acl tutorial on textual entailment
DESCRIPTION
TRANSCRIPT

1
Textual Entailment
Dan Roth, University of Illinois, Urbana-ChampaignUSA
ACL -2007
Ido DaganBar Ilan UniversityIsrael
Fabio Massimo ZanzottoUniversity of RomeItaly

Page 2
1. Motivation and Task Definition2. A Skeletal review of Textual Entailment
Systems3. Knowledge Acquisition Methods4. Applications of Textual Entailment5. A Textual Entailment view of Applied
Semantics
Outline

Page 3
I. Motivation and Task Definition

Page 4
Motivation
Text applications require semantic inference
A common framework for applied semantics is needed, but still missing
Textual entailment may provide such framework

Page 5
Desiderata for Modeling Framework
A framework for a target level of language processing should provide:
1) Generic (feasible) module for applications
2) Unified (agreeable) paradigm for investigating language phenomena
Most semantics research is scattered
WSD, NER, SRL, lexical semantics relations… (e.g. vs. syntax)
Dominating approach - interpretation
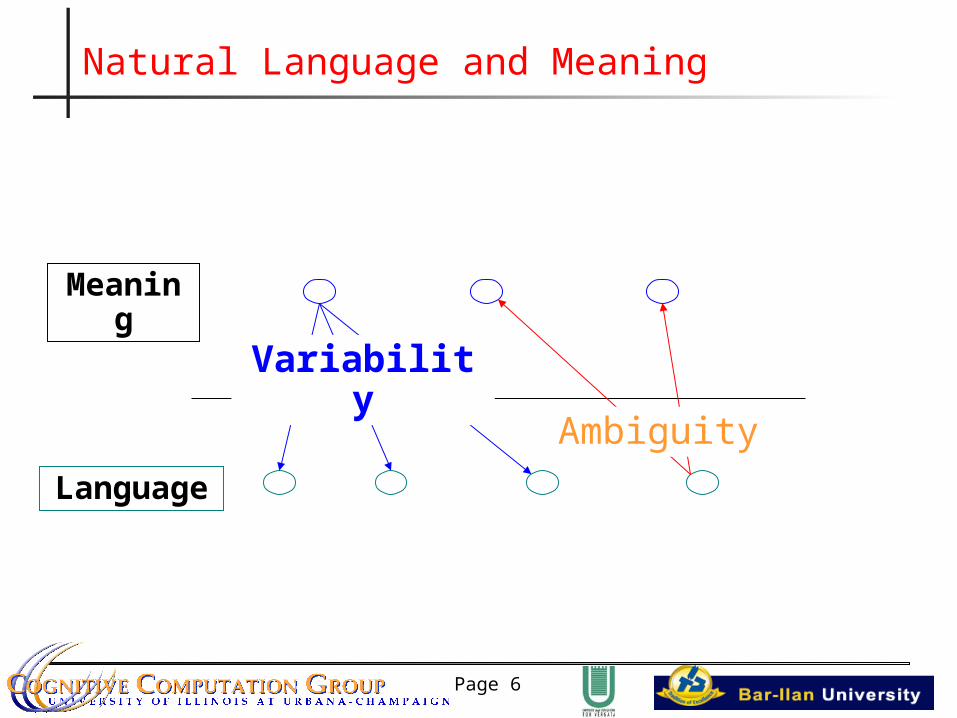
Page 6
Natural Language and Meaning
Meaning
LanguageAmbiguity
Variability

Page 7
Variability of Semantic Expression
Model variability as relations between text expressions:
Equivalence: text1 text2 (paraphrasing) Entailment: text1 text2 the general case
Dow ends up
Dow climbs 255
The Dow Jones Industrial Average closed up 255
Stock market hits a record high
Dow gains 255 points

Page 8
Typical Application Inference: Entailment
Overture’s acquisition by Yahoo
Yahoo bought Overture
Question Expected answer formWho bought Overture? >> X bought Overture
text hypothesized answer
entails
Similar for IE: X acquire Y Similar for “semantic” IR: t: Overture was
bought for … Summarization (multi-document) – identify
redundant info MT evaluation (and recent ideas for MT) Educational applications

Page 9
KRAQ'05 Workshop - KNOWLEDGE and REASONING for ANSWERING QUESTIONS (IJCAI-05)
CFP: Reasoning aspects:
* information fusion, * search criteria expansion models * summarization and intensional answers, * reasoning under uncertainty or with incomplete
knowledge, Knowledge representation and integration:
* levels of knowledge involved (e.g. ontologies, domain knowledge),
* knowledge extraction models and techniques to optimize response accuracy
… but similar needs for other applications – can entailment provide a common empirical framework?

Page 10
Classical Entailment Definition
Chierchia & McConnell-Ginet (2001):A text t entails a hypothesis h if h is true in every circumstance (possible world) in which t is true
Strict entailment - doesn't account for some uncertainty allowed in applications

Page 11
“Almost certain” Entailments
t: The technological triumph known as GPS … was incubated in the mind of Ivan Getting.
h: Ivan Getting invented the GPS.

Page 12
Applied Textual Entailment
A directional relation between two text fragments: Text (t) and Hypothesis (h):
t entails h (th) if humans reading t will infer that h is most likely true
Operational (applied) definition: Human gold standard - as in NLP applications Assuming common background knowledge –
which is indeed expected from applications

Page 13
Probabilistic Interpretation
Definition: t probabilistically entails h if:
P(h is true | t) > P(h is true) t increases the likelihood of h being true ≡ Positive PMI – t provides information on h’s truth
P(h is true | t ): entailment confidence The relevant entailment score for applications In practice: “most likely” entailment expected

Page 14
The Role of Knowledge
For textual entailment to hold we require: text AND knowledge hbut knowledge should not entail h alone
Systems are not supposed to validate h’s truth regardless of t (e.g. by searching h on the web)

Page 15
PASCAL Recognizing Textual Entailment (RTE) Challenges
EU FP-6 Funded PASCAL Network of Excellence 2004-7
Bar-Ilan University ITC-irst and CELCT, TrentoMITRE Microsoft Research

Page 16
Generic Dataset by Application Use
7 application settings in RTE-1, 4 in RTE-2/3 QA IE “Semantic” IR Comparable documents / multi-doc summarization MT evaluation Reading comprehension Paraphrase acquisition
Most data created from actual applications output
RTE-2/3: 800 examples in development and test sets
50-50% YES/NO split

Page 17
RTE Examples
TEXT HYPOTHESIS TASK ENTAIL-MENT
1Regan attended a ceremony in Washington to commemorate the landings in Normandy.
Washington is located inNormandy.
IE False
2 Google files for its long awaited IPO. Google goes public. IR True
3
…: a shootout at the Guadalajara airport in May, 1993, that killed Cardinal Juan Jesus Posadas Ocampo and six others.
Cardinal Juan Jesus Posadas Ocampo died in 1993.
QA True
4
The SPD got just 21.5% of the votein the European Parliament elections,while the conservative opposition partiespolled 44.5%.
The SPD is defeated bythe opposition parties.
IE True

Page 18
Participation and Impact Very successful challenges, world
wide: RTE-1 – 17 groups RTE-2 – 23 groups
~150 downloads RTE-3 – 25 groups
Joint workshop at ACL-07 High interest in the research
community Papers, conference sessions and areas,
PhD’s, influence on funded projects Textual Entailment special issue at JNLE ACL-07 tutorial

Page 19
Methods and Approaches (RTE-2) Measure similarity match between t and h
(coverage of h by t): Lexical overlap (unigram, N-gram, subsequence) Lexical substitution (WordNet, statistical) Syntactic matching/transformations Lexical-syntactic variations (“paraphrases”) Semantic role labeling and matching Global similarity parameters (e.g. negation, modality)
Cross-pair similarity Detect mismatch (for non-entailment) Interpretation to logic representation + logic
inference

Page 20
Dominant approach: Supervised Learning
Features model similarity and mismatch Classifier determines relative weights of information
sources Train on development set and auxiliary t-h corpora
t,hSimilarity Features:
Lexical, n-gram,syntacticsemantic, global
Feature vector
Classifier
YES
NO

Page 21
RTE-2 Results
First Author (Group) AccuracyAverage Precision
Hickl (LCC) 75.4% 80.8%
Tatu (LCC) 73.8% 71.3%
Zanzotto (Milan & Rome) 63.9% 64.4%
Adams (Dallas) 62.6% 62.8%
Bos (Rome & Leeds) 61.6% 66.9%
11 groups 58.1%-60.5%
7 groups 52.9%-55.6%
Average: 60%Median: 59%

Page 22
Analysis
For the first time: methods that carry some deeper analysis seemed (?) to outperform shallow lexical methods
Cf. Kevin Knight’s invited talk at EACL-06, titled:
Isn’t linguistic Structure Important, Asked the Engineer
Still, most systems, which do utilize deep analysis, did not score significantly better than the lexical baseline

Page 23
Why?
System reports point at: Lack of knowledge (syntactic transformation
rules, paraphrases, lexical relations, etc.) Lack of training data
It seems that systems that coped better with these issues performed best:
Hickl et al. - acquisition of large entailment corpora for training
Tatu et al. – large knowledge bases (linguistic and world knowledge)

Page 24
Some suggested research directions
Knowledge acquisition Unsupervised acquisition of linguistic and world
knowledge from general corpora and web Acquiring larger entailment corpora Manual resources and knowledge engineering
Inference Principled framework for inference and fusion of
information levels Are we happy with bags of features?

