airs2016
TRANSCRIPT

The Effect of Score Standardisation on
Topic Set Size Design@tetsuyasakai
Waseda University, Japan
http://www.f.waseda.jp/tetsuya/sakai.html
November 30, 2016@AIRS 2016, Beijing.

TALK OUTLINE
1. Score standardisation
2. Topic set size design
3. NTCIR-12 tasks
4. Results
5. Conclusions
6. Future work: NTCIR WWW
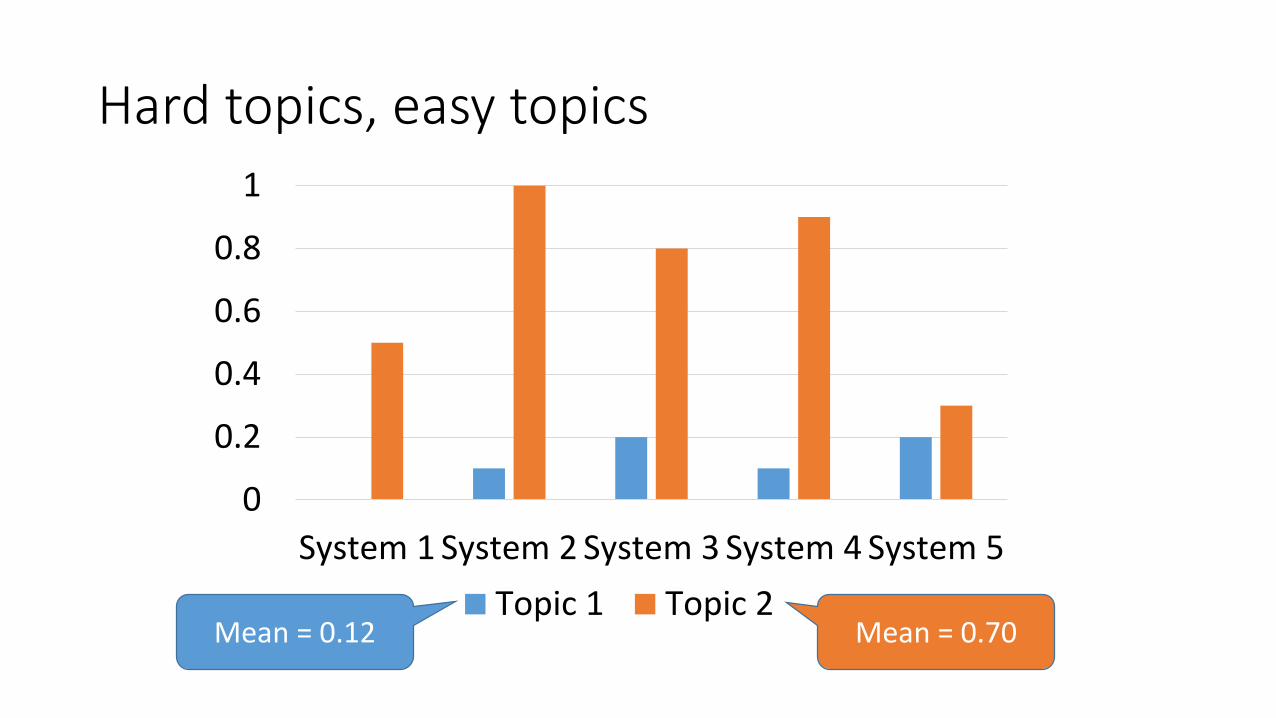
Hard topics, easy topics
Mean = 0.12
0
0.2
0.4
0.6
0.8
1
System 1 System 2 System 3 System 4 System 5
Topic 1 Topic 2Mean = 0.70

Low-variance topics, high-variance topics
standard deviation = 0.08
0
0.2
0.4
0.6
0.8
1
System 1 System 2 System 3 System 4 System 5
Topic 1 Topic 2 standard deviation = 0.29

Score standardisation [Webber+08]
standardised score for i-th system, j-th topic
j
i
raw
Topics
Systems
j
i
std
Topics
Systems
Subtract mean;divide by standard deviation
How good is i compared to “average” in standard
deviation units?
Standardising factors

Now for every topic, mean = 0, variance = 1.
-2
-1
0
1
2
System 1System 2System 3System 4System 5
Topic 1 Topic 2
Comparisons across different topic sets and test collections are possible!

Standardised scores have the [-∞, ∞] range and are not very convenient.
-2
-1
0
1
2
System 1System 2System 3System 4System 5
Topic 1 Topic 2
Transform them back into the [0,1] range!

std-CDF: use the cumulative density function of the standard normal distribution [Webber+08]
0
0.2
0.4
0.6
0.8
1
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
TREC04
Each curve is a topic, with 110 runs represented as dots
raw nDCG
std-CDFnDCG
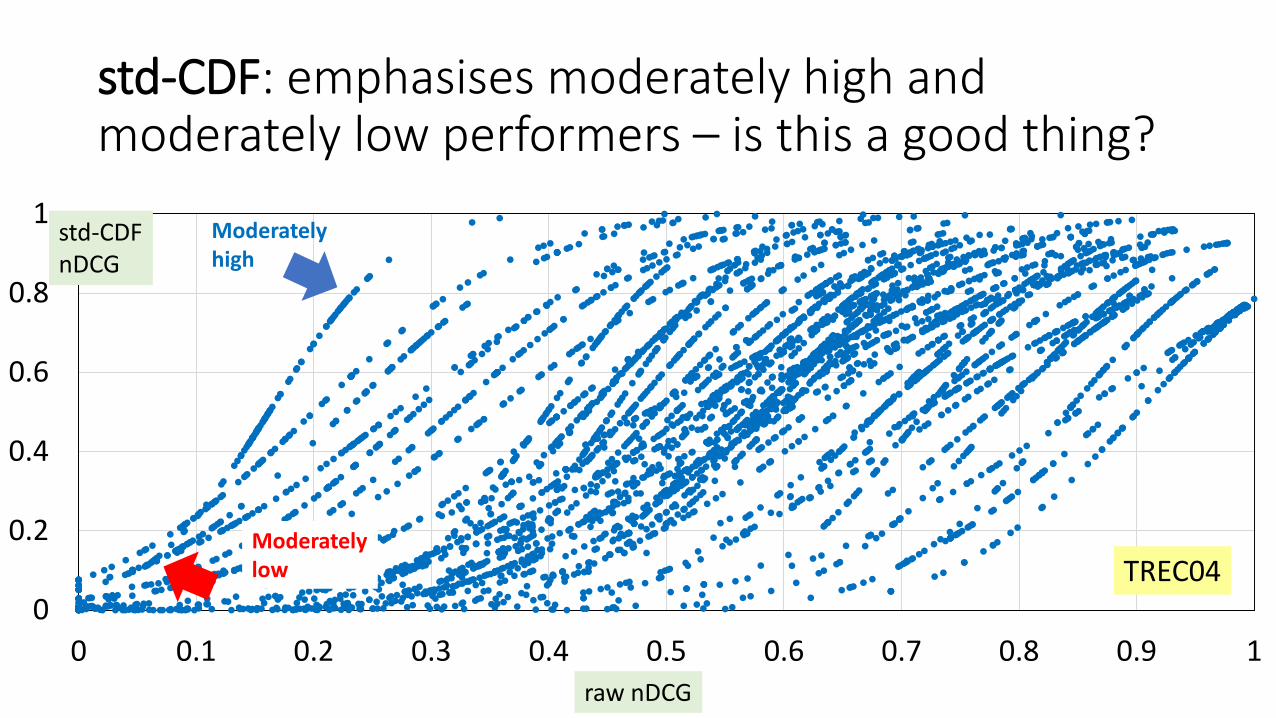
std-CDF: emphasises moderately high and moderately low performers – is this a good thing?
0
0.2
0.4
0.6
0.8
1
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
TREC04
raw nDCG
std-CDFnDCG
Moderatelyhigh
Moderatelylow

