algebra de procesos awn
TRANSCRIPT

DRAFT May 9, 2011
A Process Algebra for Wireless Mesh Networksused for
Modelling, Verifying and Analysing AODV
Ansgar FehnkerNICTA
Sydney, AustraliaComputer Science and Engineering
University of New South WalesSydney, Australia
Rob van GlabbeekNICTA
Sydney, AustraliaComputer Science and Engineering
University of New South WalesSydney, Australia
Peter HofnerNICTA
Sydney, AustraliaComputer Science and Engineering
University of New South WalesSydney, Australia
Annabelle McIverDepartment of Computing
Macquarie UniversitySydney, Australia
NICTASydney, Australia
Marius PortmannNICTA
Brisbane, AustraliaInformation Technology and
Electrical EngineeringUniversity of Queensland
Brisbane, Australia
Wee Lum TanNICTA
Brisbane, AustraliaInformation Technology and
Electrical EngineeringUniversity of Queensland
Brisbane, Australia
We propose a process algebra for wireless mesh networks that combines novel treatments of broad-cast, prioritised unicast and data structures. In this framework, we model the Ad-hoc On-DemandDistance Vector (AODV) routing protocol. We give a complete specification of AODV, where onlytiming aspects are omitted. The process algebra allows us to state and (dis)prove crucial propertiesof mesh network routing protocols such as loop freedom and packet delivery.
Contents
1 Introduction 3
2 Ad-Hoc On-Demand Distance Vector Routing Protocol 32.1 Basic Protocol . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42.2 Detailed Examples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
3 Abstractions Chosen 83.1 Timing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83.2 Optional Protocol Features . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83.3 Flags . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
4 A Process Algebra for Wireless Mesh Routing Protocols 104.1 A Language for Sequential Processes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104.2 A Language for Parallel Processes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124.3 A Language for Networks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134.4 Results on the Process Algebra . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 154.5 Optional Augmentation to Ensure Non-Blocking Broadcast . . . . . . . . . . . . . . . . 15

2 Modelling AODV with Process Algebra
5 Data Structure for AODV 175.1 Mandatory Types . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 175.2 Modelling Routes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 175.3 Routing Tables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 185.4 Updating Routing Tables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
5.4.1 Updating Precursor Lists . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 205.4.2 Inserting New Information in Routing Tables . . . . . . . . . . . . . . . . . . . 205.4.3 Invalidating Routes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
5.5 Route Requests . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 215.6 Queued Packets . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 225.7 Messages and Message Queues . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 235.8 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
6 Modelling AODV 256.1 The Basic Routine . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 256.2 Data Packet Handling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 276.3 Receiving Route Requests . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 286.4 Receiving Route Replies . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 306.5 Receiving Route Errors . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 316.6 The Message Queue and Synchronisation . . . . . . . . . . . . . . . . . . . . . . . . . 326.7 Initial State . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
7 Invariants 337.1 State and Transition Invariants . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 337.2 Notion and Notation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 347.3 Basic Properties . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 347.4 Further Properties . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 367.5 Loop Freedom . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
8 Formalising Temporal Properties of Routing Protocols 43
9 Related Work 44
10 Conclusion and Outlook 45

A. Fehnher, R.J. van Glabbeek, P. Hofner, A. McIver, M. Portmann & W.L. Tan 3
1 Introduction
Wireless Mesh Networks (WMNs) have recently gained considerable popularity and are increasinglydeployed in a wide range of application scenarios, including emergency response communication, in-telligent transportation systems, mining, video surveillance, etc. WMNs are essentially self-organisingwireless ad-hoc networks that can provide broadband communication without relying on a wired back-haul infrastructure. This has the benefit of rapid and low-cost network deployment. WMNs can beconsidered a superset of Mobile Ad-hoc Networks (MANETs), where a network consists exclusively ofmobile end user devices such as laptops or smartphones. In contrast to MANETs, WMNs typically alsocontain stationary infrastructure devices called mesh routers. However, this distinction is not relevant forthe purpose of this paper; important is that both MANETs and WMNs share the characteristic of highlydynamic network topologies, due to node mobility and the variable nature of wireless links.
In WMNs, a routing protocol is used to establish and maintain network connectivity through pathsbetween source and destination node pairs. As a consequence, the routing protocol is one of the key fac-tors determining the performance and reliability of WMNs. Traditionally, the main tools for evaluatingand validating network protocols are simulation and test-bed experiments. The key limitations of theseapproaches are that they are very expensive, time consuming and non-exhaustive, i.e., they only cover avery limited set of network scenarios. As a result, protocol errors and limitations are still found manyyears after the definition and standardisation; for example, see [17].
Formal methods have a great potential in helping to address this problem, and can provide valuabletools for the design, evaluation and verification of WMN routing protocols. The overall goal is to reducethe “time-to-market” for better (new or modified) WMN protocols, and to increase the reliability andperformance of the corresponding networks.
In this paper, we propose a process algebra that provides a step towards this goal. It combines noveltreatments of broadcast, prioritised unicast and data structures and allows formalisation of all importantaspects of a routing protocol. We demonstrate how our algebra can be used to formally model and reasonabout the Ad-Hoc On-Demand Distance Vector (AODV) routing protocol [19], which is one of the mostrelevant and widely used routing protocols in WMNs. The process algebra allows us to prove criticalprotocol properties like loop freedom.
Our model covers all core components of AODV, but none of the optional features, and abstractsfrom timing issues. As a further abstraction, we assume that any broadcast message is received by allnodes within transmission range. In reality, communication is only half-duplex: a network node cannotreceive messages while sending. However, the CSMA protocol used at the link layer—not modelledhere—keeps the probability of packet loss due to two nodes (within range) sending at the same timerather low. Here we abstract from probabilistic reasoning and assume that any message from a nodewithin range is received. This abstraction enables us to interpret a failure of guaranteed message delivery(under assumptions on the network topology) as an imperfection in the protocol, rather than as a resultof a chosen formalism not allowing guaranteed delivery.
2 Ad-Hoc On-Demand Distance Vector Routing Protocol
AODV [19] is a widely-used routing protocol designed for MANETs, and is one of the four protocolscurrently standardised by the IETF MANET working group1. It also forms the basis of new WMNrouting protocols, including the upcoming IEEE 802.11s wireless mesh network standard [12].
1http://datatracker.ietf.org/wg/manet/charter/

4 Modelling AODV with Process Algebra
(a)
d
b
s
a
(b)
d
b
s
a
RREQ
RREQ
RREQ
RREQ
RR
EQ
RR
EQ
(c)
d
b
s
aRREPR
REP
Figure 1: Example network topology
2.1 Basic Protocol
AODV is a reactive protocol: routes are established only on demand. A route from a source node sto a destination node d is a sequence of nodes [s,n1, . . . ,nk,d], where n1, . . . , nk are intermediate nodeslocated on the path from s to d. Its basic operation can best be explained using a simple example topologyshown in Figure 1(a), where edges connect nodes within transmission range. We assume node s wantsto send a data packet to node d, but s does not have a valid routing table entry for d. Node s initiates aroute discovery mechanism by broadcasting a route request (RREQ) message, which is received by s’simmediate neighbours a and b. We assume that neither a nor b knows a route to the destination node d.2
Therefore, they simply re-broadcast the message, as shown in Figure 1(b). Each RREQ message has aunique identifier which allows nodes to ignore duplicate RREQ messages that they have handled before.
When forwarding the RREQ message, each intermediate node updates its routing table and adds a“reverse route” entry to s, indicating via which next hop the node s can be reached, and the distance innumber of hops. Once the first RREQ message is received by the destination node d (we assume via a),d also adds a reverse route entry in its routing table, saying that node s can be reached via node a, at adistance of 2 hops.
Node d then responds by sending a route reply (RREP) message back to node s, as shown in Fig-ure 1(c). In contrast to the RREQ message, the RREP is unicast, i.e., it is sent to an individual next-hopnode only. The RREP is sent from d to a, and then to s, using the reverse routing table entries createdduring the forwarding of the RREQ message. When processing the RREP message, a node creates a“forward route” entry into its routing table. For example, upon receiving the RREP via a, node s createsan entry saying that d can be reached via a, at a distance of 2 hops. At the completion of the routediscovery process, a route has been established from s to d, and data packets can start to flow.
In the event of link and route breaks, AODV uses route error (RERR) messages to inform affectednodes. Sequence numbers are another important aspect of AODV, and are used to indicate the freshnessof routing table entries for the purpose of preventing routing loops.
2.2 Detailed Examples
Each node ip maintains its own routing table, consisting of exactly one entry for each known destinationdip. In this paper we represent a routing table entry as a tuple (dip , dsn , flag , hops , nhip , pre), indicatingthat nhip is the next hop on a route to dip of length hops; dsn is a sequence number measuring thefreshness of this information. The flag flag indicates if the route is valid (val)—it can be used—or if itis outdated (inv). Finally, pre is the set of neighbours who are “interested” in the route to dip—they areexpected to use ip as the next hop in their own routes to dip. Each node ip stores in its routing table a“route” (ip,sqn,val,0, ip, /0) to itself, where its own sequence number sqn is maintained.
We illustrate the AODV protocol in the example of Figure 2, where AODV is used to establish aroute between nodes a and c. For simplicity, we leave out the last component pre of routing table entries;hence each entry is a 5-tuple here.
2In case an intermediate node knows a route to d, it directly sends a route reply back.

A. Fehnher, R.J. van Glabbeek, P. Hofner, A. McIver, M. Portmann & W.L. Tan 5
Figure 2(a) shows the initial state. The routing tables of nodes a, b, c and d have only one entry,consisting of the node’s route to itself, with the initial sequence number 1. We assume that node awants to send a data packet to node c. First, a checks its routing table and finds that it does not havea (valid) routing table entry for the destination node c. Therefore it initiates a route discovery processby generating a RREQ message. For ease of explanation, we represent the generated RREQ messageas rreq(hops , rreqid , dip , dsn , oip , osn , sip), indicating that the route request originates from node oipwith sequence number osn, searching for a route to destination dip with sequence number at least dsn.This sequence number is taken from the entry for dip in the routing table maintained by node a. If noentry for dip is available, dsn is set to the special value 0 (“unknown”). In addition, hops is the numberof hops the message has already travelled from oip, rreqid is the unique identifier of the route request,and sip denotes the sender of the message.3
When generating a new RREQ message, the originator node must increment its own sequencenumber before copying it into the RREQ message. Therefore, the RREQ message from node a isrreq(0 , rreqid , c , 0 , a , 2 , a). This RREQ message is broadcast to all its neighbours (Figure 2(b)).Nodes b and d receive the request and update their routing tables to insert an entry for node a. Sincenodes b and d do not know a route to node c (they have no routing table entry with destination c), theyboth re-broadcast the RREQ message, as shown in Figure 2(c). Before forwarding the message, nodes band d increment the hops information in the RREQ message from 0 to 1, meaning that the distance to ais now 1.
(a) a wants to send a packet to c. (b) a broadcasts a new RREQ message;nodes b,d receive the RREQ and update their RTs.
d(d,1,val,0,d)
a(a,1,val,0,a)
b
(b,1,val,0,b)
c(c,1,val,0,c)
d(a,2,val,1,a)(d,1,val,0,d)
a(a,2,val,0,a)
b
(a,2,val,1,a)(b,1,val,0,b)
c(c,1,val,0,c)
RREQ
RREQ
(c) d forwards the RREQ; node a receives it. (d) c unicasts a RREP message to b.b forwards the RREQ; nodes a,c receive it.
d(a,2,val,1,a)(d,1,val,0,d)
a(a,2,val,0,a)(b,0,val,1,b)(d,0,val,1,d)
b
(a,2,val,1,a)(b,1,val,0,b)
c
(a,2,val,2,b)(b,0,val,1,b)(c,1,val,0,c)
RREQ
RREQ
RREQ
d(a,2,val,1,a)(d,1,val,0,d)
a(a,2,val,0,a)(b,0,val,1,b)(d,0,val,1,d)
b
(a,2,val,1,a)(b,1,val,0,b)(c,1,val,1,c)
c
(a,2,val,2,b)(b,0,val,1,b)(c,1,val,0,c)
RREP
Figure 2: Simple Example
3Following the RFC specification of AODV, the sender address sip is not part of the message itself; however a node thatreceives a message is able to obtain it from the source IP address field in the IP header of the message.

6 Modelling AODV with Process Algebra
(e) b unicasts the RREP to a.
d(a,2,val,1,a)(d,1,val,0,d)
a(a,2,val,0,a)(b,0,val,1,b)(c,1,val,2,b)(d,0,val,1,d)
b
(a,2,val,1,a)(b,1,val,0,b)(c,1,val,1,c)
c
(a,2,val,2,b)(b,0,val,1,b)(c,1,val,0,c)
RREP
Figure 2 (cont’d): Simple Example
The forwarded RREQ messages from nodes b and d are then received by node a. Through thesemessages node a knows that nodes b and d are 1-hop neighbours. Therefore, node a creates routing tableentries for its neighbours, but with unknown sequence number 0. Apart from this, since node a is theoriginator of the RREQ, it will ignore these messages.
The same RREQ message forwarded by node b is also received by node c. Node c reacts by creatingrouting table entries for both its previous-hop neighbour (node b) and the originator of the RREQ (nodea). It then responds by generating a RREP message. Again, for ease of explanation, we represent theRREP message as rrep(hops , dip , dsn , oip , sip), where hops now indicates the distance to dip. Asbefore, sip is the sender of the message. Since the destination node’s sequence number specified in thereceived RREQ message is unknown (dsn = 0), node c copies its own sequence number into the RREPmessage. Hence the RREP message from node c is rrep(0 , c , 1 , a , c).
From node c, the RREP message is unicast back to its previous-hop node b, on the path back towardsthe originator node a (Figure 2(d)). Node b processes the RREP message and updates its routing tableto insert an entry for node c. It also increments the hops information in the RREP message from 0 to 1before forwarding it to node a (Figure 2(e)). When node a receives the RREP message, this completesthe route discovery process and a route is now established from node a to node c. Data packets fromnode a can now be sent to node c.
We next describe a more interesting example of how AODV operates in a changing network topology.In this example, we will show that due to the changing network topology and subsequent updates to therouting table, a route reply message is not necessarily sent back to the node which had forwarded theroute request previously.
Figure 3(a) shows the initial network topology, and the initial state in the routing tables of the nodesin the topology. We assume that node s wants to send a data packet to node d; hence it generates andbroadcasts a route request message RREQ1 (rreq(0 , rreqid , d , 0 , s , 2 , s)), as shown in Figure 3(b).
Next, the network topology changes whereby node s is now within the transmission range of noded. This change in the network topology can be due to node mobility (i.e., node s moves into the trans-mission range of node d), or due to the improved quality of the wireless link between node s and noded. Figure 3(d) then shows the situation where node s wants to send a data packet to node a, thereby gen-erating and broadcasting a new route request message RREQ2 (rreq(0 , rreqid , a , 0 , s , 3 , s)) destinedto node a. Note that RREQ2 is received by node d, which results in the insertion of an entry for node swith sequence number 3 in node d’s routing table. At the same time, the previous route request RREQ1is forwarded to node b on its path towards node d.

A. Fehnher, R.J. van Glabbeek, P. Hofner, A. McIver, M. Portmann & W.L. Tan 7
(a) The initial state. (b) s broadcasts a new RREQ message destined to d.
a (a,1,val,0,a)
b
(b,1,val,0,b)
s(s,1,val,0,s) d(d,1,val,0,d)
a (a,1,val,0,a)
b
(b,1,val,0,b)
s(s,2,val,0,s) d(d,1,val,0,d)
RR
EQ
1
(c) Network topology changes; s moves into the transmission range of d(d) s broadcasts a new RREQ message destined to a; (e) d forwards RREQ2; nodes a,b,s receive it;
RREQ1 is forwarded. b updates its routing table entry to s.
b
(b,1,val,0,b)(s,2,val,2,!)
a (a,1,val,0,a)s(s,3,val,0,s) d(d,1,val,0,d)(s,3,val,1,s)
RR
EQ
2
RREQ1
RREQ2
b
(b,1,val,0,b)(d,0,val,1,d)(s,3,val,2,d)
a(a,1,val,0,a)(d,0,val,1,d)(s,3,val,2,d)
s(d,0,val,1,d)(s,3,val,0,s) d
(d,1,val,0,d)(s,3,val,1,s)
RREQ2
RR
EQ
2
RREQ2
(f) All steps that would follow as a reaction to RREQ2 are skipped, because they are not important here.(g) b forwards RREQ1; it is received by node d. (h) d generates a reply to RREQ1;
this reply is not sent back to b; it is sent to s.
b
(b,1,val,0,b)(d,0,val,1,d)(s,3,val,2,d)
a(a,1,val,0,a)(d,0,val,1,d)(s,3,val,2,d)
s(d,0,val,1,d)(s,3,val,0,s) d
(b,0,val,1,b)(d,1,val,0,d)(s,3,val,1,s)
RR
EQ
1
RREQ1b
(b,1,val,0,b)(d,0,val,1,d)(s,3,val,2,d)
a(a,1,val,0,a)(d,0,val,1,d)(s,3,val,2,d)
s(d,1,val,1,d)(s,3,val,0,s) d
(b,0,val,1,b)(d,1,val,0,d)(s,3,val,1,s)
RREP1
Figure 3: An Example with Changing Network Topology
Figure 3(e) shows that node d forwards RREQ2, which is received by nodes a, b, and s. The sub-sequent steps in response to RREQ2, i.e. the generation of a RREP message by node a, and its unicastto node d and subsequent forwarding to the originator node s, are not shown in Figure 3 as they do notcontribute towards the objective of this example.
Figure 3(g) shows that RREQ1 is forwarded by node b and finally received by the destination noded. Since the destination sequence number for node s in RREQ1 (dsn = 2) is older than the correspondingdestination sequence number information in node d’s routing table entry for node s (dsn = 3), the routingtable entry for node s is not updated. Node d then generates a RREP message in response to RREQ1.The destination node d searches in its routing table for a reverse route entry for node s, and finds thatthe next hop nhip for the route towards node s is node s itself. Therefore, the RREP message is not sentback to node b (from which the RREQ1 message is received), but instead is sent back directly to node s(Figure 3(h)).

