advanced performance diagnostics for sql in db2 9.7 david kalmuk ibm platform: db2 for linux, unix,...
TRANSCRIPT

Advanced Performance Diagnostics for SQL in DB2 9.7
David KalmukIBM
Platform: DB2 for Linux, Unix, Windows

Objectives
• Learn how to leverage the latest DB2 performance monitoring features and time spent metrics to identify that you have an SQL problem
• Learn how to pinpoint your most expensive statements using the package cache table functions
• Learn about the new runtime explain capabilities and how you can perform an explain from the actual compiled section in the catalogs or the package cache to understand the query plan.
• Learn how to leverage the new section actuals explain capabilities to examine the actual cardinalities from the execution of your problem queries
• Take away practical examples you can try out in your own environment.

Agenda
• A quick review of the new Monitoring Capabilities introduced in DB2 9.7
• Time Spent Metrics
• Identifying query related performance problems
• Identifying high impact queries
• Analyzing queries using Time Spent
• Advanced diagnostics using Runtime Explain and Section Actuals
• Final thoughts

A Quick Review of the New Performance Monitoring Capabilities Introduced in DB2 9.7

New Lightweight Monitoring Functions
• New set of MON_* SQL functions introduced starting in DB2 9.7
• Less impact / more efficient then snapshot functions• Direct in-memory access through trusted routines (not fenced wrappers over
snapshot)• Much less latch contention
• Uses new infrastructure that pushes data up to accumulation points rather than forcing monitor queries to do extensive drilldown
• Lower CPU consumption• Significantly faster response time• Less FCM resource usage / internode traffic
• Monitoring data collection carries low overhead – is enabled by default on new databases

New Monitoring Perspectives and Dimensions
• Starting in 9.7, DB2 allows monitoring metrics to be accessed through a number of different dimensions
• Allows more effective drilldown, and different perspectives on the data to help isolate problems
• Three main dimensions, each consisting of a number of reporting points with corresponding SQL functions
• System• Provide total perspective of application work being done by database system• Aggregated through the WLM infrastructure
• Data objects• Provide perspective of impact of all activity occurring with the scope of data
objects• Aggregated through data storage infrastructure
• Activity• Provide perspective of work being done by specific SQL statements• Aggregated through the package cache infrastructure

In-Memory Metrics: System Perspective
Connection ∑R
Service Class ∑R
Service Class ∑R
DB2 AgentCollects Data
Database Request
Workload Definition∑R
Request Metrics
Workload Occurrence (UOW) ∑R
LegendΣR = Accumulation of request metrics collected by agent

Access Points: System Perspective
• MON_GET_UNIT_OF_WORK• MON_GET_WORKLOAD• MON_GET_CONNECTION• MON_GET_SERVICE_SUBCLASS
• Also provide interfaces that produce XML output:• MON_GET_UNIT_OF_WORK_DETAILS• MON_GET_WORKLOAD_DETAILS• MON_GET_CONNECTION_DETAILS• MON_GET_SERVICE_SUBCLASS_DETAILS

DB2 Agent Collects Data
Table
Database Request
Tablespace
TableMetrics
TablespaceMetrics
Bufferpool
Tablespace TablespaceContainer
ContainerMetrics
BufferpoolMetrics
LOB /Data
XML DataIndex
Row Data
TempTablespace
In-Memory Metrics: Data Object Perspective

Access Points: Data Object Perspective
• MON_GET_TABLE• MON_GET_INDEX• MON_GET_BUFFERPOOL• MON_GET_TABLESPACE• MON_GET_CONTAINER• MON_GET_EXTENT_MOVEMENT_STATUS• MON_GET_APPL_LOCKWAIT [9.7FP1]
• MON_GET_LOCKS [9.7FP1]
• MON_GET_FCM [9.7FP2]
• MON_GET_FCM_CONNECTION_LIST [9.7FP2]

In-Memory Metrics: Activity Perspective
DB2 AgentCollects Data
WLM Activity ∑A
Package Cache ∑A
Database Request
ActivityMetrics
Activity Level
LegendΣA = Accumulation of metrics from activity execution portion of request

Access Points: Activity Perspective
• MON_GET_PKG_CACHE_STMT• Both static and dynamic SQL
• MON_GET_PKG_CACHE_STMT_DETAILS• XML based output
• MON_GET_ACTIVITY_DETAILS (XML)• Details for an activity currently in progress

Time Spent Metrics

Time Spent Metrics
• A new set of metrics are being introduced into DB2 that represent a breakdown of where time is spent within DB2• Represents sum of time spent by each agent thread in the system (foreground
processing)• Provides user with a relative breakdown of time spent, showing which areas are
the most expensive during request / query processing• Available in both system and activity perspectives
• This presentation will focus on analysis from the activity perspective• Can be used for rapid identification and diagnosis of performance problems
• Times are divided into:• Wait times
• Time agent threads spend blocking on I/O, network communications, etc• Processing times (starting in 9.7FP1)
• Time spent processing in different component areas when the agent was not stuck on a wait
• Summary / total times• Total time spent in a particular component area including both processing + wait
times

“Time Spent” Metrics: Breakdown of Wait + Processing Times in DB2
Total Request Time in DB2Direct I/O
Bufferpool I/O
Lock Wait Time
Compile ProcTime
Section Proc Time
Commit / RollbackProc Time
Other Proc Time

