adaptive and robust broadcast algorithm takeshi sekiya chikayama-taura lab. 2007/4/13
TRANSCRIPT
Adaptive and Robust Broadcast Algorithm
Takeshi Sekiya
Chikayama-Taura Lab.
2007/4/13
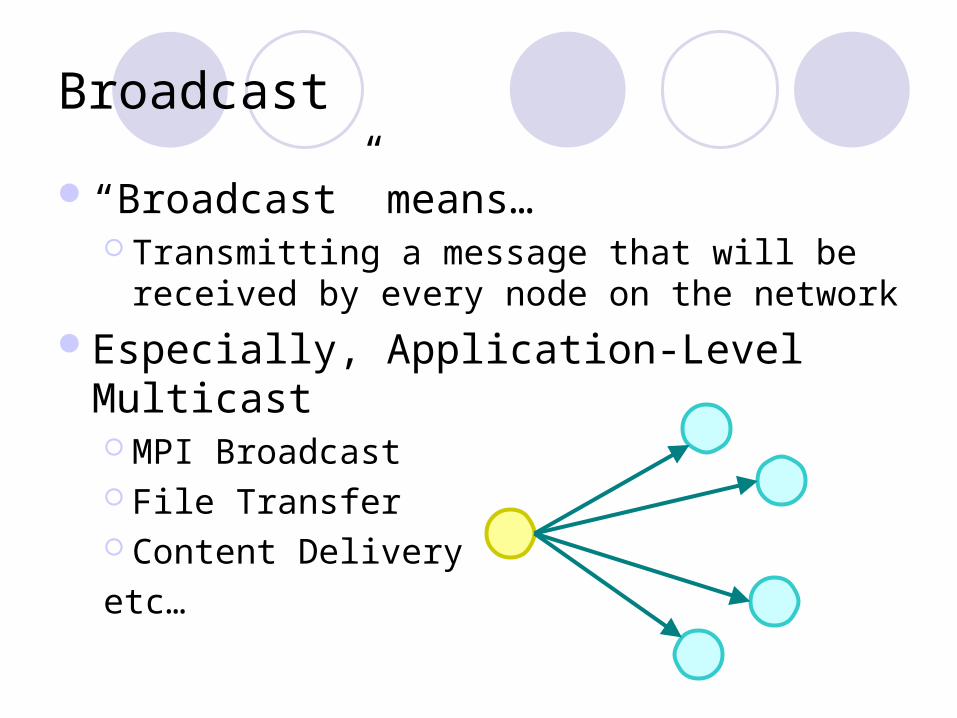
Broadcast
“Broadcast” means… Transmitting a message that will be received by
every node on the network
Especially, Application-Level Multicast MPI Broadcast File Transfer Content Delivery
etc…

Objective
Designing a broadcast algorithm1. Low latency sending small messages
2. High throughput sending large messages
3. Robustness with low redundancy

Agenda
BackgroundBroadcast Algorithms and Problem Setting
s Application Layer Multicast MPI Bcast Gossip-Based Broadcast
Our ApproachRelated WorksConclusion
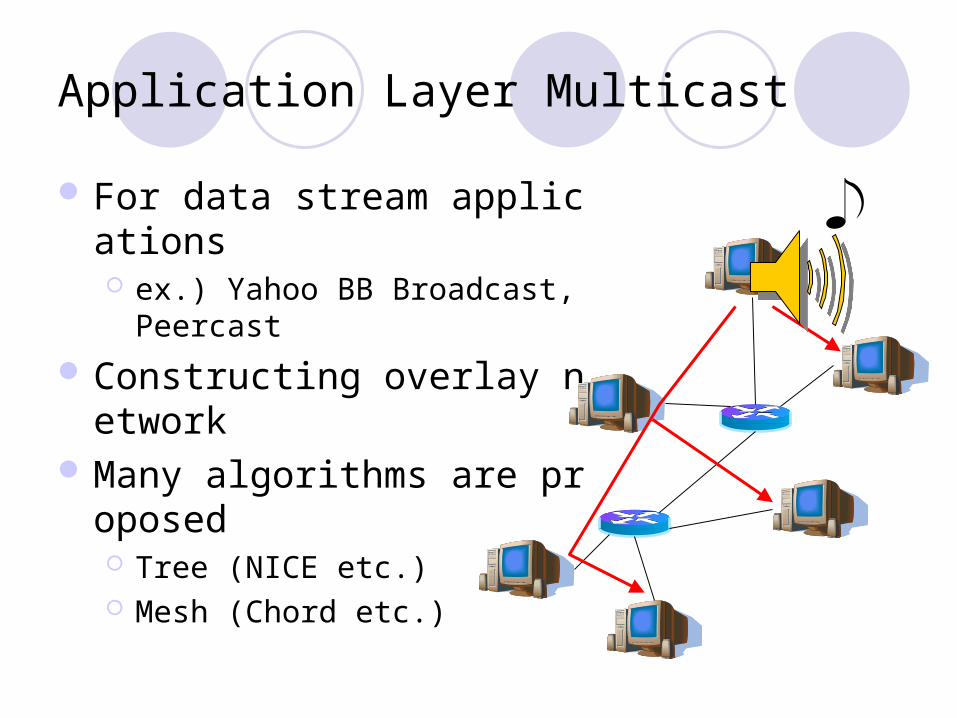
Application Layer Multicast
For data stream applications ex.) Yahoo BB Broadcast, Peerca
st
Constructing overlay network Many algorithms are proposed
Tree (NICE etc.) Mesh (Chord etc.)
