announcing tesla k20 family nvidia tesla update sumit ... · general manager tesla accelerated...
TRANSCRIPT

1
NVIDIA Tesla Update
Supercomputing’12 Sumit Gupta
General Manager
Tesla Accelerated Computing
Announcing Tesla K20 Family
Sumit Gupta
General Manager
Tesla Accelerated Computing

Today’s information is embargoed until
November 12 – 6:00 am US Pacific Time

Accelerated Computing Meets Increased Demand for Science
http://www.teragridforum.org/mediawiki/images/f/f8/TGQR_2011Q1_Report.pdf
50x
0
40x
30x
20x
10x
2008 2009 2010 2011 2012
Fermi
Launches
Top500 Systems OEM Systems
Industry Apps Universities
Normalized to 2008
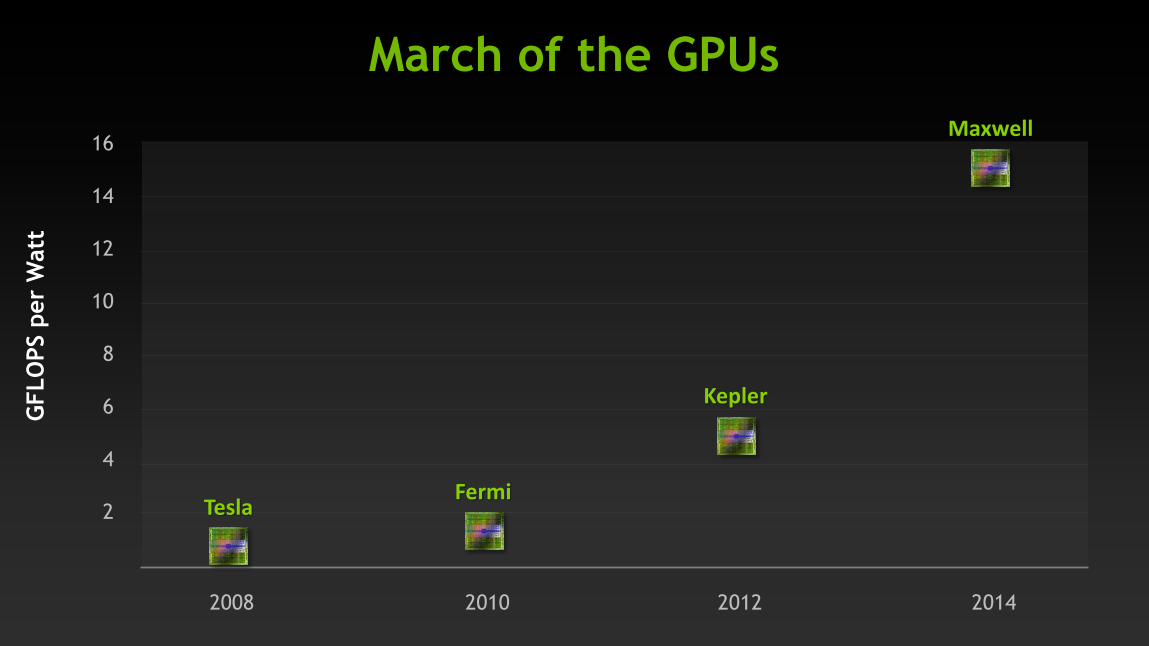
March of the GPUs
16
2
4
6
8
10
12
14
GFLO
PS p
er
Watt
2008 2010 2012 2014
Tesla Fermi
Kepler
Maxwell

Tesla K20 Family
World’s Fastest, Most Effi ient A elerator 1
2 Powered y CUDA: World’s Most Pervasive Parallel Programming Model
3 Delivers World Record Performance for Scientific Apps

