abstract this presentation questions the need for reinforcement learning and related paradigms from...
TRANSCRIPT

Abstract
This presentation questions the need for reinforcement learning and related paradigms from machine-learning, when trying to optimise the behavior of an agent. We show that it is fairly simple to teach an agent complicated and adaptive behaviors under a free-energy principle. This principle suggests that agents adjust their internal states and sampling of the environment to minimize their free-energy. In this context, free-energy represents a bound on the probability of being in a particular state, given the nature of the agent, or more specifically the model of the environment an agent entails. We show that such agents learn causal structure in the environment and sample it in an adaptive and self-supervised fashion. The result is a policy that reproduces exactly the policies that are optimized by reinforcement learning and dynamic programming. Critically, at no point do we need to invoke the notion of reward, value or utility. We illustrate these points by solving a benchmark problem in dynamic programming; namely the mountain-car problem using just the free-energy principle. The ensuing proof of concept is important because the free-energy formulation also provides a principled account of perceptual inference in the brain and furnishes a unified framework for action and perception.
Action and active inference:A free-energy formulation

Perception, memory and attention(Bayesian Brain)
Action and value learning(Optimum control)
argmax ( ( ) | )a
V s a argmin ( ( | ) || ( | ))D q p s
causes ()
Prediction error
sensory input
( | )q S
R
Q
CS
reward (US)
action
S-R
S-S
The free-energy principle
,argmin ( ( ), )
aF s
s
s
av

Overview
The free energy principle and actionActive inference and prediction errorOrientation and stabilizationIntentional movementsCued movementsGoal-directed movements Autonomous movementsForward and inverse models

agent - menvironment
( , )s g a w
argmin ( , )a
a F s
argmin ( , )F s
( , )f a z
Separated by a Markov blanket
External states
Internal states
Sensation
Action
Exchange with the environment

Perceptual inference Perceptual learning Perceptual uncertainty
ln ( ( ) | , ) ( || ( ))
argmin
argmax ln ( | , )
q
a
qa
F p s a m D q p
a F
p s m
Action to minimise a bound on surprise
The free-energy principleln ( , | ) ln ( )
q qF p s m q
ln ( | ) ( ( | ) || ( | ))
argmin
( | ) ( | )
F p s m D q p s
F
q p s
Perception to optimise the bound
( | ) ( | ) ( | ) ( | )uq q u q q
argminu F
argmin F
argmin F
The conditional density and separation of scales