Page 25
Complementary Evaluation Modes
“Seek” mode: Input: h and corpus Output: all entailing t ’s in corpus Captures information seeking needs, but
requires post-run annotation (TREC-style) Entailment subtasks evaluations
Lexical, lexical-syntactic, logical, alignment… Contribution to various applications
QA – Harabagiu & Hickl, ACL-06; RE – Romano et al., EACL-06

Page 26
II. A Skeletal review of Textual Entailment Systems

Page 27
Textual Entailment
Eyeing the huge market potential, currently led by Google, Yahoo took over search company Overture Services Inc. last year
Yahoo acquired Overture
EntailsSubsumed by
Overture is a search company Google is a search company ……….Google owns OverturePhrasal verb
paraphrasingEntity matching
Semantic Role Labeling
Alignment
IntegrationHow
?

Page 28
A general Strategy for Textual Entailment
Given a sentence T
DecisionFind the set of
Transformations/Features
of the new representation
(or: use these to create a cost
function) that allows
embedding of H in T.
Given a sentence H
eRe-represent TLexical Syntactic
Semantic
Knowledge Base semantic; structural
& pragmatic Transformations/rules
Re-represent TRe-represent
T
Re-represent HLexical Syntactic
Semantic
Re-represent TRe-represent T Re-represent
TRe-represent TRe-represent
T
Representation

Page 29
Details of The Entailment Strategy
Preprocessing Multiple levels of lexical
pre-processing Syntactic Parsing Shallow semantic
parsing Annotating semantic
phenomena Representation
Bag of words, n-grams through tree/graphs based representation
Logical representations
Knowledge Sources Syntactic mapping rules Lexical resources Semantic Phenomena
specific modules RTE specific knowledge
sources Additional Corpora/Web
resources Control Strategy &
Decision Making Single pass/iterative
processing Strict vs. Parameter
based Justification
What can be said about the decision?

Page 30
The Case of Shallow Lexical Approaches
Preprocessing Identify Stop Words
Representation Bag of words
Knowledge Sources Shallow Lexical
resources – typically Wordnet
Control Strategy & Decision Making
Single pass Compute Similarity; use
threshold tuned on a development set (could be per task)
Justification It works

Page 31
Shallow Lexical Approaches (Example) Lexical/word-based semantic overlap: score
based on matching each word in H with some word in T
Word similarity measure: may use WordNet May take account of subsequences, word order ‘Learn’ threshold on maximum word-based match
score
Text: The Cassini spacecraft has taken images that show rivers on Saturn’s moon Titan.
Hyp: The Cassini spacecraft has reached Titan.
Text: NASA’s Cassini-Huygens spacecraft traveled to Saturn in 2006.
Text: The Cassini spacecraft arrived at Titan in July, 2006.
Clearly, this may not appeal to what we think as understanding, and it is
easy to generate cases for which this does not work well.
However, it works (surprisingly) well with respect to current evaluation
metrics (data sets?)

Page 32
An Algorithm: LocalLexcialMatching For each word in Hypothesis, Text
if word matches stopword – remove word if no words left in Hypothesis or Text return 0
numberMatched = 0; for each word W_H in Hypothesis for each word W_T in Text HYP_LEMMAS = Lemmatize(W_H); TEXT_LEMMAS = Lemmatize(W_T);
Use Wordnet’s if any term in HYP_LEMMAS matches any term in
TEXT_LEMMAS using LexicalCompare()
numberMatched++; Return: numberMatched/|HYP_Lemmas|

Page 33
An Algorithm: LocalLexicalMatching (Cont.) LexicalCompare()
if(LEMMA_H == LEMMA_T) return TRUE;
if(HypernymDistanceFromTo(textWord, hypothesisWord) <= 3) return TRUE;
if(MeronymyDistanceFromTo(textWord, hypothesisWord) <= 3) returnTRUE;
if(MemberOfDistanceFromTo(textWord, hypothesisWord) <= 3) return TRUE:
if(SynonymOf(textWord, hypothesisWord) return TRUE;
Notes: LexicalCompare is Asymmetric & makes use of single relation type Additional differences could be attributed to stop word list (e.g,
including aux verbs) Straightforward improvements such as bi-grams do not help. More sophisticated lexical knowledge (entities; time) should help.
LLM Performance:RTE2: Dev: 63.00 Test: 60.50RTE 3: Dev: 67.50 Test: 65.63

Page 34
Details of The Entailment Strategy (Again)
Preprocessing Multiple levels of lexical
pre-processing Syntactic Parsing Shallow semantic
parsing Annotating semantic
phenomena Representation
Bag of words, n-grams through tree/graphs based representation
Logical representations
Knowledge Sources Syntactic mapping rules Lexical resources Semantic Phenomena
specific modules RTE specific knowledge
sources Additional Corpora/Web
resources Control Strategy &
Decision Making Single pass/iterative
processing Strict vs. Parameter
based Justification
What can be said about the decision?

Page 35
Preprocessing Syntactic Processing:
Syntactic Parsing (Collins; Charniak; CCG) Dependency Parsing (+types)
Lexical Processing Tokenization; lemmatization For each word in Hypothesis, Text Phrasal verbs Idiom processing Named Entities + Normalization Date/Time arguments + Normalization
Semantic Processing Semantic Role Labeling Nominalization Modality/Polarity/Factive Co-reference
}often used only during decision making
} often used only during decision making
Only a few systems

Page 36
Details of The Entailment Strategy (Again)
Preprocessing Multiple levels of lexical
pre-processing Syntactic Parsing Shallow semantic
parsing Annotating semantic
phenomena Representation
Bag of words, n-grams through tree/graphs based representation
Logical representations
Knowledge Sources Syntactic mapping rules Lexical resources Semantic Phenomena
specific modules RTE specific knowledge
sources Additional Corpora/Web
resources Control Strategy &
Decision Making Single pass/iterative
processing Strict vs. Parameter
based Justification
What can be said about the decision?

Page 37
Basic Representations
MeaningRepresentation
Raw Text
Inference
Representation
Textual Entailment
Local Lexical
Syntactic Parse
Semantic Representation
Logical Forms
Most approaches augment the basic structure defined by the processing level with additional annotation and make use of a tree/graph/frame-based system.

Page 38
Basic Representations (Syntax)
Local Lexical
Syntactic Parse
Hyp: The Cassini spacecraft has reached Titan.

Page 39
Basic Representations (Shallow Semantics: Pred-Arg )
T: The government purchase of the Roanoke building, a former prison, took place in 1902.
H: The Roanoke building, which was a former prison, was bought by the government in 1902.
The govt. purchase… prison
take
place in 1902ARG_0 ARG_1 ARG_2
PRED
The government
buyThe Roanoke … prison
ARG_0 ARG_1
PRED
The Roanoke building
bea former prison
ARG_1 ARG_2
PRED
purchase
The Roanoke buildingARG_1
PRED
In 1902AM_TMP
Roth&Sammons’07

Page 40
Basic Representations (Logical Representation)
[Bos & Markert] The semantic
representationlanguage is a first-order fragment a language
used in Discourse
Representation Theory (DRS), conveying argument structure with
a neo-Davidsonian analysis
and Including the recursive
DRS structure to cover
negation, disjunction, and
implication.

Page 41
Representing Knowledge Sources Rather straight forward in
the Logical Framework:
Tree/Graph base representation may also use rule based transformations to encode different kinds of knowledge, sometimes represented as generic or knowledge based tree transformations.

Page 42
Representing Knowledge Sources (cont.) In general, there is a mix of procedural
and rule based encodings of knowledge sources
Done by hanging more information on parse tree or predicate argument representation [Example from LCC’s system]
Or different frame-based annotation systems for encoding information, that are processed procedurally.

Page 43
Details of The Entailment Strategy (Again)
Preprocessing Multiple levels of lexical
pre-processing Syntactic Parsing Shallow semantic
parsing Annotating semantic
phenomena Representation
Bag of words, n-grams through tree/graphs based representation
Logical representations
Knowledge Sources Syntactic mapping rules Lexical resources Semantic Phenomena
specific modules RTE specific knowledge
sources Additional Corpora/Web
resources Control Strategy &
Decision Making Single pass/iterative
processing Strict vs. Parameter
based Justification
What can be said about the decision?