Announcing Tesla K20 Accelerator Family
Tesla K20X
Tesla K20X Tesla K20
Peak Double Precision 1.31 TF 1.17 TF
Peak Single Precision 3.95 TF 3.52 TF
Memory Bandwidth 250 GB/s 208 GB/s
Memory size 6 GB 5 GB
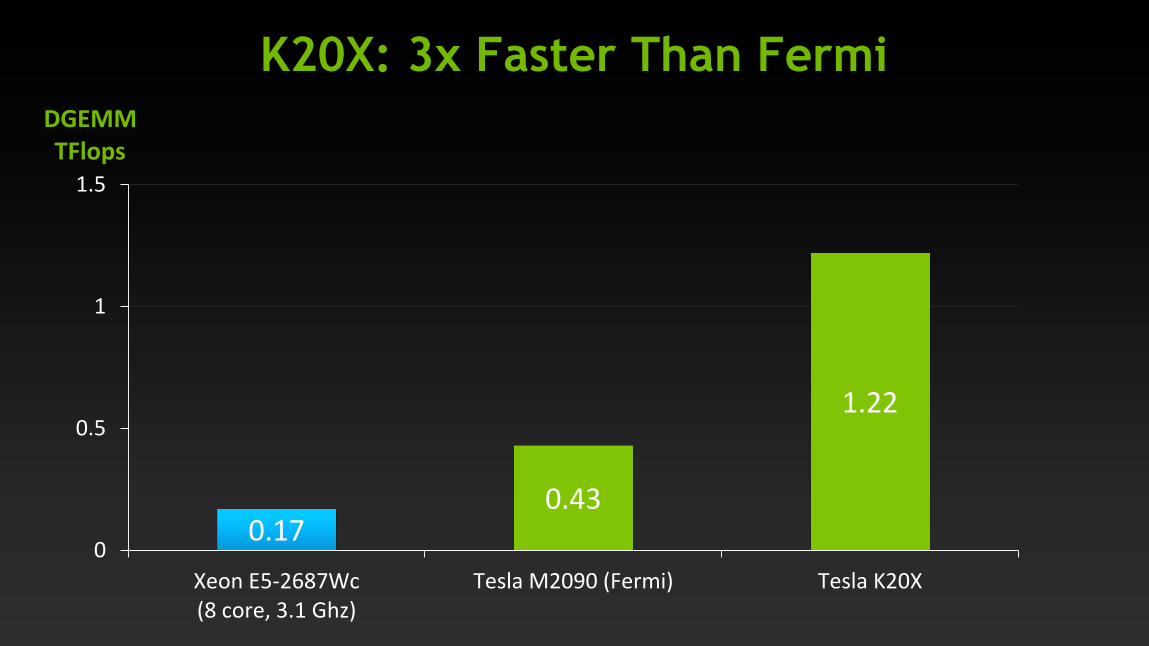
K20X: 3x Faster Than Fermi
0.17 0.43
1.22
0
0.5
1
1.5
Xeon E5-2687Wc
(8 core, 3.1 Ghz)
Tesla M2090 (Fermi) Tesla K20X
DGEMM
TFlops
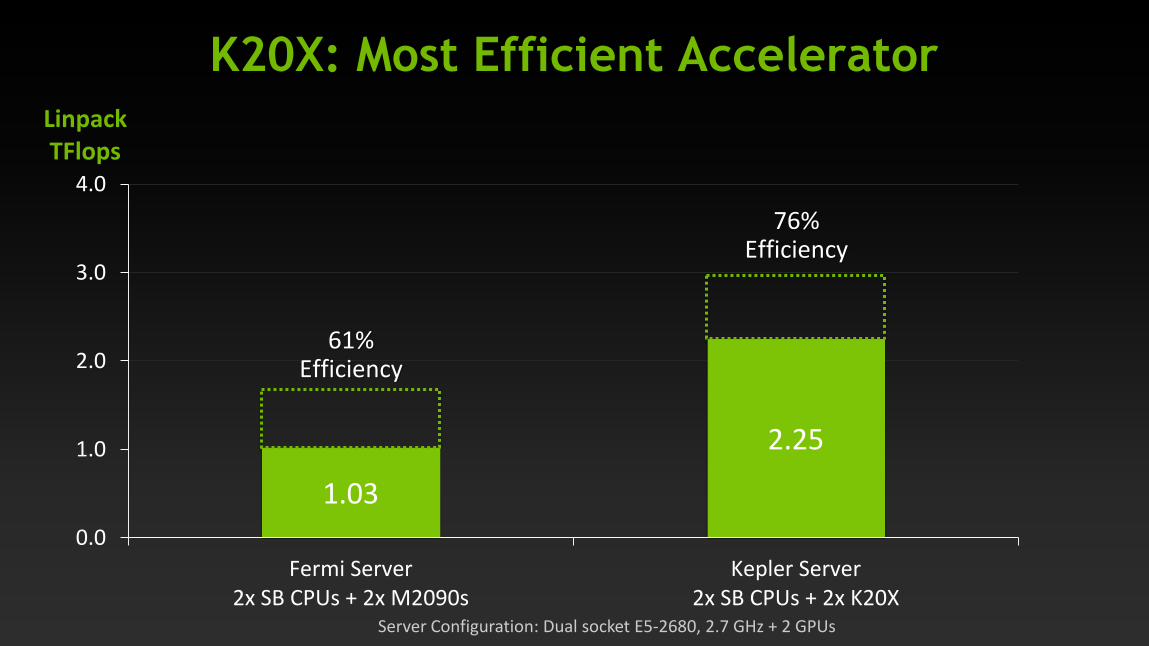
K20X: Most Efficient Accelerator
1.03
2.25
0.0
1.0
2.0
3.0
4.0
Fermi Server
2x SB CPUs + 2x M2090s
Kepler Server
2x SB CPUs + 2x K20X
Linpack
TFlops
61% Efficiency
76% Efficiency
Server Configuration: Dual socket E5-2680, 2.7 GHz + 2 GPUs