Overview
The free energy principle and actionActive inference and prediction errorOrientation and stabilizationIntentional movementsCued movementsGoal-directed movements Autonomous movementsForward and inverse models
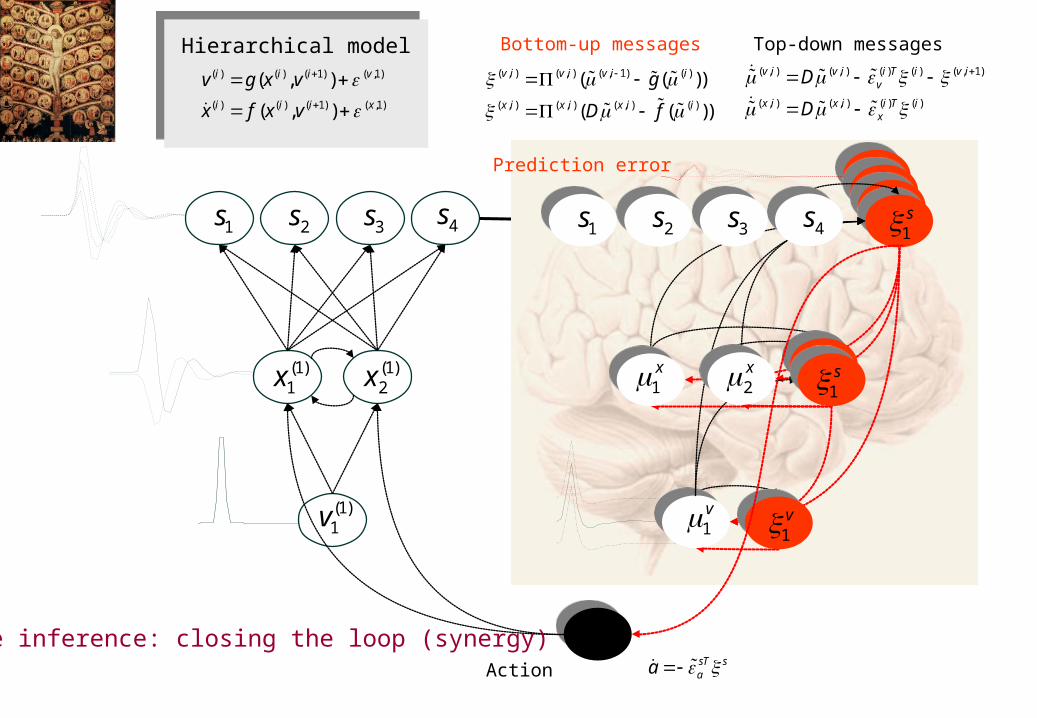
)1(1x
)1(2x
2s 3s 4s1s
( ) ( ) ( 1) ( ,1)
( ) ( ) ( 1) ( ,1)
( , )
( , )
i i i v
i i i x
v g x v
x f x v
Hierarchical model Top-down messagesBottom-up messages( , ) ( , ) ( ) ( ) ( , 1)
( , ) ( , ) ( ) ( )
v i v i i T i v iv
x i x i i T ix
D
D
( , ) ( , ) ( , 1) ( )
( , ) ( , ) ( , ) ( )
( ( ))
( ( ))
v i v i v i i
x i x i x i i
g
D f
)1(1v
Prediction error
1s1s 2s 3s 4s
1s1
x 2x
1v1
v
asT saa Action
Active inference: closing the loop (synergy)

sT sa aa F ( )uV t D
a
action
s
perception
Action needs access to sensory-level prediction error
( ( ) ( ))s s s a g
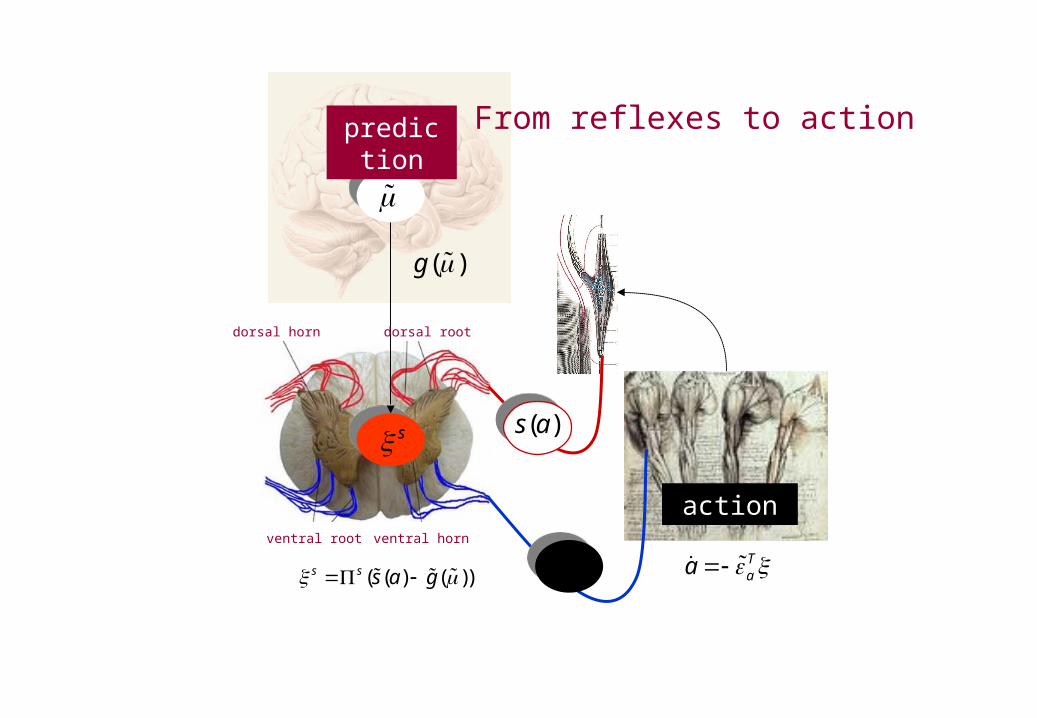
Taa
s
prediction From reflexes to action
( ( ) ( ))s s s a g a
( )g
action
( )s a
dorsal horn dorsal root
ventral root ventral horn