8 Modelling AODV with Process Algebra
3 Abstractions Chosen
Our formalisation of AODV tries to accurately model the protocol as defined in the IETF RFC 3561specification [19]. The model focusses on layer 3 of the protocol stack, i.e., the routing and forwardingof messages and packets, and abstracts from lower layer network protocols and mechanisms such asthe Carrier Sense Multiple Access (CSMA) protocol. The presented formalisation includes all corecomponents of the protocol, but, at the moment, abstracts from timing issues and optional protocolfeatures. This keeps our specification manageable. Our plan is to extend our model step by step. Eventhough our model currently does not cover all aspects, it allows us to point to shortcomings in AODV andto discuss some possible improvements. The model also allows us to reason about protocol behaviourand to prove critical protocol characteristics.
In this section, we list all items that are not yet part of our formal model.
3.1 Timing
We abstract from all timing issues. Surely, this is a big decision and there are good reasons to add timeas a next step. However, this abstraction makes the verification of properties much easier:
No entry of a routing table or route reply message has the field lifetime that maintains the expirationor deletion time of the route in AODV. Informally this means that no valid route is set to invalid due totiming, that no invalid route disappears from the routing table (except when it is overwritten), and thatwe never delete elements of the set rreqs of already seen requests (described in Section 5.5). In terms ofthe RFC that means that ACTIVE_ROUTE_TIMEOUT, DELETE_PERIOD and PATH_DISCOVERY_TIME areset to infinity.
3.2 Optional Protocol Features
A route may be locally repaired if a link break in an active route occurs. In that case, the node upstreamof that break may choose to initiate a local repair if the destination was no farther than MAX_REPAIR_TTLhops away. Local repair is optional; therefore we do not model this feature here.
To avoid unnecessary network-wide dissemination of RREQs, the originating node should use anexpanding ring search technique. This is again an optional feature, which is not modelled here; we cansay that the RING_TRAVERSAL_TIME is set to infinity.
A route request may be sent multiple times. This happens if a node, after broadcasting a RREQ, doesnot receive the corresponding RREP within a given amount of time. In that case the node may broadcastanother RREQ, up to a maximum of RREQ_RETRIES. Since the default value for RREQ_RETRIES is onlytwo, and moreover this whole procedure is optional, we have not modelled this resending of RREQmessages.
If a route discovery has been attempted RREQ_RETRIES times without receiving any RREP, a desti-nation unreachable message should be delivered to the client (application) hooked up at the originator.This interaction between different layers of the protocol stack has not been modelled here since it is nota core part of the protocol itself.
When a node wants to increment its sequence number, but the largest possible number (232!1) hasalready been assigned to it, a sequence number rollover has to be accomplished. This rollover violates theproperty that sequence numbers are monotonically increased over time; therefore it would be possible tocreate routing loops. It appears that loops as a consequence of rollover are rare in practice and thereforewe decided to model sequence numbers by the unbounded set of natural numbers.
Interfaces, as part of routing table entries, store information concerning the network link, e.g., thatthe node is connected via ethernet. This is because AODV should operate smoothly over wired as well as

A. Fehnher, R.J. van Glabbeek, P. Hofner, A. McIver, M. Portmann & W.L. Tan 9
wireless networks. Here we assume that nodes have only one type of network interface and consequentlyleave out this field.
Another phenomenon which may yield complications and possibly routing loops, are node crashes.For now, we have neither modelled crashes nor actions after reboot.
By default, our process algebra establishes only bidirectional links4. We will point out how by atrivial change it can model unidirectional links (Section 4). We have decided not to make this our defaulthere, since, by doing so, fundamental properties such as route correctness would not hold for AODV anylonger. Unidirectional links come along with “blacklist” sets, which we also do not model.
We further do not model the optional support for aggregate networks and the use of AODV with othernetworks, as loosely discussed in Sections 7 and 8 of the AODV RFC.
Finally, hello messages can be used as an optional feature to offer connectivity information to anode’s neighbours. Since in our model all optional parts are skipped, we do not model hello messageseither; information about 1-hop neighbours is established by receiving AODV control messages.
3.3 Flags
Following the RFC [19], AODV control messages and routing table entries have to maintain a series ofstate and routing flags such as the repair flag, the unknown sequence number flag, and the gratuitousRREP flag. For most of these flags there is no compulsion to ever set them. An exception is the unknownsequence number (‘U’) flag. This flag is not needed if the set of sequence numbers reserves a specialelement for the unknown sequence number. This is for example done in the implementation AODV-UU [1]. In our model, we follow this approach, use 0 as the special element, and therefore skip the ‘U’flag.
Besides the ‘U’ flag, each route request has the join (‘J’), the repair (‘R’), the gratuitous RREP(‘G’) and the destination only (‘D’) flag. The ‘J’ and ‘R’ flag are reserved for multicast, an optionalfeature not fully specified in the RFC. We do not model multicast, and hence ignore these two flags.The ‘G’ flag indicates whether a gratuitous RREP should be unicast, by an intermediate node answeringthe RREQ message, to the destination node of the original message; the ‘D’ flag indicates that only thedestination may respond to this RREQ. Both flags may be set when a request is initiated. Since this isalso optional, we have decided to skip these features for the moment. However, their inclusion should bestraightforward.
A route reply carries two flags: the repair (‘R’) flag, used for multicast, and the acknowledgment (‘A’)flag, which indicates that a route reply acknowledgment message must be sent in response to a RREPmessage. We do not model these flags: the former since we do not model multicast at all; the latter sincethis flag is optional. Consequently, we have no need to model the route reply acknowledgment (RREP-ACK) message, which—next to RREQ, RREP and RERR—constitutes a fourth kind of AODV controlmessage.
Finally, an error message only maintains the no delete (‘N’) flag. It is set if a node has performed alocal repair. Since we do not model local repair, we are able to abstract from that flag.
Flags pertaining to local repair, but stored in the routing tables, are the repairable and the beingrepaired flags. For the same reasons, we skip these flags as well.
4A bidirectional link means that if a node b is in transmission range of a (a can send messages to b), then a is also in rangeof b. A bidirectional link does not mean that if a knows a route to b, then b knows a route to a.

10 Modelling AODV with Process Algebra
4 A Process Algebra for Wireless Mesh Routing Protocols
In this section we propose a language for the specification of routing protocols for WMNs, such asAODV. Our language is a variant of standard process algebras [16, 11, 2, 4], adapted to the problem athand. For example, our process algebra allows us to embed data structures. In our language a WMNis modelled as an encapsulated parallel composition of network nodes. On each node several sequentialprocesses may be running in parallel. Network nodes communicate with their direct neighbours—thosenodes that are in communication range—using either broadcast or unicast. Our formalism maintainsfor each node the set of nodes that are currently in communication range. Due to mobility of nodesand variability of wireless links, nodes can move in or out of communication range. The encapsulationof the entire network inhibits communications between network nodes and the outside world, with theexception of the receipt and delivery of data packets from or to clients5 of the modelled protocol thatmay be hooked up to various nodes.
4.1 A Language for Sequential Processes
The internal state of a process is determined, in part, by the values of certain data variables that aremaintained by that process. To this end, we assume a data structure with several types, variables rangingover these types, operators and predicates. First order predicate logic yields terms (or data expressions)and formulas to denote data values and statements about them. Our data structure always contains thetypes DATA, MSG, IP and P(IP) of data packets, messages, IP addresses—or any other node identifiers—and sets of IP addresses.
In addition, we assume a type SPROC of sequential processes, and a collection of process names,each being an operator of type TYPE1" · · ·"TYPEn # SPROC for certain data types TYPEi. Each processname X comes with a defining equation
X(var1, . . . ,varn)def= p ,
in which, for each i = 1, . . . ,n, vari is a variable of type TYPEi and p a sequential process expressiondefined by the grammar below. p may contain the variables vari as well as X ; however, all occurrencesof data variables in p have to be bound.6 The choice of the underlying data structure and the processnames with their defining equations can be tailored to any particular application of our language; ourdecisions made for modelling AODV are presented in Sections 5 and 6. The process names are used todenote the processes that feature in this application, with their arguments vari binding the current valuesof the data variables maintained by these processes.
The sequential process expressions are given by the following grammar:
SP ::= X(exp1, . . . ,expn) | [!]SP | [[var := exp]]SP | SP+SP | ".SP | unicast(dest , ms).SP ! SP" ::= broadcast(ms) | groupcast(dests , ms) | send(ms) | deliver(data) | receive(msg)
Here X is a process name, expi a data expression of the same type as vari, ! a data formula, var :=expan assignment of a data expression exp to a variable var of the same type, dest, dests, data and ms dataexpressions of types IP, P(IP), DATA and MSG, respectively, and msg a data variable of type MSG.
Given a valuation of the data variables by concrete data values, the sequential process [!]p acts asp if ! evaluates to true, and deadlocks if ! evaluates to false. In case ! contains free variables that
5The application layer that initiates packet sending and awaits receipt of a packet.6An occurrence of a data variable in p is bound if it is one of the variables vari, a variable msg occurring in a subexpression
receive(msg).q, a variable var occurring in a subexpression [[var := exp]]q, or an occurrence in a subexpression [!]q of avariable occurring free in ! . Here q is an arbitrary sequential process expression.

A. Fehnher, R.J. van Glabbeek, P. Hofner, A. McIver, M. Portmann & W.L. Tan 11
# ,broadcast(ms).p broadcast(# (ms))!!!!!!!!!# # , p
# ,groupcast(dests , ms).p groupcast(# (dests) ,# (ms))!!!!!!!!!!!!!!!# # , p
# ,unicast(dest , ms).p ! q unicast(# (dest) ,# (ms))!!!!!!!!!!!!!# # , p
# ,unicast(dest , ms).p ! q ¬unicast(# (dest))!!!!!!!!!# # ,q
# ,send(ms).p send(# (ms))!!!!!!# # , p
# ,deliver(data).p deliver(# (data))!!!!!!!!!# # , p
# ,receive(msg).p receive(m)!!!!!# # [msg := m], p ($m % MSG)
# , [[var := exp]]p $!# # [var := # (exp)], p
/0[vari := # (expi)]ni=1, p a!# % , p&
# ,X(exp1, . . . ,expn)a!# % , p&
(X(var1, . . . ,varn)def= p) ($a % Act)
# , p a!# % , p&
# , p+q a!# % , p&# ,q a!# % ,q&
# , p+q a!# % ,q&# !# %
# , [!]p $!# % , p($a % Act)
Table 1: Structural operational semantics for sequential process expressions
are not yet interpreted as data values, values are assigned to these variables in any way that satisfies ! ,if possible. The sequential process [[var := exp]]p acts as p, but under an updated valuation of the datavariables. The sequential process p + q may act either as p or as q, depending on which of the two isable to act at all. In a context where both are able to act, it is not specified how the choice is made. Thesequential process ".p first performs the action " and subsequently acts as p. The action broadcast(ms)broadcasts (the data value bound to the expression) ms to the other network nodes within range, whereasunicast(dest , ms).p ! q is a sequential process that tries to unicast the message ms to the destinationdest; if successful it continues to act as p and otherwise as q. The process groupcast(dests , ms).p triesto unicast ms to all destinations dests, and proceeds as p regardless of whether any of the unicasts issuccessful. The action send(ms) synchronously transmits a message to another process running on thesame network node; this action can occur only when this other sequential process is able to receive themessage. The sequential process receive(msg).p receives any message m (a data value of type MSG)either from another node, from another sequential process running on the same node or from the clienthooked up to the local node. It then proceeds as p, but with the data variable msg bound to the value m.In particular, receive(newpkt(d , dip)) models the submission of a data packet from a client, where thefunction newpkt generates a message containing the packet d and the intended destination dip. A datapacket is delivered to the client by deliver(data).
The internal state of a sequential process described by an expression p in this language is determinedby p, together with a valuation # associating data values # (var) to the data variables var maintainedby this process. Valuations naturally extend to # -closed data expressions—those in which all variablesare either bound or in the domain of # . The structural operational semantics of Table 1 is in the styleof Plotkin [20] and describes how one internal state can evolve into another by performing an action.The set Act of actions consists of broadcast(m), groupcast(D , m), unicast(dip , m), ¬unicast(dip),send(m), deliver(d), receive(m) and internal actions $ , for each choice of m%MSG, dip%IP, D%P(IP)and d%DATA. Here, ¬unicast(dip) denotes a failed unicast. Moreover # [var := v] denotes the valua-tion that assigns the value v to the variable var, and agrees with # on all other variables. The empty

12 Modelling AODV with Process Algebra
valuation /0 assigns values to no variables. Hence /0[vari := vi]ni=1 is the valuation that only assigns thevalues vi to the variables vari for i = 1, . . . ,n. The transition rule for process names in Table 1 (Line9) says that a process, named X , has the same transitions as the body p of its defining equation. In
CCS [16], such a rule isp a!# p&
X a!# p&. Adding data variables as arguments of process names would yield
# , p a!# % , p&
# ,X(var1, . . . ,varn)a!# % , p&
. However, a sequential process expression may call a process name with
data expressions filled in for these variables. This necessitates a translation from a given valuation # ofthe variables that may occur in these data expressions to a new valuation # # of the variables vari thatoccur in the defining equation of X :
# #,X(var1, . . . ,varn)a!# % , p&
# ,X(exp1, . . . ,expn)a!# % , p&
.
Here # #(vari) = # (expi). Moreover, in defining # # we drop all bindings of variables other than the vari.Example 4.1 Given the defining equation
X(numa) def= send(numa+1) .receive(numb) .X(numa+numb)
and the valuation given by # (numa) = 3 and # (numb) = 4, with numa and numb data variables of typeIN, we have
# ,X(numa+numb) send(8)!!!!# % ,receive(numb) .X(numa+numb) ,
where % (numa) = 7 and % (numb) is undefined.Finally, # !# % says that % is an extension of # , i.e., a valuation that agrees with # on all variables onwhich # is defined, and valuates the other variables occurring free in ! , such that the formula ! holdsunder % .Example 4.2 Let # (numa) = 7 and # (numb), # (numc) be undefined. Then the sequential process givenby the pair # , [numa = numb+numc]p admits several transitions of the form
# , [numa = numb+numc]p $!# % , p
such as the one with % (numb) = 2 and % (numc) = 5. On the other hand, # , [numa = numb+ 8]p admitsno transitions, since numb % IN.
4.2 A Language for Parallel Processes
Parallel process expressions are given by the grammar
PP ::= # ,SP | PP ''PP
where SP is a sequential process expression and # a valuation. An expression # , p denotes a sequentialprocess expression equipped with a valuation of the variables it maintains. The process P ''Q is aparallel composition of P and Q, running on the same network node. As formalised in Table 2, an actionreceive(m) of P synchronises with an action send(m) of Q into an internal action $ . These receiveactions of P and send actions of Q cannot happen separately. All other actions of P and Q, includingreceive actions of Q and send actions of P, occur interleaved in P''Q. Thus, in an expression (P''Q)''R,for example, the send and receive actions of Q can communicate only with P and R, respectively, butthe receive actions of R, as well as the send actions of P, remain available for communication withthe environment. Therefore, a parallel process expression denotes a parallel composition of sequentialprocesses # ,P with information flowing from right to left. The variables of different sequential processesrunning on the same node are maintained separately, and thus cannot be shared.

A. Fehnher, R.J. van Glabbeek, P. Hofner, A. McIver, M. Portmann & W.L. Tan 13
P a!# P&
P ''Q a!# P& ''Q($a (= receive(m))
Q a!# Q&
P ''Q a!# P ''Q&($a (= send(m))
P receive(m)!!!!!# P& Q send(m)!!!!# Q&
P ''Q $!# P& ''Q&($m % MSG)
Table 2: Structural operational semantics for parallel process expressions
4.3 A Language for Networks
We model network nodes in the context of a wireless mesh network by node expressions of the formip : P : R. Here ip % IP is the address of the node, P is a parallel process expression, and R %P(IP) isthe range of the node—the set of nodes that are currently within communication range of ip.
P broadcast(m)!!!!!!!# P&
ip : P : R R :*cast(m)!!!!!!# ip : P& : R
P groupcast(D ,m)!!!!!!!!!# P&
ip : P : R R)D :*cast(m)!!!!!!!!# ip : P& : R
P unicast(dip ,m)!!!!!!!!# P& dip % R
ip : P : R {dip} :*cast(m)!!!!!!!!# ip : P& : R
P ¬unicast(dip)!!!!!!!# P& dip (% R
ip : P : R $!# ip : P& : R
P deliver(d)!!!!!# P&
ip : P : R ip :deliver(d)!!!!!!!# ip : P& : R
P receive(m)!!!!!# P&
ip : P : R {ip}¬ /0 : listen(m)!!!!!!!!!# ip : P& : R
P $!# P&
ip : P : R $!# ip : P& : Rip : P : R /0¬{ip} : listen(m)!!!!!!!!!# ip : P : R
ip : P : R connect(ip,ip&)!!!!!!!!# ip : P : R*{ip&} ip : P : R disconnect(ip,ip&)!!!!!!!!!# ip : P : R!{ip&}
ip : P : R connect(ip&,ip)!!!!!!!!# ip : P : R*{ip&} ip : P : R disconnect(ip&,ip)!!!!!!!!!# ip : P : R!{ip&}
ip (% {ip&, ip&&}
ip : P : R connect(ip&,ip&&)!!!!!!!!# ip : P : R
ip (% {ip&, ip&&}
ip : P : R disconnect(ip&,ip&&)!!!!!!!!!!# ip : P : R
Table 3: Structural operational semantics for node expressions
A partial network is then modelled by a parallel composition + of node expressions, one for everynode in the network, and a complete network is a partial network within an encapsulation operator [ ]that inhibits any communication with nodes outside the network. This yields the following grammar fornetwork expressions:
N ::= [M] M ::= ip : P : R | M+M .
The operational semantics of node and network expressions of Tables 3 and 4 uses transition labelsR :*cast(m), H¬K : listen(m), connect(ip, ip&), disconnect(ip, ip&), ip :newpkt(d,dip), ip :deliver(d)and $ . As before, m % MSG, d % DATA, R % P(IP), and ip, ip& % IP. Moreover, H,K % P(IP) aresets of IP addresses. The action R :*cast(m) casts a message m that can be received by the set R of net-work nodes. We do not distinguish whether this message has been broadcast, groupcast or unicast—thedifferences show up merely in the value of R. Recall that D %P(IP) denotes a set of intended destina-tions, and dip % IP a single destination. A failed unicast attempt on the part of its process is modelled

