announcements midterm next week! no class next friday review this friday
TRANSCRIPT

AnnouncementsMidterm next week!
No class next Friday
Review this Friday

More than one way to solve a problem
There’s always more than one way to solve a problem.You can walk to a given place by going around the
block, or by taking a shortcut across a parking lot.
Some solutions are better than others.
How do you compare them?

Our programs (functions) implement algorithms
Algorithms are descriptions of behavior for solving a problem.
Programs (functions for us) are executable interpretations of algorithms.
The same algorithm can be implemented in many different languages.

How do we compare algorithms?
There’s more than one way to search.How do we compare algorithms to say that one is
faster than another?
Computer scientists use something called Big-O notation It’s the order of magnitude of the algorithm
Big-O notation tries to ignore differences between languages, even between compiled vs. interpreted, and focuses on the number of steps to be executed.

What question are we trying to answer?
If I am given a larger problem to solve (more data), how is the performance of the algorithm affected?
If I change the input, how does the running time change?

How can we determine the complexity?
Step 1: we must determine the “input” or what data the algorithm operates over
Step 2: determine how much “work” is needed to be done for each piece of the input
Step 3: eliminate constants and smaller terms for big O notation

Lets take a step back …
In the first week we introduce the notion of searching a phone book as an algorithm
Algorithm 1:Start at the front, check each name one by one
Algorithm 2:Use the index to jump to the correct letter
Algorithm 3:Split in half, choose which half has the name, repeat
until found

Nested loops are multiplicative
def loops():
count = 0
for x in range(1,5):
for y in range(1,3):
count = count + 1
print (x,y,"--Ran it",count,"times”)
>>> loops()
1 1 --Ran it 1 times
1 2 --Ran it 2 times
2 1 --Ran it 3 times
2 2 --Ran it 4 times
3 1 --Ran it 5 times
3 2 --Ran it 6 times
4 1 --Ran it 7 times
4 2 --Ran it 8 times

Big-O notation ignores constants
Consider if we executed a particular statement 3 times in the body of the loop If we execute each loop 1 million times this
constant becomes meaningless (ie: n = 1,000,000)
O(n2) is the same as O(3n2)def loops(n): count = 0 for x in range(1,n): for y in range(1,n): count = count + 1 count = count + 1 count = count +1

Lets compare our phone book search algorithms
Algorithm 1:Start at the front, check each name one by one
O(n)
Algorithm 2:Use the index to jump to the correct letter
O(n/26) … O(1/26 * n) … O(n)
Algorithm 3:Split in half, choose which half has the name, repeat
until foundO(log n)

More on big O notationhttp://en.wikipedia.org/wiki/Big_Oh_notation
Additional background
We mentioned that big O notation ignores constantsLets look at this more formally:Big O notation characterizes functions (algorithms
in our case) by their growth rate

Identify the term that has the largest growth rate
Num of steps growth term complexity
6n + 3 6n O(n)
2n2 + 6n + 3 2n2 O(n2)
2n3 + 6n + 3 2n3 O(n3)
2n10 + 2n + 3 2n O(2n)
n! + 2n10 + 2n + 3 n! O(n!)

Comparison of complexities:
fastest to slowestO(1) – constant time
O(log n) – logarithmic time
O(n) – linear time
O(n log n) – log linear time
O(n2) – quadratic time
O(2n) – exponential time
O(n!) – factorial time

Do we know of any O(1) algorithms?
These are “constant time” algorithms
Simple functions that contain no loops are usually O(1)
Example:
def randomChoice(list): return list[int(random.random() * len(list))]

Finding something in the phone book
O(n) algorithmStart from the beginning.Check each page, until you find what you want.
Not very efficientBest case: One stepWorse case: n steps where n = number of pagesAverage case: n/2 steps

What about algorithm 2?Recall that algorithm 2 for finding a name in the
phone book used the index
Can we make this algorithm faster by having an index for each letter?
Would such an algorithm have a lower running time than our binary search?Would it have a lower complexity?

What about our encrypt and decrypt functions?
How might we reason about the complexity of the functions we wrote in project 3?
First lets determine the input!The message we want to encrypt or decrypt
How much work do we do for each character?We do a constant amount of work

Clicker QuestionWhat is the complexity of the encrypt function?
A: O(n) B: O(n2)C: O(1)

Some errors in Project 3What is the complexity?
def columnarEncipher(msg, key): m = … #create matrix for x in msg: for x in range(rows):
for y in range (columns): # some calculation

Not all algorithms are the same complexity
There is a group of algorithms called sorting algorithms that place things (numbers, names) in a sequence.
Some of the sorting algorithms have complexity around O(n2) If the list has 100 elements, it’ll take about 10,000 steps
to sort them.
However, others have complexity O(n log n) The same list of 100 elements would take only 460 steps.
Think about the difference if you’re sorting your 100,000 customers…