Overview
The free energy principle and actionActive inference and prediction errorOrientation and stabilizationIntentional movementsCued movementsGoal-directed movements Autonomous movementsForward and inverse models

sensory prediction and error hidden states (location)
cause (perturbing force) perturbation and action
Active inference under flat priors(movement with percept)
10 20 30 40 50 60-0.4
-0.2
0
0.2
0.4
0.6
0.8
1
time10 20 30 40 50 60
-2
-1
0
1
2
time
10 20 30 40 50 60-0.2
0
0.2
0.4
0.6
0.8
1
1.2
time10 20 30 40 50 60
-0.2
0
0.2
0.4
0.6
0.8
1
1.2
time
Visual stimulus
Sensory channels
a
v
s
1x1
x 2x
vv
s
x
v
( )g
av

sensory prediction and error hidden states (location)
cause (perturbing force) perturbation and action
Active inference under tight priors(no movement or percept)a
v
s
1x1
x 2x
vv
s
10 20 30 40 50 60
0
0.5
1
time10 20 30 40 50 60
-2
-1
0
1
2
time
10 20 30 40 50 60-0.2
0
0.2
0.4
0.6
0.8
1
1.2
time10 20 30 40 50 60
-1
-0.5
0
0.5
1
time
x
v
( )g
a
v

under flat priors under tight priors
actionperceived andtrue perturbation
Retinal stabilisation or tracking induced
by priors
Visual stimulus
a-2 -1 0 1 2
-2
-1
0
1
2
displacement
-2 -1 0 1 2-2
-1
0
1
2
displacement
10 20 30 40 50 60-1
-0.5
0
0.5
1
time
10 20 30 40 50 60-1
-0.5
0
0.5
1
time
real
perceived
x
x
a
v
v

Overview
The free energy principle and actionActive inference and prediction errorOrientation and stabilizationIntentional movementsCued movementsGoal-directed movements Autonomous movementsForward and inverse models
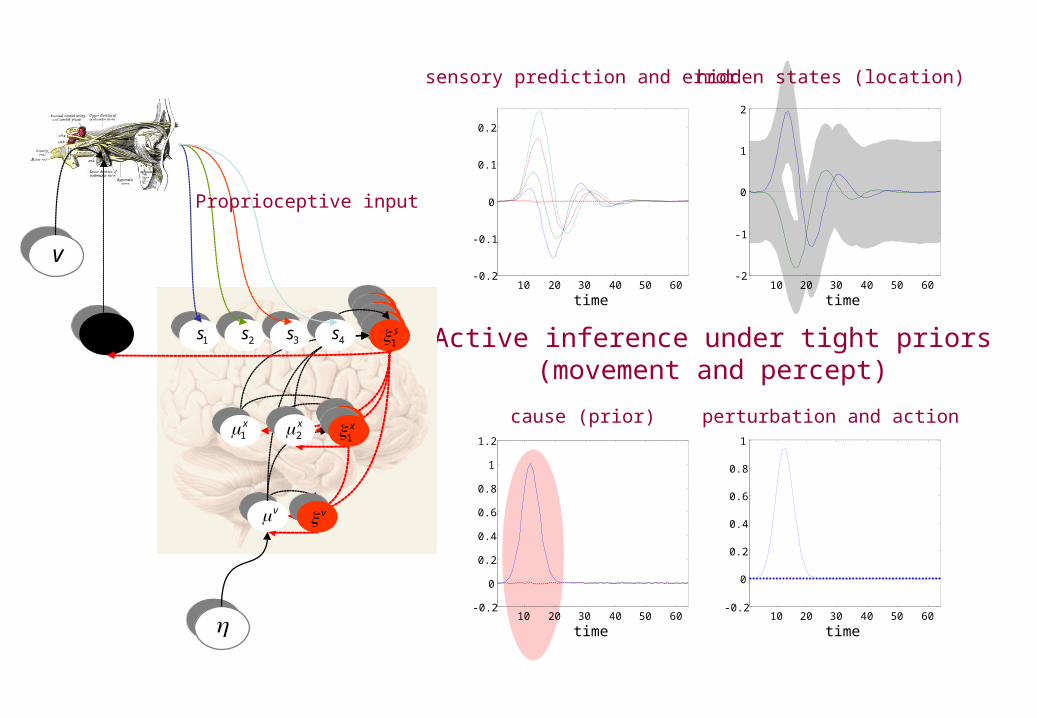
sensory prediction and error
cause (prior) perturbation and action
Active inference under tight priors(movement and percept)
a
v
1s1s 2s 3s 4s
1x1
x 2x
vv
Proprioceptive input
10 20 30 40 50 60-0.2
0
0.2
0.4
0.6
0.8
1
1.2
time10 20 30 40 50 60
-0.2
0
0.2
0.4
0.6
0.8
1
time
10 20 30 40 50 60-2
-1
0
1
2
time10 20 30 40 50 60
-0.2
-0.1
0
0.1
0.2
time
hidden states (location)