14 Modelling AODV with Process Algebra
M R :*cast(m)!!!!!!#M& N H¬K : listen(m)!!!!!!!!# N&
M+N R :*cast(m)!!!!!!#M&+N&
!H , R
K)R = /0
" M H¬K : listen(m)!!!!!!!!#M& N R :*cast(m)!!!!!!# N&
M+N R :*cast(m)!!!!!!#M&+N&
!H , R
K)R = /0
"
M H¬K : listen(m)!!!!!!!!#M& N H &¬K& : listen(m)!!!!!!!!!# N&
M+N (H*H &)¬(K*K&) : listen(m)!!!!!!!!!!!!!!!#M&+N&
M ip :deliver(d)!!!!!!!#M&
M+N ip :deliver(d)!!!!!!!#M&+N
N ip :deliver(d)!!!!!!!# N&
M+N ip :deliver(d)!!!!!!!#M+N&
M $!#M&
M+N $!#M&+NN $!# N&
M+N $!#M+N&
M connect(ip,ip&)!!!!!!!!#M& N connect(ip,ip&)!!!!!!!!# N&
M+N connect(ip,ip&)!!!!!!!!#M&+N&
M disconnect(ip,ip&)!!!!!!!!!#M& N disconnect(ip,ip&)!!!!!!!!!# N&
M+N disconnect(ip,ip&)!!!!!!!!!#M&+N&
M connect(ip,ip&)!!!!!!!!#M&
[M] connect(ip,ip&)!!!!!!!!# [M&]
M disconnect(ip,ip&)!!!!!!!!!#M&
[M] disconnect(ip,ip&)!!!!!!!!!# [M&]
M R :*cast(m)!!!!!!#M&
[M] $!# [M&]M $!#M&
[M] $!# [M&]
M ip :deliver(d)!!!!!!!#M&
[M] ip :deliver(d)!!!!!!!# [M&]
M {ip}¬K : listen(newpkt(d ,dip))!!!!!!!!!!!!!!!!!#M&
[M] ip :newpkt(d,dip)!!!!!!!!!# [M&]
Table 4: Structural operational semantics for network expressions
as an internal action $ on the part of a node expression. The action send(m) of a process does not giverise to any action of the corresponding node—this action of a sequential process cannot occur withoutcommunicating with a receive action of another sequential process running on the same node.
Our language is based on the assumption that, at any time, all nodes listen to all messages that couldbe send to them, and that any message that is transmitted to a node within range of the sender is actuallyreceived by that node. This is modelled by H¬K : listen(m), saying that the set of nodes H*K is listeningto receive the message m, while H are the nodes that actually hear it and K the ones that cannot—theones that are out of range of the sender. The rules of Table 4 let a *cast(m) of one node synchronisewith a listen(m) of all other nodes, where this listen(m) induces a receive(m) in the process running ona node exactly when that node is in transmission range of the *cast(m).
Internal actions $ and the action ip :deliver(d) are simply inherited by node expressions from theprocesses that run on these nodes, and are interleaved in the parallel composition of nodes that makes upa network. Finally, we allow actions connect(ip, ip&) and disconnect(ip, ip&) for ip, ip& % IP modelling achange in network topology. Each node needs to synchronise with such an action. These actions can bethought of as occurring nondeterministically, or as actions instigated by the environment of the modellednetwork protocol. In this formalisation node ip& is in the range of node ip, meaning that ip& can receivemessages sent by ip, if and only if ip is in the range of ip&. To break this symmetry, one just skips thelast four rules of Table 3 and replaces the synchronisation rules for connect and disconnect in Table 4by interleaving rules (like the ones for deliver and $).
The main purpose of the encapsulation operator is to ensure that no messages will be received thathave never been sent. In a parallel composition of network nodes, any action receive(m) of one of thenodes ip manifests itself as an action H¬K : listen(m) of the parallel composition, with ip % H. Suchactions can happen (even) if within the parallel composition they do not communicate with an action*cast(m) of another component, because they might communicate with a *cast(m) of a node that isyet to be added to the parallel composition. However, once all nodes of the network are accounted

A. Fehnher, R.J. van Glabbeek, P. Hofner, A. McIver, M. Portmann & W.L. Tan 15
for, we need to inhibit unmatched listen actions, as otherwise our formalism would allow any node atany time to receive any message. One exception however are those listen actions that stem from anaction receive(newpkt(d , dip)) of a sequential process running on a node, as those actions representcommunication with the environment.
The encapsulation operator passes through internal actions, as well as delivery of data packets atdestination nodes, this being an interaction with the outside world. *cast(m)-actions are declared internalactions at this level; they cannot be steered by the outside world. The connect and disconnect actionsare passed through in Table 4, thereby placing them under control of the environment; to make themnondeterministic, their rules should have a $-label in the conclusion, or alternatively connect(ip, ip&)and disconnect(ip, ip&) should be thought of as internal actions. Finally, actions listen(m) are simplyblocked by the encapsulation—they cannot occur without synchronising with a *cast(m)—except for{ip}¬K : listen(newpkt(d , dip)) with d % DATA and dip % IP. This action represents a new data packetd that is submitted by a client of the modelled protocol to node ip, for delivery at destination dip.
4.4 Results on the Process Algebra
Our process algebra admits translation into one without data structures (although we cannot describe thetarget algebra without using data structures). The idea is to replace any variable by all possible values itcan take. Formally, processes # , p are replaced by T# (p), where T# is defined inductively by
T# (broadcast(ms) . p) = broadcast(# (ms)) .T# (p)T# (groupcast(dests , ms) . p) = groupcast(# (dests) , # (ms)) .T# (p)T# (unicast(dest , ms) . p ! q) = unicast(# (dest) , # (ms)) .T# (p) ! T# (q)T# (send(ms) . p) = send(# (ms)) .T# (p)T# (deliver(data) . p) = deliver(# (data)) .T# (p)T# (receive(msg) . p) = !m%MSG receive(m) .T# [msg:=m](p)T# ([[var := exp]]p) = $ .T# [var:=# (exp)](p)T# ([!]p) = !{% |# !#%} $ .T% (p)T# (p+q) = T# (p)+T# (q)T# (X(exp1, . . . ,expn)) = X# (exp1),...,# (expn) .
The last equation requires the introduction of a process name X!v for every substitution instance!v of thearguments of X . The resulting process algebra has a structural operational semantics in the de Simoneformat, generating the same transition system—up to strong bisimilarity,-—as the original. It followsthat-, and many other semantic equivalences, are congruences on our language [22].
Theorem 4.3 '' is associative, and + is associative and commutative, up to-.
Proof. The operational rules for these operators fit a format presented in [6], guaranteeing associativityup to-. Commutativity of + follows by symmetry. ./
4.5 Optional Augmentation to Ensure Non-Blocking Broadcast
Our process algebra, as presented above, is intended for networks in which each node is input en-abled [13], meaning that it is always ready to receive any message, i.e., able to engage in the transitionreceive(m) for any m % MSG. In our model of AODV (Section 6) we will ensure this by equipping eachnode with a message queue that is always able to accept messages for later handling—even when themain sequential process is currently busy. This makes our model non-blocking, meaning that no sendercan be delayed in transmitting a message simply because one of the potential recipients is not ready toreceive it.

16 Modelling AODV with Process Algebra
However, the operational semantics does allow blocking if one would (mis)use the process algebrato model nodes that are not input enabled. This is a logical consequence of insisting that any broadcastmessage is received by all nodes within transmission range.
Since the possibility of blocking can regarded as a bad property of broadcast formalisms, one maywish to take away the expressiveness of the language that allows modelling a blocking broadcast. Thisis the purpose of the following optional augmentations of our operational semantics.
The first possibility is the addition of the rule
P receive(m)!!!!!!(#
ip : P : R {ip}¬ /0 : listen(m)!!!!!!!!!# ip : P : R.
It states that a message may arrive at a node ip regardless whether the node is ready to receive it; if it isnot ready, the message is simply ignored, and the process running on the node remains in the same state.
A variation on the same idea stems from the Calculus of Broadcasting Systems [21]. It consistsin eliminating the negative premise in the above rule in favour of actions ignore(m) % Act—in [21]called discard actions w : —which can be performed by a process exactly when it is not ready to do areceive(m). The rule above then becomes
P ignore(m)!!!!!# P&
ip : P : R {ip}¬ /0 : listen(m)!!!!!!!!!# ip : P& : R
and we need the extra rules:
# ,broadcast(ms).p ignore(m)!!!!!# # ,broadcast(ms).p
# ,groupcast(dests , ms).p ignore(m)!!!!!# # ,groupcast(dests , ms).p
# ,unicast(dest , ms).p ! q ignore(m)!!!!!# # ,unicast(dest , ms).p ! q
# ,send(ms).p ignore(m)!!!!!# # ,send(ms).p
# ,deliver(data).p ignore(m)!!!!!# # ,deliver(data).p
# , [[var := exp]]p ignore(m)!!!!!# # , [[var := exp]]p
# , [!]p ignore(m)!!!!!# # , [!]p
# , p ignore(m)!!!!!# % , p& # ,q ignore(m)!!!!!# % &,q&
# , p+q ignore(m)!!!!!# # , p+q
for all m % MSG. Furthermore, the first rule for '' from Table 3 is replaced by
P a!# P&
P ''Q a!# P& ''Q($a (= receive(m), ignore(m)).
These rules ensure that for all P and m we always have P ignore(m)!!!!!#Q 0 (Q = P1P receive(m)!!!!!!(#).Either of these two optional augmentations of our semantics gives rise to the same transition system.
Moreover, when modelling networks in which all nodes are input enabled—as we do in this paper—the added rule for node expressions will never be used, and the resulting transition system is the samewhether we use augmentation or not.

A. Fehnher, R.J. van Glabbeek, P. Hofner, A. McIver, M. Portmann & W.L. Tan 17
5 Data Structure for AODV
In this section we set out the basic data structure needed for the detailed formal specification of AODV.As well as describing types for the information handled at the nodes during the execution of the protocolwe also define functions which will be used to describe the precise intention—and overall effect—of thevarious update mechanisms in an AODV implementation. The definitions are grouped roughly accordingto the various “aspects” of AODV and the host network.
5.1 Mandatory Types
As stated in the previous section, the data structure always consists of data packets, messages, IP ad-dresses and sets of IP addresses.
(a) The ultimate purpose of AODV is to deliver data packets. The type DATA describes a set of datapackets. An item of data is thus a particular element of that set, denoted by the variable data% DATA.
(b) Messages are used to send information via the network. In our specification we use the variable msgof the type MSG. Furthermore we use AODV control messages (route request, route reply, and routeerror) as well as messages for sending a data packet (see Section 5.7).
(c) The type IP describes a set of IP addresses or, more generally, a set of node identifiers. In the RFC3561 [19], IP is defined as the set of all IP addresses. We assume that each node has a uniqueidentifier ip % IP. Moreover, in our model, each node ip maintains a variable ip which always hasthe value ip. In any AODV control message, the variable sip holds the IP address of the sender, andif the message is part of the route discovery process—a route request or route reply message—weuse oip and dip for the origin and destination of the route sought. Furthermore, rip denotes anunreachable destination and nhip the next hop on some route.
5.2 Modelling Routes
In a network, pairs (ip0, ipk)% IP"IP of nodes are considered to be “connected” if ip0 can send to ipk di-rectly, i.e., ip0 is in the range of ipk and vice versa. We say that such nodes are connected by a single hop.When ip0 is not connected to ipk then messages from ip0 directed to ipk need to be “routed” through inter-mediate nodes. We say that a route (from ip0 to ipk) is made up of a sequence [ip0, ip1, ip2, . . . , ipk!1, ipk],where (ipi, ipi+1), i = 0, . . . ,k!1, are connected pairs; the length or hop count of the route is the numberof single hops, and any node ipi needs only to know the “next hop” address ipi+1 in order to be able toroute messages intended for the final destination ipk.
In operation, routes to a particular destination are requested and, when finally established, need to bere-evaluated in regard to their “validity”. Routes may become invalid if one of the pairs (ipi, ipi+1) in thehop-to-hop sequence gets disconnected. Then AODV may be reinvoked, as the need arises, to discoveralternative routes. Meanwhile, an invalid route remains invalid until fresh information is received whichestablishes a valid replacement route.
In addition to the next hop and hop count, AODV also “tags” routes with their validity and so-calledsequence numbers. The latter is a measure approximating the relative freshness of the information held—a smaller number denotes older information. We denote the set of sequence numbers by SQN and assumeit to be totally ordered. By default we take SQN to be IN, and use standard functions such as max. Wereserve a special element 0 % SQN whose semantics is that the sequence number is “invalid or unknown”.The initial sequence number is 1. The variables osn, dsn and rsn of type SQN are used to denote thesequence numbers of routes leading to the nodes oip, dip and rip.

18 Modelling AODV with Process Algebra
For every route, a node stores also a list of precursors, modelled as a set of IP addresses. Thisset collects all nodes which are currently potential users of the route, and are located one hop further“upstream”. When the interest of other nodes emerges, these nodes are added to the precursor list7; themain purpose of recording this information is to inform those nodes when the route becomes invalid.
In summary, following the RFC, a routing table entry (or entry for short) is given by 6 components:
(a) The destination IP address, which is an element of IP;
(b) The destination sequence number—an element of SQN;
(c) A flag tagging the route as being valid or invalid—an element of the set F = {val,inv}. We use thevariable flag to range over type F;
(d) The hop count, which is an element of IN. The variable hops ranges over the type IN and we makeuse of the standard function +1;
(e) The next hop, which is again an element of IP; and
(f) A list of precursors, which is an element of P(IP). We use the variable pre to range over P(IP).
We denote the type of routing table entries by R, use the variable r, and define a generation function
( , , , , , ) : IP"SQN"F" IN"IP"P(IP) # R .
A tuple (dip,dsn,flag,hops,nhip,pre) describes a route to dip of length hops and validity flag; the verynext node on this route is nhip; the last time the entry was updated the destination sequence number wasdsn. Finally, pre is a set of all neighbours who are “interested” in the route to dip. A node being “inter-ested” in the route is somewhat sketchily defined as one which has previously used the current node toroute messages to dip. Interested nodes are recorded in case the route to dip should ever become invalid,so that they may subsequently be informed. We use projections &1, . . .&6 to select the correspondingcomponent from the 6-tuple: For example, &5 : R# IP determines the next hop.
5.3 Routing Tables
Nodes store all their information about routes in their routing tables; a node ip’s routing table consists ofa set of routing table entries, exactly one for each known destination. Thus, a routing table is defined asa set of entries, with the restriction that each has a different destination dip, i.e., the first component ofeach entry in a routing table is unique.8 Formally, we define the type RT of routing tables by
RT := {rt | rt %P(R) 1 $r,s % rt : &1(r) (= &1(s)} .
In the specification and implementation of AODV during route finding nodes choose between alternativeroutes if necessary to ensure that only one route per destination ends up in their routing table.
In the formal model (and indeed in any AODV implementation) we need to extract the componentsof the entry for any given destination from a routing table. To this end, we define the following partialfunctions—they are partial because the routing table need not have an entry for the given destination. Webegin by selecting the entry in a routing table corresponding to a given destination dip:
'route : RT"IP " R
'route(rt , dip) :=#
(dip , dsn , flag , hops , nhip , pre) if (dip , dsn , flag , hops , nhip , pre) % rtundefined otherwise .
By the projections &1, . . . ,&6, defined above, we can now select the components of a selected entry:7The RFC does not mention a situation where nodes are dropped from the list, which seems curious.8As an alternative to restricting the set, we could have defined routing tables as partial functions from IP to R, in which case
it makes more sense to define an entry as a 5-tuple, not including the the destination IP as the first component.

A. Fehnher, R.J. van Glabbeek, P. Hofner, A. McIver, M. Portmann & W.L. Tan 19
(a) The destination sequence number relative to the destination dip:
sqn : RT"IP # SQN
sqn(rt , dip) :=#
&2('route(rt , dip)) if 'route(rt , dip) is defined0 otherwise
(b) The validity status of a recorded route:
flag : RT"IP " Fflag(rt , dip) := &3('route(rt , dip))
(c) The hop count of the route from the current node (hosting rt) to dip:
dhops : RT"IP " INdhops(rt , dip) := &4('route(rt , dip))
(d) The identity of the next node on the route to dip (if such a route is known):
nhop : RT"IP " IPnhop(rt , dip) := &5('route(rt , dip))
(e) The set of precursors or neighbours interested in using the route from ip to dip:
precs : RT"IP " P(IP)precs(rt , dip) := &6('route(rt , dip))
The domain of these partial functions changes during the operation of AODV as more routes are discov-ered and recorded in the routing table rt. The first function is extended to be a total function: wheneverthere is no route to dip inside the routing table under consideration, the sequence number is set to “un-known”. In the same style each partial function could be turned into a total one. However, in thespecification we use these function only when they are defined.
We are not only interested in information about a single route, but also in general information on arouting table:(a) The set of destination IP addresses for valid routes in rt is given by
vD : RT # P(IP)vD(rt) := {dip | (dip , 2 , val , 2 , 2 , 2) % rt}
(b) The set of destination IP addresses for invalid routes in rt is
iD : RT # P(IP)iD(rt) := {dip | (dip , 2 , inv , 2 , 2 , 2) % rt}
(c) Last, we define the set of destination IP addresses for known routes by
kD : RT # P(IP)kD(rt) := vD(rt)*iD(rt) = {dip | (dip , 2 , 2 , 2 , 2 , 2) % rt}
Obviously, the partial functions 'route, flag, dhops, nhop and precs are defined for rt and dip exactlywhen dip % kD.
In our model, each node ip maintains a variable rt, whose value is the current routing table of thenode. This routing table will always list a route (ip,sqn,val,0, ip, /0) to ip, where sqn is the sequencenumber of the node itself. In fact, each node maintains its own sequence number, which increases overtime, and in our model it is stored only in the node’s routing table entry to itself. All sequence numbersof routes to ip stored in the routing tables of other nodes all ultimately derived from ip’s own sequencenumber at the time such a route was discovered.

