anhai doan university of illinois joint work with pedro derose, robert mccann, yoonkyong lee,...
TRANSCRIPT

AnHai DoanUniversity of Illinois
Joint work with Pedro DeRose, Robert McCann, Yoonkyong Lee, Mayssam Sayyadian, Warren Shen, Wensheng Wu, Quoc Le, Hoa Nguyen, Long Vu, Robin Dhamankar, Alex Kramnik, Luis Gravano, Weiyi Meng, Raghu Ramakrishnan, Dan Roth, Arnon Rosenthal, Clemen Yu
From Data Integration to From Data Integration to Community Information ManagementCommunity Information Management
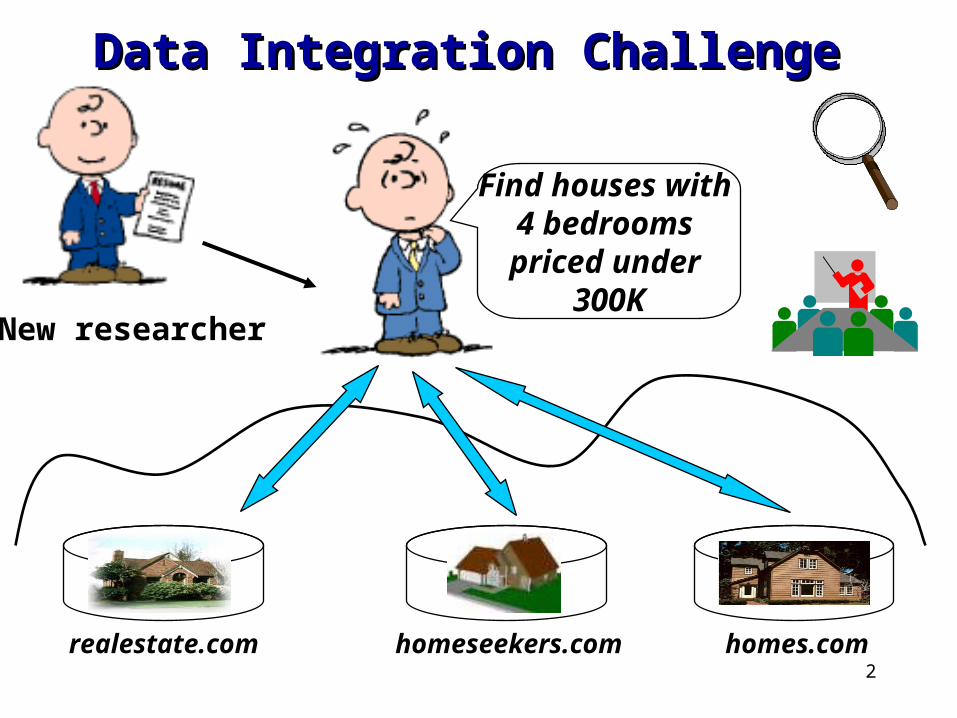
2
New researcher
Find houses with 4 bedrooms priced under
300K
homes.comrealestate.com homeseekers.com
Data Integration ChallengeData Integration Challenge

3
Actually Bought a House in 2004Actually Bought a House in 2004
Buying period– queried 7-8 data sources over 3 weeks– some of the sources are local, not “indexed” by national sources– 3 hours / night 60+ hours– huge amount of time on querying, post processing
Buyer-remorse period– repeated the above for another 3 weeks!
We really need to automate data integration ...

4
Architecture of Data Integration SystemsArchitecture of Data Integration Systems
mediated schema
houses.comhomes.com
source schema 2
realestate.com
source schema 3source schema 1
Find houses with 4 bedroomspriced under 300K
wrapper wrapperwrapper

5
Current State of Affairs Current State of Affairs
Vibrant research & industrial landscape Research since the 70s, accelerated in past decade
– database, AI, Web, KDD, Semantic Web communities– 14+ workshops in past 3 years: ISWC-03, IJCAI-03, VLDB-04, SIGMOD-04,
DILS-04, IQIS-04, ISWC-04, WebDB-05, ICDE-05, DILS-05, IQIS-05, IIWeb-06, etc.
– main database focuses: – modeling, architecture, query processing, schema/tuple matching– building specialized systems: life sciences, Deep Web, etc.
Industry– 53 startups in 2002 [Wiederhold-02]
– many new ones in 2005
Despite much R&D activities, however …

