai risultati prodotti da questi progetti di ricerca è costituito dal Gruppo Bracco, articolato nelle due aziende principali Bracco SpA e Bracco Imaging SpA. Quest’ultima è anche il principale finanziatore dei singoli progetti nel settore dell’imaging, e lo sarà per almeno i prossimi due anni. 3.1.1 Progetto CAD MR-mammography con Sistemi
Artificiali Adattivi per la classificazione e previsione di masse tumorali
Obiettivo del progetto Lo scopo del progetto consiste nella costruzione di un sistema
prototipale, che fornisca la base scientifica e tecnologica per realizzare un prodotto industriale che funzioni come CAD mammografico intelligente. Cioè un sistema che fornisca al radiologo la possibilità di effettuare una diagnosi assistita (Computer Aided Diagnosis Magnetic Resonance Mammography) per il cancro della mammella, su mammografia realizzata con risonanza magnetica.
Il sistema contiene modelli di elaborazione che utilizzano software proprietario del Semeion (Semeion©), alcuni dei quali brevettati. Il primo progetto è finalizzato alla individuazione di masse tumorali, sia di tipo benigno che di tipo maligno.
Risultati conseguiti Il protocollo di realizzazione del progetto prevede diversi step per
effettuare due diverse tipologie di classificazioni funzionali delle masse tumorali: la funzione di Detection e la funzione di Diagnosi.
La Detection è finalizzata a distinguere il tessuto sano dal tessuto con presenza di lesioni, indipendentemente dal fatto che tali lesioni siano maligne o benigne.

128
La Diagnosi è invece finalizzata a distinguere fra lesioni maligne e lesioni benigne.
Ovviamente queste due funzioni prevedono un uso del risultato diverso da parte del radiologo. La Detection può essere utilizzata in una fase di screening focalizzata ad individuare i soggetti sani da quelli potenzialmente malati. La Diagnosi, invece, costituisce una fase successiva che approfondisce la pericolosità della lesione dovendo discriminare fra i pazienti con lesioni, quelli che presentano le lesioni benigne, da quelli che presentano le lesioni maligne.
Il lavoro svolto finora ha portato a risultati giudicati molto interessanti dai medici radiologi che operano in questo settore. Riportiamo i risultati delle elaborazioni di tre diversi tipi di target:
- tessuto con lesioni VS tessuto sano; - lesioni maligne VS lesioni benigne; - lesioni maligne VS tessuto sano. Lo schema delle elaborazioni effettuate in tutta la fase
sperimentale è rappresentato nella figura sottostante.
PROTOCOLLO ELABORAZIONI
ROI
PVT* ACM* (AntiCMBase)
IFAST*
(MLP)
TWIST*
Supervised
1/0
SOM
Selezione campioni Tuning/Prediction
IFAST*
(MLP)
SOM
Selezione campioni Tuning/Prediction
Supervised
1/0
PVT*
TWIST*
Supervised
1/0
Supervised
1/0
Livello decisionale del processo
PROTOCOLLO ELABORAZIONI
ROI
PVT* ACM* (AntiCMBase)
IFAST*
(MLP)
TWIST*
Supervised
1/0
SOM
Selezione campioni Tuning/Prediction
IFAST*
(MLP)
SOM
Selezione campioni Tuning/Prediction
Supervised
1/0
PVT*
TWIST*
Supervised
1/0
Supervised
1/0
Livello decisionale del processo
Schema delle elaborazioni sulle masse tumorali i modelli con l’asterisco sono Semeion©

129
Lo schema contiene 4 modelli del Semeion, tre dei quali sono stati brevettati:
1. Pixel Vector Theory (PVT), [vedi § 2.3. del capitolo Ricerca di Base];
2. Active Connection Matrix (ACM), [vedi § 2.2. del capitolo Ricerca di Base];
3. Implicit Function as Squashing Time (IFAST), [vedi § 2.4. del capitolo Ricerca di Base]2;
4. Training With Input Selection and Testing (TWIST), [vedi Rapporto di Ricerca 2006, p. 50].
Inoltre vengono utilizzate reti neurali supervisionate e reti SOM, tutte implementate in software proprietari del Semeion, con modifiche e miglioramenti degli algoritmi classici di riferimento.
I risultati, costituiti dalla media di 50 diverse reti neurali, sono stati confrontati con quelli realizzati, con tecniche diverse, da sistemi attualmente presenti sul mercato. Le tre tabelle che seguono sintetizzano i risultati ottenuti sui diversi target.
Tessuto con lesioni VS Tessuto sano
Sensitivity Specificity Semeion Systems Current products
84% 85%
60% 33%
Tabella 1: risultati medi di 50 RNA tessuto con lesioni VS tessuto sano Nella tabella emerge che la sensitività, cioè la capacità predittiva dei
sistemi del Semeion rispetto al tessuto malato rimane sostanzialmente invariata (-1%) rispetto ai prodotti esistenti sul mercato. L’aspetto più significativo è il livello di specificità, che nei modelli del Semeion quasi raddoppia rispetto ai prodotti esistenti sul mercato. Questo risultato ha una ricaduta importante sul lavoro del medico, in quanto gli consente di risparmiare tempo mantenendo sostanzialmente inalterata l’accuratezza diagnostica, infatti, il numero dei falsi positivi, cioè dei falsi allarmi, viene praticamente dimezzato.
2 I riferimenti dettagliati ai tre brevetti (PVT, ACM e IFAST) sono riportati nei rispettivi paragrafi del capitolo Ricerca di Base.

130
Lesioni maligne VS Lesioni benigne
Sensitivity Specificity Semeion Systems Current products
87% -----
80% -----
Tabella 2: risultati medi di 50 RNA lesioni maligne VS lesioni benigne
In questa seconda tabella i sistemi Semeion evidenziano la possibilità di offrire al medico risposte anche di tipo diagnostico, cosa attualmente non presente in altri prodotti esistenti sul mercato.
Lesioni maligne VS Tessuto sano
Sensitivity Specificity Semeion Systems Current products
90% -----
77% -----
Tabella 3: risultati medi di 50 RNA lesioni maligne VS tessuto sano Quest’ultima tabella mostra la possibilità di fornire una risposta
ibrida, che ha lo scopo di rafforzare la confidenza del medico rispetto alle lesioni maligne.
Equipe di ricerca e partner esterni L’equipe dei ricercatori che stanno portando avanti questo lavoro
è composta da: M. Intraligi e M. Capriotti. Il partner esterno, finanziatore del progetto è la Bracco Imaging
SpA. Sviluppi Attualmente il lavoro di ricerca è orientato in due direzioni:
aumento del numero di casi da sottoporre ai sistemi del Semeion, e mantenimento della capacità predittiva delle reti neurali con ul teriore riduzione dei falsi positivi.

131
3.1.2 Progetto CAD MR-mammography con Sistemi Artificiali Adattivi per la classificazione e previsione di microcalcificazioni tumorali
Obiettivo del progetto Lo scopo del progetto è identico al precedente, con la differenza
che in questo caso la focalizzazione non è sulle masse, ma sulle microcalcificazioni tumorali. Anche la struttura del progetto e i relativi protocolli di addestramento dei sistemi sono molto simili.
Risultati conseguiti Il protocollo di tuning dei sistemi è relativamente più semplice di
quello descritto nel precedente progetto, le elaborazioni erano finalizzate a distinguere fra due target:
- tessuto con microcalcificazioni VS tessuto sano. Nella figura sottostante riportiamo lo schema dei protocolli di
elaborazione e dei modelli utilizzati.
ROI
WAVELET
SUPERVISED1/0
ACM*
SUPERVISED1/0
WAVELET
ACM*
SUPERVISED1/0
SUPERVISED1/0
Livello decisionale del processo
histogram histogram histogram histogram
ROI
WAVELET
SUPERVISED1/0
ACM*
SUPERVISED1/0
WAVELET
ACM*
SUPERVISED1/0
SUPERVISED1/0
Livello decisionale del processo
histogram histogram histogram histogram
Schema delle elaborazioni sulle microcalcificazioni tumorali i modelli con l’asterisco sono Semeion©
In questo protocollo viene utilizzato il modello ACM, brevettato
dal Semeion, insieme ad altri sistemi di ricodifica dell’immagine originaria, come una wavelet. Inoltre, così come in precedenza, sono

132
state utilizzate reti neurali Supervisionate, con miglioramenti degli algoritmi classici.
Infine, anche in questo caso, i risultati sono stati confrontati con quelli provenienti da diversi prodotti esistenti sul mercato. Nella tabella che segue vengono mostrati i risultati ottenuti dai sistemi del Semeion.
Microcalcificazioni VS Tessuto sano Sensitivity Specificity Semeion Systems Current products
99% 98%
76% 33%
Risultati medi di 50 RNA tessuto con microcalcificazioni VS tessuto sano
Questi risultati dimostrano che i sistemi del Semeion, oltre a migliorare leggermente la sensitività sul tessuto che presenta microcalcificazioni (+1%), riescono ad eliminare circa ¾ dei Falsi Positivi che i prodotti sul mercato presentano. In termini operativi questo significa che il medico risparmia tempo, in quanto il numero dei falsi allarmi al quale è normalmente sottoposto si riduce in modo considerevole.
Equipe di ricerca e partner esterni L’equipe dei ricercatori che stanno portando avanti questo lavoro
è composta da: M. Buscema, G. Massini, M. Intraligi e M. Capriotti. Il partner esterno, finanziatore del progetto è la Bracco Imaging
SpA.
Sviluppi In questo secondo progetto sul CAD mammografico l’obiettivo è
quello di consolidare i risultati raggiunti, aumentando il numero di pazienti sottoposti all’analisi dei modelli di elaborazione.

133
3.1.3 Progetto sviluppo di Meta-Classificatori per l’ottimizzazione delle previsioni sui tumori
Obiettivo del progetto Lo sviluppo del progetto è strettamente connesso, essendone la
diretta conseguenza, al lavoro di ricerca di base sui Meta-Classificatori, ampiamente descritto nel capitolo 2.5 del presente volume.
Come normalmente accade, i primi risultati della ricerca di base hanno consentito di pianificare un primo progetto applicativo nel quale utilizzare i Meta-Classificatori attualmente disponibili.
Nel caso specifico il progetto si pone l’obiettivo di applicare i sistemi di metaclassificazione alle lesioni tumorali sia benigne che maligne, allo scopo di aumentare l’accuratezza dei processi previsionali e consolidare la stabilità dei risultati ottenibili, sfruttando la capacità predittiva di diversi modelli di classificazione in parallelo.
Risultati conseguiti Nella fase sperimentale della ricerca di base i Meta-Classificatori
del Semeion sono stati confrontati con i risultati conseguiti da altri Meta-Classificatori reperibili in letteratura. Questo confronto è stato effettuato con diversi tipi di dataset, su cui sono state misurate le performance dei sistemi di metaclassificazione.
I risultati sperimentali finora conseguiti hanno quasi sempre collocato i Meta-Classificatori del Semeion nelle prime posizioni. La prima conseguenza di ciò è stata la decisione di utilizzare questi nuovi sistemi nell’ambito dell’imaging bio-medicale per la classificazione dei tumori.
Equipe di ricerca e partner esterni L’equipe dei ricercatori che stanno lavorando al progetto è
composta da: S. Terzi e R. Petritoli. Il partner esterno, finanziatore del progetto è la Bracco Imaging
SpA.

134
Sviluppi Qualora i risultati prodotti dai Meta-Classificatori confermassero
il miglioramento e/o il consolidamento dei risultati per la diagnosi dei tumori, un’architettura informatica che implementa tali sistemi andrebbe a sostituire quella attualmente presente nel CAD mammografico. 3.1.4 Sistema di analisi dell’imaging biomedicale per far
emergere l’informazione nascosta
Obiettivo del progetto Il progetto ha lo scopo di verificare in ambito clinico un sistema
di imaging diagnostico, basato su uno dei modelli di elaborazione del Semeion, per far emergere l’informazione nascosta contenuta nell’immagine ottenuta con la tecnica della tomografia computerizzata multistrato. Il modello denominato J-Net, appartiene alla famiglia dei modelli ACM, sinteticamente descritti nella sezione della ricerca di base di questo volume (cap. 2.2). L’obiettivo operativo del progetto consiste nel verificare la capacità, del modello J-Net, di discriminazione caratterizzante tra immagini che presentano noduli polmonari benigni e immagini di noduli polmonari maligni, al fine di effettuare screening e diagnosi.
Risultati conseguiti Dalle prime evidenze delle sperimentazioni attualmente in corso il
sistema J-Net sembra in grado di evidenziare le differenze dei bordi delle lesioni, attraverso un algoritmo deterministico che estrae le caratteristiche morfologiche nascoste all’occhio umano. I primi risultati mostrano la possibilità che i medici specialistici possano utilizzarli per identificare i noduli polmonari maligni.
I noduli polmonari maligni modificano la loro forma nei primi step di elaborazione del parametro a di J-Net, mentre per i noduli polmonari benigni il comportamento è molto diverso, e le modifiche di forma si registrano solo nella parte finale del processo di elaborazione. I risultati prodotti dal sistema sono stati confrontati con una valutazione qualitativa, fatta da medici radiologo esperti.

135
Anche se su un numero di pazienti ancora limitato il lavoro di ricerca finora svolto, dimostra l’esistenza di una forte correlazione tra la natura dei noduli polmonari e le immagini processate dal modello J-Net.
Equipe di ricerca e partner esterni L’equipe di ricerca che stanno lavorando al progetto è composta
da: M. Buscema, S. Terzi e R. Petritoli. Il partner istituzionale esterno che ha messo a disposizione la
competenza medico-radiologica è costituito dal Dipartimento di Radiologia Università degli Studi “La Sapienza”, diretto dal Prof. R. Passariello.
Sviluppi Anche per questo progetto l’obiettivo principale è quello di poter
confermare i risultati finora ottenuti, su una casistica superiore a quella attualmente disponibile. A tal proposito è stato da tempo richiesto un finanziamento al Ministero dell’Università e della Ricerca in forma di FIRB, sul quale si attende l’esito.

