addressing mpsoc hw/sw platform challenges - ida >...
TRANSCRIPT

1
Addressing MPSoC HW/SWplatform challenges A snapshot of ongoing research activity in the MPSoC group
Luca [email protected]
DEIS Università di Bologna
Research thrusts
n Power modeling and optimizationn Networks on chipn MPSoC architectures: modeling
platform, software analysis and optimization

2
People involvedn Senior staff members
n Luca Benini (PI), Davide Bertozzi (PL)n Graduate students (core team)
n Federico Angiolini, Francesco Poletti, Martino Ruggiero, Mirko Loghi
n In cooperation withn Stanford (2), IMEC (1), UNICA (1), TUD
(1), PSU (1), UM, UNIVR (1)
Power analysis and optimization
Storage and communication EnergyPower management (VFS)

3
Power analysis platformn MPARM: complete MPSoC functional
simulation (cycle accurate)n Technology omogeneous power models
n Parameterized models provided by STMn HW and SW centric power profiling
n Per-component breakdownn Per-function breakdown
n Supports energy aware architectural explorationn Cores and memoryn Communication
0
500000
1000000
1500000
2000000
2500000
3000000
3500000
4000000
512 1024 2048 4096 8192 16384
data cache size
pJ*s
ec
512102420484096819216384
I$ size
Sensitivity analysis andDesign space exploration
n Example: Strong sensitivity to I$ size of ARM coren Points to the criticality of cache power minimization
4
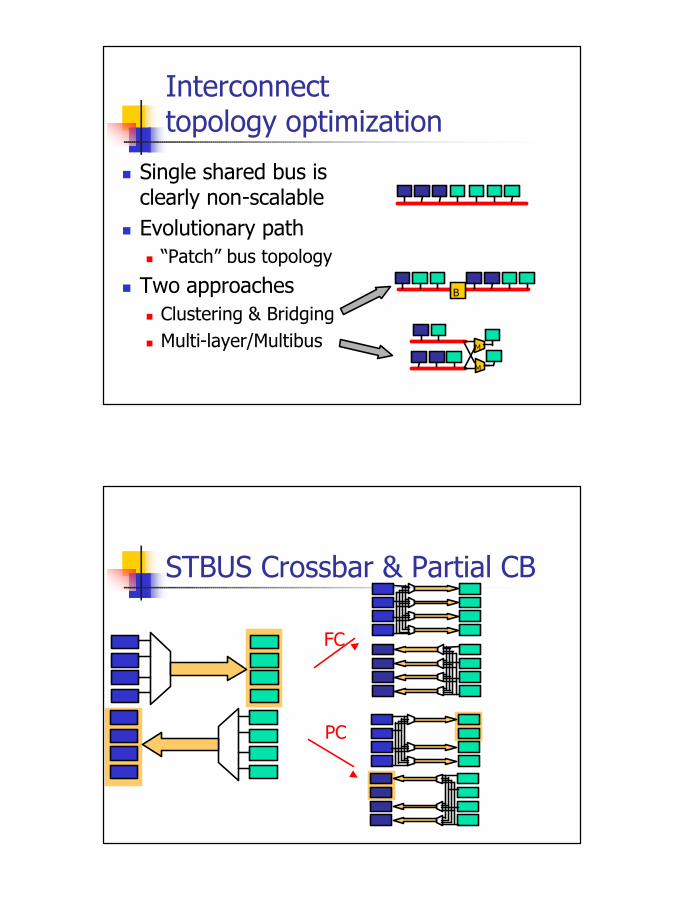
Interconnect topology optimization
n Single shared bus isclearly non-scalable
n Evolutionary pathn “Patch” bus topology
n Two approachesn Clustering & Bridgingn Multi-layer/Multibus
B
M
M
STBUS Crossbar & Partial CB
PC
FC
5
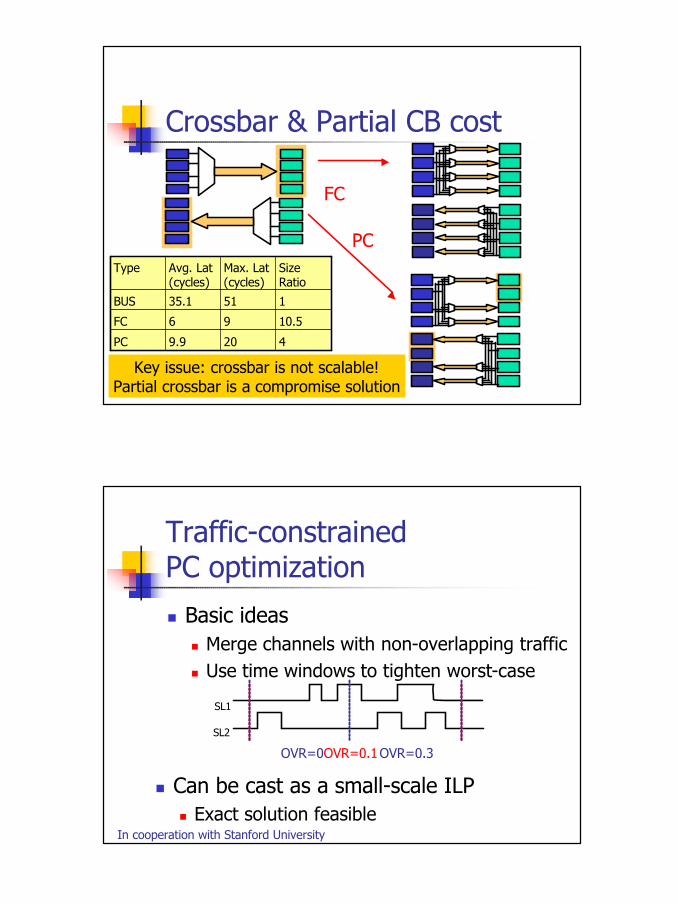
Crossbar & Partial CB cost
PC
FC
Key issue: crossbar is not scalable!Partial crossbar is a compromise solution
4209.9PC
10.596FC
15135.1BUS
SizeRatio
Max. Lat (cycles)
Avg. Lat (cycles)
Type
Traffic-constrained PC optimization
n Basic ideasn Merge channels with non-overlapping trafficn Use time windows to tighten worst-case
OVR=0.1OVR=0 OVR=0.3
SL1
SL2
n Can be cast as a small-scale ILPn Exact solution feasible
In cooperation with Stanford University
6
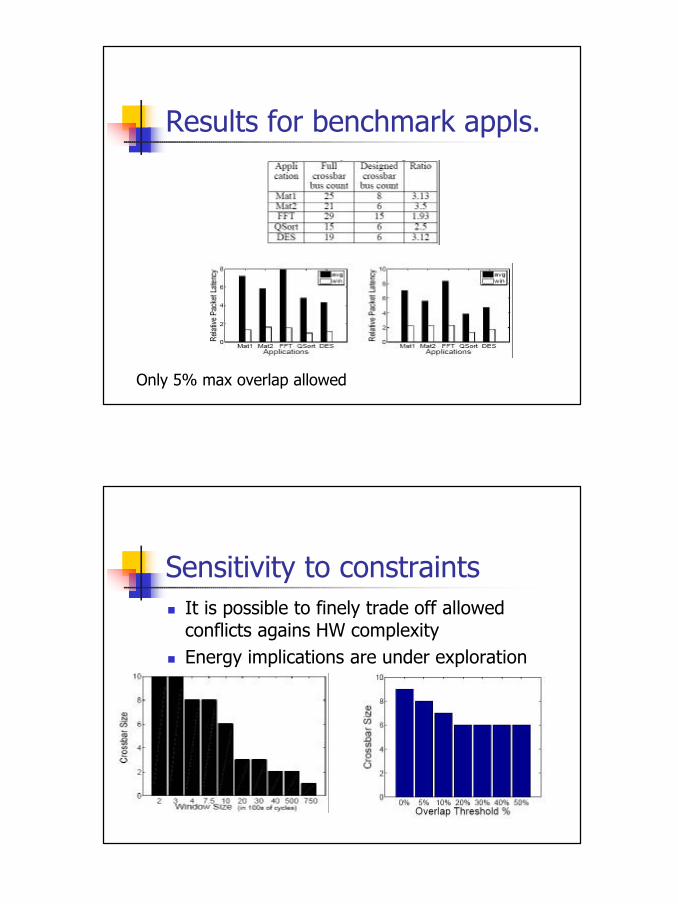
Results for benchmark appls.
Only 5% max overlap allowed
Sensitivity to constraintsn It is possible to finely trade off allowed
conflicts agains HW complexityn Energy implications are under exploration