Titan: World’s #1 Open Science Supercomputer 18,688 Tesla K20X GPUs
27 Petaflops Peak: 90% of Performance from GPUs
17.59 Petaflops Sustained Performance on Linpack
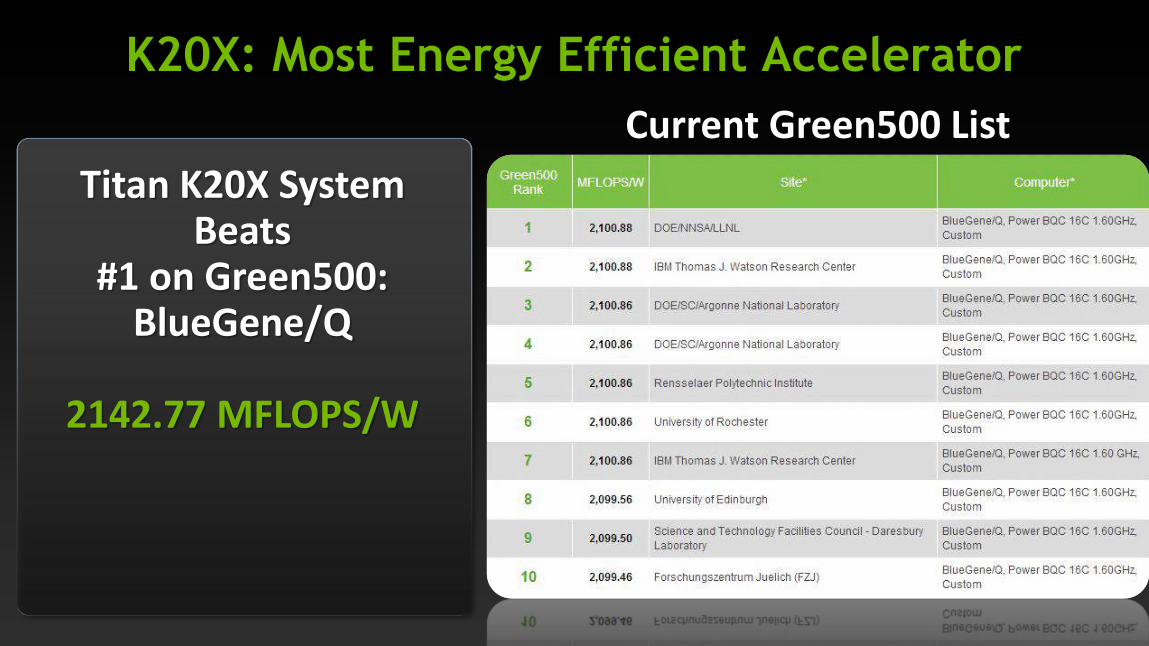
Current Green500 List
K20X: Most Energy Efficient Accelerator
Titan K20X System Beats
#1 on Green500: BlueGene/Q
2142.77 MFLOPS/W