136
3.2 Campo Biomedicale settore clinico
Il secondo settore medico particolarmente interessato alle potenzialità applicative dei Sistemi Artificiali Adattivi del Semeion è il settore clinico. In questo ambito si è fatto un considerevole lavoro negli ultimi 8 anni. In particolare sono stati sottoposti all’analisi dei modelli Semeion 76 diversi dataset, e sono stati pubblicati 25 articoli su riviste scientifiche internazionali di ambito biomedicale. L’insieme delle patologie cliniche sulle quali si è concentrata l’attività di elaborazione e sperimentazione sono state:
- patologie dell’apparato gastroenterologico; - malattia di Alzheimer; - patologie cardiovascolari. Questo lavoro di analisi ha prodotto una serie di progetti
applicativi sostanzialmente orientati alla diffusione dei modelli di elaborazione nel mondo medico sia attraverso corsi di formazione finalizzati alla conoscenza delle potenzialità che questi modelli offrono, soprattutto ai medici specialistici e lo sviluppo di software applicativi, che consentono di utilizzare praticamente tali modelli, nell’ambito della quotidiana attività del medico. 3.2.1 Corsi di formazione sull’Intelligenza Artificiale per
medici specialistici
Obiettivo del progetto Le scienze bio-mediche hanno per oggetto i fenomeni complessi.
L’uomo è per definizione il sistema vivente più complesso esistente al mondo, e paradossalmente come paziente viene spesso curato e analizzato come se fosse un oggetto meccanico. In genere la medicina tenta di trovare una risposta al funzionamento del paziente nei singoli elementi che lo compongono. Spesso non si considera che questi elementi esistono e funzionano in un certo modo solo perché coagiscono nella compattezza di uno specifico spazio completamente interconnesso.
È ormai divenuto evidente in diversi campi che per capire i fenomeni complessi serve una matematica complessa. I Sistemi

137
Artificiali Adattivi costituiscono ad oggi il risultato e contemporaneamente una delle più importanti linee di sviluppo dei nuovi approcci della matematica ai campi dove la complessità è la norma.
In questa prospettiva il Semeion ha iniziato a promuovere, in collaborazione con la Bracco, un’attività di formazione con lo scopo di consentire ai medici di avvicinarsi ai temi della complessità acquisendo un bagaglio di competenze di base sui Sistemi Artificiali Adattivi. L’obiettivo è non solo quello di favorire l’uso di nuovi strumenti di analisi delle malattie, ma anche di fornire gli strumenti pratici per lavorare in modo nuovo sui dati, legati a diverse patologie, che vengono quotidianamente raccolti dai medici specialisti.
Risultati conseguiti Nel corso degli ultimi anni sono stati realizzati numerosi meeting
formativi, e in particolare nel 2007 sono stati effettuati 3 specifici corsi di formazione due dei quali diretti a medici gastroenterologi e il terzo a medici psichiatri, che si occupano di patologie quali Alzheimer e altre forme di demenza.
I risultati formativi ottenuti sono stati molto incoraggianti e hanno registrato un grande interesse da parte dei medici provenienti da diverse specializzazioni. Infatti, nei questionari di valutazione di fine corso, la quasi totalità dei partecipanti hanno espresso un esplicito interesse a partecipare ad altri corsi di approfondimento sui temi dell’ “Intelligenza Artificiale in medicina”.
Alleghiamo di seguito il programma completo di uno dei corsi di formazione realizzati nel 2007.

138
INTELLIGENZA ARTIFICIALE IN
MEDICINA:
Back to the future
Corso di formazione III
Semeion Centro Ricerche
Roma 14 – 17 Novembre 2007
Programma del corso
Programma 15 Novembre
9.00 – 9.30
Arrivo e registrazione dei partecipanti
9.30 – 10.30
Intelligenza Artificiale e complessità in medicina: obiettivi funzionali e operativi del corso di formazione (E. Grossi) 10.30 – 13.30
Scelta delle variabili e Data Management (G. Maurelli e M. Intraligi):
1. I principi guida per la scelta delle variabili e la raccolta dei dati
2. Organizzazione dei dati in tabelle Excel
3. Manipolazione delle variabili
Pausa Pranzo 14.30 – 15.30 Esercitazioni ed esempi pratici su dataset medici (M. Intraligi)
15.30 – 18.30
Le Reti Neurali Artificiali (M. Buscema)
1. Architettura delle Reti Neurali Artificiali
2. Reti Neurali Artificiali: strategie d’apprendimento
3. Reti Neurali Supervisionate 4. Reti Neurali Auto-Associate 5. Reti Self Organizing Maps

139
Programma 16 Novembre
9.30 – 10.00
Le Reti Neurali Supervisionate i protocolli di elaborazione (S. Terzi): 1. Protocollo 5x2 cross validation 2. Confronto fra Analisi Discriminante
Lineare e Reti Neurali Artificiali
10.00 – 11.30
Approfondimento sulle Reti Neurali Supervisionate con laboratorio di sperimentazione su dataset medici (S. Terzi e M. Intraligi) 11.30 – 12.30
Le Reti SOM i protocolli di elaborazione e l’uso del software (G. Massini)
12.30 – 13.30
Approfondimento sulle Reti SOM con laboratorio di sperimentazione su dataset medici (G. Massini e M. Intraligi)
Pausa Pranzo 14.30 -15.30 La rete Auto-Contractive Map e il Semantic Connections Map: nuove forme di elaborazione e visualizzazione dei dati (M. Buscema)
Programma 16 Novembre
15.30 – 17.30
Suddivisione dei corsisti in due gruppi per esercitazioni sui dataset medici con il software Semantic Connections Map (E. Grossi, M. Buscema, G. Massini, S. Terzi, M. Intraligi)
17.30 – 18.00
Rassegna sulle applicazioni mediche dei Sistemi Artificiali Adattivi (E. Grossi)
18.00 – 19.00
Discussione sulle esercitazioni effettuate dai corsisti, riflessioni e prospettive
21.00 Cena sociale
Materiali didattici distribuiti durante il corso: 1. CD contenente una bibliografia
selezionata di articoli scientifici sull’Intelligenza Artificiale in Medicina
2. CD contenente i PPT didattici utilizzati dai docenti durante l’attività di formazione
Equipe di ricerca e partner esterni L’equipe di docenti è composta dai ricercatori del Semeion, a cui
si aggiungono anche docenti esterni con specifica competenza in campo medico. Il partner esterno che partecipa alla realizzazione del progetto formativo e la Bracco SpA.
Sviluppi Dato l’interesse finora suscitato dai corsi di formazione, dei quali
si è ormai standardizzato un programma che consente ai medici di venire a conoscenza sia degli aspetti teorici dei Sistemi Artificiali Adattivi, sia di verificare sui propri dati le potenzialità applicative di questi sistemi, nel prossimo triennio è prevista un incremento dei corsi di formazione. In particolare si sta valutando anche l’ipotesi di andare a promuovere l’attività formativa a medici operano in ambito europeo.

140
3.2.2 Software applicativi per l’elaborazione complessa di dataset clinici
Obiettivo del progetto Parallelamente all’attività di formazione, sopra descritta, negli
ultimi due anni il Semeion ha voluto fare un ulteriore passo in avanti nella logica di diffusione di una filosofia di approccio ai fenomeni complessi in medicina. In modo complementare alla formazione sui Sistemi Artificiali Adattivi si è pensato di dotare i medici di software applicativi, dedicati a specifiche patologie, che funzionano come strumenti di supporto alle decisioni per aiutare lo specialista sia nell’attività di screening che nella diagnosi.
L’obiettivo è quello di sfruttare la grande potenzialità di questi sistemi, anche nella logica di un supporto concreto alla pratica quotidiana dello specialista. Tale passo si è concretizzato nella decisione di progettare e realizzare una serie di software applicativi su specifiche patologie, la cui diagnosi rientra nelle difficoltà di identificazione legate alle caratteristiche dinamicamente sfumate delle patologie stesse.
Risultati conseguiti Negli ultimi due anni sono stati realizzati 8 software applicativi
relativi alle seguenti patologie: - l’esofagite, sulla base del quale sono stati sviluppati due diversi
software applicativi: EST (Esophagitis Screening Test) ed EDT (Esophagitis Diagnostic Test);
- la sindrome dell’intestino irritabile: SIBI (Screening Irritable Bowel Investigation);
- la gastrite cronica atrofica: GASTROCAT (Gastritis Chronic Atrophic Test);
- la pancreatite cronica: GAIA evoluzione della pancreatite cronica; - la conversione della patologia MCI (Mild Cognitive Impairment) in
Alzheimer: MCI-SW; - il sanguinamento gastrointestinale: GastroBleed-SW nella versione
di screening (GastroBleed-Fast) e nella versione diagnostica (GastroBleed).

141
Equipe di ricerca e partner esterni L’equipe dei ricercatori che hanno lavorato alla individuazione,
progettazione e sviluppo dei software applicativi è composta da: R. Petritoli, E. Grossi, M. Intraligi, G. Maurelli e M. Capriotti.
Il partner esterno, finanziatore del progetto, è la Bracco SpA.
Sviluppi La prospettiva di sviluppo dei software applicativi è legata in
prima istanza al grado di interesse dei medici nelle potenzialità dello strumento, che finora ha avuto riscontri positivi. Ma l’ostacolo maggiore è costituito dalla scarsa consuetudine dei medici nell’utilizzare modelli informatici intelligenti di supporto alle decisioni. In questo contesto è evidente che la diffusione di software applicativi che hanno tali funzioni non può essere slegata da una contemporanea attività di formazione sui modelli matematici di riferimento, e da un addestramento operativo finalizzato all’acquisizione di un livello di confidenza con questi strumenti. 3.2.3 Progetto IMPROVE sul rischio cardiovascolare
Obiettivo del progetto Lo scopo principale del progetto IMPROVE consiste nel valutare
se e in che misura la presenza dell’ispessimento medio-intimale carotideo (IMT) e la sua progressione nel tempo, consenta di predire gli eventi cardiovascolari nei tre anni successivi in una determinata categoria di pazienti. I pazienti inseriti nello studio hanno subito eventi cardiovascolari riconducibili ad almeno tre tipi di fattori di rischio vascolari (VRFs).
Lo studio, attraverso un approccio integrato, intende anche districare le complesse relazioni esistenti tra i polimorfismi dei geni e la progressione dell’ispessimento medio intimale della carotide.
Il progetto, oltre alla parte medica che persegue un’ipotesi innovativa per la previsione di eventi vascolari basandosi sui fattori di rischio sia convenzionali che non convenzionali e sui risultati degli ultrasuoni, promuove un approccio innovativo anche dal punto di vista dei modelli di elaborazione che intende utilizzare,

142
comparando i metodi statistici tradizionali con le reti neurali artificiali e i Sistemi Artificiali Adattivi del Semeion.
Si tratta di un progetto Europeo che coinvolge 7 centri di eccellenza distribuiti in sei paesi europei (Italia, Francia, Gran Bretagna, Svezia, Finlandia e Olanda), con oltre 3.500 pazienti arruolati.
Risultati conseguiti Ormai da alcuni anni le applicazioni di reti neurali artificiali in
ambito medico hanno dimostrato di essere in grado di conseguire risultati significativamente superiori ai metodi statistici convenzionali, soprattutto su patologie la cui complessità diagnostica è molto alta. Sul tema delle malattie cardiovascolari i ricercatori del Semeion hanno già lavorato, ottenendo risulti giudicati clinicamente molto interessanti. In particolari nel 2004 è stato pubblicato un articolo scientifico nei quali i modelli di elaborazione del Semeion hanno raggiunto un sensitivity del 92% e una specificity del 83% nel riconoscere, in cieco, pazienti con presenza di eventi cardiovascolari rispetto a pazienti senza eventi cardiovascolari3. I modelli di elaborazione che verranno utilizzati nel corso del progetto, sono stati implementati in software di ricerca proprietari del Semeion, si tratta sia di reti neurali supervisionate, che di reti neurali autoassociate 4.
Equipe di ricerca e partner esterni L’equipe dei ricercatori che hanno lavorato e lavoreranno al
progetto è composta da: M. Intraligi, M. Capriotti e G. Maurelli. Il partner esterno, finanziatore del progetto, è la Bracco SpA.
3 Baldassarre D, Grossi E, Buscema M, Intraligi M, Amato M, Tremoli E, Pustina L, Castelnuovo S, Sanvito S, Gerosa L, Sirtori C R, Recognition of patients with cardiovascular disease by artificial neural networks, in Annals of Medicine, 36 pp. 630-640, 2004. 4 SuperVised ver. 12.5, Shell to program feed forward and highly recurrent ANNs. Semeion software n. 12 (1999-2007), M. Buscema. SOM ver. 7.0, Shell to program Self Organizing Maps, Semeion software (2007), G. Massini.

143
Sviluppi Qualora i risultati delle applicazioni dei Sistemi Artificiali Adattivi
al database dei 3500 pazienti del progetto IMPROVE, ottenessero un’accuratezza previsionale considerata clinicamente utile, sarebbe possibile passare alla progettazione e allo sviluppo di un software applicativo su queste patologie cardiovascolari in funzione di screening e diagnostica. 3.2.4 Progetto Nazionale Emorragia Digestiva (PNED)
Obiettivo del progetto Lo scopo del progetto consiste nell’identificare quelle variabili
cliniche che consentono di predire il rischio di decesso in pazienti che presentano emorragia digestiva, applicando i modelli di elaborazione del Semeion basati su Reti Neurali Artificiali. Dal punto di vista medico l’obiettivo primario del progetto consiste nella elaborazione di uno score predittivo del rischio degli outcomes negativi (morte, intervento chirurgico, risanguinamento).
Si tratta di uno studio prospettico osservazionale realizzato sul territorio nazionale, che coinvolge strutture ospedaliere, policlinici universitari ed Istituti di Ricerca a Carattere Scientifico. I centri che partecipano allo studio sono 25, e la numerosità stimata del campione è di 1.600 soggetti. La durata prevista dello studio è di due anni, l’arruolamento dei pazienti è iniziato a gennaio 2007.
Risultati conseguiti Lo studio epidemiologico costituisce il naturale proseguimento di
un precedente studio che ha permesso di raccogliere informazioni, a livello nazionale, che hanno consentito di realizzare un database aggiornato sulle emorragie digestive alte. Si tratta della fase 1 del PNED realizzata nel periodo da marzo 2003 a marzo 2004. I sistemi di elaborazione del Semeion che verranno applicati ad entrambi i database per consolidare la consistenza dello score predittivo, sono

144
stati implementati nei già citati software di ricerca proprietari del Semeion5.
Equipe di ricerca e partner esterni L’equipe dei ricercatori che hanno lavorato e lavoreranno al
progetto è composta da: M. Intraligi, M. Capriotti e G. Maurelli. Il partner esterno, finanziatore del progetto, è la Bracco SpA.
Sviluppi Anche per questo progetto se i risultati ottenuti dalle elaborazioni
effettuate con i Sistemi Artificiali avessero un’accuratezza previsionale considerata clinicamente utile, sarebbe possibile passare alla progettazione e allo sviluppo di un software applicativo sull’emorragia digestiva in funzione di screening e diagnostica. 3.2.5 Progetto per l’identificazione di nuovi biomarkers
nell’Alzheimer Disease
Obiettivo del progetto Il programma di ricerca è strutturato su due obiettivi principali
che consentiranno un approfondimento nell’esplorazione della malattia di Alzheimer, rispetto alle attuali conoscenze scientifiche:
- sul piano clinico l’individuazione di nuovi biomarkers, dei quali si intende esplorare ed approfondire la funzione di identificazione predittiva della patologia, che potrebbe migliorare l’accuratezza dell’analisi clinica, e facilitare la verifica di possibili terapie future;
- sul piano matematico e di processi di elaborazione, l’identificazione dei più recenti modelli e meta-modelli di Sistemi Artificiali Adattivi, che sperimentalmente hanno dimostrato un’elevata capacità di affrontare problemi nei quali il grado di complessità delle patologia è molto alto, in
5 SuperVised ver. 12.5, Shell to program feed forward and highly recurrent ANNs. Semeion software n. 12 (1999-2007), M. Buscema. SOM ver. 7.0, Shell to program Self Organizing Maps, Semeion software (2007), G. Massini.

