accelerating cuda graph algorithms at maximum warp
TRANSCRIPT

Accelerating CUDA Graph Algorithms at
Maximum Warp
By: Sungpack Hong, Sang Kyun Kim, Tayo Oguntebi, Kunle Olukotun
Presenter: Thang M. Le

Authors
Sungpack Hong
Ph.D graduate from Stanford
Currently, a principal member of technical staff at Oracle
Sang Kyun Kim
Ph.D candidate at Stanford
Tayo Oguntebi
Ph.D candidate at Stanford
Kunle Olukotun
Professor of Electrical Engineering & Computer
Science at Stanford
Director of Pervasive Parallel Laboratory

Agenda
What Is the Problem?
Why Does the Problem Exist?
Warp-Centric Programming Method
Other Techniques
Experimental Results
Study of Architectural Effects
Q&A

What Is the Problem?
The Parallel Random Access Machine (PRAM)
abstract is often used to investigate theoretical
parallel performance of graph algorithm
PRAM approximation is quite accurate in
supercomputer domains such as Cray XMT
PRAM based algorithms fail to perform well on GPU
architectures due to the workload imbalance among
threads

Why Does the Problem Exist?
CUDA thread model exhibits certain discrepancies
with the GPU architecture
Notably, no explicit notion of warps
Different behaviors when accessing memory
Requests targeting the same address are merged
Spatial locality accesses are maximally coalesced
All other memory requests are serialized

Why Does the Problem Exist?
SIMT eliminates SIMD constraints by allowing
threads in a warp to pursue on different paths (aka
path divergence)
Path divergence provides more flexibilities at the
cost of performance
Path divergence leads to hardware underutilization
Scattering memory access patterns

Why Does the Problem Exist?
Path divergence
A thread that processes
a high-degree node will
iterate the loop at line
23 many more times
than other threads,
stalling other threads in
the warp

Why Does the Problem Exist?
Non-coalesced memory

Warp-Centric Programming Method
A program can be run in either SISD phase or SIMT
phase:
SISD:
all threads in a warp are executed on the same data
degree of parallelism (per SM) = O(# concurrent warps)
SIMT:
Each thread is executed on different data
degree of parallelism (per SM) = O(# threads in a warp x #
concurrent warps)
By default, all threads in a warp are executed
following SISD
When appropriate, switch to SIMT to exploit data
parallelism

Warp-Centric Programming Method
Is it safe to run a logic in SISD on GPU architecture?
Since methodA will be executed many times by
different threads on the same input, the logic of
methodA must be deterministic to guarantee the
correctness in SISD phase
input output methodA

Warp-Centric Programming Method
Advantages:
No path divergence
Increase memory coalescing
Allows to take advantage of shared memory

