accessing “other data” - fdw, dblink, pglogical, plproxy, · somehow this all fall out of the...
TRANSCRIPT

https://2ndQuadrant.com© 2ndQuadrant 2001-20171
Accessing “other data” - fdw, dblink, pglogical, plproxy, ...
Hannu Krosing, Quito 2017.12.01
https://2ndQuadrant.com© 2ndQuadrant 2001-20172
Arctic Circle

https://2ndQuadrant.com© 2ndQuadrant 2001-20173
Who am I
● Coming from Estonia
● PostgreSQL user since about 1990 (when it was just Postgres 4.2)
● Hacking on various parts since about 1996
● Was the first DBA at Skype
– Scaled database through first few millions of users
– Invented pl/proxy language for infinite database scalability
● after I left Skype when it was sold to eBay in 2005, Simon Riggs invented me to PostgreSQL
● Senior Consultant at 2ndQuadrant ever since
● Author of 2 books (for now :) ) on PostgreSQL

https://2ndQuadrant.com© 2ndQuadrant 2001-20174
PostgreSQL Administration Cookbook
PostgreSQL Server Programming

https://2ndQuadrant.com© 2ndQuadrant 2001-20175
Accessing data FROM database
● WHY ?
– Why would one want to access data from inside the database ?
– Should it not be the other way around ?
– Should the data not be in the database and used from outside?

https://2ndQuadrant.com© 2ndQuadrant 2001-20176
Accessing data FROM database
● WHY ?
– Why would one want to access data from inside the database ?
– Should it not be the other way around ?
– Should the data not be in the database and used from outside?
● Let’s start with another question :
– What is a database ?

https://2ndQuadrant.com© 2ndQuadrant 2001-20177
DB is not a Simple Bucket for Data
Simple Bucket view of Database
● you put data in →
● you get the data out ←
this would be a NoSQL key/value store, not aRelational Database Management System (RDBMS)

https://2ndQuadrant.com© 2ndQuadrant 2001-20178
RDBMS is much more
It is a complex machine for all the basic data management tasks
Atomicity for a set of actions either they all happen or none of them do
Consistency if data is in database, it is guaranteed to comply with a certain set of rules
Isolation related to A - you will not see a set of changes until they all are complete
Durability if database says the data is stored, it is guaranteed to be there
Some of these needs you usually do even know you have when you start a project

https://2ndQuadrant.com© 2ndQuadrant 2001-20179
And PostgreSQL is much more than “just a RDBMS”
Of course it is a fast and solid RDBMS which can cover all you RDBMS needs as well or better as any other RDBMS, either Open Source or Commercial
● with ACID data management
But it is also a general data server with:
● Build in procedural languages (SQL, C and “PL”)
● Extensible everything
– Data types
– Indexes
– Operators
– ... and more
● A few ways to access external data

https://2ndQuadrant.com© 2ndQuadrant 2001-201710
PostgreSQL is extensible
Still the database clients still just see “an SQL database”
where
● SQL goes in →
● And Data tables come out ←
but on the server side,
anything can happen

https://2ndQuadrant.com© 2ndQuadrant 2001-201711
PostgreSQL is extensible
● But if you ALSO use all the other possibilities that PostgreSQL offers
● And are ready to think out of the box
● You will come up with really powerful

https://2ndQuadrant.com© 2ndQuadrant 2001-201712
The data source for any query in PostgreSQL can be one of
● TABLE (obviously)
● VIEW
● MATERIALIZED VIEW
● FUNCTION
● FOREIGN TABLE

https://2ndQuadrant.com© 2ndQuadrant 2001-201713
The last two can directly access data not stored in database
● FUNCTION
– C and untrusted functions can do anything any program running as user `postgres` can
● FOREIGN TABLE
– Depends on FDW (Foreign Data Wrapper)

https://2ndQuadrant.com© 2ndQuadrant 2001-201714
● TABLE can be locally generated, or automatically replicated from another database
● VIEW can be defined on top of a set-returning function, to make it look like “ordinary table”
● MATERIALIZED VIEW can also be on top of some FOREIGN TABLE to speed up access to data which changes seldom.

https://2ndQuadrant.com© 2ndQuadrant 2001-201715
Functions for accessing PostgreSQL DB
For accessing data in other PostgreSQL databases there are two possibilities
● Dblink – comes in PostgreSQL contrib package
● Pl/proxy – a separate package originally developed at Skype for sharding but can also used for simple 1:1 calls to other PostgreSQL databases.

https://2ndQuadrant.com© 2ndQuadrant 2001-201716
DBLINK sample usage
dblink is a module that supports connections to other PostgreSQL databases from within a database session.