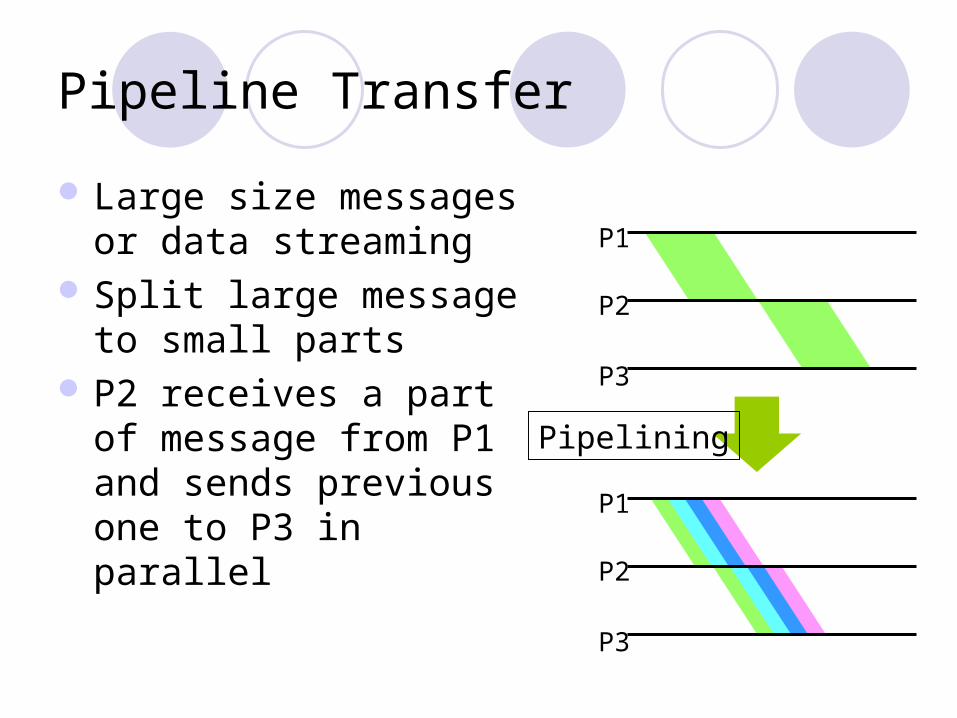
Pipeline Transfer
Large size messages or data streaming
Split large message to small parts
P2 receives a part of message from P1 and sends previous one to P3 in parallel
P1
P2
P3
P1
P2
P3
Pipelining
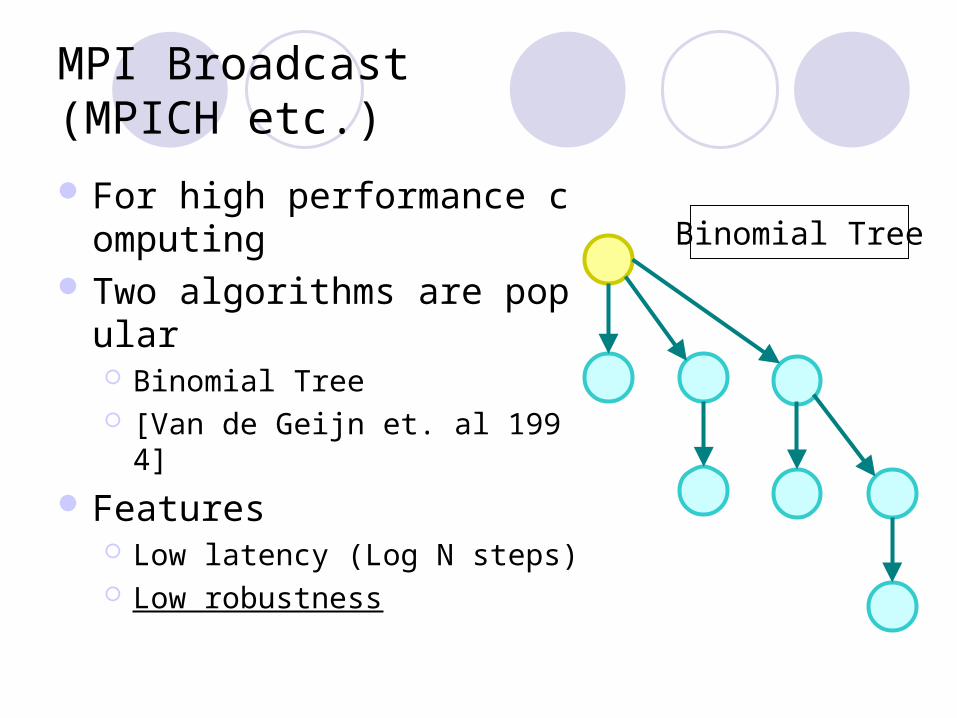
MPI Broadcast(MPICH etc.)