30 Petaflops in 30 Days

K20 / K20X Availability
Shipping this week
General Availability: November-December

Tesla K20 Family
World’s Fastest, Most Effi ient A elerator 1
2 Powered y CUDA: World’s Most Pervasive Parallel Programming Model
3 Delivers World Record Performance for Scientific Apps

CUDA: World’s Most Pervasive Parallel Programming Model
629 University Courses
In 62 Countries 8,000 Institutions with
CUDA Developers
1,500,000 CUDA Downloads
395,000,000 CUDA GPUs Shipped
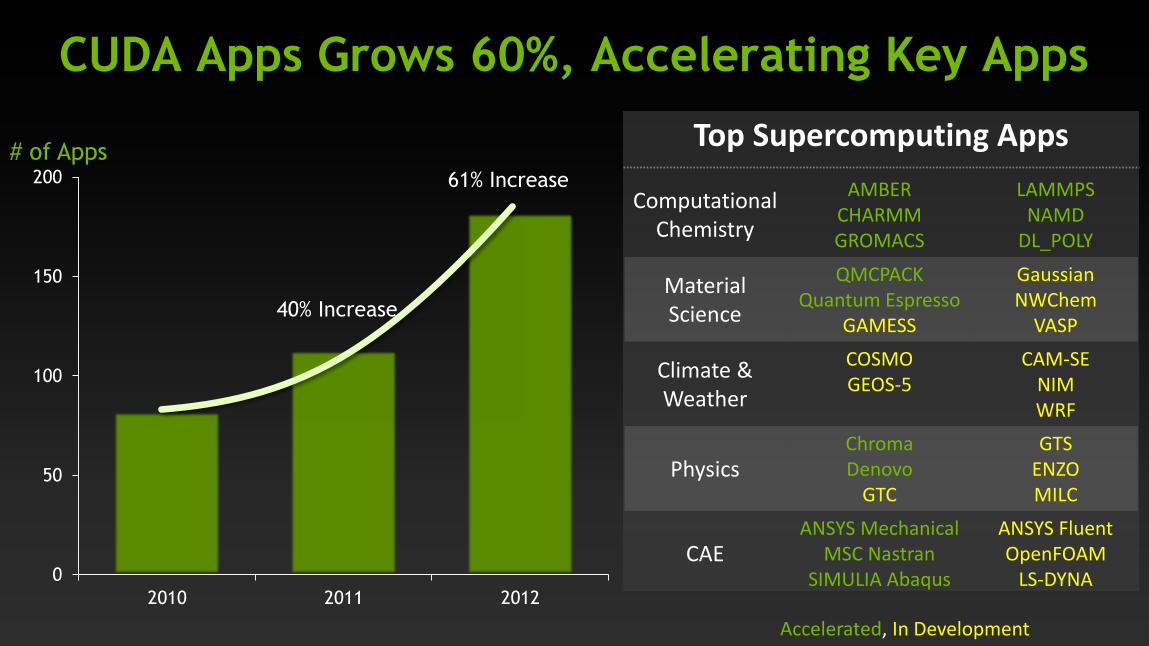
Top Supercomputing Apps
Computational
Chemistry
AMBER
CHARMM
GROMACS
LAMMPS
NAMD
DL_POLY
Material
Science
QMCPACK
Quantum Espresso
GAMESS
Gaussian
NWChem
VASP
Climate &
Weather
COSMO
GEOS-5
CAM-SE
NIM
WRF
Physics Chroma
Denovo
GTC
GTS
ENZO
MILC
CAE ANSYS Mechanical
MSC Nastran
SIMULIA Abaqus
ANSYS Fluent
OpenFOAM
LS-DYNA
CUDA Apps Grows 60%, Accelerating Key Apps
0
50
100
150
200
2010 2011 2012
# of Apps
40% Increase
61% Increase
Accelerated, In Development