https://2ndQuadrant.com© 2ndQuadrant 2001-201717
Pl/proxy - (how we scaled Skype databases)
● Started with single PostgreSQL server in 2003
● After public launch very fast growth 100 000 users in a few days
● 20% per week growth first year
● Soon in millions of users
● Started the usual way – split database by functionality
– UserDB, CallDB, AccountingDB
and had logical replication moving data between them

https://2ndQuadrant.com© 2ndQuadrant 2001-201718
How we scaled Skype
● Started the usual way – split database by functionality
– UserDB
– CallDB
– AccountingDB
● Moved data using logical replication (Slony, later our own Londiste)
● Started doing some remote DB queries using pl/python

https://2ndQuadrant.com© 2ndQuadrant 2001-201719
How we scaled Skype
But still was not enough ...
● After introduction of “Friend Lists” we saw that we could not continue like that,because:
– it did not fit in our server
– with our growth it would not fit the largest server on market soon
– Replication does not help, as it is mostly (95%) writes

https://2ndQuadrant.com© 2ndQuadrant 2001-201720
How we scaled Skype
● So decided to do sharding
● Fortunately we had from the start been accessing database only through functions
SELECT * FROM create_user(<username>, <pwd>);
● So we could put the sharding code inside the functions

https://2ndQuadrant.com© 2ndQuadrant 2001-201721
How we scaled Skype
● At first we used pl/python functions, which selected a partition database based on username and then connected to other databases and called a function there
● Soon a pattern emerged.
● And so we created a special language for partitioning pl/proxy

https://2ndQuadrant.com© 2ndQuadrant 2001-201722
How we scaled Skype using pl/proxy

https://2ndQuadrant.com© 2ndQuadrant 2001-201723
How we scaled Skype

https://2ndQuadrant.com© 2ndQuadrant 2001-201724
How we scaled Skype
Ok, now we have infinite scalability ...
● … but what about the Enterprise stuff – Services, Components, SOA,ESB ?
Somehow this all fall out of the design at no additional effort
● SOA (Service Oriented Architecture)
– yes, everything is a well defined service, in form of a PostgreSQL function which defines precisely the input and output data
● ESB (Enterprise Service Bus)
– Yes, you can connect to any of the set of configured pl/proxy hosts and call your funtion, and it is automatically routed to the right service (called in right database)
So everything is really easy to develop and manage

https://2ndQuadrant.com© 2ndQuadrant 2001-201725
And we could make everything redundant
If you look closely, this architecture implements SOA and ESB

https://2ndQuadrant.com© 2ndQuadrant 2001-201726
At Skype we ended up using this architecture for
● More than 1000 databases, including live replicas
● largest sharded databases at least 64 partitions
● 24/7 operation
● no downtime caused by databases
and released nice open source projects pl/proxy and pgbouncer so everybody else can do it as well

https://2ndQuadrant.com© 2ndQuadrant 2001-201727
Conclusion
● Yes, use PostgreSQL as a good SQL database
● But also remember, that you can do so much more in the database
● And if you are creative enough, then there is no task too complex for a database or no data too big to handle.

https://2ndQuadrant.com© 2ndQuadrant 2001-201728
FDW – Foreign Data Wrappers
Foreign Data Wrappers is how PostgreSQL can make any data source look like a PostgreSQL table
Source type Wrappers available
SQL DB PostgreSQL, Oracle, MySQL, Informix, MonetDB, ..
Generic ODBC, JDBC, VirtDB
NoSQL BigTable, Cassandra, MongoDB, Redis, CouchDB, ...
File CSV, TAR, XML, ZIP, JSON, ...
GEO GDAL/OGR, Geocode / GeoJSON, Open Street Map PBF
Generic Multicorn

https://2ndQuadrant.com© 2ndQuadrant 2001-201729
FDW – Multicorn
The most interesting one is Multicorn
● You can do anything with multricorn just by writing a python class