20 Modelling AODV with Process Algebra
5.4 Updating Routing Tables
Routing tables can be updated for three principal reasons. The first is when a node needs to adjust its listof precursors relative to a given destination; the second is when a received request or response carriesinformation about network connectivity; and the last when information is received to the effect that apreviously valid route should now be considered invalid. We define an update function for each case.
5.4.1 Updating Precursor Lists
Recall that the precursors of a given node ip relative to a particular destination dip are the nodes thatare “interested” in a route to dip via ip. The function addpre takes a routing table entry and a set of IPaddresses npre and updates the entry by adding npre to the list of precursors already present:
addpre : R"P(IP) # Raddpre((dip , dsn , flag , hops , nhip , pre) , npre) := (dip , dsn , flag , hops , nhip , pre*npre) .
5.4.2 Inserting New Information in Routing Tables
If a node gathers new information about a route to a destination dip, then it updates its routing tabledepending on its existing information on a route to dip. If no route to dip was known at all, it inserts a newentry in its routing table recording the information received. If it already has some (partial) informationthen it may update this information, depending on whether the new route is fresher or shorter then theone it has already. The following definition will be applied only when r is a valid routing table entry, i.e.,&3(r) = val.
update : RT"R# RT
update(rt , r) :=
$%%%%%%&
%%%%%%'
rt*{r} if &1(r) (% kD(rt)nrt*{nr} if sqn(rt , &1(r)) < &2(r)nrt*{nr} if sqn(rt , &1(r)) = &2(r) 1 dhops(rt , &1(r)) > &4(r)nrt*{nr} if sqn(rt , &1(r)) = &2(r) 1 flag(rt , &1(r)) = inv
nrt*{ns} otherwise ,
where s := 'route(rt , &1(r)) is the current entry in the routing table for the destination of r (if it exists),and nrt := rt!{s} is the routing table without that entry. The entry nr := addpre(r , &6(s)) is identical tor except that the precursors from s are added and ns := addpre(s , &6(r)) is generated from s by addingthe precursors from r.
The first case describes the situation where the routing table does not contain any information on aroute to dip. The fourth case, and part of the second, updates an invalid route with a valid one; this isdone only when it does not result in a lower sequence number. The remaining cases assume both routesto be valid and hence the routing table should contain the entry with the greater sequence number; if theyare equal we decide based on the hop count. In either case we take the union of the precursors of bothentries.
Note that we do not update if we receive a new entry where the sequence number and the hop countare identical to the current entry in the routing table. Following the RFC, the time period (till the validroute becomes invalid) should be reset; however at the moment we do not model timing aspects.
5.4.3 Invalidating Routes
Invalidating routes is a main feature of AODV; if a route is not valid any longer its validity flag has to beset to invalid. By doing this, the stored information about the route, such as the sequence number or the

A. Fehnher, R.J. van Glabbeek, P. Hofner, A. McIver, M. Portmann & W.L. Tan 21
hop count, remains accessible. The process of invalidating a routing table entry follows four rules: (a)any known sequence number is incremented by 1, (b) the unknown sequence number is not incremented,(c) the validity flag of the entry is set to inv, and (d) an invalid entry cannot be invalidated. However,in exception to (a) and (b), when the invalidation is in response to an error message, this message alsocontains a new (and already incremented) sequence number for each destination to be invalided.
Incrementing the sequence number (Part (a) and (b)) is modelled by
inc : SQN # SQN
inc(dsn) =#
dsn+1 if dsn (= 0dsn otherwise .
The function for invalidating routing table entries takes as arguments a routing table and a set ofdestinations dests % P(IP" SQN). Elements of this set are (rip,rsn)-pairs that not only identify anunreachable destination rip, but also a sequence number that describes the freshness of the faulty route.As for routing tables, we restrict ourselves to sets that have at most one entry for each destination.9 Weuse the variable dests to range over such sets. When invoking invalidate we either distil dests froman error message, or determine dests as a set of pairs (rip,inc(sqn(rt , rip)), where the operator inctakes care of (a) and (b).
invalidate : RT"P(IP"SQN)# RTinvalidate(rt , dests) := rt!{'route(rt , rip) | (rip,2) % dests
1 'route(rt , rip) defined 1 flag(rt , rip) = val}* {(rip,rsn,inv,hops,nhip,pre) | (rip,rsn) % dests
1 'route(rt , rip) defined 1 flag(rt , rip) = val1 (rip,2,val,hops,nhip,pre) = 'route(rt , rip)}
First, all valid entries for a destination rip in dests are withdrawn from the routing table; then, all theseentries are modified and inserted again. The modification replaces the sequence number in an entry withthe corresponding sequence number from dests; furthermore, it replaces the flag val by inv.
5.5 Route Requests
A route request—RREQ—for a destination dip is initiated by a node (with routing table rt) if this nodewants to transmit a data packet to dip but there is no valid entry for dip in the routing table, i.e. dip (%vD(rt). When a new route request is sent out it contains the identity of the originating node oip, and aroute request identifier (RREQ ID); the type of all such identifiers is denoted by RREQID, and the variablerreqid ranges over this type. This information does not change, even when the request is re-broadcast byany receiving node that does not already know a route to the requested destination. In this way any requeststill circulating through the network can be uniquely identified by the pair (oip,rreqid) % IP"RREQID.For our specification we set RREQID = IN. In our model, each node maintains a variable rreqs of type
P(IP"RREQID)
of sets of such pairs to store the sets of route requests seen by the node so far. Within this set, the noderecords the requests it has previously initiated itself. To ensure a fresh rreqid for each new RREQ itgenerates, the node ip applies the following function:
nrreqid : P(IP"RREQID)"IP # RREQIDnrreqid(rreqs , ip) := max{n | (ip,n) % rreqs}+1 ,
where we take the maximum of the empty set to be zero.9Thus dests can be defined as partial function from IP to SQN.

22 Modelling AODV with Process Algebra
5.6 Queued Packets
Strictly speaking the task of sending data packets is not regarded as part of the AODV protocol—however,failure to send a packet because either a route to the destination is unknown, or a previously knownroute has become invalid, prompts AODV to be activated. In our modelling we describe this interactionbetween packet sending and AODV, providing the minimal infrastructure for our specification.
If a new packet is submitted by a client of AODV to a node, it may need to be stored until a routeto the packet’s destination has been found and the node is not busy carrying out other AODV tasks. Weuse a queue-style data structure for modelling the store of packets at a node, noting that at each nodethere may be many data queues, one for each destination. In general, we denote queues of type TYPE by[TYPE], denote the empty queue by [ ], and make use of the standard (partial) functions head : [TYPE] "TYPE, tail : [TYPE] " [TYPE] and append : TYPE" [TYPE]# [TYPE] that returns the “oldest” elementin the queue, removes the “oldest” element, and adds a packet to the queue, respectively. The datatype STORE 3P(IP" [DATA]) describes stores of enqueued data packets for various destinations Here(dip,q) % IP" [DATA] denotes the queue q of packets destined for dip. As for routing tables, we requirethat there is at most one entry for every IP address. In our model, each node maintains a variable storeof type STORE to record its current store of data packets.
We define some functions for inspecting a store:(a) Similar to 'route, we need a function that is able to extract the queue for a given destination.
'queue : STORE"IP # [DATA]
'queue(store , dip) :=#
q if (dip,q) % store[ ] otherwise
(b) We define a function qD to extract the destinations for which there are unsent packets:
qD : STORE # P(IP)qD(store) := {ip | (ip,2) % store} .
Finally, we define operations for adding and removing data packets from a store.(c) Adding a data packet for a particular destination to a store is defined by:
add : DATA"IP"STORE# STORE
add(data , dip , store) :=
$&
'
store*{(dip,append(data , [ ]))} if (dip,2) /% storestore!{(dip,q)}
*{(dip,append(data , q))} if (dip,q) % store .
Informally, the process selects the entry (dip , q) % store % STORE, where dip is the destination of thedata packet data, and appends data to the queue q of dip in that pair. In case there is no entry for dipin store, the process creates a new queue [data] of stored packets that only contains the data packetunder consideration and inserts it—together with dip—into the store.
(d) To delete the oldest packet for a particular destination from a store , we define:
drop : IP"STORE " STORE
drop(dip , store) :=
$&
'
store!{(dip,q)} if tail(q) = [ ]store!{(dip,q)}
*{(dip,tail(q))} otherwise ,
where q = 'queue(store , dip) is the selected queue for destination dip. Note that if data is the lastqueued packet for a specific destination, the whole entry for the destination is removed from store.
In our model of AODV we use only add and drop to update a store. This ensures that the store willnever contain a pair (dip, [ ]) with an empty data queue.

A. Fehnher, R.J. van Glabbeek, P. Hofner, A. McIver, M. Portmann & W.L. Tan 23
5.7 Messages and Message Queues
Messages are the main ingredient of any routing protocol. The message types used in the AODV protocolare route request, route reply, and route error. To generate theses messages, we use functions
rreq : IN"RREQID"IP"SQN"IP"SQN"IP# MSGrrep : IN"IP"SQN"IP"IP# MSGrerr : P(IP"SQN)"IP# MSG .10
The function rreq(hops , rreqid , dip , dsn , oip , osn , sip) generates a route request, where hops indicatesthe hop count from the originator oip—that, at the time of sending, had the sequence number osn—tothe sender of the message sip; rreqid uniquely identifies the route request; and dsn is the least levelof freshness of a route to dip that is acceptable to oip; it has been obtained by incrementing the latestsequence number received in the past by oip for a route towards dip. By rrep(hops, dip , dsn , oip , sip)a route reply message is obtained. Originally, it was generated by dip—where dsn denotes the sequencenumber of dip at the time of sending—and is destined for oip; the last sender of the message was thenode with IP address sip and the distance between dip and sip is given by hops. The error message isgenerated by rerr(dests , sip), where dests%P(IP"SQN) is the list of unreachable destinations and sipdenotes the sender. Every unreachable destination rip comes together with the incremented last-knownsequence number rsn.
Next to these AODV control messages, we use for our specification messages that carry data packets.
newpkt : DATA"IP# MSGpkt : DATA"IP"IP# MSG
Although these messages are not part of the protocol itself, they are necessary to initiate error messages,and to trigger the route discovery process. newpkt(data , dip) generates a message containing a new datapacket data destined for a particular destination dip. Such a message is submitted to a node, by a clientof the AODV protocol hooked up to that node. The function pkt(data , dip , sip) generates a messagesent by the sender sip, transmitting a data packet data to the next hop of the route towards dip.
All messages received by a particular node are first stored in a queue (see Section 6.6 for a detaileddescription). To model this behaviour we use a message queue, denoted by the variable msgs of type[MSG]. As for every other queue, we will freely use the functions head, tail and append.
5.8 Summary
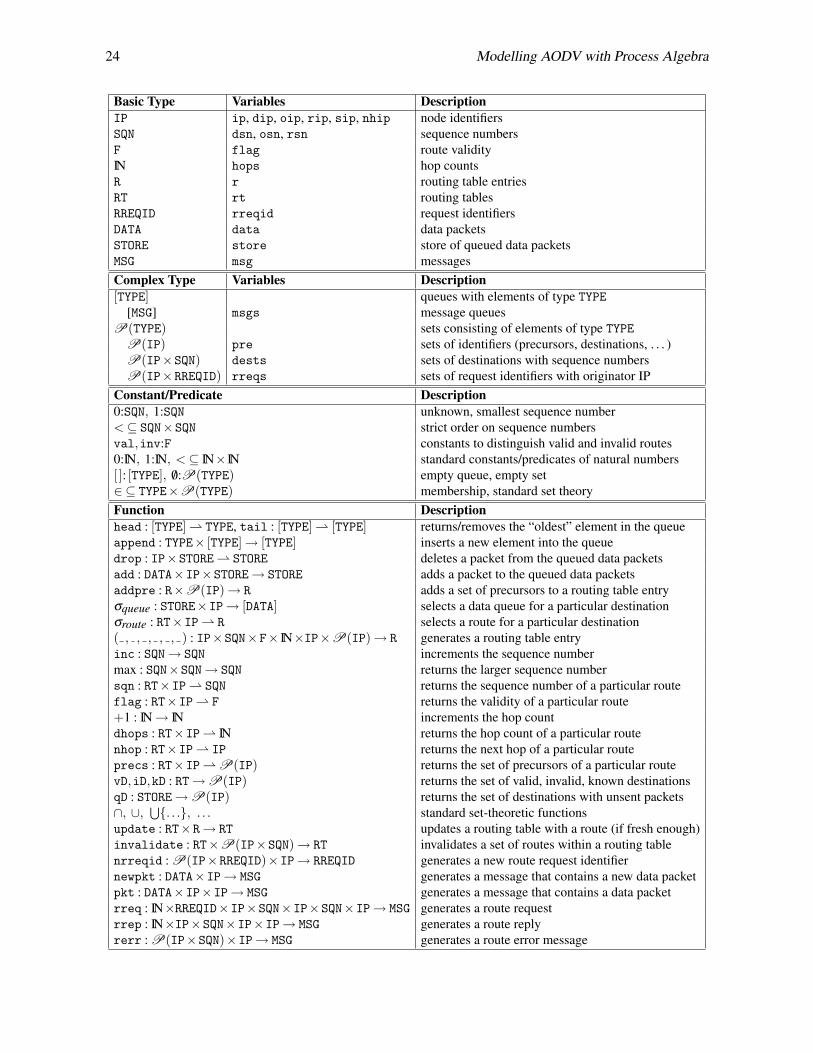
The following table describes the entire data structure we use.
10The ordering of the arguments follows the RFC.
24 Modelling AODV with Process Algebra
Basic Type Variables DescriptionIP ip, dip, oip, rip, sip, nhip node identifiersSQN dsn, osn, rsn sequence numbersF flag route validityIN hops hop countsR r routing table entriesRT rt routing tablesRREQID rreqid request identifiersDATA data data packetsSTORE store store of queued data packetsMSG msg messagesComplex Type Variables Description[TYPE] queues with elements of type TYPE
[MSG] msgs message queuesP(TYPE) sets consisting of elements of type TYPE
P(IP) pre sets of identifiers (precursors, destinations, . . . )P(IP"SQN) dests sets of destinations with sequence numbersP(IP"RREQID) rreqs sets of request identifiers with originator IP
Constant/Predicate Description0:SQN, 1:SQN unknown, smallest sequence number<, SQN"SQN strict order on sequence numbersval,inv:F constants to distinguish valid and invalid routes0:IN, 1:IN, <, IN" IN standard constants/predicates of natural numbers[ ]: [TYPE], /0:P(TYPE) empty queue, empty set% , TYPE"P(TYPE) membership, standard set theoryFunction Descriptionhead : [TYPE] " TYPE, tail : [TYPE] " [TYPE] returns/removes the “oldest” element in the queueappend : TYPE" [TYPE]# [TYPE] inserts a new element into the queuedrop : IP"STORE " STORE deletes a packet from the queued data packetsadd : DATA"IP"STORE# STORE adds a packet to the queued data packetsaddpre : R"P(IP)# R adds a set of precursors to a routing table entry'queue : STORE"IP# [DATA] selects a data queue for a particular destination'route : RT"IP " R selects a route for a particular destination( , , , , , ) : IP"SQN"F" IN"IP"P(IP)# R generates a routing table entryinc : SQN# SQN increments the sequence numbermax : SQN"SQN# SQN returns the larger sequence numbersqn : RT"IP " SQN returns the sequence number of a particular routeflag : RT"IP " F returns the validity of a particular route+1 : IN# IN increments the hop countdhops : RT"IP " IN returns the hop count of a particular routenhop : RT"IP " IP returns the next hop of a particular routeprecs : RT"IP " P(IP) returns the set of precursors of a particular routevD,iD,kD : RT#P(IP) returns the set of valid, invalid, known destinationsqD : STORE#P(IP) returns the set of destinations with unsent packets), *,
({. . .}, . . . standard set-theoretic functions
update : RT"R# RT updates a routing table with a route (if fresh enough)invalidate : RT"P(IP"SQN)# RT invalidates a set of routes within a routing tablenrreqid : P(IP"RREQID)"IP# RREQID generates a new route request identifiernewpkt : DATA"IP# MSG generates a message that contains a new data packetpkt : DATA"IP"IP# MSG generates a message that contains a data packetrreq : IN"RREQID"IP"SQN"IP"SQN"IP# MSG generates a route requestrrep : IN"IP"SQN"IP"IP# MSG generates a route replyrerr : P(IP"SQN)"IP# MSG generates a route error message

A. Fehnher, R.J. van Glabbeek, P. Hofner, A. McIver, M. Portmann & W.L. Tan 25
6 Modelling AODV
In this section, we present a specification of the AODV protocol using process algebra. The modelincludes a mechanism to describe the delivery of data packets; though this is not part of the protocolitself it is necessary to trigger any AODV activity. Our model consists of 6 processes, named AODV, PKT,RREQ, RREP, RERR and QMSG:
• The basic process AODV reads a message from the message queue and, depending on the type of themessage, calls other processes. When there is no message handling going on, the process initiatesthe transmission of queued data packets.
• The process PKT describes all actions performed by a node when a data packet is received. Thisincludes accepting the packet (if the node is the destination), forwarding the packet (if the node isnot the destination), sending an error message (if forwarding fails) and the initiation of a new routerequest (if the packets originates at the node and no route to the destination is known).
• The process RREQ models all events that might occur after a route request has been received. Thisincludes updating the node’s routing table, forwarding the route request as well as the initiation ofa route reply if a route to the destination is known.
• Similarly, the RREP process describes the reaction of the protocol to an incoming route reply.
• The process RERR models the part of AODV which handles error messages. In particular, it de-scribes the modification and forwarding of the AODV error message.
• The last process QMSG concerns message handling. Whenever an AODV control message is re-ceived, it is first stored in a message queue. If the corresponding node is able to handle a messageit pops the oldest message from the queue and handles it. An example where a node is not readyto process an incoming message immediately is when it is already handling a message.
In the remainder of the section, we provide a formal specification for each of these processes andexplain them step by step. Our specification can be split into three parts: the brown lines describeupdates to be performed on the node’s data, e.g., its routing table; the black lines are other processalgebra constructs (cf. Section 4); and the blue lines are ordinary comments.
6.1 The Basic Routine
The basic process AODV either reads a message from the corresponding queue or initiates the sending ofa queued data packet. This process maintains four data variables, ip, rt, rreqs and store, in which itstores its own identity, its current routing table, the list of route requests seen so far, and its current storeof queued data packets that await transmission (cf. Section 5).
The message handling is described in Lines 1–20. First, the message has to be read from the queue ofstored messages (receive(msg)). After that, the process AODV checks the type of the message and calls aprocess that can handle the message: in case of a new data packet or an incoming data packet, the processPKT is called; in case that the incoming message is an AODV control message (route request, route replyor route error), the node updates its routing table. More precisely, if there is no entry to the message’ssender sip, the receiver-node creates an entry with the unknown sequence number 0 and hop count 1(cf. Lines 10, 14 and 18). Afterwards, the processes RREQ, RREP and RERR are called, respectively.
The second part of AODV (Lines 21–31) initiates the sending of a data packet. For that, it has to bechecked if there is a queued data packet for a destination that has a known and valid route in the routingtable (vD(rt))qD(store) (= /0). In case that there is more than one destination with stored data and a