Warp-Centric Programming Method

Warp-Centric Programming Method
Traditional approach: thread-to-data
2
3
4
5
n
n-1
n-2
.
.
.
.
Threads Level[ ]
1
0
2
3
4
5
n
n-1
n-2
.
.
.
.
1
0 mapping
Warp-Centric Programming Method
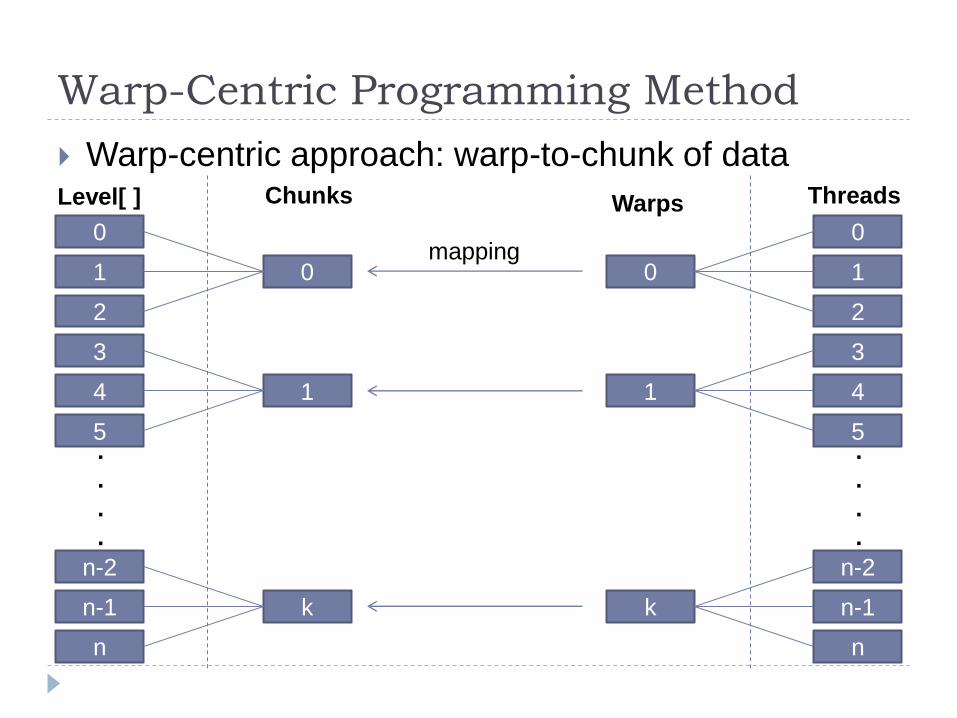
Warp-centric approach: warp-to-chunk of data
2
3
4
5
n
n-1
n-2
.
.
.
.
Threads
0
Level[ ]
1
0
Chunks
1
k
2
3
4
5
n
n-1
n-2
.
.
.
.
1
0
0
1
k
Warps
mapping

Warp-Centric Programming Method
Warp-centric approach: warp-to-chunk of data
Coarse-grained mapping
Each chunk must be mapped to a warp
Number of chunks ≤ Number of warps
Chunk size & warp size are independent
Chunk size is limited by the size of shared memory

Warp-Centric Programming Method
Disadvantages:
If native SIMT width of the user application is small, the
underlying hardware will be under-utilized (# threads
assigned to data < #physical cores)

Warp-Centric Programming Method
Disadvantages:
The ratio of the SIMT phase duration to the SISD phase
duration imposes an Amdahl’s limit on performance
Amdahl’s Law:
Improvement:

Warp-Centric Programming Method
Addressing these issues:
Partition a warp into multiple virtual warps with smaller
size
Increase parallelism within the SISD phase
Improve ALU utilization by O(K) times
Drawback: might re-introduce path divergence among
these multiple virtual warps. This is the trade-off between
path divergence and ALU utilization.
Virtual warp size =

Other Techniques
Deferring Outliners:
Define some threshold
Defer processing any node having degree greater than
the threshold
Process outliners in a separate kernel method
Dynamic Workload Distribution:
Virtual warp-centric does not prevent work imbalance
among warps in a block
Each warp fetches a chunk of work from shared work
queue
Trade-off between static/dynamic chunk of work:
static work distribution suffers from work imbalance
dynamic work distribution imposes overhead