For high performance computing
Two algorithms are popular Binomial Tree [Van de Geijn et. al 1994]
Features Low latency (Log N steps) Low robustness
Binomial Tree
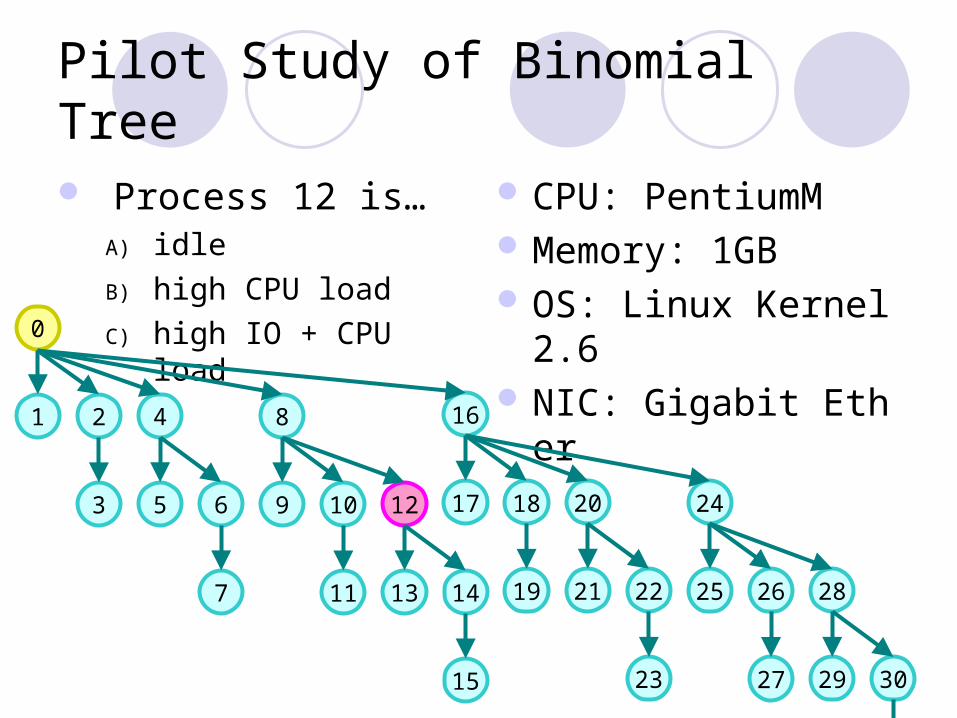
Pilot Study of Binomial Tree
Process 12 is…A) idle
B) high CPU load
C) high IO + CPU load
CPU: PentiumM Memory: 1GB OS: Linux Kernel2.6 NIC: Gigabit Ether
0
1 2
3
4
5 6
7
8
9 10
11
12
13 14
15
16
17 18
19
20
21 22
23
24
25 26
27
28
29 30
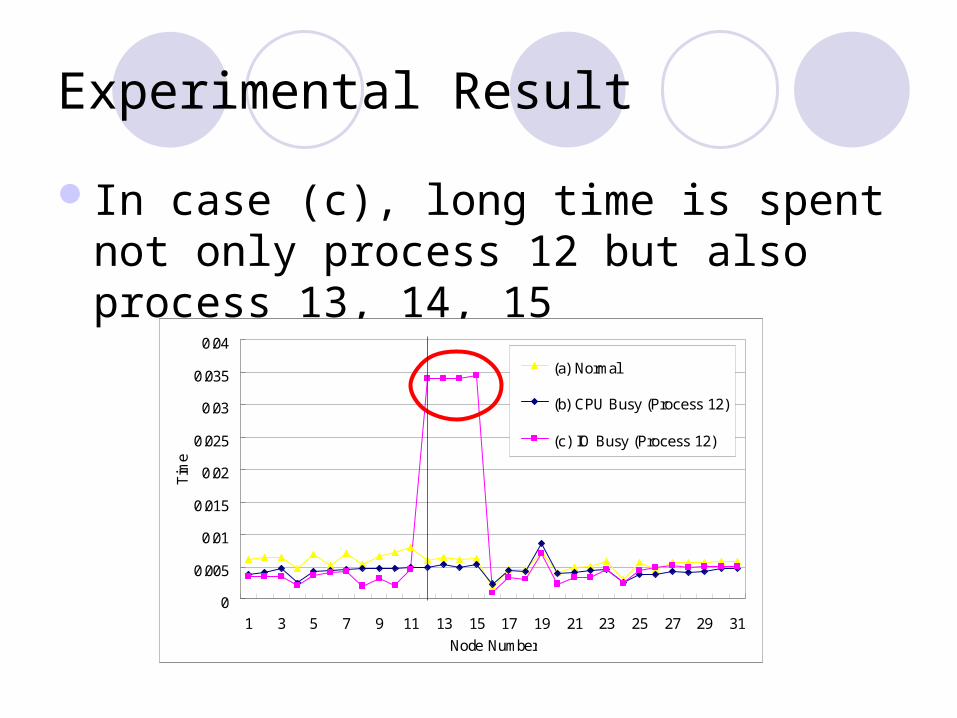
Experimental Result
In case (c), long time is spent not only process 12 but also process 13, 14, 15
0
0.005
0.01
0.015
0.02
0.025
0.03
0.035
0.04
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31
Node Number
Tim
e
(a) Normal
(b) CPU Busy (Process 12)
(c) IO Busy (Process 12)
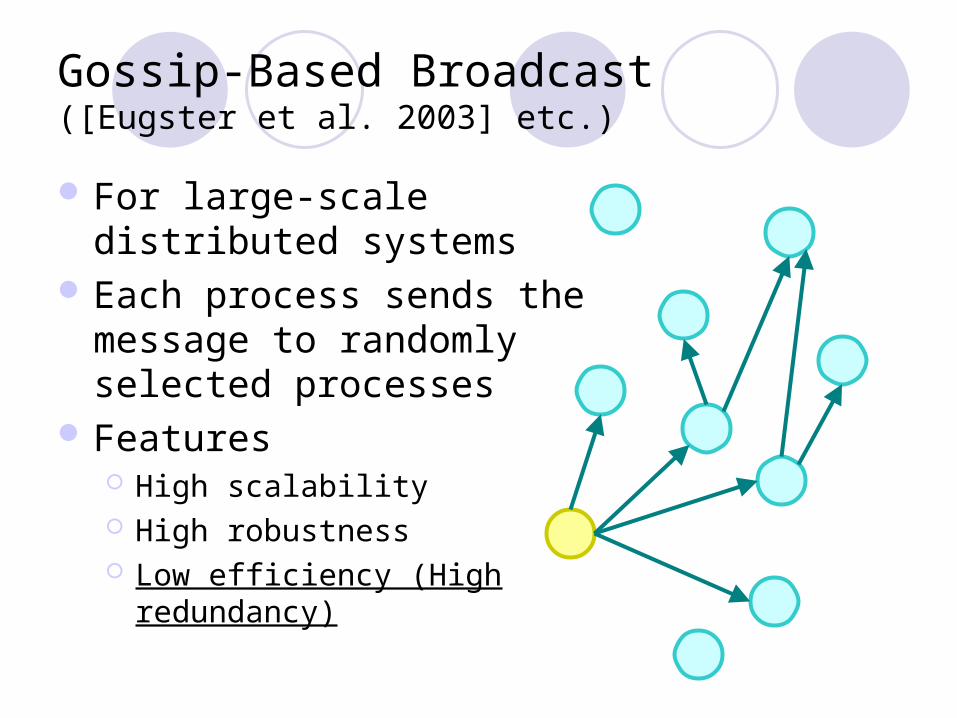