Page 44
Knowledge Sources
The knowledge sources available to the system are the most significant component of supporting TE.
Different systems draw differently the line between preprocessing capabilities and knowledge resources.
The way resources are handled is also different across different approaches.

Page 45
Enriching Preprocessing In addition to syntactic parsing several approaches
enrich the representation with various linguistics resources
Pos tagging Stemming Predicate argument representation: verb predicates and
nominalization Entity Annotation: Stand alone NERs with a variable
number of classes Acronym handling and Entity Normalization: mapping
mentions of the same entity mentioned in different ways to a single ID.
Co-reference resolution Dates, times and numeric values; identification and
normalization. Identification of semantic relations: complex nominals,
genitives, adjectival phrases, and adjectival clauses. Event identification and frame construction.

Page 46
Lexical Resources Recognizing that a word or a phrase in S
entails a word or a phrase in H is essential in determining Textual Entailment.
Wordnet is the most commonly used resoruce In most cases, a Wordnet based similarity measure
between words is used. This is typically a symmetric relation.
Lexical chains over Wordnet are used; in some cases, care is taken to disallow some chains of specific relations.
Extended Wordnet is being used to make use of Entities
Derivation relation which links verbs with their corresponding nominalized nouns.

Page 47
Lexical Resources (Cont.) Lexical Paraphrasing Rules
A number of efforts to acquire relational paraphrase rules are under way, and several systems are making use of resources such as DIRT and TEASE.
Some systems seems to have acquired paraphrase rules that are in the RTE corpus
person killed --> claimed one life hand reins over to --> give starting job to same-sex marriage --> gay nuptials cast ballots in the election -> vote dominant firm --> monopoly power death toll --> kill try to kill --> attack lost their lives --> were killed left people dead --> people were killed

Page 48
Semantic Phenomena A large number of semantic phenomena have been
identified as significant to Textual Entailment. A large number of them are being handled (in a
restricted way) by some of the systems. Very little quantification per-phenomena has been done, if at all.
Semantic implications of interpreting syntactic structures [Braz et. al’05; Bar-Haim et. al. ’07]
Conjunctions Jake and Jill ran up the hill Jake ran up the hill Jake and Jill met on the hill *Jake met on the hill
Clausal modifiers But celebrations were muted as many Iranians observed a Shi'ite
mourning month. Many Iranians observed a Shi'ite mourning month. Semantic Role Labeling handles this phenomena automatically

Page 49
Semantic Phenomena (Cont.) Relative clauses
The assailants fired six bullets at the car, which carried Vladimir Skobtsov.
The car carried Vladimir Skobtsov. Semantic Role Labeling handles this phenomena automatically
Appositives Frank Robinson, a one-time manager of the Indians, has the
distinction for the NL. Frank Robinson is a one-time manager of the Indians.
Passive We have been approached by the investment banker. The investment banker approached us. Semantic Role Labeling handles this phenomena automatically
Genitive modifier Malaysia's crude palm oil output is estimated to have risen.. The crude palm oil output of Malasia is estimated to have risen .

Page 50
Logical Structure
Factivity : Uncovering the context in which a verb phrase is embedded
The terrorists tried to enter the building. The terrorists entered the building.
Polarity negative markers or a negation-denoting verb (e.g. deny, refuse, fail)
The terrorists failed to enter the building. The terrorists entered the building.
Modality/Negation Dealing with modal auxiliary verbs (can, must, should), that modify verbs’ meanings and with the identification of the scope of negation.
Superlatives/Comperatives/Monotonicity: inflecting adjectives or adverbs.
Quantifiers, determiners and articles

Page 51
Some Examples [Braz et. al. IJCAI workshop’05;PARC Corpus]
T: Legally, John could drive. H: John drove.. S: Bush said that Khan sold centrifuges to North Korea. H: Centrifuges were sold to North Korea.. S: No US congressman visited Iraq until the war. H: Some US congressmen visited Iraq before the war.
S: The room was full of women. H: The room was full of intelligent women.
S: The New York Times reported that Hanssen sold FBI secrets to the Russians and could face the death penalty.
H: Hanssen sold FBI secrets to the Russians.
S: All soldiers were killed in the ambush. H: Many soldiers were killed in the ambush.

Page 52
Details of The Entailment Strategy (Again)
Preprocessing Multiple levels of lexical
pre-processing Syntactic Parsing Shallow semantic
parsing Annotating semantic
phenomena Representation
Bag of words, n-grams through tree/graphs based representation
Logical representations
Knowledge Sources Syntactic mapping rules Lexical resources Semantic Phenomena
specific modules RTE specific knowledge
sources Additional Corpora/Web
resources Control Strategy &
Decision Making Single pass/iterative
processing Strict vs. Parameter
based Justification
What can be said about the decision?

Page 53
Control Strategy and Decision Making
Single Iteration Strict Logical approaches are, in principle, a single stage
computation. The pair is processed and transform into the logic form. Existing Theorem Provers act on the pair along with the
KB. Multiple iterations
Graph based algorithms are typically iterative. Following [Punyakanok et. al ’04] transformations are
applied and entailment test is done after each transformation is applied.
Transformation can be chained, but sometimes the order makes a difference. The algorithm can be a greedy algorithm or can be more exhaustive, and search for the best path found [Braz et. al’05;Bar-Haim et.al 07]

Page 54
Transformation Walkthrough [Braz et. al’05]
T: The government purchase of the Roanoke building, a former prison, took place in 1902.
H: The Roanoke building, which was a former prison, was bought by the government in 1902.
Does ‘H’ follow from ‘T’?

Page 55
Transformation Walkthrough (1)T: The government purchase of the Roanoke building, a
former prison, took place in 1902.
H: The Roanoke building, which was a former prison, was bought by the government in 1902.
The govt. purchase… prison
take
place in 1902ARG_0 ARG_1 ARG_2
PRED
The government
buyThe Roanoke … prison
ARG_0 ARG_1
PRED
The Roanoke building
bea former prison
ARG_1 ARG_2
PRED
purchase
The Roanoke buildingARG_1
PRED
In 1902AM_TMP

Page 56
Transformation Walkthrough (2)T: The government purchase of the Roanoke building,
a former prison, took place in 1902.
The government purchase of the Roanoke building, a former prison, occurred in 1902.
H: The Roanoke building, which was a former prison, was bought by the government.
The govt. purchase… prison
occur
in 1902ARG_
0ARG_
2
PRED
Phrasal Verb Rewriter

Page 57
Transformation Walkthrough (3)T: The government purchase of the Roanoke building, a
former prison, occurred in 1902.
The government purchase the Roanoke building in 1902.
H: The Roanoke building, which was a former prison, was bought by the government in 1902.
The government
purchase
ARG_0 ARG_
1
PRED
Nominalization Promoter
the Roanoke building, a former prison AM_TMP
In 1902
NOTE: depends on earlier
transformation: order is
important!

Page 58
Transformation Walkthrough (4)T: The government purchase of the Roanoke building, a
former prison, occurred in 1902.
The Roanoke building be a former prison.
H: The Roanoke building, which was a former prison, was bought by the government in 1902.
The Roanoke building
be
ARG_1
ARG_2
PRED
Apposition Rewriter
a former prison

Page 59
Transformation Walkthrough (5)T: The government purchase of the Roanoke building, a
former prison, took place in 1902.
H: The Roanoke building, which was a former prison, was bought by the government in 1902.The
government
buyThe Roanoke … prison
ARG_0 ARG_1
PRED
The Roanoke building
bea former prison
ARG_1 ARG_2
PRED
In 1902AM_TMP
The government
purchaseThe Roanoke … prison
ARG_0 ARG_1
PRED
The Roanoke building
bea former prison
ARG_1 ARG_2
PRED
In 1902AM_TMP
WordNet

Page 60
Characteristics
Multiple paths => optimization problem Shortest or highest-confidence path through
transformations Order is important; may need to explore different
orderings Module dependencies are ‘local’; module B does
not need access to module A’s KB/inference, only its output
If outcome is “true”, the (optimal) set of transformations and local comparisons form a proof

Page 61
Summary: Control Strategy and Decision Making
Despite the appeal of the Strict Logical approaches as of today, they do not work well enough.
Bos & Markert: Strict logical approach is failing significantly behind good
LLMs and multiple levels of lexical pre-processing Only incorporating rather shallow features and using it in
the evaluation saves this approach. Braz et. al.:
Strict graph based representation is not doing as well as LLM.
Tatu et. al Results show that strict logical approach is inferior to
LLMs, but when put together, it produces some gain. Using Machine Learning methods as a way to combine
systems and multiple features has been found very useful.