std-AB: How about a simple linear transformation? [Sakai16ICTIR]
0
0.2
0.4
0.6
0.8
1
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
std-CDF nDCG std-AB nDCG (A=0.10) std-AB nDCG (A=0.15)
TREC04
raw nDCG
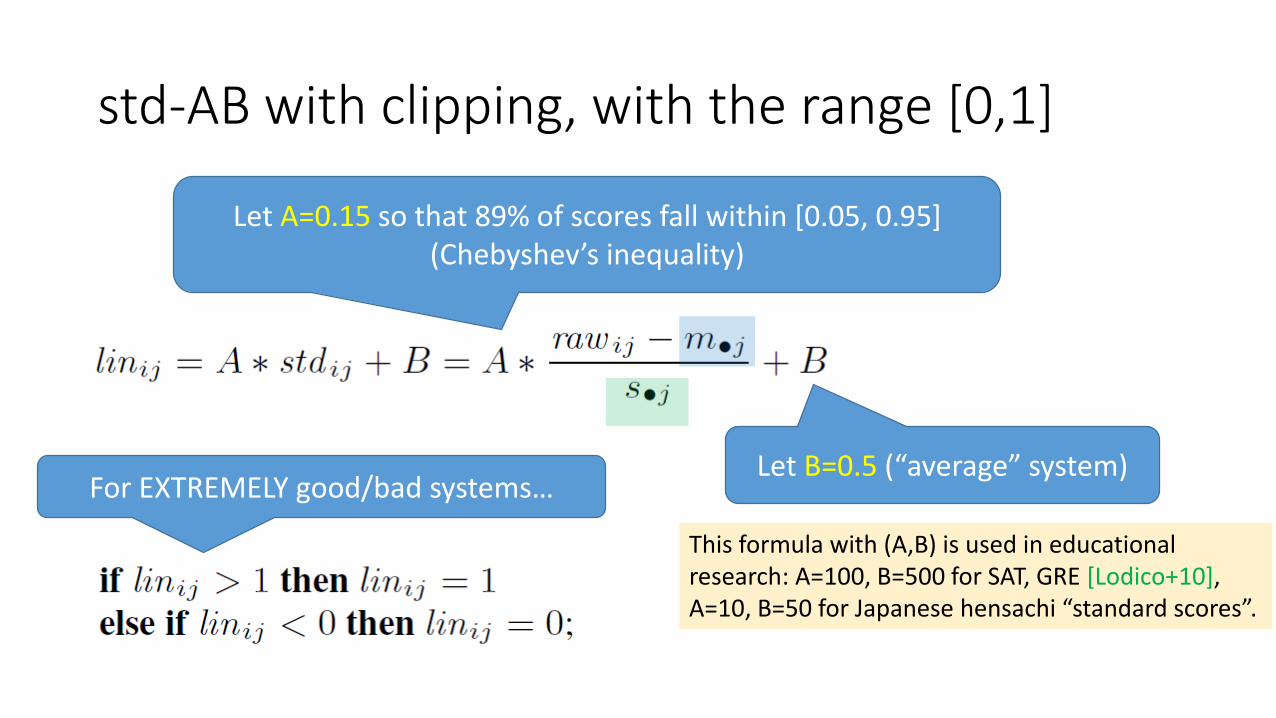
std-AB with clipping, with the range [0,1]
Let B=0.5 (“average” system)
Let A=0.15 so that 89% of scores fall within [0.05, 0.95](Chebyshev’s inequality)
For EXTREMELY good/bad systems…
This formula with (A,B) is used in educational research: A=100, B=500 for SAT, GRE [Lodico+10],A=10, B=50 for Japanese hensachi “standard scores”.
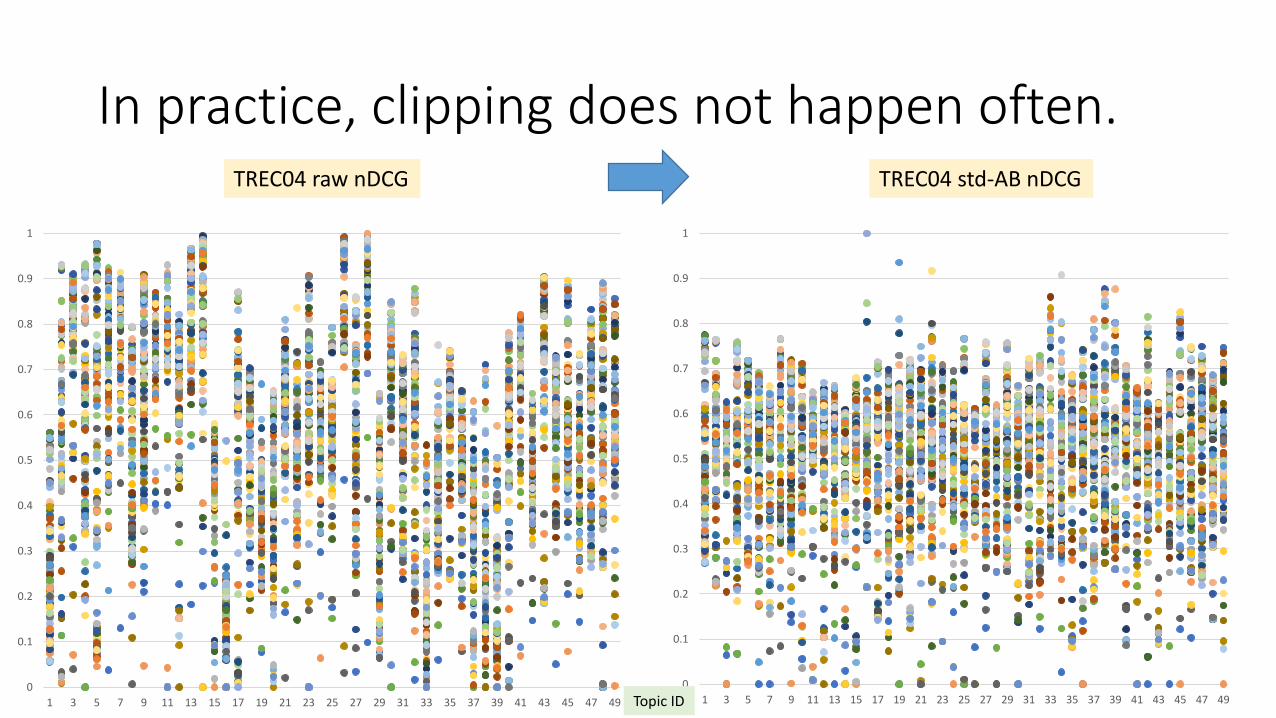
In practice, clipping does not happen often.
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47 49
TREC04 raw nDCG
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47 49
TREC04 std-AB nDCG
Topic ID

[Sakai16ICTIR] bottom line
• Advantages of score standardisation:
- removes topic hardness, enables comparison across test collections
- normalisation becomes unnecessary
• Advantages of std-AB over std-CDF:
Low within-system variances and therefore
- Substantially lower swap rates (higher consistency across different data)
- Enables us to consider realistic topic set sizes in topic set design
Swap rates for std-CDF can be higher than those for raw scores, probably due to its
nonlinear transformation
std-AB is a good alternative to std-CDF.

TALK OUTLINE
1. Score standardisation
2. Topic set size design
3. NTCIR-12 tasks
4. Results
5. Conclusions
6. Future work: NTCIR WWW

Topic set size design (1) [Sakai16IRJ]
• Provides answers to the following question:
“I’m building a new test collection. How many topics should I create?”
• A prerequisite: a small topic-by-run score matrix based on pilot data, for estimating within-system variances.
• Three approaches (with easy-to-use Excel tools), based on [Nagata03]:
(1) paired t-test power
(2) one-way ANOVA power
(3) confidence interval width upperbound.

Topic set size design (2) [Sakai16IRJ]Method Input required
Paired t-test α (Type I error probability), β (Type II error probability),minDt (minimum detectable difference: whenever the diff between two systems is this much or larger, we want to guarantee (1-β)% power),
: variance estimate for the score delta.
one-way ANOVA α (Type I error probability), β (Type II error probability), m (number of systems),minD (minimum detectable range: whenever the diff between the best and worst systems is this much or larger, we want to guarantee (1-β)% power),
: estimate of the within-system variance under the homoscedasticity assumption.
Confidence intervals α (Type I error probability), δ (CI width upperbound: you want the CI for the diff between any system pair to be this much or smaller),
: variance estimate for the score delta.

Topic set size design (3) [Sakai16IRJ]
Test collection designs should evolve based on past data
topic-by-runscore matrix withpilot data
About 25 topicswith runs from a few teamsprobably sufficient[Sakai+16EVIA]
n1 topics
m runs
Estimate n1 based on thewithin-system varianceestimate
TREC 201X TREC 201(X+1)
n2 topics
n0 topics
Estimate n2 based on thewithin-system varianceestimate
A more accurate estimate