Gossip-Based Broadcast([Eugster et al. 2003] etc.)
For large-scale distributed systems
Each process sends the message to randomly selected processes
Features High scalability High robustness Low efficiency (High redundancy)

Redundancy of Gossip-Based Broadcast
Each process sends to k processesTo ensure enough reliability,
it needs to be k 3≧Number of messages (n processes)
Binomial tree: n-1 Gossip : 2kn
If the message size is large, network load becomes worse
2k times

Tradeoffs
Robustness VS Low Redundancy Gossip-based VS Spanning-Tree Flooding
High Throughput VS Low Latency Single Chain VS Flat Tree

Objective (again)
Designing a broadcast algorithm1. Low latency sending small messages
2. High throughput sending large messages
3. Robustness with low redundancy

Problem Settings
Messages are pushed toward a queue with random probability Frequent: split large message Rare: small message
Nodes may fail except root node (adjacent nodes can detect)
Algorithm must … send more number of messages in
queue with fixed time reduce time which one message is
received by all nodes

Agenda
BackgroundBroadcast Algorithms and Problem
SettingsOur Approach
Graph Configuration Algorithm
Related WorksConclusion
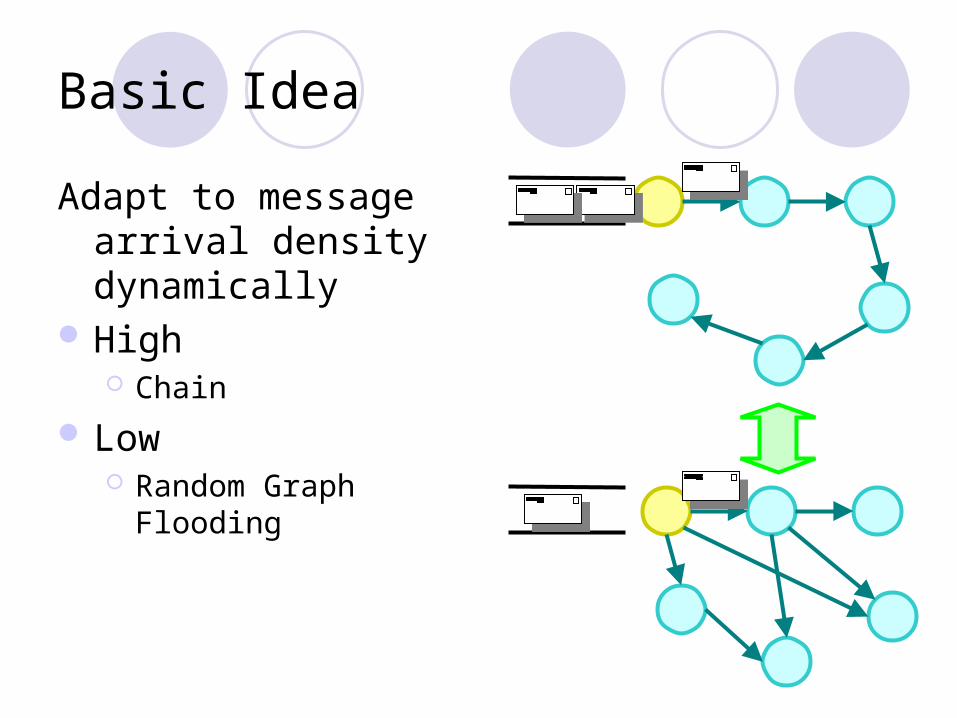
Basic Idea
Adapt to message arrival density dynamically
High Chain
Low Random Graph Flooding
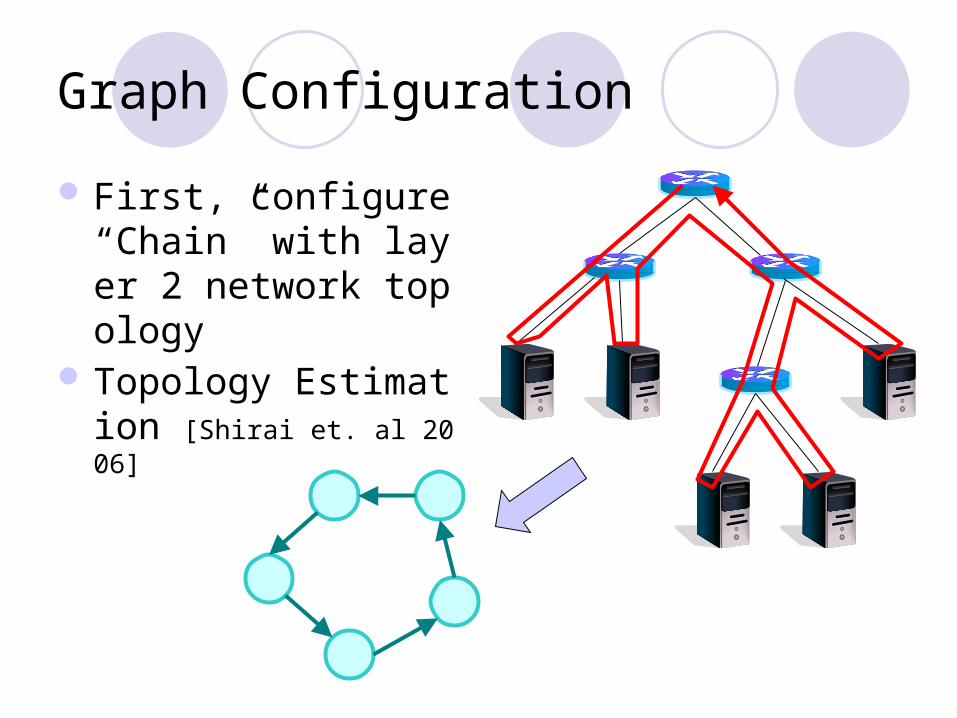
Graph Configuration
First, configure “Chain” with layer 2 network topology
Topology Estimation [Shirai et. al 2006]
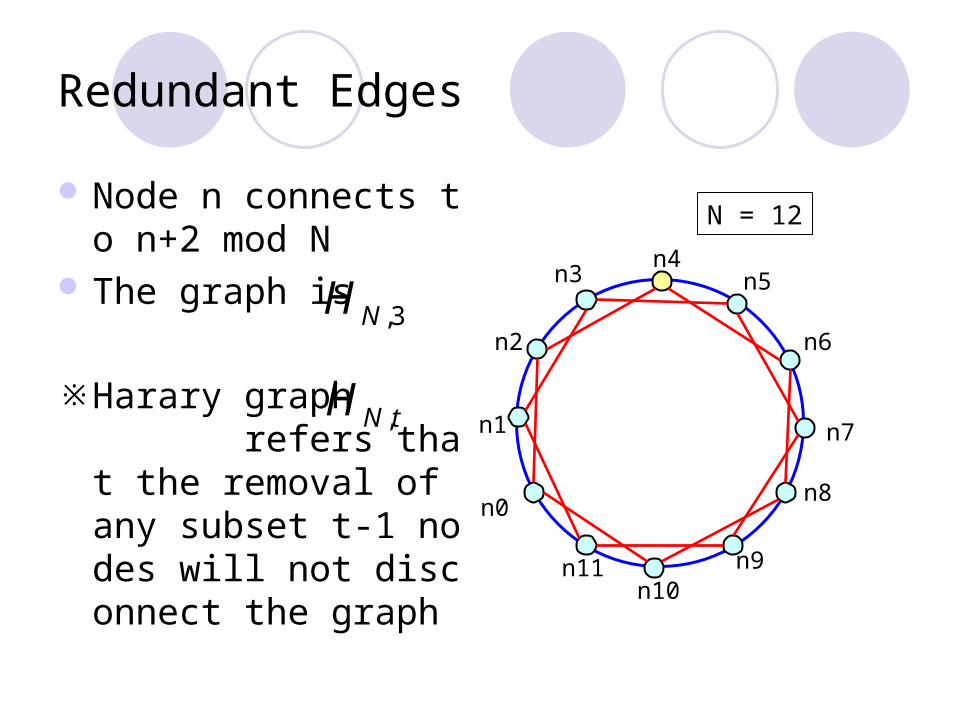
Redundant Edges
Node n connects to n+2 mod N
The graph is
※ Harary graph refers that the removal of any subset t-1 nodes will not disconnect the graph
