an introduction to sparse coding, sparse sensing, and optimizationcse.msu.edu/~cse902/s14/ppt/sparse...
TRANSCRIPT

An Introduction to Sparse Coding and Dictionary Learning
Kai Cao January 14, 2014
1

Outline
• Introduction • Mathematical foundation • Sparse coding • Dictionary learning • Summary
2

Introduction
3

What is sparsity?
• Sparsity implies many zeros in a vector or a matrix
4
FFT transform
Sparse representation
Fingerprint patch FFT response
Reconstructed patch
IFFT transform
Usage: Compression Analysis Denoising ……

Sparse Representation
Dictionary Learning Problem
Sparse Coding Problem
x α≈ D
≈

Application---Denoising
[M. Elad, Springer 2010]
Dictionary
Source
Result 30.829dB
Noisy image PSNR 22.1dB=

Application---Compression
[O. Bryta, M. Elad, 2008]
550 bytes per image
9.44
15.81
14.67
15.30
13.89
12.41
12.57
10.66
10.27
6.60
5.49
6.36
Original JPEG JPEG 2000 PCA
Dictionary based
Bottom: RMSE values

Mathematical foundation
8

Derivatives of vectors
• First order
• Second order
• Exercise
9
T Ta x x a ax x
∂ ∂= =
( )T
Tx Bx B B xx
∂= +
∂
2 22 2
1min || || || || , ,2m
n n mx D x R D Rα
α λ α ×
∈− + ∈ ∈
1( )T TD D I D xα λ −= +

Trace of a Matrix
• Definition
• Properties
10
1( ) ,n
iiiTr A a
==∑ ( ) n n
ijA a R ×= ∈
2 2
1 1|| || ( ),
n nT
F iji j
A a Tr A A= =
= =∑∑
( ) ( ) ( ),Tr ABC Tr BCA Tr CAB= =
( ) ( ),TTr A Tr A=
( ) ( ),Tr A B Tr A B+ = +
( ) ( ),Tr aA aTr A=
( ) ( ),Tr AB Tr BA=
n nB R ×∈
a R∈n nB R ×∈
, n nB C R ×∈

Derivatives of traces
• First order
• Derivatives of traces
• Exercise
11
( ) TTr XA AX∂
=∂
( )T TTr X XA XA XAX∂
= +∂
( )TTr X A AX∂
=∂
( )T TTr X BX B X BXX∂
= +∂
2 2min || || || || , ,k m
n m n kF FA R
X DA A X R D Rλ×
× ×
∈− + ∈ ∈
1( )T TA D D I D Xλ −= +

Sparse coding
12

Sparse linear model
• Let x ϵ Rn be a signal
• Let D =[d1, d2, …, dm] ϵ Rn×m be a set of normalized “basis vectors” (dictionary)
• Sparse representation is to find a sparse vector α ϵ
Rm such that x ≈ Dα, where α is regarded as sparse code
13
D
x
( 1)Ti id d =

The sparse coding model
• Objective function
• The regularization term can be – the l2 norm. – the l0 norm. – the l1 norm. – …
14
22
1min || || ( )2m
x Dα
α λϕ α∈
− +
Data fitting term Regularization term
ϕ2 22 1
|| || mii
α α=∑
0|| || # | 0ii aα ≠
1 1|| || | |m
iiα α
=∑ Sparsity inducing

Matching pursuit
1. Initialization: α = 0, residual r = x 2. while ||α||0 <L 3. Select the element with maximum correlation with the residual
4. Update the coefficients and residual
5. End while
15
22
1min || ||2m
x Dα
α∈
−
0|| || Lα ≤s. t.
1,...,
ˆ arg max | |Ti
i mi d r
==
ˆˆˆT
i i id rα α= +
ˆˆ( )Ti ir r d r d= −