Activity Time Spent Hierarchy
STMT_EXEC_TIMETOTAL__ACT_WAIT_TIME
LOCK_WAIT_TIMELOG_BUFFER_WAIT_TIMELOG_DISK_WAIT_TIMEFCM_SEND/RECV_WAIT_TIME FCM_MESSAGE_SEND/RECV_WAIT_TIME FCM_TQ_SEND/RECV_WAIT_TIMEDIAGLOG_WRITE_WAIT_TIMEPOOL_READ/WRITE_TIMEDIRECT_READ/WRITE_TIMEAUDIT_SUBSYSTEM_WAIT_TIMEAUDIT_FILE_WRITE_TIME
TOTAL_SECTION_PROC_TIMETOTAL_SECTION_SORT_PROC_TIME
TOTAL_ROUTINE_NON_SECT_PROC_TIME TOTAL_ROUTINE_USER_CODE_PROC_TIME(Other – nested section execution)
Time performing query plan execution
•“Time spent” metrics are mutually exclusive and in aggregate form a hierarchy (shown below) that breaks down the time spent executing queries in the database server on behalf of the client. Below we show the hierarchy for the activity perspective.

Navigating the “time spent” hierarchy
• The row based formatting functions introduced in 9.7 FP1 offer an easy way to navigate the time spent hierarchy in a generic fashion• MON_FORMAT_XML_TIMES_BY_ROW
• Shows breakdown of waits + processing times
• MON_FORMAT_XML_WAIT_TIMES_BY_ROW• Shows breakdown of just wait times
• MON_FORMAT_XML_COMPONENT_TIMES_BY_ROW• Shows breakdown of processing time as well as overall time spent in each
“component” of DB2
• MON_FORMAT_XML_METRICS_BY_ROW• Outputs all metrics in generic row based form

Exampleselect r.metric_name, r.parent_metric_name, r.total_time_value as time, r.count, p.member, s.stmt_text as stmt
from table(mon_get_pkg_cache_stmt_details(‘S',null,null,-2)) as p
table(mon_get_pkg_cache_stmt(null,p.executable_id,null,-2)) as s,
table(mon_format_xml_times_by_row(p.details)) as r,
where s.stmt_text like ‘UPDATE stock%‘
order by total_time_value desc
METRIC_NAME PARENT_METRIC_NAME TIME COUNT MEMBER STMT ------------------------- -------------------- ----------- --------- ------ --------------------TOTAL_SECTION_PROC_TIME STMT_EXEC_TIME 1030980 2134223 0 UPDATE stock…STMT_EXEC_TIME - 1030980 2134223 0 UPDATE stock…WLM_QUEUE_TIME_TOTAL - 0 0 0 UPDATE stock… LOCK_WAIT_TIME TOTAL_ACT_WAIT_TIME 0 0 0 UPDATE stock… DIRECT_READ_TIME TOTAL_ACT_WAIT_TIME 0 0 0 UPDATE stock… DIRECT_WRITE_TIME TOTAL_ACT_WAIT_TIME 0 0 0 UPDATE stock… LOG_BUFFER_WAIT_TIME TOTAL_ACT_WAIT_TIME 0 0 0 UPDATE stock… LOG_DISK_WAIT_TIME TOTAL_ACT_WAIT_TIME 0 0 0 UPDATE stock… POOL_WRITE_TIME TOTAL_ACT_WAIT_TIME 0 0 0 UPDATE stock… POOL_READ_TIME TOTAL_ACT_WAIT_TIME 0 0 0 UPDATE stock… AUDIT_FILE_WRITE_WAIT_TIM TOTAL_ACT_WAIT_TIME 0 0 0 UPDATE stock… AUDIT_SUBSYSTEM_WAIT_TIME TOTAL_ACT_WAIT_TIME 0 0 0 UPDATE stock… DIAGLOG_WRITE_WAIT_TIME TOTAL_ACT_WAIT_TIME 0 0 0 UPDATE stock… FCM_SEND_WAIT_TIME TOTAL_ACT_WAIT_TIME 0 0 0 UPDATE stock… FCM_RECV_WAIT_TIME TOTAL_ACT_WAIT_TIME 0 0 0 UPDATE stock… TOTAL_ACT_WAIT_TIME STMT_EXEC_TIME 0 - 0 UPDATE stock……
Show me the full hierarchy
of waits + processing times for a particular statement

Example 2select r.metric_name, r.parent_metric_name, r.total_time_value as time, r.count, p.member, s.stmt_text as stmt
from table(mon_get_pkg_cache_stmt_details(‘S',null,null,-2)) as p
table(mon_get_pkg_cache_stmt(null,p.executable_id,null,-2)) as s,
table(mon_format_xml_wait_times_by_row(p.details)) as r,
where s.stmt_text like ‘UPDATE stock%‘
order by total_time_value desc
METRIC_NAME PARENT_METRIC_NAME TIME COUNT MEMBER STMT ------------------------- -------------------- ----------- --------- ------ --------------------WLM_QUEUE_TIME_TOTAL - 0 0 0 UPDATE stock LOCK_WAIT_TIME TOTAL_ACT_WAIT_TIME 0 0 0 UPDATE stock DIRECT_READ_TIME TOTAL_ACT_WAIT_TIME 0 0 0 UPDATE stock DIRECT_WRITE_TIME TOTAL_ACT_WAIT_TIME 0 0 0 UPDATE stock LOG_BUFFER_WAIT_TIME TOTAL_ACT_WAIT_TIME 0 0 0 UPDATE stock LOG_DISK_WAIT_TIME TOTAL_ACT_WAIT_TIME 0 0 0 UPDATE stock POOL_WRITE_TIME TOTAL_ACT_WAIT_TIME 0 0 0 UPDATE stock POOL_READ_TIME TOTAL_ACT_WAIT_TIME 0 0 0 UPDATE stock AUDIT_FILE_WRITE_WAIT_TIM TOTAL_ACT_WAIT_TIME 0 0 0 UPDATE stock AUDIT_SUBSYSTEM_WAIT_TIME TOTAL_ACT_WAIT_TIME 0 0 0 UPDATE stock DIAGLOG_WRITE_WAIT_TIME TOTAL_ACT_WAIT_TIME 0 0 0 UPDATE stock FCM_SEND_WAIT_TIME TOTAL_ACT_WAIT_TIME 0 0 0 UPDATE stock FCM_RECV_WAIT_TIME TOTAL_ACT_WAIT_TIME 0 0 0 UPDATE stock TOTAL_ACT_WAIT_TIME STMT_EXEC_TIME 0 - 0 UPDATE stock …
Show me the just the wait
times perspective