26 Modelling AODV with Process Algebra
Process 1 The basic routineAODV(ip , rt , rreqs , store)
def=1. receive(msg) .2. /* depending on the message, the node calls different processes */3. (4. [ msg = newpkt(data , dip) ] /* new DATA packet */5. PKT(data , dip , ip ; ip , rt , rreqs , store)6. + [ msg = pkt(data , dip , oip) ] /* incoming DATA packet */7. PKT(data , dip , oip ; ip , rt , rreqs , store)8. + [ msg = rreq(hops , rreqid , dip , dsn , oip , osn , sip) ] /* RREQ */9. /* update the route to sip in rt */
10. [[rt := update(rt , (sip,0,val,1,sip, /0))]] /* 0 is the sequence number “unknown” */11. RREQ(hops , rreqid , dip , dsn , oip , osn , sip ; ip , rt , rreqs , store)12. + [ msg = rrep(hops , dip , dsn , oip , sip) ] /* RREP */13. /* update the route to sip in rt */14. [[rt := update(rt , (sip,0,val,1,sip, /0))]]15. RREP(hops , dip , dsn , oip , sip ; ip , rt , rreqs , store)16. + [ msg = rerr(dests , sip) ] /* RERR */17. /* update the route to sip in rt */18. [[rt := update(rt , (sip,0,val,1,sip, /0))]]19. RERR(dests , sip ; ip , rt , rreqs , store)20. )21. + [ Let dip % vD(rt))qD(store) ] /* send a queued data packet if a valid route is known */22. [[data := head('queue(store , dip))]]23. unicast(nhop(rt , dip) , pkt(data , dip , ip)) .24. /* the queue is only updated if the transmission was successful. */25. [[store := drop(dip , store)]]26. AODV(ip , rt , rreqs , store)27. ! /* an error is produced and the routing table is updated */28. [[dests := {(rip,inc(sqn(rt , rip))) |rip % vD(rt) 1 nhop(rt , rip) = nhop(rt , dip)}]]29. [[rt := invalidate(rt , dests)]]30. [[pre :=
({precs(rt , rip) |(rip,2) % dests}]]
31. groupcast(pre , rerr(dests , ip)) . AODV(ip , rt , rreqs , store)
known route, an arbitrary destination is chosen and denoted by dip (Line 21).11 Moreover data is setto the first data packet that should be sent (data := head('queue(store , dip))).12 This data packet isunicast to the next hop on the route to dip. If the unicast is successful, the data packet data is removedfrom store (Line 25). Finally, the process calls itself—stating that the node is ready for handling anew message or initiating the sending of another packet towards a destination. In case the unicast isnot successful, the data packet has not been transmitted. Therefore data is not removed from store.Moreover, the node knows that the link to the next hop on the route to dip is faulty and, most probably,broken. An error message is initiated. Generally, route error and link breakage processing requiresthe following steps: (a) invalidating existing routing table entries, (b) listing affected destinations, (c)determining which neighbours may be affected (if any), and (d) delivering an appropriate AODV errormessage to such neighbours [19]. Therefore, the process determines all destinations dests that havethis unreachable node as next hop (Line 28) and marks these routes as invalid (Line 29). In Line 30 theprecursors (the neighbouring nodes listed as having a route to one of the affected destinations passingthrough the broken link) are determined and, finally, an error message is sent to them (Line 31).
11Although the word “let” is not part of the syntax, we add it to stress the nondeterminism happening here.12Following the RFC, data packets waiting for a route should be buffered “first-in, first-out” (FIFO).

A. Fehnher, R.J. van Glabbeek, P. Hofner, A. McIver, M. Portmann & W.L. Tan 27
6.2 Data Packet Handling
The process PKT describes all actions performed by a node when a data packet is received or created. Thisincludes the acceptance (if the node is the destination), the forwarding (if the node is not the destination),the initiation of a new route request (if the node is the originator of the packet), as well as the sending ofan error message in case something went wrong. Although packet handling itself is not part of AODV,it is necessary to include it in our formalisation, since a failure to transmit a data packet triggers AODVactivity.
Process 2 Routine for packet handling
PKT(data , dip , oip ; ip , rt , rreqs , store)def=
1. /* routine for handling a received packet */2. [ dip = ip ] /* the DATA packet is intended for this node */3. deliver(data) . AODV(ip , rt , rreqs , store)4. + [ dip (= ip ] /* the DATA packet is not intended for this node */5. (6. [ dip % vD(rt) ] /* valid route to dip */7. /* forward packet */8. unicast(nhop(rt , dip) , pkt(data , dip , oip)) . AODV(ip , rt , rreqs , store)9. ! /* If the packet transmission is unsuccessful, a RERR message is generated */
10. [[dests := {(rip,inc(sqn(rt , rip))) |rip % vD(rt) 1 nhop(rt , rip) = nhop(rt , dip)}]]11. [[rt := invalidate(rt , dests)]]12. [[pre :=
({precs(rt , rip) |(rip,2) % dests}]]
13. groupcast(pre , rerr(dests , ip)) . AODV(ip , rt , rreqs , store)14. + [ dip (% vD(rt) ] /* no valid route to dip */15. (16. [ oip = ip ] /* this node is the originator/source of the DATA packet */17. (18. [ dip % qD(store) ] /* we have already started a RREQ to dip */19. /* update store by adding the data packet */20. [[store := add(data , dip , store)]]21. AODV(ip , rt , rreqs , store)22. + [ dip (% qD(store) ] /* a route discovery process RREQ is initiated */23. /* update store by adding the data packet */24. [[store := add(data , dip , store)]]25. /* increment sqn(rt , ip) */26. [[(ip,dsn,flag,hops,nhip,pre) := 'route(rt , ip);
r := (ip,dsn+1,flag,hops,nhip,pre); rt := update(rt , r)]]27. /* update rreqs by adding (ip,nrreqid(rreqs , ip)) */28. [[rreqid := nrreqid(rreqs , ip); rreqs := rreqs*{(ip,rreqid)}]]29. broadcast(rreq(0 , rreqid , dip , sqn(rt , dip) , ip , sqn(rt , ip) , ip)) .30. AODV(ip , rt , rreqs , store)31. )32. + [ oip (= ip ] /* this node is not the originator of the DATA packet */33. /* no local repair occurs; data is lost */34. (35. [ dip % iD(rt) ] /* invalid route to dip */36. /* if the route is invalid, a RERR is sent to the precursors */37. groupcast(precs(rt , dip) , rerr({(dip,sqn(rt , dip))} , ip)) . AODV(ip , rt , rreqs , store)38. + [ dip (% iD(rt) ] /* route not in rt */39. /* if the route is not known, a RERR is broadcast */40. /* sqn(rt , dip) = 0 (the sequence number is unknown) */41. broadcast(rerr({(dip,sqn(rt , dip))} , ip)) . AODV(ip , rt , rreqs , store)42. )43. )44. )

28 Modelling AODV with Process Algebra
The process PKT first checks whether it is the intended addressee of the data packet. If this is thecase, it delivers the data and returns to the basic routine AODV. If the node is not the intended destination(dip (= ip, Line 4) more activity is needed.
In case that the node has a valid route to the data’s destination dip (dip % vD(rt)), it forwards thepacket using a unicast to the next hop nhop(rt , dip) on the way to dip. Similar to the unicast of theprocess AODV, it has to be checked whether the transmission is successful: no further action is necessaryif the transmission succeeds, and the node returns to the basic routine AODV. If the transmission fails, thelink to the next hop nhop(rt , dip) is assumed to be broken. As before, all destinations dests that arereached via that broken link are determined (Line 10) and all precursors interested in at least one of thesedestinations are informed via an error message (Line 13). Moreover, all the routing table entries usingthe broken link have to be invalidated in the node’s routing table rt (Line 11).
In case that the node has no valid route to the destination dip, the process checks whether the node isthe “originator of the packet”. If the data packet just “appeared” at the current node (oip= ip, Line 16),we know that the packet must have originated from a client hooked up to the local node, and transmittedto the AODV process using a newpkt message. In that case the data must be added to the data queue fordip (Lines 20 and 24). Following the RFC, “data packets waiting for a route (i.e., waiting for a RREPafter a RREQ has been sent) SHOULD be buffered.” [19]. If there were already data packets stored forthe destination of data (dip % qD(store), Line 18), the node has already started a route request and iswaiting for a reply. In this case there is nothing more to do and PKT calls the basic routine AODV (Line 21).If there were no data packet stored for the destination dip, the process initiates a new route request. Thisis achieved in three steps: First, the node’s own sequence number is increased by 1 (Line 26). Second,by determining nrreqid(rreqs , ip), a new message broadcast id is created and stored—together withthe node’s ip—in the set rreqs of route requests already seen (Line 28). Third, the message itself issent (Line 29) using broadcast. In contrast to unicast, transmissions via broadcast are not checked onsuccess. The information inside the message follows strictly the RFC. In particular, the hop count isset to 0, the message broadcast id previously created is used, etc. This ends the handling of a new datapacket submitted by a client of the AODV protocol through the local node.
If the node is not the originator of the data packet (Line 32) and still has no valid route to thedestination, an error message is sent. If there is an invalid route in the routing table (Line 35), thepossibly affected neighbours can be determined and the error is only sent to these precursors (Line 37).If there is no information about a route towards dip, the error message is broadcast.
6.3 Receiving Route Requests
The process RREQ models all events that may occur after a route request has been received.The process first reads the unique identifier (oip,rreqid) of the route request received. If this pair
is already stored in the node’s data rreqs, the route request has been handled before and the messagecan silently be ignored (Lines 2–3).
If the received message is new to this node ((oip,rreqid) (% rreqs, Line 4), the node establishesa route of length hops+ 1 back to the originator oip of the message. If this route is “better” than theroute to oip in the current routing table, the routing table is updated by this route (Line 6). Moreover theunique identifier has to be added to the set rreqs of already seen (and handled) route requests (Line 8).
After these updates the process checks if the node is the intended destination (dip= ip, Line 10). Inthat case, a route reply must be initiated: first, the node’s sequence number is—according to the RFC—set to the maximum of the current sequence number and the destination sequence number in the RREQpacket (Line 12). Then the reply is unicast to the next hop on the route back to the originator oip of theroute request. The content of the new route reply is as follows: the hop count is set to 0, the destinationand originator are copied from the route request received and the destination’s sequence number is read

A. Fehnher, R.J. van Glabbeek, P. Hofner, A. McIver, M. Portmann & W.L. Tan 29
from the routing table; of course the sender’s IP of this message has to be set to the node’s ip. As before(cf. Sections 6.1 and 6.2), the process sends an error message to all relevant precursors if the unicasttransmission fails.
Process 3 RREQ handling
RREQ(hops , rreqid , dip , dsn , oip , osn , sip ; ip , rt , rreqs , store)def=
1. /* routing that describes the handling of a received route request */2. [ (oip , rreqid) % rreqs ] /* the RREQ has been received previously */3. AODV(ip , rt , rreqs , store) /* silently ignore RREQ, i.e. do nothing */4. + [ (oip , rreqid) (% rreqs ] /* the RREQ is new to this node */5. /* update the route to oip in rt */6. [[rt := update(rt , (oip,osn,val,hops+1,sip, /0))]]7. /* update rreqs by adding (oip , rreqid) */8. [[rreqs := rreqs*{(oip,rreqid)}]]9. (
10. [ dip = ip ] /* this node is the destination node */11. /* update the sqn of ip by setting it to max(sqn(rt , ip),dsn) */12. [[rt := update(rt , (ip,dsn,val,0,ip, /0))]]13. /* unicast a RREP towards oip of the RREQ */14. unicast(nhop(rt , oip) , rrep(0 , dip , sqn(rt , ip) , oip , ip)) . AODV(ip , rt , rreqs , store)15. ! /* If the packet transmission is unsuccessful, a RERR message is generated */16. [[dests := {(rip,inc(sqn(rt , rip))) |rip % vD(rt) 1 nhop(rt , rip) = nhop(rt , oip)}]]17. [[rt := invalidate(rt , dests)]]18. [[pre :=
({precs(rt , rip) |(rip,2) % dests}]]
19. groupcast(pre , rerr(dests , ip)) . AODV(ip , rt , rreqs , store)20. + [ dip (= ip ] /* this node is not the destination node */21. (22. [ dip % vD(rt)1dsn4 sqn(rt , dip)1sqn(rt , dip) (= 0 ] /* valid route to dip that is fresh enough */23. /* update rt by adding precursors */24. [[r := addpre('route(rt , dip) , {sip}); rt := update(rt , r)]]25. [[r := addpre('route(rt , oip) , {nhop(rt , dip)}); rt := update(rt , r)]]26. /* unicast a RREP towards the oip of the RREQ */27. unicast(nhop(rt , oip) , rrep(dhops(rt , dip) , dip , sqn(rt , dip) , oip , ip)) .
AODV(ip , rt , rreqs , store)28. ! /* If the packet transmission is unsuccessful, a RERR message is generated */29. [[dests := {(rip,inc(sqn(rt , rip))) |rip % vD(rt) 1 nhop(rt , rip) = nhop(rt , oip)}]]30. [[rt := invalidate(rt , dests)]]31. [[pre :=
({precs(rt , rip) |(rip,2) % dests}]]
32. groupcast(pre , rerr(dests , ip)) . AODV(ip , rt , rreqs , store)33. + [ dip (% vD(rt)5sqn(rt , dip) < dsn5sqn(rt , dip) = 0 ] /* no valid route that is fresh enough */34. /* no further update of rt */35. broadcast(rreq(hops+1 , rreqid , dip , max(sqn(rt , dip),dsn) , oip , osn , ip)) .36. AODV(ip , rt , rreqs , store)37. )38. )
If the node is not the destination dip of the message but an intermediate hop along the path fromthe originator to the destination, it is allowed to generate a route reply only if the information in its ownrouting table is fresh enough. This means that (a) the node has a valid route to the destination, (b) the des-tination sequence number in the node’s existing routing table entry for the destination (sqn(rt , dip))is greater than or equal to the requested destination sequence number dip of the message and (c) thesequence number is valid, i.e., it is not unknown (sqn(rt , dip) (= 0). If these three conditions aresatisfied—the check is done in Line 22—the node generates a new route reply and sends it to the next

30 Modelling AODV with Process Algebra
hop on the way back to the originator oip of the received route request.13. To this end, it copies thesequence number for the destination dip from the routing table rt into the destination sequence numberfield of the RREP message and it places its distance in hops from the destination (dhops(rt , dip)) inthe corresponding field of the new reply (Line 27). As usual, the unicast might fail which causes theusual error handling (Lines 29–32). Just before transmitting the unicast, the intermediate node updatesthe forward route entry to dip by placing the last hop node (sip)14 into the precursor list for the for-ward route entry (Line 24). Likewise, it updates the reverse route entry to oip by placing the first hopnhop(rt , dip) towards dip in the precursor list for that entry (Line 25).15
If the node is not the destination and there is either no route to the destination dip inside the routingtable or the route is not fresh enough, the route request received has to be forwarded. This happens inLine 35. The information inside the forwarded request is mostly copied from the request received. Onlythe hop count is increased by 1 and the destination sequence number is set to the maximum of destinationsequence number in the RREQ packet and the the current sequence number for dip in the routing table.In case dip is an unknown destination, sqn(rt , dip) returns the unknown sequence number 0.
6.4 Receiving Route Replies
The process RREP describes the reaction of the protocol to an incoming route reply. Our model firstchecks if a forward routing table entry is going to be created or updated. This is the case if (a) the nodehas no known route to the destination, or (b) the destination sequence number in the node’s existingrouting table entry for the destination (sqn(rt , dip)) is smaller than the destination sequence numberdsn in the RREP message, or (c) the two destination sequence numbers are equal and, in addition, eitherthe hop count of the RREP received is strictly larger than the one in the routing table, or the entry fordip in the routing table is invalid (Line 2).
In case that one of these conditions is true, the routing table is updated in Line 5. If the node is theintended addressee of the route reply (oip = ip) nothing else happens and the protocol returns to itsbasic process AODV. Otherwise (oip (= ip) the message should be forwarded. Following the RFC [19],“If the current node is not the node indicated by the Originator IP Address in the RREP message AND aforward route has been created or updated [. . . ], the node consults its route table entry for the originatingnode to determine the next hop for the RREP packet, and then forwards the RREP towards the originatorusing the information in that route table entry.” This action needs a valid route to the originator oip of theroute request to which the current message is a reply (oip % vD(rt), Line 11). The content of the RREPmessage to be sent is mostly copied from the RREP received; only the sender has to be changed (it is nowthe node’s ip) and the hop count is incremented. Prior to the unicast, the node nhop(rt , oip), to whichthe message is sent, is added to the list of precursors for the routes to dip (Line 13) and to the next hopon the route to dip (Line 14). Although not specified in the RFC, it would make sense to add a precursorto the reverse route by [[r := addpre('route(rt , oip) , {nhop(rt , dip)}); rt := update(rt , r)]]. Asusual, if the unicast fails, the affected routing table entries are invalidated and the precursors of all routesusing the broken link are determined and an error message is sent (Lines 18–21). In the unlikely situationthat a reply should be forwarded but no valid route is known by the node, nothing happens. Followingthe RFC, no precursor has to be notified and no error message has to be sent—even if there is an invalidroute.
If a forward routing table entry is not created or is not updated, the reply is silently ignored and thebasic process is called (Lines 26–28).
13This next hop will often, but not always, be sip; see Figure 3 in Section 2.14This is a mistake in the RFC; it should have been nhop(rt , oip).15Unless the gratuitous RREP flag is set, which we do not model in this paper, this update is rather useless, as the precursor
nhop(rt , dip) in general is not aware that it has a route to oip.