7
Bus clustering and frequency assignment
n Applied in an AMBA busn Key ideas
n Cluster tightly coupled masters and slavesn Assign frequencies based on bus utilization
P0
M0 M2 M3 M4 M5 M6 M7M1
P1 P2 P3P0
M0
M2 M3
M4M5 M6 M7
M1P1 P2 P3
In cooperation with Penn State University
Experimental resultsn Using high-level simulation model (to be
validated in MPARM)n Optimal configuration found using GA
Single bus 250MHzSingle bus 500MHz

8
Multiprocessor DPM
n Multi-task application (one task per processor) n Unbalanced computationsn Synchronization and inter-task communication n Throughput constraint is given
n Assign nominal core frequenciesn Static analysis (Pareto curve for single task)n Compose Pareto curves
n Dynamic tuning for workload fluctuationsn Use data queues for feedback control
Example (energy vs. time)
1. Producer-consumer's freq. determines energy reduction beyond a threshold
2. Working processor's freq. determines execution time before a threshold
1/Throughput
P
WK(fmax)PR/CN (f↓)
fWK/fPR/CN=const
1

9
Sources of non ideality
Prod
Work
Work
Work
Work
Cons
P
1/Througput
f↓
P
1/Througput
f↓
M-bound vs. CPU-bound tasksCost of communicationCost of synchronization
Analysis of communication architectures for MPSoCs
Advances inprotocols and topologies

10
Network on chip design
Xpipes Architecture and Toolset
Parallel programming on MPSoCs
Hardware supportSoftware analysis and optimization
11
Support for Message passing
Matching the architecture to programming paradigms
n Hardware extensions for messagesn Distributed memory systemn Queues, distributed semaphores, interrupts
n Software support for messagesn System software (task suspension)n Application software (library of APIs for MP)
In cooperation with IMEC
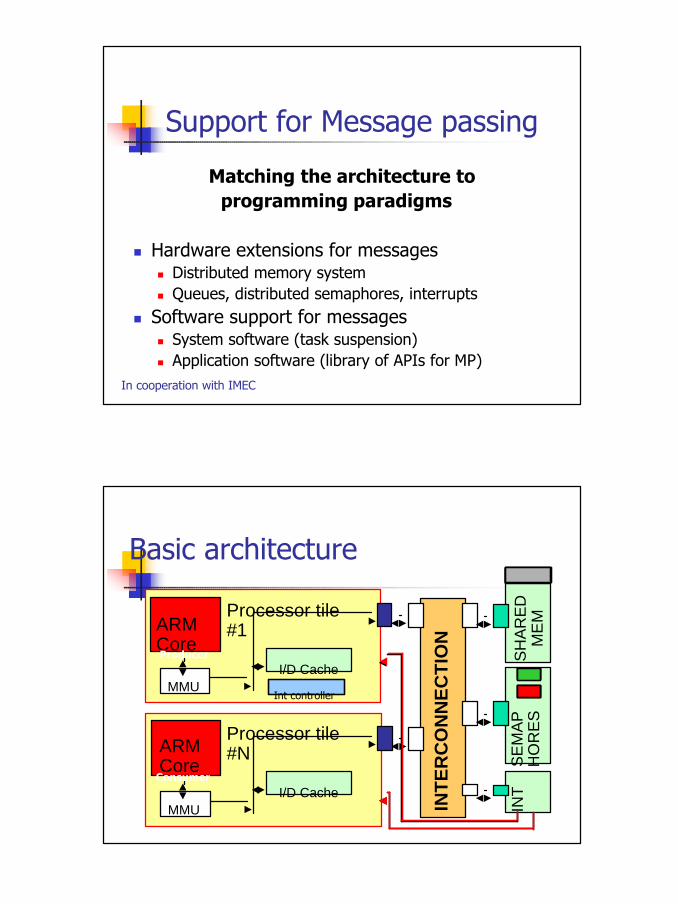
Basic architecture
MMUI/D Cache
INT
ER
CO
NN
EC
TIO
N
ARM Core
SH
AR
ED
M
EMProcessor tile
#1
SE
MA
PH
OR
ES
MMUI/D Cache
ARM Core
Processor tile#N
Producer
Consumer
INT
Int controller