Topic set size design (4) [Sakai16IRJ]
ANOVA-based results for m=10 can be used instead
of CI-based results
ANOVA-based results for m=2 can be used instead of
t-test-based results
In practice, you can deduce t-test-based and CI-based results from ANOVA-based results
Caveat: the ANOVA-based tool can only handle (α, β)=(0.05, 0.20), (0.01, 0.20),
(0.05, 0.10), (0.01, 0.10).
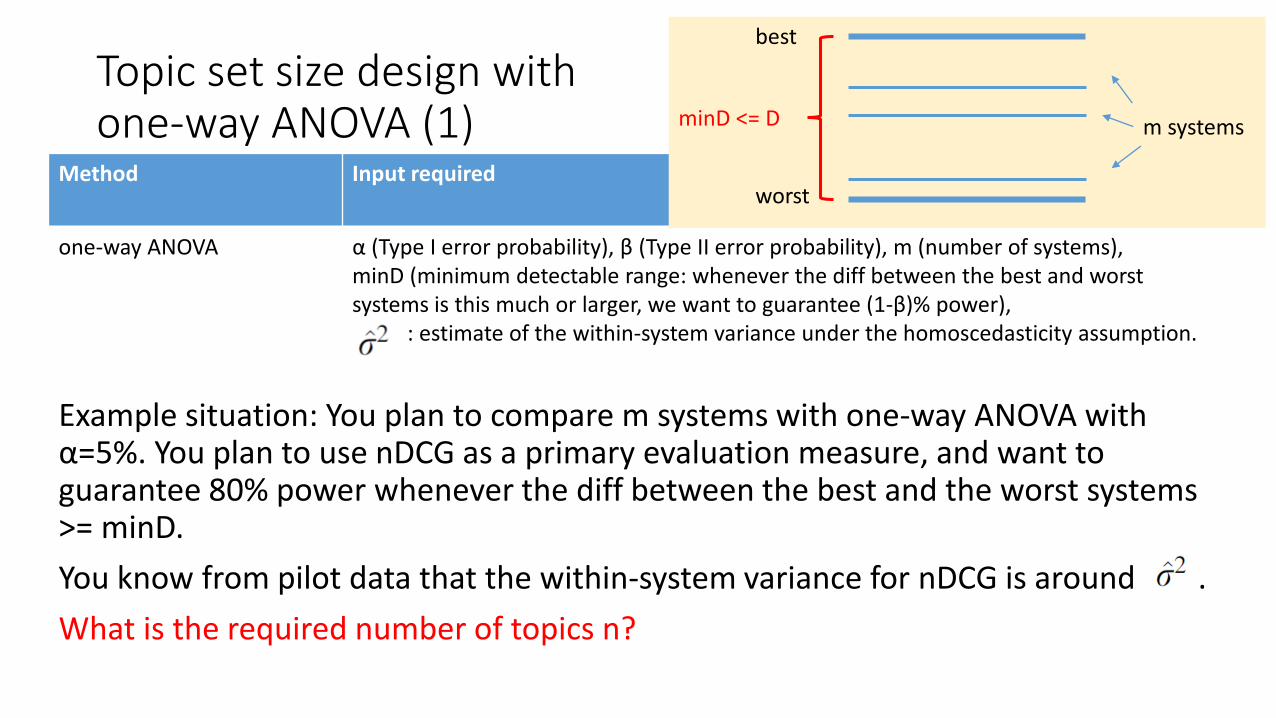
Method Input required
one-way ANOVA α (Type I error probability), β (Type II error probability), m (number of systems),minD (minimum detectable range: whenever the diff between the best and worst systems is this much or larger, we want to guarantee (1-β)% power),
: estimate of the within-system variance under the homoscedasticity assumption.
Example situation: You plan to compare m systems with one-way ANOVA with α=5%. You plan to use nDCG as a primary evaluation measure, and want to guarantee 80% power whenever the diff between the best and the worst systems >= minD.
You know from pilot data that the within-system variance for nDCG is around .
What is the required number of topics n?
Topic set size design withone-way ANOVA (1) m systems
best
worst
minD <= D
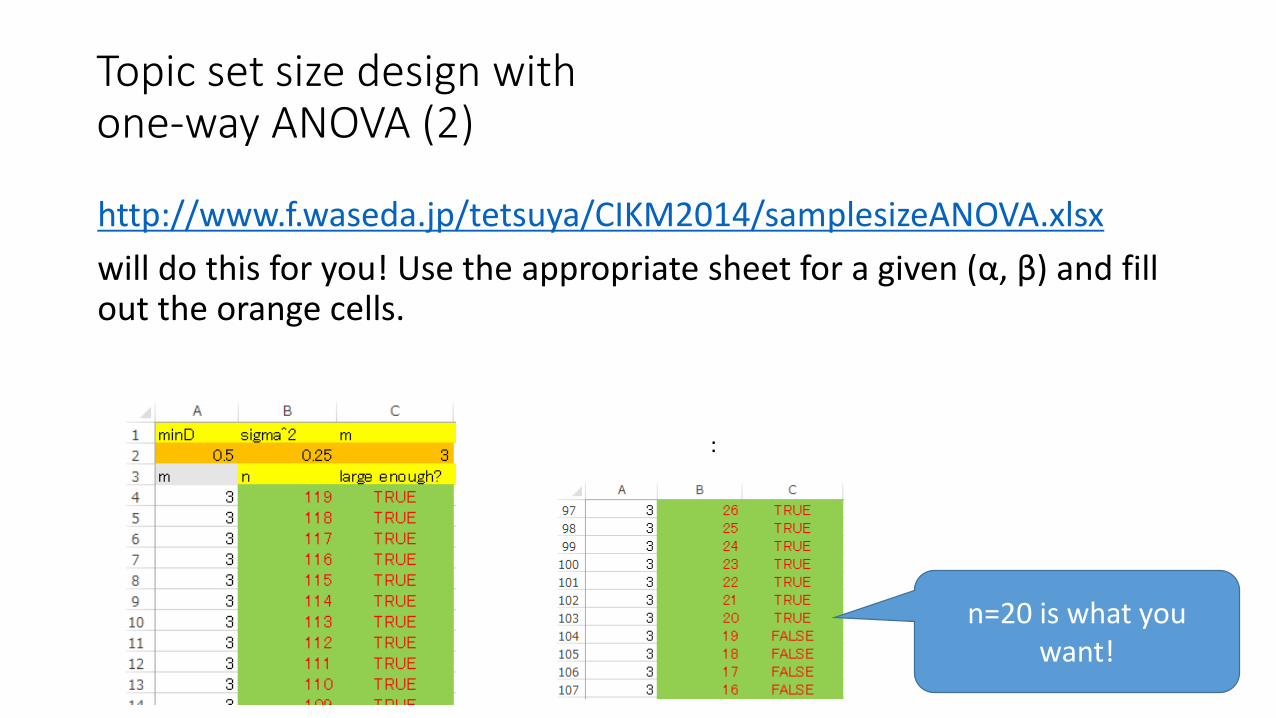
http://www.f.waseda.jp/tetsuya/CIKM2014/samplesizeANOVA.xlsx
will do this for you! Use the appropriate sheet for a given (α, β) and fill out the orange cells.
:
n=20 is what you want!
Topic set size design withone-way ANOVA (2)

Estimating the variance (1)
We need for topic set size design based on one-way ANOVA
and for that based on the paired t-test or CI.
From a pilot topic-by-run score matrix, obtain:
Then, if possible, pool multiple estimates to enhance accuracy:
Pooled estimate
By-product of one-way ANOVA
(use two-way w/o replilcation for tighter
estimates)
Multiple data not availablein this study

TALK OUTLINE
1. Score standardisation
2. Topic set size design
3. NTCIR-12 tasks
4. Results
5. Conclusions
6. Future work: NTCIR WWW

Variances obtained from NTCIR-12 tasksmC nC
Variances are substantiallysmallerafter applyingstd-AB.Unnormalisedmeasures canbe handled without anyproblems.

Why the variances are smaller after applying std-AB
The initial estimate of n with the one-way ANOVA topic set size design is given by [Nagata03]
where,
for (α, β)=(0.05, 0.20), λ ≒
So n will be small if is small.
With std-AB, is indeed small because A is small (e.g. 0.15) and it can be shown that
Noncentrality parameter of a noncentralchi-square distribution
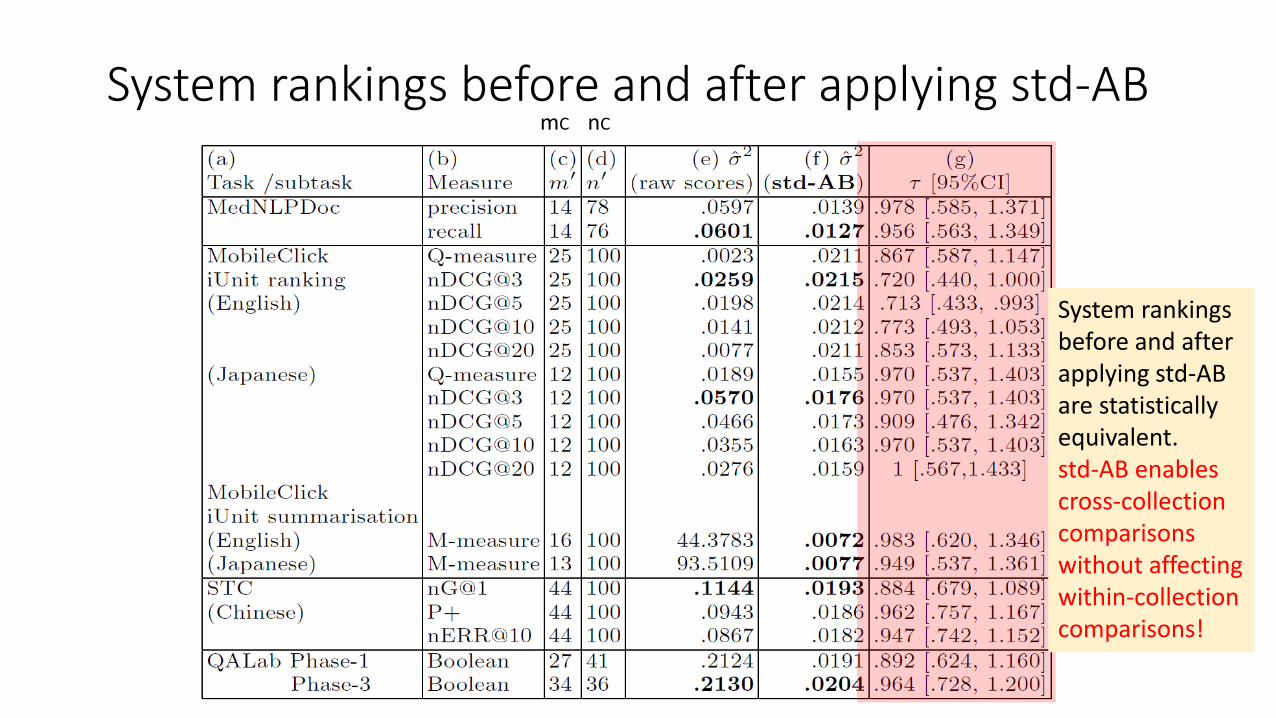
System rankings before and after applying std-ABmC nC
System rankingsbefore and afterapplying std-ABare statisticallyequivalent.std-AB enablescross-collectioncomparisonswithout affectingwithin-collectioncomparisons!