Leading Apps Now Accelerated by GPUs
Fluid Dynamics Structual Mechanics Life Sciences
CHARMM

Tesla K20 Family
World’s Fastest, Most Effi ient A elerator 1
2 Powered y CUDA: World’s Most Pervasive Parallel Programming Model
3 Delivers World Record Performance for Scientific Apps
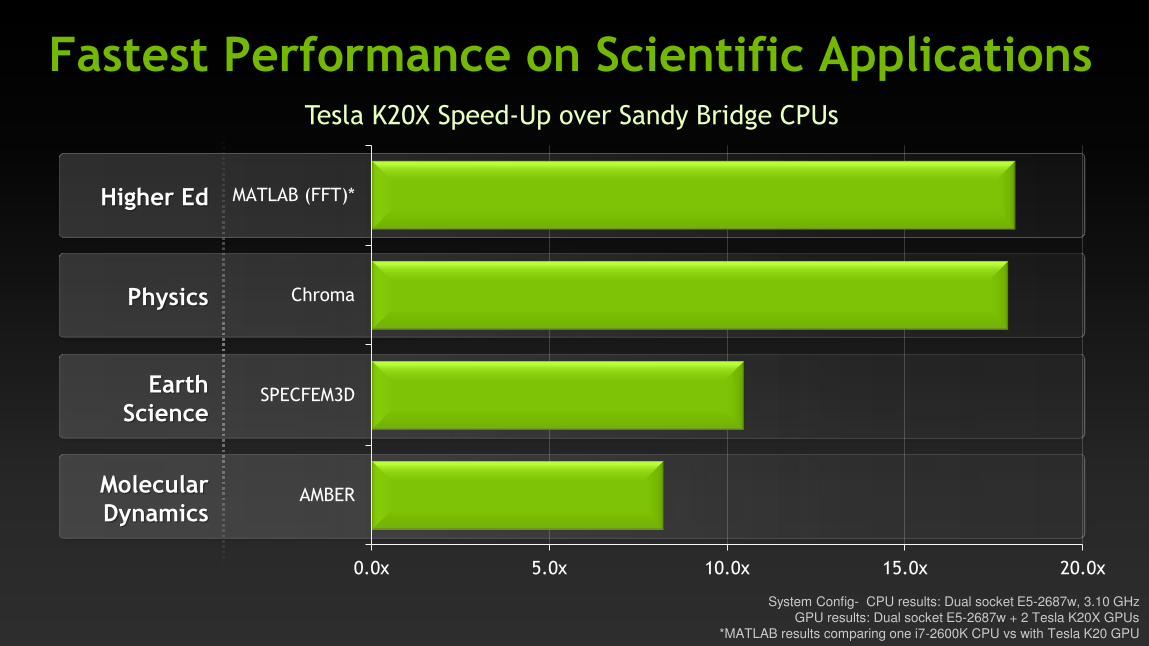
0.0x 5.0x 10.0x 15.0x 20.0x
AMBER
SPECFEM3D
Chroma
MATLAB (FFT)*Higher Ed
Earth
Science
Physics
Molecular
Dynamics
Fastest Performance on Scientific Applications Tesla K20X Speed-Up over Sandy Bridge CPUs
System Config- CPU results: Dual socket E5-2687w, 3.10 GHz
GPU results: Dual socket E5-2687w + 2 Tesla K20X GPUs
*MATLAB results comparing one i7-2600K CPU vs with Tesla K20 GPU