A. Fehnher, R.J. van Glabbeek, P. Hofner, A. McIver, M. Portmann & W.L. Tan 31
Process 4 RREP handling
RREP(hops , dip , dsn , oip , sip ; ip , rt , rreqs , store)def=
1. /* routing that describes the handling of a received route reply */2. [ dip (% kD(rt)5sqn(rt , dip)<dsn5 (sqn(rt , dip)=dsn1 (dhops(rt , dip)>hops+15flag(rt , dip)=inv)) ]3. /* the routing table has to be updated */4. (5. [[rt := update(rt , (dip,dsn,val,hops+1,sip, /0))]]6. [ oip = ip ] /* this node is the originator of the corresponding RREQ */7. /* a packet may now be sent; this is done in the process AODV */8. AODV(ip , rt , rreqs , store)9. + [ oip (= ip ] /* this node is not the originator; forward RREP */
10. (11. [ oip % vD(rt) ] /* valid route to oip */12. /* add next hop towards oip as precursor and forward the route reply */13. [[r := addpre('route(rt , dip) , {nhop(rt , oip)}); rt := update(rt , r)]]14. [[r := addpre('route(rt , nhop(rt , dip)) , {nhop(rt , oip)}); rt := update(rt , r)]] 16
15. unicast(nhop(rt , oip) , rrep(hops+1 , dip , dsn , oip , ip)) .16. AODV(ip , rt , rreqs , store)17. ! /* If the packet transmission is unsuccessful, a RERR message is generated */18. [[dests := {(rip,inc(sqn(rt , rip))) |rip % vD(rt) 1 nhop(rt , rip) = nhop(rt , oip)}]]19. [[rt := invalidate(rt , dests)]]20. [[pre :=
({precs(rt , rip) |(rip,2) % dests}]]
21. groupcast(pre , rerr(dests , ip)) . AODV(ip , rt , rreqs , store)22. + [ oip (% vD(rt) ] /* no valid route to oip */23. AODV(ip , rt , rreqs , store)24. )25. )26. + [ dip%kD(rt)1 (sqn(rt , dip)>dsn5 (sqn(rt , dip)=dsn1dhops(rt , dip)4hops+11flag(rt , dip)=val)) ]27. /* the routing table is not updated */28. AODV(ip , rt , rreqs , store)
6.5 Receiving Route Errors
The process RERR models the part of AODV which handles error messages. An error message consistsof a set dests of pairs of an unreachable destination IP address rip and the corresponding unreachabledestination sequence number rsn.
Process 5 RERR handling
RERR(dests , sip ; ip , rt , rreqs , store)def=
1. /* invalidate broken routes */2. [[dests := {(rip,rsn) |(rip,rsn) % dests 1 rip % vD(rt) 1 nhop(rt , rip) = sip}]]3. [[rt := invalidate(rt , dests)]]4. /* forward the RERR to all precursors for rt entries for broken connections */5. [[pre :=
({precs(rt , rip) |(rip,2) % dests}]]
6. groupcast(pre , rerr(dests , ip)) . AODV(ip , rt , rreqs , store)
If a node receives an AODV error message from a neighbour for one or more valid routes, it has toinvalidate the entries for those routes in its own routing table and forward the error message. The nodecompares the set dests of unavailable destinations from the incoming error message with its own entriesin the routing table. If the routing table lists a valid route with a (rip,rsn)-combination from destsand if the next hop on this route is the sender sip of the error message, this entry is affected by the errormessage. It has to be invalidated and all precursors of this particular route have to be informed. This has

32 Modelling AODV with Process Algebra
to be done for all affected routes.In fact, the process first determines all (rip,rsn)-pairs that have effects on its own routing table and
that should be forwarded as content of a new error message (Line 2). After that, all entries to unavailabledestinations are invalidated (Line 3), and in Line 5, the set of all precursors (affected neighbours) of theunavailable destinations are summarised in the set pre. Finally, the message is sent (Line 6).
6.6 The Message Queue and Synchronisation
We assume that any message sent by a node sip to a node ip that happens to be within communicationrange of sip is actually received by ip. For this reason, ip should always be able to perform a receiveaction, regardless of which state it is in. However, the main process AODV that runs on the node ip canreach a state, such as PKT, RREQ, RREP or RERR, in which it is not ready to perform a receive action. Forthis reason we introduce a process QMSG, modelling a message queue, that runs in parallel with AODV orany other process that might be called. Every incoming message is first stored in this queue, and pipedfrom there to the process AODV, whenever AODV is ready to handle a new message. The process QMSG isalways ready to receive a new message, even when AODV is not. The whole parallel process running on anode is then given by an expression of the form
(# ,AODV(ip , rt , rreqs , store)) '' (% ,QMSG(msgs)) .
Process 6 Message Queue
QMSG(msgs)def=
1. /* store incoming message at the end of msgs */2. receive(msg) . QMSG(append(msg , msgs))3. + [ msgs (= [] ] /* the queue is not empty */4. /* pop top message */5. send(head(msgs)) . QMSG(tail(msgs))
6.7 Initial State
To finish our specification, we have to define an initial state. The initial network expression is an en-capsulated parallel composition of node expressions ip : P : R, where the (finite) number of nodes andthe range R of each node expression is left unspecified (can be anything). However, each node in theparallel composition is required to have a unique IP address ip. The initial process P of ip is given by theexpression (# ,AODV(ip , rt , rreqs , store)) '' (% ,QMSG(msgs)), with
# (ip) = ip 1 # (rreqs) = /0 1 # (store) = /0 1 % (msgs) = [ ] .
This says that initially each node is correctly informed abouts its own identity and the list of RREQsseen, the store of queued data packets as well at the message queue are empty.
For routing tables, we assume that in the beginning each node only knows the 0-hop route to itself—in this routing table entry a node maintains its own sequence number—and that the sequence number forall nodes is initialised to 1, i.e.,
(ip,1,val,0, ip, /0) % # (rt) 1 |# (rt)| = 1 . (1)

A. Fehnher, R.J. van Glabbeek, P. Hofner, A. McIver, M. Portmann & W.L. Tan 33
7 Invariants
Using our process algebra for wireless mesh networks and the proposed model of AODV we can now for-malise and prove crucial properties of AODV. In this section we verify properties that can be expressedas invariants, i.e., statements that hold all the time when the protocol is executed.
The most important invariant we establish is loop freedom; most prior results can be regarded asstepping stones towards this goal.
7.1 State and Transition Invariants
A (state) invariant is a statement that holds for all reachable states of our model. Here states are networkexpressions, as defined in Section 4.3. It is usually verified by showing that it holds for all possible initialstates, and that, for any transition N #!# N& derived by our operational semantics, if it holds for state Nthen it also holds for state N&.
Besides (state) invariants, we also establish statements we call transition invariants. A transitioninvariant is a statement that holds for each reachable transition N #!# N& derived by the operationalsemantics. In establishing a transition invariant for a particular transition, we usually assume it has al-ready been obtained for all prior transitions, those that occurred beforehand. Since the transition systemgenerated by our operational semantics may have cycles, we need to give a well-founded definition of“beforehand”. To this end we treat a statement about a transition as one about a transition occurrence,defined as a path in our transition system, stating in an initial state, and ending with the transition underconsideration. This way the induction is performed on the length of such a path. We speak of inductionon reachability.
To facilitate formalising transition invariants, we present a taxonomy of the transitions that can begenerated by our operational semantics, along with some notation: the label # of a transition N #!# N&
can be either connect(ip, ip&), disconnect(ip, ip&), ip :newpkt(d,dip), ip :deliver(d) or $ . We are mostinterested in the last case. A transition N $!# N& either arises from a transition R :*cast(m) performedby a network node ip, synchronising with receive actions of all nodes dip % R in transmission range, orstems from a $-transition of a network node ip.
In the former case, we write N R:*cast(m)!!!!!!#ip N&. This means that N = [M] and N& = [M&] are networkexpressions such that M R:*cast(m)!!!!!!# M&, and the cast action is performed by node ip. This transitionoriginates from an action broadcast(ms), groupcast(dests , ms), or unicast(dest , ms) (cf. Section 4).Each such action can be identified by a line number in one of the processes of Section 6.
In the latter case, a $-transition of a node ip stems either from a failed unicast, an evaluation [!], anassignment [[var := exp]], or a synchronisation of two actions send(ms) and receive(msg) performed bysequential processes running on that node. In our model these processes are AODV and QMSG, and theseactions can also be identified by line numbers in the processes of Section 6. In case of an assignment wewrite N [[var:=exp]]!!!!!!#ip N&.
The following observations are crucial in establishing many of our invariants.Proposition 7.1(a) With the exception of new packets that are submitted to a node by a client of AODV, every message
received has to be sent by some node before. More formally, we consider an arbitrary path N0#1!#
N1#2!# . . . #k!#Nk with N0 an initial state in our model of AODV. If the transition Nk!1
#k!#Nk resultsfrom a synchronisation involving the action receive(msg) from Line 1 of Pro. 1—performed by thenode ip—, where the variable msg is assigned the value m, then either m = newpkt(d , dip) or one ofthe #i with i < k stems from an action *cast(m) of a node ip& of the network.
(b) No node can receive a message (directly) from itself. Using the formalisation above, we must haveip (= ip&.

34 Modelling AODV with Process Algebra
Proof. The only way Line 1 of Pro. 1 can be executed, is through a synchronisation of the main processAODV with the message queue QMSG (Pro. 6) running on the same node. This involves the action send(m)of QMSG. Here m is popped from the message queue msgs, which started out empty. So at some pointQMSG must have performed the action receive(m). However, this action is blocked by the encapsulationoperator [ ] of Table 4, except when m has the form newpkt(d , dip) or when it synchronises with anaction *cast(m) of another node. ./
7.2 Notion and Notation
Before formalising and proving invariants, we introduce some useful notions and notations.All processes except QMSG maintain the four data variables ip, rt, rreqs and store. Next to that
QMSG maintains the variable msgs. Hence, these 5 variables can be evaluated at any time. Moreover,every node expression in the transition system looks like
ip : (# ,P '' % ,QMSG(msgs)) : R ,
where P is a state in one of the following sequential processes:AODV(ip , rt , rreqs , store) ,PKT(data , dip , oip ; ip , rt , rreqs , store) ,RREQ(hops , rreqid , dip , dsn , oip , osn , sip ; ip , rt , rreqs , store) ,RREP(hops , dip , dsn , oip , sip ; ip , rt , rreqs , store) orRERR(dests , sip ; ip , rt , rreqs , store) .
Hence the state of the transition system for a node ip is determined by the process P, the range R, and thetwo valuations # and % . If a network consists of a set IP, IP of nodes, a reachable network expressionN is an encapsulated parallel composition of node expressions—one for each ip % IP. In this section,we assume N and N& to be reachable network expressions in our model of AODV. To distil currentinformation about a node from N, we define the following projections:
PipN := P, where ip : (2,P '' 2,2) : 2 is a node expression of N,
RipN := R, where ip : (2,2 '' 2,2) : R is a node expression of N,
# ipN := # , where ip : (# ,2 '' 2,2) : 2 is a node expression of N,
% ipN := % , where ip : (2,2 ''% ,2) : 2 is a node expression of N.
For example PipN determines the sequential process the node is currently working in, Rip
N denotes the setof all nodes currently within transmission range of ip, and # ip
N (rt) evaluates the current routing tablemaintained by node ip in the network expression N. In the forthcoming proofs, when discussing theeffects of an action, identified by a line number in one of the processes of our model, # denotes thecurrent valuation # ip
N , where ip is the address of the local node, executing the action under consideration,and N is the network expression in which this action occurs, corresponding with the line number underconsideration.
In Section 5 we have defined many functions that work on evaluated routing tables # ipN (rt), e.g, sqn.
To ease readability, we abbreviate sqn(# ipN (rt) , dip) by sqnip
N (dip). Similarly, we use 'routeipN (dip),
dhopsipN (dip), flagip
N (dip) and nhopipN (dip), respectively.
7.3 Basic Properties
Proposition 7.2
(a) In each routing table there is at most one entry for each destination.
(b) In each store of queued data packets there is at most one data queue for each destination.

A. Fehnher, R.J. van Glabbeek, P. Hofner, A. McIver, M. Portmann & W.L. Tan 35
(c) In each node’s routing table, the sequence number for any given destination increases monotonically,i.e. never decreases. That is, for ip,dip% IP, if N #!# N& then sqnip
N (dip)4 sqnipN&(dip).
Proof.(a) In the initial state the invariant is satisfied, as a routing table starts out with only a singe entry (see
(1) in Section 6.7). None of the Processes 1–6 of Section 6 changes a routing table directly; the onlyway a routing table is updated is through the functions update and invalidate. The latter onlychanges the sequence number and validity status of an existing route. This kind of update has noeffect on the invariant. The former inserts a new entry into a routing table only if the destinationis unknown, that is, if no entry for this destination already exists in the routing table; otherwise theexisting entry is replaced. Therefore the invariant is maintained.
(b) In any initial state the invariant is satisfied, as each store of queued data packets starts out empty.In Processes 1–6 of Section 6 a store is updated only through the functions add and drop. Thesefunctions respect the invariant.
(c) As mentioned above, in Processes 1–6, routing tables are changed only through the functions updateand invalidate. These functions never decrement sequence numbers. Moreover, they never re-move an entry for dip altogether. ./
Properties (a) and (c) are stated in the RFC [19]; (a) and (b) are implied (or required) by our data structure.Proposition 7.2(a,b) shows that the functions defined in Section 5 respect the data structure.
The proof strategy used above can be generalised.Remark 7.3 Most of the forthcoming proofs can be done by showing the statement for each initial stateand then checking all locations in the processes where the validity of the invariant is possibly changed.Note that routing table entries are only changed by the functions update or invalidate. Thus wehave to show that an invariant dealing with routing tables is satisfied after the execution of update orinvalidate if it was valid before. In our proofs, we go through all occurrences of these functions.
Our next invariant tells that each node is correctly informed about its own identity.Proposition 7.4 For each ip % IP and each reachable state N we have # ip
N (ip) = ip.Proof. According to Section 6.7 the claim is assumed to hold for each initial state, and none of ourprocesses has an assignment changing the value of the variable ip. ./This proposition will be used implicitly in many of the proofs to follow.Proposition 7.5 A node ip % IP never queues data packets intended for itself.
ip (% qD(# ipN (store)) (2)
Proof. We first show the claim for the initial states; afterwards we go through our specification (step bystep) and look at all locations where the store of an arbitrary node ip % IP can be changed.
In an initial network expression all sets of queued data are empty. There is only one place wherea new destination is added to store, namely Pro. 2, Line 24. Here, # (dip) is added as new queueddestination. However, Line 4 shows that # (dip) (= # (ip). Note that Pro. 2, Line 20 changes only datafor existing queued destinations; it does not add new destinations. ./
Next, we show that every AODV control message contains the IP address of the sender.Proposition 7.6 If an AODV control message is sent by node ip % IP, the node sending this messageidentifies itself correctly:
N R:*cast(m)!!!!!!#ip N& 6 ip = ipc ,
where the message m is either rreq(2 , 2 , 2 , 2 , 2 , 2 , ipc), rrep(2 , 2 , 2 , 2 , ipc), or rerr(2 , ipc).The proof is straightforward: whenever such a message is sent in one of the processes of Section 6, # (ip)is set as the last argument. ./

36 Modelling AODV with Process Algebra
7.4 Further Properties
The following lemma states four properties about sending a route request.
Lemma 7.7
(a) If a route request with hop count 0 is sent by a node ipc % IP , the sender must be the originator.
N R:*cast(rreq(0 ,2 ,2 ,2 ,oipc ,2 , ipc))!!!!!!!!!!!!!!!!!!!#ip N& 6 oipc = ipc(= ip) (3)
(b) If a route request is sent by a node ipc % IP, the sender has stored the unique pair of the originator’ssequence number and the request id.
N R:*cast(rreq(2 ,rreqidc ,2 ,2 ,oipc ,2 , ipc))!!!!!!!!!!!!!!!!!!!!!!#ip N& 6 (oipc,rreqidc) % # ipcN (rreqs) (4)
(c) If a route request is sent, the originator has stored the unique pair of the originator’s sequence numberand the request id.
N R:*cast(rreq(2 ,rreqidc ,2 ,2 ,oipc ,2 ,2))!!!!!!!!!!!!!!!!!!!!!!#ip N& 6 (oipc,rreqidc) % # oipcN (rreqs) (5)
(d) The sequence number of an originator appearing in a route request can never be greater than thesequence number of the originator according to its own routing table.
N R:*cast(rreq(2 ,2 ,2 ,2 ,oipc ,osnc ,2))!!!!!!!!!!!!!!!!!!!!#ip N& 1 (oipc,osn&,2,2,2,2) % # oipcN (rt) 6 osnc 4 osn& (6)
Proof. We have to check that the consequent holds whenever a route request is sent. In all the processesthere are only two locations where this happens, namely Pro. 2, Line 29 and Pro. 3, Line 35.
(a) Pro. 2, Line 29: A request with content # (0 , 2 , 2 , 2 , ip , 2 , ip) is sent. Since the fifth and theseventh component are the same (# (ip)), the claim holds.
Pro. 3, Line 35: The message has the form rreq(# (hops)+1 , 2 , 2 , 2 , 2 , 2 , 2). Since # (hops) %IN, # (hops)+1 (= 0 and hence the antecedent does not hold.
(b) Pro. 2, Line 29: A request with content # (2 , rreqid , 2 , 2 , ip , 2 , ip) is sent. So ipc := # (ip),oipc := # (ip) and rreqidc := # (rreqid). Hence # ipc
N = # ipN = # . Right before broadcasting the
request, (# (ip),# (rreqid)) is added to the set # (rreqs) (Line 28).Pro. 3, Line 35: The information (# (oip),# (rreqid)) is added to # (rreqs) at Line 8. Moreover,
the set of handled requests # (rreqs) as well as the values of oip and rreqid do not change be-tween Line 8 and 35. Again (oipc,rreqidc)=(# (oip),# (rreqid)) % # (rreqs)=# ipc
N (rreqs).
(c) Pro. 2, Line 29: A request with content # (2 , rreqid , 2 , 2 , ip , 2 , ip) is sent. So oipc := # (ip)and rreqidc := # (rreqid). Hence # oipc
N = # . Right before broadcasting the request, the pair(# (ip),# (rreqid)) is added to the set # (rreqs) (Line 28).
Pro. 3, Line 35: A request with content # (2 , rreqid , 2 , 2 , oip , 2 , 2) is sent. The values of thevariables rreqid and oip do not change in Pro. 3; they stem, through Line 8 of Pro. 1, froman incoming RREQ message (Pro. 1, Line 1). Now the claim follows immediately from thefact the each RREQ message received, has been sent by some node (Proposition 7.1(a)), andinduction on reachability.
(d) Pro. 2, Line 29: The sender is the originator (cf. Line 16), so oipc := # (ip) = ip and # oipcN = # . The
originator sequence number for the route request is copied from the routing table. Therefore,osnc := sqn(# (rt) , # (ip)) = sqn(# oipc
N (rt) , oipc) = osn&.