Experimental Results
Input Graphs:
RMAT: scale-free graph which follows a power law degree
distribution like many real world graph. The average
vertex degree is 12.
RANDOM: uniformly distributed graph instance created
by randomly connecting m pairs of nodes out of total n
nodes. The average vertex degree is 12.
LiveJournal: real world graph, is a very irregular
structure
Patent: is relatively regular graph, has a smaller average
degree
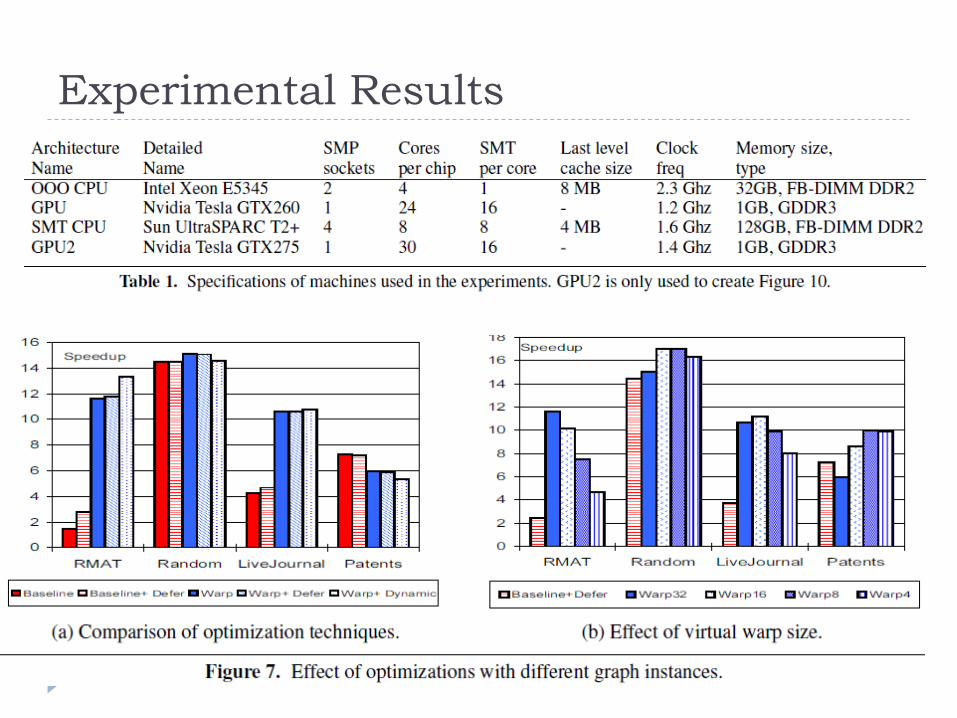
Experimental Results

Experimental Results
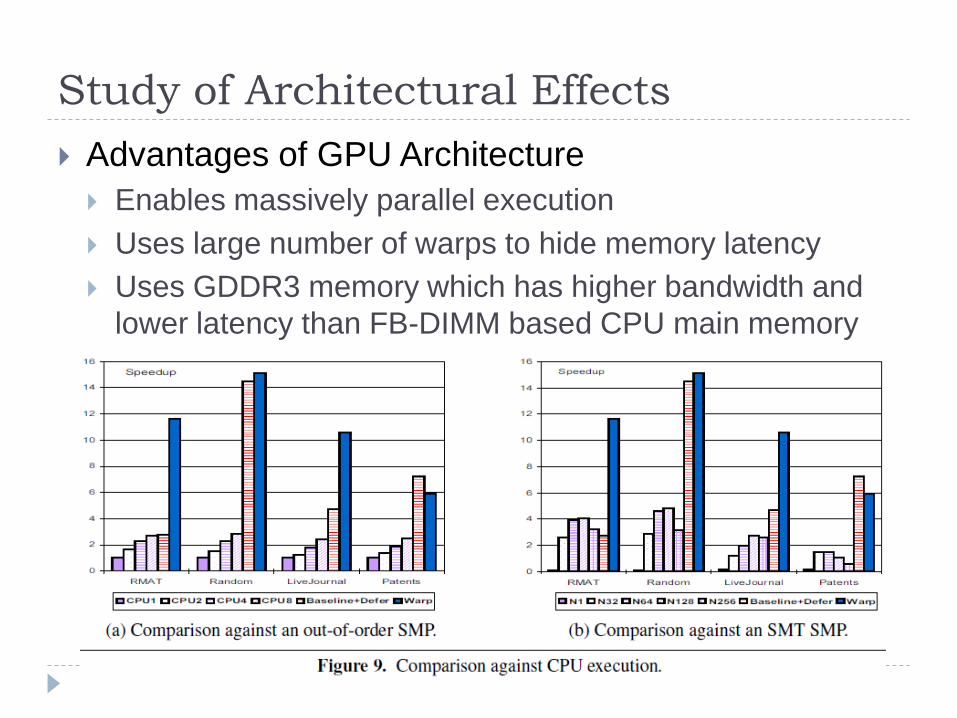
Study of Architectural Effects
Advantages of GPU Architecture
Enables massively parallel execution
Uses large number of warps to hide memory latency
Uses GDDR3 memory which has higher bandwidth and
lower latency than FB-DIMM based CPU main memory

Study of Architectural Effects
Effect of bandwidth utilization and latency hiding in
GPUs
Conclusion:
Graph algorithms are bound by memory bandwidth

Last But Not Least
A supercomputer is a device for turning compute-bound
problems into I/O-bound problems
Ken Batcher