145
relazione all’elevato livello di non linearità delle variabili che la descrivono.
La possibilità di raggiungere entrambi gli obiettivi è possibile grazie alla collaborazione scientifica che il gruppo di ricerca avrà con il Consorzio Americano del “Nun Study”, diretto dal prof. D. Snowdon, epidemiologo di fama mondiale del Sanders-Brown Center on Aging, Department of Preventive Medicine, College of Medicine, University of Kentucky, potendo accedere al database del Nun Study.
Risultati conseguiti In precedenti lavori di ricerca si sono sperimentati modelli di reti
neurali che hanno consentito di individuare le complesse relazioni esistenti tra le variabili funzionali e i dati clinici nella malattia di Alzheimer6, esplorando la logica non lineare della varietà di informazioni disponibili. I risultati finora conseguiti hanno spingono a continuare su questa promettente linea di ricerca, introducendo variabili relative a nuovi biomarkers e sfruttando incrementata capacità previsionale dei recenti sistemi di metaclassificazione.
Equipe di ricerca e partner esterni L’equipe dei ricercatori che lavoreranno al progetto è composta
da: S. Terzi, M. Intraligi, M. Capriotti. Il progetto scaturisce da una partnership fra il Semeion, l’IRCCS
San Raffaele di Roma e tre Unità di Ricerca dell’Istituto Superiore di Sanità. L’ente finanziatore è il Ministero della Salute.
Sviluppi L’applicazione di Sistemi Artificiali Adattivi più avanzati potrebbe
fornire un utile strumento di orientamento e di valutazione indiretta
6 Grossi E, Buscema M, Snowdon D, Antuono P, Neuropathological findings processed by artificial neural networks (ANNs) can perfectly distinguish Alzheimer's patients from controls in the Nun Study, BMC Neurology 2007, 7:15. Buscema M, Grossi E, Snowdon D, Antuono P, Maurelli G, Savarè R, Artificial Neural Networks and Artificial Organisms can predict Alzheimer pathology in individual patients only on the basis of cognitive and functional status, Neuroinformatics vol. 2, n. 4, pp. 399-416, 2004.

146
della regressione della patologia di Alzheimer prevista in singoli soggetti, fatto questo estremamente significativo nel caso in cui si rendessero disponibili trattamenti in grado di far regredire le lesioni cerebrali. L’analisi delle variabili cliniche basata su sistemi adattivi può costituire un valido test predittivo sulle patologie complesse come l’Alzheimer e nello stesso tempo uno strumento di elaborazione di ipotesi sui meccanismi dell’insorgenza e dello sviluppo della malattia.

147
3.3 Social Security Nel campo della sicurezza sociale, inteso nella sua accezione più
ampia, il Semeion svolge la sua attività di ricerca dai tempi della sua fondazione. Infatti per circa 10 anni, dal 1986 fino al 1995, il Progetto Sonda è stato uno dei progetti di prevenzione dal disagio sociale e dall’uso di sostanze stupefacenti più diffuso in Italia, oltre che il più innovativo sotto il profilo metodologico.
Alla fine degli anni novanta, l’esperienza acquista in quel progetto e la grande spinta prodotta dai nuove scoperte effettuate dai ricercatori del Semeion nel campo dell’intelligenza artificiale, ha favorito la definizione di una importante partnership con New Scotland Yard. Questa partnership si è concretizzata con la realizzazione del progetto Central Drug Trafficking Database (CDTD).
Nel 2007, inoltre, è stato siglata un’importante convenzione, nella forma del protocollo d’intesa, fra il Consiglio Nazionale delle Ricerche (CNR), Dipartimento ICT, ed il Semeion relativa ad un grande “Progetto Interdipartimentale sulla Sicurezza”, che diventerà operativo nel prossimo triennio. Al progetto, i cui contenuti sono al momento ancora riservati, partecipano numerosi altri Centri di Ricerca ed Università, oltre a numerose aziende di dimensione nazionale e internazionale che operano sulla sicurezza ai più alti livelli da diversi anni.
Nel prossimo triennio (2008-2010) si prevede un notevole incremento delle attività di ricerca del Semeion nel campo della Social Security. In particolare mettendo a disposizione delle strutture che si occupano di sicurezza, dagli apparati militari alle diverse forze di polizia, metodi e tecniche che possono aiutare a risolvere numerosi problemi legati alla sicurezza interna ed esterna del nostro paese.

148
3.3.1 Progetto Central Drug Trafficking Database (CDTD) Obiettivo del progetto L’obiettivo originario del progetto CDTD ha consentito di
costruire un database relazionale sul traffico di droga nella città di Londra, dotandola di un motore di elaborazione basato sui Sistemi Artificiali Adattivi. Tale impostazione del progetto ha consentito di far emergere, dai diversi dataset che compongono l’intero database, quelle informazioni invisibili ad altri strumenti, che spesso risultato fondamentali per prendere decisioni strategiche e tattiche.
Il prossimo obiettivo del progetto è quello di rendere operativo sul territorio il sistema realizzato, inserendo degli specifici applicativi software che funzionino come strumenti di supporto alle decisioni nel lavoro degli analisti di New Scotland Yard.
per mettere nelle condizioni gli analisti di New Scotland Yard, di aiutare la polizia metropolitana e le altre strutture investigative che operano sul territorio, ad analizzare le dinamiche del problema droga nella città di Londra con questi nuovi strumenti che possono migliorare sensibilmente le strategie di contrasto alla diffusione dei fenomeni criminali.
Risultati conseguiti Il progetto CDTD, conclusosi nel 2007 come costruzione del
sistema, ha affrontato una serie di verifiche finalizzate a valutare il livello di affidabilità dei risultati ottenuti nei diversi settori del progetto. Inoltre il rapporto di ricerca finale è stato sottoposto ad una valutazione del Professor Emmanuel Ifeachor, ordinario della cattedra di “Intelligent Electronics Systems” dell’Università di Plymouth (UK) e capo del “Signal Processing and Multimedia Communications Group”. Forniamo un breve estratto del documento di valutazione redatto dal Prof. Ifeachor:
“The methodology and techniques used are entirely appropriate and very effective. The mathematical models are sound and underpinned by sound academic/scientific work and peer reviewed publications. The implementation was with proprietary software and so it would be very difficult to reproduce the results without considerable efforts. The methodology used in the design and application of the models is based on best practice.

149
Overall, when completed the work will represent a significant contribution to knowledge and understanding of drug market and drug movement.”
Equipe di ricerca e partner esterni I ricercatori impegnati nei nuovi sviluppi progettuali sono: M.
Buscema, G. Massini, S. Terzi, M. Intraligi, G. Pieri, M. Breda, M. Capriotti. In questo caso New Scotland Yard oltre ad essere partner progettuale è anche l’ente finanziatore.
Sviluppi Il prossimi step progettuali mirano a fornire nuovi strumenti
operativi agli analisti di New Scotland Yard per aiutare la polizia metropolitana, e le altre strutture investigative che operano sul territorio, ad analizzare le dinamiche del fenomeno droga nella città di Londra, contribuendo a migliorare sensibilmente le strategie di contrasto alla diffusione dei fenomeni criminali. 3.3.2 Progetto Sicurezza integrata su 4 livelli
Obiettivo del progetto L’ipotesi progettuale consiste nell’affrontare il problema della
sicurezza di un territorio con lo scopo di proteggere le comunità evitando o riducendo i danni alle persone, proprietà, luoghi, istituzioni e simboli, ma anche impedendo la pianificazione di danni ad altre comunità.
Il progetto prevede 4 livelli di sicurezza: Protettivo, Preventivo e Repressivo sul piano manifesto, Meta-logico sul piano immanente.
La sicurezza protettiva consiste nella capacità di una comunità di costruire:
- sistemi di trasporto dell’informazione, dell’energia, delle merci e delle persone;
- sistemi di funzionamento (luoghi, edifici, istituzioni e simboli) capaci di riorganizzarsi in caso di danno e di attacco.
La riorganizzazione automatica del sistema di sicurezza protettiva è connessa all’uso di sistemi automatici intelligenti.
La sicurezza preventiva consiste nella capacità di una comunità di:

150
- prevedere il come, il chi, il quando e il dove di futuri attacchi e danni;
- agire in modo tale da ridurli e/o minimizzarli. La capacità di prevedere localmente danni e/o attacchi dipende
dall’esistenza di banche dati continuamente aggiornate e di sistemi artificiali intelligenti capaci di utilizzare la storia di tali dati per anticipare scenari possibili.
La sicurezza repressiva consiste nella capacità di una comunità di: - individuare i soggetti e/o gli eventi responsabili di danni e/o
attacchi; - impedire loro di agire nuovamente. La capacità repressiva dipende da sistemi intelligenti in grado di
risalire dalle tracce di un evento accaduto alle condizioni e/o persone che lo hanno determinato.
La sicurezza meta-logica, infine, è la capacità di una comunità di proteggere le informazioni sul funzionamento dei 3 tipi di sistemi di sicurezza definiti.
I tipi di sicurezza descritti sono legati all’uso di dati e di sistemi automatici intelligenti, quindi, l’intelligenza di un sistema di sicurezza si basa su sistemi informativi e su sistemi di elaborazione dell’informazione.
Risultati conseguiti La competenza sui sistemi automatici intelligenti ormai
consolidata da molti anni in diversi campi di applicazione, nonché la considerevole esperienza acquisita sui dati reali con il progetto CDTD di New Scotland Yard, costituiscono una solida base per consentire lo start-up del progetto.
Equipe di ricerca e partner esterni I ricercatori previsti nella realizzazione del progetto sono: M.
Buscema, G. Massini, M. Intraligi, M. Capriotti. I partner esterni sono formati da componenti delle forze dell’ordine (Polizia e Carabinieri).
Il primo documento progettuale è stato scritto da M. Buscema e consegnato alla Direzione Generale della Ricerca del MIUR nel 2007.

151
I potenziali enti finanziatori del progetto sono il Ministero dell’Università e della Ricerca e il Ministero dell’Interno.
Sviluppi Una volta costruiti i modelli di elaborazione, e misurato il grado
di affidabilità con cui rispondono alle richieste degli operatori della sicurezza, sarà possibile elaborare diversi database, sia localmente che globalmente (fondendo più basi informative), a seconda delle specifiche esigenze delle forze dell’ordine.

152
3.3.3 Progetto telecamera intelligente e firma micro-gestuale
Obiettivo del progetto L’idea di base del progetto nell’ipotizzare che i micro-movimenti,
individuali e collettivi, di soggetti umani siano nel loro insieme un messaggio inconsapevole in codice che contiene il contenuto attendibile dei loro progetti di azione a breve scadenza. Si sta affermando che i micro-movimenti di ogni persona, anche all’interno di un gruppo occasionale, si sintonizzano in modo più o meno forte con i micro-movimenti delle altre persone a seconda dei piani e/o delle disposizioni, consapevoli e/o inconsapevoli, che o sono già presenti nel gruppo, oppure che si stanno formando in relazione a specifici eventi. In altre parole i micromovimenti di tutti i soggetti tenderanno a sintonizzarsi in una o più “danze”, e quindi a dividersi in uno o più gruppi, a seconda dei piani e delle disposizioni all’azione di ciascun soggetto e/o gruppo.
Se questa ipotesi risultasse verificata sperimentalmente, allora una telecamera fissa che inquadra una zona di uno stadio potrebbe registrare, tramite un’opportuna funzione di interpolazione del cambio del valore dei grigi di ogni suo pixel, i ritmi tramite i quali le persone riprese si raggruppano e si predispongono a diversi repertori di azione, comprese le azioni di violenza.
Di conseguenza le immagini prodotte da tale telecamera analizzate da specifici algoritmi matematici potrebbe costituire la base di un sistema intelligente per individuare situazioni pericolose in zone particolarmente affollate (stadi di calcio, manifestazioni, metropolitane, ecc.).
Un sistema hardware e software opportunamente tarato, quindi, dovrebbe essere in grado di predire e individuare sullo schermo azioni di violenza nella loro fase incubata. Trattando i micro-cambiamenti della matrice dei pixel sullo schermo come una “impronta digitale temporale” dei piani azioni di una o più persone, si possono far scattare opportuni segnali di allerta.
Per sperimentare un’ipotesi di questo tipo sono necessarie: - un campione di filmati che riprendano parti della popolazione
di uno stadio in occasioni diverse (scene che sono degenerate