Page 62
Hybrid/Ensemble Approaches
Bos et al.: use theorem prover and model builder Expand models of T, H using model builder, check sizes of
models Test consistency with background knowledge with T, H Try to prove entailment with and without background
knowledge Tatu et al. (2006) use ensemble approach:
Create two logical systems, one lexical alignment system Combine system scores using coefficients found via search
(train on annotated data) Modify coefficients for different tasks
Zanzotto et al. (2006) try to learn from comparison of structures of T, H for ‘true’ vs. ‘false’ entailment pairs
Use lexical, syntactic annotation to characterize match between T, H for successful, unsuccessful entailment pairs
Train Kernel/SVM to distinguish between match graphs

Page 63
Justification
For most approaches justification is given only by the data Preprocessed
Empirical Evaluation Logical Approaches
There is a proof theoretic justification Modulo the power of the resources and the ability
to map a sentence to a logical form.
Graph/tree based approaches There is a model theoretic justification The approach is sound, but not complete, modulo
the availably of resources.

Page 64
R - a knowledge representation language, with a well defined
syntax and semantics or a domain D.
For text snippets s, t: rs, rt - their representations in R. M(rs), M(rt) their model theoretic representations
There is a well defined notion of subsumption in R, defined model theoretically
u, v 2 R: u is subsumed by v when M(u) µ M(v)
Not an algorithm; need a proof theory.
Justifying Graph Based Approaches [Braz et. al 05]

Page 65
The proof theory is weak; will show rs µ rt only when they are relatively similar syntactically.
r 2 R is faithful to s if M(rs) = M(r)
Definition: Let s, t, be text snippets with representations rs, rt 2 R.
We say that s semantically entails t if there is a representation r 2 R that is faithful to s, for which we can prove that r µ rt
Given rs need to generate many equivalent representations r’s and test r’s µ rt
Defining Semantic Entailment (2)
Cannot be done exhaustively How to generate alternative representations?

Page 66
A rewrite rule (l,r) is a pair of expressions in R such that l µ r
Given a representation rs of s and a rule (r,l) for which rs µ l the augmentation of rs via (l,r) is r’s = rs Æ r.
Claim: r’s is faithful to s. Proof: In general, since r’s = rs Æ r then M(r’s)= M(rs) Å
M(r) However, since rs µ l µ r then M(rs) µ M(r). Consequently: M(r’s)= M(rs) And the augmented representation is faithful to s.
Defining Semantic Entailment (3)
rs l µ r, rs µ lµ
r’s = rs Æ r

Page 67
The claim suggests an algorithm for generating alternative (equivalent) representations and for semantic entailment.
The resulting algorithm is a sound algorithm, but is not complete.
Completeness depends on the quality of the KB of rules.
The power of this algorithm is in the rules KB. l and r might be very different syntactically, but by
satisfying model theoretic subsumption they provide expressivity to the re-representation in a way that facilitates the overall subsumption.
Comments

Page 68
The problem of determining non-entailment is harder, mostly due to it’s structure.
Most approaches determine non-entailment heuristically. Set a threshold for a cost function. If not met by the pair,
say ‘now’ Several approach has identified specific features the hind
on non-entialment.
A model Theoretic approach for non-entailment has also been developed, although it’s effectiveness isn’t clear yet.
Non-Entailment

Page 69
What are we missing?
It is completely clear that the key resource missing is knowledge.
Better resources translate immediately to better results. At this point existing resources seem to be lacking in
coverage and accuracy. Not enough high quality public resources; no
quantification. Some Examples
Lexical Knowledge: Some cases are difficult to acquire systematically.
A bought Y A has/owns Y Many of the current lexical resources are very noisy.
Numbers, quantitative reasoning Time and Date; Temporal Reasoning. Robust event based reasoning and information integration

Page 70
Textual Entailment as a Classification Task

Page 71Page 71
RTE as classification task
RTE is a classification task: Given a pair we need to decide if T implies H or T
does not implies H
We can learn a classifier from annotated examples
What do we need: A learning algorithm A suitable feature space

Page 72Page 72
Defining the feature space How do we define the feature space?
Possible features “Distance Features” - Features of “some” distance
between T and H “Entailment trigger Features” “Pair Feature” – The content of the T-H pair is represented
Possible representations of the sentences Bag-of-words (possibly with n-grams) Syntactic representation Semantic representation
T1
H1
“At the end of the year, all solid companies pay dividends.”
“At the end of the year, all solid insurance companies pay dividends.”
T1 H1

Page 73Page 73
Distance Features
Possible features Number of words in common Longest common subsequence Longest common syntactic subtree …
T
H
“At the end of the year, all solid companies pay dividends.”
“At the end of the year, all solid insurance companies pay dividends.”
T H

Page 74Page 74
Entailment Triggers
Possible featuresfrom (de Marneffe et al., 2006) Polarity features
presence/absence of neative polarity contexts (not,no or few, without)
“Oil price surged”“Oil prices didn’t grow” Antonymy features
presence/absence of antonymous words in T and H “Oil price is surging”“Oil prices is falling down”
Adjunct features dropping/adding of syntactic adjunct when moving from T to H
“all solid companies pay dividends” “all solid companies pay cash dividends”
…

Page 75Page 75
Pair Features
Possible features Bag-of-word spaces of T and H
Syntactic spaces of T and H
T
H
“At the end of the year, all solid companies pay dividends.”
“At the end of the year, all solid insurance companies pay dividends.”
T Hen
d_T
year
_T
solid
_T
com
pani
es_T
pay_
T
divi
dend
s_T
… … end_
H
year
_H
solid
_H
com
pani
es_H
pay_
H
divi
dend
s_H
… …insu
ranc
e_H
T H

Page 76Page 76
Pair Features: what can we learn?
Bag-of-word spaces of T and H
We can learn: T implies H as when T contains “end”… T does not imply H when H contains “end”…
end_
T
year
_T
solid
_T
com
pani
es_T
pay_
T
divi
dend
s_T
… … end_
H
year
_H
solid
_H
com
pani
es_H
pay_
H
divi
dend
s_H
… …insu
ranc
e_H
T H
It seems to be totally irrelevant!!!

Page 77Page 77
(…)(…)
(…)
ML Methods in the possible feature spaces
Poss
ible
Fea
ture
s
Sentence representation
Bag-of-words Semantic
Dist
ance
Pair
(Hickl et al., 2006)
Syntactic
Enta
ilmen
t Tr
igge
r
(Zanzotto&Moschitti, 2006)
(Bos&Markert, 2006)
(Ipken et al., 2006)(Kozareva&Montoyo, 2006)
(de Marneffe et al., 2006)
(Herrera et al., 2006)(Rodney et al., 2006)

Page 78Page 78
Effectively using the Pair Feature Space
Roadmap
Motivation: Reason why it is important even if it seems not.
Understanding the model with an example Challenges A simple example
Defining the cross-pair similarity
(Zanzotto, Moschitti, 2006)

Page 79Page 79
Observing the Distance Feature Space…
T1
H1
“At the end of the year, all solid companies pay dividends.”
“At the end of the year, all solid insurance companies pay dividends.”
T1 H1
T1
H2
“At the end of the year, all solid companies pay dividends.”
“At the end of the year, all solid companies pay cash dividends.”
T1 H2
(Zanzotto, Moschitti, 2006)
% common syntactic dependencies
% common words
T1 H1In a distance feature space…
… the two pairs are very likely the same point
T1 H2

Page 80Page 80
What can happen in the pair feature space?
T1
H1
“At the end of the year, all solid companies pay dividends.”
“At the end of the year, all solid insurance companies pay dividends.”
T1 H1
T1
H2
“At the end of the year, all solid companies pay dividends.”
“At the end of the year, all solid companies pay cash dividends.”
T1 H2
T3
H3
“All wild animals eat plants that have scientifically proven medicinal properties.”
“All wild mountain animals eat plants that have scientifically proven medicinal properties.”
T3 H3
S2 S1<
(Zanzotto, Moschitti, 2006)

Page 81Page 81
Observations
Some examples are difficult to be exploited in the distance feature space…
We need a space that considers the content and the structure of textual entailment examples
Let us explore: the pair space! … using the Kernel Trick: define the space
defining the distance K(P1 , P2) instead of defining the feautures
T1 H1
T1 H2
K(T1 H1,T1 H2)

Page 82
Target
How do we build it: Using a syntactic interpretation of sentences Using a similarity among trees KT(T’,T’’): this
similarity counts the number of subtrees in common between T’ and T’’
This is a syntactic pair feature space
Question: do we need something more?
Page 82
(Zanzotto, Moschitti, 2006)
Cross-pair similarityKS((T’,H’),(T’’,H’’)) KT(T’,T’’)+
KT(H’,H’’)

Page 83Page 83
Observing the syntactic pair feature space
Can we use syntactic tree similarity?(Zanzotto, Moschitti, 2006)