Example 3select r.metric_name, r.parent_metric_name as parent_metric, r.total_time_value as total_time,r.proc_metric_name, r.parent_proc_metric_name as parent_proc_metric, r.proc_time_value as proc_time, r.count, p.member, s.stmt_text as stmt
from table(mon_get_pkg_cache_stmt_details('S',null,null,-2)) as p,
table (mon_get_pkg_cache_stmt(null,p.executable_id,null,-2)) as s,
table(mon_format_xml_component_times_by_row(p.details)) as r
where s.stmt_text like 'UPDATE stock%'
order by total_time_value desc
METRIC_NAME PARENT_METRIC TOTAL_TIME PROC_METRIC_NAME PARENT_PROC_METRIC PROC_TIME COUNT MEMBER STMT-------------------- ---------------- ---------- -------------------- ------------------ --------- ------ ------ -------STMT_EXEC_TIME - 1031684 - - - 0 0 UPDATE…TOTAL_SECTION_TIME TOTAL_RQST_TIME 1031684 TOTAL_SECTION_PROC TOTAL_RQST_TIME 1031684 2134223 0 UPDATE…TOTAL_SECTION_SORT_T TOTAL_SECTION_TIME 0 TOTAL_SECTION_SORT_P TOTAL_SECTION_PROC 0 0 0 UPDATE…TOTAL_ROUTINE_NON_SE TOTAL_ROUTINE_TIME 0 TOTAL_ROUTINE_NON_SE TOTAL_ROUTINE_TIME 0 0 0 UPDATE…TOTAL_ROUTINE_TIME STMT_EXEC_TIME 0 - - - 0 0 UPDATE…TOTAL_ROUTINE_USER_C TOTAL_ROUTINE_NON_S 0 TOTAL_ROUTINE_USER_C TOTAL_ROUTINE_NON_S 0 0 0 UPDATE…
Show me the just the
times for each
individual component
area

Identifying Query Related Performance Problems

Identifying Query Related Performance Problems
• Generally we will want to try to identify and address any system level bottlenecks / non query related issues first before proceeding to more granular investigation at the statement or query level
• We will look at some initial indicators here to help rule out broad system-wide or non query related problems
• This will help us narrow down whether the performance issues we are observing are related to statement execution or plan issues specifically rather than other system bottlenecks, and that tuning individual queries will give us some bang for our buck
• The following examples will show some of the basic indicators that may be useful in helping to make this determination

“How much time on the database is spent doing query processing?”
select sum(total_rqst_time) as rqst_time, sum(total_act_time) as act_time, sum(total_section_time) as sect_time, (case when sum(total_rqst_time) > 0 then (sum(total_act_time) * 100) / sum(total_rqst_time) else 0 end) as act_pct (case when sum(total_rqst_time) > 0 then (sum(total_section_time) * 100) / sum(total_rqst_time) else 0 end) as sect_pctfrom table(mon_get_connection(null,-2)) as t
Added some percentages for readability
RQST_TIME ACT_TIME SECT_TIME ACT_PCT SECT_PCT----------------- ----------------- ----------------- ----------------- ----------------- 18188462 8419265 8419265 46 46
About 46% of time spent executing query plans

create view dbtimemetrics (metric_name, parent_metric_name, total_time_value, count)
as select u.metric_name, u.parent_metric_name, sum(u.total_time_value), sum(u.count)from table(mon_get_service_subclass_details(null,null,-2)) as t, table(mon_format_xml_times_by_row(t.details)) as ugroup by metric_name, parent_metric_name
create global temporary table timesamplesas (select * from dbtimemetrics) definition only on commit delete rows
create view dbtimedelta (metric_name, parent_metric_name, total_time_value, count)as select t2.metric_name, t2.parent_metric_name, t2.total_time_value - t1.total_time_value, t2.count - t1.countfrom dbtimemetrics as t2, timesamples as t1 where t2.metric_name = t1.metric_name
“Are there any system-wide bottlenecks?”
A bit of scripting /
setup to help obtain deltas

(continued)
Get wait times on database
sampled over 1 minute
insert into timesamples select * from dbtimemetrics<sleep for 60s sampling period>select * from dbtimedelta order by total_time_value desc
fetch first 5 rows only
METRIC_NAME PARENT_METRIC_NAME TOTAL_TIME_VALUE COUNT MEMBER ------------------------- ------------------------- -------------------- -------------------- ------ TOTAL_RQST_TIME - 14694008 31778866 0 TOTAL_WAIT_TIME TOTAL_RQST_TIME 7471599 - 0 CLIENT_IDLE_WAIT_TIME - 7230313 - 0TOTAL_SECTION_PROC_TIME TOTAL_RQST_TIME 7220409 29277233 0 LOG_DISK_WAIT_TIME TOTAL_WAIT_TIME 7001599 103341 0…
(Be sure to run with auto-commit disabled when using CLP)