153
in violenza, scene di movimenti normali, scene di tifo non pericolose, ecc.);
- un insieme di algoritmi matematici i grado di elaborare i filmati in questione;
- un protocollo di validazione in cieco che permetta di stabilire statisticamente la solidità di questa ipotesi.
Il progetto prevede la verifica sperimentale dell’ipotesi progettuale e la realizzazione di un prototipo del sistema.
Risultati conseguiti Da un punto di vista teorico e metodologico a partire dai primi
anni sessanta ad oggi esistono innumerevoli studi e ricerche, sia in ambito psichiatrico sia in ambito antropologico, che accreditano in modo consistente l’ipotesi brevemente descritta7. Inoltre il considerevole know-how acquisito dai modelli di elaborazione delle immagini Semeion© (vedi in particolare il capitolo 2.2 del presente volume), forniscono la seconda piattaforma sulla quale può ragionevolmente poggiare l’ipotesi progettuale, permettendone l’applicazione in situazioni concrete.
Equipe di ricerca e partner esterni I ricercatori previsti per la realizzazione del progetto sono: M.
Buscema, G. Massini, S. Terzi, M. Intraligi, R. Petritoli. I partner esterni anche in questo caso sono componenti delle forze dell’ordine (Polizia e Carabinieri), ma anche dipartimenti di altre Università e dell’INFN.
7 RL Birdwhistell, Kinesics and Context, Un Ph Press, Philadelphia,1970; ET Hall, The Hidden Dimension, Doubleday, 1966, NY; ET Hall, Beyond Culture, Doubleday, 1976, NY; OM Watson, Proxemic Behavior, Mouton, 1970, The Hague; TA Sebeok, AS Hayes, MC Bateson, Approaches to Semiotics, Mouton, 1964, The Hague; H Osmond, Function as the Basis of Psychiatric Ward Design, Mental Hospital, April, 1967; RA Hinde(ed), Non Verbal Communication, Cambridge Un Press, 1972, Cambridge; P Ekman, Telling lies, Norton, 1985, NY; AE Scheflen, How Behavior Means, Gordon and Breach, 1973, NY; J Ruesch, G Bateson, Communication. The Social Matrix of Psychiatry, Norton, 1968, New York; M Buscema, G Massini, Gesturing Test: a model of qualitative ergonomics, 2o International Conference “Vehicle Comfort Ergonomic, Vibrational, Noise and Thermal Aspects”, T.P. Vol.1, pp.99-109, Un. Of Southampton, ATA, Un. of Bologna, Bologna 1992.

154
Anche in questo caso un primo documento progettuale è stato scritto da M. Buscema e consegnato alla Direzione Generale della Ricerca del MIUR, nel 2007.
I potenziali enti finanziatori del progetto sono il Ministero dell’Università e della Ricerca e il Ministero dell’Interno.
Sviluppi Ad esempio tutte le zone di uno stadio in questo modo
potrebbero essere monitorate in funzione predittiva e pro-attiva. Con una disponibilità di HW libera a piacere, tutto questo
processo potrebbe ripetersi anche ogni 10 secondi. E’ evidente che se l’ipotesi della “firma gestuale” mostrasse una
sua validità, l’aumento di campioni di addestramento (nuovi filmati) e la conseguente ri-taratura di tutte le ANN off line, non farebbe che aumentare l’affidabilità previsionale delle stesse on line.

155
3.3.4 Progetto analisi e previsione del traffico mercantile nel mediterraneo
Obiettivo del progetto L’idea progettuale consiste nell’analizzare diversi tipi di database
in possesso di strutture del Ministero della Difesa per monitorare e prevedere le rotte del traffico mercantile nel mediterraneo. L’obiettivo è quello di verificare se i Sistemi Artificiali Adattivi del Semeion sono in grado di far emergere determinate informazioni che spesso sfuggono ad altri metodi di elaborazione.
Risultati conseguiti Il progetto, nella sua dimensione operativa, ha carattere
sperimentale in quanto non è possibile conoscere a priori l’accuratezza previsionale che il sistema di elaborazione potrà raggiungere. È comunque opportuno sottolineare che con tipologie di problemi strutturalmente simili affrontati con Algoritmi Evolutivi e Reti Neurali Artificiali si sono sempre ottenuti risultati significativamente superiori ai modelli di elaborazione tradizionali, in particolare quando la natura del fenomeno è tipicamente non-lineare, come in questa ipotesi progettuale. Dal punto di vista funzionale si è deciso di formare un gruppo operativo di lavoro misto, composto da ricercatori del Semeion e da esperti militari.
Equipe di ricerca e partner esterni I ricercatori previsti nella realizzazione del progetto sono: M.
Buscema, M. Intraligi, M. Capriotti. Il potenziale ente finanziatore del progetto è il Ministero della Difesa.
Sviluppi Qualora il sistema sia in grado di ottenere risultati
significativamente utili, lo sviluppo del progetto è indirizzato nella costruzione di un sistema di monitoraggio costante del traffico mercantile nel mediterraneo.

156
3.3.5 Progetto Selezione del personale nelle Forze Armate
Obiettivo del progetto Anche questo progetto ha carattere sperimentale e intende
rispondere ad una domanda del tipo “è possibile ottimizzare i processi di selezione del personale nelle Forze Armate al fine di ottimizzarne le abilità e le competenze in rapporto alla missione primaria di uno specifico corpo militare?”. L’obiettivo della ricerca consiste nel verificare la possibilità di misurare e prevedere, in singoli soggetti, l’eventuale predisposizione e la capacità di affrontare le diverse difficoltà della carriera militare.
Risultati conseguiti Trattandosi di un progetto sperimentale sarà importante poter
misurare il grado di approssimazione della stima previsionale per valutarne l’effettiva utilità sul campo. I risultati del progetto consentiranno di effettuare questa valutazione, anche al fine di mettere in condizioni i responsabili dei singoli corpi militari di assumere eventuali e successive decisioni in funzione dei risultati della selezione.
Equipe di ricerca e partner esterni I ricercatori previsti nella realizzazione del progetto sono: G.
Massini, M. Intraligi, G. Maurelli. Il potenziale ente finanziatore del progetto è il Ministero della Difesa.
Sviluppi Sulla base dei risultati sperimentali conseguiti sarà possibile
valutare la costruzione di un sistema per la selezione del personale militare, che sia anche in grado di fornire un orientamento alle potenziali carriere dei singoli individui.

157
3.4 Industria, marketing e mondo del lavoro
Il campo che abbiamo denominato industria marketing e mondo del lavoro, racchiude un settore nel quale il Semeion ha iniziato a lavorare alcuni anni fa, e che oggi sembra più attento e predisposto ad accettare metodi innovativi per affrontare diversamente i problemi che circondano questo mondo.
Da un punto di vista generale si può ragionevolmente affermare che in questi ultimi anni la tendenza delle aziende, in particolare quelle che lavorano con grandi moli di dati, si sono spesso trovate di fronte a domande a cui i tradizionali metodi statistici non riescono a dare risposta. In questa prospettiva la competenza e l’esperienza acquisita dal Semeion sui modelli di elaborazione intelligente, sta diventando sempre più ricercata.
Date queste considerazioni nel prossimo triennio (2008-2010) si prevede un incremento delle applicazioni dei modelli del Semeion al mondo delle imprese. 3.4.1 Previsione di classi di fumatori sulla base di analisi
cliniche e variabili socio-anagrafiche
Obiettivo del progetto La British American Tobacco rientra in una di quelle aziende che
ha iniziato a porsi problemi che la statistica tradizionale non è in grado di risolvere con soddisfazione. Lo scopo del progetto è, infatti, quello di poter classificare, e successivamente predire, quattro classi di soggetti così definiti: fumatori pesanti, fumatori moderati, ex fumatori e non fumatori. Ognuna delle 4 classi è definita da una serie di variabili di tipo anagrafico e biochimico. Nel progetto sono stati utilizzati alcuni modelli di reti neurali Supervisionate, le reti Self Organizing Maps 8 e le reti AutoCM9 con applicazione dell’MST (i modelli Semeion© sono stati descritti nella sezione ricerca di base di questo volume).
8 SOM (Shell for programming Self Organizing Maps) ver. 7.0 (2007), G. Massini. 9 Constraints Satisfaction Networks, ver. 10.0 (2001-2008), M. Buscema.

158
Risultati conseguiti Il progetto è iniziato nel 2007 e continuerà per i prossimi tre anni.
La prima serie di sperimentazioni sono state fatte su un campione di 80 soggetti, distribuiti in gruppi di 20 e articolati nelle 4 classi sopra indicate.
DB Tot HEAVY MODERATE NEVER EXSubjects 80 20 20 20 20Male 40 10 10 8 10Female 40 10 10 12 10
Classes
Distribuzione del campione
Il dataset completo era costituito da 31 variabili: sesso, età e
risultati di analisi bio-chimiche.
Dataset 311_Female2_Male3_Age4_B/HDL_Chol(mmol/L)5_B/LDL_Chol(mmol/L)6_B/IgA(g/L)7_B/IgG(g/L)8_B/IGM(g/L)9_B/CRP(mg/L)10_B/Trygl(mmol/L)11_B/SAA(ug/ml)12_B/PAI(ng/ml)13_B/IL-6(pg/ml)14_B/FactVII(%)15_U/Vol(ml)16_U/Creat (g)17_U/11D-TBX(ug/g_creat)18_U/OHP(mg/g_creat)19_U/Isoprost(ug/g_creat)20_U/2,3TBX(ug/g_creat)21_U/8OH2dG(ug/g_creat)22_U/NNAL(ng/g_creat)23_U/Nic(ug/g_creat)24_U/Cot(ug/g_creat)25_U/OH(ug/g_creat)26_Years27_Pack/Years28_CurrentTarDay29_TotalNicEquivalent(mg)30_MeanEstNic/Day(mg)31_Conversion(%)
Le variabili del Dataset

159
Il protocollo di sperimentazione comprendeva l’utilizzazione di due categorie di reti neurali: reti Supervisionate e reti NonSupervisionate. Nelle sperimentazioni con le reti non supervisionate i risultati ottenuti sono stati confrontati con quelli della Linear Discriminant Analysis (LDA), per le reti non supervisionate sono state utilizzate due diversi modelli di reti la SOM, e la AutoCM (Semeion©).
Protocol
DB
NOT SUPERVISED ANNs
Random (5x2CV)
LDA SupervisedANNs
Optimization
TWIST(Var selection/Distribution)
Supervised ANNs
CLASSIFICATION
SOM(Self Organising Maps)
AUTOCM
MST/MTGMinimum Spanning Tree
Minimum TemporalGraph
Protocol
DB
NOT SUPERVISED ANNs
Random (5x2CV)
LDA SupervisedANNs
Optimization
TWIST(Var selection/Distribution)
Supervised ANNs
CLASSIFICATION
SOM(Self Organising Maps)
AUTOCM
MST/MTGMinimum Spanning Tree
Minimum TemporalGraph
Protocollo di sperimentazione del progetto
Il Dataset originario di 31 variabili è stato sottoposto ad un processo di ottimizzazione utilizzando un algoritmo evolutivo denominato TWIST10 (Semeion©), che ha selezionato quelle variabili ritenute portatrici di significato. Di conseguenza le elaborazioni sono state effettuate sia sul Dataset completo, che su diversi sottoinsiemi di esso. La tabella seguente sintetizza i risultati ottenuti da una serie di elaborazioni fatte con le reti Supervisionate, e confrontate con la LDA, utilizzando lo stesso protocollo di sperimentazione.
10 Twist, Input Search & T&T Reverse ver. 2.0 (2007), M. Buscema.
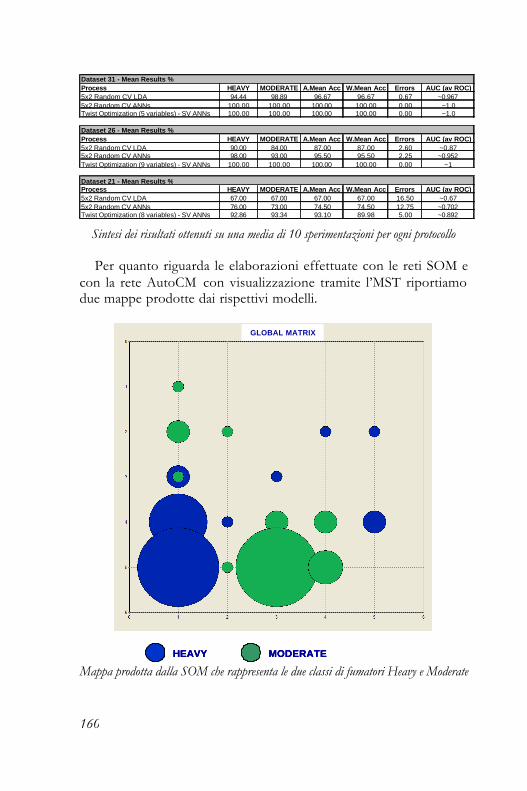
160
Process HEAVY MODERATE A.Mean Acc W.Mean Acc Errors AUC (av ROC)5x2 Random CV LDA 94.44 98.89 96.67 96.67 0.67 ~0.9675x2 Random CV ANNs 100.00 100.00 100.00 100.00 0.00 ~1.0Twist Optimization (5 variables) - SV ANNs 100.00 100.00 100.00 100.00 0.00 ~1.0
Process HEAVY MODERATE A.Mean Acc W.Mean Acc Errors AUC (av ROC)5x2 Random CV LDA 90.00 84.00 87.00 87.00 2.60 ~0.875x2 Random CV ANNs 98.00 93.00 95.50 95.50 2.25 ~0.952Twist Optimization (9 variables) - SV ANNs 100.00 100.00 100.00 100.00 0.00 ~1
Process HEAVY MODERATE A.Mean Acc W.Mean Acc Errors AUC (av ROC)5x2 Random CV LDA 67.00 67.00 67.00 67.00 16.50 ~0.675x2 Random CV ANNs 76.00 73.00 74.50 74.50 12.75 ~0.702Twist Optimization (8 variables) - SV ANNs 92.86 93.34 93.10 89.98 5.00 ~0.892
Dataset 31 - Mean Results %
Dataset 26 - Mean Results %
Dataset 21 - Mean Results %
Sintesi dei risultati ottenuti su una media di 10 sperimentazioni per ogni protocollo Per quanto riguarda le elaborazioni effettuate con le reti SOM e
con la rete AutoCM con visualizzazione tramite l’MST riportiamo due mappe prodotte dai rispettivi modelli.
GLOBAL MATRIX
HEAVY MODERATE
GLOBAL MATRIXGLOBAL MATRIX
HEAVYHEAVY MODERATEMODERATE Mappa prodotta dalla SOM che rappresenta le due classi di fumatori Heavy e Moderate