12
ARM CoreARM CORE
Support for UMA
CACHE
BUS*
SNOOPDEVICE
Invalidate/Update
Address and Data
Processor tile#1
*cannot be a generic interconnect!
Support for message passing
MMU
I/D Cache
SPM
INT
ER
CO
NN
EC
TIO
N
ARM Core
SH
AR
ED
M
EM
Processor tile#1
Semaphores
MMU
I/D Cache
SPM
ARM Core
Processor tile#2
Semaphores
Consumer
Producer

13
Hardware support for MP
n More efficient access to data by using the scratch-pad memory, energy and delay-wise
n Avoids centralized slaves bottleneckn More scalable approachn Allows active polling on local semaphores
without generating bus traffic for synchn If semaphore unlocking triggers an interrupt,
suspended slaves can be reactivated
Key advantages
No centralized bottlenecks
8 cores0.00%
25.00%
50.00%
75.00%
100.00%
125.00%
150.00%
175.00%
200.00%
225.00%
250.00%
275.00%
SharedBridgingMultiLayer
Rel
ativ
e ex
ecut
ion
tim
e
8 c o r e s0 .00%
10 .00%
20 .00%
30 .00%
40 .00%
50 .00%
60 .00%
70 .00%
80 .00%
90 .00%
1 0 0 . 0 0 %
1 1 0 . 0 0 %
1 2 0 . 0 0 %
S h a r e dBridgingMultiLayer
Rel
ativ
e ex
ecut
ion
tim
e
Matrix Pipeline with basic architectureMatrix Pipeline with message passing support
170%
20%
Send+Receive cost: 35KCycles (basic architecture) vs. 4KCycles (MP support)Configuration: 4 Processors, Shared bus

14
Supporting interrupts
n 1 task/core: overhead for interrupt handling and idle task scheduling
n 2 task/core: interrupts allow better exploitation of computation resources
0
0.2
0.4
0.6
0.8
1
1.2
1.4
FC8 HC8
Relat
ive E
xecu
tion
Shared Shared+interrupt
HW support HW support+interrupt
4 core, 2 task/core8 core, 1 task/coreARM
CoreProducer
Semaphores
Int controller
Application partitioningn Mapping applications onto MPSoC platforms
n The HW-SW designer perspective: bridging the gapn MPSIM simulator for analyzing partitioning solutionsn Degree of parallelism: the energy-performance
trade-off. MPEG-2 case study
0
200
400
600
800
1000
1200
Mili
on
i
Exe
cutio
n t
ime
(clo
ck c
ycle
s)
1 proc
2 proc
4 proc
800
820
840
860
880
900
920
940
960
Total Energy for 1s decoding
Ene
rgy
(mJ)
1 proc
2 proc
4 proc