Record Breaking Simulation
WL-LSMS: Material Science
Discover better materials for
magnetic storage
New Record 10+ PFLOPS
Old Record 3.1 PFLOPS
Effort 2% Lines of Code
2011 Gordon Bell Winner at 3.08 Petaflops on K Computer
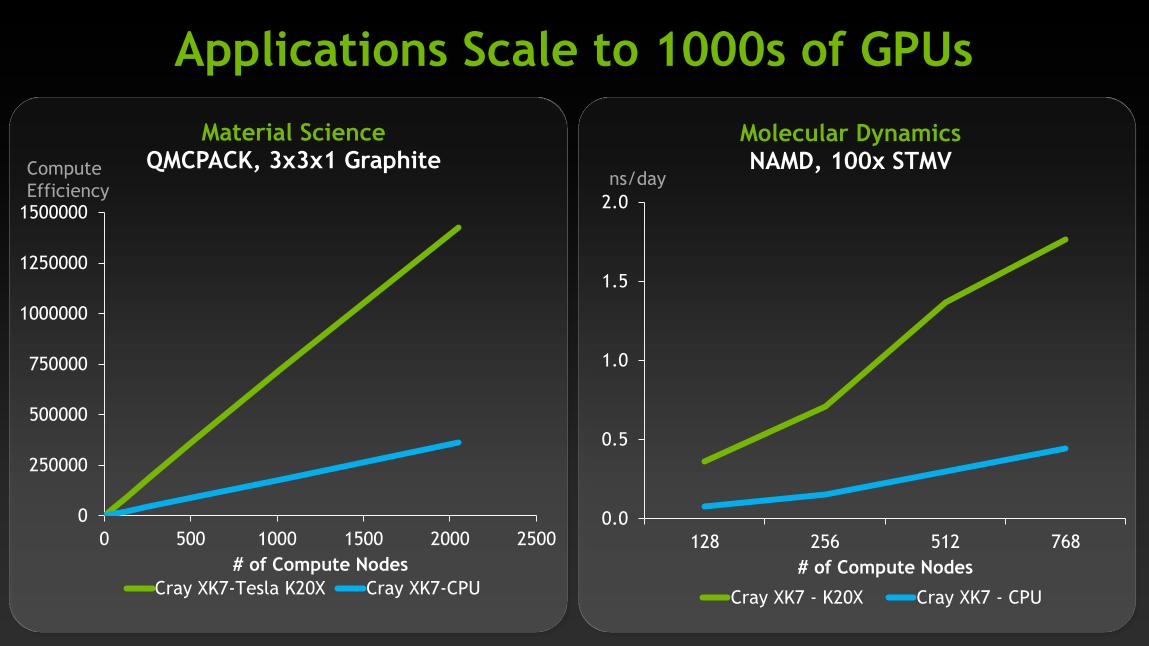
Applications Scale to 1000s of GPUs
0.0
0.5
1.0
1.5
2.0
128 256 512 768
# of Compute Nodes
Molecular Dynamics NAMD, 100x STMV
Cray XK7 - K20X Cray XK7 - CPU
ns/day
0
250000
500000
750000
1000000
1250000
1500000
0 500 1000 1500 2000 2500
# of Compute Nodes
Material Science QMCPACK, 3x3x1 Graphite
Cray XK7-Tesla K20X Cray XK7-CPU
Compute
Efficiency
The Era of Accelerated Computing is Here
1980 1990 2000 2010 2020
Era of
Vector Computing
Era of
Accelerated Computing
Era of
Distributed Computing

SC12 News Summary
Introducing the Tesla K20 Accelerator Family 1
2 New CUDA Accelerated Apps and Growing Ecosystem
3 Record Setting Performance on Scientific Applications
Embargoed Until Nov 12 – 6:00 am US PT