MedNLPDoc (1) [Aramaki+16]https://sites.google.com/site/mednlpdoc/
• INPUT: a medical record
• OUTPUT: ICD (international classification of diseases) codes of possible disease names
• MEASURES: precision and recall of ICDs
precisionrecall
14 runs 14 runs
78 topics76 topics
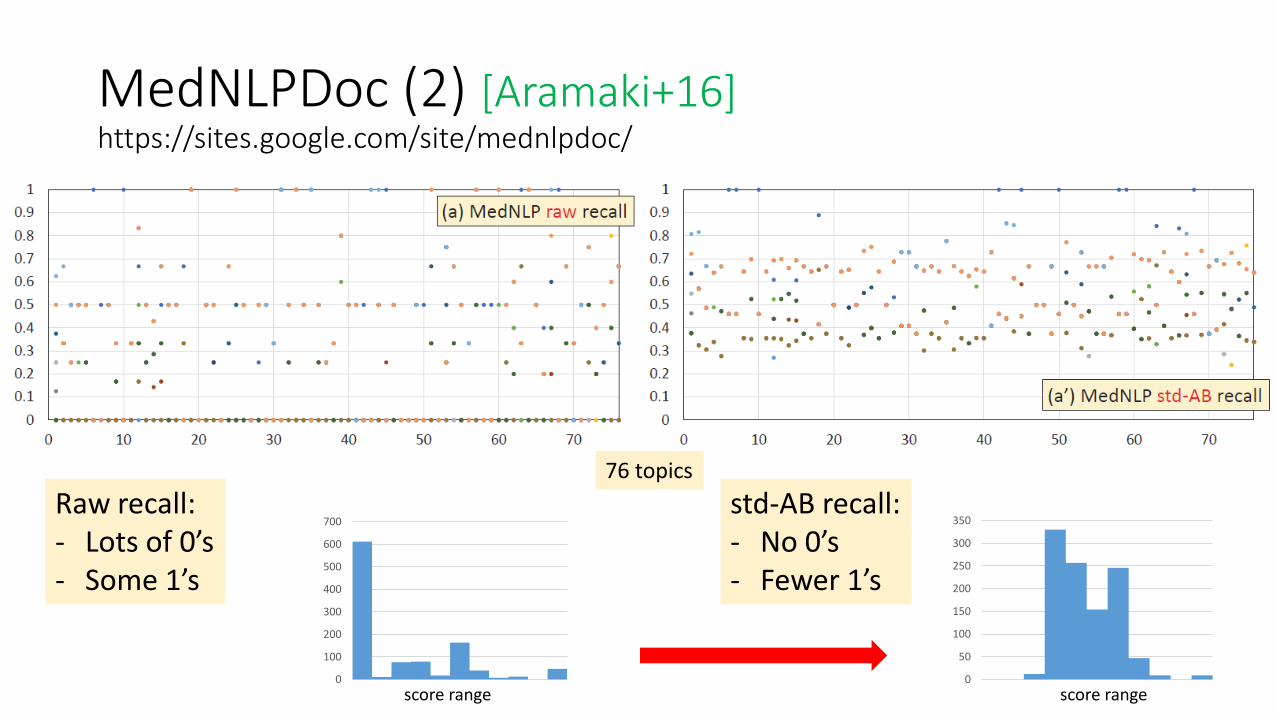
MedNLPDoc (2) [Aramaki+16]https://sites.google.com/site/mednlpdoc/
76 topics
Raw recall:- Lots of 0’s- Some 1’s
std-AB recall:- No 0’s- Fewer 1’s
0
100
200
300
400
500
600
700
0
50
100
150
200
250
300
350
score range score range

MobileClick-2 iUnit ranking (1) [Kato+16]http://mobileclick.org/
• INPUT: iUnits (relevant nuggets for a mobile search summary)
• OUTPUT: iUnits ranked by relevance
• MEASURES:
nDCG [Jarvelin+02]
= Σ g(r)/log(r+1) / Σ g*(r)/log(r+1)
Q-measure [Sakai05AIRS04]
= (1/R) Σ I(r) BR(r) where BR(r) = ( Σ I(k) + β Σ g(k) )/( r + βΣ g*(k) )
lr=1
lr=1
r
rk=1
rk=1
rk=1
gain at r in an ideal list
1 if relevant, 0 otherwise

MobileClick-2 iUnit ranking (2) [Kato+16]http://mobileclick.org/
Raw nDCG:- hard topics, easy topics
0
100
200
300
400
500
600
700
0
100
200
300
400
500
600
700
std-AB nDCG:- topics look more comparableto one another

MobileClick-2 iUnit summarisation (1) [Kato+16]http://mobileclick.org/
• INPUT: iUnits (relevant nuggets for a mobile search summary)
• OUTPUT: two-layered textual
summary
• MEASURES:
M-measure, a variant of the
intent-aware U-measure
[Sakai+13SIGIR]
M-measure is an unnormalisedmeasure: does not have the [0,1] range.(Intent-aware measures difficult to normalise.)
[Kato+16]

MobileClick-2 iUnit summarisation (2) [Kato+16]http://mobileclick.org/
Raw M-measure:- unnormalised, unbounded,extremely large variances- topics definitely not comparable(note the different scale of the y axis)
std-AB M-measure:- no problem!
0
100
200
300
400
500
0
100
200
300
400
500
600
40-45 0.9-1.0
Clearly violates i.i.d
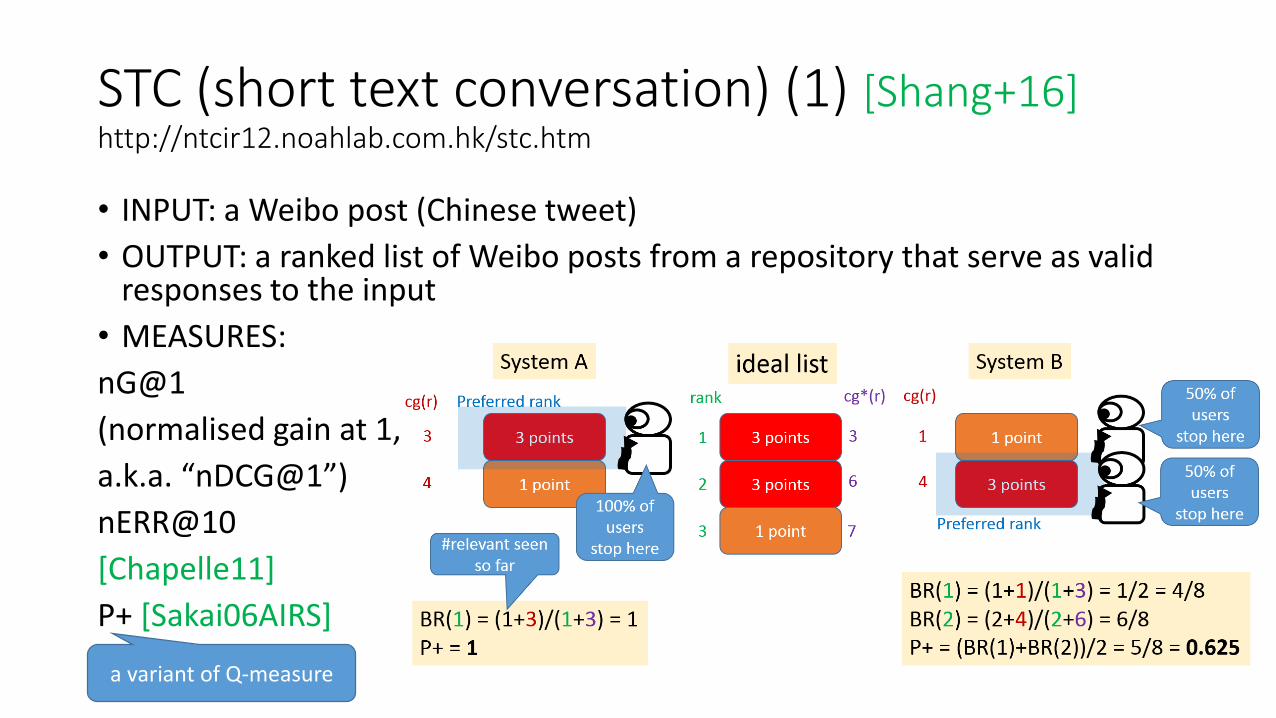
STC (short text conversation) (1) [Shang+16]http://ntcir12.noahlab.com.hk/stc.htm
• INPUT: a Weibo post (Chinese tweet)
• OUTPUT: a ranked list of Weibo posts from a repository that serve as valid responses to the input
• MEASURES:
nG@1
(normalised gain at 1,
a.k.a. “nDCG@1”)
nERR@10
[Chapelle11]
P+ [Sakai06AIRS]
a variant of Q-measure

STC (short text conversation) (2) [Shang+16]http://ntcir12.noahlab.com.hk/stc.htm
Raw P+:- Lots of 1’s 0’s- Gap in the [0.625, 1] range(see previous slide)
std-AB P+:- Looks like a continuous measure!- Fewer 1’s- No 0’s
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1 4 7
10
13
16
19
22
25
28
31
34
37
40
43
46
49
52
55
58
61
64
67
70
73
76
79
82
85
88
91
94
97
10
0
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1 4 7
10
13
16
19
22
25
28
31
34
37
40
43
46
49
52
55
58
61
64
67
70
73
76
79
82
85
88
91
94
97
10
0
0
500
1000
1500
0
500
1000
1500

STC (short text conversation) (3) [Shang+16]http://ntcir12.noahlab.com.hk/stc.htm
Raw nG@1:- 0 or 1/3 or 1!
0
1000
2000
3000
0
500
1000
1500
2000
2500
std-AB nG@1:- Looks like a continuous measure!- Fewer 1’s- No 0’s

QALab-2 (1) [Shibuki+16]http://research.nii.ac.jp/qalab/
• INPUT: a multiple-choice Japanese National Center Test (university entrance exam) question on world history
• OUTPUT: choice deemed correct by system
• MEASURES:
Boolean: 1 (correct) or 0 (incorrect)

QALab-2 (2) [Shibuki+16]http://research.nii.ac.jp/qalab/
36 topicsRaw Boolean:- 0 or 1!
std-AB Boolean:- Two distinct ranges of values[0.2999, 0.4460] and [0.6091, 0.9047]
Normal assumption still clearly violated: our topic set size design results should be interpreted as those for normally-distributed measures
that happen to have variances similar to Raw/std-AB Boolean.
QALab-2 organisers sorted the topicsby #systems_correctly_answeredbefore providing the matrices to the present author
0
200
400
600
800
0
200
400
600