15
Programming paradigm
Which workload allocation policy?Message passing or shared memory?
MULTIMEDIAAPPLICATIONS
Each programming model has an architecture optimized for it!
Exploration space
Data size Comp.-Comm.Ratio
Data size Comp.-Comm.Ratio
CommonProcessing Data
DisjointProcessing Data
Pipelining
Master-
Slave
Workload Allocation
Policy
Application Features
Parallel MatrixMultiply
DESEncryption
PipelinedMatrix Multiply
3 algorithms were used forspace exploration

16
Master-slave partitioningCommon
processing dataDisjoint
processing data
Master-Slavecommon processing data
n Computation is O(N ), communication is O(N )n For large data sets, computation efficiency of MP (thanks to
data localization) starts making the differencen Cache size strongly impacts SHM performancen Energy plots are similar
Execution Time for Parallel Matrix Multiply
0,7
0,80,9
1
1,1
1,21,3
1,4
8 16 32
Matrix size
MP/
SHM
1 KB
2 KB
4 KB
3 2
17
Master-SlaveCommon Processing Data
Execution time for Parallel Sum of Matrices
0,7
1,2
1,7
2,2
2,7
3,2
3,7
4,2
8 16 32
Matrix size
MP
/SH
M
1 KB
2 KB
4 KB
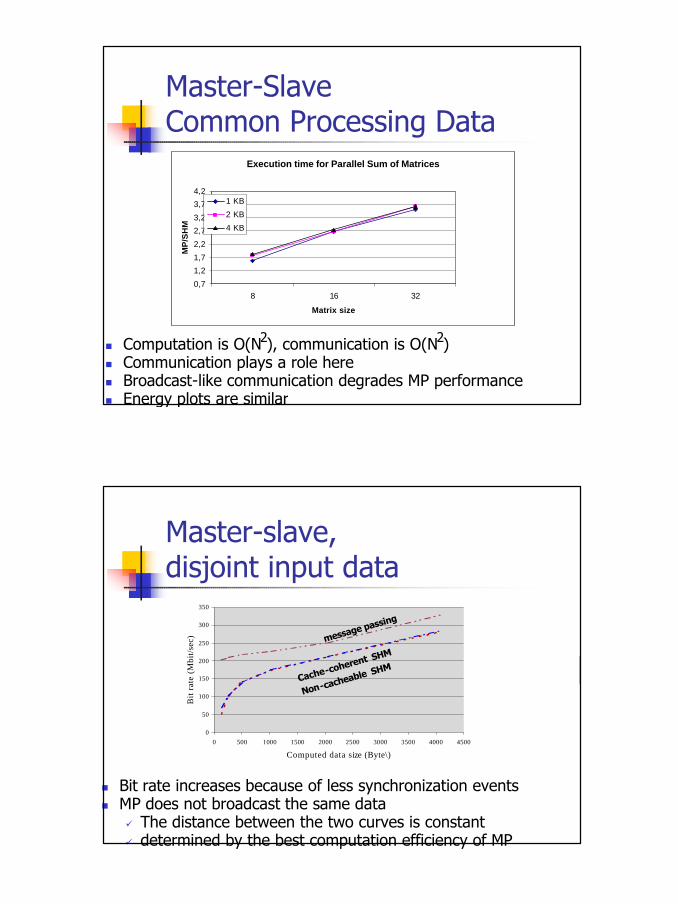
n Computation is O(N ), communication is O(N )n Communication plays a role heren Broadcast-like communication degrades MP performancen Energy plots are similar