robust to perturbation
and change in motor gain
displacement time
trajectories
real
perceived
action and causes
action
perceived cause (prior)
exogenous cause
Self-generated movements
induced by priors
-2 -1 0 1 2-2
-1
0
1
2
10 20 30 40 50 60-0.5
0
0.5
1
-2 -1 0 1 2-2
-1
0
1
2
10 20 30 40 50 60-0.5
0
0.5
1
-2 -1 0 1 2-2
-1
0
1
2
10 20 30 40 50 60-0.5
0
0.5
1

Overview
The free energy principle and actionActive inference and prediction errorOrientation and stabilizationIntentional movementsCued movementsGoal-directed movements Autonomous movementsForward and inverse models

from reflexes to action
a
vis vis
vs w
J
pro pros x w
svis
,x v
x
v
spro
v v Tv
x x Tx
D
D
( ( ))
( ( ))
( )
s s
x x x
v v v
s g
D f
( )J x
1J
1x
2x2J
(0,0)
1x
1 2( , )v vJointed arm
Cued movementsand sensorimotor
integration

10 20 30 40 50 60-0.5
0
0.5
1
1.5
2
2.5prediction and error
time10 20 30 40 50 60
-0.5
0
0.5
1
1.5
2hidden states
time
10 20 30 40 50 60-0.2
0
0.2
0.4
0.6
0.8
1
1.2causal states
time10 20 30 40 50 60
-0.5
0
0.5
1
1.5
time
perturbation and action
1x
2x
1x
2x
3v
1,2v
3v
1,2v1a
2a
-0.5 0 0.5 1 1.5
0
0.5
1
1.5
2
position
posit
ion
1 2( , )v v
( , )J x t
Trajectory
Cued reaching with noisy proprioception
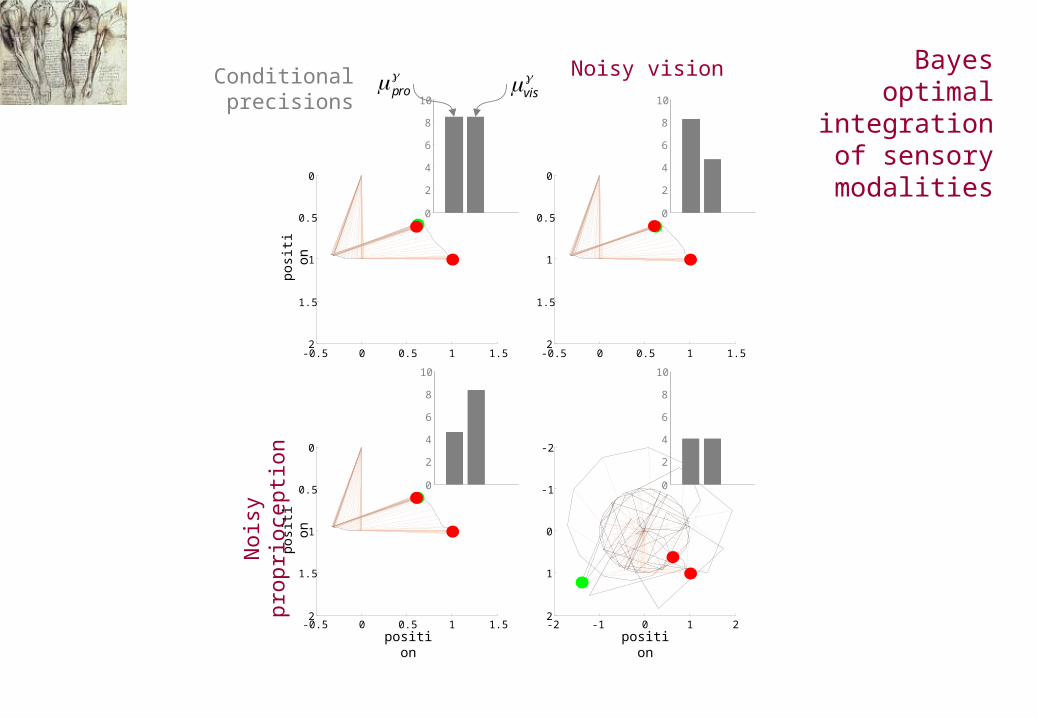
-0.5 0 0.5 1 1.5
0
0.5
1
1.5
2-0.5 0 0.5 1 1.5
0
0.5
1
1.5
2
-0.5 0 0.5 1 1.5
0
0.5
1
1.5
2-2 -1 0 1 2
-2
-1
0
1
2
0
2
4
6
8
10
0
2
4
6
8
10
0
2
4
6
8
10
0
2
4
6
8
10
Noisy
pro
prio
cept
ion
Noisy vision
position position
posit
ion
posit
ion
Conditional precisionspro
vis
Bayes optimal integration of
sensory modalities

Overview
The free energy principle and actionActive inference and prediction errorOrientation and stabilizationIntentional movementsCued movementsGoal-directed movements Autonomous movementsForward and inverse models