TALK OUTLINE
1. Score standardisation
2. Topic set size design
3. NTCIR-12 tasks
4. Results
5. Conclusions
6. Future work: NTCIR WWW
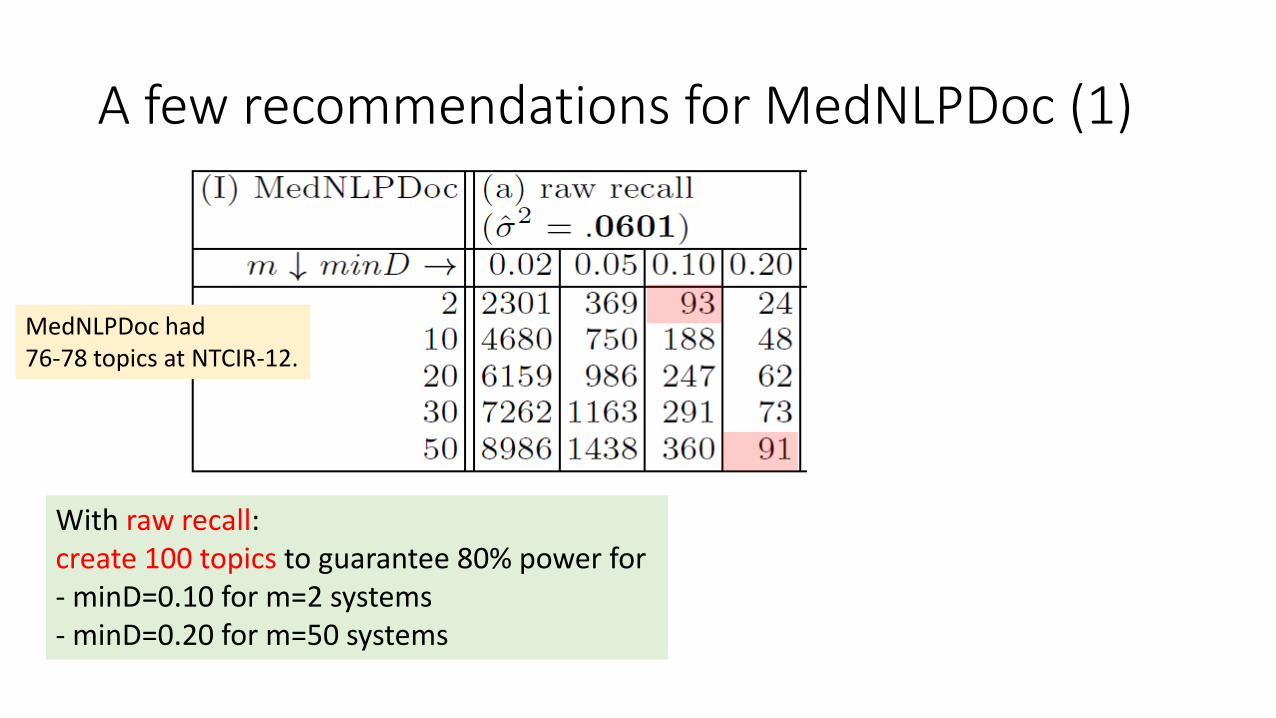
A few recommendations for MedNLPDoc (1)
With raw recall:create 100 topics to guarantee 80% power for- minD=0.10 for m=2 systems- minD=0.20 for m=50 systems
MedNLPDoc had 76-78 topics at NTCIR-12.
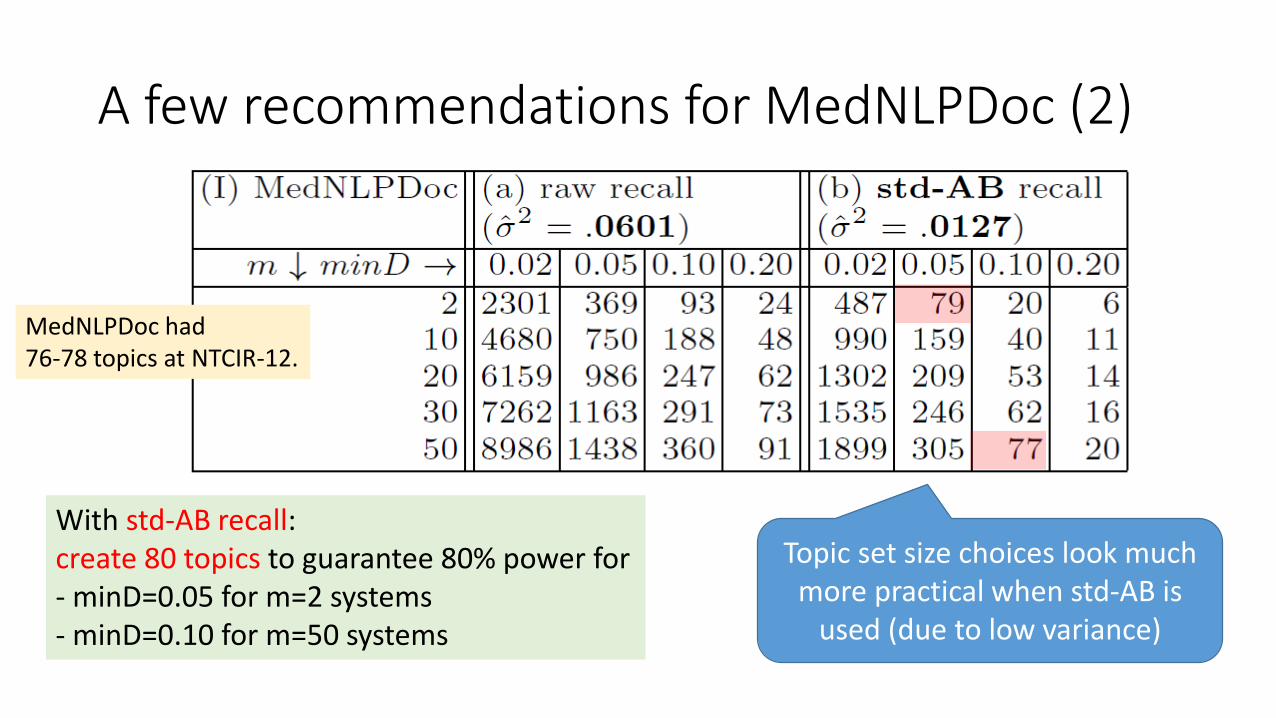
A few recommendations for MedNLPDoc (2)
With std-AB recall:create 80 topics to guarantee 80% power for- minD=0.05 for m=2 systems- minD=0.10 for m=50 systems
MedNLPDoc had 76-78 topics at NTCIR-12.
Topic set size choices look much more practical when std-AB is
used (due to low variance)
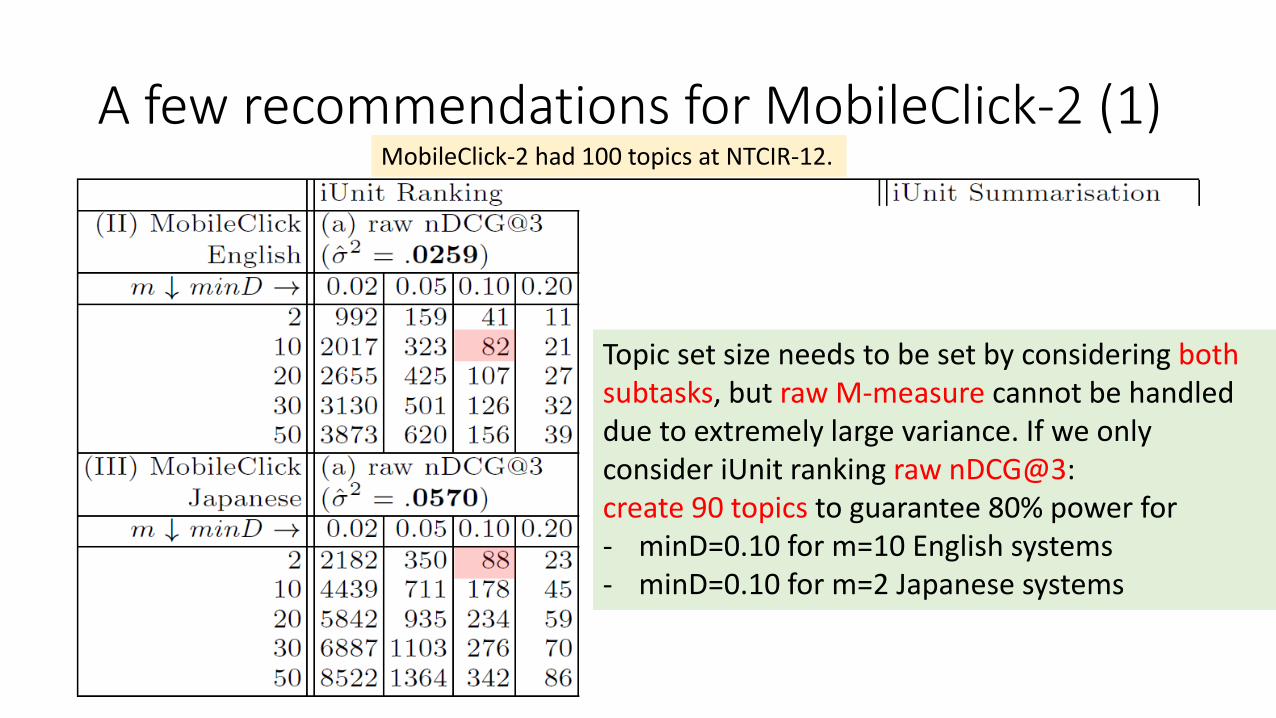
A few recommendations for MobileClick-2 (1)MobileClick-2 had 100 topics at NTCIR-12.
Topic set size needs to be set by considering both subtasks, but raw M-measure cannot be handled due to extremely large variance. If we only consider iUnit ranking raw nDCG@3:create 90 topics to guarantee 80% power for- minD=0.10 for m=10 English systems- minD=0.10 for m=2 Japanese systems
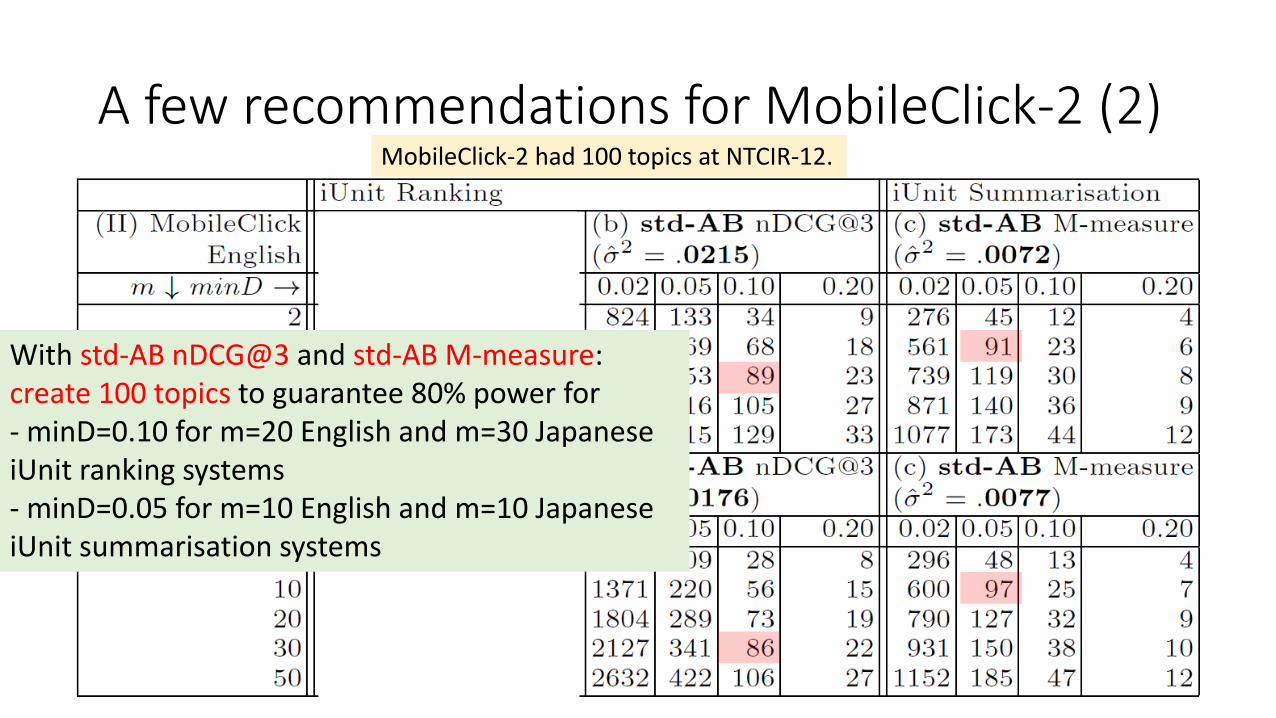
A few recommendations for MobileClick-2 (2)MobileClick-2 had 100 topics at NTCIR-12.
With std-AB nDCG@3 and std-AB M-measure:create 100 topics to guarantee 80% power for- minD=0.10 for m=20 English and m=30 Japanese iUnit ranking systems- minD=0.05 for m=10 English and m=10 Japanese iUnit summarisation systems