2 2
Master-slave, disjoint input data
0
50
100
150
200
250
300
350
0 500 1000 1500 2000 2500 3000 3500 4000 4500
Computed data size (Byte\)
Bit
rat
e (M
bit/
sec)
Message passing
Non cacheable shared memory
Cache coherent shared memory
message passing
Cache-coherent SHM
Non-cacheable SHM
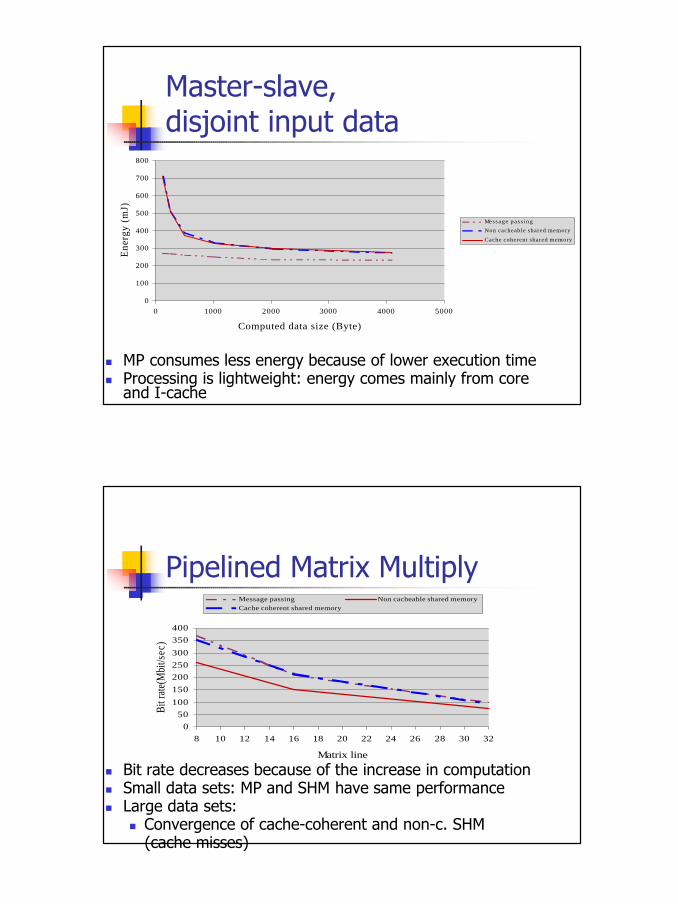
n Bit rate increases because of less synchronization eventsn MP does not broadcast the same data
ü The distance between the two curves is constantü determined by the best computation efficiency of MP
18
Master-slave,disjoint input data
0
100
200
300
400
500
600
700
800
0 1000 2000 3000 4000 5000
Computed data size (Byte)
Ene
rgy
(mJ)
Message pass ing
Non cacheable shared memory
Cache coherent shared memory
n MP consumes less energy because of lower execution timen Processing is lightweight: energy comes mainly from core
and I-cache
Pipelined Matrix Multiply
050
100
150200250300
350400
8 10 12 14 16 18 20 22 24 26 28 30 32
Matrix line
Bit r
ate(M
bit/s
ec)
Message passing Non cacheable shared memoryCache coherent shared memory
n Bit rate decreases because of the increase in computationn Small data sets: MP and SHM have same performancen Large data sets:
n Convergence of cache-coherent and non-c. SHM(cache misses)