A. Fehnher, R.J. van Glabbeek, P. Hofner, A. McIver, M. Portmann & W.L. Tan 37
Pro. 3, Line 35: Here oipc := # (oip) and osnc := # (osn). The values of the variables oip and osndo not change in Pro. 3; they stem from Line 8 of Pro. 1. By Proposition 7.1(a), a transitionlabelled R :*cast(rreq(2 , 2 , 2 , 2 , oipc , osnc , 2)) must have occurred before, say in state N†.Thus, by induction and Prop. 7.2(c), osnc 4 sqnoipc
N† (oipc)4 sqn(# oipcN (rt) , oipc) = osnc. ./
The following transition invariant can be established in the similar way.
Lemma 7.8 The sequence number of a destination appearing in a route reply can never be greater thanthe sequence number of the destination according to its own routing table.
N R:*cast(rrep(2 ,dipc ,dsnc ,2 ,2))!!!!!!!!!!!!!!!!!#ip N& 1 (dipc,dsn&,2,2,2,2) % # dipcN (rt) 6 dsnc 4 dsn& (7)
./
Lemma 7.9(a) If a node ip has a routing table entry where the next hop is the node itself, then the hop count is 0
and the destination is also the node itself.
(dip,2,2,hops, ip,2) % # ipN (rt) 6 dip = ip 1 hops = 0 (8)
(b) Each node ip knows a route to itself at any time.
(ip,dsn,val,0, ip,2) % # ipN (rt) with dsn7 1 . (9)
Proof.
(a) In an initial state the invariant is trivially satisfied (see (1) in Section 6.7). The invariant is maintainedby the function invalidate, and thus we only need examine calls of update.Pro. 1, Lines 10, 14, 18; Pro. 3, Line 6; Pro. 4, Line 5: These updates are of the form
update(# (rt) , (2,2,2,2,# (sip),2)) ;
in each of these cases the value of the variable sip stems, through Line 8, 12 or 16 in Pro. 1,from an incoming AODV control message (Line 1)—nowhere else in any of the processesis the value of sip modified. By Proposition 7.1(a) this incoming AODV control messagemust have been sent beforehand by some node ip&. Proposition 7.6 tells that in this message,the sender ip& correctly identifies itself, i.e., # (sip) = ip&. Hence Proposition 7.1(b) yields# (sip) (= ip. Therefore the routing table entries described inside these updates do not have theform (2,2,2,2, ip,2) and hence do not affect the validity of the invariant.
Pro. 2, Line 26: This update only increases the sequence number of an existing route. In particular,it changes neither entries for next hops nor hop counts.
Pro. 3, Line 12: The routing table entry used for the update (# (ip,dsn,val,0,ip, /0)) has exactlythe shape of the invariant’s antecedent. However it also satisfies the conclusion.
Pro. 3, Lines 24, 25; Pro 4, Lines 13, 14: These updates only changes the precursors of an existingroute (via addpre), i.e., the last component of a routing table entry (dip,2,2,hops, ip,2). Thusthe invariant is maintained.
(b) As above, by Statement (1), the claim is trivially true for an initial state. As usual we have to checkwhether the invariant is satisfied after the execution of update and invalidate.
Pro. 1, Lines 10, 14, 18: These updates have the form # (sip , 2 , 2 , 2 , 2 , 2). By Proposition 7.1(b)# (sip) (= ip; see (a) above for details. Therefore the routing table entries described do not haveip as destination and hence do not affect the validity of the invariant.

38 Modelling AODV with Process Algebra
Pro. 1, Line 29: We prove by contradiction that the invariant holds after the call of invalidate:we assume that the routing table entry for ip is invalidated by executing this line, and thenobtain a contradiction by showing that this implies # (dip) = ip, which contradicts (2). Due tothis, the function invalidate cannot work on a route with destination ip.If the entry with destination ip from # (rt) is invalidated at Line 29 then (ip,2) % # (dests)and, by Line 28, there is a route (ip,2,val,2,# (nhop(rt , dip)),2) % # (rt), where # (dip)is the destination chosen at Line 21 (# (dip) is not changed between Line 21 and 29). ByProposition 7.2(a) there is only one routing table entry for each destination. Therefore
# (nhop(rt , dip)) = ip
holds by the assumption that the invariant holds before the statement.Hence the entry for dip must have the form (# (dip),2,2,2, ip,2). Therefore, using Invari-ant (8), we conclude that # (dip) = ip and obtain, by Line 21, that there is a queued data packetfor ip at node ip:
ip % vD(# (rt)))qD(# (store)), qD(# (store)) .
This contradicts Invariant (2), and thus our assumption that the call of invalidate in Line 29invalidates a route with destination ip is false. Hence the entry for ip remains unchanged andthe invariant is maintained.
Pro. 2, Line 11: The Lines 10 and 11 are the same as Lines 28 and 29 of Pro. 1. Therefore, wereason as for the previous case, and conclude similarly that # (dip) = ip = # (ip). We nowhave a contradiction to Line 4 of Pro. 2.
Pro. 2, Line 26: This update only increases the sequence number of an existing route. In particular,if the invariant was valid before the update it is valid afterwards.
Pro. 3, Line 6: The update has the form # (oip,osn,val,hops+1,sip,2), where the values oip :=# (oip) and osn := # (osn) arise, through Line 8 of Pro. 1, from an incoming RREQ message.By Proposition 7.1(a) and Invariant (6), osn4 sqnoip
N (oip).Since the invariant under consideration has to hold before the update, we know that a validroute to ip exists, and hence dsn := sqnip
N (ip) is defined.The update only affects the invariant if oip = ip.Inspection of the definition of update shows that the update occurs in three circumstances:(a) if dsn < osn (indicating fresher incoming information),(b) if dsn = osn and the hop count of the incoming message is strictly greater than the hop
count currently in the routing table (indicating better incoming information), or(c) if the current flag is invalid (indicating “outdated” information).
(a) does not apply, since osn 4 dsn; (b) and (c) do not apply, since, as the invariant underconsideration holds before, there is a valid route with hop count 0 in the current routing table.Hence the routing table does not change and the invariant is maintained.
Pro. 3, Line 12: The entry used for the update has the form
# (ip,dsn,val,0,ip,2) = (ip,# (dsn),val,0, ip,2) .
It has exactly the shape required by the invariant.If # (dsn) = 0, the entry for ip is not inserted into the routing table. The reason for this is that,by the assumption that the invariant holds before the statement, there is an entry in the routingtable with destination ip and sequence number dsn 7 1. Therefore, by definition of update,the routing table is not changed.

A. Fehnher, R.J. van Glabbeek, P. Hofner, A. McIver, M. Portmann & W.L. Tan 39
Pro. 3, Lines 17, 30: Lines 16–17 and Lines 29–30, respectively, are the same as Lines 28–29 ofPro. 1, except that oip replaces dip. The same reasoning as above shows that # (oip) = ip.The variables oip and rreqid are not modified in Pro. 3; they stem from an incoming RREQmessage. By Proposition 7.1(a) and Invariant 5, we know that the originator of that RREQmessage (# (oip)), has already stored their values: (# (oip),# (rreqid)) % # # (oip)
N (rreqs).Since # (oip) evaluates to ip, we have (# (oip),# (rreqid)) % # ip
N (rreqs). This contradictsLine 4 (taking into account that no element can be removed from # ip
N (rreqs).Pro. 3, Line 24, 25; Pro 4, Lines 13, 14: The update only changes the precursors of an existing
routing table entry. Therefore the invariant is maintained.Pro. 4, Line 5: The update has the form # (dip,dsn,val,hops+1,2,2), where the values # (dip)
and # (dsn) arise, through Line 12 of Pro. 1, from an incoming RREP message. By Proposi-tion 7.1(a) and Invariant (7), # (dsn)4 sqn# (dip)
N (# (dip)).Since the invariant under consideration has to hold before the update, a valid route to ip mustexist. The update only affects the invariant if # (dip) = ip. Similar to Pro. 3, Line 6 we showthat the update does not change the routing table:(a) sqnip
N (ip) < # (dsn) does not hold, by the inequality derived above;(b) sqnip
N (ip) = # (dsn) 1 dhopsipN (ip) > # (hops)+1 is not satisfied, since the hop count in
the current routing table is 0 and therefore dhopsipN (ip) = 0 < # (hops)+1 for all possible
evaluations of hops;(c) flagip
N (ip) = inv does not hold due to the invariant under consideration.By this, the update does not change the routing table if # (dip) = ip and hence the claim holds.
Pro. 4, Line 19: Similar to the second case, we conclude # (oip) = ip, which contradicts Line 9.Pro. 5, Line 3: Lines 2–3 are similar to Lines 28–29 of Pro. 1, except that nhop(rt , dip) is re-
placed by sip and Line 2 does not increment the sequence number. We again assume that theroute to ip is invalidated and construct a contradiction. The fact (ip,2)% # (dests) immediatelyimplies, by Line 2,
ip = # (nhop(rt , ip)) = # (sip) ,
since the invariant has to hold before Line 3. The variable sip is not modified in Pro. 5; it iscopied from an incoming RERR message, and by Proposition 7.6 correctly identifies the senderof that message. This contradicts the observation that nodes cannot send messages directly tothemselves (Proposition 7.1(b)).
./Proposition 7.10(a) If a route request is sent by a node ipc, the content of ipc’s routing table must be at least as fresh as
the information inside the message.
N R:*cast(rreq(hopsc ,2 ,2 ,2 ,oipc ,osnc , ipc))!!!!!!!!!!!!!!!!!!!!!!!#ip N&
6 'routeipcN (oipc) is defined 1
)sqnipc
N (oipc) > osnc
5 (sqnipcN (oipc) = osnc 1 dhopsipc
N (oipc)4 hopsc 1 flagipcN (oipc) = val)
* (10)
(b) If a route reply is sent by a node ipc, the content of ipc’s routing table must be at least as fresh as theinformation inside the message.
N R:*cast(rrep(hopsc ,dipc ,dsnc ,2 , ipc))!!!!!!!!!!!!!!!!!!!!!#ip N&
6 'routeipcN (dipc) is defined 1
)sqnipc
N (dipc) > dsnc
5 (sqnipcN (dipc) = dsnc 1 dhopsipc
N (dipc)4 hopsc 1 flagipcN (dipc) = val)
* (11)

40 Modelling AODV with Process Algebra
Proof.
(a) We have to check that the consequent holds whenever a route request is sent:Pro. 2, Line 29: A new route request is initiated with oipc = ipc := # (ip) = ip. So # ipc
N = # . ByInvariant (9), there is a valid entry for # (ip) with hop count 0 in the routing table # (rt) of ip.The sequence number in the route request message is taken from this entry:
osnc := sqn(# (rt) , # (ip)) = sqnipcN (oipc)
hopsc := 0 = dhops(# (rt) , # (ip)) = dhopsipcN (oipc) .
Pro. 3, Line 35: The broadcast message in Line 35 has the form
# (rreq(hops+1 , rreqid , dip , max(sqn(rt , dip),dsn) , oip , osn , ip)) .
Hence hopsc := # (hops)+1, oipc := # (oip), osnc := # (osn), ipc := # (ip) = ip and # ipcN = # .
At Line 6 we update the routing table using # (oip,osn,val,hops+1,sip, /0) as new entry.The routing table does not change between Lines 6 and 35; nor do the values of the variableshops, oip and osn. If the new (valid) entry is inserted into the routing table, then
sqnipcN (oipc) = sqn(# (rt) , # (oip)) = # (osn) = osnc
dhopsipcN (oipc) = dhops(# (rt) , # (oip)) = # (hops)+1 = hopsc .
In case the new entry is not inserted into the routing table, by the definition of update,sqnipc
N (oipc) = sqn(# (rt) , # (oip))7 # (osn) = osnc, and in case that sqn(# (rt) , # (oip)) =# (osn) we see that dhopsipc
N (oipc) = dhops(# (rt) , # (oip))4 # (hops)+1 = hopsc and more-over flagipc
N (oipc) = flag(# (rt) , # (oip)) = val. Therefore the invariant holds.
(b) We have to check that the consequent holds whenever a route reply is sent.Pro. 3, Line 14: A new route reply with ipc := # (ip) = ip is initiated. So # ipc
N = # . Moreover, byLine 10, dipc := # (dip) = # (ip) = ip. By Invariant (9), in the routing table # (rt) of ip a validentry for # (ip) with hop count 0 exists. The sequence number in the route reply message istaken from this routing table entry:
dsnc := sqn(# (rt) , # (ip)) = sqnipcN (dipc) ,
hopsc := 0 = dhops(# (rt) , # (ip)) = dhopsipcN (dipc) .
Pro. 3, Line 27: Similar to the previous case, all information is taken from the routing table. Againwe have # ipc
N = # , and by Line 22 there is a valid routing table entry for dipc := # (dip).
dsnc := sqn(# (rt) , # (dip)) = sqnipcN (dipc) ,
hopsc := dhops(# (rt) , # (dip)) = dhopsipcN (dipc) .
Pro. 4, Line 15: The unicast message in Line 15 has the form
# (rrep(hops+1 , dip , dsn , oip , ip)) .
Hence hopsc := # (hops)+1, dipc := # (oip), dsnc := # (osn), ipc := # (ip) = ip and # ipcN = # .
Using (# (dip),# (dsn),val,# (hops)+1,# (sip), /0) as new entry, the routing table is updatedat Line 5. With exception of its precursors, which are irrelevant here, the routing table doesnot change between Lines 5 and 15; nor do the values of the variables hops, dip and dsn. If,during the update in Line 5, the new entry is inserted into the routing table, then

A. Fehnher, R.J. van Glabbeek, P. Hofner, A. McIver, M. Portmann & W.L. Tan 41
sqnipcN (dipc) = sqn(# (rt) , # (dip)) = # (dsn) = dsnc
dhopsipcN (dipc) = dhops(# (rt) , # (dip)) = # (hops)+1 = hopsc .
In case the new entry is not inserted into the routing table, by the definition of update,sqnipc
N (dipc) = sqn(# (rt) , # (dip))7 # (dsn) = dsnc, and in case that sqn(# (rt) , # (dip)) =# (dsn) we see that dhopsipc
N (dipc) = dhops(# (rt) , # (dip)) 4 # (hops)+1 = hopsc as wellas flagipc
N (oipc) = flag(# (rt) , # (oip)) = val. Therefore the invariant holds. ./
7.5 Loop Freedom
The classical notion of loop freedom is a term that informally means that “a packet never goes roundin cycles without (at some point) being delivered”. This dynamic definition is rather inconvenient toformalise, but the sense of it is captured by a simpler static invariant.
To this end we define the routing graph of network expression N with respect to destination dip byRN(dip) :=(IP,E), where all nodes of the network form the set of vertices and there is an arc (ip, ip&)% Eiff ip (=dip and (dip,2,val,2, ip&,2)%# ip
N (rt).An arc in a routing graph states that ip& is the next hop on a valid route to dip known by ip; a path in a
routing graph describes a route towards dip discovered by AODV. We say that a network expression N isloop free if the corresponding routing graphs RN(dip) are loop free, for all dip%IP. A routing protocol,such as AODV, is loop free iff all reachable network expressions are loop free.
To prove loop freedom of AODV, we employ a useful function, that takes validity in combination withthe sequence number into account. A net sequence number is defined by a function nsqn : RT"IP# SQN
nsqn(rt , dip) :=#
sqn(rt , dip) if flag(rt , dip) = val 5 sqn(rt , dip) = 0sqn(rt , dip)!1 otherwise .
This avoids tedious case distinctions in the following proofs. As with other functions on routing tables,we shorten nsqn(# ip
N (rt) , dip) to nsqnipN (dip). Note that nsqnip
N (dip) 7 sqnipN (dip)! 1. An important
property of net sequence numbers is that they remain unchanged under execution of the sequence ofupdates
[[dests := {(rip,inc(sqn(rt , rip))) |rip % vD(rt) 1 nhop(rt , rip) = nhop(rt , dip)}]][[rt := invalidate(rt , dests)]] .
Proposition 7.11 Suppose N [[rt:=invalidate(rt ,dests)]]!!!!!!!!!!!!!!!!!#ip N& for N a network state satisfying
(rip,rsn) % # ipN (dests)6 rsn = inc(sqnip
N (rip)) . (12)
Then nsqnipN (dip) = nsqnip
N&(dip) for any destination dip % IP.
Proof. Following the definition of invalidate, the entry for dip in # ipN (rt) changes only if
(dip,2) % # (dests) 1 'routeipN (dip) is defined 1 flagip
N (dip) = val .
In this case, flagipN (dip) changes from val to inv, and 'route
ipN (dip) is incremented by 1, unless it is 0.
Hence nsqnipN (dip) stays then same. ./
Theorem 7.12 If, in a network expression N, a node ip%IP has an entry to dip, the next hop has adip-entry with larger net sequence number or smaller hop count.
'routeipN (dip) is defined 1 dhopsip
N (dip)7 16 'route
nhipN (dip) is defined 1 nsqnnhip
N (dip)7 nsqnipN (dip) 1)
(nsqnnhipN (dip) = nsqnip
N (dip) 1 flagnhipN (dip) = val) 6 dhopsnhip
N (dip) < dhopsipN (dip)
*,
(13)
where nhip := nhopipN (dip).