161
Nella elaborazione prodotta dalla rete SOM le due classi di fumatori: pesanti e moderati, vengono ben distinti sulla mappa, a conferma della capacità del sistema di effettuare un clustering significativo.
Mappa prodotta dalla rete AutoCM con visualizzazione ottenuta tramite l’MST Nella elaborazione prodotta dalla rete AutoCM con
rappresentazione grafica dell’MST delle variabili, oltre a vedere il diverso posizionamento dei due tipi di fumatori, segnati dal cerchietto, si evidenzia il percorso delle variabili che ne determinano la differenziazione.
Equipe di ricerca e partner esterni I ricercatori che lavorano al progetto sono: M. Intraligi, S. Terzi,
M. Capriotti, G. Maurelli. Il partner esterno, finanziatore del progetto è la British American Tabacco SpA.
Sviluppi Anche per questo progetto l’obiettivo principale è quello di poter
incrementare la casistica attualmente disponibile, tentando di

162
confermare i risultati finora ottenuti. Nel prossimo triennio la British American Tobacco, ha attivato una campagna per il reclutamento di nuovi soggetti fumatori con caratteristiche strutturali simili a quelli delle 4 classi analizzate. 3.4.2 Analisi e simulazione dinamica dei comportamenti di
consumo
Obiettivo del progetto Nel 2007 si è stabilita un’importante partnership fra il Semeion e
la GPF SpA, una società che si occupa da molti anni di analisi dei comportamenti di consumo della popolazione e di sondaggi nel campo del marketing strategico. La spinta ad iniziare una collaborazione strutturata con il Semeion è stata determinata, da parte della direzione della GPF, dalla volontà di innovare i sistemi di elaborazione con cui la GPF attualmente lavora. Per tale ragione anche la GPF rientra in quelle società che intendono esplorare nuovi metodi per estrarre informazioni significative dai dati.
L’obiettivo della collaborazione consiste nel sperimentare sul campo gli algoritmi del Semeion applicandoli all’analisi dei comportamenti di consumo in funzione della costruzione di nuove strategie di marketing per l’analisi dei mercati.
Risultati conseguiti Il rapporto di collaborazione è iniziato alla fine del 2007, ma ha
già prodotto alcuni primi risultati interessanti che pongono le basi per la buona prosecuzione dei progetti comuni. Mostriamo alcuni esempi di elaborazioni effettuate su diversi database.
Un primo database era composto da 2504 soggetti, a cui è stato sottoposto un questionario riguardante il cosiddetto Monitor 3SC, che è un sistema di ricerca e consulenza per cogliere e interpretare il mutamento socioculturale e di consumo della società, il sistema viene applicato all’analisi sociale da oltre 20 anni.
I dati raccolti riguardavano la rilevazione relativa all’anno 2006. gli items del questionario sono stati strutturati in 53 indici sintetici, che rappresentano le correnti socioculturali della nostra società.

163
Nella mappa che segue viene mostrata un’articolazione, ottenuta tramite la rete AutoCM e l’MST, di 427 soggetti che nel campione risultavano abbonati alla televisione Sky. Gli input della rete erano 106, costituiti dai 53 indici raddoppiati secondo la categoria:
- 0 = assenza nel primo quartile; - 1 = presenza nel primo quartile.
Mappa degli abbonati Sky prodotta dalla rete AutoCM sulla base dei dati 3SC
Lo stesso database, da cui sono state estratte 319 variabili, è stato
elaborato con il sistema Populations11, ideato nel 2006 da G. Massini (vedi rapporto di ricerca del Semeion, anno 2006). Le 319 variabili di input del sistema erano le seguenti:
11 Populations, ver. 2.0 (2007), G. Massini.

164
- 241 items d’opinione, atteggiamento, aspettative della vita, atteggiamento verso il futuro;
- 69 informazioni socio-anagrafiche; - 3 variabili di consumo (abbonamenti Sky, lettori medio-forti
quotidiani, acquisto libri); - 6 variabili che riguardavano gli orientamenti politici. L’immagine sottostante rappresenta un esempio di tre
elaborazioni diverse, da cui è possibile trarre alcune considerazioni.
Tre elaborazioni con Populations dei dati 3SC sugli atteggiamenti politici
Nell’elaborazione del sistema emergono tre brevi considerazioni
sinteticamente così esprimibili: - chi si definisce di Centro è maggiormente vicino a chi si
considera di centro destra; - chi si considera di centro destra e chi si considera di destra
non formano mai un gruppo compatto; - il gruppo di chi “non risponde” è distanziato rispetto agli altri.
Un ultimo esempio riguarda sempre i dati del monitor 3SC elaborati con il sistema PST, i cui risultati sono stati proiettati poi su una mappa di Voronoi. La figura seguente rappresenta tale elaborazione.

165
Elaborazione del PST su mappa di Voronoi dei dati 3SC
Questa mappa costituisce una nuova e interessante
rappresentazione del posizionamento delle correnti socioculturali nel monitor 3SC, che i ricercatori della GPF stanno studiando per estrarre le informazioni più utili per la configurazione degli scenari dinamici futuri.
Equipe di ricerca e partner esterni I ricercatori che lavorano al progetto sono: G. Massini, M.
Intraligi e G. Maurelli. Il partner finanziatore del progetto è la GPF SpA.
Sviluppi La collaborazione fra GPF e Semeion è stata pianificata in tre
anni con possibilità di rinnovo. Nel prossimo triennio gli sviluppi dei progetti comuni saranno orientati nella sperimentazione operativa dei modelli di elaborazione del Semeion, sulla maggior parte delle ricerche che GPF conduce da anni sui comportamenti di consumo in Italia e in altri paesi.

166
3.4.3 Analisi e ottimizzazione dei percorsi lavorativi
Obiettivo del progetto Il Semeion si è occupato delle dinamiche del mondo del lavoro a
partire dal 1998. In quell’anno è iniziato un importante progetto, finanziato dal Ministero del Lavoro e dal Fondo Sociale Europeo, che aveva l’obiettivo di sperimentare e sviluppare sistemi informatici intelligenti per orientare soggetti in età lavorativa, verso una professione in grado di valorizzare le loro abilità cognitive e pragmatiche. Il contenuto teorico e metodologico del progetto è stato pubblicato dall’editore Franco Angeli nel 200212.
A seguito di questa esperienza nel 2007 è iniziato un rapporto di collaborazione con Italia Lavoro, per iniziare ad applicare Sistemi Artificiali Adattivi del Semeion al fine di prevedere ed ottimizzare il percorso lavorativo di diverse categorie di lavoratori distribuiti su tutto il territorio nazionale.
Il primo obiettivo operativo della collaborazione consisteva nel prevedere il prossimo contratto di lavoro che un soggetto andrà a firmare a partire dalla tipologia dei suoi precedenti contratti di lavoro.
Risultati conseguiti Per rispondere al quesito descritto sono state effettuate diverse
sperimentazioni con due categorie di modelli: reti neurali Supervisionate e reti SOM13.
Con le reti Supervisionate sono state effettuate 4 diverse elaborazioni con l’obiettivo di prevedere il contratto di lavoro (denominato tecnicamente avviamento avv-1) più recente, a partire dai precedenti avviamenti.
Il database sul quale sono state fatte tutte le elaborazioni era composto da 5043 soggetti descritti da 54 variabili.
Complessivamente ogni modello di elaborazione ha ricevuto 642 input. La prime 30 variabili erano di tipo anagrafico. Le altre 612
12 M. Buscema e Semeion Research Group Reti Neurali Artificiali per l’orientamento professionale – Progetto LOOP, Franco Angeli, Milano, 2002. 13 Supervised ANNs and Organism ver. 12.5 (1999-2007), M. Buscema. SOM (Shell for programming Self Organizing Maps) ver. 7.0 (2007), G. Massini.

167
descrivevano gli ultimi 8 avviamenti di ognuno dei soggetti inclusi nel database. I due tipi di contratto assunti come target erano: tempo determinato e tempo indeterminato.
Input Input
1 Sesso 2 31 Anno avviamento 5 72 Eta' 1 32 Tipo rapporto avv 5 33 Cittadinanza 2 33 Qualifica rapporto avv 5 94 Stato Civile 8 34 Motivo cessasione avv 5 75 Qualifica prevalente 9 35 Attivita' azienda 5 466 Macro Titolo Studio 8 36 Dipendenti azienda 5 47 Anno avviamento 1 7 37 Anno avviamento 6 78 Tipo di rapporto avv 1 3 38 Tipo rapporto avv 6 39 Qualifica rapporto avv 1 9 39 Qualifica rapporto avv 6 9
10 Motivo cessazione avv 1 7 40 Motivo cessasione avv 6 711 Macro attivita' azienda 1 48 41 Attivita' azienda 6 4612 Dipendenti azienda 1 4 42 Dipendenti azienda 6 413 Anno avviamento 2 7 43 Anno avviamento 7 714 Tipo di rapporto avv 2 3 44 Tipo rapporto avv 7 315 Qualifica rapporto avv 2 9 45 Qualifica rapporto avv 7 916 Motivo cessazione avv 2 7 46 Motivo cessasione avv 7 717 Attivita' azienda 2 46 47 Attivita' azienda 7 4718 Dipendenti azienda 2 4 48 Dipendenti azienda 7 419 Anno avviamento 3 7 49 Anno avviamento 8 720 Tipo di rapporto avv 3 3 50 Tipo rapporto avv 8 321 Qualifica rapporto avv 3 9 51 Qualifica rapporto avv 8 922 Motivo cessazione avv 3 7 52 Motivo cessasione avv 8 723 Attivita' azienda 3 44 53 Attivita' azienda 8 4724 Dipendenti azienda_3 4 54 Dipendenti azienda 8 425 Anno avviamento 4 726 Tipo rapporto avv 4 327 Qualifica rapporto avv 4 928 Motivo cessasione avv 4 729 Attivita' azienda 4 4830 Dipendenti azienda 4 4
Variabili Variabili
Avv 4(78 input)
Avv 5(76 input)
Avv 6(76 input)
Avv 7(77 input)
Avv 8(77 input)
Anagr(30 input)
Avv 1(78 input)
Avv 2(76 input)
Avv 3(74 input)
Struttura del database di avviamento al lavoro Il protocollo di elaborazione utilizzato è stato l’ormai conosciuto
è il random 5x2 Cross-Validation. Con questo protocollo dal database di riferimento vengono selezionati tre diversi campioni, i primi due sono necessari all’addestramento delle Reti Supervisionate. Il terzo campione é quello dove si verifica in cieco la capacità previsionale delle Reti Neurali.
Ogni classe di sperimentazione aveva i dati dei primi avviamenti per prevedere quello temporalmente più vicino. La struttura delle sperimentazioni era organizzata a scalare.
I risultati raggiunti, in una media di 10 elaborazioni per ogni classe di input, sui campioni di validation, cioè quelli assolutamente sconosciuto ai modelli, sono i seguenti:
- con 260 input: variabili anagrafiche + (6° 7° e 8° avviamento) = 74.73% di capacità previsionale nel distinguere soggetti con

168
contratto a tempo determinato rispetto a soggetti con tempo indeterminato dell’avviamento più recente (Avv-1);
- con 336 input: variabili anagrafiche + (5° 6° 7° e 8° avviamento) = 74.97% di capacità previsionale nel distinguere soggetti con contratto a tempo determinato rispetto a soggetti a tempo indeterminato dell’avviamento più recente (Avv-1);
- con 414 input: variabili anagrafiche + (4° 5° 6° 7° e 8° avviamento) = 75.76% di capacità previsionale nel distinguere soggetti con contratto a tempo determinato rispetto a soggetti a tempo indeterminato dell’avviamento più recente (Avv-1);
- con 488 input: variabili anagrafiche + (3° 4° 5° 6° 7° e 8° avviamento) = 75.77% di capacità previsionale nel distinguere soggetti con contratto a tempo determinato rispetto a soggetti a tempo indeterminato dell’avviamento più recente (Avv-1).
Un secondo insieme di elaborazioni sono state effettuate con una rete SOM, i cui risultati sono stati proiettati su una matrice 25x25, sulla base delle quali sono state costruite delle mappe che visualizzano le diverse distribuzioni dei 5043 lavoratori del campione di riferimento. Ne riportiamo una a titolo di esempio.
Mappa di distribuzione dei lavoratori a tempo determinato (cerchi in rosso a sinistra)
tempo indeterminato (cerchi in giallo a destra)
Nelle mappe i cerchi rappresentano i soggetti distribuiti, e le dimensioni dei cerchi ne indicano la relativa numerosità. Queste due

169
mappe mostrano che le due categorie di lavoratori sono ben distinti dalla Rete SOM, nell’avviamento più lontano nel tempo.
Dall’insieme di elaborazioni fatte con le reti SOM emergono alcune considerazioni:
- la rete neurale, utilizzando tutte le variabili disponibili, disegna distribuzioni diverse in relazione al tipo di contratto di lavoro;
- esiste una mobilità piuttosto limitata nel passare dal tipo di contratto a tempo determinato a quello a tempo indeterminato;
- esiste una certa stabilità nel conservare il tipo di contratto di partenza, con una certa prevalenza per il contratto a tempo determinato.
Equipe di ricerca e partner esterni I ricercatori che lavorano al progetto sono: M. Intraligi, M.
Capriotti e G. Maurelli. Si è costituita un gruppo di lavoro misto composto da esperti del mondo del lavoro e ricercatori del Semeion.
Il partner finanziatore del progetto è Italia Lavoro SpA.
Sviluppi Sulla base dei risultati preliminari raggiunti, il progetto si
svilupperà nel prossimo triennio, con diverse fasi sperimentali. L’obiettivo sarà quello di esplorare, con i modelli del Semeion, numerosi database che descrivono globalmente la condizione dei lavoratori in Italia, per poter prevedere i flussi dinamici delle trasformazioni contrattuali ed i potenziali percorsi di carriera.
3.4.4 Analisi e previsione della concentrazione di gas sulla base di sistemi di nanosensori
Obiettivo del progetto Nell’aprile del 2007 è stato firmato un accordo riservatezza tra la
Selex Communications SpA e il Semeion, per iniziare una discussione tecnica al fine di poter valutare l’applicabilità dei Sistemi Artificiali Adattivi, proprietari del Semeion, al particolare contesto applicativo del software di riconoscimento per nanosensori della