Identifying High Impact / Expensive Queries

Identifying Problem Queries
• Once we’ve ruled out general system-wide bottlenecks that might be impacting our performance we’ll want to identify the highest impact / worst performing queries on the system as possible candidates for tuning
• Time spent metrics can be used to drill down in a number of different useful ways in order to help identify high impact queries.
• Among the many things we can look at are:• Queries with the most execution time in server• Queries with the worst velocity in terms of processing vs wait• CPU intensive queries• Least efficient query plans
• The following examples will show you several ways you can leverage the time spent metrics to drill down and identify your problem queries

Finding High Impact Queries
select stmt_exec_time, num_executions, stmt_text
from table(mon_get_pkg_cache_stmt(null,null,null,-2)) as s
order by stmt_exec_time desc fetch first 5 rows only
Top 5 queries by statement
execution time in server
STMT_EXEC_TIME NUM_EXECUTIONS STMT -------------------- -------------------- ----------------------------------------------- 3951764 2218111 SELECT s_quantity, s_dist_01, s_dist_02, … 902078 195866 SELECT c_balance, c_delivery_cnt … 619547 212999 DECLARE CUST_CURSOR1 CURSOR FOR SELEC … 480681 221873 SELECT w_tax, c_discount, c_last, c_credit … 441494 20124 SELECT count(distinct S_I_ID) INTO :H …
Statement with most execution time in the server
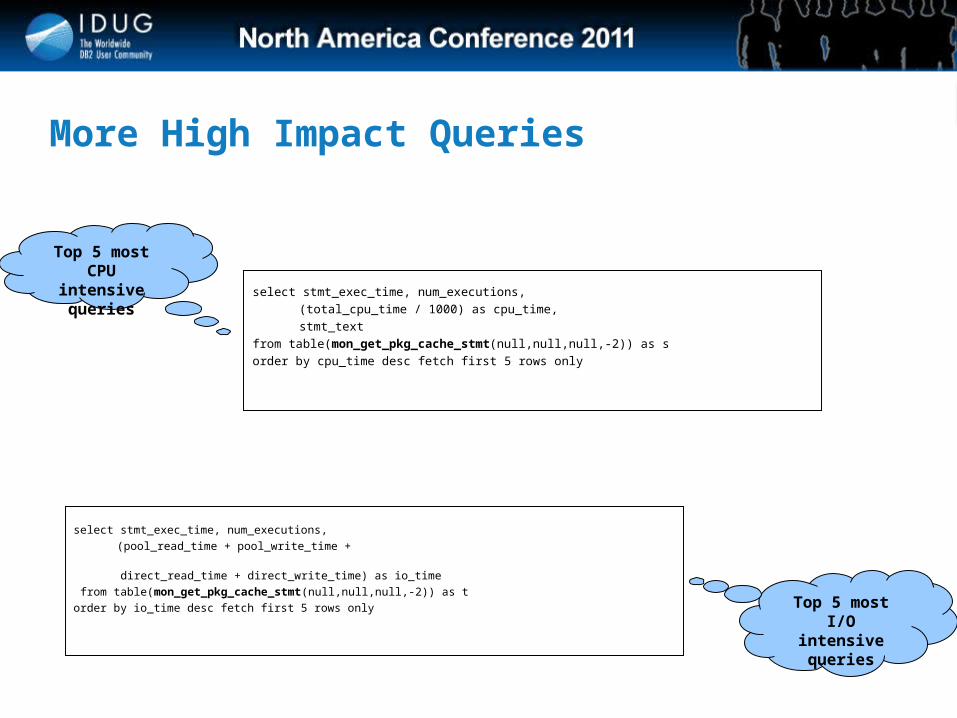
More High Impact Queries
select stmt_exec_time, num_executions,
(total_cpu_time / 1000) as cpu_time,
stmt_text
from table(mon_get_pkg_cache_stmt(null,null,null,-2)) as s
order by cpu_time desc fetch first 5 rows only
Top 5 most CPU
intensive queries
select stmt_exec_time, num_executions,
(pool_read_time + pool_write_time +
direct_read_time + direct_write_time) as io_time
from table(mon_get_pkg_cache_stmt(null,null,null,-2)) as t
order by io_time desc fetch first 5 rows only Top 5 most I/O intensive
queries

Queries with the Worst Relative Velocity
select total_act_time, total_act_wait_time, (case when total_act_time > 0
then ((total_act_time – total_act_wait_time) * 100 / total_act_time) else 100 end) as relvelocity,
stmt_textfrom table (mon_get_pkg_cache_stmt(null,null,null,-2)) as torder by relvelocity fetch first 5 rows only
Relative velocity
shows the degree to
which progress of the query is impacted by
waits
Compute percentage of query time where we’re processing
TOTAL_ACT_TIME TOTAL_ACT_WAIT_TIME RELVELOCITY STMT_TEXT-------------------- -------------------- -------------------- -------------------- 1481597 1457690 1 DECLARE READ_ORDERLI … 228 223 2 create view dbtimeme … 28 27 3 alter table activity … 30 29 3 create event monitor … 35 33 5 create event monitor …
Majority of query time spent in waits!