A few recommendations for STC (1)
With (a normally distributed measure whose variance is similar to that of) raw nG@1:create 120 topics to guarantee 80% power for- minD=0.20 for m=20 systems
STC had 100 topics at NTCIR-12.

A few recommendations for STC (2)
STC had 100 topics at NTCIR-12.
With std-AB nG@1:create 100 topics to guarantee 80% power for- minD=0.10 for m=30 systems
Topic set size choices look much more practical when std-AB is
used (due to low variance)
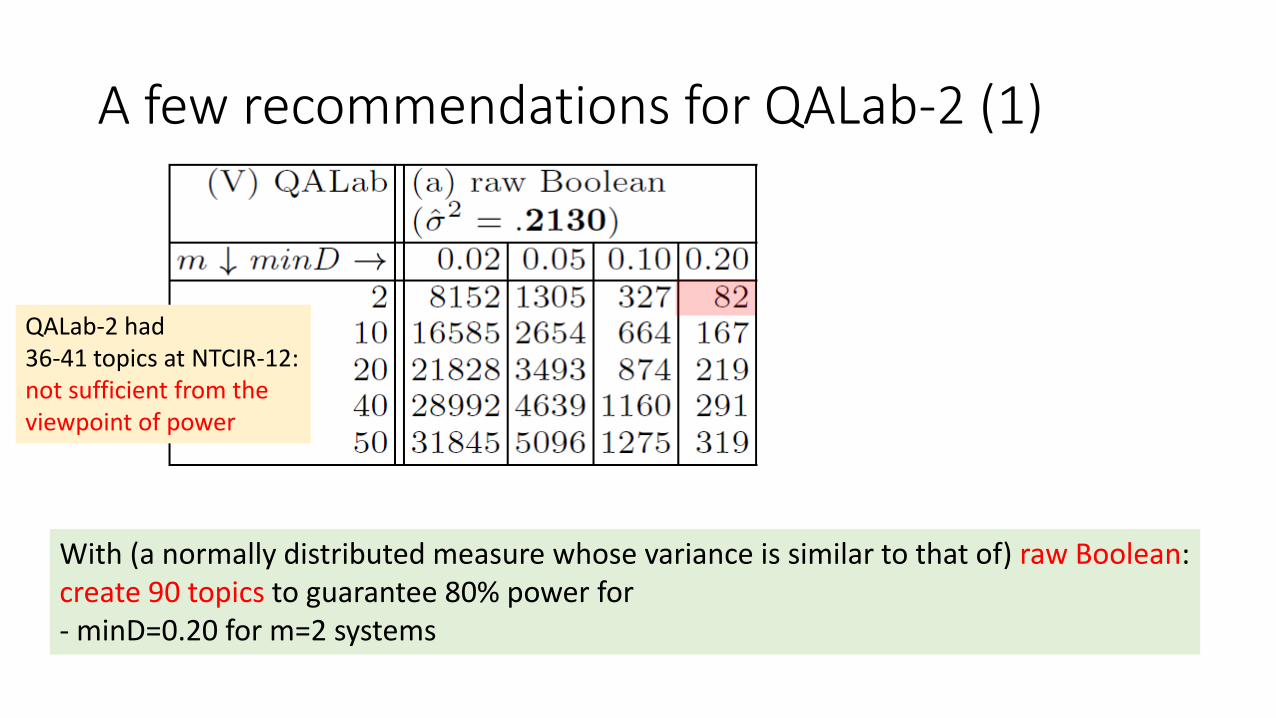
A few recommendations for QALab-2 (1)
QALab-2 had 36-41 topics at NTCIR-12:not sufficient from theviewpoint of power
With (a normally distributed measure whose variance is similar to that of) raw Boolean:create 90 topics to guarantee 80% power for- minD=0.20 for m=2 systems
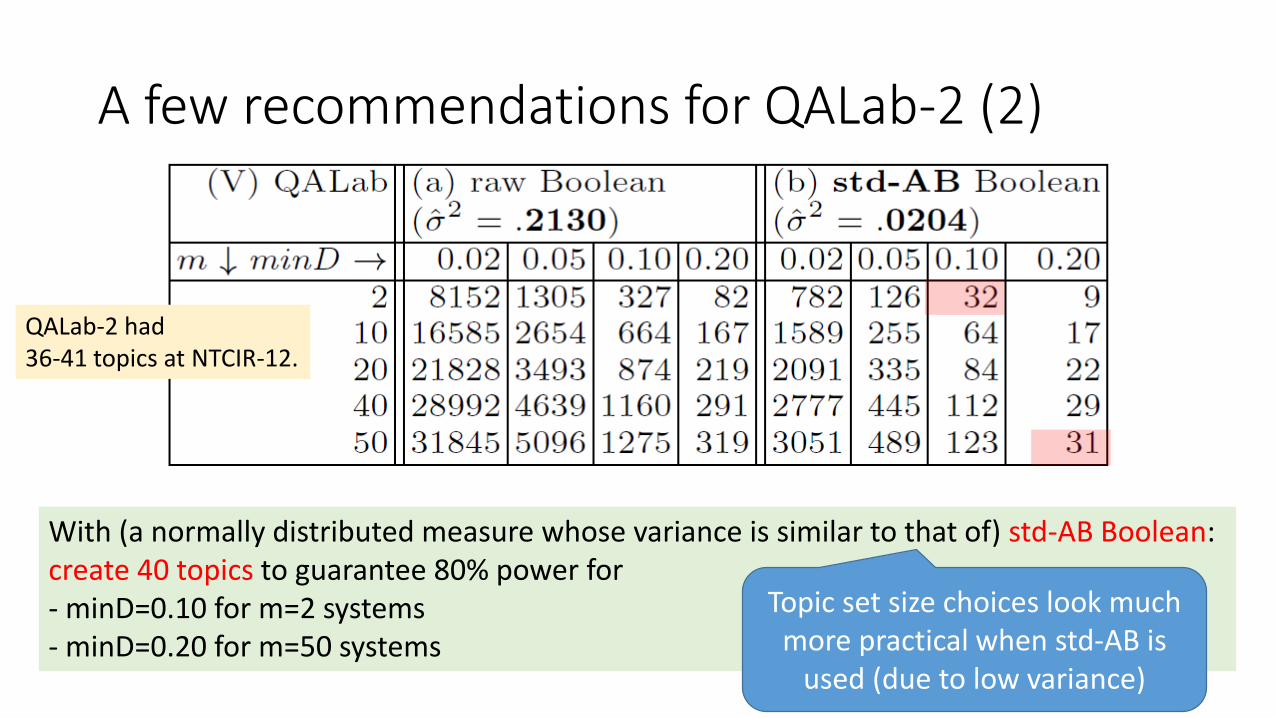
A few recommendations for QALab-2 (2)
QALab-2 had 36-41 topics at NTCIR-12.
With (a normally distributed measure whose variance is similar to that of) std-AB Boolean:create 40 topics to guarantee 80% power for- minD=0.10 for m=2 systems- minD=0.20 for m=50 systems
Topic set size choices look much more practical when std-AB is
used (due to low variance)