Page 84Page 84
Observing the syntactic pair feature space
Can we use syntactic tree similarity?(Zanzotto, Moschitti, 2006)

Page 85Page 85
Observing the syntactic pair feature space
Can we use syntactic tree similarity? Not only!(Zanzotto, Moschitti, 2006)

Page 86Page 86
Observing the syntactic pair feature space
Can we use syntactic tree similarity? Not only!We want to use/exploit also the implied
rewrite rule
(Zanzotto, Moschitti, 2006)
a b c d
a b c d
a b c d
a b c d

Page 87Page 87
Exploiting Rewrite Rules
To capture the textual entailment recognition rule (rewrite rule or inference rule), the cross-pair similarity measure should consider:
the structural/syntactical similarity between, respectively, texts and hypotheses
the similarity among the intra-pair relations between constituents
How to reduce the problem to a tree similarity computation?
(Zanzotto, Moschitti, 2006)

Page 88Page 88
Exploiting Rewrite Rules(Zanzotto, Moschitti, 2006)
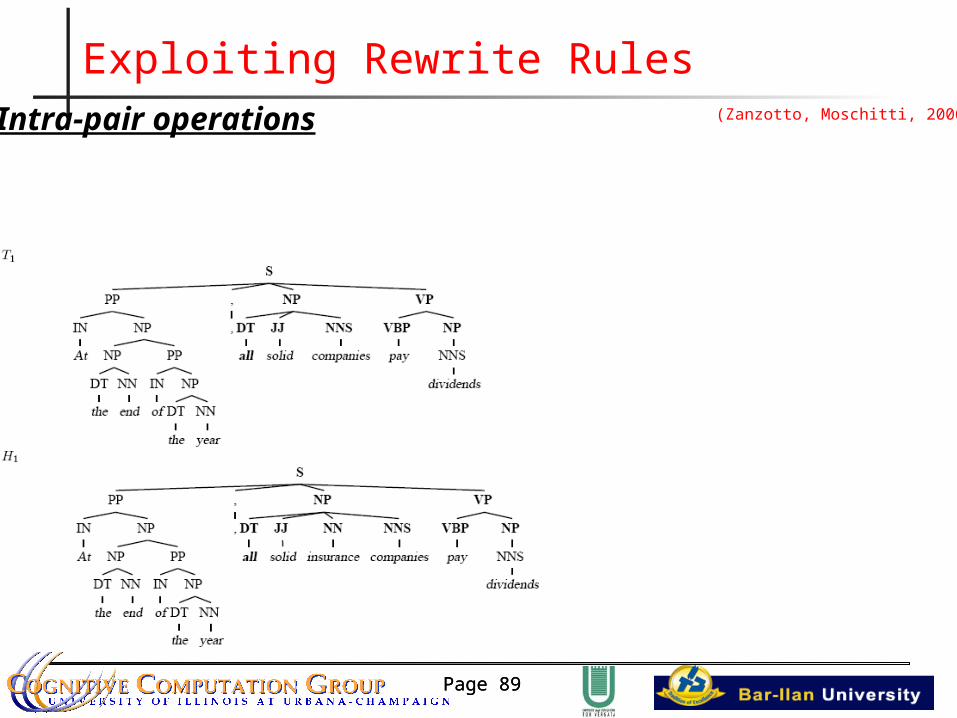
Page 89Page 89
Exploiting Rewrite RulesIntra-pair operations (Zanzotto, Moschitti, 2006)

Page 90Page 90
Exploiting Rewrite RulesIntra-pair operations Finding anchors
(Zanzotto, Moschitti, 2006)

Page 91Page 91
Exploiting Rewrite RulesIntra-pair operationsFinding anchors
Naming anchors with placeholders
(Zanzotto, Moschitti, 2006)

Page 92Page 92
Exploiting Rewrite RulesIntra-pair operationsFinding anchorsNaming anchors with placeholders
Propagating placeholders
(Zanzotto, Moschitti, 2006)

Page 93Page 93
Exploiting Rewrite RulesIntra-pair operationsFinding anchorsNaming anchors with placeholdersPropagating placeholders
Cross-pair operations (Zanzotto, Moschitti, 2006)

Page 94Page 94
Cross-pair operationsMatching placeholders across pairs
Exploiting Rewrite RulesIntra-pair operationsFinding anchorsNaming anchors with placeholdersPropagating placeholders
(Zanzotto, Moschitti, 2006)

Page 95Page 95
Exploiting Rewrite RulesCross-pair operationsMatching placeholders across pairs
Renaming placeholders
Intra-pair operationsFinding anchorsNaming anchors with placeholdersPropagating placeholders

Page 96Page 96
Intra-pair operationsFinding anchorsNaming anchors with placeholdersPropagating placeholders
Exploiting Rewrite RulesCross-pair operationsMatching placeholders across pairsRenaming placeholdersCalculating the similarity between syntactic trees with co-indexed leaves

Page 97Page 97
Intra-pair operationsFinding anchorsNaming anchors with placeholdersPropagating placeholders
Exploiting Rewrite RulesCross-pair operationsMatching placeholders across pairsRenaming placeholdersCalculating the similarity between syntactic trees with co-indexed leaves
(Zanzotto, Moschitti, 2006)

Page 98Page 98
Exploiting Rewrite Rules
The initial example: sim(H1,H3) > sim(H2,H3)?(Zanzotto, Moschitti, 2006)

Page 99Page 99
Defining the Cross-pair similarity The cross pair similarity is based on the distance
between syntatic trees with co-indexed leaves:
where C is the set of all the correspondences between anchors of
(T’,H’) and (T’’,H’’) t(S, c) returns the parse tree of the hypothesis (text) S
where placeholders of these latter are replaced by means of the substitution c
i is the identity substitution KT(t1, t2) is a function that measures the similarity
between the two trees t1 and t2.
(Zanzotto, Moschitti, 2006)

Page 100
Page 100
Defining the Cross-pair similarity

Page 101
Page 101
Refining Cross-pair Similarity Controlling complexity
We reduced the size of the set of anchors using the notion of chunk
Reducing the computational cost Many subtree computations are repeated during the
computation of KT(t1, t2). This can be exploited for a better dynamic progamming algorithm (Moschitti&Zanzotto, 2007)
Focussing on information within a pair relevant for the entailment:
Text trees are pruned according to where anchors attach
(Zanzotto, Moschitti, 2006)

Page 102
BREAK (30 min)

Page 103
III. Knowledge Acquisition Methods

Page 104
Page 104
Knowledge Acquisition for TE
What kind of knowledge we need? Explicit Knowledge (Structured Knowledge
Bases) Relations among words (or concepts)
Symmetric: Synonymy, cohypohymy Directional: hyponymy, part of, …
Relations among sentence prototypes Symmetric: Paraphrasing Directional : Inference Rules/Rewrite Rules
Implicit Knowledge Relations among sentences
Symmetric: paraphrasing examples Directional: entailment examples

Page 105
Page 105
Acquisition of Explicit Knowledge

Page 106
Page 106
Acquisition of Explicit Knowledge
The questions we need to answer What?
What we want to learn? Which resources do we need?
Using what? Which are the principles we have?
How? How do we organize the “knowledge acquisition”
algorithm

Page 107
Page 107
Acquisition of Explicit Knowledge: what?
Types of knowledge Symmetric
Co-hyponymyBetween words: cat dog
SynonymyBetween words: buy acquireSentence prototypes (paraphrasing) : X bought Y X acquired Z% of the
Y’s shares Directional semantic relations
Words: cat animal , buy own , wheel partof carSentence prototypes : X acquired Z% of the Y’s shares
X owns Y

Page 108
Page 108
Acquisition of Explicit Knowledge : Using what?
Underlying hypothesis
Harris’ Distributional Hypothesis (DH) (Harris, 1964)“Words that tend to occur in the same contexts tend
to have similar meanings.”
Robison’s Point-wise Assertion Patterns (PAP) (Robison, 1970)“It is possible to extract relevant semantic relations
with some pattern.”
sim(w1,w2)sim(C(w1), C(w2))
w1 is in a relation r with w2 if the context pattern(w1, w2 )

Page 109
Page 109
Words or Forms Context (Feature) Space
simw(W1,W2)simctx(C(W1), C(W2))
w1= constitute
w2= compose
C(w1)
C(w2)
Distributional Hypothesis (DH)
Corpus: source of contexts
… sun is constituted of hydrogen …
…The Sun is composed of hydrogen …

Page 110
Page 110
Point-wise Assertion Patterns (PAP)
w1 is in a relation r with w2 if the contexts patternsr(w1, w2 )
relation w1 part_of w2 patterns “w1 is constituted of
w2”
“w1 is composed of w2”
Corpus: source of contexts
… sun is constituted of hydrogen …
…The Sun is composed of hydrogen …
part_of(sun,hydrogen)selects correct vs incorrect relations among words
Statistical IndicatorScorpus(w1,w2)