Queries with the Least Efficient Plans This query shows us how much data we
processed to produce a
single row of results
ROWS_RETURNED ROWS_READ RATIO STMT -------------------- -------------------- -------------------- ------------------------- 2 11137814 5568907 select count(*) from acti… 1 5568907 5568907 select min(time_completed 3 9 3 select * from syscat.WORK… 9 9 1 select substr(serviceclas… 9 9 1 select * from dbtimedelta… 2843729 2843729 1 DECLARE CUST_CURSOR1 CURS… 2843729 2843729 1 SELECT w_street_1, w_stre… 29599464 29599528 1 SELECT s_quantity, s_dist… 0 14 0 alter table control drop… 0 13 0 create view dbtimemetrics…
select rows_returned, rows_read, (case when rows_returned > 0 then rows_read / rows_returned else 0 end) as ratio, stmt_text as stmtfrom table(mon_get_pkg_cache_stmt(null,null,null,-2)) as porder by ratio descfetch first 10 rows only
Ratio of rows read to rows returned

The “Executable ID”
• In order to facilitate tracking of individual statements, DB2 9.7 introduced the new concept of an “executable id”• Short identifier that uniquely identifies a section in the package cache (not
an individual execution, but an individual statement in a particular compilation environment)
• Can be obtained from activity monitoring interfaces such as MON_GET_PKG_CACHE_STMT / MON_GET_PKG_CACHE_STMT_DETAILS, MON_GET_ACTIVITY_DETAILS or the package cache and activity event monitors
• Can be subsequently used as input to the package cache interfaces to retrieve data for that particular section without the statement text
• In the next section we will leverage the executable ID that uniquely identifies our statements of interest in order to perform further drilldown

Analyzing Individual Statements Using Time Spent

Analyzing Individual Queries Using Time Spent
• Once we have pinpointed our statements of interest, our next step is to drill down into these individual statements to understand where they are spending their time
• By understanding where the time is being spent in the query we can identify where the database server is spending effort, and look for opportunities for tuning
• Using the executable id from problem statements identified in the previous section we can now perform an analysis of the time spent breakdown for those statements

“Where is my time being spent?”
select p.executable_id, r.metric_name, r.parent_metric_name,
r.total_time_value as time, r.count, p.member
from
(select stmt_exec_time, executable_id
from table(mon_get_pkg_cache_stmt(null,null,null,-2)) as s
order by stmt_exec_time desc fetch first row only) as stmts,
table(mon_get_pkg_cache_stmt_details(null,
stmts.executable_id,
null,
-2)) as p,
table(mon_format_xml_times_by_row(p.details)) as r
order by stmts.executable_id, total_time_value desc
Executable ID for our statement(s) of interest
Find statement with most time in server
Show me the full hierarchy
of waits + processing times for a particular statement
Format XML details to produce row based format for time spent metrics

(continued)
EXEC_ID METRIC_NAME PARENT_METRIC_NAME TIME COUNT MEMBER------------ -------------------------------- ---------------------- ------- ------ ------x'00000001…' STMT_EXEC_TIME - 6676617 110191 0x'00000001…' TOTAL_ROUTINE_NON_SECT_PROC_TIME TOTAL_ROUTINE_TIME 6008956 110191 0x'00000001…' TOTAL_ROUTINE_USER_CODE_PROC_TIME TOTAL_ROUTINE_NON_S 6008956 110191 0x'00000001…' POOL_READ_TIME TOTAL_ACT_WAIT_TIME 372754 52135 0x'00000001…' TOTAL_ACT_WAIT_TIME STMT_EXEC_TIME 372754 - 0x'00000001…' TOTAL_SECTION_PROC_TIME STMT_EXEC_TIME 294907 0 0x'00000001…' WLM_QUEUE_TIME_TOTAL - 0 0 0x'00000001…' FCM_TQ_RECV_WAIT_TIME FCM_RECV_WAIT_TIME 0 0 0x'00000001…' FCM_MESSAGE_RECV_WAIT_TIME FCM_RECV_WAIT_TIME 0 0 0x'00000001…' FCM_TQ_SEND_WAIT_TIME FCM_SEND_WAIT_TIME 0 0 0x'00000001…' FCM_MESSAGE_SEND_WAIT FCM_SEND_WAIT_TIME 0 0 0x'00000001…' LOCK_WAIT_TIME TOTAL_ACT_WAIT_TIME 0 0 0x'00000001…' DIRECT_READ_TIME TOTAL_ACT_WAIT_TIME 0 0 0x'00000001…' DIRECT_WRITE_TIME TOTAL_ACT_WAIT_TIME 0 0 0x'00000001…‘ LOG_BUFFER_WAIT_TIME TOTAL_ACT_WAIT_TIME 0 0 0x'00000001…' LOG_DISK_WAIT_TIME TOTAL_ACT_WAIT_TIME 0 0 0x'00000001…' POOL_WRITE_TIME TOTAL_ACT_WAIT_TIME 0 0 0x'00000001…' AUDIT_FILE_WRITE_WAIT_TIME TOTAL_ACT_WAIT_TIME 0 0 0x'00000001…' AUDIT_SUBSYSTEM_WAIT_TIME TOTAL_ACT_WAIT_TIME 0 0 0x'00000001…' DIAGLOG_WRITE_WAIT_TIME TOTAL_ACT_WAIT_TIME 0 0 0x'00000001…' FCM_SEND_WAIT_TIME TOTAL_ACT_WAIT_TIME 0 0 0x'00000001…' FCM_RECV_WAIT_TIME TOTAL_ACT_WAIT_TIME 0 0 0x'00000001…' TOTAL_SECTION_SORT_PRO TOTAL_SECTION_PROC_T 0 0 0
…
Row based breakdown of where
time is being spent