6
DI Systems are Still Very DifficultDI Systems are Still Very Difficultto Build and Maintainto Build and Maintain
Builder must execute multiple tasks
Most tasks are extremely labor intensive Total cost often at 35% of IT budget [Knoblock et. al. 02]
– systems often take months or years to develop
High cost severely limits deployment of DI systems
select data sources
create wrappers
create mediated schemas
match schemas
eliminate duplicate tuples
monitor changes
etc.
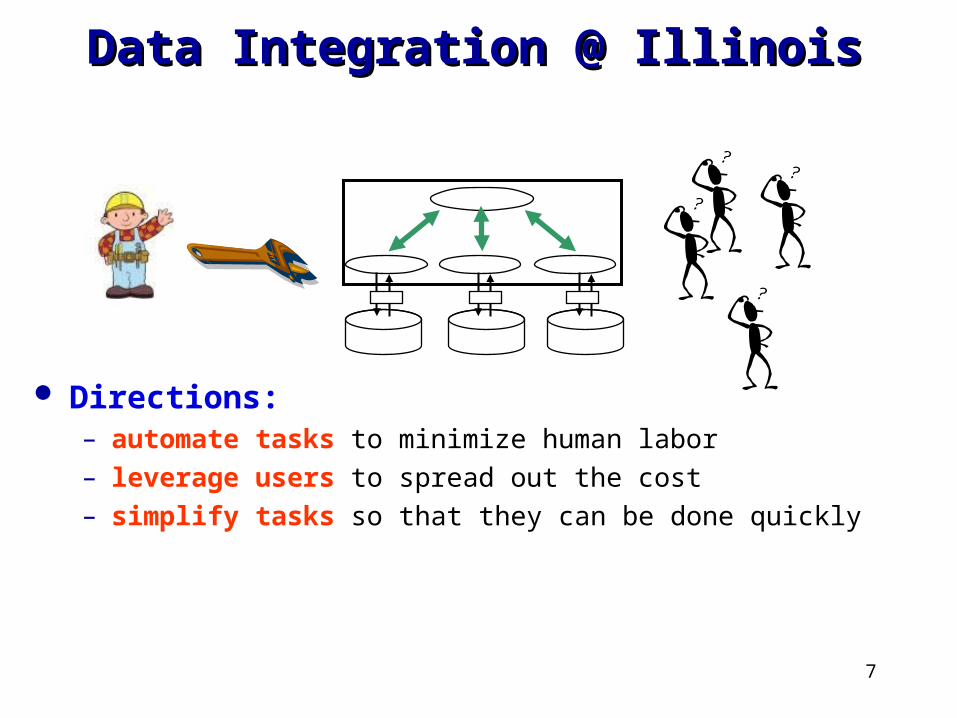
7
Data Integration @ Illinois Data Integration @ Illinois
Directions:– automate tasks to minimize human labor – leverage users to spread out the cost– simplify tasks so that they can be done quickly

8
price agent-name address
Sample Research on Automating Sample Research on Automating Integration Tasks: Schema MatchingIntegration Tasks: Schema Matching
1-1 match complex match
homes.com listed-price contact-name city state
Mediated-schema
320K Jane Brown Seattle WA240K Mike Smith Miami FL

9
Schema Matching is Ubiquitous!Schema Matching is Ubiquitous! Fundamental problem in numerous applications Databases
– data integration, – model management– data translation, collaborative data sharing– keyword querying, schema/view integration– data warehousing, peer data management, …
AI– knowledge bases, ontology merging, information gathering agents, ...
Web– e-commerce, Deep Web, Semantic Web, Google Base, next version of
My Web 2.0?
eGovernment, bio-informatics, e-sciences

10
Why Schema Matching is DifficultWhy Schema Matching is Difficult
Schema & data never fully capture semantics!– not adequately documented
Must rely on clues in schema & data – using names, structures, types, data values, etc.
Such clues can be unreliable– same names different entities: area location or square-feet– different names same entity: area & address location
Intended semantics can be subjective– house-style = house-description?
Cannot be fully automated, needs user feedback

11
Current State of AffairsCurrent State of Affairs Schema matching is now a key bottleneck!
– largely done by hand, labor intensive & error prone– data integration at GTE [Li&Clifton, 2000]
– 40 databases, 27000 elements, estimated time: 12 years
Numerous matching techniques have been developed– Databases: IBM Almaden, Wisconsin, Microsoft Research, Purdue,
BYU, George Mason, Leipzig, NCSU, Illinois, Washington, ... – AI: Stanford, Toronto, Rutgers, Karlsruhe University, NEC, USC, …
"everyone and his brother is doing ontology mapping"
Techniques are often synergistic, leading to multi-component matching architectures– each component employs a particular technique– final predictions combine those of the components