Page 111
Page 111
Words or Forms Context (Feature) Space
w1= constitute
w2= compose
C(w1)
C(w2)
DH and PAP cooperate
Corpus: source of contexts
… sun is constituted of hydrogen …
…The Sun is composed of hydrogen …
Distributional Hypothesis Point-wise assertion Patterns

Page 112
Page 112
Knowledge Acquisition: Where methods differ?
On the “word” side Target equivalence classes: Concepts or
Relations Target forms: words or expressionsOn the “context” side Feature Space Similarity function
Words or Forms Context (Feature) Space
w1= cat
w2= dog
C(w1)
C(w2)

Page 113
Page 113
KA4TE: a first classification of some methods
Type
s of
kno
wle
dge
Underlying hypothesis
Distributional Hypothesis
Point-wise assertion Patterns
Sym
met
ricDi
rect
iona
l
ISA patterns(Hearst, 1992)
Verb Entailment(Zanzotto et al., 2006)
Concept Learning(Lin&Pantel, 2001a)
Inference Rules (DIRT) (Lin&Pantel, 2001b)
Relation Pattern Learning (ESPRESSO)(Pantel&Pennacchiotti, 2006)
HearstESPRESSO
(Pantel&Pennacchiotti, 2006)
Noun Entailment(Geffet&Dagan, 2005)
TEASE(Szepktor et al.,2004)

Page 114
Page 114
Noun Entailment Relation
Type of knowledge: directional relations Underlying hypothesis: distributional
hypothesis Main Idea: distributional inclusion hypothesis
(Geffet&Dagan, 2006)
w1 w2
ifAll the prominent features
of w1 occur with w2 in a
sufficiently large corpus
Words or Forms Context (Feature) Space
++++
++ +
++
w1
w2
C(w1)
C(w2)
w1 w2
I(C(w2))
I(C(w1))

Page 115
Page 115
Verb Entailment Relations
Type of knowledge: oriented relations Underlying hypothesis: point-wise assertion
patterns Main Idea:
win play? player wins!
(Zanzotto, Pennacchiotti, Pazienza, 2006)
relation v1 v2 patterns “agentive_nominalization(v2)
v1”
Point-wise Mutual information
Statistical IndicatorS(v1,v2)

Page 116
Page 116
Verb Entailment Relations
Understanding the idea Selectional restriction
fly(x) has_wings(x)
in generalv(x) c(x) (if x is the subject of v then x has the
property c) Agentive nominalization
“agentive noun is the doer or the performer of an action v’”
“X is player” may be read as play(x)
c(x) is clearly v’(x) if the property c is derived by v’ with an agentive nominalization
(Zanzotto, Pennacchiotti, Pazienza, 2006)
Skipped

Page 117
Page 117
Verb Entailment Relations
Understanding the ideaGiven the expression
player wins Seen as a selctional restriction
win(x) play(x) Seen as a selectional preference
P(play(x)|win(x)) > P(play(x))
Skipped

Page 118
Page 118
Knowledge Acquisition for TE: How?
The algorithmic nature of a DH+PAP method Direct
Starting point: target words Indirect
Starting point: context feature space Iterative
Interplay between the context feature space and the target words

Page 119
Page 119
Words or Forms Context (Feature) Space
sim(w1,w2)sim(C(w1), C(w2))
w1= cat
w2= dog
C(w1)
C(w2)
Direct Algorithm
sim(w1, w2)
I(C(w1))
I(C(w2))sim(I(C(w1)), I(C(w2)))
sim(w1,w2)sim(I(C(w1)), I(C(w2)))
1. Select target words wi from the corpus or from a dictionary
2. Retrieve contexts of each wi and represent them in the feature space C(wi )
3. For each pair (wi, wj)1. Compute the
similarity sim(C(wi), C(wj )) in the context space
2. If sim(wi, wj )= sim(C(wi), C(wj ))>wi and wj belong to the same equivalence class W
sim(C(w1), C(w2))

Page 120
Page 120
1. Given an equivalence class W, select relevant contexts and represent them in the feature space
2. Retrieve target words (w1, …, wn) that appear in these contexts. These are likely to be words in the equivalence class W
3. Eventually, for each wi, retrieve C(wiI) from the corpus
4. Compute the centroid I(C(W))
5. For each for each wi, if sim(I(C(W), wi)<t, eliminate wi from W.
Words or Forms Context (Feature) Space
sim(w1,w2)sim(C(w1), C(w2))
w1= cat
w2= dog
C(w1)
Indirect Algorithm
C(w2)
sim(w1, w2)
sim(w1,w2)sim(I(C(w1)), I(C(w2)))
sim(C(w1), C(w2))

Page 121
Page 121
1. For each word wi in the equivalence class W, retrieve the C(wi) contexts and represent them in the feature space
2. Extract words wj that have contexts similar to C(wi)
3. Extract contexts C(wj) of these new words
4. For each for each new word wj, if sim(C(W), wj)>, put wj in W.
Words or Forms Context (Feature) Space
sim(w1,w2)sim(C(w1), C(w2))
w1= cat
w2= dog
C(w1)
Iterative Algorithm
C(w2)
sim(C(w1), C(w2))
sim(w1, w2)
sim(w1,w2)sim(I(C(w1)), I(C(w2)))

Page 122
Page 122
Knowledge Acquisition using DH and PAH
Direct Algorithms Concepts from text via clustering (Lin&Pantel, 2001) Inference rules – aka DIRT (Lin&Pantel, 2001) …
Indirect Algorithms Hearst’s ISA patterns (Hearst, 1992) Question Answering patterns (Ravichandran&Hovy,
2002) …
Iterative Algorithms Entailment rules from Web – aka TEASE (Szepktor et al.,
2004) Espresso (Pantel&Pennacchiotti, 2006) …

Page 123
Page 123
TEASE
Type: Iterative algorithmOn the “word” side Target equivalence classes: fine-grained relations
Target forms: verb with arguments
On the “context” side Feature Space
Innovations with respect to reasearches < 2004 First direct algorithm for extracting rules
prevent(X,Y)
X_{filler}:mi?,Y_{filler}:mi?
call
indictable
subjobj
mod
XYfinally
mod
(Szepktor et al., 2004)

Page 124
Page 124
TEASE
WEB
LexiconInput template:
Xsubj-accuse-objY
Sample corpus for input template:Paula Jones accused Clinton…BBC accused Blair…Sanhedrin accused St.Paul……
Anchor sets:{Paula Jonessubj; Clintonobj}{Sanhedrinsubj; St.Paulobj}…
Sample corpus for anchor sets:Paula Jones called Clinton indictable…St.Paul defended before the Sanhedrin …
Templates:X call Y indictableY defend before X…
TEASE
Anchor Set Extraction(ASE)
Template Extraction(TE)
iterate
(Szepktor et al., 2004)
Skipped

Page 125
Page 125
TEASE
Innovations with respect to reasearches < 2004
First direct algorithm for extracting rules A feature selection is done to assess the
most informative features Extracted forms are clustered to obtain the
most general sentence prototype of a given set of equivalent forms
(Szepktor et al., 2004)
call{1}
indictable{1}
subj {1}
obj {1}mod {1}
X{1}
Y{1}
harassment{1}
for {1}
S1: call{2}
indictable{2}
subj {2}
obj {2}mod {2}
X{2} Y
{2}
S2:
finally {2}
mod {2}
call{1,2}
indictable{1,2}
subj {1,2}obj {1,2}
mod {1,2}
X{1,2}
Y{1,2}
harassment{1}
for {1}
finally {2}
mod {2}
Skipped

Page 126
Page 126
Espresso
Type: Iterative algorithmOn the “word” side Target equivalence classes: relations
Target forms: expressions, sequences of tokens
Innovations with respect to reasearches < 2006 A measure to determine specific vs. general
patterns (ranking in the equivalent forms)
Y is composed by X, Y is made of X
compose(X,Y)
(Pantel&Pennacchiotti, 2006)

Page 127
Page 127
Espresso
Pattern Induction
Sentence retrieval
Sentence generalization
SEEDS
Frequency count
Pattern Ranking / Selection
Pattern Reliability ranking
Pattern selection
Instance Extraction
GENERIC PATTERN FILTERING
Pattern instantiation
Low Redundancy Test
yes
no
yes
Syntactic Expansion
Web Expansion
Generic Test Google
Web Instance Filter
Instance Ranking / Selection
Instance Reliability ranking
Instance selection
(leader , panel)(city , region)
(oxygen , water)
Y is composed by XX,Y
Y is part of Y
1.0 Y is composed by X0.8 Y is part of X0.2 X,Y
(tree , land)(oxygen , hydrogen)
(atom, molecule)(leader , panel)
(range of information, FBI report)(artifact , exhibit)
…
1.0 (tree , land)0.9 (atom, molecule)0.7 (leader , panel)0.6 (range of information, FBI report)0.6 (artifact , exhibit)0.2 (oxygen , hydrogen)
(Pantel&Pennacchiotti, 2006)
Skipped

Page 128
Page 128
Espresso
Innovations with respect to reasearches < 2006
A measure to determine specific vs. general patterns (ranking in the equivalent forms)
Both pattern and instance selections are performed
Different Use of General and specific patterns in the iterative algorithm
(Pantel&Pennacchiotti, 2006)
1.0 Y is composed by X0.8 Y is part of X0.2 X,Y Skipped

Page 129
Page 129
Acquisition of Implicit Knowledge
Page 130
Page 130
Acquisition of Implicit Knowledge
The questions we need to answer What?
What we want to learn? Which resources do we need?
Using what? Which are the principles we have?