“Tesla K20 GPU is 2.3x faster than Tesla M2070, and
no change was required in our code! ” Associate Professor in Mechanical Engineering
Inanc Senocak
“Results are amazing! It is 160x faster than our CPU
code and 2.5x faster than Fermi for our solutions ” Professor in Computer Science
Estaban Clua
Research Scientist
Oreste Villa, Antonino Tumeo
“Tesla K20 is very impressive. Our application
runs 20x faster compared to a Sandy Bridge CPU. ”
Customers Seeing Impressive K20 Speedups

Teaching Parallel Programming with CUDA
Professor Chris Lupo
Cal Poly San Luis Obispo
“I have found GPU programming using CUDA to be one of the easiest ways
to introduce students to parallel programming. ” Professor Eric Darve
Stanford University
“My students are amazed to find how easy the parallel programming with
CUDA is and are thrilled by the performance from NVIDIA GPUs. ” Professor Miaoqing Huang
University of Arkansas
“CUDA allows me to teach students with no prior parallel programming
experience to parallelize real-world apps in just a few weeks.
”

OpenACC Makes GPU Accelerator Easier
S3D: Fuel Combustion
Design alternative fuels with
up to 50% higher efficiency
Titan
10 days
Jaguar
42 days
Minimal Effort
with OpenACC
Modified <1%
Lines of Code
4x Faster