TALK OUTLINE
1. Score standardisation
2. Topic set size design
3. NTCIR-12 tasks
4. Results
5. Conclusions
6. Future work: NTCIR WWW

Conclusions
• std-AB suppresses score variances and thereby enables test collection builders to consider realistic choices of topic set sizes.
• topic set size design with std-AB can handle even unnormalised such as M-measure (U-measure, TBG, alpha-nDCG, ERR-IA etc.).
• Even discrete measures such as nG@1 (0 or 1/3 or 1) look more continuous after applying std-AB, which makes the topic set size design results (based on normality and i.i.d assumptions) perhaps a little more believable.
• Test collection designs should evolve based on experiences (i.e. variances pooled from past data).

TALK OUTLINE
1. Score standardisation
2. Topic set size design
3. NTCIR-12 tasks
4. Results
5. Conclusions
6. Future work: NTCIR WWW
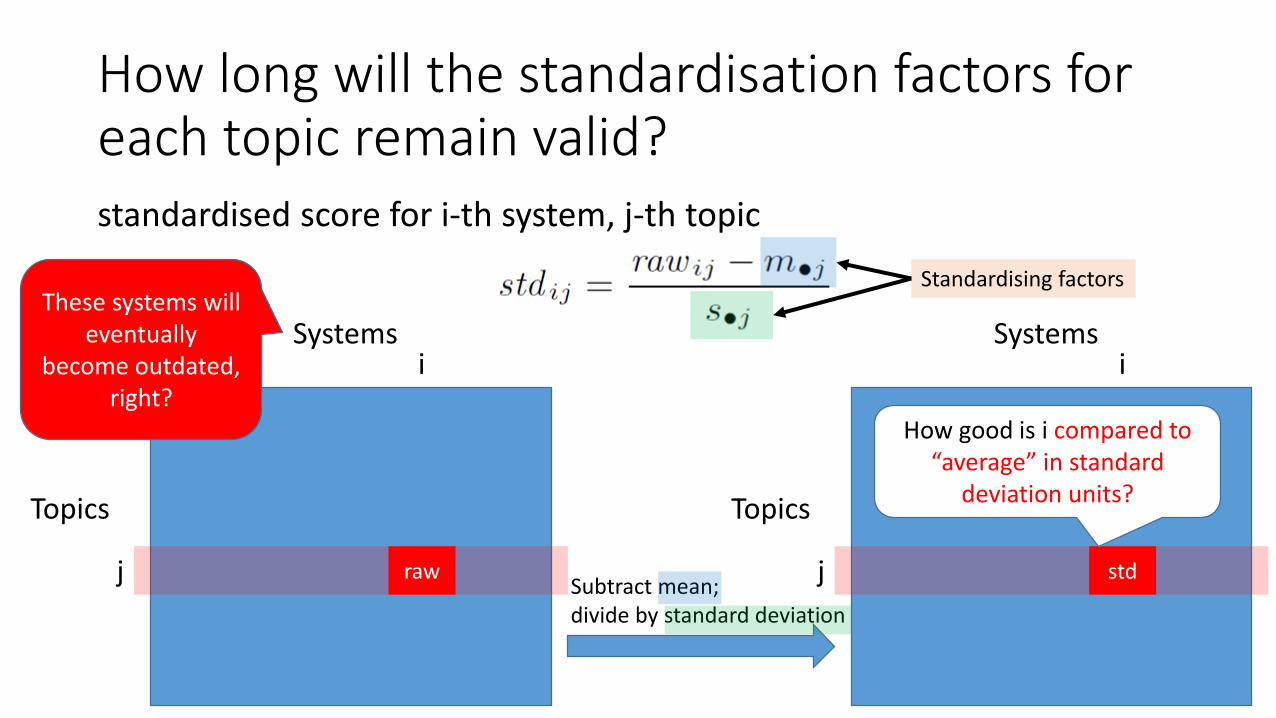
How long will the standardisation factors for each topic remain valid?standardised score for i-th system, j-th topic
j
i
raw
Topics
Systems
j
i
std
Topics
Systems
Subtract mean;divide by standard deviation
How good is i compared to “average” in standard
deviation units?
Standardising factorsThese systems will
eventually become outdated,
right?

We Want Web@NTCIR-13 (1) http://www.thuir.cn/ntcirwww/
NTCIR-13 (Dec 2017)
frozen topic set
NTCIR-13 fresh topic set
NTCIR-13 systems
New runs pooled for
frozen + fresh topics

We Want Web@NTCIR-13 (2) http://www.thuir.cn/ntcirwww/
NTCIR-13 (Dec 2017)
frozen topic set
NTCIR-13 fresh topic set
NTCIR-13 systems
Official NTCIR-13results discussed with the fresh topics
Qrels + std. factors based onNTCIR-13systems
NOT released
Qrels + std. factors based onNTCIR-13 systemsreleased
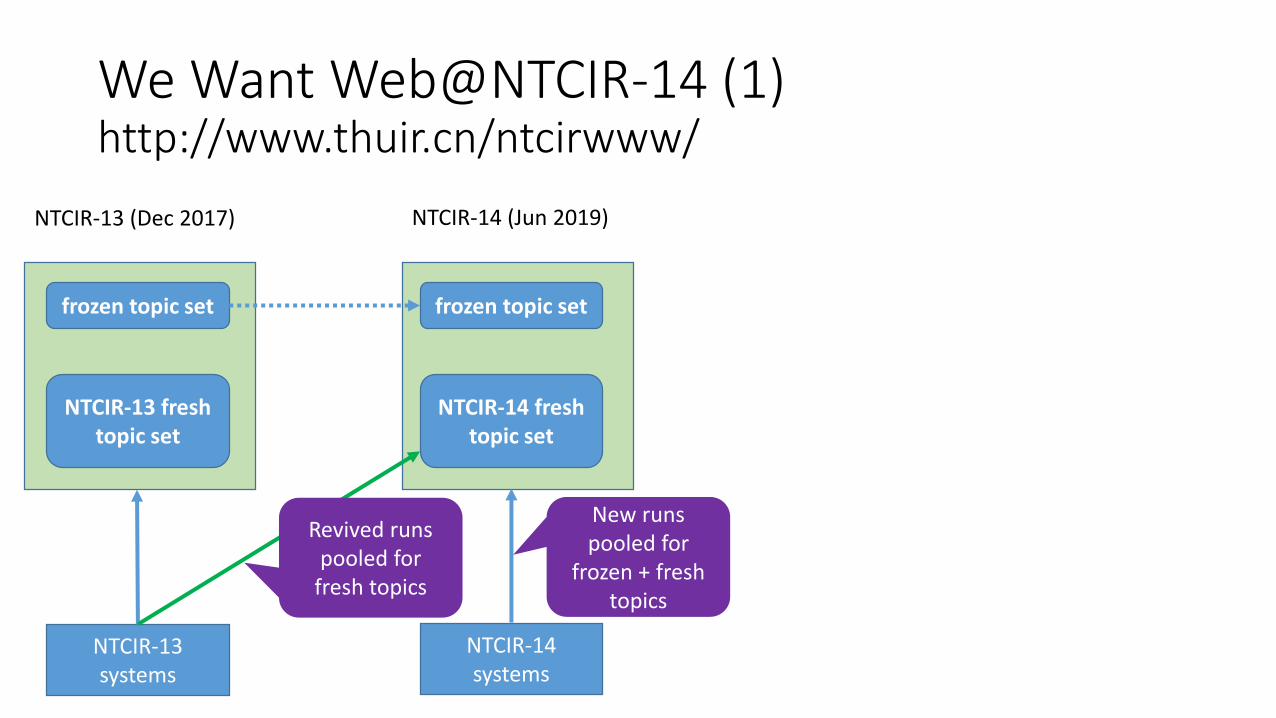
We Want Web@NTCIR-14 (1) http://www.thuir.cn/ntcirwww/
NTCIR-13 (Dec 2017) NTCIR-14 (Jun 2019)
frozen topic set frozen topic set
NTCIR-13 fresh topic set
NTCIR-14 fresh topic set
NTCIR-13 systems
NTCIR-14 systems
New runs pooled for
frozen + fresh topics
Revived runs pooled for
fresh topics