Patch from latent Dictionary elements
…… d1 d2 d3 d4 d5
An example for matching pursuit
x
c1=-0.039 c2= 0.577 c3=0.054 c4=-0.031 c5 =-0.437
……
= - ×0.577 Residual r
Correlation ci= diT x
…… Correlation ci= diT r
d1 d2 d3 d4 d5
c1=-0.035 c2= 0 c3=0.037 c4=-0.046 c5 =-0.289
= - - × (-0.289) Residual r × 0.577
Coefficient does not update !
Reconstructed patch = + × 0.577 × (-0.289) x2ˆ|| || 0.763x x− =

Orthogonal matching pursuit
1. Initialization: α = 0, residual r = x, active set Ω = Æ 2. while ||α||0 <L 3. Select the element with maximum correlation with the residual
4. Update the active set, coefficients and residual
5. End while 17
22
1min || ||2m
x Dα
α∈
−
0|| || Lα ≤s. t.
1,...,
ˆ arg max | |Ti
i mi d r
==
1( )T Td d d rα −Ω Ω Ω Ω=
r x d αΩ Ω= −
iΩ = Ω∪

An example for orthogonal matching pursuit
2ˆ|| || 0.759x x− =× (-0.309)
= - - ×(-0.309)
Reconstructed patch =
Residual r × 0.499
+ × 0.499 x
Patch from latent Dictionary elements
…… d1 d2 d3 d4 d5 x
c1=-0.039 c2= 0.577 c3=0.054 c4=-0.031 c5 =-0.437
……
= - ×0.577 Residual r
Correlation ci= diT x
…… Correlation ci= diT r
d1 d2 d3 d4 d5
c1=-0.035 c2= 0 c3=0.037 c4=-0.046 c5 =-0.289
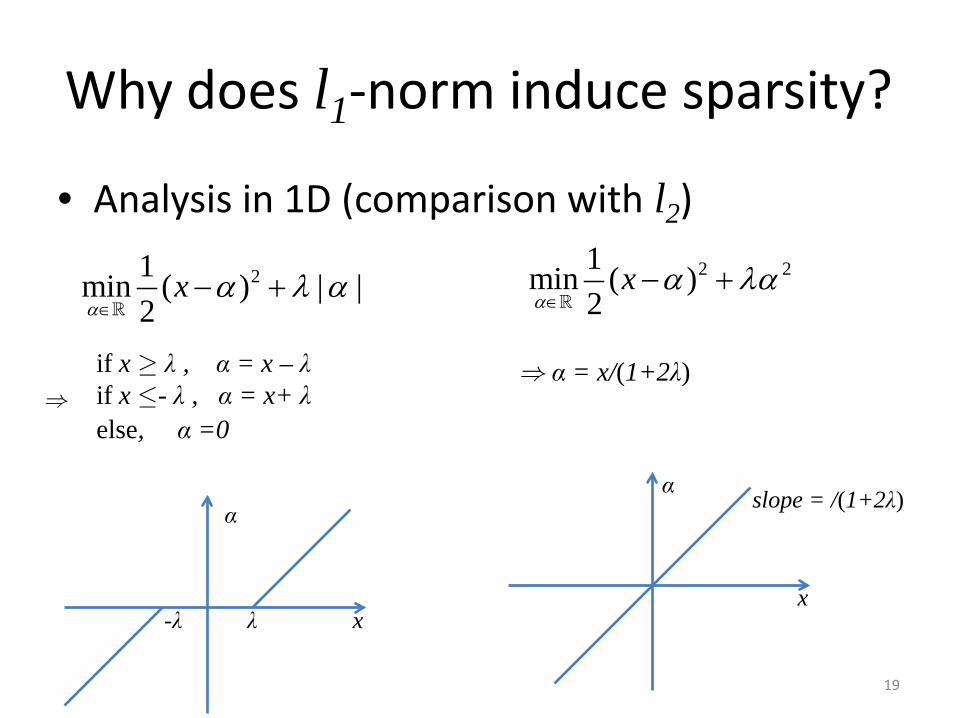
Why does l1-norm induce sparsity?
• Analysis in 1D (comparison with l2)
19
21min ( ) | |2
xα
α λ α∈
− +
2 21min ( )2
xα
α λα∈
− +
if x ³ λ , α = x – λ if x £- λ , α = x+ λ else, α =0
Þ α = x/(1+2λ)
x λ
α
-λ x
α slope = /(1+2λ)
Þ
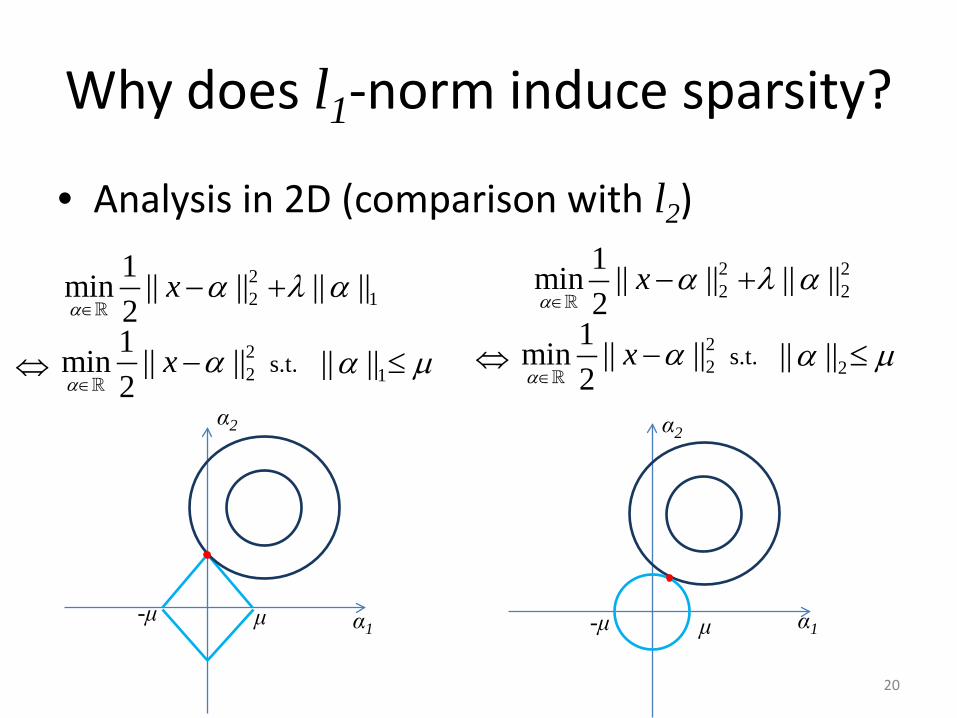
Why does l1-norm induce sparsity?
• Analysis in 2D (comparison with l2)
20
22 1
1min || || || ||2
xα
α λ α∈
− +
2 22 2
1min || || || ||2
xα
α λ α∈
− +
22
1min || ||2
xα
α∈
−
1|| ||α µ≤s.t. ⇔22
1min || ||2
xα
α∈
−
2|| ||α µ≤s.t. ⇔
μ -μ
α2
α1 α1
α2
μ -μ