12
Example: LSD Example: LSD [Doan et al. SIGMOD-01][Doan et al. SIGMOD-01]
Mediated schema
Urbana, IL James Smith Seattle, WA Mike Doan
address agent-name
area contact-agent
Peoria, IL (206) 634 9435 Kent, WA (617) 335 4243
homes.com
Name Matcher
Naive BayesMatcher
Combiner
0.3
agent
name
contact
agent0.5
0.1
area => (address, 0.7), (description, 0.3)contact-agent => (agent-phone, 0.7), (agent-name, 0.3)
comments => (address, 0.6), (desc, 0.4)
Match Selector
ConstraintEnforcer
Only one attribute of source schema matches address
area = address
contact-agent = agent-phone
...
comments = desc
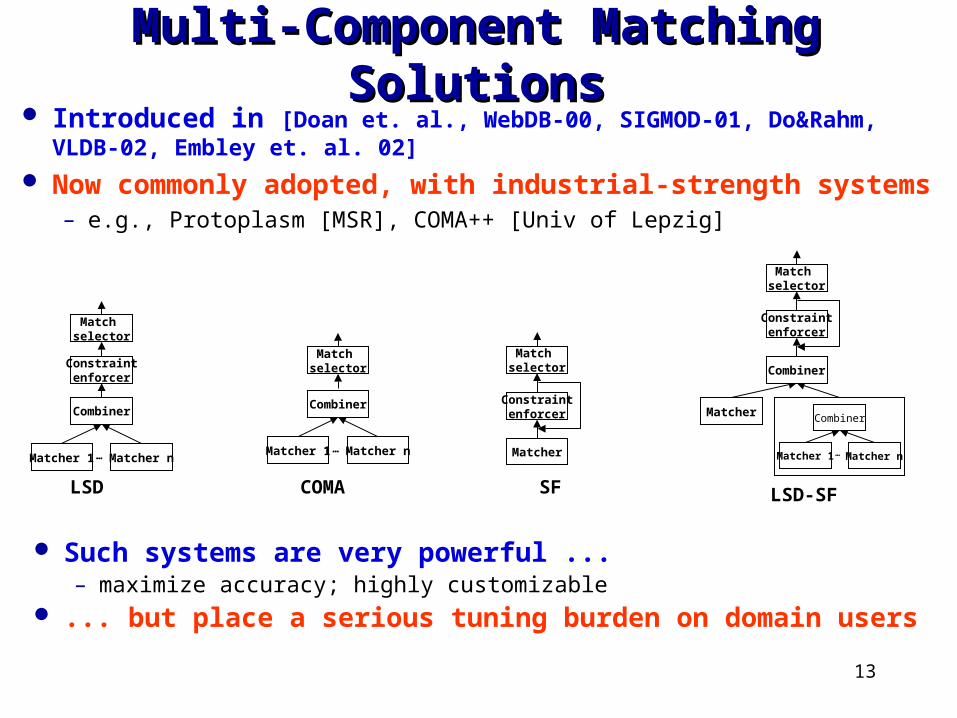
13
Multi-Component Matching SolutionsMulti-Component Matching Solutions
Such systems are very powerful ...– maximize accuracy; highly customizable
... but place a serious tuning burden on domain users
Constraintenforcer
Match selector
Matcher
Matcher Combiner
… Matcher 1 Matcher n
Constraintenforcer
Match selector
Combiner
Matcher 1 Matcher n…
Constraintenforcer
Match selector
Combiner
Matcher 1 Matcher n…
Match selector
Combiner
LSD COMA SF LSD-SF
Introduced in [Doan et. al., WebDB-00, SIGMOD-01, Do&Rahm, VLDB-02, Embley et. al. 02]
Now commonly adopted, with industrial-strength systems– e.g., Protoplasm [MSR], COMA++ [Univ of Lepzig]
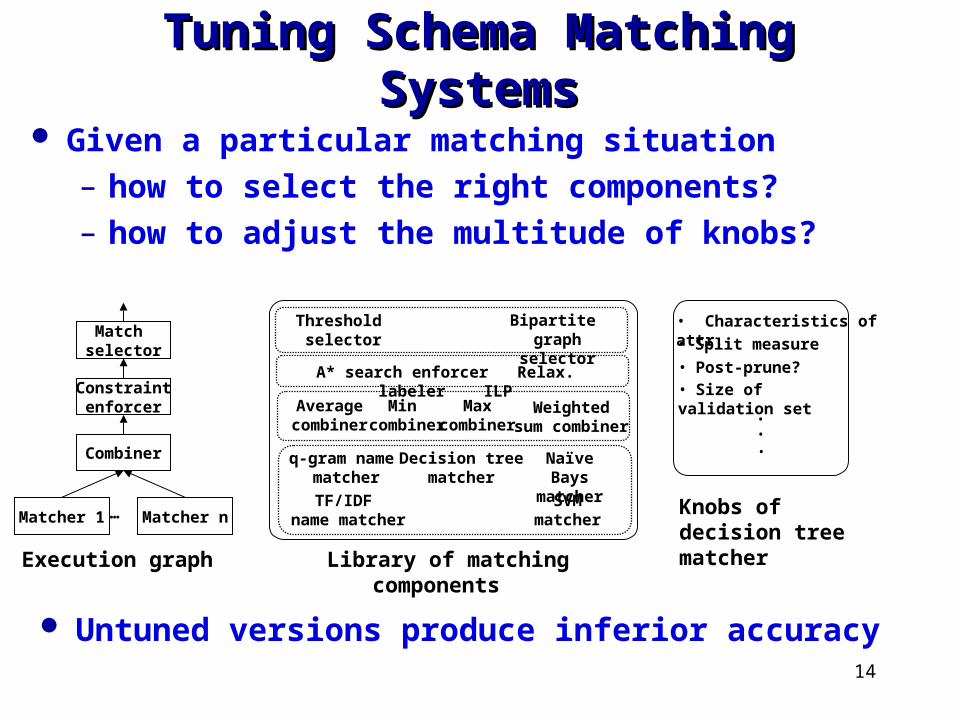
14
Tuning Schema Matching SystemsTuning Schema Matching Systems
Library of matching components
Constraintenforcer
Match selector
Combiner
Matcher 1 Matcher n…
Execution graph
Knobs of decision tree matcher
Threshold selector
Bipartite graph selector
A* search enforcer Relax. labeler ILP
Average combiner
Min combiner
Max combiner
Weightedsum combiner
q-gram name matcher
Decision treematcher
Naïve Baysmatcher
TF/IDF name matcher
SVMmatcher
• Characteristics of attr.
• Post-prune?• Size of validation set
• Split measure
•••
Given a particular matching situation– how to select the right components? – how to adjust the multitude of knobs?
Untuned versions produce inferior accuracy