170
Selex Communications. Dopo la fase preliminare di conoscenza reciproca si è impostato un primo progetto finalizzato ad individuare e pianificare le sperimentazioni necessarie ad affrontare un problema di classificazione e previsione di uno specifico sistema di sensoristica.
Gli obiettivi del progetto sono articolati su tre livelli: - un obiettivo operativo che consiste nell’effettuare una serie di
sperimentazioni su un database (secondo il protocollo Training, Testing e Validation set) prodotto da regolari sessioni di misura per classificare e prevedere la reale concentrazione di gas in miscele, a seconda delle varie condizioni di temperatura del sensore e umidità relativa dell’ambiente di misura, estrapolando livelli di concentrazione e intervalli di confidenza associati;
- un obiettivo valutativo che consiste nel confrontare il grado di accuratezza raggiunto dai modelli matematici del Semeion© con la Learning Machine utilizzata da Selex Communications, per lo svolgimento dello stesso compito;
- un obiettivo esplorativo che consiste nel verificare la possibilità di impiegare i modelli del Semeion per affrontare anche altri problemi con caratteristiche simili, a cui Selex Communications possa essere interessata.
Risultati conseguiti Per poter delineare l’architettura delle sperimentazioni del
progetto sono state fatte una serie di analisi preliminari, che hanno consentito di definire alcune caratteristiche del database sperimentale di riferimento.
Il database tipo su cui verranno realizzate le sperimentazioni sarà composto, indicativamente, da 9 variabili (come di seguito specificato) per circa 32.000 records (ogni record, corrispondente a un minuto secondo di misura):
- la prima variabile è il tempo (ordinale dell’intervallo temporale);
- dalla seconda alla quinta variabile sono espressi i valori di 4 sensori, registrati in quel determinato intervallo temporale;

171
- la sesta variabile è costituita dal valore della temperatura del sensore;
- le ultime tre variabili indicano le concentrazioni delle sostanze in esame.
L’obiettivo sperimentale è riuscire a prevedere i valori della “concentrazione” a partire dai valori di input espressi dalle misure sui 4 sensori, e dalle misure di temperatura.
La definizione dei termini dei protocolli della sperimentazione costituisce un primo step del lavoro di ricerca.
Equipe di ricerca e partner esterni I ricercatori che lavorano al progetto sono: M. Buscema, S. Terzi
e M. Intraligi. Il partner finanziatore del progetto è la Selex Communications SpA.
Sviluppi Gli sviluppi progettuali sono ovviamente connessi ai risultati che
verranno raggiunti in relazione ai tre obiettivi descritti nel paragrafo iniziale.


Sintesi delle Ricerche del 2007
a cura di M. Buscema, G. Massini, S. Terzi, M. Intraligi, G. Maurelli


175
4. Novità della Ricerca di Base nell’anno 2007
Alla fine del 2007 si è deciso di strutturare in modo diverso il consueto rapporto di ricerca che il Semeion pubblica regolarmente ogni anno. Questa decisione è stata stimolata da una serie di riflessioni sul fatto di definire una preventiva programmazione delle attività sia della Ricerca di Base che della Ricerca Applicata. Inoltre il contributo dei membri del Comitato Tecnologico Scientifico costituitosi nel 2007, è stato significativo nel suggerire di inquadrare il lavoro di ricerca in un piano triennale di programmazione delle attività. Data questa impostazione è evidente che lo sforzo esplicativo del lavoro di ricerca, con tutti gli strumenti ad esso connesso (scoperte, brevetti e softwares) è contenuto nel piano triennale. Quest’ultima parte del volume intende segnalare quelle novità, in termini di scoperte che sono avvenute nel corso dell’anno, ma che si inquadrano nel contesto teorico e metodologico già ampiamente descritto nelle sezione delle Ricerca di Base presente in questo volume.

176
4.1 Active Connection Matrix (ACM): evoluzioni Il sistema ACM, il cui stato dell’arte è stato ampiamente descritto
nel cap. 2.2 di questo volume, ha subito delle evoluzioni in termini di implementazione di nuove funzioni che migliorano gli strumenti software.
Sulla rete neurale J-Net, appartenente alla grande famiglia degli algoritmi del sistema ACM e scoperta nel 2006, sono state effettuate ulteriori approfondimenti sperimentali per consolidare i primi risultati precedentemente ottenuti lo scorso anno. Molte sperimentazioni si sono concentrate nel verificare la stabilità di funzionamento del parametro alfa (a ), in particolare nella sua funzione temporale. Ricordiamo che in J-Net il parametro a , determina la sensibilità del modello alla luminosità dell’immagine, regolando diversamente e indipendentemente la scalatura dei valori. In questo modo il ricercatore, prima dell’elaborazione, può decidere la “messa in sintonia” del modello, attraverso il parametro a , decidendo di evidenziare diversi tipi di bordi nell’immagine da elaborare. Questa possibilità di sintonizzazione, derivata dai diversi valori assunti dal parametro a , è particolarmente interessante in quanto evidenzia che la radiografia di un tumore, colto come luogo di luminosità particolare, può essere bordato così come appare nel suo massimo della luminosità, ma anche nelle diverse luminosità periferiche che appaiono intorno al tumore. Queste luminosità sembrano in grado di predire gli stati successivi di avanzamento del tumore, cioè indicarne le dinamiche di sviluppo.
Nei due esempi che seguono appaiono due diverse elaborazioni su tumori al polmone in cui i livelli del parametro a, fanno emergere le diverse dinamiche di sviluppo del tumore.

177
J-Net (alfa -0.9) (alfa -0.8) (alfa -0.7) (alfa -0.6) (alfa -0.5)
(alfa -0.4) (alfa -0.3) (alfa -0.2) (alfa -0.1) (alfa 0) (alfa +0.1) Elaborazione della rete J-Net con diversi gradi del parametro a su un tumore benigno
La figura mostra come i diversi gradi di elaborazione
dell’immagine tramite il parametro a non modificano la forma del tumore benigno, evidenziato nell’immagine originale.
J-Net (alfa -0.7) (alfa -0.6) (alfa -0.5) (alfa -0.4) (alfa -0.3)
(alfa -0.2) (alfa -0.1) (alfa 0) (alfa +0.1) (alfa +0.2) Elaborazione della rete J-Net con diversi gradi del parametro a su un tumore maligno
La figura mostra come i diversi gradi di elaborazione
dell’immagine tramite il parametro a modificano la forma del tumore maligno, evidenziandone l’aspetto di sfrangiamento tipico dei noduli maligni.
Software (ACM SW ver. 11.0 Semeion©) Progetto e sviluppo: M. Buscema Nel corso del 2007 la rete neurale J-Net è stata implementata
nella versione 11.0 del software ACM.

178
Nella precedente versione del software la convergenza avveniva tramite la propagazione di onde dai bordi dell’immagine verso la parte luminosa. In questa nuova versione gli effetti del 3° ordine si propagano solo se confermati in funzione AND con gli effetti del 2° e del 1° ordine. Per questa ragione i bordi risultano particolarmente chiari e netti al termine dell’elaborazione. Mentre le prime equazioni del modello J-Net si basavano sull’unione degli effetti del 1° e del 3° ordine, queste nuove equazioni consentono di tenere conto dell’intersezione, degli oggetti del 1° e del 3° ordine. Agendo sul parametro a è possibile seguire l’evoluzione dinamica dell’elaborazione. Nelle due immagini che seguono mostriamo il caso di un paziente che è stato sottoposto ad una TAC. Nella prima immagine il parametro è (a-4) nella seconda è (a+4), la seconda immagine mette in evidenza la forma di un tumore, che ad una prima analisi era apparso benigno e che invece è risultato maligno.
Il sistema ha evidenziato con (a+4) la forma irregolare del nodulo.
Elaborazione della rete J-Net con parametro (a-4)

179
Elaborazione della rete J-Net con parametro (a+4)
Mostriamo, inoltre, due videate del software la prima con
l’immagine originale di una TAC, la seconda con un altro esempio di elaborazione.

180
Videata di ACM SW (ver. 11.0) che mostra l’immagine originale
Pagina principale di ACM SW (ver. 11.0) con risultato della elaborazione

181
4.2 Clustering Dinamico La ricerca di nuovi metodi di clustering che consentano di
estrarre sempre informazioni diverse dall’elaborazione di dati è una costante attività dei ricercatori che lavorano in questo ambito. Nel 2007 questo lavoro ha portato M. Buscema a definire un nuovo tipo di Clustering denominato “Dinamico”. Il processo che genera questo clustering è piuttosto articolato e coinvolge diversi modelli e algoritmi.
Innanzitutto si addestrano i pesi di una qualsiasi rete neurale, per poi fare una serie di interrogazioni con una rete Constraint Satisfaction (CS), che a sua volta genera un campione di tutte le interrogazioni possibili, tramite l’esplorazione con metodo montecarlo dello spazio degli attrattori. Ad ogni ciclo, necessario alla CS per rispondere all’interrogazione, vengono salvati i valori assunti da ogni singola variabile in gioco.
Questo processo produce un database di come tutte le variabili hanno negoziato dinamicamente i loro valori quando sono state sottoposte ad un campione rappresentativo di tutte le interrogazioni possibili. I pesi della rete neurale, addestrata in precedenza, definiscono quello che si potrebbe chiamare il sistema “osseo, muscolare e nervoso” del database; cioè l’insieme di vincoli all’interno dei quali le variabili del database possono assumere in modo condizionato dei valori (condizionato in un rapporto molti a molti). Le attivazioni, con diversi vincoli, operate attraverso la rete CS sono in grado di sondare le diverse dinamiche interne attraverso le quali il database può far interagire tutte le sue variabili, quando il contesto di immersione del database varia.
Il nuovo database, prodotto da questa complessa dinamica, dovrebbe essere in grado di rappresentare un’informazione più completa sul database originale. Infatti essa è in grado di tener conto della dinamica tramite la quale ognuna delle variabili in gioco, assumendo certi valori, retroagisce su tutte le altre.

182
Software (CS SW ver. 9.0 Semeion©) Progetto e sviluppo: M. Buscema La funzione che permette di effettuare il Clustering Dinamico è
stata introdotta nell’ultima versione software della rete CS (CS SW ver. 9.0), essa consente di generare un file di dati che registra tutte le modificazioni delle singole variabili sulla base di un insieme di interrogazioni della rete neurale. La visualizzazione dei clusters prodotti è poi affidata ai grafi ottenuti tramite MST, MTG e MRG. Mostriamo la videata principale del versione 9.0 del software CS.
Pagina principale del CS SW (ver. 9.0) con la funzione di Clustering Dinamico

183
4.3 La Funzione Hubness (H): evoluzioni Il capitolo 2.7 della Ricerca di Base ha trattato in maniera
dettagliata la Funzione H, che misura la complessità globale di un grafo, la quale era stata già descritta nel Rapporto di Ricerca del 2006, anno della sua scoperta.
Le novità prodotte nel 2007 sulla Funzione H riguardano l’introduzione di nuove equazioni che ne consentono la generalizzazione per ogni tipo di grafo. Inoltre è stato ideato, da M. Buscema, un nuovo tipo di grafo chiamato Maximally Regular Graph (MRG) (anch’esso descritto nel § 2.7 del presente volume), che consente di definire le strutture rilevanti e regolari che legano in modo nascosto le informazioni di un database qualsiasi.
Per comprendere le caratteristiche di questo tipo di grafo mostriamo un esempio di rappresentazione di un database composto da 226 società, selezionate tra quelle quotate alla borsa di Milano, che avevano almeno un consigliere d’amministrazione che sedeva in due società diverse. I consiglieri d’amministrazione in totale erano 1873.
Grafo che connette le società che hanno consiglieri d’amministrazione in comune

184
Come si può notare questo primo grafo, che connette semplicemente le 226 società che hanno consiglieri in comune, è caotico e non consente di analizzare alcunché della struttura del database.
Grafo prodotto dall’MRG sul database delle 226 società
Questo secondo grafo mette in evidenza una struttura, composta
da 8 nodi che rappresentano altrettante società, che influenzano i restanti nodi del grafo. L’analisi del significato dei singoli nodi, e delle relative società che rappresentano, è oggetto di uno studio attualmente in corso, effettuato da un gruppo di economisti.

185
4.4 SOM Maps Nella logica di migliorare i metodi per aumentare il grado di
precisione ottenibile nelle elaborazioni che producono clustering, nel 2007 M. Buscema ha individuato due diverse tipi di misure dell’errore per valutare la clusterizzazione prodotta da una rete Self Organizing Map (SOM). Si tratta in pratica di due nuovi criteri che la rete SOM deve apprendere per analizzare la complessità di un dataset. I due criteri sono denominati:
- Map Compactness Error (MC); - Centroids Compactness Error (CC).
Il primo misura il grado compattezza della mappa prodotta dalla SOM, il secondo misura la compattezza dei centroidi contenuti nella mappa. Questi due criteri sono stati implementati nel software di ricerca SOM Maps, che inoltre utilizza tre diversi metodi di sviluppo del Learning Rate.

186
Elaborazioni effettuate con SOM Map SW (ver. 1.0)
Le quattro mappe prodotte dal software SOM Map riguardano un
set di dati sulle tattiche del progetto CDTD di Scotland Yard. Dall’analisi delle mappe emerge che il mercato della droga a Londra è principalmente in mano agli afro-caraibici ed agli europei bianchi, mentre gli europei di colore e gli asiatici svolgono un ruolo piuttosto marginale.
Sempre nella logica di incrementare le capacità di analisi dei dataset sono stati inseriti nel software SOM Map altri tre indici per la valutazione dell’errore: l’errore topografico, l’errore del codebook, l’errore di quantizzazione.
L’algoritmo con cui le SOM costituiscono le classi, ognuna con il suo codebook, tende a mettere topograficamente vicine quelle classi i cui elementi sono più simili tra loro. Non solo le classi devono essere costituite dai record più simili tra loro, ma devono essere disposte sulla matrice in modo da essere contigue ad altre classi simili. L’errore topografico viene calcolato misurando la distanza vettoriale che ogni record ha con tutte le classi.
L’errore del codebook riguarda la rappresentatività del codebook rispetto agli elementi contenuti nella sua classe. Poiché l’appartenenza di un record ad una classe si determina assegnandolo alla classe la cui distanza è minore, ci si aspetta che i records interni ad una classe abbiano una distanza minima dal codebook e dunque che quel codebook sia effettivamente rappresentativo di quei

187
records. Per misurare l’errore del codebooks si va rilevare se ci sono records che non sono rappresentati dalla classe nella quale l’algoritmo della SOM li ha inseriti.
L’errore medio di quantizzazione è un indice complessivo della rappresentatività delle classi di una SOM. Questo indice può aiutare a capire quanto una SOM è stata costruita con dimensioni sbagliate, ad esempio una SOM che ha un numero di celle troppo piccolo per la varianza dei records da classificare.