42 Modelling AODV with Process Algebra
Proof. As before, we first check the initial states of our transition system and then check all locationsin Processes 1–6 where a routing table is updated. For an initial network expression, the invariant holdssince there is no routing table entry with hop count larger than 0.
An update to # nhipN (rt) is harmless, as it can only increase nsqnnhip
N (dip), and can only increasedhopsnhip
N (dip) when also increasing nsqnnhipN (dip).
It remains to examine all invalidates and updates to # ipN (rt). Moreover, if the function update
occurs, we can assume w.l.o.g. that a new route is actually inserted into the corresponding routing ta-ble; if the routing table is not changed by update, the invariant—which is assumed to hold before—ismaintained.
Pro. 1, Lines 10, 14, 18: The entry # (sip , 0 , val , 1 , sip , /0) is used for the update. Let sip := # (sip).So the update results in a new entry for sip, with nsqnip
N (sip) = 0. he next hop for this entry isnhip := # (sip) = sip. By Invariant (9) there is an entry
(sip,dsn,val,0,sip,2) % # sipN (rt)
with net sequence number nsqnsipN (sip) = dsn7 1 > nsqnip
N (sip). Hence the invariant holds.
Pro. 1, Line 29; Pro. 2, Line 11; Pro. 3, Lines 17, 30; Pro. 4, Line 19:In these cases (12) holds, so by Proposition 7.11 the net sequence number remains unchanged,and, since the hop count is not affected by invalidate either, the invariant is maintained.
Pro. 2, Line 26: The routing table # ipN (rt) is updated with an entry (ip,2,2,2,2,2). By Invariant (9) we
have (before and after the update)dhopsip
N (ip) = 0 .
Therefore, the antecedent of the invariant to be proven is not satisfied.
Pro. 3, Line 6: As usual, we assume that the routing table entry # (oip,osn,val,hops+1,sip,2) is in-serted into # (rt); if not the routing table # (rt) remains unchanged and the invariant is maintained.So dip := # (oip), nhip := # (sip), nsqnip
N (dip) := # (osn) and dhopsipN (dip) := # (hops)+1.
Next to that we know that the information is distilled from a received route request message (cf.Lines 1 and 8 of Pro. 1); the sender of this message is # (sip).By Invariant (10), with ipc := # (sip) = nhip, oipc := # (oip) = dip, osnc := # (osn) and hopsc :=# (hops), we get that 'route
nhipN (dip) = 'route
ipcN (oipc) is defined, and that
sqnnhipN (dip) = sqnipc
N (oipc) > osnc = # (osn) , or
sqnnhipN (dip) = # (osn) 1 dhopsnhip
N (dip)4 # (hops) 1 flagnhipN (dip) = val .
We first assume that the first line holds: Then, by definition of net sequence numbers,
nsqnnhipN (dip)7 sqnnhip
N (dip)!17 # (osn) = nsqnipN (dip)
and in case flagnhipN (dip) = val we have nsqnnhip
N (dip) = sqnnhipN (dip) > # (osn) = nsqnip
N (dip).We now assume the second line to be valid. By definition of net sequence numbers, we get
nsqnnhipN (dip) = sqnnhip
N (dip) = # (osn) = nsqnipN (dip).
Moreover, dhopsnhipN (dip) 4 # (hops) < # (hops)+1 = dhopsip
N (dip) .
Pro. 3, Line 12: An entry with hop count 0 might be inserted into the routing table. Such entries do notaffect the invariant.

A. Fehnher, R.J. van Glabbeek, P. Hofner, A. McIver, M. Portmann & W.L. Tan 43
Pro. 3, Line 24, 25; Pro 4, Lines 13, 14: The update only changes the precursors of an existing route.Thus the invariant is maintained.
Pro. 4, Line 5: The update is similar to the one of Pro. 3, Line 6. The only difference is that the infor-mation stems from an incoming RREP message and that a routing table entry to # (dip) (insteadof # (oip)) is established. Therefore, the proof is similar to the one of Pro. 3, Line 6; instead ofInvariant (10) we use Invariant (11).
Pro. 5, Line 3: To be supplied. ./
From this, we can conclude
Theorem 7.13 AODV is loop free.
Proof. If there were a loop in a routing graph RN(dip), then for any edge (ip,nhip) on that loop onehas nsqnip
N (dip) 4 nsqnnhipN (dip), by Theorem 7.12. Hence the value of nsqnip
N (dip) is the same for allnodes ip on the loop. Moreover, for each node nhip on the loop one has flagnhip
N (dip) = val. Thus,by Theorem 7.12, the sequence numbers keep decreasing when travelling around the loop, which isimpossible. ./
8 Formalising Temporal Properties of Routing Protocols
Our formalism enables verification of correctness properties. While some properties, such as loop free-dom, are invariants on the routing tables, others require reasoning about the temporal order of transitions.Here we use Computation Tree Logic (CTL) to specify and discuss one such property, namely packetdelivery.
CTL uses the path quantifiers A and E, and the temporal operators G,F,X, and U. The (state)formula A( is satisfied in a state if all paths starting in that state satisfy ( , while E( is satisfied if somepath satisfies ( . The (path) formulas G( ,F( and X( mean that ( holds globally in all states, in somestate, and in the next state of a path, respectively. The until (U) means that, until a state occurs along thepath that satisfies ) , property ( has to hold. In CTL a temporal operator is always immediately precededby a path quantifier.
The property of packet delivery says that if a client submits a packet, it will eventually be delivered.However, in a WMN it is known beforehand that this property does not hold, since nodes can get discon-nected. A useful formulation has to be weaker. AODV should guarantee delivery of a packet submittedby a client at node oip with destination dip, when oip is connected to dip and afterwards no link in thenetwork gets disconnected. This means that for any pair oip and dip, and any data d, the following shouldhold:
AG(oip : newpkt(d,dip)1 connected2(oip,dip))6 AF(disconnect(2,2)5 (dip : deliver(d))) .
oip :newpkt(d,dip) models submission of a new packet at oip, dip :deliver(d) that the destination re-ceives it, and disconnect(2,2) the action of disconnecting. We treat these transitions as predicates, withthe understanding that along a path the state immediately succeeding such a transition satisfies it. Thepredicate connected2(oip,dip) is true if there exist nodes ip0, . . . , ipn such that ip0 =oip, ipn =dip andipi%Ripi!1
N for i=1, . . . ,n.This formulation of packet delivery does not specify any particular route, but merely requires that d
will eventually be delivered. The property does not require a packet to arrive once any link connectionbreaks. Surprisingly, AODV does not satisfy this property.
Theorem 8.1 AODV does not satisfy the property packet delivery.

44 Modelling AODV with Process Algebra
We show this by an example (Figure 4). In particular, we show that a route reply may be dropped. Thisproblem has been raised before, back in Oct 2004.17 We will discuss modifications to solve this problemin the final version of this paper. Figure 4 shows a network consisting of 3 nodes in a linear topology.Two nodes (a and s) are both searching for a route to destination d. First, node a broadcasts a routerequest, RREQ1 (Figure 4 (b)). As usual all recipients update their routing tables. Since node s stillhas no information about d, it also initiates a route request, RREQ2. After a has forwarded that request(Figure 4(c)), d initiates a route reply as a consequence of RREQ1. When node a receives this reply, itupdates its own routing table (Figure 4(d)). Finally, node d reacts on the second route request received(RREQ2) and sends yet another route reply. Node a receives RREP2, but does not forward it. This isbecause RREP2 does not contain any newer information about destination d, in comparison with theinformation in node a’s existing routing table entry for d. As a result, RREP2 is dropped at node a, andnode s never receives a route reply for its route request. Looking at our model (Process 4), the node doesnot forward a request since Line 2 evaluates to false whereas Line 26 evaluates to true.
(a) The initial state. (b) nodes d,s receive the RREQ and update their RTs.
d (d,1,val,0,d)s(s,1,val,0,s) a(a,1,val,0,a)
d (a,2,val,1,a)(d,1,val,0,d)s(a,2,val,1,a)
(s,1,val,0,s) a(a,2,val,0,a)
RREQ1 RREQ1
(c) s broadcasts a new RREQ destined to d; (d) d handles RREQ1 and unicasts a RREP to a.a forwards it.
d(a,2,val,1,a)(d,1,val,0,d)(s,2,val,2,a)
s(a,2,val,1,a)(s,2,val,0,s) a
(a,2,val,0,a)(s,2,val,1,s)
RREQ2 RREQ2d
(a,2,val,1,a)(d,1,val,0,d)(s,2,val,2,a)
s(a,2,val,1,a)(s,2,val,0,s) a
(a,2,val,0,a)(d,1,val,1,d)(s,2,val,1,s)
RREP1
(e) d handles RREQ2 and unicasts a RREP to a. (f) This ends the work of AODV;s will never get an answer for its RREQ.
d(a,2,val,1,a)(d,1,val,0,d)(s,2,val,2,a)
s(a,2,val,1,a)(s,2,val,0,s) a
(a,2,val,0,a)(d,1,val,1,d)(s,2,val,1,s)
RREP2
Figure 4: Route not found
At first glance, it seems that this behaviour can be fixed by a repeated route request. If node swould initiate and broadcast another route request, node a would receive it and generate a route replyimmediately. The AODV RFC specifies that a node can broadcast another route request if it has notreceived a route reply within a pre-defined time. However, a repeated route request does not guaranteethe receipt of a route reply. It is easy to construct an example similar to Figure 4 where, instead of a lineartopology with 3 nodes, we use a linear topology with n + 2 nodes, where n is the maximum number ofrepeated route requests.
9 Related Work
Several process algebras for MANETs have been proposed: CBS# [18], CWS [15], CMAN [8], CMN [14],the *-calculus [23] and RBPT [7]. All these languages, as well as ours, feature a form of local broad-cast, in which a single message, sent by one node, can be received by other nodes within transmissionrange, given an arbitrary topology. In CWS the topology is fixed, whereas the other formalisms deal witharbitrary changes in topology.
17http://www.ietf.org/mail-archive/web/manet/current/msg05702.html

A. Fehnher, R.J. van Glabbeek, P. Hofner, A. McIver, M. Portmann & W.L. Tan 45
The latter four formalisms model a lossy broadcast, in which a potential receiver may lose a message;in CBS# and CWS, any node within range must receive a message m sent to it, provided the node is readyto receive it, i.e., in a state that admits a transition receive(m). This proviso makes all these calculi non-blocking, meaning that no sender can be delayed in transmitting a message simply because one of thepotential recipients is not ready to receive it (cf. Section 4.5).
The syntax of CBS# and CWS does not permit the construction of meaningful nodes that are alwaysready to receive a message. Hence our model is the first that assumes that any message is received by apotential recipient within range. It is this feature that allows us to evaluate whether a protocol satisfiesthe packet delivery property. Any routing protocol formalised in any of the other formalisms wouldautomatically fail to satisfy such a property.
Besides this ensured broadcast, the novel prioritised unicast operator chooses a continuation processdependent on whether the message can be delivered. This operator is essential for the correct formal-isation of AODV. In practice such an operator may be implemented by means of an acknowledgmentmechanism; however, this is done at the link layer, from which the AODV specification [19], and henceour formalism, abstracts. One could formalise a prioritised unicast as a unprioritised unicast in the scopeof a priority operator [5]; however, our operator prioritises, while allowing an operational semanticswithin the de Simone format.
Although our treatment of data structures follows the classical approach of universal algebra, andis in the spirit of formalisms like µCRL [10], we have not seen a process algebra that freely mixes inimperative programming constructs like variable assignment. Yet this helps to properly capture AODV.
Our complete formalisation of AODV, presented here, has grown from elaborating a partial formali-sation of AODV in [23].
A preliminary draft of AODV has been shown to be not loop free in [3], and the suggestions madethere to guarantee loop freedom have not been included in the current standard. In [25] a proof sketch ofloop freedom for a restricted version of AODV is given, using an interactive theorem prover.
Next to process calculi also algebraic techniques involving a.o. semirings and matrices are used todescribe routing protocols [24, 9].
10 Conclusion and Outlook
We have proposed a novel algebra covering major aspects of WMN routing protocols. We have accuratelymodelled the core of AODV, a widely used protocol of practical relevance. In contrast to other works, ourmodel covers the crucial aspect of data handling, such as maintaining routing table information. We haveformalised and proven some of AODV’s general properties. Our model provides, in combination withabstraction from lower network layers, a practical and powerful tool for WMN protocol specification,evaluation and verification.
More detailed analysis requires the addition of time and probability: the former to cover aspectssuch as AODV’s handling (deletion) of stale routing table entries and the latter to model the probabilityassociated with lossy links. We expect that the resulting algebra will be also applicable to a wide rangeof other wireless protocols.
References[1] AODV-UU: An Implementation of the AODV routing protocol (IETF RFC 3561). http://sourceforge.
net/projects/aodvuu/ (accessed May 9, 2011).[2] J.A. Bergstra & J.W. Klop (1986): Algebra of communicating processes. In J.W. de Bakker, M. Hazewinkel &
J.K. Lenstra, editors: Mathematics and Computer Science. CWI Monograph 1, North-Holland, pp. 89–138.

46 Modelling AODV with Process Algebra
[3] K. Bhargavan, D. Obradovic & C.A. Gunter (2002): Formal Verification of Standards for Distance VectorRouting Protocols. J. ACM 49(4), pp. 538–576, doi:10.1145/581771.581775.
[4] T. Bolognesi & E. Brinksma (1987): Introduction to the ISO Specification Language LOTOS. ComputerNetworks 14, pp. 25–59.
[5] R. Cleaveland, G. Luttgen & V. Natarajan (2001): Priority in Process Alegbra. In: Handbook of ProcessAlgebra, chapter 12. Elsevier, pp. 711–765.
[6] S. Cranen, M. R. Mousavi & M. A. Reniers (2008): A Rule Format for Associativity. In: Proc. CONCUR’08.LNCS 5201, Springer, Toronto,Canada, pp. 447–461, doi:10.1007/978-3-540-85361-9 35.
[7] F. Ghassemi, W.J. Fokkink & A. Movaghar (2008): Restricted Broadcast Process Theory. In A. Cerone& S. Gruner, editors: Sixth IEEE International Conference on Software Engineering and Formal Meth-ods (SEFM 2008), Cape Town, South Africa, November 2008. IEEE Computer Society, pp. 345–354,doi:10.1109/SEFM.2008.25.
[8] J. C. Godskesen (2007): A Calculus for Mobile Ad Hoc Networks. In: Proc. COORDINATION’07. LNCS4467, Springer, pp. 132–150, doi:10.1007/978-3-540-72794-1 8.
[9] T.G. Griffin & J. Sobrinho (2005): Metarouting. SIGCOMM Comp. Com.. Rev. 35, pp. 1–12,doi:10.1145/1090191.1080094.
[10] J. F. Groote & A. Ponse (1995): The syntax and semantics of µCRL. In: Algebra of Communicating Processes’94. Workshops in Computing, Springer, pp. 26–62.
[11] C.A.R. Hoare (1985): Communicating Sequential Processes. Prentice Hall, Englewood Cliffs.[12] IEEE (2009): Draft Standard for Information Technology – Telecommunications and Information Exchange
Between Systems – LAN/MAN Specific Requirements – Part 11: Wireless Medium Access Control (MAC) andPhysical Layer (PHY) Specifications: Amendment 10: Mesh Networking. IEEE unapproved draft.
[13] N. Lynch & M. Tuttle (1989): An Introduction to Input/Output automata. CWI-Quarterly 2(3), pp. 219–246.Centrum voor Wiskunde en Informatica, Amsterdam, The Netherlands.
[14] M. Merro (2009): An Observational Theory for Mobile Ad Hoc Networks (full version). Inf. Comput. 207(2),pp. 194–208, doi:10.1016/j.ic.2007.11.010.
[15] N. Mezzetti & D. Sangiorgi (2006): Towards a Calculus For Wireless Systems. Electr. Notes Theor. Comput.Sci. 158, pp. 331–353, doi:10.1016/j.entcs.2006.04.017.
[16] R. Milner (1989): Communication and Concurrency. Prentice Hall, Englewood Cliffs.[17] S. Miskovic & E.W. Knightly (2010): Routing Primitives for Wireless Mesh Networks: Design, Analysis and
Experiments. In: INFOCOM’10: Conference on Information communications. IEEE Press, pp. 2793–2801,doi:10.1109/INFCOM.2010.5462111.
[18] S. Nanz & C. Hankin (2006): A framework for security analysis of mobile wireless networks. Theor. Comput.Sci. 367, pp. 203–227, doi:10.1016/j.tcs.2006.08.036.
[19] C. Perkins, E. Belding-Royer & S. Das (2003): Ad hoc On-Demand Distance Vector (AODV) Routing. RFC3561 (Experimental). Available at http://www.ietf.org/rfc/rfc3561.txt.
[20] G.D. Plotkin (2004): A Structural Approach to Operational Semantics. The Journal of Logic and AlgebraicProgramming 60–61, pp. 17–139, doi:10.1016/j.jlap.2004.05.001. Originally appeared in 1981.
[21] K.V.S. Prasad (1995): A Calculus of Broadcasting Systems. Sci. Comput. Program. 25(2-3), pp. 285–327,doi:10.1016/0167-6423(95)00017-8.
[22] R. de Simone (1985): Higher-Level Synchronising Devices in MEIJE-SCCS. Theor. Comput. Sci. 37, pp.245–267.
[23] A. Singh, C.R. Ramakrishnan & S.A. Smolka (2010): A process calculus for Mobile Ad Hoc Networks.Science of Computer Programming 75, pp. 440–469, doi:10.1016/j.scico.2009.07.008.
[24] J. Sobrinho (2002): Algebra and algorithms for QoS path computation and hop-by-hop routing in the internet.IEEE/ACM Trans. Networking 10(4), pp. 541–550, doi:10.1109/TNET.2002.801397.
[25] M. Zhou, H. Yang, X. Zhang & J. Wang (2009): The Proof of AODV Loop Freedom. In: Wireless Commu-nications & Signal Processing (WCSP09). IEEE Press, pp. 1–5, doi:10.1109/WCSP.2009.5371479.