11 2 34
2 1/2 2 2 3/2
( , )( ( ) )
2 1 : 0
(1 5 ) 5 (1 5 ) : 0
xxf x
G x x x x vx
x xG
x x x x
position
velo
city
null-clines
-2 -1 0 1 2-2
The mountain car problem
0 x
x
equations of motion
-2 -1 0 1 20
0.1
0.2
0.3
0.4
0.5
0.6
0.7
position
Height
-2 -1 0 1 2-1.5
-1
-0.5
0
0.5
1
1.5
2
2.5
3
position
Forces
Desired location
1

flow and density nullclines
velo
city
-2 -1 0 1 2-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
-2 -1 0 1 2-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
velo
city
-2 -1 0 1 2-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
-2 -1 0 1 2-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
position
velo
city
-2 -1 0 1 2-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
position-2 -1 0 1 2
-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
0
Q
Uncontrolled
Controlled
Expected
x
x
argmin
( | )( | ) ln
( | )
| ( ( ))
Q
x
D
p x mD p x m dx
Q x m
p x m eig f
argmin
0
F
a

100 200 300 400 500-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
2.5prediction and error
time100 200 300 400 500
-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
2.5hidden states
time
100 200 300 400 500-5
0
5causes - level 2
time100 200 300 400 500
-1
-0.5
0
0.5
1
time
perturbation and action
20 40 60 80 100 120-1.5
-1
-0.5
0
0.5
1
1.5prediction and error
time20 40 60 80 100 120
-1.5
-1
-0.5
0
0.5
1
1.5hidden states
time
20 40 60 80 100 120-8
-6
-4
-2
0
2
4
6x 10
-4 causes - level 2
time20 40 60 80 100 120
-15
-10
-5
0
5
10
15
time
perturbation and action
Learning in controlled environment
Active inference in uncontrolled environment