15
Large number of knobs– e.g., 8-29 in our experiments
Wide variety of techniques – database, machine learning, IR, information theory, etc.
Complex interaction among components Not clear how to compare quality of knob configs
Long-standing problem since the 80s, getting much worse with multiple-component systems
But Tuning is Extremely Difficult But Tuning is Extremely Difficult
Developing efficient tuning techniques is now crucial

16
The eTuner Solution The eTuner Solution [VLDB-05a][VLDB-05a] Given schema S & matching system M
– tunes M to maximize average accuracy of matching S with future schemas
– commonly occur in data integration, warehousing, supply chain
Challenge 1: Evaluation– score each knob config K of matching system M– return K*, the one with highest score– but how to score knob config K?
– if we know a representative workload W = {(S,T1), ..., (S,Tn)},and correct matches between S and T1, …, Tn can use W to score K
Challenge 2: Huge or infinite search space

17
Solving Challenge 1: Solving Challenge 1: Generate Synthetic Input/Output Generate Synthetic Input/Output
Need workload W = {(S,T1), (S,T2), …, (S,Tn)}
To generate W– start with S– perturb S to generate T1– perturb S to generate T2– etc.
Know the perturbation know matches between S & Ti

18
emp-last id wage
Laup 1 45200
Brown 2 59328
Emps
Perturb # of columns
Perturb table and column names
Perturb data tuples
id = idfirst = NONElast = emp-lastsalary = wage
id first last salary ($)
1 Bill Laup 40,000 $
2 Mike Brown 60,000 $
Employees
last id salary ($)
Laup 1 40,000 $
Brown 2 60,000 $
Employees emp-last id wage
Laup 1 40,000$
Brown 2 60,000$
Emps
Generate Synthetic Input/Output Generate Synthetic Input/Output
Schema S
1
23 312
Make sure tables do not share tuples Rules are applied probabilistically

19
The eTuner ArchitectureThe eTuner Architecture
StagedSearcher
Tuning Procedures
Workload Generator
Perturbation Rules
Matching Tool M
SyntheticWorkload
Tuned Matching Tool M
S Ω1 T1
S Ω2 T2
S Ωn Tn Schema S
More details / experiments in– Sayyadian et. al., VLDB-05

20
eTuner: Current StatuseTuner: Current Status Only the first step
– but now we have a line of attack for a long-standing problem
Current directions– find optimal synthetic workload– develop faster search methods– extend for other matching scenarios
– adapt ideas to scenarios beyond schema matching – wrapper maintenance [VLDB-05b]– domain-specific search engine?