Page 131
Page 131
Acquisition of Implicit Knowledge: what?
Types of knowledge Symmetric
Nearly Synonymy between sentences Acme Inc. bought Goofy ltd. Acme Inc. acquired 11% of the Goofy ltd.’s
shares Directional semantic relations
Entailment between sentencesAcme Inc. acquired 11% of the Goofy ltd.’s shares Acme Inc. owns Goofy ltd.
Note: ALSO TRICKY NOT-ENTAILMENT ARE RELEVANT

Page 132
Page 132
Acquisition of Implicit Knowledge : Using what?
Underlying hypothesis
Structural and content similarity“Sentences are similar if they share enough
content”
A revised Point-wise Assertion Patterns“Some patterns of sentences reveal relations among
sentences”
sim(s1,s2) according to relations from s1 and s2

Page 133
Page 133
A first classification of some methodsTy
pes
of k
now
ledg
e
Underlying hypothesis
Structural and content similarity
Revised Point-wise assertion
Patterns
Sym
met
ricDi
rect
iona
l
Relations among sentences(Hickl et al., 2006)
Paraphrase Corpus(Dolan&Quirk, 2004)
enta
ils
not
enta
ils
Relations among sentences(Burger&Ferro, 2005)

Page 134
Page 134
Entailment relations among sentences
Type of knowledge: directional relations (entailment)
Underlying hypothesis: revised point-wise assertion patterns
Main Idea: in headline news items, the first sentence/paragraph generally entails the title
(Burger&Ferro, 2005)
relation s2 s1 patterns “News Item
Title(s1)
First_Sentence(s2)”
This pattern works on the structure of the text

Page 135
Page 135
Entailment relations among sentencesexamples from the web
New York Plan for DNA Data in Most CrimesEliot Spitzer is proposing a major expansion of New York’s database of DNA samples to include people convicted of most crimes, while making it easier for prisoners to use DNA to try to establish their innocence. …
TitleBody
Chrysler Group to Be Sold for $7.4 BillionDaimlerChrysler confirmed today that it would sell a controlling interest in its struggling Chrysler Group to Cerberus Capital Management of New York, a private equity firm that specializes in restructuring troubled companies. …
TitleBody

Page 136
Page 136
Tricky Not-Entailment relations among sentences
Type of knowledge: directional relations (tricky not-entailment)
Underlying hypothesis: revised point-wise assertion patterns
Main Idea: in a text, sentences with a same name entity generally
do not entails each other Sentences connected by “on the contrary”, “but”, … do
not entail each other
(Hickl et al., 2006)
relation s1 s2 patterns
s1 and s2 are in the same text and share at least a named entity“s1. On the contrary, s2”

Page 137
Page 137
Tricky Not-Entailment relations among sentences
examples from (Hickl et al., 2006)
One player losing a close friend is Japanese pitcherHideki Irabu, who was befriended by Wells during spring training last year.Irabu said he would take Wells out to dinnerwhen the Yankees visit Toronto.
T
H
According to the professor, present methods of cleaning up oil slicks are extremely costly and are never completely efficient.
T
H In contrast, he stressed, Clean Mag has a 100percent pollution retrieval rate, is low cost and can be recycled.

Page 138
He used a Phillips head to tighten the screw.
The bank owner tightened security after a spat of local crimes.
The Federal Reserve will aggressively tighten monetary policy.
Context Sensitive Paraphrasing
……….
LoosenStrengthenStep upToughenImproveFastenImposeIntensifyEaseBeef upSimplifyCurbReduce
LoosenStrengthenStep upToughenImproveFastenImposeIntensifyEaseBeef upSimplifyCurbReduce

Context Sensitive Paraphrasing
Can speak replace command?
The general commanded his troops. The general spoke to his troops.
The soloist commanded attention. The soloist spoke to attention.

Context Sensitive Paraphrasing Need to know when one word can paraphrase
another, not just if. Given a word v and its context in sentence S, and
another word u: Can u replace v in S and have S keep the same or entailed
meaning. Is the new sentence S’ where u has replaced v entailed by
previous sentence S
The general commanded [V] his troops. [Speak = U]
The general spoke to his troops. YES
The soloist commanded [V ] attention. [Speak = U] The soloist spoke to attention. NO

Related Work
Paraphrase generation: Given a sentence or phrase, generate paraphrases of that
phrase which have the same or entailed meaning in some context. [DIRT;TEASE]
A sense disambiguation task – w/o naming the sense
Dagan et. al’06 Kauchak & Barzilay (in the context of improving MT
evaluation) SemEval word Substitution Task; Pantel et. al ‘06
In these cases, this was done by learning (in a supervised way) a single classifier per word u

Context Sensitive Paraphrasing [Connor&Roth ’07]
Use a single global binary classifierf(S,v,u) ! {0,1}
Unsupervised, bootstrapped, learning approach
Key: the use of a very large amount of unlabeled data to derive a reliable supervision signal that is then used to train a supervised learning algorithm.
Features are amount of overlap between contexts u and v have both been seen with
Include context sensitivity by restricting to contexts similar to S
Are both u and v seen in contexts similar to local context S Allows running the classifier on previously unseen pairs
(u,v)

Page 143
IV. Applications of Textual Entailment

Page 144
Relation Extraction (Romano et al. EACL-06) Identify different ways of expressing a target
relation Examples: Management Succession, Birth - Death,
Mergers and Acquisitions, Protein Interaction
Traditionally performed in a supervised manner Requires dozens-hundreds examples per relation Examples should cover broad semantic variability
Costly - Feasible???
Little work on unsupervised approaches

Page 145
Proposed Approach
Input TemplateX prevent Y
Entailment Rule Acquisition
TemplatesX prevention for Y, X treat Y, X reduce Y
Syntactic Matcher
Relation Instances<sunscreen, sunburns>
TEASE
TransformationRules

Page 146
Dataset
Bunescu 2005 Recognizing interactions between
annotated proteins pairs 200 Medline abstracts
Input template : X interact with Y

Page 147
Manual Analysis - Results 93% of interacting protein pairs can be identified with
lexical syntactic templates
Phenomenon % Phenomenon %
transparent head 34 relative clause 8
apposition 24 co-reference 7
conjunction 24 coordination 7
set 13 passive form 2
R(%) # templates R(%) # templates10 2 60 3920 4 70 7330 6 80 10740 11 90 14150 21 100 175
Frequency of syntactic phenomena:
Number of templates vs. recall (within 93%):

Page 148
TEASE Output for X interact with Y
A sample of correct templates learned:X bind to Y X binding to YX activate Y X Y interactionX stimulate Y X attach to YX couple to Y X interaction with Yinteraction between X and Y
X trap Y
X become trapped in Y X recruit YX Y complex X associate with YX recognize Y X be linked to YX block Y X target Y

Page 149
Iterative - taking the top 5 ranked templates as input
Morph - recognizing morphological derivations(cf. semantic role labeling vs. matching)
Experiment Recallinput 39%input + iterative 49%input + iterative + morph
63%
TEASE Potential Recall on Training Set

Page 150
Performance vs. Supervised Approaches
Supervised: 180 training abstracts

Page 151
Textual Entailment for Question Answering
Sanda Harabagiu and Andrew Hickl (ACL-06) : Methods for Using Textual Entailment in Open-Domain Question Answering
Typical QA architecture – 3 stages:1) Question processing2) Passage retrieval3) Answer processing
Incorporated their RTE-2 entailment system at stages 2&3, for filtering and re-ranking

Page 152
Integrated three methods
1) Test entailment between question and final answer – filter and re-rank by entailment score
2) Test entailment between question and candidate retrieved passage – combine entailment score in passage ranking
3) Test entailment between question and Automatically Generated Questions (AGQ) created from candidate paragraph Utilizes earlier method for generating Q-A pairs from
paragraph Correct answer should match that of an entailed AGQ
TE is relatively easy to integrate at different stages Results: 20% accuracy increase

Page 153
Answer Validation Exercise @ CLEF 2006-7
Peñas et al., Journal of Logic and Computation (to appear)
Allow textual entailment systems to validate (and prioritize) the answers of QA systems participating at CLEF
AVE participants receive:1) question and answer – need to generate full hypothesis2) supporting passage – should entail the answer
hypothesis Methodologically: Enables to measure TE systems
contribution to QA performance, across many QA systems TE developers do not need to have full-blown QA system

Page 154
V. A Textual Entailment view of Applied Semantics

Page 155
Classical Approach = Interpretation
Stipulated Meaning
Representation(by scholar)
Language(by nature)
Variability
Logical forms, word senses, semantic roles, named entity types, … - scattered interpretation tasks
Feasible/suitable framework for applied semantics?