188
4.5 Hidden Input Discovery (HID)
Come ampiamente descritto nella sezione Ricerca di Base di questo volume, nel 2007 è stata elaborata, da M. Buscema, una nuova tecnica per affrontare il problema della generazione dei dati virtuali. Questa tecnica, ancora in fase di sperimentazione, è stata denominata Hidden Input Discovery (HID). In questa sezione del volume è opportuno segnalare, come sempre accade per i nuovi algoritmi scoperti, che il modello è stato implementato in un software di ricerca.
Software (Hidden Input Discovery SW ver. 1.0 Semeion©) Progetto e sviluppo: M. Buscema La prima versione del software HID è del 2007. Mostriamo una
videata della software, che coglie un diverso momento di elaborazione, della figura inserita nella sezione Ricerca di Base.
Videata di HID SW (ver. 1.0) in fase di elaborazione

189
4.6 Meta-Classificatori modelli e software
Nel 2007 all’interno del Semeion si è deciso di lavorare sui sistemi di classificazione per migliorarne l’accuratezza. Si è trattato di un tema su cui si sono investite risorse, in quanto l’argomento è importante sotto il profilo funzionale, ma anche sotto l’aspetto teorico. Non è un caso che molti ricercatori nel mondo si stanno occupando di questo problema.
L’impostazione teorica del Semeion sull’argomento è stata descritta nel capitolo 2.5. Le prime sperimentazioni applicative sono state inserite nel progetto “Sviluppo di Meta-Classificatori per il miglioramento delle previsioni sui tumori”, illustrato nella sezione Ricerca Applicata § 3.1.3. Per consentire le elaborazioni sperimentali sono stati implementati, nella nuova versione del software Meta-Nets, numerosi nuovi classificatori e Meta-Classificatori
Software (Meta-Nets SW ver. 2.2 Semeion©) Progetto e sviluppo: M. Buscema Nella versione del 2007 il software Meta-Nets implementa tutti i
metaclassificatori finora ideati dai ricercatori del Semeion, l’elenco completo è quello riportato nel cap. 2.5.
Mostriamo due videate del software, che evidenziano la consistente varietà dei modelli implementati.

190
Videata di Meta-Nets SW (ver. 2.2) in fase di elaborazione
Nella videata principale si può notare che i metaclassificatori
ideati nel 2007 da M. Buscema sono: - Local Meta-Sum; - Global Prior Probability Algorithm; - Global Meta-Auto Contractive Map; - Local Meta-Auto Contractive Map; - Local Meta Armonic Memory.

191
Videata di Meta-Nets SW (ver. 2.2) confronto delle performance tra i modelli
Il metaclassificatore Local Meta Armonic Memory, è stato
implementato anche in un nuovo software, ancora in versione provvisoria denominato MetaCS (ver. 0.5). Questo software consente di effettuare l’apprendimento utilizzando una matrice dei pesi che, invece di essere bidimensionale (nodo sorgente à nodo destinazione), presenta una struttura tridimensionale (nodo sorgente à nodo destinazione à tipo di peso). Ciò significa che il sistema è in grado di mixare più matrici dei pesi nel rispondere tramite la rete Constraint Satisfaction (CS). Dalle prime sperimentazioni si evidenziano delle risposte che riescono a cogliere aspetti più sottili, della struttura interna del database. A titolo puramente indicativo mostriamo un tipo di risposta che il software è in grado di offrire al ricercatore.

192
Videata di MetaCS SW (ver. 0.5) in elaborazione
In questa videata si mostra l’elaborazione del database Jet e Shark
che utilizza la legge di apprendimento Armonic Memory. Attivando la variabile Jet, nel riquadro in basso a destra si può notare l’efficace minimizzazione dell’energia che porta l’errore praticamente a zero (Rmse 0.00000001), e la curva del valore di Goodness.
Nella videata sottostante, la stessa interrogazione mostra la complessa dinamica di attivazione delle altre variabili.
193
MetaCS SW (ver. 0.5) dinamica di attivazione delle variabili
Un trattamento a parte merita il metaclassificatore MetaGen,
ideato da M. Buscema nel maggio del 2007. MetaGen si può definire un sistema evolutivo per combinare in
modo intelligente le classificazioni prodotte da più classificatori funzionanti in parallelo, a vantaggio dell’accuratezza della classificazione finale.
In pratica, quando per effettuare la classificazione di uno stesso campione si usano più classificatori con caratteristiche matematiche diverse, si pone il problema delle soglie ottime per ogni classificatore, in modo tale che la loro combinazione risulti anch’essa ottima. Il problema presenta una crescita esponenziale degli esperimenti da effettuare al crescere del numero dei classificatori e del numero delle soglie che si intendono utilizzare per ognuno di questi.

194
Dato che per ogni classificatore, specie se una Rete Neurale Supervisionata, la curva ROC è teoricamente una curva continua e tipicamente non lineare, il campionamento delle soglie, per essere significativo, dovrebbe essere piuttosto fine.
In pratica, se abbiamo a disposizione 10 classificatori e per ognuno di questi sperimentiamo 20 soglie, per essere esaustivi e trovare per ogni classificatore la soglia ottima dovremmo effettuare 10,240,000,000,000 esperimenti (210). Per approssimare una soluzione ottima che esplori un universo delle possibili soluzioni così vasto è stato utilizzato un algoritmo evolutivo piuttosto potente 14 come motore di ottimizzazione, ed è stata ideata una nuova architettura per il calcolo della soluzione ottimale, denominata appunto MetaGen. Nella figura sottostante viene mostrata la struttura generale del processo di elaborazione all’interno del quale agisce MetaGen.
14 Buscema M. (2004), Genetic Doping Algorithm (GenD): theory and applications, in Expert Systems, Vol. 2 no. 2, May 2004, pp. 63-79, Blackwell Publishing.

195
Architettura del metaclassificatore MetaGen
Software (SuperVised SW ver. 11.5 Semeion©) Progetto e sviluppo: M. Buscema Il metaclassificatore MetaGen è stato implementato nella versione
11.5 del software SuperVised, di cui mostriamo la videata dell’elaborazione di una curva ROC.

196
SuperVised SW (ver. 11.5) videata di una curva ROC prodotta da MetaGen
Sempre nell’ambito del lavoro di ricerca sui modelli di
classificazione, nel 2007 è stato ideato da M. Buscema un nuovo classificatore vettoriale con tre tipi di funzione: Gauss, Sigmoid e Mexican Hat. Si tratta di una rete neurale supervisionata con apprendimento locale a quantificazione vettoriale, in cui ogni nodo hidden diventa un prototipo degli input che classifica. La rete denominata Adaptive vector Quantization (AQ) è attualmente implementata nel software SuperVised 12.5. Questo modello di rete neurale ha come vantaggio una notevole velocità di apprendimento, anche se normalmente arriva ad una codifica meno precisa di altre reti. Nella logica di moltiplicazione dei diversi punti di vista su uno stesso dataset, incrementare il numero di classificatori con caratteristiche differenti appare una strategia vincente. La rete AQ rientra in questa strategia di ricerca.

197
4.7 Multidimensional Scaling modelli e software
Le cosiddette tecniche di Multidimensional Scaling e/o di Topographic Mapping sono procedure finalizzate a comprimere un dataset per successivamente proiettarlo da uno spazio a molte dimensioni ad uno spazio con meno dimensioni, avendo il vincolo di conservare il più possibile, la metrica presente nello spazio d’origine. Il capitolo 2.8 della sezione Ricerca di Base descrive il problema, indicando i metodi e gli strumenti matematici con cui il Semeion lo ha finora affrontato. I due algoritmi originali ideati dal Semeion in questo campo sono il Pick and Squash Tracking di M. Buscema e Populations di G. Massini. Ovviamente i due algoritmi sono stati implementati in specifici softwares.
Software (PST SW ver. 7.0 Semeion©) Progetto e sviluppo: M. Buscema Per consentire un uso facilmente comparabile dei risultati dei due
algoritmi, all’interno della versione 2007 del software PST è stato implementato anche l’algoritmo Populations. Mostriamo una videata del PST ver. 7.0.
Videata di PST SW (ver. 7.0) clustering di un database

198
4.8 Semantic Connection Map
Nella prospettiva di sviluppare modelli e conseguentemente strumenti che consentano una efficace visualizzazione dei risultati prodotti dall’elaborazione dei modelli, si colloca il software Semantic Connection Map (SCM) (ver. 1.0), ideato e sviluppato da G. Massini. Si tratta di un software applicativo che implementa l’algoritmo della rete neurale Auto-Contractive Map (AutoCM), nell’ambito del lavoro di ricerca che si è sviluppato al Semeion sugli auto-associatori non lineari (vedi cap. 2.6 della sezione Ricerca di Base).
Lo scopo del software consiste nel permettere un’analisi approfondita di un database, sfruttando la potenza di calcolo è le caratteristiche strutturali della rete AutoCM, che riesce a far emergere le relazioni esistenti tra le variabili, con un elevato grado di accuratezza rispetto alla popolazione osservata. Successivamente i pesi che rappresentano le relazioni fra le variabili vengono automaticamente visualizzati tramite un grafo Minimum Spanning Tree, per consentire una facile analisi da parte del ricercatore. Nel corso del 2007 il software è già stato applicato all’elaborazione di database che descrivono diverse patologie (Alzheimer, Gastrite, ecc.).
Il processo di elaborazione avviene in 4 fasi: - apprendimento con la rete AutoCM fino alla stabilizzazione
delle connessioni; - sulla matrice delle connessioni dello strato Hidden-Output
viene calcolata la distanza vettoriale dei valori delle connessioni che convergono ai nodi di output, e viene quindi definita una matrice delle distanze;
- applicazione sulla matrice delle distanze del Minimum Spanning Tree (MST);
- visualizzazione del MST tramite il sistema Trees Visualizer (G. Massini, 2006, confronta Rapporto di Ricerca n. 5, anno 2006, pp. 62-63).
Mostriamo di seguito tre immagini, il front page seguito da due videate che illustrano il processo di elaborazione del software.

199
SCM SW (1.0) Front page
SCM SW (1.0) visualizzazione della fase di apprendimento della rete AutoCM

200
SCM SW (1.0) visualizzazione dell’albero MST ottenuto sulla matrice delle distanze
tra le connessioni dello strato Hidden-Output di una rete AutoCM

201
5. Pubblicazioni scientifiche Nel corso del 2007 l’attività di pubblicazione scientifica si è
concentrata principalmente su articoli scientifici finalizzati a presentare e descrivere i nuovi modelli matematici recentemente scoperti.
Per ogni articolo pubblicato riportiamo il frontespizio, che identifica, anche visivamente, la rivista, gli autori e contiene l’abstract. In questo modo chiunque sia interessato ad avere l’articolo completo può facilmente rivolgersi all’editore della rivista.
Complessivamente nel 2007 sono stati pubblicati 10 articoli scientifici su diverse riviste internazionali.

202

203

204

205

206

207

208

209

210

211

212

213
6. Attività di formazione
Dalla ormai quasi decennale esperienza che il Semeion ha maturato nel campo medico, grazie anche alla consolidata partnership con il Gruppo Bracco, nel 2007 è nata l’idea di effettuare dei corsi di formazione sui nuovi modelli matematici per i medici specialisti.
Lo scopo dell’attività di formazione è quello di consentire ai medici di avvicinarsi ai temi della complessità acquisendo un bagaglio di competenze di base sui Sistemi Artificiali Adattivi. L’obiettivo centrale non solo è quello di favorire l’uso di nuovi strumenti di analisi delle malattie, ma anche di fornire gli strumenti pratici per lavorare in modo nuovo sui dati che vengono quotidianamente raccolti dai medici specialisti, in riferimento a specifiche patologie. Per questa ragione oltre a diverse ore di lezione frontale, durante il corso sono stati previsti una serie di laboratori pratici, nei quali i medici hanno potuto sperimentare direttamente l’uso di strumenti software che implementano i modelli di elaborazione descritti nella parte teorica del corso.
I corsi sono organizzati in modo da fare due giorni pieni di formazione, per un totale di 16 ore complessive per ogni singolo corso. Il corso fornisce in primo luogo una guida alla costruzione corretta di un database, sia in termini di scelta delle variabili sia in termini di numerosità dei campioni da raccogliere, in secondo luogo insegna ad utilizzare modelli di elaborazione che rispondono a domande alle quali spesso la statistica tradizionale non è in grado di rispondere. Il vantaggio di possedere un database sui propri pazienti aggiornato e correttamente strutturato è certamente un aiuto utile anche all’attività clinica quotidiana, la possibilità di elaborarli facilmente con modelli matematici avanzati costituisce un valore aggiunto per la diagnosi clinica.
Nell’anno 2007 si è tenuto un primo meeting formativo di preparazione alla costruzione corsi, e successivamente tre corsi completi. Il corpo docente era costituito dai ricercatori del Semeion, nello specifico: M. Buscema, G. Massini, S. Terzi, M. Intraligi, G. Maurelli, ed un associato di ricerca E. Grossi. I partecipanti ai corsi erano medici gastroenterologi, neurologi, psicologi clinici.

214
I corsi si sono tenuti nelle seguenti date: - 11 Maggio 2007: Meeting di preparazione presso la sede delle
Bracco a Milano sul tema “Intelligenza Artificiale in Gastroenterologia: Back to the future”;
- 4-7 Luglio 2007: 1o corso “Intelligenza Artificiale in Gastroenterologia”, effettuato presso la sede del Semeion a Roma;
- 5-8 Settembre 2007: 2o corso “Intelligenza Artificiale in Gastroenterologia”, effettuato presso la sede del Semeion a Roma;
- 14-17 Novembre 2007: 3o corso “Intelligenza Artificiale in Medicina”, effettuato presso la sede del Semeion a Roma.