We want to choose the algorithm with the best
complexity
We want an algorithm which will be fastA “lower” complexity mean an algorithm will
perform better on large input

HomeworkStudy for the midterm

Announcements Midterm on Tuesday

Lists, Tuples, Dictionaries, Strings
All use bracket notation to access elements []
Lists, Tuples, and Strings use an index to access an elementWe consider such structures ordered
Dictionaries use keys to access elementsWe consider dictionaries unordered

Creating StructuresLists – use the [ ] notation
List = [1, 2, 3, 4, 5, “foo”]
Strings use the “ “ notation (or ‘ ‘ , or ‘’’ ‘’’)String = “this is my string”
Dictionaries use the { } notationDictionary = {“key1”:”value1”, “key2”:”value2”}
Tuples use the ( ) notationTuple = (1, 2, 3, 4, 5, “foo”)

Immutable StructuresTuples and Strings are considered immutable
What does this mean in practice?We cannot assign new values to the indexes in
such structures
Errors for strings and tuples:A = “mystring” A[3] = “b”B = (1, 3, 4, “foo”) B[2] = 5

Structures can contain other structures
Lists, Dictionaries, and Tuples can contain elements which themselves are Lists, Dictionaries, or Tuples
What have we seen before?a = [(“key1”, “value1”), (“key2”, “value2”)]Dictionary = dict(a)a is a list of tuples

What else can we do?We could have a tuple of lists:
d = ([0,1,2], [3,4,5])print (d[0][2])A = [4,5,6]C= (A, A)
We could have a list of dictionaries:e = [{“key1”:”value1”, “key2”:”value2”},
{“key3”:”value3”, “key4”:”value4”}]print (e[1][“key4”])

A few notes on Dictionaries
Review how to print a dictionary and how to print just the keys
What happens when “key” is not a valid key in the dictionary dictionary and we do:dictionary[“key”] = value
This adds a new entry into the dictionary!

Specialized Structures built from structures containing structures
MatricesRepresented as a list of listsThe internal lists are either rows or columns
TreesRepresented as an arbitrary nesting of listsThe structure of the elements represents the
branching of the tree

MatricesReview matrix multiplication
Review how to populate a matrix Go through the pre lab examples
Review how to create a matrixPython short hand

Traversing a MatrixIs B encoded column by column or row by row?
We do not know …. But what if I told you this loop prints the matrix
row by row?
B = [[1, 0, 0], [0.5, 3, 4], [-1, -3, 6], [0, 0, 0]]for j in range(3): for i in range(4): print (B[i][j])

How do we find out how the matrix is encoded?
Step one: figure out the order in which the values are printed1, 0.5, -1, 0, 0, 3, -3, 0 , 0, 4, 6, 0
Step two: compare this to the matrixB = [[1, 0, 0], [0.5, 3, 4], [-1, -3, 6], [0, 0, 0]]
Step three: deduce the encoding by comparing the order to the matrixThe matrix is encoded column by column!

Applying the same intuition to matrices
Lets traverse the matrix the other way!
B = [[1, 0, 0], [0.5, 3, 4], [-1, -3, 6], [0, 0, 0]]for j in range(3): for i in range(4): print (B[i][j])for i in range(4): for j in range(3): print (B[i][j])

TreesKnow how to select elements from a tree
Know how to construct a tree using lists
You do not need to know how to add trees