n1
n2
n3n4
n5
n6
n7
n8
n9n10
n11
n0
N = 12
3,NH
tNH ,
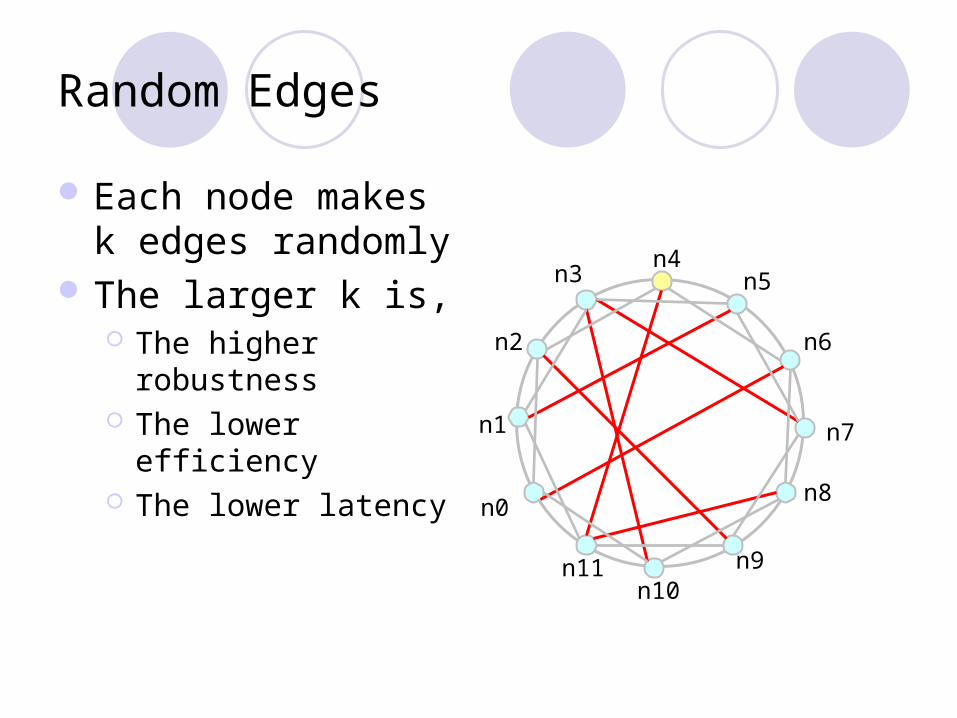
Random Edges
Each node makes k edges randomly
The larger k is, The higher robustness The lower efficiency The lower latency n1
n2
n3n4
n5
n6
n7
n8
n9n10
n11
n0
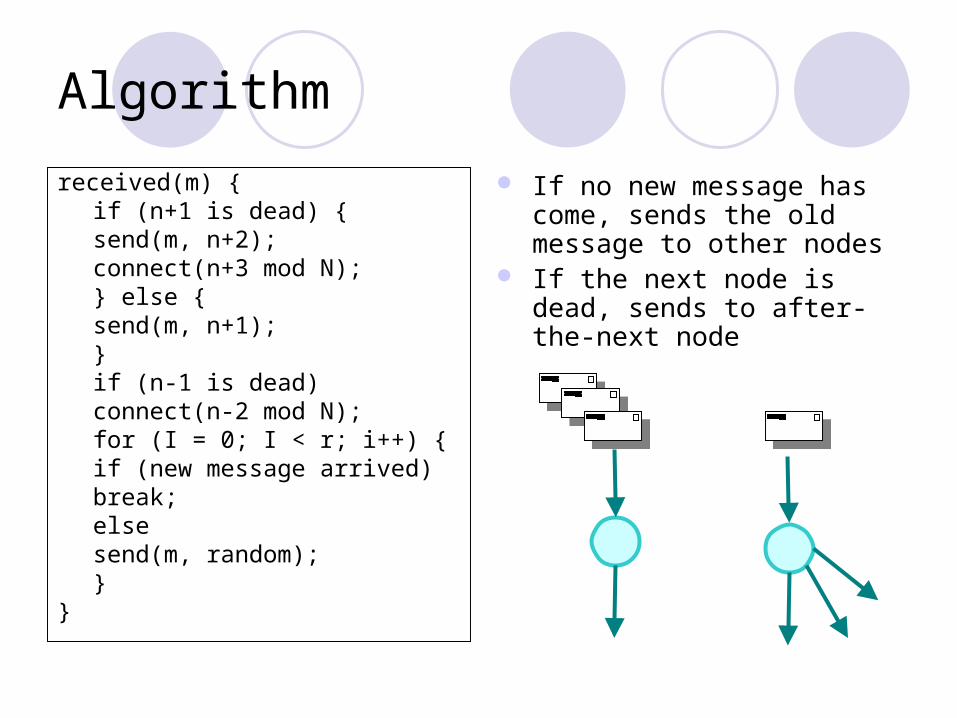
Algorithm
received(m) {if (n+1 is dead) {
send(m, n+2); connect(n+3 mod N);
} else {send(m, n+1);
}if (n-1 is dead)
connect(n-2 mod N);for (I = 0; I < r; i++) {
if (new message arrived)break;
elsesend(m, rando
m);}
}
If no new message has come, sends the old message to other nodes
If the next node is dead, sends to after-the-next node
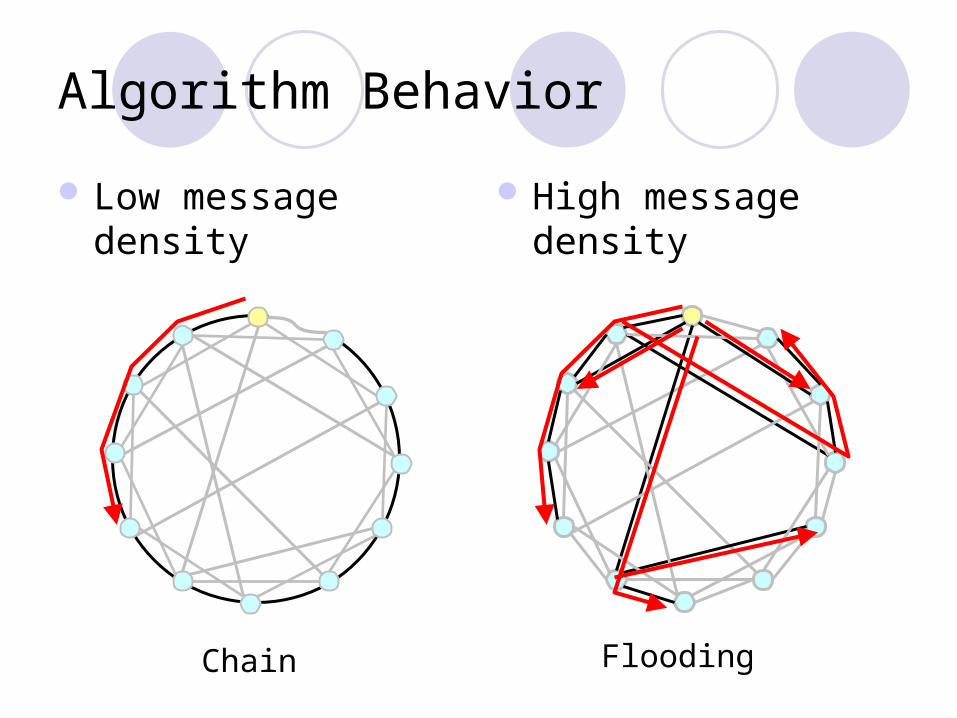
Algorithm Behavior
Low message density High message density
Chain Flooding
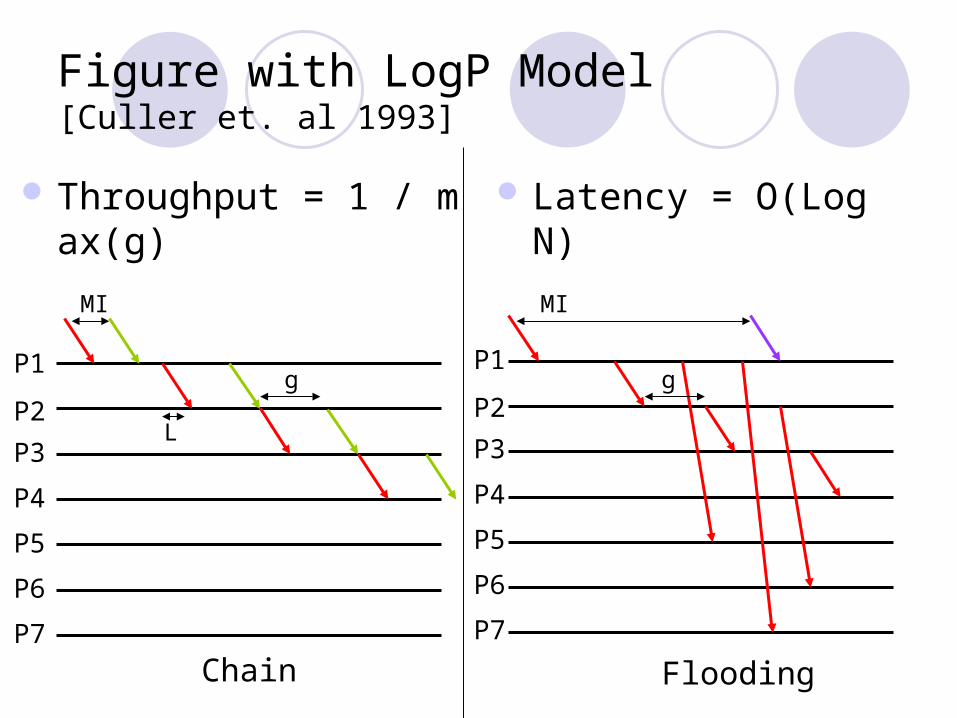