215
7. Collaborazioni e brevetti
Le relazioni più significative che il Semeion ha instaurato con istituzioni pubbliche e private, centri di ricerca, enti ed aziende, delineano un quadro storico-evolutivo del Semeion nel tempo. Abbiamo pensato di fornire un elenco completo per consentire, a chi è interessato, di farsi un’idea di coloro che hanno contribuito all’esistenza Semeion, dalla sua nascita fino ad oggi.
Nel 2007 vanno segnalati alcuni dei nuovi rapporti istituzionali particolarmente significativi che il Semeion ha stabilito:
- convenzione con il Consiglio Nazionale delle Ricerche (CNR) Dipartimento ICT per la partecipazione al “Progetto Interdipartimentale sulla Sicurezza”;
- membro dell’Osservatorio per la Sicurezza Nazionale (OSN), organismo militare diretto dal CASD-CeMiSS (Centro Alti Studi Difesa e Centro Militare di Studi Strategici) e dalla Elsag Datamat Spa, che annovera fra i suoi membri Ministeri, Università e Aziende, che lavorano sinergicamente sul tema della sicurezza;
- membro della sezione italiana di Armed Forces Communications and Electronics Association (AFCEA);
- main contractor per l’organizzazione della Conferenza Internazionale dal titolo “How Science Speaks to Drug Policy” su incarico del “United Nations Office on Drugs and Crime (UNODC)” tenutasi a Roma, dal 3 al 5 novembre 2007.
7.1 Collaborazioni e cooperazioni istituzionali
Le collaborazioni sono suddivise in 3 ambiti istituzionali: - Università e Centri di ricerca nazionali e internazionali; - Enti pubblici e privati; - Aziende. Delle Università e Centri di Ricerca nazionali e internazionali
forniamo un elenco, in ordine alfabetico: 1. Abo Academy University, Department of Pharmacy, Turku
(Finland) 2. ACFE (Association of Certified Fraud Examiners), Roma

216
3. British American Tobacco – Italia, Roma 4. Centro Sviluppo Materiali S.p.A., Roma-Terni 5. College of Medicine, University of Kentucky, NunStudy
Project, Lexington (KY-USA) 6. Consorzio Universitario Nettuno, Network per l’Università
Ovunque, Roma 7. Consorzio Universitario Padova Ricerche, Padova 8. ENEA - Centro Ricerche Energia della Casaccia, Roma 9. Istituto Galeazzi di Milano, Dipartimento di Radiologia,
Milano 10. Istituto Nazionale di Fisica Nucleare, Roma 11. Istituto di Ricovero e Cura “Santa Lucia” (Roma) 12. Istituto di Ricovero e Cura “S. Giovanni di Dio
Fatebenefratelli” (Brescia) 13. Jerusalem Methadone Centre, Jerusalem (Israel) 14. Middle Eastern Summer Institute on Drug Use, Jerusalem
(Israel) 15. National Institute of Health, Laboratory of Adaptive Systems,
John Hopkins University (USA) 16. New Scotland Yard, Specialist Crime Directorate,
Metropolitan Police Service, London (UK) 17. Ospedale Niguarda Ca’ Granda, Laboratorio Clinico di
Chimica e Ematologia, Milano 18. Politecnico di Milano, Facoltà di Architettura, Dipartimento
di Scienze del Territorio, Milano 19. Prevention Research Centre Pacific Institute for Research &
Evaluation, Berkeley (CA-USA) 20. Sanders-Brown Center on Aging, Department of Preventive
Medicine, College of Medicine, University of Kentucky (USA)
21. Scuola Centrale Tributaria “Ezio Vanoni”, Ministero delle Finanze, Roma
22. SUPEA, Research Unit, Losanna (CH) 23. Tri-Ethnic Center for Prevention Research, Colorado State
University (Colorado, USA) 24. Università di Alessandria, Dipartimento di Scienze Sociali,
Alessandria

217
25. Università di Bologna, Dipartimento di Scienze dell’Educazione, Bologna
26. Università degli Studi di Chieti-Pescara “G. d’Annunzio”, Pescara
27. Università di Firenze, Dipartimento di Scienze Economiche, Firenze
28. Università di Milano Bicocca, Facoltà di Sociologia, Milano 29. Università di Napoli, Dipartimento di Sociologia, Napoli 30. Università di Roma La Sapienza, Istituto di Farmacologia,
Roma 31. Università degli Studi di Venezia, IUAV, Venezia 32. Università Campus Biomedico di Roma 33. University of Kentucky, Centre on Drug & Alcohol Research,
Lexington (KY-USA) 34. University of Mainz “J. Gutenberg”, Dipartimento di
Radiologia, Mainz (D) Per gli Enti pubblici e privati le collaborazioni più significative
sono e sono state con: 1. Ministero dell’Università e della Ricerca 2. Ministero del Lavoro 3. Ministero della Salute 4. Ministero Affari Sociali 5. Ufficio Italiano Cambi, Banca d’Italia 6. Confindustria 7. Regione Emilia-Romagna 8. Regione Veneto 9. Regione Basilicata 10. ASL di Vigevano 11. ASL di Castelfranco Veneto 12. ASL di Salerno 13. ASL di Siena 14. ASL di Bari 15. Ospedale Militare Marittimo di La Spezia Nell’ambito del mondo aziendale segnaliamo alcune delle
collaborazioni più significative, relativamente all’applicazione dei modelli scientifici per la risoluzione di problemi:

218
1. Gruppo Bracco S.p.A. 2. Santander Consumer-Banca S.p.A. 3. Experian S.p.A. 4. Alitalia S.p.A. 5. Consiel S.p.A. (Gruppo Telecom Finsiel) 6. Istituto di Credito Sportivo S.p.A. 7. Telesoft S.p.A. 8. Performa Confcommercio S.c. a r.l. 9. Computer Associates S.p.A. 10. TNT Global Express S.p.A. 11. Union Key S.r.l. 12. Atlantis S.p.A.
7.2 Elenco dei brevetti
Le domande di brevetto sono iniziate nel 2001, quando il Semeion ha avuto l’opportunità di incontrare aziende interessate a sfruttare economicamente i risultati delle ricerche sviluppate al suo interno. L’inventore di tutti i brevetti è M. Buscema che, in qualche caso, ha condiviso l’ideazione con altri ricercatori. A titolo informativo forniamo un elenco completo dei brevetti depositati fino alla fine 2007.
- Brevetto Internazionale, denominato: “Metodo e dispositivo per valutare la prestazione cognitiva di un individuo” (TSP GenD: Genetic Doping Algorithm for Resolution Traveling Sales Person Problem), coinventore Enzo Grossi, (domanda n. PCT/IT01/00542 depositata il 24-10-2001).
- Brevetto Europeo, denominato: “Metodo per la codifica di pixel di immagini e metodo di elaborazione d'immagine per il riconoscimento qualitativo dell'oggetto riprodotto da uno o più pixel di immagine” (Pixel Vector Theory PVT) (domanda n. 02425141.5 depositata il 11-03-2002).
- Brevetto USA, denominato: “Metodo per l'ottimizzazione di un database per eseguire il training ed il testing di un algoritmo di predizione, particolarmente di una rete neurale” (Sistema Training and Testing, T&T) (domanda n. US60/440, 210 depositata il 15-01-2003).

219
- Brevetto Internazionale, denominato: “Metodo per la codifica di pixel di immagini e metodo di elaborazione d'immagine per il riconoscimento qualitativo dell'oggetto riprodotto da uno o più pixel di immagine” (Pixel Vector Theory, PVT) (domanda n. PCT/EP03/02400 depositata il 10-03-2003).
- Brevetto Europeo, denominato: “Algoritmo per la proiezione di dati di informazioni appartenenti ad uno spazio multidimensionale in uno spazio avente meno dimensioni. Un metodo per l’analisi cognitiva dei dati di informazioni multidimensionali “basati su detto algoritmo e un programma comprendente il detto algoritmo memorizzato su un supporto registrabile” (Pick and Squash Tracking, PST) (domanda n. 03425436.7 depositata il 01-07-2003).
- Brevetto Europeo, denominato “Un algoritmo per il riconoscimento di relazioni tra i dati di un database e un metodo per il riconoscimento di forme di immagini basato su detto algoritmo” (Active Connection Matrix, ACM), (domanda n. 03425559.6 depositata il 22-08-2003).
- Brevetto Europeo, denominato “Rete Neurale Artificiale” (Sine Net), (domanda n. 03425582.8 depositata il 09-09-2003).
- Brevetto Internazionale “Metodo per l'ottimizzazione di un database per eseguire il training ed il testing di un algoritmo di predizione particolarmente di una rete neurale” (Sistema Training and Testing, T&T), (domanda n. PCT/EP04/00157 depositata il 13-01-2004).
- Brevetto Internazionale, denominato: “An Algorithm for projecting information data belonging to a multidimensional space into a space having less dimensions a method for the cognitive analysis of multidimensional information data based on the said algorithm and a program comprising the said algorithm stored on a recordable support” (Pick and Squash Tracking, PST), (domanda n. PCT/EP2004/051190 depositata il 22-06-2004).
- Brevetto Internazionale, denominato “Un algoritmo per il riconoscimento di relazioni tra i dati di un database e un metodo per il riconoscimento di forme di immagini basato su

220
detto algoritmo” (Active Connection Matrix, ACM), (domanda n. PCT/EP2004/05182 depositato il 18-08-2004).
- Brevetto Internazionale “Una Rete Neurale Artificiale” (Sine Net), (domanda PCT/EP2004/05189 depositata il 28-08-2004).
- Brevetto Europeo, denominato “Metodo di elaborazione di segnali multicanale e multivariati e metodo di classificazione di sorgenti di segnali multicanale operante in base a detto metodo di elaborazione” (Implicit Function As Squashing Time, IFAST), (domanda n. 06115223.7 depositata il 09-06-2006).
- Brevetto Internazionale “Metodo di elaborazione di segnali multicanale e multivariati e metodo di classificazione di sorgenti di segnali multicanale e multivariati operante in base al detto metodo di elaborazione” (Implicit Function As Squashing Time, IFAST), (domanda n. PCT/EP2007/055646 depositata il 08-06-2007).
- Brevetto Europeo denominato “Un algoritmo per il processamento di immagini in grado di evidenziare l’informazione nascosta nei pixel” (Active Connection Matrix J-Net), (domanda n. 07425419.4 depositata il 06-07-2007).

221
8. Partecipazione a conferenze e convegni
Le relazioni che i ricercatori del Semeion tengono ogni anno, partecipando a conferenze e convegni, costituiscono un’attività di comunicazione e divulgazione del lavoro di ricerca di base e sperimentale. Tale attività consente anche lo scambio e il confronto d’idee con altri ricercatori che lavorano nello stesso campo, o in campi simili.
Elenchiamo gli eventi più significativi ai quali hanno partecipato i ricercatori nell’anno 2007 in qualità di relatori.
- 23 gennaio 2007, relazione dal titolo "Sistemi Artificiali Adattivi nella Ricerca Medica", nell’ambito della sezione “Metodi alternativi alla sperimentazione animale”, organizzato dalla Facoltà di Medicina e Chirurgia, dell’Università degli Studi di Bologna.
- 24-27 giugno 2007, partecipazione al convegno “2007 Annual Meeting of the North American Fuzzy Information Processing Society”, con una relazione dal titolo “The added value of ‘Artificial Organisms’ in the analysis of medical data: six years of experience”, San Diego, California USA.
- 19-21 luglio 2007, partecipazione al convegno “L’immagine nel discorso scientifico: statuti e dispositivi di visualizzazione” organizzato dal Centro Internazionale di Semiotica e Linguistica di Urbino, Università di Urbino, con una relazione dal titolo “Le immagini nei dati: modelli di estrazione e visualizzazione”, Urbino.
- 26 settembre 2007, relazione sul tema “Artificial Adaptive Systems for the analysis of biomarkers to predict and cluster four classes of smokers”, seminario interno tenutosi a Southampton presso il Centro Ricerche della BAT (British American Tobacco).
- 7-10 ottobre 2007, partecipazione al convegno “2007 IEEE International Conference on Systems, Man and Cybernetics (SMC 2007)” con una relazione dal titolo “A novel adapting mapping method for emergent properties discovery in data bases: experience in medical field”, Montreal, Canada.

222
- 3-5 novembre 2007, partecipazione al convegno “How Science Speaks to Drug Policy” con tre relazioni dal titolo “Using artificial adaptive systems to analyse drug trafficking data in London”, “Using artificial adaptive systems to predict drug misuse vulnerability among Italian army conscripts (TBC)” e “Using artificial adaptive systems to evaluate police drug enforcement tactics” organizzato dalla United Nations Office on Drugs and Crime (UNODC) e dal Semeion Centro Ricerche, Roma.
- 14-15 novembre 2007, partecipazione al “European Fraud Conference” 2007, con una relazione sul tema “Management of operational risks through neural network analysis of bureau data: process and technology innovation”, Roma.
- 27 novembre 2007, relatore sul tema “Modelli matematici nelle scienze sociali. Da Paul F. Lazarsfeld alle Reti Neurali Artificiali” con il Prof. Vittorio Capecchi, all’ambito della II Edizione del Premio “Gianni Statera” presso l’Università degli Studi di Roma “La Sapienza”.
- 8-9 dicembre 2007, partecipazione al convegno “Matematica e Società” in occasione dei 40 anni della rivista “Quality and Quantity International Journal of Methodology”, con quattro relazioni dal titolo “Sistemi Artificiali Adattivi nell’imaging medico e nella sicurezza”, “La Rete Neurale MetaMultiSOM su dati medici”, “I modelli di Metaclassificazione” e “Applicazione delle Reti Neurali Artificiali ai fenomeni criminali”, organizzato dall’Università degli Studi di Bologna.


Finito di stampare nel mese di maggio del 2008dalla tipografia « Braille Gamma S.r.l. » di Santa Rufina di Cittaducale (Ri)
per conto della « Aracne editrice S.r.l. » di Roma
CARTE: Copertina: Burgo Digit Linen 270 g/m2 plastificata opaca; Interno: Patinata opaca Bravomatt 115 g/m2
ALLESTIMENTO: Legatura a filo di refe / brossura
Stampa realizzata in collaborazione con la Finsol S.r.l. su tecnologia Canon Image Press