Given the picture can you generate the python list?
Root
Leaf1
Leaf2
Leaf3 Leaf4 Leaf5
Tree = [[‘Leaf0’,‘Leaf1’], ‘Leaf2’, [‘Leaf3’, ‘Leaf4’, ‘Leaf5’]]
Leaf0
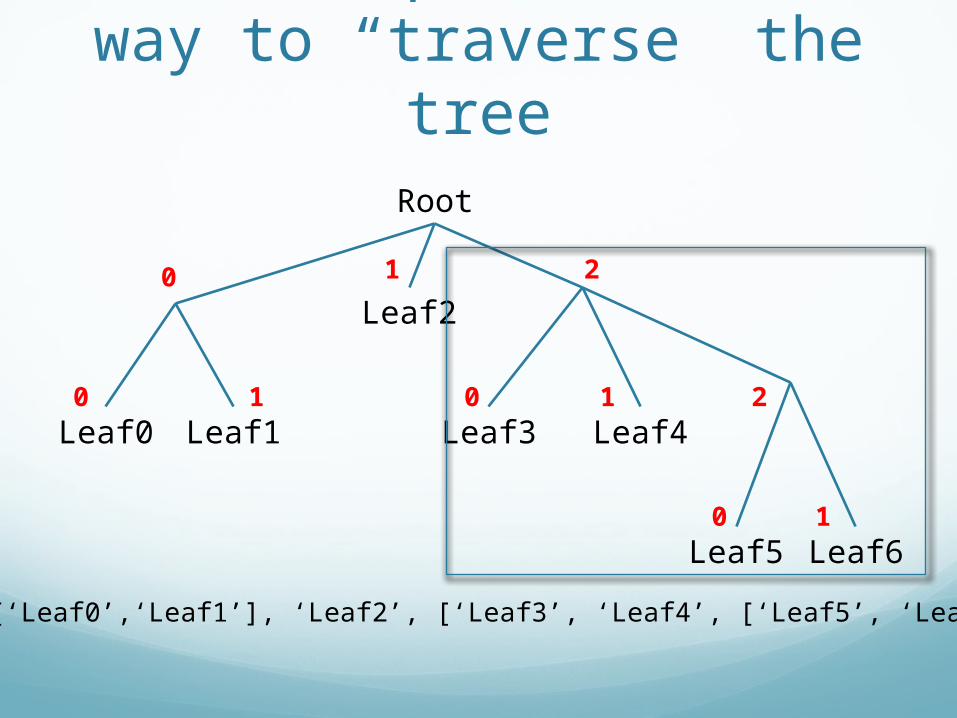
Indexes provide us a way to “traverse” the tree
Root
Leaf1
Leaf2
Leaf3 Leaf4
Leaf6
Tree = [[‘Leaf0’,‘Leaf1’], ‘Leaf2’, [‘Leaf3’, ‘Leaf4’, [‘Leaf5’, ‘Leaf6’]]]Tree[2]
Leaf0
Leaf5
0
0
0
0 1
1
1
1
2
2
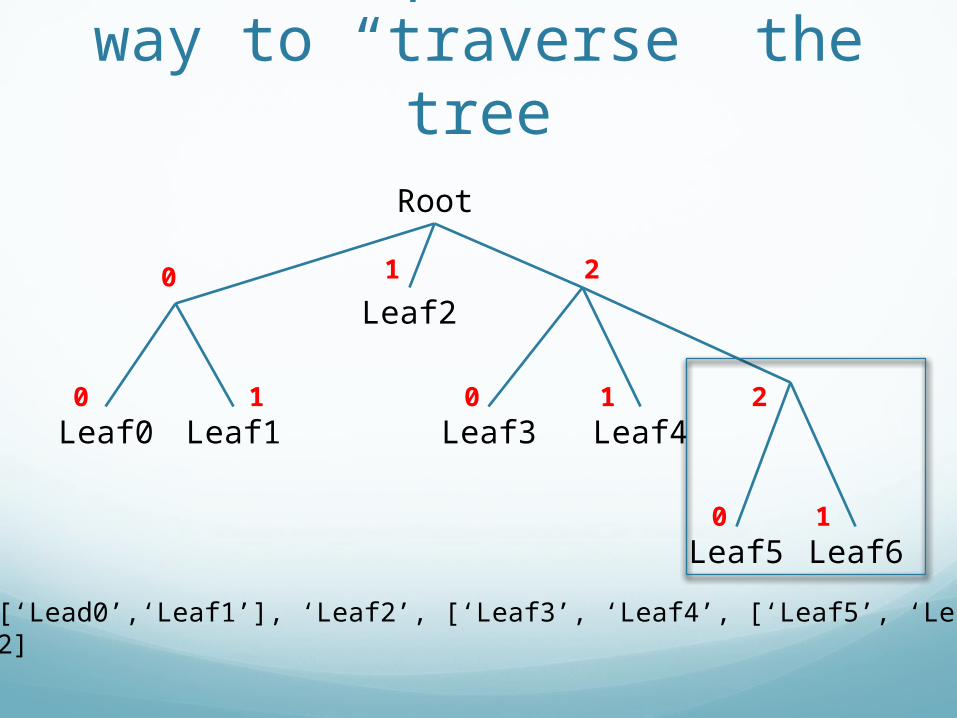
Indexes provide us a way to “traverse” the tree
Root
Leaf1
Leaf2
Leaf3 Leaf4
Leaf6
Tree = [[‘Lead0’,‘Leaf1’], ‘Leaf2’, [‘Leaf3’, ‘Leaf4’, [‘Leaf5’, ‘Leaf6’]]]Tree[2][2]
Leaf0
Leaf5
0
0
0
0 1
1
1
1
2
2
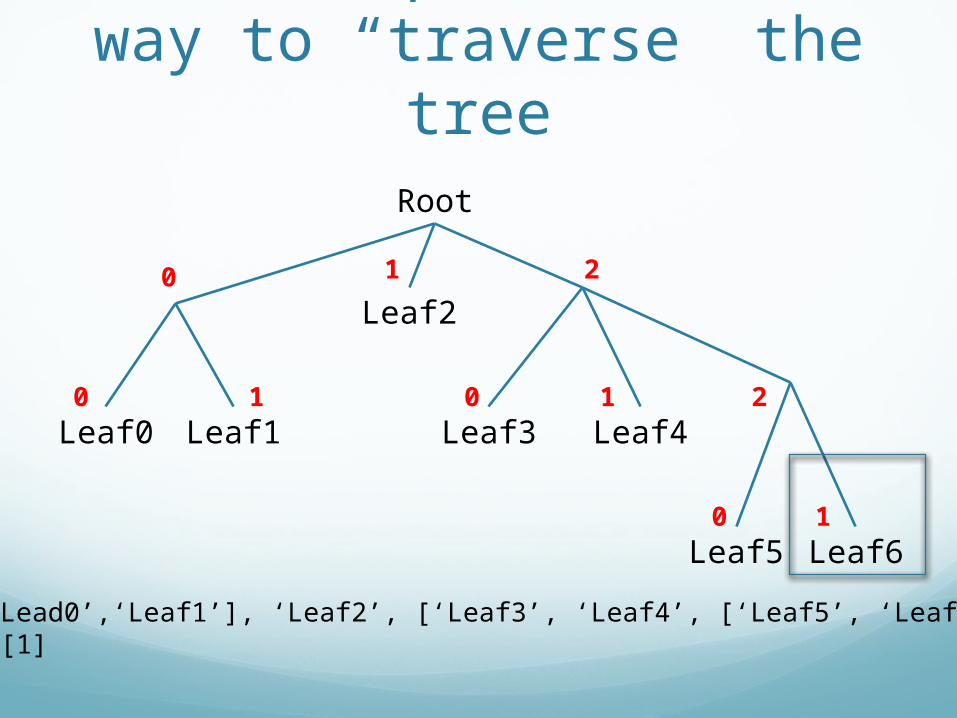
Indexes provide us a way to “traverse” the tree
Root
Leaf1
Leaf2
Leaf3 Leaf4
Leaf6
Tree = [[‘Lead0’,‘Leaf1’], ‘Leaf2’, [‘Leaf3’, ‘Leaf4’, [‘Leaf5’, ‘Leaf6’]]]Tree[2][2][1]
Leaf0
Leaf5
0
0
0
0 1
1
1
1
2
2