https://2ndQuadrant.com© 2ndQuadrant 2001-201730
FDW – Multicorn
● And then introducing this to PostgreSQL
● Where myfdw is where this python code is located
https://2ndQuadrant.com© 2ndQuadrant 2001-201731
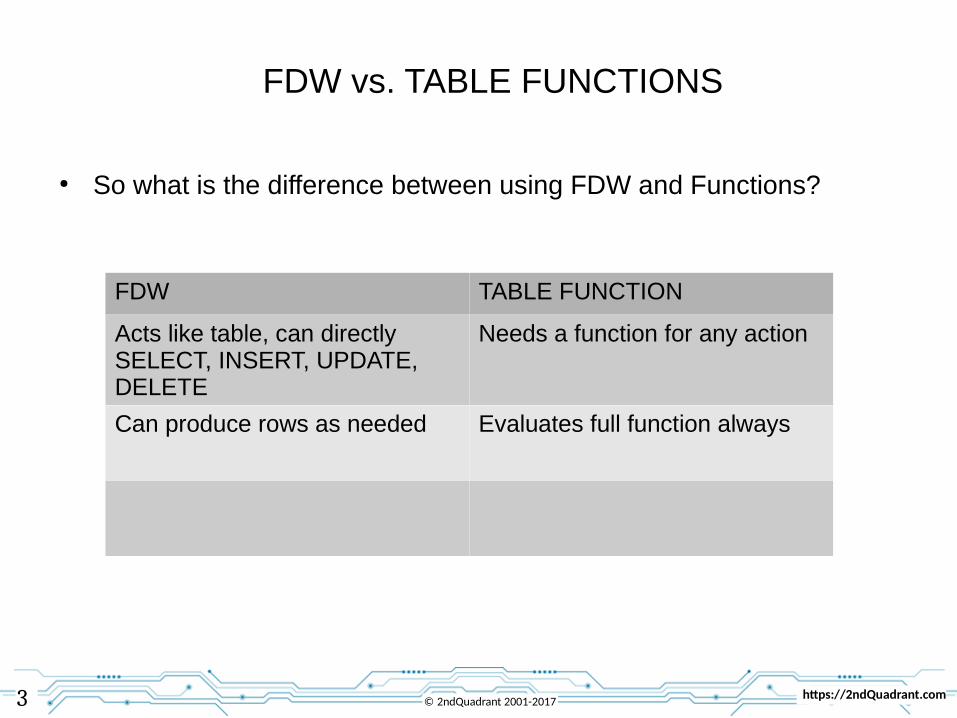
FDW vs. TABLE FUNCTIONS
● So what is the difference between using FDW and Functions?
FDW TABLE FUNCTION
Acts like table, can directly SELECT, INSERT, UPDATE, DELETE
Needs a function for any action
Can produce rows as needed Evaluates full function always
https://2ndQuadrant.com© 2ndQuadrant 2001-201732
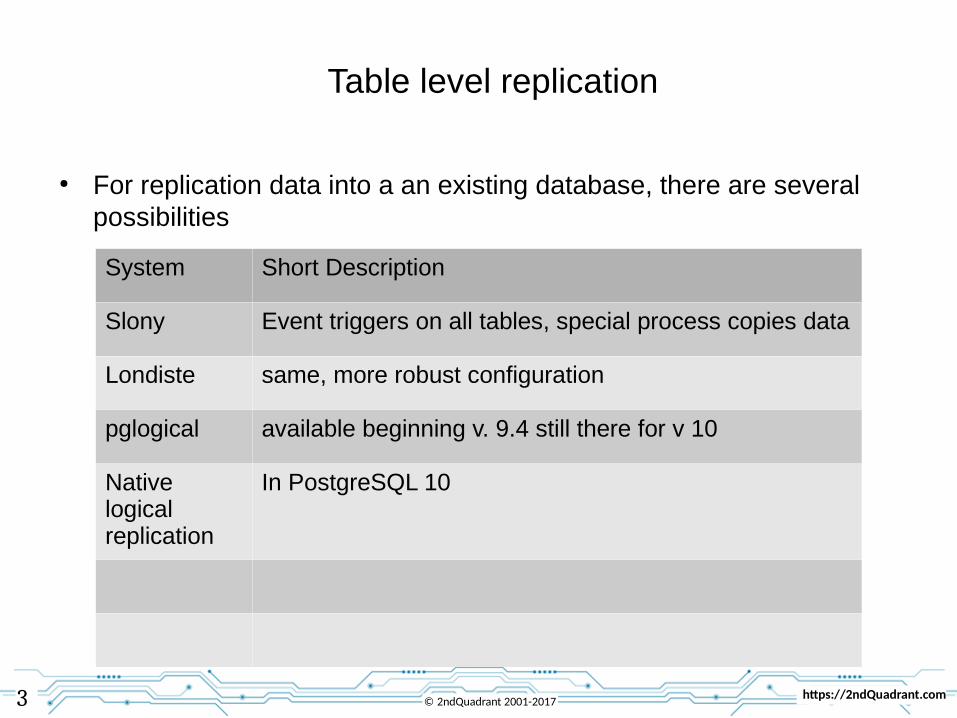
Table level replication
● For replication data into a an existing database, there are several possibilities
System Short Description
Slony Event triggers on all tables, special process copies data
Londiste same, more robust configuration
pglogical available beginning v. 9.4 still there for v 10
Native logical replication
In PostgreSQL 10

https://2ndQuadrant.com© 2ndQuadrant 2001-201733
Muchas Gracias!