Optimality condition for l1-norm regularization
• Directional derivative in the direction u at α
• g is subgradient of J at α if and only if
• Proposition 1: • Proposition 2: if J is differentiable at α, • Proposition 3: α is optimal if and only if for all u,
21
22 1
1min ( ) || || || ||2m
J x Dα
α α λ α∈
= − +
0
( ) ( )( , ) limt
J tu JJ ut
α αα+→
+ −∇ =
, ( ) ( ) ( )m Tt R J t J g tα α∀ ∈ ≥ + −
( , ) 0J uα∇ ≥( , ) ( )TJ u J uα α∇ = ∇
, ( , )m Tu R g u J uα⇔∀ ∈ ≤∇g is a subgradient

• Example: f(x) = |x|
22
Subgradient for l1-norm regularization
x
f(x) = |x|
x
subgradient
1
-1
| | 0( , )
( ) 0u x
f x usign x u x
=∇ = ≠

Subgradient for l1-norm regularization
• g is a subgradient at α if and only if for all i
23
22 1
1min ( ) || || || ||2m
J x Dα
α α λ α∈
= − +
, 0 , 0( , ) ( ) sign( ) | |
i i
T Ti i i
i a i aJ u u D x D a u uα α λ λ
≠ =
∇ = − − + +∑ ∑
| ( ) |Ti ig d x Dα λ− − ≤ if 0ia =
0ia ≠( ) sign( )Ti i ig d x D aα λ= − + if