Figure with LogP Model[Culler et. al 1993]
Throughput = 1 / max(g) Latency = O(LogN)
Chain Flooding
MI MI
g gP1
P2
P3
P4
P5
P6
P7
P1
P2
P3
P4
P5
P6
P7
L
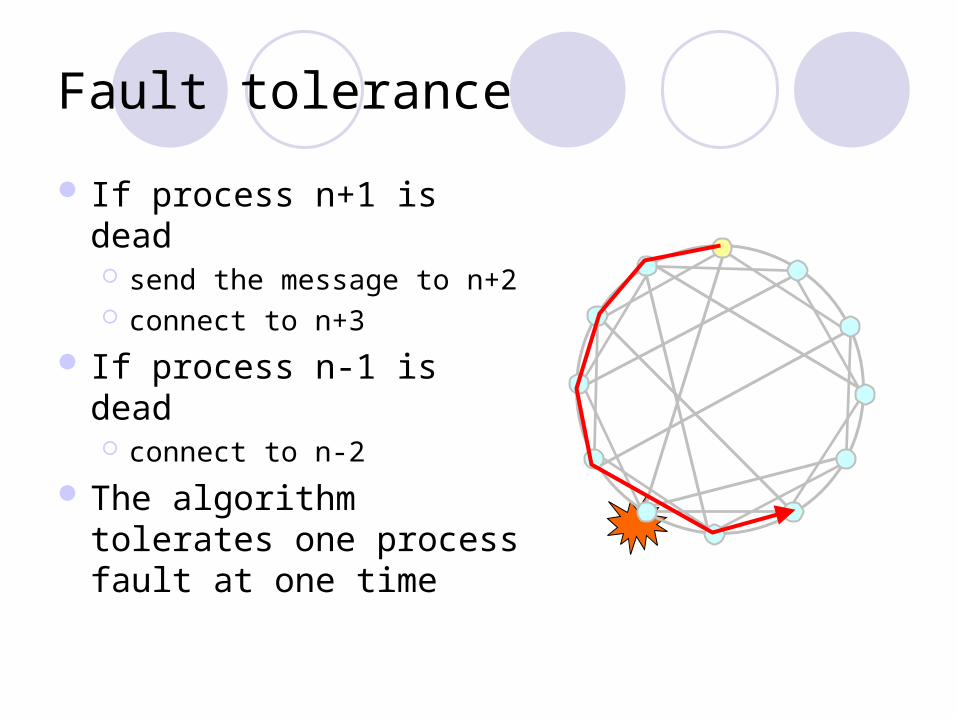
Fault tolerance
If process n+1 is dead send the message to n+2 connect to n+3
If process n-1 is dead connect to n-2
The algorithm tolerates one process fault at one time

Features of Algorithm
Adapt to message size dynamically Random graph flooding (small messages) Single chain pipelining (large messages)
Robustness Redundancy depending on randomness Fault tolerance by redundant edges

Agenda
BackgroundBroadcast Algorithms and Problem
SettingsOur ApproachRelated Works
STAR-MPI
Conclusion

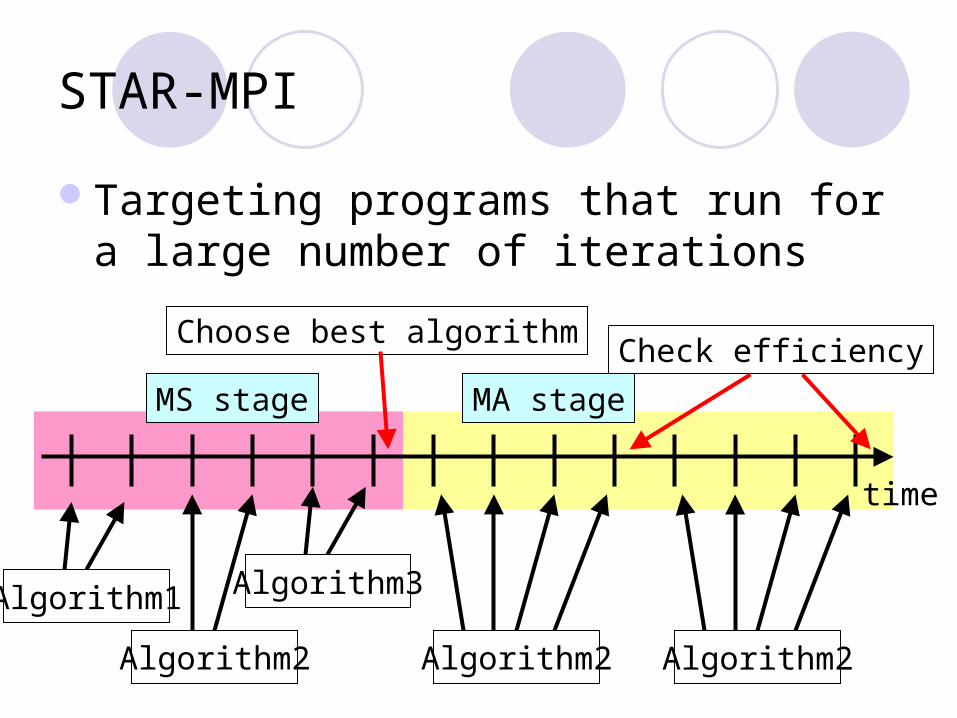
STAR-MPI [Faraj et al.]
Change collective MPI algorithm dynamically
Select best algorithm at run timeMS (Mesure_Select) stage
Trying each algorithm and choose the best one
MA (Monitor_Adapt) stage Checking efficiency of the algorithm
STAR-MPI
Targeting programs that run for a large number of iterations
Algorithm1
Algorithm2
Algorithm3
Algorithm2
Choose best algorithmCheck efficiency
Algorithm2
MS stage MA stage
time

Agenda
BackgroundBroadcast Algorithms and Problem
SettingsOur ApproachRelated WorksConclusion

Conclusion
Proposed the robust algorithm that adapts message size
Future work Implementation and evaluation Deciding best (better) “k” with evaluation

Publications
1. 関谷岳史,田浦健次朗,近山隆.適応的並列計算を支援するプロトコルの設計と正当性の証明.並列/分散/協調処理に関するサマーワークショップ( SWoPP2006), pp.169-174,高知, 2006 年 7 月 .
2. 関谷岳史 , 田浦健次朗 , 近山隆 . 適応的並列計算を支援するプロトコルの設計と正当性の証明 . 先進的計算基盤システムシンポジウム(SACSIS2007). May 2007. (発表予定 )