Hyper-Q
Easy speed-up for legacy MPI codes
Kepler: GPU Acceleration Made Easier Than Ever
Dynamic Parallelism
GPU generates work for itself
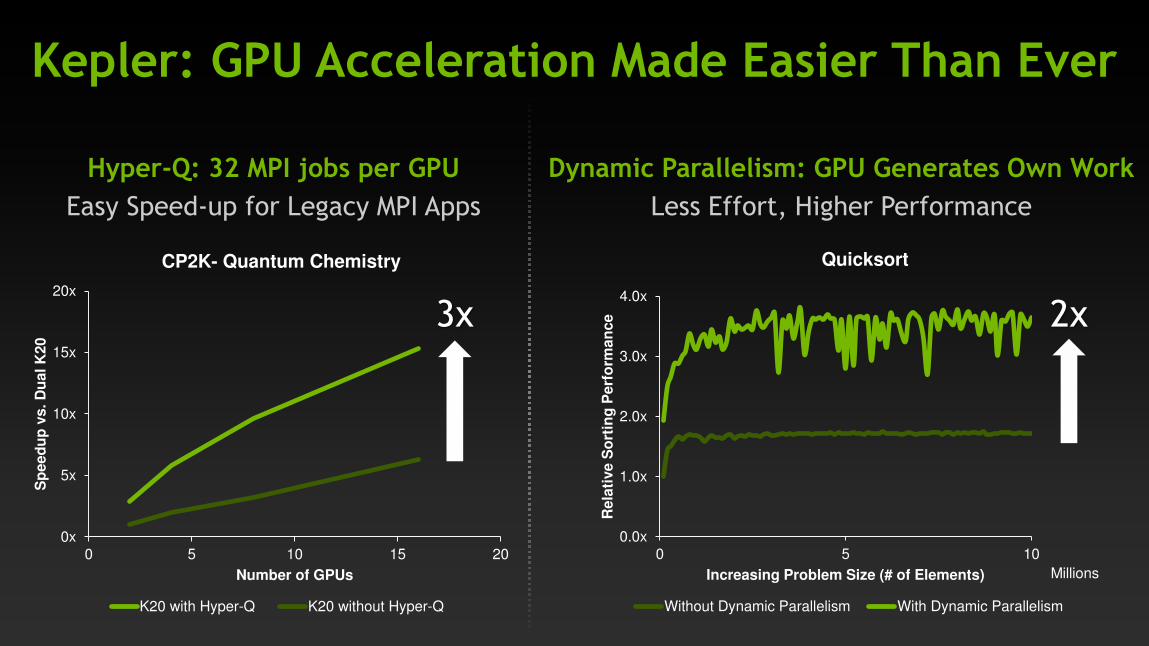
Hyper-Q: 32 MPI jobs per GPU
Easy Speed-up for Legacy MPI Apps
Kepler: GPU Acceleration Made Easier Than Ever
Dynamic Parallelism: GPU Generates Own Work
Less Effort, Higher Performance
0x
5x
10x
15x
20x
0 5 10 15 20
Sp
ee
du
p v
s. D
ual
K2
0
Number of GPUs
CP2K- Quantum Chemistry
K20 with Hyper-Q K20 without Hyper-Q
3x
0.0x
1.0x
2.0x
3.0x
4.0x
0 5 10
Re
lati
ve
So
rtin
g P
erf
orm
an
ce
Increasing Problem Size (# of Elements) Millions
Quicksort
Without Dynamic Parallelism With Dynamic Parallelism
2x
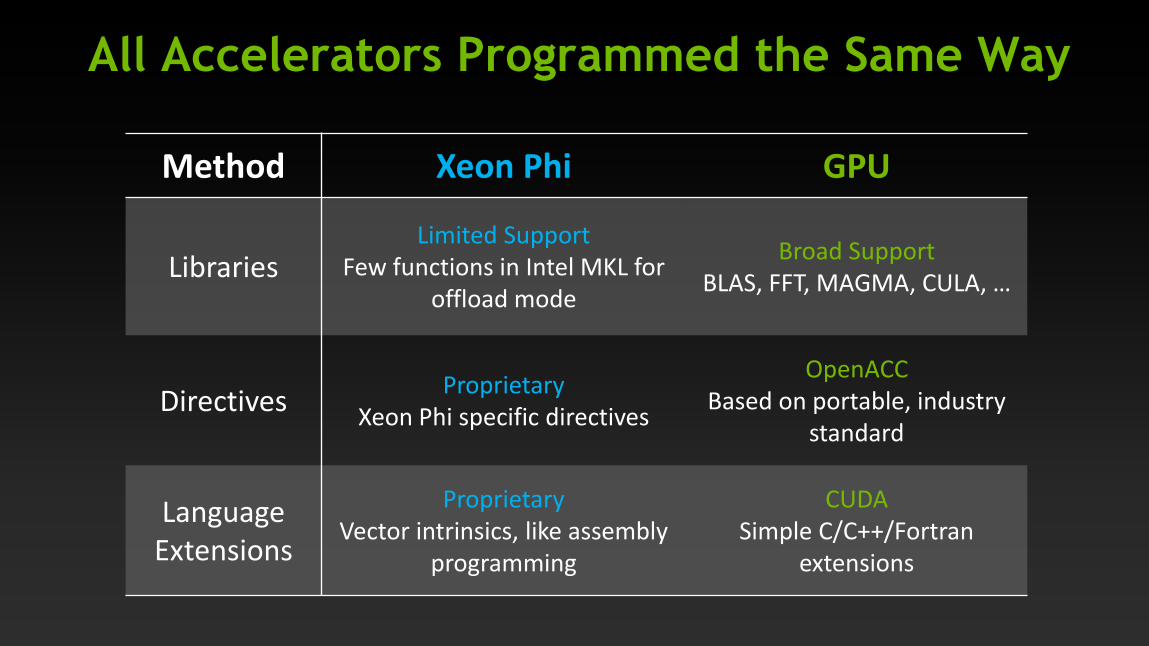
All Accelerators Programmed the Same Way
Method Xeon Phi GPU
Libraries Limited Support
Few functions in Intel MKL for
offload mode
Broad Support
BLAS, FFT, MAGMA, CULA, …
Directives Proprietary
Xeon Phi specific directives
OpenACC
Based on portable, industry
standard
Language
Extensions
Proprietary
Vector intrinsics, like assembly
programming
CUDA
Simple C/C++/Fortran
extensions