First order method for convex optimization
• Differentiable objective – Gradient descent: – With line search for a decent ht – Diminishing step size: e.g., ht=(t+t0)-1
• Non differentiable objective – Subgradient decent: , gt is a subgradient – With line search – Diminishing step size
24
1 ( )t t t tJα α η α+ = − ∇
1t t t tgα α η+ = −

Reformulation as quadratic program
25
22 1
1min || || || ||2m
x Dα
α λ α∈
− +
22
,
1min || || (1 1 )2m
T Tx D Dα α
α α λ α α+ − +
+ − + −∈
− + + +

Dictionary Learning
26

Dictionary selection
• Which D to use? • A fixed set of basis:
– Steerable wavelet – Contourlet – DCT Basis – ……
• Data adaptive dictionary – learn from data – K-SVD (l0-norm)
– On-line dictionary learning (l1-norm)
27

The examples are linear combinations
of atoms from D
The objective function for K-SVD
D ≈ X A
2
,min || ||FD A
X DA− 0|| ||j Lα ≤"j, s.t.
Each example has a sparse representation with
no more than L atoms
www.cs.technion.ac.il/~ronrubin/Talks/K-SVD.ppt 28

K–SVD – An Overview
D Initialize D
Sparse Coding Use MP or OMP
Dictionary Update
Column-by-Column by SVD computation
X T
www.cs.technion.ac.il/~ronrubin/Talks/K-SVD.ppt 29
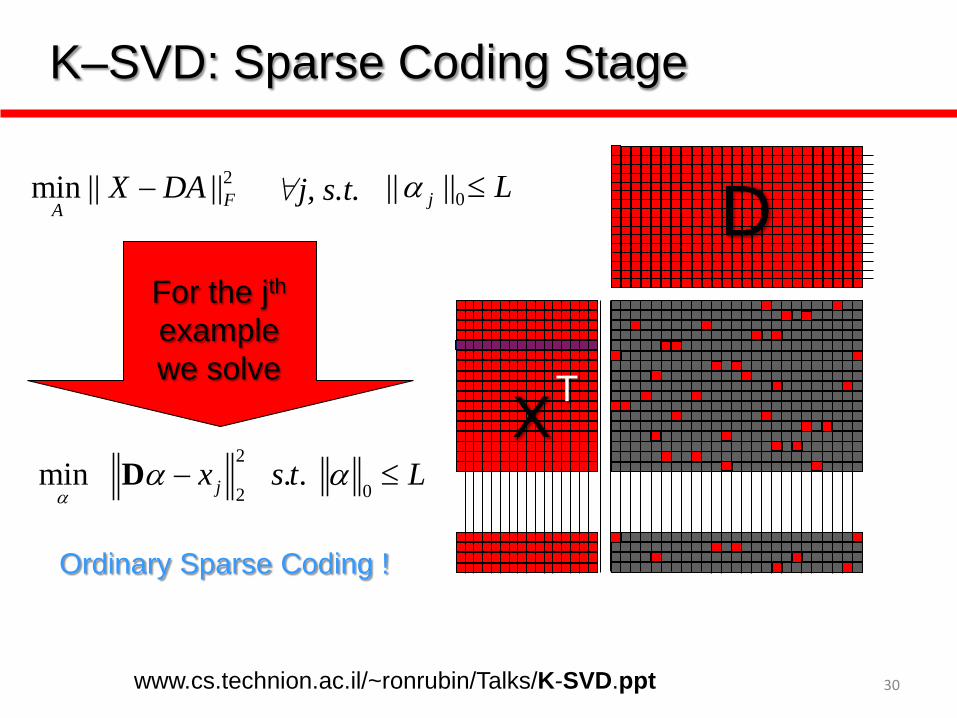
K–SVD: Sparse Coding Stage
D
X
For the jth example we solve
Ordinary Sparse Coding !
T 2
02min . .jx s t Lα
α α− ≤D
www.cs.technion.ac.il/~ronrubin/Talks/K-SVD.ppt
2min || ||FAX DA− 0|| ||j Lα ≤"j, s.t.
30