21
Automate Integration Tasks: SummaryAutomate Integration Tasks: Summary Schema matching
– architecture: WebDB-00, SIGMOD-01, WWW-02– long-standing problems: SIGMOD-04a, eTuner [VLDB-05a]– learning/other techniques: CIDR-03, VLDBJ-03, MLJ-03, WebDB-03,
SIGMOD-04b, ICDE-05a, ICDE-05b– novel problem: debug schemas for interoperability [ongoing]– industry transfer: involving 2 startups – promote research area: workshop at ISWC-03, special issues in
SIGMOD Record-04 & AI Magazine-05, survey
Query reformulation: ICDE-02
Mediated schema construction: SIGMOD-04b, ICDM-05, ICDE-06
Duplicate tuple removal: AAAI-05, Tech report 06a, 06b
Wrapper maintenance: VLDB-05b

22
Research DirectionsResearch Directions
Automate integration tasks– to minimize human labor
Leverage users– to spread the cost
Simplify integration tasks– so that they can be done quickly

23
The MOBS ProjectThe MOBS Project Learn from multitude of users to improve tool accuracy,
thus significantly reducing builder workload
MOBS = Mass Collaboration to Build Systems
Questions
Answers

24
Mass CollaborationMass Collaboration Build software artifacts
– Linux, Apache server, other open-source software
Knowledge bases, encyclopedia– wikipedia.com
Review & technical support websites– amazon.com, epinions.com, quiq.com,
Detect software bugs– [Liblit et al. PLDI 03 & 05]
Label images/pages on the Web– ESPgame, flickr, del.ici.ous, My Web 2.0
Improve search engines, recommender systems
Why not data integration systems?

25
Example: Duplicate Data MatchingExample: Duplicate Data Matching
Hard for machine, but easy for human
Mouse for Dell laptop 200 series ...
Dell X200; mouse at reduced price ...
Dell laptop X200 with mouse ...
Serious problem in many settings (e.g., e.com)

26
Key Challenges Key Challenges How to modify tools to learn from users? How to combine noisy user answers
How to obtain user participation?– data experts, often willing to help (e.g., Illinois Fire Service)– may be asked to help (e.g., e.com)– volunteer (e.g., online communities), "payment" schemes
Multiple noisy oracles
–build user models, learn them via interaction with users–novel form of active learning

27
Current StatusCurrent Status
Develop first-cut solutions– built prototype, experimented with 3-132 users,
for source discovery and schema matching– improve accuracy by 9-60%, reduced workload by 29-88%
Built two simple DI systems on Web – almost exclusively with users
Building a real-world application– DBlife (more later)
See [McCann et al., WebDB-03, ICDE-05,
AAAI Spring Symposium-05, Tech Report-06]

28
Research DirectionsResearch Directions
Automate integration tasks– to minimize human labor
Leverage users– to spread the cost
Simplify integration tasks– so that they can be done quickly

29
Simplify Mediated Schema Simplify Mediated Schema Keyword Search over Multiple DatabasesKeyword Search over Multiple Databases
Novel problem Very useful for urgent / one-time DI needs
– also when users are SQL-illiterate (e.g., Electronic Medical Records)– also on the Web (e.g., when data is tagged with some structure)
Solution [Kite, Tech Report 06a]– combines IR, schema matching, data matching, and AI planning

30
Simplify Wrappers Simplify Wrappers Structured Queries over Text/Web DataStructured Queries over Text/Web Data
Novel problem– attracts attention from database / AI / Web researchers at Columbia,
IBM TJ Watson/Almaden, UCLA, IIT-Bombay
[SQOUT, Tech Report 06b], [SLIC, Tech Report 06c]
SELECT ... FROM ... WHERE ...
E-mails, text, Web data, news, etc.