19
Pipelined sum of matrices
0
500
1000
1500
2000
2500
3000
8 10 12 14 16 18 20 22 24 26 28 30 32
Matrix line
Bit r
ate
(Mbi
t/sec
)
Message passing Non cacheable shared memoryCache coherent shared memory
n Computation is O(N ), communication efficiency comes into playn For large data sets…
n SHM outperforms MPn Large matrices: convergence of cache coherent and non-coh. SHM
n Energy plots are similar
2
Summing up…
Computation/communicationratio
MPSHM
Sharing of processing data
SHMMP
Some trends are emerging…..
trade-offs might be imposed by conflicting application features

20
System modeling infrastructure
Speeding up ValidationEnhancing modeling capabilities
Directions of improvement
n Issues:n stressing performance bottlenecks with
easily configurable amounts of trafficn triggering bugs in rarely used coden simulation speed!
n Traffic Generatorsn FPGA mapping
21
Traffic Generator architecture
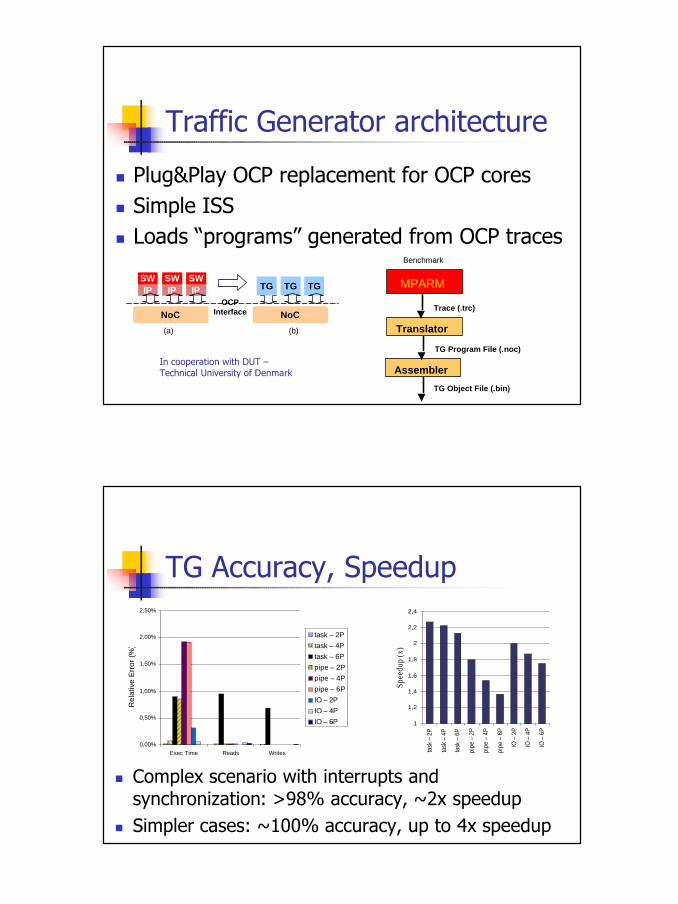
n Plug&Play OCP replacement for OCP coresn Simple ISSn Loads “programs” generated from OCP traces
MPARM
Benchmark
Trace (.trc)
Translator
Assembler
TG Object File (.bin)
TG Program File (.noc)
NoC
IP IPIPSW
NoC
(a)
TG TG TGSW SW
(b)
OCP Interface
In cooperation with DUT –Technical University of Denmark
TG Accuracy, Speedup
0,00%
0,50%
1,00%
1,50%
2,00%
2,50%
Exec Time Reads Writes
Rel
ativ
e E
rror
(%
)
task – 2Ptask – 4Ptask – 6Ppipe – 2Ppipe – 4Ppipe – 6PIO – 2PIO – 4PIO – 6P 1
1,2
1,4
1,6
1,8
2
2,2
2,4
task
– 2
P
task
– 4
P
task
– 6
P
pipe
– 2
P
pipe
– 4
P
pipe
– 6
P
IO –
2P
IO –
4P
IO –
6P
Spee
dup
(x)
n Complex scenario with interrupts andsynchronization: >98% accuracy, ~2x speedup
n Simpler cases: ~100% accuracy, up to 4x speedup

22
FPGA mappingn NoC analysis environment available
n VirtexII Pro platformn Stochastic and trace-based analysis
n MPARM porting on FPGA underway
In cooperation with Stanford University, Universidad Complutense de Madrid
Model enhancementsn Interconnects
n AMBA AHB Multilayern AMBA AXI
n Coresn LXn MIPS, PPC, Xscale (with some limitations)
n Peripheralsn DSP Coprocessor with DMA (FFT)n Smart memories (DMA capable)

23
Future workn Power optimization
n Better integration and validation of communication and storage power optimization
n Deeper MP DPM exploration n NoC
n Compare area, power timing w.r.t. STBus on layoutn Additional features: link protocol, QoS support, multiple
outstanding transactionsn MPSoC hw and sw architectures
n Communication libraryn Improve software parallelization analysis (parallelization advisor)
n Modeling platformn Improve IO and External memory interface models (Memory
controller)n Eterogeneous platform support