We Want Web@NTCIR-14 (2) http://www.thuir.cn/ntcirwww/
NTCIR-13 (Dec 2017) NTCIR-14 (Jun 2019)
frozen topic set frozen topic set
NTCIR-13 fresh topic set
NTCIR-14 fresh topic set
NTCIR-13 systems
NTCIR-14 systems
Official NTCIR-14results discussed with the fresh topics
Qrels + std. factors based on
NTCIR-13+14 systems
NOT released
Qrels + std. factors based on
NTCIR-(13+)14 systemsreleased
Using the NTCIR-14 fresh topics, compare new NTCIR-14 runs with revived runs and quantify progress.
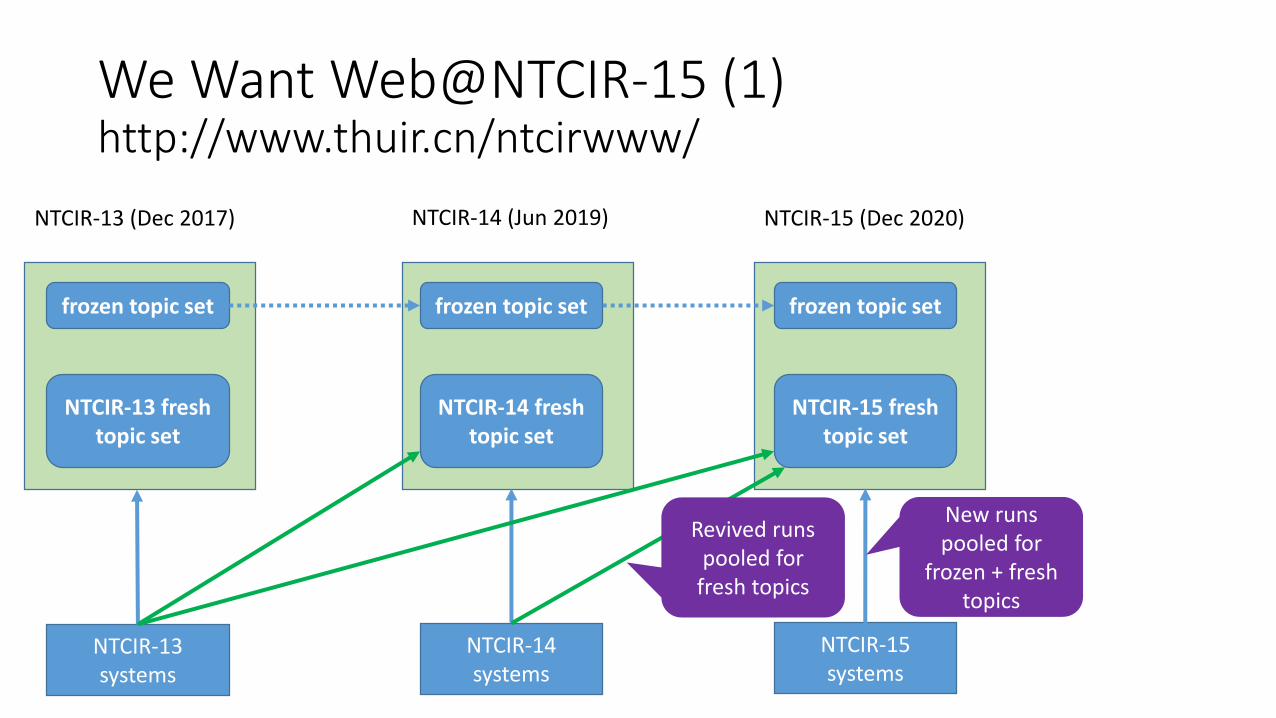
We Want Web@NTCIR-15 (1) http://www.thuir.cn/ntcirwww/
NTCIR-13 (Dec 2017) NTCIR-14 (Jun 2019) NTCIR-15 (Dec 2020)
frozen topic set frozen topic set frozen topic set
NTCIR-13 fresh topic set
NTCIR-14 fresh topic set
NTCIR-15 fresh topic set
NTCIR-13 systems
NTCIR-14 systems
NTCIR-15 systems
New runs pooled for
frozen + fresh topics
Revived runs pooled for
fresh topics

We Want Web@NTCIR-15 (2) http://www.thuir.cn/ntcirwww/
NTCIR-13 (Dec 2017) NTCIR-14 (Jun 2019) NTCIR-15 (Dec 2020)
frozen topic set frozen topic set frozen topic set
NTCIR-13 fresh topic set
NTCIR-14 fresh topic set
NTCIR-15 fresh topic set
NTCIR-13 systems
NTCIR-14 systems
NTCIR-15 systems
Official NTCIR-15results discussed with the fresh topics
Qrels + std. factors based on
NTCIR-(13+14+)15 systemsreleased
Using the NTCIR-15 fresh topics, compare new NTCIR-15 runs with revived runs and quantify progress.

We Want Web@NTCIR-15 (3) http://www.thuir.cn/ntcirwww/
NTCIR-13 (Dec 2017) NTCIR-14 (Jun 2019) NTCIR-15 (Dec 2020)
frozen topic set frozen topic set frozen topic set
NTCIR-13 fresh topic set
NTCIR-14 fresh topic set
NTCIR-15 fresh topic set
NTCIR-13 systems
NTCIR-14 systems
NTCIR-15 systems
Official NTCIR-15results discussed with the fresh topics
Qrels + std. factors based on
NTCIR-13+14 systemsreleased
Qrels + std. factors based onNTCIR-13systems
released
How do the standardisationfactors for each frozen topic differ across the 3 rounds?
Qrels + std. factors based on
NTCIR-13+14+15 systemsreleased
Qrels + std. factors based on
NTCIR-(13+14+)15 systemsreleased

We Want Web@NTCIR-15 (4) http://www.thuir.cn/ntcirwww/
NTCIR-13 (Dec 2017) NTCIR-14 (Jun 2019) NTCIR-15 (Dec 2020)
frozen topic set frozen topic set frozen topic set
NTCIR-13 fresh topic set
NTCIR-14 fresh topic set
NTCIR-15 fresh topic set
NTCIR-13 systems
NTCIR-14 systems
NTCIR-15 systems
Qrels + std. factors based on
NTCIR-(13+14+)15 systemsreleased
Official NTCIR-15results discussed with the fresh topics
Qrels + std. factors based on
NTCIR-13+14+15 systemsreleased
Qrels + std. factors based on
NTCIR-13+14 systemsreleased
Qrels + std. factors based onNTCIR-13 systemsreleased
How do the NTCIR-15 system rankings differ across the 3 rounds, with and w/o standardisation?
NTCIR-15 systems ranking
NTCIR-15 systems ranking
NTCIR-15 systems ranking

See you all in Tokyo, in August/December 2017!

Selected references (1)
[Aramaki+16] Aramaki et al.: Overview of the NTCIR-12 MedNLPDoc task, NTCIR-12 Proceedings, 2016.
[Carterette+08] Carterette et al.: Evaluation over Thousands of Queries, SIGIR 2008.
[Chapelle+11] Chapelle et al.: Intent-based Diversification of Web Search Results: Metrics and Algorithms, Information Retrieval 14(6), 2011.
[Jarvelin+02] Jarvelin and Kelalainen: Cumulated Gain-based Evaluation of IR techniques, ACM TOIS 20(4), 2002.
[Gilbert+79] Gilbert and Sparck Jones:, Statistical Bases of Relevance assessment for the `IDEAL’ Information Retrieval Test Collection, Computer Laboratory, University of Cambridge, 1979.
[Kato+16] Kato et al.: Overview of the NTCIR-12 MobileClick task, NTCIR-12 Proceedings, 2016.
[Nagata03] Nagata: How to Design the Sample Size (in Japanese), Asakura Shoten, 2003.

Selected references (2)
[Sakai05AIRS04] Sakai: Ranking the NTCIR Systems based on Multigrade Relevance, AIRS 2004 (LNCS 3411), 2005.
[Sakai06AIRS] Sakai: Bootstrap-based Comparisons of IR Metrics for Finding One Relevant Document, AIRS 2006 (LNCS 4182).
[Sakai+13SIGIR] Sakai and Dou: Summaries, Ranked Retrieval and Sessions: A Unified Framework for Information Access Evaluation, SIGIR 2013.
[Sakai16ICTIR] Sakai: A simple and effective approach to score standardisaiton, ICTIR 2016.
[Sakai16ICTIRtutorial] Sakai: Topic set size design and power analysis in practice (tutorial), ICTIR 2016.
[Sakai16IRJ] Sakai: Topic set size design, Information Retrieval, 19(3), 2016. OPEN ACCESS: http://link.springer.com/content/pdf/10.1007%2Fs10791-015-9273-z.pdf
[Sakai+16EVIA] Sakai and Shang: On Estimating Variances for Topic Set Size Design, EVIA 2016. http://research.nii.ac.jp/ntcir/workshop/OnlineProceedings12/pdf/evia/02-EVIA2016-SakaiT.pdf

Selected references (3)
[Shang+16] Shang et al.: Overview of the NTCIR-12 short text conversation task, NTCIR-12 Proceedings, 2016.
[Shibuki+16] Shibuki et al.: Overview of the NTCIR-12 QA Lab-2 task, NTCIR-12 Proceedings, 2016.
[SparckJones+75] Sparck Jones and Van Rijsbergen: Report on the Need for and Provision on an `Ideal’ Information Retrieval Test Collection, Computer Laboratory, University of Cambridge, 1975.
[Voorhees+05] Voorhees and Harman: TREC: Experiment and Evaluation in Information Retrieval, The MIT Press, 2005.
[Voorhees09] Voorhees: Topic Set Size Redux, SIGIR 2009.
[Webber+08SIGIR] Webber, Moffat, Zobel: Score standardisation for inter-collection comparison of retrieval systems, SIGIR 2008.
[Webber+08CIKM] Webber, Moffat, Zobel: Statistical power in retrieval experimentation, CIKM 2008.