Understanding the Time Metrics: Wait Times
• Wait Times represent the time an agent spends blocking / waiting on particular subsystems
• Large % wait times in a particular subsystem may indicate is a bottleneck, and is preventing agents working on statement processing from making optimal progress
• In some cases the presence of large wait times may indicate a potential query problem• For example, larger than expected bufferpool read time resulting from unexpected
table scan activity might indicate a missing index rather than an I/O problem• It might also be an indication of a bad disk though
• In other cases just the presence of a wait time on its own may indicate a problem• For example, direct reads / writes when we are expecting LOBs to be inlined, or FCM
TQ waits for a query that is expected to be co-located on a partitioned system would directly indicate a problem

Wait Times (Activity)
Metric What it MeansLOCK_WAIT_TIME Time the agent is spending waiting on locks. Shows the impact that lock conflicts
are having on query performance.
LOG_BUFFER_WAIT_TIME / LOG_DISK_WAIT_TIME
Indicates we are blocking on the logger subsystem. Occurs most often during commit processing which would be outside query execution, but can occur during queries. Large log times may indicate an insufficient log buffer size, applications committing too frequently, or that the log disk speeds are insufficient for the workload running on DB2.
DIAGLOG_WRITE_WAIT_TIME Indicates the agent is spending time writing to the db2diag.log. Generally indicates the DIAGLEVEL dbm config parameter is set too high on the instance
POOL_READ_TIME/
POOL_WRITE_TIMEThe amount of time agent threads are spending performing synchronous bufferpool reads or writes. It may indicate a problem with the bufferpool subsystem including bufferpool size or the prefetcher and page cleaner configuration. Could also be indicative of inefficient / problem queries.
DIRECT_READ_TIME/
DIRECT_WRITE_TIMEIndicates time spent performing I/O’s outside of the bufferpool. This is an indicator that LOB reads or writes are occurring – if inline lobs are being used this is an indication that the inline lob length may be insufficient.
FCM_SEND/RECV_WAIT_TIME
(also FCM_MESSAGE_SEND/RECV_WAIT_TIME, FCM_TQ_SEND/RECV_WAIT_TIME)
This is the amount of time server threads spend waiting for acknowledgements from remote partitions when performing work in DPF environments. Usually it makes sense to exclude these metrics and subtract them from the total time as they represent times when remote processing is taking place, however a trending increase in FCM times may indicate a potential network bottleneck, or bottleneck on the FCM subsystem.

More Wait Times (Activity)
Metric What it MeansWLM_QUEUE_TIME Reflects the amount of time server threads spent waiting on a WLM threshold
queue before they were allowed to execute.
AUDIT_SUBSYSTEM_WAIT_TIME / AUDIT_FILE_WRITE_TIME
Indicates the amount of time server threads spend waiting on the audit subsystem to capture audit records. If these times are large it may indicate that the audit buffers are configured too small, or that the level of data being captured is large enough to adversely impact the particular workload.

Understanding the Time Metrics: Processing / Component Times
• Processing / Component Times represent the time an agent thread spends processing / consuming CPU in a particular component area of DB2• Broken down into two pieces - the processing portion of in the component as
well as the total time in the component
• Large % processing times in a particular component subsystem indicates that most of our processing is taking place there• Whether this is an issue depends on what the component is
• For example, large times in sort might be expected in a particular query, whereas their presence in others might indicate a problem

Processing/Component Times (Activity)
Metric What it MeansTOTAL_SECTION_TIME / TOTAL_SECTION_PROC_TIME
The amount of time spent actually executing the query plan (excluding the time spent preparing / rebinding / etc).
TOTAL_SECTION_SORT_TIME / TOTAL_SECTION_SORT_PROC_TIME
The amount of time spent performing sort processing within section execution. Helps to gauge which queries are performing sorts, and how much effort is going towards sort processing vs. other aspects of the query execution.
TOTAL_ROUTINE_NON_SECT_TIME / TOTAL_ROUTINE_NON_SECT_PROC_TIME
The amount of time within a routine spent performing non-section / non-sql processing. This differentiates the time spent actually executing SQL vs. the time spent performing other request types such as prepare, describe, commit, rollback, or time spent executing user routine code outside of DB2.
TOTAL_ROUTINE_USER_CODE_TIME / TOTAL_ROUTINE_USER_CODE_PROC_TIME
The total amount of time spent executing outside of known DB2 components during routine execution. This indicates the amount of time / effort we spend in user code in routines. Note that we report both a total and a processing time only for completeness of the hierarchy. We cannot differentiate processing vs wait time within user code, so the entirety of the time spent there is assumed to be processing.