Modulesurllib
Allows us to get data directly from webpages
RandomAllows us to generate random numbers and
choose randomly from a list

Examples Using Randomrandom.random()
Returns a random floating point number between 0 and 1 (but not including 1)
How might we generate a random number between 0 and 9? int(random.random() * 10)Why is this the case? Why do we need int?How might we generate a random number
between 0 and 99?

Randomly selecting from a list
random.choice(list)Example: random.choice([“a”, “b”, “c”]) Will return either “a”, “b”, or “c”
How might we do this a different way?We know we can choose a random number within
a specific range (previous slide)We know we can use an integer as an index

Combining our intuitionrandom.choice([“a”, “b”, “c”])
[“a”, “b”, “c”][int(random.random() *3)]
Both these are equivalent, why?

File I/OWhat is the difference between the various
modes?We saw in class “w” “r”
What is the difference between read, readline, and readlines?

Methods on Filesobject.method() syntax: this time files are our
objectExample: file = open(“myfile”, “w”)
file.read() -- reads the file as one string
file.readlines() – reads the file as a list of strings
file.write() – allows you to write to a file
file.close() – closes a file

Strings and ParsingWhat are the most important operations?
findrfindsplitSlicing

Lets Review Some Pythonstring.find(sub) – returns the lowest index where
the substring sub is found or -1
string.find(sub, start) – same as above, except using the slice string[start:]
string.find(sub, start, end) – same as above, except using the slice string[start:end]

Lets Review Some Pythonstring.rfind(sub) – returns the highest index
where the substring sub is found or -1
string.rfind(sub, start) – same as above, except using the slice string[start:]
string.rfind(sub, start, end) – same as above, except using the slice string[start:end]

The String Method SplitString.split(delimiter) breaks the string String
into parts, separated by the delimiterprint (“a b c d”.split(“ “))
Would print: [‘a’, ‘b’, ‘c’, ‘d’]

Concrete Examplefoo = ”there their they’re”
elem = foo.split(" ”)
for i in elem:
print(i.split(“e"))
[‘th', ‘r’, ‘’]
[‘th', ‘ir']
[‘th', “y’r”, ‘’]

Manipulating StringsHow might we reverse a string?
How might we encrypt a given message?
We used the same technique for the problemsBuild up a new string piece by piece

Example: Reversing Strings
def reverse(str): output = "” for i in range(0, len(str)): output = output + str[len(str)-i-1] print (output)

Useful things to knowrange function
ord and chr functions
int function