Page 156
Textual Entailment = Text Mapping
Assumed Meaning (by humans)
Language(by nature)
Variability
Page 157
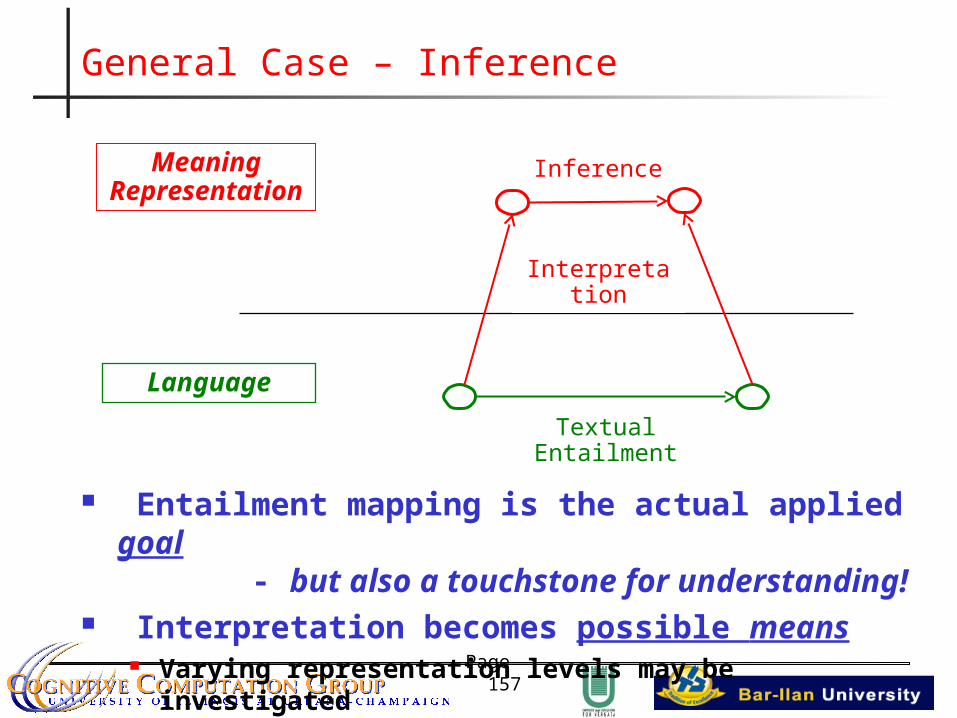
General Case – Inference
MeaningRepresentation
Language
Inference
Interpretation
Textual Entailment
Entailment mapping is the actual applied goal - but also a touchstone for understanding!
Interpretation becomes possible means Varying representation levels may be investigated

Page 158
Some perspectives
Issues with semantic interpretation Hard to agree on a representation language Costly to annotate semantic representations for
training Difficult to obtain - is it more difficult than
needed? Textual entailment refers to texts
Texts are theory neutral Amenable for unsupervised learning “Proof is in the pudding” test

Page 159
Entailment as an Applied Semantics Framework
The new view: formulate (all?) semantic problems as entailment tasks
Some semantic problems are traditionally investigated as entailment tasks
But also… Revised definitions of old problems Exposing many new ones

Page 160
Some Classical Entailment Problems
Monotonicity – traditionally approached via entailment
Given that: dog animal Upward monotone: Some dogs are nice Some animals are
nice Downward monotone: No animals are nice No dogs are nice
Some formal approaches – via interpretation to logical form Natural logic – avoids interpretation to FOL (cf. Stanford @
RTE-3)
Noun compound relation identification a novel by Tolstoy Tolstoy wrote a novel Practically an entailment task, when relations are
represented lexically (rather than as interpreted semantic notions)

Page 161
Revised definition of an Old Problem: Sense Ambiguity
Classical task definition - interpretation: Word Sense Disambiguation
What is the RIGHT set of senses? Any concrete set is problematic/subjective … but WSD forces you to choose one
A lexical entailment perspective: Instead of identifying an explicitly stipulated sense
of a word occurrence ... identify whether a word occurrence (i.e. its implicit
sense) entails another word occurrence, in context Dagan et al. (ACL-2006)

Page 162
Synonym Substitution
Source = record Target = disc
This is anyway a stunning disc, thanks to the playing of the Moscow Virtuosi with Spivakov.
He said computer networks would not be affected and copies of information should be made on floppy discs.
Before the dead soldier was placed in the ditch his personal possessions were removed, leaving one disc on the body for identification purposes.
positive
negative
negative

Page 163
Unsupervised Direct: kNN-ranking
Test example score: Average Cosine similarity of target example with k most similar (unlabeled) instances of source word
Rational: positive examples of target will be similar to some
source occurrence (of corresponding sense) negative target examples won’t be similar to
source examples Rank test examples by score
A classification slant on language modeling

Page 164
Results (for synonyms): Ranking
kNN improves 8-18% precision up to 25% recall

Page 165
Other Modified and New Problems Lexical entailment vs. classical lexical semantic relationships
synonym ⇔ synonym hyponym ⇒ hypernym (but much beyond WN – e.g. “medical
technology”) meronym ⇐ ? ⇒ holonym – depending on meronym type, and
context boil on elbow ⇒ boil on arm vs. government voted ⇒ minister voted
Named Entity Classification – by any textual type Which pickup trucks are produced by Mitsubishi?
Magnum pickup truck Argument mapping for nominalizations (derivations)
X’s acquisition of Y X acquired Y X’s acquisition by Y Y acquired X
Transparent head sell to an IBM division sell to IBM sell to an IBM competitor ⇏ sell to IBM
…

Page 166
The importance of analyzing entailment examples
Few systematic manual data analysis works were reported
Vanderwende et al. at RTE-1 workshop Bar-Haim et al. at ACL-05 EMSEE Workshop Within Romano et al. at EACL-06 Xerox Parc Data set; Braz et. IJCAI workshop’05
Contribute a lot to understanding and defining entailment phenomena and sub-problems
Should be done (and reported) much more…

Page 167
Unified Evaluation Framework
Defining semantic problems as entailment problems facilitates unified evaluation schemes (vs. current state)
Possible evaluation schemes:1) Evaluate on the general TE task, while creating corpora which
focus on target sub-tasks E.g. a TE dataset with many sense-matching instances Measure impact of sense-matching algorithms on TE performance
2) Define TE-oriented subtasks, and evaluate directly on sub-task E.g. a test collection manually annotated for sense-matching Advantages: isolate sub-problem; researchers can investigate
individual problems without needing a full-blown TE system (cf. QA research)
Such datasets may be derived from datasets of type (1) Facilitates common inference goal across semantic
problems

Page 168
Summary: Textual Entailment as Goal
The essence of the textual entailment paradigm: Base applied semantic inference on entailment
“engines” and KBs Formulate various semantic problems as entailment
sub-tasks Interpretation and “mapping” methods may
compete/complement at various levels of representations
Open question: which inferences can be represented at “language” level? require logical or specialized representation and
inference? (temporal, spatial, mathematical, …)

Page 169
Textual Entailment ≈ Human Reading Comprehension
From a children’s English learning book(Sela and Greenberg):
Reference Text: “…The Bermuda Triangle lies in the Atlantic Ocean, off the coast of Florida. …”
Hypothesis (True/False?): The Bermuda Triangle is near the United States
???

Page 170
Cautious Optimism: Approaching the Desiderata?
1) Generic (feasible) module for applications
2) Unified (agreeable) paradigm for investigating language phenomena
Thank you!

Page 171
Lexical Entailment for Applications Sense equivalence
T1: IKEA announced a new comfort chair
Q: announcement of new models of chairs
T2: MIT announced a new CS chair position
T1: IKEA announced a new comfort chair
Q: announcement of new models of furniture
T2: MIT announced a new CS chair position
Sense entailment

Page 172
Meeting the knowledge challenge – by a coordinated effort?
A vast amount of “entailment knowledge” needed
Speculation: can we have a joint community effort for knowledge acquisition?
Uniform representations (yet to be defined) Mostly automatic acquisition (millions of “rules”) Human Genome Project analogy
Teaser: RTE-3 Resources Pool at ACLWiki(set up by Patrick Pantel)