Other Important Time Metrics
• A few time (and time related) metrics that bear mention here:• STMT_EXEC_TIME
• The total time spent executing a statement (included the time spent in any nested invocations)
• TOTAL_ACT_WAIT_TIME• The total time spent blocking on waits while executing this particular section (does
not include wait times for nested invocations however which are reported in the section entry for those individual statements)
• TOTAL_ROUTINE_TIME• The total amount of time the statement spent executing within routines (UDFs or
Stored Procedures) • TOTAL_CPU_TIME
• Not a metric in the actual “time spent” hierarchy, but generally a critical time-related metric

Advanced Diagnostics Using Runtime Explain and Section Actuals

Introducing Runtime Explain
• There may be cases when a more detailed analysis of query execution is required than can be provided with basic monitoring metrics such as time spent
• In these cases the tool we typically turn to is the EXPLAIN feature of DB2 – which herein we will refer to as the SQL Compiler EXPLAIN• This capability compiles an input SQL statement and allows you to format and view
the query plan• Expected to be a generally accurate approximation of the query you actually ran• May differ due to differences in compilation environment and/or table statistics from
when your query was compiled• An exciting new feature introduced in DB2 9.7 FP1 is the ability to perform a
“runtime explain” (or “Explain From Section”) which produces explain output directly from a compiled query plan (or section) in the engine
• Allows you to obtain the plan from the actual section you are executing

Explain from Section Procedures
• A set of stored procedures provided in DB2 9.7 FP1 allow you to explain a runtime section into the explain tables• EXPLAIN_FROM_CATALOG• EXPLAIN_FROM_SECTION• EXPLAIN_FROM_ACTIVITY• EXPLAIN_FROM_DATA
• Explain table content can then be processed using any existing explain tools (eg. db2exfmt)
• Explain output can be generated from the following sources:• Static or dynamic statement entries in the package cache• Any cache entry (DETAILED) captured by the new package cache event monitor• Static statement from the catalog tables• Statement execution captured with section by the activity event monitor

Section Actuals
• One of the key benefits of the explain from section capability is the ability to capture and format “section actuals”• All Explain output will contain cardinality estimates for individual operators in
the plan• When a section based explain is performed on a statement captured by the
activity event monitor we can also capture the actual cardinalities for each operator for that execution
• Examining this data gives you an indication of what actually happened during the query execution, and whether the estimates the optimizer used in generating the query plan were accurate
• In order to examine the actuals we will need to capture the execution of our SQL statement of interest using the activity event monitor

Capturing Activities to Obtain Actuals
• The activity event monitor in DB2 allows the capture of execution details for individual SQL statements as well as several other recognized activities (eg. Load)
• It can be configured to capture a variety of different metrics as well as the section data
• Starting in DB2 9.7 FP1 the section data captured by the activity event monitor has been enhanced to now include section actuals
• Since the capture of individual activities is quite granular we offer a fair degree of flexibility allowing the following data capture options:• Capture data for all activities running in a particular WLM workload• Capture data for all activities running in a particular WLM service class• Capture data for activities that violate a particular WLM threshold
• We can also enable the capture of activities run by a specific application using the WLM_SET_CONN_ENV procedure first introduced in DB2 9.7 FP2
• Our final example will demonstrate how to capture a statement of interest using the activity event monitor and then obtain the section actuals using the new explain capabilities in DB2 9.7 FP1

create event monitor actEvmon for activities write to table
activity ( table activity, in monitorTBS),
activityvals ( table activityvals, in monitorTBS ),
activitystmt ( table activitystmt, in monitorTBS ),
control ( table control, in monitorTBS )
manualstart
Step I: Required Setup Steps
Create the activity event
monitor
Execute ~/sqllib/misc/EXPLAIN.DDL
Create the explain tables…

Step II: Capturing the Activity Data
set event monitor actEvmon state 1
call wlm_set_conn_env(null,
'<collectactdata>WITH DETAILS, SECTION</collectactdata>
<collectactpartition>ALL</collectactpartition>
<collectsectionactuals>BASE</collectsectionactuals>')
call wlm_set_conn_env(null, '<collectactdata>NONE</collectactdata>
<collectsectionactuals>BASE</collectsectionactuals>')
set event monitor actEvmon state=0
Enable the event
monitor and setup to capture a
statement on my
connection
Disable collection and the event
monitoring once I am
done
select t1.ident, sum(t1.data) as data,
sum(t2.moredata) as moredata
from t1,t2
where t1.ident=t2.ident
group by t1.ident
Execute the statement
I’m interested in

Step II: Another approach
set event monitor actEvmon state 1
update db cfg using section_actuals base
alter service class sysdefaultsubclass under sysdefaultuserclass
collect activity data on all database partitions with details,section
alter service class sysdefaultsubclass under sysdefaultuserclass
collect activity data none
update db cfg using section_actuals none
set event monitor actEvmon state 0
Enable the event
monitor on the default
subclass, and collect
details and section data
Disable the event
monitor once I am done
( Queries of interest run and are captured… )

Step III: Locating the activity of interest
select a.appl_id, a.uow_id, a.activity_id, a.appl_name, s.executable_id, s.stmt_textfrom activity_actevmon as a, activitystmt_actevmon as s where a.appl_id = s.appl_id and a.uow_id = s.uow_id and a.activity_id = s.activity_id and s.stmt_text like 'select t1.ident, sum(t1.data)%'
Show me the executions
captured for a particular statement
APPL_ID UOW_ID ACTIVITY_ID EXECUTABLE_ID STMT_TEXT APPL_NAME ------------------------- ------ ------------ --------------- -------------------------- ---------- *LOCAL.davek.100917004844 62 1 x'010000…1E00' select t1.ident, sum(t1.d… db2bp
Identifiers for the activity