K–SVD: Dictionary Update Stage
D
X T
For the kth atom
we solve
(the residual)
2min || ||FDX DA− 0|| ||j Lα ≤"j, s.t.
2min || ||k
kk T k Fd
d Eα −
ik i T
i kE d Xα
≠
= −∑
Solve with SVD 31
TkE U V= Λ 1kd u=
www.cs.technion.ac.il/~ronrubin/Talks/K-SVD.ppt

K–SVD Dictionary Update Stage
Only some of the examples use column dk!
When updating ak, only recompute the coefficients corresponding to those examples
dk ak
T
−
Solve with SVD!
We want to solve:
Ek
www.cs.technion.ac.il/~ronrubin/Talks/K-SVD.ppt 32
−

Compare K-SVD with K-means
33
Initialize Dictionary
Sparse Coding Use MP or OMP
Dictionary Update
Column-by-Column by SVD computation
Initialize Cluster Centers
Assignment for each vector
Cluster centers update
Cluster-by-cluster
K-SVD K-means

dictionary learning with l1-norm regularization
• Objective function for l1-norm regularization
• Advantages of online learning: – Handle large and dynamic datasets, – Could be much faster than batch algorithms.
34
22 1
1
1 1min || || || ||2
t
i i iD ix D
tα λ α
=
− +∑
22 1
1arg min || || || ||2m
i iR
x Dα
α α λ α∈
− +
where

dictionary learning with l1-norm regularization
35
22 1
1
11
1 1( ) || || || ||2
1 1( ( ) ( )) || ||2
t
t i i ii
tT T
t t ii
F D x Dt
Tr D DA Tr D Bt
α λ α
λ α
=
=
= − +
= − +
∑
∑where
1,
tT
t i ii
A α α=
=∑1
tT
t i ii
B xα=
=∑
( ) 1( )tt t
F D DA BD t
∂= −
∂
1 1 1,T
t t t tA A α α+ + += +For a new xt+1, 1 1 1T
t t t tB B x α+ + += +

On-line dictionary learning 1) Initialization: D0 ϵ Rn×m; A0=0; B0=0; 2) For t=1,…,T 3) Draw xt from the training data set
4) Get sparse code
5) Aggregate sufficient statistics
6) Dictionary update
7) End for
36
21 2 1
1arg min || || || ||2m
t t tR
x Dα
α α λ α−∈
= − +
1 ,Tt t t tA A α α−= + 1 ,T
t t t tB B xα−= +
1( )t
t tF DD D
Dρ−
∂= −
∂

Toolbox - SPAMS • SPArse Modeling Software:
– Sparse coding • l0-norm regularization • l1-norm regularization • ……
– Dictionary learning • K-SVD • Online dictionary learning • ……
• C++ implemented with Matlab interface • http://spams-devel.gforge.inria.fr/
37

Summary
• Sparsity and sparse representation • Sparse coding with l0- and l1-norm regularization
– Orthogonal matching pursuit/matching pursuit – Subgradient and optimal condition
• Dictionary learning with l0- and l1-norm regularization – K-SVD – Online dictionary learning
• Try to use it !!
38

References • T. T. Cai, Lie Wang ,Orthogonal Matching Pursuit for Sparse Signal Recovery
With Noise, IEEE Transactions on Information Theory, 57(7): 4680-4688,2011 • Efron, T. Hastie, I. Johnstone, and R. Tibshirani. Least angle regression. Annals
of statistics, 32(2):407–499, 2004. • M. Aharon, M. Elad, and A. M. Bruckstein. The K-SVD: An algorithm for
designing of overcomplete dictionaries for sparse representations. IEEE Transactions on Signal Processing, 54(11):4311-4322, November 2006.
• J. Mairal, F. Bach, J. Ponce, and G. Sapiro. Online dictionary learning for sparse coding. In Proceedings of the International Conference on Machine Learning (ICML), 2009a.
39

Thank you for listening
40