Using just the free-energy principle and a simple gradient ascent scheme, we have solved a benchmark problem in optimal control theory with just a handful of learning trials. At no point did we use reinforcement learning or dynamic programming.
Goal-directed behaviour and trajectories

prediction and error
time
hidden states
time
velo
city
behaviour action
position
velo
city
time
perturbation and actionbehaviour
20 40 60 80 100 120-1.5
-1
-0.5
0
0.5
1
1.5
20 40 60 80 100 120-1.5
-1
-0.5
0
0.5
1
1.5
-2 -1 0 1 2-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
20 40 60 80 100 120-3
-2
-1
0
1
2
3
-2 -1 0 1 2-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
20 40 60 80 100 120-3
-2
-1
0
1
2
3
Action under perturbation

8s
20 40 60 80 100 120-1.5
-1
-0.5
0
0.5
1
1.5
hidden states
time20 40 60 80 100 120
-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
hidden states
time20 40 60 80 100 120
-1
-0.5
0
0.5
hidden states
time
5.5x 4x
6x
Simulating Parkinson's disease?

Overview
The free energy principle and actionActive inference and prediction errorOrientation and stabilizationIntentional movementsCued movementsGoal-directed movements Autonomous movementsForward and inverse models

-20 -10 0 10 20
-30
-20
-10
0
10
20
30
-20 -10 0 10 20
-30
-20
-10
0
10
20
30
velo
city
-20 -10 0 10 20
-30
-20
-10
0
10
20
30
-20 -10 0 10 20
-30
-20
-10
0
10
20
30
velo
city
position-20 -10 0 10 20
-30
-20
-10
0
10
20
30
-20 -10 0 10 20
-30
-20
-10
0
10
20
30
position
velo
city
controlled
velo
city
velo
city
velo
city
before
after
trajectoriesdensities
Q
0
Learning autonomous behaviour

50 100 150 200 250-30
-20
-10
0
10
20
30
40
50prediction and error
time50 100 150 200 250
-30
-20
-10
0
10
20
30
40
50hidden states
time
position
velo
city
learnt
-20 -10 0 10 20
-30
-20
-10
0
10
20
30
50 100 150 200 250-10
-5
0
5
10
time
perturbation and action
Autonomous behaviour under
random perturbations

Overview
The free energy principle and actionActive inference and prediction errorOrientation and stabilizationIntentional movementsCued movementsGoal-directed movements Autonomous movementsForward and inverse models

( , , )s x v a
s
,x v
a
,x vDesired and inferred
states
Sensory prediction error
Motor command (action)
Forward model (generative model)
Forward model (generative model){ , }x v s
Inverse modelInverse models a
Desired and inferred states
Sensory prediction error
Forward modelForward model{ , , }x v a s
Motor command (action)
EnvironmentEnvironment{ , , }x v a s
s
,x v
a
,x v
EnvironmentEnvironment{ , , }x v a s
( , , )s x v a
Free-energy formulation Forward-inverse formulation
Inverse model (control policy)
Inverse model (control policy){ , }x v a
Corollary dischargeEfference copy

Summary
• The free-energy can be minimised by action (through changes in states generating sensory input) or perception (through optimising the predictions of that input)
• The only way that action can suppress free-energy is through reducing prediction error at the sensory level (speaking to a juxtaposition of motor and sensory systems)
• Action fulfils expectations, which can manifest as an explaining away of prediction error through resampling sensory input (e.g., visual tracking);
• Or intentional movement, fulfilling expectations furnished by empirical priors.
• In an optimum control setting a training environment can be constructed by minimising the cross-entropy between the ensemble density and some desired density. This can be learnt and reproduced under active inference.