Step III: Another approach
select a.appl_id, a.uow_id, a.activity_id, a.appl_name, r.value as total_cpu_time, s.executable_id, s.stmt_text from activity_actevmon as a, activitystmt_actevmon as s, table(mon_format_xml_metrics_by_row(a.details_xml)) as r where a.appl_id = s.appl_id and a.uow_id = s.uow_id and a.activity_id = s.activity_id and r.metric_name='TOTAL_CPU_TIME' order by total_cpu_time desc fetch first 5 rows only
Find the captured activities with the
largest CPU time
APPL_ID UOW_ID ACTIVITY_ID APPL_NAME TOTAL_CPU_TIME EXECUTABLE_ID STMT_TEXT ------------------------- ------ ----------- --------- -------------- ------------- -------------------------*LOCAL.davek.100917004844 62 1 db2bp 30500 x'0100…01E00' select t1.ident, sum(t1.d … *LOCAL.davek.100917004844 64 1 db2bp 5360 x'0100…00900' CALL wlm_set_conn_env(?,? … *LOCAL.davek.100917001050 105 1 db2bp 4603 x'0100…04A00' CALL wlm_set_conn_env(?,? … *LOCAL.davek.100919015109 20 1 db2bp 444 x'0100…05000' SELECT TABNAME, TABSCHEMA … *LOCAL.davek.100919015109 25 1 db2bp 406 x'0100…05000' SELECT TABNAME, TABSCHEMA …
Statement executable id
Identifiers for the activity

Step IV: Performing and Formatting the Explain from Section
call explain_from_activity(‘*LOCAL.davek.100715194643’,
85,1, ’ACTEVMON’, null,
?,?,?,?,?)
Perform an explain on the activity of interest…
db2exfmt -d sample -w -1 -n %% -# 0 -s %% -o explain.txt
Now format the most
recent data in the explain
tables to a readable text
file
Identifiers for the activity
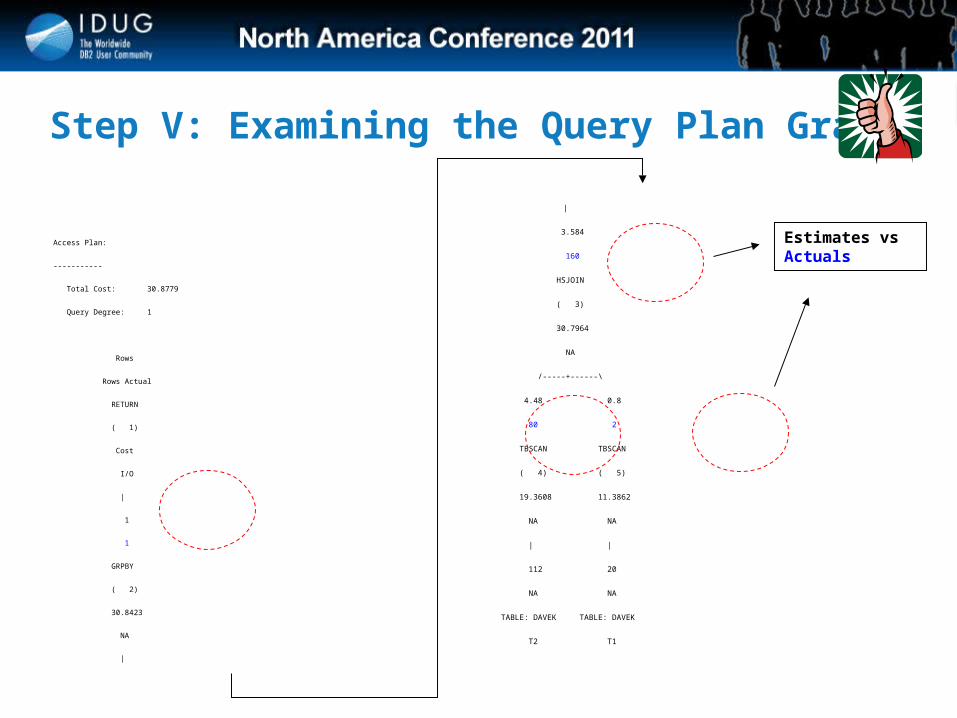
Step V: Examining the Query Plan Graph
Access Plan:
-----------
Total Cost: 30.8779
Query Degree: 1
Rows
Rows Actual
RETURN
( 1)
Cost
I/O
|
1
1
GRPBY
( 2)
30.8423
NA
|
|
3.584
160
HSJOIN
( 3)
30.7964
NA
/-----+------\
4.48 0.8
80 2
TBSCAN TBSCAN
( 4) ( 5)
19.3608 11.3862
NA NA
| |
112 20
NA NA
TABLE: DAVEK TABLE: DAVEK
T2 T1
Estimates vs Actuals

Final Thoughts

In Closing
• We’ve introduced you to some of the new monitoring capabilities introduced in DB2 9.7 and how you can leverage these to help diagnose and solve query performance problems
• The key thing to keep in mind is that performance analysis is as much an art as it is a science:• There’s never a single hard and fast “best” way to approach performance problems• Different problems may be best attacked from the top-down, bottom-up, or even
sideways • It should be fair to say that generally it’s desirable to first isolate and resolve system
level problems before trying to analyze individual queries, but people will find different approaches work best depending on their environment
• Hopefully the examples in this presentation have given you some ideas on ways you can leverage the latest DB2 Monitoring capabilities in your own environment

Questions?

DB2 Monitoring Resources

DB2 Monitoring Resources
• DB2 9.7 documentation:• http://publib.boulder.ibm.com/infocenter/db2luw/v9r7/index.jsp
• Related IDUG NA 2011 presentations:• New Ways to Solve Your Locking Problems with DB2 9.7 (C06)

David [email protected] Performance Diagnostics for SQL in DB2 9.7