31
Research DirectionsResearch Directions
Automate integration tasks– to minimize human labor
Leverage users – to spread the cost
Simplify integration tasks– so that they can be done quickly
Integration is difficult
Do best-effort integration
Integrate with text
Should leverage human
Build on this to promote Community Information Management

32
Community Information ManagementCommunity Information Management Numerous communities on the Web
– database researchers, movie fans, legal professionals, bioinformatics, etc.
– enterprise intranets, tech support groups
Each community = many disparate data sources + people Members often want to query, monitor, discover info.
– any interesting connection between researchers X and Y?– list all courses that cite this paper– find all citations of this paper in the past one week on the Web– what is new in the past 24 hours in the database community? – which faculty candidates are interviewing this year, where?
Current integration solutions fall short of addressing such needs

33
Cimple Project @ Illinois/WisconsinCimple Project @ Illinois/Wisconsin Software platform that can be rapidly deployed and
customized to manage data-rich online communities
Web pages
Text documents
* **
** * ***
SIGMOD-04
**
** give-talk
Jim Gray
Keyword search
SQL querying
Question answering
Browse
Mining
Alert/Monitor
News summary
Jim Gray
SIGMOD-04
**
Share / aggregation
Researcher
Homepages
Conference
Pages
Group Pages
DBworld
mailing list
DBLP
Import & personalize data
Tag entities/relationship / create new contents
Context-dependent services

34
Prototype System: DBlifePrototype System: DBlife 1164 data sources, crawled daily, 11000+ pages / day
160+ MB, 121400+ people mentions 5600+ persons

35
Structure Related ChallengesStructure Related Challenges
Extraction– better blackboxes, compose blackboxes, exploit domain knowledge
Maintenance– critical, but very little has been done
Exploitation– keyword search over extracted structure? SQL queries?– detect interesting events?
Web pages
Text documents
* **
** * ***
SIGMOD-04
**
** give-talk
Jim Gray
Keyword search
SQL querying
Question answering
Browse
Mining
Alert/Monitor
News summary
Jim Gray
SIGMOD-04
**
Researcher
Homepages
Conference
Pages
Group Pages
DBworld
mailing list
DBLP
36
User Related ChallengesUser Related Challenges Users should be able to
– import whatever they want – correct/add to the imported data – extend the ER schema– create new contents for share/exchange– ask for context-dependent services
Examples– user imports a paper, system provides bib item– user imports a movie, add desc, tags it for exchange
Challenges– provide incentives, payment– handle malicious/spam users– share / aggregate user activities/actions/content
give-talk
Jim Gray
SIGMOD-04

37
Comparison to Current My Web 2.0Comparison to Current My Web 2.0
Cimple focuses on domain-specific communities– not the entire Web
Besides page level– also considers finer granularities of entities / relations / attributes– leverages automatic “best-effort” data integration techniques
Leverages user feedback to further improve accuracy– thus combines both automatic techniques and human efforts
Considers the entire range of search + structured queries– and how to seamlessly move between them
Allows personalization and sharing– consider context-dependent services beyond keyword search
(e.g., selling, exchange)

38
Applying Cimple to My Web 2.0: Applying Cimple to My Web 2.0: An ExampleAn Example
Going beyond just sharing Web pages Leveraging My Web 2.0 for other actions
– e.g., selling, exchanging goods (turning it to a classified ads platform?)
E.g., want to sell my house– create a page describing the house – save it to my account on My Web 2.0– tag it with “sell:house, sell, house, champaign, IL” – took me less than 5 minutes (not including creating the page)
– now if someone searches for any of these keywords …

39

40

41
Here a button can be added to facilitate the “sell” action provide context-dependent services

42
The Big Picture The Big Picture [Speculative Mode][Speculative Mode]
Structured data
(relational, XML)Unstructured data
(text, Web, email)
Multitude of users
Database: SQLIR/Web/AI/Mining: keyword, QA
Semantic Web
Industry/Real World
Many apps will involve all three
Exact integration will be difficult - best-effort is promising - should leverage human
Apps will want broad range of services - keyword search, SQL queries - buy, sell, exchange, etc.

43
SummarySummary Data integration: crucial problem
– at intersection of database, AI, Web, IR
Integration @ Illinois in my group: – automate tasks to minimize human labor – leverage users to spread out the cost– simplify tasks so that they can be done quickly
Best-effort integration, should leverage human The Cimple project @ Illinois/Wisconsin
– builds on current work to study Community Information Management
A step toward managing structured + text + users synergistically!
See “anhai” on Yahoo for more details